
ในยุคที่บริการทางการเงินแบบกระจายศูนย์ (DeFi) กลายเป็นเป้าหมายสำคัญของการโจมตีทางไซเบอร์ ความผิดพลาดเล็กน้อยในสมาร์ทคอนแทรกต์สามารถหมายถึงการสูญเสียเงินมูลค่าหลายล้านดอลลาร์ ทำให้การทดสอบความปลอดภัยก่อนขึ้นโปรดักชันกลายเป็นหัวใจสำคัญของการพัฒนา ล่าสุดสตาร์ทอัพด้านความปลอดภัยเปิดตัวเครื่องมือ Generative‑AI ที่สร้างการโจมตีจำลองบนสมาร์ทคอนแทรกต์ได้แบบอัตโนมัติ เป้าหมายคือค้นหาช่องโหว่เชิงรุกก่อนที่โค้ดจะถูกนำขึ้นเครือข่ายจริง เพื่อลดความเสี่ยงและลดต้นทุนในการตรวจสอบความปลอดภัย
เครื่องมือนี้ใช้โมเดลเชิงสร้างสรรค์ (generative models) ในการสังเคราะห์เวกเตอร์การโจมตี เช่น payloads สำหรับการโจมตีแบบ reentrancy, flash‑loan, manipulation ของราคาออราเคิล หรือข้อผิดพลาดเชิงตรรกะ พร้อมสามารถจำลองสถานะเครือข่ายและปรับสภาพแวดล้อมเพื่อทดสอบกรณีมุมต่าง ๆ ได้อย่างกว้างขวาง ผู้พัฒนายังระบุว่ามีการออกแบบให้เชื่อมต่อกับ pipeline การพัฒนา (CI/CD) เพื่อให้การทดสอบเกิดขึ้นเป็นส่วนหนึ่งของกระบวนการปล่อยซอฟต์แวร์ ช่วยลดเวลาตรวจสอบด้วยมือและเสริมการตรวจสอบแบบดั้งเดิม เช่น การ audit โดยมนุษย์และการพิสูจน์เชิงคณิตศาสตร์
ผลลัพธ์ที่คาดหวังคือการลดความเสี่ยงก่อนขึ้นโปรดักชันและการประหยัดเวลาในกระบวนการรีวิวโค้ด ซึ่งอาจแปลเป็นการลดความสูญเสียทางการเงินและความเชื่อมั่นของผู้ใช้ในระบบนิเวศ DeFi บทความนี้จะพาไปดูรายละเอียดการทำงานของเครื่องมือ ตัวอย่างการโจมตีจำลอง ผลลัพธ์การทดสอบ รวมถึงข้อดีข้อจำกัดและความหมายต่ออนาคตของการรักษาความปลอดภัยสมาร์ทคอนแทรกต์
1. บทนำ: ทำไมต้องมีเครื่องมือทดสอบเชิงโจมตีสำหรับ Smart Contracts
1. บทนำ: ทำไมต้องมีเครื่องมือทดสอบเชิงโจมตีสำหรับ Smart Contracts
โลกของการเงินแบบกระจายศูนย์ (DeFi) เติบโตอย่างรวดเร็ว ทั้งปริมาณทรัพย์สินที่ถูกล็อกไว้ (Total Value Locked — TVL) และจำนวนโปรโตคอลที่ให้บริการด้านการกู้ยืม, แลกเปลี่ยน, สภาพคล่อง และอนุพันธ์ดิจิทัล แต่การเติบโตนี้มาพร้อมกับความเสี่ยงด้านความปลอดภัยของ Smart Contracts ที่เป็นหัวใจของระบบ โดยมีรายงานจากหน่วยงานวิเคราะห์หลายแห่ง เช่น Chainalysis, CertiK, Elliptic และฐานข้อมูลสรุปเหตุการณ์ความปลอดภัยของ DeFi ระบุว่า ตั้งแต่ช่วงกลางทศวรรษ 2010 จนถึงปัจจุบันมีมูลค่าความเสียหายจากการโจมตีและช่องโหว่ในระบบคริปโตและ DeFi อยู่ในระดับ หลายพันล้านดอลลาร์ ทั้งจากการขโมยโดยตรง การโจมตีทางเศรษฐกิจ และการสูญเสียเชิงสภาพคล่องในโปรโตคอลต่างๆ
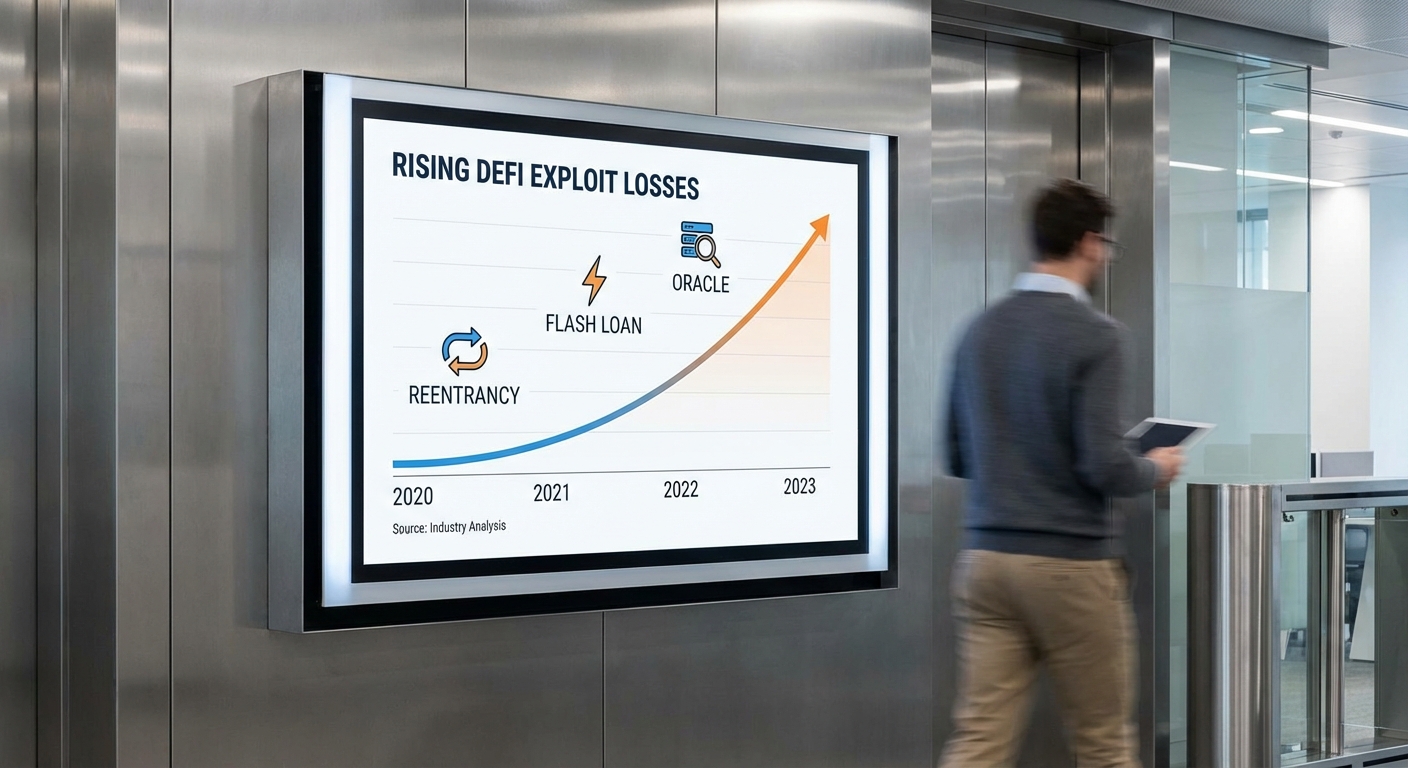
ตัวอย่างเหตุการณ์สำคัญที่สะท้อนถึงความเสี่ยงเชิงเทคนิค ได้แก่
- Reentrancy (การเรียกซ้อนกลับ) — เหตุการณ์ที่เป็นสัญลักษณ์คือ The DAO (2016) ซึ่งทำให้เกิดการสูญเสียครั้งใหญ่และเป็นจุดเริ่มต้นของการตระหนักเรื่องการตรวจสอบ Smart Contract แบบจริงจัง
- Flash loan attacks — การยืมทุนขนาดใหญ่ชั่วคราวเพื่อนำไปสร้างแรงกดดันทางราคาและแสวงหากำไรจากช่องโหว่เชิงตรรกะ เช่น กรณี bZx (2020) และ PancakeBunny (2021)
- Oracle manipulation — การบิดเบือนข้อมูลราคาจากแหล่งภายนอกเพื่อทำกำไรจากตำแหน่งที่ถูกคำนวณจากข้อมูลราคา เช่น กรณี Harvest Finance (2020) และหลายเหตุการณ์ที่เกี่ยวข้องกับการจัดการราคาในสภาพแวดล้อมสภาพคล่องต่ำ
การโจมตีเหล่านี้มักไม่ได้เกิดจากข้อผิดพลาดเล็ก ๆ ในโค้ดเท่านั้น แต่เกิดจากการผสมผสานของปัจจัย เช่น การออกแบบตรรกะธุรกรรม (business logic), ปฏิสัมพันธ์ระหว่างโปรโตคอลหลายราย, สถานะเศรษฐกิจแบบเวลาจริง และการใช้เครื่องมือทางการเงินเช่น flash loans เพื่อสร้างสถานการณ์ที่ไม่เคยถูกทดสอบมาก่อน ซึ่งเป็นเหตุผลที่การตรวจสอบแบบเดิมมักไม่เพียงพอ
ข้อจำกัดของการทดสอบ Smart Contracts แบบเดิมที่พบบ่อย ได้แก่:
- การวิเคราะห์แบบ Static (Static Analysis) — แม้จะช่วยค้นหาข้อบกพร่องเชิงโค้ดทั่วไปได้ แต่มีความเสี่ยงของ false negatives กล่าวคือพลาดช่องโหว่ที่เกิดขึ้นจากสภาวะการทำงานจริงหรือการปฏิสัมพันธ์ข้ามโปรโตคอล
- การตรวจสอบด้วยมนุษย์ (Manual Audits) — มีคุณค่าและละเอียด แต่มีต้นทุนสูง ใช้เวลาเป็นสัปดาห์ถึงเดือน และไม่สามารถครอบคลุมทุกกรณีมุมมองเชิงเศรษฐกิจหรือการโจมตีเชิงกลยุทธ์ที่ผู้โจมตีอาจสร้างขึ้นได้อย่างต่อเนื่อง
- ข้อจำกัดของการจำลองเชิงสถานะ — การจำลองสภาพแวดล้อมที่สมจริงต้องใช้ข้อมูลตลาด, ปริมาณสภาพคล่อง, ผู้เล่นอื่นๆ และเหตุการณ์ภายนอก ซึ่งทำให้การสร้างกรณีทดสอบเชิงรุกมีความซับซ้อนและมีช่องว่างในการครอบคลุม
ด้วยเหตุนี้จึงเกิดแรงจูงใจในการใช้เทคโนโลยีเชิงรุก เช่น Generative‑AI เพื่อสร้างโจมตีจำลอง (adversarial attack simulations) อัตโนมัติ ซึ่งสามารถ
- สร้างสคริปต์โจมตีและกรณีทดสอบเชิงกลยุทธ์ที่หลากหลายโดยไม่ขึ้นกับรูปแบบที่มนุษย์นึกถึงเพียงอย่างเดียว
- จำลองการปฏิสัมพันธ์แบบไดนามิกระหว่างโปรโตคอล และทดสอบผลกระทบทางเศรษฐกิจ (economic exploit scenarios)
- ลดเวลาและต้นทุนในการค้นหาช่องโหว่ พร้อมลดความเสี่ยงของ false negatives เมื่อเทียบกับการพึ่งพาเฉพาะ static analysis หรือ manual audits เท่านั้น
สรุปแล้ว ในสภาพแวดล้อมของ DeFi ที่มีความซับซ้อนและเปลี่ยนแปลงรวดเร็ว การนำเครื่องมือที่สามารถทดสอบเชิงโจมตีเชิงรุก—รวมถึงการใช้ Generative‑AI เพื่อจำลองพฤติกรรมผู้โจมตีและสถานการณ์เศรษฐกิจที่หลากหลาย—เข้ามาใช้ก่อนการขึ้นโปรดักชัน เป็นแนวทางเชิงรุกที่ตอบโจทย์ทั้งด้านความปลอดภัย ความคุ้มค่า และการปกป้องทรัพย์สินของผู้ใช้อย่างเป็นระบบ
2. เทคโนโลยีเบื้องหลัง: Generative‑AI ผสานกับเทคนิคตรวจสอบความปลอดภัย
2. เทคโนโลยีเบื้องหลัง: Generative‑AI ผสานกับเทคนิคตรวจสอบความปลอดภัย
ระบบตรวจสอบสัญญาอัจฉริยะที่รวม Generative‑AI เข้ากับเทคนิคดั้งเดิม จะเริ่มจากการดึงข้อมูลเชิงไวยากรณ์และไบนารีของคอนแทร็กต์ (AST/bytecode) โดยใช้เครื่องมือเช่น solc สำหรับ Solidity, disassembler/evm‑tooling สำหรับ EVM bytecode และตัววิเคราะห์ static เช่น Slither หรือ Mythril เพื่อสร้าง representation เบื้องต้นของโค้ดและ pattern ของความเสี่ยง (reentrancy, integer overflow, access control) ข้อมูลโครงสร้าง (AST), control‑flow graph (CFG) และ data‑flow graph จะถูกจัดเก็บเป็น input ให้ pipeline ต่อไป ซึ่งช่วยให้โมดูล Generative‑AI รู้บริบทเชิงโครงสร้างก่อนจะเริ่ม "คิด" สร้างโจมตีจำลอง
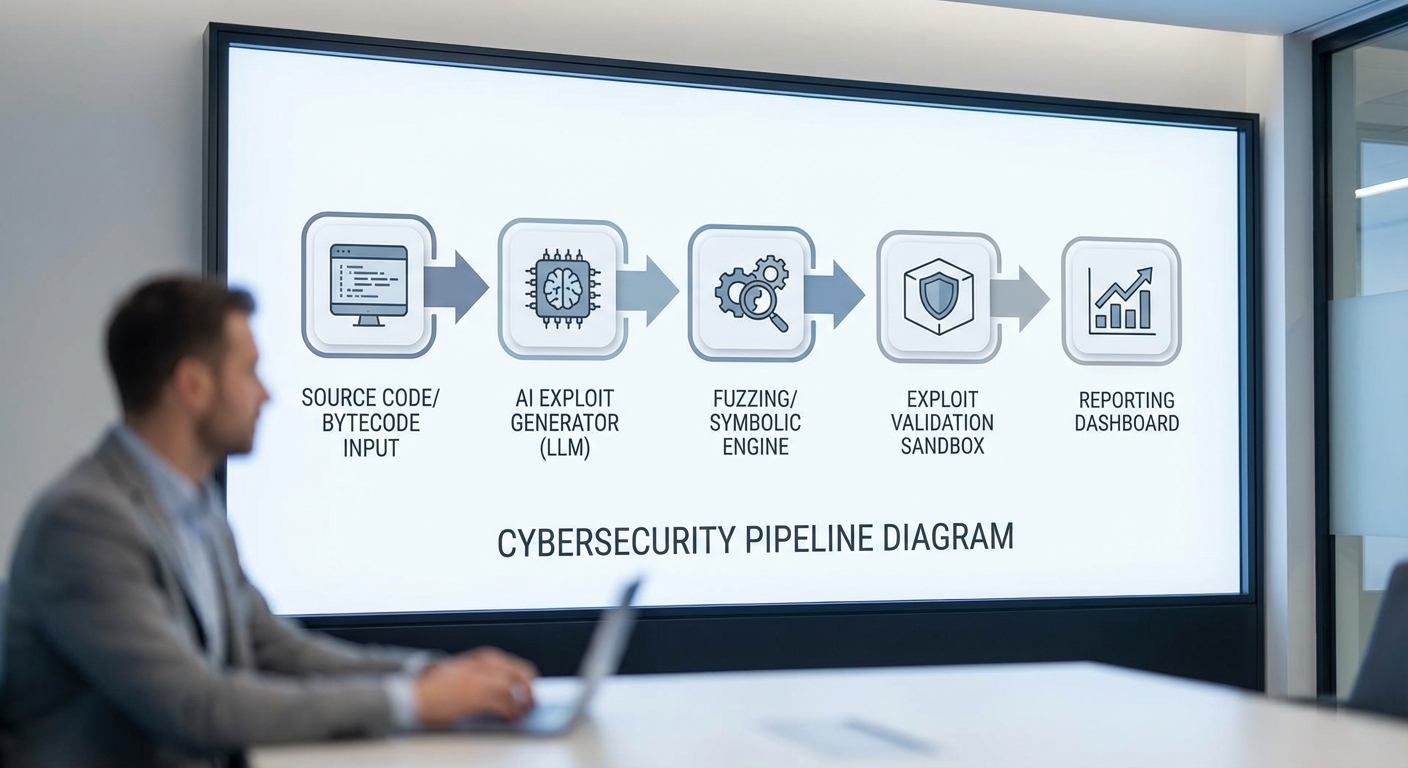
การใช้ LLMs ในการ 'คิด' สร้างโจมตีจำลอง — โมเดลภาษาใหญ่ทำหน้าที่หลายชั้น: (1) preprocessing prompt design เพื่อสกัดข้อสันนิษฐานและสร้าง hypothesis ของช่องโหว่ (2) ใช้ chain‑of‑thought และ few‑shot prompting เพื่อสาธิตตรรกะการโจมตีเช่นลำดับทริกเกอร์ของฟังก์ชัน, การตั้งค่า state ที่จำเป็น และการอธิบาย invariant ที่ต้องละเมิด และ (3) code synthesis เพื่อสร้างสคริปต์ PoC (ตัวอย่างโค้ดที่ใช้ Hardhat/Foundry, ethers.js, web3.py หรือ Brownie) ที่สามารถรันในเครือข่ายทดสอบได้ ในการออกแบบ prompt จะมีการฝัง context เช่น AST snippet, taint sinks/sources, และตัวอย่าง exploit templates ในรูปแบบ few‑shot เพื่อให้โมเดลสามารถผลิตโค้ดเชิงปฏิบัติที่มีทั้ง sequence ของธุรกรรม (transactions) และค่า input ที่เป็นไปได้
โมเดลจะส่งออกทั้งข้อความอธิบายเชิงตรรกะและโค้ด ซึ่ง pipeline จะตรวจสอบความถูกต้องของซินแทกซ์โดยใช้ static analysis และ unit tests เบื้องต้น ก่อนส่งไปยังขั้นตอนต่อไป นอกจากนี้การใช้ chain‑of‑thought แบบควบคุมช่วยให้ทีมสามารถดูเหตุผลเชิงกลางของโมเดล (เช่น ทำไมต้องทำ approve ก่อน transfer) เพื่อเพิ่มความโปร่งใสและลดความเสี่ยงจากการสร้าง PoC ที่ผิดพลาด
การผสาน fuzzing และ symbolic execution เพื่อขยายการสำรวจ state‑space — Generative‑AI ให้ hypothesis และตัวอย่างอินพุตเริ่มต้น ในขณะที่ fuzzing (เช่น AFL‑style, property‑based fuzzers แบบ Echidna หรือ fuzzers ที่รองรับ transaction sequences) จะใช้ชุดเริ่มต้นนี้เป็น seed เพื่อสำรวจชุดข้อมูลอินพุตที่หลากหลายและทำการค้นหา corner cases โดยอาศัย mutation strategies และ guided coverage metrics ในเวลาเดียวกัน symbolic/concolic execution (เช่น Manticore, Mythril integration หรือใช้ SMT solver อย่าง Z3) จะถอด path conditions จาก bytecode/CFG เพื่อตั้งสมการเงื่อนไขที่ต้องเป็นจริงสำหรับ path เฉพาะ ซึ่งช่วยเจาะลึกไปยังสภาวะที่ fuzzing แบบดำเนินการสุ่มอาจไม่ถึง
การผสานทั้งสองเทคนิคนี้ทำให้ได้ประโยชน์ร่วมกัน: fuzzing ให้การสำรวจเชิงสถิติและครอบคลุมของ input space ขณะที่ symbolic execution ให้การพิสูจน์เชิงตรรกะของ path ที่พบ การผสมผสานยังรวมถึงเทคนิคเช่น path prioritization (ให้คะแนน path ตามความร้ายแรงที่คาดการณ์โดย LLM และ static heuristics), constraint prioritization (แก้สมการที่ง่ายก่อน) และ state summarization เพื่อลดปัญหา state‑space explosion ผลการทดลองภายในของสตาร์ทอัพหลายรายระบุว่าแนวทางผสานนี้ช่วยเพิ่มอัตราการค้นพบช่องโหว่จริงได้ราว 20–40% เมื่อเทียบกับการใช้ static analysis เพียงอย่างเดียว และลด false positives ได้ในระดับหนึ่งโดยการยืนยันเชิงปฏิบัติการ
Workflow แบบครบวงจร (initial scan → exploit generation → exploit validation → report)
- Initial scan: ดึงแหล่งที่มา/bytecode → สร้าง AST/CFG/DFG → รัน static analyzers และ pattern matchers เพื่อหาจุดสนใจ (suspicious functions, missing checks)
- Exploit generation: ใช้ LLMs เพื่อผลิต hypothesis, sequence ของธุรกรรม และ PoC code (few‑shot prompts, chain‑of‑thought) → สคริปต์ที่ได้จะถูกปรับรูปแบบเป็น transaction templates (nonce, gas, call data)
- Exploit validation: รัน PoC ใน sandboxed forked chain (Ganache/Anvil/Hardhat fork) พร้อม instrumentation เพื่อตรวจจับ state changes, balance shifts, event emissions และ assertions ทั้งจาก dynamic fuzzing (mutate inputs, sequence) และ symbolic execution (solve path constraints) เพื่อให้ได้การยืนยันเชิงปฏิบัติการ หาก symbolic solver ยืนยัน path constraints จะถือเป็นหลักฐานเชิงตรรกะประกอบกับผลลัพธ์เชิงปฏิบัติการ
- Report generation: รวบรวมหลักฐาน (AST snippet, bytecode offset, transaction trace), โค้ด PoC, replayable script พร้อมคำอธิบาย chain‑of‑thought ของ LLM, severity scoring และ recommendations สำหรับ remediation (patch diff, invariant checks, access control fixes) โดยระบบยังรวม metrics เช่น coverage, successful exploit rate และเวลาในการค้นพบ
สุดท้ายระบบต้องมีการป้องกันเชิงปฏิบัติการ เช่น sandboxing ของการรันโค้ดที่สร้างโดย LLM, rate limiting ของ fuzzing jobs, การตรวจจับการสร้าง payloads ที่เป็นอันตรายต่อเครือข่ายจริง และกระบวนการ human‑in‑the‑loop เพื่อตรวจสอบ PoC ที่สำคัญก่อนส่งให้ลูกค้าหรือเผยแพร่ รายงานแบบอัตโนมัติที่มีทั้ง reproduction steps และ PoC script ช่วยให้องค์กรสามารถทำ remediation ได้รวดเร็วและมีหลักฐานยืนยันว่าช่องโหว่นั้นเกิดขึ้นจริงและสามารถแก้ไขได้อย่างไร
3. วิธีการโจมตีจำลอง (Adversarial Simulation) — ขั้นตอนและตัวอย่าง
3. วิธีการโจมตีจำลอง (Adversarial Simulation) — ขั้นตอนและตัวอย่าง
การโจมตีจำลองหรือ Adversarial Simulation เป็นกระบวนการสร้างและรันชุดทดสอบเชิงรุกเพื่อตรวจหาช่องโหว่ของ smart contracts ก่อนขึ้นโปรดักชัน โดยเครื่องมือ Generative‑AI สมัยใหม่จะทำงานเป็นไพพ์ไลน์อัตโนมัติที่ประกอบด้วยการสร้าง test cases, การตั้งสภาพแวดล้อมจำลอง และการรันลำดับธุรกรรมเชิงซับซ้อนเพื่อตรวจจับการละเมิดสมบัติ (invariants) หรือการเกิดผลลัพธ์ที่ไม่คาดคิด เช่น การสูญเสียเงินหรือสถานะไม่สอดคล้องกัน
ขั้นตอนหลักของการโจมตีจำลอง มักแบ่งออกเป็นขั้นตอนต่อไปนี้: การสร้างเคสทดสอบ, การตั้งสถานะเริ่มต้น, การรันลำดับธุรกรรมเชิงเวลา, การเฝ้าระวัง invariants และการลดขนาด (minimization) เพื่อรายงานผลที่เข้าใจได้ ขั้นตอนโดยย่อคือ
- สร้าง test cases: ใช้เทคนิคเช่น mutation, property‑based testing และ guided search เพื่อสร้างอินพุตและลำดับธุรกรรมที่หลากหลาย
- ตั้งสภาพแวดล้อม: ใช้การ fork mainnet/local chain, ตั้งยอดเงินของบัญชี, ดีพลอยคอนแทรกต์ม็อกและ oracle ปลอม เพื่อสะท้อนสภาพแวดล้อมจริง
- รันลำดับธุรกรรมเชิงเวลา: รัน multi‑transaction sequences รวมถึง inter‑contract calls, flash loans และการจัดเรียงธุรกรรมใน mempool เพื่อเลียนแบบการโจมตีแบบจริง
- ตรวจจับและวิเคราะห์: ตรวจสอบการละเมิด invariants เช่น totalSupply, balance consistency, หรือการ transfer ที่ล้มเหลวจาก unchecked-send
- ลดขนาดและรายงาน: ทำการ minimize ลำดับที่ก่อให้เกิดปัญหาเพื่อให้ reproducible และสร้างรายงานพร้อม PoC ให้ทีมพัฒนาปรับแก้
เทคนิคการสร้าง test cases ที่สำคัญมีดังนี้:
- Mutation (Fuzzing แบบเปลี่ยนค่า): เปลี่ยนพารามิเตอร์เช่น amounts (0, 1, max uint256-1), addresses (contract vs EOA), token approvals และค่าพิเศษ เช่น gasStipend หรือ calldata ขนาดใหญ่ เทคนิคนี้สามารถค้นหาข้อบกพร่องเช่น unchecked-send หรือการจัดการค่าศูนย์/ขอบเขตที่ผิดพลาด
- Property‑based testing: กำหนดสมบัติที่ต้องเป็นจริง เช่น ยอดรวมของ token ต้องคงที่หลังการโอน (เว้นการ mint/burn) หรือไม่ควรมีการลดลงของทุนของผู้ฝากโดยไม่บันทึกเหตุผล จากนั้นสร้างชุดข้อมูลแบบสุ่มเพื่อลองล้มสมมติฐานเหล่านี้—เหมาะสำหรับค้นหา integer overflow/underflow หรือ invariant violations
- Guided search (search‑based/test prioritization): ใช้ feedback จากการรันก่อนหน้าเพื่อชี้นำการสร้างเคสถัดไป เช่น coverage‑guided fuzzing, symbolic execution หรือ reinforcement learning ที่มุ่งหาเส้นทางการรันที่เข้าถึงบล็อกโค้ดสำคัญ เทคนิคนี้เพิ่มประสิทธิภาพการค้นหาลำดับธุรกรรมที่ซับซ้อนและหา exploit chain ได้เร็วขึ้น
การจำลองสถานการณ์เชิงเวลาจริง เป็นหัวใจของการโจมตีจำลองที่มีประสิทธิภาพ เนื่องจากช่องโหว่หลายอย่างเกิดขึ้นจากการเปลี่ยนสถานะทีละขั้นตอนหรือจากปฏิสัมพันธ์ระหว่างคอนแทรกต์หลายตัว ระบบต้องสามารถรัน:
- Multi‑transaction sequences: ลำดับธุรกรรมหลายรายการที่ทำให้สถานะค่อยๆ เปลี่ยน เช่น deposit → sync oracle → withdraw ซึ่งหลาย exploit ต้องการการเตรียมสถานะข้ามธุรกรรม
- Inter‑contract calls และ callbacks: เลียนแบบการเรียกกลับ (callbacks) ระหว่างคอนแทรกต์ รวมถึงสตับบ์/ม็อกของ external contracts เพื่อทดสอบ reentrancy หรือ unexpected state changes
- Flash‑loan scenarios: สร้าง/คืน flash loan ในลำดับเดียวกันเพื่อลองทำ price manipulation, oracle abuse หรือ liquidation attack ที่ต้องใช้ความสามารถในการยืมเงินจำนวนมากภายใน transaction เดียว
- Mempool ordering & MEV effects: จำลองการจัดเรียงธุรกรรม, front‑run/back‑run และ gas price war เพื่อดูว่า ordering สามารถนำไปสู่ exploitation ได้หรือไม่
การทดสอบขอบเขตของ gas/nonce มีบทบาทสำคัญเพราะข้อผิดพลาดมักเกิดเมื่อ transaction ล้มกลางทาง เช่น การใช้ gas ไม่เพียงพอทำให้ state ถูกเปลี่ยนส่วนหนึ่งแต่คอนแทรกต์อื่นคาดหวังการกระทำครบชุด เครื่องมือจำลองจะสุ่มค่า gasLimit, gasPrice, และ nonce sequencing เพื่อค้นหากรณีเช่น:
- transaction กลางลำดับถูก revert แต่ขั้นตอนก่อนหน้าถูก commit ทำให้เกิด inconsistent state
- nonce ที่ซ้อนกันหรือการส่งพร้อมกันจากหลายที่ทำให้ tx ถูกกดทับหรือไม่สามารถรันได้
- การใช้ gas stipend ในการส่ง ETH ด้วย call ที่ทำให้ fallback function ถูกเรียกซ้ำจนเกินขอบเขต
ตัวอย่างโจมตีที่ระบบสามารถสร้างและตรวจจับได้จริง (ตัวอย่างเชิงปฏิบัติการ):
- Reentrancy (ตัวอย่างลำดับ):
- 1) ผู้โจมตี deploy contract ที่มี fallback function จะเรียกกลับ
- 2) เรียก vulnerableContract.withdraw(amount) ซึ่งส่ง Ether ก่อนอัปเดตยอดคงเหลือ
- 3) fallback ของผู้โจมตีเรียก withdraw ซ้ำในขณะที่ยอดใน vulnerableContract ยังไม่ถูกรายงานใหม่
- ผล: ดำเนินการซ้ำจนถอนทุนทั้งหมด ระบบจำลองจะตรวจจับการลดลงอย่างผิดปกติของ balance และรายงาน PoC
- Unchecked‑send / Failure to check return value:
- Tool จะสร้างเคสที่ส่ง ETH ไปยัง contract ที่อาจ revert ใน fallback แต่ตัวต้นทางไม่ได้เช็กผลลัพธ์ของ call/transfer ทำให้ยอดเงินอาจสูญหรือถูกล็อก
- Integer overflow/underflow:
- โดยการใช้ค่า extremes เช่น max uint256 หรือการคำนวณที่ผสมกับภาษี/fee ระบบจะสร้างสถานะที่ทำให้ overflow เกิดขึ้น (เช่น mint/burn ผิดพลาด) ซึ่ง property‑based tests จะจับ inconsistency ของ totalSupply หรือ balance
- Flash‑loan + Oracle manipulation:
- Simulator จะสร้างลำดับ: ยืม flash loan → ซื้อ/ขายใน AMM ปรับราคาที่ oracle อ้างอิง → กระทำ liquidation/borrow exploit → คืน flash loan ภายในสมุดเดียว ผลคือทำกำไรจากความผิดพลาดของ oracle หรือการคำนวณราคา
- Gas/Nonce edge case:
- กรณีทดสอบที่ส่ง transaction ด้วย gas ต่ำจนทำให้ call กลับล้ม แต่ state อื่นๆ ไม่สอดคล้อง ทำให้เกิด locked funds หรือ partial execution ซึ่งระบบจะบันทึกการเปลี่ยนสถานะที่ผิดปกติ
สรุปแล้ว การโจมตีจำลองโดยเครื่องมือ Generative‑AI รวมการสร้างเคสด้วย mutation, property‑based และ guided search เข้ากับการจำลองสภาพแวดล้อมเชิงเวลา เช่น multi‑tx, inter‑contract calls และ flash‑loan scenarios พร้อมการทดสอบขอบเขตของ gas/nonce ผลลัพธ์ที่ได้คือการค้นพบช่องโหว่เช่น reentrancy, unchecked‑send, integer overflow/underflow และ exploit chain ที่ซับซ้อน ซึ่งหากนำมาใช้เชิงรุกก่อนขึ้นโปรดักชันจะช่วยลดความเสี่ยงทางการเงินและเชิงธุรกิจอย่างมีนัยสำคัญ
4. กรณีศึกษา: ผลลัพธ์เชิงปฏิบัติและตัวเลขสมมติ
4. กรณีศึกษา: ผลลัพธ์เชิงปฏิบัติและตัวเลขสมมติ
ในกรณีศึกษาจำลองนี้ ทีมสตาร์ทอัพได้นำเครื่องมือ Generative‑AI สำหรับทดสอบ Smart Contracts ไปใช้งานกับชุดสัญญา ERC‑20 ของโปรเจกต์ DeFi ขนาดกลาง (มีสภาพคล่องรวมประมาณ $1.2M) ผลลัพธ์เป็นไปในเชิงปฏิบัติที่สามารถวัดได้ทั้งด้านเทคนิคและเชิงธุรกิจ โดยตัวเลขทั้งหมดเป็นตัวอย่างสมมติที่อิงตามการทดลองภายใน (proof‑of‑concept) เพื่อแสดงศักยภาพของระบบในการค้นหาและยืนยันช่องโหว่แบบอัตโนมัติ
ตัวอย่างการค้นพบช่องโหว่ประเภท reentrancy ในสัญญา ERC‑20: เครื่องมือใช้การผสมผสานระหว่าง symbolic execution และ generative exploit synthesis เพื่อสร้างสคริปต์โจมตีอัตโนมัติ พบจุดที่เกิดลำดับการเรียกกลับ (external call) ก่อนการอัปเดตสถานะ (state update) ในฟังก์ชัน transfer/transferFrom เมื่อระบบตรวจพบความเป็นไปได้ของ reentrancy เครื่องมือจะทำการสร้างคอนทรแร็กต์โจมตีจำลอง (attacker contract) และรันการโจมตีภายใน sandbox ที่เป็น EVM forked snapshot เพื่อยืนยันว่าโจมตีสำเร็จจริงหรือไม่
กระบวนการ validate exploit ภายใน sandbox ประกอบด้วยขั้นตอนย่อยดังนี้ (ตัวอย่างไทม์ไลน์การค้นพบและการแก้ไข):
- T+00:00 — การสแกนเริ่มต้น: เครื่องมือรัน static analysis + symbolic pass; ใช้เวลาเฉลี่ย 5–15 นาทีต่อสัญญาเพื่อระบุจุดเสี่ยง
- T+00:14 — การสังเกตลักษณะ reentrancy: พบ pattern ที่เป็นไปได้ของ reentrancy ในฟังก์ชัน transfer; ระบบสร้าง payload เพื่อทดสอบ
- T+00:20 — การจำลองและยืนยันใน sandbox: สร้าง attacker contract และรันบน EVM snapshot (forked) เพื่อตรวจสอบการเปลี่ยนแปลงยอดคงเหลือและเรียก trace call stack; หาก exploit ผ่านการยืนยัน ระบบจะเก็บหลักฐาน transaction trace และรายงานเชิงเทคนิค
- T+01:30 — การแก้ไขเบื้องต้น: นักพัฒนาทำการแก้ไข (เช่นเพิ่ม reentrancy guard / ใช้ checks‑effects‑interactions pattern) และส่งโค้ดกลับไปให้เครื่องมือทดสอบซ้ำ
- T+02:00 — การยืนยันหลังแก้ไข: รัน suite การทดสอบอัตโนมัติซ้ำผลที่แสดงว่า exploit ไม่สามารถทำงานได้อีกต่อไป
เมตริกสมมติที่ได้จากการทดลอง (ตัวอย่างเชิงการศึกษา):
- เวลาเฉลี่ยในการค้นพบช่องโหว่ (จากเริ่มสแกนถึงยืนยัน exploit): median = 14 นาที (สำหรับช่องโหว่ประเภท reentrancy ที่มีสัญลักษณ์ชัดเจน)
- ลดเวลา audit: ก่อนใช้เครื่องมือ ทีม audit ต้องใช้เวลาเฉลี่ย 72 ชั่วโมง (รวม manual review และการเขียน PoC) หลังใช้เครื่องมือลดเหลือเฉลี่ย 4 ชั่วโมง (รวมการตรวจสอบผลที่เครื่องมือรายงานและการแก้ไขเบื้องต้น) — ลดเวลาเฉลี่ยประมาณ 94%
- branch coverage (ตัวอย่าง): ก่อนการใช้เครื่องมือ coverage อยู่ที่ 27% หลังรันกลยุทธ์ generative tests เพิ่มเป็น 82% — เพิ่มขึ้น 55 percentage points
- อัตราการตรวจจับ (detection rate) สำหรับ vulnerability classes ที่เครื่องมือเทรนมา: ประมาณ 94% (reentrancy, unchecked-send, authorization bypass ในชุดทดสอบสมมติ)
- false positive rate: อยู่ที่ประมาณ 7% — ทีมพัฒนาต้องตรวจสอบประมาณ 1 ใน 14 รายการเพื่อยืนยันว่าเป็น false alert
- มูลค่าที่ช่วยป้องกันได้ (สมมติ): ในเคสนี้เครื่องมือยืนยัน reentrancy ที่สามารถดึงเงินได้สูงสุด ~$1.2M การแพตช์ก่อนขึ้นโปรดักชันช่วยลดความเสี่ยงมูลค่าที่อาจสูญเสียเหลือ ~$80k (โอกาสโจมตีที่เหลือ/edge cases) = การลดความเสี่ยงเชิงมูลค่าประมาณ 93%
การเปรียบเทียบเชิงธุรกิจก่อน/หลังนำเครื่องมือไปใช้ (สรุป):
- ความเร็วในการส่งโปรดักชัน: รอบการตรวจสอบสั้นลงจากหลายวันเป็นไม่กี่ชั่วโมง ทำให้ time‑to‑market เร็วขึ้นและลด backlog ของ releases
- ต้นทุนการตรวจสอบและประกันภัย: ลดชั่วโมงมนุษย์สำหรับการเขียน PoC และ manual audit ส่งผลให้ค่าใช้จ่ายด้าน audit ลดลงโดยตรง (ตัวอย่างสมมติ: ลดค่า audit ต่อ release ประมาณ 60%)
- ความเสี่ยงทางการเงิน: การป้องกันช่องโหว่ที่อาจนำไปสู่การสูญเสีย $1.2M ช่วยป้องกันความเสียหายทางการเงินและ reputational loss โดยตรง — ในตัวอย่างนี้มูลค่าที่ป้องกันได้มีค่าเทียบเท่ากับการลด exposure ทางการเงินมากกว่า 90%
บทสรุป: กรณีศึกษานี้แสดงให้เห็นว่าเมื่อรวม Generative‑AI กับ sandboxed exploit validation จะได้ทั้งความรวดเร็ว ความแม่นยำ และหลักฐานเชิงปฏิบัติที่เพียงพอสำหรับทีมธุรกิจและทีมความปลอดภัยเพื่อตัดสินใจได้เร็วขึ้น ตัวเลขสมมติข้างต้นชี้ว่าเครื่องมือดังกล่าวสามารถเปลี่ยนกระบวนการ audit จากงานที่ใช้เวลานานและมีความเสี่ยงสูง เป็นกระบวนการอัตโนมัติที่ให้ coverage สูงและลดความเสี่ยงเชิงมูลค่าได้อย่างมีนัยสำคัญ
5. ความเสี่ยงด้านกฎหมาย จริยธรรม และข้อจำกัดของเทคโนโลยี
5. ความเสี่ยงด้านกฎหมาย จริยธรรม และข้อจำกัดของเทคโนโลยี
การนำเครื่องมือ Generative‑AI มาใช้ในการทดสอบหรือสร้างโจมตีจำลองสำหรับ Smart Contracts มีลักษณะ dual‑use ชัดเจน — หมายความว่าเครื่องมือเดียวกันสามารถถูกใช้ประโยชน์เพื่อปรับปรุงความปลอดภัย หรือถูกใช้โดยผู้ไม่หวังดีเพื่อค้นหาและนำช่องโหว่ไปใช้โจมตีจริงได้ ในเชิงธุรกิจ นี่เป็นความเสี่ยงทั้งด้านชื่อเสียงและความรับผิดทางกฎหมาย ดังนั้นการออกแบบมาตรการควบคุมการเข้าถึง (access control) และรูปแบบการอนุญาตใช้งาน (licensing) จึงมีความสำคัญ ตัวอย่างแนวทางที่ธุรกิจและสตาร์ทอัพควรพิจารณา ได้แก่ การกำหนดสิทธิ์เป็นชั้น (role‑based access), การทำ KYC/KYB กับผู้สมัครใช้งาน, การจำกัดฟีเจอร์ขั้นสูงให้เฉพาะพันธมิตรที่ผ่านการตรวจสอบแล้ว, การเก็บล็อกกิจกรรม (audit logs) และระบบ rate‑limiting เพื่อลดโอกาสการสแกนแบบอัตโนมัติในวงกว้าง
ด้านกฎหมาย การรันโจมตีจำลองหรือการเผยแพร่ข้อมูลช่องโหว่อาจเข้าข่ายความผิดตามกฎหมายคอมพิวเตอร์และอาชญากรรมไซเบอร์ในหลายเขตอำนาจ เช่น การเข้าถึงระบบโดยไม่ได้รับอนุญาต การกระทำที่ก่อให้เกิดความเสียหายต่อทรัพย์สินดิจิทัล และการช่วยเหลือในการก่ออาชญากรรม ทางปฏิบัติ สตาร์ทอัพควรมีนโยบาย responsible disclosure ที่ชัดเจนและกระบวนการจัดการการเปิดเผยช่องโหว่อย่างเป็นระบบ (coordinated disclosure) — ระบุช่องทางการรายงาน ระยะเวลาในการแจ้งเตือนเจ้าของสัญญา สถานะการสื่อสาร และเงื่อนไขการเปิดเผยสู่สาธารณะ ตัวอย่างการปฏิบัติที่แพร่หลายคือการให้ระยะเวลาตั้งแต่ 30–90 วันสำหรับผู้พัฒนาหรือโปรเจกต์ในการแก้ไขก่อนการเปิดเผยสู่สาธารณะ พร้อมข้อยกเว้นหากช่องโหว่ถูกใช้โจมตีจริงในระหว่างนั้น
ทางเทคนิค เครื่องมือที่อาศัย LLM และเทคนิค generative อื่น ๆ มีข้อจำกัดสำคัญที่ต้องคำนึงถึง โดยเฉพาะ false positives และ false negatives — รายงานจากวงการการวิเคราะห์ซอฟต์แวร์ชี้ว่าอัตรา false positive ในเครื่องมือตรวจจับช่องโหว่อัตโนมัติอาจอยู่ในช่วงกว้าง (เช่นประมาณ 10–40% ขึ้นอยู่กับเทคนิคและโดเมน) ซึ่งหมายความว่าทีมความปลอดภัยอาจต้องใช้ทรัพยากรมากในการตรวจสอบผลลัพธ์ที่ไม่ถูกต้อง ในทางกลับกัน false negatives (การไม่ตรวจจับช่องโหว่ที่สำคัญ) อาจนำไปสู่เหตุการณ์สูญเสียทรัพย์สินได้จริง — ในโลกของ DeFi เหตุการณ์แฮ็กทำให้มีมูลค่าความเสียหายรวมเป็นพันล้านดอลลาร์ในช่วงหลายปีที่ผ่านมา ซึ่งชี้ให้เห็นว่าการพึ่งพาเครื่องมืออัตโนมัติเพียงอย่างเดียวมีความเสี่ยงสูง
นอกจากนี้ LLM มีพฤติกรรม hallucination — สร้างคำตอบที่ฟังดูน่าเชื่อถือ แต่ผิดพลาดหรือไม่มีหลักฐานรองรับ เมื่อสั่งให้โมเดล "สร้าง exploit" สำหรับ smart contract ความเป็นไปได้ที่โมเดลจะเสนอขั้นตอนที่ไม่ถูกต้อง หรือสมมติสภาพแวดล้อมบนบล็อกเชนที่ไม่มีอยู่จริง สูงมาก อีกประเด็นที่ต้องระวังคือความเข้าใจจำกัดของโมเดลต่อระดับต่ำ เช่น EVM bytecode, ความแตกต่างของตัวคอมไพเลอร์และ optimizer (เช่น Solidity compiler versions และ optimizer settings) ซึ่งสามารถเปลี่ยนรูปแบบ bytecode และพฤติกรรมการทำงานของสัญญาได้อย่างมีนัยสำคัญ ส่งผลให้เครื่องมือที่วิเคราะห์เฉพาะบน AST หรือ source code อาจพลาดปัญหาเมื่อนำไปใช้งานกับ bytecode ในเครือข่ายจริง
แนวทางลดความเสี่ยงที่ควรนำมาปฏิบัติได้แก่:
- การผสมผสานวิธีการวิเคราะห์ — รวม static analysis, symbolic execution, fuzzing และ on‑chain emulation เพื่อชดเชยจุดอ่อนของแต่ละเทคนิค
- มนุษย์เป็นผู้ตัดสินขั้นสุดท้าย — ใช้คนเชี่ยวชาญทบทวนผลลัพธ์จาก AI ก่อนเผยแพร่หรือดำเนินการเชิงปฏิบัติการ
- นโยบายการเข้าถึงและสัญญาทางกฎหมาย — ข้อตกลง safe‑harbor, NDA, และเงื่อนไขการให้บริการที่ชัดเจนเพื่อปกป้องทั้งผู้พัฒนาและเจ้าของสัญญา
- ระบบ responsible/coordinated disclosure — กำหนดช่องทาง รายละเอียดการตอบสนอง และกรอบเวลาที่โปร่งใส รวมถึงการร่วมมือกับโปรเจกต์ DeFi และทีมรักษาความปลอดภัย
- การติดตามและบันทึกเชิงลึก — เก็บ audit trails, telemetry และการแจ้งเตือนที่สามารถใช้สืบสวนกรณีการใช้งานที่เป็นภัย
- จำกัดฟีเจอร์ที่เพิ่มความเสี่ยง — เช่น ปิดฟังก์ชันการสร้าง exploit อัตโนมัติสำหรับผู้ใช้ทั่วไป ให้เฉพาะผู้ผ่านการตรวจสอบเท่านั้น
โดยสรุป แม้เครื่องมือ Generative‑AI สำหรับทดสอบ Smart Contracts จะเป็นประโยชน์และมีศักยภาพในการลดความเสี่ยงของระบบ DeFi แต่สตาร์ทอัพและองค์กรต้องรับมือกับความเสี่ยงด้านจริยธรรมและกฎหมายอย่างจริงจัง ผ่านการออกแบบนโยบายการเข้าถึง การจัดทำนโยบายการเปิดเผยช่องโหว่อย่างรับผิดชอบ และการยืนยันผลลัพธ์ด้วยวิธีการทางเทคนิคและการตรวจสอบจากมนุษย์ เพื่อให้การนำเทคโนโลยีไปใช้เป็นไปอย่างปลอดภัยและยั่งยืน
6. แนวทางการนำไปใช้จริงสำหรับทีม DeFi และแนวปฏิบัติที่แนะนำ
6. แนวทางการนำไปใช้จริงสำหรับทีม DeFi และแนวปฏิบัติที่แนะนำ
การผสานเครื่องมือ Generative‑AI เพื่อทดสอบ Smart Contracts เข้ากับกระบวนการพัฒนาเป็นเรื่องที่ต้องออกแบบอย่างรอบคอบเพื่อไม่ให้เกิดความล่าช้าต่อสายงาน (workflow) และเพื่อสร้างการป้องกันเชิงรุกที่มีประสิทธิภาพ สำหรับทีม DeFi ขอแนะนำแนวทางปฏิบัติแบบเป็นขั้นตอนดังนี้
การรวมเข้ากับ CI/CD — แยกงานตามความถี่และน้ำหนักของการทดสอบ: ในขั้นตอน pre‑merge (PR checks) ควรรันชุดตรวจสอบที่เบาและรวดเร็ว เช่น static analysis, symbolic execution แบบสแกนอย่างรวดเร็ว และ fuzz แบบจำกัดเวลา เพื่อให้ผู้พัฒนาทราบผลก่อน merge โดยตั้งเป็น non‑blocking สำหรับความเสี่ยงระดับต่ำหรือ medium แต่ต้องเป็น blocking สำหรับ high/critical findings โดย pipeline ควรปฏิเสธการ merge อัตโนมัติหากพบความเสี่ยงระดับร้ายแรง พร้อมส่ง ticket หรือแจ้งเตือนไปยังเจ้าของโค้ดทันที นอกเหนือจากนี้ ให้ตั้งงาน nightly jobs สำหรับ nightly fuzzing และการทดสอบเชิงลึกโดยใช้เวลารันนานกว่า (เช่น 4–24 ชั่วโมง) เพื่อค้นหาชุดเคสเชิงซับซ้อนและสร้าง corpus ของอินพุตที่มีค่าในการสืบสวนต่อไป
Sandbox และสภาพแวดล้อมทดสอบ — สร้าง sandbox แบบยืดหยุ่นและใกล้เคียงสภาวะจริงที่สุด: ใช้การ fork mainnet (เช่น Anvil/Ganache fork) ร่วมกับ state snapshots เพื่อรันการโจมตีจำลองโดยไม่กระทบโปรดักชัน ตั้งค่า ephemeral environments ใน CI เพื่อรันสคริปต์ PoC และ fuzz campaigns แบบแยกกัน พร้อมการเก็บล็อกและ trace ที่ละเอียด (transaction traces, revert reasons, stack traces) เพื่อให้ง่ายต่อการ reproduce และการส่งต่อให้ auditor หรือทีมตอบสนองเหตุการณ์
การทำงานร่วมกับ Audit Firms และ Bug Bounty — สร้างการป้องกันแบบหลายชั้น (defense‑in‑depth): ก่อนส่งให้ auditor ภายนอก ควรรันเครื่องมือ Generative‑AI เพื่อทำการ pre‑audit และจัดลำดับความสำคัญ findings ให้ผู้ตรวจสอบช่วยโฟกัสที่จุดที่มีความเสี่ยงจริงจัง ลดเวลาการตรวจสอบแบบแมนนวล บ่อยครั้งเครื่องมืออัตโนมัติจะค้นเจอข้อมูลเชิงเทคนิคที่ช่วยให้ auditor ทำงานได้เร็วขึ้น ในทางกลับกัน ให้เชื่อมต่อผลการทดสอบกับโปรแกรม bug bounty (เช่นผ่านแพลตฟอร์มเช่น Immunefi หรือ HackerOne) โดยส่งรายงานสรุปความเสี่ยงและ reproduction steps ให้ผู้ล่าข้อบกพร่องเพื่อร่วมกันลดความเสี่ยง ผลลัพธ์ที่ดีที่สุดคือการผนวกรายงานจาก AI, auditor และนักวิจัยภายนอกเป็น pipeline เดียวที่มีการจัดการ vulnerability lifecycle ตั้งแต่ detection → triage → fix → verify
การวัดผลและ ROI — นิยามตัวชี้วัดชัดเจนเพื่อประเมินประสิทธิภาพ: ควรกำหนดเป้าหมายเชิงตัวเลขสำหรับตัวชี้วัดหลัก ได้แก่ Mean Time to Detect (MTTD), Mean Time to Remediate (MTTR) และ Reduction in Critical Findings Post‑Deployment. ตัวอย่างแนวทางเป้าหมายสำหรับทีม DeFi ขนาดกลาง‑ใหญ่: MTTD < 24 ชั่วโมง (สำหรับ findings ที่ถูกแจ้งผ่าน CI/monitoring), MTTR < 72 ชั่วโมงสำหรับความเสี่ยงระดับ high, และลดสัดส่วน critical findings หลังขึ้นโปรดักชันลงอย่างน้อย 70–80% เมื่อเทียบกับ baseline ก่อนใช้เครื่องมือ การคำนวณ ROI ควรนำมาพิจารณาทั้งมูลค่าความเสี่ยงที่หลีกเลี่ยงได้ (expected loss avoided) เทียบกับค่าใช้จ่ายในการรันเครื่องมือ (license, compute) และค่าแรงคนทำงาน เช่น ROI = (expected_loss_avoided − cost_of_tooling) / cost_of_tooling โดยทีมควรเก็บข้อมูลเหตุการณ์จริงเช่นจำนวนการโจมตีที่หลุดรอดและค่าใช้จ่ายการแก้ไขเพื่อหาค่า baseline ที่น่าเชื่อถือ
กลยุทธ์การจัดการ False Positives — ลด noise และเพิ่มความแม่นยำในกระบวนการ triage: เริ่มจากตั้งระดับความน่าเชื่อถือ (confidence score) ในผลลัพธ์ของ AI และผนวกกับกฎการกรองเบื้องต้น เช่น whitelist patterns ที่เป็น known safe, deduplication ของ findings ที่ซ้ำซ้อน, และการจัดกลุ่มแบบอัตโนมัติตาม transaction trace similarity การมี human‑in‑the‑loop สำหรับการยืนยัน high/critical findings จะช่วยลด false positive ที่อาจบล็อกการ deploy โดยควรสร้าง workflow ให้ developer สามารถปฏิเสธผลที่เป็น false positive ได้พร้อมเหตุผลและ reference เพื่อเป็นข้อมูลย้อนกลับ (feedback loop) ให้โมเดลปรับปรุงต่อไป
นโยบายการบล็อกและการยกเว้น — นิยาม severity taxonomy และการอนุมัติการยกเว้น: กำหนดให้ผลการทดสอบที่มี severity ระดับ high/critical เป็น blocking ใน CI และต้องมี ticket ติดตามก่อนอนุญาตให้ merge โดยหากทีมจำเป็นต้องยกเว้นชั่วคราว ให้มีกระบวนการอนุมัติอย่างเป็นทางการ (expiring waiver) พร้อมกำหนด mitigation plan และ timeline ในการแก้ไข เพื่อป้องกันการยอมให้ความเสี่ยงคงอยู่ในโปรดักชันโดยไม่จำเป็น
สรุป: การนำ Generative‑AI สำหรับทดสอบ Smart Contracts มาใช้จริงต้องเป็นส่วนหนึ่งของ ecosystem การพัฒนา ตั้งแต่ pre‑merge checks, nightly fuzzing, sandboxed reproduction, การทำงานร่วมกับ auditors และ bug bounty รวมถึงการวัดผลด้วย MTTD, MTTR และการลด critical findings การออกแบบ pipeline ที่ชัดเจน การจัดการ false positives และการกำหนดนโยบายบล็อก/ยกเว้น จะทำให้ทีม DeFi ได้การป้องกันที่รัดกุมและมีประสิทธิภาพ พร้อมลดความเสี่ยงทางการเงินและความเสียหายต่อชื่อเสียงของโปรโตคอล
7. แนวโน้มอนาคตและข้อสรุปเชิงนโยบาย
7. แนวโน้มอนาคตและข้อสรุปเชิงนโยบาย
ทิศทางเทคโนโลยีสำหรับการทดสอบสมาร์ทคอนแทรกต์ด้วยเครื่องมือ Generative‑AI มีแนวโน้มชัดเจนไปสู่การพัฒนาโมเดลที่เป็น domain‑specific มากขึ้น — กล่าวคือ LLMs ที่ถูกฝึกด้วยข้อมูลโค้ดบล็อกเชน, bytecode, ABI, และตัวอย่างการโจมตีจริง เพื่อให้เข้าใจบริบทการทำงานของ smart contract ในระดับลึกขึ้น รวมทั้งการเชื่อมต่อแบบเรียลไทม์กับเทคนิคเชิงสัญลักษณ์ (symbolic execution), fuzzing, และ SMT‑based solvers ที่ใช้ใน formal verification แนวผสานนี้จะช่วยให้ระบบสามารถสร้างโจมตีจำลองที่สมเหตุสมผลและตรวจจับช่องโหว่ที่ซับซ้อนได้มากกว่าเครื่องมือเดิม ๆ ที่พึ่งพา pattern‑matching เพียงอย่างเดียว
ในด้านการประยุกต์ใช้งาน เราคาดว่าจะเห็นการนำโมเดลเฉพาะโดเมนมาใช้เป็นส่วนหนึ่งของ pipeline การพัฒนา — ตั้งแต่การเขียน unit tests อัตโนมัติ การแนะนำการแก้ไขโค้ดแบบอัตโนมัติ ไปจนถึงการสร้าง red‑team simulations ก่อนปล่อยโปรดักชัน ตัวอย่างจากเหตุการณ์ความเสี่ยงในอดีต (เช่น การโจมตีสะพานข้ามเชนและการแฮ็ก smart contract ระดับองค์กร) แสดงให้เห็นว่าความเสียหายมักมีมูลค่าระดับหลายสิบจนถึงหลายร้อยล้านดอลลาร์ ซึ่งตอกย้ำความจำเป็นที่องค์กรจะต้องปรับใช้การทดสอบเชิงรุกและการยืนยันความถูกต้องเชิงรูปธรรม (formal proofs) ร่วมกับ AI เพื่อยกระดับความน่าเชื่อถือ
ความจำเป็นในการออกมาตรฐานและแนวปฏิบัติระดับอุตสาหกรรมจึงมีความสำคัญยิ่ง สถาบันมาตรฐานและหน่วยงานกำกับดูแลควรร่วมมือกับภาคอุตสาหกรรมเพื่อกำหนดกรอบการทดสอบเชิงรุกที่ชัดเจน เช่น ขอบเขตการทดสอบ red‑team ที่ยอมรับได้, ระดับความครอบคลุมของการพิสูจน์เชิงรูปธรรม, มาตรการ responsible disclosure สำหรับผลการสแกนและการโจมตีจำลอง รวมถึงหลักเกณฑ์ด้านการจัดการความเสี่ยงหลังการค้นพบช่องโหว่ กรอบมาตรฐานเหล่านี้จะช่วยลดความไม่แน่นอนทางกฎหมายและสร้างความเชื่อมั่นให้ทั้งผู้พัฒนา ผู้ลงทุน และผู้ใช้
สำหรับนโยบายเชิงปฏิบัติ ผู้กำกับดูแลควรพิจารณานโยบายที่สร้างสมดุลระหว่างการส่งเสริมนวัตกรรมกับการปกป้องผู้ใช้ ข้อเสนอเชิงนโยบายที่ควรพิจารณา ได้แก่
- กำหนดมาตรฐานการทดสอบก่อนขึ้นโปรดักชัน — ระบุขั้นต่ำของการทดสอบเชิงรุก เช่น การรัน red‑team simulations, fuzz testing และการใช้ formal verification ในระดับที่เหมาะสมกับความเสี่ยงของโปรดักชัน
- นโยบาย disclosure ที่เป็นมาตรฐาน — กำหนดกรอบเวลาและขั้นตอนสำหรับการเปิดเผยผลการทดสอบช่องโหว่และการแจ้งเตือนผู้มีส่วนได้เสีย รวมถึงการปกป้องนักวิจัยผู้รายงานช่องโหว่อย่างมีความรับผิดชอบ
- การรับรองและการให้แรงจูงใจ — ส่งเสริมการใช้การรับรองความปลอดภัยของ smart contract ผ่านมาตรฐานอุตสาหกรรม เพิ่มแรงจูงใจทางการเงินหรือภาษีสำหรับองค์กรที่ผ่านการตรวจสอบชั้นสูง และส่งเสริมโปรแกรม bug‑bounty ที่มีการกำกับดูแล
- การจัดทำกรอบกฎหมายและความรับผิดชอบ — กำหนดความรับผิดชอบทางกฎหมายสำหรับการปล่อยโปรดักชันที่ไม่ได้ผ่านการทดสอบขั้นต่ำ และกำหนดข้อบังคับการรายงานเหตุการณ์ด้านความปลอดภัย
- ความร่วมมือสาธารณะแบบสถาบัน — จัดตั้งแพลตฟอร์มแลกเปลี่ยนข้อมูลภัยคุกคามและแนวทางปฏิบัติที่ดีที่สุดระหว่างหน่วยงานรัฐ ผู้ให้บริการบล็อกเชน และชุมชนความปลอดภัย
สำหรับผู้บริหารระดับสูง คำแนะนำเชิงปฏิบัติประกอบด้วย: ลงทุนในเครื่องมือเชิงรุก ที่รวม AI‑driven fuzzing, domain‑specific LLMs และ integration กับ formal verification; จัดทำนโยบาย disclosure ภายในและภายนอก ที่ชัดเจนเพื่อจัดการความเสี่ยงด้านภาพลักษณ์และกฎหมาย; และ ส่งเสริมการฝึกอบรม ให้ทีมพัฒนาและทีมความปลอดภัยมีทักษะด้านการทดสอบเชิงรุก การอ่านผลการพิสูจน์เชิงรูปธรรม และการตอบสนองต่อเหตุการณ์ โดยควรทดสอบความพร้อมเป็นประจำผ่าน tabletop exercises และการจำลองเหตุการณ์จริง
สรุปแล้ว การผสานเทคโนโลยี Generative‑AI กับ formal methods จะกลายเป็นแนวทางหลักในการยกระดับความปลอดภัยของระบบ DeFi และสมาร์ทคอนแทรกต์ แต่เพื่อให้เกิดผลจริงเชิงระบบ จำเป็นต้องมีมาตรฐานอุตสาหกรรม กรอบการเปิดเผยข้อมูลที่ชัดเจน และการลงทุนเชิงกลยุทธ์จากทั้งภาคเอกชนและภาครัฐ เพื่อให้เกิดสมดุลระหว่างนวัตกรรมและการคุ้มครองผู้ใช้ในระยะยาว
บทสรุป
เครื่องมือ Generative‑AI สำหรับการทดสอบ Smart Contracts สามารถยกระดับการป้องกันเชิงรุกในระบบ DeFi โดยสร้างการโจมตีจำลองเพื่อค้นหาช่องโหว่ก่อนขึ้นโปรดักชัน ผลลัพธ์จากการใช้งานเบื้องต้นชี้ว่าเครื่องมืออัตโนมัติช่วยลดระยะเวลาในการตรวจสอบและต้นทุนได้อย่างมีนัยสำคัญ — ผู้พัฒนาและรายงานภาคสนามบางส่วนระบุการลดเวลาในการตรวจสอบได้ถึง 50–70% และการลดต้นทุนการตรวจสอบในบางเคสมากกว่าครึ่งหนึ่ง อย่างไรก็ตาม เทคโนโลยีนี้มีความเสี่ยงเชิงจริยธรรมและความเสี่ยงจากการใช้งานผิดวัตถุประสงค์ (dual‑use) หากไม่มีมาตรการควบคุม เช่น การเข้าถึงที่จำกัด การตรวจสอบผลลัพธ์โดยมนุษย์ และการป้องกันการสร้าง payloads ที่เป็นอันตราย)
การผนวกเครื่องมือ Generative‑AI เข้ากับกระบวนการ DevSecOps, การตรวจสอบ (audit) แบบมืออาชีพ และโปรแกรม bug bounty จะให้ประสิทธิผลสูงสุด โดยการรวมการทดสอบอัตโนมัติกับการตรวจสอบเชิงรูปธรรม (formal verification) และการทดสอบโดยคนจริงจะช่วยลด false positive/negative และเพิ่มความเชื่อมั่นก่อนปล่อยสู่สภาพแวดล้อมจริง องค์ประกอบสำคัญต่ออนาคตคือการพัฒนามาตรฐาน กรอบแนวทางการใช้งานที่รับผิดชอบ (responsible disclosure, rate‑limited model access, ethical use policies) และการร่วมมือระหว่างสตาร์ทอัพ ผู้ให้บริการ audit ตลาดทุน และชุมชน security เพื่อสร้างแนวปฏิบัติร่วมและการกำกับดูแลที่เหมาะสม ในภาพรวม เทคโนโลยีนี้มีศักยภาพจะ “shift left” งานความปลอดภัยในวงการบล็อกเชน แต่ความสำเร็จในระยะยาวขึ้นกับการออกแบบมาตรการคุ้มครองและมาตรฐานอุตสาหกรรมที่เข้มแข็ง



