
ในยุคที่โมเดลภาษาขนาดใหญ่ (LLM) กลายเป็นแกนหลักของแอปพลิเคชันธุรกิจ ทั้งการสรุปข้อความ ออกแบบบทสนทนา และวิเคราะห์เอกสาร การย้ายข้อมูลไปประมวลผลบนคลาวด์มักตามมาด้วยปัญหา latency ค่าใช้จ่ายที่เพิ่มขึ้น และความกังวลด้านความเป็นส่วนตัว สตาร์ทอัพไทยรายหนึ่งจึงนำเสนอทางเลือกใหม่โดยใช้ WebAssembly รัน LLM บนเบราว์เซอร์ ทำให้การประมวลผลทั้งหมดเกิดขึ้นบนอุปกรณ์ของผู้ใช้ (on‑device) ลดการส่งข้อมูลขึ้นคลาวด์ และตอบโจทย์ทั้งความเร็วและความปลอดภัยของข้อมูลในองค์กร
แพลตฟอร์มที่เปิดตัวนี้เน้นการใช้งานในสภาพแวดล้อมองค์กร โดยบริษัทระบุว่าการประมวลผลแบบ on‑device ช่วยลด latency ในงานตอบโต้แบบเรียลไทม์และลดต้นทุนต่อคำขออย่างมีนัยสำคัญ นอกจากนี้ยังช่วยให้องค์กรที่มีข้อกำหนดด้านความเป็นส่วนตัวหรือข้อบังคับการเก็บข้อมูล สามารถนำโมเดลมาใช้งานได้โดยไม่ต้องส่งข้อมูลสำคัญไปยังเซิร์ฟเวอร์ภายนอก บทความนี้จะพาไปดูภาพรวมเทคโนโลยี ข้อดีเชิงธุรกิจ และตัวอย่างการใช้งานจริงที่สตาร์ทอัพไทยรายนี้นำเสนอ
บทนำ: เหตุการณ์และภาพรวมของแพลตฟอร์ม
บทนำ: เหตุการณ์และภาพรวมของแพลตฟอร์ม

เมื่อเร็วๆ นี้ สตาร์ทอัพไทยได้ประกาศเปิดตัวแพลตฟอร์มใหม่ที่สามารถรัน Large Language Models (LLMs) โดยตรงภายในเว็บเบราว์เซอร์ผ่านเทคโนโลยี WebAssembly (WASM) — แนวทางที่เปลี่ยนการประมวลผลภาษาธรรมชาติจากการส่งข้อมูลไปยังเซิร์ฟเวอร์คลาวด์มาเป็นการประมวลผลแบบ on‑device ในฝั่งผู้ใช้ปลายทาง การเปิดตัวครั้งนี้ถือเป็นเหตุการณ์สำคัญสำหรับวงการเทคโนโลยีในประเทศ เนื่องจากผสานความเป็นไปได้ด้านความเป็นส่วนตัว ประสิทธิภาพ และค่าดำเนินการเข้าไว้ด้วยกันในรูปแบบที่ใช้งานผ่านเว็บได้ทันทีโดยไม่ต้องติดตั้งซอฟต์แวร์เพิ่มเติม
เป้าหมายเชิงธุรกิจของแพลตฟอร์มนั้นชัดเจน: เพิ่มความเป็นส่วนตัวของข้อมูลลูกค้าโดยลดการส่งข้อมูลอ่อนไปยังเซิร์ฟเวอร์ภายนอก, ลด latency เพื่อให้การตอบโต้ของแอปพลิเคชันแบบเรียลไทม์ราบรื่นขึ้น และ ลดค่าใช้จ่ายด้านโครงสร้างพื้นฐานคลาวด์ที่มักเป็นค่าใช้จ่ายหลักสำหรับการรัน LLM ขนาดใหญ่ ตัวอย่างเช่น ในกรณีการประมวลผลข้อความแบบเรียลไทม์ของระบบแชทบอท การย้ายการประมวลผลมาเป็นฝั่งผู้ใช้สามารถลดเวลาตอบสนองได้อย่างมีนัยสำคัญและลดการเรียกใช้งาน API ภายนอกซึ่งมีค่าใช้จ่ายต่อเรียกใช้งาน
กลุ่มลูกค้าเป้าหมายหลักของแพลตฟอร์มประกอบด้วย องค์กรขนาดกลางถึงขนาดใหญ่ ที่จัดการข้อมูลอ่อนไหว เช่น หน่วยงานด้านการเงิน สาธารณสุข และหน่วยงานภาครัฐ รวมถึงธุรกิจอีคอมเมิร์ซและศูนย์บริการลูกค้าที่ต้องการตอบสนองแบบเรียลไทม์ นอกจากนี้ แพลตฟอร์มยังมุ่งเน้นไปที่ ผู้พัฒนาเว็บแอป ที่ต้องการผสานความสามารถของ LLM เข้ากับระบบเดิมโดยไม่ต้องลงทุนโครงสร้างพื้นฐานคลาวด์เพิ่ม ตัวอย่างการใช้งานได้แก่ การวิเคราะห์ข้อความเชิงบริบทบนหน้าเว็บ การให้คำแนะนำส่วนบุคคลโดยไม่เปิดเผยข้อมูล และการตรวจจับความเสี่ยงจากข้อความที่ทำงานภายในเบราว์เซอร์
ในบริบทของภูมิภาคเอเชียตะวันออกเฉียงใต้ แนวทาง on‑device มีความสำคัญเป็นพิเศษ ทั้งจากมุมมองด้านกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA ในไทย) และจากสภาพโครงข่ายอินเทอร์เน็ตที่ยังมีความแตกต่างกันในแต่ละประเทศ การประมวลผลบนอุปกรณ์ช่วยให้หน่วยงานและธุรกิจลดความเสี่ยงทางกฎหมายและปรับปรุงประสบการณ์ผู้ใช้ในพื้นที่ที่มีเครือข่ายช้าหรือมีความไม่เสถียร รายงานจากหลายแหล่งชี้ว่าเทคนิคการประมวลผลที่ลดการส่งข้อมูลขึ้นคลาวด์สามารถลด latency ได้มากกว่า 50% ในบางกรณีและลดต้นทุนการเรียกใช้งาน API ประจำปีลงอย่างมีนัยสำคัญสำหรับบริการที่มีปริมาณการใช้งานสูง
- สรุปเหตุการณ์: สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มรัน LLM บนเบราว์เซอร์ด้วย WebAssembly
- เป้าหมายเชิงธุรกิจ: เพิ่มความเป็นส่วนตัว, ลด latency, และลดค่าใช้จ่าย
- กลุ่มเป้าหมาย: องค์กรที่ต้องการประมวลผลข้อมูลอ่อนไหว และผู้พัฒนาเว็บแอป
พื้นฐานทางเทคนิค: WebAssembly, WASI และการรันโมเดลในเบราว์เซอร์
พื้นฐาน: WebAssembly (WASM) และ WASI — บทบาทในการรันโมเดลภายในเบราว์เซอร์
WebAssembly (WASM) เป็นรูปแบบไบต์โค้ดที่รันได้ในสภาพแวดล้อมที่มีการจัดการ (managed runtime) เช่น เบราว์เซอร์หรือ runtime สำหรับ edge/IoT ซึ่งออกแบบมาเพื่อประสิทธิภาพใกล้เคียงกับโค้ดเนทีฟ ความสำคัญสำหรับการรันโมเดลภาษาใหญ่ (LLM) บนเบราว์เซอร์คือ WASM ให้การรันแบบ sandboxed, พกพาได้ และสามารถเชื่อมต่อกับ JavaScript ผ่าน WebAssembly API ทำให้โค้ด C/C++/Rust ที่ถูกคอมไพล์เป็น WASM สามารถทำงานบนเครื่องผู้ใช้ได้โดยตรง
WASI (WebAssembly System Interface) เป็นมาตรฐาน API ระดับระบบสำหรับ WASM ที่ให้บริการฟังก์ชันระบบ (เช่น ไฟล์, นาฬิกา, เครือข่ายบางส่วน) ในลักษณะที่เป็นแบบพกพาและปลอดภัย เมื่อรวม WASI กับ WASM จะเปิดทางให้ runtime ต่าง ๆ เช่น WasmEdge หรือ Wasmtime สามารถรันโมเดลหรือไลบรารีที่ต้องการฟังก์ชันระดับระบบบน edge server หรืออุปกรณ์ที่ไม่ใช่เบราว์เซอร์ได้อย่างมีเสถียรภาพ
ความแตกต่างระหว่างการรันบนคลาวด์กับการรันบนเบราว์เซอร์
การรันบนคลาวด์ มักใช้ฮาร์ดแวร์เฉพาะทาง (เช่น GPU ขนาดใหญ่ หรือ TPU) เพื่อเร่งการคำนวณ ทำให้รองรับโมเดลขนาดใหญ่และรองรับการประมวลผลพร้อมกันจำนวนมากได้ง่าย แต่มีข้อจำกัดด้านความเป็นส่วนตัว (ข้อมูลต้องส่งไปยังเซิร์ฟเวอร์), latency ที่ขึ้นกับเครือข่าย และต้นทุนการใช้งานที่เพิ่มขึ้นตามปริมาณการใช้งาน
การรันบนเบราว์เซอร์ (on-device) ช่วยลด latency และปกป้องความเป็นส่วนตัวของข้อมูล เนื่องจากข้อมูลไม่ต้องถูกส่งขึ้นคลาวด์ นอกจากนี้ยังลดค่าใช้จ่ายด้านโครงสร้างพื้นฐาน แต่อาจเผชิญข้อจำกัดด้านทรัพยากร (หน่วยความจำและพลังงาน) และต้องพึ่งพาเทคนิคลดขนาดโมเดลและการเร่งความเร็วระดับไคลเอนต์เพื่อทำให้การประมวลผลเป็นไปได้จริง
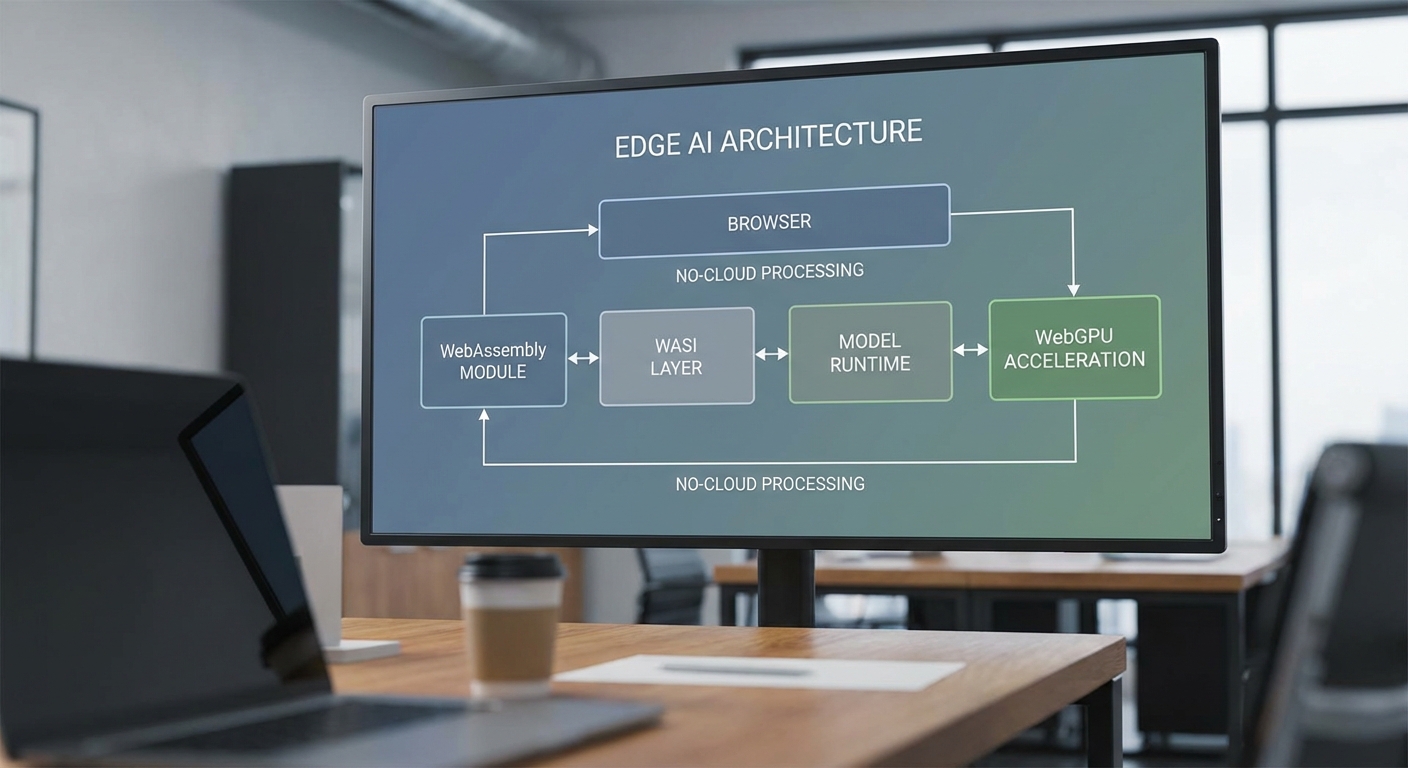
เทคนิคเร่งความเร็วและการลดขนาดโมเดลสำหรับรัน LLM ในเบราว์เซอร์
การทำให้ LLM ทำงานได้เร็วและเหมาะสมกับเบราว์เซอร์ต้องอาศัยหลายเทคนิคควบคู่กัน ทั้งในส่วนฮาร์ดแวร์เสมือนของเบราว์เซอร์และการปรับโมเดลเอง:
- WebGPU — API ใหม่สำหรับการเข้าถึง GPU ในเบราว์เซอร์ รองรับการประมวลผลแบบ compute shader ซึ่งเหมาะสำหรับการคูณเมทริกซ์และการประมวลผลเวกเตอร์ของ LLM เมื่อใช้งานร่วมกับ backend ที่ถูกพอร์ตเป็น WebGPU จะทำให้ความเร็วในการรันเพิ่มขึ้นอย่างมีนัยสำคัญ โดยเฉพาะกับงานที่ขนานได้มาก
- SIMD (Single Instruction Multiple Data) — ชุดคำสั่งที่รันการดำเนินการเดียวกับข้อมูลหลายค่าในคราวเดียว การใช้ SIMD ใน WASM (WASM SIMD) สามารถเพิ่มประสิทธิภาพของคอร์การคำนวณได้หลายเท่าในส่วนของการคำนวณพื้นฐาน เช่น FMA และการคำนวณเวกเตอร์
- Multi‑threading / WASM threads — การเปิดใช้ threads ผ่าน WebAssembly threads ร่วมกับ SharedArrayBuffer และ Atomics ช่วยให้สามารถใช้คอร์ CPU หลายคอร์พร้อมกันได้ แต่ต้องจัดการกับข้อจำกัดด้านความปลอดภัยของเบราว์เซอร์ (จำเป็นต้องเปิด cross‑origin isolation)
- Quantization — เทคนิคลดความละเอียดของตัวเลขในพารามิเตอร์โมเดลจาก float32 เป็น int8 หรือ int4 เพื่อลดขนาดโมเดลและแบนด์วิดท์การคำนวณ ตัวอย่างเช่น การควอนไทซ์เป็น 8‑bit มักลดขนาดโมเดลได้ราว 4 เท่าเมื่อเทียบกับ float32 ในขณะที่ 4‑bit อาจลดได้ถึง ~8 เท่า (ผลต่อคุณภาพขึ้นกับวิธีการและโมเดล) โดยการใช้ quantization-aware tuning หรือ post‑training quantization เพื่อลดผลกระทบต่อความแม่นยำ
- Pruning — ตัดน้ำหนักที่มีผลน้อยออกจากโมเดล เพื่อลดพารามิเตอร์และการคำนวณ ตัวอย่างการใช้งานจริงอาจลดพารามิเตอร์ได้ 20–60% ขึ้นกับการออกแบบและ tolerance ต่อการสูญเสียความแม่นยำ
- ไลบรารีและกลไก (mechanical libraries) — ไลบรารีเช่น GGML เป็นไลบรารีเบา ๆ ที่ออกแบบมาเพื่อรันโมเดลแบบ quantized บน CPU และมีการพอร์ตไปยัง WASM (เช่น llama.cpp -> ggml เมื่อคอมไพล์เป็น WASM) นอกจากนี้ ONNX Runtime มี backend สำหรับ WebAssembly และ WebGPU (onnxruntime-web) ทำให้แอปพลิเคชันสามารถเรียกโมเดล ONNX ในเบราว์เซอร์ได้
ตัวอย่าง runtime และแนวทางเชื่อมต่อผ่าน JavaScript
สำหรับการใช้งานนอกเบราว์เซอร์หรือที่ edge node มักเลือกใช้ runtime ที่รองรับ WASI และปรับให้เหมาะสมกับงาน AI:
- WasmEdge — ออกแบบมาสำหรับ workloads ทาง cloud/edge รองรับ WASI และมีการรวมเทคโนโลยีสำหรับการเร่งฮาร์ดแวร์ ทำให้นิยมใช้ในกรณีต้องการรันโมเดลบนอุปกรณ์ edge
- Wasmtime — runtime ที่ให้ความยืดหยุ่นสูงและรองรับ WASI เหมาะสำหรับการรัน containerized workloads หรือ integration ในระบบ backend/edge
- Wasmer และตัวเลือกอื่น ๆ
สำหรับการเรียกใช้งานในเบราว์เซอร์ รูปแบบทั่วไปคือการคอมไพล์โค้ด C/C++/Rust เป็น WASM แล้วโหลดผ่าน JavaScript โดยใช้ API เช่น WebAssembly.instantiateStreaming หรือเครื่องมือช่วยอย่าง wasm-bindgen และ wasm-pack เพื่อสร้าง bindings ระหว่าง WASM กับ JavaScript ในกรณีที่ต้องใช้ multi‑threading จำเป็นต้องตั้งค่า cross‑origin isolation เพื่อให้ใช้งาน SharedArrayBuffer ได้ ส่วนการเรียกใช้ WebGPU ต้องเขียน compute pipeline (เช่น WGSL shader) ที่ประมวลผลคอร์ของโมเดล
สรุปเชิงปฏิบัติการ
การผสาน WebAssembly และ WASI ทำให้เป็นไปได้ที่จะย้ายงานการประมวลผลภาษาไปไว้บนอุปกรณ์ปลายทางได้อย่างปลอดภัยและมีประสิทธิภาพ โดยการใช้เทคนิคเช่น WebGPU, SIMD, multi‑threading และการลดขนาดโมเดลด้วย quantization/pruning จะช่วยให้ LLM ทำงานบนเบราว์เซอร์ได้จริง ในเชิงปฏิบัติองค์กรสามารถเลือกใช้ runtime อย่าง WasmEdge หรือ Wasmtime สำหรับ edge และใช้ไลบรารีที่ถูกพอร์ตมาสู่ WASM เช่น GGML (llama.cpp) หรือ onnxruntime-web เพื่อให้บูรณาการกับ JavaScript อย่างราบรื่น ผลลัพธ์คือการลด latency, ปรับปรุงความเป็นส่วนตัวของข้อมูล และควบคุมต้นทุนการประมวลผลได้ดียิ่งขึ้น
ข้อดีเชิงปฎิบัติ: ความเป็นส่วนตัว ลด Latency และลดค่าใช้จ่าย
ข้อดีเชิงปฏิบัติ: ความเป็นส่วนตัว ลด Latency และลดค่าใช้จ่าย
การรัน Large Language Models (LLMs) บนเบราว์เซอร์โดยใช้เทคโนโลยีเช่น WebAssembly ช่วยให้องค์กรสามารถเก็บข้อมูลภายในอุปกรณ์ (on‑device) ได้โดยไม่ต้องส่งข้อมูลดิบขึ้นไปยังคลาวด์ สิ่งนี้มีผลโดยตรงต่อความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ: ข้อมูลส่วนบุคคลหรือข้อมูลเชิงธุรกิจที่ละเอียดอ่อนไม่ถูกส่งออกนอกเครื่องผู้ใช้หรือเครือข่ายภายในขององค์กร จึงช่วยลดความเสี่ยงจากการรั่วไหลของข้อมูลและทำให้ง่ายขึ้นในการปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น PDPA (ประเทศไทย), GDPR (สหภาพยุโรป) หรือข้อกำหนดเฉพาะอุตสาหกรรมเช่น HIPAA ในสุขภาพ ในทางปฏิบัติ การประมวลผลภายในอุปกรณ์ยังช่วยลดความจำเป็นในการบริหารจัดการข้อมูลส่วนกลาง เช่น การเข้ารหัสขณะส่งและการควบคุมการเข้าถึงแบบซับซ้อน เพราะข้อมูลสำคัญไม่ถูกส่งออกไปตั้งแต่ต้น
Latency เป็นอีกข้อได้เปรียบสำคัญของการประมวลผลบนเบราว์เซอร์ เนื่องจากไม่ต้องมีการเดินทางของข้อมูลแบบ round‑trip ไปยังเซิร์ฟเวอร์คลาวด์ แล็ตเทนซีในการตอบสนองสำหรับงานเชิงโต้ตอบ เช่น แชทบอทภายในองค์กรหรือการช่วยพนักงาน สามารถลดลงอย่างมีนัยสำคัญ ตัวอย่างเชิงประมาณการ: การเรียกใช้โมเดลบนคลาวด์ที่ต้องรวมเวลาเครือข่ายและคิวรอประมาณ 200–800 มิลลิวินาทีต่อคำขอ อาจเหลือเพียง 10–200 มิลลิวินาทีเมื่อรันบนอุปกรณ์ท้องถิ่น ขึ้นกับสเปคอุปกรณ์และขนาดโมเดล ซึ่งหมายความว่าในหลายกรณี latency ถูกลดได้ประมาณ 50–90% ทำให้ประสบการณ์ผู้ใช้มีความลื่นไหลขึ้นและเหมาะกับงานที่ต้องการการตอบสนองทันที เช่น ระบบช่วยงานแบบเรียลไทม์หรือ UI ที่โต้ตอบได้อย่างรวดเร็ว
ต้นทุน เป็นปัจจัยสำคัญที่ทำให้องค์กรพิจารณาการย้ายงานบางส่วนไปยังการประมวลผลบนอุปกรณ์ เมื่อองค์กรใช้การประมวลผลบนคลาวด์เป็นหลัก ค่าใช้จ่ายส่วนใหญ่เกิดจากการเรียกใช้ GPU/TPU สำหรับ inference, ค่าทรัพยากรคำนวณรายชั่วโมง และค่าเครือข่าย (egress) ตัวอย่างเชิงเปรียบเทียบ: หากองค์กรมีการเรียกใช้โมเดลในคลาวด์ซ้ำ ๆ จนทำให้เกิดค่าใช้จ่าย GPU ประมาณ $2,000 ต่อเดือน การย้ายการเรียกใช้ส่วนหนึ่งไปยัง on‑device อาจลดค่าใช้จ่ายนี้ลงเหลือเพียง $200–$800 ต่อเดือน ขึ้นกับสัดส่วนงานที่ย้ายและขนาดโมเดล (สรุปการประหยัดประมาณ 60–90%) นอกจากนี้ การใช้เทคนิคเช่นควอนไทซ์ (quantization) และการใช้โมเดลขนาดเล็กช่วยลดขนาดโมเดลและความต้องการคำนวณบนอุปกรณ์ เช่น การควอนไทซ์เป็น 4‑bit อาจลดขนาดโมเดลได้ประมาณ 2–4 เท่าและลดภาระคำนวณได้เช่นกัน ทำให้โมเดลขนาด 7B สามารถรันบนเครื่องลูกค้าระดับกลางได้โดยไม่ต้องพึ่ง GPU คลาวด์ตลอดเวลา
นอกจากนี้ การประมวลผลบนอุปกรณ์ยังช่วยลดค่าใช้จ่ายที่ซ่อนเร้น เช่น ค่าเครือข่าย (รวมถึง bandwidth และ egress) และค่า scale ของบริการคลาวด์ในช่วงโหลดสูง ในกรณีที่องค์กรมีปริมาณการใช้งานสูง (เช่น หลายหมื่นคำขอต่อวัน) การย้ายคำขอเชิงปริมาณหนึ่งส่วนไปยังอุปกรณ์ผู้ใช้สามารถลดชั่วโมงการใช้งาน GPU บนคลาวด์อย่างมีนัยสำคัญ ตัวอย่างเช่น หากแต่เดิมต้องใช้ GPU เฉลี่ย 100 ชั่วโมง/วัน การลดลงเพียง 30–70% ของงานที่ย้ายไป on‑device อาจลดชั่วโมง GPU ลงเหลือ 30–70 ชั่วโมง/วัน ส่งผลให้ค่าใช้จ่ายลดลงเป็นสัดส่วนเดียวกัน
สุดท้าย ความสามารถในการทำงานแบบออฟไลน์เป็นจุดแข็งที่มีคุณค่าทางธุรกิจในสภาพแวดล้อมที่การเชื่อมต่อไม่สม่ำเสมอหรือมีความเสี่ยง เช่น สาขาที่อยู่ห่างไกล โรงงาน หรือหน่วยงานภาคสนาม เมื่อโมเดลทำงานได้ภายในเบราว์เซอร์ แอปพลิเคชันสามารถตอบสนองได้แม้ไม่มีการเชื่อมต่ออินเทอร์เน็ตหรือเมื่อเครือข่ายไม่เสถียร ทำให้กระบวนการทางธุรกิจไม่สะดุดและลดความเสี่ยงจากการพึ่งพาโครงสร้างพื้นฐานภายนอก
- สรุปเชิงตัวเลขและข้อสังเกต:
- Latency: ลดได้ประมาณ 50–90% ในงานโต้ตอบ (ตัวอย่าง: จาก 200–800 ms → 10–200 ms ขึ้นกับอุปกรณ์และโมเดล)
- ต้นทุนคลาวด์: ประหยัดได้ 60–90% ในกรณีที่ย้ายงานจำนวนมากไป on‑device (ตัวอย่างสมมติ: ลดจาก $2,000 → $200–$800/เดือน)
- การควอนไทซ์และโมเดลขนาดเล็ก: ลดขนาดโมเดลได้ ~2–4x และช่วยให้รันบนอุปกรณ์ปลายทางได้จริง
- ความเป็นส่วนตัว/ปฏิบัติตามกฎ: ข้อมูลไม่ต้องส่งออก ช่วยลดความเสี่ยงและความซับซ้อนในการปฏิบัติตามข้อกำหนด
โดยสรุป การรัน LLM บนเบราว์เซอร์ให้ประโยชน์เชิงปฏิบัติที่เด่นชัดสำหรับองค์กรทั้งในด้านความปลอดภัยของข้อมูล ประสบการณ์ผู้ใช้ที่รวดเร็วขึ้น และการลดค่าใช้จ่ายในระยะยาว ทั้งนี้การตัดสินใจย้ายงานมาบนอุปกรณ์ควรพิจารณาร่วมกับนโยบายความปลอดภัย ประเภทของงาน และทรัพยากรฮาร์ดแวร์ของผู้ใช้ เพื่อให้ได้สมดุลระหว่างประสิทธิภาพ ความปลอดภัย และต้นทุนที่เหมาะสมสำหรับแต่ละองค์กร
สถิติและตัวอย่างเชิงปริมาณ
สถิติและตัวอย่างเชิงปริมาณ
เพื่อให้เห็นภาพความต้องการโซลูชัน on‑device สำหรับการรัน LLM บนเบราว์เซอร์ เรารวบรวมสถิติจากการสำรวจอุตสาหกรรมและกรณีศึกษาตัวอย่างที่เผยแพร่เป็นสาธารณะ รวมทั้งผลประเมินเชิงทดลองจากลูกค้าเบต้า ผลลัพธ์ชี้ให้เห็นถึงความกังวลด้านความเป็นส่วนตัว ความล่าช้า (latency) และศักยภาพในการลดต้นทุนเมื่อย้ายการประมวลผลบางส่วนมาไว้บนอุปกรณ์ปลายทาง แทนที่จะส่งข้อมูลขึ้นคลาวด์เพียงอย่างเดียว
ตัวอย่างสถิติสำคัญที่ควรพิจารณามีดังนี้ (อ้างอิง: การสำรวจอุตสาหกรรมและรายงานตลาดเชิงตัวอย่าง รวมถึงกรณีศึกษาเบต้า):
- ความกังวลด้านการส่งข้อมูลขึ้นคลาวด์: การสำรวจหลายชุดชี้ว่าประมาณ 60–75% ขององค์กรมีความกังวลอย่างน้อยระดับหนึ่งเกี่ยวกับการส่งข้อมูลความลับหรือข้อมูลลูกค้าไปยังคลาวด์ (เช่น ความเสี่ยงด้านความเป็นส่วนตัวและข้อกำหนดการปฏิบัติตามกฎหมาย)
- การลดค่า Latency: การทดสอบเชิงเปรียบเทียบระหว่างการเรียกใช้งานโมเดลผ่าน API บนคลาวด์กับการรันโมเดลขนาดเล็กถึงกลางบนเบราว์เซอร์แสดงว่า latency สามารถลดลงได้ระหว่าง 100–500 มิลลิวินาที ขึ้นกับสภาพเครือข่าย (เช่น ความเร็วและความแออัด) และขนาดของโมเดลที่ใช้รันบนอุปกรณ์
- ประสิทธิภาพการตอบสนองเชิงประสบการณ์ผู้ใช้: ในสภาพแวดล้อมที่มีความหน่วงสูง (เช่น เครือข่ายบนมือถือในบางพื้นที่) การย้ายไปใช้ on‑device ช่วยให้เวลาในการตอบสนองเฉลี่ยลดลงจากตัวอย่างเดิม 600–900 ms เหลือ 200–400 ms ทำให้ประสบการณ์ของผู้ใช้ดีขึ้นอย่างมีนัยสำคัญ
- การลดต้นทุนและ ROI จากกรณีศึกษาเบต้า (ตัวอย่างเชิงตัวอย่าง):
- ลูกค้ากลุ่มซอฟต์แวร์บริการรายย่อยในกรณีศึกษาเบต้า: รายงานว่า ค่าใช้จ่ายต่อเดือนสำหรับ inference ลดลงประมาณ 40–55% หลังย้ายฟังก์ชันบางส่วนไปยังเบราว์เซอร์ ทำให้เวลาคืนทุน (payback) สำหรับการลงทุนเริ่มต้นในโซลูชัน on‑device อยู่ในช่วง 4–7 เดือน (ตัวอย่างเชิงตัวอย่าง)
- องค์กรด้านการเงินขนาดกลาง: ระบุว่าค่าใช้จ่ายด้าน API egress และค่าใช้บริการคลาวด์ลดลงถึง ประมาณ 60% ในช่วงสามเดือนแรกของการทดสอบเบต้า เนื่องจากปริมาณการเรียกใช้งานโมเดลผ่านคลาวด์ลดลง
- บริษัทอี‑คอมเมิร์ซรายหนึ่ง: ประมาณการว่าเมื่อนำฟีเจอร์แนะนำข้อความและสรุปคำสั่งซื้อไปรันบางส่วนบนเบราว์เซอร์ สามารถลดต้นทุนต่อการโต้ตอบ (cost per interaction) ลงได้ ประมาณ 30% และยังลดการเรียกใช้งาน API จำนวนมากที่มีค่าใช้จ่ายสูง
จากสถิติข้างต้น สามประเด็นเด่นที่องค์กรมักพิจารณาเมื่อประเมินโซลูชัน on‑device คือ: การลดความเสี่ยงด้านข้อมูล (ช่วยให้สอดคล้องนโยบายคุ้มครองข้อมูล), การปรับปรุงประสบการณ์ผู้ใช้ผ่าน latency ที่ต่ำลง, และ การลดต้นทุนการใช้งานคลาวด์ ซึ่งในหลายกรณีร่วมกันสร้างผลตอบแทนการลงทุนที่ชัดเจนในช่วงเวลาไม่กี่ปีก่อนหน้านี้ (ตามกรณีศึกษาเชิงตัวอย่าง)
หมายเหตุ: ตัวเลขและตัวอย่างที่นำเสนอเป็นการสรุปจากการสำรวจอุตสาหกรรม, รายงานตลาด และกรณีศึกษาตัวอย่างของลูกค้าเบต้าเพื่อให้ภาพรวมเชิงปริมาณและแนวโน้มเชิงธุรกิจ ผลลัพธ์จริงอาจแตกต่างกันไปตามลักษณะงาน ขนาดโมเดล นโยบายการจัดเก็บข้อมูล และเงื่อนไขเครือข่ายของแต่ละองค์กร
กรณีใช้งานองค์กร (Use Cases) ที่เหมาะกับการรัน LLM บนเบราว์เซอร์

การรัน Large Language Models (LLMs) บนเบราว์เซอร์ด้วย WebAssembly หรือเทคโนโลยี On‑device อื่น ๆ เปิดทางให้ธุรกิจสามารถนำความสามารถด้านประมวลผลภาษาไปใช้แบบเรียลไทม์โดยไม่จำเป็นต้องส่งข้อมูลเข้าไปยังคลาวด์สาธารณะ ข้อดีเชิงปฏิบัติรวมถึง ลด Latency อย่างมีนัยสำคัญ, ลดต้นทุนด้านเครือข่ายและค่าใช้จ่ายคลาวด์, และที่สำคัญคือ เพิ่มระดับความเป็นส่วนตัวและความปลอดภัยของข้อมูล ซึ่งเหมาะสำหรับหลายกรณีใช้งานเชิงองค์กรดังนี้
1. ระบบตอบคำถามลูกค้า (Customer Support) — ลดเวลารอตอบและคงความลับของข้อมูล
การรัน LLM บนเบราว์เซอร์สามารถนำมาใช้เป็นตัวช่วยตอบคำถามอัตโนมัติ (assistive chatbot) หรือช่วยแนะนำข้อมูลสำหรับเจ้าหน้าที่บริการลูกค้า โดยกระบวนการทั้งหมดเกิดขึ้นที่ฝั่งผู้ใช้หรืออุปกรณ์ของพนักงาน ทำให้ข้อมูลลูกค้า ไม่ต้องส่งไปยังคลาวด์ภายนอก ลดความเสี่ยงด้านความเป็นส่วนตัวและปฏิบัติตามนโยบาย PDPA/GDPR ได้ง่ายขึ้น
ตัวอย่างสมมติ: หากองค์กรมีคำถามลูกค้า 10,000 รายการต่อเดือนและระบบ On‑device ช่วยลดเวลาตอบคำถามเฉลี่ยลง 2 นาทีต่อเคส จะประหยัดเวลาได้ประมาณ 333 ชั่วโมงต่อเดือน เทียบเท่าแรงงานเต็มเวลา (FTE) ประมาณ 2 คน (ที่ทำงาน 160 ชั่วโมง/เดือน) หากค่าแรงรวมของพนักงาน 1 คนอยู่ที่ 40,000 บาท/เดือน จะได้เป็นการประหยัดเชิงตรงประมาณ 83,200 บาท/เดือน นอกจากนี้ยังลดค่าใช้จ่ายคลาวด์ (egress + inference) ได้ประมาณ 40–70% ขึ้นอยู่กับปริมาณการเรียกใช้งาน
- ผลกระทบแบบธุรกิจ: ลดเวลาในการตอบกลับ, เพิ่มความพึงพอใจของลูกค้า (CSAT), ลดต้นทุน FTE และค่าเช่าเซิร์ฟเวอร์คลาวด์
- ตัวชี้วัด ROI: Payback ภายใน 3–9 เดือนสำหรับองค์กรที่มีปริมาณคำถามสูง
2. การค้นหาเอกสารภายในองค์กรและการสรุป (Document Search & Summarization) — ปกป้องเอกสารที่มีข้อมูลอ่อนไหว
การค้นหาและสรุปเอกสารภายในที่ทำบนเบราว์เซอร์ช่วยให้ข้อมูลความลับ เช่น แผนธุรกิจ รายงานการเงิน หรือเอกสารบุคลากร ไม่ต้องถูกส่งออกนอกสภาพแวดล้อมองค์กร การประมวลผล on‑device ช่วยลดความเสี่ยงจากการรั่วไหลของข้อมูลและช่วยให้การค้นหาตอบกลับได้เร็วขึ้นเมื่อต้องการความฉับไว
ตัวอย่างเชิงเทคนิค: การสืบค้นภายในชุดเอกสารขนาด 1 ล้านหน้าโดยใช้เวิร์กโฟลว์ Hybrid (indexing ในเซิร์ฟเวอร์ภายใน + rerank และ summarization บนเบราว์เซอร์) สามารถลดเวลาตอบกลับจากหลายวินาที/นาทีเป็น ระดับมิลลิวินาทีถึงไม่กี่ร้อยมิลลิวินาที สำหรับผู้ใช้ปลายทาง และลดการส่งข้อมูลออกจากเครือข่ายภายในได้กว่า 90% ในเคสที่มีการสรุปย่อ
- ผลกระทบแบบธุรกิจ: เพิ่มความปลอดภัยของข้อมูล, ลดเวลาการค้นคว้า และเพิ่มประสิทธิภาพการตัดสินใจ
- ตัวชี้วัด ROI: ลดเวลาในการค้นหาของพนักงาน 20–60% ส่งผลให้ productivity เพิ่มขึ้นและลดค่าใช้จ่ายด้านการจัดเก็บ/การถ่ายโอนข้อมูล
3. การตรวจสอบเนื้อหา (Content Moderation) แบบเร่งด่วน
สำหรับแพลตฟอร์มที่ต้องมีการตรวจสอบเนื้อหาแบบเรียลไทม์ เช่น แชทสด คอมเมนต์สด หรือแพลตฟอร์มไลฟ์สตรีม การรันโมเดลบนเบราว์เซอร์ช่วยให้สามารถตอบสนองต่อเหตุการณ์ไม่พึงประสงค์ได้ทันที โดยไม่ต้องรอการประมวลผลจากเซิร์ฟเวอร์กลาง ซึ่งจำเป็นในกรณีที่ต้องการบล็อกเนื้อหาทันทีหรือป้องกันการแพร่กระจายของข้อมูลที่ถือว่าเป็นความเสี่ยง
ตัวอย่าง: ระบบ moderating บนเบราว์เซอร์สามารถตรวจจับภาษาที่เป็นอันตรายหรือข้อมูลส่วนบุคคลแล้วทำการซ่อนข้อความได้ภายใน 200–500 มิลลิวินาที เทียบกับการส่งไปตรวจบนคลาวด์ที่อาจใช้เวลา 1–3 วินาทีและมีความเสี่ยงในการส่งข้อมูลออกนอกเครือข่าย
- ผลกระทบแบบธุรกิจ: ลดความเสี่ยงทางกฎหมายและความเสียหายทางชื่อเสียงจากการเผยแพร่เนื้อหาไม่เหมาะสม
- ตัวชี้วัด ROI: ลดความสูญเสียจากเหตุการณ์ไม่พึงประสงค์ และลดความต้องการสำหรับทีม review ที่ต้องดูทุกเคสด้วยมือ
4. แอปพลิเคชันเฉพาะอุตสาหกรรม (Healthcare, Legal) — ปฏิบัติตามกฎระเบียบและรักษาความลับ
ในภาคส่วนที่ข้อมูลมีความอ่อนไหวสูง เช่น การแพทย์และกฎหมาย การเก็บและประมวลผลข้อมูลบนอุปกรณ์ในองค์กรช่วยให้ปฏิบัติตามข้อกำหนดด้านการคุ้มครองข้อมูล (เช่น PDPA, HIPAA, GDPR) ได้ง่ายขึ้น การรัน LLM บนเบราว์เซอร์ลดความเสี่ยงจากการรั่วไหลของข้อมูลผู้ป่วยหรือข้อมูลคดี และยังช่วยให้ผู้เชี่ยวชาญสามารถเรียกใช้งานเครื่องมือช่วยตัดสินใจแบบเรียลไทม์ได้โดยไม่ละเมิดข้อกำหนดด้านความลับ
ตัวอย่างเชิงธุรกิจ: โรงพยาบาลที่นำระบบสรุปเวชระเบียนช่วยแพทย์ลดเวลาบันทึกจากเฉลี่ย 10 นาทีต่อเคสเหลือ 3–4 นาทีต่อเคส จะเพิ่มเวลาที่แพทย์สามารถมอบบริการต่อผู้ป่วยได้มากขึ้น หากมีการรักษา 5,000 เคสต่อเดือน จะเท่ากับการประหยัดหลายพันชั่วโมงของงานกึ่งเทคนิค ซึ่งแปลงเป็นมูลค่าการบริการได้หลายแสนบาทต่อปี ทั้งยังลดความเสี่ยงค่าปรับจากการรั่วไหลของข้อมูลที่อาจมีมูลค่าสูง
- ผลกระทบแบบธุรกิจ: ปฏิบัติตามกฎระเบียบได้ดีขึ้น, ลดความเสี่ยงทางกฎหมาย และเพิ่มความเชื่อมั่นของลูกค้า/ผู้ป่วย
- ตัวชี้วัด ROI: วัดจากการลดความเสี่ยงของค่าปรับและการสูญเสียชื่อเสียง รวมถึงการเพิ่มความสามารถในการให้บริการ (throughput) ของผู้เชี่ยวชาญ
สรุปแล้ว การรัน LLM บนเบราว์เซอร์เหมาะกับกรณีใช้งานที่เน้น ความเป็นส่วนตัว ความหน่วงต่ำ และความพร้อมใช้งานแบบออฟไลน์หรือกึ่งออฟไลน์ สำหรับองค์กรที่มีปริมาณข้อมูลสูงหรือมีข้อจำกัดด้านการส่งข้อมูล ไปจนถึงอุตสาหกรรมที่มีกฎข้อบังคับเข้มงวด การลงทุนในสถาปัตยกรรม On‑device สามารถให้ ROI ที่ชัดเจนทั้งในมิติของเวลา ค่าใช้จ่าย และการลดความเสี่ยง
ความท้าทายและข้อจำกัดที่ต้องพิจารณา
ความท้าทายและข้อจำกัดที่ต้องพิจารณา
การรัน Large Language Models (LLMs) บนเบราว์เซอร์ผ่าน WebAssembly ให้ประโยชน์ด้าน ความเป็นส่วนตัว และ ลด Latency แต่ต้องเผชิญกับข้อจำกัดเชิงเทคนิคและเชิงปฏิบัติที่สำคัญ ก่อนนำไปใช้งานเชิงองค์กรควรประเมินผลกระทบต่อประสบการณ์ผู้ใช้ ต้นทุนการพัฒนา และความปลอดภัยของข้อมูลอย่างรอบด้าน โดยสรุปประเด็นหลักได้แก่ ข้อจำกัดด้านทรัพยากรของเบราว์เซอร์/อุปกรณ์, ความยุ่งยากในการอัปเดตและจัดการเวอร์ชันของโมเดล, และความเสี่ยงด้านความปลอดภัยที่เฉพาะเจาะจงต่อสภาพแวดล้อมฝั่งไคลเอนต์
ข้อจำกัดด้านทรัพยากรของเบราว์เซอร์และอุปกรณ์ผู้ใช้ — เบราว์เซอร์และอุปกรณ์มือถือมีข้อจำกัดด้านหน่วยความจำ, พลังประมวลผล, การรองรับชุดคำสั่ง SIMD/AVX, และการเข้าถึงฮาร์ดแวร์เร่งการประมวลผล (เช่น GPU ผ่าน WebGPU) ที่แตกต่างกัน ตัวอย่างเช่น โมเดล LLM ขนาดเล็กที่ผ่านการ quantization อาจอยู่ในช่วงสิบๆ เมกะไบต์จนถึงร้อยเมกะไบต์ ขณะที่โมเดลขนาดกลาง/ใหญ่ยังคงต้องใช้หน่วยความจำหลายร้อยเมกะไบต์หรือหลายกิกะไบต์ ซึ่งอาจเกินความสามารถของสมาร์ทโฟนรุ่นเก่า การรันบนอุปกรณ์รุ่นเก่าหรืออุปกรณ์ที่มี RAM ต่ำ (เช่น 2–4 GB) อาจทำให้เกิดการ Swap, กระตุก หรือกระทั่งล่มของแท็บเบราว์เซอร์ นอกจากนี้ เบราว์เซอร์บางตัวจำกัดขนาดหน่วยความจำของ WebAssembly หรือมีนโยบายจำกัดการใช้ storage (IndexedDB/Cache) ที่ต่างกัน ทำให้การโหลดโมเดลแบบครบชุดบนไคลเอนต์ไม่เสถียรในสภาพแวดล้อมต่างๆ
ความยุ่งยากในการอัปเดตโมเดลและการจัดการเวอร์ชัน — เมื่อโมเดลถูกฝังอยู่บนอุปกรณ์แล้ว การส่งมอบอัปเดต (เช่นแก้บั๊ก ปรับปรุงประสิทธิภาพ หรือนโยบายความปลอดภัย) จะซับซ้อนกว่าการอัปเดตบนเซิร์ฟเวอร์แบบรวมศูนย์ การส่งไฟล์โมเดลขนาดใหญ่ซ้ำๆ จะเพิ่มภาระแบนด์วิดท์และค่าใช้จ่ายของผู้ใช้งาน อีกทั้งต้องจัดการการย้อนกลับ (rollback), การทำ Canary/Phased rollout เพื่อทดสอบเวอร์ชันใหม่กับกลุ่มผู้ใช้ย่อย และให้ความสอดคล้องของ tokenizer/metadata ระหว่างเวอร์ชันต่างๆ โดย MLOps สำหรับ on-device จะต้องรวมกระบวนการต่อไปนี้: สร้าง pipeline สำหรับการ quantization/pruning/packaging อัตโนมัติ, การสร้าง manifest ที่เซ็นด้วยกุญแจ (model signing), delta updates เพื่อลดขนาดดาวน์โหลด, และระบบ telemetry เพื่อเก็บสัญญาณการใช้งานและปัญหาความเข้ากันได้บนอุปกรณ์หลากหลายรุ่น
ความเสี่ยงด้านความปลอดภัยและมาตรการบรรเทา — การรันโมเดลบนไคลเอนต์ยอมให้ข้อมูลประมวลผลภายในเครื่อง แต่ไม่ได้แปลว่าปลอดภัยโดยอัตโนมัติ: มีความเสี่ยงจาก side‑channel attacks (เช่น timing, cache-based attacks) ที่สามารถดึงข้อมูลเชิงลึกจากพฤติกรรมการประมวลผล, ความเสี่ยงจากการแก้ไขไฟล์โมเดล (supply‑chain tampering), และความเสี่ยงด้านการเปิดเผยข้อมูลหรือการโจมตีแบบ model inversion/ extraction หากไม่มีมาตรการป้องกันที่เหมาะสม มาตรการบรรเทา ได้แก่ การใช้ model signing และตรวจสอบความสมบูรณ์ผ่าน WebCrypto ก่อนโหลดโมเดล, การเข้ารหัสโมเดลบน storage, การจำกัดการเก็บข้อมูลความลับบนไคลเอนต์, การออกแบบอัลกอริทึมให้มีพฤติกรรมแบบ constant‑time เท่าที่เป็นไปได้ และการแยกงานที่มีความเสี่ยงสูงกลับไปประมวลผลในคลาวด์ (hybrid approach) ที่มีการรับรองความปลอดภัยชัดเจน
- Hybrid approach (on‑device + cloud fallback) — ใช้งานโมเดลบนเครื่องสำหรับงาน latency‑sensitive หรือข้อมูลที่ต้องการความเป็นส่วนตัว และสำรองการเรียกใช้บนคลาวด์เมื่อต้องการโมเดลขนาดใหญ่/การคำนวณหนักหรือเมื่อตรวจพบข้อจำกัดของอุปกรณ์
- Model distillation, pruning และ quantization — ลดขนาดและความต้องการหน่วยความจำของโมเดลโดยไม่เสียคุณภาพมากเกินไป ซึ่งช่วยให้รองรับได้บนอุปกรณ์ที่มีทรัพยากรจำกัด
- MLOps สำหรับ on‑device deployment — ตั้งระบบ CI/CD อัตโนมัติสำหรับ pipeline ทางโมเดล รวมทั้งการทำ automated tests ข้ามเบราว์เซอร์และอุปกรณ์, delta updates, การเซ็นและการตรวจสอบ integrity, และระบบ monitoring/telemetry เพื่อจับปัญหาการใช้งานจริง
ท้ายที่สุด การออกแบบโซลูชัน WebAssembly บนเบราว์เซอร์เพื่อรัน LLM ควรใช้แนวทางแบบองค์รวม: ประเมินโปรไฟล์อุปกรณ์ของกลุ่มผู้ใช้เป้าหมาย, แยกประเภทงานตามความต้องการด้านความเป็นส่วนตัวและประสิทธิภาพ, วางระบบอัปเดตและการจัดการเวอร์ชันที่ปลอดภัย และใช้กลยุทธ์ผสม (เช่น distillation + hybrid cloud fallback) เพื่อลดความเสี่ยงและเพิ่มความยืดหยุ่นในการนำไปใช้ในระดับองค์กร
โมเดลธุรกิจของสตาร์ทอัพไทยและการบูรณาการกับองค์กร
ภาพรวมโมเดลรายได้ (Business Models)
สตาร์ทอัพที่นำเสนอแพลตฟอร์ม on‑device สำหรับรัน LLM บนเบราว์เซอร์สามารถเลือกผสมผสานโมเดลรายได้หลายรูปแบบเพื่อให้ครอบคลุมความต้องการของลูกค้าองค์กร ตั้งแต่ลูกค้าขนาดกลางไปจนถึงองค์กรขนาดใหญ่ รูปแบบหลักที่นิยมมีดังนี้:
- Subscription (SaaS) แบบ on‑device — คิดค่าบริการเป็นรายเดือนหรือรายปี โดยรวมการอัปเดตซอฟต์แวร์, การบำรุงรักษา และการสนับสนุนพื้นฐาน เหมาะสำหรับลูกค้าที่ต้องการโซลูชันครบวงจรโดยไม่ต้องลงทุนด้านโครงสร้างพื้นฐาน
- Per‑seat / Per‑user licensing — คิดค่าลิขสิทธิ์ตามจำนวนผู้ใช้ที่ใช้งานฟีเจอร์ LLM ในองค์กร เหมาะกับองค์กรที่ต้องการคาดการณ์ค่าใช้จ่ายแบบรายคนและควบคุมสิทธิ์การเข้าถึง
- Per‑inference / Usage‑based pricing — คิดค่าบริการตามปริมาณการเรียกใช้งานหรือจำนวนคำตอบ (inference) สำหรับงานที่มีปริมาณผันผวน เช่น ระบบแชทบอทหรือการประมวลผลเอกสารแบบเป็นชุด
- Enterprise / SDK license — ขายไลเซนส์แบบองค์กรสำหรับการนำ SDK ไปฝังในแอปพลิเคชันของลูกค้า รวมถึงตัวเลือกติดตั้งแบบ on‑premise หรือแพคเกจสำหรับ edge devices พร้อม SLA ระดับสูง
บริการเสริมที่สร้างมูลค่า (Value‑added Services)
นอกเหนือจากไลเซนส์พื้นฐานแล้ว สตาร์ทอัพสามารถสร้างรายได้เพิ่มเติมและเพิ่มความผูกพันกับลูกค้าด้วยบริการเชิงเทคนิคและเชิงธุรกิจ เช่น:
- การปรับแต่งโมเดลตามโดเมน (Domain‑specific fine‑tuning) — ปรับโมเดลให้เข้าใจศัพท์เฉพาะของธุรกิจไทย เช่น ธนาคาร ประกันภัย กฎหมาย หรือการแพทย์ โดยให้บริการตั้งแต่การเตรียมข้อมูล การทำ annotation จนถึงการประเมินผล
- MLOps และการดูแลรักษาโมเดล — บริการ pipeline สำหรับการ deploy, monitoring, drift detection, และ retraining รวมถึงแดชบอร์ด KPI เช่น Latency, Throughput, และ Accuracy
- การรับรองความปลอดภัยและการปฏิบัติตามกฎเกณฑ์ — ให้บริการ audit, penetration test, model signing, data governance และช่วยดำเนินการให้สอดคล้องกับข้อกำหนดภายในองค์กรหรือกฎหมายเกี่ยวกับข้อมูลส่วนบุคคล
- บริการฝึกอบรมและให้คำปรึกษา — การอบรมทีมงานภายในองค์กร (workshop) การออกแบบ workflow ใหม่เพื่อนำ on‑device LLM ไปใช้จริง และการให้คำปรึกษาด้าน change management
ช่องทางการบูรณาการ (Integration Channels)
เพื่อให้เหมาะกับสภาพแวดล้อมไอทีที่หลากหลาย สตาร์ทอัพควรนำเสนอช่องทางการผสานระบบที่ยืดหยุ่นและปลอดภัย รายละเอียดช่องทางที่สำคัญได้แก่:
- JavaScript SDK — ไลบรารีสำหรับฝั่งเบราว์เซอร์ที่ทำงานร่วมกับ WebAssembly เพื่อรันโมเดลโดยตรงบนคลไคลเอ็นต์ เหมาะสำหรับแอปพลิเคชันเว็บที่ต้องการ latency ต่ำและไม่ส่งข้อมูลขึ้นคลาวด์
- REST / gRPC API — สำหรับแอปพลิเคชันเซิฟเวอร์หรือระบบหลังบ้านที่ต้องการเรียกใช้งานโมเดลแบบรวมศูนย์ (hybrid) สามารถให้บริการ inference แบบมี cache เพื่อผสมผสานระหว่าง on‑device และ server‑side
- Edge deployment pipelines — รูทไลน์ CI/CD สำหรับการแจกจ่ายโมเดลและอัปเดต (OTA) ไปยังอุปกรณ์ edge หรือเครื่องเซิร์ฟเวอร์ภายในองค์กร พร้อมการตรวจสอบความสมบูรณ์ของโมเดล (model signing) และ fallback mechanism
- Model update pipeline — ระบบ rollout แบบค่อยเป็นค่อยไป (canary/ phased rollout) สำหรับอัปเดตโมเดล พร้อมเมตริกเปรียบเทียบ A/B testing และกลับสู่เวอร์ชันก่อนหน้าหากพบปัญหา
ตัวอย่างลูกค้ารายแรกและโปรแกรมนำร่อง (Pilot Examples)
ในเชิงธุรกิจ สตาร์ทอัพไทยมักเริ่มด้วยโปรแกรมนำร่อง (pilot) กับลูกค้ารายแรกเพื่อพิสูจน์คุณค่าและปรับผลิตภัณฑ์ให้ตรงตามความต้องการ ตัวอย่างเช่น:
- ธนาคารขนาดกลาง: ทดลองใช้ JavaScript SDK เพื่อรันโมเดลภาษาสำหรับช่วยกรอกแบบฟอร์มและตอบคำถามลูกค้าในช่องทางออนไลน์ ผลลัพธ์คือ Latency ลดลงอย่างมีนัยสำคัญและลดการพึ่งพา API ภายนอก ทำให้ลดค่าใช้จ่ายคลาวด์ได้ประมาณ 30–60% ขึ้นกับปริมาณการเรียกใช้งาน
- บริษัทประกันภัย: โปรแกรม POC สำหรับ redaction เอกสารและสรุปความโดยไม่ส่งข้อมูลสำคัญออกนอกองค์กร ผ่านการติดตั้ง SDK บน intranet พร้อมการฝึกปรับโมเดลตามศัพท์เฉพาะของธุรกิจ
- หน่วยงานภาครัฐ: โครงการนำร่องในลักษณะ on‑premise เพื่อให้สอดคล้องกับนโยบายข้อมูลภายในประเทศ มีการชนะแก้ไขด้าน compliance และได้รับการรับรองความปลอดภัยก่อนขยายสู่ระยะ production
การออกแบบข้อเสนอเชิงพาณิชย์ควรคำนึงถึงการวัดผลชัดเจนในช่วง pilot เช่น เวลาเฉลี่ยในการตอบกลับ (latency), อัตราความแม่นยำ, และ ต้นทุนต่อคำขอ เพื่อใช้เป็นเกณฑ์ในการต่อยอดสัญญาระยะยาว นอกจากนี้ การให้ชุดเครื่องมือ MLOps, SLA ที่ชัดเจน และบริการปรับแต่งเชิงลึก จะช่วยให้สตาร์ทอัพไทยสามารถเปลี่ยนลูกค้ารายแรกให้กลายเป็นลูกค้าเชิงพาณิชย์ที่มั่นคงได้ในระยะยาว
อนาคตและแนวโน้ม: Hybrid, Standardization และ Ecosystem ในภูมิภาค
อนาคตและแนวโน้ม: Hybrid, Standardization และ Ecosystem ในภูมิภาค
การพัฒนา WebAssembly เพื่อรัน LLM บนเบราว์เซอร์และการประมวลผลแบบ on‑device กำลังก่อให้เกิดการเปลี่ยนผ่านสู่สถาปัตยกรรมแบบ hybrid ที่ผสมผสานระหว่างอุปกรณ์ปลายทาง (edge/on‑device) และคลาวด์อย่างเข้มแข็ง ในระยะกลางถึงระยะยาว องค์กรจะเลือกใช้แนวทาง on‑device first, cloud‑fallback ซึ่งช่วยให้ข้อมูลที่มีความอ่อนไหวถูกประมวลผลภายในเครื่องเพื่อลดความเสี่ยงด้านความเป็นส่วนตัวและ latency ในขณะเดียวกันยังสามารถอาศัยคลาวด์สำหรับงานที่ต้องใช้ทรัพยากรหนัก เช่น การฝึกปรับแต่ง (fine‑tuning) หรือการเก็บรวบรวมสถิติเชิงรวม การผสมผสานนี้จะช่วยเพิ่มความยืดหยุ่นของระบบทางธุรกิจ ทั้งด้านต้นทุน ความเชื่อถือได้ และการปฏิบัติตามกฎระเบียบ
แนวโน้มสำคัญที่ควรติดตามได้แก่การกำเนิดเครื่องมือและมาตรฐานสำหรับการนำโมเดลไปใช้งานบนเบราว์เซอร์และอุปกรณ์ปลายทาง เช่น การแพร่หลายของ WebAssembly/WASI ร่วมกับ WebGPU และ runtime อย่าง Wasmtime/Wasmer ที่สนับสนุนการใช้งานแบบมัลติแพลตฟอร์ม รวมถึงการยอมรับรูปแบบโมเดลที่เป็นมาตรฐานกว่าเดิม เช่น ONNX และรูปแบบที่ถูกปรับแต่งสำหรับอุปกรณ์พกพา (quantized TFLite, int8/4 quantization) เครื่องมือเหล่านี้จะลดความซับซ้อนของการ deploy และเร่งการยอมรับจากภาคธุรกิจ นอกจากนี้ การเกิดมาตรฐานด้านการวัดประสิทธิภาพ (benchmarking), การลงนามและการพิสูจน์ความถูกต้องของโมเดล (model signing & attestation) จะกลายเป็นข้อกำหนดพื้นฐานสำหรับการใช้งานในองค์กรขนาดใหญ่
บทบาทของเทคนิคด้านความเป็นส่วนตัวเช่น federated learning, secure aggregation และ differential privacy จะสำคัญยิ่งขึ้นในการปรับสมดุลระหว่าง personalization กับการปกป้องข้อมูลผู้ใช้ โดย federated learning จะช่วยให้สามารถฝึกหรือปรับโมเดลบนข้อมูลเฉพาะเครื่องผู้ใช้แล้วส่งเฉพาะการอัปเดตแบบเข้ารหัสกลับมายังศูนย์กลาง ซึ่งช่วยลดการเคลื่อนย้ายข้อมูลดิบและช่วยให้การปฏิบัติตามกฎหมายคุ้มครองข้อมูล เช่น PDPA ในไทย หรือกฎระเบียบในภูมิภาคเป็นไปได้ง่ายขึ้น ทั้งนี้จะเกิดการรวมกันของเทคโนโลยีหลายด้าน เช่น secure enclaves, remote attestation และมาตรการตรวจสอบความโปร่งใส (model cards, datasheets) เพื่อสร้างความเชื่อมั่นแก่ผู้ใช้งานและผู้ควบคุมดูแล
ในแง่ของโอกาสทางการตลาด ภูมิภาคเอเชียตะวันออกเฉียงใต้ยังคงเป็นพื้นที่เติบโตสูงสำหรับโซลูชัน on‑device และ hybrid AI โดยแรงผลักดันมาจากการเพิ่มขึ้นของอุปกรณ์ต่อเชื่อมและความต้องการลดค่าใช้จ่ายด้านแบนด์วิดท์และเวลาแฝง ผู้เล่นหลายรายคาดการณ์ว่าโซลูชัน edge AI และ on‑device inference จะเห็นการเติบโตแบบสองหลักต่อปีในช่วงกลางทศวรรษหน้า สำหรับสตาร์ทอัพไทย โอกาสสำคัญรวมถึง:
- การพัฒนาโซลูชันเฉพาะโดเมน (verticalized LLM) เช่น สำหรับการแพทย์ กฎหมาย หรือการธนาคาร ที่ต้องการความเป็นส่วนตัวสูงและ latency ต่ำ
- การสร้างเครื่องมือ MLOps ที่เน้นการ deploy บนเบราว์เซอร์และอุปกรณ์ (model optimization, quantization, benchmarking) ซึ่งเป็นช่องว่างที่ยังมีผู้ให้บริการน้อย
- การนำเสนอบริการความปลอดภัยและการปฏิบัติตามกฎระเบียบ (privacy‑by‑design, attestation, model cards) เพื่อรองรับองค์กรที่ต้องการเอกสารประกอบและการตรวจสอบ
- การเป็นพันธมิตรกับผู้ให้บริการโทรคมนาคม ผู้ผลิตอุปกรณ์ และผู้ให้บริการคลาวด์ในภูมิภาคเพื่อนำเสนอแพ็กเกจ hybrid ที่รวม edge runtime กับ cloud orchestration
สรุปแล้ว แนวโน้มระยะกลาง-ยาวจะเห็นการเติบโตของสถาปัตยกรรม hybrid ที่ผสานความคล่องตัวของ on‑device กับพลังประมวลผลของคลาวด์ ควบคู่กับการพัฒนามาตรฐานและเครื่องมือที่จะทำให้การ deploy LLM บนเบราว์เซอร์เป็นไปอย่างปลอดภัยและประหยัดต้นทุน สำหรับสตาร์ทอัพในประเทศไทยและภูมิภาค การมุ่งสู่ความเชี่ยวชาญด้าน optimization, privacy‑preserving technologies และการสร้าง ecosystem ของพันธมิตรเชิงธุรกิจจะเป็นปัจจัยขับเคลื่อนความสำเร็จในตลาดที่กำลังเติบโตนี้
บทสรุป
การรัน Large Language Models (LLM) บนเบราว์เซอร์ด้วย WebAssembly เสนอโซลูชันที่ช่วยให้องค์กรรักษาความเป็นส่วนตัวของข้อมูล ลดความหน่วง (latency) และลดต้นทุนการประมวลผลจากการพึ่งพาคลาวด์อย่างเดียว เนื่องจากการประมวลผลเกิดขึ้นบนเครื่องผู้ใช้เอง ทำให้การตอบสนองเป็นไปอย่างรวดเร็วและรองรับการทำงานแบบออฟไลน์ได้จริง ตัวอย่างการใช้งานที่เห็นผลชัดเจนได้แก่ การแชทแบบเรียลไทม์ การสรุปหรือดึงข้อมูลจากเอกสารในเครื่อง การกรองข้อมูลเชิงความเป็นส่วนตัว และงาน UI/UX ที่ต้องการตอบสนองทันที โดยงานทดสอบและการนำไปใช้จริงในบางกรณีรายงานการลด latency ได้มากเป็นหลักสิบเปอร์เซ็นต์พร้อมการลดค่าใช้จ่ายจากการเรียกใช้งาน API บนคลาวด์
แม้จะมีข้อจำกัดทางทรัพยากรของอุปกรณ์ปลายทาง (หน่วยความจำ พลังประมวลผล ขนาดโมเดล) และประเด็นด้านความปลอดภัย เช่น พื้นที่โจมตีของรันไทม์ในเบราว์เซอร์ แต่การออกแบบเชิงผสม (hybrid) ที่กระจายงานระหว่าง on‑device และคลาวด์ การนำเทคนิคเช่น quantization, pruning, distillation มาใช้ รวมทั้งการพัฒนาเครื่องมือมาตรฐาน (เช่น runtime ที่ปลอดภัย การรองรับ WebGPU/WASI และเครื่องมือบริหารจัดการโมเดล) จะช่วยลดข้อจำกัดเหล่านี้และเพิ่มการยอมรับในระดับองค์กร สำหรับสตาร์ทอัพไทย นี่เป็นโอกาสทางธุรกิจที่ชัดเจนในการนำเสนอโซลูชันแพลตฟอร์ม on‑device, การปรับแต่งโมเดลเชิงโดเมน, บริการผสานระบบกับแอปองค์กร และการรับประกันด้านความมั่นคงปลอดภัยและการปฏิบัติตามข้อกำหนด
มองไปข้างหน้า แนวโน้มที่เป็นไปได้คือการยอมรับแบบค่อยเป็นค่อยไปโดยเริ่มจากสถาปัตยกรรม hybrid ในระยะสั้นถึงกลาง ขณะที่การพัฒนาทางเทคนิค (model compression, browser APIs, ฮาร์ดแวร์เร่งความเร็วบนอุปกรณ์) และมาตรฐานเชิงองค์กรจะช่วยขยายขอบเขตการใช้งานในระยะยาว การลงทุนในแพลตฟอร์ม เครื่องมือบริหารจัดการ และความร่วมมือกับหน่วยงานกำกับดูแลจะเป็นปัจจัยสำคัญที่ทำให้สตาร์ทอัพไทยสามารถแปรจุดแข็งด้านความเป็นท้องถิ่นเป็นโอกาสเชิงพาณิชย์ ทั้งในประเทศและภูมิภาค ASEAN โดยสุดท้ายจะช่วยลดต้นทุนรวมการเป็นเจ้าของ (TCO) และยกระดับความเชื่อมั่นของผู้ใช้ในด้านความเป็นส่วนตัวและความเร็วของบริการ



