
กระทรวงแรงงานประกาศเริ่มโครงการนำร่องที่น่าจับตามอง: นำระบบปัญญาประดิษฐ์ประเภท Graph‑ML มาผสานกับทักษะออนโทโลยี เพื่อจับคู่งานระหว่างผู้หางานกับนายจ้างแบบเรียลไทม์ โครงการนี้มุ่งหวังสร้างเครือข่ายเชื่อมโยงข้อมูลตำแหน่งงาน ทักษะ รูปแบบการฝึกอบรม และความต้องการของภาคธุรกิจในรูปแบบกราฟความสัมพันธ์ (knowledge graph) ทำให้การจับคู่ไม่เป็นเพียงการเทียบคำสำคัญบนเรซูเม่ แต่เป็นการวิเคราะห์ความสอดคล้องเชิงโครงสร้างของทักษะและบทบาทงานอย่างมีชั้นเชิง
บทนำนี้ชี้ให้เห็นประเด็นสำคัญที่บทความจะขยายต่อ — วิธีการทำงานของ Graph‑ML ร่วมกับมาตรฐานทักษะออนโทโลยี, เป้าประสงค์เพื่อลดช่องว่างทักษะและเพิ่มอัตราการจ้างงาน, รวมถึงการยกระดับบริการจัดหางานสู่มาตรฐานดิจิทัลที่รองรับการอัปเดตแบบเรียลไทม์ นอกจากนี้โครงการยังให้ความสำคัญกับการประเมินผลในด้านเวลาในการจับคู่คุณภาพการจ้างงาน และการคุ้มครองข้อมูลส่วนบุคคลของผู้ใช้ เพื่อให้ผลลัพธ์ทั้งทางสถิติและเชิงนโยบายนำไปสู่การขยายระบบในวงกว้างหากผลการทดลองเป็นบวก
บทนำ: เหตุผลและบริบทของโครงการทดลอง
กระทรวงแรงงานได้ริเริ่มโครงการทดลองระบบปัญญาประดิษฐ์เพื่อการจับคู่งานด้วยเทคโนโลยี Graph‑ML ผสานกับ Skill Ontology และกลไก real‑time matching โดยมีเป้าหมายเชิงนโยบายและเชิงปฏิบัติการเพื่อแก้ไขปัญหาช่องว่างทักษะ (skills gap) ที่ส่งผลต่อประสิทธิภาพตลาดแรงงาน ความล่าช้าในการสรรหา และอุปสรรคต่อการฟื้นตัวทางเศรษฐกิจ โครงการนี้ถูกออกแบบมาให้เป็นการทดลองเชิงปฏิบัติการ (pilot) ที่เน้นการสร้างข้อมูลเชิงนโยบาย ค้นหาแนวทางการยกระดับทักษะ และเพิ่มอัตราการจับคู่ที่สอดคล้องกันระหว่างผู้หางานกับนายจ้างในเวลาจริง

วัตถุประสงค์หลักและเป้าหมายระยะสั้น/ระยะยาว
วัตถุประสงค์หลักของการทดลองคือ: ลดช่องว่างทักษะ, เร่งการจับคู่งานระหว่างผู้หางานกับนายจ้าง และ สร้างฐานข้อมูลเชิงนโยบายที่เชื่อถือได้ เพื่อใช้ในการออกแบบมาตรการฝึกอบรมและส่งเสริมอาชีพในอนาคต สำหรับเป้าหมายเชิงปริมาณที่กำหนดไว้ระยะสั้น ได้แก่การลด time‑to‑hire ประมาณ 20% ภายใน 6–9 เดือนของการทดลอง และเพิ่มอัตราการจับคู่ที่มีคุณภาพ (qualified match rate) ขึ้นราว 25–30% โดยใช้เกณฑ์การคัดกรองตามความสอดคล้องของทักษะและความต้องการของตำแหน่งงาน
ในระยะยาว กระทรวงมุ่งหวังให้ระบบนี้กลายเป็นโครงสร้างพื้นฐานด้านข้อมูลแรงงานของประเทศที่สามารถสนับสนุนนโยบายการพัฒนากำลังคน เช่น การออกแบบหลักสูตรฝึกอบรมเชิงทักษะที่สอดคล้องกับความต้องการตลาด การคาดการณ์แรงงานตามภาคเศรษฐกิจ และการวิเคราะห์ความเสี่ยงของช่องว่างทักษะในอนาคต โดยตั้งเป้าว่าใน 3–5 ปีข้างหน้าจะสามารถลดช่องว่างทักษะในกลุ่มเปราะบางและอุตสาหกรรมเปลี่ยนผ่านดิจิทัลได้อย่างมีนัยสำคัญ
ขอบเขตการทดลอง (ภูมิภาค ตัวอย่างผู้ใช้ ระยะเวลา)
การทดลองจะดำเนินในรูปแบบ pilot ครอบคลุม 3 ภูมิภาคตัวอย่างที่เป็นตัวแทนของสภาพเศรษฐกิจและตลาดแรงงานที่หลากหลาย ได้แก่ กรุงเทพมหานคร (ภูมิภาคเมือง), จังหวัดเชียงใหม่ (ภูมิภาคเหนือเชิงเทคโนโลยีและการท่องเที่ยว) และจังหวัดสงขลา (ภูมิภาคใต้ที่มีภาคการผลิตและโลจิสติกส์) ระยะเวลาของโครงการทดลองวางไว้ที่ประมาณ 9–12 เดือน เพื่อให้มีเวลารวบรวมข้อมูล สังเกตพฤติกรรมการจับคู่ และปรับแต่งอัลกอริทึม
ตัวอย่างผู้ใช้ที่จะเข้าร่วมในการทดลองประกอบด้วยผู้หางานประมาณ 5,000 คน ครอบคลุมกลุ่มวัยแรงงานที่มีทักษะแตกต่างกันทั้งระดับเบื้องต้นและระดับเชี่ยวชาญ และนายจ้าง/ผู้ประกอบการประมาณ 500 ราย จากภาคอุตสาหกรรมต่างๆ เช่น เทคโนโลยีสารสนเทศ การผลิต การบริการ และการค้าปลีก ข้อมูลตัวอย่างรวมถึงเรซูเม่ ข้อกำหนดตำแหน่งงาน และข้อมูลผลตอบรับจากการสัมภาษณ์เพื่อใช้เป็นป้อนกลับในการเรียนรู้ของระบบ
ผู้มีส่วนได้ส่วนเสียและบทบาท
- กระทรวงแรงงาน — รับผิดชอบการกำหนดกรอบนโยบาย กำกับดูแลความเป็นธรรมของข้อมูล และนำผลการทดลองไปออกแบบมาตรการฝึกอบรมและแรงงานระดับชาติ
- ศูนย์ข้อมูลแรงงานแห่งชาติ / หน่วยงานวิเคราะห์ข้อมูล — จัดการคลังข้อมูล เชื่อมโยงแหล่งข้อมูลภายในและภายนอก และจัดทำดัชนี (KPIs) เพื่อวัดผลการทดลอง
- ผู้ประกอบการ/นายจ้าง — ให้ข้อมูลตำแหน่งงาน เกณฑ์ทักษะ และให้ข้อเสนอแนะต่อประสิทธิภาพการจับคู่ รวมถึงร่วมทดสอบกระบวนการสรรหาที่ระบบแนะนำ
- ผู้หางาน — เข้าร่วมระบบ เพิ่มข้อมูลทักษะ ประวัติการทำงาน และให้ฟีดแบ็กต่อคุณภาพของการจับคู่ เพื่อช่วยให้โมเดลปรับปรุงความแม่นยำ
- พันธมิตรเทคโนโลยีและสถาบันวิจัย — ให้บริการด้าน AI/ML (Graph‑ML), ออกแบบและมาตรฐาน Skill Ontology, พัฒนากลไก real‑time matching และประเมินผลเชิงเทคนิค รวมถึงให้การสนับสนุนด้านความเป็นส่วนตัวของข้อมูลและการปฏิบัติตามกฎหมาย
โดยสรุป โครงการทดลองนี้เป็นการเชื่อมโยงระหว่างนโยบายสาธารณะและเทคโนโลยีสมัยใหม่ โดยใช้ Graph‑based machine learning ในการเรียนรู้เครือข่ายความสัมพันธ์ระหว่างทักษะ ตำแหน่งงาน และเส้นทางอาชีพ ร่วมกับ Skill Ontology ที่ช่วยมาตรฐานคำอธิบายทักษะและความสามารถ และระบบ real‑time matching ที่ช่วยให้การจับคู่เกิดขึ้นได้อย่างรวดเร็วและสอดคล้องกับบริบทของตลาดแรงงาน ซึ่งข้อมูลและบทเรียนจากการทดลองจะถูกนำมาใช้เป็นฐานในการกำหนดนโยบายและมาตรการพัฒนากำลังคนในวงกว้างต่อไป
ปัญหาช่องว่างทักษะในตลาดแรงงานไทยและนานาชาติ
ปัญหาช่องว่างทักษะ (Skills Gap) ในประเทศไทยและภาพรวมระดับโลก
นิยามและผลกระทบต่อเศรษฐกิจ
ช่องว่างทักษะ (skills gap) หมายถึงความไม่สอดคล้องระหว่างทักษะที่ผู้ประกอบการต้องการกับทักษะที่แรงงานมีอยู่จริง ซึ่งรวมทั้งทักษะด้านเทคนิค (technical skills) และทักษะเชิงสังคม/การทำงานร่วมกัน (soft skills) ปรากฏการณ์นี้ไม่เพียงทำให้ตำแหน่งงานว่างคงค้าง แต่ยังส่งผลต่อประสิทธิภาพการผลิต รายได้ของแรงงาน และอัตราการเติบโตของเศรษฐกิจในภาพรวม ตัวอย่างผลกระทบเช่นการเพิ่มต้นทุนการจ้างงาน (recruitment costs) การชะลอการขยายตัวของธุรกิจ และการเพิ่มขึ้นของ unfilled vacancies ที่อาจทำให้ GDP ที่เป็นไปได้ลดลง
สถิติเชิงตัวเลขและแนวโน้ม
ปัญหานี้ปรากฏทั้งในระดับประเทศและระดับโลก โดยมีสถิติจากการสำรวจและรายงานหลายฉบับที่ชี้ให้เห็นแนวโน้มสำคัญดังนี้:
- อัตราการว่างงานเชิงโครงสร้าง: แม้หลายประเทศรวมถึงประเทศไทยจะมีอัตราการว่างงานรวมค่อนข้างต่ำหลังการฟื้นตัวจากโควิด-19 แต่ อัตราการว่างงานเชิงโครงสร้าง (structural unemployment) ที่สะท้อนปัญหาความไม่ตรงกันของทักษะยังคงมีนัยสำคัญ — ในหลายการวิเคราะห์เชิงนโยบายแสดงให้เห็นว่าอัตรานี้อาจอยู่ในช่วงหลายเปอร์เซ็นต์ของแรงงานที่พร้อมทำงาน ซึ่งแตกต่างกันตามอุตสาหกรรมและระดับภูมิภาค (แหล่งอ้างอิง: รายงาน ILO, World Bank, และรายงานภายในของกระทรวงแรงงาน/กรมการจัดหางาน)
- เวลาที่ใช้ในการหางานเฉลี่ย: ตัวเลขเวลาในการหางาน (time-to-hire หรือ time-to-placement) แตกต่างกันตามทักษะและอุตสาหกรรม โดยตำแหน่งที่ต้องการทักษะเชิงเทคนิคหรือดิจิทัลมักใช้เวลานานกว่า — การสำรวจระดับภูมิภาคและแพลตฟอร์มจัดหางานระบุว่าเวลาหาตำแหน่งงานเฉลี่ยอาจอยู่ในช่วง หลายสัปดาห์ถึงหลายเดือน (ตัวอย่างเช่น 8–20 สัปดาห์สำหรับตำแหน่งที่ต้องการทักษะเฉพาะ) ซึ่งสะท้อนต้นทุนทางสังคมและธุรกิจจากการจ้างงานที่ล่าช้า (แหล่งอ้างอิง: รายงานจากสำนักงานสถิติแห่งชาติ/กระทรวงแรงงาน, LinkedIn Economic Graph, ManpowerGroup)
- การขาดแคลนทักษะด้านดิจิทัล: การสำรวจระดับนานาชาติชี้ว่าระหว่าง 40–70% ของนายจ้างในหลายประเทศรายงานความยากลำบากในการหาบุคลากรที่มีทักษะดิจิทัลที่ต้องการ เช่น การวิเคราะห์ข้อมูล การพัฒนาแอปพลิเคชัน และความเชี่ยวชาญด้านคลาวด์และไซเบอร์ซีเคียวริตี้ (แหล่งอ้างอิง: รายงาน WEF, ManpowerGroup, OECD, LinkedIn)
ความท้าทายในระบบข้อมูลแรงงานแบบเดิม
ปัญหาช่องว่างทักษะยังถูกขยายความรุนแรงโดยข้อจำกัดของระบบข้อมูลแรงงานแบบดั้งเดิม ซึ่งมีปัญหาหลักหลายประการ ได้แก่:
- ข้อมูลไม่เป็นมาตรฐาน: หลายหน่วยงานใช้มาตรฐานคำอธิบายตำแหน่งงานที่แตกต่างกัน ระบุทักษะด้วยคำศัพท์หรือหมวดหมู่ที่ไม่สอดคล้องกัน ทำให้การจับคู่ตำแหน่งกับทักษะเป็นไปอย่างไม่แม่นยำ
- ขาดการอัปเดตแบบเรียลไทม์: ระบบราชการและฐานข้อมูลแบบดั้งเดิมมักอัปเดตด้วยความล่าช้า เดือนหรือไตรมาสหนึ่งครั้ง ข้อมูลจึงไม่สะท้อนความต้องการทักษะที่เปลี่ยนแปลงอย่างรวดเร็ว โดยเฉพาะด้านเทคโนโลยีหลังการระบาดของโควิด-19
- ข้อมูลแยกเป็นกลุ่ม (siloed) และเข้าถึงได้จำกัด: ข้อมูลตำแหน่งว่างจากภาครัฐ แพลตฟอร์มสาธารณะ และแพลตฟอร์มเอกชนมักอยู่คนละที่ ทำให้ไม่สามารถรวมวิเคราะห์เชิงลึกได้ง่าย และยากต่อการประเมินอุปสงค์-อุปทานทักษะแบบภาพรวม
- การพึ่งพาชื่อหน้าที่งานมากกว่าทักษะจริง: ระบบค้นหางานแบบเดิมมักจับคู่โดยใช้ตำแหน่งงาน (job title) ซึ่งอาจซ่อนความหลากหลายของทักษะจริงที่ต้องการ ทำให้การค้นหากลายเป็นกระบวนการที่ไม่แม่นยำและยืดเยื้อ
- แรงงานนอกระบบและทักษะที่ไม่ได้รับการรับรอง: ในหลายประเทศรวมทั้งประเทศไทย แรงงานนอกระบบและผู้ที่มีทักษะจากการเรียนรู้ด้วยตนเองมักไม่ได้ถูกบันทึกครบถ้วน ทำให้การประเมินกำลังแรงงานที่แท้จริงคลาดเคลื่อน
แนวโน้มหลังโควิดและความจำเป็นของข้อมูลที่ทันเวลา
หลังการระบาดของโควิด-19 ความต้องการทักษะดิจิทัลเพิ่มขึ้นอย่างชัดเจน ไม่เพียงแต่ในภาคเทคโนโลยีเท่านั้น แต่ยังรวมถึงภาคบริการ การผลิต และการเงิน ธุรกิจต้องการการจ้างงานที่ยืดหยุ่นและบุคลากรที่สามารถปรับตัวได้เร็ว จึงเกิดความต้องการระบบจับคู่งานที่ อิงทักษะเป็นหลัก (skills-based matching) และอัปเดตแบบเรียลไทม์ เพื่อช่วยลดช่องว่างทักษะและลดเวลาที่ตลาดแรงงานต้องใช้ในการปรับสมดุล
แหล่งข้อมูลที่ควรใช้ยืนยันและอ้างอิง
เพื่อการวางนโยบายและพัฒนาเครื่องมือแก้ปัญหาช่องว่างทักษะอย่างมีประสิทธิภาพ ควรอ้างอิงจากแหล่งข้อมูลต่อไปนี้: รายงานกระทรวงแรงงาน/กรมการจัดหางานของไทย, สำนักงานสถิติแห่งชาติ (NSO), สำนักงานสภาพัฒนาเศรษฐกิจและสังคมแห่งชาติ (NESDC), รายงานธนาคารโลกและ ILO, WEF (Future of Jobs), OECD, ManpowerGroup, LinkedIn Economic Graph ซึ่งแต่ละแหล่งจะช่วยให้เห็นภาพทั้งอุปสงค์-อุปทานทักษะ รายละเอียดตามอุตสาหกรรม และแนวโน้มการจ้างงานหลังโควิดได้ชัดเจนยิ่งขึ้น
เทคโนโลยีเบื้องหลัง: Graph‑ML, Skill Ontology และการจับคู่เชิงเรียลไทม์
พื้นฐานของ Graph‑ML และบทบาทในการจับคู่งาน
Graph Machine Learning (Graph‑ML) เป็นกรอบวิธีการที่ออกแบบมาเพื่อเรียนรู้จากข้อมูลที่มีโครงสร้างเป็นกราฟ ซึ่งประกอบด้วย nodes (ตัวแทนเช่น ผู้หางาน ตำแหน่งงาน ทักษะ สถาบันการศึกษา) และ edges (ความสัมพันธ์เช่น เคยทำงานที่เดียวกัน มีทักษะเดียวกัน ผ่านการสอบหรือมีการฝึกอบรมร่วมกัน) ข้อมูลเหล่านี้มักมีคุณสมบัติประกอบ (features) เช่น ระดับประสบการณ์ คะแนนการประเมิน หรือประวัติการฝึกอบรม
การทำงานของ Graph‑ML มักอาศัยการแปลงโครงสร้างกราฟเป็น embeddings ซึ่งเป็นเวกเตอร์เชิงตัวเลขที่จับความหมายเชิงโครงสร้างและเชิงเนื้อหาของโหนดไว้ ทำให้สามารถคำนวณความคล้ายคลึง (similarity) ระหว่างผู้หางานกับตำแหน่งงานได้อย่างมีประสิทธิภาพ ตัวอย่างอัลกอริทึมที่นิยมใช้ได้แก่ Graph Neural Networks (GNNs) เช่น GCN, GraphSAGE, GAT ที่สามารถเรียนรู้การรวมข้อมูลจากเพื่อนบ้านบนกราฟ และอัลกอริทึม embedding แบบไม่ใช้กราฟเชิงลึกเช่น node2vec ที่สร้างตัวอย่างการเดินสุ่ม (random walks) บนกราฟแล้วเรียนรู้เวกเตอร์โดยวิธีการฝังคำ (word2vec‑style)
ตัวอย่างเชิงปฏิบัติ: การทดสอบเบื้องต้นในระบบที่ใช้ Graph‑ML แสดงให้เห็นว่าการพิจารณาความสัมพันธ์บนกราฟ (เช่น เครือข่ายอาชีพและการฝึกอบรมร่วมกัน) สามารถเพิ่มความแม่นยำในการจับคู่ (precision@10) ประมาณ 15–30% เมื่อเทียบกับการจับคู่แบบดั้งเดิมที่ใช้เพียง keyword matching หรือ TF‑IDF
บทบาทของ Skill Ontology ในการทำให้ทักษะมีความหมายร่วมกัน
Skill Ontology เป็นโครงสร้างเชิงความหมาย (semantic layer) ที่นิยามและจัดระบบทักษะอย่างเป็นมาตรฐาน โดยมีองค์ประกอบสำคัญ เช่น การแมปคำพ้องความหมาย (synonyms), การจัดลำดับชั้นของทักษะ (hierarchies เช่น "การเขียนโปรแกรม" > "ภาษาโปรแกรม" > "Python"), และการกำหนดระดับความสามารถ (competency levels) เช่น เบื้องต้น/ปานกลาง/เชี่ยวชาญ
บทบาทหลักของ ontology ในระบบจับคู่งานคือการทำให้คำอธิบายทักษะจากแหล่งข้อมูลต่าง ๆ สามารถตีความร่วมกันได้ เช่น เมื่อผู้ประกอบการระบุว่า "Java developer" และผู้หางานเขียนในเรซูเม่ว่า "Spring framework" ระบบ ontology จะช่วยแมปความสัมพันธ์เชิงความหมายและระบุระดับความเชี่ยวชาญที่สอดคล้องกัน นอกจากนี้ ontology ยังรองรับการแมปกับมาตรฐานภายนอก (เช่น ESCO, O*NET) เพื่อให้สามารถเปรียบเทียบทักษะในระดับประเทศหรือระหว่างอุตสาหกรรมได้
Pipeline การจับคู่แบบเรียลไทม์: จากการรับข้อมูลถึงการเรียนรู้จากผลลัพธ์
ระบบจับคู่งานเชิงเรียลไทม์ต้องประกอบด้วยขั้นตอนที่เชื่อมต่อกันอย่างเป็นระบบ ตั้งแต่การรับข้อมูล (data ingestion) จนถึงการปรับปรุงโมเดลจากผลลัพธ์จริง (feedback loop) โดย pipeline หลักประกอบด้วย:
- Data ingestion & streaming: รับข้อมูลแบบเรียลไทม์จาก API ของแพลตฟอร์มสมัครงาน ระบบ ATS (Applicant Tracking System) และแหล่งข้อมูลภายนอก ผ่านระบบข้อความต่อเนื่อง (เช่น Apache Kafka หรือ Apache Pulsar) เพื่อรองรับปริมาณข้อมูลสูงและความหน่วงต่ำ
- Normalization & Preprocessing: ทำความสะอาดข้อมูล แปลงฟิลด์ที่ไม่สอดคล้องให้อยู่ในรูปแบบเดียวกัน และใช้ Skill Ontology ในการแมปคำทักษะ คำพ้องความหมาย และการระบุระดับความสามารถ (เช่น แปลง "senior", "Lead", "5+ years" เป็นระดับ competency ที่สอดคล้อง)
- Graph construction: สร้างกราฟแบบไฮบริดที่รวมโหนดหลายประเภท (ผู้หางาน, ตำแหน่งงาน, ทักษะ, บริษัท, คอร์ส) และขอบเชิงความสัมพันธ์ (เช่น มีทักษะ, ผ่านการอบรม, เคยทำงานร่วมกัน) เพื่อให้โครงสร้างข้อมูลสะท้อนบริบทเชิงสังคมและเชิงอาชีพ
- Embedding & Representation learning: ใช้ GNNs หรือวิธี embedding อื่น ๆ (เช่น node2vec เป็น baseline ที่เบาและเร็ว) เพื่อเรียนรู้เวกเตอร์แทนโหนดและความสัมพันธ์ โดยพิจารณาทั้ง features ของโหนดและโครงสร้างกราฟ
- Similarity scoring & Ranking: คำนวณความคล้ายคลึงระหว่างเวกเตอร์ของผู้หางานและตำแหน่งงาน (cosine similarity, dot product) และรวมสัญญาณเชิงธุรกิจเพิ่มเติม เช่น ความพร้อมที่จะย้ายงาน คะแนนความเข้ากันของวัฒนธรรมบริษัท และความต้องการด่วน เพื่อจัดลำดับผลลัพธ์ให้เหมาะสม
- Feedback loop & Online learning: บันทึกเหตุการณ์เชิงพฤติกรรม (เช่น click‑through, การส่งใบสมัคร, การสัมภาษณ์, การจ้างงาน) แล้วใช้ข้อมูลนั้นในการปรับน้ำหนักของกราฟหรือปรับพารามิเตอร์โมเดลอย่างต่อเนื่องด้วยเทคนิค online learning หรือ incremental retraining เพื่อให้โมเดลตอบสนองต่อแนวโน้มตลาดแรงงานแบบเรียลไทม์
สถาปัตยกรรมเรียลไทม์และการบูรณาการกับระบบภายนอก
เพื่อรองรับการจับคู่แบบเรียลไทม์ ระบบต้องออกแบบให้มี latency ต่ำและสามารถ scale ได้ ตัวอย่างองค์ประกอบทางสถาปัตยกรรมที่สำคัญได้แก่ การใช้ระบบ streaming (Kafka), processing แบบสตรีม (Flink, Spark Structured Streaming), บริการ embedding แบบแมนนาที (model‑serving) และฐานข้อมูลกราฟที่สามารถอ่าน/เขียนด้วยความเร็วสูง (เช่น Neo4j, Amazon Neptune หรือฐานข้อมูลเวกเตอร์สำหรับการค้นหาใกล้เคียง) นอกจากนี้ API integration จะเชื่อมต่อกับระบบ HR ของนายจ้างเพื่อดึงข้อมูลตำแหน่งงานอย่างต่อเนื่อง และส่งผลลัพธ์การแมตช์กลับไปแบบ synchronous หรือ asynchronous ตามความต้องการของลูกค้า
การเรียนรู้แบบออนไลน์ (online learning) เป็นหัวใจสำคัญของการปรับปรุงโมเดลในสภาพแวดล้อมที่เปลี่ยนแปลงเร็ว: แทนที่จะรอการฝึกซ้ำแบบ batch ขนาดใหญ่ ระบบสามารถอัปเดต embedding หรือน้ำหนักของ GNN จากสัญญาณเชิงพฤติกรรมที่เข้ามาใหม่ ทำให้โมเดลคงความสอดคล้องกับตลาดแรงงาน เช่น หากมีการเพิ่มความต้องการทักษะใหม่ การเรียนรู้ออนไลน์จะช่วยให้คำแนะนำมีความสอดคล้องทันที
โดยสรุป การผสมผสานระหว่าง Graph‑ML ที่จับความสัมพันธ์เชิงโครงสร้างได้อย่างลึกซึ้ง กับ Skill Ontology ที่ทำให้คำอธิบายทักษะมีความหมายร่วมกัน พร้อมสถาปัตยกรรมเรียลไทม์ที่รองรับการ ingest, stream และ online learning จะช่วยให้ระบบจับคู่งาน‑ผู้หางานมีความแม่นยำ โปร่งใส และปรับตัวได้เร็วต่อความเปลี่ยนแปลงของตลาดแรงงาน
การออกแบบการทดลองของกระทรวง: วิธีการ วัตถุชี้วัด และกลุ่มตัวอย่าง
โครงสร้างการทดลอง (Pilot Design)
การออกแบบการทดลองของกระทรวงจะใช้กรอบ A/B testing แบบสุ่มควบคุม (randomized controlled trial) เพื่อเปรียบเทียบประสิทธิภาพของระบบจับคู่งานแบบเดิมกับระบบใหม่ที่ขับเคลื่อนด้วย Graph‑ML และออนโทโลยีทักษะ โดยจะแบ่งผู้เข้าร่วมเป็นสองกลุ่มหลัก: กลุ่มควบคุม ที่ยังใช้กระบวนการจับคู่แบบปัจจุบัน และ กลุ่มทดลอง ที่ใช้ระบบ AI ใหม่เต็มรูปแบบ การสุ่มจะทำในระดับผู้หางาน (individual-level randomization) และ/หรือระดับศูนย์จัดหางาน (cluster randomization) ขึ้นอยู่กับบริบทพื้นที่เพื่อลดการแพร่กระจายของผลกระทบ (spillover).

ขนาดตัวอย่าง พื้นที่นำร่อง และระยะเวลา
แผนการทดลองเบื้องต้นแนะนำขนาดตัวอย่างรวมประมาณ 3,000–5,000 ผู้หางาน และประมาณ 300–500 นายจ้าง ในพื้นที่นำร่อง 3–5 จังหวัดที่มีลักษณะตลาดแรงงานต่างกัน (เช่น เขตเมืองใหญ่ เขตอุตสาหกรรม และพื้นที่ชนบท) ตัวอย่างเป็นการผสมระหว่างผู้สมัครงานที่ลงทะเบียนใหม่และผู้ที่มีโปรไฟล์ในฐานข้อมูลเดิม การทดลองจะดำเนินการตลอดระยะเวลาอย่างน้อย 6 เดือน (รวมช่วงทดลองใช้งานจริง 3–4 เดือน และติดตามผลระยะยาว 3–6 เดือนเพิ่มเติมสำหรับการวัด retention)
การสุ่มตัวอย่างและการจัดกลุ่ม
- การสุ่มแบบเท่ากัน (1:1) แบ่งผู้หางานเป็นกลุ่ม A (ระบบเดิม) และกลุ่ม B (ระบบ AI) เพื่อให้ความสามารถในการเปรียบเทียบชัดเจน
- การสุ่มแบบกลุ่ม (cluster) ในกรณีศูนย์จัดหางาน เพื่อป้องกันการรั่วไหลของการเรียนรู้และการนำระบบมาใช้ร่วมกัน ระบุศูนย์ 30–50 ศูนย์ แบ่งเป็น control vs treatment
- เกณฑ์การรวมตัวอย่าง ระบุอายุ การศึกษา สาขาอาชีพ ประสบการณ์ และระดับทักษะ เพื่อให้แน่ใจว่าการเปรียบเทียบมีความสมดุลและสามารถทำการปรับเทียบ (stratification) ได้
- การคำนวณขนาดตัวอย่าง ตั้งสมมติฐานผลการทดสอบ เช่น ต้องการตรวจจับการเพิ่มขึ้นของ match rate ร้อยละ 8–10 ด้วยพลังทางสถิติ 80% และระดับนัยสำคัญ 5%
ตัวชี้วัด (KPI) เชิงปริมาณและเกณฑ์ความสำเร็จ
กำหนด KPI หลักเพื่อประเมินความสำเร็จของระบบอย่างเป็นรูปธรรมและวัดผลได้ ดังนี้
- Match rate: สัดส่วนผู้หางานที่ได้รับการจับคู่ที่เหมาะสมต่อผู้สมัครทั้งหมด เป้าหมายความสำเร็จเบื้องต้น: เพิ่มขึ้นอย่างน้อย 10% เทียบกับระบบเดิม
- Time‑to‑hire: เวลาตั้งแต่การโพสต์งาน/ส่งใบสมัครจนถึงการยอมรับข้อเสนอ เป้าหมาย: ลดลงอย่างน้อย 20%
- Retention rate: สัดส่วนผู้ถูกจ้างที่ยังคงทำงานในตำแหน่งนั้นหลัง 3 และ 6 เดือน เป้าหมาย: เพิ่มขึ้นอย่างน้อย 15%
- Satisfaction score: คะแนนความพึงพอใจของผู้หางานและนายจ้าง (Likert scale หรือ NPS) เป้าหมาย: ขยับขึ้นอย่างมีนัยสำคัญทางสถิติ
- Quality of match: ดัชนีประเมินความสอดคล้องทักษะ (skill-fit score) ที่คำนวณจากออนโทโลยีและผลสัมภาษณ์เบื้องต้น
เกณฑ์ความสำเร็จรวมถึงผลที่มีความแตกต่างทางสถิติ (p < 0.05) ระหว่างกลุ่มทดลองและกลุ่มควบคุม และประสิทธิผลทางธุรกิจที่ชัดเจน เช่น ลดต้นทุนการสรรหาต่อการจ้างได้จริง
มาตรการบันทึกผลและการประเมินผลทางสถิติ
การบันทึกผลจะทำโดยระบบล็อกอีเวนท์ (event logging) ครอบคลุมการกระทำสำคัญ เช่น การค้นหา การจับคู่ การตอบรับข้อเสนอ และการเริ่มงาน พร้อมบันทึกเมตาดาต้า (timestamp, source, profile id) เพื่อสนับสนุนการวิเคราะห์แบบ intent‑to‑treat และ per‑protocol analyses นอกจากนี้จะใช้การทดสอบทางสถิติ เช่น t‑test, chi‑square, และ regression models เพื่อควบคุมตัวแปรรบกวนและวัดขนาดผล (effect size) โดยตั้งค่าเบื้องต้นให้มีการตรวจสอบความแตกต่างแบบ pre‑specified interim analysis หากจำเป็น
การเก็บข้อมูลเชิงคุณภาพและการประเมินเชิงภาคสนาม
นอกเหนือจากข้อมูลเชิงปริมาณ จะมีการเก็บข้อมูลเชิงคุณภาพผ่านหลายช่องทางเพื่อให้เข้าใจบริบทและประสบการณ์ของผู้ใช้งาน เช่น
- สัมภาษณ์เชิงลึก (In‑depth interviews): กับกลุ่มผู้หางานและนายจ้างอย่างน้อย 50–100 ราย เพื่อสอบถามถึงความเหมาะสมของผลลัพธ์ ความเข้าใจต่อคำแนะนำของระบบ และอุปสรรคในการนำไปใช้
- การสังเกตการณ์ภาคสนาม (Field observation): ติดตามการใช้งานจริงในศูนย์จัดหางานและสถานประกอบการเพื่อบันทึกการโต้ตอบกับระบบ
- เวิร์กช็อปกลุ่มโฟกัส (Focus groups): เพื่อเก็บความคิดเห็นเชิงสังคมและข้อเสนอแนะเชิงนโยบาย
- การเก็บบันทึกเหตุการณ์สำคัญ: กรณีตัวอย่างของการจับคู่ที่ประสบความสำเร็จหรือไม่สำเร็จ เพื่อนำมาวิเคราะห์เชิงคุณภาพ
การมีส่วนร่วมของนายจ้าง ศูนย์จัดหางาน และแผนการฝึกอบรม
เพื่อให้การทดลองเกิดผลจริง กระทรวงจะกำหนดบทบาทชัดเจนสำหรับนายจ้างและศูนย์จัดหางาน รวมทั้งจัดแผนการฝึกอบรมดังนี้:
- การมีส่วนร่วมของนายจ้าง: จัดทำข้อตกลงความร่วมมือ (MOU) ระบุเป้าหมายการทดลอง ให้สิทธิพิเศษในการเข้าถึงรายงานสรุปผล เป็นผู้ให้ feedback ในการปรับปรุงโมเดล
- บทบาทศูนย์จัดหางาน: ทำหน้าที่เป็นจุดติดต่อพื้นที่ รับผิดชอบการคัดกรองเบื้องต้น ช่วยประสานงานสัมภาษณ์ และเก็บข้อมูลภาคสนาม
- แผนการฝึกอบรมผู้ใช้งาน: จัดคอร์สฝึกอบรมแบบผสมผสาน (classroom + e‑learning) เน้นวิธีการใช้งานระบบ การตีความผลลัพธ์ และการจัดการข้อร้องเรียน ตลอดจนจัดคู่มือและสายช่วยเหลือ (helpdesk) ตลอดช่วง pilot
การออกแบบนี้เน้นความโปร่งใส ความเป็นธรรมในกระบวนการทดลอง และการวัดผลที่เข้มงวดเพื่อให้ข้อมูลเชิงประจักษ์แก่การตัดสินใจขยายระบบในวงกว้างต่อไป
ผลลัพธ์เบื้องต้นและเคสศึกษาที่น่าสนใจ
ผลลัพธ์เบื้องต้นและเคสศึกษาที่น่าสนใจ
จากการทดลองระบบจับคู่งานด้วย Graph‑ML ร่วมกับออนโทโลยีทักษะในชุดนำร่องของกระทรวงแรงงาน (ตัวอย่างข้อมูล: ผู้หางาน n=2,500, นายจ้าง n=780) พบผลลัพธ์เชิงสถิติที่ชัดเจนเมื่อนำมาเปรียบเทียบกับกระบวนการจับคู่งานแบบเดิมที่ใช้คีย์เวิร์ดและการคัดกรองด้วยมนุษย์เพียงอย่างเดียว โดยสรุปเบื้องต้นได้ดังนี้:
ตัวชี้วัดหลัก (ก่อน-หลัง):
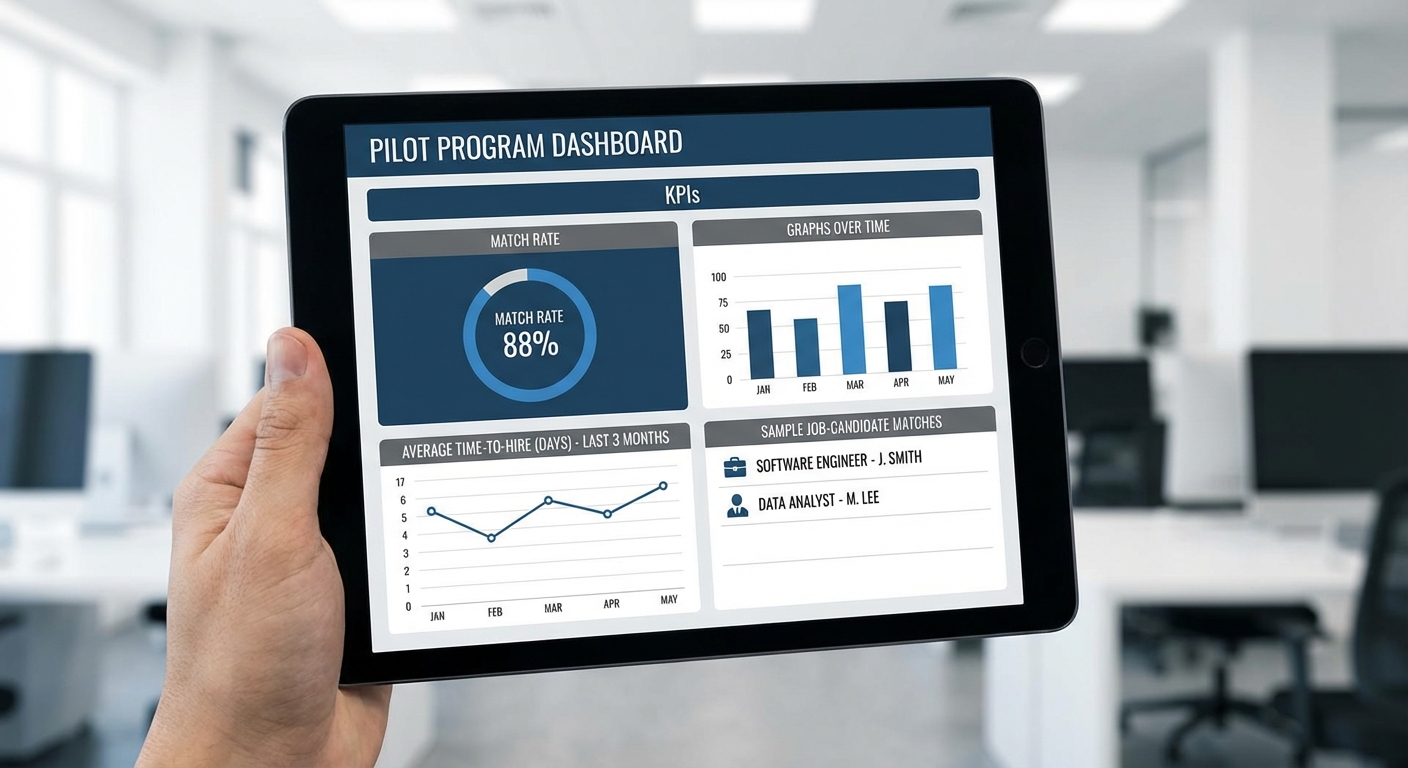
- อัตราการจับคู่ (match rate) เพิ่มจากเฉลี่ย 42% เป็น 63% (เพิ่ม +21 จุด หรือเพิ่มเชิงสัมพัทธ์ประมาณ +50%) ในช่วงทดลอง 3 เดือนแรก
- เวลาเฉลี่ยในการจับคู่จนได้ผู้สมัครที่ผ่านการคัดกรองเบื้องต้น ลดจาก 28 วัน เป็น 9 วัน (ลดลง 19 วัน หรือประมาณ 68% ของเวลาเดิม)
- เวลาในการคัดกรองต่อผู้สมัครโดยนายจ้าง ลดจาก 120 นาทีเป็น 35 นาทีต่อผู้สมัคร (ลดลง ~71%) เนื่องจากระบบจัดลำดับความสัมพันธ์ทักษะและความเหมาะสมเชิงบริบทได้ดีกว่า
- คุณภาพการจับคู่ (employer satisfaction) ตามแบบสอบถามหลังจ้างงานเพิ่มจากค่าเฉลี่ย 3.2 เป็น 4.1 จาก 5 คะแนน และอัตราการคงงานที่ 3 เดือน (3‑month retention) เพิ่มจาก 62% เป็น 78%
ผลตัวเลขข้างต้นสะท้อนว่าการรวม Graph‑ML สำหรับการวิเคราะห์เครือข่ายทักษะกับออนโทโลยีที่นิยามความสัมพันธ์เชิงความหมายระหว่างทักษะ ช่วยเพิ่มความแม่นยำในการแมปทักษะข้ามสาขา (skill transferability) และลดเวลาที่ทั้งผู้หางานและนายจ้างใช้ในการค้นหาและคัดกรอง ซึ่งเป็นประโยชน์เชิงเศรษฐกิจและสังคมเมื่อขยายสเกลการใช้งานต่อไป
เคสศึกษา 1 — ครูม.ปลายสู่ผู้พัฒนาหลักสูตรฝึกอบรมภาคเอกชน
- บริบทและปัญหาเดิม: ครูผู้สอนวิชาวิทยาศาสตร์ระดับมัธยม มีประสบการณ์สอนและออกแบบบทเรียน แต่พบอัตราการว่างงานชั่วคราวเมื่อต้องเปลี่ยนงานหรือย้ายพื้นที่ เนื่องจากคำประกาศงานภาคเอกชนไม่ระบุคำว่า “การสอน” แต่ต้องการทักษะด้านการออกแบบการเรียนการสอนและการประเมินผล
- การจับคู่ใหม่โดยระบบ: ออนโทโลยีแมปความสัมพันธ์ระหว่างทักษะเชิงการสื่อสาร การออกแบบหลักสูตร การประเมินผลการเรียนรู้ และการใช้สื่อการสอน เข้ากับตำแหน่ง “Learning & Development Specialist” ผ่านกราฟเชิงความสัมพันธ์ (Graph‑ML) ที่ชี้ให้เห็น transferable skills
- ผลลัพธ์: ผู้หางานได้รับเชิญสัมภาษณ์ภายใน 7 วัน ถูกจ้างภายใน 14 วันจากการแมป และรายได้เพิ่มขึ้นประมาณ 15% เมื่อเทียบกับรายได้ก่อนหน้านี้ พร้อมการประเมินความพึงพอใจจากนายจ้าง 4.3/5
เคสศึกษา 2 — ช่างเทคนิคอุตสาหกรรมสู่ผู้ปฏิบัติงานโลจิสติกส์พร้อมระบบอัตโนมัติ
- บริบทและปัญหาเดิม: ช่างเทคนิคที่มีทักษะการบำรุงรักษาเครื่องจักร อาจไม่มีคำสำคัญตรงกับตำแหน่งโลจิสติกส์ที่ต้องการความเข้าใจระบบอัตโนมัติและการตรวจสอบเครื่องมือ
- การจับคู่ใหม่โดยระบบ: Graph‑ML ระบุความสัมพันธ์ระหว่างทักษะการอ่านชาร์ตเครื่องจักร ทักษะการตรวจวัด และความรู้ด้านการควบคุมคุณภาพ สามารถแมปไปยังตำแหน่ง “Operator ระบบจัดเก็บอัตโนมัติ” พร้อมคำแนะนำหลักสูตรฝึกอบรมเฉพาะจุด 40 ชั่วโมง
- ผลลัพธ์: ลดเวลาในการฝึกงานลง 30% เมื่อเทียบกับโปรแกรมมาตรฐาน ผู้สมัครสามารถปฏิบัติงานได้เต็มรูปแบบภายใน 3 สัปดาห์และอัตราการคงงาน 6 เดือนอยู่ที่ 85%
เคสศึกษา 3 — นักวิเคราะห์ข้อมูลระดับเริ่มต้นจากสาขาสถิติสู่บทบาท Product Insights
- บริบทและปัญหาเดิม: ผู้สำเร็จการศึกษาสาขาสถิติที่มีความสามารถด้านการวิเคราะห์ แต่ไม่มีประสบการณ์ด้านธุรกิจหรือการสื่อสารเชิงผลิตภัณฑ์ มักถูกปัดตกโดยระบบกรองคีย์เวิร์ด
- การจับคู่ใหม่โดยระบบ: ออนโทโลยีและ Graph‑ML ระบุความสัมพันธ์ระหว่างทักษะเชิงตัวเลขกับทักษะการเล่าเรื่องข้อมูล (data storytelling) และการใช้เครื่องมือ BI จึงแมปผู้สมัครกับตำแหน่ง “Product Insights Analyst” โดยระบุช่องว่างทักษะชัดเจนและแนะนำหลักสูตรไมโครเลิร์นนิง 20 ชั่วโมง
- ผลลัพธ์: ผู้สมัครได้รับข้อเสนอภายในเดือนแรกของการประกาศตำแหน่ง เข้าทำงานและได้รับการประเมินผลเชิงบวกจากทีมผลิตภัณฑ์ โดยลดขั้นตอนสัมภาษณ์ลง 40% และเพิ่มความหลากหลายทางทักษะในทีม
ข้อสังเกตและปัจจัยที่อาจส่งผลต่อความสำเร็จ
- คุณภาพข้อมูล: ระบบพึ่งพาข้อมูลเรซูเม่และคำบรรยายงานที่ครบถ้วนและมีโครงสร้าง หากเรซูเม่เป็นข้อความไม่เป็นระบบหรือคำบรรยายงานไม่อัปเดต อัตราความแม่นยำจะลดลงอย่างมีนัยสำคัญ (ประเมินว่า ข้อมูลที่ไม่สมบูรณ์ลด match rate ลง 15–25%)
- ความร่วมมือจากนายจ้าง: นายจ้างที่ปรับคำอธิบายงานให้มีเมตาดาต้าและเปิดรับ transferable skills จะได้ผลลัพธ์ดีขึ้น นักวิเคราะห์ของโครงการพบว่าองค์กรที่ให้ข้อมูลเพิ่มเติมเกี่ยวกับระดับทักษะที่ต้องการมีอัตราการรับสมัครเพิ่มขึ้นกว่าองค์กรที่ไม่ให้ข้อมูลชัดเจนถึง 1.8 เท่า
- ความเป็นส่วนตัวและความโปร่งใสของอัลกอริทึม: ความกังวลด้านความเป็นส่วนตัวและการอธิบายเหตุผลที่ระบบจับคู่เป็นสิ่งที่นายจ้างและผู้หางานร้องขอ หากไม่มีฟีเจอร์ explainability จะส่งผลต่อความเชื่อมั่นและการยอมรับในระยะยาว
- อคติในข้อมูลและออนโทโลยี: หากออนโทโลยีถูกออกแบบจากชุดข้อมูลเฉพาะกลุ่ม อาจนำไปสู่อคติต่อบางอาชีพหรือกลุ่มประชากร จำเป็นต้องมีการตรวจสอบ fairness และการทดสอบกับชุดข้อมูลภายนอก
- สเกลและการบูรณาการกับระบบเดิม: การเชื่อมต่อแบบเรียลไทม์กับระบบ LMS, HRIS หรือพอร์ทัลสมัครงานของภาคเอกชนต้องการมาตรฐาน API และความร่วมมือทางเทคนิค มิฉะนั้นเวลาตอบสนองแบบเรียลไทม์จะลดลง
สรุปได้ว่าผลการทดลองในระยะเริ่มต้นชี้ให้เห็นศักยภาพของการใช้ Graph‑ML ร่วมกับออนโทโลยีทักษะในการลดช่องว่างทักษะและเพิ่มประสิทธิภาพการจับคู่ แต่ความสำเร็จเชิงปริมาณที่ยั่งยืนยังขึ้นกับการปรับปรุงคุณภาพข้อมูล ความร่วมมือของนายจ้าง และการออกแบบนโยบายการคุ้มครองข้อมูลและการป้องกันอคติของอัลกอริทึม
จริยธรรม ความเป็นส่วนตัว และความเอนเอียงของอัลกอริธึม
จริยธรรม ความเป็นส่วนตัว และความเอนเอียงของอัลกอริธึม
เมื่อกระทรวงแรงงานนำระบบ AI ที่ใช้ Graph‑ML และออนโทโลยีมาจับคู่งานแบบเรียลไทม์ ประเด็นด้านจริยธรรมและความเป็นส่วนตัวไม่ได้เป็นเพียงข้อพิจารณาทางกฎหมายเท่านั้น แต่เป็นปัจจัยสำคัญที่ส่งผลต่อความเชื่อมั่นของผู้หางานและนายจ้าง รวมถึงความเป็นธรรมของตลาดแรงงาน ระบบเหล่านี้อาศัยข้อมูลเชิงลึกจากประวัติการทำงาน ทักษะ การศึกษา และข้อมูลส่วนบุคคลอื่น ๆ ซึ่งการจัดการข้อมูลต้องสอดคล้องกับหลักการพื้นฐาน ได้แก่ การยินยอมอย่างชัดเจน (consent), การลดข้อมูลให้จำเป็นที่สุด (data minimization), และ การเก็บรักษาอย่างปลอดภัยและจำกัดเวลา (storage limitation) เพื่อให้สอดคล้องกับมาตรฐาน PDPA, GDPR และแนวปฏิบัติสากล
ในแง่ของความเป็นส่วนตัว ควรมีนโยบายที่ชัดเจนทั้งการขอและการจัดการความยินยอม: ต้องแจ้งให้ผู้ใช้ทราบว่าข้อมูลใดถูกเก็บ มีวัตถุประสงค์ใด จะใช้ในระยะเวลาเท่าใด และผู้ใช้สามารถเพิกถอนความยินยอมได้ตลอดเวลา นอกจากนี้ระบบต้องมีมาตรการทางเทคนิค เช่น การ pseudonymization และการเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง (encryption at rest & in transit) รวมถึงการจำกัดสิทธิ์การเข้าถึงข้อมูลภายในหน่วยงานและผู้รับจ้างภายนอก (third‑party processors) เพื่อกันไม่ให้เกิดการใช้ข้อมูลเกินวัตถุประสงค์เดิม
ประเด็นการเอนเอียง (bias) ของโมเดลเป็นความเสี่ยงที่มีผลกระทบเชิงโครงสร้าง ตัวอย่างเช่น กรณีของบริษัทเทคโนโลยีข้ามชาติที่ต้องยุติระบบคัดเลือกผู้สมัครหลังพบว่าโมเดลมีอคติเพราะข้อมูลฝึกมีการถ่วงน้ำหนักเพศ หรือกรณีการประเมินความเสี่ยงในระบบยุติธรรมที่มีอคติทางเชื้อชาติ (เช่น กรณีที่รายงานโดยสำนักข่าวและงานวิจัยต่างประเทศ) จากประสบการณ์ในภาคสนาม พบว่า การทดสอบความเป็นธรรมเบื้องต้นมักเผยความต่างของผลลัพธ์ระหว่างกลุ่มประชากรอยู่ในระดับสองหลัก (เช่น 10–30%) หากไม่ได้ป้องกันตั้งแต่ต้น
เพื่อป้องกันและลดอคติ ควรบังคับให้มีการทดสอบความเป็นธรรมก่อนใช้งานและแบบต่อเนื่อง (fairness testing) โดยใช้มาตรการเชิงสถิติหลายมิติ เช่น equality of opportunity, demographic parity, calibration และการทดสอบแบบข้ามกลุ่ม (cross‑group testing) รวมถึงกลไกแก้ไข (bias mitigation) ที่เป็นทั้งก่อนการฝึก (rebalancing, reweighting), ระหว่างการฝึก (fairness‑aware learning, adversarial debiasing) และหลังการฝึก (post‑hoc calibration, threshold adjustment) การนำกลยุทธ์หลายวิธีมาประยุกต์พร้อมการตรวจวัดผลเชิงปริมาณจะช่วยลดความเสี่ยงได้มากขึ้น
ความโปร่งใสและความสามารถในการอธิบายผลลัพธ์ (explainability) เป็นหัวใจสำคัญสำหรับการยอมรับระบบ โดยผู้หางานและนายจ้างต้องสามารถเข้าใจเหตุผลเบื้องต้นของคำแนะนำหรือการปฏิเสธ เช่น ทำไมระบบแนะนำตำแหน่งหนึ่งแทนอีกตำแหน่งหนึ่ง ควรมีระดับคำอธิบายที่เหมาะสมทั้งแบบสั้นเพื่อผู้ใช้ทั่วไปและแบบเชิงเทคนิคสำหรับผู้เชี่ยวชาญ HR/กฎหมาย ตัวอย่างวิธีการที่ใช้ได้แก่การนำเสนอ "ฟีเจอร์ที่มีผลมากที่สุด" (feature importance), คำอธิบายเชิงกรณีตัวอย่าง (counterfactual explanations), และเทคนิคเชิงสถิติ/โมเดลเช่น SHAP หรือ LIME สำหรับการอธิบายเฉพาะคำตัดสินของโมเดล
สุดท้าย กรอบกำกับดูแล (governance) ที่เข้มแข็งเป็นสิ่งจำเป็นและควรประกอบด้วยนโยบายและกระบวนการที่ชัดเจน ดังนี้
- Consent & purpose limitation: เอกสารขอความยินยอมที่เข้าใจง่าย ระบุวัตถุประสงค์การใช้งาน และช่องทางเพิกถอน
- Data minimization & retention policy: เก็บข้อมูลเฉพาะที่จำเป็น กำหนดระยะเวลาการเก็บและกระบวนการลบเมื่อหมดวัตถุประสงค์
- Audit trail & logging: บันทึกการเข้าถึงข้อมูลและการตัดสินใจของระบบเพื่อตรวจสอบย้อนหลัง (forensicability)
- Impact assessment: ดำเนินการ Data Protection Impact Assessment (DPIA) และ Algorithmic Impact Assessment ก่อนเปิดใช้ และทบทวนเป็นระยะ
- Independent audit & redress: เปิดรับการตรวจสอบจากหน่วยงานอิสระ มีช่องทางอุทธรณ์และเยียวยาสำหรับผู้ได้รับผลกระทบ
- Monitoring & retraining: ติดตามตัวชี้วัดความเป็นธรรมและประสิทธิภาพ โมเดลต้องถูกปรับปรุง/รีเทรนเมื่อพบการเสื่อมคุณภาพหรือการเกิดอคติใหม่
- Human‑in‑the‑loop: กำหนดจุดที่มนุษย์ตรวจสอบการตัดสินใจสำคัญ โดยเฉพาะกรณีที่มีผลกระทบเชิงลบต่อผู้เปราะบาง
สรุปแล้ว การนำ Graph‑ML และออนโทโลยีมาจับคู่แรงงานต้องเดินควบคู่กับมาตรการด้านจริยธรรมและการกำกับดูแลที่เป็นรูปธรรม ทั้งด้านความเป็นส่วนตัว การทดสอบและแก้ไขอคติ ความโปร่งใสในการอธิบายการตัดสินใจ และกรอบการตรวจสอบภายนอก หากออกแบบและบริหารจัดการอย่างรัดกุม ระบบจะสามารถเพิ่มประสิทธิภาพการจับคู่และลดช่องว่างทักษะได้โดยไม่แลกด้วยความเสี่ยงต่อสิทธิมนุษยชนและความเป็นธรรมในตลาดแรงงาน
แนวทางขยายผล เชิงนโยบาย และข้อเสนอแนะสำหรับการนำไปใช้จริง
แนวทางขยายผลเชิงนโยบาย: แนวทางสู่การนำระบบไปใช้ในระดับประเทศ
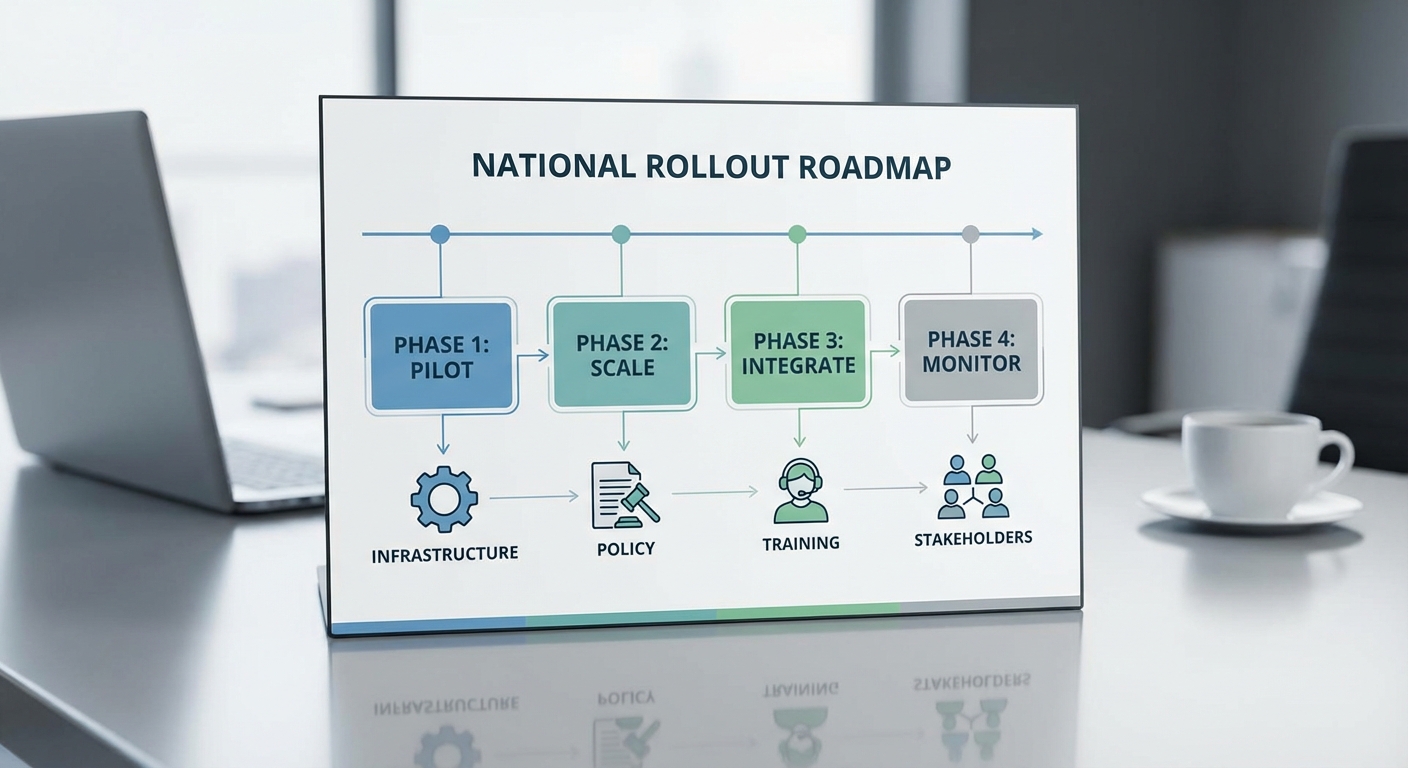
การขยายระบบ AI จับคู่งานด้วย Graph‑ML และทักษะออนโทโลยีไปสู่ระดับประเทศ ควรดำเนินการในรูปแบบแบบเป็นขั้นตอน (phased rollout) ที่มีการประเมินผลเชิงพื้นที่ก่อนขยายวงกว้าง โดยเริ่มจากการเลือกจังหวัดนำร่อง 3–5 แห่งที่มีลักษณะเศรษฐกิจและโครงสร้างแรงงานหลากหลาย เพื่อทดสอบการเชื่อมต่อกับศูนย์แรงงานจังหวัด สำนักงานจัดหางาน และกลุ่ม SMEs ในท้องถิ่น ขั้นตอนการขยายผลที่แนะนำได้แก่:
- เฟส 0 — เตรียมความพร้อมเชิงนโยบาย: จัดตั้งคณะทำงานระดับชาติ ประกอบด้วยกระทรวงแรงงาน กระทรวงศึกษาธิการ กระทรวงดิจิทัล และตัวแทนภาคเอกชน เพื่อกำหนดกรอบการกำกับดูแล การปกป้องข้อมูล และมาตรฐานทักษะร่วม
- เฟส 1 — นำร่องเชิงภูมิภาค: เปิดใช้งานในจังหวัดนำร่องพร้อม KPI ชัดเจน เช่น อัตราการจับคู่ (placement rate), เวลาจับคู่อ้างอิง (time-to-match) และการยอมรับจากนายจ้าง
- เฟส 2 — ขยายเป็นเครือข่ายภูมิภาค: ขยายสู่เครือข่ายจังหวัด/ภาค โดยใช้ศูนย์ข้อมูลภูมิภาค (regional data hubs) และแพลตฟอร์มกลางแบบเปิด (open APIs) เพื่อผสานข้อมูลกับแพลตฟอร์มภาครัฐ/เอกชน
- เฟส 3 — สเกลเป็นระดับประเทศ: ปรับสเกลโครงสร้างพื้นฐานด้านเทคนิคและการงบประมาณบนคลาวด์หรือไฮบริด เสริมมาตรการสนับสนุน SMEs และผนวกระบบเข้ากับสวัสดิการและการศึกษาอย่างถาวร
การสร้างและกำกับมาตรฐานทักษะระดับชาติ (National Skill Taxonomy)
การมี national skill taxonomy เป็นหัวใจสำคัญสำหรับความสำเร็จของระบบจับคู่งาน AI เนื่องจากเป็นฐานข้อมูลกลางที่ทำให้การแมปทักษะของผู้หางานและความต้องการของนายจ้างเป็นมาตรฐานเดียวกัน ควรมีกระบวนการดังนี้:
- จัดตั้งคณะทำงานสร้างมาตรฐานทักษะที่มีตัวแทนจากภาครัฐ สถาบันการศึกษา สมาคมวิชาชีพ และภาคเอกชน
- นำแนวปฏิบัติระดับสากล เช่น ESCO, O*NET มาปรับใช้และแมปกับบริบทแรงงานไทย
- กำหนดระดับความเชี่ยวชาญ (skill levels) และคำอธิบายตำแหน่งงาน (job profiles) ที่สามารถอ่านได้ทั้งโดยมนุษย์และเครื่อง (machine-readable)
- กำหนดกระบวนการอัปเดตเป็นรุ่น (versioning) ทุก 12–24 เดือน เพื่อสะท้อนการเปลี่ยนแปลงของตลาดงาน
การผสานกับระบบสวัสดิการและการศึกษา
เพื่อเพิ่มประสิทธิภาพของการจับคู่ ควรผสานข้อมูลและกระบวนการกับระบบสวัสดิการและการศึกษา โดยออกแบบให้ระบบสามารถ:
- ส่งต่อผู้ถูกคัดเลือกไปยังโปรแกรมฝึกทักษะ (upskilling/reskilling) ของสถาบันอาชีวะ มหาวิทยาลัย หรือผู้ให้บริการฝึกอบรมภาคเอกชน พร้อมสิทธิ์รับเงินอุดหนุนหรือคูปองการฝึกอบรม
- เชื่อมโยงกับระบบสวัสดิการเช่น เบี้ยว่างงาน การสนับสนุนการฝึกฝน เพื่อให้ผู้ถูกคัดเลือกได้รับการอุปถัมภ์ในช่วงเปลี่ยนงาน
- รองรับการออกและยืนยันวุฒิบัตรดิจิทัล (digital credentials) และการตรวจสอบประวัติทักษะ (skills verification) โดยมีมาตรการปกป้องข้อมูลส่วนบุคคล
แผนการฝึกอบรมบุคลากรและการเตรียมทรัพยากรด้านเทคนิค
การดำเนินระบบ AI ในระดับชาติจำเป็นต้องมีการลงทุนในบุคลากรทั้งเชิงเทคนิคและเชิงปฏิบัติการ แผนฝึกอบรมที่แนะนำประกอบด้วย:
- การอบรมเชิงเทคนิค: หลักสูตรสำหรับ data engineers, machine learning engineers, และ data stewards เพื่อดูแลการป้อนข้อมูล การฝึกโมเดล Graph‑ML และการบริหารระบบ MLOps
- การอบรมเชิงปฏิบัติการ: ฝึกอบรมเจ้าหน้าที่ศูนย์แรงงานและที่ปรึกษาอาชีพเกี่ยวกับการอ่านผลการจับคู่ การใช้งานแดชบอร์ด และการให้คำปรึกษาเชิงทักษะ
- การสร้างชุมชนการปฏิบัติ (communities of practice): เครือข่ายผู้เชี่ยวชาญเพื่อแลกเปลี่ยนกรณีศึกษา ปรับปรุงโมเดล และซ่อมบำรุงความรู้
ในด้านทรัพยากรเทคนิค ควรประเมินความต้องการเช่น ความจุฐานข้อมูล ปริมาณการประมวลผลสำหรับ Graph computations และค่าใช้จ่ายคลาวด์ โดยเบื้องต้นสำหรับการสเกลระดับภูมิภาค–ระดับประเทศ อาจต้องเผื่องบประมาณสำหรับ:
- ค่าสถาปัตยกรรมระบบและการพัฒนา API
- ต้นทุนคลาวด์/ฮาร์ดแวร์สำหรับการรัน Graph‑ML แบบเรียลไทม์
- ค่าใช้จ่ายด้านความมั่นคงปลอดภัยข้อมูลและการปฏิบัติตามกฎหมายคุ้มครองข้อมูล
ข้อเสนอเชิงนโยบายเพื่อสนับสนุนการนำระบบไปใช้ต่อเนื่อง
ข้อเสนอเชิงนโยบายที่ควรพิจารณาเพื่อให้ระบบสามารถดำเนินงานได้อย่างยั่งยืน ได้แก่:
- ออกประกาศมาตรฐานทักษะแห่งชาติ: ทำให้การอ้างอิงทักษะเป็นมาตรฐานเดียวที่หน่วยงานภาครัฐใช้ในการจัดสรรงบประมาณและออกใบรับรอง
- มาตรการสนับสนุน SMEs: ให้เงินอุดหนุนค่าธรรมเนียมการใช้งานแพลตฟอร์ม ช่องทางให้คำปรึกษาและเครื่องมือประเมินความต้องการทักษะ และสิทธิประโยชน์ทางภาษีสำหรับการจ้างงานตามระบบ
- แหล่งงบประมาณผสมผสาน: รวมงบกลางของรัฐ กองทุนสังคมสงเคราะห์ เงินกู้/เงินทุนจากองค์กรระหว่างประเทศ (เช่น ADB, World Bank) และการร่วมลงทุนจากภาคเอกชน (PPP) เพื่อกระจายความเสี่ยงและเพิ่มความยั่งยืนทางการเงิน
- กรอบกำกับดูแลข้อมูลและจริยธรรม AI: กำหนดแนวปฏิบัติเกี่ยวกับความโปร่งใส การอธิบายผลการจับคู่ และการป้องกันอคติ (bias mitigation)
ข้อพิจารณาด้านเทคนิค งบประมาณ และแผนการประเมินผลระยะยาว
ในการประเมินความสามารถในการสเกล ควรพิจารณาแยกเป็นมิติทางเทคนิคและงบประมาณอย่างชัดเจน โดยมีประเด็นสำคัญดังนี้:
- เทคนิค: ความต้องการแบนด์วิดท์และความหน่วงต่ำ (low-latency) สำหรับการจับคู่เรียลไทม์ ระบบแคชชิ่งสำหรับคำค้นหาซ้ำ การบริหารจัดการเวอร์ชันโมเดล และการสำรองข้อมูล (disaster recovery)
- งบประมาณ: แยกต้นทุนเป็นค่า CAPEX (โครงสร้างพื้นฐาน ฮาร์ดแวร์) และ OPEX (ค่าบริการคลาวด์ การบำรุงรักษา ทีมงาน) พร้อมประมาณการเป็นช่วง (เช่น งบประมาณเริ่มต้นสำหรับการขยาย 12 เดือนแรกอาจอยู่ในระดับ tens to hundreds of millions THB ขึ้นอยู่กับสโคปและการใช้คลาวด์)
- ระบบวัดผลระยะยาว: กำหนดชุดตัวชี้วัด (KPIs) ที่ชัดเจน เช่น อัตรการจับคู่สำเร็จ, เวลาจับคู่อาจลดลง (time-to-hire), อัตรการรักษางาน (job retention) 6–12 เดือนหลังการจ้าง, ผลกระทบต่อรายได้ของแรงงาน และดัชนีช่องว่างทักษะ (skill gap index)
- แผนประเมิน: ดำเนินการประเมินเบสไลน์ก่อนใช้งาน ลงมือประเมินเชิงกึ่งปี (6 เดือน) และประเมินเต็มรูปแบบที่ 12 เดือน จากนั้นกำหนดการประเมินประจำปี พร้อมใช้การออกแบบการทดลองเชิงนโยบาย เช่น stepped-wedge หรือ randomized controlled trials (RCTS) ในส่วนที่เหมาะสมเพื่อประเมินสาเหตุและผลลัพธ์เชิงสังคม-เศรษฐกิจ
สรุปแล้ว การขยายระบบ AI จับคู่งานสู่ระดับประเทศต้องอาศัยทั้งกรอบนโยบายที่ชัดเจน การสร้างมาตรฐานทักษะระดับชาติ การผสานกับระบบสวัสดิการและการศึกษา การลงทุนในทรัพยากรเทคนิคและบุคลากร ตลอดจนแผนประเมินผลระยะยาวเพื่อปรับปรุงอย่างต่อเนื่อง ซึ่งหากได้รับการออกแบบและสนับสนุนอย่างรอบด้าน จะช่วยลดช่องว่างทักษะ สนับสนุนการจ้างงานที่มีคุณภาพ และเพิ่มประสิทธิภาพตลาดแรงงานของประเทศ
บทสรุป
กระทรวงแรงงานทดลองระบบการจับคู่งานด้วยเทคนิค Graph‑ML ผสานกับ Skill Ontology เพื่อเชื่อมโยงผู้หางานและนายจ้างแบบเรียลไทม์ ซึ่งจากโครงการนำร่องและงานวิจัยเชิงเปรียบเทียบพบศักยภาพในการลดช่องว่างทักษะและเร่งความเร็วการจับคู่งาน ตัวอย่างโครงการนำร่องในประเทศอื่นและภาคเอกชนระบุผลเบื้องต้น เช่น อัตราการจับคู่งานเพิ่มขึ้นประมาณ 20–40% และระยะเวลาการสรรหาลดลงราว 15–30% ทั้งนี้ความสำเร็จของระบบขึ้นกับปัจจัยหลัก 3 ประการ ได้แก่ คุณภาพของข้อมูล (ข้อมูลทักษะต้องครบถ้วนและเป็นมาตรฐาน), การมีส่วนร่วมของนายจ้าง (การให้ข้อมูลตำแหน่งและความต้องการจริง) และ มาตรการกำกับดูแลด้านจริยธรรม เพื่อลดความลำเอียงและปกป้องสิทธิส่วนบุคคลของผู้ใช้
การขยายผลในวงกว้างจำเป็นต้องเดินควบคู่กับการพัฒนาองค์ประกอบเชิงนโยบายและโครงสร้างพื้นฐาน ได้แก่ การจัดมาตรฐานทักษะระดับชาติ การลงทุนในโครงสร้างพื้นฐานดิจิทัล (เช่น ระบบฐานข้อมูลกลาง API สำหรับแลกเปลี่ยนทักษะและประวัติการทำงาน) และกรอบนโยบายที่รับประกัน ความเป็นธรรม, ความโปร่งใส และ ความเป็นส่วนตัว ของผู้ใช้งาน เช่น นโยบายการยินยอม การตรวจสอบอัลกอริทึมเป็นระยะ และตัวชี้วัดความสำเร็จ (KPIs) เพื่อการปรับปรุงต่อเนื่อง หากดำเนินการอย่างรอบด้าน ระบบนี้มีโอกาสช่วยลดอัตราว่างงานระยะยาว เพิ่มประสิทธิภาพการจับคู่องาน และสนับสนุนโครงการพัฒนาทักษะ (upskilling/reskilling) ให้สอดคล้องกับความต้องการตลาดแรงงานในอนาคต



