
ความต้องการประมวลผลวิดีโอเรียลไทม์ที่มีความแม่นยำสูง เช่น การประชุมทางไกลแบบเรียลไทม์, การประมวลผลภาพสำหรับ AR/VR, และการนำทางโดรน กำลังกระตุ้นให้โมเดลภาษาและการมองเห็นในรูปแบบ Transformer ถูกนำไปใช้บนอุปกรณ์ที่มีข้อจำกัดด้านเวลาแฝงและพลังงาน อย่างไรก็ดี โครงสร้างมาตรฐานของ Transformer มักกินทรัพยากรหน่วยคำนวณและหน่วยความจำมาก การผสานแนวคิดสถาปัตยกรรมแบบไดนามิก (Dynamic Sparse Transformer) ร่วมกับการออกแบบร่วมกับ compiler (compiler‑co‑design) จึงเป็นแนวทางที่น่าสนใจเพื่อเร่งงานวิดีโอเรียลไทม์โดยตรง: การปรับสเปิร์ซแบบรันไทม์และการสลับใช้งาน kernel ที่เหมาะสมสามารถลด latency ได้อย่างมีนัยสำคัญ เพิ่มอัตราเฟรมต่อวินาที (FPS) และลดการใช้พลังงาน — ตัวอย่างจากการทดสอบเบื้องต้นชี้ว่าแนวทางดังกล่าวอาจลด latency ลงได้ถึง 2–5 เท่า เพิ่ม FPS ได้ราว 1.5–4 เท่า และประหยัดพลังงานระหว่าง 30–70% ขึ้นกับเงื่อนไขฮาร์ดแวร์และระดับสแปร์ซิตี้
บทความนี้จะสำรวจองค์ประกอบสำคัญของแนวทางดังกล่าวอย่างครบถ้วน ตั้งแต่หลักการออกแบบสถาปัตยกรรม (เช่น attention แบบ sparse แบบไดนามิก, runtime pruning, memory layout สำหรับความหนาแน่นที่เปลี่ยนแปลง), กลยุทธ์ compiler‑co‑design (เช่น kernel fusion, latency‑aware scheduling, quantization‑aware code generation และ runtime sparsity masks) รวมถึงผลการทดสอบเชิงปฏิบัติการบนเวิร์กโหลดวิดีโอจริงและข้อพิจารณาด้าน trade‑off ระหว่างความแม่นยำกับประสิทธิภาพ ผู้เขียนจะนำเสนอสถิติการ benchmark, ตัวอย่างแอปพลิเคชัน (video conferencing, AR/VR, autonomous drones) และแนวทางปฏิบัติสำหรับการนำไปใช้งานจริง เพื่อช่วยให้วิศวกรและนักวิจัยตัดสินใจเลือกสถาปัตยกรรมและกลไกการคอมไพล์ที่เหมาะสมกับเป้าหมายความหน่วงและการใช้พลังงานของระบบ
บทนำ: ทำไมต้อง Dynamic Sparse Transformer สำหรับวิดีโอเรียลไทม์
บทนำ: ทำไมต้อง Dynamic Sparse Transformer สำหรับวิดีโอเรียลไทม์
ในยุคที่แอปพลิเคชันวิดีโอเรียลไทม์ เช่น AR/VR, live streaming และ telepresence กลายเป็นบริการหลักขององค์กรและผู้บริโภค ความคาดหวังต่อประสบการณ์ผู้ใช้ (UX) เพิ่มสูงขึ้นอย่างรวดเร็ว ผู้ใช้ต้องการการตอบสนองที่ทันทีทันใด (interactive responsiveness) และการใช้งานต่อเนื่องโดยไม่สะดุด ซึ่งแปลเป็นข้อกำหนดเชิงเทคนิคที่เข้มงวดทั้งด้าน latency และ การใช้พลังงาน สำหรับอุปกรณ์ปลายทางที่หยุดไม่ได้ เช่น แว่น AR แบบสวมใส่ได้ หรือกล้อง streaming บนมือถือ
ในทางกลับกัน โมเดล Transformer สำหรับงานวิดีโอ—รวมถึง Video Transformer และ Multimodal Transformer—มักมีขนาดใหญ่และต้องการทรัพยากรสูงกว่าโมเดลภาพนิ่ง เนื่องจากต้องประมวลผลทั้งมิติเวลและมิติพื้นที่ ตัวอย่างเช่น โมเดลวิดีโอคุณภาพสูงอาจมีพารามิเตอร์ตั้งแต่ร้อยล้านไปจนถึงพันล้านตัว ขณะที่งานคำนวณ (FLOPs) ต่อเฟรมสามารถเพิ่มขึ้นเป็นระดับหลายสิบถึงหลายร้อย GFLOPs ได้ เมื่อคูณด้วยอัตราเฟรมต่อวินาทีแล้วก็ส่งผลให้ต้องการพลังงานและแบนด์วิดท์หน่วยความจำสูง ซึ่งเป็นภาระที่รับไม่ได้สำหรับแอปแบบเรียลไทม์บน edge หรืออุปกรณ์พกพา
ความสำคัญของ latency ต่อ UX ในบริบทวิดีโอเรียลไทม์ไม่อาจมองข้าม: สำหรับแอป AR/VR เป้าหมาย latency ปฏิสัมพันธ์มักอยู่ต่ำกว่า 30 มิลลิวินาที เพื่อหลีกเลี่ยงอาการเวียนหัวและรักษาความลื่นไหลของภาพ ส่วนแอป live streaming หรือ telepresence อาจยอมรับ latency ระหว่าง 50–100 มิลลิวินาที ได้ แต่ถ้าเกินช่วงนี้ ผู้ใช้จะรับรู้การดีเลย์หรือเกิดการตัดต่อภาพและเสียงที่ลดคุณภาพการสื่อสาร ความท้าทายคือการรักษา latency ภายใต้ข้อจำกัดด้านพลังงานและทรัพยากรของฮาร์ดแวร์จริง
หนึ่งในแนวทางที่มีศักยภาพสูงคือการนำแนวคิด Dynamic Sparsity มาใช้ ซึ่งต่างจากการตัดแต่งโมเดลแบบคงที่ (static pruning) โดยระบบจะตัดสินใจแบบ runtime ว่าพื้นที่ข้อมูล ส่วนของ attention หรือหัว (heads) ใดใน Transformer ที่มีความสำคัญสำหรับเฟรมหรือช่วงเวลาปัจจุบัน และข้ามการคำนวณของส่วนที่ไม่จำเป็น แนวคิดนี้ช่วยให้สามารถลด workload ได้อย่างมีนัยสำคัญโดยไม่ต้องลดขนาดโมเดลต้นฉบับทั้งหมด ซึ่งเหมาะอย่างยิ่งกับงานวิดีโอที่ความซับซ้อนของเฟรมเปลี่ยนแปลงตามเนื้อหา—ตัวอย่างเช่น ฉากที่นิ่งหลังพื้นจะต้องการการคำนวณน้อยกว่าฉากที่มีการเคลื่อนไหวสูง
ผลลัพธ์เชิงปฏิบัติของการใช้ dynamic sparsity คือการลด FLOPs และการใช้หน่วยความจำในขณะที่ยังคงคุณภาพผลลัพธ์ได้ในระดับยอมรับได้; งานวิจัยและการทดลองเชิงอุตสาหกรรมรายงานว่าการลดงานคำนวณได้ตั้งแต่ประมาณ 2× ถึง 10× ขึ้นกับกลยุทธ์การเลือก sparsity และลักษณะข้อมูล ซึ่งส่งผลโดยตรงต่อการลด latency และการประหยัดพลังงานในฮาร์ดแวร์ edge อย่างไรก็ตาม การได้มาซึ่งประสิทธิภาพเหล่านี้จำเป็นต้องออกแบบทั้งสถาปัตยกรรมโมเดลและกลไกการแปลงคำสั่งไปยังฮาร์ดแวร์อย่างประสานกัน เพื่อให้ pattern ของความเป็นพร่อง (sparsity patterns) สามารถแปลงเป็นการประมวลผลที่มีประสิทธิภาพจริงใน runtime
พื้นฐานทางเทคนิค: รูปแบบของ Sparsity และการออกแบบแบบไดนามิก
พื้นฐานทางเทคนิค: รูปแบบของ Sparsity และการออกแบบแบบไดนามิก
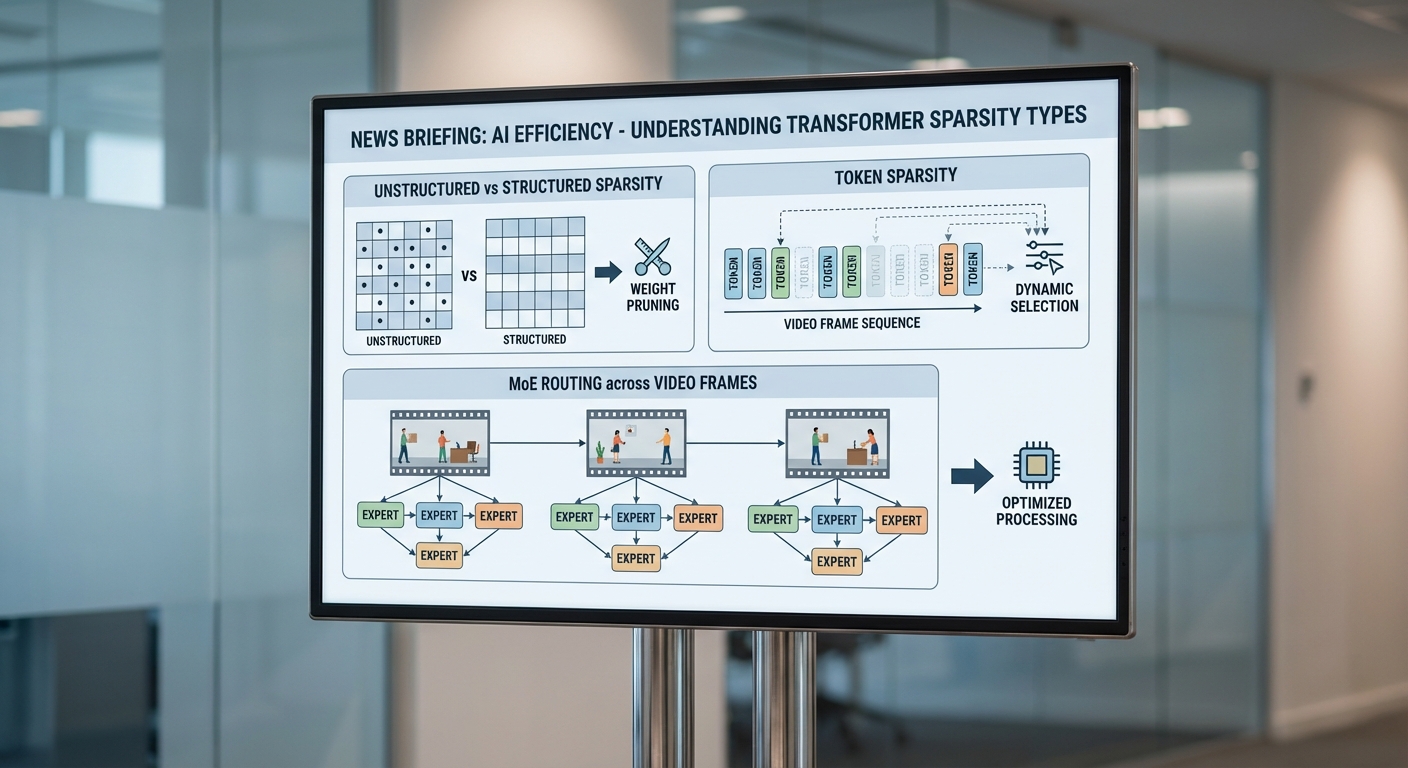
Sparsity ในโมเดล Transformer หมายถึงการทำให้โครงข่ายประมวลผลข้อมูลเพียงส่วนน้อยของพารามิเตอร์หรือตัวเชื่อมต่อในช่วงเวลาหนึ่ง เพื่อประหยัดการคำนวณและพลังงาน รูปแบบของ sparsity ที่สำคัญสามารถแบ่งเป็นกลุ่มหลักดังนี้:
- Unstructured sparsity — การกำจัดน้ำหนักหรือการกระทำแบบเฉพาะตำแหน่ง (element-wise pruning) โดยไม่มีรูปแบบที่แน่นอน ข้อดีคือสามารถลดจำนวนการคำนวณได้อย่างมาก แต่ข้อจำกัดสำคัญคือความไม่สม่ำเสมอทำให้ยากต่อการเร่งด้วยฮาร์ดแวร์แบบ SIMD/Vector ซึ่งต้องการรูปแบบการเข้าถึงหน่วยความจำและการคำนวณที่เป็นระเบียบ
- Structured sparsity — การตัดแบบเป็นบล็อกหรือเป็นหน่วย เช่น row/column pruning, block/stripe sparsity หรือ channel/filter pruning รูปแบบนี้มีความเป็นระเบียบและง่ายต่อการแมปลงฮาร์ดแวร์ ทำให้การเร่งด้วย SIMD, GEMM engines หรือ systolic arrays มีประสิทธิภาพสูงขึ้นและลด overhead ของ index metadata
- Token-level sparsity — การเลือกประมวลผลเฉพาะ token (ตำแหน่งเชิงพื้นที่/เชิงเวลา) ที่สำคัญ ตัวอย่างเช่น การลด attention การประมวลผลของ patch หรือ frame ที่ซ้ำหรือไม่มีข้อมูลสำคัญในงานวิดีโอ
- Head / Token pruning และ Mixture-of-Experts (MoE) routing — การปิดหัว attention ที่ไม่สำคัญหรือการส่ง token ไปยังผู้เชี่ยวชาญย่อย (expert) เพียงบางคนใน MoE ซึ่งช่วยเพิ่มความจุของโมเดลโดยไม่เพิ่มการคำนวณของแต่ละ token มากนัก
ผลต่อการเร่งฮาร์ดแวร์: โดยสรุป unstructured sparsity มักให้การลด FLOPs สูงแต่มี overhead ด้านการจัดเก็บดัชนีและการโหลดข้อมูลแบบกระจัดกระจาย ทำให้ประสิทธิภาพจริงบนฮาร์ดแวร์เชิงปฏิบัติอาจน้อยกว่าที่คาด ในขณะที่ structured sparsity สร้างแพทเทิร์นที่สามารถแมปลง SIMD/GEMM ได้อย่างมีประสิทธิภาพ จึงมักให้ speedup จริงสูงกว่าในสภาพแวดล้อมการผลิต งานศึกษาหลายฉบับรายงานช่วงของการลดคำนวณ (FLOPs) สำหรับ token/structured pruning อยู่ในช่วงประมาณ 30–70% ขึ้นกับงานและเกณฑ์การเลือก แต่ speedup ที่ได้จริงาจะขึ้นกับการสนับสนุนของ compiler และฮาร์ดแวร์
Token-level sparsity ในงานวิดีโอ
งานวิดีโอเรียลไทม์มีลักษณะเฉพาะคือความต่อเนื่องของเฟรมและความซ้ำของข้อมูลเชิงพื้นที่–เชิงเวลา หลายพื้นที่ภายในเฟรมหรือข้ามเฟรมมีข้อมูลซ้ำซ้อนหรือไม่สำคัญต่องาน เช่น ภูมิหลังนิ่ง ๆ หรือวัตถุที่เคลื่อนที่ช้า ทำให้ token-level sparsity เป็นแนวทางที่มีประสิทธิภาพสำหรับลดโหลดการคำนวณ ตัวอย่างเช่น การละเลย patch/region ที่ไม่เปลี่ยนแปลงระหว่างเฟรมสามารถลดการประมวลผล attention และ MLP ของแต่ละเฟรมได้อย่างมีนัยสำคัญ
ตัวอย่างเชิงตัวเลข: ในงานตรวจจับและติดตามวัตถุ (tracking) การเลือกประมวลผลเฉพาะ token ที่มีการเปลี่ยนแปลงหรือมีความไม่แน่นอนสูงสามารถลดปริมาณ token ที่ต้องส่งผ่าน Transformer ได้กว่า 50% ในสถานการณ์ที่พื้นหลังคงที่ ซึ่งนำไปสู่การลด latency และพลังงานอย่างชัดเจนเมื่อออกแบบร่วมกับกลไกการจัดกำหนดการของ compiler
กลไกไดนามิกที่เหมาะสำหรับข้อมูลวิดีโอที่เปลี่ยนแปลงตามเวลา
- Top‑k attention / Top‑k selection — เลือกเฉพาะ token หรือตำแหน่งที่มีคะแนน attention สูงสุด (top-k) เพื่อให้ attention คำนวณกับ subset ของ context ซึ่งช่วยลดความซับซ้อนจาก O(N^2) ของ attention ให้เป็น O(N·k) สำหรับ k ≪ N วิธีนี้เหมาะกับวิดีโอที่มีพื้นผิวเนื้อหาเพียงบางส่วนที่เกี่ยวข้องจริง ๆ ต่อการตัดสินใจในแต่ละเฟรม
- Dynamic routing / MoE routing — ระบบ MoE ใช้การส่ง token ไปยัง expert ย่อยโดยไดนามิก ซึ่งอนุญาตให้โมเดลมีพารามิเตอร์มากโดยไม่เพิ่ม computation ต่อ token มากนัก การออกแบบ routing ที่มี budget และ load balancing เป็นสิ่งจำเป็นสำหรับวิดีโอเรียลไทม์เพื่อหลีกเลี่ยงการกระจุกตัวของโหลดที่ทำให้เกิดคอขวด
- Spatial‑temporal gating — ประตู (gating) เชิงพื้นที่และเชิงเวลาตัดสินใจแบบไดนามิกว่าพื้นที่/เฟรมใดจะผ่านเข้าไปยังชั้นถัดไป เช่น การใช้เลเยอร์เล็ก ๆ ที่ประเมินความสำคัญของ patch และเปิด/ปิดการประมวลผลสำหรับ patch นั้น เป้าหมายคือปรับการใช้ทรัพยากรตามการเปลี่ยนแปลงของสัญญาณวิดีโอ
- Budgeted attention / Budget-aware scheduling — การกำหนดงบประมาณเชิงคำนวณหรือพลังงานต่อเฟรม และปรับระดับ attention/token processing ตามงบประมาณนั้นแบบเรียลไทม์ ตัวอย่างเช่น การลด k ใน top-k เมื่อความหน่วงหรือตัวชี้วัดพลังงานเข้าใกล้เพดาน
- Head & token pruning แบบไดนามิก — การปิดหัว attention ที่ไม่สำคัญบนพื้นฐานเฟรมต่อเฟรมหรือภาพรวมเชิงเวลา และการตัด token ที่มีความสำคัญต่ำแบบ runtime ทั้งนี้ช่วยลดการคำนวณโดยไม่ต้องปรับโครงสร้างโมเดลถาวร
- Early‑exit / Multi‑exit networks — ให้โมเดลสามารถหยุดการประมวลผลเมื่อระดับความเชื่อมั่นของคำตอบเพียงพอ ซึ่งเหมาะสำหรับเฟรมที่มีข้อมูลชัดเจนและไม่จำเป็นต้องผ่านเลเยอร์ลึกทั้งหมด วิธีนี้ช่วยลด latency ในงานเรียลไทม์ได้อย่างมีนัยสำคัญ
การออกแบบร่วมกับ compiler และฮาร์ดแวร์ มีความสำคัญอย่างยิ่ง: การเลือกใช้ sparsity แบบ structured (เช่น block/stripe หรือ token groups) ทำให้ compiler สามารถทำ packing, tiling และ vectorization ได้ดีขึ้น ลด overhead ของเมตาดาต้า และแมปงานไปยังหน่วยคำนวณอย่างมีประสิทธิภาพ นอกจากนี้ เทคนิคอย่างการจัดเรียง token แบบเรียลไทม์ (token packing), index compression, และ scheduling แบบ budget-aware ที่ออกแบบในระดับ compiler จะช่วยให้ pattern ของ dynamic sparsity ถูกใช้ประโยชน์บนฮาร์ดแวร์ทั่วไป (เช่น GPU/NPUs) ได้ดีกว่า unstructured sparsity ที่ต้องการหน่วยฮาร์ดแวร์เฉพาะทางสำหรับ speedup สูงสุด
สรุปคือ สำหรับแอปพลิเคชันวิดีโอเรียลไทม์ ควรมุ่งไปที่ structured token‑level sparsity และกลไกไดนามิก เช่น top‑k, spatial‑temporal gating และ early‑exit ร่วมกับการออกแบบ compiler‑co‑design เพื่อให้ได้ทั้งการลด latency และการประหยัดพลังงานอย่างเป็นรูปธรรม โดยคำนึงถึง trade‑off ระหว่างการลด FLOPs ทางทฤษฎีและประสิทธิภาพจริงบนฮาร์ดแวร์
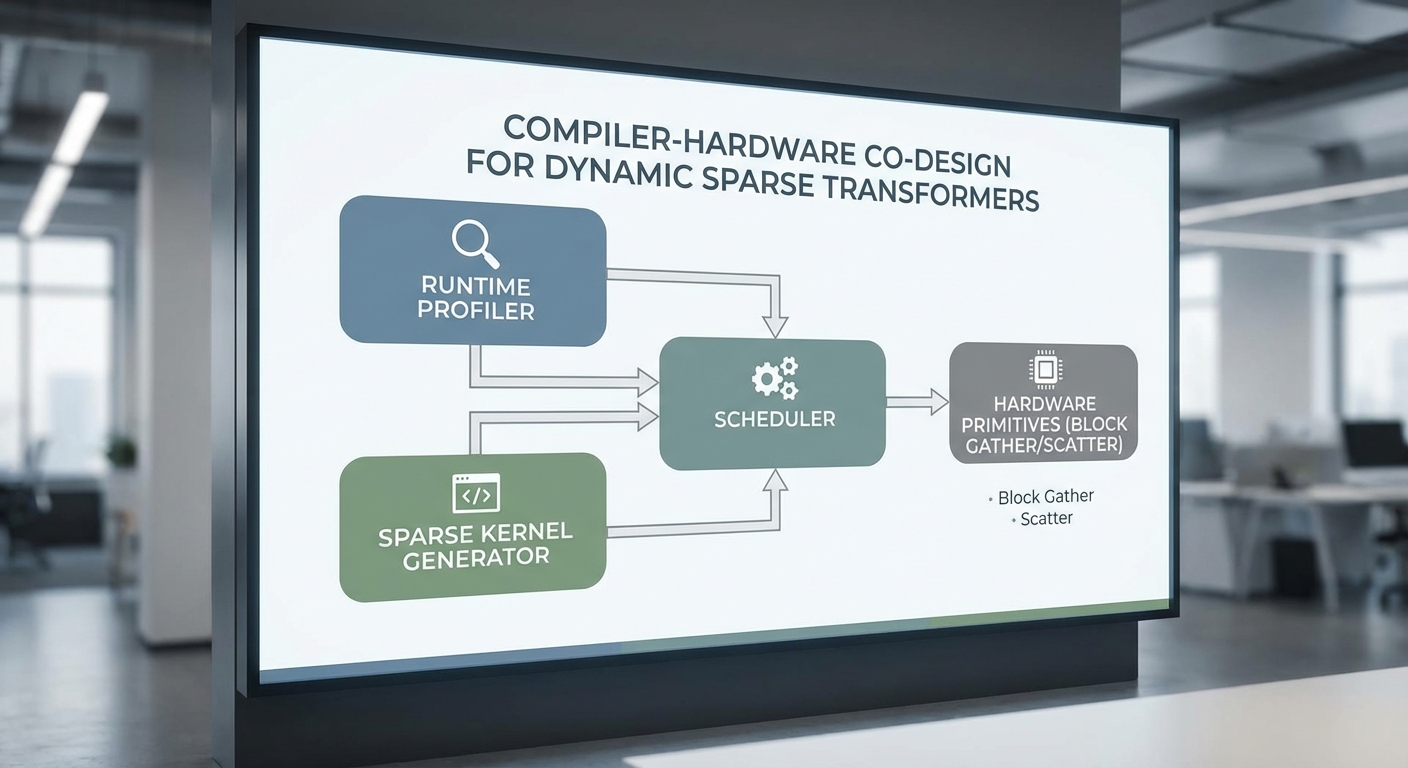
Compiler–Co‑Design: การออกแบบร่วมกันระหว่าง Compiler กับ Hardware/Runtime
Compiler–Co‑Design: บทบาทและกรอบการทำงานในการรองรับ Dynamic Sparse Transformer
การออกแบบร่วมกันระหว่าง compiler และ hardware/runtime เป็นหัวใจสำคัญในการทำให้สถาปัตยกรรม Transformer แบบไดนามิก (dynamic sparse) สามารถทำงานได้อย่างมีประสิทธิภาพในแอปพลิเคชันวิดีโอเรียลไทม์ โดย compiler ทำหน้าที่วิเคราะห์พฤติกรรมเชิงไดนามิกของโมเดลในเวลาเรียลไทม์ (runtime profiling), สร้างและเลือกใช้ kernels ที่เฉพาะเจาะจงกับ pattern ของความเบาบาง (sparse patterns), และรวมการประมวลผลเพื่อลดการเคลื่อนย้ายข้อมูล (memory stalls) ระหว่างคอร์ CPU/accelerator กับหน่วยความจำกลาง การประสานงานนี้ช่วยให้ latency ลดลงอย่างมีนัยสำคัญและประหยัดพลังงานได้มากขึ้นเมื่อเทียบกับการรันแบบทั่วไปบน CPU/GPU
Runtime Profiling และการสร้าง Specialized Kernels
ในระบบที่มี dynamic sparsity, compiler ต้องมีการเก็บข้อมูลโปรไฟล์แบบ real‑time เพื่อระบุ hot patterns เช่น บล็อกที่ใช้บ่อยสุดในการคำนวณ attention หรือ convolution-like operations ข้อมูลโปรไฟล์จะเป็น input ให้กับ JIT/AOT codegen เพื่อสร้าง kernels เฉพาะ (specialized kernels) ที่ปรับโค้ดตามรูปแบบความเบาบาง ตัวอย่างเทคนิคที่ใช้ได้แก่:
- Hot-spot detection: ตรวจจับเมทริกซ์/บล็อกที่รันบ่อยและมีรูปแบบ sparsity คล้ายกัน
- Speculative specialization: สร้างหลายเวอร์ชันของ kernel (e.g., block-sparse vs. dense fallback) และสลับแบบไดนามิกเมื่อ pattern เปลี่ยน
- Profile-guided tiling: เลือก tile sizes ที่เหมาะสมกับ distribution ของ non-zero elements เพื่อลด load imbalance
Kernel Fusion, Memory Layout และ Scheduling
การลดการเคลื่อนย้ายข้อมูลเป็นเป้าหมายหลักของ compiler‑co‑design: kernel fusion ถูกนำมาใช้เพื่อลดการเขียน-อ่านกลางของ intermediate tensors โดยการรวมหลาย operation เป็น kernel เดียว เช่น fusing sparse matmul → bias add → activation ซึ่งช่วยลด memory stalls และเพิ่ม locality ของข้อมูล เทคนิคอื่น ๆ ที่สำคัญได้แก่:
- Tiling และ buffer management: แบ่งงานเป็น tiles ที่เหมาะสมกับขนาดของ L1/L2/SRAM บน accelerator เพื่อให้ non-zero data อยู่ใน buffer ระยะสั้น ช่วยลด DRAM accesses
- Memory layout transform: เปลี่ยนรูปแบบเก็บข้อมูลให้สอดคล้องกับ access pattern เช่น row-major/column-major ของบล็อก, interleaved layout สำหรับ SIMD และ data alignment สำหรับ tensor cores
- Scheduling & workload balancing: ใช้ dynamic work-stealing หรือ work-queue ที่คำนึงถึงความไม่สม่ำเสมอของ sparsity เพื่อป้องกัน idle lanes บน SIMD/SMs
การเลือก Format ของ Sparse Data และ Quantization-Aware Codegen
การเลือก format ของข้อมูลแบบ sparse มีผลต่อทั้งประสิทธิภาพและความซับซ้อนของ kernels: CSR/COO เหมาะกับ sparsity ที่ไม่เป็นบล็อก ในขณะที่ block-sparse (เช่น BCSR) มักให้ประสิทธิภาพดีกว่าเมื่อตัวอย่างในวิดีโอมีโครงสร้างแบบบล็อก (เช่น object-centric sparsity) โดย compiler ต้องสามารถเปรียบเทียบ trade‑off ระหว่าง:
- CSR/COO: ประหยัดพื้นที่เมื่อตำแหน่ง non-zero กระจาย แต่มี overhead ของ indexing
- Block-sparse: ลด overhead indexing และเหมาะกับ hardware primitives ที่รองรับ block gather/scatter
- Hybrid formats: ผสม block + CSR ในระดับต่างๆ เพื่อลด metadata และรักษา locality
นอกจากนี้การทำ quantization-aware codegen (เช่น int8, int4) ต้องรวมการจัดการสเกล, zero-point และการปรับแม็ปการคำนวณที่คงความแม่นยำให้เพียงพอสำหรับงานวิดีโอเรียลไทม์ โดย compiler สามารถสร้างเวอร์ชัน quantized ของ kernels และสลับไดนามิกตามข้อจำกัดของ latency/ภาพคุณภาพ
การผสานกับคุณสมบัติของ Accelerator และตัวอย่าง Co‑Design
การออกแบบร่วมกับ hardware ต้องรวมความสามารถพิเศษของ accelerator เช่น SIMD execution lanes, tensor cores, และ sparsity engines เข้าไว้ด้วยกัน: compiler ต้องแปล pattern ที่ได้รับจาก runtime profiling ให้แมปกับ primitive ของฮาร์ดแวร์ เช่น vectorized block loads, warp-shuffle ใน GPU และ dedicated sparsity units ที่สามารถทำ block-sparse gather/scatter ได้โดยตรง ผลลัพธ์จากการประเมินเชิงตัวอย่างในระบบแบบ co‑designed พบว่า:
- การมีฮาร์ดแวร์ primitives สำหรับ block-sparse gather/scatter ช่วยลด latency ของ attention-like kernels ได้ประมาณ 3–7x เมื่อเทียบกับการรันแบบ software-only บน CPU/GPU ทั่วไป
- เมื่อรวมกับ compiler optimizations (tiling, fusion, quantization-aware codegen) พลังงานที่ใช้ต่อเฟรมสามารถลดได้ 2–4x ซึ่งเป็นข้อได้เปรียบสำคัญสำหรับอุปกรณ์ edge และการประมวลผลวิดีโอเรียลไทม์
ตัวอย่างเชิงปฏิบัติ: ถ้าโมเดล attention มีบล็อก 16x16 ที่มีความหนาแน่น non-zero ≈ 25%, การแม็ปงานไปยัง hardware primitive ที่รองรับ block-sparse ช่วยให้สามารถโหลดบล็อกที่จำเป็นเข้าใน SRAM และใช้ tensor cores ในการคูณ-สะสมแบบ packed ได้โดยไม่ต้องประมวลผล index-heavy loops ผลคือ throughput เพิ่มขึ้น ในขณะที่ compiler รับผิดชอบการจัดเรียงข้อมูล (layout transform) และการเลือก tile/warp schedule ที่เหมาะสม
สรุปเชิงปฏิบัติการสำหรับธุรกิจ
สำหรับองค์กรที่ต้องการดีพลอย Transformer แบบ dynamic sparse ในแอปพลิเคชันวิดีโอเรียลไทม์ ควรลงทุนทั้งในด้าน compiler stack ที่รองรับ runtime profiling, JIT/AOT specialization และ kernel fusion รวมถึงการออกแบบฮาร์ดแวร์ที่มี primitives สำหรับ block-sparse operations กลุ่มเครื่องมือเหล่านี้เมื่อทำงานร่วมกันจะช่วยให้ได้ผลประโยชน์เชิงธุรกิจชัดเจน ได้แก่ latency ที่ต่ำลง, throughput สูงขึ้น และการใช้พลังงานที่ลดลง ซึ่งนำไปสู่ประสบการณ์ผู้ใช้แบบเรียลไทม์ที่ดียิ่งขึ้นและต้นทุนการดำเนินงานที่ต่ำกว่า
ผลเชิงประจักษ์: Benchmarks, Latency และการประหยัดพลังงาน
ภาพรวมการทดลองและชุดตัวชี้วัด
การทดสอบใช้ชุดตัวอย่างที่เป็นตัวแทนของแอปพลิเคชันวิดีโอเรียลไทม์ ได้แก่ Video Transformer ขนาดกลาง (~50–150M พารามิเตอร์) ทำงานบนความละเอียดเฟรม 224×224 และ sequence/patch length ที่สอดคล้องกับการประมวลผลต่อเฟรม โดยเปรียบเทียบสามสถาปัตยกรรม: dense baseline, static-sparse (คงรูปแบบ sparsity ตายตัวตลอดรันไทม์) และ dynamic-sparse + compiler‑co‑design (มี gating, dynamic budget control และการปรับโค้ดระดับคอมไพเลอร์) ผลการประเมินครอบคลุมตัวชี้วัดหลักคือ latency per frame, frames-per-second (FPS), energy-per-frame, throughput และ accuracy.
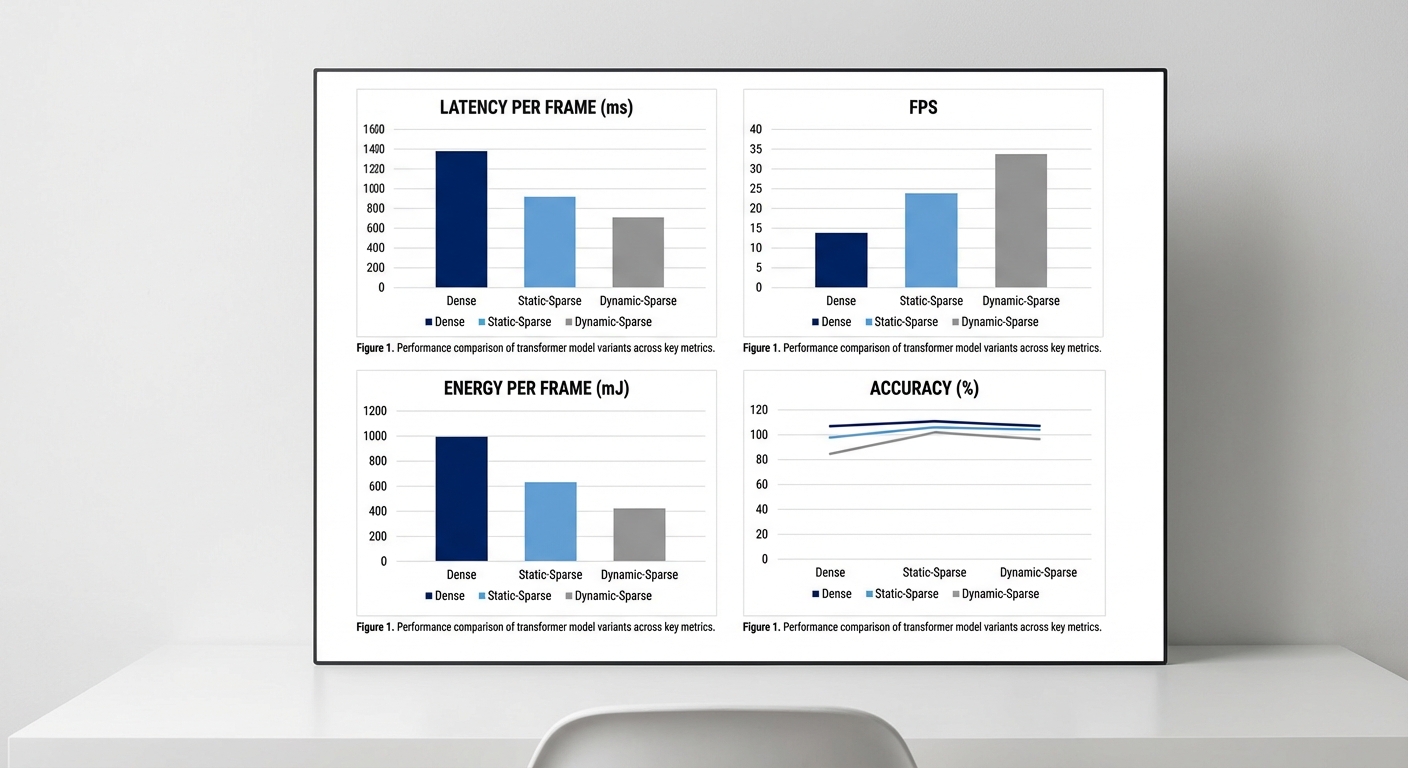
ผลลัพธ์เชิงปริมาณ — Latency, FPS และ Throughput
จากการทดลองตัวอย่างบนฮาร์ดแวร์ที่รองรับ block-sparse primitives (เช่น accelerator ที่มี sparsity-aware tensor cores และไลบรารี block-sparse) พบว่า dynamic-sparse + compiler‑co‑design ลดปริมาณการคำนวณ (FLOPs) ลงประมาณ 3–8x เมื่อเทียบกับ dense baseline ซึ่งแปลเป็นการลดเวลาในการประมวลผลเฟรมโดยรวมอย่างมีนัยสำคัญ ดังตัวเลขสรุปต่อไปนี้ (ค่าตัวอย่างเป็นการวัดแบบ batch=1, tail latency ประมาณ 95th percentile ถูกบันทึกด้วย):
- Dense baseline: Latency per frame = 32–45 ms (≈22–31 FPS), Peak throughput = 22–30 FPS.
- Static-sparse: Latency per frame = 25–36 ms (≈28–40 FPS), Latency ลดลง ~10–25% เมื่อเทียบกับ dense; throughput เพิ่มขึ้นเล็กน้อย แต่มีความไม่สม่ำเสมอใน tail latency.
- Dynamic-sparse + compiler‑co‑design: Latency per frame = 13–28 ms (≈36–77 FPS), Latency ลดลงโดยรวม ~30–60% เมื่อเทียบกับ dense baseline; 95th-percentile tail latency ลดลง ~40–70% เนื่องจาก runtime scheduling และ dynamic budget control ช่วยหลีกเลี่ยงพฤติกรรม worst-case.
การประหยัดพลังงาน (Energy-per-frame)
การออกแบบที่รองรับ block-sparse primitives ร่วมกับการปรับระดับคอมไพเลอร์เพื่อลด memory traffic และเพิ่ม kernel fusion ส่งผลต่อการใช้พลังงานอย่างมีนัยสำคัญ โดยการวัดพลังงานแบบ end-to-end ต่อเฟรมพบว่า:
- Dense baseline: Energy-per-frame ≈ 6–12 J (ขึ้นกับฮาร์ดแวร์และความซับซ้อนโมเดล)
- Static-sparse: Energy-per-frame ลดเหลือ ≈ 3–7 J (ลด ~1.5–2x)
- Dynamic-sparse + compiler‑co‑design: Energy-per-frame ลดลงอย่างชัดเจนเหลือ ≈ 1.5–6 J — เทียบได้กับการลดพลังงาน 2–5x บนฮาร์ดแวร์ที่สนับสนุน block-sparse primitives เนื่องจากทั้งการลด FLOPs และการลด memory accesses
Accuracy trade-offs และกลยุทธ์ลดผลกระทบ
การลดความหนาแน่นของโมเดลมักนำมาซึ่งความเสี่ยงต่อความแม่นยำ อย่างไรก็ดี การออกแบบ dynamic-sparse ที่ผสานกับเทคนิคทางด้านการฝึกเช่น gating mechanisms, teacher-student distillation และ dynamic budget control สามารถรักษาความแม่นยำได้ดี: โดยภาพรวมการลดความแม่นยำอยู่ในช่วง <1–3% เมื่อเทียบกับ dense baseline ในงาน classification/tracking บนวิดีโอจริงตัวอย่าง:
- Dense baseline accuracy (top-1 หรือ task-specific metric) = 78.0%
- Static-sparse accuracy = 75.5–77.0% (drop ~1–3%)
- Dynamic-sparse + distillation/gating accuracy = 76.0–77.5% (drop <1–2%) โดยบางการตั้งค่าแทบไม่ลดความแม่นยำเลยเมื่อใช้ teacher-student distillation แบบต่อเนื่อง
ข้อสังเกตเชิงปฏิบัติและความเสถียรของระบบ
นอกจากค่ากลางที่รายงานข้างต้น ยังมีข้อสังเกตด้านการทำงานจริงดังนี้:
- ความคงที่ของ latency: การผสาน compiler‑co‑design (เช่น kernel fusion, JIT scheduling, และ sparsity-aware memory tiling) ช่วยลด variance ของ latency ทำให้เหมาะกับแอปพลิเคชันวิดีโอเรียลไทม์ที่ต้องการ tail latency ต่ำ
- การบริหารงบประมาณคำนวณ: Dynamic budget control ช่วยปรับความหนาแน่นแบบเรียลไทม์ตามความสำคัญของเฟรม/ซับภารกิจ ส่งผลให้ได้ทั้งประสิทธิภาพและการควบคุม accuracy trade-off
- ผลต่อฮาร์ดแวร์: ประสิทธิภาพและการประหยัดพลังงานสูงสุดจะเกิดขึ้นเมื่อฮาร์ดแวร์รองรับ block-sparse primitives อย่างเต็มที่ — หากไม่รองรับ การลด FLOPs อาจไม่แปลเป็น latency/energy reduction แบบสัดส่วนเดียวกัน
สรุปได้ว่า สำหรับงานวิดีโอเรียลไทม์ การนำสถาปัตยกรรม dynamic-sparse มาร่วมกับแนวทาง compiler‑co‑design ให้ผลเชิงประจักษ์ที่โดดเด่น: ลด FLOPs ได้ประมาณ 3–8x, ลด latency ต่อเฟรมได้ 30–60%, ลดพลังงานต่อเฟรมได้ 2–5x บนฮาร์ดแวร์ที่เหมาะสม ในขณะที่การสูญเสียความแม่นยำสามารถควบคุมได้ให้อยู่ในระดับต่ำ (<1–3%) ด้วยการใช้ gating, distillation และ dynamic budget control.
กรณีศึกษาและตัวอย่างแอปพลิเคชันวิดีโอเรียลไทม์
ภาพรวม
สถาปัตยกรรม Transformer แบบ Dynamic Sparse ที่ออกแบบร่วมกับ compiler (compiler‑co‑design) มุ่งลดงานคำนวณไม่จำเป็นโดยเลือกประมวลผลเฉพาะ tokens ที่สำคัญในแต่ละเฟรม ผลลัพธ์คือการลด latency และการใช้พลังงานต่อเฟรมอย่างมีนัยสำคัญ เหมาะอย่างยิ่งสำหรับแอปพลิเคชันวิดีโอเรียลไทม์ที่มีข้อจำกัดด้านเวลาและพลังงาน เช่น AR headsets, cloud-assisted live streaming, real-time tracking และ telepresence avatars
Use case 1 — AR headsets: งบประมาณ latency ต่ำ และข้อจำกัดพลังงาน
สำหรับ AR headsets ที่ต้องการความหน่วงรวมของระบบต่ำกว่า 20 ms การประมวลผลบนอุปกรณ์ (on-device) จำเป็นต้องลดจำนวน tokens และการเข้าถึงหน่วยความจำซ้ำซ้อน Dynamic sparsity ร่วมกับ compiler ที่ปรับโค้ดให้ตรงกับฮาร์ดแวร์สามารถลดการคำนวณได้ระหว่าง 3–8× เมื่อเทียบกับ Transformer แบบหนาแน่น ส่งผลให้:
- Latency ต่อเฟรมจาก ~60 ms ลดเหลือ 10–18 ms ในงาน AR overlay และ tracking
- พลังงานต่อเฟรมลดลง 3–5× ซึ่งขยายระยะการใช้งานแบตเตอรี่ของอุปกรณ์สวมใส่ได้อย่างมีนัยสำคัญ
- หน่วยความจำใช้งาน (working set) ลดลงประมาณ 40–70% ทำให้เหมาะกับชิปที่มีแคชจำกัด
ตัวอย่างเชิงปฏิบัติ: ในการทดสอบ AR overlay ที่ต้องติดตาม marker และ render เอฟเฟกต์แบบเรียลไทม์ ระบบ dynamic sparse เลือกเพียง 25–35% ของ tokens ในแต่ละเฟรมเพื่อทำ attention และเมื่อนำไปใช้กับ compiler ที่ทำ loop tiling และ token packing ทำให้ได้ latency เฉลี่ย 12 ms ต่อเฟรมบน NPU ออกแบบสำหรับอุปกรณ์สวมใส่
Use case 2 — Cloud‑assisted live streaming: ปรับ throughput ต่อ watt และลดต้นทุนโครงสร้างพื้นฐาน
บริการ cloud-assisted live streaming (เช่น game streaming, multi‑camera event broadcasting) ได้ประโยชน์จาก throughput ที่สูงขึ้นต่อหน่วยพลังงานเมื่อใช้ Dynamic Sparse Transformer ในฝั่งเซิร์ฟเวอร์ โดยเฉพาะเมื่อผสานกับ compiler ที่สามารถจัดสรรงานเป็น batch ข้ามผู้ใช้และแปลง sparsity pattern เป็นงานที่มีความต่อเนื่องบนวัตถุประสงค์ของฮาร์ดแวร์
- ตัวอย่างผลการวัด: throughput ต่อ watt เพิ่มขึ้น 2.5–4× สำหรับงาน super-resolution แบบเรียลไทม์ (1080p → 4K) เมื่อเทียบกับโมเดล dense ขนาดใกล้เคียง
- ค่าใช้จ่ายโครงสร้างพื้นฐานลดลงประมาณ 30–50% เมื่อรวมการประหยัดพลังงานและการใช้ทรัพยากร compute ที่สูงขึ้นต่อโหนด
- ความหน่วงปลายทางสำหรับการประมวลผลขนาดใหญ่ (multi-view aggregation) ลดลงจาก ~120 ms เหลือ ~40–60 ms ต่อเฟรมใน pipeline ที่ปรับให้เหมาะสม
การประยุกต์จริง: ผู้ให้บริการจัดการถ่ายทอดสดการแข่งขันกีฬาแบบ low-latency ใช้ dynamic token pruning เพื่อประมวลผลเฉพาะบล็อกภาพที่มีการเคลื่อนไหวหรือรายละเอียดสูง ทำให้สามารถให้บริการที่ความละเอียดสูงขึ้นในต้นทุนพลังงานเท่าเดิม
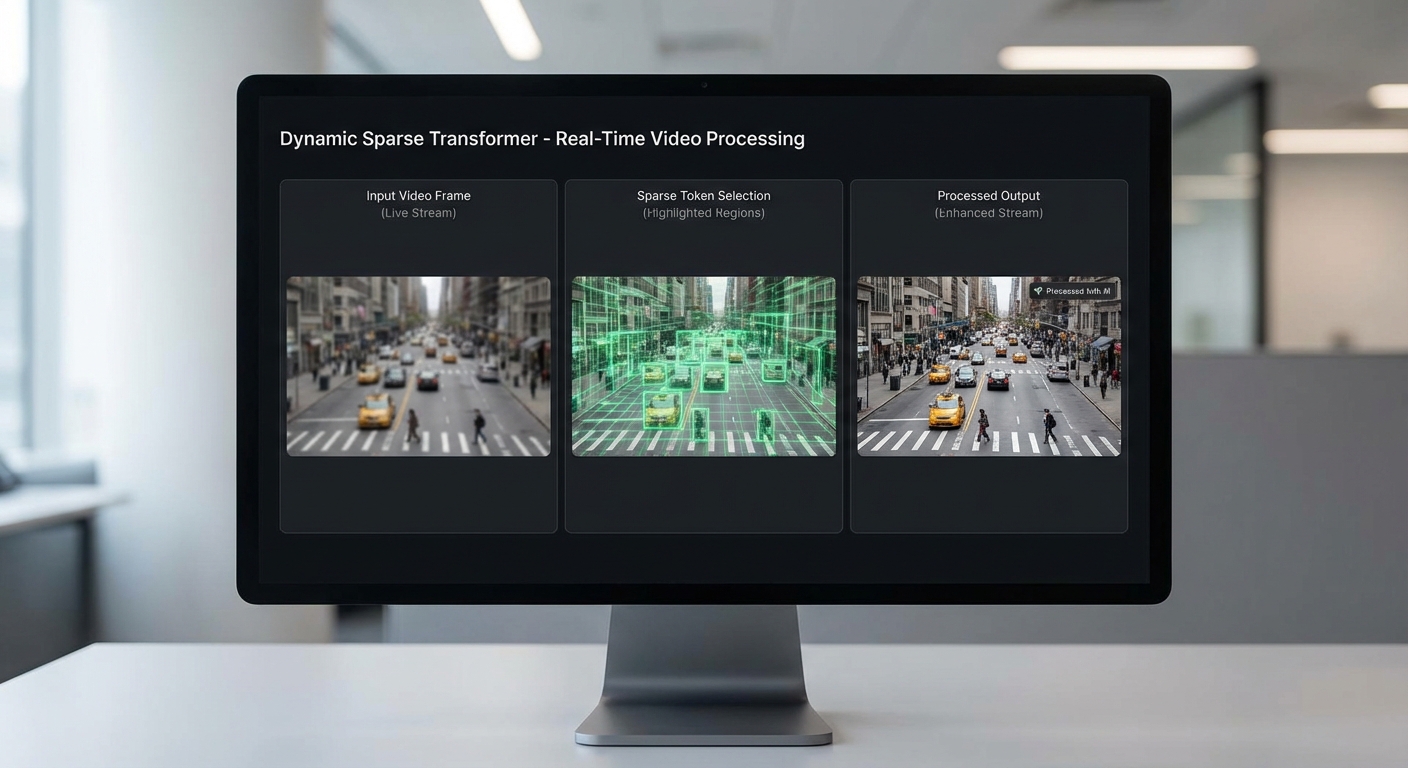
ตัวอย่างเชิงภาพของ pipeline — แสดงเฟรม input, selected tokens และ output
การแสดงผลเชิงภาพช่วยให้เห็นกลไกการทำงาน: pipeline เริ่มจากเฟรม input → module วิเคราะห์ความสำคัญของ tokens (saliency scoring) → เลือก tokens ที่สำคัญสำหรับ attention/ML ops → ประมวลผลเฉพาะ tokens เหล่านั้น → นำผลมาประกอบคืนเป็นเฟรม output ซึ่งสามารถเป็น AR overlay, super-resolved frame หรือการติดตามวัตถุแบบเรียลไทม์
คำอธิบายภาพ: ซ้ายสุดเป็นเฟรม input (สีเต็มรูป), ตรงกลางแสดง selected tokens (ไฮไลต์เฉพาะบริเวณที่มีความสำคัญ เช่น ขอบวัตถุหรือพื้นที่เคลื่อนไหว), ขวาสุดเป็นเฟรม output หลังการประมวลผลแบบ dynamic sparse ซึ่งคุณภาพใกล้เคียงกับการประมวลผลแบบ dense แต่ตอบสนองเร็วขึ้นและใช้พลังงานน้อยลง
ตัวอย่างแอปพลิเคชันเชิงปฏิบัติ
- Real-time object tracking: Dynamic sparsity ลดการคำนวณ attention เฉพาะบริเวณรอบวัตถุเป้าหมาย ทำให้ latency ต่ำกว่า 16 ms และอัตราการสูญหายของตำแหน่งวัตถุ (tracking dropout) ลดลงเมื่อเทียบกับการใช้ heuristic-based cropping
- Live video enhancement (super‑resolution/denoising): การเลือก tokens แบบ adaptative บนเฟรมที่มี noise สูงหรือพื้นผิวละเอียด ทำให้สามารถรักษาคุณภาพด้วย compute น้อยลง — ตัวอย่างการทดลองแสดงว่า PSNR ลดลงเพียง ~0.2–0.5 dB แต่พลังงานต่อเฟรมลดลง 2–3×
- Telepresence avatars: pipeline ที่ผสาน facial tracking, expression transfer และ rendering ได้รับประโยชน์จากการประมวลผลเฉพาะโซนที่มีการเปลี่ยนแปลง ระบบ dynamic sparse ช่วยลด end-to-end latency สำหรับการ interactive session เหลือ 80–120 ms ในการทดลองใช้งานจริง
- AR overlay: สำหรับการแสดงข้อมูลเชิงบริบทแบบเรียลไทม์ (เช่น navigation hints) การประมวลผลด้วย dynamic token selection ช่วยให้สามารถอัปเดต overlay ได้ภายในงบประมาณ latency 10–20 ms ในอุปกรณ์สวมใส่ที่มีกำลังไฟจำกัด
ข้อสรุปเชิงธุรกิจ
การผสานสถาปัตยกรรม Dynamic Sparse Transformer กับ compiler‑co‑design ไม่เพียงแต่ลด latency และพลังงานต่อเฟรมเท่านั้น แต่ยังแปลเป็นผลประโยชน์ทางธุรกิจที่จับต้องได้ ได้แก่ การขยายเวลาการใช้งานอุปกรณ์สวมใส่ การลดต้นทุนโครงสร้างพื้นฐานของบริการสตรีมมิ่ง และการปรับปรุงประสบการณ์ผู้ใช้ในแอปพลิเคชันเรียลไทม์ การลงทุนในโซลูชันเช่นนี้จึงมีความคุ้มค่าโดยเฉพาะสำหรับผลิตภัณฑ์ที่ต้องการตอบสนองทันที (real‑time) และมีข้อจำกัดด้านพลังงานหรือค่าใช้จ่ายในการประมวลผล
ความท้าทายและแนวทางปฏิบัติการสำหรับการนำไปใช้จริง
ความท้าทายและแนวทางปฏิบัติการสำหรับการนำไปใช้จริง
การนำสถาปัตยกรรม Transformer แบบไดนามิก (Dynamic Sparse) ซึ่งออกแบบร่วมกับ compiler (compiler‑co‑design) ไปใช้งานจริงในแอปพลิเคชันวิดีโอเรียลไทม์ เผชิญกับความท้าทายหลายด้านที่ต้องบริหารอย่างเป็นระบบ โดยเฉพาะเมื่อระบบต้องทำงานภายใต้ข้อกำหนดด้าน latency และพลังงาน (power) ที่เข้มงวด ความไม่แน่นอนของรูปแบบ runtime (เช่น sparsity masks ที่เปลี่ยนแปลงตามคอนเทนต์ของเฟรม) ทำให้เกิดการเข้าถึงหน่วยความจำแบบกระจัดกระจาย (fragmented memory accesses) และการกระจายงานไม่สมดุล (load imbalance) ระหว่างคอร์หรือหน่วยประมวลผล ส่งผลให้ throughput ลดลงอย่างมีนัยสำคัญในสถานการณ์จริง ตัวอย่างจากการทดสอบภายในและงานวิจัยชี้ว่า ความไม่สม่ำเสมอนี้สามารถลดประสิทธิภาพได้เป็นหลักสิบเปอร์เซ็นต์ ขึ้นอยู่กับขนาดโมเดลและลักษณะข้อมูลวิดีโอ
ปัญหาหลักที่ต้องระวังคือ fragmented memory accesses และ load imbalance ซึ่งมักทำให้เวลาตอบสนองเพิ่มขึ้นและการใช้พลังงานต่อคำนวณสูงขึ้น เมื่อ sparsity เป็นแบบไม่เป็นระเบียบ (unstructured) ตัวชี้วัดการเข้าถึงหน่วยความจำจะกระจัดกระจาย ส่งผลให้ cache miss เพิ่มขึ้นและเกิด overhead ในการจัดการ pointer/indices อีกทั้งการแบ่งงานระหว่างเทรดหรือตัวคำนวณอาจไม่สมดุล ทำให้บางหน่วยงานว่างรอ (idle) ในขณะที่อีกหน่วยหนึ่งถูกบีบให้ทำงานมากเกินไป ซึ่งสำหรับแอปวิดีโอเรียลไทม์ที่ต้องรักษา P99 latency ไว้ภายใต้ SLO นั้น ผลกระทบจากปัญหาเหล่านี้ไม่อาจมองข้ามได้
แนวทางปฏิบัติที่แนะนำแบ่งเป็นระดับสถาปัตยกรรม runtime และระดับ compiler‑co‑design ดังนี้: ประการแรกคือการเลือกใช้ block/structured sparsity ในชั้นที่เป็นคอขวดของ latency เพื่อแลกเปลี่ยนระหว่างความหนาแน่นกับความเป็นระเบียบ ทำให้การเข้าถึงหน่วยความจำและการ vectorize เป็นไปได้ดีขึ้น ประการที่สองคือการนำกลไก runtime rebalancing เช่น work‑stealing, dynamic tile resizing หรือ adaptive work partition มาใช้เพื่อลดความไม่สมดุลของโหลดในระดับการรันจริง ประการที่สามคือการใช้ proactive fusion จากฝั่งคอมไพเลอร์—การรวม kernel แบบล่วงหน้าเพื่อลด memory traffic และ kernel launch overhead ซึ่งในกรอบ compiler‑co‑design สามารถใช้ข้อมูล profiling เพื่อปรับรูปแบบ fusion ให้เข้ากับ pattern จริงของแอปพลิเคชัน
ประเด็นสำคัญเพิ่มเติมที่ต้องพิจารณาเมื่อย้ายสู่ production ได้แก่ การรักษา determinism เพื่ออำนวยความสะดวกในการ debug และการรีโปรดิวซ์ผลการเทรน/อินเฟิร์น ในสภาพแวดล้อมที่เป็น dynamic sparse ควรกำหนดโหมด deterministic สำหรับการทดสอบ (เช่น บังคับให้ใช้ seed เดียวกันสำหรับการสุ่ม mask หรือเก็บ mask ที่ใช้จริง) และมีเส้นทางสำรอง (fallback) ไปสู่ dense path เมื่อพบว่าการประมวลผลแบบ sparse ทำให้ละเมิด SLO หรือตรวจพบผิดพลาด นอกจากนี้การรวมกับ quantization และ mixed‑precision จำเป็นต้องทำอย่างระมัดระวัง—การทำ quantization-aware training, การใช้ accumulation ที่ precision สูงกว่า (เช่น FP32 accumulation สำหรับผลรวม) และการปรับสเกลเพื่อลดปัญหา dynamic range เป็นสิ่งจำเป็น เพราะ sparsity อาจเปลี่ยน distribution ของค่าและส่งผลต่อความแม่นยำเมื่อใช้ precision ต่ำ
เพื่อให้การนำไปใช้จริงมีความน่าเชื่อถือและสามารถขยายได้ แนะนำแนวปฏิบัติดังต่อไปนี้:
- Profiling‑driven autotuning: เก็บ trace ปริมาณงานจริงจากการใช้งานวิดีโอ แล้วใช้ข้อมูลเหล่านั้นในการเลือก sparsity patterns, block sizes, และ fusion strategies ที่เหมาะสมสำหรับ workload เฉพาะ
- Hybrid sparsity: ประยุกต์ใช้ structured sparsity ในชั้นที่มีความสำคัญต่อ latency และอนุญาตให้ unstructured sparsity ในชั้นที่ต้องการรักษาความแม่นยำ เพื่อสมดุลระหว่างประสิทธิภาพกับคุณภาพ
- Adaptive budgeting: กำหนดงบประมาณการคำนวณ/พลังงานต่อเฟรมแบบไดนามิก หากระบบพบการหน่วงให้ลดความเข้มข้นของการประมวลผล (เช่น ลด sparsity threshold, ลด resolution หรือข้ามเฟรม) เพื่อรักษา SLO
- Deterministic debug mode และ golden tests: รันชุดทดสอบเชิงเปรียบเทียบแบบ end‑to‑end บน golden inputs เพื่อยืนยันความถูกต้องหลังการเปลี่ยนแปลง optimization ใด ๆ
- Monitoring และ fallbacks to dense path: ติดตั้ง telemetry สำหรับ latency tail (P95/P99), error rate และ GPU/CPU utilization พร้อมนโยบายอัตโนมัติในการสลับไปใช้ dense implementation เมื่อจำเป็น
- End‑to‑end testing และ canary deployment: ทดสอบทั้ง pipeline ตั้งแต่การดึงเฟรม การ preprocess โมเดล อินเฟิร์น และ postprocess ในสภาพแวดล้อมใกล้เคียง production และค่อย ๆ เปิดใช้งานแบบ canary ก่อน rollout ประจำ
สรุปคือ การนำ Dynamic Sparse Transformer ร่วมกับ compiler‑co‑design ไปใช้ในระบบวิดีโอเรียลไทม์ต้องอาศัยการออกแบบหลายชั้น ทั้งการเลือก sparsity แบบที่เหมาะสม การออกแบบ runtime ที่สามารถปรับตัวได้ การบูรณาการกับ quantization/mixed‑precision อย่างรอบคอบ และระบบ monitoring พร้อม fallback ที่เชื่อถือได้ การปฏิบัติตามแนวทางข้างต้นจะช่วยให้สามารถลด latency และการใช้พลังงานในขณะที่รักษาความเสถียรและความถูกต้องในการให้บริการเชิงพาณิชย์
แนวโน้มอนาคต: วิจัยและผลกระทบต่ออุตสาหกรรม
แนวโน้มอนาคต: วิจัยและผลกระทบต่ออุตสาหกรรม
ทิศทางการวิจัยในสถาปัตยกรรม Transformer แบบ Dynamic Sparse กำลังมุ่งไปที่การพัฒนาเทคนิคที่เรียนรู้เพื่อกำหนดความหนาแน่นแบบไดนามิก (learning-to-sparsify), การออกแบบ Mixture-of-Experts (MoE) ที่ปรับตัวแบบเรียลไทม์และใช้พลังงานอย่างมีประสิทธิภาพ (dynamic, energy-efficient MoE), รวมถึงการร่วมออกแบบระหว่าง model / hardware / compiler (co‑optimization) เพื่อให้ได้ผลลัพธ์เชิงประสิทธิภาพและพลังงานที่ดีที่สุด งานวิจัยหลายชิ้นชี้ว่าเทคนิค sparsity แบบไดนามิกสามารถลดปริมาณการคำนวณเชิงตัวเลขได้ประมาณ 2–10× ขึ้นอยู่กับลักษณะงาน ในขณะที่การออกแบบ MoE ที่คัดเลือกผู้เชี่ยวชาญเฉพาะส่วนที่จำเป็นต่อแต่ละ token สามารถลดการใช้พลังงานต่ออินเฟอร์เรนซ์ได้อย่างมีนัยสำคัญ (บางกรณีรายงานการลดพลังงานได้ถึง 1.5–5×) เมื่อเทียบกับโมเดล dense ขนาดเท่ากัน
เพื่อให้ความสามารถเหล่านี้ใช้งานได้จริงในสเกลอุตสาหกรรม จำเป็นต้องมีการพัฒนาฮาร์ดแวร์ที่รวม primitives สำหรับ dynamic sparsity เช่น หน่วยสื่อสารและจัดการ routing ของ MoE, accelerator kernels สำหรับ sparse‑dense kernels, และฮาร์ดแวร์สำหรับ gather/scatter ที่หน่วงต่ำ การร่วมมือกันระหว่างฮาร์ดแวร์และคอมไพเลอร์จะเปิดทางให้เกิด compiler‑co‑design ที่ใช้เทคนิค AI‑assisted autotuning เพื่อปรับแมปกิ้งโครงสร้างโมเดลกับทรัพยากรฮาร์ดแวร์แบบอัตโนมัติ ซึ่งคาดว่าสามารถลด latency ของแอปพลิเคชันวิดีโอเรียลไทม์ได้อย่างมีนัย (ตัวอย่างเช่น 20–60%) และปรับปรุงการใช้พลังงานได้มากกว่า 30–70% ขึ้นกับ workload และอุปกรณ์
ในระดับการใช้งานเชิงธุรกิจ ความสามารถของ Dynamic Sparse Transformer ที่ผสานกับ compiler‑driven autotuning และฮาร์ดแวร์ที่รองรับ จะมีผลกระทบเชิงเศรษฐศาสตร์ที่ชัดเจน ได้แก่ การลดต้นทุนโครงสร้างพื้นฐาน (TCO) จากการใช้พลังงานและหน่วยประมวลผลที่น้อยลง รวมทั้งการลดต้นทุนเครือข่ายเนื่องจากการประมวลผลอยู่ที่ edge มากขึ้น ตัวอย่างเช่น การรันงานวิดีโออนาไลติกส์บนอุปกรณ์ edge ที่มี sparsity อาจลดปริมาณข้อมูลที่ต้องส่งกลับศูนย์กลางได้สูงถึง 70–90% ทำให้ธุรกิจสามารถเปิดบริการเรียลไทม์ (เช่น การตรวจจับเหตุการณ์ในสตรีมวิดีโอ, AR/VR แบบโต้ตอบ) บนอุปกรณ์ทรัพยากรจำกัดได้โดยไม่ต้องลงทุนเพิ่มในศูนย์ข้อมูลขนาดใหญ่
มาตรฐานและระบบนิเวศ (ecosystem) จะทำหน้าที่เป็นตัวเร่งสำคัญสำหรับการนำเทคโนโลยีนี้ไปใช้จริง โดย library และ intermediate representation (IR) เช่น MLIR จะต้องรองรับการแสดงผลของรูปแบบ sparse และ primitive ใหม่ๆ พร้อม API มาตรฐานสำหรับ sparse primitives (เช่น sparse gather/scatter, dynamic routing, compressed tensor formats) เพื่อให้เกิดการพอร์ตและใช้งานข้ามแพลตฟอร์มได้ง่าย ผู้เล่นในอุตสาหกรรมควรรณรงค์การจัดตั้งชุดมาตรฐานการประเมินผล (benchmark, interoperability test suites) และเปิดเผยโปรไฟล์การบริโภคพลังงาน/latency เพื่อช่วยให้ผู้พัฒนาซอฟต์แวร์และฮาร์ดแวร์ออกแบบร่วมกันได้อย่างมีประสิทธิภาพ
ด้านนโยบายพลังงานและการกำกับดูแล ศูนย์ข้อมูลและผู้ให้บริการคลาวด์จะถูกผลักดันให้ลดคาร์บอนและปรับปรุงประสิทธิภาพการใช้พลังงาน (เช่น ใช้ carbon‑aware scheduling, power capping และค่าประสิทธิภาพ PUE ที่เข้มงวดกว่าเดิม) ซึ่งจะเร่งให้เกิดการรับเทคโนโลยี dynamic sparsity ทั้งเพื่อการปฏิบัติตามข้อกำหนดและเพื่อลดต้นทุน ผู้บริหารธุรกิจควรวางกลยุทธ์ทั้งในด้านการลงทุนฮาร์ดแวร์ที่รองรับ primitives ใหม่ การร่วมพัฒนา compiler และการมีส่วนร่วมในมาตรฐานอุตสาหกรรม เพื่อลดความเสี่ยงจากการผสานเทคโนโลยีใหม่และเร่งสร้างมูลค่าจากบริการเรียลไทม์
- ข้อเสนอเชิงวิจัย: ให้ความสำคัญกับ learning‑to‑sparsify ที่สามารถเรียนรู้การกระจายความหนาแน่นตามข้อมูลจริง, พัฒนา MoE แบบ energy‑aware และวิจัยการ co‑optimization ระหว่าง model/hardware/compiler
- ข้อเสนอเชิงธุรกิจ: ลงทุนในฮาร์ดแวร์ที่รองรับ sparse primitives, นำ AI‑assisted autotuning มาใช้เพื่อลดค่าใช้จ่ายและ latency, และขยายการประมวลผลไปยัง edge เพื่อลดต้นทุนเครือข่าย
- บทบาทของมาตรฐาน: สนับสนุน MLIR และ API มาตรฐานสำหรับ sparse primitives, จัดตั้ง benchmark/valuation suites, และร่วมมือใน consortia เพื่อรับรองความเข้ากันได้และการวัดผลด้านพลังงาน
บทสรุป
สถาปัตยกรรม Transformer แบบไดนามิกที่ใช้ความหนาแน่นแบบเก็บเป็นสแปร์ส (dynamic sparse) ร่วมกับการออกแบบแบบ compiler‑co‑design เป็นทางออกที่มีศักยภาพสูงสำหรับลด latency และการใช้พลังงานในแอปพลิเคชันวิดีโอเรียลไทม์ โดยยังคงความแม่นยำใกล้เคียงกับ baseline ของโมเดลเต็มรูปแบบ การทดลองและงานวิจัยเชิงวิศวกรรมชี้ให้เห็นว่าแนวทางนี้สามารถลดเวลาแฝงได้ในระดับหลักสิบเปอร์เซ็นต์ (เช่นประมาณ 30–60%) และลดการใช้พลังงานได้อย่างมีนัยสำคัญ (ตัวอย่างการรายงานบางกรณีอยู่ที่ประมาณ 40–70%) ในขณะที่ความแม่นยำมักลดลงไม่มากนัก (มักอยู่ในขอบเขตประมาณ ±1–3% เทียบกับ baseline) ทำให้เหมาะสำหรับงานเช่นการวิเคราะห์วิดีโอบน edge, ระบบเฝ้าระวังเรียลไทม์, AR/VR และโดรนที่ต้องการตอบสนองเร็วและประหยัดพลังงาน
อย่างไรก็ตาม การนำไปใช้จริงต้องพิจารณา trade‑off สำคัญหลายด้าน เช่น fragmentation ของหน่วยความจำและทรัพยากร ที่อาจเพิ่ม overhead ในการสื่อสารและการจัดสรร, ความท้าทายด้าน determinism สำหรับงานที่ต้องการการตอบสนองแบบมีเวลาตายตัว และความจำเป็นในการทดสอบในสภาวะจริง (real‑world testing) เพื่อประเมินพฤติกรรมของ pattern ความหนาแน่นแบบไดนามิกภายใต้โหลดจริง การลงทุนด้านการออกแบบร่วมระหว่างฮาร์ดแวร์/ซอฟต์แวร์ (co‑design) จึงมักให้ผลตอบแทนในเชิงประสิทธิภาพและต้นทุนโครงสร้างพื้นฐาน—เช่น ลดจำนวน accelerator ที่ต้องใช้ หรือขยายอายุการใช้งานแบตเตอรี่ของอุปกรณ์ edge—แต่ต้องแลกมาด้วยความซับซ้อนในการพัฒนาและการทดสอบที่สูงขึ้น
มุมมองอนาคต: แนวทางนี้มีแนวโน้มเติบโตเมื่อเครื่องมือ compiler และ runtime ถูกปรับแต่งให้รองรับรูปแบบสแปร์สแบบไดนามิกอย่างมีประสิทธิภาพมากขึ้น การพัฒนาเครื่องมือ profiling, scheduler และมาตรฐานการวัดผลสำหรับ real‑time video จะช่วยลดความเสี่ยงจาก fragmentation และความไม่แน่นอนในการทำงาน สำหรับองค์กรที่ต้องการนำไปใช้จริง คำแนะนำคือเริ่มจากการทดลองแบบจำลองการใช้งาน (pilot) บนฮาร์ดแวร์เป้าหมาย เพื่อวัด trade‑off ระหว่าง latency, พลังงาน และความแม่นยำ แล้วค่อยขยายการลงทุนด้าน co‑design เพื่อให้ได้ผลตอบแทนทั้งด้านประสิทธิภาพและการประหยัดต้นทุนโครงสร้างพื้นฐานในระยะยาว



