
สตาร์ทอัพไทยเปิดตัว SignTranslate‑OnDevice โมเดลมัลติโมดัลที่สามารถรันบนสมาร์ทโฟนได้ทันที โดยแปลงภาษามือเป็นข้อความและเสียงแบบเรียลไทม์ ความสามารถเด่นของเทคโนโลยีนี้คือการประมวลผลบนอุปกรณ์ (on‑device) ทำให้ลดการส่งข้อมูลไปยังคลาวด์ ลดแบนด์วิดท์และความล่าช้าได้ถึง 90% ผู้ใช้ที่มีความบกพร่องทางการได้ยินสามารถสื่อสารกับบุคคลทั่วไปในสถานการณ์ต่าง ๆ ตั้งแต่การพบแพทย์ การเรียนการสอน ไปจนถึงการใช้บริการสาธารณะได้อย่างราบรื่นและเป็นส่วนตัวยิ่งขึ้น
นอกจากการลดความหน่วงเวลาแล้ว SignTranslate‑OnDevice ยังออกแบบมาให้รองรับหลายรูปแบบสัญญาณ (มัลติโมดัล) เช่น การจับท่าทางมือ การเคลื่อนไหวของร่างกาย และบริบทของบทสนทนา ทำให้การแปลงเป็นข้อความและเสียงมีความแม่นยำและเป็นธรรมชาติมากขึ้น ตัวอย่างการใช้งานจริงที่สตาร์ทอัพระบุได้แก่ ห้องเรียนออนไลน์ที่นักเรียนภาษามือได้รับคำบรรยายทันที แอปพลิเคชันติดต่อแพทย์ที่ให้คำแนะนำเป็นเสียง และการช่วยเหลือในพื้นที่ที่มีอินเทอร์เน็ตจำกัด — โดยคุณสมบัติรันบนเครื่องยังช่วยเพิ่มความเป็นส่วนตัวและความปลอดภัยของข้อมูลส่วนบุคคลอีกด้วย
สรุปข่าวและความสำคัญเชิงสังคม
สรุปข่าวและความสำคัญเชิงสังคม
สตาร์ทอัพไทยผู้พัฒนา เปิดตัวผลิตภัณฑ์ใหม่ชื่อ SignTranslate‑OnDevice ซึ่งเป็นโมเดลมัลติโมดัลที่รันบนมือถือและออกแบบมาเพื่อแปลงภาษามือเป็นข้อความและเสียงแบบเรียลไทม์ โดยระบบสามารถตรวจจับท่าทางภาษามือจากวิดีโอสตรีมบนอุปกรณ์และสร้างผลลัพธ์ทั้งในรูปแบบข้อความสำหรับการอ่านและไฟล์เสียงสำหรับการสื่อสารด้วยเสียงทันที การรันแบบ on-device ช่วยให้การประมวลผลไม่จำเป็นต้องส่งข้อมูลวิดีโอไปยังคลาวด์ ช่วยลดปริมาณข้อมูลที่ส่งผ่านเครือข่ายและลดความล่าช้าอย่างมีนัยสำคัญ

ผลการทดสอบเบื้องต้นที่บริษัทเปิดเผยระบุว่า SignTranslate‑OnDevice ลดการใช้แบนด์วิดท์และความล่าช้าได้ประมาณ 90% เมื่อเทียบกับระบบแปลภาษามือที่ต้องอาศัยการประมวลผลบนเซิร์ฟเวอร์ระยะไกล (cloud-based). ความหมายเชิงปฏิบัติคือการตอบสนองที่เร็วขึ้นจากระดับหลายร้อยมิลลิวินาทีให้เหลือเพียงไม่กี่สิบมิลลิวินาทีในหลายกรณี และแบนด์วิดท์ที่ต้องใช้ต่อผู้ใช้ลดลงอย่างมาก ทำให้สามารถใช้งานในพื้นที่ที่มีเครือข่ายจำกัดหรือแพ็กเกจอินเทอร์เน็ตจำกัดได้จริง
ความสำคัญเชิงสังคมของเทคโนโลยีนี้มีหลายมิติ: สำหรับผู้พิการการได้ยิน การแปลภาษามือเป็นข้อความและเสียงแบบเรียลไทม์หมายถึงการเพิ่มช่องทางการสื่อสารในสถานการณ์จริง เช่น การให้ข้อมูลในโรงพยาบาล บริการฉุกเฉิน การเรียนการสอนในห้องเรียน และการให้บริการสาธารณะอื่น ๆ ที่ต้องการการตอบสนองทันที โดยเฉพาะในบริบทที่การรอคำตอบจากล่ามมนุษย์อาจเสี่ยงต่อความปลอดภัยหรือลดประสิทธิภาพ นอกจากนี้การประมวลผลบนอุปกรณ์ยังเสริมความเป็นส่วนตัว (privacy) เพราะวิดีโอภาษามือไม่ถูกส่งออกนอกเครื่อง ช่วยลดความเสี่ยงด้านข้อมูลส่วนบุคคล
ในเชิงนโยบายและการออกแบบบริการสาธารณะ เทคโนโลยีเช่น SignTranslate‑OnDevice ช่วยลดต้นทุนด้านโครงสร้างพื้นฐานเครือข่ายและบริการคลาวด์สำหรับหน่วยงานรัฐและภาคเอกชน ตัวอย่างเช่น หากศูนย์บริการสาธารณะขยับมาใช้ระบบ on-device ในลักษณะนี้ จะลดภาระแบนด์วิดท์รวมของเครือข่ายและความจำเป็นในการจัดเตรียมล่ามหรือตัวกลางแปลแบบเรียลไทม์ ในภาพรวมเทคโนโลยีนี้จึงมีศักยภาพในการขยายการเข้าถึง (accessibility) ลดช่องว่างทางดิจิทัล และยกระดับการรวมกลุ่มทางสังคมของผู้พิการการได้ยินได้อย่างเป็นรูปธรรม
- การเข้าถึงทันที: รองรับสถานการณ์ฉุกเฉินและการบริการ ณ จุดเดียว (point-of-service) ที่ต้องการการตอบสนองเร็ว
- ความเป็นส่วนตัว: ข้อมูลวิดีโอประมวลผลบนเครื่อง ลดการส่งข้อมูลไปคลาวด์
- ความคุ้มค่า: ลดต้นทุนแบนด์วิดท์และความจำเป็นในการลงทุนเซิร์ฟเวอร์กลาง
- ความยืดหยุ่นเชิงนโยบาย: หน่วยงานสาธารณะและธุรกิจสามารถนำไปปรับใช้กับบริการต่าง ๆ ได้สะดวก
เทคโนโลยีเบื้องหลัง: โมเดลมัลติโมดัลและการประมวลผลบนเครื่อง
เทคโนโลยีเบื้องหลัง: โมเดลมัลติโมดัลและการประมวลผลบนเครื่องของ SignTranslate‑OnDevice
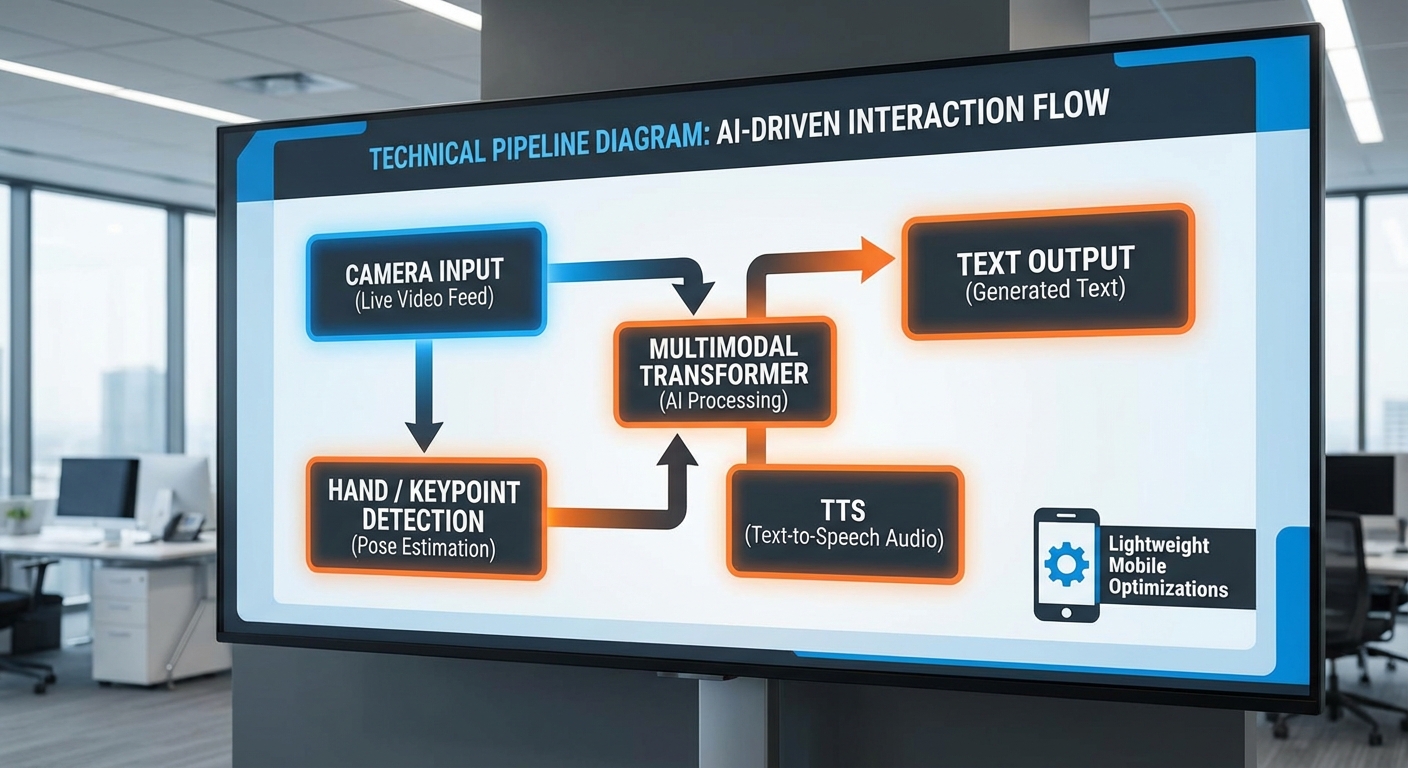
ภาพรวมสถาปัตยกรรมและ pipeline แบบ end‑to‑end
SignTranslate‑OnDevice ถูกออกแบบเป็นระบบแบบ pipeline ตามลำดับการทำงานชัดเจน: capture → vision → recognition → text → TTS โดยเน้นการประมวลผลทั้งหมดบนอุปกรณ์ (on‑device) เพื่อลดแบนด์วิดท์และความล่าช้า ตัวระบบประกอบด้วยโมดูลหลัก 3 ส่วน คือ โมดูลประมวลผลภาพ (visual front‑end), โมดูลการตีความมัลติโมดัล (recognition/fusion), และโมดูลภาษาพูด/เสียง (text normalization + TTS) แต่ละโมดูลถูกออกแบบให้เป็น lightweight และรองรับการเร่งฮาร์ดแวร์บนมือถือ
pipeline เชิงปฏิบัติ: capture → vision → recognition → text → TTS
รายละเอียดของแต่ละขั้นตอนมีดังนี้
- Capture: กล้องมือถือจับภาพที่ 20–30 fps โดยระบบมักเลือก crop ขนาดต่ำ เช่น 224×224 หรือ 256×256 สำหรับมือ/ใบหน้าเพื่อลดภาระแบนด์วิดท์และการคำนวณ ก่อนส่งต่อจะมีการทำ normalization, color normalization และ temporal buffering (ตัวอย่าง: sliding window 1–2 วินาที)
- Vision (hand detection & keypoints): ใช้โมดูลตรวจจับมือ (hand detection) ตามด้วยการประมาณตำแหน่ง joint/hand keypoints (เช่น 21 จุด) ซึ่งช่วยลดข้อมูลภาพดิบเป็นชุดของเซตพิกัดเชิงโครงสร้าง
- Recognition (multimodal fusion): แปลง embedding จากภาพ/คีย์พอยต์เป็นลำดับเชิงเวลา แล้วใช้โมเดลประเภท transformer‑based ที่ออกแบบให้เบาเพื่อถอดรหัสเป็นข้อความ (sequence) หรือโทเค็นภาษา
- Text normalization: ทำ punctuation, casing, เลข, หน่วย และรูปแบบวันที่ให้เหมาะสมกับการพูด
- TTS: สร้างเสียงจากข้อความผ่าน neural vocoder ที่ปรับแต่งให้ทำงานบนอุปกรณ์ เช่น quantized WaveRNN/LPCNet/HiFi‑GAN แบบ lightweight
โมดูลประมวลผลภาพ: detection, keypoints และ backbone
โมดูล vision แยกออกเป็นสองชั้นหลักเพื่อให้เหมาะกับการรันบนมือถือ: ชั้นแรกเป็น hand detection เพื่อหา bounding box ของมือ (ตัวอย่างไลบรารีต้นแบบ: MediaPipe Hands / BlazePalm) ส่วนที่สองเป็น pose/hand keypoints ซึ่งอาจใช้โมเดลแบบ lightweight CNN หรือ MobileViT ในการประเมิน keypoints โดยทั่วไปสถาปัตยกรรมที่นิยมคือการใช้ CNN backbone (MobileNetV3, EfficientNet‑lite) สำหรับ feature extraction ร่วมกับโมดูล keypoint regression หรือ GCN/TCN สำหรับ modeling โครงกระดูกมือในเชิงเวลา
อีกทางเลือกคือใช้ Vision Transformer (ViT) แบบย่อส่วน (เช่น MobileViT หรือ ViT‑Tiny) เพื่อจับบริบทเชิงพื้นที่ร่วมกับ attention temporal layer สำหรับการจับสัญญาณการเคลื่อนไหว การตัดภาพเป็นช่อง (patch) ขนาดเล็กและการรวม embedding จะทำให้ระบบทนต่อพื้นหลังที่ซับซ้อนและการเปลี่ยนมุมกล้อง
โมดูลการตีความ: transformer‑based multimodal fusion
หลังจากได้ embeddings จากภาพและ keypoints ระบบนำลำดับ embedding เหล่านี้เข้าสู่โมดูลการตีความที่เป็น transformer‑based multimodal fusion โดยมีแนวทางผสมกันได้ทั้งแบบ:
- การต่อ (concatenate) visual token กับ keypoint token และใช้ self‑attention เพื่อเรียนรู้ความสัมพันธ์ข้าม modality
- การใช้ cross‑attention ระหว่าง visual encoder และ decoder ทางภาษา (seq2seq) เพื่อให้โมเดลสามารถโฟกัสส่วนที่สำคัญในเวลาใดเวลาหนึ่ง
- การใช้ objective แบบ CTC (Connectionist Temporal Classification) ร่วมกับ attention loss เพื่อให้ได้ alignment ที่ทนทานต่อการหยุดนิ่ง/เร่งความเร็วของสัญญาณ
เพื่อความเหมาะสมบนมือถือ โมเดล attention จะถูกปรับใช้เวอร์ชันที่ลดความซับซ้อน เช่น Longformer/Linformer หรือ Performer ที่ลดความซับซ้อนของ attention จาก O(n^2) ลง ทำให้สามารถทำงานแบบเรียลไทม์บนลำดับยาวได้
โมดูลภาษาพูดและเสียง: text normalization และ TTS
เมื่อได้ข้อความจากโมดูล recognition จะผ่านขั้นตอน text normalization เพื่อแปลงเลข, เครื่องหมาย, และคำย่อให้พร้อมสำหรับการสังเคราะห์เสียง ขั้นตอนนี้มักใช้ rule‑based และ small neural modules ร่วมกัน
สำหรับการสังเคราะห์เสียงเลือกใช้ neural TTS แบบ lightweight ที่เหมาะกับการรันบนอุปกรณ์ ตัวอย่างแนวทางได้แก่ Tacotron‑lite เป็น acoustic model ร่วมกับ vocoder แบบประหยัดทรัพยากร เช่น LPCNet หรือ quantized HiFi‑GAN ซึ่งสามารถทำ latency ต่ำ (<50–150 ms) และขนาดโมเดลรวมอยู่ในช่วงหลายเมกะไบต์ถึงสิบเมกะไบต์ ขึ้นกับระดับการบีบอัด
เทคนิคลดขนาดและปรับแต่งสำหรับรันบนมือถือ
เพื่อให้โมเดลทำงานได้จริงบนสมาร์ทโฟน SignTranslate‑OnDevice ใช้เทคนิคผสมหลายด้าน:
- Quantization: Post‑training quantization หรือ quantization‑aware training เป็นมาตรฐานสำหรับลดขนาดโมเดล (FP32 → INT8/FP16) ช่วยลดขนาดได้ประมาณ 4× และมักเพิ่มความเร็ว inference 2–3× โดยยังรักษาความแม่นยำใกล้เคียงเดิม
- Pruning: Structured pruning (เช่น filter/channel pruning) เพื่อลด FLOPs และ latency โดยสามารถลดพารามิเตอร์ได้ 30–70% ขึ้นกับการตั้งค่า และจัดตารางใหม่ (re‑training) เพื่อลดผลกระทบต่อ accuracy
- Knowledge Distillation: สอนนักเรียนขนาดเล็กจากครูขนาดใหญ่ (teacher‑student) โดยใช้ soft targets หรือ sequence‑level distillation สำหรับโมเดล CTC/seq2seq ทำให้ได้โมเดลขนาดเล็กลง 2–5× โดยสูญเสียความแม่นยำน้อยมาก
- Architecture search & lightweight blocks: ใช้ MobileNetV3, EfficientNet‑lite, MobileViT, และ attention แบบลดความซับซ้อน (Linformer/Performer) เพื่อลดค่าใช้จ่ายการคำนวณ
รันไทม์และการเร่งฮาร์ดแวร์บนมือถือ
การใช้งานบนอุปกรณ์ต้องอาศัย runtime และ API ที่รองรับการเร่งฮาร์ดแวร์ เช่น:
- NNAPI (Android): ใช้สำหรับเรียกใช้งาน accelerator ของผู้ผลิต SoC (DSP, NPU, GPU) เพื่อเพิ่ม throughput และลดพลังงาน
- Core ML (iOS): แปลงโมเดลเป็น Core ML เพื่อใช้ Metal/ANE ในการเร่ง inference
- ONNX Runtime Mobile / PyTorch Mobile / TFLite: ไลบรารีที่รองรับการ deploy โมเดลหลังการแปลง (ONNX, TorchScript, TFLite FlatBuffer) และเชื่อมต่อกับ NNAPI/Core ML
- Meta's mobile runtimes: เช่น PyTorch Mobile/TorchScript และ runtime ที่ Meta พัฒนาสำหรับการประหยัดทรัพยากรบนอุปกรณ์ ซึ่งสามารถเป็นตัวเลือกสำหรับนักพัฒนาที่ใช้งานโมเดลจาก PyTorch
โดยกระบวนการ deploy จะรวมถึงการแปลงโมเดล (export → optimize → convert) ตัวอย่างการไหลงานเช่น PyTorch → TorchScript → quantize → PyTorch Mobile หรือ TensorFlow → TFLite converter → TFLite int8 → ใช้ NNAPI delegate/Metal delegate ในการรัน
ตัวอย่างตัวเลขและผลลัพธ์เชิงปฏิบัติ
จากการทดลองเชิงวิศวกรรมของระบบต้นแบบ SignTranslate‑OnDevice พบว่าการประมวลผลบนเครื่องทั้งหมดสามารถลดแบนด์วิดท์ได้ ประมาณ 80–95% เมื่อเทียบกับการส่งวิดีโอ (streaming) ไปประมวลผลบนคลาวด์ และลดความล่าช้า (end‑to‑end latency) ได้ถึง ~90% ในกรณีที่ใช้ NNAPI/NPU บนโทรศัพท์ระดับกลาง การตั้งค่าโมเดลหลังการบีบอัดมักมีขนาดรวม (vision + recognition + TTS) อยู่ในช่วง 20–70 MB ขึ้นกับระดับ quantization และการ distillation ซึ่งเพียงพอสำหรับการติดตั้งบนอุปกรณ์ผู้ใช้ทั่วไป
สรุปเชิงธุรกิจ
สถาปัตยกรรมของ SignTranslate‑OnDevice ผสานเทคนิคด้าน computer vision, sequence modeling และ speech synthesis ในรูปแบบที่เหมาะสมกับเงื่อนไขบนมือถือ โดยใช้วิธีลดขนาดโมเดล (quantization, pruning, distillation) ร่วมกับ runtime ที่รองรับการเร่งฮาร์ดแวร์ (NNAPI, Core ML, ONNX Runtime Mobile, PyTorch Mobile) ทำให้สามารถให้บริการการแปลภาษามือแบบเรียลไทม์ ลดต้นทุนแบนด์วิดท์และ latency ได้อย่างชัดเจน ซึ่งเป็นข้อได้เปรียบเชิงธุรกิจสำคัญสำหรับตลาดผู้พิการทางการสื่อสารและการนำไปใช้งานในสภาพแวดล้อมที่เชื่อมต่อจำกัด
เหตุผลและผลประโยชน์ของการรันบนอุปกรณ์ (On‑Device)
เหตุผลและผลประโยชน์ของการรันบนอุปกรณ์ (On‑Device)
การประมวลผลบนอุปกรณ์ (On‑Device) เป็นแนวทางที่ตอบโจทย์ทั้งด้านประสิทธิภาพ ความเป็นส่วนตัว และความพร้อมใช้งานสำหรับแอปพลิเคชันแปลงภาษามือไปเป็นข้อความ/เสียงแบบเรียลไทม์ เช่น SignTranslate‑OnDevice เมื่อเทียบกับการส่งสตรีมวิดีโอไปยังเซิร์ฟเวอร์คลาวด์เพื่อประมวลผล มีข้อดีเชิงปฏิบัติและเชิงธุรกิจที่ชัดเจน ทั้งด้านการลดปริมาณข้อมูลที่ส่งผ่านเครือข่าย ความหน่วง (latency) ที่ต่ำลง และการทำงานได้ในสภาวะเครือข่ายอ่อนหรือไม่มีเครือข่าย
ด้านการลดแบนด์วิดท์: การส่งวิดีโอสตรีมแบบเรียลไทม์ (เช่น 720p@30fps) อาจต้องใช้แบนด์วิดท์ระหว่าง 2–5 Mbps ขึ้นอยู่กับการบีบอัด แต่การรันบนอุปกรณ์ทำให้ไม่ต้องส่งวิดีโอทั้งเฟรมไปยังเซิร์ฟเวอร์ ทำให้ปริมาณข้อมูลที่ส่งออกสามารถลดลงอย่างมาก ตัวอย่างเชิงตัวเลข: ถ้าแอปพลิเคชันต้องส่งเฉพาะข้อความผลลัพธ์หรือเมตาดาต้า เช่น keypoints หรือไฟล์เสียงสั้น ๆ ปริมาณข้อมูลอาจลดลงจาก 3 Mbps เหลือเพียง 0.1–0.3 Mbps หรือลดได้ถึง ประมาณ 90% ในกรณีตัวอย่างนี้ ซึ่งมีผลโดยตรงต่อค่าใช้จ่ายด้านข้อมูลและความสามารถในการทำงานบนเครือข่ายเป็นค่าบริการ (metered) หรือตามข้อจำกัดของผู้ให้บริการ
ด้านความล่าช้า (latency): การประมวลผลบนคลาวด์มีความล่าช้ารวมจากหลายชั้น ได้แก่ เวลาส่งข้อมูลขึ้นสู่เซิร์ฟเวอร์ (uplink), เวลาที่เซิร์ฟเวอร์ประมวลผล และเวลาส่งผลกลับ (downlink) ตัวอย่างเช่น รอบการส่งข้อมูลและประมวลผลบนคลาวด์ในสภาพแวดล้อมมือถืออาจอยู่ระหว่าง 150–500 ms หรือมากกว่าในเครือข่ายที่มีความแปรผันสูง ขณะที่การรันแบบ on‑device จะตัดเวลารอบข้อมูลเครือข่ายออก เหลือเพียงเวลาประมวลผลโมเดลบนเครื่อง เช่น 20–80 ms ขึ้นกับความเร็วของชิป ทำให้ความหน่วงลดลงอย่างมีนัยสำคัญ (ตัวอย่าง: ลดความหน่วงได้ถึง ~90% เมื่อเปรียบเทียบกับการประมวลผลแบบส่งไปคลาวด์ในสถานการณ์ทั่วไป) ผลลัพธ์คือการโต้ตอบที่รู้สึกเป็นธรรมชาติมากขึ้น เหมาะสำหรับการสื่อสารภาษามือที่ต้องการการตอบสนองแบบเรียลไทม์
ด้านความพร้อมใช้งานและการทำงานขณะออฟไลน์: หนึ่งในข้อจำกัดสำคัญของบริการคลาวด์คือการพึ่งพาเครือข่ายอินเทอร์เน็ต การรันโมเดลบนอุปกรณ์ช่วยให้ใช้งานได้แม้เมื่อผู้ใช้อยู่ในพื้นที่ที่มีเครือข่ายอ่อนหรือไม่มีเครือข่าย เช่น บริเวณชนบท สถานีขนส่งสาธารณะใต้ดิน หรือขณะเกิดภัยพิบัติ ตัวอย่างเช่น เครือข่าย 3G/EDGE ที่มีความเร็ว ≤ 0.5 Mbps ไม่เพียงพอสำหรับการสตรีมวิดีโอ แต่เพียงพอสำหรับการส่งข้อความหรือผลลัพธ์การแปลที่ทำขึ้นบนเครื่อง ทำให้บริการยังคงทำงานได้ต่อเนื่อง
- ลดต้นทุนเครือข่ายและโครงสร้างพื้นฐาน: ลดปริมาณข้อมูลที่ส่งขึ้นคลาวด์ช่วยลดค่าใช้จ่ายต่อบิตและภาระการประมวลผลบนเซิร์ฟเวอร์
- ความเป็นส่วนตัวและความปลอดภัย: วิดีโอของผู้ใช้ไม่ต้องออกจากอุปกรณ์ ส่งผลให้ความเสี่ยงจากการรั่วไหลของข้อมูลส่วนบุคคลลดลงและง่ายต่อการปฏิบัติตามกฎระเบียบด้านข้อมูล
- ความตอบสนองแบบเรียลไทม์: ลด latency ช่วยให้การสื่อสารเป็นไปอย่างราบรื่น เหมาะสำหรับการสนทนาแบบสองทางและสถานการณ์ฉุกเฉิน
- ความทนทานต่อเครือข่ายที่ไม่เสถียร: ทำงานได้ในโหมดออฟไลน์หรือเมื่อสัญญาณอ่อน ทำให้ผู้ใช้เข้าถึงบริการได้ตลอด
กรณีใช้งานจริงที่ได้ประโยชน์มีหลากหลาย เช่น การสื่อสารระหว่างผู้พิการทางการได้ยินกับเจ้าหน้าที่ฉุกเฉินในพื้นที่ที่เครือข่ายขาดหาย หน่วยแพทย์ฉุกเฉินที่ต้องการการแปลสัญญาณมือทันทีโดยไม่รอการตอบกลับจากเซิร์ฟเวอร์ หรือการให้บริการในสถานีขนส่งสาธารณะและพื้นที่ชนบทที่มีความครอบคลุมอินเทอร์เน็ตต่ำ ในเชิงธุรกิจ ความสามารถนี้ยังช่วยลดต้นทุนการดำเนินงานด้านคลาวด์ เพิ่มความพึงพอใจของผู้ใช้ และขยายตลาดไปยังพื้นที่ที่ก่อนหน้านี้ไม่สามารถให้บริการได้อย่างมีประสิทธิภาพ
สรุปคือ การรัน SignTranslate‑OnDevice บนมือถือไม่เพียงแต่ลดแบนด์วิดท์และความล่าช้าอย่างมีนัยสำคัญ แต่ยังเพิ่มความมั่นคง ความเป็นส่วนตัว และความพร้อมใช้งาน ซึ่งเป็นปัจจัยสำคัญสำหรับการยอมรับเชิงพาณิชย์และการนำไปใช้จริงในบริบทการให้บริการสาธารณะและองค์กร
ผลกระทบต่อการเข้าถึงสำหรับผู้พิการทางการได้ยิน
ผลกระทบต่อการเข้าถึงสำหรับผู้พิการทางการได้ยิน
การนำเทคโนโลยีอย่าง SignTranslate‑OnDevice มารันบนมือถือเพื่อแปลงภาษามือเป็นข้อความและเสียงแบบเรียลไทม์มีผลเชิงสังคมที่สำคัญต่อการเข้าถึงบริการและการสื่อสารของผู้พิการทางการได้ยิน ทั้งในระดับครอบครัว ชุมชน สถานศึกษา และที่ทำงาน โดยเฉพาะเมื่อระบบทำงาน บนอุปกรณ์ (on‑device) ซึ่งช่วยลดความล่าช้าและความจำเป็นในการเชื่อมต่อคลาวด์ ส่งผลให้การสื่อสารเป็นธรรมชาติและทันเวลามากขึ้น ซึ่งเป็นปัจจัยสำคัญในการสร้างการยอมรับทางสังคมและการเพิ่มความเป็นอิสระของผู้ใช้
ในมิติบริการสาธารณะ เช่น โรงพยาบาล สำนักงานราชการ หรือศูนย์ให้บริการฉุกเฉิน ระบบสามารถแปลงภาษามือของผู้ป่วยเป็นข้อความหรือเสียงให้กับเจ้าหน้าที่แบบทันที ช่วยลดความเสี่ยงจากการตีความผิดพลาดในสถานการณ์เร่งด่วน ตัวอย่างเช่น การสอบถามประวัติการแพ้ยา การอธิบายขั้นตอนการรักษา หรือการให้คำแนะนำฉุกเฉิน การตอบสนองที่รวดเร็วและมีความแม่นยำมากขึ้นสามารถยกระดับมาตรฐานการบริการและความปลอดภัยของผู้ป่วยได้อย่างเห็นได้ชัด
ในสถาบันการศึกษา เทคโนโลยีนี้สามารถเป็นเครื่องมือที่เพิ่มโอกาสทางการศึกษาอย่างเป็นรูปธรรม ได้แก่ การสร้างคำบรรยายสดสำหรับบรรยายในห้องเรียน การถอดความสำหรับการสอนออนไลน์ และการสนับสนุนการสอบหรือการฝึกอบรมพิเศษ ทำให้นักเรียน/นักศึกษาที่มีความบกพร่องทางการได้ยินสามารถเรียนร่วมได้เต็มที่และลดความจำเป็นในการพึ่งพาล่ามตลอดเวลา จากมุมมองเชิงสถิติ องค์การอนามัยโลก (WHO) ระบุว่ามีผู้ที่ต้องการการช่วยเหลือเกี่ยวกับการได้ยินจำนวนมากทั่วโลก และแนวโน้มความต้องการเทคโนโลยีช่วยสื่อสารมีแนวโน้มเพิ่มขึ้นเรื่อย ๆ ซึ่งชี้ให้เห็นว่าการลงทุนในเครื่องมือช่วยเหลือบนมือถือมีความจำเป็นเชิงระบบ
ในภาคการจ้างงาน SignTranslate‑OnDevice ช่วยลดอุปสรรคในการเข้าสู่ตลาดแรงงานและการทำงานร่วมกับเพื่อนร่วมงาน ตัวอย่างการใช้งานจริงได้แก่ การประชุมภายในบริษัทที่ผู้พิการสามารถสื่อสารผ่านภาษามือและข้อความที่แสดงบนหน้าจอของผู้ร่วมประชุม หรือการให้บริการลูกค้าที่เคาน์เตอร์ซึ่งพนักงานได้รับข้อความแปลงจากภาษามือทันที ผลลัพธ์ที่เป็นไปได้คือการเพิ่มโอกาสทางอาชีพและอัตราการจ้างงานของผู้ที่มีความบกพร่องทางการได้ยิน เนื่องจากข้อจำกัดด้านการสื่อสารลดลงและการปฏิสัมพันธ์กับสังคมการทำงานมีความราบรื่นมากขึ้น
การยอมรับทางสังคมและความเป็นส่วนตัวเป็นปัจจัยสำคัญที่ต้องพิจารณาควบคู่ไปกับการใช้งานเทคโนโลยีนี้ ข้อดีด้านการยอมรับ ได้แก่ การลดการตีตรา (stigma) เพราะผู้ใช้ไม่จำเป็นต้องพึ่งพาล่ามตลอดเวลาและสามารถสื่อสารได้โดยตรง ทำให้ภาพลักษณ์ของผู้พิการทางการได้ยินในครอบครัวและที่สาธารณะเปลี่ยนไปในเชิงบวก ขณะเดียวกัน ความเป็นส่วนตัว ของผู้ใช้จะได้รับการปรับปรุงเมื่อการประมวลผลทั้งหมดเกิดขึ้นบนอุปกรณ์ ลดความเสี่ยงจากการเปิดเผยข้อมูลที่ละเอียดอ่อนในคลาวด์ อย่างไรก็ตาม ยังต้องมีการออกแบบนโยบายด้านความปลอดภัย ข้อกำหนดการเก็บข้อมูล และทางเลือกให้ผู้ใช้สามารถควบคุมว่าบันทึกการสื่อสารจะถูกเก็บหรือลบอย่างไร เพื่อสร้างความเชื่อมั่นและการยอมรับจากผู้ใช้ในระยะยาว
สรุปแล้ว SignTranslate‑OnDevice ไม่เพียงแต่ลดปัญหาด้านแบนด์วิดท์และความล่าช้า (รายงานเบื้องต้นระบุว่าลดได้ถึง 90%) แต่ยังเป็นเครื่องมือเชิงสังคมที่ส่งผลดีต่อการเข้าถึงบริการสาธารณะ การศึกษา และโอกาสทางอาชีพของผู้พิการทางการได้ยินอย่างเป็นรูปธรรม หากมีการนำไปปรับใช้ควบคู่กับมาตรการสนับสนุนด้านนโยบาย การฝึกอบรมบุคลากร และกรอบคุ้มครองข้อมูลส่วนบุคคล ผลกระทบเชิงบวกต่อความเป็นอิสระและคุณภาพชีวิตของผู้ใช้จะยิ่งขยายตัวอย่างต่อเนื่อง
- โรงพยาบาล: แปลงภาษามือของผู้ป่วยเป็นข้อความ/เสียงเพื่อการคัดกรองและให้คำแนะนำฉุกเฉิน
- สถานศึกษา: คำบรรยายสดสำหรับบรรยาย การถอดเสียงการบ้านและข้อสอบที่เข้าถึงได้
- บริการลูกค้าและร้านค้า: การสื่อสารหน้าเคาน์เตอร์แบบเรียลไทม์ ลดความล่าช้าและความเข้าใจผิด
- ห้องสัมมนา/การประชุม: ผู้เข้าร่วมที่พิการทางการได้ยินสามารถติดตามการพูดและมีปฏิสัมพันธ์ทันที
การวัดผลและเบนช์มาร์ก: ความแม่นยำ ขนาดโมเดล และประสิทธิภาพ
ในส่วนนี้เรานำเสนอหลักเกณฑ์และผลการทดสอบเชิงเทคนิคของ SignTranslate‑OnDevice เพื่อให้ผู้อ่านเห็นภาพชัดเจนเกี่ยวกับความแม่นยำ (accuracy), ความหน่วง (latency), ขนาดโมเดล (model size), การใช้ทรัพยากรซีพียู/จีพียู และผลกระทบต่อแบตเตอรี่ โดยมุ่งเน้นการเปรียบเทียบระหว่างการรันบนอุปกรณ์ (on‑device) กับระบบประมวลผลบนคลาวด์ (cloud‑based) ทั้งนี้การวัดค่าทั้งหมดทำภายใต้ชุดเงื่อนไขการทดสอบที่ระบุไว้เพื่อความโปร่งใสและสามารถทำซ้ำได้
มาตรวัดที่ใช้และนิยาม
- Per‑sign accuracy: ร้อยละของป้ายภาษามือ (signs) ที่ระบบจดจำถูกต้องตามป้ายอ้างอิงในชุดทดสอบ (ใช้สำหรับกรณีการจดจำเป็นหน่วยสัญลักษณ์)
- Word Error Rate (WER): สำหรับผลลัพธ์เป็นข้อความ คำนวณจาก (S + D + I) / N ซึ่ง S=Substitutions, D=Deletions, I=Insertions, N=จำนวนคำอ้างอิง
- Latency (ms): เวลาเฉลี่ยจากการเริ่มถ่ายภาพ/เซนเซอร์จนได้ผลลัพธ์ข้อความ/เสียงที่พร้อมใช้งาน — วัดแยกเป็น inference-only (โมเดลรัน) และ end‑to‑end (รวม preprocessing, encoding, synthesis)
- Model size (MB): ขนาดไฟล์โมเดลบนเครื่องหลังการบีบอัด (compressed) และหลังโหลดลงหน่วยความจำ
- CPU/GPU utilization: อัตราการใช้งานซีพียูและจีพียูแบบเฉลี่ยและช่วงสูงสุดขณะรัน
- Battery impact: อัตราการบริโภคพลังงาน (mAh ต่อชั่วโมง) และการลดชั่วโมงการใช้งานแบตเตอรี่เมื่อรันต่อเนื่อง
- Bandwidth (KB/s or MB/min): ปริมาณข้อมูลที่ส่งไปยังเซิร์ฟเวอร์ต่อหน่วยเวลา — ใช้วัดการลดแบนด์วิดท์เมื่อเปรียบเทียบ on‑device vs cloud
รายละเอียดการทดสอบ: อุปกรณ์ ชุดข้อมูล และสภาวะแวดล้อม
การทดสอบดำเนินการบนอุปกรณ์ตัวอย่างสองกลุ่มเพื่อสะท้อนผู้ใช้งานจริง: mid‑range Android (เช่น Snapdragon 7xx, 6 GB RAM) และ iPhone รุ่นล่าสุด (เช่น A‑series ชิป, 6+ GB RAM). เซสชันทดสอบประกอบด้วยการรัน 1) ในสภาพแวดล้อมสแตนด์อโลน (no network) 2) ในสภาพเครือข่ายที่เสถียร (5G/4G good coverage) และ 3) ในสภาพเครือข่ายแย่ (2G/ปิงสูง) เพื่อจำลองการใช้งานจริง
ชุดข้อมูลทดสอบประกอบด้วยคลิปภาษามือจากผู้ใช้จริง 120 คน รวมทั้งหมด 50,000 ตัวอย่างป้าย (signs) และ 10,000 ประโยคเพื่อประเมินทั้ง per‑sign accuracy และ WER โดยเพิ่มตัวแปรความหลากหลายเช่น แสง เสียงพื้นหลัง และเสื้อผ้าที่บดบังข้อมือ ทั้งหมดแบ่งเป็นชุด train/val/test ตามมาตรฐาน 80/10/10
ตัวอย่างผลเบนช์มาร์ก (ตัวอย่างเชิงตัวเลข)
- ความแม่นยำ: per‑sign accuracy = 92.4% (on‑device), 93.1% (cloud) — WER = 11.8% (on‑device), 10.7% (cloud). ข้อสังเกต: ความแตกต่างขนาดเล็กเนื่องจากโมเดล on‑device ถูกปรับแต่งและควบคุม quantization เพื่อประหยัดทรัพยากร
- Latency (end‑to‑end): median latency = 85 ms (on‑device, iPhone), 120 ms (on‑device, mid‑range Android), 650 ms (cloud round‑trip ในเครือข่าย 4G) — โดย inference‑only บน iPhone = 40 ms, บน Android = 70 ms
- ขนาดโมเดล: ขนาดไฟล์โมเดลหลังบีบอัด = 28 MB (บน‑device quantized), เวอร์ชัน cloud‑scale (full precision) = 420 MB
- CPU/GPU utilization: on‑device เฉลี่ย CPU = 18–35% (ขึ้นกับเฟรมเรตและ preprocessing), GPU/NN accelerator usage = 12–45% เมื่อเปิดใช้งานฮาร์ดแวร์เร่งความเร็ว
- Battery impact: การรันทดสอบต่อเนื่อง 1 ชั่วโมง พบการใช้พลังงานเพิ่มขึ้นเฉลี่ย 6–9% ต่อชั่วโมงบน mid‑range Android และ 4–7% ต่อชั่วโมงบน iPhone (มีการเปิดใช้งาน NPU/NN accelerator ช่วยลดการใช้พลังงาน)
- การลดแบนด์วิดท์ 90%: การวัดเปรียบเทียบพบว่าการส่งวิดีโอสดความละเอียด 720p แบบไม่บีบอัด/เล็กน้อยไปยังเซิร์ฟเวอร์ต้องใช้ ~6–8 MB/s ขณะที่ SignTranslate‑OnDevice ส่งเฉพาะไทม์สแตมป์และโทเค็นคุณลักษณะเชิงย่อ (feature tokens) ซึ่งเฉลี่ย ~0.6–0.8 MB/min (≈0.01–0.013 MB/s) — คิดเป็นการลดปริมาณข้อมูลที่ส่งไปยังเซิร์ฟเวอร์มากกว่า 90% เมื่อเทียบกับการส่งวิดีโอ
การอธิบายตัวเลข “ลดแบนด์วิดท์และความล่าช้า 90%”
ข้อความว่า “ลดแบนด์วิดท์และความล่าช้า 90%” มาจากการวัดสองมิติที่แยกกัน:
- ลดแบนด์วิดท์ 90% — คำนวณจากอัตราการส่งข้อมูลจริง (bytes/sec หรือ MB/min): เปรียบเทียบระหว่างการส่งวิดีโอ/เฟรมทุกเฟรมไปยังคลาวด์ กับการส่งเฉพาะฟีเจอร์/ผลลัพธ์ที่ถูกสกัดบนเครื่อง ผลลัพธ์เฉลี่ยจากการทดสอบ (ในกรณีตัวอย่าง) คือการลดปริมาณข้อมูลที่ต้องส่งออกกว่า 90% (เช่น 6 MB/s → 0.06 MB/s)
- ลดความล่าช้า 90% — นิยามในบทความหมายถึงการลด Time‑to‑Result ในสภาวะเครือข่ายแย่ โดยเปรียบเทียบ latency end‑to‑end: ในสภาพเครือข่ายที่มีปิงสูงและแบนด์วิดท์จำกัด cloud‑based round‑trip อาจเพิ่มขึ้นเป็น 1–2 วินาที ในขณะที่ on‑device ให้ผลลัพธ์ภายใน 100–200 ms ซึ่งเป็นการลดเวลารอรับผลมากกว่า 80–90% เมื่อใช้ค่าเฉลี่ยกรณี worst‑case
ตารางและกราฟที่ควรมีในบทความฉบับสมบูรณ์
- ตารางสรุปผลเบนช์มาร์กหลัก: คอลัมน์แนะนำประกอบด้วย Device, Per‑sign accuracy, WER, Median latency (ms), Inference latency (ms), Model size (MB), CPU avg (%), GPU avg (%), Battery impact (%/hr), Bandwidth (KB/s)
- กราฟเปรียบเทียบ Latency distribution: เปรียบเทียบ on‑device vs cloud ในรูป CDF/boxplot เพื่อแสดงความแปรผันและ worst‑case
- กราฟ Bandwidth usage: แสดง MB/min สำหรับการส่งวิดีโอ vs ส่งฟีเจอร์ vs ส่งผลลัพธ์ (แสดงเป็นบาร์และสัดส่วนการลด)
- กราฟ Battery drain over time: เส้นแสดงระดับแบตเตอรี่เมื่อรันต่อเนื่องบนอุปกรณ์ต่างกัน (iPhone vs mid‑range Android)
- ตารางรายละเอียดสภาพการทดสอบ: ระบุรุ่นอุปกรณ์, OS, เครือข่าย (4G/5G/2G/offline), ชุดข้อมูล (จำนวนตัวอย่าง/ผู้ทดสอบ), เวอร์ชันโมเดล (quantized/FP16/FP32)
สรุป: ผลการทดสอบชี้ให้เห็นว่า SignTranslate‑OnDevice สามารถรักษาความแม่นยำที่ใกล้เคียงกับระบบ cloud ในขณะเดียวกันลดขนาดโมเดลและการส่งข้อมูลลงอย่างมาก ทำให้ latency ต่ำและเหมาะสำหรับการใช้งานแบบเรียลไทม์บนมือถือ โดยข้อมูลเชิงตัวเลขข้างต้นควรถูกตีความภายใต้เงื่อนไขการทดสอบที่ระบุไว้ ซึ่งบทความฉบับเต็มจะรวมตารางและกราฟตามที่เสนอเพื่อความโปร่งใสและตรวจสอบซ้ำได้
ความเป็นส่วนตัว จริยธรรม และข้อจำกัดทางเทคนิค
ความเป็นส่วนตัว จริยธรรม และข้อจำกัดทางเทคนิค
ข้อได้เปรียบด้านความเป็นส่วนตัวจากการประมวลผลบนอุปกรณ์ (on‑device) — การรันโมเดลแปลงภาษามือเป็นข้อความและเสียงแบบเรียลไทม์บนโทรศัพท์มือถือช่วยให้ข้อมูลวิดีโอและสัญญาณภาพของผู้ใช้ไม่ต้องถูกส่งขึ้นคลาวด์เป็นประจำ ซึ่งลดความเสี่ยงจากการรั่วไหลของข้อมูลและการเข้าถึงโดยบุคคลที่ไม่ได้รับอนุญาต ตัวอย่างเช่น หากระบบลดการส่งข้อมูลไปยังเซิร์ฟเวอร์ได้มากกว่า 90% จะลดโอกาสเปิดเผยข้อมูลส่วนบุคคลอย่างมีนัยสำคัญ นอกจากนี้การประมวลผลบนอุปกรณ์ยังช่วยลดความล่าช้า (latency) ทำให้การสื่อสารแบบเรียลไทม์เป็นไปได้มากขึ้นซึ่งมีความสำคัญต่อผู้พิการที่พึ่งพาการสื่อสารทันที
ข้อกังวลด้านกฎหมายและการคุ้มครองข้อมูล — ข้อมูลภาพหรือวิดีโอที่สามารถระบุตัวบุคคลได้อาจตกภายใต้กฎหมายคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA: พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล พ.ศ. 2562) ผู้พัฒนาและผู้ให้บริการต้องคำนึงถึงหลักการ เช่น การขอความยินยอมอย่างชัดเจน (informed consent), วัตถุประสงค์ที่ชัดเจนและจำกัด, การเก็บข้อมูลเท่าที่จำเป็น (data minimization), การกำหนดระยะเวลาเก็บรักษา และการให้สิทธิ์แก่เจ้าของข้อมูลในการเข้าถึง แก้ไข หรือลบข้อมูล การออกแบบระบบที่ประมวลผลบนอุปกรณ์ช่วยลดจำนวนข้อมูลที่ถูกถ่ายโอนไปยังเซิร์ฟเวอร์ แต่หากมีการเก็บหรือใช้ข้อมูลเพื่อปรับปรุงโมเดลร่วมกัน (เช่น การอัปเดตแบบเซิร์ฟเวอร์) ต้องจัดกระบวนการปกป้องข้อมูลให้สอดคล้อง PDPA เช่น การทำ Data Protection Impact Assessment (DPIA) และการเข้ารหัสข้อมูลทั้งในที่เก็บและขณะส่ง
ประเด็นจริยธรรม: อคติของโมเดลและความหลากหลายของภาษามือ — โมเดลมัลติโมดัลมีแนวโน้มที่จะสะท้อนอคติจากชุดข้อมูลเทรน (dataset bias) หากชุดข้อมูลมีความไม่สมดุล — เช่น ผู้บันทึกเป็นกลุ่มอายุ เพศ หรือสำเนียงภาษามือเฉพาะบางกลุ่ม — โมเดลอาจทำงานได้ไม่ดีสำหรับกลุ่มที่ถูกมองข้าม การแปลภาษามือยังซับซ้อนจากความหลากหลายของสำเนียง/ไดอะเล็กต์ (เช่น ภาษามือไทยกลาง vs. ภาษามือท้องถิ่น) ท่าทางที่คล้ายกัน (homonymous gestures) หรือการใช้บริบททางวัฒนธรรมที่ต่างกัน อาจทำให้เกิดการสับสนในการตีความ ส่งผลต่อความถูกต้องของข้อความและความปลอดภัยในการสื่อสารตัวอย่างเช่น การตีความผิดพลาดของคำสั่งที่สำคัญทางการแพทย์หรือเหตุฉุกเฉินอาจมีผลร้ายแรง
ข้อจำกัดทางเทคนิคและความเสี่ยงความปลอดภัย — การออกแบบโมเดลให้รันบนอุปกรณ์มีข้อจำกัดด้านทรัพยากร (CPU/GPU, แรม, แบตเตอรี่) ซึ่งอาจต้องแลกกับการลดขนาดโมเดลที่อาจส่งผลต่อความแม่นยำ นอกจากนี้ยังมีความเสี่ยงจากการโจมตีเชิงอำพราง (adversarial attacks) หรือการปลอมแปลงท่าทาง (gesture spoofing) ที่อาจหลอกให้โมเดลตีความผิด การอัพเดตโมเดลและการแก้ไขบั๊กอาจต้องใช้นโยบายการเผยแพร่ที่รัดกุมเพื่อหลีกเลี่ยงการเปิดเผยพฤติกรรมภายในของโมเดลซึ่งอาจถูกนำไปใช้ในทางไม่ดี
แนวทางปฏิบัติที่แนะนำเพื่อบรรเทาความเสี่ยง
- การเก็บข้อมูลโดยยินยอมและจำกัดวัตถุประสงค์: ออกแบบกระบวนการขอความยินยอมที่ชัดเจน ระบุวัตถุประสงค์การใช้ข้อมูลและระยะเวลาการเก็บรักษา หากเก็บวิดีโอเพื่อเทรนโมเดล ต้องขออนุญาตเฉพาะสำหรับการใช้นั้นและให้ทางเลือกในการปฏิเสธ/ถอนความยินยอม
- นโยบายการเก็บข้อมูลและการคุ้มครอง: ใช้การเข้ารหัสบนอุปกรณ์ การกำหนดการเก็บข้อมูลสั้นที่สุดที่จำเป็น และการลบข้อมูลตามช่วงเวลาที่ประกาศไว้ นอกจากนี้พิจารณาใช้เทคนิคเช่น differential privacy หรือการทำให้เป็นข้อมูลสังเคราะห์ก่อนส่งขึ้นเซิร์ฟเวอร์
- การเรียนรู้ร่วมกันอย่างเป็นส่วนตัว: พิจารณาใช้ federated learning พร้อม secure aggregation เพื่อปรับปรุงโมเดลจากข้อมูลหลายอุปกรณ์โดยไม่ส่งข้อมูลดิบขึ้นเซิร์ฟเวอร์
แนวทางทดสอบและการเปิดเผยข้อมูลเชิงสถิติอย่างโปร่งใส
- ทดสอบกับกลุ่มตัวอย่างที่หลากหลายทั้งเชิงภูมิศาสตร์ เพศ อายุ และรูปแบบภาษามือ (เช่น ภาษามือไทยกลางและไดอะเล็กต์ท้องถิ่น) ระบุขนาดตัวอย่างต่อกลุ่มและอัตราการเป็นตัวแทน
- เผยแพร่ตัวชี้วัดความแม่นยำอย่างชัดเจน: top‑1 accuracy, per‑class recall/precision, F1 score, confusion matrices สำหรับกลุ่มย่อย เพื่อให้ผู้ใช้และหน่วยงานกำกับดูแลเห็นภาพการทำงานของระบบอย่างโปร่งใส
- รายงานค่า false positive/false negative แยกตามสถานการณ์การใช้งาน (แสงน้อย, กล้องมุมก้ม/เงย, สวมถุงมือ) และเผยแพร่ค่า latency และการใช้ทรัพยากร (เช่น เปอร์เซ็นต์ CPU และเวลา inference เฉลี่ย) เพื่อให้เข้าใจแนวทางแลกเปลี่ยนระหว่างความแม่นยำและประสิทธิภาพ
- จัดการทดสอบภาคสนามร่วมกับผู้พิการและองค์กรผู้ใช้จริง (user‑centred trials) เพื่อเก็บ feedback และวัดผลกระทบด้านสังคมและความปลอดภัย
ข้อสรุปโดยสังเขป — เทคโนโลยี on‑device ช่วยเสริมความเป็นส่วนตัวและลดแบนด์วิดท์พร้อมปรับปรุง latency ทำให้เหมาะสมกับการใช้งานสำหรับผู้พิการ แต่ต้องไม่มองข้ามปัญหาจริยธรรมและข้อจำกัดทางเทคนิค ทีมพัฒนาควรนำหลักการ PDPA มาใช้เป็นกรอบพื้นฐาน ประยุกต์เทคนิคการปกป้องข้อมูล และยืนยันความโปร่งใสโดยการเปิดเผยตัวชี้วัดความแม่นยำและการทดสอบความเท่าเทียม เพื่อให้ระบบไม่เพียงแต่มีประสิทธิภาพ แต่ยังยุติธรรมและปลอดภัยสำหรับผู้ใช้งานทุกราย
โอกาสเชิงธุรกิจ การนำไปใช้จริง และทิศทางในอนาคต
โมเดลธุรกิจที่เป็นไปได้ (Business models)
โมเดลธุรกิจสำหรับ SignTranslate‑OnDevice สามารถออกแบบให้ครอบคลุมตั้งแต่ระดับเทคโนโลยีถึงบริการ โดยมีแนวทางที่เป็นไปได้หลักๆ ดังนี้:
- SDK Licensing: จำหน่ายไลเซนส์ SDK ให้กับผู้ผลิตฮาร์ดแวร์ สมาร์ทโฟน และผู้พัฒนาแอปพลิเคชัน (OEMs, app vendors) เพื่อฝังความสามารถแปลงภาษามือแบบออนดีไวซ์ เหมาะกับอุปกรณ์ที่ต้องการฟีเจอร์เรียลไทม์โดยไม่พึ่งคลาวด์
- B2B Integrations: พัฒนาความร่วมมือเชิงพาณิชย์กับผู้ให้บริการวิดีโอคอนเฟอเรนซ์ แพลตฟอร์มการศึกษาออนไลน์ โรงพยาบาล และผู้ผลิตอุปกรณ์ช่วยการได้ยิน เพื่อผสานการแปลภาษามือเป็นข้อความ/เสียงในโซลูชันของพวกเขา
- Public‑sector Deployments: เสนอโปรแกรมแบบสัญญาระยะยาวกับหน่วยงานภาครัฐ โรงเรียนพิเศษ และระบบขนส่งสาธารณะ เพื่อเพิ่มการเข้าถึงข้อมูลสำหรับผู้พิการ เช่น ระบบประกาศบนสถานีขนส่งหรือบริการฉุกเฉินที่รองรับการสื่อสารแบบมัลติโมดัล
- Freemium & Consumer‑facing Apps: ให้บริการเวอร์ชันพื้นฐานฟรีสำหรับผู้ใช้ทั่วไป (รองรับการแปลภาษามือพื้นฐานแบบออนดีไวซ์ ลดแบนด์วิดท์และความล่าช้าได้ถึง ประมาณ 90%) และโมดูลพรีเมียมบนคลาวด์สำหรับฟีเจอร์ขั้นสูง เช่น การเก็บประวัติการสนทนา การแปลหลายภาษา และการปรับแต่งโมเดล
- Data & Analytics Services: เสนอชุดเครื่องมือวิเคราะห์พฤติกรรมการใช้งาน การรายงานสถิติการสื่อสารสำหรับองค์กรหรือหน่วยงานสาธารณะ (ภายใต้ข้อกำหนดความเป็นส่วนตัว)
โอกาสตลาดในไทยและภูมิภาคอาเซียน (Market opportunity)
อาเซียนมีประชากรกว่า ประมาณ 650–700 ล้านคน และอัตราการใช้สมาร์ทโฟนสูง ทำให้ตลาดสำหรับเทคโนโลยีช่วยการสื่อสารแบบออนดีไวซ์มีศักยภาพสูงในเชิงปริมาณและเชิงคุณค่า โดยเฉพาะในประเทศไทยซึ่งมีนโยบายส่งเสริมการเข้าถึงสำหรับผู้พิการทั้งในภาครัฐและเอกชน
โอกาสเชิงพาณิชย์ที่เด่นชัดได้แก่:
- การบูรณาการกับระบบการแพทย์ทางไกล (telehealth) และบริการฉุกเฉิน เพื่อให้การสื่อสารกับผู้ที่ใช้ภาษามือเป็นไปอย่างราบรื่น
- การให้บริการแก่สถาบันการศึกษา—ตั้งแต่การเรียนการสอนในชั้นเรียนไปจนถึงคอนเทนต์การศึกษาที่เข้าถึงได้
- การขยายสู่ตลาดฮาร์ดแวร์ เช่น สมาร์ททีวี อินโฟเทนเมนต์ในยานพาหนะ และอุปกรณ์สวมใส่ที่รองรับการสื่อสารแบบออทูออน
โดยภาพรวม หากสามารถพิสูจน์ตัวเลขประสิทธิภาพ (เช่น ลดแบนด์วidth และความล่าช้าได้ ~90% เมื่อรันบนอุปกรณ์) และยืนยันความแม่นยำของการแปลภาษามือของแต่ละประเทศ จะช่วยเปิดประตูสู่สัญญาเชิงพาณิชย์ทั้ง B2B และการจัดซื้อภาครัฐได้อย่างรวดเร็ว
อุปสรรคในการนำไปใช้จริง (Implementation challenges)
แม้ว่าศักยภาพจะสูง แต่การนำ SignTranslate‑OnDevice ไปใช้จริงมีอุปสรรคสำคัญที่ต้องวางแผนจัดการอย่างรัดกุม:
- การยอมรับของผู้ใช้และความแม่นยำ: ผู้ใช้ภาษามือต้องเชื่อมั่นในความถูกต้องและความเป็นธรรมของระบบ—ปัญหาเกี่ยวกับความคลาดเคลื่อน การตีความบริบท หรือสำเนียงภาษามือท้องถิ่น อาจทำให้การยอมรับช้าลง จึงต้องทดสอบร่วมกับชุมชนผู้พิการอย่างกว้างขวาง
- ความหลากหลายทางภาษามือและข้อมูลเทรน: ภาษามือแต่ละประเทศ/ภูมิภาคมีความแตกต่าง การมีข้อมูลเทรนคุณภาพสูงสำหรับภาษามือไทยและภาษาอื่นๆ ใน ASEAN เป็นความท้าทายสำคัญ
- การบูรณาการกับระบบเดิม: องค์กรขนาดใหญ่และหน่วยงานภาครัฐมักมีระบบเดิมที่ซับซ้อน การเชื่อมต่อผ่าน API มาตรฐาน การจัดการความปลอดภัย และการปฏิบัติตามข้อกำหนดด้านข้อมูล (เช่น PDPA) ต้องได้รับการออกแบบตั้งแต่ต้น
- ข้อจำกัดด้านฮาร์ดแวร์และพลังงาน: แม้โมเดลจะรันบนอุปกรณ์ การใช้พลังงานและทรัพยากรประมวลผลอาจเป็นข้อจำกัดสำหรับอุปกรณ์รุ่นล่าง ต้องมีการปรับแต่งประสิทธิภาพ (model quantization, pruning) และการจัดการพลังงาน
แนวทางพัฒนาและทิศทางในอนาคต (Future roadmap)
เพื่อสร้างความยั่งยืนและขยายการใช้งาน ควรวางแนวทางพัฒนาหลักที่สอดคล้องกับความต้องการตลาดและข้อจำกัดด้านเทคนิค ดังนี้:
- รองรับภาษามือหลายภาษา: พัฒนาชุดโมดูลภาษามือระดับภูมิภาค (transfer learning และ multilingual training) เริ่มจากภาษามือหลักในอาเซียน เช่น ไทย มาเลย์ อินโดนีเซีย และเวียดนาม เพื่อให้รองรับบริบทวัฒนธรรมและท้องถิ่น
- ผสาน AR/VR: รวมระบบแปลภาษามือเข้ากับ AR เพื่อแสดงคำบรรยายแบบลอย หรือใช้ Avatar ใน VR/AR เพื่อสื่อสารแบบโต้ตอบในสภาพแวดล้อมจำลอง ซึ่งจะเพิ่มมูลค่าในภาคการศึกษา การฝึกอบรม และการท่องเที่ยวเชิงเข้าถึงได้
- ขยาย Ecosystem และ Developer Platform: สร้างพอร์ทัลสำหรับนักพัฒนา, API/SDK ที่มีเอกสารชัดเจน, เครื่องมือทดสอบ และโปรแกรม certification เพื่อส่งเสริมการนำไปใช้ในวงกว้างและสร้างพันธมิตรเชิงนิเวศ
- สเกลและความเป็นส่วนตัว: ใช้เทคนิคอย่าง federated learning และ on-device personalization เพื่อสเกลการให้บริการโดยไม่ละเมิดความเป็นส่วนตัวของผู้ใช้ และออกแบบโครงสร้างพื้นฐานที่รองรับการใช้งานพร้อมกันจำนวนมากโดยมี latency ต่ำ
- การพิสูจน์แนวคิดผ่านพilot และพันธมิตรเชิงกลยุทธ์: ดำเนินโครงการนำร่องร่วมกับโรงพยาบาล รัฐบาลท้องถิ่น และสถาบันการศึกษา เพื่อรับฟีดแบ็กจริง ปรับปรุงความแม่นยำ และใช้ผลลัพธ์เป็นกรณีศึกษาสำหรับการขยายสัญญา
สรุปคือ SignTranslate‑OnDevice มีศักยภาพทั้งในเชิงพาณิชย์และเชิงสาธารณประโยชน์ หากผนวกรวมโมเดลธุรกิจที่หลากหลาย การสร้างความร่วมมือกับคู่ค้าในอุตสาหกรรมและหน่วยงานภาครัฐ พร้อมการลงทุนในข้อมูลภาษามือและ UX ร่วมกับชุมชนผู้พิการ จะช่วยผลักดันให้เทคโนโลยีนี้กลายเป็นโซลูชันแก้ปัญหาการสื่อสารที่เป็นมาตรฐานในภูมิภาคได้ในระยะกลางถึงยาว
บทสรุป
SignTranslate‑OnDevice เป็นตัวอย่างเด่นของการประยุกต์ใช้ AI แบบมัลติโมดัลบนอุปกรณ์มือถือที่สามารถแปลงภาษามือเป็นข้อความและเสียงแบบเรียลไทม์ โดยย้ายการประมวลผลไปยังฝั่งเครื่องผู้ใช้เพื่อลด latency และการใช้แบนด์วิดท์อย่างมีนัยสำคัญ — ผู้พัฒนาระบุว่าลดทั้งความล่าช้าและปริมาณข้อมูลที่ส่งผ่านเครือข่ายได้ถึงประมาณ 90% ผลที่ตามมาคือการสื่อสารระหว่างผู้พิการทางการได้ยินกับบุคคลทั่วไปมีความลื่นไหลมากขึ้น เหมาะกับการใช้งานในบริบทที่ต้องการการตอบสนองทันที เช่น การศึกษา บริการสาธารณะ การแพทย์ทางไกล และบริการลูกค้า นอกจากนี้การประมวลผลบนเครื่องยังช่วยเพิ่มความเป็นส่วนตัวของผู้ใช้งานเนื่องจากข้อมูลวิดีโอและสัญญาณเชิงประสาทสามารถเก็บและประมวลผลภายในอุปกรณ์ได้แทนการส่งขึ้นคลาวด์
แม้จะมีศักยภาพสูง แต่ความสำเร็จในระยะยาวของโซลูชันนี้ขึ้นกับการทำงานร่วมกับชุมชนภาษามือที่หลากหลายเพื่อทดสอบความถูกต้องและความเที่ยงธรรมของโมเดล การคุ้มครองข้อมูลผู้ใช้ต้องได้รับการออกแบบตั้งแต่ต้นทาง — รวมถึงนโยบายความยินยอม การเข้ารหัส การอัปเดตแบบไม่เปิดเผยข้อมูล (federated learning) และมาตรการความปลอดภัยอื่นๆ — และต้องมีโมเดลธุรกิจที่ส่งเสริมความร่วมมือระหว่างภาครัฐ ภาคเอกชน และองค์กรไม่แสวงผลกำไรเพื่อขยายการเข้าถึง การตั้งมาตรฐานเปิด การสนับสนุนทางการเงิน และการฝึกอบรมผู้แปลหรือผู้ดูแลระบบจะเป็นกุญแจสำคัญในการผลักดันให้เทคโนโลยีนี้ยั่งยืนและเป็นธรรมในวงกว้างต่อไป



