
ในช่วงหลังจากการแพร่ระบาดและการเปลี่ยนแปลงทางเศรษฐกิจ ธนาคารไทยเริ่มหันมาใช้เครื่องมือวิเคราะห์ข้อมูลเชิงสาเหตุ (Causal ML) และการวิเคราะห์เชิงสมมติฐานย้อนเหตุการณ์ (Counterfactual Analysis) เพื่อประเมินผลของนโยบายสินเชื่อและโปรโมชั่นแบบเรียลไทม์ แนวทางนี้แตกต่างจากการวิเคราะห์เชิงสหสัมพันธ์แบบเดิมตรงที่มุ่งหาความสัมพันธ์เชิงเหตุผล ช่วยให้สถาบันการเงินสามารถจำลองสถานการณ์ "what‑if" ปรับแคมเปญหรือเงื่อนไขสินเชื่อได้ทันที และลดความเสี่ยงที่จะเกิดผลกระทบไม่พึงประสงค์ต่อกลุ่มเปราะบาง เช่น ผู้มีรายได้น้อย ผู้สูงอายุ หรือผู้ที่เข้าถึงบริการทางการเงินอย่างจำกัด
บทนำนี้จะชี้ให้เห็นภาพรวมของการนำ Causal ML และ Counterfactual Analysis มาปรับใช้จริงในภาคธนาคารไทย โดยครอบคลุมตัวอย่างการทดสอบนำร่อง วิธีการวัดผลแบบเรียลไทม์ ผลประโยชน์ที่คาดว่าจะได้รับทั้งด้านการลดความเสี่ยงต่อกลุ่มเปราะบางและการเพิ่มความยืดหยุ่นในการตัดสินใจ รวมถึงข้อท้าทายด้านข้อมูล ความเป็นส่วนตัว และการกำกับดูแลที่ต้องพิจารณาควบคู่กันไป เพื่อให้ผู้อ่านเห็นทั้งศักยภาพและขอบเขตการประยุกต์ใช้เทคโนโลยีนี้ในบริบทของระบบการเงินไทย
1) บทนำ: ทำไมเรื่องนี้จึงสำคัญต่อธนาคารไทย
บทนำ: ทำไมเรื่องนี้จึงสำคัญต่อธนาคารไทย
ในช่วงไม่กี่ปีที่ผ่านมา สถาบันการเงินในภูมิภาคเอเชียตะวันออกเฉียงใต้รวมถึงประเทศไทยได้เร่งลงทุนในเทคโนโลยีปัญญาประดิษฐ์และแมชชีนเลิร์นนิงเพื่อเพิ่มประสิทธิภาพการดำเนินงานและสร้างรายได้ใหม่ การสำรวจเชิงอุตสาหกรรมหลายฉบับชี้ว่า มากกว่า 50–70% ของธนาคารและสถาบันการเงินกำลังทดลองหรือขยายการใช้ AI/ML ในกระบวนการด้านความเสี่ยง การให้สินเชื่อ และการตลาด การเคลื่อนไหวนี้ไม่ได้เกิดขึ้นเพียงเพราะโอกาสทางธุรกิจเท่านั้น แต่ยังได้รับแรงกดดันจากกรอบกำกับดูแลที่เข้มงวดขึ้นและความคาดหวังด้านความรับผิดชอบต่อสังคม (social responsibility) ของผู้มีส่วนได้ส่วนเสียด้วย
หนึ่งในความท้าทายสำคัญคือธนาคารต้องมีเครื่องมือที่สามารถวัดผลเชิงนโยบายในมิติของ เหตุ-ผลเชิงสาเหตุ (causal impact) ไม่ใช่เพียงความสัมพันธ์เชิงสถิติแบบเดิม การใช้โมเดลที่พึ่งพาความสัมพันธ์เพียงอย่างเดียวอาจนำไปสู่การตัดสินใจที่ปล่อยให้เกิดอคติหรือผลกระทบด้านสังคมต่อกลุ่มเปราะบาง เช่น ผู้สูงอายุ ผู้มีรายได้น้อย หรือผู้ที่ไม่มีประวัติทางการเงินเพียงพอ ผู้กำกับดูแลทั้งในประเทศและระดับภูมิภาคจึงให้ความสำคัญกับความโปร่งใส ความเป็นธรรม และการประเมินผลกระทบต่อผู้บริโภค ทำให้ความสามารถในการชี้ชัดว่า “นโยบายนี้เป็นสาเหตุของผลลัพธ์ใด” กลายเป็นปัจจัยจำเป็นสำหรับการออกแบบนโยบายสินเชื่อและโปรโมชั่น
การประยุกต์ใช้ Causal ML และการวิเคราะห์ counterfactual ยังเปิดโอกาสเชิงธุรกิจเชิงสำคัญ โดยเฉพาะเมื่อผสานกับระบบการตัดสินใจแบบเรียลไทม์ ธนาคารสามารถปรับข้อเสนอสินเชื่อหรือโปรโมชันให้เหมาะสมกับบริบทและความเสี่ยงของลูกค้าแต่ละรายแบบทันที ลดความเสี่ยงในการนำเสนอสินค้าที่ไม่เหมาะสม และเพิ่มอัตราการตอบรับจากลูกค้า ตัวอย่างจากการทดลองนำร่องในภูมิภาคชี้ว่า การออกแบบโปรโมชั่นบนพื้นฐานของการวิเคราะห์เชิงสาเหตุสามารถเพิ่มอัตราการแปลง (conversion) ได้ในกรอบประมาณ 5–15% ขณะที่อัตรา default หรือผลกระทบเชิงลบต่อกลุ่มเปราะบางลดลงในระดับที่มีนัยสำคัญทางธุรกิจ (ตัวเลขจะแตกต่างกันตามบริบทและข้อมูลของแต่ละสถาบัน)
โดยสรุป ความสนใจของธนาคารไทยที่เพิ่มขึ้นต่อ Causal ML และ Counterfactual Analysis มาจากการผสานปัจจัยหลายด้านทั้งแรงกดดันจากผู้กำกับดูแล ความเสี่ยงทางสังคมที่ต้องบริหารจัดการ และโอกาสทางธุรกิจในการทำ personalization แบบเรียลไทม์ ซึ่งช่วยให้การกำหนดนโยบายสินเชื่อและโปรโมชั่นมีทั้งประสิทธิผลและมีความรับผิดชอบต่อสังคมมากยิ่งขึ้น
- แรงกดดันจากผู้กำกับดูแล: หน่วยงานกำกับดูแลเน้นความโปร่งใส ความเป็นธรรม และการประเมินผลกระทบต่อผู้บริโภค
- ต้องการเครื่องมือเชิงสาเหตุ: การวัด causal impact จำเป็นต่อการแยกสาเหตุจากความสัมพันธ์และลดความเสี่ยงของการตัดสินใจที่มีอคติ
- โอกาสเชิงธุรกิจจากการปรับแบบเรียลไทม์: การปรับโปรโมชั่นและข้อเสนอสินเชื่อตามผลเชิงสาเหตุแบบเรียลไทม์ช่วยลดความเสี่ยง เพิ่มการตอบรับ และยกระดับรายได้
2) Causal ML และ Counterfactual Analysis คืออะไร — อธิบายแบบไม่เชิงเทคนิค
2) Causal ML และ Counterfactual Analysis คืออะไร — อธิบายแบบไม่เชิงเทคนิค
Causal Machine Learning (Causal ML) คือกรอบการวิเคราะห์เชิงสาเหตุที่ออกแบบมาเพื่อตอบคำถามว่า การกระทำหนึ่ง ๆ (เช่น การให้ส่วนลดดอกเบี้ย หรือการเสนอโปรโมชั่นสินเชื่อ) มีผลเชิงสาเหตุต่อผลลัพธ์ที่เราสนใจอย่างไร ต่างจากการทำโมเดลคาดการณ์แบบเดิมที่มักมุ่งเพียงทำนายว่าเหตุการณ์จะเกิดหรือไม่ Causal ML สนใจวัดขนาดของผลกระทบ (treatment effect) ทั้งในภาพรวมของประชากรและในระดับรายบุคคล เพื่อให้ผู้บริหารสามารถตัดสินใจเชิงนโยบายโดยคำนึงถึงสาเหตุจริง ไม่ใช่ความสัมพันธ์ที่อาจเกิดจากปัจจัยอื่น ๆ
ความแตกต่างสำคัญระหว่างการคาดการณ์ (prediction) กับการวิเคราะห์เชิงสาเหตุ (causation) คือ การคาดการณ์ตอบว่า "อะไรจะเกิดขึ้น" ในขณะที่การวิเคราะห์เชิงสาเหตุตอบว่า "อะไรเป็นสาเหตุให้เกิด" ตัวอย่างเชิงภาพ: โมเดลคาดการณ์อาจบอกว่า ลูกค้ากลุ่มหนึ่งมีความเสี่ยงสูงที่จะผิดนัดชำระ แต่ไม่บอกว่า ถ้าปรับลดอัตราดอกเบี้ยให้กลุ่มนี้จะช่วยลดการผิดนัดได้จริงหรือไม่ ขณะที่ Causal ML จะพยายามประเมินว่า การลดอัตราดอกเบี้ยเป็นสาเหตุโดยตรง ที่ลดอัตราการผิดนัดหรือเพียงแค่สัมพันธ์กับปัจจัยอื่น ๆ เช่น ประวัติการชำระเงินหรือสถานะทางการเงิน
อีกเครื่องมือที่สำคัญคือ Counterfactual Analysis ซึ่งตอบคำถามแบบ "จะเกิดอะไรขึ้นถ้า..." — เช่น "จะเกิดอะไรขึ้นถ้าเราปรับเงื่อนไขสินเชื่อให้กับลูกค้ากลุ่ม A?" หรือ "ถ้าไม่ให้โปรโมชั่นนี้ ผลลัพธ์จะเป็นอย่างไร?" Counterfactual ไม่ได้ดูเฉพาะสิ่งที่เกิดขึ้นแล้ว แต่จำลองสถานการณ์ทางเลือกที่ไม่ได้เกิดขึ้นในความจริง (the road not taken) เพื่อประเมินผลกระทบของนโยบายต่าง ๆ ตัวอย่างเชิงปฏิบัติ: ธนาคารอาจใช้ counterfactual เพื่อเปรียบเทียบอัตราการผิดนัดในกลุ่มลูกค้าที่ได้รับการลดดอกเบี้ยกับผลลัพธ์ที่คาดว่าจะเกิดขึ้นหากกลุ่มเดียวกันไม่ได้รับการลดดอกเบี้ย
เทคนิคที่นิยมใช้ในงานนี้รวมถึง:
- Propensity score — การจับคู่หรือปรับน้ำหนักเพื่อลดอคติจากความแตกต่างเชิงพื้นฐานระหว่างกลุ่มที่ได้รับการรักษา (treated) และที่ไม่ได้รับ
- Causal forests — ต้นไม้ตัดสินใจที่ออกแบบมาเพื่อประมาณ treatment effect ในระดับบุคคล (heterogeneous treatment effects)
- Double/Debaised ML — วิธีการที่รวมโมเดลการคาดการณ์หลายตัวเพื่อให้ได้การประมาณเชิงสาเหตุที่ทนทานต่อการบิดเบือนของตัวแปรรบกวน
- Synthetic controls — การสร้างกลุ่มเปรียบเทียบแบบสังเคราะห์จากชุดข้อมูลของหน่วยอื่น ๆ เมื่อต้องประเมินผลนโยบายในระดับองค์กรหรือภูมิภาค
ตัวอย่างง่าย ๆ ในบริบทธนาคาร: สมมติธนาคารปรับลดอัตราดอกเบี้ยสินเชื่อฉุกเฉินสำหรับกลุ่มลูกค้าช่วงรายได้ต่ำ โมเดลคาดการณ์อาจบอกว่าอัตราการผิดนัดลดลงจาก 6% เป็น 4% หลังมาตรการ แต่คำถามเชิงสาเหตุคือ "การลดดอกเบี้ยเป็นสาเหตุที่แท้จริงหรือไม่" Causal ML และ counterfactual analysis จะช่วยประเมินว่า ถ้ากลุ่มเดียวกันไม่ได้รับการลดดอกเบี้ย ผลลัพธ์จะยังคงเป็น 6% หรือไม่ — หากการวิเคราะห์ชี้ว่าการลดดอกเบี้ยลดการผิดนัดลงจริง ธนาคารก็มีข้อมูลเชิงสาเหตุที่แข็งแรงพอจะขยายหรือปรับนโยบายต่อไป
สรุปคือ Causal ML และ Counterfactual Analysis ช่วยให้หน่วยงานทางการเงินเปลี่ยนจากการตัดสินใจโดยอาศัยความสัมพันธ์หรือการคาดเดา มาเป็นการตัดสินใจเชิงนโยบายที่มีหลักฐานเชิงสาเหตุ รองรับการออกแบบโปรโมชั่นและสินเชื่อที่ลดความเสี่ยงต่อกลุ่มเปราะบางได้อย่างมีประสิทธิภาพและเป็นธรรม
3) เหตุผลเชิงปฏิบัติที่ธนาคารนำไปใช้ได้จริง
3) เหตุผลเชิงปฏิบัติที่ธนาคารนำไปใช้ได้จริง
การประยุกต์ใช้ Causal ML และการวิเคราะห์ Counterfactual ในการบริหารนโยบายสินเชื่อและโปรโมชั่นให้ผลในเชิงปฏิบัติที่ชัดเจนสำหรับธนาคาร เชิงธุรกิจหลักคือความสามารถในการระบุและจัดการกับความแตกต่างของการตอบสนองในกลุ่มลูกค้าที่ต่างกันหรือที่เรียกว่า Heterogeneous Treatment Effects การวิเคราะห์เชิงสาเหตุช่วยให้ธนาคารแยกแยะได้ว่าแคมเปญหรือการปรับเงื่อนไขสินเชื่อมีผลต่อกลุ่มลูกค้าบางกลุ่มอย่างไร — บางกลุ่มเพิ่มการกู้ยืมและการใช้จ่าย ในขณะที่บางกลุ่มอาจเสี่ยงต่อการผิดนัดชำระหรือได้รับภาระทางการเงินเพิ่มขึ้น การรู้ข้อมูลนี้ช่วยให้การออกแบบนโยบายมีความแม่นยำและเป็นธรรมมากขึ้น
ในมุมปฏิบัติ ธนาคารสามารถนำผลวิเคราะห์ดังกล่าวมาใช้เพื่อลดความเสี่ยงที่นโยบายหรือโปรโมชั่นจะส่งผลกระทบต่อกลุ่มเปราะบางอย่างไม่เป็นสัดส่วน ตัวอย่างเช่น การวิเคราะห์ counterfactual สามารถชี้ให้เห็นว่าโปรโมชั่นลดดอกเบี้ยสำหรับวงเงินสินเชื่อหมุนเวียนอาจเพิ่มการก่อหนี้ในกลุ่มผู้มีรายได้น้อยได้มากกว่ากลุ่มอื่น หากธนาคารไม่ปรับ กลุ่มเปราะบางอาจเผชิญความเสี่ยงต่อการติดหนี้เพิ่มขึ้น การใช้โมเดลเชิงสาเหตุจึงช่วยในการออกแบบข้อเสนอที่มีข้อจำกัดหรือการให้คำแนะนำแบบเฉพาะกลุ่ม (targeted guardrails) เพื่อลดผลข้างเคียงดังกล่าว
การปรับโปรโมชั่นแบบ ไดนามิก (real-time) เป็นอีกเหตุผลเชิงปฏิบัติที่สำคัญ เมื่อระบบเชื่อมต่อกับข้อมูลพฤติกรรมลูกค้าแบบเรียลไทม์และฟีดแบ็กจากการทดลองเล็ก ๆ (A/B หรือ quasi-experimental) โมเดล causal ML สามารถประเมินผลลัพธ์เชิงสาเหตุทันทีและแนะนำการแก้ไขแคมเปญภายในชั่วโมงหรือวัน ซึ่งช่วยลด ค่าเสียโอกาส และ ค่าเสียหาย ตัวอย่างเช่น ธนาคารที่ทดสอบโปรโมชั่นบัตรเครดิตอาจปรับวงเงินหรือข้อเสนอสำหรับเซกเมนต์ที่วิเคราะห์แล้วว่ามีความเสี่ยงสูง ส่งผลให้ลดอัตราการผิดนัดและเพิ่ม ROI ของแคมเปญได้อย่างมีนัยสำคัญ
ในเชิงธุรกิจ ยังมีผลประหยัดต้นทุนและเพิ่มประสิทธิภาพการบริหารพอร์ตสินเชื่อได้ชัดเจน ดังนี้
- ลดต้นทุนของการให้สิทธิ์ที่ไม่จำเป็น: การกำหนดกลุ่มเป้าหมายด้วยโมเดล uplift ช่วยให้ธนาคารไม่ต้องแจกโปรโมชั่นให้ลูกค้าที่ไม่มีโอกาสตอบสนอง ส่งผลให้ประหยัดต้นทุนโปรโมชั่นได้มากขึ้น
- ลดความเสี่ยงของพอร์ต (credit risk mitigation): การปรับนโยบายตามผลเชิงสาเหตุช่วยลดการสะสมของลูกค้ากลุ่มที่มีแนวโน้มผิดนัด ซึ่งช่วยลดอัตรา default rate ของพอร์ตโดยรวม
- เพิ่มประสิทธิภาพการสำรองเงิน (capital efficiency): การลดความไม่แน่นอนเชิงนโยบายทำให้การประเมินความเสี่ยงและการตั้งสำรองมีความแม่นยำมากขึ้น ส่งผลให้สามารถใช้ทุนได้อย่างมีประสิทธิภาพ
- ปกป้องภาพลักษณ์และลดความเสี่ยงด้านกฎระเบียบ: การสามารถอธิบายเชิงสาเหตุว่าทำไมนโยบายหนึ่ง ๆ ถูกปรับเปลี่ยนหรือจำกัด จะช่วยลดความเสี่ยงด้านการถูกตรวจสอบจากหน่วยงานกำกับและการฟ้องร้องทางสังคม
สรุปได้ว่า การนำ Causal ML และ Counterfactual Analysis มาใช้ในธนาคารไม่ใช่เพียงเทคโนโลยีเชิงทดลอง แต่เป็นเครื่องมือเชิงปฏิบัติที่ช่วยให้การตัดสินใจด้านนโยบายสินเชื่อและโปรโมชั่นมีความละเอียดระดับกลุ่มย่อย ปรับได้ตามสถานะการณ์จริง และลดผลกระทบต่อกลุ่มเปราะบาง ในทางปฏิบัติ ธนาคารที่ลงทุนในโครงสร้างข้อมูลที่รองรับการวิเคราะห์เชิงสาเหตุและระบบการตัดสินใจแบบเรียลไทม์ จะได้เปรียบเชิงแข่งขันทั้งในด้านต้นทุน ความเสี่ยง และความยั่งยืนของพอร์ตการให้สินเชื่อ
4) กรณีใช้งานจริง: วัดผลโปรโมชันสินเชื่อแบบเรียลไทม์ (ตัวอย่างเชิงตัวเลข)
4) กรณีใช้งานจริง: วัดผลโปรโมชันสินเชื่อแบบเรียลไทม์ (ตัวอย่างเชิงตัวเลข)
สมมติธนาคารทดลองโปรโมชันลดอัตราดอกเบี้ย 1.5% ให้กับกลุ่มลูกค้าเป้าหมาย (treatment) และเปรียบเทียบกับกลุ่มควบคุม (control) เพื่อวัดผลต่ออัตราการผิดนัดชำระ (default rate) โดยใช้เครื่องมือ Causal ML และการวิเคราะห์ counterfactual แบบเรียลไทม์ จุดประสงค์คือหา Average Treatment Effect (ATE) เพื่อดูผลรวม และ Conditional Average Treatment Effect (CATE) เพื่อตรวจสอบผลต่างตามเซ็กเมนต์ เช่น ผู้มีรายได้ต่ำ หรือผู้ที่มีพอร์ตเครดิตอ่อน

การออกแบบการทดลองและการกำหนด counterfactual สามารถทำได้ทั้งในรูปแบบ randomized controlled trial (RCT) หรือวิธี quasi-experimental เมื่อการสุ่มไม่ได้สะดวก เช่น
- ใช้การสุ่มเชิงปฏิบัติ (cluster randomization) เพื่อกระจายความเสี่ยง
- ใช้ propensity score matching หรือ inverse probability weighting เพื่อสร้างกลุ่มควบคุมเชิงเทียมเมื่อการสุ่มไม่สมบูรณ์
- ใช้ difference-in-differences เมื่อมีข้อมูลก่อน-หลัง และมีกลุ่มเปรียบเทียบที่มีแนวโน้มก่อนหน้าใกล้เคียง
- ใช้โมเดลแบบ causal forest หรือ doubly robust estimators เพื่อประเมิน CATE แบบไม่ต้องอาศัยสมมติฐานเชิงเส้นมาก
ตัวอย่างเชิงตัวเลข (ตัวเลขสมมติและคำนวณพื้นฐาน): สมมติทำ RCT ขนาดเท่ากัน
- Ntreatment = 50,000, Ncontrol = 50,000
- อัตรา default ในกลุ่มควบคุม observed = 3.5% (0.035)
- อัตรา default ในกลุ่ม treatment observed = 3.0% (0.030)
คำนวณ ATE (โดยประมาณ):
- ATE = E[Y(1) − Y(0)] ≈ mean(default|treatment) − mean(default|control)
- ATE = 0.030 − 0.035 = −0.005 (เท่ากับลดอัตรา default 0.5 percentage points)
- ถ้าค่า 95% CI จากการบูตสแตร็ปหรือสมการความคลาดเคลื่อนอยู่ที่ [−0.007, −0.003] และ p‑value < 0.01 → ผลลด default โดยรวมมีนัยสำคัญทางสถิติ
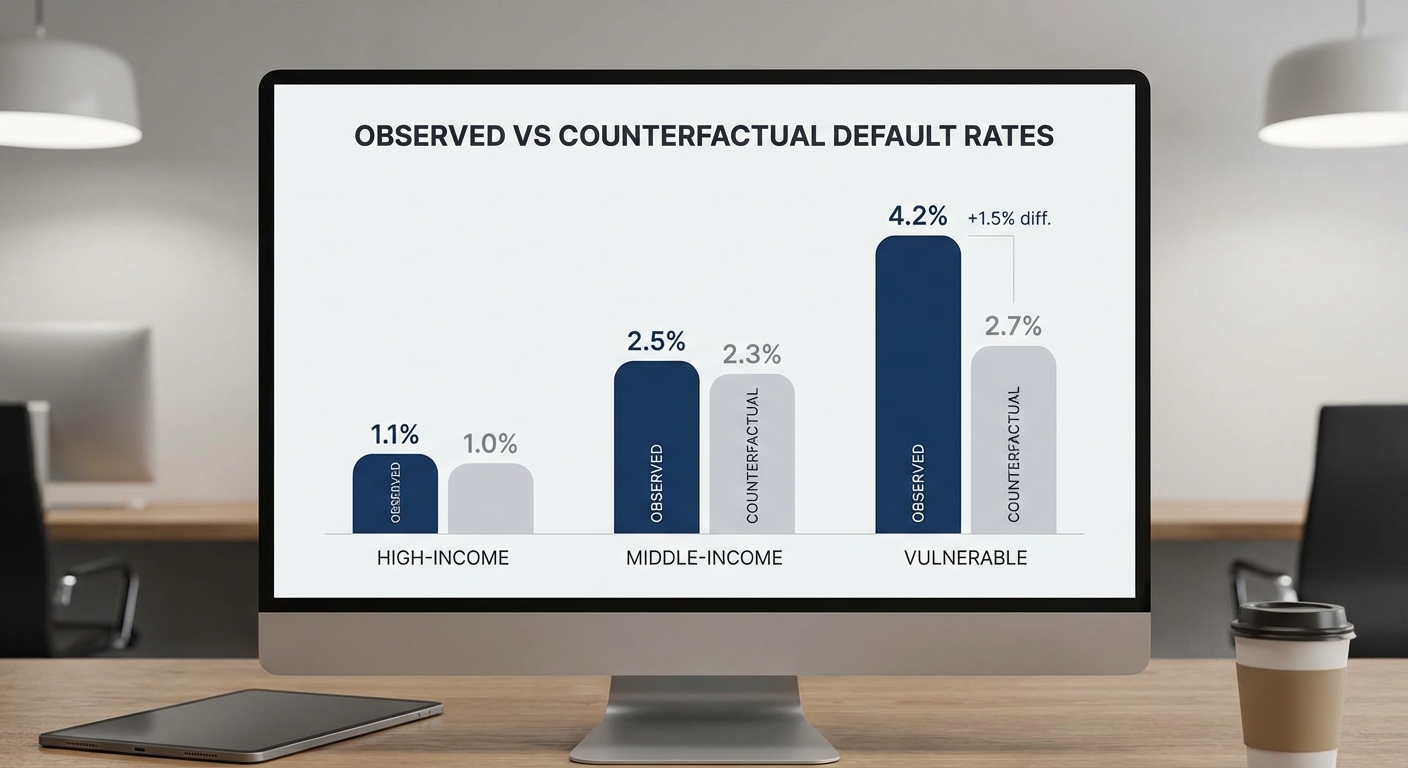
แต่การดูเพียง ATE อาจปกปิดผลกระทบที่ไม่พึงประสงค์ต่อกลุ่มเปราะบาง ดังตัวอย่าง CATE:
- กลุ่มผู้มีรายได้ต่ำ (low-income): default ใน control = 4.0% (0.040), default ใน treatment = 4.8% (0.048)
- CATE_low-income = 0.048 − 0.040 = +0.008 (เพิ่มขึ้น 0.8 percentage points)
- กลุ่มผู้มีเครดิตพอร์ตค่อนข้างอ่อน (weak-credit): สมมติ CATE_weak-credit = +0.006 (เพิ่มขึ้น 0.6 p.p.)
การตีความ: แม้ ATE โดยรวมจะบอกว่าการลดดอกเบี้ย 1.5% ช่วยลด default โดยรวม 0.5 p.p. แต่ผลของ CATE แสดงว่า กลุ่มเปราะบางได้รับผลกระทบด้านลบ (default เพิ่มขึ้น 0.8 p.p. ในกลุ่มรายได้ต่ำ) ซึ่งเป็นสัญญาณว่ามาตรการดังกล่าวทำให้ความเสี่ยงถูกย้ายไปยังกลุ่มที่อาจรับผลกระทบรุนแรงกว่า
แนวทางการตัดสินใจเชิงนโยบายจากผลลัพธ์เรียลไทม์:
- ตั้งเกณฑ์ทางปฏิบัติ เช่น หาก CATE ของกลุ่มใดมีการเพิ่มของ default > 0.5 p.p. ให้หยุดหรือทบทวนโปรโมชันทันที
- ใช้การวิเคราะห์แบบต่อเนื่อง (sequential monitoring) และปรับโมเดลทุกสัปดาห์/ทุกเดือนเพื่อจับสัญญาณเร็ว เช่น ใช้ online causal inference หรือ contextual bandit สำหรับการจัดสรรโปรโมชันแบบไดนามิก
- หากพบผลกระทบเชิงลบต่อกลุ่มเปราะบาง ให้ดำเนินมาตรการบรรเทา เช่น ระงับการมอบโปรโมชันแก่เซ็กเมนต์นั้น ปรับเงื่อนไข (ขนาดวงเงิน ระยะเวลา) หรือออกโปรแกรมสนับสนุนทางการเงิน/ให้คำปรึกษาเฉพาะกลุ่ม
- ใช้การควบคุมหลายการทดสอบ (เช่น Benjamini–Hochberg) และรายงานความไม่แน่นอน (CI, p‑value) ก่อนตัดสินใจเชิงนโยบาย
สรุป: การนำ Causal ML และ counterfactual analysis มาใช้ช่วยให้ธนาคารสามารถวัดผลโปรโมชันแบบเรียลไทม์ได้อย่างมีนัยสำคัญทั้งในระดับรวม (ATE) และตามเซ็กเมนต์ (CATE) — ซึ่งเป็นสิ่งจำเป็นเพื่อป้องกันไม่ให้มาตรการส่งผลกระทบทางลบต่อกลุ่มเปราะบาง แม้ผลรวมจะดูดีก็ตาม การกำหนดเกณฑ์การเฝ้าระวังและมาตรการแก้ไขทันที (เช่น หยุดโปรโมชัน ปรับเป้าหมาย หรือให้การสนับสนุนเฉพาะกลุ่ม) ควรถูกบูรณาการเป็นส่วนหนึ่งของกระบวนการตัดสินใจทางนโยบาย
5) แหล่งข้อมูล ตัวชี้วัด และความท้าทายทางเทคนิค
5) แหล่งข้อมูล ตัวชี้วัด และความท้าทายทางเทคนิค
การนำ Causal ML และ Counterfactual Analysis มาประยุกต์ใช้ในระบบสินเชื่อและโปรโมชั่นแบบเรียลไทม์สำหรับธนาคารไทย จำเป็นต้องอาศัยชุดข้อมูลที่หลากหลายและมีความละเอียดสูง โดยเฉพาะอย่างยิ่งต้องมีทั้ง ข้อมูลระดับรายการ (transactional) และ ข้อมูลผู้ใช้ (demographics, credit score) เพื่อให้สามารถระบุผลเชิงสาเหตุต่อพฤติกรรมและความเสี่ยงของลูกค้าได้อย่างแม่นยำ ตัวอย่างข้อมูลสำคัญได้แก่:
- Transactional data — รายการการใช้จ่าย ยอดคงเหลือ การชำระคืน วัน/เวลาทำธุรกรรม และรายละเอียดผลิตภัณฑ์ที่รับหรือปฏิเสธ (ตัวอย่าง: ประวัติ 12–24 เดือน, ความถี่การใช้จ่ายต่อหมวดหมู่)
- Credit bureau / credit score — คะแนนเครดิต ประวัติสินเชื่อภายนอก การผิดนัดชำระหนี้ (สำหรับการประเมินความเสี่ยงระยะยาว)
- Socio‑demographic — อายุ เพศ รายได้ กลุ่มอาชีพ ที่อยู่ (ระดับพื้นที่) เพื่อวิเคราะห์ผลกระทบเชิงกลุ่มและวัดมาตรฐานความเป็นธรรม
- Interaction logs — ประวัติการตอบรับข้อเสนอ คลิก การเปิดอีเมล แชท และแอตทริบิวชันของแคมเปญ (จำเป็นสำหรับการวัด uplift และการทำ attribution แบบ causal)
- ระบบเหตุการณ์เวลาจริง — สตรีมเหตุการณ์ (event stream) สำหรับการให้คะแนนแบบเรียลไทม์และการอัปเดตคุณลักษณะ (feature) เช่น session features, recent behavior window
สำหรับการประเมินผลทางนโยบายและการควบคุมผลกระทบต่อกลุ่มเปราะบาง ควรใช้ชุดมาตรวัดที่ครอบคลุมทั้งผลรวมและผลแบบมีเงื่อนไข ดังนี้:
- Average Treatment Effect (ATE) — ผลเฉลี่ยของนโยบาย (เช่น โปรโมชั่น) ต่อกลุ่มประชากรทั้งหมด (ตัวอย่าง: ATE = 0.03 แปลว่าโปรโมชั่นเพิ่มอัตราอนุมัติ/conversion 3%)
- Conditional Average Treatment Effect (CATE) — ผลเฉลี่ยตามกลุ่ม/บุคคล เช่น CATE แยกตามระดับรายได้หรือคะแนนเครดิต (ตัวอย่าง: CATE รายได้สูง = 0.05, CATE กลุ่มเปราะบาง = −0.01 ชี้ให้เห็นว่ามาตรการมีประโยชน์ต่างกันข้ามกลุ่ม)
- Uplift — การเพิ่มขึ้นของพฤติกรรมที่ตั้งใจวัดหลังได้รับการแทรกแซง (สำคัญสำหรับการจัดสรรโปรโมชั่นแบบกำหนดเป้าหมาย)
- Fairness metrics — เช่น disparate impact (อัตราสัดส่วนผลลัพธ์ระหว่างกลุ่ม, ใช้กฎ 0.8 เป็นเกณฑ์อ้างอิง), false positive rate by group (FPR แยกตามกลุ่ม) และความแตกต่างของ CATE ข้ามกลุ่ม เพื่อประเมินผลกระทบเชิงนโยบายต่อกลุ่มเปราะบาง
แม้มีข้อมูลและมาตรวัดครบถ้วน จะต้องเผชิญกับความท้าทายทางเทคนิคหลายประการ ซึ่งหากไม่จัดการอาจบิดเบือนการตีความหรือสร้างความเสี่ยงด้านความเป็นธรรมได้:
- Confounding bias และ selection bias — ลูกค้าที่ได้รับโปรโมชั่นอาจแตกต่างจากกลุ่มควบคุมในปัจจัยที่ไม่ได้สังเกต (unobserved confounders) ทำให้การตีความสาเหตุผิดพลาด แนวทางบรรเทา: ออกแบบการทดลองสุ่ม (A/B หรือ encouragement designs) เมื่อเป็นไปได้; ใช้เครื่องมือเชิงสาเหตุ เช่น instrumental variables, propensity score methods, doubly robust estimators และการทำ sensitivity analysis เพื่อตรวจสอบความทนทานของผล
- Data sparsity และ limited label availability — ป้ายกำกับสำคัญ (เช่นการผิดนัดชำระ) อาจเกิดขึ้นหลังผ่านไประยะยาว หรือในกลุ่มเล็กทำให้ตัวอย่างน้อย แนวทางบรรเทา: ใช้ survival analysis/competing risk models สำหรับผลลัพธ์ยาวนาน, pooling ข้อมูลโดยใช้ hierarchical models, semi‑supervised learning, และการสร้าง proxy labels ที่แสดงผลเชิงสัญญาณชั่วคราว เช่น atraso 30 วันเป็น proxy สำหรับความเสี่ยง
- Data drift และ concept drift — พฤติกรรมลูกค้า เศรษฐกิจ และนโยบายมีการเปลี่ยนแปลง ทำให้โมเดลที่ฝึกในอดีตไม่สอดคล้องกับปัจจุบัน แนวทางบรรเทา: ติดตั้งระบบตรวจจับ drift (เช่น PSI, KL divergence, drift detectors), ตั้งกระบวนการ re‑training แบบกำหนดเงื่อนไข และใช้ online learning หรือ incremental update เพื่อลดการล้าสมัย
- Latency และการอัปเดตแบบเรียลไทม์ — การให้คะแนนเชิงสาเหตุแบบเรียลไทม์ต้องการ pipeline ที่รวดเร็วและ feature store ที่สามารถอ่าน/เขียนได้ทันเวลา แนวทางบรรเทา: แยกการคำนวนเป็น offline (precomputed features, embeddings) และ online (recent-session features), ใช้ caching และ approximate algorithms เพื่อให้ latency ต่ำ (ตัวอย่างเป้าหมายเชิงปฏิบัติ: <100–200 ms สำหรับการตัดสินใจลูกค้าที่มีปฏิสัมพันธ์แบบเรียลไทม์)
- ความเป็นส่วนตัวและความปลอดภัยของข้อมูล — การเชื่อมโยงข้อมูลระดับรายการกับข้อมูลบุคคลจำเป็นต้องคำนึงถึงกฎ PDPA และแนวปฏิบัติด้านความเป็นส่วนตัว แนวทางบรรเทา: ใช้การลบข้อมูลระบุตัวตน, aggregation ในระดับที่ปลอดภัย, differential privacy เจือจาง (where required), และเทคนิคการทำงานร่วมกันแบบปลอดภัย (SMPC, federated learning) เมื่อไม่สามารถย้ายข้อมูลได้
เพื่อให้ระบบประเมินเชิงสาเหตุทำงานได้จริงในบริบทธนาคารไทย แนะนำแนวทางปฏิบัติผสมผสานดังนี้: เริ่มด้วยการออกแบบการทดลองหรือ quasi‑experimental เมื่อเป็นไปได้เพื่อรับตัวชี้วัด ATE ที่เชื่อถือได้ ประกอบด้วยการวัด CATE/Uplift เพื่อระบุผลต่างผ่านกลุ่มประชากร จากนั้นติดตั้งระบบมอนิเตอร์ด้าน drift และ fairness (เช่น รายงานความแตกต่างของ FPR, disparate impact per cohort เป็นรายสัปดาห์/รายวัน) สุดท้ายให้มีกระบวนการไร้สัมประสิทธิ์ (robustness tests, sensitivity analysis) และแผนการแก้ไขอัตโนมัติเมื่อค้นพบ bias หรือ degradation ของโมเดล เพื่อปกป้องกลุ่มเปราะบางและคงความสอดคล้องของนโยบายสินเชื่อในระยะยาว
6) จริยธรรม กฎระเบียบ และการปกป้องกลุ่มเปราะบาง
6) จริยธรรม กฎระเบียบ และการปกป้องกลุ่มเปราะบาง
การนำ Causal ML และ Counterfactual Analysis มาใช้ในการตัดสินใจเชิงนโยบายสินเชื่อและโปรโมชั่นแบบเรียลไทม์ของธนาคาร ต้องมาพร้อมกับกรอบจริยธรรมและการกำกับดูแลที่เข้มแข็ง เพื่อป้องกันผลกระทบด้านลบต่อกลุ่มเปราะบาง ตัวอย่างความเสี่ยงที่พบบ่อยได้แก่ การเลือกปฏิบัติที่ไม่ตั้งใจ (unintentional discrimination) เพราะตัวแปรสังเคราะห์หรือ proxy variables ที่เชื่อมโยงกับเชื้อชาติ เพศ หรือพื้นที่อยู่อาศัย นอกจากนี้ยังมีความเสี่ยงจากความไม่โปร่งใสของโมเดล (black-box) ที่ทำให้ผู้กำกับดูแลและลูกค้าไม่เข้าใจเหตุผลเบื้องหลังการปฏิเสธหรือการให้เงื่อนไขที่แตกต่างกัน
เพื่อจัดการกับความเสี่ยงเหล่านี้ ธนาคารควรจัดให้มีการทดสอบความเป็นธรรม (fairness testing) ทั้งก่อนและหลังการใช้งานจริง โดยกำหนดมาตรฐานการตรวจวัด เช่น demographic parity และ equalized odds รวมถึงกำหนดเกณฑ์ความแตกต่างสูงสุดที่ยอมรับได้ (disparity thresholds) เช่น ไม่เกิน 5–10% ของอัตราการอนุมัติระหว่างกลุ่มประชากรสำคัญ การตรวจสอบผลกระทบควรถูกบันทึกและรายงานต่อหน่วยงานกำกับดูแลอย่างสม่ำเสมอ — ตัวอย่างเช่น รายงานรายไตรมาสที่แสดงผลกระทบเชิง Demographic, รายงานเหตุการณ์ความเสี่ยง และแผนการแก้ไขเมื่อพบความเบี่ยงเบน
ในระดับการปกป้องกลุ่มเปราะบาง ควรมีมาตรการเชิงปฏิบัติที่ชัดเจน ได้แก่
- Threshold protection: หลีกเลี่ยงการตัดสินใจอัตโนมัติสำหรับผู้ที่มีคะแนนหรือสัญญาณเสี่ยงใกล้เคียงเกณฑ์ตัดสิน ด้วยการกำหนด dead zone ที่ต้องส่งเข้าสู่การทบทวนด้วยคน (manual review)
- Manual review: จัดทีมผู้เชี่ยวชาญหรือหน่วยงานปฏิบัติการเพื่อทบทวนกรณีที่มีความเสี่ยงสูงหรือที่อาจกระทบกลุ่มเปราะบาง โดยต้องมีขั้นตอนการบันทึกเหตุผลและการทวนผลลัพธ์เพื่อความโปร่งใส
- Targeted relief and remediation: หากมีการตรวจพบผลกระทบทางสังคมอย่างมีนัยสำคัญต้องมีมาตรการชดเชย เช่น การเสนอเงื่อนไขสินเชื่อทดแทน การเยียวยาทางการเงิน หรือโปรแกรมสนับสนุนเฉพาะกลุ่ม
นโยบายการกำกับดูแล (governance) ของโมเดลต้องรวมองค์ประกอบสำคัญเช่น model registry ที่บันทึกรุ่นโมเดล สถานะการทดสอบ และสเปคการใช้งาน, audit trails ที่เก็บล็อกการตัดสินใจและการเปลี่ยนแปลงโค้ดอย่างไม่เปลี่ยนแปลงได้ (immutable logs), รวมถึงการควบคุมการเข้าถึงแบบ role-based เพื่อป้องกันการเปลี่ยนแปลงโดยไม่ได้รับอนุญาต การมี registry ยังเอื้อต่อการย้อนกลับ (rollback) ไปยังรุ่นที่ปลอดภัยเมื่อพบปัญหา
Impact assessments ควรเป็นขั้นตอนบังคับทั้งในช่วงก่อนการนำโมเดลขึ้นใช้งาน (pre-deployment impact assessment) และการติดตามผลหลังการใช้งาน (post-deployment monitoring) โดยการประเมินล่วงหน้าควรรวมการทดลองเชิงนโยบาย (pilot) ที่ใช้ counterfactual analysis เพื่อคาดการณ์ผลทางสังคมและเศรษฐกิจ การติดตามหลังใช้งานควรรวมดัชนีชี้วัดเช่น อัตราการปฏิเสธของกลุ่มเปราะบาง การเปลี่ยนแปลงความสามารถในการเข้าถึงสินเชื่อ และการร้องเรียนจากลูกค้า โดยหากพบผลกระทบรุนแรงให้มี rollback rules ชัดเจน เช่น ระงับการใช้งานทันที เปิดการสอบสวนภายในภายใน 72 ชั่วโมง และกำหนดการแก้ไขภายในกรอบเวลาที่แจ้งไว้ต่อผู้กำกับดูแล
สุดท้าย การออกแบบระบบควรยึดหลัก human-in-the-loop ตลอดวงจรการตัดสินใจ เพื่อให้การตัดสินใจเชิงนโยบายยังคงมีการทบทวนโดยมนุษย์ในกรณีที่มีความสุ่มซับซ้อนหรือความเสี่ยงต่อสิทธิมนุษยชน ตัวอย่างเช่น กรณีที่โมเดลแนะนำการปฏิเสธสินเชื่อกับผู้สูงอายุหรือพื้นที่มีรายได้ต่ำ ควรต้องมีขั้นตอนการตรวจสอบโดยผู้ปฏิบัติงานที่ได้รับการฝึกอบรม พร้อมทั้งมีช่องทางการอุทธรณ์ที่เข้าถึงได้ง่ายสำหรับลูกค้า
7) แนวทางปฏิบัติและขั้นตอนการนำไปใช้งาน (deployment & governance)
7) แนวทางปฏิบัติและขั้นตอนการนำไปใช้งาน (deployment & governance)
สรุปแนวทางแบบเป็นขั้นตอน (roadmap) — เพื่อให้ธนาคารสามารถนำ Causal ML และ Counterfactual Analysis ไปใช้วัดผลเชิงนโยบายสินเชื่อ‑โปรโมชั่นแบบเรียลไทม์ได้อย่างปลอดภัยและมีประสิทธิภาพ ควรเดินหน้าเป็นระยะ ๆ ดังนี้: PoC → Pilot แบบควบคุม → ขยายผลเชิงผลิต → การกำกับดูแล (governance) ระดับองค์กรมากขึ้น โดยแต่ละขั้นตอนต้องมีเกณฑ์ผ่าน (gate) ชัดเจนก่อนเลื่อนขั้น
- Phase 1 — Proof‑of‑Concept (8–12 สัปดาห์)
- เลือกกรณีใช้งานขนาดเล็ก (เช่น โปรโมชั่นสินเชื่อสำหรับพอร์ตลูกค้า 5,000–20,000 ราย) ใช้วิธี synthetic control หรือ uplift modeling เพื่อประเมิน causal effect เบื้องต้น
- กำหนดระยะก่อน/หลังอย่างน้อย 6–12 เดือนสำหรับ synthetic control และจัดทดลองแบบ randomized subset หากเป็นไปได้เพื่อยืนยัน validity
- มาตรฐานความสำเร็จตัวอย่าง: ความสอดคล้องของผลระหว่างวิธี (concordance > 80%), p‑value < 0.05 ในผล zentral metric และไม่มีสัญญาณผลกระทบเชิงลบต่อกลุ่มเปราะบางในเบื้องต้น
- Phase 2 — Pilot แบบควบคุม (3–6 เดือน)
- ขยายสเกลเป็น cohort ที่ใหญ่ขึ้นและทำการทดลองแบบควบคุม (A/B หรือ cluster randomized) เพื่อตรวจสอบผลลัพธ์แบบเรียลไทม์และความแตกต่างของกลุ่มย่อย (by income, geography, credit score)
- ติดตั้งระบบสตรีมมิงสำหรับเก็บเหตุการณ์และผลลัพธ์ (real‑time logging) เพื่อคำนวณ KPI แบบเรียลไทม์
- Checkpoint ความพร้อมเลื่อนสู่ production: false alarm rate ตามกลุ่มเป้าหมายต่ำกว่าเกณฑ์ (ตัวอย่างเป้าหมาย 5%), time‑to‑detection ภายใน 24 ชั่วโมง, และไม่มีการเพิ่มขึ้นชัดเจนของอัตรา default หลังการแทรกแซง (delta default < 0.5 percentage points ใน 90 วันแรก)
- Phase 3 — ขยายผลเชิงผลิต (production rollout)
- นำโมเดลและระบบไปใช้งานในสภาพแวดล้อม production แบบค่อยเป็นค่อยไป (canary rollout / phased rollout) โดยมี rollback plan ชัดเจน
- ตั้ง SLA สำหรับ latency ของ online inference (เช่น sub‑100 ms ต่อเหตุการณ์สำหรับ scoring แบบเรียลไทม์) และ SLA สำหรับการตรวจจับเหตุการณ์ผิดปกติ
- ติดตามการเปลี่ยนแปลงของตัวชี้วัดระยะยาว เช่น change‑in‑default post‑intervention ในช่วง 30/60/90 วัน, uplift in conversion, และ metrics ด้านความเท่าเทียม (disparate impact ratio)
- Phase 4 — การกำกับดูแล (Governance & Continuous Improvement)
- จัดตั้งทีม Governance ประกอบด้วย Data Science, Risk, Compliance, Legal, Consumer Protection และตัวแทนธุรกิจ เพื่อประชุมรายสัปดาห์/รายเดือนและอนุมัติการเปลี่ยนแปลงสำคัญ
- กำหนดนโยบายการทดสอบและการอนุมัติ (model approval policy) รวมถึงการจัดเก็บ Model Cards, Audit Logs และ Data Lineage
- จัดกระบวนการตรวจสอบอิสระ (third‑party audit) และเตรียมรายงานสรุปผลต่อผู้กำกับดูแลเมื่อจำเป็น
KPI ที่ต้องติดตาม (ตัวอย่างและค่าเป้าหมายเชิงปฏิบัติ)
- Time‑to‑detection: เวลาจากเหตุการณ์เกิดจนระบบแจ้งเตือน — เป้าหมาย <24 ชั่วโมง
- False alarm rate by group: อัตราการแจ้งเตือนเท็จจำแนกตามกลุ่มประชากร — เป้าหมาย <5%
- Change‑in‑default post‑intervention: การเปลี่ยนแปลงอัตรา default ภายหลังแคมเปญ/นโยบาย — ติดตามที่ 30/60/90 วัน, เป้าหมายไม่เกิน +0.5 pp
- Uplift / causal effect size: ขนาดผลกระทบที่แท้จริงของแคมเปญ (เช่น เพิ่ม conversion 2–5%)
- Fairness metrics: disparate impact, equalized odds gap ระหว่างกลุ่ม — ระบุ threshold ที่ยอมรับได้ (เช่น ratio > 0.8)
- Operational metrics: model latency, throughput, model drift rate, data freshness
สแต็กเทคโนโลยีและสถาปัตยกรรมแนะนำ
- Data ingestion & streaming: Kafka / Kinesis สำหรับ event stream, Apache Flink หรือ Apache Beam สำหรับ streaming analytics และ feature computation แบบ near‑real‑time
- Feature store: ระบบกลาง (เช่น Feast, Hopsworks) เพื่อรองรับ feature reuse และการรับประกันความสอดคล้องระหว่าง offline/online features
- Model training & MLOps: Kubeflow / MLflow / Airflow สำหรับ workflow, model registry และ experiment tracking; ติดตั้ง CI/CD สำหรับโมเดลและ data pipelines
- Online inference layer: Seldon/KFServing หรือ custom microservices บน Kubernetes สำหรับ low‑latency scoring พร้อม autoscaling
- Monitoring & alerting: Prometheus + Grafana สำหรับระบบ metric; Evidently / WhyLabs / Fiddler สำหรับ model drift และ data drift; ระบบแจ้งเตือนผ่าน Slack/PagerDuty เมื่อ KPI เกินเกณฑ์
- Explainability & human review: ใช้ Alibi/SHAP/Integrated Gradients เพื่อให้เหตุผลประกอบการตัดสินใจ และมี UI สำหรับ human‑in‑the‑loop เพื่อให้เจ้าหน้าที่สามารถทบทวนและยกเลิกการตัดสินใจแบบอัตโนมัติ
- Audit & compliance: เก็บ audit logs, model cards, และ data lineage ใน central repository พร้อมสิทธิ์เข้าถึงที่ชัดเจน
การวางสถาปัตยกรรมเชิงองค์ประกอบ (high‑level)
- Layer 1 — Data Layer: event stream, transactional DB, data warehouse (สำหรับ historical analysis)
- Layer 2 — Feature & ETL Layer: feature store + batch/stream pipelines
- Layer 3 — Model Layer: training infra, model registry, experiment tracking
- Layer 4 — Serving Layer: online inference, ranking/decision engine, policy engine
- Layer 5 — Governance Layer: monitoring, alerting, audit logs, human review UI, compliance workflows
แผนรับมือเมื่อโมเดลสร้างผลกระทบทางลบ (incident response)
- Detection: เมื่อ KPI เกิน threshold (เช่น false alarm rate by group > 5%, หรือ change‑in‑default เกินขอบเขต) ระบบส่ง alarm อัตโนมัติ
- Immediate containment: เปิดใช้ circuit breaker — หยุดการตัดสินใจอัตโนมัติที่เกี่ยวข้อง และย้อนกลับเป็น rule‑based หรือ human review โดยอัตโนมัติ
- Root cause analysis: ทีม Data Science & Engineering ร่วมกับ Risk และ Compliance วิเคราะห์สาเหตุ (data drift, concept drift, bug ใน feature pipeline, biased training data)
- Remediation: เปิดตัว hotfix หรือ rollback model เก่า ถ้าจำเป็น และรัน re‑training ด้วยชุดข้อมูลที่แก้ไขหรือเพิ่ม fairness constraint
- Communication: แจ้งผู้บริหารและหน่วยงานกำกับดูแลตามนโยบาย พร้อมแผนเยียวยาลูกค้าที่ได้รับผลกระทบ
- Post‑incident review: ปรับปรุง process, เพิ่ม monitoring rule และอัปเดต governance checklist เพื่อป้องกันซ้ำ
บทสรุปเชิงปฏิบัติ — การนำ Causal ML มาวัดผลนโยบายสินเชื่อแบบเรียลไทม์ต้องเริ่มจาก PoC ที่มีกระบวนการตรวจสอบความถูกต้อง (synthetic control, uplift, randomized checks) ขยายเป็น pilot แบบควบคุมก่อนถึง production และต้องมีสแต็กเทคโนโลยีที่รองรับ feature store, online inference, monitoring + alerting และ human review loop ควบคู่ไปกับทีม governance ข้ามสายงานและแผนรับมือเหตุฉุกเฉินที่ชัดเจน เพื่อให้การใช้งานเกิดประโยชน์สูงสุดและลดความเสี่ยงต่อกลุ่มเปราะบาง
บทสรุป
การนำ Causal ML และ Counterfactual Analysis มาใช้ในภาคการเงินของไทยเปิดช่องทางใหม่ให้ธนาคารสามารถวัดผลเชิงสาเหตุของนโยบายสินเชื่อและโปรโมชั่นแบบเรียลไทม์ ทำให้สามารถประเมินได้ว่าโปรโมชั่นหรือการปรับนโยบายเป็นสาเหตุของการเปลี่ยนแปลงพฤติกรรมผู้รับบริการหรือความเสี่ยงด้านเครดิตจริงหรือไม่ การวัดเชิงสาเหตุนี้ช่วยลดการตัดสินใจที่อาจสร้างผลกระทบเชิงลบต่อกลุ่มเปราะบาง เช่น การกำหนดเงื่อนไขสินเชื่อที่ไม่เป็นธรรม หรือโปรโมชั่นที่ทำให้ผู้มีรายได้น้อยเผชิญความเสี่ยงเพิ่มขึ้น โดยเมื่อผสานกับระบบการแจ้งเตือนเชิงนโยบายแบบเรียลไทม์ ธนาคารสามารถปรับแก้หรือยกเลิกการปฏิบัติที่ก่อผลเสียได้ทันทีเพื่อเพิ่มความเป็นธรรมในการให้บริการ
การใช้งานจริงจำเป็นต้องมาพร้อมองค์ประกอบสนับสนุนที่แข็งแกร่ง ได้แก่ คุณภาพและความหลากหลายของข้อมูล โครงสร้างการกำกับดูแลภายในและภายนอกที่ชัดเจน และการทดสอบด้านจริยธรรม (ethical testing) เพื่อประเมินผลกระทบต่อกลุ่มเปราะบางอย่างเป็นระบบ ทั้งนี้ควรเริ่มจากโครงการนำร่องที่มีการตรวจสอบโดยผู้เชี่ยวชาญและผู้มีส่วนได้ส่วนเสียหลายฝ่าย สร้างกรอบการกำกับดูแลที่โปร่งใส และตั้งกลไกติดตามผลแบบต่อเนื่อง เพื่อให้เทคโนโลยีช่วยยกระดับความเป็นธรรมและลดความเสี่ยงโดยไม่ก่อผลกระทบที่ไม่ตั้งใจในวงกว้างในอนาคต



