เมื่อขอบเขตการสร้างคอนเทนต์ด้วยปัญญาประดิษฐ์ (AI) ขยายตัวอย่างรวดเร็ว ปัญหา deepfake และข่าวปลอมที่ทำให้เกิดความสับสนทางข้อมูลกลายเป็นความท้าทายด้านความมั่นคงข้อมูลและความน่าเชื่อถือของสื่อ หน่วยงานไทยจึงเริ่มทดสอบการผสานเทคโนโลยี Model‑Watermarking—การฝังลายน้ำเชิงข้อมูลในระดับโมเดล AI—เข้ากับระบบบัญชีแหล่งที่มาบนเครือข่ายคริปโต เพื่อสร้างกลไกติดตามและพิสูจน์ว่าคอนเทนต์ใดถูกสร้างหรือปรับแต่งโดยเครื่องจักร เป้าหมายคือการลดการแพร่กระจายของสื่อปลอม เพิ่มความโปร่งใสของแหล่งที่มาของข้อมูล และเสริมความมั่นใจให้แก่ประชาชนและสื่อมวลชน
บทความนี้สรุปภาพรวมการทดสอบของหน่วยงานไทยที่ผสานสองแนวทางดังกล่าว พร้อมนำเสนอผลการทดลองเบื้องต้น ตัวอย่างการใช้งานเชิงปฏิบัติ แนวทางการประเมินความแม่นยำและความทนทานต่อการลบลายน้ำ รวมถึงข้อพิจารณาด้านนโยบาย ความเป็นส่วนตัว และกฎหมายที่เกี่ยวข้อง ผู้อ่านจะได้รับข้อมูลเชิงวิเคราะห์ว่ากลยุทธ์ทางเทคนิคและกรอบกฎระเบียบแบบใดที่อาจช่วยสกัดกั้น deepfake และข่าวปลอมได้อย่างมีประสิทธิภาพในบริบทของประเทศไทย
1. บทนำข่าวและเหตุผลของการทดสอบ
บทนำข่าวและเหตุผลของการทดสอบ
หน่วยงานของประเทศไทยได้เริ่มโครงการนำร่องเพื่อตรวจสอบและประเมินการใช้งานเทคโนโลยี Model‑Watermarking ควบคู่กับระบบบัญชีแหล่งที่มาแบบใช้โครงสร้างคริปโต (cryptographic provenance ledger) เพื่อเพิ่มความโปร่งใสในการระบุว่าเนื้อหาใดถูกสร้างหรือปรับแต่งด้วยปัญญาประดิษฐ์ (AI) โครงการนี้เป็นความร่วมมือระหว่าง กระทรวงดิจิทัลเพื่อเศรษฐกิจและสังคม, หน่วยงานวิจัยของมหาวิทยาลัยชั้นนำในประเทศ, ศูนย์ไซเบอร์แห่งชาติ และพันธมิตรภาคเอกชน ได้แก่ ผู้ให้บริการคลาวด์และสตาร์ทอัพด้าน AI รายสำคัญ โดยมีเป้าหมายทดลองในสภาพแวดล้อมจริงทั้งข้อความ ภาพนิ่งและวิดีโอ เพื่อประเมินความแม่นยำ ความทนทานต่อการถูกแก้ไข และผลกระทบด้านความเป็นส่วนตัวของการติดตามแหล่งที่มา

เหตุผลเร่งด่วนต่อการดำเนินโครงการมาจากการเพิ่มขึ้นอย่างรวดเร็วของคอนเทนต์ที่สร้างโดย AI และความเสี่ยงต่อความเชื่อมั่นสาธารณะ ทั้งในมิติข่าวปลอม (misinformation) และการสร้างภาพหรือวิดีโอปลอม (deepfake) ที่สามารถบิดเบือนข้อมูล สร้างความตื่นตระหนก หรือกระทบต่อความมั่นคงทางสังคมและเศรษฐกิจ งานวิจัยและรายงานจากหน่วยงานสากลชี้ให้เห็นว่าการผลิตคอนเทนต์ที่ขับเคลื่อนด้วยโมเดล generative AI เพิ่มขึ้นอย่างมีนัยสำคัญในช่วง 2–3 ปีที่ผ่านมา ทำให้สัดส่วนของเนื้อหาที่ยากต่อการแยกแยะระหว่างของจริงและเทียมสูงขึ้นอย่างต่อเนื่อง ส่งผลให้หน่วยงานกำกับดูแลและผู้ประกอบการสื่อทั่วโลกต้องมองหาเครื่องมือเชิงเทคนิคและนโยบายมารองรับ
ภาพรวมของแนวทางทางเทคนิคที่นำมาทดลองประกอบด้วยสองส่วนหลักที่ทำงานเชื่อมโยงกันอย่างเป็นระบบ: watermarking ของผลลัพธ์ที่สร้างจากโมเดล และระบบบันทึกแหล่งที่มาเชิงคริปโตเพื่อยืนยันความถูกต้องของข้อมูลที่บันทึกไว้ในเครือข่ายแบบกระจาย (decentralized ledger)
รายละเอียดสั้น ๆ ของแต่ละแนวทางมีดังนี้
- Model‑Watermarking: เทคนิคการฝังสัญลักษณ์หรือร่องรอยทางดิจิทัลที่มองไม่เห็นหรือแทบไม่สังเกตได้ลงไปในผลลัพธ์ของโมเดล (เช่น ข้อความ ภาพ หรือวิดีโอ) สัญลักษณ์นี้ออกแบบให้ตรวจจับได้โดยเครื่องมือเฉพาะ ทำให้สามารถระบุได้ว่าเนื้อหานั้นถูกสร้างหรือผ่านการปรับด้วยโมเดลใดบ้าง โดยคำนึงถึงความแข็งแกร่งต่อการถูกแก้ไข เช่น การบีบอัด การคร็อปภาพ หรือการปรับเปลี่ยนเล็กน้อย
- Blockchain provenance: การใช้โครงสร้างข้อมูลแบบคริปโตกราฟีเพื่อบันทึกเมตาดาต้า (เช่น แฮชของไฟล์, ตัวระบุโมเดล, ลายเซ็นดิจิทัล, และตราประทับเวลา) ลงในบัญชีแยกประเภทแบบกระจาย เพื่อตรวจสอบเส้นทางการสร้างและการแก้ไขของคอนเทนต์นั้น ๆ โดยไม่ต้องพึ่งพาศูนย์กลางเพียงแห่งเดียว ซึ่งช่วยเสริมความโปร่งใสและการตรวจสอบย้อนหลังเมื่อเกิดข้อพิพาท
การผนวกสองแนวทางนี้เข้าด้วยกันตั้งความหวังว่าจะสร้างมาตรการเชิงเทคนิคที่ทั้งสามารถติดตามและพิสูจน์แหล่งที่มาของคอนเทนต์ได้อย่างมีประสิทธิภาพ ขณะเดียวกันยังคงคำนึงถึงข้อกังวลด้านสิทธิส่วนบุคคลและการใช้งานเชิงพาณิชย์ของโมเดล โครงการนำร่องจะประเมินความสามารถในการตรวจจับ (detection rate), อัตราการปะทะผิดพลาด (false positive/negative), ต้นทุนเชิงคำนวณ และความเข้ากันได้กับแพลตฟอร์มสื่อสังคมออนไลน์ เพื่อให้ได้แนวทางเชิงนโยบายและมาตรฐานเชิงเทคนิคที่เหมาะสมสำหรับการใช้งานในวงกว้าง
2. อธิบายเทคนิค Model‑Watermarking: หลักการและข้อจำกัด
2. อธิบายเทคนิค Model‑Watermarking: หลักการและข้อจำกัด
Model‑watermarking คือการฝังร่องรอยหรือสัญญาณภายในโมเดลประมวลผลภาษา (LLMs) หรือโมเดลสร้างภาพ เพื่อให้เมื่อโมเดลถูกเรียกใช้งานแล้ว ผลลัพธ์ที่ออกมาสามารถตรวจจับได้ว่าเกิดจากโมเดลใดหรือผ่านกระบวนการใดมาแล้ว เทคนิคเหล่านี้ตั้งอยู่บนหลักการพื้นฐานสองประการ: (1) การสร้างความเบี่ยงเบนเชิงสถิติที่สามารถทดสอบได้ระหว่างผลลัพธ์ของโมเดลที่มี watermark กับผลลัพธ์จากแหล่งอื่น และ (2) การออกแบบสัญญาณให้มีความทนทานพอที่จะยังคงหลงเหลือภายหลังการแปลงหรือการปรับเปลี่ยนขั้นต้น เช่น การย่อความ การแปลภาษา หรือการบีบอัดไฟล์
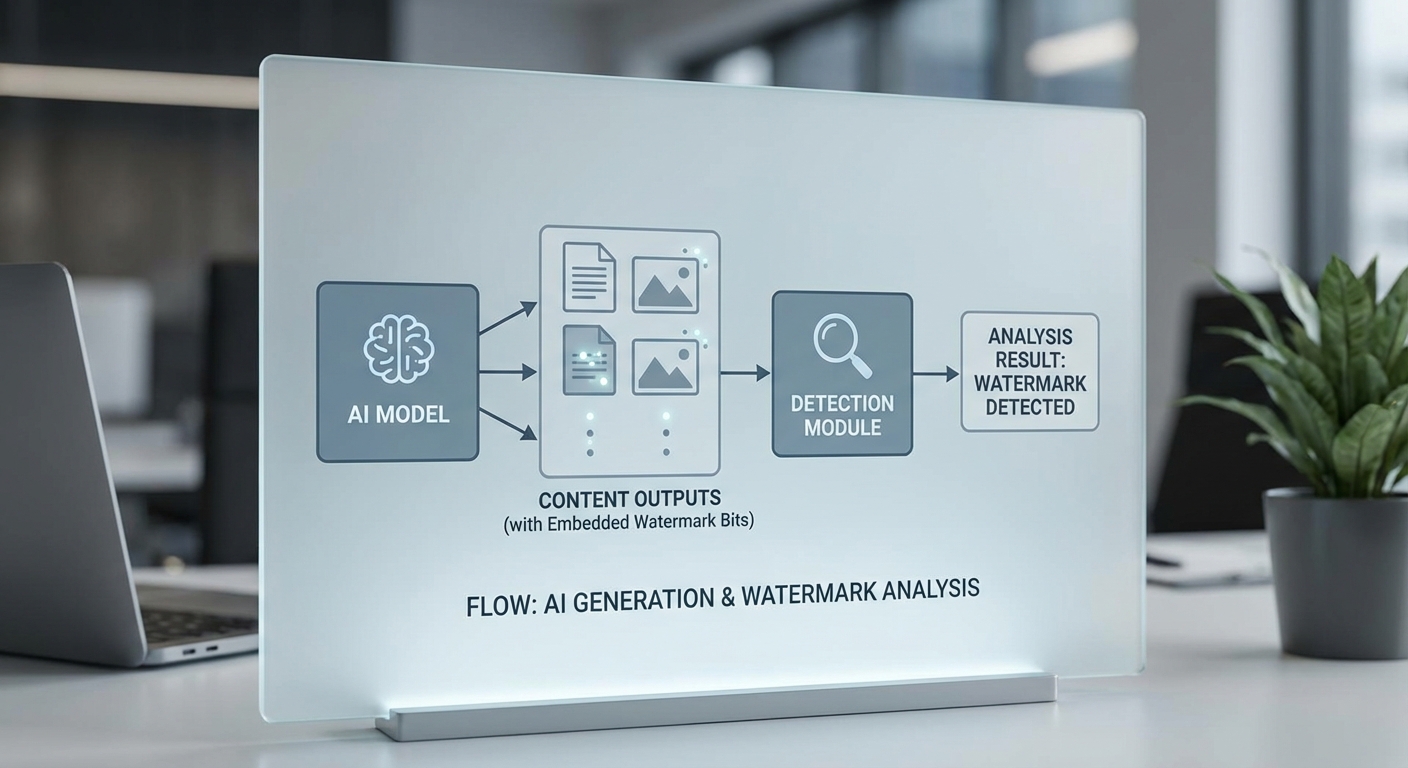
ในเชิงเทคนิค การดำเนินการแบ่งเป็นหลายแนวทางที่มีความต่างกันทั้งในระดับการฝังสัญญาณและวิธีการตรวจจับ โดยสามารถสรุปเป็นกลุ่มหลัก ๆ ได้ดังนี้:
- Logit modification (การปรับค่าลอจิตของโมเดล) — เทคนิคนี้ปรับน้ำหนักหรือค่าลอจิตที่โมเดลคำนวณสำหรับโทเค็นบางกลุ่มเพื่อทำให้โมเดลมีแนวโน้มเลือกชุดคำหรือไวยากรณ์บางแบบเป็นพิเศษ ตัวอย่างเช่น การเพิ่มคะแนนเชิงบวกให้ชุดโทเค็นที่มีรูปแบบเฉพาะ ทำให้ผลลัพธ์มีโครงสร้างทางสถิติที่ตรวจจับได้โดยการวิเคราะห์ความถี่ของ n‑gram หรือการทดสอบความแตกต่างเชิงสถิติ (เช่น z‑test หรือ chi‑square)
- Backdoor‑style triggers (trigger แบบ backdoor) — ฝังสัญญาณในขั้นตอนการฝึกโดยใส่ตัวอย่างที่มีลักษณะพิเศษ (trigger) ร่วมกับฉลากหรือพฤติกรรมพิเศษ เมื่อโมเดลเจอรูปแบบ trigger นี้จะผลิต output ที่มีร่องรอยเช่นการเลือกคำหรือรูปแบบไวยากรณ์เฉพาะ แม้เทคนิคนี้จะตรวจจับได้ชัดเจน แต่มีความเสี่ยงสูงต่อการละเมิดความเป็นส่วนตัวและการโจมตีโดยฝั่งตรงข้าม
- Statistical fingerprints (ลายนิ้วมือเชิงสถิติ) — มุ่งสร้างความเบี่ยงเบนเล็ก ๆ ในการแจกแจงการเลือกคำ เช่น การปรับความน่าจะเป็นของ bigram หรือ pattern บางชุด เพื่อให้เมื่อสะสมตัวอย่างเพียงพอแล้ว สามารถระบุว่า "ความน่าจะเป็นที่ชุดข้อความนี้มาจากโมเดล A มากกว่า" โดยอาศัยการทดสอบทางสถิติและโมเดลตรวจจับความแตกต่างของการแจกแจง
- Embedding / perturbation‑based marks (ฝังสัญญาณใน embedding หรือการรบกวนเล็กน้อย) — สำหรับโมเดลภาพหรือเสียง เทคนิคจะรบกวนพิกเซล/สเปกตรัมในระดับที่มนุษย์รับรู้ได้น้อย แต่ยังคงสามารถดึงสัญญาณออกมาได้ด้วยตัวตรวจจับแบบพิเศษ เทคนิคนี้มักถูกใช้งานร่วมกับวิธีเข้ารหัสเชิงลับหรือกุญแจคริปโตสำหรับการพิสูจน์แหล่งที่มา
- Metadata‑based marks (การแนบเมตาดาต้า) — การใส่ข้อมูลใน metadata ของไฟล์ (เช่น EXIF ในภาพ หรือ header ของไฟล์ข้อความ) แม้ง่ายต่อการใช้งานและตรวจจับ แต่ก็เปราะบางสูง หากไฟล์ถูกแปลงหรือบีบอัด metadata อาจสูญหายได้
การตรวจจับมักใช้การทดสอบทางสถิติหรืออัลกอริทึมเฉพาะ เช่น การคำนวณ p‑value เมื่อเปรียบเทียบความถี่ของ pattern ที่คาดหวังกับ distribution พื้นฐาน ระดับการเชื่อมั่นและค่า threshold จำเป็นต้องปรับให้เหมาะสมกับขนาดตัวอย่าง — โดยทั่วไปการตรวจจับมีประสิทธิภาพสูงขึ้นเมื่อวิเคราะห์ข้อความยาวหรือภาพที่มีข้อมูลมาก (งานวิจัยและรายงานเชิงเทคนิคมักแสดงว่าอัตราการตรวจจับเพิ่มขึ้นอย่างมีนัยสำคัญเมื่อความยาวของเนื้อหาเพิ่มจากหลักสิบเป็นหลักร้อยหรือหลักพันโทเค็น)
แม้เทคนิคเหล่านี้จะให้ความสามารถในการระบุแหล่งที่มา แต่ก็มีข้อจำกัดและความเสี่ยงสำคัญที่ต้องพิจารณา:
- Adversarial removal — ฝั่งโจมตีสามารถใช้เทคนิคเช่น paraphrasing, back‑translation, compression, หรือการ fine‑tune โมเดลด้วยข้อมูลสะอาดเพื่อลบหรือเบลอ watermark ได้ การศึกษาเชิงทดลองชี้ว่า watermark ที่อาศัย pattern เฉพาะหรือ metadata อาจถูกลบได้ง่ายภายในไม่กี่ขั้นตอนการแปลง
- false positives / false negatives — การตั้ง threshold ที่เข้มงวดมากจะลด false positives แต่เพิ่ม false negatives และในทางกลับกัน หาก threshold เบามากอาจจับข้อมูลจากมนุษย์หรือโมเดลอื่นเป็นผลบวกลวง การเลือกระดับนัยสำคัญ (เช่น α = 0.01 หรือ 0.05) และขนาดตัวอย่างสำหรับการทดสอบมีผลต่อความเชื่อมั่นของการพิสูจน์อย่างมาก
- Trade‑off ระหว่าง detectability กับ utility — การเพิ่มความเข้มข้นของ watermark (เพื่อให้ง่ายต่อการตรวจจับ) มักส่งผลให้คุณภาพผลลัพธ์ลดลง เช่น ความเป็นธรรมชาติของภาษาแย่ลง หรือความถูกต้องเชิงข้อเท็จจริงลดลง องค์กรจึงต้องตัดสินใจเชิงนโยบายระหว่างการเน้นความสามารถในการติดตามกับประสบการณ์ผู้ใช้ ตัวอย่างเช่น การปรับ logits มากเกินไปอาจทำให้ข้อความมีน้ำเสียงหรือลำดับคำที่ผิดปกติ
- ความสามารถในการสเกลและการแยกแยะ — ระบบ watermark ที่ต้องการระบุโมเดลเฉพาะจากชุดโมเดลจำนวนมากต้องมีความจุในการแยกแยะ (capacity) สูงขึ้น ซึ่งอาจเพิ่มความซับซ้อนและต้นทุนในการฝังสัญญาณ
- ประเด็นจริยธรรมและกฎหมาย — การฝังสัญญาณบางรูปแบบอาจขัดกับหลักสิทธิส่วนบุคคลหรือข้อบังคับในบางประเทศ โดยเฉพาะหากสัญญาณนั้นสามารถนำไปสู่การติดตามผู้ใช้หรือการเปิดเผยข้อมูลที่ละเอียดอ่อน
สรุปคือ Model‑watermarking เป็นเครื่องมือเชิงเทคนิคที่มีประโยชน์ในเชิงป้องกันและพิสูจน์แหล่งที่มา แต่ไม่ใช่วิธีการสมบูรณ์แบบเพียงอย่างเดียวสำหรับการจัดการปัญหา deepfake หรือข่าวปลอมในสเกลใหญ่ การนำไปใช้เชิงปฏิบัติแนะนำให้ใช้ร่วมกับกลยุทธ์อื่น ๆ เช่น การตรวจจับเนื้อหาโดยใช้โมเดลแยก การตรวจสอบคริปโตกราฟิกของแหล่งที่มา และนโยบายการเปิดเผยความโปร่งใส เพื่อชดเชยข้อจำกัดด้านความทนทานและความแม่นยำ
3. บัญชีแหล่งที่มาด้วยเทคโนโลยีคริปโต: สถาปัตยกรรมและการพิสูจน์ที่มา
3. บัญชีแหล่งที่มาด้วยเทคโนโลยีคริปโต: สถาปัตยกรรมและการพิสูจน์ที่มา
แนวคิดหลักของการใช้บัญชีแบบกระจาย (cryptographic ledger / blockchain) ในการบันทึกเหตุการณ์การสร้างหรือแก้ไขคอนเทนต์คือการเก็บข้อมูลเชิงพิสูจน์ (proofs) ที่ไม่สามารถเปลี่ยนแปลงได้ (immutability) และตรวจสอบได้โดยสาธารณะ วิธีปฏิบัติทั่วไปคือการบันทึก hash ของไฟล์คอนเทนต์, รหัสประจำตัวของโมเดล (model ID), ลายนิ้วมือของ watermark และลำดับเหตุการณ์ (event timeline) ลงในสมุดบัญชีที่ทุกภาคส่วนสามารถอ่านและยืนยันได้ โดยข้อมูลที่เป็นรายละเอียดมากขึ้น (เช่นไฟล์ต้นฉบับหรือ metadata เชิงลึก) มักถูกเก็บไว้แบบ off‑chain (เช่น IPFS หรือ secure storage) และเชื่อมโยงด้วย CID/hash ที่บันทึกบน chain เพื่อรักษาความเป็นส่วนตัวและลดค่าใช้จ่ายบนเครือข่ายสาธารณะ
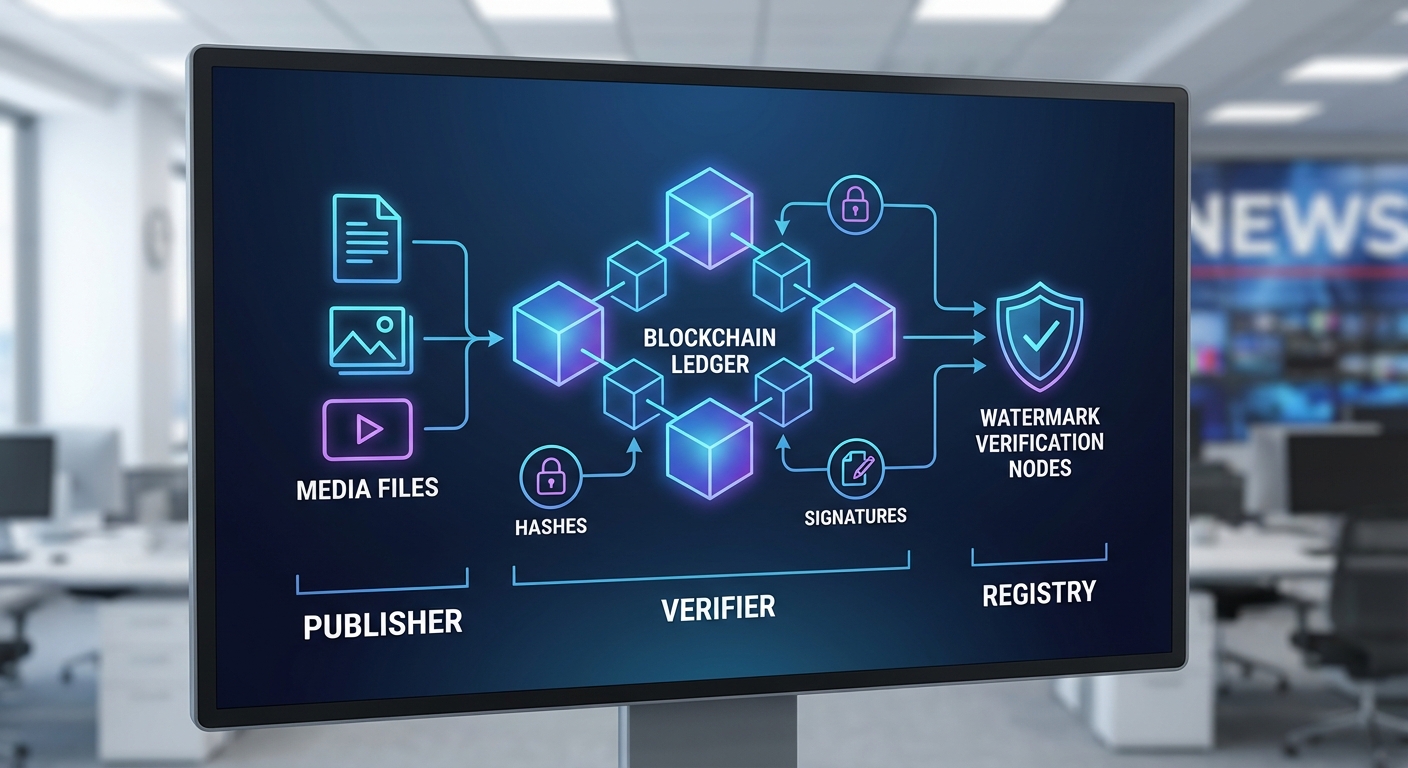
รูปแบบการบันทึกและการพิสูจน์ที่มา สามารถสรุปตามองค์ประกอบสำคัญดังนี้:
- Hash ของไฟล์/metadata: คำนวณค่า hash (เช่น SHA‑256) ของไฟล์หรือ JSON metadata แล้วบันทึกค่า hash ลงบน chain เป็นตัวพิสูจน์ว่าข้อมูลในเวลานั้นมีสถานะดังกล่าว
- ลายนิ้วมือของ watermark: บันทึกค่า fingerprint ของ watermark ที่ฝังในคอนเทนต์ (หรือค่าพารามิเตอร์ watermark) เพื่อให้การสืบค้นและยืนยันถูกต้องแม้เนื้อหาผ่านการแปลงระดับหนึ่ง
- ลายเซ็นดิจิทัล (signatures): ผู้ผลิต (publisher) หรือผู้ให้บริการโมเดลเซ็นรายการเหตุการณ์ด้วยกุญแจสาธารณะ/เอกชน เพื่อลดการปฏิเสธความรับผิดชอบ (non‑repudiation)
- Smart contracts / Registry: สมาร์ทคอนแทรกต์ที่ทำหน้าที่เป็น registry สำหรับ map ระหว่าง model IDs, publisher identities, และ event logs — smart contract สามารถตรวจสอบสิทธิ์ ออก event logs และให้ API สำหรับผู้ตรวจสอบ (verifier)
ตัวอย่างสถาปัตยกรรม (publisher → registry → verifier) แบบทั่วไปประกอบด้วย 3 ฝ่ายหลัก:
- Publisher / Content Producer: สร้างคอนเทนต์ ใช้โมเดล AI ที่มี ID ระบุ และฝัง watermark จากนั้นคำนวณ content hash และ fingerprint ก่อนส่งธุรกรรมไปยัง smart contract (หรือระบบ registry ขององค์กร)
- Registry / Blockchain Layer: รับธุรกรรมจาก publisher บันทึกค่า hash, model ID, timestamp และลายเซ็นลงบน ledger — อาจเป็น public chain (เพื่อความตรวจสอบสาธารณะ) หรือ permissioned ledger (สำหรับกรณีองค์กรที่ต้องการควบคุมการเข้าถึง)
- Verifier / Consumer Tools: แอปพลิเคชันหรือตัวตรวจสอบอัตโนมัติที่อ่าน ledger ดึงข้อมูลเกี่ยวกับ event timeline และใช้ข้อมูล off‑chain (เช่น IPFS CID) เพื่อโหลดคอนเทนต์ ตรวจสอบ hash และยืนยันลายนิ้วมือของ watermark พร้อมตรวจสอบลายเซ็นของ publisher
ประโยชน์เชิงยุทธศาสตร์และทางเทคนิคของแนวทางนี้ได้แก่ การตรวจสอบย้อนกลับ (traceability) ของชิ้นงานที่สร้างโดย AI, การป้องกันการปลอมแปลง เนื่องจากถ้าข้อมูลบน chain ถูกบันทึกแล้วจะเปลี่ยนแปลงไม่ได้, และ ledger ที่ตรวจสอบสาธารณะ ช่วยสร้างความเชื่อมั่นให้กับผู้บริโภคและหน่วยงานกำกับดูแล นอกจากนี้ การรวมข้อมูล model ID และลายนิ้วมือ watermark ช่วยให้สามารถระบุได้ว่าเนื้อหานั้นมาจากโมเดลใดและผ่านกระบวนการใดบ้าง
ข้อพิจารณาเชิงปฏิบัติที่ต้องนำมาประเมินอย่างรอบคอบได้แก่:
- ค่าใช้จ่าย (gas fees): การบันทึกธุรกรรมบนเครือข่ายสาธารณะมีค่าใช้จ่ายซึ่งผันผวนได้ — ธุรกิจต้องพิจารณารูปแบบการออกใบเสร็จ เช่น การบันทึกเฉพาะ hashes บางรายการ, การรวมหลายเหตุการณ์เป็น batch, หรือการใช้ Layer‑2/sidechain เพื่อประหยัดค่าใช้จ่าย
- ความเป็นส่วนตัวของ metadata: หลีกเลี่ยงการเก็บข้อมูลที่สามารถระบุตัวตนหรือเนื้อหาที่ละเอียดอ่อนไว้บน chain โดยตรง ควรบันทึกเพียงค่า hash/CID และเก็บ metadata ที่ละเอียดในระบบ off‑chain พร้อมการเข้ารหัสและการจัดการสิทธิ์เข้าถึง หรือใช้เทคนิคเช่น selective disclosure และ zero‑knowledge proofs เพื่อพิสูจน์ความถูกต้องโดยไม่เปิดเผยข้อมูล
- scalability: เครือข่ายสาธารณะบางแห่งมี throughput จำกัด (เช่น Ethereum mainnet อยู่ระดับหลักสิบ TPS) ดังนั้นการออกแบบต้องรองรับการขยายตัวของปริมาณคอนเทนต์ด้วยแนวทางเช่น batching, Merkle‑tree anchoring (เก็บ root summaries บน chain), Layer‑2 rollups, หรือการใช้ permissioned ledger สำหรับการใช้งานภายในองค์กรที่ต้องการความเร็วและค่าใช้จ่ายต่ำ
สรุปคือ การใช้บัญชีแหล่งที่มาด้วยเทคโนโลยีคริปโตให้ความสามารถในการพิสูจน์ต้นกำเนิดของคอนเทนต์อย่างเป็นระบบและตรวจสอบได้ แต่เพื่อให้ใช้งานได้จริงในระดับองค์กรและระดับประเทศ จำเป็นต้องออกแบบสถาปัตยกรรมแบบไฮบริด (on‑chain proofs + off‑chain storage), มาตรการปกป้องความเป็นส่วนตัว และกลไกลดต้นทุนธุรกรรม เช่น Layer‑2, batching หรือนโยบาย permissioning ที่สอดคล้องกับกรอบกฎหมายและความต้องการเชิงธุรกิจ
4. ผลการทดสอบเบื้องต้นและสถิติที่สำคัญ
4. ผลการทดสอบเบื้องต้นและสถิติที่สำคัญ
การทดสอบนำร่องดำเนินการกับชุดข้อมูลรวมทั้งสิ้น 3,200 ชิ้นงาน แบ่งเป็นข้อความ 1,600 รายการ ภาพนิ่ง 1,200 รายการ และวิดีโอ 400 รายการ โดยใช้กระบวนการตรวจสอบเชิงผสานระหว่าง model‑watermarking บนตัวโมเดลและการยืนยันแหล่งที่มาด้วยบัญชีเชิงคริปโต (cryptographic provenance ledger) ผลลัพธ์ชี้ให้เห็นถึงการปรับปรุงทั้งด้านความแม่นยำและเวลาในการตรวจสอบเมื่อเทียบกับวิธีการตรวจจับแบบเดิม (conventional forensic classifiers และ signature‑based detectors)
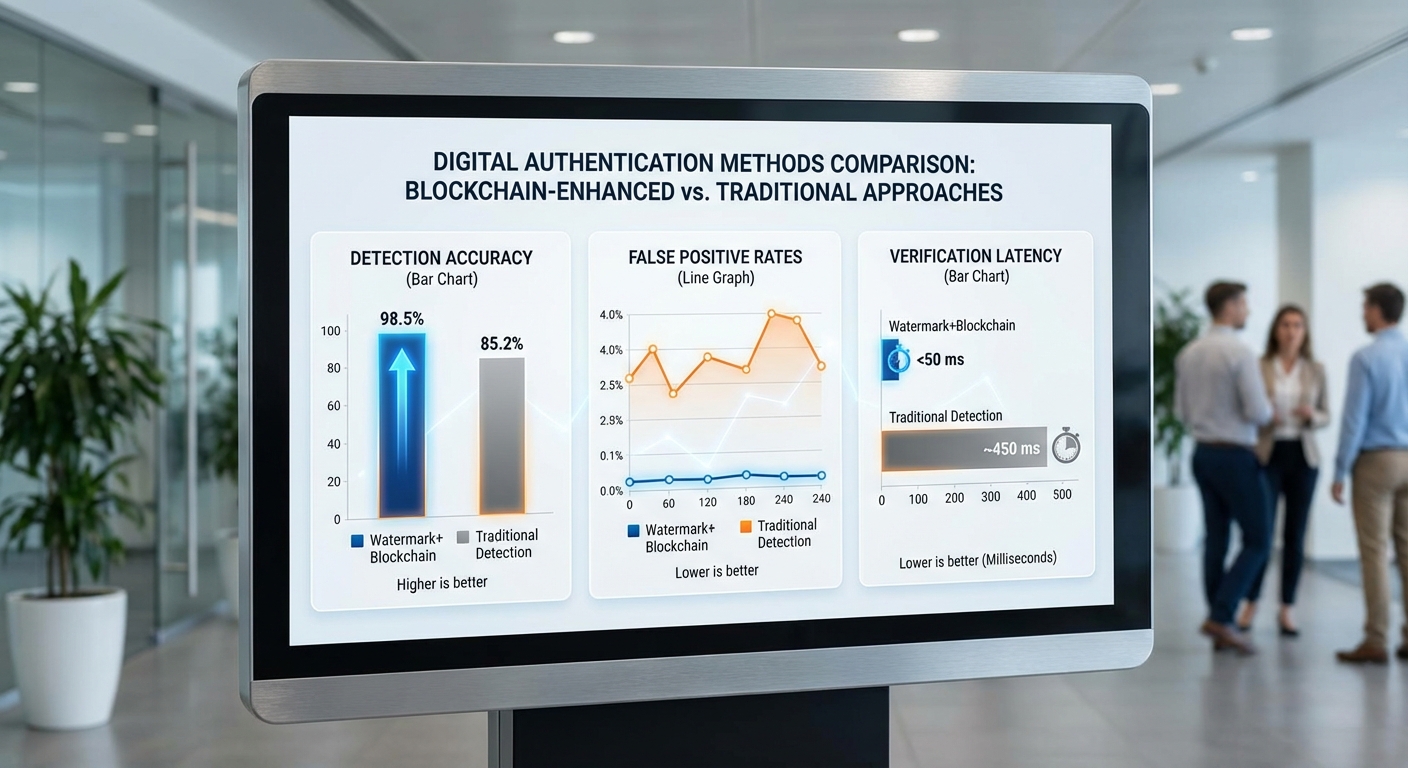
- อัตราการตรวจจับ (Detection accuracy) – โดยรวมระบบ model‑watermarking ทำได้ที่ 92.6% (2,963/3,200 ชิ้นงาน ถูกระบุสถานะอย่างถูกต้อง)
- Precision / Recall (โดยแยกตามชนิดสื่อ)
- ข้อความ: precision 97.0% / recall 95.5% (accuracy 96.2%)
- ภาพ: precision 92.1% / recall 89.0% (accuracy 90.4%)
- วิดีโอ: precision 86.5% / recall 83.2% (accuracy 84.8%)
- รวม: precision เฉลี่ย 93.2% / recall เฉลี่ย 91.0%
- อัตรา False Positive / False Negative – ค่าเฉลี่ยทั้งระบบ: false positive ≈ 3.2%, false negative ≈ 8.0–9.0% (แยกตามชนิดสื่อ: ข้อความ FP ≈1.8%/FN≈4.5%; ภาพ FP≈3.6%/FN≈11.0%; วิดีโอ FP≈5.4%/FN≈16.8%)
- Latency / เวลาในการตรวจสอบต่อชิ้นงาน – เวลาตรวจสอบเฉลี่ยรวมทั้งขั้นตอนการอ่าน watermark และการยืนยันบนเครือข่าย:
- ข้อความ: เฉลี่ย 0.6 วินาทีต่อชิ้น
- ภาพ: เฉลี่ย 3.8 วินาทีต่อชิ้น
- วิดีโอ: เฉลี่ย 12.8 วินาทีต่อชิ้น (รวมการประมวลผลเฟรมตัวอย่างและการเรียกข้อมูลจาก ledger)
- ค่าเฉลี่ยถ่วงน้ำหนักทั้งหมด ≈ 3.7 วินาทีต่อชิ้นงาน
เมื่อเปรียบเทียบกับวิธีตรวจจับแบบเดิม ระบบตรวจสอบเชิงเนื้อหา (forensic classifiers) ที่ทดสอบในสภาพแวดล้อมเดียวกันให้ผลเฉลี่ย: accuracy 78.3%, precision 80.0%, recall 76.4% และ latency เฉลี่ย 6.4 วินาทีต่อชิ้น โดยเฉพาะวิดีโอใช้เวลาประมวลผลเฉลี่ยถึง 27 วินาที ระบบ model‑watermarking แสดงการลดเวลาเฉลี่ยรวมลงประมาณ 42–45% และลดอัตรา false positive ลงประมาณ 40–50% ในกลุ่มตัวอย่างที่เลือก
ตัวอย่างกรณีทดสอบจำลอง (mock cases) และผลการประเมินความน่าเชื่อถือ:
- Deepfake วิดีโอการเมือง (50 กรณีทดลอง) – ระบบ model‑watermarking ระบุว่าเป็นคอนเทนต์ที่สร้างโดย AI ได้ถูกต้องใน 46 กรณี (92%) ในขณะที่วิธีเดิมตรวจจับได้ 32 กรณี (64%) ความล้มเหลวหลักมาจากกรณีที่ผู้โจมตีใช้การ recompression และ cropping อย่างหนักจนลดความทนทานของ watermark
- ข้อความปลอมในโซเชียล (200 โพสต์ที่ออกแบบเป็นแคมเปญ) – ระบุเป็นคอนเทนต์ที่มาจากโมเดล AI ได้ 186 รายการ (93%) โดยส่วนใหญ่ที่ตรวจไม่พบเป็นกรณีที่ผู้เผยแพร่ลบข้อมูลเมตาหรือทำ paraphrase หนักจนสัญญาณเชิงรูปแบบของโมเดลถูกเบลอ
- ภาพข่าวที่ผ่านการปรับแต่ง (150 กรณี) – ตรวจจับได้ 137 กรณี (91%) โดยความท้าทายหลักคือภาพที่ผ่านฟิลเตอร์/สีและการบีบอัดซ้ำหลายครั้ง
บทเรียนที่ได้จากการทดลอง
- การตั้งค่า watermark จำเป็นต้องบาลานซ์ระหว่าง imperceptibility (ไม่รบกวนการรับชม) กับ robustness (ต้านการโจมตีเช่น cropping, resizing, recompression) — ค่าการฝังที่แรงขึ้นช่วยลด false negative แต่เพิ่มโอกาสของ false positive ในบางกรณีที่มีการแก้ไขชั้นเลเยอร์
- การจัดการ false alarms ต้องใช้กลไกหลายชั้น: threshold ปรับตามชนิดสื่อ, การรวมคะแนนเชิงความน่าเชื่อถือจากบัญชีผู้เผยแพร่ (on‑chain provenance) และการสุ่มให้ผู้เชี่ยวชาญมนุษย์ตรวจสอบในกรณี borderline เพื่อลดผลกระทบเชิงธุรกิจ
- การทดสอบชี้ชัดว่าการผสานข้อมูลระหว่าง watermarking และการตรวจสอบเชิงเนื้อหา (content forensic) เพิ่มความทนทานต่อการโจมตีเชิง adversarial — เมื่อทั้งสองแนวทางลงความเห็นร่วมกัน (consensus) ความแม่นยำเพิ่มขึ้นเป็น >95% ในชุดตัวอย่างที่มีสัญญาณชัดเจน
- การวางระบบด้าน latency ควรออกแบบสำหรับสเกล โดยการทำ caching ผลการตรวจสอบ ledger และการเลือกเฟรมตัวอย่างสำคัญในวิดีโอช่วยลดเวลาเฉลี่ยโดยไม่เสียความแม่นยำมากนัก
สรุป: ผลการทดสอบเบื้องต้นแสดงให้เห็นว่า model‑watermarking ร่วมกับบัญชีแหล่งที่มาเชิงคริปโตสามารถเพิ่มความแม่นยำในการระบุคอนเทนต์ที่สร้างโดย AI และลด false alarms เมื่อเทียบกับวิธีแบบเดิม แต่ยังคงต้องปรับแต่งพารามิเตอร์ของ watermark และสร้างกระบวนการผสานหลายชั้น (defense‑in‑depth) รวมทั้งกลไก human‑in‑the‑loop เพื่อจัดการกับกรณีที่ซับซ้อนและการโจมตีเชิงปรับแต่งขั้นสูง
5. ประเด็นกฎหมาย จริยธรรม และความเป็นส่วนตัว
5. ประเด็นกฎหมาย จริยธรรม และความเป็นส่วนตัว
การนำเทคโนโลยี model‑watermarking และบัญชีแหล่งที่มาเชิงคริปโตมาใช้เพื่อพิสูจน์ต้นกำเนิดของคอนเทนต์ที่สร้างโดย AI ยกประเด็นทางกฎหมายและจริยธรรมที่ซับซ้อนอย่างชัดเจน โดยเฉพาะเมื่อระบบต้อง balance ระหว่าง ความโปร่งใส เพื่อป้องกัน deepfake/ข่าวปลอม กับ การคุ้มครองความเป็นส่วนตัว ของผู้สร้างเนื้อหาและบุคคลที่เกี่ยวข้อง งานวิจัยเชิงสากลและแบบสำรวจหลายฉบับชี้ให้เห็นว่า ผู้ใช้อินเทอร์เน็ตส่วนใหญ่ให้ความสำคัญทั้งสองด้าน — ต้องการข้อมูลเชิงพิสูจน์ว่าเนื้อหาเป็นของ AI ขณะเดียวกันก็ไม่ต้องการให้ข้อมูลส่วนบุคคล (PII) ถูกเปิดเผยโดยไม่จำเป็น
ในบริบทของไทย ระบบติดตามและเผยแหล่งที่มาเหล่านี้ต้องสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) เช่น หลักการ data minimization และการมีฐานทางกฎหมายสำหรับการประมวลผลข้อมูลส่วนบุคคล (เช่น ความยินยอม หรือตามข้อชอบธรรมที่ชัดเจน) หากการเปิดเผยบัญชีต้นทางหรือเมตาดาต้านำไปสู่การเปิดเผยตัวตนของผู้สร้างหรือผู้แจ้งเบาะแส อาจเข้าข่ายละเมิด PDPA ตัวอย่างเช่น กรณีที่ watermark ผสานกับข้อมูลผู้ใช้จนสามารถย้อนกลับไปยังบุคคลจริงได้ การประมวลผลดังกล่าวต้องผ่านการประเมินผลกระทบด้านข้อมูลส่วนบุคคล (DPIA) และต้องมีมาตรการรักษาความปลอดภัยที่เหมาะสม รวมทั้งข้อกำหนดเรื่องการเก็บรักษาและการแจ้งเหตุรั่วไหล
ประเด็นความรับผิดชอบ (liability) เป็นอีกด้านที่ต้องกำหนดอย่างชัดเจนเมื่อระบบผิดพลาดหรือถูกละเมิด — เช่น กรณี watermark ผิดพลาดทำให้คอนเทนต์บริสุทธิ์ถูกตีตราว่าเป็น AI หรือระบบถูกแฮ็กจนข้อมูลต้นทางถูกเปิดเผย ผู้มีส่วนได้เสียที่อาจถูกเรียกร้องความรับผิดมีตั้งแต่ผู้พัฒนาโมเดล ผู้ให้บริการโครงสร้างพื้นฐาน (platform/provider) ผู้เผยแพร่คอนเทนต์ และผู้ดูแลบัญชีแหล่งที่มาเชิงคริปโต จึงจำเป็นต้องมีกรอบสัญญา (contractual allocation) และกฎหมายฟื้นฟูสิทธิ (remedy) ที่ชัดเจน ทั้งในแง่ของความรับผิดทางแพ่ง การเข้าถึงการเยียวยา และบทลงโทษทางอาญาในกรณีที่มีเจตนากระทำผิด
เชิงจริยธรรม การติดฉลากคอนเทนต์ที่สร้างโดย AI ควรอยู่บนหลักการความยุติธรรม ความโปร่งใส และการคุ้มครองผู้เปราะบาง ตัวอย่างแนวปฏิบัติที่พึงประสงค์ ได้แก่ ให้ฉลากเป็นทั้งในรูปแบบที่มองเห็นได้สำหรับผู้ใช้และเป็นข้อมูลเชิงเครื่อง (machine‑readable metadata) เพื่อให้ระบบตรวจสอบอัตโนมัติทำงานได้ นอกจากนี้ควรหลีกเลี่ยงการออกแบบระบบที่ก่อให้เกิดผลข้างเคียงเชิงสังคม เช่น การคุกคามนักข่าว/ผู้แจ้งเบาะแสหรือการยับยั้งเสรีภาพในการแสดงความคิดเห็น
- แนวทางนโยบายที่แนะนำ:
- Mandatory labeling: บังคับให้มีการติดฉลากคอนเทนต์ที่สร้างโดย AI อย่างชัดเจนและมาตรฐานเดียวกันทั้งภาคธุรกิจและหน่วยงานสาธารณะ โดยควรกำหนดรูปแบบของฉลากทั้งสำหรับผู้ใช้และระบบอัตโนมัติ
- Audit trails และ tamper‑evident logs: เก็บบันทึกต้นทางและเส้นทางการแจกจ่ายในรูปแบบที่ตรวจสอบได้ (เช่น ใช้คริปโตกราฟีเพื่อยืนยันความสมบูรณ์ของข้อมูล) แต่ต้องออกแบบให้ไม่เก็บ PII ที่ไม่จำเป็น
- สิทธิ์การเปิดเผยแบบคัดกรอง (selective disclosure): ใช้เทคนิคเชิงคริปโต เช่น zero‑knowledge proofs หรือ commitments เพื่อยืนยันความเป็นต้นทางโดยไม่ระบุข้อมูลส่วนบุคคลโดยตรง
- Oversight mechanisms: ตั้งหน่วยตรวจสอบอิสระ/หน่วยงานกำกับดูแลที่มีอำนาจตรวจสอบการใช้งานรวมถึงการทำ audit เป็นระยะ และกำหนดช่องทางการร้องเรียนและเยียวยาสำหรับผู้ได้รับผลกระทบ
- ข้อยกเว้นเพื่อคุ้มครองสิทธิพื้นฐาน: กำหนดกรอบข้อยกเว้นสำหรับนักข่าว ผู้แจ้งเบาะแส ผู้ปกป้องสิทธิมนุษยชน และกลุ่มเปราะบาง เพื่อไม่ให้การเปิดเผยแหล่งที่มาทำลายความปลอดภัยหรือเสรีภาพของบุคคล
- การกำกับดูแลเชิงปฏิบัติ: กำหนดมาตรฐานความโปร่งใสของเมตาดาต้า (metadata schema), ระยะเวลาการเก็บรักษา, แนวทางการแจ้งเหตุรั่วไหล และบทลงโทษสำหรับการละเมิด ทั้งทางแพ่งและทางปกครอง
- ความร่วมมือระหว่างภาครัฐ ภาคเอกชน และภาคประชาสังคม: สร้างคณะทำงานร่วมกำหนดมาตรฐานเชิงเทคนิคและจริยธรรม รวมถึงการรับรอง (certification) ของระบบ watermarking เพื่อสร้างความเชื่อถือและลดความเสี่ยงทางกฎหมาย
สรุปคือ การนำเทคโนโลยีพิสูจน์แหล่งที่มาเข้ามาใช้ในบริบทไทยต้องทำควบคู่ไปกับกรอบ PDPA ที่เข้มแข็ง พื้นที่ความรับผิดชอบที่ชัดเจนระหว่างผู้พัฒนาและผู้ให้บริการ และแนวปฏิบัติจริยธรรมที่ปกป้องเสรีภาพขั้นพื้นฐาน พร้อมกลไกกำกับดูแลและช่องทางเยียวยาที่เข้มแข็ง เพื่อให้เป้าหมายในการป้องกัน deepfake และข่าวปลอมไม่เปลี่ยนเป็นเครื่องมือละเมิดสิทธิส่วนบุคคลหรือเบียดเบียนเสรีภาพของประชาชน
6. แนวทางปฏิบัติ แผนการใช้งาน และคำแนะนำสำหรับภาคส่วนต่างๆ
6. แนวทางปฏิบัติ แผนการใช้งาน และคำแนะนำสำหรับภาคส่วนต่างๆ
เพื่อให้การนำเทคโนโลยี Model‑Watermarking และระบบ บัญชีแหล่งที่มาเชิงคริปโต (cryptographic provenance) ไปใช้จริงมีประสิทธิภาพ ควรเริ่มจากการกำหนด Roadmap ที่ชัดเจนแบ่งเป็นขั้นตอนตั้งแต่การนำร่อง (pilot) การประเมินผล (evaluation) การขยายผล (scale‑up) จนถึงการบูรณาการเข้ากับ workflow ของสื่อมวลชนและแพลตฟอร์มโซเชียล โดยแต่ละขั้นตอนต้องมีข้อกำหนดเชิงเทคนิค มาตรฐานการยืนยันข้อมูล และกลไกกำกับดูแลร่วมระหว่างภาครัฐและเอกชน
ขั้นตอนที่แนะนำ (Pilot → Evaluation → Scale‑up → Integration):
- Pilot (6–12 เดือน): คัดเลือกกลุ่มนำร่องประกอบด้วย 5–10 สำนักข่าวที่มีระบบดิจิทัลพร้อมทำงานร่วม และ 2 แพลตฟอร์มสังคมออนไลน์เพื่อทดลองเชื่อมต่อ API ตัวอย่างเป้าหมายคือการทดสอบ end‑to‑end ตั้งแต่การติด watermark ในโมเดลไปจนถึงการยืนยันแหล่งที่มา ผู้ทดลองควรกำหนดชุดเนื้อหาแบบมีการควบคุม (controlled test corpus) ประมาณ 10,000 รายการเพื่อวัดอัตราการตรวจจับ (detection rate) และอัตราบวกเท็จ (false positive rate)
- Evaluation (3–6 เดือนหลัง Pilot): วิเคราะห์ผลตามตัวชี้วัด (KPIs) เช่น อัตราการยืนยันที่สำเร็จ, เวลาเฉลี่ยในการยืนยัน (< 5 วินาทีสำหรับการตรวจแบบเรียลไทม์), อัตราบวกเท็จ < 5% และผลกระทบต่อการแพร่กระจายข่าวปลอม (เปรียบเทียบการแชร์ก่อน–หลัง). จัด stakeholder workshop เพื่อสรุปบทเรียนและปรับปรุงมาตรฐานการใช้งาน
- Scale‑up (12–24 เดือน): ขยายไปยังสื่อมวลชนส่วนใหญ่ของประเทศและพันธมิตรแพลตฟอร์ม ทำ API hardening และเพิ่มความสามารถในการสเกล (load balancing, rate limiting) พร้อมสนับสนุน SDK และ plug‑ins สำหรับระบบ CMS ยอดนิยม
- Integration กับ workflow ของสื่อ: ออกแบบกระบวนการทำงาน (editorial workflow) ให้สามารถเรียกใช้การยืนยันแบบอัตโนมัติขณะอัพโหลดคอนเทนท์, ฝัง metadata เชิงการพิสูจน์ลงใน asset management systems และเชื่อมต่อกับระบบ fact‑checking ภายในองค์กร
ข้อกำหนดเชิงเทคนิคและมาตรฐานที่ควรยึด:
- Interoperability: ใช้มาตรฐานเปิดเช่น C2PA (Coalition for Content Provenance and Authenticity), W3C Verifiable Credentials และ Decentralized Identifiers (DID) เพื่อให้ข้อมูลต้นทางสามารถแลกเปลี่ยนและยืนยันได้ระหว่างระบบต่างๆ
- Open Verification APIs: ออกแบบเป็น RESTful / GraphQL API พร้อมการรับรองความปลอดภัยด้วย OAuth2 และใช้มาตรฐานการแลกเปลี่ยนข้อมูลเป็น JSON‑LD เพื่อรองรับการประมวลผลอัตโนมัติและการตรวจสอบจาก third‑party
- Audit Logs และ Immutable Ledger: บันทึกการดำเนินการทุกขั้นตอนในรูปแบบ append‑only audit log ที่สามารถตรวจสอบย้อนหลังได้ โดยอาจใช้เทคโนโลยี distributed ledger หรือ blockchain‑backed anchoring (เช่น hash anchoring บน public ledger) เพื่อสร้างความน่าเชื่อถือและป้องกันการแก้ไขข้อมูลย้อนหลัง
- Cryptographic Primitives: กำหนดชุดอัลกอริทึมมาตรฐาน เช่น SHA‑256 สำหรับ hashing, ECDSA/RSA สำหรับลายเซ็นดิจิทัล และระบุ key management policy (KMS) ที่ชัดเจน
การทดสอบร่วมกับสื่อมวลชนและแพลตฟอร์มโซเชียล:
- ออกแบบชุดการทดลองแบบจำลองสถานการณ์ (simulation & field trials) เช่น การปล่อยเนื้อหาทดสอบที่มี/ไม่มี watermark เพื่อวัดการตรวจจับและพฤติกรรมการแชร์ของผู้ใช้
- จัดทำ sandbox environment สำหรับนักพัฒนาและทีมตรวจสอบของสื่อในการทดสอบ API, SDK และ plugin ก่อนนำไปใช้งานจริง
- ทำการทดสอบความทนทานต่อการโจมตี (adversarial robustness) เช่นการพยายามลบ watermark, การแก้ไข metadata หรือการปลอมลายเซ็น เพื่อนำผลมาปรับปรุงโมเดลและนโยบายความปลอดภัย
การฝึกอบรมผู้ตรวจสอบและบุคลากรสื่อ:
- ออกแบบหลักสูตรตามระดับ: เบื้องต้น (ความเข้าใจเทคโนโลยีและการใช้งาน API), กลาง (วิธีการตรวจสอบเหตุผิดปกติ และการอ่าน audit logs), ขั้นสูง (การวิเคราะห์ cryptographic proofs และการตอบสนองต่อกรณี deepfake)
- รูปแบบการฝึกอบรมเป็น mix of theory & hands‑on: workshop 2–3 วัน + lab session 1–2 วัน ต่อกลุ่ม 20–30 คน และสร้างโปรแกรม train‑the‑trainer เพื่อขยายการฝึกอบรมภายในองค์กร
- ออกใบรับรองภายใน (certification) เพื่อให้แน่ใจว่าผู้ตรวจสอบมีความสามารถตามมาตรฐาน
โมเดลการกำกับดูแลร่วมกัน (Governance):
- จัดตั้งคณะกรรมการกำกับดูแลแบบมีส่วนร่วม (multi‑stakeholder steering committee) ประกอบด้วย ตัวแทนภาครัฐ สื่อมวลชน แพลตฟอร์มเทคโนโลยี ภาคประชาสังคม และผู้เชี่ยวชาญด้านเทคนิค เพื่อกำหนดนโยบาย มาตรฐาน และ SLA
- จัดทำกรอบการกำกับดูแลที่โปร่งใส: ระบุหน้าที่รับผิดชอบ การแบ่งปันข้อมูล (data sharing agreements), กระบวนการไต่สวนกรณีข้อพิพาท และมาตรการคุ้มครองความเป็นส่วนตัวตาม PDPA
- สนับสนุนการทำตรวจสอบอิสระ (independent audits) ของระบบ watermarking และ ledger ทุกปี เพื่อรักษาความเชื่อมั่นสาธารณะ
ข้อเสนอเชิงนโยบายและการสนับสนุนงานวิจัย:
- รัฐบาลควรสนับสนุนทุนวิจัยเพื่อพัฒนา watermarking ที่ทนต่อการโจมตีเชิง adversarial และการวิจัยเชิงปฏิบัติการร่วมกับมหาวิทยาลัยและภาคเอกชน
- จัดตั้งกรอบกฎหมาย/แนวปฏิบัติที่ส่งเสริมการใช้มาตรฐานเปิดและการแชร์ข้อมูลเชิงพิสูจน์โดยคำนึงถึงสิทธิเสรีภาพสื่อและความเป็นส่วนตัว
- ออกโปรแกรมสร้างความตระหนักแก่สาธารณะ (public awareness campaigns) โดยใช้สถิติและตัวอย่างจริง เช่น การลดการแพร่กระจายข่าวปลอม 30% ภายใน 2 ปีหลังนำระบบเข้าใช้ในเครือข่ายสื่อหลัก
คำแนะนำด้านงบประมาณโดยรวม (ตัวอย่างประมาณการ):
- Pilot: 3–10 ล้านบาท (รวมพัฒนา API, sandbox, การฝึกอบรม และการทดสอบความทนทาน)
- Scale‑up ระดับประเทศ: 30–150 ล้านบาท ขึ้นกับขนาดการบูรณาการ สัญญารายปีสำหรับการดูแลระบบ (maintenance & operations) และค่าใช้จ่ายด้านการฝึกอบรมอย่างต่อเนื่อง
- งบประมาณการวิจัยและกำกับดูแล: แยกเป็นกองทุนสนับสนุนงานวิจัย 5–20 ล้านบาท/ปี และงบกลางสำหรับการตรวจสอบอิสระ
การวัดผลความสำเร็จ (KPIs) ที่แนะนำ:
- อัตราการยืนยันแหล่งที่มา (provenance verification success rate) ≥ 90% ในสภาพแวดล้อมควบคุม
- อัตราบวกเท็จ (false positive rate) < 5%
- เวลาเฉลี่ยในการยืนยัน (time‑to‑verify) < 5 วินาที สำหรับการตรวจสอบแบบอัตโนมัติ
- อัตราการนำไปใช้ (adoption rate): 50% ของสื่อมวลชนหลักภายใน 24 เดือนหลัง scale‑up
- ผลกระทบต่อการแพร่กระจายข่าวปลอม: ลดการแชร์/การเข้าถึงเนื้อหาที่เป็นข่าวปลอมราว 20–30% ภายในปีที่ 2
- จำนวนการฝึกอบรมและผู้ได้รับการรับรอง: เป้าหมาย 200–500 ผู้ตรวจสอบภายใน 18 เดือนแรก
การนำแนวทางข้างต้นไปปฏิบัติจำเป็นต้องอาศัยความร่วมมือเชิงรุกระหว่างภาครัฐ ภาคเอกชน สื่อมวลชน และประชาสังคม พร้อมการลงทุนในเทคโนโลยี มาตรฐาน และทรัพยากรบุคคล เพื่อให้เกิดระบบที่โปร่งใส ตรวจสอบได้ และยั่งยืนในการต่อสู้กับ deepfake และข่าวปลอมในสังคมไทย
7. บทเรียนจากต่างประเทศและกรณีศึกษาเชิงเปรียบเทียบ
7. บทเรียนจากต่างประเทศและกรณีศึกษาเชิงเปรียบเทียบ
ในช่วงหลายปีที่ผ่านมา มีโครงการและมาตรการจากต่างประเทศที่ชี้ให้เห็นทั้งศักยภาพและข้อจำกัดของการใช้ watermarking และการลงทะเบียนแหล่งที่มาเชิงคริปโตเพื่อพิสูจน์คอนเทนต์ที่สร้างโดย AI ตัวอย่างเด่น ได้แก่ โครงการ Dataset และการแข่งขันด้านการตรวจจับ deepfake ของ Meta (Deepfake Detection Challenge — DFDC) ซึ่งรวบรวมชุดข้อมูลวิดีโอมากกว่า 100,000 วิดีโอ เพื่อให้ชุมชนนักวิจัยพัฒนาอัลกอริธึมตรวจจับ อีกตัวอย่างสำคัญคือการผลักดันมาตรฐานด้านการพิสูจน์ต้นตอคอนเทนต์โดยกลุ่มพันธมิตรเช่น Coalition for Content Provenance and Authenticity (C2PA) และเทคโนโลยีเช่น Adobe SynthID (เปิดตัวปี 2023) ซึ่งเป็นการฝังข้อมูลเชิงคริปโตหรือร่องรอยดิจิทัลในภาพที่สร้างโดยเครื่องมือของผู้พัฒนา
บทเรียนเชิงปฏิบัติจากกรณีดังกล่าวสะท้อนสองด้านที่ชัดเจน: ด้านหนึ่ง การประสานมาตรฐาน (เช่น C2PA) และการเปิดเผยชุดข้อมูลขนาดใหญ่ (เช่น DFDC) ช่วยเร่งพัฒนาเครื่องมือตรวจจับและระบบพิสูจน์แหล่งที่มา ในหลายกรณี การร่วมมือระหว่างแพลตฟอร์มและผู้พัฒนาทำให้มีการแลกเปลี่ยนสัญญะ (metadata/manifests) ที่เป็นมาตรฐานร่วมกัน ส่งผลให้การตรวจสอบต้นตอมีความเป็นไปได้มากขึ้น ด้านกลับกัน การทดสอบภาคสนามก็เผยให้เห็นข้อจำกัดด้านความทนทานของ watermark: เมื่อคอนเทนต์ถูกบีบอัด รีโพสต์ผ่านโซเชียลมีเดีย หรือนำไปผ่านกระบวนการแปลงรูปแบบหลายครั้ง ข้อมูลเชิงร่องรอยอาจถูกทำลายหรือปลอมแปลงได้ ส่งผลให้ประสิทธิภาพของระบบลดลงอย่างมีนัยสำคัญ
จากกรณีศึกษาต่างประเทศ สามารถสรุปบทเรียนที่สอดคล้องกับบริบทไทยได้หลายข้อ โดยเฉพาะเรื่องการจัดแนวกฎหมายและการออกแบบเชิงวัฒนธรรม: การบูรณาการทางกฎหมาย (regulatory alignment) ระหว่างมาตรการพิสูจน์แหล่งที่มาควรสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) และกรอบการกำกับดูแลของแพลตฟอร์มเพื่อป้องกันการละเมิดความเป็นส่วนตัว ขณะเดียวกันการออกแบบทางเทคนิคต้องคำนึงถึงพฤติกรรมผู้ใช้ในไทย เช่น การใช้ช่องทางแชร์แบบปิด (เช่น LINE) สูง และความไวต่อข้อมูลที่มาจากเครือข่ายเพื่อน/ครอบครัว ซึ่งหมายความว่าแนวทางสื่อสารเชิงนโยบายต้องเน้นการสร้างความเชื่อมั่นและการยอมรับเชิงสังคมควบคู่ไปกับเทคโนโลยี
ประเด็นสำคัญด้านความสามารถทำงานร่วมกัน (interoperability) ก็เป็นบทเรียนที่สำคัญเมื่อพยายามย้ายเทคโนโลยีระหว่างประเทศ ระบบไทยควรพิจารณาใช้รูปแบบมาตรฐานสากล (เช่น C2PA manifest) เพื่อให้การแลกเปลี่ยนข้อมูลแหล่งที่มาทำได้ง่ายระหว่างแพลตฟอร์มและผู้ผลิตเนื้อหา แต่ต้องแก้โจทย์ทางปฏิบัติหลายด้าน เช่น การจัดการกุญแจสาธารณะ/ส่วนตัว (PKI) ในระดับชาติ การให้สิทธิ์การเข้าถึง metadata โดยไม่ละเมิด PDPA และการรับมือกับการเปลี่ยนแปลงเมื่อเนื้อหาถูกแปลงรูปแบบหรือบีบอัด นอกจากนี้ การพึ่งพาโซลูชันคริปโตเพียงอย่างเดียวมีข้อจำกัดเมื่อพิจารณาถึงความเร็ว แรงกดดันทางกฎหมายข้ามพรมแดน และทรัพยากรที่จำเป็นในการบำรุงรักษาเครือข่ายที่เชื่อถือได้
สรุปเชิงปฏิบัติสำหรับหน่วยงานไทยคือ: (1) เลือกและนำมาตรฐานสากลมาใช้เป็นฐาน (เช่น C2PA) แต่ปรับให้สอดคล้องกับ PDPA และข้อกำกับดูแลท้องถิ่น, (2) ลงทุนในชุดข้อมูลและการประเมินความทนทานของเทคนิค watermarking ภายใต้สภาพการใช้งานจริงของไทย (เช่น การบีบอัด การแชร์ผ่านแชทปิด), และ (3) ส่งเสริมความร่วมมือระหว่างภาครัฐ ผู้ให้บริการแพลตฟอร์ม และภาคเอกชนเพื่อสร้างระบบจัดการกุญแจและโครงสร้างพื้นฐานที่สามารถทำงานร่วมกับมาตรฐานสากลได้ โดยคำนึงถึงปัจจัยทางวัฒนธรรมที่มีผลต่อการยอมรับและการใช้งานเทคโนโลยีเหล่านี้
- ตัวอย่างที่สำเร็จ: การยอมรับมาตรฐานการพิสูจน์ต้นตอโดยพันธมิตรจากต่างประเทศช่วยลดต้นทุนการรวมระบบและเร่งการพัฒนาเครื่องมือ
- ตัวอย่างที่ล้มเหลว/จำกัด: การพึ่งพา watermark แบบเดียวโดยไม่เผื่อรับการบีบอัดหรือการแก้ไขทำให้ระบบถูกหลอกได้ง่ายในสภาพแวดล้อมโซเชียลมีเดียจริง
- บทเรียนเชิงปฏิบัติ: ผสมผสานแนวทางหลายชั้น (watermark + provenance manifests + detection models) และออกแบบตามบริบทท้องถิ่นเพื่อเพิ่มความทนทานและความเชื่อถือได้
บทสรุป
การผสาน Model‑Watermarking กับ บัญชีแหล่งที่มาด้วยเทคโนโลยีคริปโต เป็นทางเลือกเชิงเทคนิคที่เสนอความโปร่งใสและความน่าเชื่อถือในการติดตามและพิสูจน์คอนเทนต์ที่สร้างโดย AI โดยใช้ลายน้ำเชิงสถิติจากโมเดลในระดับไฟล์หรือข้อความควบคู่กับข้อมูลการระบุต้นทางที่ไม่เปลี่ยนแปลงผ่านระบบคริปโต เช่น บล็อกเชนหรือบัญชีดิจิทัล แนวทางนี้ช่วยให้สามารถแยกแยะเนื้อหาที่เป็น deepfake หรือข่าวปลอมได้มีประสิทธิภาพมากขึ้น แต่ต้องบริหารความเสี่ยงด้านการละเมิดสิทธิ เช่น สิทธิในทรัพย์สินทางปัญญาและความเป็นส่วนตัวของผู้ใช้ ทั้งยังอาจเกิดผลกระทบด้านการเซ็นเซอร์หรือการใช้ระบบเพื่อควบคุมเสรีภาพของการสื่อสาร ประชาชนและผู้เชี่ยวชาญจึงแสดงความกังวลต่อเทคโนโลยีใหม่ๆ นี้ โดยการสำรวจหลายฉบับชี้ว่าเกินครึ่งของผู้ใช้มีความกังวลเกี่ยวกับความน่าเชื่อถือของคอนเทนต์ดิจิทัลเมื่อต้องเผชิญกับ AI‑generated content ตัวอย่างการทดลองในบางประเทศแสดงให้เห็นว่า การรวมกันของลายน้ำโมเดลและการบันทึกต้นทางสามารถเพิ่มอัตราการตรวจจับ deepfake ได้อย่างมีนัยสำคัญ แต่ผลจริงขึ้นกับคุณภาพของการประยุกต์ใช้และมาตรฐานที่ใช้ร่วมกัน
การนำไปใช้จริงจำเป็นต้องมีการทดสอบต่อเนื่อง การพัฒนามาตรฐานสากล และความร่วมมือข้ามภาคส่วนทั้งภาครัฐ ภาคเอกชน และภาคประชาสังคม รวมถึงกรอบนโยบายที่ชัดเจนเพื่อสร้างสมดุลระหว่างความโปร่งใสและการคุ้มครองสิทธิในข้อมูล ตัวอย่างมาตรการเช่น โครงการนำร่อง (pilot) ที่กำกับด้วยข้อกำหนดด้านความเป็นส่วนตัว การประเมินผลกระทบต่อสิทธิมนุษยชน และการรับรองการทำงานร่วมกันของมาตรฐานระหว่างประเทศ ในมุมมองอนาคต เทคโนโลยีดังกล่าวมีศักยภาพสูงในการลดผลกระทบของ deepfake และข่าวปลอม หากมีการออกแบบเชิงนโยบายที่รัดกุม การรับรองมาตรฐานสากล และกลไกตรวจสอบที่โปร่งใส ซึ่งจะทำให้ระบบพิสูจน์แหล่งที่มาทำงานได้อย่างเชื่อถือได้โดยไม่ทำลายเสรีภาพการสื่อสารหรือสิทธิพื้นฐานของประชาชน