
โรงงานไทยกำลังก้าวสู่ยุค Self‑Optimizing อย่างรวดเร็ว เมื่อเทคโนโลยี Edge‑Vision ที่ติดตั้งบนกล้องและอุปกรณ์ขอบเครือข่าย (edge) ถูกผสานเข้ากับ TinyLLM โมเดลภาษาขนาดเล็กที่รันได้ใกล้กับแหล่งข้อมูล ผลลัพธ์คือระบบตรวจจับข้อบกพร่องแบบเรียลไทม์ที่ไม่ต้องพึ่งพาคลาวด์ตลอดเวลา และสามารถสั่งปรับสายการผลิตอัตโนมัติทันทีเมื่อพบปัญหา การผสานเทคโนโลยีทั้งสองช่วยลดความหน่วง (latency) เพิ่มความแม่นยำในการคัดกรองชิ้นงาน และทำให้การตัดสินใจเชิงปฏิบัติการเกิดขึ้นใกล้แหล่งข้อมูลมากขึ้น ส่งผลให้ของเสียลดลง คุณภาพผลิตภัณฑ์ดีขึ้น และเวลาตอบสนองโดยรวมสั้นลง
บทความนี้จะพาอ่านแนวคิดสำคัญของโรงงาน Self‑Optimizing ตั้งแต่สถาปัตยกรรม Edge‑Vision, บทบาทของ TinyLLM ในการแปลงข้อมูลภาพเป็นคำสั่งควบคุม, ตัวอย่างการใช้งานจริง และผลลัพธ์เชิงตัวเลขที่น่าสนใจ — เช่น การทดลองในโรงงานนำร่องบางแห่งที่รายงานการลดของเสียได้ถึง 30–50% พร้อมการย่นระยะเวลาการตอบสนองของสายการผลิตอย่างมีนัยสำคัญ นอกจากนี้ยังวิเคราะห์ความท้าทายด้านการใช้งานจริง ทั้งเรื่องการผสานฮาร์ดแวร์ ซอฟต์แวร์ การจัดการแรงงาน และการคำนวณค่าใช้จ่าย-ผลตอบแทน ให้ผู้อ่านได้เห็นภาพรวมที่ชัดเจนของโอกาสและความเสี่ยงก่อนการนำระบบไปใช้
ภาพรวม: โรงงาน Self‑Optimizing คืออะไร และทำไมถึงสำคัญ
ภาพรวม: โรงงาน Self‑Optimizing คืออะไร และทำไมถึงสำคัญ
โรงงาน Self‑Optimizing หมายถึงระบบการผลิตที่สามารถตรวจจับ ประเมิน และปรับการทำงานของสายการผลิตได้แบบอัตโนมัติและต่อเนื่องโดยอาศัยข้อมูลเรียลไทม์จากเซนเซอร์และกล้องอุตสาหกรรม (Edge‑Vision) ร่วมกับความสามารถด้านการประมวลผลเชิงภาษาและการตัดสินใจขนาดเล็ก (TinyLLM) เพื่อสร้างวงป้อนกลับ (closed‑loop) ที่ลดการแทรกแซงจากมนุษย์ในงานระดับปฏิบัติการ ผลลัพธ์คือการปรับพารามิเตอร์เครื่องจักร การเปลี่ยนแผนการผลิต หรือการแจ้งเตือนผู้ปฏิบัติงานอย่างทันที เพื่อรักษาคุณภาพและอัตราการเดินเครื่องที่เหมาะสม
เชิงยุทธศาสตร์ โรงงานที่สามารถปรับตัวได้เองแบบนี้มีข้อได้เปรียบสำคัญ ได้แก่ ความยืดหยุ่นในการตอบสนองต่อเหตุผิดปกติ, การลดค่าใช้จ่ายจากของเสียและการหยุดเดินเครื่อง, และ การเพิ่มประสิทธิภาพทรัพยากร ตัวอย่างเช่น การตรวจจับข้อบกพร่องด้วย Edge‑Vision ที่ประมวลผลบนอุปกรณ์ขอบเครือข่ายช่วยให้ลดความหน่วง (latency) และลดการพึ่งพาแบนด์วิดท์ไปยังคลาวด์ ในขณะที่ TinyLLM ให้บริบทเชิงความหมายสำหรับการตัดสินใจ เช่น สาเหตุที่เป็นไปได้ของ defect และแนวทางแก้ไขแบบเรียลไทม์ ทำให้การปรับสายการผลิตเป็นไปอย่างแม่นยำและรวดเร็ว
จากมุมมองทางธุรกิจ ผลกระทบที่วัดได้มักรวมถึงการลด Scrap/废品, เพิ่มค่า OEE (Overall Equipment Effectiveness) และลด MTTR (Mean Time To Repair) โดยทั่วไปบริษัทผู้ผลิตที่นำเทคโนโลยีอัตโนมัติและวิเคราะห์ข้อมูลเชิงลึกมาใช้สามารถลดอัตราข้อบกพร่อง (defect rate) ได้ระหว่าง 20–60% ขึ้นอยู่กับระดับปัญหาเริ่มต้น และมักเห็นการเพิ่มขึ้นของ Throughput หรือผลผลิตจริงได้ประมาณ 5–20% นอกจากนี้การตอบสนองเชิงเวลาจริงช่วยให้ลด MTTR ได้อย่างมีนัยสำคัญ เช่น ลดเวลาเฉลี่ยในการซ่อมแซมลง 30–50% ซึ่งตรงกับเป้าหมาย KPI ที่โรงงานส่วนใหญ่ให้ความสำคัญ
สถิติแนวโน้มการลงทุนชี้ชัดว่าการก้าวสู่โรงงาน Self‑Optimizing ไม่ใช่แนวโน้มระยะสั้น: ตามการสำรวจเชิงสากลและรายงานอุตสาหกรรมหลายแห่ง พบว่า ราว 60–75% ของผู้ผลิตตั้งใจจะลงทุนเพิ่มเติมใน AI, Edge computing หรือการวิเคราะห์แบบเรียลไทม์ภายใน 2–3 ปีข้างหน้า ส่วนในบริบทของไทย ข้อมูลเชิงสำรวจจากหน่วยงานภาครัฐและเอกชนรวมถึงสมาคมอุตสาหกรรมชี้ว่าประมาณ 40–55% ของโรงงานมีแผนหรืออยู่ระหว่างโครงการนำร่องเทคโนโลยีดังกล่าว เพื่อเพิ่มความสามารถในการแข่งขัน ทั้งนี้การลงทุนมักถูกจัดลำดับความสำคัญตามผลกระทบต่อ KPI เช่น defect rate, throughput, OEE, MTTR และค่าใช้จ่ายต่อหน่วย
- ตัวอย่าง KPI ที่โรงงานใช้วัดความสำเร็จของระบบ Self‑Optimizing:
- Defect rate (เป้าหมายเช่น <1% ขึ้นกับอุตสาหกรรม)
- Throughput / ผลผลิตจริง (เพิ่มเป็น % เทียบกับก่อนนำระบบเข้าใช้)
- OEE (เพิ่มขึ้นเป็น +5–15% เป็นเป้าหมายทั่วไป)
- MTTR (ลดลงเป็นเป้าหมายเช่น 30–50%)
- Scrap rate และค่าใช้จ่ายต่อหน่วย (ลดลงเป็นตัวเงินหรือเปอร์เซ็นต์)
สรุปคือ ในบริบทการผลิตของไทย การผสาน Edge‑Vision กับ TinyLLM ทำให้เกิดระบบ Self‑Optimizing ที่ให้ทั้งการตรวจจับเชิงภาพความหน่วงต่ำ การทำความเข้าใจเชิงสาเหตุ และการตัดสินใจเชิงปฏิบัติการแบบกระชับและทันท่วงที ผลลัพธ์คือการลดของเสีย เพิ่มอัตราผลิตได้จริง และเพิ่มความยืดหยุ่นเชิงธุรกิจ ซึ่งเป็นปัจจัยสำคัญในการสร้างความอยู่รอดและการแข่งขันในตลาดที่เปลี่ยนเร็วในปัจจุบัน
เทคโนโลยีหลัก: Edge‑Vision และ TinyLLM อธิบายการทำงาน
เทคโนโลยีหลัก: Edge‑Vision และ TinyLLM — การทำงาน
Edge‑Vision: บทบาทเชิงเทคนิคในการจับภาพและตรวจจับข้อบกพร่องเรียลไทม์
Edge‑Vision ทำหน้าที่เป็นชั้นแรกของระบบ Self‑Optimizing ในโรงงาน โดยประกอบด้วยกล้องอุตสาหกรรม เซนเซอร์ภาพ และโหนดประมวลผลที่อยู่ใกล้กับแหล่งข้อมูล (on‑edge) เพื่อให้สามารถอ่านภาพและทำการตรวจจับข้อบกพร่องได้แบบเรียลไทม์โดยไม่ต้องส่งข้อมูลดิบไปยังคลาวด์ การออกแบบฮาร์ดแวร์มักใช้กล้องที่รองรับ global shutter สำหรับการจับภาพวัตถุเคลื่อนไหวสูง รวมทั้งการควบคุมแสงและชุดฟิลเตอร์ที่เหมาะสมเพื่อเพิ่ม SNR
ในเชิงซอฟต์แวร์ Edge‑Vision ใช้พายพ์ไลน์มาตรฐาน: รับภาพ → Pre‑processing (resize, normalize, augment บางกรณี) → อินเฟอร์เรนซ์โมเดลตรวจจับ → Post‑processing (NMS, classification threshold) → event generation สำหรับส่งต่อไปยังชั้นควบคุม/LLM เพื่อสรุปผล ตัวอย่างโมเดลน้ำหนักเบาที่นิยมใช้ในงานตรวจจับข้อบกพร่องบน edge ได้แก่ MobileNetV2/V3 สำหรับงานคลาสิฟาย และตัวแยกวัตถุแบบเบาเช่น YOLO‑nano / Tiny‑YOLO / EfficientDet‑Lite ซึ่งเมื่อนำมา convert เป็น ONNX แล้วใช้เรนไทม์เช่น ONNX Runtime หรือ TensorRT (บน NVIDIA) จะได้ประสิทธิภาพที่เหมาะสมกับข้อกำหนดเวลา
การเพิ่มประสิทธิภาพที่สำคัญได้แก่การทำ quantization (FP16 / INT8), pruning และการปรับ batch เป็น 1 เพื่อให้ latency ต่ำสุด ตัวอย่างเป้าหมายเชิงปฏิบัติคือ latency ต่อภาพระดับ <50ms (บางกรณีตั้งเป้า <20–30ms) และความแม่นยำสำหรับข้อบกพร่องแบบชัดเจนที่ >95% (precision/recall หรือ mAP ขึ้นอยู่กับชนิดของ defect) ฮาร์ดแวร์ที่ใช้บ่อยได้แก่ NVIDIA Jetson (Xavier NX / Orin), Google Coral Edge TPU, Intel Movidius / OpenVINO‑ready CPUs และ NPU บนแพลตฟอร์ม ARM
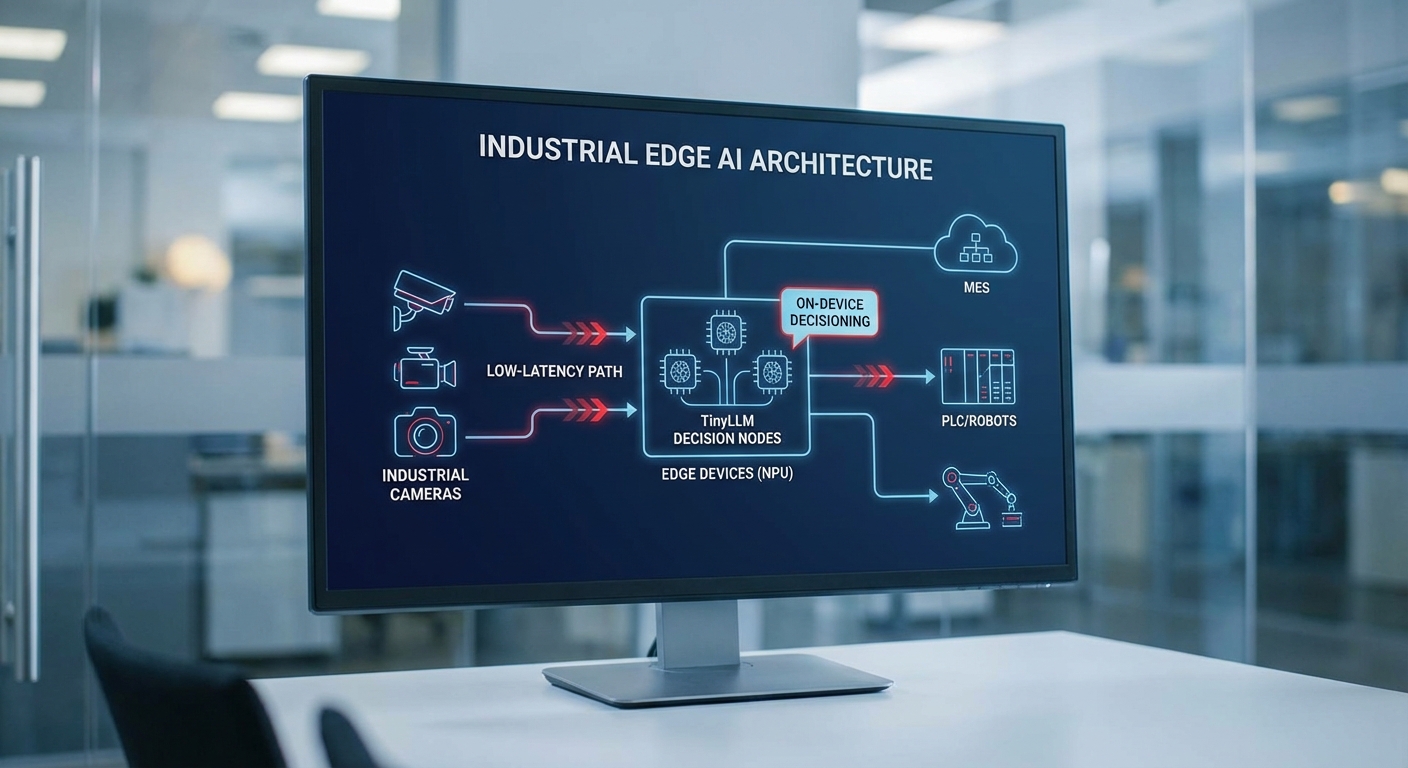
TinyLLM: บทบาทเชิงเทคนิคในการสรุป ตัดสินใจ และสร้างคำสั่งเชิงบริบท
TinyLLM คือ LLM ขนาดเล็กที่ถูกออกแบบให้ทำงานบนโหนด edge หรือโหนดใกล้ขอบเครือข่าย โดยเน้นที่ความเร็ว, ขนาดโมเดล และความต้องการทรัพยากรขั้นต่ำ ข้อดีสำคัญคือความสามารถในการสรุปสถานะ แปลผลจากสัญญาณเชิงตัวเลขและข้อความจาก Edge‑Vision แล้วแปลงเป็นคำสั่งเชิงบริบทสำหรับ PLC, MES หรือระบบ SCADA
เช่น เมื่อ Edge‑Vision ส่ง event รายการข้อบกพร่องพร้อมความเชื่อมั่น (bounding box, defect type, confidence, timestamp) TinyLLM จะทำหน้าที่:
- สรุปสภาพรวมของเหตุการณ์ในรูปแบบที่มนุษย์อ่านง่าย เช่น "พบรอยร้าวบนชิ้นงาน 12 ฉบับ ในสายการผลิต A ภายใน 2 นาทีที่ผ่านมา"
- ตัดสินใจเชิงธุรกิจ/การผลิต เช่น "ลดความเร็วสายการผลิต 10% และสั่งหยุดเครื่อง X เพื่อทำการตรวจสอบ" โดยใช้กฎธุรกิจที่ฝังอยู่ใน prompt หรือการปรับเทรนเฉพาะโดเมน
- สร้างคำสั่งเชิงบริบท (contextual control commands) สำหรับส่งต่อไปยังระบบควบคุมแบบอัตโนมัติ
ตัวอย่างโมเดลที่ใช้ได้แก่ Llama‑2‑Tiny หรือเวอร์ชัน LLM ขนาดเล็กที่ถูกปรับเทรนเฉพาะโดเมน (ขนาดโดยทั่วไปในช่วง 100M–1B พารามิเตอร์) โมเดลเหล่านี้มักถูก fine‑tune ด้วย LoRA/PEFT บนข้อมูลเหตุการณ์การผลิตเพื่อให้สามารถให้คำสั่งแบบเฉพาะกิจได้อย่างแม่นยำ การรันแบบ quantized (เช่น INT8/INT4) หรือใช้เครื่องมือ inference เช่น GGML/llama.cpp/Alpaca‑optimized runtimes ช่วยให้ได้ latency ในระดับที่ยอมรับได้ (ตัวอย่างเป้าหมายสำหรับคำสั่งเชิงบริบทคือ <100–200ms ขึ้นกับขนาดโมเดลและฮาร์ดแวร์)
การผสานรวมและมาตรวัด (latency, accuracy, model size, ฮาร์ดแวร์)
เมื่อรวม Edge‑Vision กับ TinyLLM เป็นระบบตรวจจับข้อบกพร่องอัตโนมัติ จะมีเกณฑ์วัดผลที่สำคัญดังนี้:
- Latency (end‑to‑end): เป้าหมายการแจ้งเตือนภายในระบบควรต่ำกว่า 50ms สำหรับการตรวจจับแบบเรียลไทม์เฉพาะภาพ (Edge inference) และถ้ารวมการตัดสินใจจาก TinyLLM อาจมีเป้าหมายรวมที่ 100–250ms ขึ้นกับกรณีใช้งาน
- Accuracy / Quality: สำหรับการตรวจจับ defect ที่มีความชัดเจน ควรตั้งเป้า precision/recall หรือ mAP ที่ > 95% โดยการวัดต้องคำนึงถึง imbalance ของคลาสและสภาพแสง
- Model size & Memory footprint: Edge model ควรมีขนาดที่เหมาะสมต่อหน่วยความจำบนอุปกรณ์ เช่น MobileNet/Tiny‑YOLO เวอร์ชัน quantized อาจอยู่ในระดับ 10–50MB ส่วน TinyLLM ที่ปรับเทรนมาอาจอยู่ในช่วง 100–800MB ขึ้นกับการ quantize และวิธีรัน
- ฮาร์ดแวร์: กำหนดโดย latency และ throughput ที่ต้องการ — ตัวอย่างเช่น Jetson Xavier NX สามารถรองรับ inference ของ MobileNet/YOLO‑nano ที่ quantized เฉลี่ย <30ms ต่อภาพ ขณะที่ TinyLLM ขนาดเล็กบนอุปกรณ์เดียวกันอาจต้องการการปรับแต่งเพื่อให้ได้ latency <200ms
- การวัดและการทดสอบ: ให้วัด p50/p95/p99 latency, throughput ที่ batch size = 1 (real‑time), และทดสอบความทนทานภายใต้สภาพแวดล้อมจริง (แสงแปรผัน ฝุ่น สั่นสะเทือน)
แนวทางเชิงปฏิบัติ: เริ่มจากการออกแบบโมเดลตรวจจับที่เบาและทำ quantization/benchmark บนฮาร์ดแวร์เป้าหมาย (เช็ก latency แบบวอร์มขึ้นและสภาวะจริง) จากนั้นสร้าง pipeline ข้อมูล (structured event) ที่เป็นอินพุตให้ TinyLLM และฝึก/ปรับเทรน LLM ด้วยตัวอย่างคำสั่งเชิงบริบทและกฎทางธุรกิจเพื่อให้การตัดสินใจสอดคล้องกับนโยบายการผลิต
สรุปคือ Edge‑Vision ให้การมองเห็นและการตอบสนองเชิงเทคนิคแบบความเร็วสูง ในขณะที่ TinyLLM เติมเต็มบทบาทด้านการสรุปและการตัดสินใจเชิงบริบท ทำให้ระบบ Self‑Optimizing ในโรงงานสามารถตรวจจับข้อบกพร่องและปรับสายการผลิตอัตโนมัติได้อย่างมีประสิทธิภาพและปลอดภัยต่อการปฏิบัติงานจริง
สถาปัตยกรรมระบบและการติดตั้งจริง
สถาปัตยกรรมระบบและการติดตั้งจริง
สถาปัตยกรรมสำหรับระบบ Self‑Optimizing ในโรงงานไทยที่ผสาน Edge‑Vision และ TinyLLM ต้องออกแบบเป็นชั้น ๆ เพื่อรองรับการไหลของข้อมูลแบบเรียลไทม์ การตัดสินใจเชิงควบคุม และการบูรณาการกับ PLC/robotics รวมถึงโซลูชัน MES/SCADA ในภาพรวม ระบบจะประกอบด้วย: กล้องอุตสาหกรรมที่เชื่อมกับ Edge Node (การเร่งด้วย NPU/VPU หรือ MCU ที่รองรับ TinyLLM), ตัวประมวลผล TinyLLM สำหรับการตีความผลตรวจจับเชิงบริบท, และการส่งสัญญาณคำสั่งกลับไปยัง PLC/robot หรือระบบ MES/SCADA เพื่อปรับสายการผลิตแบบอัตโนมัติ

การไหลของข้อมูลระดับสูงสามารถอธิบายเป็นลำดับดังนี้ เพื่อความชัดเจนและนำไปปฏิบัติได้จริง:
- Capture: กล้อง Edge‑Vision ถ่ายภาพหรือวิดีโอความละเอียดที่เหมาะสม พร้อม Pre‑processing (เช่น ROI crop, normalization) บนตัวกล้องหรือ Edge Node
- Edge Node Inference: Edge Node (มี NPU/VPU หรือ MCU ที่เร่ง inference) รันโมดูล Computer Vision ตรวจจับข้อบกพร่องเบื้องต้น และส่ง feature/metadata ไปยัง TinyLLM ที่ทำหน้าที่ตีความเชิงบริบท (เช่น สาเหตุที่เป็นไปได้, ความรุนแรง, ข้อเสนอแนะการแก้ไข)
- Decision & Actuation: เมื่อตัดสินใจเสร็จ TinyLLM ส่งคำสั่งเชิงควบคุมกลับไปยัง PLC/robot ผ่านโปรโตคอลมาตรฐานอุตสาหกรรม (OPC UA, Modbus TCP, EtherCAT) เพื่อปรับพารามิเตอร์สายการผลิตหรือสั่งหยุดฉุกเฉิน
- Coordination กับ MES/SCADA: ข้อมูลสรุป (เหตุการณ์สำคัญ, logs, KPI) ถูกส่งไปยัง MES/SCADA และคลาวด์เพื่อการวิเคราะห์เชิงลึก, บันทึกการผลิต และการเรียนรู้แบบต่อเนื่อง
การตัดสินใจว่าควรทำ inference และ action ที่ใดนั้น มี trade‑offs สำคัญที่ผู้บริหารและสถาปนิกระบบต้องพิจารณา:
- On‑device (ภายในกล้อง/Edge Node): ให้ latency ต่ำสุด เหมาะกับการตัดสินใจวิกฤตที่ต้องตอบสนองภายในไม่กี่สิบมิลลิวินาที (ตัวอย่างเช่น การหยุดสายพานทันทีเมื่อพบข้อบกพร่องอันตราย) ช่วยลดแบนด์วิธและความเสี่ยงด้านความเป็นส่วนตัว เพราะข้อมูลภาพไม่ต้องส่งออก อย่างไรก็ดี ความซับซ้อนของโมเดลจำกัดด้วยทรัพยากรและความจุของฮาร์ดแวร์
- Edge Server (ภายในโรงงาน): เหมาะกับงานที่ต้องรวบรวมข้อมูลจากหลายกล้อง/เครื่องจักรเพื่อการตัดสินใจเชิงบริบทระดับสายการผลิต เช่น ปรับโหลดแบบพลวัต หรือตารางการซ่อมบำรุงเชิงคาดการณ์ (predictive maintenance) มีความสมดุลระหว่างความเร็วและความสามารถในการประมวลผล แต่ยังคงมี latency ต่ำกว่า cloud และสามารถรักษาความเป็นส่วนตัวได้ดี
- Cloud: เหมาะสำหรับการฝึกโมเดลขนาดใหญ่, การเก็บประวัติระยะยาว และการวิเคราะห์เชิงธุรกิจระดับสูง เช่น การวิเคราะห์แนวโน้มการผลิตรายเดือนหรือการทำ retraining ของโมเดล โมเดลใน cloud มักมี latency สูงและต้องพึงพาแบนด์วิธ จึงไม่ควรใช้สำหรับการตัดสินใจเวลาจริงที่มีผลต่อความปลอดภัยหรือการควบคุมทันที
ตัวอย่างเชิงตัวเลขเพื่อประกอบการตัดสินใจ: การรัน inference บน Edge Node ที่เร่งด้วย NPU สามารถลด latency ได้เหลือ 10–50 มิลลิวินาที ในขณะที่การส่งข้อมูลไปประมวลผลบนคลาวด์อาจมี latency อยู่ในระดับหลายร้อยมิลลิวินาทีถึงหลายวินาที และการประมวลผลบน Edge ยังช่วยลดแบนด์วิธการส่งวิดีโอลงกว่า 80–90% ในการใช้งานจริง
ข้อกำหนดฮาร์ดแวร์สำหรับการสเกลระบบ Self‑Optimizing ควรพิจารณาดังนี้:
- NPU/VPU (สถาปัตยกรรมเร่งความเร็ว): ตัวอย่างที่ใช้งานบ่อย ได้แก่ Google Edge TPU, Intel Movidius Myriad, NVIDIA Jetson family (สำหรับการใช้งานที่ต้องการ throughput สูง) เหมาะสำหรับรันทั้ง CV models และ TinyLLM ที่ผ่าน quantization/optimizations
- Edge GPU/SoC: เช่น NVIDIA Jetson Orin, Xavier เหมาะกับกรณีที่ต้องการความสามารถคำนวณสูงและรองรับหลายสตรีมของวิดีโอพร้อมกัน
- MCU ที่รองรับ TinyLLM / TinyML: สำหรับ use‑case ที่โมเดลมีขนาดเล็กมากและต้องการการใช้พลังงานต่ำ สามารถเลือก MCU ที่รองรับ runtimes เช่น TensorFlow Lite Micro หรือ runtime สำหรับ TinyLLM แบบ lightweight
- Network & OT Integration: สวิตช์อุตสาหกรรม, gateway ที่รองรับ OPC UA/Modbus/TCP/IP, และระบบ time‑synchronization (PTP/NTP) เพื่อให้การสั่งงานกับ PLC/robot มีความแม่นยำตามต้องการ
แนวทางการจัดการอัปเดตโมเดล (OTA) ที่แนะนำสำหรับสภาพแวดล้อมอุตสาหกรรม:
- Versioning และ A/B rollout: ปล่อยโมเดลเวอร์ชันใหม่เป็นกลุ่มเล็ก ๆ ตรวจสอบผลกระทบจริงก่อนขยายการใช้งาน เพื่อป้องกันการรบกวนสายการผลิต
- Signed & Encrypted Models: เซ็นแบบดิจิทัลและเข้ารหัสไฟล์โมเดลเพื่อป้องกันการแก้ไข และใช้ช่องทางการสื่อสารที่ปลอดภัย (TLS/DTLS, VPN)
- Delta updates & Compression: ส่งเฉพาะความแตกต่างของโมเดล (delta patch) เพื่อลดแบนด์วิธ และใช้ quantized model เพื่อจำกัดขนาดไฟล์
- Validation & Rollback: ก่อนสลับใช้งาน production ให้รัน validation tests บน Edge Node จริง หากผลไม่เป็นไปตามเกณฑ์ต้องสามารถ rollback อัตโนมัติภายในเวลาอันสั้น
- Monitoring & Drift Detection: เก็บ metrics และ telemetry บน Edge/Cloud เพื่อตรวจจับ data drift หรือ performance degradation และกระตุ้นกระบวนการ retraining
ท้ายที่สุด การออกแบบสถาปัตยกรรมต้องคำนึงถึงความปลอดภัย ความสามารถในการบำรุงรักษา และการคุ้มทุน โดยแนะนำให้เริ่มจากการวาง PoC บน Edge Node ที่เป็นตัวแทนของสายการผลิตจริง เพื่อวัด latency, throughput และความแม่นยำ จากนั้นค่อยขยายสเกลพร้อมมาตรการ OTA, authentication, และการผสานกับ MES/SCADA เพื่อให้ระบบ Self‑Optimizing สามารถทำงานได้อย่างยั่งยืนและสอดคล้องกับเป้าหมายการปฏิรูปดิจิทัลของโรงงานไทย
กรณีศึกษา: โรงงานไทยตัวอย่างและผลลัพธ์เชิงตัวเลข
กรณีศึกษา: โรงงานไทยตัวอย่างและผลลัพธ์เชิงตัวเลข
ตัวอย่างจากโรงงานประกอบอิเล็กทรอนิกส์ขนาดกลางในนิคมอุตสาหกรรมชานกรุงเทพฯ ซึ่งมีสายการผลิต PCB Assembly และบรรจุภัณฑ์ เป็นโรงงานที่ได้รับโจทย์ด้านคุณภาพและความต่อเนื่องการผลิตมากที่สุด เนื่องจากความผิดพลาดเล็ก ๆ น้อย ๆ เช่น ชิ้นส่วนวางผิดตำแหน่ง, สะพานลวดบัดกรี (solder bridge), น็อตหาย หรือการบรรจุไม่ครบ อาจก่อให้เกิดการ rework สูงและเสียเวลาในสายการผลิต ทั้งนี้โรงงานได้ทดลองติดตั้งระบบ Edge‑Vision จำนวน 24 กล้องความละเอียดสูงพร้อมหน่วยประมวลผล Edge ที่รัน TinyLLM สำหรับการวิเคราะห์ภาพเชิงบริบทแบบเรียลไทม์ และเชื่อมต่อกับระบบ MES เพื่อสั่งปรับสปีดสายพานหรือเรียกงานซ่อมอัตโนมัติเมื่อพบความผิดปกติ

ผลลัพธ์เชิงตัวเลขหลังการทดลองใช้งานระยะ 6 เดือนมีดังนี้: อัตราข้อบกพร่องลดลง 40% (จากเฉลี่ย 5.0% เหลือ 3.0% ต่อหน่วยที่ส่งออก), OEE เพิ่มขึ้น 8% (จาก 72.0% เป็น 77.8%), และ เวลาแก้ไขเฉลี่ย (MTTR) ลดจาก 30 นาทีเหลือ 8 นาที สำหรับกรณีที่ระบบตรวจจับแล้วต้องมีการหยุดสายหรือสั่งงานฝ่ายซ่อม ข้อมูลเพิ่มเติมที่บันทึกได้คือ Throughput เพิ่มขึ้นประมาณ 6% เนื่องจากการลดเวลา rework และสอดคล้องกับการลดของเสียที่เกิดขึ้น การแจ้งเตือนที่แม่นยำบน Edge ทำให้จำนวนการหยุดฉุกเฉิน (unplanned stoppages) ลดลง 22% และอัตราการแจ้งเตือนผิดพลาด (false positive) อยู่ที่ประมาณ 4–6% หลังจากปรับจูนโมเดล
คำบอกเล่าจากผู้ใช้งานจริงช่วยยืนยันผลลัพธ์ดังกล่าว—“ก่อนหน้านี้ทีมผลิตมักเสียเวลาเฉลี่ยวันละ 2–3 ชั่วโมงกับงาน rework ที่ตรวจไม่พบตั้งแต่ต้นสาย ระบบ Edge‑Vision ทำให้เรารู้ปัญหาทันทีและ TinyLLM ช่วยตีความบริบทได้ดีขึ้น ทำให้ทีมปฏิบัติการตอบสนองได้เร็วขึ้นอย่างเห็นได้ชัด” — ผู้จัดการฝ่ายผลิต และจากมุมมองฝ่าย IT — “การรัน TinyLLM บน Edge ช่วยลดการส่งภาพขึ้นคลาวด์ ทำให้ latency ต่ำและข้อมูลส่วนตัวของกระบวนการยังอยู่ภายในเครือข่ายโรงงาน การผสานกับ MES ทำได้โดย API แบบ event‑driven ช่วยให้การปรับสายเป็นไปแบบอัตโนมัติ”
บทเรียนสำคัญจากการทดลองครั้งนี้สามารถสรุปได้เป็นข้อ ๆ ดังนี้
- ข้อมูลฝึกสอนคุณภาพสูงสำคัญมาก: การเก็บตัวอย่างความผิดพลาดจริงจากสายการผลิตไทยและการติดป้ายกำกับ (labeling) อย่างละเอียดลด false positive ได้อย่างชัดเจน
- ตั้งเกณฑ์การตอบสนองแบบหลายระดับ: แยกระดับการแจ้งเตือนเป็น (1) แจ้งผู้ปฏิบัติงาน, (2) หยุดชั่วคราวสายบางส่วน, (3) หยุดสายทั้งเส้น เพื่อหลีกเลี่ยงการหยุดเกินความจำเป็น แต่ยังคงรักษาคุณภาพ
- การบูรณาการกับระบบเดิม: การเชื่อมต่อกับ MES/ERP ต้องวางแผน API และ security ให้รัดกุม การทำงานแบบ event‑driven ช่วยให้ระบบ Self‑Optimizing ทำงานได้จริง
- วัดผลอย่างเป็นระบบ: แนะนำให้ติดตาม KPI หลัก ได้แก่ defect rate, OEE, MTTR, detection latency, false positive rate และผลกระทบด้าน throughput/ปริมาณผลิต
- วงจรปรับปรุงต่อเนื่อง: ตั้งกระบวนการ retraining แบบเป็นรอบ (เช่น ทุกเดือนหรือเมื่อตรวจพบ drift) และมี human‑in‑the‑loop สำหรับเคสใหม่ๆ
ข้อเสนอแนะสำหรับโรงงานที่ต้องการวัดผลและขยายระบบให้ได้ผลเชิงธุรกิจคือ:
- เริ่มด้วยโครงการนำร่องที่ครอบคลุมสายการผลิตจุดที่มีความสูญเสียสูงที่สุด เพื่อให้เห็น ROI ชัดเจน (เป้าหมาย payback ภายใน 6–12 เดือนเป็นไปได้สำหรับหลายกรณี)
- กำหนด KPI ก่อนติดตั้งและติดตามผลแบบรายสัปดาห์และรายเดือน เพื่อเปรียบเทียบสภาวะก่อน/หลังอย่างเป็นระบบ
- รวมทีมข้ามสายงาน (ผลิต, วิศวกรรมคุณภาพ, IT/OT) ตั้งแต่ขั้นออกแบบเพื่อให้การบูรณาการและการตอบสนองมีประสิทธิผล
- บันทึกเคสตัวอย่างและวิดีโอประกอบเหตุการณ์เพื่อใช้เป็นข้อมูลฝึกสอนและตรวจสอบประสิทธิภาพของ TinyLLM ในกรณีเฉพาะหน้า
สรุปได้ว่า การผสาน Edge‑Vision กับ TinyLLM ในโรงงานตัวอย่างของไทยช่วยลดข้อบกพร่องและเวลาแก้ไขอย่างมีนัยสำคัญ พร้อมทั้งยกระดับ OEE ในระดับที่เห็นผลเชิงธุรกิจ การลงทุนในข้อมูลคุณภาพ การตั้ง KPI ที่ชัดเจน และการบูรณาการระบบเป็นปัจจัยสำคัญที่จะทำให้โครงการ Self‑Optimizing ประสบความสำเร็จและยั่งยืน
การบูรณาการกับระบบเดิมและแนวทางการปฏิบัติ
อินเทอร์เฟซและโปรโตคอลยอดนิยมสำหรับการเชื่อมต่อกับระบบโรงงาน
การบูรณาการ Edge‑Vision และ TinyLLM เข้ากับระบบเดิมต้องอาศัยอินเทอร์เฟซและโปรโตคอลมาตรฐานเพื่อให้การสื่อสารมีความเสถียร ปลอดภัย และตรวจสอบได้ โดยระบบหลักที่ต้องพิจารณาคือ MES, ERP, SCADA และ PLC ซึ่งมักรองรับโปรโตคอลและวิธีเชื่อมต่อดังต่อไปนี้:
- OPC‑UA — โปรโตคอลอุตสาหกรรมสำหรับข้อมูลเรียลไทม์และประวัติการทำงาน เหมาะสำหรับผสานข้อมูลจาก PLC, SCADA และ Historian ด้วยความปลอดภัย (TLS) และโมเดลข้อมูลเชิงลำดับชั้น
- MQTT — น้ำหนักเบา เหมาะสำหรับการส่ง Telemetry จากอุปกรณ์ Edge ไปยังคลาวด์หรือตัวกลาง (broker) ใช้สำหรับสถานะเหตุการณ์/แจ้งเตือนแบบกะทันหัน
- RESTful / GraphQL APIs — สำหรับเชื่อมต่อกับ MES/ERP เพื่ออ่าน/เขียนคำสั่งการผลิต ข้อมูลล็อต (batch) และสถานะคำสั่งงาน (work order)
- Modbus / Profinet / EtherNet/IP — โปรโตคอลเชื่อมต่อ PLC ระดับสายการผลิตสำหรับการสั่งหยุด/เริ่มอุปกรณ์โดยตรง เมื่อจำเป็นต้องให้การดำเนินการตอบสนองเชิงกายภาพ (actuation)
- WebSocket / gRPC — ใช้ในกรณีต้องการช่องทางสื่อสารแบบ low‑latency ระหว่าง Edge node กับบริการการตัดสินใจ (TinyLLM) เพื่อให้การตอบกลับมีความรวดเร็ว
นอกจากนี้ ควรกำหนดมาตรฐานด้านความปลอดภัย เช่น mutual TLS, RBAC, network segmentation และการตรวจสอบ (audit logging) ของคำสั่งการสั่งหยุด (stop command) เพื่อป้องกันการสั่งงานที่ไม่พึงประสงค์หรือการโจมตีจากภายนอก
Workflow ตัวอย่าง: จากการตรวจจับ → ตัดสินใจ → ดำเนินการ
ตัวอย่าง workflow อัตโนมัติในโรงงานที่ผสาน Edge‑Vision กับ TinyLLM สามารถสรุปเป็นลำดับขั้นตอนดังนี้ โดยกำหนดเป้าหมาย latency และกฎการยอมรับ (acceptance criteria) ชัดเจนเพื่อป้องกัน false positive:
- 1) ตรวจจับ (Edge‑Vision) — กล้องและโมดูลประมวลผลที่ขอบเครือข่าย (Edge) ตรวจจับข้อบกพร่องบนชิ้นงานในเวลา ≤ 120 ms ต่อภาพ พร้อมส่งเมตาดาต้า (ตำแหน่ง, confidence score, image snippet, timestamp, lot ID จาก MES) ผ่าน MQTT/OPC‑UA ไปยัง decision service
- 2) ประเมินเบื้องต้น (Edge Rules) — กฎระดับ Edge (thresholds, rate limiting) กรองเหตุการณ์ที่มี confidence ต่ำกว่า 0.7 หรือลักษณะที่ไม่เข้าข่าย เช่น เงา/ส่องไฟผิดพลาด เพื่อจำกัดจำนวน false alarm
- 3) ตัดสินใจเชิงบริบท (TinyLLM) — TinyLLM ประมวลผลข้อมูลภาพ เมตาดาต้า และข้อมูลบริบทจาก MES/SCADA (อุณหภูมิ, ความเร็วสาย, recipe/lot) โดยมีเวลาตอบกลับเป้าหมาย 200–500 ms เพื่อสรุปแผนปฏิบัติการ เช่น หยุดสายทันที (emergency stop), ลดความเร็วสาย, หรือส่งให้ผู้ควบคุมตรวจสอบแบบ human‑in‑the‑loop
- 4) ดำเนินการ (PLC/SCADA) — เมื่อ TinyLLM ตัดสินใจให้หยุดสาย จะส่งคำสั่งผ่าน OPC‑UA/Modbus หรือ REST API ไปยัง SCADA/PLC พร้อมเหตุผลและระดับความมั่นใจ; PLC ปฏิบัติการ (เช่น หยุดสาย) ภายใน 100–300 ms ขึ้นอยู่กับสถาปัตยกรรมเครือข่าย
- 5) แจ้งเตือนและบันทึก — ระบบส่งการแจ้งเตือนแบบหลายช่องทาง (HMI, SMS/Line/Teams, Email) พร้อมข้อความสรุปและลิงก์ไปยังภาพและเหตุผลจาก TinyLLM; ข้อมูลทั้งหมดถูกบันทึกลงใน MES/TSDB เพื่อการวิเคราะห์ย้อนหลัง
ตัวอย่างเชิงตัวเลข: หากโรงงานตั้งค่า threshold ให้ TinyLLM ตัดสินใจหยุดสายเมื่อ confidence ≥ 0.9 และมี defect rate เพิ่มขึ้น > 3σ จาก baseline ภายใน 5 นาที ระบบจะสั่งหยุดทันทีและสร้าง work order บน MES เพื่อรอการตรวจสอบจากผู้ควบคุม
การทำ Root Cause Analysis (RCA) โดย TinyLLM และการส่งแจ้งเตือนไปยังผู้ควบคุม
TinyLLM สามารถทำ RCA แบบกึ่งอัตโนมัติ โดยผสานข้อมูลหลายแหล่งเพื่อสร้างสมมติฐานต้นเหตุและแนะนำมาตรการแก้ไขได้ในรูปแบบที่เข้าใจง่ายสำหรับผู้ปฏิบัติงาน:
- Input ที่ใช้: ภาพจาก Edge‑Vision, ค่า Telemetry จาก SCADA/PLC (อุณหภูมิ, แรงดัน, ความเร็ว), ข้อมูลล็อตและสูตรการผลิตจาก MES, การเปลี่ยนแปลงวัสดุหรือคำสั่งซื้อจาก ERP, และ log ของการบำรุงรักษาจาก CMMS
- กระบวนการ: TinyLLM ประมวลผลข้อมูลข้ามโดเมน (multi‑modal) เพื่อเรียงลำดับสาเหตุที่เป็นไปได้ เช่น การปรับค่าพารามิเตอร์ผิด, วัสดุมีคุณภาพต่ำ, หรือชิ้นส่วนชำรุดใน PLC และให้ความน่าจะเป็นเชิงสถิติแก่แต่ละสาเหตุ
- Output: รายงานสั้นที่ประกอบด้วยสาเหตุที่เป็นไปได้ 3 อันดับแรก, คำแนะนำเชิงปฏิบัติการ (เช่น ตรวจ sensor A, เปลี่ยนหัวฉีด, ปรับ recipe), ลิงก์ไปยังเหตุการณ์ที่เกี่ยวข้อง และคำยืนยันความเชื่อมั่นของโมเดล
เมื่อ TinyLLM สรุป RCA ระบบจะส่งแจ้งเตือนตามลำดับขั้นดังนี้: (1) แจ้งเตือนฉุกเฉินไปยัง HMI/SCADA และมือถือของผู้ควบคุม, (2) สร้างงานตรวจสอบบน MES พร้อมรายการตรวจเช็คที่แนะนำ, (3) บันทึกเหตุการณ์และคำตัดสินใน Audit Trail เพื่อให้ทีม QA/Engineering ตรวจสอบภายหลัง
แนวทางการจัดการ Change Management, ฝึกอบรมพนักงาน และการทดสอบแบบ A/B
การนำระบบ Self‑Optimizing เข้าสู่การใช้งานจริงต้องมีแผนการบริหารการเปลี่ยนแปลง (Change Management) ที่ชัดเจน ประกอบด้วยขั้นตอนดังนี้:
- Stakeholder alignment — ระบุผู้มีส่วนได้เสีย (production, QA, maintenance, IT, safety) และกำหนด KPI ก่อน-หลัง เช่น defect rate, throughput, MTTR, false positive rate
- Pilot และ Phased rollout — เริ่มจากสายการผลิตตัวอย่าง (pilot line) นาน 4–8 สัปดาห์ เพื่อเก็บข้อมูลและปรับจูนก่อนขยายสู่ทั้งโรงงาน
- Training & competency — จัดหลักสูตรผสมผสาน (e‑learning, workshop, on‑the‑job training) โดยเน้นการอ่านผลจาก TinyLLM, การใช้ HMI ใหม่, ขั้นตอนการยกเลิก automated action (rollback) และการบำรุงรักษา Edge devices; กำหนด KPI ความชำนาญ เช่น ผ่านทดสอบปฏิบัติจริง ≥ 90%
- Governance & SOP — สร้างมาตรฐานปฏิบัติ (SOP) และนโยบายความปลอดภัย รวมทั้งแผนสำรองเมื่อระบบอัตโนมัติล้มเหลว เช่น โหมด manual override และขั้นตอนการตรวจสอบหลังเกิดการหยุด
การทดสอบแบบ A/B เพื่อยืนยันประสิทธิภาพต้องออกแบบอย่างมีหลักการ: แบ่งสายการผลิตหรือช่วงเวลาเป็นกลุ่มควบคุม (A) ที่ใช้งานแบบเดิม และกลุ่มทดลอง (B) ที่ใช้ Edge‑Vision + TinyLLM ประเมินผลตาม KPI ที่กำหนด (ตัวอย่าง: ลด defect 10% ที่ระดับความเชื่อมั่น 95% CI) โดยควรใช้การคำนวณขนาดตัวอย่าง (sample size/power analysis) เพื่อให้ผลทดสอบมีนัยสำคัญทางสถิติ ตัวอย่างแนวปฏิบัติคือทดสอบอย่างน้อย 30–100 รอบต่อกลุ่มในกรณีเหตุการณ์หายาก และ 1,000+ รอบสำหรับเมตริก throughput ที่มีความผันผวนต่ำ
สุดท้าย การปรับจูนระบบควรทำแบบวงจร (closed‑loop): เก็บ feedback จากผู้ปฏิบัติงานและบันทึกผลการดำเนินการเพื่อนำมาปรับ threshold, calibration ของโมเดล และ policy ของ TinyLLM อย่างต่อเนื่อง โดยจัดกระบวนการ MLOps/DevOps ที่รวมการทดสอบ regression, Canary rollout และ rollback plan เพื่อให้การเปลี่ยนแปลงในโรงงานเป็นไปอย่างมั่นคง ปลอดภัย และวัดผลได้
ความท้าทายด้านเทคนิค กฎหมาย และความปลอดภัย
ความท้าทายด้านเทคนิค กฎหมาย และความปลอดภัย
การนำระบบ Edge‑Vision ร่วมกับ TinyLLM มาใช้เพื่อให้โรงงานไทยก้าวสู่การปรับสายการผลิตแบบ self‑optimizing นำมาซึ่งผลประโยชน์เชิงประสิทธิภาพและตอบสนองได้แบบเรียลไทม์ แต่ในทางปฏิบัติองค์กรต้องเผชิญกับความเสี่ยงทางเทคนิคและเชิงนโยบายที่ซับซ้อน ตั้งแต่ความไม่แน่นอนของข้อมูล (data drift) การจำกัดทรัพยากรบนอุปกรณ์ขอบเครือข่าย ไปจนถึงการคุกคามเชิงไซเบอร์และข้อกำหนดด้านกฎหมายแรงงานในประเทศไทย หากละเลยประเด็นเหล่านี้ อาจส่งผลให้ความแม่นยำของการตรวจจับตกชันในเวลาไม่นานและก่อให้เกิดความเสียหายทั้งทางการผลิตและความเชื่อมั่นของลูกค้า
ปัญหา data drift และการตรวจสอบประสิทธิภาพอย่างต่อเนื่อง — ระบบตรวจจับข้อบกพร่องที่ฝึกบนชุดข้อมูลเดิมอาจสูญเสียความแม่นยำเมื่อสภาวะการผลิตเปลี่ยน เช่น วัตถุดิบ สีแสง กล้องที่สึกหรอ หรือการอัปเดตสายการผลิต งานวิจัยอุตสาหกรรมชี้ว่าโมเดลวิชันสามารถลดความแม่นยำได้ระหว่าง 10–40% ภายใน 6–12 เดือน หากไม่มีการตรวจจับและปรับปรุงอย่างเป็นระบบ เพื่อลดความเสี่ยงควรติดตั้งระบบการตรวจสอบแบบเรียลไทม์ที่รายงานเมตริกสำคัญ (accuracy, false positive/negative, calibration) และใช้กลไกดังต่อไปนี้:
- การใช้งาน shadow mode และ canary deployment เพื่อตรวจสอบผลการทำงานของโมเดลใหม่ในสภาพแวดล้อมจริงก่อนออกใช้งานเต็มรูปแบบ
- ระบบแจ้งเตือนการเกิด data drift ด้วยสถิติและเทคนิคการตรวจจับ drift (เช่น population stability index, KS test, concept drift detectors)
- กำหนดนโยบายรีเทรนนิงและวงจรการตรวจสอบ (retraining cadence) ที่ชัดเจน พร้อมเก็บตัวอย่างข้อมูลที่มีป้ายกำกับเพื่อใช้ประเมิน
- บันทึก (logging) และการตรวจสอบแบบต่อเนื่องเพื่อทำ root cause analysis เมื่อประสิทธิภาพลดลง
ความเสี่ยงด้านไซเบอร์และแนวทาง hardening — การปรับใช้โมเดลบน edge เพิ่มพื้นผิวการโจมตี: model poisoning, การโจมตีแบบ adversarial, การรั่วไหลของข้อมูล (data leakage) และการเข้าถึงโมเดลโดยไม่ได้รับอนุญาต ปัญหาเหล่านี้ไม่เพียงทำลายความถูกต้องของระบบ แต่ยังส่งผลต่อความปลอดภัยของสายการผลิตและทรัพย์สินทางปัญญา แนวทางสำคัญในการ hardening ได้แก่:
- ใช้ secure boot และการตรวจสอบลายเซ็นของเฟิร์มแวร์/โมเดล (signed models) เพื่อป้องกันการรันโค้ดหรือโมเดลที่ถูกดัดแปลง
- ใช้องค์ประกอบความปลอดภัยบนฮาร์ดแวร์ เช่น TPM หรือ Hardware Security Module (HSM) สำหรับจัดการคีย์และการพิสูจน์ตัวเครื่อง (attestation)
- เข้ารหัสข้อมูลทั้งที่เก็บและที่ส่ง (TLS, mTLS) และใช้การแยกสิทธิ (RBAC) กับการตรวจสอบตัวตนแบบหลายปัจจัย (MFA)
- นำแนวทาง MLOps มาประยุกต์ใช้ เช่น การเซ็น model artifacts, immutable logging, และ pipeline ที่มีการตรวจสอบความสมบูรณ์ของข้อมูล/โมเดลก่อน deployment
ประเด็นกฎหมายและผลกระทบต่อแรงงานในบริบทไทย — ทางด้านกฎหมาย การเก็บและประมวลผลข้อมูลภาพและเมตาดาต้าในโรงงานอาจตกอยู่ภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) โดยเฉพาะหากข้อมูลระบุตัวพนักงานหรือเชื่อมโยงกับข้อมูลบุคคลอื่นๆ โรงงานจึงต้องพิจารณาเรื่องการเก็บความยินยอม การกำหนดวัตถุประสงค์ การจำกัดระยะเวลาเก็บข้อมูล และการถ่ายโอนข้อมูลข้ามพรมแดน นอกจากนี้การนำระบบอัตโนมัติมาใช้อาจส่งผลต่อการจ้างงานและบทบาทของแรงงาน เช่น การลดตำแหน่งงานบางประเภทและการต้องการทักษะใหม่ๆ เพื่อควบคุมและดูแลระบบ
- ปฏิบัติตาม PDPA: ประเมินผลกระทบด้านข้อมูล (DPIA), จัดทำข้อมูลการประมวลผล, และให้สิทธิตามกฎหมายแก่บุคคลที่เกี่ยวข้อง
- วางแผนการเปลี่ยนผ่านแรงงาน: นโยบาย reskilling/upskilling, การมีส่วนร่วมของตัวแทนแรงงานหรือสหภาพ, และการออกแบบงานให้มีการควบคุมร่วมระหว่างมนุษย์กับเครื่องจักร (human‑in‑the‑loop)
- จัดทำกรอบการกำกับดูแลภายใน (AI governance) ที่รวมข้อกำหนดทางกฎหมายและหลักจริยธรรม เช่น การจัดทำ model cards, audit trail, และนโยบายความรับผิดชอบเมื่อเกิดความผิดพลาด
สรุปแล้ว การนำ Edge‑Vision และ TinyLLM มาใช้ในโรงงานไทยต้องมีการวางโครงสร้างบริหารความเสี่ยงที่ผสมผสานทั้งด้านเทคนิค การรักษาความปลอดภัย และการปฏิบัติตามกฎหมาย ควรออกแบบแผนการตรวจสอบประสิทธิภาพแบบต่อเนื่อง ใช้เทคนิคเช่น federated learning หรือ differential privacy เมื่อจำเป็นเพื่อคุ้มครองข้อมูล ส่วนการ hardening ฮาร์ดแวร์และซอฟต์แวร์ รวมถึงการเตรียมมาตรการรองรับผลกระทบต่อแรงงาน จะช่วยให้การเปลี่ยนผ่านสู่ระบบ self‑optimizing เป็นไปอย่างยั่งยืนและมีความเสี่ยงต่ำสุด
ผลกระทบเชิงธุรกิจและแนวทางการวางแผน ROI
ผลกระทบเชิงธุรกิจและสรุป ROI ของการนำ Edge‑Vision + TinyLLM มาใช้
การผสานระบบ Edge‑Vision กับโมเดลขนาดเล็ก (TinyLLM) ในสายการผลิตทำให้เกิดการตรวจจับข้อบกพร่องแบบเรียลไทม์และการปรับพารามิเตอร์สายการผลิตอัตโนมัติ ซึ่งมีผลกระทบเชิงธุรกิจทั้งด้านต้นทุน คุณภาพ และความต่อเนื่องในการผลิต โดยเฉพาะในแง่ของการลดของเสีย (scrap), ลดงาน rework, เพิ่มอัตราผลิตได้ (throughput) และลดเวลาหยุดการผลิต (downtime) ที่เกิดจากการตรวจสอบด้วยคนหรือการปฏิบัติการเชิงปฏิกิริยา ระบบแบบนี้ยังช่วยให้การตัดสินใจเชิงปฏิบัติการเป็นไปได้อย่างต่อเนื่องด้วยข้อมูล (closed‑loop control) ทำให้ประสิทธิภาพของสายการผลิตปรับปรุงเป็นแบบไดนามิกตามสภาวะจริง
ตัวอย่างการคำนวณ ROI — สมมติฐานและการคำนวณแบบง่าย
ตัวอย่างสมมติสำหรับสายการผลิตหนึ่งสาย (ตัวเลขสำหรับอธิบายและสามารถปรับได้ตามสภาพจริงของโรงงาน):
- สมมติฐานพื้นฐาน
- กำลังการผลิต: 5,000,000 หน่วยต่อปี
- มาร์จิ้นต่อหน่วย (contribution margin): ฿200/หน่วย
- อัตราข้อบกพร่องปัจจุบัน: 500 DPM (defects per million)
- อัตราข้อบกพร่องหลังติดตั้ง: 100 DPM
- ต้นทุนลงทุน (CAPEX) — หนึ่งสาย
- ฮาร์ดแวร์ Edge‑Cameras + Edge Compute (NPU/TPU) + กล่องกันฝุ่น: ฿450,000
- ซอฟต์แวร์ TinyLLM (ไลเซนส์เริ่มต้น + โมเดลปรับแต่ง): ฿250,000
- การติดตั้ง อินทิเกรชันกับ PLC/MES และการทดสอบ: ฿200,000
- ค่าอบรมและการยืนยันคุณภาพ (validation): ฿100,000
- รวม CAPEX เบื้องต้น = ฿1,000,000
- ค่าใช้จ่ายประจำปี (OPEX)
- การบำรุงรักษา ซอฟต์แวร์แพตช์ และไลเซนส์ต่อเนื่อง: ฿120,000/ปี
- ค่าไฟและเครือข่ายของอุปกรณ์ Edge: ฿30,000/ปี
- การสนับสนุนและปรับจูนโมเดล: ฿50,000/ปี
- รวม OPEX = ฿200,000/ปี
- ประโยชน์ทางการเงิน (ตัวอย่างการประเมิน)
- การลดข้อบกพร่อง: จาก 500 DPM → 100 DPM = ลด 400 DPM = 400 × 5 = 2,000 หน่วย/ปี (กับ 5M หน่วย) → ประหยัดจาก scrap = 2,000 × ฿200 = ฿400,000/ปี
- การลดงาน rework และค่าแรงตรวจสอบ (อัตโนมัติ): ประมาณ ฿300,000/ปี
- การเพิ่ม throughput / ลด downtime (เช่นลด downtime 8% ของเวลาทำงาน): ประมาณเพิ่มผลผลิตเชิงมูลค่า ฿600,000/ปี
- รวมผลประโยชน์ก่อนหัก OPEX ≈ ฿1,300,000/ปี
การคำนวณแบบง่าย — Net Annual Benefit = ประโยชน์รวม − OPEX = ฿1,300,000 − ฿200,000 = ฿1,100,000/ปี
Payback (คืนทุน) = CAPEX / Net Annual Benefit = ฿1,000,000 / ฿1,100,000 ≈ 0.9 ปี (≈ 11 เดือน)
เพื่อความเป็นจริง ควรพิจารณาสถานการณ์สามแบบ:
- Conservative: ประโยชน์จริงเพียง 60% ของคาดการณ์ → Payback ≈ 1.6–2.0 ปี
- Realistic: ประโยชน์ 100% → Payback ≈ 9–12 เดือน
- Aggressive: ได้ประโยชน์ขยาย (รวมการผสานสายอื่น/ห่วงโซ่อุปทาน) → Payback < 8 เดือน และ IRR สูงขึ้น
KPI ที่ควรติดตามเพื่อพิสูจน์ความคุ้มค่า
- Cost per unit (ต้นทุนต่อหน่วย) — ติดตามค่าใช้จ่ายรวม (รวม scrap & rework) ต่อหน่วยก่อนและหลังติดตั้ง (วัดรายเดือน)
- Defects per Million (DPM) — ตัวชี้วัดคุณภาพที่ชัดเจน ถ้าลดจาก 500 → 100 DPM คือความสำเร็จเชิงคุณภาพ (วัดรายสัปดาห์/เดือน)
- Yield (%) — อัตราส่วนหน่วยที่ผ่านการตรวจสอบโดยไม่ต้อง rework (วัดแบบต่อเนื่อง)
- Throughput (units/hour) และ Production Volume (units/day, month, year)
- Uptime / Availability (%) และ OEE (Overall Equipment Effectiveness) — ตรวจสอบผลกระทบของการลด downtime
- Mean Time To Detect (MTTD) และ Mean Time To Repair (MTTR) — ชี้วัดการตอบสนองอัตโนมัติหลังพบปัญหา
- Inference Latency และ Model Accuracy (Precision / Recall) — ด้านเทคนิคที่มีผลต่อ false positives/negatives ซึ่งส่งผลต่อ cost per unit
- False Reject Rate / False Accept Rate — สำคัญในกรณีที่ระบบปฏิเสธสินค้าที่ดีหรือรับสินค้าที่เสีย
- Operational KPIs เช่น เวลาในการยอมรับผลการปรับพารามิเตอร์อัตโนมัติ (cycle-to-act) และจำนวนการปรับปรุงต่อเดือน
แนะนำให้ตั้งเป้าหมาย KPI แบบ SMART (Specific, Measurable, Achievable, Relevant, Time‑bound) และวัดผลในช่วง baseline 3 เดือนก่อนระบบใช้งานจริง เพื่อใช้เป็นเกณฑ์เปรียบเทียบ
แนวทางการสเกลจาก Pilot ไปสู่การขยายผลระดับโรงงานและห่วงโซ่อุปทาน
การสเกลระบบ Edge‑Vision + TinyLLM ควรเป็นกระบวนการมีขั้นตอนชัดเจน ไม่ใช่การติดตั้งพร้อมกันทั้งไซต์ เพื่อให้มั่นใจว่าผลที่วัดได้เป็นไปตามเป้าหมายและลดความเสี่ยงการลงทุนซ้ำซ้อน ขั้นตอนแนะนำมีดังนี้:
- 1) ระบุขอบเขต pilot และเป้าหมายเชิงธุรกิจ — เลือกสายที่มีปัญหาชัดเจน (เช่นอัตรา defect สูงหรือต้นทุน rework สูง) ตั้ง KPI สำคัญและเป้าหมายการลด DPM / ลด downtime ภายใน 3–6 เดือน
- 2) ทำ baseline data collection — รวบรวมข้อมูลเดิม (DPM, throughput, downtime, cost per unit) อย่างน้อย 3 เดือนก่อนเริ่ม เพื่อใช้ประเมินผล
- 3) พัฒนาและปรับโมเดลบน edge — ฝึกและทดสอบ TinyLLM กับชุดข้อมูลจริงของโรงงาน ปรับ threshold เพื่อลด false positive/negative และยืนยัน latency ตอบสนองสำหรับการควบคุมแบบเรียลไทม์
- 4) การวัดผลเชิงทดลอง (A/B testing) — เปิดใช้งานระบบแบบขนานในช่วงเวลาหนึ่ง เทียบกับกระบวนการเดิม เพื่อยืนยันประโยชน์ก่อนขยายต่อ
- 5) ทำ playbook สำหรับการขยายผล — สร้างไฟล์มาตรฐาน (deployment package) ประกอบด้วย configuration, model weights, integration scripts กับ PLC/MES, คู่มือการติดตั้ง, และแนวทางการทดสอบ
- 6) จัดการการเปลี่ยนแปลง (Change Management) — ฝึกอบรมพนักงานสายผลิต, เจ้าหน้าที่ QC และฝ่ายบำรุงรักษา รวมทั้งกำหนด owner สำหรับ model lifecycle และการรับผิดชอบ KPI
- 7) Governance และ cybersecurity — ตั้งกระบวนการควบคุมเวอร์ชันโมเดล, การ監査 log, และมาตรการป้องกันข้อมูล โดยเฉพาะเมื่อขยายไปยังหลายไซต์หรือเชื่อมต่อกับระบบ ERP/MES
- 8) ขยายแบบเป็นขั้นบันได (Phased Rollout) — ขยายไปทีละสาย → ทีละโซน → ทั้งโรงงาน → ข้ามโรงงานในเครือ โดยใช้เวลาแต่ละขั้น 2–6 เดือน ขึ้นกับความซับซ้อน
- 9) ขยายสู่ห่วงโซ่อุปทาน — เมื่อได้ผลในโรงงาน ให้พิจารณาขยายไปยังซัพพลายเออร์ที่มีส่วนสำคัญต่อคุณภาพ (Tier‑1) เพื่อยกระดับคุณภาพรวมทั้งระบบและลด Cost of Poor Quality ในห่วงโซ่
การติดตาม KPI อย่างสม่ำเสมอและการทำ post‑implementation review จะช่วยให้มองเห็นโอกาสปรับปรุงเพิ่มเติม เช่น การผสาน predictive maintenance, การรวมข้อมูลคุณภาพเข้า ERP เพื่อคำนวณ cost‑to‑serve แบบเรียลไทม์ และการนำผลที่ได้ไปต่อยอดสู่โครงการ Lean/Industry 4.0 อื่น ๆ
สรุป: ด้วยการตั้งสมมติฐานที่ชัดเจนและการออกแบบ pilot ที่เหมาะสม โรงงานไทยสามารถคาดหวัง การคืนทุนในช่วง 12–24 เดือน ภายใต้กรอบ realistic ถึง conservative โดยการติดตาม KPI ที่ถูกต้องและการสเกลอย่างเป็นระบบจะเป็นตัวกำหนดความสำเร็จทั้งทางเทคนิคและเชิงธุรกิจ
บทสรุป

การผสานของ Edge‑Vision กับ TinyLLM ช่วยให้โรงงานไทยก้าวสู่รูปแบบการผลิตแบบ Self‑Optimizing โดยสามารถตรวจจับข้อบกพร่องแบบ เรียลไทม์ และสั่งปรับสายการผลิตอัตโนมัติ ส่งผลให้ลดของเสีย เพิ่มอัตราการผ่านมาตรฐาน และเพิ่มความคล่องตัวของการผลิต ตัวอย่างจากงานวิจัยอุตสาหกรรมและกรณีศึกษาพบว่าการนำระบบตรวจจับบน Edge ร่วมกับโมเดลขนาดเล็ก (TinyLLM) สามารถลดของเสียได้ในช่วงประมาณ 10–40% และลดเวลาหยุดสายการผลิตได้ราว 10–30% ขึ้นกับการออกแบบและสภาพการผลิตจริง ซึ่งสะท้อนถึงศักยภาพในการเพิ่มประสิทธิภาพและลดต้นทุนต่อหน่วยได้อย่างมีนัยสำคัญ
การนำไปใช้ในภาพรวมจำเป็นต้องคำนึงถึงหลายมิติเพื่อให้เกิดผลลัพธ์เชิงธุรกิจที่ชัดเจน ได้แก่ การออกแบบสถาปัตยกรรม (Edge ↔ Fog ↔ Cloud) ที่เหมาะสม การเลือกฮาร์ดแวร์ Edge ที่รองรับประมวลผลภาพและโมเดล TinyLLM แบบ latency ต่ำ การบริหารจัดการด้านความปลอดภัยของข้อมูลและโมเดล รวมถึงการบูรณาการกับระบบเดิม (MES, ERP, PLC) อย่างไร้รอยต่อ นอกจากนี้ต้องมีกลยุทธ์วัดผลเชิงธุรกิจ (KPIs เช่น อัตราข้อบกพร่อง, OEE, MTTR, ค่าใช้จ่ายต่อหน่วย) เพื่อประเมิน ROI และปรับนโยบายการลงทุนให้เกิดผลตอบแทนที่ชัดเจน
มุมมองอนาคตชี้ว่าโรงงานไทยที่นำแนวทางนี้ไปปรับใช้จะขยายขอบเขตจากการตรวจจับข้อบกพร่องไปสู่การบำรุงรักษาเชิงคาดการณ์ (predictive maintenance), การปรับพารามิเตอร์แบบอัตโนมัติด้วย feedback loop, และการเรียนรู้ร่วมแบบ federated learning ระหว่างไซต์การผลิต ทั้งยังต้องลงทุนในทักษะบุคลากร การกำกับดูแลมาตรฐาน และกรอบข้อบังคับเพื่อรองรับการใช้งานในวงกว้าง เมื่อออกแบบสถาปัตยกรรมและแผนวัดผลอย่างรัดกุม ระบบดังกล่าวจะกลายเป็นหัวใจของการผลิตที่ยืดหยุ่น มีประสิทธิภาพ และแข่งขันได้ในเวทีโลก



