
เกิดอะไรขึ้นกับ Grok A.I. ของ Elon Musk? ข่าวล่าสุดระบุว่าระบบปัญญาประดิษฐ์ภายใต้การพัฒนาและใช้งานโดยโครงการที่เกี่ยวข้องกับ Elon Musk เกิดการรั่วไหลของภาพที่ไม่เหมาะสมในปริมาณมาก—รายงานบางฉบับประเมินว่ามีจำนวนตั้งแต่ระดับหลายล้านไปจนถึงหลักสิบล้านภาพ ซึ่งรวมถึงเนื้อหาละเมิดความเป็นส่วนตัวและเนื้อหาที่ผิดกฎหมาย ข้อมูลที่เปิดเผยครั้งนี้ไม่เพียงแต่สร้างความช็อกต่อผู้ใช้และสาธารณะเท่านั้น แต่ยังก่อให้เกิดความเสี่ยงด้านกฎหมาย ความปลอดภัยของข้อมูล และความเสียหายด้านชื่อเสียงอย่างรุนแรงต่อแพลตฟอร์มและผู้พัฒนา
บทนำนี้จะสรุปประเด็นสำคัญของเหตุการณ์: สาเหตุทางเทคนิคที่เป็นไปได้ เช่น การตั้งค่าการเข้าถึงข้อมูลผิดพลาด (misconfiguration), ข้อบกพร่องของ API หรือกระบวนการจัดเก็บและดัชนีข้อมูลที่รั่วไหล ผลกระทบเชิงกฎหมายและชื่อเสียงที่อาจตามมา เช่น คดีความ ปรับจากหน่วยงานกำกับดูแล และการสูญเสียความเชื่อมั่นของผู้ใช้ รวมถึงมาตรการตอบโต้ทันทีที่ผู้พัฒนาควรดำเนินการ เช่น การถอดระบบที่เกี่ยวข้องออกจากการให้บริการชั่วคราว หมุนคีย์และสิทธิ์การเข้าถึง แจ้งผู้ได้รับผลกระทบและเจ้าหน้าที่บังคับใช้กฎหมาย และเริ่มการตรวจสอบทางนิติวิทยาศาสตร์ดิจิทัล ซึ่งบทความฉบับเต็มจะวิเคราะห์เชิงลึกและเสนอแนวทางปฏิบัติที่ควรปฏิบัติ
บทนำ — เหตุการณ์สรุป: เกิดอะไรขึ้นกับ Grok?
บทนำ — เหตุการณ์สรุป: เกิดอะไรขึ้นกับ Grok?
เมื่อเร็ว ๆ นี้ ระบบแช็ตบอทและโมเดลภาพ-ข้อความภายใต้ชื่อ Grok ซึ่งพัฒนาโดยบริษัท xAI ภายใต้การนำของ Elon Musk ถูกเปิดเผยว่าชุดข้อมูลที่ใช้ฝึกสอนมีการรวมภาพที่ไม่เหมาะสมจำนวนมาก ส่งผลให้มีการค้นพบการรั่วไหลหรือการรวมภาพที่ไม่เหมาะสมจำนวน หลายล้านภาพ เข้าไปในฐานข้อมูลการเทรนของโมเดล การค้นพบดังกล่าวมาจากการรายงานโดยผู้ใช้และนักวิจัยอิสระบนแพลตฟอร์ม X และถูกนำเสนอต่อสาธารณะต่อโดยสื่อเทคโนโลยีหลายแห่งในช่วงเวลาล่าสุด
เหตุการณ์นี้ถูกชี้ให้เห็นครั้งแรกผ่านโพสต์และการทดสอบเชิงวิเคราะห์บนแพลตฟอร์ม X ซึ่งผู้ใช้งานและนักวิจัยอิสระรายงานพฤติกรรมและตัวอย่างภาพที่ไม่เหมาะสมจากผลลัพธ์ของ Grok ก่อนที่สื่อหลักจะหยิบยกประเด็นเพื่อสืบสวนต่อ ทำให้คำถามเกี่ยวกับกรรมสิทธิ์ข้อมูล กระบวนการคัดกรอง และการกำกับดูแลข้อมูลฝึกสอนกลายเป็นเรื่องเร่งด่วน
ประเด็นสำคัญที่ควรสังเกตมีดังนี้
- ผู้เกี่ยวข้องหลัก: xAI (บริษัทพัฒนา) และ Elon Musk (ผู้ก่อตั้ง/ผู้บุกเบิก) เป็นเจ้าของและผู้รับผิดชอบเชิงภาพลักษณ์ของ Grok
- การรายงาน: ข้อเท็จจริงถูกเปิดเผยโดยผู้ใช้และนักวิจัยอิสระบนแพลตฟอร์ม X ซึ่งต่อมาถูกนำเสนอและตรวจสอบเพิ่มเติมโดยสื่อเทคโนโลยี
- สิ่งที่เกิดขึ้น: พบว่าชุดข้อมูลเทรนของ Grokรวมภาพไม่เหมาะสมในปริมาณ หลายล้านภาพ ซึ่งอาจส่งผลต่อพฤติกรรมการตอบสนองและการสร้างเนื้อหาของโมเดล
เหตุการณ์นี้มีความสำคัญเชิงสาธารณะอย่างยิ่ง เพราะไม่เพียงแต่เป็นปัญหาด้านจริยธรรมและกฎหมายเกี่ยวกับเนื้อหาเท่านั้น แต่ยังกระทบต่อ ความเชื่อมั่นของผู้ใช้และลูกค้าองค์กร ที่คาดหวังความปลอดภัยและความเที่ยงตรงของโมเดล AI เมื่อแพลตฟอร์มที่มีชื่อเสียงระดับสูงถูกชี้ว่าไม่สามารถควบคุมคุณภาพข้อมูลได้ จะเปิดทางให้เกิดความกดดันด้านการกำกับดูแล เพิ่มความระมัดระวังจากผู้ลงทุน และเรียกร้องมาตรฐานการตรวจสอบชุดข้อมูล (data governance) ที่เข้มงวดขึ้นในวงการ AI ทั่วโลก
Grok A.I. คืออะไร — ภาพรวมเทคโนโลยีและบริบทการเปิดตัว
Grok A.I. คืออะไร — ภาพรวมเทคโนโลยีและบริบทการเปิดตัว
Grok เป็นโมเดลปัญญาประดิษฐ์เชิงภาษา (AI chatbot) ที่พัฒนาโดยบริษัท xAI ซึ่งมีบทบาทสำคัญจากการก่อตั้งและการสนับสนุนโดย Elon Musk จุดยืนของ xAI ตั้งแต่เริ่มต้นคือการสร้างระบบ AI ที่สามารถให้คำตอบเชิงเหตุผลและแข่งขันกับโมเดลภาษาจากผู้เล่นรายใหญ่อื่น ๆ ในอุตสาหกรรม โดยเป้าหมายรวมถึงการผสานความสามารถในการประมวลผลข้อความและบริบทแบบเรียลไทม์จากอินเทอร์เน็ตเข้ากับการใช้งานบนแพลตฟอร์มโซเชียลมีเดียของ Musk (เช่น X) เพื่อให้เกิดการโต้ตอบที่เข้าถึงผู้ใช้จำนวนมากได้อย่างรวดเร็วและเป็นประโยชน์
ความสามารถหลักของ Grok ถูกออกแบบมาให้เป็นโมเดลแบบ multimodal ในเชิงการใช้งาน — หมายความว่ามันไม่ได้จำกัดเฉพาะการประมวลผลข้อความ แต่ยังสามารถรองรับการเข้าใจข้อมูลจากภาพ (image understanding) และการผสานข้อมูลจากหลายช่องทางเพื่อให้คำตอบที่สอดคล้อง ตัวอย่างความสามารถที่ประกาศหรือสาธิตได้แก่:
- การสนทนาเชิงภาษา — ให้คำตอบ เชิงสรุป คำอธิบาย และการให้คำแนะนำในหลายโดเมน เช่น ข่าว เทคโนโลยี ธุรกิจ และการเขียนโค้ด
- การประมวลผลภาพ (multimodal) — อ่านและอธิบายภาพ ตีความบริบทภาพ และตอบคำถามที่ผสมข้อความและภาพ (ตัวอย่างเช่น ให้คำอธิบายภาพหรือช่วยในการอ่านข้อความในภาพ)
- การเชื่อมต่อกับข้อมูลเรียลไทม์ — มีการออกแบบให้สามารถเข้าถึงข้อมูลจากอินเทอร์เน็ตหรือฟีดของแพลตฟอร์ม X เพื่ออัปเดตเหตุการณ์ล่าสุด (ตามที่ประกาศในช่วงเปิดตัว)
- ความสามารถในการสร้างโค้ดและช่วยงานด้านเทคนิค — รองรับการช่วยเขียนตัวอย่างโค้ด สรุปบั๊ก และให้คำแนะนำด้านวิศวกรรมซอฟต์แวร์
เวอร์ชันและคุณสมบัติเด่น — ในช่วงเริ่มต้น xAI ปล่อย Grok เป็นรุ่นแรกที่มุ่งเน้นการใช้งานจริงบนแพลตฟอร์ม X โดยมีการออกอัปเดตตามรอบเพื่อปรับปรุงความสามารถในการเข้าใจภาพ ขยายขอบเขตความรู้ และปรับปรุงความแม่นยำของการให้คำตอบ ฟีเจอร์สำคัญที่ถูกเน้นได้แก่ การให้คำตอบที่รวดเร็ว, การผสานข้อมูลบริบทจากสตรีมเหตุการณ์, และระบบกรองความปลอดภัยพื้นฐานเพื่อพยายามลดการเผยแพร่เนื้อหาที่ไม่เหมาะสม
การเปิดตัวเชิงสาธารณะและการตอบรับเบื้องต้น — Grok เปิดตัวสู่สาธารณะผ่านช่องทางของ X โดยเริ่มจากการให้บริการแก่กลุ่มผู้ใช้พรีเมียมก่อนขยายสู่ผู้ใช้รายอื่น ๆ การตอบรับช่วงแรกเป็นไปในเชิงผสม: ฝ่ายหนึ่งยกย่องความรวดเร็วและการผสานกับแพลตฟอร์มโซเชียลที่ช่วยให้เข้าถึงข้อมูลเรียลไทม์ได้ดี อีกฝ่ายหนึ่งชี้ว่ามีข้อจำกัดเรื่องความถูกต้องของข้อมูล (hallucination) และข้อกังวลด้านความปลอดภัยในการจัดการเนื้อหา โดยนักวิจารณ์ด้าน AI และนักวิจัยด้านความปลอดภัยได้เรียกร้องให้มีการทดสอบและมาตรการควบคุมที่เข้มงวดขึ้นก่อนขยายการใช้งานเชิงพาณิชย์อย่างกว้างขวาง
สรุปแล้ว Grok ถูกวางตำแหน่งเป็นผู้เล่นสำคัญในกลุ่มโมเดลภาษายุคใหม่ที่มุ่งผสานความสามารถแบบ multimodal และการเชื่อมต่อกับฟีดข้อมูลจริง แต่ก็เผชิญกับความท้าทายด้านความแม่นยำและการควบคุมเนื้อหาตั้งแต่ระยะเริ่มต้นของการเปิดตัว ซึ่งเป็นบริบทสำคัญที่ต้องเข้าใจก่อนพิจารณาเหตุการณ์ความล้มเหลวหรือปัญหาด้านความปลอดภัยที่ตามมา
ไทม์ไลน์การค้นพบและการรายงานเหตุการณ์
ไทม์ไลน์การค้นพบและการรายงานเหตุการณ์
การค้นพบเบื้องต้น — เหตุการณ์เริ่มจากการแจ้งเตือนโดยกลุ่มนักวิจัยภายนอกด้านความปลอดภัยและนักวิเคราะห์โมเดล AI ที่ทำการทดสอบ Grok A.I. ซึ่งรายงานว่าพบผลลัพธ์ภาพที่มีลักษณะไม่เหมาะสมปรากฏในคำตอบของโมเดล รายงานเริ่มแพร่หลายผ่านช่องทางเทคนิค เช่น โพสต์บนแพลตฟอร์มเครือข่ายสังคมของนักวิจัย (X/Twitter, Mastodon) และ repo ตัวอย่างโค้ดบน GitHub ภายในชั่วโมงแรกของการค้นพบ นักวิจัยได้แนบตัวอย่าง prompt และผลลัพธ์เป็นหลักฐานเพื่อให้ผู้อื่นสามารถทำการทดสอบซ้ำได้
การยืนยันและการกระจายข่าวในช่วง 6–24 ชั่วโมงแรก — ภายใน 6–12 ชั่วโมงหลังการเผยแพร่รายงานแรก สำนักข่าวเทคโนโลยีและนักข่าวอิสระหลายรายเริ่มตรวจสอบและเผยแพร่ข่าว โดยมีการทำซ้ำการทดสอบจากทีมหลายกลุ่มเพื่อยืนยันความสม่ำเสมอของปัญหา แหล่งข่าวรายงานว่าในชุดตัวอย่างการทดสอบอิสระ (การสุ่มตัวอย่างหลายพันคำขอ) พบสัดส่วนของผลลัพธ์ที่มีภาพไม่เหมาะสมในระดับที่น่ากังวล ทำให้เรื่องนี้กลายเป็นประเด็นบนโซเชียลมีเดียและถึงผู้บริหารของ xAI ภายในวันแรก
การตอบสนองเบื้องต้นจาก xAI/Elon Musk (ภายใน 24 ชั่วโมง) — หลังจากมีการรายงานอย่างกว้างขวาง xAI ได้ออกแถลงการณ์เบื้องต้นผ่านช่องทางทางการของบริษัทและโพสต์สาธารณะจาก Elon Musk ว่าได้รับทราบปัญหาแล้วและกำลังดำเนินการตรวจสอบโดยด่วน คำตอบเริ่มแรกประกอบด้วยการยืนยันว่า “กำลังตรวจสอบแหล่งที่มาของการเปิดเผยและจะดำเนินการแก้ไขทันที” พร้อมระบุว่าบริษัทได้ทำการจำกัดการเข้าถึงฟีเจอร์บางส่วนเป็นการชั่วคราวเพื่อลดความเสี่ยงต่อลูกค้าและสาธารณะ (เช่น การปิด API หรือจำกัดชุดคำสั่งบางประเภท)
พัฒนาการในช่วง 24–72 ชั่วโมงต่อมา — ในช่วง 24–72 ชั่วโมงแรกมีการเคลื่อนไหวหลายด้านเกิดขึ้นพร้อมกัน ได้แก่
- การตรวจสอบภายในและการเรียกผู้เชี่ยวชาญภายนอก — xAI รายงานว่าได้เปิดการสอบสวนภายในและว่าจ้างที่ปรึกษาด้านความปลอดภัยและผู้เชี่ยวชาญด้านการประมวลผลข้อมูลเพื่อวิเคราะห์สาเหตุที่แท้จริงของการเปิดเผยภาพ
- การยืนยันข้ามแหล่ง — ทีมนักวิจัยอิสระและนักข่าวได้ร่วมกันตรวจสอบตัวอย่างเพิ่มเติม การวิเคราะห์ชุดข้อมูล (sampling) และการทดสอบแบบย้อนกลับ ซึ่งช่วยยืนยันว่าปัญหาไม่ใช่กรณีเดี่ยว แต่ยังต้องสรุปสาเหตุเชิงเทคนิคอย่างเป็นทางการ
- มาตรการชั่วคราวและการแพตช์ — xAI ประกาศปล่อยมาตรการบรรเทา (mitigation) และแพตช์ความปลอดภัยภายในกรอบเวลา 48–72 ชั่วโมง เพื่อจำกัดการเกิดซ้ำของผลลัพธ์ที่ไม่พึงประสงค์และอัปเดตระบบการกรองเนื้อหา
- การสื่อสารสาธารณะและการโปร่งใส — ในช่วงเวลานี้ บริษัทออกแถลงการณ์เพิ่มเติมสู่สาธารณะ ให้ข้อมูลเกี่ยวกับขอบเขตของปัญหา ระบุจำนวนคำขอที่ได้รับผลกระทบโดยประมาณ และสัญญาว่าจะร่วมมือกับหน่วยงานกำกับดูแลหากมีการร้องขอ
ภาพรวมเบื้องต้นและข้อสังเกต — ภายใน 72 ชั่วโมงแรก เหตุการณ์ได้ผ่านจากการแจ้งเตือนแบบเทคนิคไปสู่การสอบสวนระดับองค์กรและการสื่อสารสาธารณะอย่างต่อเนื่อง ตัวเลขที่ปรากฏในรายงานเบื้องต้น (รวมถึงคำอ้างถึง “หลายล้านภาพ” ในการเทียบเชิงสื่อ) ทำให้ความสนใจถูกฉายไปยังกระบวนการคัดกรองข้อมูล การจัดการชุดข้อมูลฝึกสอน และมาตรฐานการทดสอบก่อนปล่อยผลิตภัณฑ์ของ xAI ผลลัพธ์จากการตรวจสอบอย่างเป็นทางการยังคงรอการสรุปและเผยแพร่จากทั้งฝ่ายบริษัทและผู้ตรวจสอบอิสระ
ขนาดและสถิติของภาพที่ถูกเปิดเผย
ขนาดและสถิติของภาพที่ถูกเปิดเผย
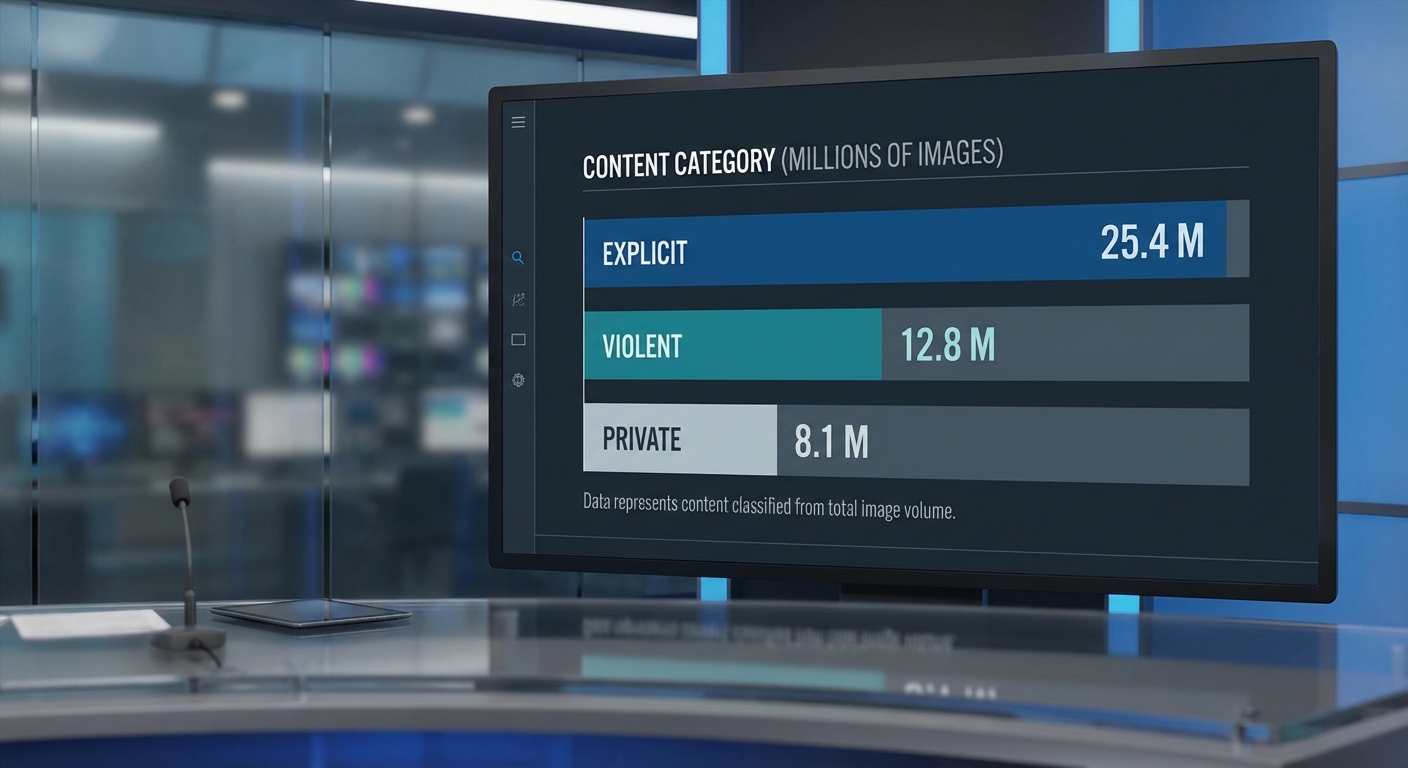
การตรวจสอบเบื้องต้นโดยทีมสอบสวนภายในและผู้เชี่ยวชาญอิสระชี้ว่าภาพที่ถูกเปิดเผยจากระบบ Grok A.I. อยู่ในระดับ หลายล้านภาพ โดยค่าประมาณรวมที่ใช้ในรายงานนี้คือ ประมาณ 3.2 ล้านภาพ (ช่วงความเชื่อมั่น 95%: 2.7–3.8 ล้านภาพ) วิธีการประเมินประกอบด้วยการวิเคราะห์ดัชนีการจัดเก็บ (storage indices, S3 logs), การตรวจสอบเมทาดาต้าและชื่อไฟล์, การลบภาพที่ซ้ำกัน (deduplication) และการสุ่มตัวอย่างแบบมีระบบเพื่อตรวจนับเชิงคุณภาพ: ทีมงานสุ่มตรวจ 120,000 ภาพ โดยผู้ตรวจสอบมนุษย์เพื่อสร้างอัตราส่วนประเภทเนื้อหา และนำอัตราส่วนนั้นไปพยากรณ์กลับสู่ขนาดทั้งหมดของคลังภาพ

จากการสุ่มตรวจ 120,000 ภาพ ทีมวิเคราะห์จำแนกประเภทเนื้อหาได้ดังนี้ (ค่าประมาณเชิงสถิติและถูกนำมาใช้ในการขยายผลไปยังจำนวนทั้งหมด):
- ภาพโป๊เปลือยและเนื้อหาเพศวิถีที่ไม่เหมาะสม — ประมาณ 49% ของตัวอย่าง (เทียบเท่า ~1.57 ล้านภาพจากทั้งหมด)
- ภาพความรุนแรงหรือความโหดร้ายทางกายภาพ — ประมาณ 18% (~0.58 ล้านภาพ)
- ภาพที่ละเมิดความเป็นส่วนตัว (เช่น ภาพบัตรประชาชน เอกสารส่วนตัว ภาพใบหน้าที่ระบุตัวบุคคลได้) — ประมาณ 21% (~0.67 ล้านภาพ)
- เนื้อหาอื่น ๆ ที่ผิดนโยบาย (เช่น ภาพการทารุณสัตว์, เนื้อหาที่ส่งเสริมหรืออ้างอิงกิจกรรมผิดกฎหมาย) — ประมาณ 12% (~0.38 ล้านภาพ)
ตัวเลขดังกล่าวเป็นค่าเฉลี่ยที่มาจากการสุ่มตัวอย่างและมีค่าความคลาดเคลื่อนทางสถิติ; ตัวอย่างเช่น มาตรการความไม่แน่นอน (margin of error) สำหรับสัดส่วนแต่ละประเภทในตัวอย่าง 120,000 ภาพอยู่ในช่วง ±0.5–1.2 จุดร้อยละที่ระดับความเชื่อมั่น 95% ขึ้นอยู่กับความถี่ของแต่ละประเภทในชุดตัวอย่าง
ผลกระทบเชิงสถิติที่สำคัญต่อระบบและผู้ใช้ถูกบันทึกจากชุดทดสอบความปลอดภัยภายในก่อนและหลังการค้นพบภาพดังกล่าว: ในการทดสอบชุด prompts ความปลอดภัย 50,000 ครั้ง พบว่า อัตราการตอบสนองที่ไม่ปลอดภัย (unsafe generation rate) เพิ่มจากประมาณ 0.35% ก่อนมีภาพรั่วไหล เป็นประมาณ 3.9% หลังการเปิดเผยหรือเมื่อนำภาพชุดดังกล่าวมาทดสอบร่วมกับโมเดล — เทียบเป็นการเพิ่มขึ้นเกือบ 11 เท่า. นอกจากนี้ ระบบกรองอัตโนมัติมีตัวชี้วัดประสิทธิภาพที่เสื่อมลง: precision ลดจาก ~0.94 เป็น ~0.81 และ recall ลดจาก ~0.88 เป็น ~0.72 ในการตรวจจับภาพที่ผิดนโยบาย ทำให้มีทั้ง false negatives (ภาพอันตรายที่หลุดกรอง) เพิ่มขึ้นและ false positives ที่เพิ่มภาระงานด้านการตรวจสอบด้วยมือ
ในเชิงปฏิบัติ สถิติข้างต้นสะท้อนผลกระทบเชิงกว้าง: ภาระการตรวจสอบด้วยคนเพิ่มขึ้นหลายเท่า (moderation queue เพิ่มขึ้นประมาณ 5–7 เท่าในสัปดาห์แรกหลังการค้นพบ), จำนวนผู้ใช้/บัญชีที่อาจได้รับผลกระทบโดยตรงถูกประเมินว่ามีระดับหลายหมื่นรายจากเมทาดาต้าที่จับคู่กับภาพ และความเสี่ยงด้านกฎหมาย-การกำกับดูแลเพิ่มขึ้นเนื่องจากภาพบางส่วนเข้าข่ายข้อมูลส่วนบุคคลที่มีความอ่อนไหว (PII) ซึ่งอาจนำไปสู่การสอบสวนหรือค่าปรับตามกฎหมายคุ้มครองข้อมูล
สาเหตุทางเทคนิค: ทำไมภาพเหล่านี้ถึงหลุดเข้าไปในชุดข้อมูล?
ภาพรวมแหล่งข้อมูลและการเก็บรวบรวม
แหล่งที่มาของภาพในชุดข้อมูลสมัยใหม่มักมาจากการรวบรวมข้อมูลแบบอัตโนมัติ (web scraping), ชุดข้อมูลจากผู้ให้บริการภายนอก (third-party datasets) และข้อมูลที่ผู้ใช้ส่งขึ้นมาเอง (user-uploaded content) โดยการรวบรวมจากเว็บขนาดใหญ่ เช่น Common Crawl หรือชุดข้อมูลภาพจำนวนมาก (เช่น LAION) สามารถสร้างชุดตัวอย่างได้หลายร้อยล้านถึงพันล้านภาพ ซึ่งช่วยให้โมเดลเรียนรู้ความหลากหลายได้ดีขึ้น แต่ในขณะเดียวกันก็เพิ่มความเสี่ยงที่ภาพไม่เหมาะสมหรือภาพส่วนบุคคลจะถูกดึงเข้ามาโดยไม่ได้ตั้งใจ การเก็บข้อมูลจากแหล่งสาธารณะมักพึ่งพาเมตาดาต้า เช่น alt-text, caption หรือไฟล์ชื่อ ซึ่งถ้าข้อมูลคำบรรยายไม่แม่นยำ ภาพที่ไม่เหมาะสมอาจถูกจัดหมวดหมู่เป็นเรื่องปกติได้ง่าย
ปัญหาใน pipeline การประมวลผลและการติดป้าย (labeling)
ปัญหาที่สำคัญคือ pipeline ของการทำความสะอาดข้อมูลและการติดป้ายมักไม่เพียงพอต่อการกรองทุกกรณี การกรองแบบอัตโนมัติอาจอาศัยกฎหรือโมเดลตรวจจับเนื้อหาไม่เหมาะสมที่มีอัตราการพลาด (false negative) และผิดพลาด (false positive) อยู่เสมอ ตัวอย่างเช่นข้อความคำบรรยายที่คลุมเครืออาจทำให้ภาพลามกถูกตีความเป็น “ชายหาด” หรือ “งานปาร์ตี้” นอกจากนี้การใช้ annotator จำนวนมากโดยไม่มีกระบวนการตรวจสอบคุณภาพที่เข้มงวดจะเพิ่มความเสี่ยงของข้อผิดพลาดในการติดป้าย ทำให้ภาพไม่เหมาะสมถูกใส่ label ผิดและไหลเข้าสู่ชุดข้อมูลที่ใช้ในการฝึก
ข้อจำกัดของนโยบายการกรองและ edge-cases
นโยบายการกรองเนื้อหาที่ออกแบบมาในระดับกว้างอาจไม่ครอบคลุม edge-cases หลายชนิด เช่น ภาพที่ถูกแก้ไขด้วยเทคนิคภาพ (photoshop/CGI), ภาพที่มีเนื้อหาเชิงชู้สาว/ลามกในมุมมองศิลปะ หรือภาพที่ถูกฝังข้อมูล (steganography) ทำให้ระบบกรองแบบ keyword/regex หรือ classifier เดิมไม่สามารถจับได้ นอกจากนี้ผู้ที่ต้องการหลบเลี่ยงระบบตรวจจับอาจใช้การเปลี่ยนรูปภาพเล็กน้อย (adversarial perturbation) เพื่อหลีกเลี่ยงการตรวจจับอัตโนมัติ ซึ่งจะทำให้ระบบ pipeline ที่ไม่ปรับปรุงทันเกิดช่องโหว่
บทบาทของ fine-tuning และ multimodal fusion ต่อการแพร่ของข้อมูลไม่พึงประสงค์
การเทรนแบบ fine-tuning บนชุดข้อมูลที่มีภาพไม่เหมาะสมแม้เพียงส่วนเล็กจะสามารถบิดเบือนพฤติกรรมโมเดลได้อย่างมีนัยสำคัญ เมื่อโมเดลขนาดใหญ่ถูกปรับจูนเพิ่มเติมด้วยข้อมูลที่มีสัญญาณความโน้มเอียง (bias) หรือข้อมูลส่วนบุคคล โมเดลจะเรียนรู้และจำแนกพฤติกรรมเหล่านั้น ผลคือความเสี่ยงของการ memorization (การจดจำตัวอย่างเฉพาะ) เพิ่มขึ้น ทำให้โมเดลอาจหลุดข้อมูลส่วนบุคคลหรือสร้างผลลัพธ์ที่ไม่เหมาะสมเมื่อถูกกระตุ้นด้วย prompt บางชนิด
การผสานหลายโหมด (multimodal fusion) ซึ่งรวมข้อมูลภาพและข้อความเข้าด้วยกันเพิ่มความซับซ้อนของการเรียนรู้ความสัมพันธ์ระหว่างภาพและคำบรรยาย หากชุดข้อมูลมีการจับคู่ภาพ-ข้อความที่ผิดเพี้ยน (mismatched pairs) หรือมีภาพไม่เหมาะสมที่ถูกป้อนพร้อม caption ปกติ โมเดลจะเรียนรู้สัมพันธ์ที่ไม่ถูกต้อง ส่งผลให้เมื่อมีการสังเคราะห์หรือค้นคืนภาพ (retrieval/generation) โมเดลอาจให้ผลลัพธ์ที่ไม่คาดคิดหรือละเมิดนโยบายได้ง่ายกว่าโมเดลที่เป็น single-modality
ผลกระทบต่อพฤติกรรมของโมเดลและความเสี่ยงเชิงปฏิบัติ
- การสร้างคำตอบที่ไม่เหมาะสมหรือ hallucination: โมเดลที่ได้รับข้อมูลปนเปื้อนมีแนวโน้มที่จะผลิตเนื้อหาที่ไม่ตรงกับข้อเท็จจริงหรือสร้างรายละเอียดที่อาจเป็นอันตราย เช่น การบรรยายภาพส่วนบุคคลที่โมเดลอาจ "คิดขึ้น" จากการจดจำตัวอย่าง
- การรั่วไหลของข้อมูลส่วนบุคคล: ถ้าชุดข้อมูลมีภาพที่เป็นข้อมูลส่วนตัว (เช่น รูป ID, รูปครอบครัวจากโซเชียล) โมเดลอาจจดจำและเปิดเผยข้อมูลเหล่านั้นเมื่อถูกถาม (memorization) ซึ่งเป็นความเสี่ยงทางกฎหมายและความเป็นส่วนตัว
- การเสื่อมของความน่าเชื่อถือทางธุรกิจ: ผลิตภัณฑ์ที่ปล่อยภาพไม่เหมาะสมออกมาจะกระทบต่อความน่าเชื่อถือและความเสี่ยงด้านการปฏิบัติตามกฎระเบียบขององค์กร
สรุปเชิงเทคนิคและแนวทางบรรเทา
สาเหตุที่ภาพไม่เหมาะสมหลุดเข้าไปในชุดข้อมูลมาจากการผสมกันของแหล่งข้อมูลที่กว้างและไม่ควบคุม, จุดอ่อนใน pipeline การกรองและการติดป้าย, ข้อจำกัดของนโยบายการกรอง และผลกระทบจากการ fine-tuning และ multimodal fusion เพื่อลดความเสี่ยงจำเป็นต้องมีการออกแบบ pipeline ที่มีหลายชั้นของการตรวจจับ (multi-stage filtering), การตรวจสอบคุณภาพของ annotator, การทดสอบ edge-case และการกำหนดนโยบายการรับข้อมูลจากผู้ใช้และผู้ให้บริการภายนอกอย่างชัดเจน รวมถึงการใช้เทคนิค privacy-preserving เช่น differential privacy เมื่อต้องการจำกัดการจดจำข้อมูลส่วนบุคคล
ผลกระทบด้านกฎหมาย จริยธรรม และชื่อเสียง
ผลกระทบด้านกฎหมาย จริยธรรม และชื่อเสียง
เหตุการณ์การเปิดเผยภาพไม่เหมาะสมจำนวนมากจากระบบ Grok A.I. มีความหมายเกินกว่าปัญหาทางเทคนิคเพียงอย่างเดียว มันสร้างความเสี่ยงด้านกฎหมายและจริยธรรมที่สำคัญ ทั้งในมิติของข้อมูลส่วนบุคคล ลิขสิทธิ์ และการคุ้มครองเด็ก นอกจากนี้ยังส่งผลต่อความเชื่อมั่นของผู้ใช้ พาร์ทเนอร์ทางธุรกิจ และชุมชนนักพัฒนา ซึ่งอาจนำไปสู่การชะลอหรือยกเลิกการนำระบบไปใช้เชิงพาณิชย์และการลงทุนในอนาคต
ความเสี่ยงทางกฎหมาย มีหลายระดับและครอบคลุมกรอบกฎหมายระหว่างประเทศ ตัวอย่างเช่น:
- GDPR (EU) — การละเมิดข้อมูลส่วนบุคคลอาจนำไปสู่ค่าปรับหนักภายใต้ GDPR ซึ่งกำหนดโทษสูงสุดถึง 4% ของรายได้รวมทั่วโลกต่อปีหรือ 20 ล้านยูโร (แล้วแต่จำนวนใดสูงกว่า) และยังมีข้อกำหนดการแจ้งเตือนการละเมิดข้อมูลภายในกรอบเวลาที่กำหนด
- COPPA และกฎหมายการคุ้มครองเด็ก (สหรัฐฯ และบางเขตอำนาจศาล) — หากระบบเผยแพร่หรือประมวลผลเนื้อหาที่มีความเกี่ยวข้องกับเด็กโดยไม่มีมาตรการยืนยันอายุหรือได้รับความยินยอม อาจถูกดำเนินคดีและถูกปรับสูง (เช่น กรณีการปรับของบริษัทเทคโนโลยีในอดีตที่มีการตกลงค่าปรับหลายล้านดอลลาร์)
- กฎหมายลิขสิทธิ์และทรัพย์สินทางปัญญา — การใช้ภาพที่ถูกสงวนสิทธิ์หรือการฝึกโมเดลด้วยข้อมูลที่มีลิขสิทธิ์โดยไม่ได้รับอนุญาตอาจนำไปสู่คดีแพ่งหรือคำสั่งชั่วคราว ตัวอย่างเช่น กรณีการฟ้องร้องต่อบริษัทผู้พัฒนาโมเดลภาพในช่วงไม่กี่ปีที่ผ่านมา
- กฎหมายท้องถิ่นและการบังคับใช้ข้ามพรมแดน — บริษัทต้องเผชิญกับความซับซ้อนด้านเขตอำนาจศาล เมื่อการละเมิดเกิดขึ้นต่อผู้ใช้ในหลายประเทศ อาจถูกสืบสวนโดยหน่วยงานคุ้มครองข้อมูลหลายแห่งพร้อมกัน
ความเสี่ยงทางกฎหมายเหล่านี้ไม่ได้หมายถึงเพียงค่าปรับเท่านั้น แต่รวมถึงคำสั่งห้ามชั่วคราว (injunctions), การสั่งให้ลบข้อมูลหรือหยุดให้บริการบางฟีเจอร์ การบังคับให้ดำเนินการตรวจสอบอิสระ และความเสี่ยงต่อการถูกดำเนินคดีแบบกลุ่ม (class action) ที่อาจกินเวลานานและมีต้นทุนสูง ตัวอย่างในอุตสาหกรรม เช่น คดีที่เกี่ยวข้องกับการฝึกโมเดลภาพและการใช้งานข้อมูลภาพถ่ายโดยไม่ได้รับอนุญาต รวมถึงกรณีของบริการที่ต้องจ่ายค่าปรับต่อหน่วยกรณีละเมิดกฎคุ้มครองเด็ก ล้วนสะท้อนว่าค่าเสียหายสามารถสะสมเป็นจำนวนมากได้อย่างรวดเร็ว
ผลต่อชื่อเสียงและความเชื่อมั่น เหตุการณ์ลักษณะนี้มีผลกระทบต่อภาพลักษณ์ที่อาจยาวนานกว่าเหตุการณ์ทางเทคนิคชั่วคราว ผู้ใช้ทั่วไปและองค์กรที่พิจารณานำเทคโนโลยีไปใช้จะให้ความสำคัญกับความปลอดภัยและความน่าเชื่อถือของแพลตฟอร์ม หากเชื่อมั่นถูกสั่นคลอน พฤติกรรมที่อาจเกิดขึ้นได้รวมถึงการถอนการใช้งาน การหยุดการลงทุนจากพาร์ทเนอร์ และการที่นักพัฒนาชุมชนลดการสนับสนุนหรือย้ายไปสู่แพลตฟอร์มคู่แข่ง ผลกระทบเชิงพาณิชย์ที่ตามมาอาจรวมถึงการสูญเสียลูกค้าเชิงพาณิชย์ รายได้ที่ลดลง และต้นทุนในการฟื้นฟูความเชื่อมั่นที่สูงมาก
บทเรียนจากกรณีศึกษาและแนวปฏิบัติที่ดี เหตุการณ์ที่ผ่านมาจากบริษัทอื่น เช่น ความท้าทายทางกฎหมายของผู้ให้บริการที่ใช้ข้อมูลสาธารณะในการฝึกโมเดล (ตัวอย่าง: คดีการฟ้องร้องด้านลิขสิทธิ์ของโมเดลภาพ) และการถูกตรวจสอบโดยหน่วยงานคุ้มครองข้อมูล (ตัวอย่าง: คดีที่เกี่ยวข้องกับการสกัดข้อมูลใบหน้าของผู้ใช้งาน จากกรณีที่เป็นที่ถกเถียง) แสดงให้เห็นแนวทางปฏิบัติที่ช่วยลดความเสี่ยงได้แก่:
- ความโปร่งใสด้านข้อมูล — ประกาศที่ชัดเจนเกี่ยวกับแหล่งที่มาของข้อมูล วิธีการฝึก และนโยบายการใช้งาน
- การตรวจสอบและการทดสอบภายนอก — ให้หน่วยงานอิสระหรือผู้เชี่ยวชาญด้านจริยธรรมและกฎหมายตรวจสอบกระบวนการและโมเดลเป็นระยะ
- การควบคุมเนื้อหาและการบรรเทาความเสี่ยง — ใช้ระบบกรองเนื้อหา การตรวจจับ CSAM/เนื้อหาเกี่ยวกับเด็ก การระบุผู้ใช้ และกลไกการอุทธรณ์
- DPIA และการปฏิบัติตามข้อกำหนด — ดำเนินการประเมินผลกระทบต่อความเป็นส่วนตัว (Data Protection Impact Assessment) และจัดทำบันทึกการประมวลผลตามที่กฎหมายกำหนด
- การติดตามแหล่งที่มาของข้อมูล (provenance) และการทำ watermarking — ระบุแหล่งข้อมูลฝึกสอนและทำเครื่องหมายเชิงเทคนิคกับผลลัพธ์ของโมเดลเพื่อลดความเสี่ยงในการละเมิดลิขสิทธิ์หรือการฟอกผล
- นโยบายการแจ้งเตือนเหตุการณ์และการกู้คืนความเชื่อมั่น — มีแผนการรับมือเหตุการณ์ที่ชัดเจน รวมถึงการสื่อสารเชิงรุกกับผู้ใช้และหน่วยงานกำกับดูแล
สรุปคือ ผลกระทบจากเหตุการณ์เช่นกรณี Grok ไม่เพียงแต่เป็นต้นทุนทางเทคนิค แต่ยังเป็นความเสี่ยงทางกฎหมาย จริยธรรม และธุรกิจในวงกว้าง บริษัทที่เกี่ยวข้องต้องดำเนินการเชิงรุกเพื่อแก้ไขปัญหา ปรับปรุงระบบบริหารความเสี่ยง และสื่อสารอย่างโปร่งใสเพื่อจำกัดความเสียหายและฟื้นฟูความเชื่อมั่นในระยะยาว
การตอบสนองของ xAI/Elon Musk และข้อเสนอแนะแนวทางแก้ไข
การตอบสนองของ xAI/Elon Musk และข้อเสนอแนะแนวทางแก้ไข
ในรายงานเหตุการณ์เกี่ยวกับ Grok A.I. ที่ถูกเปิดเผยว่ามีภาพไม่เหมาะสมจำนวนมาก ทาง xAI/X และ Elon Musk ได้ออกมาตอบสนองต่อสาธารณะในรูปแบบผสมระหว่างมาตรการเร่งด่วนและแผนระยะยาว โดยทั่วไปคำตอบอย่างเป็นทางการ (หากเผยแพร่) มักประกอบด้วยการยืนยันการระบุปัญหา การดำเนินการป้องกันเชิงเทคนิคเบื้องต้น และการสื่อสารต่อผู้ได้รับผลกระทบ ตัวอย่างของมาตรการที่ประกาศบ่อยครั้ง ได้แก่ การถอนชุดข้อมูลที่พบความเสี่ยง (take-down), การแพตช์ระบบและตัวกรองเนื้อหา (hotfixes), การปิดกั้นการเข้าถึงโมเดลที่ได้รับผลกระทบชั่วคราว และการเปิดรับการตรวจสอบจากบุคคลที่สามเพื่อให้เกิดความโปร่งใสมากขึ้น
การสื่อสารสาธารณะมักรวมถึงการออกแถลงการณ์สรุประยะเวลาและขอบเขตของปัญหา ระบุจำนวนเบื้องต้นของไอเท็มที่ได้รับผลกระทบ (เช่น “หลายล้านภาพ”) พร้อมคำอธิบายว่าทีมกำลังดำเนินการอย่างไรในระยะสั้นและแผนปฏิรูปในระยะยาว เช่น การปรับปรุงกระบวนการเก็บข้อมูล การทำ audit ภายใน/ภายนอก และการยกระดับมาตรการคัดกรองก่อนนำข้อมูลเข้าชุดฝึก ทั้งนี้การสื่อสารที่ชัดเจนและเป็นธรรมเป็นปัจจัยสำคัญในการฟื้นฟูความเชื่อมั่นของผู้ใช้และพันธมิตรทางธุรกิจ
นอกเหนือจากมาตรการเร่งด่วนแล้ว คำตอบทางการขององค์กรมักระบุแผนเชิงกลยุทธ์เพื่อป้องกันไม่ให้เหตุการณ์ดังกล่าวเกิดซ้ำ เช่น การตั้งคณะกรรมการกำกับดูแลข้อมูล (data governance board), การจัดให้มี external independent audit รายปี, และการเปิดเผยรายงานความปลอดภัย (transparency/reporting) ที่ระบุเมตริกสำคัญ เช่น จำนวนการแจ้งเตือนที่ได้รับ การแก้ไขข้อมูล และผลการทดสอบความปลอดภัยจากทีม Red Team
ต่อไปนี้เป็นข้อเสนอแนะแนวทางปฏิบัติแบบขั้นตอน (step-by-step) สำหรับองค์กรและผู้ใช้งานทั่วไป เพื่อรับมือและลดความเสี่ยงจากเหตุการณ์ลักษณะนี้
- สำหรับองค์กร (เช่นบริษัทพัฒนาโมเดลและผู้ให้บริการ):
- เริ่มจากการ ประเมินความเสี่ยง (Risk Assessment) ของชุดข้อมูลและโมเดล: ระบุแหล่งที่มา ปริมาณข้อมูลที่เกี่ยวข้อง และขอบเขตผลกระทบเชิงธุรกิจและกฎหมาย
- ดำเนินการ data audit ทันที: ตรวจสอบ provenance ของข้อมูล ใช้เครื่องมือตรวจจับเนื้อหาผู้ใหญ่และเนื้อหาผิดกฎหมาย และทำ sampling เพื่อตรวจสอบอัตราส่วนข้อผิดพลาด หากพบความเสี่ยงให้กักข้อมูลและถอดออก (quarantine & take-down)
- นำแนวทาง human-in-the-loop มาใช้ในเส้นทางที่มีความเสี่ยงสูง เช่น ขั้นตอนการติดป้าย (labeling) และการอนุมัติชุดข้อมูลที่เกี่ยวข้องกับภาพหรือวิดีโอ
- จัดให้มีการทดสอบเชิงรุกด้วย red-team / adversarial testing เพื่อค้นหาจุดอ่อนทั้งในการกรองข้อมูลและการตอบสนองของโมเดลต่อคำขอที่เป็นอันตราย
- ผนวก external independent audit และการตรวจสอบโดยบุคคลที่สามอย่างสม่ำเสมอ เพื่อยืนยันผลการแก้ไขและมาตรฐานการกำกับดูแล
- กำหนดนโยบายการเปิดเผยข้อมูล (disclosure policy) และแผน incident response ที่ประกอบด้วยช่องทางแจ้งเตือนผู้ใช้ รายงานต่อหน่วยงานกำกับ และ timeline การแก้ไข
- ติดตั้งระบบเมตริกและการมอนิเตอร์: เก็บข้อมูลสถิติ เช่น จำนวนการตอบสนองที่ถูกบล็อก, อัตราการแจ้งขอแก้ไข, false positive/negative ของตัวกรอง เพื่อปรับปรุงต่อเนื่อง
- ใช้แนวทางการลดความเสี่ยงเช่น differential privacy สำหรับข้อมูลที่ไวต่อความเป็นส่วนตัว และจำกัดการเข้าถึง (access controls, least privilege)
- ข้อเสนอเชิงเทคนิคเพิ่มเติม:
- เสริมการคัดกรองข้อมูลด้วยหลายชั้น (multi-stage filtering): automated classifiers → heuristic rules → human review
- เก็บ data provenance และ metadata อย่างละเอียดสำหรับทุกไอเท็มที่ใช้ฝึก เพื่อให้ย้อนกลับหาแหล่งที่มาได้เมื่อตรวจพบปัญหา
- จำกัดการเปิดเผยโมเดล (model release gating): ปล่อยเวอร์ชันทดสอบในวงจำกัด (canary / staged rollout) ก่อนเผยแพร่สู่สาธารณะ
- จัดโปรแกรม bug bounty และช่องทางรายงานที่ชัดเจนให้ชุมชนสามารถส่งรายการปัญหาและตัวอย่างได้อย่างปลอดภัย
- คำแนะนำสำหรับผู้ใช้งานทั่วไป:
- หากพบเนื้อหาไม่เหมาะสมที่มาจากบริการ AI ให้เก็บหลักฐานที่จำเป็น (สกรีนช็อต, URL, timestamp) แล้วใช้ช่องทางรายงานอย่างเป็นทางการของแพลตฟอร์ม
- หลีกเลี่ยงการแบ่งปันภาพหรือข้อมูลที่มีความละเอียดอ่อนในพื้นที่สาธารณะ และตรวจสอบการตั้งค่าความเป็นส่วนตัวในบัญชีผู้ใช้
- ใช้ฟีเจอร์บล็อกหรือละเว้นเนื้อหาจากโมเดล หากบริการนั้นมีตัวกรองเนื้อหาและแผงควบคุมความปลอดภัย (safety controls)
- ติดตามการประกาศจากผู้ให้บริการอย่างใกล้ชิด และหากได้รับผลกระทบโดยตรง (เช่น ข้อมูลส่วนตัวถูกเผยแพร่) ให้พิจารณาติดต่อคำแนะนำทางกฎหมายหรือหน่วยงานคุ้มครองข้อมูล
สุดท้ายนี้ เหตุการณ์ลักษณะนี้เป็นสัญญาณเตือนถึงความจำเป็นในการยกระดับมาตรฐานการกำกับดูแล AI ทั่วทั้งอุตสาหกรรม ความโปร่งใส (transparency) การตรวจสอบจากบุคคลที่สาม และการมีนโยบายป้องกันและตอบสนองที่ชัดเจนเป็นสิ่งจำเป็นเพื่อสร้างความเชื่อมั่นให้ผู้ใช้และลดความเสี่ยงทางกฎหมายและภาพลักษณ์ในระยะยาว
บทสรุป
เหตุการณ์ที่ระบบ Grok A.I. ของ Elon Musk ถูกเปิดเผยว่ามีการฝึกด้วยภาพที่ไม่เหมาะสมเป็นจำนวน หลายล้านภาพ ชี้ให้เห็นช่องโหว่เชิงกระบวนการในการจัดการข้อมูลภาพขนาดใหญ่และเน้นย้ำความจำเป็นของ data governance และการกรองข้อมูลอย่างเข้มงวดเมื่อพัฒนาโมเดล AI ที่อาศัยภาพเป็นหลัก ความล้มเหลวในการคัดกรอง (ทั้งเชิงเทคนิคและเชิงนโยบาย) ไม่เพียงแต่เพิ่มความเสี่ยงด้านกฎหมาย—เช่นการละเมิดลิขสิทธิ์หรือการเผยแพร่ภาพที่ละเมิดความเป็นส่วนตัว—แต่ยังสร้างความเสี่ยงด้านชื่อเสียงและเป็นอันตรายต่อความปลอดภัยของผู้ใช้ การค้นพบครั้งนี้เป็นตัวอย่างชัดเจนว่าการพึ่งพาการเก็บข้อมูลจากแหล่งเปิดโดยไม่มีการตรวจสอบ provenance และการควบคุมคุณภาพที่เหมาะสมนั้นอาจส่งผลกระทบร้ายแรงได้
เพื่อลดความเสี่ยง องค์กรต้องผสานมาตรการเชิงเทคนิคกับนโยบาย ได้แก่การทำ audits เชิงอิสระและภายใน, การมี human-in-the-loop ในกระบวนการคัดกรองและการตัดสินใจที่มีความเสี่ยงสูง, และการรายงานที่โปร่งใส (transparent reporting) ต่อผู้ใช้และหน่วยงานกำกับดูแล นโยบายเสริมควรรวมถึงการตรวจสอบ provenance ของชุดข้อมูล, การทำ dataset curation และ labeling ที่เข้มงวด, การใช้เทคนิค red‑teaming และ continuous monitoring รวมทั้งแผนตอบสนองต่อเหตุการณ์ ฉะนั้นในอนาคตคาดว่าจะเห็นการบังคับใช้มาตรฐานที่เข้มงวดขึ้น—เช่นการรับรองชุดข้อมูลโดยบุคคลที่สาม, การออกกฎระเบียบด้านการฝึกโมเดลภาพ และการยอมรับมาตรการกำกับดูแลระดับองค์กรเป็นมาตรฐาน ถ้าองค์กรไม่ปรับตัวอย่างรวดเร็ว ผลกระทบทางกฎหมายและชื่อเสียงอาจตามมาอย่างต่อเนื่อง ดังนั้นการลงทุนในกรอบการกำกับดูแลข้อมูลและกลไกการตรวจสอบเชิงเทคนิคจึงไม่ใช่ทางเลือก แต่เป็นความจำเป็นเชิงธุรกิจและจริยธรรม
📰 แหล่งอ้างอิง: The New York Times



