
ในยุคที่โมเดลปัญญาประดิษฐ์ถูกนำไปใช้ตัดสินใจในงานสำคัญตั้งแต่การคัดกรองผู้สมัครงานจนถึงการวินิจฉัยทางการแพทย์ ความโปร่งใสและการพิสูจน์แหล่งที่มาของโมเดลกลายเป็นหัวใจสำคัญของความน่าเชื่อถือ สตาร์ทอัพไทยล่าสุดได้เปิดตัว "Model Provenance Ledger" บนเทคโนโลยีบล็อกเชน เพื่อบันทึกข้อมูลสำคัญอย่างแหล่งข้อมูลที่ใช้ กระบวนการเทรน และเวอร์ชันของโมเดลอย่างไม่เปลี่ยนแปลง ทำให้การตรวจสอบย้อนกลับ (audit trail) เป็นไปได้และเชื่อถือได้ยิ่งขึ้น
บทความนี้จะพาอ่านถึงประเด็นหลักที่ผู้บริหารและทีมเทคนิคต้องรู้: วิธีการทำงานของ Ledger บนบล็อกเชน ผลกระทบต่อความรับผิดชอบด้าน AI ในองค์กร ประโยชน์เช่นความโปร่งใสและการรองรับการตรวจสอบ รวมถึงกรณีศึกษาจริงและแนวทางปฏิบัติที่องค์กรสามารถนำไปปฏิบัติ เพื่อให้การใช้งาน AI ขององค์กรมีความน่าเชื่อถือ ปลอดภัย และสอดคล้องกับข้อกำหนดด้านจริยธรรมและกฎหมาย
บทนำ: ทำไม 'Provenance' ของโมเดล AI จึงสำคัญ
บทนำ: ทำไม Provenance ของโมเดล AI จึงสำคัญ
ในยุคที่องค์กรทั่วโลกเร่งนำปัญญาประดิษฐ์ (AI) มาใช้งานเพื่อเพิ่มผลิตภาพ ตัดสินใจเชิงธุรกิจ และให้บริการลูกค้า การสามารถตอบคำถามว่า “ข้อมูลนี้มาจากไหน” และ “โมเดลนี้ถูกสร้างขึ้นอย่างไร” กลายเป็นหัวใจของการบริหารความเสี่ยงทางเทคโนโลยีและการกำกับดูแลภายในองค์กร คำว่า provenance ในบริบทของ AI จึงไม่ได้หมายถึงเพียงแหล่งที่มาของข้อมูลเท่านั้น แต่ยังครอบคลุมถึงกระบวนการเทรน, เวอร์ชันของโมเดล, และเมตาดาต้าที่อธิบายเงื่อนไขการฝึกสอนและการปรับแต่ง
การขาดระบบพิสูจน์แหล่งที่มา ส่งผลให้เกิดความเสี่ยงในหลายมิติ ทั้งปัญหาความลำเอียงของโมเดล (bias), การรั่วไหลของข้อมูล (data leakage), และการไม่ปฏิบัติตามข้อกำหนดด้านกฎหมายและจริยธรรม (compliance failure) ตัวอย่างที่ชัดเจนเช่นกรณีการวิจัยเกี่ยวกับระบบประเมินความเสี่ยงผู้ต้องหา (COMPAS) ซึ่งถูกวิพากษ์วิจารณ์ว่ามีอคติทางเชื้อชาติ หรือเหตุการณ์การเก็บและใช้ข้อมูลส่วนบุคคลโดยหน่วยงานภายนอกที่ถูกเปิดเผยในกรณี Cambridge Analytica เหล่านี้ชี้ให้เห็นถึงผลกระทบร้ายแรงทั้งต่อสิทธิพลเมืองและชื่อเสียงขององค์กร
ในเชิงปฏิบัติ provenance ของโมเดล AI หมายถึงชุดข้อมูลที่บันทึกเพื่อให้สามารถตรวจสอบย้อนกลับได้ ซึ่งรวมถึงแต่ไม่จำกัดเพียง:
- แหล่งที่มาของข้อมูล (data sources) — ระบุเจ้าของข้อมูล, วิธีการเก็บข้อมูล, และสิทธิ์การใช้งาน
- กระบวนการเทรน (training pipeline) — เวอร์ชันของโค้ด, พารามิเตอร์การเทรน, สภาพแวดล้อมการรัน
- เวอร์ชันของโมเดล (model versions) — การเปลี่ยนแปลง, จุดที่นำมาใช้งานจริง (deployment), และผลการทดสอบ
- เมตาดาต้า (metadata) — วันเวลา, ค่าความเชื่อมั่น, ชุดทดสอบที่ใช้สำหรับประเมิน
ความต้องการด้านความโปร่งใสไม่ได้มาจากภาคธุรกิจเพียงฝ่ายเดียว แต่เป็นแรงกดดันจากหน่วยกำกับดูแลและผู้บริโภคด้วย องค์กรที่ไม่สามารถยืนยันแหล่งข้อมูลหรืออธิบายกระบวนการตัดสินใจของโมเดลอาจเผชิญทั้งบทลงโทษทางกฎหมาย การเรียกร้องค่าเสียหาย และการสูญเสียความไว้วางใจจากลูกค้า งานสำรวจเชิงอุตสาหกรรมหลายชิ้นระบุว่าองค์กรส่วนใหญ่ให้ความสำคัญกับการกำกับดูแลโมเดลและการจัดการแหล่งที่มาอย่างน้อยในระดับสูงสุด เนื่องจากเป็นเงื่อนไขพื้นฐานสำหรับการประเมินความเสี่ยง การรายงานต่อ regulator และการรับรองความรับผิดชอบต่อผู้มีส่วนได้ส่วนเสีย
ดังนั้น การพัฒนาโครงสร้างพื้นฐานที่สามารถบันทึกและยืนยัน provenance ของโมเดล — ไม่ว่าจะเป็นเอกสารประกอบชุดข้อมูล การติดตาม pipeline การเทรน หรือระบบการติดตามเวอร์ชันบนแพลตฟอร์มที่เชื่อถือได้ — จึงไม่ใช่เรื่องเสริม แต่เป็นข้อกำหนดเชิงกลยุทธ์สำหรับองค์กรที่ต้องการใช้ AI อย่างปลอดภัย ยั่งยืน และเป็นไปตามกฎกติกาทั้งในเชิงกฎหมายและจริยธรรม
รู้จัก 'Model Provenance Ledger' — ฟีเจอร์และการทำงานหลัก
รู้จัก "Model Provenance Ledger" — ฟีเจอร์และการทำงานหลัก
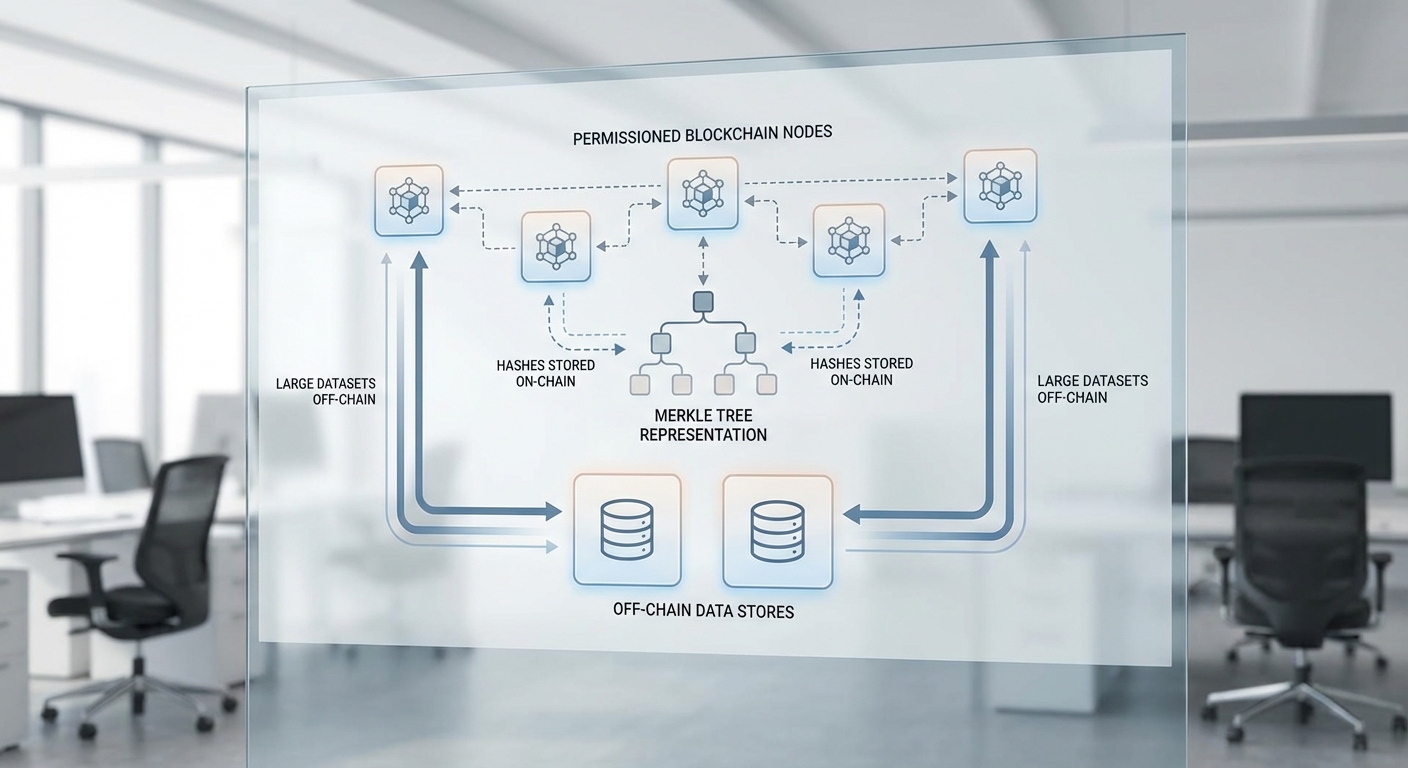
Model Provenance Ledger ของสตาร์ทอัพไทยเป็นโซลูชันที่ออกแบบมาเพื่อบันทึกและยืนยันแหล่งที่มาของข้อมูล กระบวนการเทรน และเวอร์ชันของโมเดลอย่างเป็นระบบบนบล็อกเชน โดยมีเป้าหมายเพื่อเพิ่มความโปร่งใสและความรับผิดชอบ (accountability) ของการพัฒนา AI ในองค์กร โซลูชันนี้ผสานการเก็บข้อมูลแบบ off-chain สำหรับอาร์ติแฟกต์ขนาดใหญ่ (เช่น dataset และโมเดล) ร่วมกับการบันทึกค่าอ้างอิงเชิงพิสูจน์ (เช่น hash) บนบล็อกเชนเพื่อให้เกิดความ immutability และตรวจสอบได้จากภายนอก
การบันทึก metadata เป็นฟีเจอร์พื้นฐานของระบบ โดยจะเก็บข้อมูลเชิงบริบทที่สำคัญ เช่น dataset ID, โครงสร้างข้อมูล (schema), วิธีการสุ่มตัวอย่าง (sampling method) และขั้นตอนการเตรียมข้อมูล (preprocessing steps) เพื่อให้เมื่อต้องตรวจสอบผลการทดสอบหรือข้อผิดพลาด สามารถย้อนกลับไปดูที่มาของข้อมูลได้อย่างแม่นยำ รายการ metadata หลักที่ระบบบันทึกได้แก่:
- Dataset ID และแหล่งจัดเก็บ (URI)
- Schema (ฟิลด์, ชนิดข้อมูล, ความหมายของคอลัมน์)
- Sampling method เช่น stratified/probability sampling หรือ timestamp-based split
- Preprocessing steps เช่น normalization, tokenization, data augmentation พร้อมลำดับการทำงาน
- Fingerprint ของไฟล์ (เช่น SHA-256 hash) เพื่อยืนยันความสมบูรณ์ของ dataset
ส่วนการเก็บบันทึกกระบวนการเทรน (training provenance) จะจับข้อมูลเชิงเทคนิคที่จำเป็นต่อการทำซ้ำ (reproducibility) เช่น hyperparameters (learning rate, batch size), random seed, เฟรมเวิร์กที่ใช้ (เช่น TensorFlow/PyTorch), รวมถึงสภาพแวดล้อมการคำนวณ (เช่น Docker image digest, CUDA และไดรเวอร์ GPU, จำนวนเครื่องและสเปค) ระบบจะทำการสร้างค่า hash ของคอนฟิกทั้งหมดและลงตราดิจิทัล (digital signature) ของผู้รับผิดชอบหรือระบบอัตโนมัติ เพื่อให้สามารถยืนยันได้ว่า configuration ที่นำไปใช้เป็นของจริง ตัวอย่างข้อมูลการเทรนที่ถูกบันทึกได้แก่:
- Hyperparameters: learning_rate=0.001, batch_size=256, optimizer=Adam
- Seed & deterministic flags: seed=42, cudnn_deterministic=true
- Framework & version: PyTorch 2.0.1
- Compute environment: Docker image sha256:..., GPU model: NVIDIA A100, CUDA 12.0
- Training artifacts fingerprint: model weights hash, training logs hash
การจัดการเวอร์ชันและการพิจารณาโมเดล (model lineage) เป็นอีกฟังก์ชันสำคัญของ Ledger นี้ ระบบจะเชื่อมโยงแต่ละเวอร์ชันของโมเดลกับ metadata และการเทรนที่เกี่ยวข้อง ทำให้สามารถสร้างเส้นทางการเปลี่ยนแปลงของโมเดลตั้งแต่ต้นทางข้อมูลจนถึง deployment (จาก v0.1 → v0.2 → v1.0 เป็นต้น) โดยทุกการเปลี่ยนแปลงที่เกี่ยวข้องกับรุ่นใหม่จะถูกบันทึกเป็น entry ใหม่ที่มี timestamp และ hash ยืนยัน ทำให้เกิด immutable audit trail ซึ่งช่วยสนับสนุนการตรวจสอบภายในและการปฏิบัติตามข้อกำหนดทางกฎหมายได้อย่างชัดเจน
เชิงเทคนิค วิธีการดำเนินงานหลักประกอบด้วยการใช้ hashing (เช่น SHA-256) เพื่อสร้าง fingerprint ของ dataset, โมเดล และคอนฟิกการเทรน รวมทั้งการใช้ digital signature (เช่น ECDSA) ในการลงนาม metadata และสิทธิ์ของผู้รับผิดชอบ รายการสำคัญจะถูกจดบันทึกบนบล็อกเชนผ่าน smart contracts ซึ่งทำหน้าที่เป็น "ตราประทับ" อัตโนมัติสำหรับข้อมูลสำคัญ ได้แก่:
- การยืนยัน hash ของ dataset/model และ timestamp
- การบันทึกสถานะ approval หรือ attestation จากผู้มีอำนาจ (เช่น Data Steward, Model Owner)
- ตรรกะเชิงนโยบาย เช่น เงื่อนไขการ deploy (ต้องผ่านการทดสอบ fairness หรือ security ก่อน)
Smart contracts ยังช่วยในการจัดการสิทธิ์การเข้าถึงและกระบวนการยืนยันแบบอัตโนมัติ (attestation workflows) — ตัวอย่างเช่น เมื่อทีม QA อนุมัติโมเดล ระบบจะเขียนสัญญาว่าการอนุมัตินั้นเกิดขึ้นจากคีย์ที่ลงนามและไม่สามารถแก้ไขได้ภายหลัง (immutable approval record) ซึ่งสนับสนุนการใช้งานในบริบทของการตรวจสอบความรับผิดชอบและการทำ Compliance โดยรวมแล้ว Model Provenance Ledger ทำให้หน่วยงานสามารถพิสูจน์แหล่งที่มา (provenance) ของ AI ได้ทั้งในเชิงเทคนิคและเชิงนโยบาย ลดความเสี่ยงจากการตีความผิดพลาดและช่วยให้การตัดสินใจด้านการนำโมเดลขึ้น production มีความน่าเชื่อถือมากขึ้น
สถาปัตยกรรมเทคนิค: Blockchain, On-chain vs Off-chain และมาตรการความเป็นส่วนตัว
สถาปัตยกรรมเทคนิค: Blockchain, On-chain vs Off-chain และมาตรการความเป็นส่วนตัว
ในการออกแบบระบบ Model Provenance Ledger สำหรับองค์กร สถาปัตยกรรมต้องผสานความต้องการด้านความน่าเชื่อถือ (auditability) กับข้อจำกัดด้านความเป็นส่วนตัวและประสิทธิภาพเชิงปฏิบัติการ โดยทั่วไปมีสองแนวทางหลักคือการใช้ permissioned blockchain ในระดับองค์กร/คอนซอร์เทียม หรือการใช้เครือข่ายแบบ permissionless สาธารณะ ทั้งสองแบบมีข้อดีข้อจำกัดที่ชัดเจน: เครือข่ายสาธารณะให้ความกระจายอำนาจและความโปร่งใสสูง แต่มีข้อจำกัดด้าน throughput/latency และประเด็นความลับข้อมูล ในขณะที่ permissioned blockchain เช่น Hyperledger Fabric หรือ Corda ออกแบบมาเพื่อตอบโจทย์องค์กร โดยให้ความเร็ว (throughput) และการยืนยันรายการที่รวดเร็วกว่า พร้อมกลไกการกำกับดูแลแบบองค์กรที่ชัดเจน
เชิงปริมาณ ตัวอย่างการเปรียบเทียบเชิงคร่าว ๆ ได้แก่ Bitcoin ประมาณ 4–7 TPS และเวลาออกบล็อกเป็นนาที ในขณะที่ Ethereum mainnet มีความสามารถประมาณ 10–15 TPS (ก่อน/หลัง Layer-2 มีผลต่างกัน) ส่วนแพลตฟอร์มแบบ permissioned เช่น Hyperledger Fabric ในการตั้งค่าบางกรณีสามารถรองรับหลายร้อยถึงกว่า 1,000 TPS ได้ ข้อสรุปเชิงปฏิบัติคือ ถ้าเป้าหมายคือการบันทึก metadata และรายการการเปลี่ยนแปลงภายในองค์กรอย่างมีประสิทธิภาพและควบคุมสิทธิ์การเข้าถึง permissioned blockchain มักเป็นตัวเลือกที่เหมาะสม เพราะตอบโจทย์ด้าน latency, privacy และ governance ที่องค์กรต้องการ
อย่างไรก็ตาม หลักปฏิบัติที่นิยมในงานจัดเก็บข้อมูลเชิงสืบค้นของโมเดลคือแนวทาง hybrid ที่ผสมผสานการเก็บข้อมูลบน-chain และ off-chain โดยใช้สัญลักษณ์สำคัญดังนี้:
- เก็บเฉพาะ metadata, hash และ pointer บน-chain: บันทึกค่าแฮชของชุดข้อมูล (e.g., SHA-256 ของไฟล์หรือของ Merkle root) ร่วมกับ pointer/CID ไปยังที่เก็บข้อมูล (เช่น IPFS, S3 หรือ data lake) และข้อมูลเวอร์ชันของโมเดล เพื่อให้เกิดความไม่เปลี่ยนแปลงและตรวจสอบย้อนกลับได้
- เก็บ raw data และ artifacts off-chain: ไฟล์น้ำหนักโมเดล (model weights), ชุดข้อมูลดิบ และเอกสารเชิงละเอียดเก็บไว้ในสตอเรจภายนอกที่มีการควบคุมสิทธิ์ ซึ่งจะทำงานร่วมกับการพิสูจน์แบบ on-chain ผ่าน hash/pointer
- ใช้ Merkle trees เพื่อประสิทธิภาพการพิสูจน์: เมื่อชุดข้อมูลมีขนาดใหญ่ การคำนวณ Merkle root แล้วบันทึก root บน-chain ช่วยให้สามารถพิสูจน์ความถูกต้องของ leaf ใด ๆ ด้วย Merkle proof ที่สั้น ลดการเก็บข้อมูลบน-chain และเร่งการตรวจสอบ
มาตรการความเป็นส่วนตัวและความลับของข้อมูลเป็นหัวใจสำคัญของระบบ โดยองค์ประกอบทางเทคนิคที่ควรนำมาใช้ประกอบด้วย:
- การทำ pseudonymization และการใช้ identifiers แบบ deterministic ที่มีการเติม salt: แทนการบันทึกข้อมูลส่วนบุคคล ให้ใช้ตัวระบุที่ไม่ระบุตัวตนโดยตรง (pseudonyms) และเมื่อจำเป็นต้องจับคู่ ให้ใช้ค่าแฮชที่ผสมน้ำเกลือ (salt) เพื่อป้องกันการย้อนรอยด้วยการโจมตีแบบ dictionary
- การเข้ารหัสทั้งข้อมูลขณะพัก (data-at-rest) และขณะส่ง (data-in-transit): ใช้ AES-GCM สำหรับการเข้ารหัสข้อมูลในสตอเรจ ร่วมกับการจัดการคีย์ผ่าน HSM/KMS และการเข้ารหัสช่องทางด้วย TLS 1.3 สำหรับการรับส่งข้อมูล นอกจากนี้ metadata บางส่วนบน-chain อาจเข้ารหัสก่อนบันทึกเพื่อจำกัดการเปิดเผย
- การควบคุมการเข้าถึงเชิงบรรทัดฐานและเชิงคริปโต: ใช้ RBAC/ABAC สำหรับระดับแอปพลิเคชัน ควบคู่กับการเข้ารหัสเชิงสาธารณะแบบ attribute-based encryption หรือการใช้ระบบกุญแจแบบ threshold/secret sharing เพื่อให้การถอดรหัสต้องอาศัยหลายฝ่ายตามนโยบาย
- การปกป้องทรัพยากรการคำนวณ: เมื่อต้องการตรวจสอบกระบวนการเทรนโดยไม่เปิดเผยข้อมูลดิบ สามารถใช้เทคนิคเช่น secure enclaves (ตัวอย่างเช่น Intel SGX, AMD SEV หรือ TDX) เพื่อรันการคำนวณภายในพื้นที่ความปลอดภัยที่สามารถออกใบรับรอง (attestation) ได้ หรือใช้ Multi-Party Computation (MPC) เพื่อให้หลายฝ่ายร่วมคำนวณได้โดยไม่เปิดเผยข้อมูลดิบ
- การพิสูจน์เชิงคณิตศาสตร์ (cryptographic proofs): การนำ zk-proofs (เช่น zk-SNARKs) มาใช้ในบางกรณีช่วยให้สามารถยืนยันคุณสมบัติของกระบวนการเทรนหรือคุณภาพของโมเดลโดยไม่ต้องเปิดเผยข้อมูลหรือพารามิเตอร์ภายในทั้งหมด
นอกจากเทคนิคเชิงคริปโตแล้ว การจัดการ governance และกระบวนการปฏิบัติการมีบทบาทสำคัญ: ในสถาปัตยกรรมแบบ permissioned ควรกำหนดนโยบาย consortium เช่น ใครมีสิทธิ์เขียนรายการใส่ล็อก, ใครมีสิทธิ์อนุมัติเวอร์ชัน และขั้นตอนการถอดสิทธิ์เมื่อผู้เข้าร่วมเปลี่ยนสถานะ ทั้งนี้ระบบควรรวมการบันทึกเวลา (timestamping), ตัวระบุเวอร์ชัน และบันทึกการเข้าถึงเพื่อให้การตรวจสอบย้อนหลังเป็นไปได้โดยไม่ละเมิดกฎความเป็นส่วนตัว
สรุปสั้น ๆ คือ สำหรับองค์กรไทยที่ต้องการระบบบันทึกแหล่งที่มาของโมเดลอย่างปลอดภัยและปฏิบัติได้จริง แนวทางที่แนะนำคือการใช้ permissioned blockchain ในรูปแบบคอนซอร์เทียม ควบคู่กับสตอเรจ off-chain สำหรับ artefacts ขนาดใหญ่ รวมทั้งนำเทคนิคการเข้ารหัส, Merkle proofs, secure enclaves และ MPC เข้ามาประยุกต์เพื่อรักษาความลับและความถูกต้องของข้อมูล โดยออกแบบ governance และนโยบายการเข้าถึงให้สอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคลและข้อกำหนดภายในองค์กร
ประโยชน์เชิงธุรกิจ: ความโปร่งใส การตรวจสอบ และการปฏิบัติตามกฎระเบียบ
ประโยชน์เชิงธุรกิจ: ความโปร่งใส การตรวจสอบ และการปฏิบัติตามกฎระเบียบ
การนำระบบ Model Provenance Ledger บนบล็อกเชนมาใช้ในองค์กรนำมาซึ่งประโยชน์เชิงธุรกิจที่จับต้องได้ ทั้งในแง่ของความโปร่งใส การเร่งกระบวนการตรวจสอบ และการลดค่าใช้จ่ายเมื่อเกิดปัญหา ด้วยการบันทึกแหล่งข้อมูล กระบวนการเทรน และเวอร์ชันของโมเดลอย่างเป็นระบบ องค์กรสามารถสืบย้อนที่มาของการตัดสินใจของ AI ได้ทันที แทนการต้องรวบรวมเอกสารจากหลายฝ่ายหรือทำการสอบสวนเชิงลึกที่กินเวลานาน
ในเชิงการตรวจสอบ (audit) ระบบ provenance ช่วยเร่งกระบวนการทั้ง internal และ external audit โดยข้อมูลที่บันทึกแบบไม่เปลี่ยนแปลงบนไทม์ไลน์ของบล็อกเชนทำให้ผู้ตรวจสอบเข้าถึงหลักฐานที่เชื่อถือได้ได้ทันที จากการประเมินเชิงสมมติ องค์กรที่ติดตั้งระบบลักษณะนี้อาจลดเวลาในการตรวจสอบลงได้ระหว่าง 40–60% และลดค่าใช้จ่ายการสืบค้นต้นเหตุของเหตุการณ์ความผิดพลาดหรือการละเมิดข้อมูลลงได้ถึง 30–50% (สอดคล้องกับแนวโน้มการประเมินประสิทธิภาพการจัดการความเสี่ยงจากรายงานของ McKinsey และ Gartner)
ด้านความน่าเชื่อถือต่อผู้ใช้และลูกค้า การแสดงหลักฐาน provenance ของโมเดลให้ลูกค้าเข้าถึงหรือสรุปเป็นรายงานช่วยสร้างความมั่นใจว่าโมเดลได้รับการเทรนจากข้อมูลที่ถูกต้อง มีการควบคุมเวอร์ชัน และผ่านกระบวนการตรวจสอบที่ชัดเจน ตัวอย่างเชิงสมมติ: ธุรกิจด้านการเงินที่ให้ข้อมูล provenance ในรายงานแก่ลูกค้ารายย่อยและหน่วยงานกำกับ พบว่าความพึงพอใจของลูกค้า (customer trust score) เพิ่มขึ้นเฉลี่ย 15–25% ภายใน 6 เดือนหลังการเปิดเผยข้อมูลเชิงแหล่งที่มา ซึ่งสอดคล้องกับแนวทางปฏิบัติของสถาบันการเงินที่ระบุโดย European Commission และหน่วยงานกำกับของสหรัฐบางแห่งว่าการโปร่งใสเป็นปัจจัยสำคัญในการยอมรับ AI
สำหรับการปฏิบัติตามกฎระเบียบ (AI governance) ระบบ provenance ช่วยให้องค์กรตอบสนองต่อข้อกำหนดในการรายงานและการตรวจสอบจากหน่วยงานกำกับได้อย่างเป็นระบบและอัตโนมัติ ข้อมูลเวอร์ชัน โมเดล และแหล่งที่มาที่บันทึกไว้จะทำให้การจัดทำเอกสารการปฏิบัติตามข้อกำหนด (compliance evidence) ง่ายขึ้น ลดความเสี่ยงของค่าปรับและความเสียหายทางกฎหมาย ตัวเลขเชิงสมมติแสดงให้เห็นว่าการรวม provenance ในกระบวนการควบคุมภายในอาจลดความเสี่ยงเชิงกฎระเบียบได้ถึง 20–35% เมื่อเทียบกับองค์กรที่ยังใช้การจัดการแบบกระจัดกระจาย (อ้างอิงแนวทางเชิงนโยบายของ OECD และ UK ICO เกี่ยวกับการกำกับดูแล AI)
- เร่งการ audit: เข้าถึงหลักฐานได้ทันที ลดเวลาตรวจสอบลง 40–60% (ประเมินเชิงสมมติ)
- ลดต้นทุนการสืบค้น: ต้นทุนการสอบสวนเหตุการณ์อาจลดลง 30–50% ด้วยข้อมูลที่ติดตามได้
- เสริมความเชื่อมั่นลูกค้า: คะแนนความไว้วางใจลูกค้าเพิ่มขึ้น 15–25% หลังการเปิดเผย provenance
- รองรับการกำกับดูแล: เพิ่มความพร้อมในการรายงานต่อหน่วยงานกำกับ และลดความเสี่ยงด้านกฎระเบียบ 20–35%
- เพิ่มความรวดเร็วในการแก้ไข: สามารถระบุเวอร์ชันหรือชุดข้อมูลที่เป็นสาเหตุแล้วย้อนกลับได้เร็วขึ้น ลดเวลาหยุดชะงักของระบบ
สรุปแล้ว การลงทุนในระบบ Model Provenance Ledger ให้ผลทางธุรกิจที่หลากหลาย ตั้งแต่การลดต้นทุนและเวลาในการตรวจสอบ เพิ่มความไว้วางใจของลูกค้า และช่วยให้องค์กรปฏิบัติตามกฎระเบียบได้อย่างมีประสิทธิภาพ เมื่อคำนึงถึงผลประโยชน์เชิงปฏิบัติและความเสี่ยงที่ลดลง องค์กรขนาดกลางถึงใหญ่สามารถคาดหวังการคืนทุน (payback) ภายในกรอบเวลาที่สมเหตุสมผล เช่น 12–18 เดือน ขึ้นอยู่กับขนาดการใช้งานและระดับการบูรณาการกับกระบวนการภายใน
กรณีศึกษาและการนำร่อง: ตัวอย่างจากภาคการเงิน สุขภาพ และค้าปลีก
กรณีศึกษาและการนำร่อง: ตัวอย่างจากภาคการเงิน สุขภาพ และค้าปลีก
ในเชิงปฏิบัติ สตาร์ทอัพผู้พัฒนา Model Provenance Ledger ได้ดำเนินการนำร่อง (pilot) ร่วมกับองค์กรในสามภาคสำคัญ ได้แก่ ภาคการเงิน ภาคสุขภาพ และภาคค้าปลีก เพื่อทดสอบผลกระทบด้านความน่าเชื่อถือของโมเดล การตรวจสอบย้อนกลับ (traceability) และการปฏิบัติตามนโยบายคุ้มครองข้อมูลส่วนบุคคล (PDPA) โดยทุกการนำร่องออกแบบให้สามารถวัดผลเชิงปริมาณก่อน-หลังการใช้งาน เพื่อแสดงตัวชี้วัดที่จับต้องได้ เช่น เวลาในการ audit จำนวนการสอบสวนข้อผิดพลาด และระดับความสอดคล้องกับนโยบายภายในองค์กร
ภาคการเงิน: ตรวจสอบแหล่งข้อมูลลูกค้าเพื่อป้องกันการตัดสินใจผิดพลาด
ธนาคารระดับกลางที่เข้าร่วม pilot ใช้ Ledger ในการบันทึกที่มาของชุดข้อมูลลูกค้า ฟีเจอร์ที่มาจาก third‑party vendor และกระบวนการ preprocessing ของข้อมูลสำหรับโมเดลอนุมัติสินเชื่อ ผลลัพธ์ที่วัดได้หลังการใช้งานคือ:
- เวลาในการตรวจสอบ (audit) ลดจากเฉลี่ย 3 สัปดาห์ (ประมาณ 15 วันทำการ) เหลือ 2 วันทำการ สำหรับการยืนยันแหล่งข้อมูลและ pipeline ของโมเดล
- จำนวนการสอบสวนกรณีการตัดสินใจผิดพลาดลดลงร้อยละ 60% (จาก 25 ราย/เดือน เหลือ 10 ราย/เดือน) เนื่องจากสามารถระบุสาเหตุจากเวอร์ชันโมเดลหรือชุดข้อมูลได้รวดเร็ว
- ระดับการติดตามแหล่งที่มาของฟีเจอร์จาก vendor เพิ่มจาก 40% เป็น 98% ทำให้การประเมินความเสี่ยงด้าน PDPA และสัญญา (data licensing) เป็นไปอย่างเป็นระบบ
ภาคสุขภาพ: ยืนยันที่มาของ dataset เพื่อการวินิจฉัยที่ต้องการความแม่นยำสูง
ในเครือข่ายโรงพยาบาลเอกชนที่ทดลองใช้ Ledger กับโมเดลช่วยวินิจฉัยภาพรังสี ทางทีมงานเน้นการบันทึก metadata ของภาพต้นฉบับ ข้อมูลการอนุญาตใช้ข้อมูลผู้ป่วย (consent) และขั้นตอนการทำ augmentation ผลลัพธ์เชิงปริมาณจากการนำร่องมีดังนี้:
- เวลาในการยืนยัน provenance ของชุดข้อมูลลดจากเฉลี่ย 10 วัน เหลือ ไม่เกิน 2 ชั่วโมง เมื่อใช้ Ledger ในการเข้าถึงบันทึกแบบไม่เปลี่ยนแปลง
- การสอบสวนกรณีข้อพิพาทเกี่ยวกับผลการวินิจฉัยลดลงร้อยละ 70% (จาก 20 ราย/ปี เหลือ 6 ราย/ปี) เนื่องจากสามารถตรวจสอบเวอร์ชันของโมเดลและชุดข้อมูลที่ใช้ในช่วงเวลานั้นได้ทันที
- กระบวนการ rollback ไปยังเวอร์ชันโมเดลที่มีการยืนยันความถูกต้องใช้เวลาเฉลี่ย 1 ชั่วโมง เทียบกับเดิมที่ต้องใช้หลายวันและมีขั้นตอนตรวจสอบหลายฝ่าย
- การขอข้อมูลเพื่อสนับสนุน PDPA เช่น proof of consent สำหรับชุดข้อมูล มีอัตราการตอบรับจาก audit ภายในเพิ่มเป็น 100% สำหรับชุดข้อมูลที่ลงทะเบียนใน Ledger
ภาคค้าปลีก: ตรวจจับแหล่งที่มาของข้อมูลเชิงพฤติกรรมเพื่อลดการส่งเสริมการตลาดที่ไม่เหมาะสม
กลุ่มอีคอมเมิร์ซนำ Ledger มาใช้กับระบบแนะนำสินค้าและแคมเปญโปรโมชั่น โดยบันทึกแหล่งที่มาของข้อมูลการคลิก ตะกร้าสินค้า และข้อมูลจากพาร์ทเนอร์การตลาด ผลการนำร่องพบว่า:
- อัตราแคมเปญที่ส่งไปยังผู้ใช้ผิดกลุ่ม (mis-targeted) ลดลงร้อยละ 45% หลังจากสามารถยืนยันแหล่งที่มาของสัญญาณพฤติกรรมและเวลาที่เก็บข้อมูลได้
- เวลาในการ audit ด้านการตลาดและการปฏิบัติตามกฎ PDPA ลดจาก 2 สัปดาห์ เหลือ 3 วัน เพราะ ledger แสดงประวัติการใช้ข้อมูลแบบเรียลไทม์
- เปอร์เซ็นต์โมเดลที่มีเอกสาร provenance สมบูรณ์เพิ่มจาก 30% เป็น 95% ภายใน 6 สัปดาห์ของการนำร่อง
สรุปผลจากการนำร่องเชิงปริมาณ (pilot) แสดงให้เห็นว่า Model Provenance Ledger ช่วยลดเวลาการตรวจสอบจากระดับสัปดาห์ลงสู่ระดับวันหรือชั่วโมง ลดจำนวนการสอบสวนข้อผิดพลาดในระบบโมเดล และทำให้กระบวนการปฏิบัติตาม PDPA มีความโปร่งใสและตรวจสอบได้มากขึ้น ทั้งนี้ตัวเลขดังกล่าวเป็นผลจากการนำร่องเชิงสมมติ/ทดลองในบริบทขององค์กรที่แตกต่างกัน แต่ชี้ชัดว่าการบันทึกแหล่งที่มา กระบวนการเทรน และเวอร์ชันโมเดลบนบล็อกเชนสามารถสร้างมูลค่าทางปฏิบัติการและลดความเสี่ยงเชิงธุรกิจได้อย่างเป็นรูปธรรม
ความท้าทายและข้อพิจารณา: ความสามารถในการขยาย, ค่าใช้จ่าย และกฎหมายข้อมูล
ความท้าทายและข้อพิจารณา: ความสามารถในการขยาย, ค่าใช้จ่าย และกฎหมายข้อมูล
การนำแนวคิด Model Provenance Ledger ขึ้นบนบล็อกเชนเพื่อบันทึกแหล่งข้อมูล กระบวนการเทรน และเวอร์ชันของโมเดล AI นำมาซึ่งความท้าทายเชิงเทคนิคและเชิงนโยบายที่สำคัญ โดยเฉพาะด้านความสามารถในการขยาย (scalability) ต้นทุนการปฏิบัติงาน และกรอบกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) ที่ต้องปฏิบัติตาม ในเชิงเทคนิค บล็อกเชนสาธารณะบางแพลตฟอร์มมีข้อจำกัดด้าน throughput (เช่น เครือข่ายหลักบางแห่งทำได้เป็นหลักสิบธุรกรรมต่อวินาที) และค่าใช้จ่ายต่อธุรกรรมที่ผันผวน ซึ่งทำให้การบันทึก metadata จำนวนมากจาก pipeline การเทรนโมเดล (training logs, dataset provenance, checkpoint hash) ลงบนเชนโดยตรงเป็นไปได้ยากเมื่อระบบมีผู้ใช้งานจำนวนมากหรือมีการอัพเดตบ่อยครั้ง
เพื่อลดปัญหา throughput และ storage จึงมักต้องพิจารณาโครงสร้างแบบผสม (hybrid) ระหว่าง on-chain กับ off-chain เช่น การบันทึกเพียง hash หรือ pointer ของข้อมูลลงบนเชน แล้วเก็บรายละเอียดที่มีขนาดใหญ่ในระบบเก็บข้อมูลนอกเชน (เช่น IPFS/Filecoin, S3-compatible object storage หรือฐานข้อมูลเข้ารหัส) นอกจากนี้การใช้เทคนิคเชิงสเกล เช่น sharding, layer‑2 solutions (rollups, sidechains) หรือ state channels จะช่วยเพิ่ม throughput และลดค่าธรรมเนียมต่อธุรกรรม ตัวอย่างเช่น rollups สามารถรวมธุรกรรมหลายรายการเป็นชุดเดียวก่อนโพสต์ไปยัง mainnet ซึ่งลดภาระและต้นทุนเมื่อเทียบกับการเขียนทุกรายการลง mainnet โดยตรง
ด้านต้นทุน ควรคำนึงทั้งค่าใช้จ่ายทางตรงและทางอ้อมอย่างรอบด้าน ค่า gas/transaction fee บนเครือข่ายสาธารณะอาจผันผวนตามสภาพเครือข่าย ทำให้ค่าใช้จ่ายการอัปเดต provenance เพิ่มขึ้นอย่างรวดเร็วในช่วง congestion นอกเหนือจากนั้นยังมีค่าโฮสติ้งสำหรับข้อมูล off-chain ค่าเซอร์วิสของผู้ให้บริการโหนด/อิน덱ซิง (indexing) ค่า oracle สำหรับยืนยันสถานะภายนอก ค่า maintain ระบบ เช่น การสำรองข้อมูล การเข้ารหัส/จัดการคีย์ และต้นทุนทางกฎหมาย/การตรวจสอบ (audit & compliance) ตัวอย่างเชิงปฏิบัติ: ระบบที่ต้องบันทึก metadata หลักพันรายการต่อวันบน mainnet อาจมีค่าใช้จ่ายรวมต่อเดือนเป็นหลักพันถึงหลักหมื่นดอลลาร์สหรัฐในสภาพแวดล้อมที่มีการใช้งานสูง ยิ่งไปกว่านั้นต้นทุนทางอ้อมในการพัฒนาและการบริหารจัดการ (เช่น ทีมความปลอดภัย ข้อกำหนดการสำรองข้อมูล การทำ DR) ควรถูกประเมินรวมในแผนธุรกิจ
ในมุมกฎหมายและความเป็นส่วนตัว PDPA ของไทยวางกรอบการคุ้มครองข้อมูลส่วนบุคคลที่เกี่ยวข้องกับการเก็บ ใช้ และเปิดเผยข้อมูล การออกแบบระบบ Provenance Ledger จึงต้องยึดหลัก data protection by design and by default โดยแนวปฏิบัติที่สำคัญได้แก่ การลดข้อมูลที่บันทึกบนเชน (data minimization), การเข้ารหัสและการจัดเก็บคีย์อย่างรัดกุม, การเก็บเฉพาะ hash/pointer แทนข้อมูลดิบ, การจัดการขอความยินยอม (consent management) และการเตรียมกระบวนการตอบสนองสิทธิของเจ้าของข้อมูล (เช่น สิทธิขอเข้าถึง แก้ไข หรือลบ) ซึ่งบางกรณีอาจต้องออกแบบให้ข้อมูลจริงถูกเก็บและควบคุมในสภาพแวดล้อมที่ปฏิบัติตาม PDPA ในขณะเดียวกันระบบต้องสามารถพิสูจน์แหล่งที่มาโดยไม่ละเมิดสิทธิส่วนบุคคล
อีกประเด็นสำคัญคือตัว metadata เองอาจเป็นแหล่งความเสี่ยงทางการเปิดเผยตัวตน (re-identification) แม้จะไม่ได้บันทึกข้อมูลส่วนบุคคลโดยตรง แต่การผนวกข้อมูลเช่น แหล่งที่มา (source), ช่วงเวลา (timestamp), ชุดข้อมูลย่อย (subset IDs) หรือลักษณะการคอนทริบิวต์ อาจอนุมานและสืบย้อนกลับถึงบุคคลได้ การลดความเสี่ยงนี้สามารถทำได้โดยการใช้กลยุทธ์ เช่น การทำ aggregation ของ metadata, การใช้เทคนิคความเป็นส่วนตัวเช่น differential privacy, การทำ pseudonymization หรือการใช้การเปิดเผยแบบมีเงื่อนไข (selective disclosure) ผ่าน cryptographic primitives เช่น zero‑knowledge proofs เพื่อยืนยันความถูกต้องโดยไม่เปิดเผยข้อมูลที่สามารถระบุตัวบุคคลได้
- ทางเทคนิค: เก็บเฉพาะ hash/pointer บนเชน ใช้ layer‑2 หรือ sharding เพื่อลดภาระ mainnet และใช้ระบบเก็บข้อมูล off‑chain ที่เข้ารหัสพร้อมการสำรองและการจัดการสิทธิ์เข้าถึง
- ด้านต้นทุน: ประเมินค่า gas, ค่าโฮสติ้ง, ค่า indexing, ค่า oracle และค่า compliance ในโมเดลต้นทุนระยะยาว พร้อมกลไกลดต้นทุน เช่น batching/aggregation ของธุรกรรม
- ความเป็นส่วนตัว & กฎหมาย: ออกแบบตาม PDPA โดยหลัก data minimization, consent management, การสนับสนุนการใช้สิทธิของเจ้าของข้อมูล และมาตรการบรรเทาความเสี่ยงการสืบย้อนกลับ
- การบริหารความเสี่ยง: นำนโยบายการตรวจสอบ (audit trail), การทบทวนโดยผู้เชี่ยวชาญทางกฎหมายและความเป็นส่วนตัว และ stress testing ทางเทคนิคเพื่อประเมินผลกระทบเมื่อระบบขยายตัว
สรุปแล้ว การนำระบบ Model Provenance Ledger มาประยุกต์ใช้ในองค์กรไทยต้องอาศัยการออกแบบเชิงสถาปัตยกรรมที่สมดุลระหว่างความโปร่งใสและความสามารถในการขยาย โดยคำนึงถึงต้นทุนการดำเนินงานและกรอบ PDPA ตั้งแต่ขั้นตอนออกแบบ (design phase) เพื่อให้ระบบสามารถพิสูจน์แหล่งที่มาได้อย่างน่าเชื่อถือโดยไม่ละเมิดสิทธิ์ของเจ้าของข้อมูลและยังคงควบคุมต้นทุนได้ในระยะยาว
แนวทางปฏิบัติสำหรับองค์กร: การติดตั้ง, MLOps Integration และมาตรฐานที่ควรมี
แนวทางปฏิบัติสำหรับองค์กร: การติดตั้ง, MLOps Integration และมาตรฐานที่ควรมี
การนำระบบ Model Provenance Ledger บนบล็อกเชนสู่การใช้งานภายในองค์กรควรเริ่มจากการวางแผนเชิงกลยุทธ์ โดยเริ่มจากโปรเจ็กต์นำร่อง (pilot) ที่มีขอบเขตชัดเจนและตัวชี้วัดความสำเร็จ (KPI) เพื่อประเมินความเป็นไปได้และผลกระทบต่อกระบวนการทำงาน ตัวอย่าง KPI ที่ควรกำหนดได้แก่: อัตราส่วนของโมเดลที่มีบันทึก provenance ครบถ้วน (% fully-provenanced models), เวลาเฉลี่ยในการตรวจสอบ (time-to-audit) น้อยกว่า 48 ชั่วโมง, และ ความสำเร็จในการทำ reproduce ของการเทรน มากกว่า 95% ในเฟส pilot ควรจำกัดจำนวนโมเดลและทีมที่เกี่ยวข้องให้เหมาะสม (เช่น 3–5 โมเดลทดลอง, ทีม ML 2–4 คน) เพื่อให้การติดตามและปรับแต่งระบบเป็นไปได้อย่างรวดเร็วและควบคุมได้
เมื่อผลจาก pilot เป็นที่ยอมรับ ให้ย้ายสู่ขั้นตอนการขยาย (scale) แบบเป็นขั้นบันได โดยใช้แนวทางที่ชัดเจน ได้แก่ (1) เพิ่มชนิดของโมเดลและกลุ่มธุรกิจอย่างค่อยเป็นค่อยไป, (2) เพิ่ม automation ใน pipeline เพื่อลดงานเชิงแมนนวล, และ (3) ติดตั้งการตรวจสอบเชิงปฏิบัติการ (operational monitoring) เช่น การแจ้งเตือนเมื่อ metadata ขาดหายหรือ hash ไม่ตรงกับค่าเดิม การขยายควรมาพร้อมกับการประเมินค่าใช้จ่าย (on-chain transaction cost, storage) และการออกแบบกลยุทธ์การเก็บข้อมูลนอกเครือข่าย (off-chain storage เช่น S3/IPFS) โดยเก็บเพียง hash และ metadata บนบล็อกเชนเพื่อรักษาความเป็นส่วนตัวและประหยัดต้นทุน
การผสาน ledger เข้ากับระบบ MLOps เป็นหัวใจสำคัญของการนำไปใช้ในระดับองค์กร แนะนำให้เชื่อมต่อ ledger เข้ากับ CI/CD สำหรับโมเดลและระบบ model registry ที่ใช้งานอยู่ เช่น MLflow หรือ Kubeflow แนวทางปฏิบัติที่แนะนำได้แก่:
- ออกแบบ pipeline ขั้นตอนมาตรฐาน: data snapshot → compute provenance_hash → trigger training run (logging training_run_id) → push model artifact ไปยัง model registry → commit provenance transaction ลง ledger พร้อม metadata
- ใช้ webhook/connector ระหว่างระบบ CI (เช่น Jenkins/GitLab CI/Kubernetes) กับ ledger เพื่อให้การบันทึกเป็นไปโดยอัตโนมัติเมื่อมีการ deploy หรือ register โมเดล
- รวม ledger transaction ID หรือ block reference เข้าไปเป็น field ใน model registry เพื่อให้สามารถเชื่อมโยงกลับได้อย่างแม่นยำ
เพื่อให้ข้อมูลที่บันทึกมีความสากลและตรวจสอบได้ ควรกำหนด schema ของ metadata มาตรฐาน ที่บังคับใช้ในทุก pipeline ตัวอย่างฟิลด์ขั้นต่ำที่ควรรวมใน schema ได้แก่:
- dataset_id — รหัสอ้างอิงของชุดข้อมูล (เชื่อมกับ data catalog)
- provenance_hash — แฮชเชิงคริปโตของ snapshot (รวม checksum ของข้อมูลและโค้ด preprocessing)
- training_run_id — รหัสสำหรับการรันการเทรนที่บันทึกทั้ง hyperparameters และ environment
- model_version — หมายเลขเวอร์ชันใน model registry
- auditor_signature — ลายเซ็นดิจิทัลจากหน่วยงานตรวจสอบภายใน/ภายนอก เพื่อยืนยันการตรวจสอบ
- timestamp, commit_hash (ของโค้ด), environment_id (container/image), metrics summary (accuracy, fairness metrics)
การบังคับใช้ schema ทำได้ด้วยเครื่องมือต่อไปนี้: ใช้ JSON Schema/Avro schema registry สำหรับ validate metadata ก่อน commit, รัน unit test ใน CI เพื่อเช็กการสร้าง provenance_hash, และตั้งค่า policy ใน model registry ให้ปฏิเสธการ register หาก metadata ไม่ครบถ้วน ยิ่งไปกว่านั้นควรออกแบบให้ metadata รองรับการขยาย (extensible) เพื่อรองรับความต้องการใหม่ เช่นข้อมูลด้านความเป็นธรรม (fairness) หรือการทดสอบเชิงความปลอดภัย (security tests)
การฝึกอบรมและการเปลี่ยนวัฒนธรรมเป็นปัจจัยสำคัญ—องค์กรควรจัดโปรแกรมอบรมให้กับทีมที่เกี่ยวข้อง ได้แก่ Data Engineers, ML Engineers, DevOps, และ Compliance Officers โดยหลักสูตรควรครอบคลุม: การทำงานกับ ledger และ smart contract, การเข้าใจ cryptographic hashing และ key management, การตั้งค่า CI/CD สำหรับโมเดล, วิธีการใช้ model registry และวิธีการตอบสนองเมื่อพบปัญหาทาง provenance (เช่น rollback และ forensic analysis) การฝึกแบบ hands-on ในสภาพแวดล้อม sandbox จะช่วยลดความเสี่ยงเมื่อย้ายสู่ production
สุดท้าย การร่วมมืออย่างใกล้ชิดกับหน่วยกำกับดูแลและกลุ่มมาตรฐานเป็นสิ่งจำเป็นเพื่อส่งเสริม interoperability และความน่าเชื่อถือของข้อมูล ตัวอย่างแนวทางที่ควรดำเนินการได้แก่:
- เข้าร่วม sandbox หรือ working group ของผู้กำกับดูแลเพื่อทดสอบกระบวนการจัดเก็บและการรายงานด้วยรูปแบบที่สอดคล้องกับกฎระเบียบ
- ร่วมกับกลุ่มมาตรฐาน เช่น ISO/IEC JTC 1/SC 42 หรือสมาคมท้องถิ่น เพื่อพัฒนามาตรฐาน metadata และ API สำหรับแลกเปลี่ยน provenance
- ออกแบบ API และ data contract ให้เป็นไปตามหลักการเปิดข้อมูล (open standards) เพื่อให้ระบบขององค์กรสามารถแลกเปลี่ยนข้อมูลกับภายนอกได้อย่างมีความหมาย
- จัดทำกระบวนการตรวจสอบร่วม (co-audit) กับผู้ตรวจสอบอิสระ และสนับสนุนการลงนามดิจิทัล (auditor_signature) เพื่อเพิ่มความโปร่งใส
การผสมผสานแนวทางด้านเทคนิค นโยบาย และการฝึกอบรมดังกล่าว จะช่วยให้องค์กรสามารถนำ Model Provenance Ledger ไปใช้ได้อย่างปลอดภัย มีประสิทธิภาพ และสามารถขยายได้ในระดับองค์กร ขณะเดียวกันยังสร้างความเชื่อมั่นให้กับผู้ใช้งานและหน่วยงานกำกับดูแลว่าระบบ AI ภายในองค์กรมีความรับผิดชอบและสามารถตรวจสอบแหล่งที่มาได้อย่างชัดเจน
บทสรุป
Model Provenance Ledger บนบล็อกเชนเป็นเครื่องมือที่ผสานจุดแข็งของความไม่เปลี่ยนแปลง (immutability) ของบล็อกเชนเข้ากับการจัดการ metadata ในวงจร MLOps เพื่อบันทึกแหล่งข้อมูล กระบวนการเทรน และเวอร์ชันของโมเดลอย่างเป็นระบบ ผลลัพธ์ที่ได้คือความโปร่งใสและความรับผิดชอบที่เพิ่มขึ้นสำหรับการใช้ AI ภายในองค์กร — ตัวอย่างของข้อมูลที่บันทึกได้รวมถึง hash ของชุดข้อมูล การตั้งค่าการเทรน (hyperparameters) สคริปต์การเตรียมข้อมูล ผลลัพธ์การประเมิน และลำดับการปรับปรุงเวอร์ชัน ทำให้องค์กรสามารถตรวจสอบย้อนกลับ (audit trail) และพิสูจน์ที่มาของโมเดลได้ชัดเจนกว่าเดิม; เช่น ในการนำร่องบางโครงการพบว่าการติดตาม provenance ช่วยลดเวลาในการตรวจสอบย้อนกลับและการระบุสาเหตุของข้อผิดพลาดลงราว 20–40% ขึ้นกับความพร้อมของระบบเดิม

แม้ว่าจะให้ประโยชน์เชิงปฏิบัติอย่างชัดเจน แต่การนำ Model Provenance Ledger ไปใช้จริงต้องเผชิญทั้งความท้าทายด้านเทคนิค (เช่น ประเด็นการเก็บข้อมูลขนาดใหญ่บน-chain vs off-chain, ประสิทธิภาพและค่าใช้จ่ายของเครือข่าย) และประเด็นทางกฎหมาย-ความเป็นส่วนตัว (เช่น การปฏิบัติตามกฎคุ้มครองข้อมูลส่วนบุคคล, การกำหนดความรับผิดชอบทางกฎหมายของโมเดล) ทางออกที่แนะนำคือเริ่มด้วยโครงการนำร่องที่ชัดเจน กำหนดมาตรฐาน metadata ที่เป็นสากลภายในองค์กร และออกแบบสถาปัตยกรรมผสม (on-chain สำหรับ hash และการพิสูจน์, off-chain สำหรับข้อมูลดิบที่มีขนาดใหญ่หรือมีข้อจำกัดเรื่องความเป็นส่วนตัว) ขณะเดียวกันการบูรณาการเทคนิคเพื่อความเป็นส่วนตัว (เช่น differential privacy, secure enclaves) และการกำหนดมาตรฐานร่วมกันในอุตสาหกรรมจะช่วยให้ระบบนี้เติบโตเป็นโครงสร้างพื้นฐานด้านการกำกับดูแล AI ที่เชื่อถือได้ในระยะยาว — ส่งผลให้ทั้งการตรวจสอบ ยึดถือกฎระเบียบ และความสามารถในการรับผิดชอบของ AI ในองค์กรแข็งแกร่งขึ้น พร้อมศักยภาพในการลดความเสี่ยงและเพิ่มความเชื่อมั่นต่อผู้มีส่วนได้ส่วนเสีย



