
โรงพยาบาลชั้นนำแห่งหนึ่งในกรุงเทพฯ เปิดตัวการทดลองใช้ "Physio‑LLM" ระบบปัญญาประดิษฐ์เชิงภาพรวม (multimodal) ที่ออกแบบมาเพื่อผสานข้อมูลจากอุปกรณ์สวมใส่ ภาพทางการแพทย์ และผลตรวจทางห้องปฏิบัติการ เพื่อทำนายภาวะฉุกเฉินทางการแพทย์ล่วงหน้า 48 ชั่วโมง โดยไม่เพียงให้ผลทำนายเท่านั้น แต่ยังสามารถสร้างคำอธิบายเชิงเหตุผล (explainability) ที่เข้าใจได้สำหรับแพทย์ เพื่อสนับสนุนการตัดสินใจทางคลินิกในช่วงเวลาสำคัญ
การทดลองนี้เน้นการประมวลผลสัญญาณชีพจากสมาร์ทวอทช์ (เช่น อัตราการเต้นหัวใจ SpO2 กิจกรรม) ร่วมกับข้อมูลภาพถ่ายรังสีและผลแลบ เพื่อระบุแนวโน้มเสี่ยงก่อนเกิดเหตุ ตัวระบบจะแสดงปัจจัยชี้นำของโมเดล เช่น การเปลี่ยนแปลงค่า HR ที่ผิดปกติ ภาพปอดที่มีสัญญาณบ่งชี้การติดเชื้อ หรือค่าผลแลบที่เปลี่ยนอย่างมีนัยสำคัญ ผลการทดลองเบื้องต้นระบุสัญญาณเชิงบวกในด้านความสามารถทำนายและการให้ข้อมูลเชิงอธิบายที่เป็นประโยชน์ต่อผู้รักษา ทีมวิจัยระบุว่าหากผ่านการตรวจสอบและขยายผล จะช่วยเพิ่มเวลาตัดสินใจ ลดการเข้าพักรักษาในหน่วยดูแลหนัก และปรับปรุงการจัดสรรทรัพยากรของโรงพยาบาลได้อย่างมีนัยสำคัญ
บทนำ: ทำไมต้อง Physio‑LLM และภาพรวมโครงการทดลอง
บทนำ: ทำไมต้อง Physio‑LLM และภาพรวมโครงการทดลอง
ในสภาวะการรักษาทันสมัย การตรวจจับภาวะฉุกเฉินของผู้ป่วยล่าช้าหรือการพึ่งพาการวัดค่าจากแหล่งข้อมูลเดียวเป็นปัญหาสำคัญที่เพิ่มความเสี่ยงต่อการเสียชีวิตและการต้องย้ายผู้ป่วยไปยังห้องผู้ป่วยหนัก (ICU) อย่างไม่จำเป็น งานวิจัยและรายงานทางคลินิกชี้ให้เห็นว่า สัญญาณเตือนล่วงหน้ามักปรากฏก่อนการลุกลามของภาวะวิกฤต แต่หลายครั้งระบบเฝ้าระวังของโรงพยาบาลยังไม่สามารถรวบรวมและตีความข้อมูลจากแหล่งต่าง ๆ เช่น ข้อมูลจากอุปกรณ์สวมใส่ (wearables), ภาพทางการแพทย์ (radiology, bedside ultrasound), ผลแลบ และบันทึกอิเล็กทรอนิกส์ของผู้ป่วย (EHR) ได้อย่างต่อเนื่องและมีประสิทธิภาพ ทำให้แพทย์และทีมพยาบาลมักต้องตัดสินใจบนพื้นฐานข้อมูลที่แยกส่วนและเวลาไม่สอดคล้องกัน
โครงการทดลอง Physio‑LLM ที่โรงพยาบาลชั้นนำในกรุงเทพฯ กำหนดขึ้นเพื่อแก้ปัญหาดังกล่าวโดยใช้การผสานข้อมูลหลายมิติและโมเดลภาษาใหญ่ (Large Language Models) ที่ปรับแต่งสำหรับการแพทย์ เพื่อให้ได้ทั้งการทำนายภาวะฉุกเฉินในระยะ ล่วงหน้า 48 ชั่วโมง และการออกรายงานอธิบายผลที่แพทย์สามารถนำไปใช้ตัดสินใจได้ทันที เป้าหมายเชิงปฏิบัติของโครงการประกอบด้วยการลดจำนวนการย้ายผู้ป่วยไป ICU ที่อาจหลีกเลี่ยงได้, เพิ่มความแม่นยำของการเตือนล่วงหน้า, และส่งมอบคำอธิบายเชิงสาเหตุ (explainable outputs) ที่ช่วยให้แพทย์เข้าใจปัจจัยที่ทำให้ความเสี่ยงเพิ่มขึ้น
การออกแบบระบบเน้นการรวมข้อมูลจากหลายแหล่ง ได้แก่ ข้อมูลเชิงสัญญาณจากอุปกรณ์สวมใส่ (อัตราการเต้นของหัวใจ ความอิ่มตัวของออกซิเจน การเคลื่อนไหว), ผลภาพถ่ายรังสีและภาพอัลตราซาวด์, ผลตรวจทางห้องปฏิบัติการ (เช่น เกล็ดเลือด, ค่าการอักเสบ), และบันทึกทางคลินิกใน EHR ระบบจะถ่ายโอนข้อมูลเหล่านี้เข้าร่วมกับโมเดล Physio‑LLM ซึ่งออกแบบมาเพื่อให้ได้ทั้ง คะแนนความเสี่ยงเชิงเวลาที่เข้าใจง่าย และ คำอธิบายเชิงสาเหตุ เช่น ตัวแปรสำคัญที่ทำให้ความเสี่ยงเพิ่มขึ้น พร้อมคำแนะนำเชิงคลินิกที่สอดคล้องกับแนวทางการรักษา
โครงการเป็นความร่วมมือของทีมสหสาขา ประกอบด้วย:
- ทีมแพทย์และพยาบาล ประกอบด้วยผู้เชี่ยวชาญประจำแผนกฉุกเฉิน เวชบำบัดวิกฤต และฝ่ายทรัพยากรคลินิก ที่กำหนดเกณฑ์การเตือนและตรวจสอบผลลัพธ์ทางคลินิก
- นักวิจัย AI และนักวิทยาศาสตร์ข้อมูล รับผิดชอบการออกแบบ ปรับแต่ง และประเมินโมเดล Physio‑LLM ให้สอดคล้องกับข้อมูลทางการแพทย์
- ทีมไอทีและความปลอดภัยข้อมูล ทำหน้าที่เชื่อมต่อระบบข้อมูล รักษาความเป็นส่วนตัว และรับรองการบูรณาการกับ EHR ของโรงพยาบาล
- บริษัทเทคโนโลยีภายนอก ที่ให้ความเชี่ยวชาญด้านแพลตฟอร์ม AI, การประมวลผลภาพ และการจัดการโครงสร้างพื้นฐานคลาวด์
ระยะเวลาการทดลองถูกกำหนดให้อยู่ในรูปแบบไตรมาส เพื่อลดความเสี่ยงและประเมินผลเป็นช่วง ๆ โดยแผนปฏิบัติการคร่าว ๆ คือ ระยะเตรียมระบบและเก็บข้อมูล (3 เดือน), ระยะพัฒนาและตรวจสอบโมเดล (6 เดือน), และ ระยะทดลองใช้งานจริงแบบจำกัดขอบเขตเพื่อวัดผลลัพธ์คลินิก (3 เดือน) โครงการตั้งเป้าว่าจะสามารถแสดงผลเบื้องต้นเรื่องความแม่นยำของการทำนายและผลต่ออัตราการย้ายผู้ป่วยไป ICU ภายในสิ้นระยะทดลอง พร้อมกรอบการประเมินทางคลินิกและ KPI เช่น อัตราการจับสัญญาณล่วงหน้า, ค่าความไว/ความจำเพาะ, และการตอบรับจากผู้ใช้คลินิก
สถาปัตยกรรมของ Physio‑LLM: การรวมข้อมูลแบบ Multi‑Modal
สถาปัตยกรรมภาพรวมและการไหลของข้อมูล
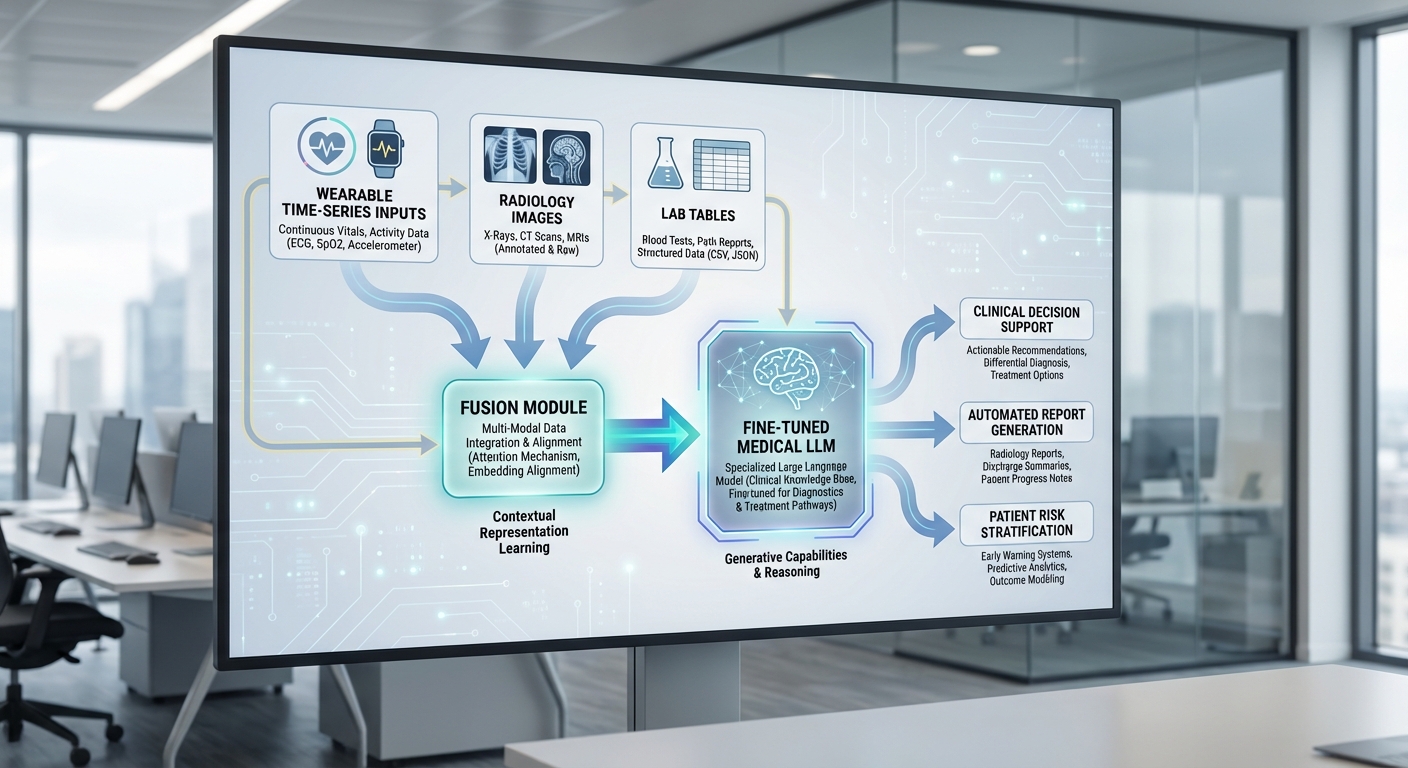
สถาปัตยกรรมของ Physio‑LLM ถูกออกแบบให้รองรับการเชื่อมโยงข้อมูลหลายรูปแบบ (multi‑modal) ตั้งแต่สตรีมเวลาจากอุปกรณ์สวมใส่ (เช่น HR, SpO2, HRV) ภาพทางการแพทย์ (CXR, CT, US) และผลตรวจทางห้องปฏิบัติการ (CBC, electrolytes) โดยโฟลว์หลักประกอบด้วย: input → preprocessing (modality‑specific) → modality encoders → fusion layer → LLM ที่ปรับแต่งเฉพาะทางการแพทย์ → output ซึ่งคืนค่าเป็น คะแนนความเสี่ยงเชิงตัวเลข พร้อม คำอธิบายที่เข้าใจได้สำหรับแพทย์ และแผนการดูแลแนะนำเบื้องต้นสำหรับการตัดสินใจแบบคลินิก (prediction horizon = 48 ชั่วโมง)
การเตรียมข้อมูลตามประเภท (Preprocessing)
การเตรียมข้อมูลเป็นก้าวสำคัญเพื่อให้ฟีเจอร์จากแต่ละโมดัลมีความสอดคล้องและพร้อมสำหรับการรวมข้อมูล ระบบใช้เทคนิคมาตรฐานทางคลินิกควบคู่กับมาตรฐาน Machine Learning ดังนี้
- ข้อมูลจากอุปกรณ์สวมใส่ (Time‑series): การ resampling เป็นมาตรฐาน — ตัวอย่างเช่น HR และ SpO2 ถูก resample เป็น 1 Hz หรือ aggregated เป็นค่าเฉลี่ย/เปอร์เซ็นไทล์ภายในหน้าต่างเวลา (e.g., 1 min, 5 min) เพื่อจัดการกับความแปรผันของ sampling rate และ packet loss; การจัดการ missing data ใช้การ forward‑fill แบบจำกัดระยะเวลา และการทำ interpolation เมื่อจำเป็น; ฟีเจอร์เสริมเช่น HRV/SDNN, RMSSD ถูกคำนวณเป็นฟีเจอร์เชิงสถิติ/ความถี่ (time‑domain & frequency‑domain).
- ภาพทางการแพทย์: การ preprocess รวมถึง DICOM windowing (สำหรับ CT), ขนาดภาพมาตรฐาน (e.g., 224×224 หรือ 512×512 แล้วแต่โมเดล), normalization ตามค่า mean/std ของชุดข้อมูลการแพทย์ และการลด noise ด้วย denoising filter; augmentation ในช่วงการฝึก เช่น rotation ±15°, scaling, horizontal flip (สำหรับ CXR ที่เหมาะสม), random brightness/contrast, elastic deformation (สำหรับ US) และ advanced augmentations เช่น CutMix/RandomErasing เพื่อลดการ overfit; นอกจากนี้ใช้การตรวจสอบคุณภาพภาพอัตโนมัติ (artifact detection) ก่อนป้อนเข้า encoder.
- ผลแลบและข้อมูลเชิงเหตุการณ์ (tabular): การจัดการหน่วยและมาตรฐาน (unit harmonization) เป็นสิ่งจำเป็น — ยกตัวอย่าง Na+ อยู่ใน mmol/L เป็นมาตรฐานเดียวกัน; การเติมค่าขาด (imputation) ใช้วิธีเฉพาะ เช่น mean/median สำหรับ missing แบบสุ่ม หรือ model‑based imputation (e.g., MICE) สำหรับ missing ที่มีรูปแบบ และการสร้างฟีเจอร์เชิงเวลา (delta from baseline, rolling mean, slope) เพื่อจับแนวโน้มก่อนหน้า.
กลยุทธ์การ fusion ระหว่างซีเควนซ์เวลาและข้อมูลภาพ/แลบ
การรวมข้อมูลหลายโมดัลต้องคำนึงทั้งด้านเชิงเวลา (temporal alignment) และความหมายเชิงเนื้อหา (semantic alignment) ของแต่ละโมดัล ระบบใช้สถาปัตยกรรมแบบ modular ที่ประกอบด้วย encoder เฉพาะโมดัลตามลักษณะข้อมูล และ fusion layer แบบปรับน้ำหนักได้เพื่อให้สอดคล้องกับบริบทคลินิก:
- Modality‑specific encoders: CNN / vision transformer สำหรับภาพทางการแพทย์, temporal convolutional network (TCN) หรือ transformer สำหรับ time‑series wearable, และ feed‑forward network สำหรับข้อมูลแลบ/ทับยูลาร์.
- Fusion strategies:
- Early fusion: แปลงข้อมูลทั้งหมดเป็น embedding ระดับไทม์สเต็ปเดียวกันและรวมก่อนป้อนโมเดลศูนย์กลาง — มีประโยชน์เมื่อต้องการจับความสัมพันธ์เชิงวินาทีระหว่างสัญญาณแต่มีข้อจำกัดด้าน missing/misaligned data.
- Late fusion: เรียกใช้งานโมเดลย่อยแต่ละโมดัลแล้วรวมผลเชิงฟีเจอร์หรือโลจิตสุดท้าย (concatenation + MLP หรือ weighted average) — มีความยืดหยุ่นสูงเมื่อโมดัลบางอย่างขาดหายหรือไม่พร้อมใช้งาน.
- Cross‑attention / Multimodal Transformer: ใช้ attention ข้ามโมดัลเพื่อให้ embedding ของ time‑series สามารถ attend ไปยัง patch/region ของภาพทางการแพทย์ และค่าแลบที่เกี่ยวข้อง (เช่น token แบบ time‑stamped) — เหมาะสำหรับการหา marker ที่สัมพันธ์กันเชิงสาเหตุในหน้าต่างเวลา 48 ชั่วโมง.
- Uncertainty‑aware weighting: แต่ละโมดัลจะถูกประเมินความเชื่อมั่น (e.g., predictive variance, quality score ของภาพ) และ fusion layer จะปรับน้ำหนักตามความน่าเชื่อถือของโมดัลนั้นในบริบทปัจจุบัน เพื่อหลีกเลี่ยง bias จากข้อมูลคุณภาพต่ำ.
- Temporal alignment & position encoding: ใช้ time‑aware position embeddings และ sliding windows (เช่น 6, 12, 24, 48 ชั่วโมง) เพื่อให้โมเดลสามารถจับ short‑term spikes และ long‑term trends ได้พร้อมกัน ตัวอย่างเช่น การ detect เหตุการณ์ที่มีลักษณะลุกลาม (progressive desaturation) จะผนวกสัญญาณ SpO2 ที่มีจังหวะและภาพปอดที่เปลี่ยนแปลงในหน้าต่างเวลาเดียวกัน.
บทบาทของ LLM ในการสร้างคำอธิบายและการตัดสินใจ (Explainability)
หลังจาก fusion layer ให้ embedding เชิงสูงสุด LLM ที่ปรับแต่งสำหรับการแพทย์จะทำหน้าที่เป็นส่วนส่งออกเชิงภาษาและการอธิบายความเสี่ยง ไม่ใช่เพียงกล่องดำ โดยมีบทบาทสำคัญดังนี้:
- แปลผลเป็นภาษาคลินิกที่อ่านเข้าใจได้: LLM สร้างสรุปแบบ concise และ evidence‑anchored เช่น “ความเสี่ยงของภาวะหายใจล้มเหลวใน 48 ชม = 22% (95% CI: 18–26%). ปัจจัยสำคัญ: SpO2 ลดต่อเนื่อง 3 ชั่วโมง, CT พบ consolidation เพิ่มขึ้น” ซึ่งช่วยให้แพทย์รับรู้สาเหตุที่ระบบให้คะแนน.
- การอธิบายเชิงภาพและเทมเพลตการตัดสินใจ: LLM สามารถรวมผลจากโมดูลการตีความภาพ (เช่น heatmap/segmentation) และ time‑series saliency เพื่อให้คำอธิบายแบบ multimodal เช่น “เห็น consolidation บริเวณฐานปอดขวา (ดูภาพฮีทแมพ) ร่วมกับ trend ของ HR ที่เพิ่มขึ้น” และแนะนำขั้นตอนแรก (e.g., ตรวจซ้ำปริมาณเลือด, ให้ O2 แนวทางเริ่มต้น, พิจารณา admit ICU ถ้าคะแนน > 40%).
- การสื่อสารความไม่แน่นอนและ provenance: LLM ถูกฝึกให้ระบุแหล่งที่มาของข้อสรุป เช่นบอกว่า “ข้อสรุปนี้อิงจากภาพ CT (เมื่อเวลา 03:12) และค่า SpO2 rolling mean 30 นาทีล่าสุด” พร้อมบอกระดับความเชื่อมั่นและแนะนำการตรวจยืนยัน — สิ่งนี้ช่วยลดความเสี่ยงจากการพึ่งพาเฉพาะตัวเลขความเสี่ยงเท่านั้น.
- counterfactuals และ actionable suggestions: ระบบสามารถให้ข้อความแบบ «ถ้า–แล้ว» เช่น “ถ้า SpO2 ไม่เพิ่มขึ้นภายใน 30 นาทีหลังให้ O2 ทางจมูก ควรพิจารณา HFNC หรือประเมินหน้าที่ทางเดินหายใจ” พร้อมเปรียบเทียบความเสี่ยงก่อน‑หลังการดำเนินการเพื่อช่วยการตัดสินใจเชิงรุก.
เพื่อยืนยันความเชื่อถือได้ ทางทีมพัฒนาวางกรอบการประเมินเชิงวัดผล (เช่น AUC, calibration curve, Brier score) และเกณฑ์การใช้งานทางคลินิก (เช่น sensitivity ≥ 0.90 ในกลุ่ม high‑risk เพื่อเป็น alert ช่วงต้น) พร้อม audit trail ทางอิเล็กทรอนิกส์ซึ่งเก็บ provenance ของข้อมูลและเหตุผลที่ LLM ให้คำแนะนำ — สิ่งเหล่านี้ทำให้ Physio‑LLM เป็นเครื่องมือช่วยตัดสินใจที่โปร่งใส และสามารถบูรณาการเข้ากับเวิร์กโฟลว์ของแพทย์ได้จริงในสภาพแวดล้อมโรงพยาบาลขนาดใหญ่.
แหล่งข้อมูลและการรวมข้อมูล: wearables, ภาพทางการแพทย์ และผลแลบ
แหล่งข้อมูลสวมใส่ (Wearables): ชนิด ความถี่ และการจับคู่สัญญาณ
การทดลอง Physio‑LLM ใช้ข้อมูลจากอุปกรณ์สวมใส่หลายชนิดเพื่อจับสัญญาณชีวภาพแบบต่อเนื่อง ได้แก่ continuous pulse oximeters (ตัวอย่างเช่น Masimo Radical‑7, Nonin และอุปกรณ์ทางการแพทย์แบบสวมใส่เช่น VitalPatch/VitalConnect), smartwatches เชิงพาณิชย์ที่มีเซนเซอร์ HR/ECG เช่น Apple Watch, Garmin, Fitbit และ ECG/patch แบบแยกชิ้น (เช่น Zio/ iRhythm) สำหรับคลื่นไฟฟ้าหัวใจความละเอียดสูง
ตัวอย่างความถี่สัญญาณที่นำมาใช้ในการทดลอง (ค่าตัวอย่างเพื่อออกแบบโมเดลและ preprocessing):
- Heart rate (HR): ตัวอย่าง 1 Hz (1 ค่าต่อวินาที) จากอุปกรณ์ทางการแพทย์ หรืออาจลดรูปเป็น 0.2–1 Hz ตามระบบ
- SpO2 (oxygen saturation): ประมาณ 0.2–0.5 Hz (หนึ่งค่ายุกต์ทุก 2–5 วินาที) ขึ้นกับอุปกรณ์
- ECG raw: 250–500 Hz เพื่อรักษารูปคลื่นสำหรับการวิเคราะห์อาร์ทิแฟกต์และฟีเจอร์ความถี่
- Accelerometer / gyroscope: 25–100 Hz สำหรับการประเมินการเคลื่อนไหวและการล้ม
- Skin temperature: ตัวอย่างทุก 30–60 วินาที (~0.017–0.033 Hz) หรือเป็นค่าเฉลี่ยต่อช่วงเวลา
การประสานเวลา (synchronization) และการจัดเก็บเบื้องต้น
เพื่อให้สามารถผสานข้อมูลหลายมิติระหว่าง wearables ภาพทางการแพทย์ และผลแลบ จำเป็นต้องมีการทำ timestamp alignment โดยใช้เวลาอ้างอิงเดียวกัน (เช่น UTC) และแก้ไขปัญหา clock drift ของอุปกรณ์ ตัวอย่างขั้นตอนคือการ resampling เป็นไทม์สเตมป์ร่วม (เช่น 1‑Hz timeline), การคงค่า mask สำหรับตำแหน่งที่ไม่มีข้อมูล และการบันทึก metadata ของแหล่งที่มา (device ID, firmware version, sampling rate) เพื่อรองรับการตรวจสอบย้อนหลังและการลดความผิดพลาด
ภาพทางการแพทย์: มาตรฐาน DICOM และการ preprocess ก่อนป้อนโมเดล
ภาพทางการแพทย์ถูกจัดเก็บตามมาตรฐาน DICOM (CT, MRI, X‑ray, Ultrasound) โดยบันทึกทั้ง pixel data และ metadata (เช่น Study/Series UID, acquisition datetime, modality) การประมวลผลเบื้องต้นประกอบด้วย:
- De‑identification: ลบหรือแทนที่ DICOM tags ที่มีข้อมูลระบุตัวบุคคล (PatientName, PatientID, AccessionNumber) ตามข้อกำหนดโรงพยาบาลและมาตรฐาน
- Windowing/Normalization: แปลงค่า pixel (เช่น Hounsfield units สำหรับ CT) ด้วย window/level ที่เหมาะสม และทำการ normalize intensity เพื่อให้โมเดลเรียนรู้ได้ดีขึ้น
- Resampling และ reorientation: ปรับ voxel size ให้สอดคล้องระหว่างสแกน (เช่น 1×1×1 mm) และจัดแนวอินทิกรัล (affine transforms) หากใช้ข้อมูล 3D
- Segmentation: สร้างมาสก์อวัยวะ/lesion โดยใช้ทั้งโมเดลอัตโนมัติ (U‑Net, nnU‑Net) และการตรวจสอบโดยรังสีแพทย์เพื่อให้ได้ region of interest (เช่น ปอด, หัวใจ, เนื้องอก) ซึ่งสำคัญต่อการดึงฟีเจอร์เชิงโครงสร้าง
- Conversion และ storage: หากต้องการใช้งานเชิงวิจัย อาจแปลงเป็น NIfTI สำหรับการประมวลผล 3D แต่เก็บ DICOM ต้นฉบับเพื่อรักษา metadata
ผลแลบ (Laboratory results): มาตรฐาน การแมป และรูปแบบ
ผลแลบถูกนำเข้าผ่านระบบแลปของโรงพยาบาลซึ่งรองรับมาตรฐาน HL7/FHIR และการเข้ารหัสตัวแปรด้วย LOINC สำหรับการทำแมปตัวแปรข้ามระบบ ข้อมูลที่สำคัญได้แก่ CBC, ABG, BUN/Cr, lactate, CRP, และผลเพาะเชื้อ รูปแบบข้อมูลเป็น time‑stamped structured values (จำนวนจริง + หน่วย) โดยมีการบันทึกสถานะตัวอย่าง (fasting, venous/arterial) และค่าที่ขาดหายเป็นเรื่องปกติ (ตัวอย่าง: lab panel อาจทำซ้ำทุก 6–24 ชั่วโมงและมี missingness ประมาณ 20–40% สำหรับค่าบางชนิดในช่วงเวลาที่กำหนด)
การแมปผู้ป่วยเพื่อรักษาความเป็นส่วนตัวและการเชื่อมข้อมูลข้ามแหล่ง
การเชื่อมข้อมูล multmodal จำเป็นต้องรักษาความลับของผู้ป่วยด้วยวิธีการดังนี้:
- Pseudonymization: แทน PatientID ด้วยรหัสภายในที่ไม่ย้อนกลับ (irreversible hash + salt ที่เก็บแยก) และเก็บตารางแมปไว้ในระบบความปลอดภัยสูง (secure enclave)
- Privacy‑preserving record linkage (PPRL): ใช้เทคนิคเช่น Bloom filters หรือ hashing ที่ไม่เปิดเผยข้อมูลดิบเมื่อแมประหว่างแหล่งข้อมูลภายนอก
- Access control และ encryption: ข้อมูลจัดเก็บแบบเข้ารหัสทั้งขณะพักและขณะส่ง (AES‑256, TLS) พร้อมการล็อกสิทธิ์ตามบทบาท (role‑based access)
- Audit trails: บันทึกการเข้าถึงและการประมวลผลเพื่อให้สามารถตรวจสอบการใช้งานข้อมูลได้
การจัดการข้อมูลขาด (Missingness) และแนวทางป้ายค่า (Labeling) สำหรับเหตุฉุกเฉิน 48 ชั่วโมง
ข้อมูลสมัยใหม่มักมี missingness ในระดับที่ต่างกัน: wearables อาจหลุดการเชื่อมต่อ (lossy Bluetooth, battery) ทำให้มี missing 5–20% ต่อวัน ขณะที่ผลแลบจะเป็น interval sampling (missing สูงในค่าเฉพาะ) ซึ่งการจัดการมีหลายระดับ:
- Masking และ indicator variables: เก็บตัวบ่งชี้การมีอยู่ของข้อมูล (1/0) เพื่อให้โมเดลเรียนรู้รูปแบบ missingness ที่เป็น informative
- Imputation แบบเรียบง่าย: forward‑fill, linear interpolation สำหรับสัญญาณต่อเนื่องระยะสั้น
- Model‑based imputation: Multiple Imputation by Chained Equations (MICE), Gaussian Process interpolation หรือ deep learning approaches เช่น BRITS หรือ GRU‑D ที่ออกแบบให้ทนต่อ missingness และ irregular sampling
- การรักษาอาร์ติแฟกต์: ตรวจจับและแทนที่ค่าที่เป็น outlier หรือ artifacts (เช่น motion artifacts ใน PPG) ก่อนการ imputation
การทำ label สำหรับเหตุฉุกเฉินที่ต้องการทำนายภายใน 48 ชั่วโมง ต้องนิยามเหตุการณ์และระยะเวลาอย่างชัดเจน:
- คำนิยามเหตุฉุกเฉิน: เช่น การเคลื่อนย้ายไปรักษาตัวใน ICU, การเริ่มการช่วยหายใจ (intubation), การเกิด cardiac arrest (code blue), การให้ยาส่งเสริมความดันฉุกเฉิน หรือการเสียชีวิตฉับพลัน
- การตั้งค่า window และ lead time: กำหนด label เป็นบวกถ้าเหตุการณ์เกิดภายใน 48 ชั่วโมงนับจากเวลาอ้างอิง และบันทึกเวลาที่เหลือ (time‑to‑event) เพื่อรองรับการเรียนรู้แบบ survival/time‑to‑event
- การรวมแหล่งข้อมูลในการ annotatation: ใช้ EHR timestamp เป็น gold‑standard ในการระบุเหตุการณ์ และยืนยันการตีความด้วยรีวิวจากแพทย์ (clinician adjudication) อย่างน้อยสองคนเพื่อลด bias; คำนวณความสอดคล้อง (เช่น Cohen’s kappa) เป็นมาตรวัดคุณภาพ annotation
- การจัดการกรณี censoring และ class imbalance: ใช้เทคนิคเช่น weighting, oversampling (SMOTE ระวังข้อมูลเชิงเวลา) หรือ loss function แบบ focal/survival loss เพื่อรับมือกับจำนวนตัวอย่างเหตุฉุกเฉินที่น้อย
โดยสรุป การผสานข้อมูลจาก wearables ภาพทางการแพทย์ และผลแลบ ต้องอาศัยมาตรฐานการเก็บข้อมูล (DICOM, FHIR/LOINC), การจัดการเวลาและ missingness ที่เหมาะสม, กระบวนการ de‑identification และ annotation ระดับคลินิกที่เข้มงวดเพื่อให้ Physio‑LLM สามารถให้การคาดการณ์ภาวะฉุกเฉินภายใน 48 ชั่วโมงได้อย่างเชื่อถือและนำไปใช้สนับสนุนการตัดสินใจของแพทย์ได้อย่างปลอดภัย
การทำนายภาวะฉุกเฉินและการอธิบายผลสำหรับแพทย์
หลักการทำนาย: time‑to‑event, คะแนนความเสี่ยง และความแน่นอน
ระบบ Physio‑LLM ใช้โมเดลผสมเชิงสถิติและเชิงลึก (เช่น deep survival models และ discrete‑time neural networks) เพื่อทำนายความน่าจะเป็นของเหตุการณ์ฉุกเฉินภายในระยะเวลา 48 ชั่วโมงข้างหน้า โดยผลลัพธ์จะรายงานทั้งในรูปแบบ time‑to‑event (ค่าประมาณเวลาจนเกิดเหตุ) และ probability of event within 48 hrs (เปอร์เซ็นต์ความเสี่ยงภายใน 48 ชม.). โมเดลยังให้ค่าคะแนนความแน่นอน (confidence / uncertainty interval) สำหรับการทำนายแต่ละครั้ง โดยใช้เทคนิคการปรับความน่าเชื่อถือ เช่น Platt scaling หรือ isotonic calibration เพื่อทำให้ค่าความเสี่ยงที่รายงานจับต้องได้และสอดคล้องกับความเป็นจริงทางคลินิก.
ในการปฏิบัติจริง ระบบอนุญาตให้โรงพยาบาลตั้งค่าขีดตัด (classification thresholds) ตามนโยบายความเสี่ยง — ตัวอย่างเช่น threshold ที่เน้นความไวสูง (sensitivity ~85%) เพื่อลดการพลาดเหตุฉุกเฉิน หรือ threshold ที่เน้นความจำเพาะสูงเพื่อลดสัญญาณเตือนเท็จ (false positives) ค่า threshold เหล่านี้จะแสดงผลต่อแพทย์ในรูปของการประเมิน trade‑off (เช่น คาดการณ์ sensitivity, specificity, positive predictive value) เพื่อให้ทีมคลินิกตัดสินใจเลือกพารามิเตอร์ที่เหมาะสมกับทรัพยากรและความเสี่ยงของหน่วยงาน.
กลไกการสร้างคำอธิบายเชิงคลินิก
เพื่อให้คำทำนายสามารถนำไปใช้ตัดสินใจได้อย่างโปร่งใส ระบบผสานเทคนิคอธิบายผลหลายมิติ ดังนี้:
- Feature‑level importance (SHAP): สำหรับข้อมูลเชิงตาราง เช่น สัญญาณทางชีพจากอุปกรณ์สวมใส่ ผลแลบ และค่าสังเกตทางคลินิก ระบบคำนวณค่า SHAP เป็นรายกรณี เพื่อแสดงว่าแต่ละตัวแปรมีผลต่อการเพิ่ม/ลดความเสี่ยงเท่าใด (เช่น Heart rate ↑ เพิ่มความเสี่ยง +0.12, SpO2 ↓ เพิ่มความเสี่ยง +0.18)
- Attention‑based highlights สำหรับภาพและสัญญาณเชิงเวลา: เมื่อข้อมูลทางการแพทย์เป็นภาพ (เช่น X‑ray, ultrasound, CT slice) หรือซีเควนซ์สัญญาณ (ECG, PPG) โมเดล attention จะสร้าง heatmap ที่เน้นพื้นที่หรือช่วงเวลาที่มีผลต่อการทำนาย เพื่อให้แพทย์สามารถตรวจสอบบริเวณที่เป็นสาเหตุได้อย่างรวดเร็ว
- Counterfactual explanations: ระบบสามารถสร้างกรณีสมมติที่ปรับค่าพารามิเตอร์บางตัวเพื่อแสดงผลกระทบต่อความเสี่ยง เช่น “หาก SpO2 เพิ่มขึ้น 2% และ HR ลดลง 5 bpm ความเสี่ยงภายใน 48 ชม. จะลดจาก 32% เป็น 18%” ซึ่งช่วยให้แพทย์เห็นว่าการแทรกแซงเฉพาะจุดใดอาจเปลี่ยนผลลัพธ์ได้
- Natural‑language clinical summary: สรุปผลเป็นข้อความเชิงคลินิกที่อ่านง่าย เช่น “ความเสี่ยงเกิดภาวะหายใจล้มเหลวภายใน 48 ชม. = 32% (CI 25–40%). ปัจจัยสำคัญ: SpO2 ลดอย่างต่อเนื่อง, HR มีแนวโน้มเพิ่ม, CRP สูงขึ้น. ข้อเสนอแนะ: พิจารณาตรวจ ABG, เพิ่มการตรวจติดตาม SpO2 ทุกชั่วโมง, และประเมินการย้ายไปการดูแลสูงขึ้น” ข้อความนี้เน้นการให้คำแนะนำที่ปฏิบัติได้จริงพร้อมเหตุผลจากตัวชี้วัด
ตัวอย่างหน้าจอ (UI) ที่แพทย์จะเห็นเมื่อมีการเตือน
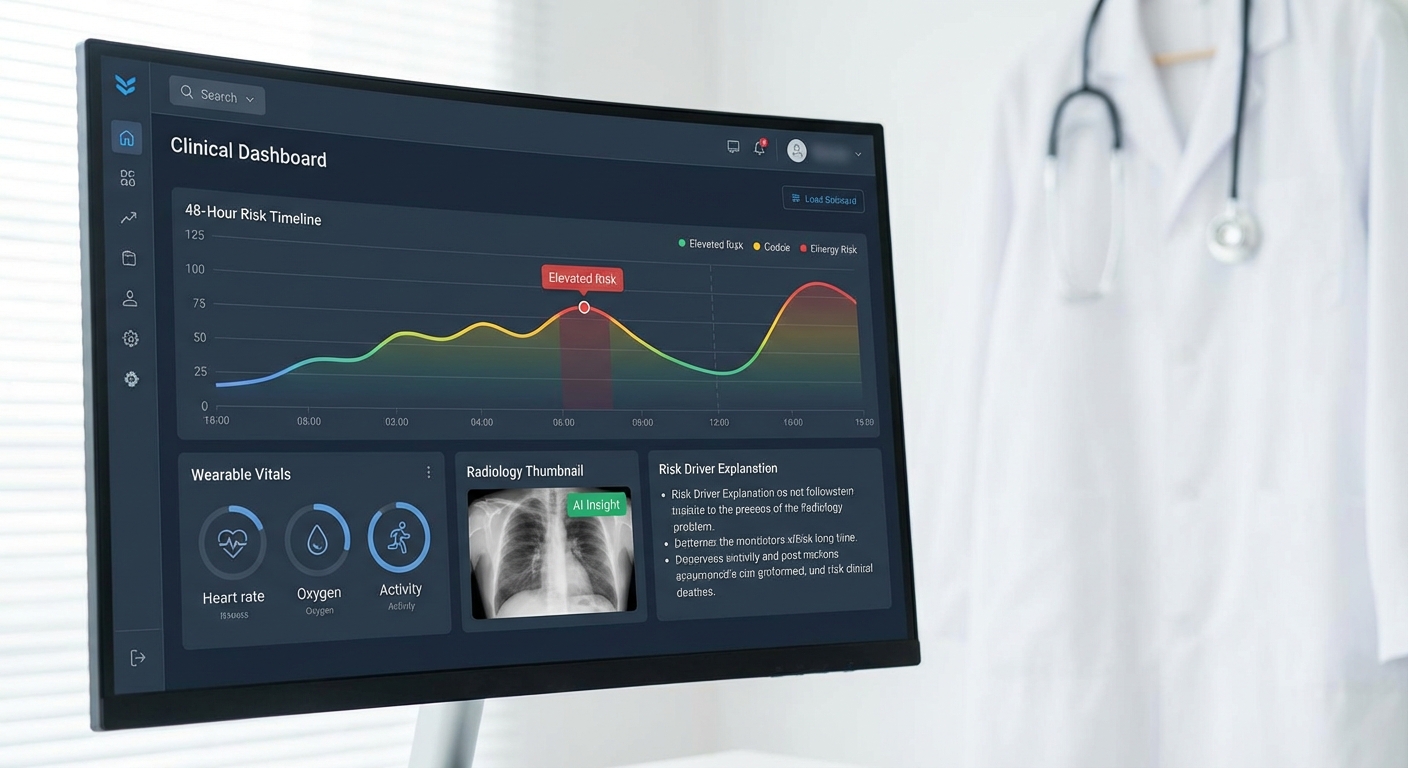
หน้าจอแจ้งเตือนออกแบบให้สรุปสาระสำคัญที่จำเป็นต่อการตัดสินใจภายในหนึ่งมองเห็น โดยองค์ประกอบหลักประกอบด้วย:
- แบนเนอร์เตือนความเสี่ยง: แสดงเปอร์เซ็นต์ความเสี่ยงภายใน 48 ชม. พร้อมระดับความเร่งด่วน (เช่น สูง/กลาง/ต่ำ) และแถบความแน่นอน (confidence band)
- Risk trajectory chart: กราฟแสดงแนวโน้มความเสี่ยงตามเวลา (48‑hr forecast) พร้อมช่วงความไม่แน่นอน เพื่อให้เห็นว่าความเสี่ยงกำลังเพิ่มขึ้นหรือลดลง
- Top contributors (SHAP list): รายการ 5‑7 ปัจจัยสำคัญพร้อมค่าเชิงปริมาณและคำอธิบายสั้น เช่น “SpO2: 88% (trend ↓) — เพิ่มความเสี่ยง +0.18”
- Image/ECG highlights: พื้นที่บนภาพทางการแพทย์หรือช่วงเวลาใน ECG ที่โมเดลให้ความสำคัญ พร้อมปุ่มขยายเพื่อดูรายละเอียดเพิ่มเติม
- Counterfactual toggle: ปุ่มให้แพทย์เลือก scenario (เช่น ปรับค่า SpO2 หรือให้ยาบางชนิด) เพื่อดูว่าการเปลี่ยนแปลงนั้นจะลดความเสี่ยงได้เท่าใด
- Suggested orders & next steps: ชุดคำแนะนำแบบปฏิบัติ (order set) เช่น “ขอ ABG, เพิ่มการตรวจ SpO2 ทุก 1 ชม., พิจารณา escalation to HDU/ICU” พร้อมปุ่มสั่งงานแบบ one‑click
- Audit trail & rationale: บันทึกเหตุผลการเตือน, โมเดลเวอร์ชัน และผู้ใช้งานที่ยืนยันหรือยกเลิกการเตือน เพื่อวัตถุประสงค์ด้านการควบคุมคุณภาพและการกำกับดูแล
Workflow เมื่อระบบเตือน: ข้อมูลที่แพทย์ได้รับและแนวทางปฏิบัติ
เมื่อ Physio‑LLM ปล่อยการเตือน แพทย์หรือทีมพยาบาลจะได้รับลำดับการทำงานดังนี้:
- การแจ้งเตือนทันที: SMS/Push notification และแสดงบนหน้าจอคนไข้ของทีมดูแล พร้อมลิงก์ตรงไปยังหน้าสรุปกรณี
- หน้าสรุปกรณีแบบครบจุด: แสดงความเสี่ยงภายใน 48 ชม., ค่า confidence, top‑3 drivers, heatmap ของภาพหรือสัญญาณ และคำสรุปเชิงคลินิกที่อ่านง่าย
- คำแนะนำการปฏิบัติ: ระบบเสนอ order set และขั้นตอนเฉพาะที่สอดคล้องกับแนวทางปฏิบัติของโรงพยาบาล (เช่น เพิ่มการตรวจติดตาม ปรับยา เริ่มการสื่อสารครอบครัว) พร้อมตัวเลือกให้แพทย์ยอมรับ ปรับ หรือปฏิเสธ
- การติดตามและอัปเดตอัตโนมัติ: โมเดลอัปเดตการทำนายแบบ near‑real‑time เมื่อมีข้อมูลใหม่จากอุปกรณ์สวมใส่ ผลแลบ หรือภาพ ทำให้แพทย์เห็นการเปลี่ยนแปลงของ risk trajectory และสามารถปรับการตัดสินใจได้ทันที
- ฟีดแบ็กและการเรียนรู้ของระบบ: การกระทำของแพทย์ (เช่น สั่งตรวจหรือย้ายห้อง) จะถูกบันทึกเป็นข้อมูลป้อนกลับเพื่อนำไปใช้ปรับปรุงโมเดลและลดการเตือนผิดพลาดในอนาคต
สรุปสั้นๆ: Physio‑LLM ให้ทั้งการทำนายเชิงเวลาและความเสี่ยงภายใน 48 ชั่วโมง พร้อมแสดงระดับความแน่นอน โดยใช้ SHAP และ attention‑based highlights เพื่ออธิบายปัจจัยสำคัญ, สนับสนุนด้วย counterfactuals และสรุปเป็นภาษาธรรมชาติ ทำให้แพทย์ได้รับข้อมูลที่ชัดเจน กระชับ และสามารถดำเนินการรักษาได้อย่างมีเหตุผลและรวดเร็ว
ผลการทดลองเบื้องต้น: สถิติ ตัวอย่างเคส และการประเมินความแม่นยำ
ผลการทดลองเบื้องต้น: สถิติการทำนายและการประเมินความแม่นยำ
การทดลองเบื้องต้นที่โรงพยาบาลขนาดใหญ่ในกรุงเทพฯ มีผู้ป่วยเข้าร่วมทั้งหมด 1,200 ราย โดยระบบ Physio‑LLM ถูกตั้งค่าเพื่อทำนายเหตุการณ์ฉุกเฉินภายใน 48 ชั่วโมง (รวมเหตุการณ์ที่ต้องย้ายผู้ป่วยไปยัง ICU, การล้มเหลวของอวัยวะรุนแรง หรือการต้องใส่ท่อช่วยหายใจ) ผลการประเมินเชิงปริมาณ (preliminary) สรุปได้ดังนี้:

- อุบัติการณ์ (prevalence) ของเหตุการณ์ฉุกเฉินภายใน 48 ชั่วโมง: ประมาณ 8.0% (96/1,200)
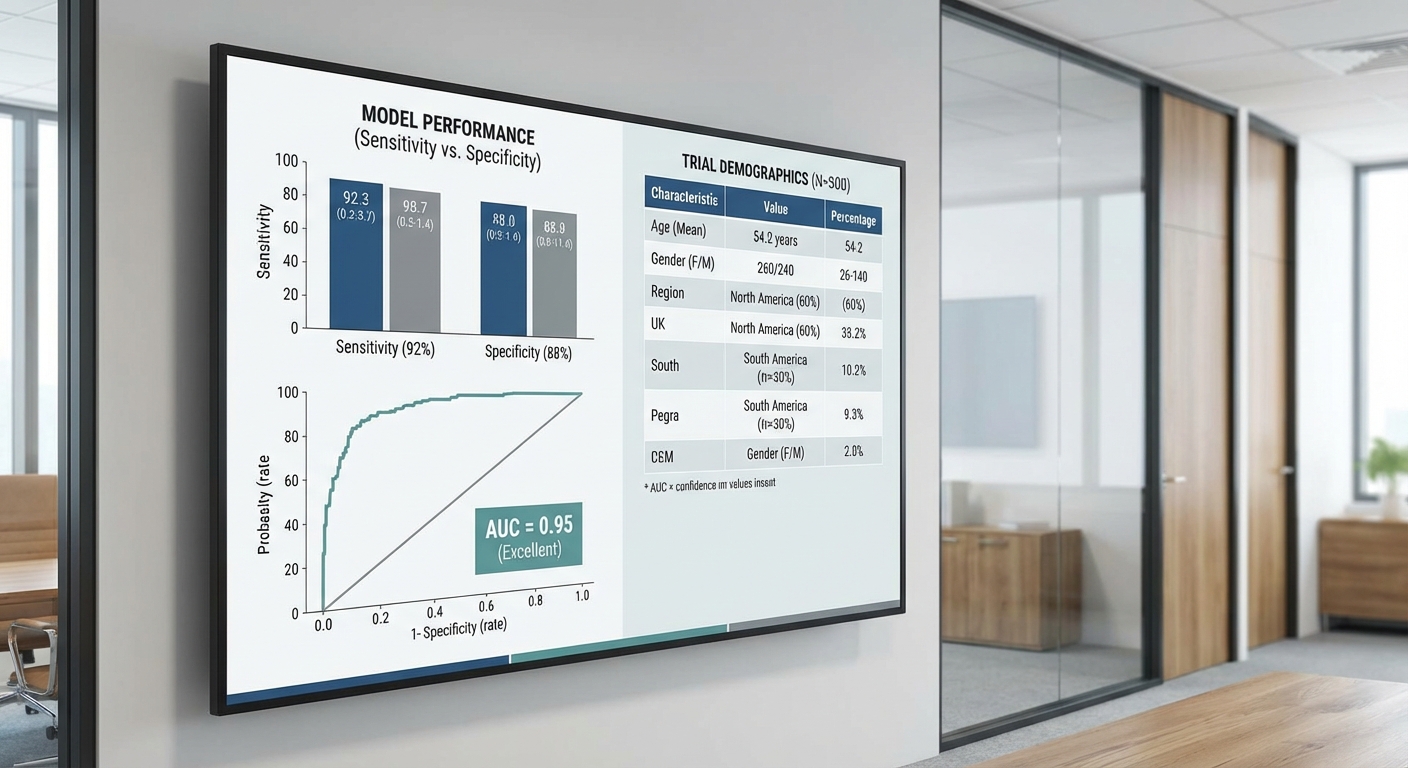
- Sensitivity (การจับเหตุการณ์จริง): 0.87 (95% CI: 0.79–0.92)
- Specificity (การคัดกรองไม่ให้แจ้งเตือนผู้ที่ไม่เกิดเหตุ): 0.88 (95% CI: 0.86–0.90)
- AUC (พื้นที่ใต้ ROC curve): 0.92 (95% CI: 0.90–0.94)
- Positive predictive value (PPV): 39.0% (84 true positives / 216 positive predictions)
- Negative predictive value (NPV): 98.8% (972 true negatives / 984 negative predictions)
- ตัวเลขสรุป (ตารางสับสนเบื้องต้น): TP = 84, FN = 12, FP = 132, TN = 972
- อัตราส่วนความน่าจะเป็น: LR+ ≈ 7.3, LR− ≈ 0.15 — แสดงว่าการแจ้งเตือนเพิ่มความน่าจะเป็นของเหตุฉุกเฉินอย่างมีนัยสำคัญ ในขณะที่การไม่แจ้งเตือนมีค่าทางการแพทย์ในการยกเว้นเหตุ
ตัวอย่างเคสที่ระบบช่วยการตัดสินใจทางคลินิก
จากเคสจริงที่บันทึกระหว่างการทดลอง มีกรณีเด่นที่แสดงถึงคุณค่าทางคลินิกของ Physio‑LLM ดังนี้ (สรุปโดยย่อเพื่อความเป็นส่วนตัวของผู้ป่วย):
- เคส A — ผู้ป่วยอายุ 72 ปี หลังผ่าตัดใหญ่: ระบบเตือนความเสี่ยงของภาวะช็อกและการติดเชื้อรุนแรงล่วงหน้า 40 ชั่วโมง โดยดึงข้อมูลจากอัตราการเต้นหัวใจที่เพิ่มขึ้นอย่างต่อเนื่องจากอุปกรณ์สวมใส่ ควบคู่กับค่า WBC ที่เพิ่มขึ้นและภาพรังสีทรวงอกมีลักษณะบ่งชี้การอักเสบ ทีมแพทย์เข้าตรวจและให้ยาต้านจุลชีพอย่างรวดเร็ว ผลคือผู้ป่วยไม่ต้องย้ายไป ICU และฟื้นตัวในหอผู้ป่วยปกติ การตัดสินใจเชิงรุกนี้คาดว่าช่วยป้องกันการย้าย ICU ที่อาจเกิดขึ้นได้
- เคส B — ผู้ป่วยโรคปอดเรื้อรัง (COPD): ระบบคาดการณ์ความเสี่ยงของภาวะหายใจล้มเหลวภายใน 36 ชั่วโมง โดยอาศัยการวัด SpO2, ความถี่การหายใจจาก wearable และภาพเอกซเรย์ที่เปลี่ยนแปลงเล็กน้อย ทีมรักษาเริ่มให้การสนับสนุนการหายใจแบบไม่รุกล้ำและปรับยาต้านการอักเสบ ผลคือหลีกเลี่ยงการใส่ท่อช่วยหายใจและลดระยะเวลาอยู่ในโรงพยาบาล
- เคส C — การเตือนล่วงหน้าที่เปลี่ยนการจัดลำดับความเร่งด่วน: ผู้ป่วยที่มีโรคประจำตัวหลายชนิดได้รับการแจ้งเตือนว่าอยู่ในกลุ่มเสี่ยง ทีมงานจึงเพิ่มความใกล้ชิดในการตรวจเชิงสังเกต ทำให้การย้ายไป ICU ที่วางแผนไว้สามารถเลื่อนหรือยกเลิกได้เมื่ออาการไม่ทุเลาลง — ตัวอย่างนี้แสดงผลของการปรับการจัดการทรัพยากรอย่างเหมาะสม
การวิเคราะห์ข้อผิดพลาด และข้อจำกัดของผลการทดลอง
แม้ผลการทดลองจะแสดงประสิทธิภาพที่ดี แต่การวิเคราะห์ข้อผิดพลาดชี้ประเด็นสำคัญที่ต้องพิจารณาก่อนการนำไปใช้จริงในวงกว้าง:
- False positives (FP): ในตัวอย่างนี้มี 132 ครั้งของการแจ้งเตือนที่ไม่ได้ตามมาด้วยเหตุฉุกเฉินจริง (FP) ซึ่งนำไปสู่การตรวจซ้ำ การสังเกตที่เพิ่มขึ้น และในบางกรณีการย้าย ICU ที่ไม่จำเป็น การวิเคราะห์เชิงคุณภาพพบว่า FP ส่วนใหญ่เกิดจากสัญญาณสะเทือนของอุปกรณ์สวมใส่ (artifacts) หรือความผันผวนชั่วคราวของค่าทางห้องปฏิบัติการที่ยังไม่มีความหมายทางคลินิก
- False negatives (FN): มี 12 กรณีที่ระบบไม่ทำนายเหตุการณ์ที่เกิดขึ้นจริง โดยสาเหตุที่พบบ่อยคือข้อมูลจากอุปกรณ์สวมใส่หายไปเป็นช่วง ๆ, การนำส่งผลตรวจที่ล่าช้า, หรือผู้ป่วยมีลักษณะทางคลินิกที่ผิดปกติและไม่เป็นไปตามรูปแบบที่ระบบเรียนรู้ไว้ (atypical presentation)
- ผลกระทบทางคลินิกและการวัดผล: ในการวัดเชิงเปรียบเทียบกับข้อมูลย้อนหลัง (historical control) โรงพยาบาลสังเกตเห็น การลดลงเชิงสัมพัทธ์ของการย้ายผู้ป่วยไป ICU แบบฉุกเฉินประมาณ 22% (จากอัตรา 8.2% ลงเหลือ 6.4% ในช่วงการทดลอง) ซึ่งเท่ากับการลดลงเชิงสัมบูรณ์ประมาณ 1.8 จุดร้อยละ — อย่างไรก็ตาม ตัวเลขนี้เป็นผลเบื้องต้นและยังต้องยืนยันด้วยการศึกษาแบบสุ่มควบคุม (randomized controlled trial) เพื่อควบคุมปัจจัยรบกวน
- ข้อจำกัดด้านข้อมูล: การทดลองเป็นแบบ single‑center และผู้เข้าร่วมต้องยอมรับการสวมอุปกรณ์และการถ่ายภาพซ้ำ จึงอาจเกิด selection bias ได้ นอกจากนี้ ความไม่สอดคล้องของเวลาการเก็บข้อมูล (time-stamping) ระหว่างอุปกรณ์ต่างชนิดยังเป็นอุปสรรคต่อการประมวลผลแบบเรียลไทม์
- การยอมรับของผู้คลินิก: อัตราการตอบสนองของแพทย์ต่อการแจ้งเตือนอยู่ที่ประมาณ 66% (การดำเนินการหรือการปรับการรักษาหลังการแจ้งเตือน) ซึ่งสะท้อนว่าการรวมระบบเข้ากับเวิร์กโฟลว์ทางคลินิกต้องการการออกแบบ UI/UX และกระบวนการฝึกอบรมเพิ่มเติม
สรุปได้ว่า Physio‑LLM ในการทดลองเบื้องต้นแสดงความสามารถในการทำนายเหตุฉุกเฉินภายใน 48 ชั่วโมงด้วยความไวและความจำเพาะที่น่าสนใจ พร้อม NPV สูงเหมาะสำหรับการยกเว้นความเสี่ยง อย่างไรก็ตาม เพื่อยืนยันผลกระทบต่อผลลัพธ์ทางคลินิกอย่างน่าเชื่อถือ จำเป็นต้องมีการทดลองแบบหลายศูนย์และการศึกษาเชิงเปรียบเทียบแบบสุ่มควบคุม พร้อมการปรับปรุงด้านการจัดการข้อมูลและการลด false positives ที่เป็นผลมาจากสัญญาณรบกวน
ความปลอดภัย จริยธรรม และกฎระเบียบในการใช้ AI ทางการแพทย์
ความปลอดภัย จริยธรรม และกฎระเบียบในการใช้ AI ทางการแพทย์
การนำระบบ AI ทางการแพทย์ เช่น Physio‑LLM ที่ผสานข้อมูลจากสวมใส่ ภาพทางการแพทย์ และผลแลบ มาใช้สนับสนุนการตัดสินใจของแพทย์ จำเป็นต้องให้ความสำคัญกับความปลอดภัยของข้อมูลและจริยธรรมในทุกขั้นตอน โดยเฉพาะเมื่อข้อมูลที่ประมวลผลเป็นข้อมูลสุขภาพซึ่งถือเป็นข้อมูลอ่อนไหวตามกฎหมาย PDPA ของไทยและมาตรฐานสากล การปฏิบัติตามข้อกำหนดเหล่านี้ไม่ได้เป็นเพียงเรื่องด้านเทคนิค แต่เป็นหัวใจของการสร้างความเชื่อมั่นให้กับผู้ป่วยและผู้ให้บริการทางการแพทย์
ข้อกำหนดด้านกฎหมายและนโยบายความเป็นส่วนตัว — ในบริบทของประเทศไทย ข้อมูลสุขภาพถูกคุ้มครองภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ซึ่งกำหนดให้มี ฐานทางกฎหมาย สำหรับการเก็บรวบรวมและประมวลผลข้อมูล การขอความยินยอมที่ชัดเจนสำหรับการใช้ข้อมูลเพื่อการวินิจฉัยหรือวิจัย การปฏิบัติตามหลักการ data minimization และการเปิดเผยจุดประสงค์ในการใช้ข้อมูลเป็นสิ่งจำเป็น นอกจากนี้ องค์กรต้องพิจารณามาตรฐานสากลที่เกี่ยวข้อง เช่น ISO 27001 (ระบบบริหารความปลอดภัยสารสนเทศ), ISO 13485 (ระบบบริหารคุณภาพอุปกรณ์การแพทย์), และข้อกำหนดสำหรับซอฟต์แวร์การแพทย์ (SaMD) ที่ได้รับการแนะนำโดย FDA/CE หรือการขึ้นทะเบียนกับสำนักงานคณะกรรมการอาหารและยา (อย.) ของไทยในกรณีที่ระบบจัดเป็นอุปกรณ์การแพทย์
มาตรการทางเทคนิคและการบริหารจัดการข้อมูล — เพื่อปกป้องความเป็นส่วนตัวและความลับของผู้ป่วย ควรนำแนวปฏิบัติดังต่อไปนี้มาใช้เป็นมาตรฐานปฏิบัติการ:
- การได้รับความยินยอมและการแจ้งวัตถุประสงค์ — ระบุการใช้ข้อมูลอย่างชัดเจน ทั้งการวินิจฉัย การฝึกโมเดล และการวิจัย พร้อมตัวเลือกให้ผู้ป่วยถอนความยินยอมได้
- การทำให้ไม่สามารถระบุตัวบุคคลได้ (de‑identification / pseudonymization) ก่อนนำข้อมูลไปใช้ฝึกหรือทดสอบโมเดล
- การเข้ารหัสข้อมูล ทั้งขณะส่งข้อมูล (in transit) และเก็บข้อมูล (at rest) รวมถึงการใช้ระบบการเข้าถึงตามบทบาท (role‑based access control) และการบันทึก log สำหรับการตรวจสอบ
- ข้อตกลงการประมวลผลข้อมูล (Data Processing Agreement) กับผู้ให้บริการคลาวด์และพันธมิตร เพื่อกำหนดความรับผิดชอบและเขตข้อมูล (data residency)
การจัดการความเสี่ยงเมื่อ AI ให้คำแนะนำผิดพลาดและกรอบความรับผิดชอบ — ระบบ AI ทางการแพทย์ต้องถูกออกแบบให้ทำงานในบทบาทของ “decision support” ไม่ใช่การทดแทนการตัดสินใจของแพทย์ โดยต้องมีแนวปฏิบัติดังนี้:
- การกำหนดขอบเขตการใช้งาน (intended use) อย่างชัดเจนในเอกสารรับรองและการสื่อสารกับผู้ใช้งาน
- การแสดงความไม่แน่นอนของการทำนาย (confidence intervals, calibration) และคำอธิบายเหตุผลเชิงโต้ตอบ เพื่อให้แพทย์ประเมินและตัดสินใจได้
- กรอบความรับผิดชอบ — ระบุความรับผิดชอบทางคลินิกและกฎหมายระหว่างโรงพยาบาล ผู้พัฒนา และผู้ให้บริการ รวมถึงนโยบายการรายงานเหตุไม่พึงประสงค์และการเรียกคืน (recall) หรือการอัพเดตโมเดลเมื่อพบปัญหา
- การประกันภัยและการจัดซื้อประกันความเสียหาย สำหรับกรณีที่เกิดความผิดพลาดของระบบ เพื่อเยียวยาผู้ป่วยและสนับสนุนการบริหารความเสี่ยงทางกฎหมาย
- การตรวจสอบและทดสอบก่อนใช้งานจริง (validation & verification) ตามมาตรฐานทางคลินิกและการทดสอบภาคสนาม (clinical validation) อย่างต่อเนื่อง
การประเมิน bias และการรับรองความเป็นธรรมข้ามกลุ่มประชากร — เครื่องมือ AI ที่ใช้ข้อมูลจากสวมใส่และภาพทางการแพทย์เสี่ยงต่อการมีอคติ (bias) หากชุดข้อมูลฝึกไม่ครอบคลุมกลุ่มประชากรที่หลากหลาย ดังนั้นการรับรองความเป็นธรรมควรรวมถึง:
- การวิเคราะห์ประสิทธิภาพแบบแบ่งย่อย (subgroup performance) โดยวัดค่าความแม่นยำ (sensitivity, specificity), อัตราการเตือนผิดพลาด (false positive rate) และการลดลงของประสิทธิภาพในกลุ่มต่าง ๆ เช่น อายุ เพศ ชนชาติ สถานะโภชนาการ และปัจจัยทางสังคม
- การใช้มาตรวัดเชิงสถิติและเชิงการแพทย์ เพื่อประเมิน fairness เช่น disparate impact, equalized odds พร้อมการตั้งเกณฑ์ยอมรับได้ที่สอดคล้องกับบริบททางคลินิก
- การขยายและปรับชุดข้อมูลฝึก เพื่อเพิ่มความเป็นตัวแทนของกลุ่มที่ด้อยโอกาส และการใช้เทคนิคการชดเชย (reweighting, data augmentation) เมื่อจำเป็น
- การตรวจสอบโดยบุคคลที่สาม (third‑party audits) และการจัดทำ model cards และ data sheets ที่โปร่งใส เพื่อให้ผู้กำกับดูแลและสาธารณะเข้าใจข้อจำกัดของโมเดล
- การตรวจสอบหลังการนำระบบไปใช้ (post‑market surveillance) เพื่อเฝ้าระวังอคติที่อาจปรากฏเมื่อระบบปะทะกับผู้ป่วยในสภาพแวดล้อมจริง
การนำแนวทางปฏิบัติเหล่านี้มารวมกับกระบวนการกำกับดูแลภายในองค์กร เช่น คณะกรรมการจริยธรรมข้อมูลสุขภาพ (data ethics board), นโยบายการตรวจประเมินด้านความปลอดภัยเป็นประจำ และการฝึกอบรมบุคลากร จะช่วยลดความเสี่ยงและเพิ่มความเชื่อมั่นต่อแพทย์และผู้ป่วย ในเชิงปฏิบัติ โรงพยาบาลควรกำหนดแผนการจัดการเหตุฉุกเฉิน (incident response), แนวทางการสื่อสารความผิดพลาดต่อผู้ป่วย และกลไกการปรับปรุงโมเดลอย่างต่อเนื่อง เพื่อให้ Physio‑LLM สามารถนำประโยชน์มาสู่วงการดูแลสุขภาพได้อย่างปลอดภัย ยุติธรรม และเป็นไปตามกฎระเบียบที่เกี่ยวข้อง
การนำไปใช้จริง: การผสานเข้ากับงานคลินิก อุปสรรค และแนวทางแก้ไข
การนำไปใช้จริง: การผสานเข้ากับงานคลินิก อุปสรรค และแนวทางแก้ไข
การนำระบบ Physio‑LLM เข้าสู่การปฏิบัติงานจริงในโรงพยาบาลขนาดใหญ่ต้องเริ่มจากการวางสถาปัตยกรรมการเชื่อมต่อข้อมูลกับระบบสารสนเทศสุขภาพเดิม (EMR) อย่างรัดกุม โดยแนะนำให้ใช้มาตรฐานสากลเช่น HL7/FHIR สำหรับการแลกเปลี่ยนข้อมูลผู้ป่วยแบบเรียลไทม์และแบบแบตช์ เพื่อให้ข้อมูลจากอุปกรณ์สวมใส่ ภาพทางการแพทย์ และผลแลบถูกผนวกรวมลงใน workflow ของแพทย์ ตัวอย่างแผนการใช้งานคือ 1) พัฒนาชุด API ที่แปลงข้อมูลจากอุปกรณ์เป็น FHIR resource, 2) กำหนดช่องทางส่งแจ้งเตือน (in-EMR alert, SMS, mobile app) และ 3) ทำ mapping ระดับเลือกระหว่างฟิลด์ใน EMR กับฟีเจอร์ของโมเดล เช่น vital signs, CXR report, lab codes (LOINC) เพื่อให้การแสดงผลและการอ้างอิงแหล่งข้อมูลชัดเจนสำหรับการตัดสินใจทางคลินิก
การตั้งค่า threshold ของการแจ้งเตือนต้องปรับตามหน่วยงาน (เช่น หน่วยดูแลผู้ป่วยวิกฤต vs. คลินิกผู้ป่วยนอก) และควรมีการกำหนดค่าเริ่มต้นที่เป็นมาตรฐานร่วมกับทีมแพทย์ เช่น ระดับความเสี่ยงที่ต้องการ sensitivity สูงสุดใน ICU และต้องการ precision สูงขึ้นในคลินิกลดการแจ้งเตือนเท็จ กระบวนการนี้ควรทำโดยคณะกรรมการคลินิก-เทคนิค (clinical-technical steering committee) โดยใช้ข้อมูลย้อนหลัง (retrospective validation) เพื่อคำนวณ trade-off ระหว่าง sensitivity และ false alarm rate การทดลอง A/B หรือการรันแบบ shadow mode (ระบบทำงานแบบเงาโดยไม่แทรกแซงการดูแลจริง) สามารถช่วยให้ได้ค่าพารามิเตอร์ที่เหมาะสมก่อนเปิดใช้งานเต็มรูปแบบ
การอบรมและการยอมรับของบุคลากรเป็นปัจจัยสำคัญต่อการนำไปใช้จริง แผนการอบรมที่มีประสิทธิผลควรรวมถึง 1) การอบรมเชิงปฏิบัติการ สำหรับแพทย์ พยาบาล และทีม IT, 2) คู่มือการใช้งานเชิงคลินิก ที่เน้นการตีความผลและการตอบสนองต่อคำแนะนำของระบบ และ 3) โมดูล e‑learning สำหรับพนักงานใหม่และการทบทวนความรู้เป็นระยะ ระบบควรมีฟีเจอร์ชี้แจงเหตุผล (explainability) เช่น การแสดงสาเหตุสำคัญที่ระบบใช้ในการคาดการณ์ (feature importance / SHAP summary) เพื่อเพิ่มความเชื่อถือของผู้ใช้ การวัดผลการยอมรับสามารถใช้ตัวชี้วัดเช่น % ของคำแนะนำที่ถูกเปิดดู, อัตราการยอมรับคำแนะนำโดยแพทย์, และผลตอบรับเชิงคุณภาพจากแบบสำรวจ
อุปสรรคทางเทคนิคและเชิงองค์กรที่คาดว่าจะพบ ได้แก่ ความไม่สมบูรณ์ของข้อมูล (missingness), ความหลากหลายของมาตรฐานข้อมูลจากอุปกรณ์หลายยี่ห้อ, ปัญหาแบนด์วิดท์และ latency ในการส่งข้อมูลเรียลไทม์, และความกังวลด้านความเป็นส่วนตัว/การปฏิบัติตามกฎหมายการคุ้มครองข้อมูล (PDPA) แนวทางแก้ไขประกอบด้วยการตั้งมาตรการการทำความสะอาดข้อมูลอัตโนมัติ (data imputation and validation pipelines), การใช้มาตรฐาน interoperability และ connector เฉพาะยี่ห้อ, การออกแบบสถาปัตยกรรมแบบ edge-processing เพื่อลดภาระเครือข่าย และการเข้ารหัสข้อมูลทั้งใน transit และ at rest พร้อมนโยบายการเข้าถึงแบบ least privilege
เพื่อให้การปรับใช้สำเร็จ แนะนำกลยุทธ์การนำไปใช้แบบเป็นขั้นตอน (phased rollout) ดังนี้:
- Pilot phase: เริ่มในหน่วยงานเดียวหรือกลุ่มผู้ป่วยเฉพาะ เช่น หน่วยกุมารเวชหรือ ICU จำนวน 50–100 ราย เพื่อทดสอบ integration, UX และการตั้ง threshold
- Scale-up phase: ขยายไปยังหลายหน่วยงานโดยปรับค่าพารามิเตอร์ตามผลจาก pilot และเริ่มเชื่อมต่อกับระบบ EMR ทั้งหมด
- Full operationalization: เปิดให้ใช้ในระดับโรงพยาบาลพร้อม SOP, governance และ SLA สำหรับทีมสนับสนุน
สุดท้าย ควรจัดตั้งกรอบกำกับดูแลทางจริยธรรมและการกำกับดูแลโมเดล (model governance) ซึ่งรวมถึงการทำ audit trail ของคำตัดสิน คำอธิบายการคาดการณ์ การทบทวนประสิทธิภาพเป็นรอบ (quarterly), และนโยบายการอัปเดตโมเดลแบบมีการควบคุม (controlled model updates) เพื่อให้แน่ใจว่า Physio‑LLM ไม่เพียงแต่ช่วยทำนายภาวะฉุกเฉินล่วงหน้า 48 ชั่วโมงได้ แต่ยังถูกใช้อย่างปลอดภัย มีความเชื่อถือ และสอดคล้องกับ workflow ทางคลินิกของโรงพยาบาลอย่างยั่งยืน
บทสรุป
Physio‑LLM เป็นระบบปัญญาประดิษฐ์ที่ผสานข้อมูลจากอุปกรณ์สวมใส่ ภาพทางการแพทย์ และผลการตรวจทางห้องปฏิบัติการ เพื่อทำนายความเสี่ยงภาวะฉุกเฉินของผู้ป่วยล่วงหน้าได้ถึง 48 ชั่วโมง และให้คำอธิบายเชิงคลินิกที่ออกแบบมาเพื่อช่วยการตัดสินใจของแพทย์ เบื้องต้นการทดลองภายในโรงพยาบาลใหญ่ในกรุงเทพฯ แสดงศักยภาพที่น่าสนใจ — ระบบสามารถชี้จุดสัญญาณเสี่ยงที่สัมพันธ์กับการลุกลามของโรคและแนะนำการตรวจหรือการเฝ้าระวังเพิ่มเติมได้ อย่างไรก็ตาม ผลลัพธ์ยังเป็นข้อมูลจากการทดลองระยะแรกและต้องการการตรวจสอบเพิ่มเติมในรูปแบบการศึกษาเชิงทดลองและการตรวจสอบภายนอก (external validation) เพื่อยืนยันความเที่ยงตรง ความเท่าเทียมทางประชากร และความคงที่ของประสิทธิภาพก่อนการใช้งานเชิงคลินิกอย่างกว้างขวาง
การนำ Physio‑LLM ไปใช้จริงจะต้องควบคู่กับมาตรการด้านความปลอดภัย ข้อบังคับ และกลยุทธ์การปรับใช้ เช่น กรอบการบริหารจัดการข้อมูล (data governance) ความเป็นส่วนตัวและการเข้ารหัส การประเมินความเสี่ยงทางไซเบอร์ การทดสอบผลกระทบต่อการทำงานของทีมคลินิกเพื่อลดปัญหา alert fatigue การกำหนดบทบาท clinician‑in‑the‑loop การบูรณาการกับระบบเวชระเบียนอิเล็กทรอนิกส์ (EHR) รวมถึงการขอการรับรองจากหน่วยงานกำกับดูแลและการออกแบบแนวทางการชดเชยค่าใช้จ่ายสำหรับการใช้งานจริง หากดำเนินตามแนวทางนี้อย่างรอบคอบ Physio‑LLM มีศักยภาพช่วยลดเหตุการณ์ไม่พึงประสงค์ เพิ่มระยะเวลาการตอบสนองทางคลินิก และยกระดับการดูแลผู้ป่วยในภาพรวม แต่ผลประโยชน์เชิงคลินิกที่ยั่งยืนจะเกิดขึ้นได้ก็ต่อเมื่อมีการยืนยันทางวิชาการ การกำกับดูแลที่ชัดเจน และการปรับใช้เชิงระบบอย่างเป็นขั้นตอน



