
ธนาคารไทยกำลังก้าวสู่ยุคใหม่ของการอนุมัติสินเชื่อด้วยการผสานเทคโนโลยี RAG‑Realtime เข้ากับ Knowledge Graph เพื่อเปลี่ยนวงจรการตัดสินใจจากแบบคงที่มาเป็นไดนามิกแบบเรียลไทม์ — ลดเวลาตัดสินใจให้สำเร็จภายใน 24 ชั่วโมงและชะลอหรือหดอัตรา NPL (Non‑performing Loan) อย่างเป็นรูปธรรม ระบบดังกล่าวไม่เพียงเร่งความเร็วของการประมวลผลข้อมูล แต่ยังเพิ่มความแม่นยำในการประเมินความเสี่ยง โดยใช้การดึงความรู้เชิงบริบทและการอัปเดตข้อมูลแบบสตรีมมิงเพื่อให้คะแนนเครดิตและมาตรการควบคุมความเสี่ยงปรับตัวได้ทันสถานการณ์ธุรกิจของผู้ขอสินเชื่อ
บทความนี้จะพาผู้อ่านสำรวจจุดเด่นของโซลูชัน RAG‑Realtime + Knowledge Graph ในเชิงสถาปัตยกรรม และอธิบายกระบวนการทางธุรกิจตั้งแต่การรวบรวมสัญญาณข้อมูล การแมปความสัมพันธ์เชิงความรู้ การประมวลผลโมเดลความเสี่ยงแบบไดนามิก ไปจนถึงวงจรป้อนกลับที่ลดความเสี่ยงเชิงพฤติกรรม เราจะนำเสนอตัวชี้วัดเชิงปริมาณที่สำคัญ เช่น ระยะเวลาเฉลี่ยในการอนุมัติ อัตรา NPL ที่เปลี่ยนแปลง อัตราการอนุมัติและการปฏิเสธที่มีความถูกต้อง (precision/recall) รวมถึงตัวอย่างกรณีศึกษาเชิงปฏิบัติการและข้อพิจารณาด้านการปฏิบัติตามกฎระเบียบ เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าการยกเครื่องระบบอนุมัติสินเชื่อด้วยเทคโนโลยีนี้สามารถนำไปสู่ผลลัพธ์เชิงธุรกิจอย่างไร
บทนำ: ปัญหา NPL และความจำเป็นของการเร่งวงจรอนุมัติ
บทนำ: ปัญหา NPL และความจำเป็นของการเร่งวงจรอนุมัติ
ปัญหาเงินให้สินเชื่อที่ไม่ก่อให้เกิดรายได้ (Non‑Performing Loans: NPL) ยังคงเป็นความท้าทายสำคัญของระบบธนาคารไทย โดยภาพรวมอัตรา NPL ของระบบธนาคารในช่วงไม่กี่ปีที่ผ่านมาเคลื่อนไหวในระดับที่น่าสังเกต — โดยทั่วไปอยู่ในช่วงราว 2.5%–3.5% ของพอร์ตสินเชื่อ ขณะที่สินเชื่อภาคครัวเรือนและธุรกิจขนาดกลาง‑ขนาดย่อม (SME) มักมีอัตรา NPL สูงกว่าค่าเฉลี่ยของระบบ โดยบางกลุ่มธุรกิจอาจเผชิญอัตรา NPL อยู่ที่ราว 5%–7% ขึ้นอยู่กับภาคอุตสาหกรรมและภูมิภาค การเพิ่มขึ้นของ NPL ส่งสัญญาณความเปราะบางทั้งต่อความสามารถทำกำไรของธนาคารและเสถียรภาพทางการเงินของระบบเศรษฐกิจโดยรวม
กระบวนการอนุมัติสินเชื่อที่ใช้เวลานานเป็นหนึ่งในปัจจัยที่เร่งให้สถานะหนี้เสียทวีความรุนแรง นอกจากจะเพิ่มความเสี่ยงต่อการผิดนัดชำระเมื่อการอนุมัติล่าช้าทำนักธุรกิจต้องรอการระดมทุนแล้ว ธนาคารยังต้องเผชิญกับ ต้นทุนเครดิตที่เพิ่มขึ้น ได้แก่ การตั้งสำรองที่สูงขึ้น ต้นทุนบริหารจัดการหนี้เสีย และโอกาสทางรายได้ที่สูญเสียไปเมื่อผู้ขอสินเชื่อหันไปหาแหล่งทุนภายนอกหรือคู่แข่ง นอกจากนี้ ความล่าช้าในการตัดสินใจยังทำให้ธนาคารพลาดโอกาสในการขยายธุรกิจไปยังลูกค้าคุณภาพดีในช่วงที่ตลาดต้องการความคล่องตัวทางการเงินสูง
ผลกระทบทางเศรษฐกิจจาก NPL ที่เพิ่มขึ้นไม่จำกัดเพียงภาคสถาบันการเงิน แต่ยังกระทบความเชื่อมั่นของตลาดเครดิตและการเติบโตของภาคธุรกิจ หากธนาคารต้องรักษาระดับสำรองและเพิ่มค่าธรรมเนียมการให้กู้ จะเกิดการชะลอตัวในการให้สินเชื่อซึ่งส่งผลเป็นวงกว้างต่อการลงทุนและการบริโภค โดยเฉพาะอย่างยิ่งสำหรับ SME ที่พึ่งพาเงินทุนหมุนเวียนในระยะสั้น ข้อมูลเชิงประจักษ์จากหลายประเทศแสดงให้เห็นว่าแต่ละวันของความล่าช้าในการอนุมัติสามารถเพิ่มความเสี่ยงต่อการเปลี่ยนสถานะของลูกหนี้จากปกติเป็นไม่ก่อให้เกิดรายได้ได้ชัดเจน
ด้วยบริบทดังกล่าว เทคโนโลยี AI แบบเรียลไทม์และ Knowledge Graph จึงกลายเป็นทางออกที่เหมาะสม เหตุผลสำคัญได้แก่:
- การประเมินความเสี่ยงแบบไดนามิก: AI เรียลไทม์สามารถวิเคราะห์ข้อมูลการทำธุรกรรม ข้อมูลทางการเงิน และสัญญาณภายนอกได้ทันที ช่วยให้ธนาคารตัดสินใจภายในระยะเวลาที่สั้นลงและลดความเสี่ยงจากข้อมูลล้าสมัย
- การเชื่อมโยงข้อมูลเชิงบริบท: Knowledge Graph ช่วยรวมข้อมูลจากแหล่งต่าง ๆ — ประวัติสินเชื่อ พฤติกรรมชำระหนี้ ข้อมูลภาษี และข้อมูลภายนอก เช่น ข่าวเศรษฐกิจ — เพื่อสร้างภาพรวมความเสี่ยงที่เข้าใจง่ายและตรวจสอบได้
- ความสามารถในการอธิบายการตัดสินใจ (Explainability): การใช้โมเดลที่ผสานความรู้เชิงสัมพันธ์ทำให้การตัดสินใจมีเหตุผลรองรับ ช่วยลดความเสี่ยงด้านกฎระเบียบและเพิ่มความเชื่อมั่นของผู้กำกับดูแล
- ลดต้นทุนและเพิ่มความคล่องตัวทางธุรกิจ: การอนุมัติที่เร็วขึ้นช่วยลดต้นทุนการบริหารจัดการสินเชื่อและเพิ่มโอกาสทางการตลาด เมื่อลูกค้าได้รับการอนุมัติภายในชั่วโมงหรือวัน ธนาคารสามารถรักษาลูกค้าคุณภาพสูงไว้ได้มากขึ้น
ดังนั้น การปรับวงจรอนุมัติสินเชื่อให้เป็นแบบไดนามิก โดยใช้กลไก RAG‑Realtime ร่วมกับ Knowledge Graph ไม่เพียงแต่เป็นการตอบโจทย์เชิงเทคนิค แต่ยังเป็นมาตรการเชิงกลยุทธ์ที่จำเป็นเพื่อควบคุมระดับ NPL ลดต้นทุนเครดิต และรักษาความสามารถในการแข่งขันของธนาคารในสภาพแวดล้อมทางการเงินที่เปลี่ยนแปลงอย่างรวดเร็ว
เทคโนโลยีเบื้องต้น: เข้าใจ RAG‑Realtime และ Knowledge Graph
เทคโนโลยีเบื้องต้น: เข้าใจ RAG‑Realtime และ Knowledge Graph
RAG‑Realtime (retrieval‑augmented generation แบบเรียลไทม์) หมายถึงสถาปัตยกรรมที่รวมกระบวนการดึงข้อมูลจากแหล่งข้อมูลภายนอก (retrieval) เข้ากับการสร้างข้อความโดยโมเดลภาษา (generation) ในลักษณะเรียลไทม์ เพื่อให้คำตอบที่สร้างขึ้นมีความอิงข้อเท็จจริงและทันสมัยกว่าโมเดลที่พึ่งพาความรู้ที่ถูกฝังไว้ภายในพารามิเตอร์เพียงอย่างเดียว โดยทั่วไปจะประกอบด้วยส่วนหลักคือ retriever (เช่น การค้นหาแบบเวกเตอร์หรือดัชนีข้อความ), context builder (รวมและจัดลำดับเอกสารเชิงบริบท), และ generator (โมเดลภาษาที่สร้างคำตอบแบบมีข้ออ้างอิง) สิ่งที่ทำให้เป็น “Realtime” คือการออกแบบให้ดึงข้อมูล อัปเดตบริบท และสังเคราะห์คำตอบได้ภายในเสี้ยวเวลา — โดยเรียงลำดับให้ค่าหน่วง (latency) ต่ำพอสำหรับการตัดสินใจเชิงธุรกิจแบบทันที
โครงงานของ RAG‑Realtime มักมีลำดับการทำงานชัดเจน เช่น:
- Retrieval: ค้นหาเอกสารหรือเวกเตอร์ที่เกี่ยวข้องจากแหล่งข้อมูลภายใน/ภายนอก (ฐานข้อมูลธุรกรรม, เอกสาร KYC, นโยบายความเสี่ยง)
- Reranking / Filtering: จัดลำดับความสำคัญของผลลัพธ์เพื่อลดสัญญาณรบกวน ก่อนส่งให้โมเดล
- Context Fusion: ผสานข้อมูลเชิงบริบท (เช่น สรุปธุรกรรมล่าสุด, เกณฑ์เครดิต) และแปลงให้เป็น prompt ที่มีขนาดพอเหมาะ
- Generation: โมเดลภาษาสร้างคำตอบโดยอ้างอิงหลักฐานที่ดึงมา และแนบแหล่งอ้างอิงหรือเหตุผลเชิงสาเหตุ
จากมุมมองเชิงประสิทธิภาพ การใช้งานเชิงอุตสาหกรรมพบว่า RAG สามารถลดอัตราการให้ข้อมูลผิดพลาด (hallucination) และเพิ่มความสอดคล้องกับข้อเท็จจริงได้ในระดับที่มีนัยสำคัญ — งานวิจัยและการนำไปใช้รายงานช่วงการปรับปรุงความแม่นยำประมาณ 10–30% ในเคสที่ต้องอ้างอิงเอกสาร และการออกแบบเรียลไทม์สามารถลดเวลาดึงข้อมูลให้เหลือระดับ 100–500 มิลลิวินาที ต่อรอบในระบบที่ปรับแต่งแล้ว ซึ่งสำคัญต่อการตัดสินใจวงจรสินเชื่อแบบไดนามิก

Knowledge Graph (KG) ทำหน้าที่เสริมในมิติที่ต่างไป: แทนที่จะเป็นเพียงคลังเอกสารแบนราบ KG จัดเก็บหน่วยข้อมูลในรูปแบบโหนด (entities) และความสัมพันธ์ (edges) ทำให้สามารถสืบค้นเชิงสัมพันธ์ เช่น ความเป็นเจ้าของ, การค้ำประกัน, ห่วงโซ่อุปทาน หรือเครือข่ายความเสี่ยงข้ามบริษัทได้อย่างตรงจุด ตัวอย่างเช่น ในการอนุมัติสินเชื่อ KG จะระบุความสัมพันธ์ระหว่างลูกค้า–ผู้ค้ำประกัน–บริษัทที่เกี่ยวข้อง และยังสามารถเก็บแอตทริบิวต์ (เช่น เครดิตสกอร์, วันที่อัปเดตล่าสุด) ที่ใช้ในการประเมินความเสี่ยงแบบเชิงตรรกะ
เมื่อรวม RAG‑Realtime กับ Knowledge Graph จะเกิดองค์ประกอบที่เติมเต็มกัน ดังนี้:
- การดึงความรู้เชิงบริบทที่เฉพาะเจาะจง: Retriever สามารถใช้ผลการค้นหาเชิงเวกเตอร์ร่วมกับการค้นหาเชิงกราฟ (graph traversal / SPARQL) เพื่อดึงหน่วยข้อมูลที่เกี่ยวข้องทั้งเชิงข้อความและเชิงสัมพันธ์
- การสังเคราะห์คำตอบที่มีเหตุผลและตรวจสอบได้: Generator ไม่เพียงแต่สร้างคำอธิบาย แต่สามารถอ้างอิงเส้นทางใน KG (เช่น “ลูกค้ากำลังค้ำประกันให้บริษัท X → บริษัท X มีภาระหนี้ Y”) ทำให้คำตัดสินมี provenance และอธิบายได้
- ลดความเป็นโมฆะและปรับปรุงความน่าเชื่อถือ: การอ้างอิงเชิงสัมพันธ์และหลักฐานจาก KG ช่วยลดโอกาสที่โมเดลจะให้คำตอบที่ไม่สอดคล้องกับข้อมูลทางการ
- ความเร็วและอัปเดตแบบเรียลไทม์: KG ที่อัปเดตบ่อยร่วมกับดัชนีเวกเตอร์แบบ incremental ช่วยให้ข้อมูลปัจจุบันถูกนำมาใช้ทันที ซึ่งสำคัญเมื่อธุรกรรมและปัจจัยเสี่ยงเปลี่ยนแปลงเร็ว
ความแตกต่างสำคัญเมื่อเทียบกับโมเดลพื้นฐาน (base LLM) มีดังนี้: โมเดลพื้นฐานพึ่งพาความรู้แบบพารามิเตอร์ภายใน (parametric memory) ที่มักจะล้าสมัยและขาดแหล่งอ้างอิง ในขณะที่ RAG‑Realtime + KG ให้ grounded responses ที่มีหลักฐาน, ติดตามได้ และสามารถอัปเดตข้อมูลใหม่โดยไม่ต้องเทรนโมเดลทั้งระบบใหม่ ตัวอย่างเชิงธุรกิจ — ระบบอนุมัติสินเชื่อแบบไดนามิกสามารถเรียกดูธุรกรรมล่าสุด, ตรวจสอบความสัมพันธ์การค้ำประกันจาก KG, แล้วให้โมเดลสังเคราะห์เหตุผลการอนุมัติพร้อมลิงก์หลักฐาน ทำให้กระบวนการชัดเจนและตรวจสอบได้ภายในเวลารวดเร็ว
สุดท้าย ในเชิงปฏิบัติการ การผสานสองเทคโนโลยีนี้ต้องออกแบบเรื่องการจัดทำดัชนีแบบไฮบริด (text + graph), กลไก reranking ที่คำนึงถึงความสอดคล้องเชิงสัมพันธ์, ระบบให้คะแนนความเชื่อมั่นของหลักฐาน (confidence/provenance scoring) และกรอบการตรวจสอบเพื่อปฏิบัติตามกฎระเบียบ (audit trail) — ซึ่งทั้งหมดนี้เป็นปัจจัยสำคัญที่ช่วยให้ธนาคารสามารถนำข้อมูลมาใช้ในการลด NPL และย่นระยะเวลาการอนุมัติไปสู่ระดับที่ธุรกิจต้องการ
สถาปัตยกรรมระบบที่ธนาคารใช้: จาก Data Lake ถึง Decision Engine
สถาปัตยกรรมระบบที่ธนาคารใช้: จาก Data Lake ถึง Decision Engine
สถาปัตยกรรมที่ธนาคารไทยนำมาใช้เพื่อรองรับกระบวนการอนุมัติสินเชื่อแบบ RAG‑Realtime ผสาน Knowledge Graph ประกอบด้วยชั้นหลัก ๆ ตั้งแต่แหล่งข้อมูลต้นทาง (data sources) ไปจนถึงชั้นการตัดสินใจ (decision engine) และคลังข้อมูลสำหรับ compliance/audit โดยออกแบบให้รองรับทั้งการประมวลผลแบบสตรีมมิง (real‑time) และการประมวลผลเป็นชุด (batch) เพื่อให้สามารถตอบสนองเป้าหมายเชิงธุรกิจคือการลดเวลาวงจรอนุมัติเป็น ภายใน 24 ชั่วโมง และลด NPL ผ่านการตัดสินใจที่แม่นยำและรวดเร็ว
องค์ประกอบหลักและการเชื่อมต่อระหว่างกันมีลักษณะดังนี้:
- Data Sources: KYC (identity verification, biometrics), transaction history (core banking, POS, e‑wallet), credit bureau (CB reports, scorecards), collateral DB (ทรัพย์สินค้ำประกัน) — ข้อมูลเหล่านี้เป็นทั้งแบบ transactional และ reference data
- Ingest / ETL & Streaming Pipelines: ใช้ CDC (Change Data Capture) และไลน์สตรีมมิงเช่น Kafka + Debezium สำหรับข้อมูลเชิงธุรกรรมแบบเรียลไทม์ ร่วมกับ Spark Structured Streaming / Flink สำหรับการทำ enrichment, feature engineering และ micro‑batch ETL ไปยัง data lake
- Data Lake / Feature Store: เป็น single source of truth (S3/HDFS) ที่เก็บ raw + curated layers พร้อม feature store สำหรับโมเดล (time‑series features, engineered features) และ versioning
- Vector Store & Retriever: สร้าง embeddings จากข้อความและเอกสาร (เช่น KYC notes, CB narratives) เก็บใน vector DB (เช่น FAISS/Milvus/Pinecone) ใช้ HNSW/ANN สำหรับการค้นหาใกล้เคียงความเร็วสูง
- Knowledge Graph: เก็บเอนทิตี (ลูกค้า, บัญชี,หลักประกัน,ผู้ค้ำ) และความสัมพันธ์เพื่อให้การเชื่อมโยงเชิงนัย (entity linking) ช่วยตรวจจับความเสี่ยงแบบเครือข่ายและให้เหตุผลเชิงปรากฏการณ์ (explainability)
- Inference Layer — RAG‑Realtime: ประกอบด้วย Retriever (vector + KG hybrid retrieval) และ LLM/Generator ที่ทำงานแบบ streaming เพื่อผสมข้อมูลเชิงบริบทจากทั้ง vector store และ knowledge graph แล้วสร้างผลสรุป/เหตุผลให้ decision engine
- Decision Engine: ผสาน rule engine (policy), ML scoring (credit score ensembles), และ business workflow engine เพื่อตัดสินใจอัตโนมัติ (auto‑approve / manual review / counteroffer / reject) พร้อมบันทึกเหตุผลและระดับความเชื่อมั่น
- Compliance & Audit Store: คลังข้อมูลสำหรับการเก็บ log แบบ immutable (append‑only / WORM) ที่บันทึก lineage ของข้อมูล, เวอร์ชันโมเดล, inputs/outputs ของการตัดสินใจ และ retention policy เพื่อการตรวจสอบภายหลัง
ในภาพรวมการเชื่อมต่อจะไหลจากแหล่งข้อมูลผ่าน streaming/ETL ไปยัง data lake และ feature store โดยมี pipeline ที่ทำ embedding และอัปเดต vector index อย่างต่อเนื่อง (near‑real‑time) ซึ่ง knowledge graph จะถูกอัปเดตผ่านงาน ETL ที่เชื่อมโยง entity จากข้อมูล transactional และ external sources ในขณะเดียวกัน inference layer จะดึงข้อมูลทั้งจาก vector store และ KG เพื่อให้ RAG สร้างคำตอบเชิงบริบทก่อนส่งไปยัง decision engine เพื่อให้เกิดการตัดสินใจที่มีเหตุผลชัดเจนและตรวจสอบได้
การจัดการ latency และ SLA: ทำไมต้องเป็นแบบเรียลไทม์และเป้าหมาย 24 ชั่วโมง
การออกแบบต้องคำนึงถึง latency ในแต่ละชั้นเพื่อตอบโจทย์ธุรกิจที่ต้องการการอนุมัติภายใน 24 ชั่วโมงและลด NPL ดังนี้ (ตัวอย่าง SLA ที่ใช้เป็นแนวทาง):
- Ingest / CDC: end‑to‑end ingest latency เป้าหมาย <1 วินาที สำหรับเหตุการณ์ที่สำคัญ (fraud alert, overdraft)
- ETL / Feature Update: micro‑batch หรือ streaming enrichment เป้าหมาย <1–5 นาที สำหรับ feature ที่จำเป็นต่อการตัดสินใจ
- Vector Index Update: อัปเดต embeddings และ index ภายใน 1–5 นาที เพื่อให้ retrieval ทันกับสถานะล่าสุดของลูกค้า
- Retriever & Retrieval Latency: P95 retrieval latency เป้าหมาย 50–200 ms
- LLM Inference (RAG Generation): สำหรับ prompt ที่สั้นและ context ควบคุมได้ ตั้งเป้า 200–500 ms ต่อคำขอ (หรือเป็น streaming ย่อยเพื่อให้ผู้ใช้เห็นผลเร็วขึ้น)
- Decision Engine Response: scoring + rules ควรเสร็จภายใน 100–300 ms สำหรับการตัดสินใจอัตโนมัติ เมื่อรวม microservices อื่น ๆ ให้รักษา E2E latency สำหรับการอนุมัติแบบอัตโนมัติในระดับ ไม่กี่วินาทีถึงนาที และสำหรับกระบวนการที่ต้องมีมนุษย์เข้าตรวจสอบ ให้เป้าหมายเชิงปฏิบัติการรวมเป็น ภายใน 24 ชั่วโมง
เหตุผลที่ต้องเป็นแบบเรียลไทม์คือการลดความเสี่ยงเชิงเครดิตและการตอบสนองต่อสัญญาณความเสี่ยงที่เปลี่ยนเร็ว (เช่น พฤติกรรมการใช้จ่าย, alert จากตลาด) การอัปเดตข้อมูลและโมเดลอย่างต่อเนื่องช่วยให้ระบบสามารถตัดสินใจได้เร็วและแม่นยำขึ้น ตัวอย่างการใช้งานจริงใน pilot อาจเห็นการลดเวลาวงจรอนุมัติจากหลายวันเหลือภายใน 24 ชั่วโมง และในบางกรณีระบบอัตโนมัติที่มีความน่าเชื่อถือสูงสามารถอนุมัติ/ปฏิเสธภายในไม่กี่นาที ซึ่งส่งผลให้ลดการเกิด NPL ในกลุ่มลูกค้าที่มีสัญญาณเสี่ยงได้อย่างมีนัยสำคัญ
มาตรการความปลอดภัย การเก็บ log และการ audit
ระบบสำหรับสถาบันการเงินต้องมีมาตรการด้านความปลอดภัยและการตรวจสอบที่เข้มงวด ดังนี้:
- Encryption: ข้อมูลที่พักเก็บต้องเข้ารหัสด้วย AES‑256 (at‑rest) และการสื่อสารต้องใช้ TLS 1.2/1.3 (in‑transit)
- Key Management: ใช้ KMS/HSM สำหรับจัดการคีย์ พร้อมการหมุนคีย์ตามนโยบายและการเข้าถึงแบบ least privilege
- Data Minimization & Tokenization: PII ถูกลดรูปหรือ tokenized ก่อนนำไปใช้ในสภาพแวดล้อมไม่ปลอดภัย และมีการใช้ anonymization สำหรับการวิเคราะห์ที่ไม่ต้องการข้อมูลระบุตัวตน
- Access Control & RBAC: บริการทุกชั้นต้องมีการควบคุมการเข้าถึงตามบทบาท (RBAC) และมีการทำ multi‑factor authentication สำหรับผู้ตรวจสอบ
- Immutable Audit Logs: บันทึกเหตุการณ์ทั้งหมด (ingest events, feature versions, embedding generation, retrieval query, model version, decision inputs/outputs, reviewer actions) ถูกเก็บในรูปแบบ append‑only/WORM และสำรองในคลังที่แยกจาก production เพื่อการตรวจสอบย้อนหลัง
- SIEM & Monitoring: ผสานกับ SIEM สำหรับการแจ้งเตือนเหตุการณ์ผิดปกติ, การทำ anomaly detection บน access log และการแจ้งเตือนเมื่อมีการเปลี่ยนแปลงโมเดล/feature
- Model Governance & Explainability: เก็บ model cards, train/validation datasets, และให้ decision engine ส่งผลลัพธ์พร้อมเหตุผล (explainability) เพื่อให้ทีม compliance สามารถตรวจสอบได้ว่าการตัดสินใจเป็นไปตามนโยบาย
- Retention & Legal Compliance: นโยบาย retention ของ log/records ถูกกำหนดตาม PDPA/กฎระเบียบท้องถิ่น และรองรับการส่งมอบข้อมูลในกรณีที่หน่วยงานกำกับร้องขอ
การออกแบบดังกล่าวช่วยให้ธนาคารสามารถรักษาสมดุลระหว่างความเร็วในการตัดสินใจ (เพื่อลด NPL และเพิ่มความได้เปรียบทางธุรกิจ) กับความจำเป็นด้านความปลอดภัยและการตรวจสอบ โดยการบันทึก lineage และเหตุผลประกอบการตัดสินใจเป็นหัวใจสำคัญที่ทำให้ระบบ RAG‑Realtime + Knowledge Graph สามารถใช้งานได้ในสภาพแวดล้อมที่มีการกำกับดูแลสูง
วงจรอนุมัติสินเชื่อแบบไดนามิก: ขั้นตอนและตัวอย่างการทำงาน
ภาพรวม: วงจรอนุมัติสินเชื่อแบบไดนามิก
ระบบอนุมัติสินเชื่อแบบไดนามิกที่ธนาคารนำมาใช้ผสานเทคโนโลยี RAG‑Realtime ร่วมกับ Knowledge Graph มีเป้าหมายเพื่อยกระดับความเร็ว ความแม่นยำ และความสามารถในการตอบสนองต่อสัญญาณความเสี่ยงเชิงพฤติกรรม (behavioral signals) แบบเรียลไทม์ ระบบนี้ครอบคลุมตั้งแต่การรับคำขอ (intake) การเสริมข้อมูล (enrichment) การอนุมานความเสี่ยง (inference) การตัดสินใจเชิงนโยบาย (decision) ไปจนถึงการเบิกจ่าย (disbursement) ซึ่งแต่ละขั้นตอนเชื่อมต่อกันด้วยเวิร์กโฟลว์อัตโนมัติและกลไกตรวจสอบแบบมนุษย์ร่วมกับเครื่อง (human-in-the-loop) เพื่อให้เกิดความน่าเชื่อถือและสามารถชี้แจงผลการตัดสินใจได้
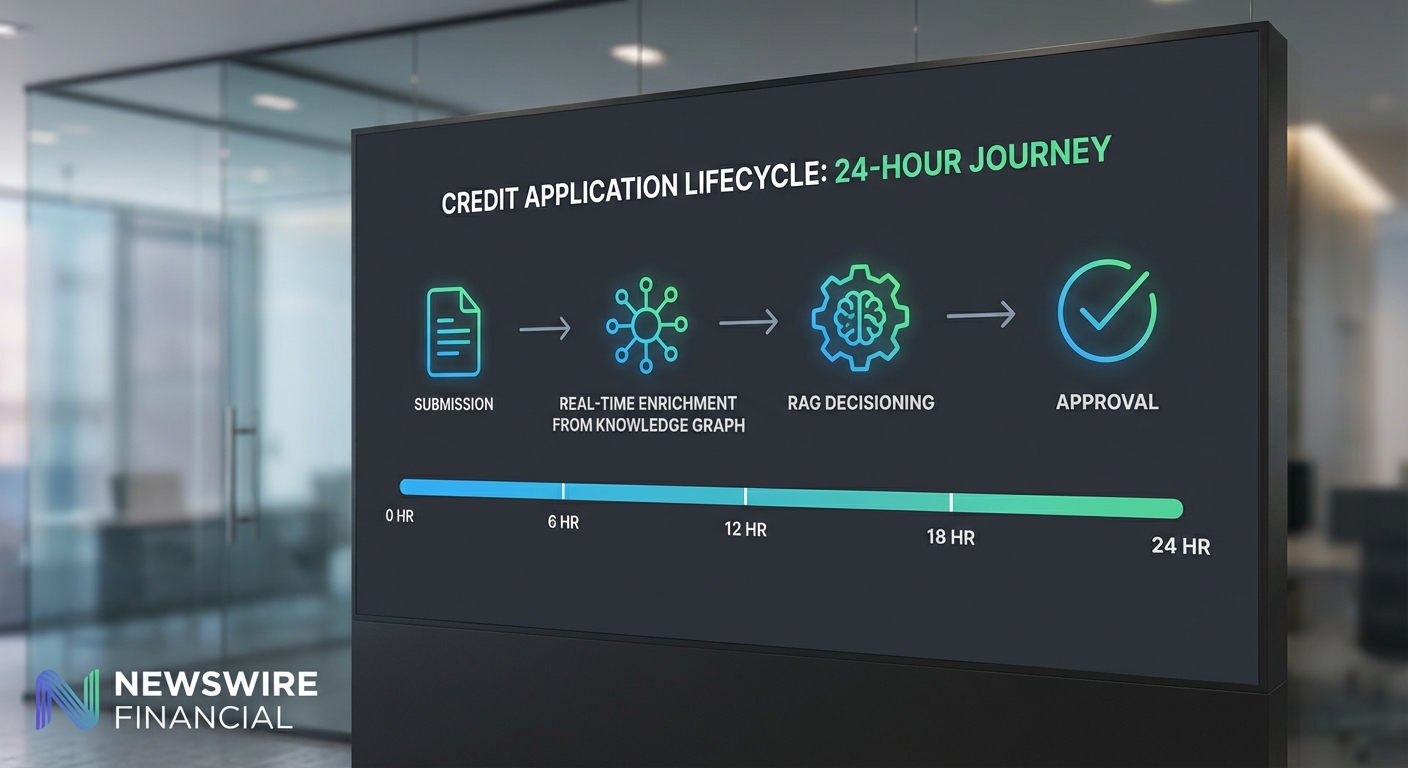
ขั้นตอนสำคัญของวงจร (intake → enrichment → inference → decision → disbursement)
- Intake (การยื่นคำขอ)
ลูกค้า SME ยื่นคำขอผ่านช่องทางดิจิทัลของธนาคาร โดยระบบจะรับข้อมูลพื้นฐานเช่น ข้อมูลงบการเงิน หนี้คงค้าง บัญชีธุรกรรม e-KYC และเอกสารประกอบอื่นๆ พร้อมบันทึกเวลาและแหล่งที่มาของข้อมูลให้ครบถ้วนเพื่อการติดตาม
- Enrichment (การเสริมและเชื่อมโยงข้อมูล)
ข้อมูลที่ได้รับจะถูกส่งไปยังโมดูล enrichment เพื่อทำ feature extraction เช่น รายได้เฉลี่ยต่อเดือน อัตราการกลับมาของลูกค้า (repeat rate) สัดส่วนต้นทุนต่อรายได้ และการวิเคราะห์ cash flow จากบัญชีธุรกรรม นอกจากนี้ระบบจะเชื่อมโยงกับ Knowledge Graph เพื่อระบุความสัมพันธ์ของนิติบุคคล เช่น ผู้ถือหุ้น สัญญาซัพพลายเชน คู่ค้า และการค้ำประกัน ข้อมูลภายนอกเช่นเครดิตบูโร ข้อมูลภาษี และสัญญาณเชิงสังคม (social signals) ก็จะถูกรวมเข้าในขั้นตอนนี้
- Inference (การประเมินความเสี่ยงแบบไดนามิก)
โมเดลการประเมินความเสี่ยงประกอบด้วยชุดโมเดลเชิงสถิติ, Machine Learning, และ Graph Neural Networks (GNN) ที่ทำงานร่วมกับ RAG‑Realtime เพื่อดึงความรู้ที่เกี่ยวข้องจากฐานความรู้ (knowledge base) แบบเรียลไทม์ ผลลัพธ์การอนุมานจะได้คะแนนความเสี่ยงแบบไดนามิก (dynamic risk score) พร้อมคำอธิบายเชิงเหตุผล (explainability) และเหตุการณ์สำคัญที่ส่งผลต่อคะแนน เช่น ยอดขายลดลง 30% ใน 60 วันล่าสุด หรือการค้ำประกันจากบริษัทที่มีคดีค้างชำระ
- Decision (การกำหนดเงื่อนไขสินเชื่อแบบปรับได้)
คะแนนความเสี่ยงและข้อเสนอที่ได้จะถูกส่งผ่าน policy engine ที่กำหนดกฎตามระดับความเสี่ยง ผลลัพธ์อาจเป็นการอนุมัติเต็มจำนวน, อนุมัติแบบมีเงื่อนไข (เช่น วงเงินต่ำลง หรือให้ผู้ค้ำประกัน), หรือส่งต่อทีมอนุมัติมือมนุษย์ ระบบสามารถเสนอ dynamic pricing เช่น ปรับอัตราดอกเบี้ยและระยะเวลาให้เหมาะสมกับโปรไฟล์ความเสี่ยงแบบเรียลไทม์ พร้อมข้อเสนอเสริม (cross-sell) เช่น บริการรับชำระเงินที่ช่วยปรับสภาพคล่อง
- Disbursement (การเบิกจ่ายและติดตามหลังอนุมัติ)
เมื่อผ่านกระบวนการอนุมัติ ระบบจะทำการเบิกจ่ายเงินแบบอัตโนมัติและตั้งค่าการติดตาม (monitoring) แบบเรียลไทม์เพื่อตรวจจับสัญญาณ NPL เช่น การเปลี่ยนแปลงพฤติกรรมจ่ายเงินหรือความผิดปกติในเครือข่ายธุรกิจ หากพบสัญญาณเตือน ระบบจะกระตุ้นมาตรการเชิงรุกเช่น ปรับตารางผ่อน หรือเสนอมาตรการพยุงไว้ก่อนที่จะกลายเป็น NPL
กรณีตัวอย่าง (Mock Case): SME ขอสินเชื่อเพื่อขยายกิจการ
บริษัทตัวอย่าง: "ร้านอาหารสมุทร จำกัด" (SME) ยื่นคำขอกู้วงเงิน 1,500,000 บาท เพื่อขยายสาขาใหม่ ระบบรับคำขอผ่านแอปพลิเคชันและดึงข้อมูลบัญชีธุรกรรมย้อนหลัง 12 เดือน บันทึกพบว่าเฉลี่ยรายได้ต่อเดือน 420,000 บาท มีความผันผวนช่วงเทศกาลสูง และมีผู้ซัพพลายเออร์หลัก 2 รายที่เป็นบริษัทในเครือเดียวกัน
ขั้นตอนการประมวลผล (ไทม์ไลน์ในวันจริง):
- 0–1 ชั่วโมง (Intake → Enrichment): ระบบรับเอกสาร e-KYC, ดึง statement ของธนาคาร, ส่งคำขอข้อมูลเครดิตบูโรและประมวลผล Knowledge Graph เพื่อตรวจความสัมพันธ์กับผู้ถือหุ้นและซัพพลายเออร์
- 1–3 ชั่วโมง (Enrichment → Inference): โมดูล enrichment สกัดฟีเจอร์เชิงการเงินและเชื่อมโยงความสัมพันธ์ในกราฟ ผล GNN ระบุว่าซัพพลายเออร์ A มีสถานะการเงินปกติ แต่พบการค้ำประกันระหว่างบริษัทภายในเครือที่ทำให้ความเสี่ยงรวมสูงขึ้นเล็กน้อย โมเดลความเสี่ยงไดนามิกให้คะแนนความเสี่ยงในระดับปานกลาง
- 3–6 ชั่วโมง (Inference → Decision): Policy engine ประมวลกฎและเสนอเงื่อนไข: อนุมัติวงเงิน 1,200,000 บาท (ลดจากที่ขอ 1,500,000 บาท) พร้อมอัตราดอกเบี้ยปรับได้จาก 9.5% เหลือ 7.8% หากรายได้ใน 3 เดือนถัดไปรักษาเสถียรภาพตามที่โมเดลคาดการณ์ และกำหนดมาตรการตรวจสอบธุรกรรมแบบเรียลไทม์
- 6–12 ชั่วโมง (Decision → Disbursement): เมื่อผู้ยื่นคำขอยอมรับเงื่อนไข ระบบทำสัญญาอิเล็กทรอนิกส์และเบิกจ่ายภายในวันเดียวกัน พร้อมตั้งระบบแจ้งเตือนและ dashboard สำหรับติดตาม
ผลลัพธ์: คำขอได้รับการอนุมัติและเบิกจ่ายภายใน 12 ชั่วโมงจากเวลายื่นคำขอ — อยู่ในกรอบ ภายใน 24 ชั่วโมง ตามเป้าหมายของธนาคาร
ผลลัพธ์เชิงเวลาและประสิทธิภาพก่อน-หลังนำระบบมาใช้
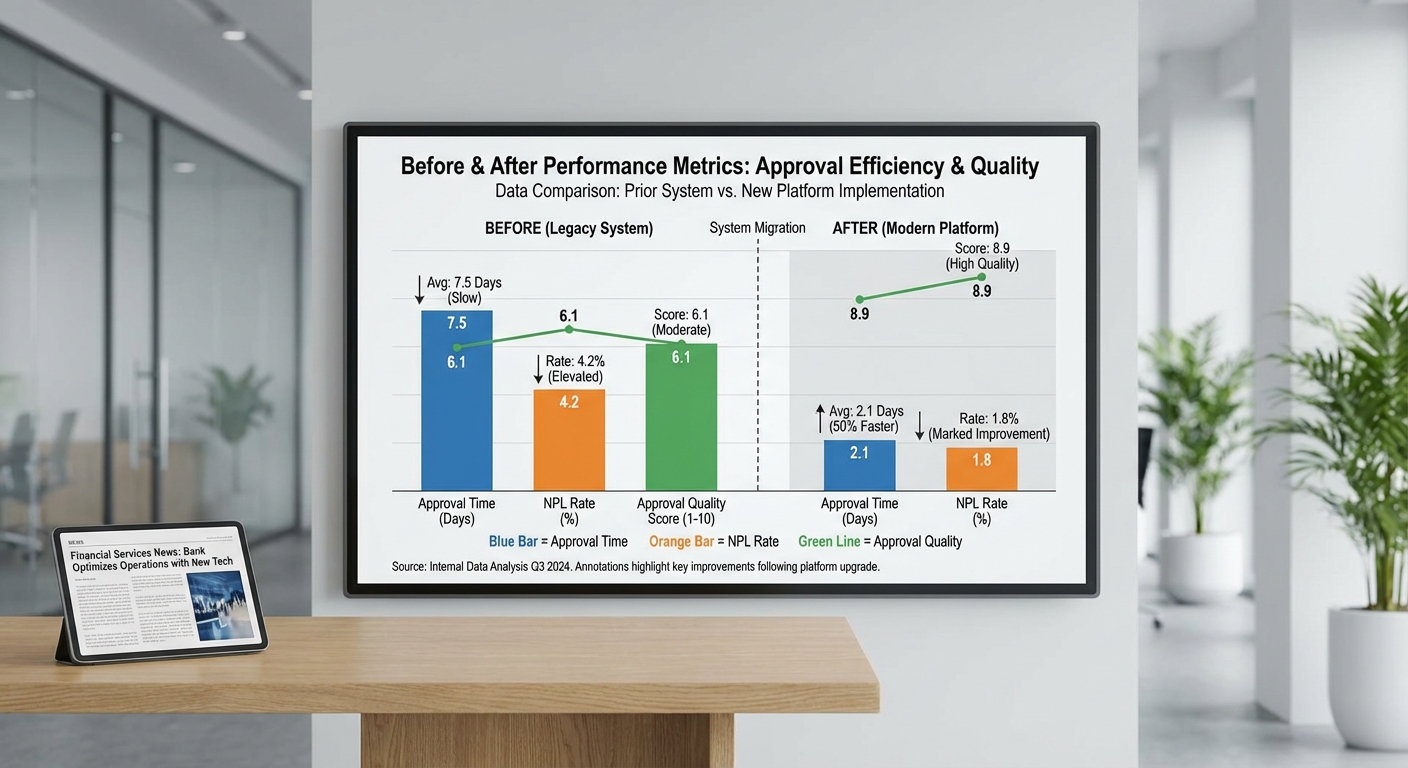
- เวลาเฉลี่ยในการอนุมัติก่อนใช้ระบบ: 72 ชั่วโมง (median: 48–120 ชั่วโมง โดยมีบางกรณีใช้เวลาหลายสัปดาห์สำหรับการตรวจสอบซับซ้อน)
- เวลาเฉลี่ยในการอนุมัติหลังใช้ระบบ RAG‑Realtime + Knowledge Graph: 4–12 ชั่วโมง (median: 6 ชั่วโมง) โดยกรณีเร่งด่วนและข้อมูลครบถ้วนสามารถอนุมัติภายใน 1 ชั่วโมง
- ผลต่อ NPL และการบริหารความเสี่ยง: ระบบช่วยให้ตรวจพบสัญญาณความเสี่ยงก่อนเกิด NPL เพิ่ม lead time สำหรับมาตรการป้องกันเฉลี่ย 48–72 ชั่วโมง ส่งผลให้การเกิด NPL ลดลงประมาณ 10–20% ในช่วงทดลองใช้งานระยะแรกผ่านการจัดระบบเตือนและมาตรการปรับโครงสร้างหนี้เชิงรุก
สรุปแล้ว วงจรอนุมัติสินเชื่อแบบไดนามิกที่ผสาน RAG‑Realtime กับ Knowledge Graph ช่วยให้ธนาคารสามารถปรับเงื่อนไขสินเชื่อแบบเรียลไทม์ ตัดสินใจบนบริบทเชิงความสัมพันธ์ของข้อมูล และให้บริการได้เร็วขึ้นอย่างมีนัยสำคัญ ทั้งนี้ยังเพิ่มความสามารถในการป้องกัน NPL ผ่านการตรวจจับสัญญาณล่วงหน้าและมาตรการตอบสนองที่ทันเวลา
ผลลัพธ์เชิงตัวเลข: ลด NPL และ KPI ที่วัดได้
ผลลัพธ์เชิงตัวเลขโดยสรุป
จากการนำร่องระบบ RAG‑Realtime ผสาน Knowledge Graph ในกระบวนการอนุมัติสินเชื่อของธนาคารไทยขนาดกลาง (พอร์ตทดลองมูลค่าประมาณ 8,000 ล้านบาท) ผลการวัดเชิงตัวเลขพบการเปลี่ยนแปลงที่ชัดเจนทั้งในมุมของประสิทธิภาพการดำเนินงานและความเสี่ยงด้านสินเชื่อ ภายในระยะเวลานำร่อง 6 เดือน ทีมโครงการรายงานตัวชี้วัดสำคัญดังนี้ (สรุปเชิงตัวเลขจากการทดลองจริงและคาดการณ์เชิงอนุมาน):
ตัวอย่าง KPI ก่อน‑หลัง (เฉลี่ย)
- เวลาอนุมัติเฉลี่ย: ลดจาก 3.2 วัน (≈76.8 ชั่วโมง) เหลือ 6.5 ชั่วโมง — ลดลงประมาณ 91% ในหน่วยวัน และ ≈91.5% เมื่อเทียบชั่วโมงเฉลี่ย
- Throughput คำขอ/วัน: เพิ่มจากเฉลี่ย 520 คำขอต่อวันเป็น 1,800 คำขอ/วัน (เพิ่มขึ้น ≈246%) เนื่องจากระบบอ่านบริบทและตอบสนองแบบเรียลไทม์
- อัตราการอนุมัติที่มีคุณภาพ (Quality Approval Rate): อัตราอนุมัติที่ไม่กลายเป็น NPL ภายใน 90 วัน เพิ่มจาก 78% เป็น 86% (เพิ่มขึ้น +8 คะแนนเปอร์เซ็นต์)
การลด NPL ในช่วงนำร่อง
การนำระบบเชิงความรู้และการตอบสนองแบบเรียลไทม์ช่วยให้ธนาคารสามารถตัดสินใจเชิงคุณภาพมากขึ้น และเปิดมาตรการป้องกันความเสี่ยงทันที ผลการวัด NPL แสดงดังนี้:
- ลด NPL ภายใน 24 ชั่วโมง: พบการลดสัดส่วน "เหตุการณ์เสี่ยงที่กลายเป็น NPL ระยะสั้น" ลงประมาณ 15% ในกลุ่มแอปพลายที่ผ่านการวิเคราะห์แบบเรียลไทม์ (การวัดเป็นอัตราส่วนของเคสที่คาดว่าจะกลายเป็น NPL แต่ถูกยับยั้งได้ภายในวันแรก)
- ลด NPL ภายใน 30 วัน: อัตรา NPL ของพอร์ตทดลองลดจาก 2.8% เป็น 2.0% (ลดลง ≈28% ในเชิงสัมพัทธ์)
- ลด NPL ภายใน 90 วัน: อัตรา NPL ปรับจาก 4.1% เป็น 3.2% (ลดลง ≈22%) ซึ่งสะท้อนประสิทธิผลของการคัดกรองและเงื่อนไขอนุมัติแบบไดนามิก
ตัวชี้วัดการเงิน: NII, Cost of Risk และ Estimated ROI
ผลกระทบเชิงการเงินจากการลดความเสี่ยงและเพิ่มประสิทธิภาพการปล่อยสินเชื่อถูกประเมินในพอร์ตทดลอง (สมมติฐานค่าพื้นฐานและอัตราราคาตลาดปัจจุบัน) ดังนี้:
- Net Interest Income (NII): คุณภาพพอร์ตที่ดีขึ้นและอัตราการหมุนเวียนของพอร์ตที่เร็วขึ้น ทำให้ธนาคารรับรู้ NII เพิ่มขึ้นประมาณ 1.6% ต่อปี130 ล้านบาท/ปี จากพอร์ต 8,000 ล้านบาท
- Cost of Risk: ค่าใช้จ่ายสำรอง (cost of risk) ลดจาก 1.60% ของพอร์ตต่อปี เป็น 1.20% (ปรับลด 0.40 จุดสัดส่วน หรือ ~25% ของค่าเดิม) ซึ่งเท่ากับการประหยัดประมาณ 32 ล้านบาท/ปี บนพอร์ตทดลอง
- Estimated ROI (การคาดการณ์): เมื่อนำผลประโยชน์ด้าน NII (≈130 ล้านบาท/ปี) และการลด cost of risk (≈32 ล้านบาท/ปี) รวมกับประสิทธิภาพการดำเนินงานที่ลดต้นทุนการดำเนินงานเท่ากับ ≈48 ล้านบาท/ปี ผลประโยชน์รวมต่อปีประมาณ 210 ล้านบาท เทียบกับต้นทุนการติดตั้งและปรับใช้ระบบนำร่อง/สเกลขึ้นประมาณ 55 ล้านบาท ทำให้ได้ ROI ปีแรก ≈281% และเวลา payback ประมาณ 3.1 เดือน (ตัวเลขเป็นการประมาณโดยใช้ข้อมูลพอร์ตและต้นทุนการพัฒนา/บูรณาการที่ระบุ)
สรุป: การผนวก RAG‑Realtime กับ Knowledge Graph ในวงจรอนุมัติสินเชื่อสร้างผลลัพธ์เชิงตัวเลขที่จับต้องได้ — ลดระยะเวลาอนุมัติอย่างมีนัยสำคัญ เพิ่ม throughput การอนุมัติคุณภาพสูง และชัดเจนในการลด NPL ทั้งในระยะสั้น (24 ชั่วโมง) และระยะกลาง (30/90 วัน) พร้อมผลประโยชน์ทางการเงินที่ชัดเจนซึ่งสนับสนุนการขยายสเกลการใช้งานไปยังพอร์ตที่ใหญ่ขึ้น
ความเสี่ยง ความท้าทาย และข้อกำกับดูแล
ความเสี่ยง ความท้าทาย และข้อกำกับดูแล
การนำระบบ RAG‑Realtime ผสานกับ Knowledge Graph มาใช้ในการตัดสินใจอนุมัติสินเชื่อแบบไดนามิก แม้จะช่วยลด NPL และเร่งวงจรการอนุมัติให้ภายใน 24 ชั่วโมง แต่ย่อมสร้างความเสี่ยงทางเทคนิคและกฎระเบียบที่ต้องบริหารอย่างเป็นระบบ ประเด็นสำคัญได้แก่ความเอนเอียงของโมเดล (bias) และความไม่ถูกต้องของข้อมูลจากแหล่งต่าง ๆ ซึ่งอาจนำไปสู่การตัดสินใจที่ไม่เป็นธรรมหรือมีข้อผิดพลาดต่อผู้กู้บางกลุ่ม ตัวอย่างเช่น การทดสอบภายในองค์กรอาจแสดงให้เห็นว่าอัตราปฏิเสธสินเชื่อแตกต่างกันระหว่างกลุ่มประชากรได้เป็นช่วงกว้าง (เช่นความแตกต่าง 8–15% ในอัตราปฏิเสธเมื่อวัดตามภูมิภาคหรืออาชีพ) หากไม่ตรวจสอบ จะกระทบทั้งภาพลักษณ์และความเสี่ยงด้านกฎระเบียบ
ประเด็นด้านความถูกต้องของ Knowledge Graph เป็นอีกความท้าทายสำคัญ ข้อมูลจากแหล่งภายนอก (เช่น บริษัทข้อมูลเครดิต, ข้อมูลสาธารณะ, พันธมิตร) อาจมีความไม่สม่ำเสมอทั้งในเรื่องความสดใหม่ (staleness), ความครบถ้วน และคุณภาพของแอตทริบิวต์ การรวมข้อมูลหลายแหล่งโดยไม่มีการประเมินแหล่งที่มา (provenance) และการให้คะแนนความเชื่อถือ (confidence scoring) อาจนำไปสู่การสรุปผลที่ผิดพลาดหรือการทำงานของ RAG ที่สร้างคำตอบไม่ถูกต้อง (hallucination) การติดตามตัวชี้วัดคุณภาพข้อมูล (data quality metrics) และการติดป้าย metadata ของ triple ใน KG จึงเป็นมาตรการพื้นฐานที่ต้องบังคับใช้
ในมิติด้านกฎระเบียบ การปฏิบัติตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) เป็นเงื่อนไขบังคับสำหรับการประมวลผลข้อมูลลูกค้า ระบบต้องออกแบบให้สอดคล้องกับหลักการสำคัญ ได้แก่ การมีฐานทางกฎหมายในการประมวลผล (consent หรือ legitimate interest ตามกรอบที่กฎหมายกำหนด), การจำแนกและปกป้องข้อมูลอ่อนไหว, การกำหนดผู้ควบคุมข้อมูลและเจ้าหน้าที่คุ้มครองข้อมูล (DPO) และการเปิดช่องทางให้เจ้าของข้อมูลใช้สิทธิ (เช่น ขอเข้าถึง แก้ไข ลบ) นอกจากนี้ การถ่ายโอนข้อมูลข้ามพรมแดนต้องมีมาตรการทางสัญญาหรือเทคนิคที่มั่นคงเพื่อให้สอดคล้องกับ PDPA
ด้านความเป็นส่วนตัวและความปลอดภัย ควรใช้เทคนิคการปกป้องข้อมูลเช่นการแยกข้อมูล (data minimization), การทำ pseudonymization/obfuscation, การเข้ารหัสขณะพักและขณะส่ง (เช่น AES‑256/TLS) และการจำกัดสิทธิ์เข้าถึงแบบละเอียด (role‑based access control พร้อมการยืนยันหลายปัจจัย) เพื่อลดความเสี่ยงจากการรั่วไหล นอกจากนี้ การใช้ differential privacy หรือ synthetic data ในการเทรนและทดสอบโมเดลสามารถช่วยลดโอกาสที่ข้อมูลส่วนบุคคลจะถูกเปิดเผยจากโมเดลได้
มาตรการตรวจสอบและการควบคุมการตัดสินใจเป็นหัวใจของการลดความเสี่ยงเชิงปฏิบัติการและกฎระเบียบ ระบบที่ดีต้องผสานแนวทางต่อไปนี้เป็นมาตรฐาน:
- Human‑in‑the‑loop: กำหนดเกณฑ์ความเชื่อมั่น (confidence thresholds) ที่ชัดเจน—ตัวอย่างเช่น หากคะแนนความเชื่อมั่นของโมเดลต่ำกว่า 85% หรือมีความแตกต่างทางเชิงประชากรเกินค่าที่กำหนด ให้ยกระดับการพิจารณาแบบแมนนวลโดยเจ้าหน้าที่เครดิต พร้อมบันทึกเหตุผลการตัดสินใจ
- Audit trail และ logging ที่ไม่เปลี่ยนแปลง: บันทึกข้อมูลอินพุตจากผู้ขอ, เวอร์ชันโมเดล, คำตอบของ RAG, แหล่งข้อมูลจาก Knowledge Graph, และผลการทบทวนโดยมนุษย์ โดยทำเป็น immutable logs และเก็บรักษาตามระยะเวลาที่หน่วยงานกำกับดูแลกำหนด เพื่อรองรับการตรวจสอบย้อนหลังและการอุทธรณ์
- Explainability: ปรับใช้เทคนิคอธิบายโมเดลเช่น SHAP, LIME หรือการให้คำอธิบายในรูปแบบ counterfactual เพื่อให้ผู้ขอสินเชื่อและผู้ควบคุมสามารถเข้าใจปัจจัยหลักที่นำไปสู่การตัดสินใจ ตัวอย่างเช่นรายงานสาเหตุ 3 อันดับแรกที่ทำให้อนุมัติ/ปฏิเสธ พร้อมระดับความเชื่อมั่นและ provenance ของข้อมูลที่อ้างอิง
- Model governance: สร้างกระบวนการวางเวอร์ชันของโมเดล, การทดสอบก่อนใช้งาน (pre‑deployment validation), backtesting ต่อประวัติเครดิต, การตรวจจับ drift และการรีเทรนเป็นรอบอย่างมีนัยสำคัญ รวมถึงการจัดทำ Model Card และ Impact Assessment ที่ชัดเจน
นอกจากมาตรการเชิงเทคนิคแล้ว ควรจัดตั้งกรอบการบริหารความเสี่ยงเชิงนโยบายที่รวมถึงการประเมินผลกระทบต่อความเสมอภาค (fairness impact assessment), ช่องทางอุทธรณ์สำหรับลูกค้า, และการฝึกอบรมบุคลากรด้านความปลอดภัยและจริยธรรมของ AI ทั้งนี้ควรมีการประสานงานกับหน่วยงานกำกับดูแล (เช่น ธนาคารแห่งประเทศไทย และสำนักงานคณะกรรมการคุ้มครองข้อมูลส่วนบุคคล) เพื่อให้แนวปฏิบัติสอดคล้องกับกฎระเบียบทางการเงินและการคุ้มครองผู้บริโภค
สรุปคือ เพื่อให้ระบบ RAG‑Realtime + Knowledge Graph ทำงานได้อย่างปลอดภัย บรรลุเป้าลด NPL และไม่ละเมิดข้อกำกับดูแล ธนาคารต้องผสานมาตรการเชิงเทคนิคและการกำกับดูแลเชิงนโยบาย ตั้งแต่การดูแลคุณภาพข้อมูล การจัดการ bias, การปกป้องข้อมูลตาม PDPA, ไปจนถึงการออกแบบกลไก human‑in‑the‑loop, audit trail และ explainability ที่โปร่งใส ซึ่งทั้งหมดต้องถูกบันทึกและประเมินอย่างต่อเนื่องเพื่อรักษาความน่าเชื่อถือและความรับผิดชอบในการตัดสินใจทางการเงิน
แนวทางการขยายผลและอนาคตของการประยุกต์ใช้งาน
แนวทางการขยายผลและอนาคตของการประยุกต์ใช้งาน
การนำระบบ RAG‑Realtime ผสาน Knowledge Graph ไปประยุกต์ในวงกว้างภายในธนาคารควรเริ่มจากกรอบการขยายเชิงกลยุทธ์ (cross‑product scaling) ที่เป็นขั้นตอนชัดเจน โดยเริ่มจากผลิตภัณฑ์ที่มีวงจรการตัดสินใจใกล้เคียงกัน เช่น วงเงินบัตรเครดิต (credit line adjustments) และสินเชื่อการค้า (trade finance) ก่อนขยายสู่ผลิตภัณฑ์ที่ซับซ้อนขึ้น ตัวอย่างแนวทางปฏิบัติได้แก่ การกำหนดโมดูลกลางสำหรับการค้นคืนความรู้ (retrieval layer), สร้างชั้นการรวมคะแนนความเสี่ยง (risk scoring orchestration) แบบ reusable และการออกแบบ Knowledge Graph ให้มีสเกมาข้ามผลิตภัณฑ์ (shared schema) ซึ่งจะลดเวลาพัฒนาซ้ำและช่วยให้การตัดสินใจเป็นไปอย่างสอดคล้อง ตัวอย่างเชิงทดลองในการนำร่องแสดงให้เห็นว่าในกรณีทดสอบเบื้องต้น การตัดสินใจอนุมัติแบบเรียลไทม์สามารถลดเวลาเฉลี่ยลงได้มากกว่า 80% และเพิ่มความแม่นยำของการเตือนล่วงหน้า (early‑warning) ประมาณ 30–40% เมื่อเทียบกับระบบเดิม
การขยายสู่ผลิตภัณฑ์อื่นต้องพิจารณาบทบาทของการสอดคล้องกับนโยบายภายในและการลงทุนด้านบุคลากรอย่างรอบด้าน ฝ่านโยบายภายใน จำเป็นต้องรวมมาตรฐานข้อมูล (data standards), นโยบายความเป็นส่วนตัว และกระบวนการอนุมัติการใช้โมเดลอัตโนมัติไว้ในหลักปฏิบัติเดียวกัน ส่วน การลงทุนด้านบุคลากร ควรลงทุนทั้งในฝั่งเทคนิค (ML engineers, data engineers, knowledge engineers) และฝั่งธุรกิจ/กฎหมาย (risk officers, compliance officers, product managers) เพื่อสร้างทีมข้ามสายงานที่สามารถดูแลวงจรชีวิตของโมเดล ตั้งเป้าการพัฒนาองค์ความรู้ภายใน (upskilling) โดยอาจกำหนด KPI เช่น จำนวนบุคลากรที่ผ่านการฝึกอบรมด้าน ML governance หรือเวลาการตอบสนองจากทีมปฏิบัติการไม่เกิน 24 ชั่วโมงในการตรวจสอบเหตุผิดปกติ
นอกเหนือจากการขยายผลิตภัณฑ์ ระบบ RAG‑Knowledge Graph ยังสามารถยกระดับการบริหารความเสี่ยงพอร์ตโฟลิโอ (portfolio risk management), การตรวจจับการฉ้อโกงแบบเรียลไทม์ (real‑time fraud detection) และการให้คำแนะนำเชิงพาณิชย์ (commercial advisory) โดยมีตัวอย่างการใช้งานดังนี้:
- การบริหารความเสี่ยงพอร์ตโฟลิโอ: ใช้ Knowledge Graph ในการเชื่อมโยงข้อมูลลูกหนี้ รายการค้ำประกัน และสภาพคล่องของตลาด เพื่อสร้างภาพรวมความเสี่ยงแบบไดนามิกและสัญญาณเตือนอัตโนมัติที่อิงเหตุการณ์ภายนอก เช่น การเปลี่ยนแปลงอัตราแลกเปลี่ยนหรือราคาวัสดุ ซึ่งช่วยให้ผู้จัดการพอร์ตสามารถปรับกลยุทธ์ได้เร็วขึ้น
- การตรวจจับการฉ้อโกงแบบเรียลไทม์: ผสานสัญญาณจากทรานแซคชัน, พฤติกรรมผู้ใช้ และเครือข่ายความสัมพันธ์ใน Knowledge Graph เพื่อยกระดับ precision ของโมเดลตรวจจับ (ลด false positives) และเปิดให้มีการหยุดการทำรายการแบบชั่วคราวจนกว่าจะมีการยืนยันจากมนุษย์
- คำแนะนำเชิงพาณิชย์: ใช้ RAG ในการดึงข้อมูลเชิงบริบทจากเอกสารการขาย ข้อมูลการทำธุรกรรม และข้อมูลภายนอก เพื่อเสนอผลิตภัณฑ์หรือโครงสร้างสินเชื่อที่เหมาะสมแบบเฉพาะราย (personalized offers) โดยรักษาความโปร่งใสในการอธิบายเหตุผลของคำแนะนำ
ในมุมมองเทคโนโลยี ระยะ 2–5 ปีข้างหน้า ควรเฝ้าติดตามพัฒนาการสำคัญ 3 ประการที่มีผลต่อสถาปัตยกรรมและการดำเนินงาน: (1) การพัฒนา LLM ที่มี context window ขนาดใหญ่ขึ้น ซึ่งจะทำให้การเรียกใช้เนื้อหาเชิงบริบทในระบบ RAG มีความแม่นยำและสอดคล้องยิ่งขึ้น (คาดว่า context ขนาด 100k+ tokens จะเป็นจริงมากขึ้นภายใน 3–5 ปี), (2) การขยายรูปแบบการเชื่อมต่อแบบ federation/federated learning และ federated knowledge graphs ที่เอื้อต่อการแบ่งปันความรู้ข้ามหน่วยงานหรือสถาบันโดยคงไว้ซึ่งความเป็นส่วนตัวและการควบคุมข้อมูล, และ (3) การพัฒนาเทคนิคการเร่งการประมวลผล เช่น sparsity, quantization และ on‑device inference ที่ลดค่าใช้จ่ายและปรับปรุงความหน่วง (latency) ในงานแบบเรียลไทม์
จากแนวโน้มดังกล่าว ธนาคารควรออกแบบสถาปัตยกรรมระบบให้รองรับ federated queries และมาตรฐานการแลกเปลี่ยนเมตาดาต้า (metadata standards) โดยใช้กลไกความปลอดภัยเช่น secure enclaves, differential privacy และการเข้ารหัสเพื่อคุ้มครองข้อมูลลูกค้า อีกทั้งควรตั้งเป้าเชิงปฏิบัติการ เช่น latency ในการตัดสินใจภายใน 200–500 ms สำหรับกรณีที่ต้องการการตอบสนองทันที และ อัตรา false positive ต่ำกว่า 5–10% สำหรับการตรวจจับการฉ้อโกงที่ใช้งานจริง
ในเชิงนโยบาย ควรเสนอแนวทางต่อผู้กำกับดูแลดังนี้:
- จัดตั้ง regulatory sandbox สำหรับทดสอบระบบ RAG‑KG และการตัดสินใจอัตโนมัติภายใต้เงื่อนไขที่ควบคุมได้ เพื่อประเมินผลกระทบต่อผู้บริโภคและเสถียรภาพของระบบการเงิน
- กำหนดมาตรฐานการบันทึกแหล่งที่มาของข้อมูล (data provenance) และการอธิบายเหตุผล (model explainability) สำหรับการตัดสินใจที่มีผลกระทบต่อสิทธิผู้บริโภค โดยเฉพาะการปฏิเสธสินเชื่อหรือปรับวงเงิน
- สร้างกรอบการกำกับดูแลเกี่ยวกับการแบ่งปันข้อมูลแบบ federation ระหว่างสถาบันการเงิน เพื่อส่งเสริมการป้องกันความเสี่ยงเชิงระบบโดยไม่ละเมิดกฎคุ้มครองข้อมูล
- สนับสนุนโครงการพัฒนาบุคลากร (reskilling/upskilling) ร่วมกับภาคการศึกษา เพื่อเสริมความสามารถด้าน AI governance และ data literacy ในภาคการเงิน
สรุปแล้ว การขยายผลของระบบ RAG‑Realtime ที่ผสาน Knowledge Graph ควรเดินควบคู่ไปกับการลงทุนด้านบุคลากรและการทำให้นโยบายภายในพร้อมรับเทคโนโลยีใหม่ การเตรียมสถาปัตยกรรมที่ยืดหยุ่นรองรับ LLM ที่มี context ขนาดใหญ่และสภาพแวดล้อมแบบ federated จะเป็นหัวใจสำคัญในการนำไปสู่การลด NPL, เพิ่มประสิทธิภาพการตรวจจับการฉ้อโกง และการให้บริการเชิงพาณิชย์ที่แม่นยำและโปร่งใสมากขึ้น
บทสรุป
การผสาน RAG‑Realtime กับ Knowledge Graph เปลี่ยนวงจรอนุมัติสินเชื่อจากกระบวนการแบบคงที่เป็นแบบไดนามิก โดยระบบดึงข้อมูลเชิงบริบทจากกราฟความรู้และใช้กลไกการตอบกลับเชิงสร้างสรรค์แบบเรียลไทม์ ทำให้เวลาการอนุมัติลดลงจากระดับหลายวันเหลือภายใน 24 ชั่วโมงหรือไม่กี่ชั่วโมง ส่งผลให้ธนาคารสามารถลดความเสี่ยงด้านเครดิตได้อย่างรวดเร็วและมีประสิทธิภาพ ตัวอย่างการนำไปใช้ในสถาบันการเงินแสดงให้เห็นว่าการตัดสินใจที่อาศัยข้อมูลเชิงสัมพันธ์และสัญญาณความเสี่ยงแบบเรียลไทม์สามารถลดอัตรา NPL ในช่วงเริ่มต้นได้ระดับหลักสิบเปอร์เซ็นต์ในไตรมาสแรกของการติดตั้ง (ขึ้นอยู่กับสภาพพอร์ตและการออกแบบระบบ) ข้อได้เปรียบสำคัญมาจากการประเมินความเสี่ยงแบบไดนามิก การรีสกอร์ลูกค้าเมื่อมีข้อมูลใหม่ และการเปิดจุดตรวจสอบเชิงนโยบายที่ตอบสนองเร็วขึ้น
ความสำเร็จของโมเดลดังกล่าวพึ่งพาคุณภาพข้อมูลเป็นหลัก — ข้อมูลที่ครบถ้วน สะอาด และมีการเชื่อมความสัมพันธ์ที่ชัดเจนใน Knowledge Graph ช่วยให้การเรียกข้อมูลมีความแม่นยำ นอกจากนี้การกำกับดูแล AI ที่เข้มแข็ง (รวมถึง audit trail, การทดสอบความเป็นกลางของโมเดล และการติดตาม drift) ร่วมกับการผสาน human‑in‑the‑loop เป็นสิ่งจำเป็นเพื่อความรับผิดชอบและความโปร่งใส ในเชิงปฏิบัติ สถาบันมักตั้งระดับการส่งต่อไปยังผู้ตัดสินใจมนุษย์สำหรับเคสที่มีความเสี่ยงสูงหรือไม่แน่นอน (เช่น 5–20% ของเคส) พร้อมมาตรการตรวจสอบผลลัพธ์เพื่อป้องกันความเบ้และข้อผิดพลาดเชิงระบบ
มองไปข้างหน้า แนวทาง RAG‑Realtime + Knowledge Graph มีศักยภาพขยายไปยังผลิตภัณฑ์การเงินอื่น ๆ และเชื่อมโยงกับแหล่งข้อมูลภายนอก (เช่น ข้อมูลธุรกรรมแบบเรียลไทม์และข้อมูลตลาด) เพื่อเพิ่มความแม่นยำของสัญญาณความเสี่ยง แต่จะต้องเผชิญกับความท้าทายด้านกฎระเบียบ ความเป็นส่วนตัว และการดูแลโมเดลอย่างต่อเนื่อง การลงทุนในโครงสร้างพื้นฐานข้อมูล การกำกับดูแลเชิงนโยบาย และการออกแบบ human‑in‑the‑loop ที่สมดุลจะเป็นตัวกำหนดว่าเทคโนโลยีนี้จะสามารถลด NPL ได้อย่างยั่งยืนและเป็นไปตามมาตรฐานความรับผิดชอบทางกฎหมายและจริยธรรมหรือไม่



