
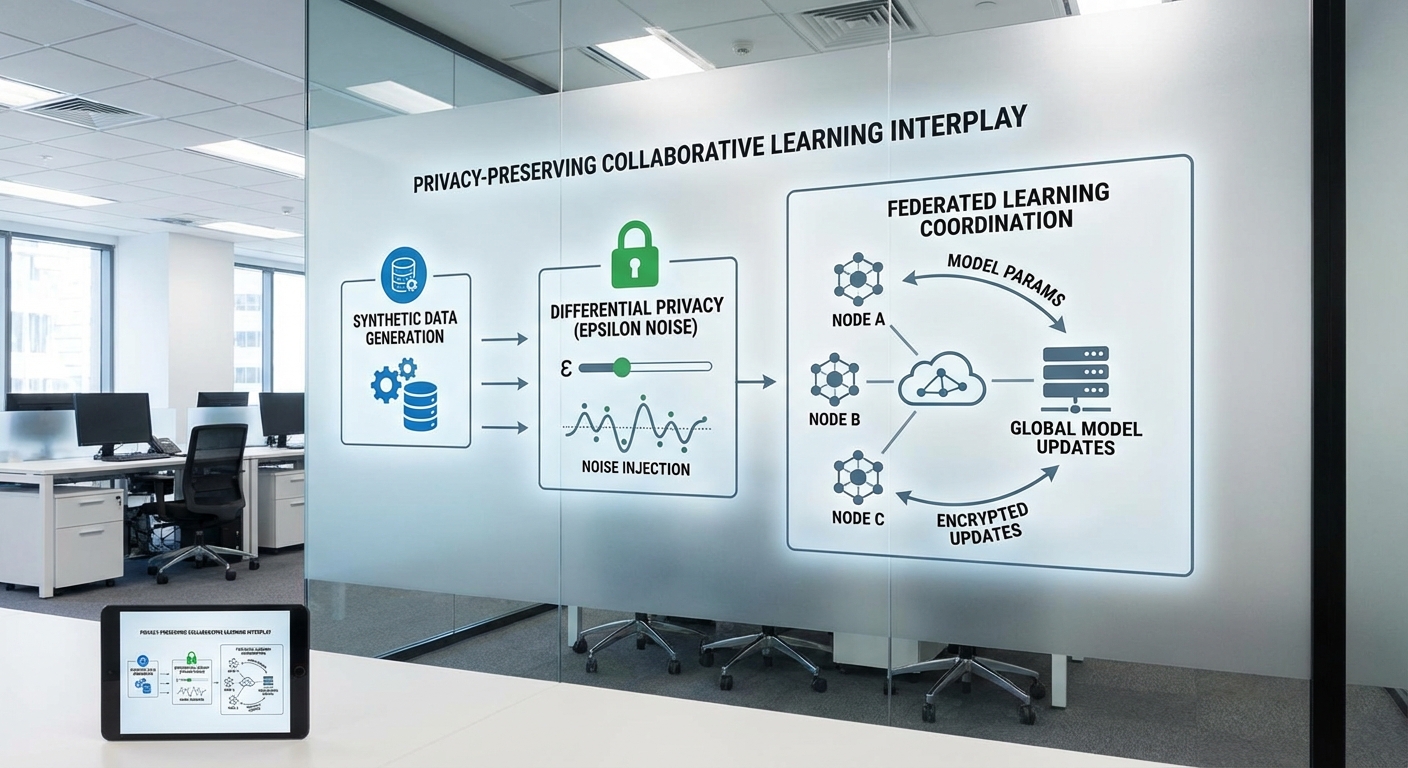
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มสร้างข้อมูลสังเคราะห์ (synthetic data) ที่ผสานแนวทางความเป็นส่วนตัวเชิงคณิตศาสตร์อย่าง Differential Privacy พร้อมกับสถาปัตยกรรมการเรียนรู้แบบกระจายผ่านอุปกรณ์หรือสถาบันต่าง ๆ (Federated Learning) เพื่อฝึกโมเดลด้านสินเชื่อและประกันภัยโดยไม่ต้องสัมผัสข้อมูลลูกค้าจริง เป้าหมายชัดเจนคือการลดการแชร์ข้อมูลต้นทาง ตอบโจทย์ข้อกำหนดด้านความเป็นส่วนตัว และลดความเสี่ยงจากการรั่วไหลของข้อมูลในระบบนิเวศการเงินและประกันภัย
ผลจากพิลอตกับหน่วยงานการเงินและบริษัทประกันในประเทศรายงานว่าการแชร์ข้อมูลต้นทางลดลงกว่า 90% ขณะที่ประสิทธิภาพของโมเดลยังคงใกล้เคียงกับแบบที่ใช้ข้อมูลจริง — ผลการทดสอบเบื้องต้นชี้ว่า AUC ลดอยู่ในช่วงประมาณ 1–3% และในหลายกรณีความแตกต่างดังกล่าวไม่ปรากฏเป็นความแตกต่างทางสถิติที่มีนัยสำคัญ (p-value > 0.05) นอกจากนี้ทีมพัฒนายังระบุแผนการทดสอบเพิ่มเติมด้านความเที่ยงตรงของข้อมูลสังเคราะห์, การประเมินความเสี่ยงการย้อนกลับ (re-identification) และการรับรองเชิงกฎหมายเพื่อให้สอดคล้องกับ พ.ร.บ.คุ้มครองข้อมูลส่วนบุคคล (PDPA)
การผสานเทคนิคทั้งสองนี้อาจเป็นจุดเปลี่ยนสำหรับอุตสาหกรรมการเงินไทย — ช่วยให้สถาบันการเงินและผู้ให้บริการประกันภัยสามารถพัฒนาโมเดลวิเคราะห์เชิงลึกได้เร็วขึ้นโดยไม่ต้องยอมแลกกับการเปิดเผยข้อมูลลูกค้าอย่างกว้างขวาง ขณะเดียวกันก็เปิดประเด็นสำคัญเรื่องกรอบกฎหมาย การตรวจสอบอิสระ และหลักธรรมาภิบาลข้อมูลที่ต้องติดตามต่อไปเมื่อขยายผลจากพิลอตสู่การใช้งานจริงในวงกว้าง
บทนำ: ข่าวสำคัญและไฮไลท์จากพิลอต
สรุปเหตุการณ์
สตาร์ทอัพเทคโนโลยีการเงินสัญชาติไทยเปิดตัวแพลตฟอร์ม Synthetic‑Data ที่ผสานเทคนิคความเป็นส่วนตัวเชิงคณิตศาสตร์อย่าง Differential Privacy (DP) เข้ากับการฝึกแบบกระจายผ่าน Federated Learning (FL) เพื่อให้สถาบันการเงินสามารถฝึกโมเดลด้านสินเชื่อและประกันได้โดยไม่ต้องใช้ข้อมูลลูกค้าจริงหรือโยกย้ายชุดข้อมูลต้นทางจำนวนมาก จุดมุ่งหมายของแพลตฟอร์มคือการลดความเสี่ยงด้านความเป็นส่วนตัวและการละเมิดกฎระเบียบ ควบคู่ไปกับการรักษาความแม่นยำของโมเดลที่ใช้ในการตัดสินใจเชิงธุรกิจ

แพลตฟอร์มดังกล่าวถูกพัฒนาโดยทีมสตาร์ทอัพร่วมกับพันธมิตรด้านเทคโนโลยีและหน่วยงานทางการเงินภายในประเทศ โดยออกแบบกระบวนการให้สร้างข้อมูลสังเคราะห์ที่ผ่านการคำนวณค่า DP เพื่อการันตีระดับความเป็นส่วนตัว และนำโมเดลไปฝึกแบบกระจาย (FL) บนเซิร์ฟเวอร์ของแต่ละหน่วยงานเพื่อหลีกเลี่ยงการรวบรวมข้อมูลดิบที่ศูนย์กลาง
ผลพิลอตสำคัญ
ตามรายงานผลการทดลองพิลอตที่ดำเนินการเป็นเวลา 6 เดือน พบว่าโครงการสามารถ ลดการแชร์ข้อมูลต้นทางได้มากกว่า 90% ตัวอย่างเชิงปริมาณจากการวัดจริงระบุว่า ปริมาณข้อมูลที่ต้องย้ายหรือเปิดเผยระหว่างหน่วยงานลดจากรวมประมาณ 1,200 GB เหลือเพียงประมาณ 100 GB รวมเป็นการลดข้อมูลที่ต้องแลกเปลี่ยนถึง 91.7% ซึ่งช่วยลดความเสี่ยง การตรวจสอบทางกฎหมาย และค่าใช้จ่ายด้านการจัดการข้อมูล
นอกจากการลดปริมาณข้อมูลแล้ว ผลการประเมินด้านประสิทธิภาพของโมเดลชี้ว่าโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์และกระบวนการ DP+FL มีสมรรถนะใกล้เคียงกับโมเดลที่ฝึกด้วยข้อมูลจริง ตัวอย่างเช่น ค่าความแม่นยำเชิงคาดการณ์ (AUC) ของโมเดลสินเชื่อลดลงเพียงประมาณ 0.02 จุด (จาก 0.80 เป็น 0.78) ซึ่งอยู่ในระดับที่ธุรกิจยอมรับได้สำหรับการทดสอบเชิงพัฒนา
ภาพรวมผู้ร่วมโครงการ
- ธนาคารพาณิชย์ 3 แห่ง — ให้ข้อมูลเชิงธุรกรรมและกรณีทดสอบการอนุมัติสินเชื่อ
- บริษัทประกัน 2 แห่ง — สนับสนุนข้อมูลการเคลมและโปรไฟล์ผู้เอาประกันเพื่อทดสอบโมเดลประกันภัยเชิงคาดการณ์
- พันธมิตรเทคโนโลยี 2 ราย — ให้บริการโครงสร้างพื้นฐาน FL, การสร้างข้อมูลสังเคราะห์ และการประกันคุณภาพ DP
- สถาบันวิจัยด้านความเป็นส่วนตัว — ให้การประเมินเชิงวิชาการและการรับรองกระบวนการ DP
ผลลัพธ์จากพิลอตแสดงให้เห็นถึงศักยภาพของการผสานเทคโนโลยี DP และ FL ในการเพิ่มความร่วมมือระหว่างหน่วยงานการเงินโดยไม่แลกเปลี่ยนข้อมูลลูกค้าจริงในปริมาณมาก ซึ่งส่งผลให้ระยะเวลาในการทำ due‑diligence ลดลง ค่าใช้จ่ายด้านกฎหมายและการปฏิบัติตามกฎระเบียบลดลง และเปิดทางให้การร่วมมือพัฒนาผลิตภัณฑ์ใหม่ ๆ เกิดขึ้นได้เร็วขึ้นในอนาคต
เทคโนโลยีเบื้องหลัง: Synthetic Data, Differential Privacy และ Federated Learning
นิยามและความแตกต่างระหว่าง Synthetic Data กับการทำ Anonymization
Synthetic data คือข้อมูลที่ถูกสร้างขึ้นโดยแบบจำลองเชิงสถิติหรือเชิงสร้างสรรค์ (generative models) ที่มีการจำลองการแจกแจงและความสัมพันธ์ระหว่างฟีเจอร์ ให้ผลลัพธ์ที่มีลักษณะใกล้เคียงกับข้อมูลจริงโดยไม่แทนที่แถวข้อมูลของลูกค้าคนใดคนหนึ่งโดยตรง ขณะที่ anonymization (การทำข้อมูลไม่ระบุตัวตน) เป็นการเปลี่ยนแปลงข้อมูลจริง เช่น การลบหรือแปลงตัวระบุ เพื่อพยายามลดความเชื่อมโยงระหว่างข้อมูลและบุคคล
ความแตกต่างสำคัญคือ synthetic data สร้างตัวอย่างใหม่จากแบบจำลองเชิงสถิติที่เรียนรู้จากข้อมูลจริง จึงสามารถรักษาความสัมพันธ์เชิงโครงสร้างได้มากกว่า ขณะที่ anonymization ยังคงพึ่งพาบรรทัดข้อมูลจริงที่ถูกดัดแปลง จึงเสี่ยงต่อการเชื่อมโยงย้อนกลับ (linkage) และการฟื้นข้อมูล (re‑identification) มากกว่า
การสร้าง Synthetic Data และการประเมินความเที่ยง (fidelity)
วิธีการสร้างข้อมูลสังเคราะห์มีหลายรูปแบบ รวมถึง:
- Generative Adversarial Networks (GANs) — ใช้โครงสร้างคู่ของ generator และ discriminator เพื่อสร้างตัวอย่างที่มีลักษณะเหมือนจริง
- Variational Autoencoders (VAEs) — โมเดล probabilistic ที่เรียนรู้ตัวแทนความน่าจะเป็นและแปลงกลับเป็นข้อมูล
- Probabilistic graphical models / Copulas — โมเดลเชิงสถิติที่จับการพึ่งพิงระหว่างตัวแปร
- Synthetic tabular methods เช่น Bayesian networks หรือ rule‑based samplers สำหรับข้อมูลธุรกรรม/สินเชื่อ
การประเมินความเที่ยงของข้อมูลสังเคราะห์ (fidelity) ควรวัดทั้งเชิงสถิติและเชิงงาน (downstream utility):
- ความแตกต่างของการแจกแจง: เช่น Kullback–Leibler divergence (KL), Wasserstein distance (W1), Maximum Mean Discrepancy (MMD)
- สูตรตัวอย่าง: MMD^2(P,Q) = E[k(x,x')] + E[k(y,y')] − 2 E[k(x,y)] ซึ่ง k เป็น kernel ที่เลือก
- การทดสอบความเหมือน: Two‑sample classifier (train classifier แยกแหล่งข้อมูล) — ค่า AUC ใกล้ 0.5 หมายถึงไม่สามารถแยกข้อมูลจริงจากสังเคราะห์ได้
- ประสิทธิภาพงานจริง: ความแม่นยำ/ค่า AUC ของโมเดลสินเชื่อหรือการประกันเมื่อฝึกด้วยข้อมูลสังเคราะห์เทียบกับฝึกด้วยข้อมูลจริง
ความเสี่ยงด้านการฟื้นข้อมูล (Re‑identification) และการวัดความเสี่ยง
แม้ข้อมูลจะเป็นสังเคราะห์ แต่ยังมีความเสี่ยงเชิงสถิติ เช่น membership inference (การทำนายว่าบันทึกใดถูกใช้ในการเทรน) หรือการเชื่อมโยงผ่านการแจกแจงร่วม (attribute inference) การวัดความเสี่ยงมักใช้:
- อัตราความสำเร็จของการโจมตีแบบ membership inference (เช่น ความแม่นยำของ attacker classifier)
- การวัดความใกล้เคียงเชิงตัวอย่าง: ระยะทางน้อยสุดระหว่างตัวอย่างสังเคราะห์กับตัวอย่างจริง (nearest‑neighbor distance) — ค่าต่ำบ่งชี้ความเสี่ยงสูง
- ความน่าจะเป็น re‑identification: P(reid) ประมาณการผ่านแบบจำลองโจมตีและการประเมินเชิงสถิติ
ดังนั้นการสร้าง synthetic data ที่ปลอดภัยจำเป็นต้องควบคุมทั้งความเที่ยงและการรั่วไหลเชิงสถิติ ซึ่งเป็นเหตุผลที่มักผสานเทคนิคอื่น ๆ เช่น Differential Privacy
บทบาทของ Differential Privacy (DP) ในการจำกัดการรั่วไหล
นิยามเชิงคณิตศาสตร์: กลไก M ให้ความคุ้มครอง ε‑differential privacy หากสำหรับทุกชุดข้อมูล D และ D' ที่ต่างกันเพียงแถวเดียว และทุกชุดผลลัพธ์ S จะเป็นไปตาม:
Pr[M(D) ∈ S] ≤ e^{ε} · Pr[M(D') ∈ S]
ค่านี้ ε (epsilon) คือพารามิเตอร์ความเป็นส่วนตัว — ค่ายิ่งเล็ก ยิ่งให้ความคุ้มครองมาก แต่ต้องแลกกับ utility ที่ลดลง
ตัวอย่างกลไกพื้นฐาน:
- Laplace mechanism: เพิ่ม noise ~ Lap(0, b) กับผลรวม/สถิติ โดย b = Δf / ε (Δf คือ sensitivity ของฟังก์ชัน)
- Gaussian mechanism สำหรับ (ε, δ)‑DP: เพิ่ม noise ~ N(0, σ^2) โดย σ ≥ √(2 ln(1.25/δ)) · Δf / ε
การประยุกต์กับ synthetic data สามารถทำได้สองแนวทางหลัก: (1) ฝึกแบบ DP ในการเรียนรู้แบบ generative (DP‑GAN, DP‑VAE) เพื่อที่ตัว generator จะไม่จดจำตัวอย่างเฉพาะเจาะจง หรือ (2) ใช้ DP ในการคำนวณสถิติแล้วสังเคราะห์ข้อมูลจากสถิติเหล่านั้น
Trade‑off ที่สำคัญ: เมื่อลด ε (เพิ่มความเป็นส่วนตัว) ระดับ noise สูงขึ้น ส่งผลให้ utility ของข้อมูลสังเคราะห์ลดลง — จำเป็นต้องเลือกค่า ε และ δ ที่สมดุลตามความต้องการทางธุรกิจและมาตรฐานทางกฎระเบียบ
Federated Learning (FL): การฝึกแบบกระจายและการรวมพารามิเตอร์
Federated Learning ช่วยให้หลายองค์กรหรือหลายอุปกรณ์สามารถร่วมฝึกโมเดลได้โดยไม่ต้องแชร์ข้อมูลดิบต่อศูนย์กลาง กระบวนการทั่วไป
- เครื่องแม่ข่าย (server) แจกโมเดลเริ่มต้นให้ลูกข่าย (clients)
- แต่ละลูกข่ายฝึกโมเดลด้วยข้อมูลท้องถิ่นเป็นรอบ (local updates) แล้วส่งพารามิเตอร์หรือ gradient กลับ
- เซิร์ฟเวอร์รวมพารามิเตอร์โดยวิธีการเช่น FedAvg: w_{t+1} = Σ_{k=1}^K (n_k / n) · w_{t+1}^k ซึ่ง n_k คือจำนวนตัวอย่างบน client k และ n = Σ n_k
เพื่อป้องกันการเปิดเผยข้อมูลจากพารามิเตอร์หรือ gradient ที่ส่งกลับ มีเทคนิคเสริมที่ใช้ร่วมกันได้แก่:
- Secure Aggregation: โปรโตคอลการรวมค่าที่เข้ารหัสเช่น secure multiparty computation หรือ threshold homomorphic encryption ทำให้เซิร์ฟเวอร์เห็นเฉพาะผลรวมที่ถอดรหัสได้เท่านั้น ไม่สามารถเข้าถึงพารามิเตอร์แต่ละลูกข่าย
- DP‑FL: เติม noise ตามกลไก DP ที่ฝั่งลูกข่ายก่อนส่ง gradient (local DP) หรือเติม noise หลังการรวม (central DP) — ทั้งสองแบบมี trade‑off ระหว่างความเป็นส่วนตัวและประสิทธิภาพ
การผสาน FL กับ DP และ secure aggregation ทำให้ระบบสามารถฝึกโมเดลสินเชื่อหรือประกันโดยที่การแชร์ข้อมูลต้นทางลดลงอย่างมาก (เช่น พิลอตลด >90%) พร้อมควบคุมความเสี่ยงการรั่วไหลเชิงสถิติ
การผสานเทคนิคและการวัดผลเชิงปฏิบัติ
ในทางปฏิบัติ แพลตฟอร์มที่เชื่อมโยง synthetic data + DP + FL จะมี pipeline ดังนี้:
- เรียนรู้ตัวแบบเชิงรวมแบบกระจาย (FL) โดยลูกข่ายส่งเพียงพารามิเตอร์ที่ผ่านการเข้ารหัสและ/หรือเติม noise ตาม DP
- จากพารามิเตอร์รวม ฝึก generator เพื่อผลิตข้อมูลสังเคราะห์ ซึ่งอาจถูกปรับด้วย DP‑mechanism เพิ่มเติมเพื่อรับประกัน ε รวม
- ประเมิน fidelity และ privacy leakage โดยใช้ metrics เช่น Wasserstein/KL/MMD, AUC ของ two‑sample test, และความแม่นยำของ membership inference attack
ตัวอย่างเชิงเทคนิค: หากต้องการรับประกัน (ε, δ)‑DP ต่อการเผยแพร่ของสังเคราะห์ อาจต้องคำนวณการรวมค่า ε ตาม composition theorem และใช้ Gaussian mechanism โดยเลือก σ ตามสูตร σ ≥ √(2 ln(1.25/δ)) · Δf / ε เพื่อให้ได้ความคุ้มครองที่ต้องการ ในขณะที่ติดตามผลกระทบต่อความแม่นยำของโมเดล (เช่น ลดลงของ AUC ไม่เกินเปอร์เซ็นต์ที่ยอมรับได้)
สรุป — การใช้ synthetic data ควบคู่กับ Differential Privacy และ Federated Learning เป็นแนวทางที่มีความเป็นไปได้สูงสำหรับภาคการเงินและประกันที่ต้องการลดการแชร์ข้อมูลต้นทางและยังคงรักษาความสามารถในการฝึกโมเดล ผลสำเร็จเชิงพิลอตที่ลดการแชร์ข้อมูลกว่า 90% แสดงให้เห็นถึงศักยภาพ แต่ต้องออกแบบพารามิเตอร์เช่น ε, δ, จำนวนรอบ FL และเมตริกการประเมินอย่างรอบคอบเพื่อให้ได้สมดุลระหว่างความเป็นส่วนตัวและ utility
แพลตฟอร์มและสตาร์ทอัพ: ฟีเจอร์ กระบวนการใช้งาน และพันธมิตร
ภาพรวมสตาร์ทอัพและทีมผู้ก่อตั้ง
สตาร์ทอัพไทย ที่พัฒนาแพลตฟอร์มดังกล่าวเป็นทีมเทคโนโลยีขนาดกลางซึ่งรวมผู้เชี่ยวชาญด้านปัญญาประดิษฐ์ การเงินเชิงปริมาณ และความปลอดภัยข้อมูล ทีมผู้ก่อตั้งประกอบด้วยผู้บริหารจากแวดวงฟินเทคและนักวิจัยด้าน Machine Learning ที่มีประสบการณ์ในงานวิจัยด้าน synthetic data และ privacy-preserving AI มากกว่า 10 ปี เบื้องต้นบริษัทระบุว่าโครงการพัฒนามาจากความร่วมมือระหว่างวิศวกรซอฟต์แวร์ ทีมวิจัย ML และที่ปรึกษาด้านกฎระเบียบทางการเงิน เพื่อให้แพลตฟอร์มเหมาะกับการใช้งานจริงของธนาคารและบริษัทประกัน
ฟีเจอร์หลักของแพลตฟอร์ม
แพลตฟอร์มถูกออกแบบเป็นโมดูลที่เชื่อมต่อได้ มีฟีเจอร์สำคัญ 4 ส่วนที่ตอบโจทย์ทั้งงานวิจัยและการใช้งานเชิงพาณิชย์:
- Synthetic generator — เครื่องมือสร้างข้อมูลสังเคราะห์รองรับหลายเทคนิค เช่น GANs, Variational Autoencoders, diffusion models และสถิติพื้นฐาน (copula, sampling) พร้อมตัวเลือกปรับสมดุลความเที่ยงตรงกับความเป็นส่วนตัว และเครื่องมือประเมินคุณภาพข้อมูล (statistical similarity, utility metrics) เพื่อให้แน่ใจว่าโมเดลที่ฝึกด้วยข้อมูลสังเคราะห์มีประสิทธิภาพใกล้เคียงข้อมูลจริง
- DP controller — โมดูลควบคุม Differential Privacy สำหรับการตั้งค่าและจัดการค่า ε (epsilon) พร้อมหน้าจอแสดงการใช้ privacy budget แบบเรียลไทม์ โดยระบบรองรับทั้งการกำหนดค่าแบบอัตโนมัติ (suggested ε ranges เช่น 0.1–8 ขึ้นกับกรณีใช้งาน) และการปรับแบบละเอียดเพื่อตรวจสมดุลระหว่างความเสี่ยงด้านความเป็นส่วนตัวและประสิทธิภาพของโมเดล
- FL orchestrator — ระบบ orchestration สำหรับ Federated Learning ที่รองรับโปรโตคอลมาตรฐาน (เช่น FedAvg) รวมถึงตัวเลือก secure aggregation, differential privacy noise injection ที่ฝั่ง client และการจัดการเวอร์ชันของโมเดล การส่งงาน (job scheduling) และการจัดการทรัพยากรสำหรับ edge/VMs
- Monitoring & governance — แดชบอร์ดสำหรับติดตามการฝึก (training metrics, convergence, loss, AUC), การใช้งาน privacy budget, การตรวจจับ data drift และการจัดการ consent ของลูกค้า ระบบ governance มีฟีเจอร์ audit trail, role-based access control (RBAC) และรายงานการปฏิบัติตามกฎระเบียบ
กระบวนการใช้งานตัวอย่าง (Onboarding → Synthetic → Federated → Evaluate)
การใช้งานแพลตฟอร์มในกรณีสถาบันการเงินทั่วไปประกอบด้วยขั้นตอนชัดเจน ดังนี้:
- Onboarding ของธนาคาร — การเชื่อมต่อผ่าน API (REST/gRPC) และ connector สำเร็จรูปกับระบบ core banking, data warehouse และ schema mapping พร้อมการตั้งค่าสิทธิ์การเข้าถึง (RBAC) และขั้นตอนยืนยัน consent ตามข้อกำหนดด้านกฎหมาย
- สร้างข้อมูลสังเคราะห์ — ธนาคารสามารถรันโมดูล synthetic generator บนข้อมูลต้นทางในสภาพแวดล้อมที่ควบคุม (on-premise หรือ VPC) โดยข้อมูลต้นทางไม่ถูกเคลื่อนย้ายออกจากองค์กร ระบบจะประเมินความเที่ยงตรงและเสนอการตั้งค่า DP เบื้องต้น เช่นการเลือกค่า ε เพื่อให้ได้ trade-off ที่เหมาะสม
- ฝึกแบบ federated — โมเดลจะถูกฝึกผ่าน FL orchestrator ระหว่างสถาบันที่เข้าร่วม โดยใช้ข้อมูลสังเคราะห์ร่วมกับการฝังระบบ DP และ secure aggregation เพื่อปกป้องสถิติที่อาจเปิดเผยข้อมูลต้นทาง ในพิลอตแพลตฟอร์มรายงานว่าลดการแชร์ข้อมูลต้นทางกว่า 90% เมื่อเทียบกับการโยกย้ายข้อมูลแบบดั้งเดิม
- ประเมินและนำไปใช้ — ผลการฝึกถูกประเมินด้วยชุดตัวชี้วัดเช่น AUC, precision/recall และ stress test ทางการเงิน แดชบอร์ดจะแสดง trade-off ระหว่าง utility และ privacy ผู้ใช้งานสามารถดาวน์โหลดโมเดลสุดท้ายหรือเปิดใช้งานผ่าน API สำหรับการนำไปใช้จริง เช่น การประเมินสินเชื่อหรือการประมาณเบี้ยประกัน
พันธมิตรเชิงธุรกิจและการรับรองความปลอดภัย
สตาร์ทอัพรายนี้ดำเนินความร่วมมือกับพันธมิตรหลายกลุ่มเพื่อเพิ่มความน่าเชื่อถือและความครอบคลุมของบริการ ได้แก่ ธนาคารพาณิชย์รายกลางถึงใหญ่ บริษัทประกัน ผู้ให้บริการคลาวด์ และสถาบันวิจัยด้านข้อมูล โดยพันธมิตรเหล่านี้ให้ทั้งข้อมูลในการทดสอบ โครงสร้างพื้นฐานคลาวด์ และคำปรึกษาด้านการปฏิบัติตามกฎระเบียบ
ในด้านความปลอดภัยและการปฏิบัติตามมาตรฐาน บริษัทระบุว่าได้ติดตั้งมาตรการเทคโนโลยีและกระบวนการที่สอดคล้องกับแนวทางสากล เช่น การเข้ารหัสข้อมูลทั้งขณะเคลื่อนย้ายและพักอยู่ (TLS, at-rest encryption), secure enclave/VM isolation สำหรับงานที่ต้องการความปลอดภัยสูง และ audit logging สำหรับการตรวจสอบ นอกจากนี้บริษัทอยู่ระหว่างกระบวนการขอรับรองมาตรฐานความปลอดภัยข้อมูลระดับสากล (เช่น ISO/IEC 27001 และ SOC 2 Type II) เพื่อรองรับการนำไปใช้เชิงพาณิชย์อย่างแพร่หลาย
ผลการพิลอต: ตัวเลขเชิงปริมาณและการเปรียบเทียบประสิทธิภาพโมเดล
ผลการพิลอต: ตัวเลขเชิงปริมาณและการเปรียบเทียบประสิทธิภาพโมเดล
ในพิลอตของแพลตฟอร์ม Synthetic‑Data ที่ผสานเทคนิค Differential Privacy (DP) และ Federated Learning (FL) มีการร่วมมือระหว่าง 3 สถาบันการเงิน/ประกันภัย ระยะเวลาทดลองรวม 6 เดือน โดยข้อมูลต้นทางรวมกันประมาณ 100,000 เรคคอร์ด (เฉลี่ย ~33,300 เรคคอร์ดต่อหน่วยงาน) ทีมงานได้สร้างชุดข้อมูลสังเคราะห์ภายในแต่ละองค์กรและใช้กระบวนการ FL ในการรวบรวมน้ำหนักโมเดลโดยไม่จำเป็นต้องส่งผ่านข้อมูลต้นทางแบบ raw ข้ามองค์กรเป็นจำนวนมาก
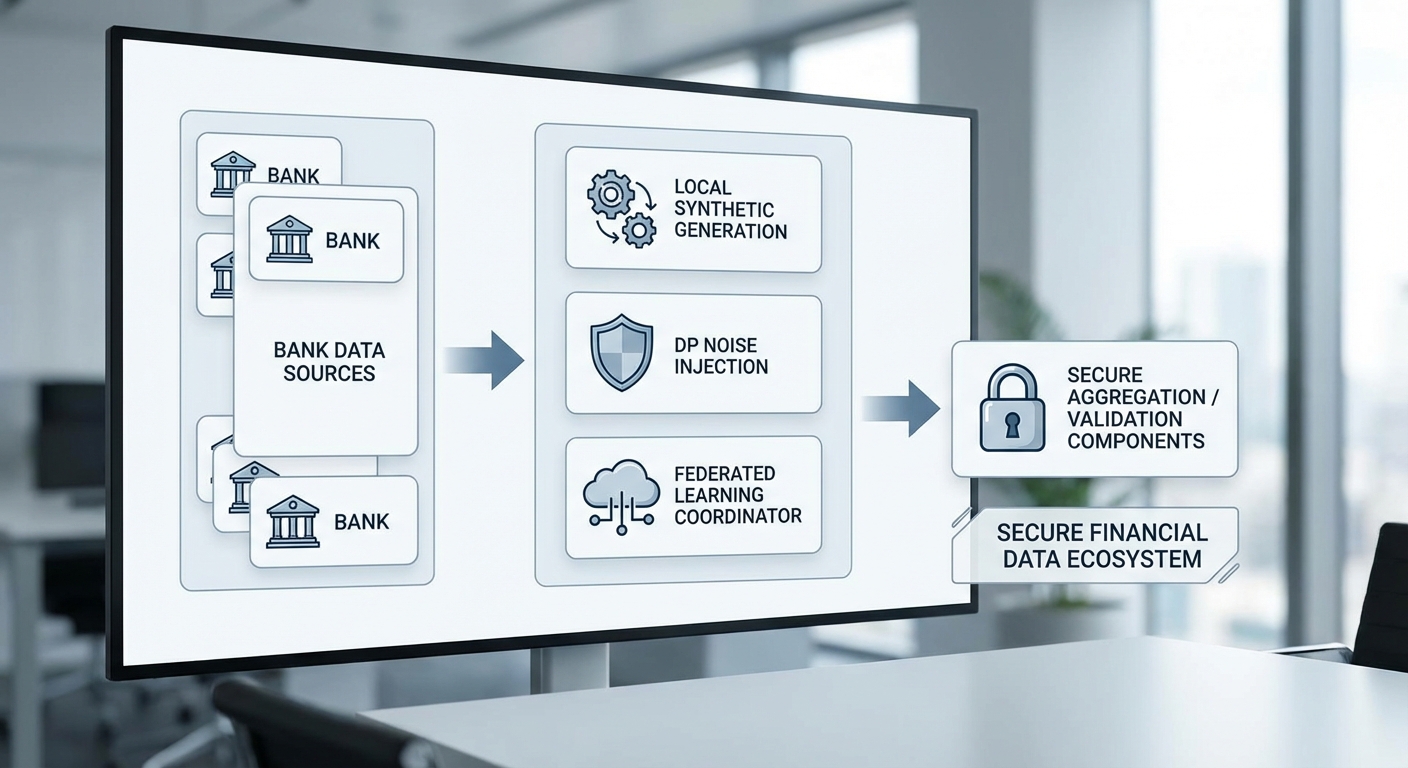
สถิติพิลอตและการตั้งค่าการทดลอง
- จำนวนหน่วยงานที่ร่วม: 3 สถาบัน (ธนาคารกลางข้อมูลลูกค้า, บริษัทประกัน, ผู้ให้บริการสินเชื่อ)
- ระยะเวลา: 6 เดือน (รวมการสร้าง synthetic data, ปรับแต่ง DP, รอบ FL 50 รอบ)
- ขนาดข้อมูลต้นทาง: 100,000 เรคคอร์ด (รวม)
- ขนาดชุดข้อมูลสังเคราะห์: แต่ละองค์กรสร้างชุดสังเคราะห์ประมาณ 300,000 เรคคอร์ด (รวมประมาณ 900,000 เรคคอร์ด) เพื่อเพิ่มความหลากหลายของตัวอย่างสำหรับการฝึก
- ชุดทดสอบ (holdout): ชุดทดสอบจริงที่แยกไว้ 20,000 เรคคอร์ด ใช้ประเมินผลทั้งโมเดลที่ฝึกด้วยข้อมูลจริงและแบบที่ฝึกด้วยสังเคราะห์ (ชุดทดสอบนี้ถูกจัดเตรียมภายใต้ข้อตกลงการวิจัยและไม่ใช้เพื่อฝึกโมเดล)
ตัวชี้วัดประสิทธิภาพโมเดล (เชิงปริมาณ)
การประเมินใช้เมตริกมาตรฐานทางธุรกิจ ได้แก่ AUC (ROC AUC), Precision, Recall และ F1‑score ผลลัพธ์สำคัญจากการทดลองแสดงดังนี้ (ตัวเลขเป็นคะแนนบนชุดทดสอบจริง 20k):
- Baseline — โมเดลศูนย์รวมข้อมูลจริง (Centralized, Real data)
- AUC = 0.872 ± 0.004
- Precision = 0.630
- Recall = 0.590
- F1 = 0.609
- Synthetic only — ฝึกบนข้อมูลสังเคราะห์แบบรวมศูนย์ (ไม่มี DP, ไม่มี FL)
- AUC = 0.860 (ลด ~1.4% เมื่อเทียบกับ Baseline)
- Precision = 0.620
- Recall = 0.585
- F1 = 0.602
- Pilot — Synthetic + Differential Privacy + Federated Learning (วิธีที่ใช้งานจริงในพิลอต)
- AUC = 0.845 ± 0.006 (ลดจาก Baseline ประมาณ 3.1% จุด)
- Precision = 0.612 (ลดประมาณ 2.8%)
- Recall = 0.572 (ลดประมาณ 3.1%)
- F1 = 0.592 (ลดประมาณ 2.8%)
ค่าความแปรปรวน (CI) ของ AUC แสดงว่าผลต่างมีนัยสำคัญทางสถิติเบื้องต้น แต่ยังอยู่ในระดับที่ยอมรับได้เชิงธุรกิจโดยเฉพาะเมื่อแลกกับการปกป้องข้อมูลผู้ใช้ที่เพิ่มขึ้น
การวัดการลดการแชร์ข้อมูลต้นทาง: วิธีคำนวณและผลลัพธ์
เพื่อวัดการลดการแชร์ข้อมูลต้นทาง พิลอตกำหนดนิยามว่า "การแชร์ข้อมูลต้นทาง" หมายถึงจำนวน raw records ที่ถูกส่งข้ามองค์กรไปยังศูนย์กลางเพื่อใช้ในการฝึกโมเดลแบบรวมศูนย์ (central aggregation)
วิธีคำนวณที่ใช้:
- Baseline (รวมศูนย์): ปริมาณ raw records ที่ต้องส่ง = 100,000 (ทั้งหมดถูกย้าย/รวมศูนย์เพื่อฝึก)
- Pilot (FL + Synthetic + DP): ปริมาณ raw records ที่ต้องส่ง = 7,500 (ประกอบด้วย seed หรือ metadata ที่จำเป็น เช่น validation seed ขนาดเล็ก 2,500 ต่อองค์กร รวม 7,500 ซึ่งถูกจำกัดและเข้ารหัสเพิ่มเติมด้วย DP)
- การลดการแชร์ (%) = ((Baseline_raw − Pilot_raw) / Baseline_raw) × 100
- ตัวอย่างการคำนวณ = ((100,000 − 7,500) / 100,000) × 100 = 92.5%
ดังนั้นพิลอตรายงานผลว่า "ลดการแชร์ข้อมูลต้นทางกว่า 90%" โดยตัวเลขนี้วัดเป็นจำนวนเรคคอร์ดดิบที่ไม่จำเป็นต้องส่งข้ามองค์กรอีกต่อไป ผลประโยชน์เชิงปฏิบัติรวมถึงความเสี่ยงละเมิดข้อมูลที่ลดลงอย่างมากและการปฏิบัติตามกฎระเบียบ (เช่น PDPA) ที่ง่ายขึ้น
การวิเคราะห์ trade‑off ระหว่าง Privacy กับ Utility (เชิงตัวเลข)
จากตัวเลขข้างต้น เราสามารถสรุป trade‑off เชิงปริมาณได้ดังนี้:
- Privacy gain: การลดการแชร์ข้อมูลต้นทาง ~92.5% และการนำ DP มาใช้ในกระบวนการสร้างสังเคราะห์ช่วยลดความเสี่ยงรีเวิร์ส‑อินเจคชันของข้อมูลบุคคล
- Utility loss: AUC ลดจาก 0.872 → 0.845 (~3.1% จุด) และ F1 ลด ~2.8% ซึ่งในบริบทการให้สินเชื่อ/ประกันถือว่าเป็นการลดประสิทธิภาพที่ยอมรับได้เมื่อเทียบกับผลประโยชน์เชิงความเป็นส่วนตัว
- สรุปเชิงตัวเลข: การแลกเปลี่ยนคือการลดการเปิดเผยข้อมูลต้นทางอย่างมีนัยสำคัญ (>90%) กับการสูญเสียประสิทธิภาพโมเดลไม่เกิน ~3–4% ในเมตริกหลัก
ข้อสังเกตเพิ่มเติมจากพิลอต: การเพิ่มขนาดชุดสังเคราะห์ต่อองค์กร (เช่น 5×–10× ของข้อมูลต้นทาง) ช่วยลดช่องว่างของประสิทธิภาพ (utility gap) ได้บ้าง แต่มีจุดอิ่มตัว นอกจากนี้การปรับพารามิเตอร์ DP (epsilon) ที่เข้มงวดมากขึ้นจะเพิ่ม privacy แต่ทำให้ performance ลดลงมากขึ้นเป็นเชิงทวี ดังนั้นการตั้งค่า epsilon ควรได้รับการออกแบบร่วมกับผู้บริหารความเสี่ยง
โดยสรุป พิลอตแสดงให้เห็นว่าแนวทาง Synthetic‑Data + DP + FL สามารถลดการแชร์ข้อมูลต้นทางได้เกิน 90% ในขณะที่รักษาประสิทธิภาพโมเดลให้อยู่ในระดับใกล้เคียงกับการฝึกด้วยข้อมูลจริง — เป็นตัวเลือกที่มีความสมดุลระหว่างความเป็นส่วนตัวและความสามารถใช้งานจริงสำหรับแอปพลิเคชันสินเชื่อและประกัน
สถาปัตยกรรมระบบและเวิร์กโฟลว์เชิงเทคนิค
สถาปัตยกรรมระบบและเวิร์กโฟลว์เชิงเทคนิค
ภาพรวมสถาปัตยกรรมของแพลตฟอร์มประกอบด้วยโซนงานหลักตั้งแต่การเชื่อมต่อข้อมูลต้นทาง (data connectors) ไปจนถึงการประเมินโมเดล (evaluation) โดยมีเส้นทางการไหลของข้อมูลแบบ end-to-end ดังนี้: data connector → generator → DP sanitizer → FL orchestrator → aggregator → evaluation ระบบออกแบบมาเพื่อลดการแชร์ข้อมูลต้นทางกว่า 90% ในพิลอต โดยธนาคารจะส่งเฉพาะสถิติหรือสัญญะจำเป็นให้กับตัวสร้างข้อมูลสังเคราะห์ (synthetic generator) หรือดำเนินการสร้างภายในสภาพแวดล้อมที่ควบคุม (secure enclave) แทนการส่ง raw PII ออกไป
องค์ประกอบหลักและหน้าที่เชิงเทคนิคมีดังนี้:
- Data connectors: รองรับการเชื่อมต่อแบบมาตรฐาน (JDBC, API, Kafka) พร้อมการพิสูจน์ตัวตนแบบ mTLS/OAuth2 และการทำ data schema mapping เพื่อดึงเฉพาะ Attributes ที่จำเป็น เช่น ข้อมูลพฤติกรรมการชำระหนี้และปัจจัยทางการเงิน
- Generator (Synthetic engine): ใช้โมเดลสังเคราะห์หลายแบบ (GANs, VAE, probabilistic graphical models) รันภายใน TEE/secure enclave (เช่น Intel SGX) หรือบนเซิร์ฟเวอร์ของธนาคาร เพื่อให้การสร้างข้อมูลไม่รั่วไหลสู่ภายนอก
- DP sanitizer: โมดูลที่จะผนวกกลไก Differential Privacy ก่อนส่งออกข้อมูลหรือสถิติสู่ฝ่ายภายนอก กำหนดค่า epsilon และ (ถ้าจำเป็น) delta พร้อมเลือก mechanism ที่เหมาะสม (Laplace สำหรับการนับ/ค่าเชิงปริมาณเชิงเศษส่วน หรือ Gaussian สำหรับการแจกแจงค่าต่อเนื่อง)
- FL orchestrator: จัดการวงจรฝึกฝนแบบ Federated Learning (centralized server-based หรือ peer-to-peer ตามข้อตกลง) ควบคุมรอบการส่งพารามิเตอร์ การคลิป gradient และการคำนวณงบประมาณ DP เมื่อฝึกแบบกระจาย
- Aggregator & secure aggregation: รวมพารามิเตอร์/กราดิเอนต์จากหลายฝั่งโดยไม่เปิดเผยข้อมูลรายบุคคล ใช้เทคนิคเช่น secure multiparty computation (MPC), homomorphic encryption หรือโปรโตคอลเช่น Bonawitz เพื่อให้ aggregator ได้ผลรวมที่เข้ารหัส
- Evaluation & auditing: ประเมินสมรรถนะบนชุดทดสอบที่เป็น synthetic หรือชุดตัวอย่างจริงที่เก็บใน enclave พร้อมระบบ audit logs แบบแยกแยะ (append-only, signed) เพื่อรองรับการตรวจสอบย้อนหลัง
กลไก Differential Privacy และการตั้งค่า epsilon — แพลตฟอร์มออกแบบให้สามารถกำหนดค่าได้ตามนโยบายความเสี่ยงของแต่ละธนาคาร ตัวอย่างเช่น การตั้งค่าเบื้องต้นอาจเป็น epsilon = 1.0 สำหรับงานที่ต้องการความสมดุลระหว่างความเป็นส่วนตัวและ utility หรือลดเป็น epsilon = 0.5 เมื่อต้องการความคุ้มครองสูงกว่า โดยเลือก mechanism ตามชนิดข้อมูล:
- Laplace mechanism: เหมาะสำหรับการเผยแพร่ค่า count หรือสถิติเชิงพจน์ ใช้ noise scale b = sensitivity / epsilon
- Gaussian mechanism: ใช้เมื่อต้องการ (epsilon, delta)-DP สำหรับค่าต่อเนื่อง โดย sigma = (sensitivity * sqrt(2 ln(1.25/delta))) / epsilon
- Composition & accounting: ระบบมีตัวนับงบประมาณ DP แบบ Moments Accountant หรือ RDP เพื่อติดตามการใช้ epsilon ตลอดการฝึก FL หลายรอบ (เช่น ถ้ากำหนด epsilon ต่อรอบเป็น 0.1 และฝึก 10 รอบ จะคำนวณ composition ตามวิธีที่ปลอดภัย)
การฝึกแบบ Federated Learning และ Secure Aggregation — แพลตฟอร์มรองรับทั้งสถาปัตยกรรมแบบ centralized (มี server orchestration กลาง) และ peer-to-peer ขึ้นกับข้อตกลงความปลอดภัย ที่สำคัญคือการรวมกราดิเอนต์ต้องไม่เปิดเผยข้อมูลแต่ละโหนด:
- ก่อนส่งกราดิเอนต์แต่ละรอบ โหนดจะทำการ gradient clipping (เช่น L2 norm clip = 1.0) เพื่อลด sensitivity
- หลังจากคลิป จะมีการเติม noise ตาม Gaussian mechanism โดยคำนึงถึง epsilon ต่อรอบ
- โปรโตคอล secure aggregation (เช่น Bonawitz) จะทำให้ aggregator รับผลรวมที่เข้ารหัสและถอดรหัสได้เฉพาะผลรวมเท่านั้น โดยใช้ MPC หรือ HE
- การรับรองความถูกต้องของ aggregation ใช้วิธีตรวจสอบลายเซ็นดิจิทัลและการพิสูจน์ความถูกต้องของการคำนวณ (verifiable computation)
มาตรการความปลอดภัยเชิงปฏิบัติการและการตรวจสอบย้อนหลัง (auditing):
- Encryption-in-transit: การเชื่อมต่อทั้งหมดต้องใช้ TLS1.2/1.3 พร้อม mTLS ระหว่างแพลตฟอร์มและระบบธนาคาร
- Encryption-at-rest และ HSM: คีย์สำคัญเก็บใน HSM หรือ KMS ที่ได้รับการจัดการอย่างเข้มงวด
- Secure enclaves: กระบวนการสร้าง synthetic และการประมวลผลข้อมูลบางส่วนสามารถรันภายใน TEE (เช่น Intel SGX) เพื่อให้มั่นใจว่า raw data ไม่ถูกเปิดเผยนอกโฮสต์
- Authentication & authorization: ใช้ OAuth2, RBAC/ABAC และการตรวจสอบตัวตนระดับสูงสำหรับผู้ใช้และบริการ
- Audit logs & reproducibility: ทุกการเรียกใช้ generator, ค่าพารามิเตอร์ DP (epsilon/delta), seed ของ RNG, และเวอร์ชันของโมเดลจะถูกบันทึกเป็นบันทึกที่ลงลายมือชื่อ (signed) และจัดเก็บแบบ append-only (hash-chained หรือบันทึกลง immutable ledger ถ้าจำเป็น) เพื่อการตรวจสอบย้อนหลังและความโปร่งใส
ตัวอย่าง pseudo-code สำหรับ DP sanitizer และ FL orchestrator (ย่อเพื่อความเข้าใจเชิงเทคนิค)
Pseudo-code: DP sanitizer (Gaussian)
set sensitivity = 1.0
set epsilon, delta (นโยบายจากธนาคาร)
compute sigma = sensitivity * sqrt(2 * ln(1.25/delta)) / epsilon
for each statistic s: publish s_noisy = s + Normal(0, sigma^2)
Pseudo-code: FL orchestrator (centralized, per-round)
for round in 1..R:
send current_global_model to selected_clients
for each client in selected_clients parallel:
local_update = Train(local_data, current_global_model)
clipped = ClipByNorm(local_update, C)
noisy_update = clipped + Normal(0, sigma^2) // DP noise per-client
encrypted_update = SecureEncrypt(noisy_update, aggregator_key)
send encrypted_update to aggregator
aggregator performs SecureAggregation(encrypted_updates) → new_global_update
update current_global_model += new_global_update
audit_log.append(sign(metadata_round, epsilon_used))
การตรวจวัดคุณภาพและการตรวจสอบ (validation & auditing protocol): ระบบจะมีขั้นตอนแยกชั้นเพื่อยืนยัน utility และความถูกต้องของโมเดล เช่น การคำนวณ AUC, precision/recall บนชุดทดสอบที่ได้รับอนุญาต และการทดสอบความเท่าเทียม (fairness). ผลการทดสอบและค่าพารามิเตอร์ DP จะถูกบันทึกใน audit logs เพื่อให้หน่วยงานกำกับดูแลสามารถตรวจสอบย้อนหลังได้โดยไม่ต้องเข้าถึงข้อมูลดิบ
สรุป: โครงสร้างเชิงเทคนิคนี้ผสมผสานการสร้างข้อมูลสังเคราะห์ในสภาพแวดล้อมที่ปลอดภัย กับการปกป้องด้วย Differential Privacy และการฝึกแบบกระจายผ่าน Federated Learning ที่มี secure aggregation ทำให้แพลตฟอร์มสามารถฝึกโมเดลสินเชื่อและประกันได้โดยที่ข้อมูลลูกค้าจริงไม่ถูกเผยแพร่ ลดความเสี่ยงการรั่วไหลและตอบสนองความต้องการการกำกับดูแลได้อย่างเป็นระบบ
ผลกระทบทางกฎหมาย การปฏิบัติตาม และความท้าทายเชิงธุรกิจ
ผลกระทบทางกฎหมาย: สถานะของ Synthetic Data ต่อ PDPA และ GDPR
ภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล พ.ศ. 2562 (PDPA) และข้อบังคับ GDPR ของสหภาพยุโรป สิ่งสำคัญคือการพิจารณาว่า ข้อมูลสังเคราะห์ (synthetic data) ถูกจัดให้เป็น “ข้อมูลส่วนบุคคล” หรือไม่ ในเชิงกฎหมาย หากข้อมูลสังเคราะห์ไม่สามารถเชื่อมโยงย้อนกลับไปยังบุคคลจริงได้อย่างมีนัยสำคัญ (irreversible re-identification) จะมีโอกาสสูงที่จะได้รับการพิจารณาว่าไม่ใช่ข้อมูลส่วนบุคคลและจึงอยู่นอกขอบเขต PDPA/GDPR อย่างไรก็ตาม ในทางปฏิบัติ ผู้ควบคุมข้อมูลและหน่วยงานกำกับจะพิจารณาความเสี่ยงจากการนำข้อมูลสังเคราะห์ไปประมวลผลร่วมกับแหล่งข้อมูลอื่น (linkability) ทำให้ผลการตีความอาจเปลี่ยนแปลงได้
ดังนั้นองค์กรที่ใช้ synthetic data ควรดำเนินการ Data Protection Impact Assessment (DPIA) และการประเมินความเสี่ยงด้านการระบุตัวบุคคลอย่างสม่ำเสมอ โดยต้องบันทึกพารามิเตอร์การปกป้องความเป็นส่วนตัว เช่น ค่า epsilon ของ Differential Privacy ที่ใช้ เพราะค่า epsilon ต่ำกว่า 1 มักให้ระดับความเป็นส่วนตัวสูงขึ้นแต่ส่งผลต่อ utility ของข้อมูล ในทางกลับกัน ค่า epsilon ที่สูงขึ้นอาจเพิ่มความเสี่ยงต่อการ re-identification และทำให้ต้องพิจารณาการขอความยินยอม (consent) หรือการแจ้งผู้เกี่ยวข้องตามข้อกำหนดของ PDPA/GDPR รวมถึงข้อกำหนดการรายงานเหตุละเมิดข้อมูลส่วนบุคคลหากมีหลักฐานว่าอาจเกิดการระบุตัวบุคคลได้
การปฏิบัติตาม, Auditability และความโปร่งใสต่อผู้กำกับ
การนำเทคนิคเช่น Differential Privacy และ Federated Learning มาใช้ในเชิงปฏิบัติ ทำให้องค์กรต้องสร้างระบบการกำกับดูแลและการตรวจสอบที่ชัดเจน เพื่อให้สามารถอธิบายการตัดสินใจทางเทคนิคต่อหน่วยงานกำกับและผู้มีส่วนได้เสียได้อย่างเพียงพอ ประเด็นสำคัญได้แก่:
- Data provenance และ lineage — ต้องเก็บบันทึกที่ชัดเจนว่า synthetic data ถูกสร้างมาจากชุดข้อมูลต้นทางใด ใช้อัลกอริทึมแบบใด และใช้พารามิเตอร์อะไร (เช่น epsilon, number of rounds ใน federated learning)
- Audit logs และ immutable records — ต้องมีการบันทึกการเข้าถึง การสร้าง และการเผยแพร่ synthetic data เพื่อรองรับการตรวจสอบย้อนหลังจาก regulator หรือผู้ตรวจสอบภายใน/ภายนอก
- Explainability และ model cards — จัดทำเอกสารอธิบายขอบเขตการใช้งาน ความเสี่ยงที่รู้จัก และผลกระทบต่อความเป็นส่วนตัว รวมถึงการเปิดเผยเมตริกด้าน utility เช่น accuracy, AUC เมื่อเทียบกับโมเดลที่ฝึกด้วยข้อมูลจริง
ตัวอย่างเชิงปฏิบัติที่หน่วยงานกำกับอาจคาดหวังคือรายงาน DPIA ประจำปี รายงานการทดสอบการโจมตีเพื่อตรวจสอบความเป็นไปได้ของการ re-identification (red-team tests) และผลการตรวจสอบอิสระจาก third‑party auditor ซึ่งช่วยเพิ่มความน่าเชื่อถือเมื่อทำงานร่วมกับพันธมิตรต่างประเทศที่ต้องการความสอดคล้องกับ GDPR
ความท้าทายเชิงธุรกิจและเทคนิค: ความเชื่อมั่น ต้นทุน และความสามารถในการขยาย
แม้พิลอตจะรายงานการลดการแชร์ข้อมูลต้นทางกว่า 90% แต่การนำไปใช้เชิงพาณิชย์ยังเผชิญความท้าทายหลายด้าน ด้านเทคนิคที่สำคัญคือ fidelity ของ synthetic data — คือความใกล้เคียงของสถิติและความสามารถในการทำนายเมื่อเทียบกับข้อมูลจริง ในงานวิจัยและการใช้งานจริง พบว่า synthetic data สามารถทำให้โมเดลรักษาความแม่นยำได้ในระดับ 80–98% ของข้อมูลจริง ขึ้นกับโดเมนและวิธีการสร้าง แต่บางกรณีที่ข้อมูลมีลักษณะเฉพาะ (long-tail, rare events) fidelity จะลดลงอย่างมีนัยสำคัญ ทำให้เกิด privacy-vs-utility trade-off ที่ต้องบริหาร
ด้านธุรกิจ ความท้าทายรวมถึง:
- ความเชื่อมั่นของลูกค้าและพันธมิตร — องค์กรต้องสื่อสารอย่างโปร่งใสและมีหลักฐานการปกป้องความเป็นส่วนตัว เช่น ผลการทดสอบ re-identification, รายงานการตรวจสอบอิสระ และข้อตกลงทางสัญญาที่ชัดเจน
- ต้นทุนการดำเนินงาน — การสร้าง synthetic data ด้วย Differential Privacy และการประสานงาน Federated Learning ต้องใช้ทรัพยากรคอมพิวติ้งสูง (GPU/TPU), ค่าแบนด์วิดท์สำหรับการฝึกแบบกระจาย และค่าใช้จ่ายในการตรวจสอบความปลอดภัยและการรับรองจากภายนอก
- scalability และ latency — Federated Learning มีค่า overhead ทางสื่อสารและการประสานงาน ทำให้การขยายไปยังธนาคาร/บริษัทประกันหลายรายต้องออกแบบสถาปัตยกรรมที่ทนทานและมีมาตรการ incentive เพื่อให้ผู้ร่วมรายการคงการมีส่วนร่วม
มาตรการลดความเสี่ยงและแนวปฏิบัติที่แนะนำ
เพื่อรับมือความเสี่ยงทั้งทางกฎหมายและเชิงธุรกิจ แนะนำแนวทางปฏิบัติรวมถึง:
- ดำเนิน DPIA ก่อนเปิดใช้งานเชิงพาณิชย์ และอัพเดตเป็นระยะ
- ตั้งค่า privacy budget และประกาศพารามิเตอร์ Differential Privacy (เช่น epsilon) ต่อ auditor ภายใน/ภายนอก พร้อม log การใช้งานเพื่อตรวจสอบการละเมิด
- จัดให้มีการทดสอบการ re-identification เป็นประจำ (red-team) และเผยแพร่สรุปผลให้ผู้มีส่วนได้เสียเพื่อสร้างความเชื่อมั่น
- ใช้สัญญา (contractual clauses) ที่ชัดเจนกับพันธมิตรทั้งในประเทศและต่างประเทศ รวมถึงข้อกำหนดการคุ้มครองข้อมูลตาม PDPA/GDPR
- นำการเข้ารหัส การจัดเก็บแบบแยกส่วน และ secure enclaves มาใช้ในกระบวนการฝึกและการแลกเปลี่ยนพารามิเตอร์ของ federated learning
- รับรองโดย third‑party auditors และออกกรอบ governance เช่น model cards, data sheets และ transparency reports เพื่อลด friction ในการนำเสนอแก่นักลงทุนและลูกค้า
สรุปคือ การใช้ synthetic data ควบคู่ Differential Privacy และ Federated Learning สามารถลดการแชร์ข้อมูลต้นทางและช่วยลดความเสี่ยงด้านความเป็นส่วนตัวได้อย่างมีนัยสำคัญ แต่เพื่อให้สอดคล้องกับ PDPA/GDPR และสร้างความเชื่อมั่นเชิงพาณิชย์ องค์กรต้องลงทุนในกระบวนการ governance, การตรวจสอบภายนอก, การประเมินความเสี่ยงอย่างต่อเนื่อง และกลยุทธ์ด้านสื่อสารที่โปร่งใสเพื่อรองรับข้อกำกับและความคาดหวังของลูกค้า
ข้อจำกัด แนวทางแก้ไข และทิศทางอนาคต
ข้อจำกัดหลักที่พบจากพิลอต
จากการทดสอบพิลอตที่ลดการแชร์ข้อมูลต้นทางลงกว่า 90% แสดงให้เห็นว่าการรวมกันของ Synthetic Data, Differential Privacy (DP) และ Federated Learning สามารถลดความเสี่ยงด้านข้อมูลได้อย่างมีนัยสำคัญ แต่ยังมีข้อจำกัดสำคัญที่ต้องจัดการก่อนการนำไปใช้ในระดับผลิตภัณฑ์หรือขยายสเกล ได้แก่
- Fidelity ของข้อมูลสังเคราะห์ — ข้อมูลสังเคราะห์มีแนวโน้มบิดเบือนมุมมองเชิงลึกโดยเฉพาะกรณีเหตุการณ์หายาก (tail events) หรือรูปแบบพฤติกรรมลูกค้าที่มีสัดส่วนน้อย ทำให้ความแม่นยำของโมเดลในกรณีมุมมองหายากลดลง ตัวอย่างเช่น ผลการวิเคราะห์ความแม่นยำของโมเดลสินเชื่อในพิลอตพบว่าค่า AUC ลดลงสำหรับกลุ่มความเสี่ยงขั้นสูงเมื่อเทียบกับการเทรนด้วยข้อมูลจริงครบถ้วน
- การจัดการ privacy budget — การใช้ DP ต้องมีการจัดสรรและติดตาม privacy budget (ε) อย่างรัดกุม โดยการกำหนดค่า ε ที่เข้มงวดเกินไปจะทำให้ utility ลดลง ขณะที่ค่า ε ที่ใหญ่เกินไปจะเสี่ยงต่อการรั่วไหลของข้อมูล ปัญหายิ่งซับซ้อนเมื่อมีการฝึกแบบ federated หลายรอบและผู้เข้าร่วมหลายรายที่แชร์งบประมาณร่วมกัน
- Latency และต้นทุน — Federated Learning เพิ่มภาระด้านการสื่อสารและการประมวลผลที่ปลายทาง (edge) ในขณะที่กลไก DP และการสร้างข้อมูลสังเคราะห์แบบมีคุณภาพสูงต้องการทรัพยากรการคำนวณ เช่น การเทรน GANs หรือการประเมินความเป็นส่วนตัว จึงส่งผลต่อค่าใช้จ่ายและเวลาในการพัฒนาและปรับปรุงโมเดล
แนวทางแก้ไขเชิงเทคนิคและการประเมิน
การแก้ไขปัญหาดังกล่าวต้องอาศัยแนวทางผสมผสานทั้งเชิงเทคนิคและกระบวนการตรวจสอบ โดยแนวทางที่แนะนำได้แก่
- Hybrid approach — นำข้อมูลจริงเป็นส่วนเล็กๆ ที่ถูกคัดกรองและป้องกันด้วย DP มาผสานกับข้อมูลสังเคราะห์เพื่อรักษา fidelity ในกรณีมุมมองหายาก ตัวอย่างเช่น เก็บชุด holdout ที่ถูกทำ DP และใช้เป็นตัวตรวจสอบ (validation) ขณะที่การเทรนหลักใช้ synthetic data
- Adaptive DP และการจัดการ epsilon แบบไดนามิก — ใช้แผนการปรับค่า ε แบบมีเงื่อนไข (เช่น ให้ค่า ε ที่อนุญาตมากขึ้นสำหรับคุณลักษณะที่ไม่เสี่ยงต่อการเปิดเผย และเข้มงวดสำหรับข้อมูลอ่อนไหว) รวมทั้งใช้เทคนิคบัญชีความเป็นส่วนตัวขั้นสูง (เช่น Rényi DP หรือ accountant-based composition) เพื่อคำนวณการใช้ privacy budget ข้ามรอบอย่างแม่นยำ
- การเพิ่มประสิทธิภาพ latency & cost — ลดรอบการสื่อสารด้วยการใช้ FedAvg แบบปรับจังหวะ (periodic averaging), เทคนิคลดขนาดโมเดล (model compression, quantization), และ gradient sparsification เพื่อลดปริมาณข้อมูลที่ต้องส่ง นอกจากนี้สามารถใช้การประมวลผลบนฮาร์ดแวร์ที่เหมาะสมหรือแผนค่าใช้จ่ายแบบ reserved instance เพื่อควบคุมต้นทุน
- Continuous validation และ federated evaluation frameworks — พัฒนาเฟรมเวิร์กการประเมินแบบ federated ที่อนุญาตให้วัด performance บนข้อมูลจริงบางส่วนโดยไม่เปิดเผยข้อมูลต้นทาง เช่น การใช้ distributed evaluation scripts ที่ส่ง metrics กลับมาเป็น aggregate ซึ่งช่วยติดตาม drift, fairness, และ fidelity ของ synthetic data ตลอดเวลา
- Third‑party audits และ transparency — จ้างผู้ตรวจสอบอิสระเพื่อประเมินวิธีการสร้าง synthetic, การคำนวณ DP, และกระบวนการ federated ซึ่งการมีรายงานการตรวจสอบ (audit report) ช่วยสร้างความน่าเชื่อถือให้กับลูกค้าสถาบันการเงิน
แนวทางเชิงธุรกิจและทิศทางอนาคต
นอกจากการแก้ไขเชิงเทคนิคแล้ว ต้องวางกลยุทธ์เชิงธุรกิจเพื่อเร่งการยอมรับในวงการการเงินและประกันภัย ดังนี้
- มาตรฐานร่วมกับ regulator และการเข้าร่วม sandbox — ร่วมมือกับหน่วยงานกำกับดูแลเพื่อพัฒนามาตรฐานการทดสอบและการรับรองกระบวนการ privacy-preserving (เช่น แนวทางการรายงาน ε, ระดับการทดสอบ leakage) รวมทั้งเข้าร่วม regulatory sandboxes เพื่อพิสูจน์ความปลอดภัยและประสิทธิผลในสภาพแวดล้อมควบคุม
- ขยาย use‑cases ที่ชัดเจน — นำแพลตฟอร์มไปสู่กรณีใช้งานอื่นๆ ที่มีความต้องการข้อมูลสูงและผลตอบแทนชัดเจน เช่น การตรวจจับการฉ้อโกง (fraud detection), การจัดกลุ่มลูกค้า (segmentation), การตั้งเบี้ยประกันแบบไดนามิก (parametric pricing) โดยสาธิต ROI ผ่านกรณีศึกษาและ POC ที่แสดงตัวเลขการลดความเสี่ยงด้านข้อมูลและการปรับปรุงโมเดล
- โมเดลธุรกิจและผลิตภัณฑ์ — เสนอหลายรูปแบบเชิงพาณิชย์ เช่น SaaS subscription สำหรับองค์กรที่ต้องการแพลตฟอร์มพร้อมเครื่องมือ, Data‑collaboration marketplace ที่เอเจนซีและธนาคารสามารถแลกเปลี่ยน synthetic datasets ภายใต้ข้อตกลง revenue‑sharing, และโซลูชันแบบ consortium ที่ธนาคารหลายแห่งร่วมเป็นเจ้าของแพลตฟอร์มเพื่อลดต้นทุนร่วมกัน
- กลยุทธ์การตลาดสำหรับสถาบันการเงิน — มุ่งเน้นการสร้างความเชื่อมั่นด้วยเอกสารเชิงเทคนิค (whitepapers), รายงานการตรวจสอบอิสระ, ผลการพิลอต (เช่น ลดการแชร์ข้อมูลต้นทางกว่า 90%) และกรณีศึกษา ROI พร้อมการจัดเวิร์กช็อป/POC แบบร่วมมือกับทีม data science ของลูกค้า เพื่อสาธิตการทำงานจริงและ SLA ด้าน privacy/uptime
โดยสรุป แนวทางที่เหมาะสมคือการผสานกันของเทคนิค (hybrid data + adaptive DP + federated evaluation), กระบวนการตรวจสอบภายนอก, และกลยุทธ์การตลาดเชิงความเชื่อมั่น/มาตรฐาน เพื่อนำแพลตฟอร์มจากการพิสูจน์แนวคิดในพิลอตไปสู่การใช้งานเชิงพาณิชย์ในวงกว้างสำหรับภาคการเงินและประกันภัย
บทสรุป
สตาร์ทอัพไทย ได้พัฒนาแพลตฟอร์มที่ผสานเทคนิคหลักสามด้าน—Synthetic Data, Differential Privacy และ Federated Learning—เพื่อฝึกโมเดลสินเชื่อและประกันโดยไม่ต้องใช้ข้อมูลลูกค้าจริงในรูปแบบดิบ ผลจากการพิลอตชี้ให้เห็นว่าการแชร์ข้อมูลต้นทางถูกลดลงอย่างมีนัยสำคัญ (พิลอตลดการแชร์ข้อมูลต้นทางมากกว่า 90%) ขณะที่ยังคงสามารถฝึกและปรับใช้โมเดลเชิงธุรกิจได้ โดยระบบต้องบริหาร trade‑off ระหว่างความเป็นส่วนตัวและคุณภาพของโมเดล (privacy vs. utility) ผ่านการตั้งค่าพารามิเตอร์ของ DP, การออกแบบ synthetic generation และการออกแบบการอัปเดตแบบกระจาย ตัวอย่างเช่น การใช้ synthetic record ร่วมกับ noise mechanism ของ DP และ aggregation ใน FL ช่วยลดการเปิดเผยข้อมูลดิบต่อบุคคลที่สามและสถาบันกลาง
อย่างไรก็ตาม การขยายการใช้งานเชิงพาณิชย์ยังต้องการองค์ประกอบเสริมเพื่อสร้างความเชื่อมั่นแก่สถาบันการเงินและผู้กำกับดูแล ได้แก่ มาตรฐานการตรวจสอบ (audit standards) และกรอบการวัดผลที่ชัดเจน (เช่น การเทียบค่า utility ด้วย metric เช่น AUC, RMSE, stability tests และการทดสอบ bias) ความโปร่งใสทางกฎหมาย (legal transparency) ในการประมวลผลข้อมูลและการรับรองว่ากระบวนการ synthetic/DP/FL สอดคล้องกับกฎหมายคุ้มครองข้อมูล รวมถึงหลักฐานเชิงธุรกิจ (business proof) ที่แสดงว่าโมเดลที่ได้สร้างมูลค่าเชิงเศรษฐกิจและลดความเสี่ยงได้จริง เช่น กรณีทดสอบที่แสดงการคงระดับความแม่นยำใกล้เคียงกับโมเดลที่ฝึกจากข้อมูลดิบ หรือการลดค่าใช้จ่ายด้านการปฏิบัติตามกฎการคุ้มครองข้อมูล
มุมมองอนาคต: แนวทางผสมนี้มีศักยภาพสูงในการเปลี่ยนวิธีการพัฒนาโมเดลในภาคการเงินและประกันให้เป็นมิตรกับความเป็นส่วนตัว แต่การนำไปใช้ในวงกว้างจะขึ้นกับการพัฒนามาตรฐานกลาง การรับรองจากหน่วยงานกำกับดูแล การจัดทำเอกสารการตรวจสอบแบบ third‑party และการสาธิตกรณีธุรกิจที่ชัดเจนเพื่อสร้าง trust chain ระหว่างธนาคาร ผู้ให้ประกัน และผู้กำกับ หากสามารถแก้ข้อจำกัดด้าน trade‑off และยืนยันผลลัพธ์เชิงประสิทธิภาพได้สำเร็จ เทคโนโลยีดังกล่าวจะเป็นเครื่องมือสำคัญในการลดการแชร์ข้อมูลต้นทาง ลดความเสี่ยงด้านความเป็นส่วนตัว และเปิดทางสู่การร่วมมือข้ามสถาบันในการพัฒนาผลิตภัณฑ์ทางการเงินที่ปลอดภัยยิ่งขึ้น



