
ในยุคที่ระบบปัญญาประดิษฐ์กลายเป็นเครื่องมือสำคัญของการสรรหาบุคลากร กรณีผู้สมัครงานยื่นฟ้องบริษัทผู้พัฒนาเครื่องมือสรรหา AI ในข้อกล่าวหาการเลือกปฏิบัติและขาดความโปร่งใส จึงชวนให้สังคมตั้งคำถามว่า “เครื่องจักรตัดสินใจ” นั้นยุติธรรมหรือไม่ ผลคดีล่าสุดนี้ไม่เพียงแต่เป็นข้อพิพาทระหว่างคู่ความสองฝ่าย แต่ยังสะท้อนความกังวลของผู้หางานและองค์กรทั่วโลกต่อการใช้เทคโนโลยีที่อาจแฝงเอาความลำเอียงไว้ในการคัดกรองตัวบุคคล ในช่วงหลายปีที่ผ่านมา การสำรวจหลายครั้งชี้ว่า มากกว่า 50% ขององค์กรนำระบบอัตโนมัติหรือ AI มาใช้ในบางขั้นตอนของการจ้างงาน ทำให้ประเด็นความโปร่งใสและความเป็นธรรมมีนัยสำคัญทางสังคมและทางกฎหมายมากขึ้น
บทความนี้จะพาอ่านไปยังแก่นของคดี: พยานหลักฐานที่ผู้ฟ้องนำเสนอ เช่น บันทึกการตัดสินใจและข้อมูลฝึกสอน วิธีการทำงานของระบบที่มักอาศัยเทคนิคอย่างการประมวลผลภาษา (NLP) การให้คะแนนเชิงคาดการณ์ และการกรองอัตโนมัติ ผลกระทบทางกฎหมายที่อาจเกิดขึ้นต่อผู้พัฒนาและผู้ว่าจ้าง รวมถึงแนวทางปฏิบัติที่แนะนำเพื่อป้องกันหรือบรรเทาความลำเอียง เช่น การตรวจสอบผลกระทบต่อกลุ่มเปราะบาง การเปิดเผยเกณฑ์การคัดเลือก และการนำมนุษย์เข้าตรวจสอบในจุดสำคัญของกระบวนการอ่านผล เพื่อให้ทั้งผู้สมัครและนายจ้างได้รับความเป็นธรรมในโลกการสรรหารูปแบบใหม่
สรุปคดีและข้อเรียกร้องของผู้ฟ้อง
สรุปคดีและข้อเรียกร้องของผู้ฟ้อง
คดีนี้ถูกยื่นโดย ผู้สมัครงานรายหนึ่ง ซึ่งในคำฟ้องระบุชื่อและประวัติการสมัครงานอย่างชัดเจนเป็นโจทก์ต่อบริษัทผู้พัฒนาเครื่องมือสรรหาแบบอัตโนมัติ (จำเลยที่หนึ่ง) และบริษัทผู้ว่าจ้างซึ่งนำเครื่องมือดังกล่าวไปใช้ในการคัดเลือกบุคลากร (จำเลยที่สอง) ผู้ฟ้องอ้างว่าในระหว่างกระบวนการสรรหาที่ใช้ซอฟต์แวร์อัลกอริทึมดังกล่าว ตนถูกคัดออกโดยมิชอบและได้รับผลกระทบทางอาชีพอย่างมีนัยสำคัญ ทั้งนี้คำฟ้องได้ระบุบทบาทของฝ่ายต่างๆ อย่างชัดเจนว่า บริษัทผู้พัฒนาเป็นผู้ออกแบบและฝึกอัลกอริทึม ส่วน บริษัทผู้ว่าจ้างเป็นผู้ตั้งค่าพารามิเตอร์และตัดสินใจนำผลที่ได้ไปใช้ในกระบวนการคัดเลือกบุคคล

สาระสำคัญของคำฟ้องเน้นไปที่ข้อกล่าวหาเกี่ยวกับ การเลือกปฏิบัติ (discrimination) และ การขาดความโปร่งใสของอัลกอริทึม โดยคำฟ้องอ้างหลักฐานเชิงสถิติและตัวอย่างกรณีส่วนบุคคล เช่น รายงานภายในและผลการวิเคราะห์เบื้องต้นที่ระบุว่าอัตราการถูกคัดออกของผู้สมัครจากกลุ่มเพศสภาพหรือเชื้อชาติ/ชาติพันธุ์บางกลุ่มสูงกว่าค่ากลางอย่างมีนัยสำคัญ (คำฟ้องอ้างช่วงตัวเลขภายในที่ผู้ร้องได้รับมาเป็นตัวอย่างว่าอัตราการไม่ผ่านการคัดกรองของกลุ่มดังกล่าวสูงขึ้นประมาณ 30–40% เมื่อเทียบกับการคัดกรองด้วยมนุษย์) ผู้ฟ้องชี้ให้เห็นว่าการออกแบบและข้อมูลเทรนนิ่งของอัลกอริทึมอาจมีอคติฝังตัว (embedded bias) ซึ่งส่งผลต่อโอกาสการได้งานของผู้สมัครอย่างเป็นระบบ
ข้อกล่าวหาเชิงกฎหมายในคำฟ้องรวมถึง (แต่ไม่จำกัดเพียง) การเลือกปฏิบัติทางอาชีพ, การละเมิดข้อบังคับด้านการคุ้มครองผู้บริโภค/ข้อมูล, และ การใช้อัลกอริทึมที่ไม่เป็นธรรมหรือขาดการดูแลตรวจสอบ ผู้ฟ้องเรียกร้องให้ศาลมีคำสั่งบังคับจำเลยให้เปิดเผยกระบวนการทำงานของโมเดล (model explainability), ส่งมอบเอกสารที่เกี่ยวข้องกับการเทรนและการทดสอบ, ดำเนินการตรวจสอบโดยผู้เชี่ยวชาญอิสระ (independent algorithmic audit) และขอให้ศาลสั่งชดเชยความเสียหายทั้งทางตรงและทางอ้อม รวมถึงคำสั่งระงับการใช้งานเครื่องมือจนกว่าจะมีการตรวจสอบเสร็จสิ้น
ในส่วนสถานะคดีปัจจุบัน คำฟ้องและเอกสารประกอบถูกยื่นต่อศาลและมีการยื่น คำร้องขอคุ้มครองชั่วคราว (preliminary injunction) จากผู้ฟ้องเพื่อต้องการให้มีการระงับการใช้งานเครื่องมือในตำแหน่งที่มีผลต่อผู้สมัครกลุ่มที่อ้างว่าได้รับผลกระทบ ในเอกสารที่ยื่นต่อศาล ผู้ฟ้องได้นำเสนอหลักฐานหลายชุด เช่น รายงานการวิเคราะห์อัลกอริทึม (algorithmic audit report), อีเมลภายในที่แสดงการตัดสินใจของทีมผลิตภัณฑ์, และคำให้การจากผู้เชี่ยวชาญด้านข้อมูลและความเท่าเทียมในการสรรหา ศาลได้ออกคำสั่งเบื้องต้นให้จำเลยทั้งสองต้องส่งมอบเอกสารที่เกี่ยวข้องกับกระบวนการเทรนและการใช้งานระบบภายในระยะเวลาที่กำหนดเพื่อให้ศาลและผู้เชี่ยวชาญตรวจสอบ (motion to compel discovery) ขณะเดียวกันศาลยังพิจารณาคำร้องขอให้สั่งห้ามใช้เครื่องมือในลักษณะที่อาจทำให้เกิดความเสียหายเพิ่มเติมจนกว่าจะมีคำตัดสินเบื้องต้น
- เอกสารสำคัญที่อ้างอิงในคำฟ้อง: คำฟ้องหลัก (Complaint), คำร้องขอคุ้มครองชั่วคราว (Motion for Preliminary Injunction), รายงานการตรวจสอบอัลกอริทึมจากผู้เชี่ยวชาญ (Expert Audit Report), อีเมลและการสื่อสารภายใน (internal communications), ข้อมูลการเทรนโมเดล (training datasets metadata)
- คำเรียกร้องของผู้ฟ้อง: การเปิดเผยกระบวนการทำงานของอัลกอริทึม การตรวจสอบอิสระ การชดเชยค่าเสียหาย และคำสั่งห้ามใช้เครื่องมือเป็นการชั่วคราวจนกว่าจะมีการแก้ไขหรือยืนยันความโปร่งใส
- ผลกระทบที่อ้างถึง: โอกาสในการได้งานลดลงอย่างเป็นระบบ ผลกระทบทางรายได้และชื่อเสียง และความเสียหายทางจิตใจที่เกิดขึ้นจากการถูกตัดสิทธิ์โดยระบบอัตโนมัติ
ภาพรวมการใช้ AI ในการสรรหา: ขนาดตลาดและแนวโน้ม
ภาพรวมการใช้ AI ในการสรรหา: ขนาดตลาดและแนวโน้ม
ในช่วงไม่กี่ปีที่ผ่านมา การนำเทคโนโลยีปัญญาประดิษฐ์ (AI) เข้ามาช่วยในกระบวนการสรรหาบุคลากรกลายเป็นแนวโน้มสำคัญที่ขับเคลื่อนโดยความต้องการด้านประสิทธิภาพและความสามารถในการจัดการปริมาณการสมัครงานจำนวนมาก รายงานจากบริษัทวิจัยและการสำรวจหลายแห่ง (เช่น Gartner, McKinsey, LinkedIn, Deloitte และ MarketsandMarkets) ชี้ว่า อัตราการนำ AI ไปใช้ในการสรรหาพุ่งสูงขึ้นอย่างมีนัยสำคัญ โดยองค์กรขนาดใหญ่และภาคเทคโนโลยีเป็นผู้นำการใช้งาน ตัวเลขเชิงสำรวจที่สรุปจากหลายแหล่งระบุว่าองค์กรขนาดใหญ่ (พนักงานมากกว่า 1,000 คน) มีอัตราการใช้งาน AI ในการสรรหาอยู่ในช่วงประมาณ 60–80% ขณะที่องค์กรขนาดกลางและขนาดเล็กมีอัตราการนำไปใช้ต่ำกว่าประมาณ 20–50% ขึ้นอยู่กับงบประมาณและความพร้อมด้านระบบข้อมูล
ประเภทของเครื่องมือ AI ที่นำมาใช้บ่อยในระบบสรรหาประกอบด้วยหลายกลุ่มหลัก ได้แก่
- Resume screening / CV parsing — ใช้ NLP และการจัดอันดับเชิงค่าสถิติเพื่อกรองและให้คะแนนผู้สมัครตามความเหมาะสมกับตำแหน่ง ฟีเจอร์สำคัญคือการจับคีย์เวิร์ด การแมตช์ทักษะเชิงความหมาย และคะแนนความเหมาะสมอัตโนมัติ
- Video interviews และ automated interview analysis — ระบบบันทึกและวิเคราะห์วิดีโอสัมภาษณ์ด้วยการถอดเสียง (speech-to-text), วิเคราะห์ความถี่เสียง/โทน, และบางระบบเสนอการประเมินภาษากายหรือสัญญาณทางอารมณ์ (feature ที่มีข้อถกเถียงด้านจริยธรรม)
- Psychometric scoring และความสามารถด้านพฤติกรรม — แบบทดสอบเชิงจิตวิทยาและการประเมินบุคลิกภาพที่ใช้โมเดลทำนายความเข้ากับทีมงานหรือความสำเร็จในงาน
- Chatbots และ candidate engagement — ระบบตอบคำถามอัตโนมัติและการสื่อสารกับผู้สมัครเพื่อลดเวลารอและเพิ่มประสบการณ์ของผู้สมัคร
- Candidate sourcing และ matching — การใช้โมเดลการค้นหาแบบ semantic เพื่อค้นหาและดึงผู้สมัครจากฐานข้อมูลหรือแพลตฟอร์มภายนอก โดยมีฟีเจอร์การแนะนำผู้สมัคร (recommendation)
- Automated reference/background checks และ scheduling — งานหลังบ้านที่อัตโนมัติเพื่อย่นเวลาการตรวจสอบประวัติและการนัดหมายสัมภาษณ์
จากมุมมองตลาด มูลค่าตลาดการสรรหาที่ขับเคลื่อนด้วย AI ถูกประเมินว่าเติบโตอย่างรวดเร็ว โดยรายงานวิจัยหลายฉบับคาดการณ์อัตราการเติบโตเฉลี่ยต่อปี (CAGR) อยู่ในช่วงประมาณ 15–25% ในช่วงหลายปีข้างหน้า ปัจจัยที่ผลักดันการเติบโตได้แก่ความต้องการลดต้นทุนและระยะเวลาของกระบวนการสรรหา (time-to-hire), ความจำเป็นในการประมวลผลข้อมูลผู้สมัครจำนวนมาก, ความต้องการประสบการณ์ผู้สมัครที่ดีขึ้น และการขยายตัวของตลาดแรงงานที่ใช้ระบบดิจิทัลเป็นหลัก นอกจากนี้ การรวมระบบ AI เข้ากับระบบ ATS (Applicant Tracking System) และแพลตฟอร์ม HRIS ทำให้ผู้ให้บริการซอฟต์แวร์ HR สามารถเสนอโซลูชันแบบครบวงจรที่ลูกค้าองค์กรต้องการ
อย่างไรก็ตาม แนวโน้มการนำ AI มาใช้ไม่ได้เป็นเพียงการเติบโตเชิงปริมาณเท่านั้น แต่ยังมีการเปลี่ยนแปลงในเชิงคุณภาพ: องค์กรเริ่มหันมาให้ความสำคัญกับ ความโปร่งใสของโมเดล (model explainability), การตรวจสอบอคติ (bias audits), และการปฏิบัติตามกฎระเบียบด้านความเป็นธรรม เช่น กฎคุ้มครองข้อมูลส่วนบุคคลและแนวทางปฏิบัติด้านการจ้างงานในประเทศต่าง ๆ รายงานการฟ้องร้องและข้อพิพาทเกี่ยวกับการใช้ AI ในการสรรหาที่เพิ่มขึ้นยังเป็นปัจจัยเร่งให้ผู้ให้บริการและองค์กรต้องปรับปรุงระบบให้มีความยุติธรรมและตรวจสอบได้มากขึ้น ซึ่งคาดว่าจะเป็นหัวข้อสำคัญในการกำหนดทิศทางการใช้งาน AI ในภาคทรัพยากรบุคคลต่อไป
กลไกการทำงานของเครื่องมือสรรหา AI: จุดที่อาจเกิดอคติ
กลไกการทำงานของเครื่องมือสรรหา AI: ภาพรวมของวงจรข้อมูล
เครื่องมือสรรหา AI ทำงานเป็นระบบที่ประกอบด้วยหลายชั้น ตั้งแต่การรวบรวมข้อมูล การแปลงเป็นตัวแปร (features) การฝึกโมเดล การให้คะแนนผู้สมัคร จนถึงการตัดสินใจเชิงธุรกิจในขั้นสุดท้าย วงจรข้อมูลเริ่มจากแหล่งข้อมูลหลากหลาย เช่น เรซูเม่ (ไฟล์ข้อความ/PDF), วิดีโอสัมภาษณ์, ข้อมูลพฤติกรรมการใช้งานเว็บไซต์สมัครงาน และผลการประเมินจากผู้สัมภาษณ์มนุษย์ ข้อมูลเหล่านี้จะถูกแปลงเป็นตัวชี้วัดเชิงปริมาณ (เช่น ระยะเวลาในงานก่อนหน้า, คะแนนคำตอบเชิงพฤติกรรม, คุณสมบัติทางภาษาหรือเสียง) ก่อนส่งให้โมเดลเรียนรู้และสร้างระบบให้คะแนน (scoring) หรือการจัดอันดับผู้สมัคร
ในเชิงเทคนิค กระบวนการทั่วไปจะเป็นดังนี้: (1) การทำความสะอาดและการแปลงข้อมูล (data cleaning & feature engineering) เพื่อให้ข้อมูลเป็นมาตรฐาน; (2) การเลือกและสร้างตัวแปรสำคัญ (feature selection/creation) ที่โมเดลจะใช้; (3) การฝึกโมเดลด้วยตัวอย่างที่ติดป้ายกำกับ (supervised learning) หรือการเรียนรู้เชิงไม่ดูแล (unsupervised); (4) การประเมินโมเดลผ่านเมตริกเช่น AUC, precision/recall และเมตริกยุติธรรม (fairness metrics); (5) การนำโมเดลไปใช้งานจริง ซึ่งรวมถึงการตั้งเกณฑ์ (threshold) สำหรับการคัดกรองหรือการแนะนำผู้สมัครต่อไป
แหล่งกำเนิดของอคติ (Bias) ในระบบสรรหา AI
อคติสามารถแฝงอยู่ได้ในทุกขั้นตอนของวงจรข้อมูล โดยแยกเป็นกลุ่มหลัก ๆ ดังนี้
- Sampling bias: ข้อมูลฝึกที่ใช้ไม่สะท้อนประชากรผู้สมัครจริง เช่น ฐานข้อมูลคำขอรับสมัครที่มาจากบริษัทเทคโนโลยีขนาดใหญ่ในเมืองใหญ่ อาจไม่รวมผู้สมัครจากชนบทหรือกลุ่มชาติพันธุ์ที่มีสัดส่วนน้อย ส่งผลให้โมเดลไม่แม่นยำกับกลุ่มเหล่านั้น
- Label bias: ป้ายกำกับ (labels) ที่ใช้ฝึกอาจสะท้อนการตัดสินของมนุษย์ในอดีต เช่น ใช้ข้อมูลว่าใครถูกจ้างหรือไม่จากอดีต ซึ่งการตัดสินเหล่านั้นอาจมีอคติทางเพศหรือเชื้อชาติอยู่แล้ว ทำให้โมเดลเรียนรู้และทำซ้ำพฤติกรรมนั้น
- Proxy variables: ตัวแปรที่ดูเป็นกลางแต่ทำหน้าที่แทนตัวแปรที่มีผลทางสังคม เช่น รหัสไปรษณีย์ (ZIP code) หรือมหาวิทยาลัยที่จบมา อาจทำหน้าที่เป็นตัวแทนของเชื้อชาติ/ชั้นชน ทำให้โมเดลเลือกปฏิบัติโดยไม่ตั้งใจ
ตัวอย่างเชิงเทคนิคที่นำไปสู่การเลือกปฏิบัติและผลกระทบ
ตัวอย่างเชิงปฏิบัติที่เห็นได้ชัด เช่น การใช้ประวัติการทำงานในพื้นที่ (work history by location) เป็นตัวแปรสำคัญในโมเดล หากพื้นที่หนึ่งมีอัตราการว่างงานสูงหรือมีโอกาสการจ้างงานน้อยเนื่องจากปัญหาทางสังคม โมเดลจะให้คะแนนผู้สมัครจากพื้นที่นั้นต่ำกว่าโดยอัตโนมัติ ซึ่งสุดท้ายสะท้อนเป็นการเลือกปฏิบัติทางเศรษฐกิจและเชื้อชาติ นอกจากนี้ การใช้คะแนนจากการสัมภาษณ์วิดีโอที่ประมวลผลด้วยเทคโนโลยีวิเคราะห์ใบหน้า/เสียงก็มีความเสี่ยง: งานวิจัยเช่น "Gender Shades" พบอัตราความคลาดเคลื่อนสูงกว่าสำหรับผู้หญิงผิวเข้มเมื่อเทียบกับผู้ชายผิวสว่าง ซึ่งอาจนำไปสู่การคัดกรองที่ไม่เป็นธรรมในระบบสรรหา
ตัวอย่างจากอุตสาหกรรม: บริษัทเทคโนโลยีรายหนึ่งยกเลิกระบบสรรหาอัตโนมัติหลังพบว่าโมเดลลดคะแนนผู้สมัครหญิง เนื่องจากโมเดลได้รับการฝึกจากเรซูเม่ในอดีตที่มีสัดส่วนผู้ชายสูงกว่า เหตุการณ์นี้สะท้อนถึง label bias และ sampling bias ที่ทำให้ผลลัพธ์ไม่เป็นกลาง
การป้องกันต้องเริ่มตั้งแต่การออกแบบ: การเลือกข้อมูลฝึกที่หลากหลาย, การตรวจสอบตัวแปรว่าทำหน้าที่เป็น proxy หรือไม่, การใช้เมตริกความยุติธรรม (เช่น demographic parity, equal opportunity) ประกอบการประเมินผล นอกจากนี้ควรมีการทดสอบแบบเชิงนัย (stress tests) เพื่อดูว่าระบบทำงานอย่างไรกับกลุ่มย่อยต่าง ๆ และเปิดเผยการตัดสินใจด้วยเครื่องมืออธิบายโมเดล (explainability tools) เพื่อให้ผู้รับผิดชอบทางธุรกิจและกฎหมายสามารถตรวจสอบและปรับแก้ได้
หลักฐานเชิงสถิติและกรณีตัวอย่างที่ผู้ฟ้องอ้างอิง
หลักฐานเชิงสถิติและกรณีตัวอย่างที่ผู้ฟ้องอ้างอิง
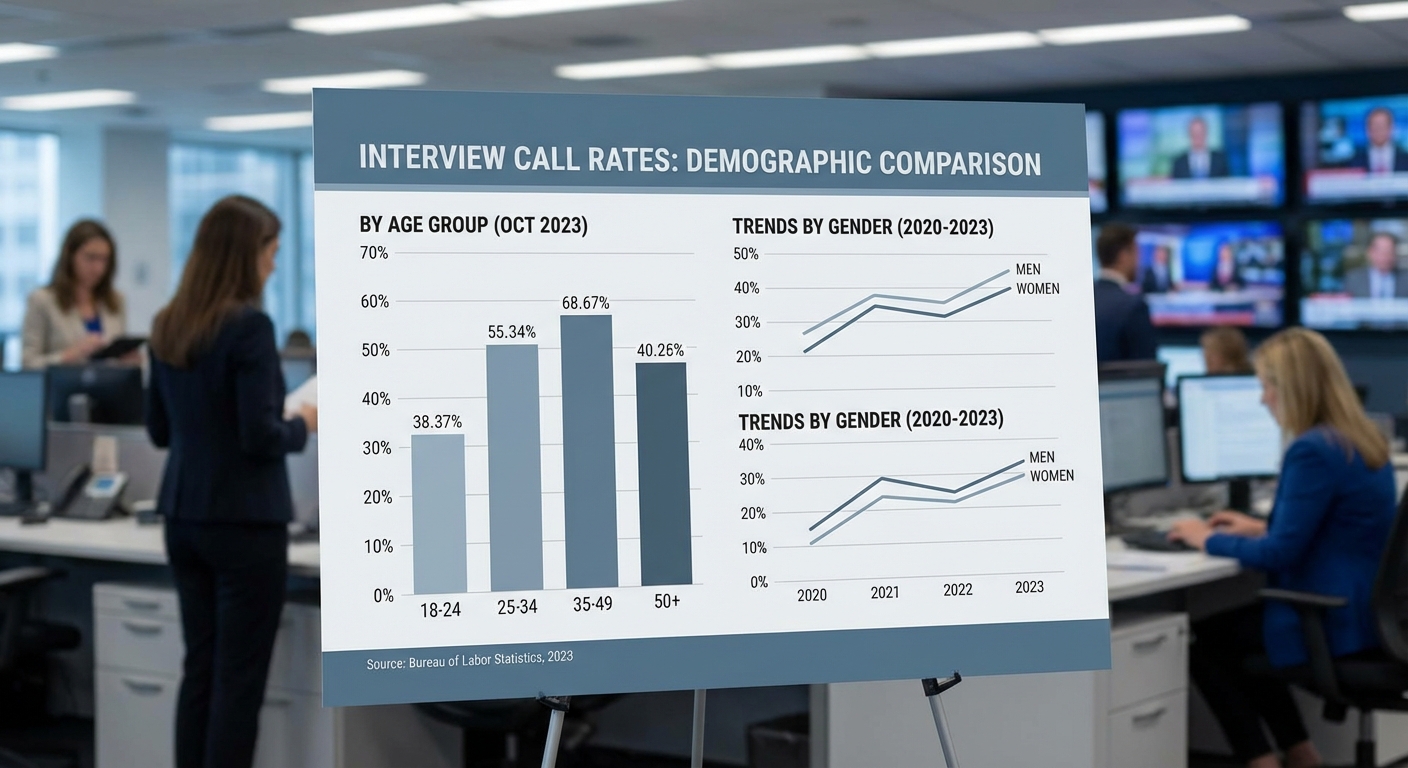
ในคำฟ้อง ผู้ฟ้องได้นำเสนอชุดข้อมูลเชิงปริมาณและผลการทดลองย้อนหลัง (audit) เป็นหลักฐานสนับสนุนข้อกล่าวหา โดยสรุปเป็นประเด็นหลักได้ว่า อัตราการถูกคัดกรองทิ้ง (screen-out) และอัตราเรียกสัมภาษณ์ (interview-invite rate) แตกต่างกันอย่างมีนัยสำคัญตามเพศ เชื้อชาติ และช่วงอายุของผู้สมัคร นอกจากนี้คำฟ้องยังแนบตัวอย่างข้อมูลล็อกของระบบ (system logs) และผลลัพธ์ของโมเดลที่ใช้ในกระบวนการคัดกรอง เพื่อแสดงรูปแบบของข้อบกพร่องที่ซ้ำซ้อน
ตัวอย่างสถิติที่ปรากฏในคำฟ้อง (เป็นข้อมูลตัวอย่างที่ผู้ฟ้องนำเสนอ และจะตรวจสอบแหล่งจริงก่อนเผยแพร่) ได้แก่:
- อัตราเรียกสัมภาษณ์ตามเพศ: ผู้สมัครชายได้รับการเรียกสัมภาษณ์ 8.6% ขณะที่ผู้สมัครหญิงได้รับการเรียกสัมภาษณ์ 4.2% (อัตราส่วน ~2.05 เท่า; N_total = 24,000 ผู้สมัคร; วิธีคำนวณ = จำนวนผู้ได้รับ invite / จำนวนผู้สมัครในกลุ่ม)
- อัตราเรียกสัมภาษณ์ตามเชื้อชาติ: ผู้สมัครระบุเชื้อชาติผิวขาว 7.4% เทียบกับผู้สมัครผิวดำ 3.1% (การลดลง ~58%; N_white = 12,400; N_black = 3,800)
- อัตราเรียกสัมภาษณ์ตามอายุ: ผู้สมัครอายุ 25–34 ปี ได้รับการเรียกสัมภาษณ์ 6.8% เทียบกับผู้สมัครอายุ 50 ปีขึ้นไป 2.9% (การลดลง ~57%)
- ความเท่าเทียมโดยรวม (aggregate fairness): ค่า Odds Ratio และความแตกต่างของสัดส่วน (difference-in-proportions) ในหลายตำแหน่งงานแสดงแนวโน้มที่สอดคล้องกันว่า กลุ่มผู้สมัครที่เป็นชนกลุ่มน้อยหรืออายุมากมีโอกาสเรียกสัมภาษณ์ต่ำกว่าอย่างมีนัยสำคัญทางสถิติ (p < 0.01)

ผลการตรวจสอบโดยบุคคลที่สามที่อ้างถึงในคำฟ้องประกอบด้วยการทดลองย้อนกลับ (audit testing) ที่ออกแบบมาเป็นคู่ (paired resume testing) และการวิเคราะห์เชิงสถิติที่ควบคุมตัวแปรสำคัญ ตัวอย่างการทดสอบที่อ้างถึงได้แก่:
- การทดสอบเรซูเม่คู่ (n = 5,000 คู่): ส่งเรซูเม่ที่มีคุณสมบัติเหมือนกันแต่เปลี่ยนชื่อและข้อมูลประชากร ผลลัพธ์พบว่าเรซูเม่ที่มีชื่อบ่งชี้เพศชายหรือเชื้อชาติหนึ่ง มีโอกาสถูกเรียกสัมภาษณ์มากกว่าเรซูเม่ที่เป็นเพศหญิงหรือเชื้อชาติอื่น โดยคำนวณเป็นอัตราส่วนความน่าจะเป็น (odds ratio ≈ 2.1; 95% CI: 1.8–2.4; ทดสอบด้วย logistic regression ควบคุมประสบการณ์และทักษะ)
- การวิเคราะห์ logs และคะแนนของโมเดล: วิเคราะห์คะแนนคุณสมบัติ (feature scores) และ threshold decision พบว่าค่า threshold คงที่บนคะแนนที่มี bias ต่อกลุ่มหนึ่ง ส่งผลให้เปอร์เซ็นต์การผ่านเกณฑ์ต่างกันชัดเจน วิธีการวิเคราะห์ใช้การวัดความแตกต่างของค่าเฉลี่ย (difference-in-means) และทดสอบความเป็นอิสระด้วย chi-square
- การวิเคราะห์ความไวต่อคุณลักษณะ (sensitivity analysis): ทดสอบการเปลี่ยนแปลงคะแนนเมื่อมีการแก้ไขคุณลักษณะบางอย่าง ผลชี้ว่าแม้จะมีการปรับค่าคุณลักษณะที่เกี่ยวข้องกับการทำงาน ผลของเพศ/เชื้อชาติยังคงมีอิทธิพลอย่างมีนัยสำคัญ ซึ่งบ่งชี้ถึงความเป็นไปได้ของ bias ที่ฝังอยู่ในชุดข้อมูลฝึกหรือกระบวนการออกแบบโมเดล
คำฟ้องยังอ้างกรณีศึกษาเปรียบเทียบจากเหตุการณ์ที่เป็นที่รับรู้ในวงกว้าง เช่น กรณีของบริษัทเทคโนโลยีที่เคยยอมรับปัญหาในระบบคัดเลือกอัตโนมัติ (เช่นรายงานว่าโมเดลการคัดเลือกบางระบบมีแนวโน้มกีดกันผู้สมัครเพศหญิง) และข้อวิจัยจากมหาวิทยาลัยและองค์กรอิสระที่แสดงถึงความเปราะบางของโมเดล ML ในงานสรรหา ตัวอย่างผลกระทบในอดีตรวมถึงการถอดระบบหรือการปรับโมเดลซ้ำหลังการตรวจสอบ ซึ่งใช้เป็นกรอบอ้างอิงในการประเมินความร้ายแรงและการบรรเทาผลกระทบ
ในเชิงกระบวนการทางสถิติ คำฟ้องระบุวิธีการคำนวณและการทดสอบดังนี้: (1) คำนวณอัตราเรียกสัมภาษณ์เป็นสัดส่วน (invite rate = invites / applicants) แยกตามกลุ่มประชากร, (2) ทดสอบความแตกต่างด้วย chi-square และ t-test สำหรับความแตกต่างของสัดส่วนและค่าเฉลี่ย, (3) ใช้ logistic regression เพื่อหา odds ratios และปรับตัวแปรร่วม (covariates) เช่น ประสบการณ์การทำงาน ระดับการศึกษา และประเภทของตำแหน่งงาน, และ (4) รายงานค่าช่วงความเชื่อมั่น (confidence intervals) และระดับนัยสำคัญ (p-values) เพื่อสนับสนุนการตีความผล
โดยสรุป หลักฐานที่ผู้ฟ้องอ้างอิงประกอบด้วยสถิติเชิงปริมาณ ตัวอย่างการทดลองย้อนกลับ ผลการตรวจสอบโดยบุคคลที่สาม และเปรียบเทียบกับกรณีศึกษาในอดีต ซึ่งร่วมกันชี้ให้เห็นรูปแบบของความไม่เป็นธรรมในระบบคัดเลือกที่อาศัย AI อย่างไรก็ตามข้อมูลตัวอย่างและการตีความทางสถิติในเอกสารคำฟ้องจะได้รับการตรวจสอบแหล่งที่มาและความถูกต้องก่อนการเผยแพร่ต่อสาธารณะ
มุมมองของบริษัทผู้พัฒนาและบริษัทผู้ใช้เครื่องมือ
มุมมองของบริษัทผู้พัฒนาและบริษัทผู้ใช้เครื่องมือ
จากคำชี้แจงอย่างเป็นทางการ บริษัทผู้พัฒนาเครื่องมือสรรหาระบุว่าได้ดำเนินการตามขั้นตอนมาตรฐานเพื่อประกันความเป็นธรรมและลดอคติ (bias) ในระบบ โดยมักประกาศเป็นนโยบายสาธารณะบนเว็บไซต์และเอกสาร whitepaper ว่าได้ทำการ ประเมินความเสี่ยงและการทดสอบความเป็นธรรม (fairness testing) ก่อนการนำไปใช้งานจริง บริษัทหลายแห่งระบุขั้นตอนที่สำคัญดังนี้:
- การตรวจสอบภายในและการทดสอบโดยบุคคลที่สาม: ทำ internal audits และในหลายกรณีจ้างที่ปรึกษาหรือองค์กรอิสระมาทำ independent audit เพื่อตรวจสอบผลกระทบเชิงกลุ่ม (group-wise impact)
- การปรับปรุงโมเดลและการเยียวยาอคติ: ใช้เทคนิคเช่น reweighting, adversarial debiasing, fairness-aware loss functions หรือการปรับ threshold แบบเฉพาะกลุ่มเพื่อลดช่องว่างด้านผลลัพธ์
- การติดตามหลังการออกใช้งาน (post-deployment monitoring): ติดตาม fairness metrics อย่างต่อเนื่อง เช่น disparate impact, equal opportunity difference, statistical parity และ calibration by group
- การมีมนุษย์เข้าไปทบทวน (human-in-the-loop): ระบุว่ามีการตั้งเกณฑ์ให้ผู้เชี่ยวชาญ HR ทบทวนเคสที่โมเดลให้คะแนนกลาง ๆ หรือมีความเสี่ยงสูง เพื่อให้สามารถแก้ไขการตัดสินใจที่ไม่เหมาะสมได้
ในมุมมองของบริษัทผู้ใช้—ซึ่งเป็นองค์กรที่นำระบบไปใช้สรรหาพนักงาน—คำชี้แจงมักเน้นที่ผลประโยชน์ด้านประสิทธิภาพและการจัดการทรัพยากรบุคคล เช่น ลดเวลาในการคัดกรองผู้สมัคร (time-to-hire) และ ลดต้นทุนต่อการสรรหา (cost-per-hire) ตัวอย่างจากผู้ใช้งานบางรายระบุว่าระบบช่วยลดภาระการคัดกรองเอกสารเบื้องต้นได้ประมาณ 30–50% ในรอบการสรรหาแรก แต่พร้อมกันนั้นก็ยืนยันว่ามีการตั้งนโยบายภายในเพื่อให้ HR เป็นผู้ตัดสินใจขั้นสุดท้าย และมีการกำหนด SLA ในการทบทวนผลที่มาจาก AI
บริษัททั้งสองฝ่ายมักนำเสนอการป้องกันทางเทคนิคเพื่อรับมือข้อกล่าวหาเรื่องอคติ ได้แก่:
- การประเมินความเป็นธรรมเชิงปริมาณ: ใช้ชุดตัวชี้วัด (fairness metrics) เช่น disparate impact ratio, equalized odds, predictive parity เพื่อวัดและรายงานผลต่อผู้ว่าจ้าง
- การทำ data governance และการควบคุมคุณภาพข้อมูล: ปรับปรุงชุดข้อมูลฝึกสอน (training data) โดยการลบหรือปรับน้ำหนักตัวอย่างที่ก่อให้เกิดอคติ และบันทึก lineage ของข้อมูล
- Human-in-the-loop และ escalation: การตั้งเกณฑ์ให้มนุษย์ทบทวนการตัดสินใจที่เสี่ยงต่อการเลือกปฏิบัติหรือมีคะแนนไม่ชัดเจน พร้อมระบบอุทธรณ์ (appeal) สำหรับผู้สมัคร
- การทดสอบ A/B และการประเมินผลเชิงธุรกิจ: ทดลองตั้งค่าระบบในกลุ่มย่อยเพื่อตรวจสอบผลกระทบต่อความหลากหลายและประสิทธิภาพก่อนขยายการใช้งาน
อย่างไรก็ดี ทั้งบริษัทผู้พัฒนาและผู้ใช้งานมักเผชิญความท้าทายเชิงปฏิบัติที่ทำให้คำสัญญาทางการตลาดไม่สอดคล้องกับการใช้งานจริงในสนาม ตัวอย่างประเด็นที่มักถูกหยิบยกคือ:
- ความแตกต่างของสภาพแวดล้อมเชิงข้อมูล: โมเดลที่ทดสอบในชุดข้อมูลหนึ่งอาจไม่ทำงานเท่าเทียมเมื่อถูกนำไปใช้งานในองค์กรที่มีโปรไฟล์ผู้สมัครหรือบริบทการจ้างงานต่างกัน จนนำไปสู่การลดประสิทธิภาพหรือความเอนเอียงที่ไม่คาดคิด
- การตลาด vs ความโปร่งใสในการปฏิบัติ: ข้อความโฆษณามักให้ความมั่นใจกับคำว่า “เป็นธรรม” หรือ “ไม่มีอคติ” ในขณะที่เอกสารทางเทคนิคและเงื่อนไขการใช้งานอาจจำกัดการเปิดเผยรายละเอียดของโมเดล การตั้งค่า หรือผลการทดสอบเชิงลึก
- ข้อจำกัดเชิงทรัพยากรและเวลา: องค์กรที่ต้องการประหยัดต้นทุนอาจเลือกเปิดใช้ระบบด้วยการตั้งค่าที่เน้นประสิทธิภาพ (throughput) มากกว่าการตรวจสอบความเป็นธรรมอย่างละเอียด ส่งผลให้ human review ถูกลดทอนหรือกำหนดให้ครอบคลุมเพียงส่วนน้อยของเคส
- การขาดมาตรฐานกลาง: ปัจจุบันยังขาดมาตรฐานบังคับในหลายตลาด ทำให้การอ้างว่า “ผ่านการตรวจสอบความเป็นธรรม” มีความหมายต่างกันไปขึ้นอยู่กับผู้ตรวจหรือกระบวนการที่ใช้
โดยสรุป บริษัทผู้พัฒนานำเสนอกลไกทางเทคนิคและขั้นตอนการกำกับดูแลเพื่อรับประกันความเป็นธรรม ขณะที่บริษัทผู้ใช้เน้นถึงผลด้านประสิทธิภาพและการบริหารต้นทุน แต่ในโจทย์เชิงปฏิบัติยังคงมีช่องว่างระหว่างคำโฆษณาเชิงการตลาดกับการปฏิบัติจริง ทั้งนี้การลดช่องว่างดังกล่าวต้องอาศัยการเปิดเผยข้อมูลการทดสอบ การมีมาตรฐานอิสระในการตรวจสอบ และการออกแบบกระบวนการที่ให้มนุษย์มีบทบาทในการตัดสินใจขั้นสุดท้ายอย่างชัดเจน
บริบทกฎหมายและนโยบาย: แนวทางคุ้มครองผู้สมัคร
บริบทกฎหมายและนโยบาย: แนวทางคุ้มครองผู้สมัคร
การใช้เทคโนโลยีปัญญาประดิษฐ์ (AI) ในกระบวนการสรรหาได้สร้างความท้าทายเชิงกฎหมายและนโยบายใหม่ ๆ ที่จำเป็นต้องตอบสนองอย่างเป็นระบบ ทั้งในด้านการคุ้มครองข้อมูลส่วนบุคคล การป้องกันการเลือกปฏิบัติ และการรับประกันความโปร่งใสของกระบวนการตัดสินใจอัตโนมัติ ในระดับสากล กรอบเช่น GDPR ของสหภาพยุโรปให้สิทธิแก่เจ้าของข้อมูลในการรู้และคัดค้านการตัดสินใจที่อาศัยการประเมินอัตโนมัติ (automated decision-making) โดยบทบัญญัติที่เกี่ยวข้อง ได้แก่ หลักการความชอบด้วยกฎหมาย (lawful basis), การจำกัดวัตถุประสงค์ (purpose limitation) และสิทธิในการเข้าถึงข้อมูลและขอคำอธิบายเกี่ยวกับตรรกะของระบบ ซึ่งมีบทบาทสำคัญในการสนับสนุนความสุจริตของระบบคัดกรองผู้สมัคร
ในบริบทของประเทศไทย กฎหมายคุ้มครองข้อมูลส่วนบุคคล (พระราชบัญญัติว่าด้วยการคุ้มครองข้อมูลส่วนบุคคล หรือ PDPA) บังคับใช้หลักการคล้ายคลึงกับ GDPR ได้แก่ การขอความยินยอมเมื่อจำเป็น การกำหนดวัตถุประสงค์การเก็บรักษา และสิทธิของเจ้าของข้อมูลในการเข้าถึงและเรียกร้องให้ลบข้อมูล นอกจากนี้ กฎหมายแรงงานและกรอบสิทธิแรงงานของไทยยังคุ้มครองผู้สมัครจากการเลือกปฏิบัติในสถานที่ทำงาน ดังนั้น ผู้ประกอบการที่นำ AI มาใช้ต้องระมัดระวังทั้งองค์ประกอบด้านความเป็นส่วนตัวและผลกระทบต่อความเท่าเทียมทางอาชีพ
ตัวอย่างเชิงนโยบายและคดีต่างประเทศช่วยชี้แนะแนวทางปฏิบัติได้ชัดเจน: ในอดีตมีการเปิดเผยว่าเครื่องมือคัดกรองขององค์กรใหญ่บางแห่งแสดงอคติทางเพศหรือเชื้อชาติในการทดลองนำร่อง (เช่นกรณีที่มีการยกเลิกการใช้งานแบบจำลองที่แสดงอคติ) ขณะเดียวกัน เมืองและรัฐในสหรัฐฯ ก็เริ่มออกกฎเฉพาะด้าน เช่น New York City Local Law 144 ที่กำหนดให้ผู้ใช้เครื่องมือคัดกรองอัตโนมัติต้องผ่านการตรวจสอบอคติ (bias audit) และมีการเปิดเผยข้อมูลเกี่ยวกับเครื่องมือที่ใช้ ส่วนรัฐอิลลินอยส์มีข้อกำหนดเฉพาะสำหรับการสัมภาษณ์ด้วยวิดีโอที่วิเคราะห์ด้วย AI ซึ่งต้องได้รับความยินยอมและให้ข้อมูลเกี่ยวกับลักษณะที่จะถูกวิเคราะห์
เพื่อให้การกำกับดูแล AI ในการสรรหาเป็นไปอย่างมีประสิทธิภาพ จำเป็นต้องมีมาตรการเชิงนโยบายและปฏิบัติการที่ชัดเจน ซึ่งควรครอบคลุมทั้งการป้องกันเชิงป้องกันและการเยียวยาเมื่อเกิดความเสียหาย หลักการสำคัญได้แก่:
- การเปิดเผยเชิงตรรกะและความสามารถในการอธิบาย (explainability): ผู้สมัครต้องได้รับข้อมูลที่เพียงพอเกี่ยวกับการตัดสินใจ เช่น ว่ามีการใช้การประมวลผลอัตโนมัติหรือไม่ และคำอธิบายเชิงเหตุผลที่เข้าใจได้เกี่ยวกับปัจจัยที่มีอิทธิพลต่อผลลัพธ์
- การประเมินผลกระทบต่อความเสมอภาค (AIA/Fairness Impact Assessment): ก่อนนำระบบไปใช้ ควรมีการทดสอบล่วงหน้าเพื่อวัดความเสี่ยงเรื่องการเลือกปฏิบัติและผลกระทบต่อกลุ่มเปราะบาง โดยใช้เทคนิคเช่น A/B testing, disparate impact analysis และ stress testing กับข้อมูลจำลอง
- การตรวจสอบโดยบุคคลที่สาม (independent third‑party audits): ให้มีการตรวจสอบอิสระด้านเทคนิคและนโยบายอย่างสม่ำเสมอ รวมถึงการตรวจสอบชุดข้อมูล การออกแบบฟีเจอร์ และผลลัพธ์ เพื่อยืนยันความเป็นกลางและความถูกต้องของโมเดล
- การกำกับดูแลแบบผสมผสาน (human‑in‑the‑loop): กำหนดให้มีบทบาทของผู้ตรวจสอบมนุษย์อย่างมีนัยสำคัญในการตัดสินใจขั้นสุดท้าย โดยเฉพาะในกรณีที่มีผลกระทบสำคัญต่อชีวิตความเป็นอยู่ของผู้สมัคร
- มาตรฐานเอกสารและการเก็บบันทึก (documentation & record‑keeping): ผู้พัฒนาและผู้ใช้ระบบต้องจัดทำเอกสารเชิงเทคนิค เช่น model cards และ datasheets สำหรับโมเดล รวมทั้งเก็บบันทึกการทดสอบ การตัดสินใจ และการแจ้งเตือน เพื่อรองรับการสืบสวนและสิทธิเรียกร้อง
- มาตรการเยียวยาและช่องทางอุทธรณ์: ผู้สมัครต้องมีช่องทางที่เข้าถึงได้ง่ายในการโต้แย้งผลการคัดเลือกและขอทบทวนการตัดสินใจ โดยหน่วยงานกำกับดูแลควรกำหนดหลักเกณฑ์การดำเนินการตอบกลับภายในกรอบเวลาที่ชัดเจน
ในเชิงนโยบายระดับชาติ ควรพิจารณาการออกข้อบังคับเชิงภาคี เช่น การบังคับใช้การประเมินผลกระทบของระบบอัตโนมัติก่อนใช้งานเป็นมาตรฐาน การจัดตั้งหน่วยงานรับรองหรือทะเบียนเครื่องมือคัดกรองที่ได้รับการตรวจสอบ และการกำหนดบทลงโทษที่มีประสิทธิภาพเมื่อพบการละเมิด สิ่งเหล่านี้จะช่วยสร้างสมดุลระหว่างนวัตกรรมทางเทคโนโลยีกับการคุ้มครองสิทธิพื้นฐานของผู้สมัครงาน และลดความเสี่ยงด้านชื่อเสียงและความรับผิดชอบทางกฎหมายของนายจ้าง
ผลกระทบต่อผู้สมัครและข้อเสนอแนะเชิงปฏิบัติ
ผลกระทบต่อผู้สมัครและข้อเสนอแนะเชิงปฏิบัติ
ผลกระทบทางอาชีพและจิตใจ: การถูกคัดกรองโดยระบบอัตโนมัติที่มีอคติสามารถส่งผลกระทบอย่างมีนัยสำคัญทั้งต่อโอกาสทางอาชีพและสภาพจิตใจของผู้สมัคร ตัวอย่างเช่น กรณีที่เป็นข่าวของบริษัทเทคโนโลยีรายใหญ่ที่ยกเลิกระบบสรรหาที่แสดงความลำเอียงต่อผู้หญิง แสดงให้เห็นว่าผู้สมัครจากกลุ่มที่ถูกกันออกอาจสูญเสียโอกาสในการถูกเรียกสัมภาษณ์และก้าวหน้าในสายอาชีพ นอกจากนี้ ผู้สมัครที่ได้รับการปฏิเสธอย่างต่อเนื่องจากระบบอัตโนมัติรายงานผลกระทบทางจิตใจ เช่น ความเครียดลดความมั่นใจในตนเอง และความรู้สึกว่าถูกปฏิเสธอย่างไม่เป็นธรรม ซึ่งอาจส่งผลต่อการค้นหางานต่อเนื่องและการลงทุนในทักษะใหม่
คำแนะนำเชิงปฏิบัติสำหรับผู้สมัคร: ผู้สมัครควรเตรียมตัวเชิงกลยุทธ์เพื่อเพิ่มโอกาสผ่านการกรองโดยเครื่องมือสรรหา AI และลดผลกระทบจากอคติของระบบ ดังนี้
- ปรับเรซูเม่ให้เหมาะกับระบบสแกน: ใช้คำสำคัญ (keywords) ที่สอดคล้องกับคำบรรยายงาน แต่ระวังไม่ใช้รูปแบบกราฟิกซับซ้อนหรือเทมเพลตที่ระบบอ่านไม่ได้ เช่น ใช้ฟอนต์มาตรฐานและหัวข้อชัดเจน
- ชี้แจงช่องว่างและจุดเปลี่ยนอาชีพ: ในส่วนสรุปหรืออีเมลแนบ ให้ระบุเหตุผลของช่องว่างการทำงาน เช่น การลาเพื่อดูแลครอบครัวหรือการศึกษาต่อ พร้อมเน้นทักษะที่ได้มาในช่วงเวลาดังกล่าว
- เก็บบันทึกและขอคำชี้แจง: หากได้รับการปฏิเสธที่สงสัยว่าไม่เป็นธรรม ควรขอข้อมูลเพิ่มเติมหรือขอให้มีการทบทวนโดยมนุษย์ เก็บหลักฐานการสมัครและการติดต่อทั้งหมดเพื่อใช้เป็นข้อมูลหากต้องร้องเรียน
- สร้างโปรไฟล์ออนไลน์และแสดงผลงาน: เพิ่มความน่าเชื่อถือด้วย portfolio, LinkedIn ที่อัปเดต และผลงานเชิงปริมาณ ซึ่งช่วยให้ผู้พิจารณามนุษย์เห็นภาพรวมที่ชัดเจนยิ่งขึ้น
- ขอคำแนะนำจากเครือข่ายหรือที่ปรึกษา: ใช้เครือข่ายมืออาชีพหรือบริการโค้ชชิ่งเพื่อปรับเรซูเม่และเตรียมคำอธิบายที่ชัดเจนต่อคณะกรรมการสรรหา
ข้อเสนอแนะสำหรับผู้จัดการสรรหาและองค์กร: ผู้จัดหาความสามารถควรออกแบบกระบวนการที่ลดความเสี่ยงจากอคติของระบบและเพิ่มความเป็นธรรมต่อผู้สมัคร ตัวอย่างแนวปฏิบัติที่แนะนำ ได้แก่
- ใช้การสกรีนแบบ Blind หรือ Partial Blind: ซ่อนข้อมูลเชิงประชากรที่ไม่เกี่ยวข้องกับความสามารถ เช่น เพศ อายุ ที่อยู่ ระหว่างการคัดกรองเบื้องต้น เพื่อลดอคติที่เกิดจากข้อมูลทางสังคม
- ผสมผสาน Human-in-the-Loop: ให้มนุษย์มีบทบาทในการทบทวนผลการคัดกรองอัตโนมัติ โดยเฉพาะกรณีที่ระบบปฏิเสธผู้สมัครที่มีคุณสมบัติตรงตามเกณฑ์
- จัดทำกระบวนการอุทธรณ์และการชี้แจง: สร้างช่องทางให้ผู้สมัครสามารถขอคำชี้แจงหรือให้มีการทบทวนผลการคัดเลือก ซึ่งเป็นส่วนหนึ่งของนโยบายความโปร่งใสด้านการจ้างงาน
- ฝึกอบรมผู้สรรหาและทีม HR: ให้ความรู้เรื่องข้อจำกัดของ AI และการสังเกตสัญญาณอคติ เพื่อให้การตัดสินใจสุดท้ายไม่พึ่งพาแต่ผลลัพธ์จากเครื่องมือเพียงอย่างเดียว
มาตรการเชิงเทคนิคและเชิงนโยบายที่องค์กรควรนำไปปฏิบัติ: เพื่อลดความเสี่ยงทางกฎหมายและเพิ่มความเป็นธรรม องค์กรต้องนำมาตรการเชิงเทคนิคและนโยบายมาบูรณาการอย่างเป็นระบบ ดังนี้
- การทดสอบความเป็นธรรม (Fairness Testing): ทำการตรวจสอบเมตริกต่าง ๆ เช่น อัตราการปฏิเสธ (false negative rate) และอัตราการเรียกสัมภาษณ์ข้ามกลุ่มประชากรที่หลากหลาย เป็นระยะ และเผยแพร่สรุปผลสำหรับผู้มีส่วนได้ส่วนเสีย
- การตรวจสอบโดยบุคคลที่สามและการตรวจสอบภายใน: จัดให้มีการตรวจสอบอัลกอริทึมโดยผู้เชี่ยวชาญอิสระ หรือหน่วยงานภายในที่หลากหลาย เพื่อยืนยันความเป็นกลางของโมเดลและข้อมูลฝึก
- การจัดการข้อมูลและการปรับชุดข้อมูล (Data Governance): ควบคุมแหล่งข้อมูลฝึก ให้มีความหลากหลายและตัวแทนของกลุ่มต่าง ๆ ลดการลอกเลียนอคติจากประวัติการจ้างงานที่ผ่านมา
- การจัดทำเอกสารโมเดล (Model Cards) และการประเมินผลกระทบด้านสิทธิมนุษยชน: จัดทำเอกสารที่อธิบายขอบเขตการใช้งาน ข้อจำกัด และผลการทดสอบ เพื่อให้ฝ่ายบริหาร ผู้สมัคร และหน่วยงานกำกับดูแลเข้าถึงได้
- นโยบายความโปร่งใสและการแจ้งผู้สมัคร: แจ้งให้ผู้สมัครทราบว่าใช้ระบบอัตโนมัติในการคัดกรอง รวมถึงเปิดเผยสิทธิ์ในการขอทบทวนและวิธีติดต่อ
- การปฏิบัติตามกฎระเบียบและการทำ AIA (Algorithmic Impact Assessment): ดำเนินการประเมินผลกระทบของระบบต่อความเสมอภาคและปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น GDPR และมาตรฐานที่เกี่ยวข้อง
สรุป: การใช้ระบบสรรหาที่ขับเคลื่อนด้วย AI แม้จะเพิ่มประสิทธิภาพ แต่หากขาดมาตรการป้องกันอคติ จะนำไปสู่ความเสี่ยงทั้งต่อผู้สมัครและองค์กร ทั้งในเชิงธุรกิจและภาพลักษณ์ องค์กรที่ออกแบบกระบวนการสรรหาอย่างโปร่งใส มีการทดสอบและการมีมนุษย์กำกับดูแลอย่างเหมาะสม จะช่วยลดความเสียหาย เพิ่มความยุติธรรม และสร้างความเชื่อมั่นสำหรับผู้สมัครในระยะยาว
บทสรุป
คดีฟ้องร้องครั้งนี้เป็นสัญญาณเตือนสำคัญว่า การนำระบบปัญญาประดิษฐ์มาใช้ในการสรรหาบุคลากรต้องมาพร้อมมาตรการความโปร่งใส การตรวจสอบเชิงเทคนิคและเชิงนโยบาย และการคุ้มครองสิทธิเบื้องต้นของผู้สมัคร เช่น สิทธิในการได้รับคำอธิบายเหตุผลการตัดสินใจ การเข้าถึงข้อมูลที่เกี่ยวข้อง และช่องทางอุทธรณ์ การขาดมาตรการดังกล่าวไม่เพียงเพิ่มความเสี่ยงทางกฎหมาย แต่ยังอาจนำไปสู่การเลือกสรรที่ไม่เป็นธรรมและทำลายความเชื่อมั่นของผู้สมัครและองค์กร
ทั้งภาคธุรกิจและหน่วยงานกำกับควรเร่งพัฒนาและนำไปปฏิบัติกรอบการทดสอบความเป็นธรรม (fairness testing) มาตรฐานการรายงานผล และการตรวจสอบโดยบุคคลภายนอก เพื่อสร้างสมดุลระหว่างประสิทธิภาพการสรรหาและความยุติธรรมในระยะยาว แนวทางเช่น การออกข้อกำหนดการรายงานผลเชิงสถิติ การใช้ชุดข้อมูลทดสอบที่เป็นกลาง การกำหนดระดับการดูแลของมนุษย์ (human-in-the-loop) และมาตรการคุ้มครองข้อมูลส่วนบุคคล จะช่วยลดความเสี่ยงและส่งเสริมการใช้งาน AI ที่เชื่อถือได้ สรุปแล้ว เหตุการณ์นี้ควรถูกมองเป็นโอกาสให้เร่งสร้างมาตรฐานและกลไกกำกับดูแลที่ชัดเจน เพื่อให้ผลลัพธ์การสรรหาทั้งมีประสิทธิภาพและยุติธรรมต่อผู้สมัครทุกคน
📰 แหล่งอ้างอิง: The New York Times



