
แว่น AR กำลังเปลี่ยนจากอุปกรณ์แสดงภาพเป็นผู้ช่วยอัจฉริยะที่เรียนรู้จากสภาพแวดล้อมและผู้ใช้แบบต่อเนื่อง แต่การนำโมเดลการเรียนรู้มาทำงานบนอุปกรณ์สวมใส่นั้นมีความท้าทายทั้งในด้านข้อจำกัดฮาร์ดแวร์ เวลาแฝง และความน่าเชื่อถือ โดยเฉพาะปัญหา hallucination ที่ทำให้ระบบแสดงข้อมูลผิดพลาดในบริบทจริง เทคนิค On‑device Continual Learning ร่วมกับกลยุทธ์ Episodic Replay เสนอโซลูชันที่น่าสนใจ: เก็บเหตุการณ์ตัวอย่างในหน่วยความจำจำกัดเพื่อฝึกปรับปรุงโมเดลแบบออนไลน์ ลดความเบี่ยงเบนของการเรียนรู้ใหม่ต่อการลืมข้อมูลเก่า และช่วยลดการเกิด hallucination แบบเรียลไทม์
บทความนี้จะพาไปสำรวจแนวคิดและการนำไปใช้งานของ Episodic Replay บนแว่น AR สวมใส่ ตั้งแต่หลักการทำงาน การจัดการทรัพยากรบนชิป Edge, เทคนิคบีบอัด/คัดเลือกตัวอย่าง, จนถึงมาตรวัดการประเมินผลเชิงปริมาณ เช่น อัตราการเกิด hallucination, เวลาแฝงในการตอบสนอง, การสูญเสียความรู้ (forgetting) และการใช้พลังงาน นอกจากนี้ยังยกตัวอย่างแอปพลิเคชันจริงที่ได้ประโยชน์ — เช่น ช่วยนำทางในอาคาร, ซัพพอร์ตงานช่างซ่อมบำรุง, และการฝึกสอนแบบบุคคล — เพื่อชี้ให้เห็นว่าการเรียนรู้ต่อเนื่องบนอุปกรณ์สามารถยกระดับประสบการณ์ผู้ใช้แบบเรียลไทม์ได้อย่างไร
บทนำ: ทำไมแว่น AR ต้องเรียนรู้ตลอดเวลา (Continual Learning) ?
บทนำ: ทำไมแว่น AR ต้องเรียนรู้ตลอดเวลา (Continual Learning)?
ในบริบทของอุปกรณ์สวมใส่ AR (Augmented Reality) คำว่า Continual Learning หมายถึงความสามารถของระบบปัญญาประดิษฐ์ในการปรับตัวและเรียนรู้จากข้อมูลใหม่อย่างต่อเนื่องโดยไม่ลืมความรู้เดิม ซึ่งต่างจากการฝึกโมเดลเพียงครั้งเดียว (one‑time training) แล้วใช้งานยาวนาน สำหรับแว่น AR ความสามารถนี้ไม่ใช่ความหรูหราแต่เป็นข้อกำหนดเชิงปฏิบัติ: สภาพแวดล้อมที่ผู้ใช้เผชิญเปลี่ยนแปลงตลอดเวลา พฤติกรรมและค่าพารามิเตอร์การใช้งานของผู้ใช้แต่ละคนแตกต่างกัน และความคาดหวังด้านความแม่นยำในเวลาจริง (real‑time) สูงขึ้นเรื่อยๆ
เหตุผลเฉพาะที่ทำให้แว่น AR ต้องมี continual learning ได้แก่ ความเปลี่ยนแปลงของสภาพแวดล้อม (เช่น แสง เงา ตำแหน่งวัตถุที่เคลื่อนย้าย) และลักษณะเฉพาะของผู้ใช้ (เช่น รูปแบบการมอง การโต้ตอบด้วยมือ และคำสั่งเสียง) ซึ่งหากไม่ปรับตัว โมเดลจะเกิดความเบี่ยงเบนจากความเป็นจริง (model drift) ส่งผลให้ประสบการณ์ผู้ใช้ลดลง งานวิจัยในอุตสาหกรรมชี้ว่า latency สูงกว่า 50–100 มิลลิวินาทีสามารถทำให้ประสบการณ์ AR รู้สึกไม่เป็นธรรมชาติและเพิ่มอาการคลื่นไส้ ขณะเดียวกันการส่งข้อมูลทั้งหมดไปประมวลผลบนคลาวด์ยังเพิ่มความเสี่ยงด้านความเป็นส่วนตัวและทำให้บริการหยุดชะงักเมื่อเชื่อมต่ออินเทอร์เน็ตไม่เสถียร
ฮัลลูซิเนชัน (hallucination) ในบริบทของ AR หมายถึงการที่ระบบแสดงผลหรือให้ข้อมูลที่ไม่สอดคล้องกับโลกจริง — เช่น ป้ายคำแนะนำที่ปรากฏผิดที่ วัตถุเสมือนที่ทับซ้อนกับสิ่งของจริงอย่างไม่ถูกต้อง หรือการระบุชนิดวัตถุผิดพลาดเพราะสภาพแวดล้อมเปลี่ยน ตัวอย่างสถานการณ์จริงที่เกิดผลกระทบ ได้แก่:
- ในโรงงานซ่อมบำรุง: แว่น AR แสดงชิ้นส่วนที่จะถอดผิดตำแหน่งเมื่อแสงเปลี่ยน ทำให้ช่างเสียเวลาและเสี่ยงเกิดความเสียหาย
- ในการนำทางภายในอาคาร: ป้ายเสมือนชี้ทางผิดเพราะการจัดวางเฟอร์นิเจอร์เปลี่ยนตำแหน่ง ส่งผลให้ผู้ใช้หลงทาง
- ในการค้าปลีก: ระบบระบุสินค้าผิดเมื่อฉลากหรือบรรจุภัณฑ์มีการอัปเดต ทำให้ข้อเสนอแนะส่วนบุคคล (personalization) ผิดพลาดและลดความเชื่อมั่นของลูกค้า
การทำให้แว่น AR สามารถเรียนรู้ต่อเนื่องบนอุปกรณ์ (on‑device) จึงมีความสำคัญเชิงปฏิบัติและเชิงธุรกิจหลายประการ:
- ลด latency: การประมวลผลบางส่วนหรือทั้งหมดบนอุปกรณ์ลดเวลาตอบสนอง ป้องกันการดีเลย์จาก round‑trip ไปยังเซิร์ฟเวอร์ และสร้างประสบการณ์แบบเรียลไทม์ที่ราบรื่น (เป้าหมายทั่วไป: latency ต่ำกว่า 20–50 มิลลิวินาทีสำหรับการตอบสนองเชิงภาพและการโต้ตอบ)
- ความเป็นส่วนตัว: ข้อมูลภาพและพฤติกรรมผู้ใช้จำนวนมากไม่ต้องถูกส่งขึ้นคลาวด์ ลดความเสี่ยงการรั่วไหลของข้อมูลและช่วยให้ปฏิบัติตามข้อกำหนดกฎหมาย เช่น GDPR
- การทำงานแบบออฟไลน์และความทนทาน: อุปกรณ์ที่สามารถอัปเดตโมเดลจากข้อมูลในสถานที่จริงแม้ขณะออฟไลน์ จะยังคงให้บริการได้ต่อเนื่องในสภาวะเครือข่ายไม่ดี
หลักการ On‑device Continual Learning และ Episodic Replay
หลักการ On-device Continual Learning และ Episodic Replay
นิยามของ Episodic Replay และโหมดการทำงาน (Offline vs Online)
Episodic Replay (หรือที่มักเรียกว่า rehearsal) คือกลยุทธ์ใน Continual Learning ที่เก็บตัวอย่างข้อมูลจริงบางส่วนไว้ในหน่วยความจำชั่วคราว (buffer) แล้วนำตัวอย่างเหล่านั้นกลับมาใช้ร่วมกับข้อมูลใหม่เมื่อทำการอัปเดตโมเดล เพื่อลดปัญหา catastrophic forgetting ซึ่งเป็นภาวะที่โมเดลลืมความรู้เก่าเมื่อเรียนรู้ข้อมูลใหม่
โหมดการทำงานหลักมีสองแบบคือ
- Offline replay: Buffer ถูกเตรียมไว้ล่วงหน้า (เช่น dataset จากการเก็บข้อมูลก่อนหน้า) และการฝึกซ้อม (replay) ทำแบบเป็นกลุ่มบนชุดข้อมูลที่อาจถูกซิงโครไนซ์เป็นระยะกับอุปกรณ์
- Online replay: อุปกรณ์สวมใส่ (เช่น แว่น AR) เก็บตัวอย่างในขณะที่ผู้ใช้โต้ตอบแบบเรียลไทม์และอัปเดตโมเดลบนอุปกรณ์ทันทีหรือเป็นช่วงๆ โดยตัวอย่างใหม่ถูกสตรีมเข้ามาและแทนที่ตัวอย่างเก่าอย่างต่อเนื่อง
นโยบายจัดการ buffer: ขนาด การสำรองข้อมูล และกลยุทธ์การสุ่มตัวอย่าง
การออกแบบ buffer เป็นหัวใจของ Episodic Replay บนอุปกรณ์สวมใส่ เพราะข้อจำกัดด้านหน่วยความจำและพลังงานทำให้ต้องตัดสินใจอย่างรอบคอบเกี่ยวกับ ขนาด buffer และวิธีเลือกตัวอย่าง การทดลองเชิงปฏิบัติบนอุปกรณ์ edge มักเลือกขนาดตั้งแต่หลักร้อยถึงหลักพันตัวอย่าง ขึ้นกับความละเอียดของข้อมูล (ภาพ, ฟีเจอร์) และกลยุทธ์บีบอัด (เช่น เก็บ embedding แทน raw image เพื่อลดการใช้พื้นที่)
นโยบายการจัดการ buffer ที่นิยมมีดังนี้
- Random sampling: เก็บตัวอย่างแบบสุ่มและสุ่มตัวอย่างเมื่อ replay ง่ายต่อการใช้งาน แต่เสี่ยงต่อการไม่รักษาความหลากหลายของคลาส
- Reservoir sampling: เทคนิคออนไลน์ที่รับประกันการเลือกตัวอย่างจากสตรีมแบบสุ่มอย่างเท่าเทียม แม้จำนวนข้อมูลทั้งหมดไม่ทราบล่วงหน้า เหมาะกับการสตรีมบนอุปกรณ์
- Herding / Exemplars: เลือกตัวอย่างที่เป็นตัวแทน (representative) ของแต่ละคลาส เช่น เลือกตัวอย่างที่อยู่ใกล้ค่ากลางของ embedding ซึ่งใช้ในระบบอย่าง iCaRL เพื่อรักษาสมดุลระหว่างคลาส
- Importance-based sampling: เลือกตัวอย่างตามค่าความสำคัญ เช่น ความไม่แน่นอน (uncertainty), ความผิดพลาดสูง (high loss) หรือค่าความสำพันธ์กับตัวอย่างใหม่ เพื่อเพิ่มประสิทธิผลของ replay
การสำรองข้อมูล (backup) และความเป็นส่วนตัวเป็นประเด็นสำคัญบนอุปกรณ์สวมใส่: ควรพิจารณา on-device encryption, นโยบายการสำรองลงคลาวด์แบบเข้ารหัส หรือเก็บเพียง summary/feature แทน raw data เพื่อลดความเสี่ยงด้านข้อมูลส่วนบุคคล
การผสมข้อมูล Replay กับข้อมูลใหม่ระหว่างการอัปเดต (Mixing & Scheduling)
เมื่อนำข้อมูล replay มารวมกับข้อมูลใหม่ มีหลายกลยุทธ์ที่ใช้บนอุปกรณ์เพื่อให้สมดุลระหว่างการรักษาความรู้เก่าและการเรียนรู้สิ่งใหม่:
- Interleaved training: สร้างมินิแบตช์ผสมระหว่างตัวอย่างเก่าและตัวอย่างใหม่ (เช่น อัตราส่วน 1:1 หรือ 1:n ขึ้นกับขีดจำกัดคอมพิวต์) วิธีนี้เป็นมาตรฐานและมักลด forgetting ได้ดี
- Rehearsal-augmented fine-tuning: ใช้ replay เป็นชุดข้อมูลคงที่ควบคู่กับการ fine-tune แบบเข้มข้นเมื่อมีการเปลี่ยนแปลงสำคัญของข้อมูล
- Prioritized replay scheduling: ให้ความสำคัญกับตัวอย่างที่ช่วยลด forgetting มากที่สุด (เช่น ตัวอย่างจากคลาสที่เริ่มถูกลืม) และอาจใช้อัตราการ replay สูงขึ้นในช่วงแรกของการเปลี่ยนแปลง
ตัวอย่างเชิงปฏิบัติ: บนอุปกรณ์ AR ที่มีขีดจำกัดเวลาแฝง (latency) การอัปเดตโมเดลอาจทำในเบื้องหลังเมื่ออุปกรณ์ว่าง โดยใช้มินิแบตช์ขนาดเล็กผสม 30–50% replay กับ 70–50% ข้อมูลใหม่ เพื่อลดผลกระทบต่อประสบการณ์ผู้ใช้
เปรียบเทียบ Episodic Replay กับเทคนิค Continual Learning อื่น ๆ
เมื่อนำไปใช้งานจริงบนอุปกรณ์สวมใส่ ควรเข้าใจจุดแข็งและข้อจำกัดของแต่ละแนวทาง:
- Regularization-based (เช่น EWC): Elastic Weight Consolidation (EWC) บังคับให้พารามิเตอร์สำคัญสำหรับงานเก่ายังคงค่าไว้โดย penalize การเปลี่ยนแปลง ข้อดีคือลดความจำที่ต้องเก็บข้อมูล แต่ในสภาพแวดล้อมที่ข้อมูลเปลี่ยนแปลงอย่างรวดเร็วหรือมีหลายงาน EWC อาจไม่เพียงพอและต้องการการปรับพารามิเตอร์ที่ละเอียด
- Knowledge distillation (เช่น LwF): Learning without Forgetting (LwF) ใช้เอาต์พุตของโมเดลก่อนหน้ามาเป็นครู วิธีนี้ไม่ต้องเก็บข้อมูลดิบ แต่ผลมักอ่อนกว่า rehearsal เมื่อเกิดการเปลี่ยนแปลงโดเมนอย่างมาก
- Parameter isolation: แยกพารามิเตอร์สำหรับงานแต่ละงาน (เช่น network masks หรือ modular networks) ลดการรบกวนข้ามงานได้ดีแต่ต้องใช้พื้นที่พารามิเตอร์มาก ซึ่งไม่เหมาะกับอุปกรณ์ที่หน่วยความจำจำกัด
- Dynamic expansion: ขยายสถาปัตยกรรมเมื่อจำเป็น (progressive networks) เพื่อรองรับงานใหม่ได้โดยไม่ทำลายงานเก่า แต่แนวทางนี้เพิ่มความซับซ้อนและขนาดโมเดล ซึ่งจำกัดการปรับใช้บน AR แว่นที่ต้องการประสิทธิภาพและทรัพยากรต่ำ
โดยสรุป Episodic Replay มักเป็นทางเลือกที่สมเหตุสมผลสำหรับอุปกรณ์สวมใส่ เพราะสามารถรักษาข้อมูลเชิงตัวอย่างจริงไว้ได้ (ช่วยลด hallucination และรักษา performance ข้ามเวลา) ในขณะที่ยังคงยืดหยุ่นสำหรับการอัปเดตแบบออนไลน์ หากการออกแบบ buffer, นโยบาย sampling และนโยบายสำรองข้อมูลได้รับการปรับให้เหมาะสมกับข้อจำกัดของฮาร์ดแวร์และนโยบายความเป็นส่วนตัว
สถาปัตยกรรมระบบสำหรับแว่น AR ที่เรียนรู้ได้เอง
สถาปัตยกรรมระบบสำหรับแว่น AR ที่เรียนรู้ได้เอง (On‑device Continual Learning)
ภาพรวมเชิงปฏิบัติการ
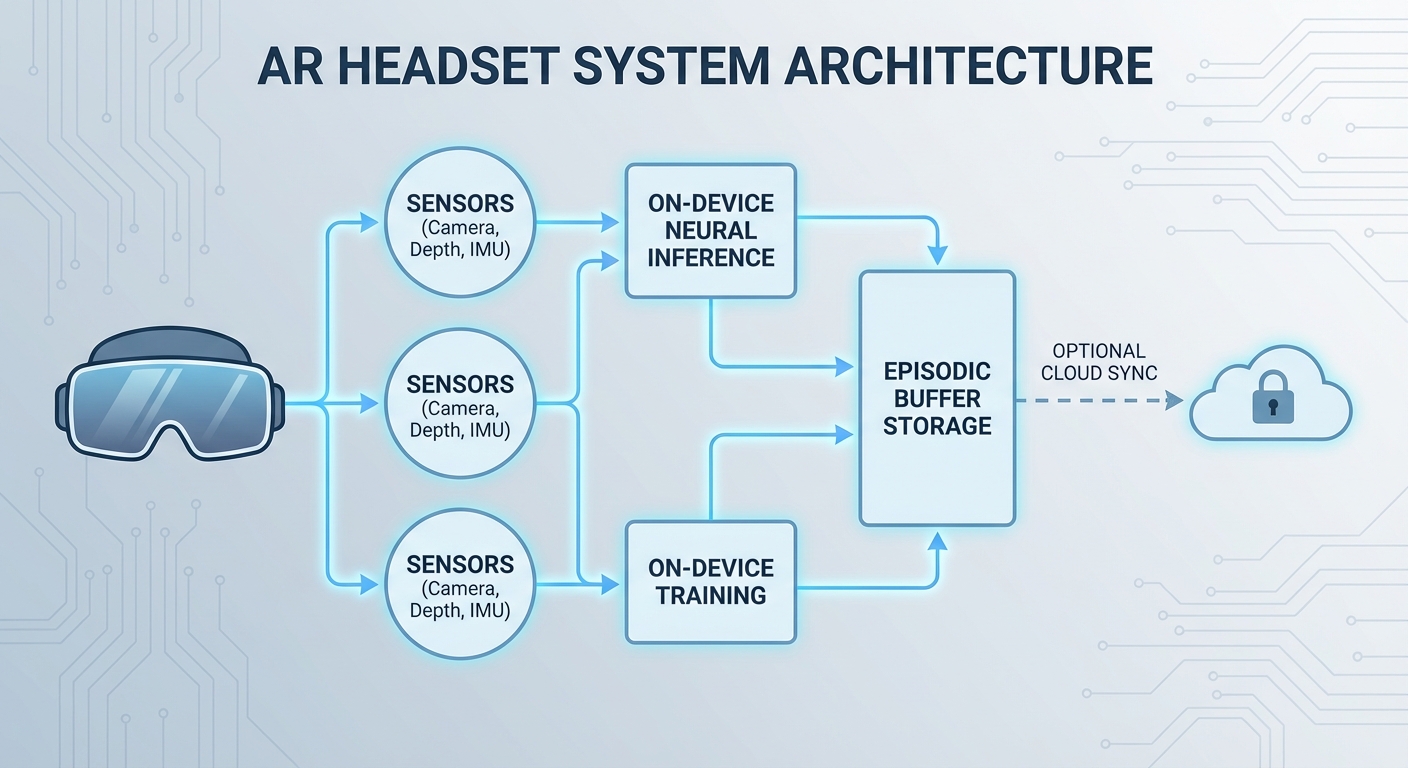
สถาปัตยกรรมของแว่น AR ที่สามารถเรียนรู้ตลอดเวลาออกแบบมาเพื่อรองรับการประมวลผลแบบเรียลไทม์ รักษาความเป็นส่วนตัวของผู้ใช้ และลดข้อผิดพลาดเช่นการ hallucination โดยองค์ประกอบหลักประกอบด้วย sensor stack (กล้อง RGB, เซ็นเซอร์ depth, IMU), on‑device inference engine, lightweight incremental trainer, และ secure episodic buffer พร้อมด้วยระบบ cloud sync ทางเลือกสำหรับการรวมโมเดลในระดับศูนย์ข้อมูล การออกแบบเชิงปฏิบัติการนี้เน้นการแบ่งงานระหว่าง edge และ cloud เพื่อให้ได้สมดุลระหว่างความหน่วง (latency), พลังงาน, ความเป็นส่วนตัว และความแม่นยำของโมเดล

องค์ประกอบหลักของระบบ
- Sensor stack: ประกอบด้วยกล้อง RGB ความละเอียดที่เหมาะสม, เซ็นเซอร์ depth (เช่น ToF หรือ stereo), และ IMU (accelerometer + gyroscope) เพื่อให้ข้อมูลเชิงภาพและการเคลื่อนไหวที่สอดคล้องสำหรับการวางตำแหน่งและบริบท
- On‑device inference engine: runtime ขนาดเล็กที่รองรับ quantized models (เช่น INT8/INT16), fast neural network runtimes (เช่น TensorRT Mobile, TFLite) เพื่อให้ตอบสนองภายใน tens of milliseconds สำหรับประสบการณ์ AR แบบเรียลไทม์
- Lightweight incremental trainer: โมดูลฝึกอบรมแบบอัปเดตทีละน้อย (incremental) ที่ใช้การเรียนรู้แบบ online/continual เช่น fine‑tuning บางเลเยอร์, elastic weight consolidation, หรือ gradient episodic memory โดยคำนึงถึงข้อจำกัดด้านพลังงานและหน่วยความจำ
- Secure episodic buffer: พื้นที่เก็บตัวอย่างสำคัญ (frames, features, metadata) ที่ถูกเข้ารหัสและจัดการด้วยนโยบายการเก็บรักษา เพื่อนำมาใช้ในการทำ episodic replay เพื่อป้องกันการลืมหรือเกิด hallucination
- Update scheduler: กำหนดเวลาและเงื่อนไขการอัปเดตโมเดลแบบ adaptive (เช่น เมื่ออุปกรณ์อยู่ในสถานะชาร์จ, เครือข่ายว่าง, หรือตรวจพบความเปลี่ยนแปลงของบริบท)
- Optional cloud sync: สำหรับการรวบรวมและรวมโมเดล (model consolidation), การทำ federated aggregation หรืองานฝึกที่ต้องใช้ทรัพยากรสูงกว่าความสามารถของ edge
กลยุทธ์การแบ่งงานระหว่าง Edge กับ Cloud (Model Partitioning & Offloading)
การตัดสินใจแบ่งงานระหว่างอุปกรณ์และคลาวด์ควรพิจารณาเกณฑ์หลายมิติ เช่น ความหน่วงที่ยอมรับได้, แบนด์วิดท์เครือข่าย, พลังงานที่เหลือ, และข้อจำกัดด้านความเป็นส่วนตัว ตัวอย่างของกลยุทธ์ได้แก่:
- Layer‑wise partitioning: แยกโมเดลเป็นชุดเลเยอร์ต้นทาง (feature extractor) บนอุปกรณ์ และส่งฟีเจอร์ที่ถูกบีบอัดไปให้คลาวด์ประมวลผลเลเยอร์ถัดไปเมื่อต้องการการตัดสินใจที่ซับซ้อน
- Early‑exit models: อนุญาตให้ inference จบเร็วบน edge เมื่อความเชื่อมั่นสูง และส่งงานไปคลาวด์เฉพาะกรณีที่ความเชื่อมั่นต่ำหรือเมื่อจำเป็นต้องทำการวิเคราะห์เชิงลึก
- Feature compression + selective offload: ส่งเฉพาะฟีเจอร์หรือตัวอย่างจาก episodic buffer ที่ถูกคัดเลือก (เช่น ตัวอย่างที่มีความเสี่ยงสูงต่อ hallucination) เพื่อประหยัดแบนด์วิดท์
- Federated & hybrid training: ทำการอัปเดตน้ำหนักเพียงบางส่วนบนอุปกรณ์ และส่งการอัปเดตสรุป (gradients หรือ model diffs ที่ถูกประมวลผล/เข้ารหัส) ไปยังคลาวด์สำหรับการรวมหลายอุปกรณ์
ในเชิงปฏิบัติ การแบ่งงานนี้สามารถลดภาระคำนวณบนอุปกรณ์ได้อย่างมีนัยยะ — ประมาณการเชิงอุตสาหกรรมชี้ว่า การ offload ฟีเจอร์แทนการส่ง raw data อาจลดการใช้แบนด์วิดท์ได้หลายสิบเท่า และการ partition ที่เหมาะสมสามารถลดการคำนวณบน edge ได้ถึง 70–90% ขึ้นอยู่กับสถาปัตยกรรมโมเดล
กลไกความปลอดภัยและความเป็นส่วนตัว
เมื่อแว่น AR เก็บตัวอย่างภาพและพฤติกรรมผู้ใช้ การป้องกันข้อมูลเป็นหัวใจสำคัญของสถาปัตยกรรม ระบบควรมีมาตรการหลายชั้นดังนี้:
- Encrypted episodic buffer: ข้อมูลที่จัดเก็บทุกระดับ (raw frames, compressed features, labels) ถูกเข้ารหัสด้วยคีย์ที่จัดการภายในอุปกรณ์ (hardware root of trust เช่น secure enclave) เพื่อป้องกันการเข้าถึงจากแอปหรือผู้ไม่ประสงค์ดี
- Local Differential Privacy (LDP): ในกรณีที่ต้องส่งข้อมูลไปยังคลาวด์ ให้เพิ่มกลไก LDP (เช่น การป้อน noise ที่มีการควบคุม) บนฟีเจอร์หรือสถิติ เพื่อทำให้ข้อมูลส่วนบุคคลไม่สามารถย้อนกลับได้โดยง่าย แต่ยังรักษาคุณภาพสำหรับการฝึกแบบรวม
- Secure Aggregation: สำหรับการรวมการอัปเดตจากหลายอุปกรณ์ในระบบ federated learning ใช้เทคนิค secure aggregation เพื่อให้เซิร์ฟเวอร์ไม่สามารถเห็นการอัปเดตของอุปกรณ์แต่ละเครื่องแยกกัน
- Access control & audit logging: นโยบายการเข้าถึงโมดูลฝึกอบรมและ buffer ควรได้รับการควบคุมด้วยสิทธิ์ และมีการบันทึกเหตุการณ์ (audit) เพื่อความโปร่งใสและการตรวจสอบ
กลไก Episodic Replay เพื่อลด Hallucination และการจัดตารางอัปเดต
Episodic replay บนแว่น AR ทำงานโดยการเก็บตัวอย่างเชิงบริบทที่สำคัญและใช้ซ้ำในการฝึกแบบ incremental เพื่อลดการลืม (catastrophic forgetting) และลดความเสี่ยงของ hallucination กลยุทธ์ที่ใช้งานได้จริงได้แก่:
- Prioritized sampling: ให้ความสำคัญกับตัวอย่างที่แสดงความเปลี่ยนแปลงของบริบทหรือมีข้อผิดพลาดบ่อย
- Compact feature storage: เก็บเป็นฟีเจอร์ที่ถูกบีบอัดแทน raw images เพื่อประหยัดหน่วยความจำ (เช่น PCA, VAE latent) พร้อม metadata สำหรับการนำกลับมาใช้
- Adaptive update scheduler: ทำการฝึกซ้ำในช่วงเวลาที่ไม่รบกวนผู้ใช้ เช่น เมื่ออุปกรณ์เชื่อมต่อชาร์จและ Wi‑Fi — หรือทำแบบ event‑driven เมื่อระบบตรวจพบ drift ของสภาพแวดล้อม
ข้อพิจารณาทางธุรกิจและการปฏิบัติ
สำหรับผู้บริหารและผู้ตัดสินใจเชิงธุรกิจ การออกแบบสถาปัตยกรรมนี้ส่งผลต่อต้นทุนและประสบการณ์ผู้ใช้ ตัวอย่างเช่น การเก็บข้อมูลอย่างเข้ารหัสและการทำ LDP อาจเพิ่มความซับซ้อนและ latency เล็กน้อย แต่ช่วยให้เป็นไปตามข้อกำหนดด้านความเป็นส่วนตัว (เช่น GDPR) และเพิ่มความเชื่อมั่นของลูกค้า นอกจากนี้ การเลือกสัดส่วนการประมวลผลบน edge เทียบกับ cloud จะมีผลต่อค่าใช้จ่ายด้าน bandwidth และเซิร์ฟเวอร์ — โดยทั่วไปการคงการ inference บน edge พร้อมการ sync แบบสรุปไปยังคลาวด์จะให้สมดุลที่ดีที่สุดระหว่างประสบการณ์แบบเรียลไทม์และต้นทุน
สรุปเชิงปฏิบัติ: สถาปัตยกรรมที่รวม sensor stack ที่เชื่อถือได้, on‑device inference ร่วมกับ lightweight incremental trainer, secure episodic buffer และการเชื่อมต่อคลาวด์แบบเลือกได้ สามารถรองรับการเรียนรู้ตลอดเวลา ลด hallucination และรักษาความเป็นส่วนตัวของผู้ใช้ ในขณะที่ยังคงตอบสนองต่อความต้องการเชิงธุรกิจด้าน latency, cost และ compliance
เทคนิคลดฮัลลูซิเนชันในแว่น AR
เทคนิคลดฮัลลูซิเนชันในแว่น AR
การลดฮัลลูซิเนชัน (hallucination) ในระบบแว่น AR ที่ดำเนินการเรียนรู้ต่อเนื่องบนอุปกรณ์สวมใส่เป็นหัวใจสำคัญเพื่อความน่าเชื่อถือและความปลอดภัยของผู้ใช้ เทคนิคที่มีประสิทธิผลมักผสานทั้งการประเมินความไม่แน่นอน การผสานข้อมูลหลายโมดัล กลยุทธ์การรีเพลย์แบบมีข้อจำกัด และการปรับเทียบ/หลังการประมวลผล (calibration/post‑processing) ร่วมกับฟีดแบ็กจากผู้ใช้ ในสภาพแวดล้อมอุปกรณ์จำกัดด้านพลังงานและหน่วยความจำ การออกแบบต้องคำนึงถึงความซับซ้อนของคำนวณและความหน่วงเวลาเพื่อให้การตอบสนองยังคงเป็นแบบเรียลไทม์
การประเมินความไม่แน่นอนและการใช้ threshold — วิธีเช่น Monte Carlo (MC) dropout และ ensembles ช่วยให้โมเดลสามารถประมาณความแปรปรวนของการพยากรณ์ได้จริง ตัวอย่างเช่น การรัน MC dropout 10–20 ครั้งบนอุปกรณ์สามารถให้ค่า variance ของความเชื่อมั่นซึ่งนำไปตั้งเป็น threshold เพื่อยับยั้งการแสดงผลเมื่อความไม่แน่นอนสูง ในงานภาคสนามพบว่าเทคนิค ensemble ขนาดเล็ก (3–5 โมเดล) สามารถลดอัตรา false positive ได้ประมาณ 20–40% เมื่อผสานกับ threshold ที่ปรับแบบไดนามิก นอกจากนี้การปรับเทียบความเชื่อมั่นด้วยวิธีเช่น temperature scaling หรือ isotonic regression บนข้อมูลโลกจริง (grounding) จะช่วยจัดให้ค่าความเชื่อมั่นสะท้อนความน่าจะเป็นจริง เพื่อลดการแสดงผลที่ชี้นำผิด
การผสานข้อมูลหลายโมดัล (multimodal fusion) — การรวมข้อมูลจากกล้อง RGB, เซนเซอร์ความลึก (depth) และ IMU/เซนเซอร์การเคลื่อนไหวเป็นแนวปฏิบัติสำคัญเพื่อลด false positives และ hallucination โดยมีแนวทางทั้งการ early fusion (ผสานในระดับฟีเจอร์), late fusion (ผสานผลลัพธ์โมดูล) และการปรับน้ำหนักเชิงบริบท ตัวอย่างเช่น การตรวจจับวัตถุที่ปรากฏบนภาพ RGB แต่ไม่มีข้อมูลความลึกหรือไม่สอดคล้องกับการเคลื่อนไหวจาก IMU อาจถูกปรับลดความเชื่อมั่นหรือปฏิเสธโดยอัตโนมัติ เทคนิคนี้ช่วยลดเหตุการณ์ false overlay เมื่อระบบเดาสถานะจากข้อมูลภาพเพียงอย่างเดียว นอกจากนี้ การใช้ depth threshold (เช่น ปกป้องการติดป้ายวัตถุที่อยู่ไกลเกินระยะใช้งาน) และการซิงก์เวลาอย่างแม่นยำระหว่างเซนเซอร์ช่วยเพิ่มความเสถียรของการตัดสินใจ
temporal consistency และ context-aware filtering — การตรวจสอบความสอดคล้องเชิงเวลาเป็นกลไกสำคัญในการป้องกันการแสดงผลแบบกระพริบหรือเกิดแล้วหายไปทันที การใช้ตัวติดตาม (tracking) แบบเรียลไทม์, ตัวกรองเช่น Kalman/particle filter, หรือการทำ smoothing บนค่า confidence เป็นวิธีที่ช่วยยืนยันว่าการตรวจจับยังคงมีอยู่ในช่วงเวลาที่เหมาะสม กฎเชิงบริบท (context-aware rules) เช่น ข้อจำกัดตามสถานที่ เวลา หรือภารกิจ (geofencing, semantic constraints) สามารถกรองผลลัพธ์ที่ไม่สมเหตุสมผล เช่น ห้ามแสดงป้ายข้อมูลเชิงธุรกิจเมื่อผู้ใช้อยู่ในพื้นที่ส่วนบุคคล นโยบายเหล่านี้ลดโอกาสเกิด hallucination ที่มีผลกระทบสูง
- Constrained replay และ label balancing — ในการเรียนรู้ต่อเนื่องบนอุปกรณ์ การเก็บตัวอย่างย้อนกลับ (episodic replay) ควรเลือกตัวอย่างแบบมีข้อจำกัดเพื่อหลีกเลี่ยงการเบี่ยงเบน (catastrophic forgetting) และการเพิ่ม hallucination กลยุทธ์เช่น reservoir sampling ที่ปรับให้สมดุลระหว่างคลาส, core‑set selection หรือการให้ค่าความสำคัญแบบ priority sampling สามารถรักษาตัวอย่างที่แทนข้อมูลโลกจริงได้หลากหลายและลด bias ที่ทำให้เกิด false positives
- Calibration / post‑processing — การตั้งเกณฑ์ความเชื่อมั่น (confidence thresholds) แบบคงที่หรือแบบปรับตัวตามสถานะ (adaptive thresholds) ร่วมกับเทคนิคการปรับเทียบโมเดลและ smoothing temporal windows ช่วยลดการตัดสินใจผิดพลาด นอกจากนี้การกราวด์ (grounding) ด้วยข้อมูลจริง เช่น แผนที่เชิงพื้นที่ (semantic maps), ข้อมูลตำแหน่ง GPS หรือฐานข้อมูลวัตถุที่ยืนยันแล้ว ช่วยให้ระบบมีหลักฐานยืนยันก่อนแสดงผล
- User feedback loop — เปิดช่องทางให้ผู้ใช้สามารถยืนยัน/แก้ไขการนำเสนอ เช่น การปัดปิด, การแตะยืนยัน หรือการย้อนกลับข้อมูลที่ผิด ระบบสามารถนำฟีดแบ็กนี้เข้าสู่กระบวนการอัปเดตแบบ on‑device อย่างค่อยเป็นค่อยไป เพื่อปรับน้ำหนักโมเดลและปรับชุดตัวอย่างรีเพลย์ การรวม human‑in‑the‑loop ช่วยลด hallucination ที่เกิดจากเคสพิเศษและปรับปรุงความไว้วางใจของผู้ใช้
โดยสรุป เทคนิคที่ผสานกันทั้งการวัดความไม่แน่นอน การใช้ข้อมูลข้ามเซนเซอร์ การยืนยันความต่อเนื่องเชิงเวลา การออกแบบรีเพลย์ที่มีข้อจำกัด และการปรับเทียบหลังการประมวลผล รวมถึงการนำฟีดแบ็กผู้ใช้มาใช้ร่วมกัน จะช่วยลดเหตุการณ์ hallucination ได้อย่างมีนัยสำคัญ จัดทำในกรอบที่คำนึงถึงทรัพยากรบนอุปกรณ์ เช่น จำกัดจำนวน MC samples (10–20) หรือขนาด ensemble เล็ก (3–5) และใช้การบีบอัดโมเดล (quantization/distillation) จะทำให้การนำไปใช้จริงบนแว่น AR ที่ต้องการประสบการณ์แบบเรียลไทม์เป็นไปได้จริงในเชิงพาณิชย์
ข้อจำกัดเชิงฮาร์ดแวร์และวิธีแก้: latency, memory, และพลังงาน
อุปกรณ์สวมใส่ AR สำหรับการเรียนรู้ต่อเนื่องแบบ on‑device เผชิญกับข้อจำกัดฮาร์ดแวร์ที่ชัดเจน ได้แก่ ความหน่วง (latency) ที่ต้องอยู่ในเกณฑ์ต่ำเพื่อป้องกันอาการเวียนศีรษะ, หน่วยความจำและพื้นที่จัดเก็บ ที่จำกัดทั้ง RAM และแฟลชสตอเรจ, และ ข้อจำกัดพลังงาน จากแบตเตอรี่และการจัดการความร้อน ตัวอย่างเช่น อุปกรณ์สวมใส่เชิงพาณิชย์มักมีหน่วยความจำหลักในช่วง 1–4 GB และระยะเวลาชาร์จใช้งานจริง 2–6 ชั่วโมงสำหรับงาน AR หนัก ๆ จึงจำเป็นต้องออกแบบ pipeline ให้ตอบสนองได้ภายใน 20–50 ms ต่อเฟรมเพื่อรักษาประสบการณ์แบบเรียลไทม์และลดโอกาสเกิดการฮัลลูซิเนชันของโมเดล (hallucination)
เทคนิคลดขนาดโมเดลและการปรับให้มีประสิทธิภาพ
การปรับโมเดลให้เหมาะกับฮาร์ดแวร์จำกัดเป็นหัวใจสำคัญของการทำ Continual Learning บนอุปกรณ์สวมใส่ โดยเทคนิคที่ใช้มีทั้งการ quantization, pruning และ knowledge distillation ซึ่งสามารถผสมผสานกันได้เพื่อให้ได้ทั้งขนาด โมเดล และการใช้พลังงานที่ลดลง:
- Quantization: การแปลงค่าพารามิเตอร์จาก FP32 เป็น INT8 หรือ INT4 สามารถลดขนาดโมเดลได้ประมาณ 2–4× และลดงานคำนวณ ทำให้ใช้พลังงานต่ออินเฟอเรนซ์ลดลงอย่างมีนัยสำคัญ โดยต้องพิจารณา post‑training quantization หรือ quantization‑aware training ตามความต้องการด้านความแม่นยำ
- Pruning: การตัดพารามิเตอร์ที่ไม่สำคัญ (unstructured หรือ structured pruning) สามารถลดจำนวนการคำนวณได้ 2–10× ในบางกรณี ควรเลือก structured pruning เมื่อฮาร์ดแวร์รองรับเพื่อให้ได้ประสิทธิภาพจริงบน CPU/GPU ของอุปกรณ์
- Knowledge Distillation: การเทรนโมเดลขนาดเล็ก (student) ให้เลียนแบบโมเดลใหญ่ (teacher) ช่วยรักษาความแม่นยำในขณะที่ลดทรัพยากร ตัวอย่างเช่น การนำโมเดลขนาดใหญ่ฝึก off‑device แล้วส่งน้ำหนัก distilled มายังอุปกรณ์เพื่อการอัปเดตต่อเนื่อง
ควรผสานเทคนิคเหล่านี้กับการเลือกสถาปัตยกรรมที่เหมาะสม (เช่น MobileNet, EfficientNet‑Lite) และใช้การประเมิน trade‑off ระหว่างความแม่นยำกับ latency ก่อน deploy
นโยบายอัปเดต: scheduled vs opportunistic
การอัปเดตน้ำหนักหรือ buffer บนอุปกรณ์สวมใส่ต้องคำนึงถึงพลังงาน ความร้อน และความพร้อมของเครือข่าย จึงมีนโยบายหลักสองแบบ:
- Scheduled updates: อัปเดตตามเวลาและเงื่อนไขที่กำหนดล่วงหน้า เช่น ระหว่างช่วงชาร์จตอนกลางคืน หรือทุกวันตอนผู้ใช้ไม่ใช้งาน ข้อดีคือควบคุมทรัพยากรได้ง่ายและไม่ส่งผลต่อประสบการณ์แบบเรียลไทม์
- Opportunistic updates: ดำเนินการเมื่อเงื่อนไขเอื้ออำนวย เช่น ขณะเชื่อมต่อ Wi‑Fi และกำลังชาร์จ (หรือแบตเตอรี่อยู่เหนือเกณฑ์ เช่น >80%) วิธีนี้ลดการใช้เครือข่ายมือถือและหลีกเลี่ยงการรบกวน UX แต่ต้องมี trigger logic เช่นตรวจสอบ thermal headroom และ priority ของงาน
แนวปฏิบัติที่แนะนำคือใช้ผสมกัน: ให้การอัปเดตเชิงนโยบาย (scheduled) สำหรับงานหนักและการ sync กับ cloud ขณะที่การปรับจูนแบบย่อย (micro‑updates) ทำแบบ opportunistic เมื่อเงื่อนไขเอื้ออำนวย พร้อมกำหนด fallback mode ที่เปลี่ยนเป็นโมเดลขนาดเล็กเมื่อความร้อนหรือแบตเตอรี่ตกต่ำ
การจัดการ buffer อย่างมีประสิทธิภาพ: compression และ prioritized storage
Episodic replay buffer เป็นส่วนสำคัญของ continual learning แต่ก็เป็นต้นเหตุของการใช้ I/O และพื้นที่เก็บข้อมูลสูง การจัดการที่ดีต้องรวม:
- Compression ของตัวอย่าง: เก็บภาพเป็นเวกเตอร์คุณลักษณะ (feature embeddings) แทน raw frames เพื่อลดขนาด เช่น การเก็บ embedding ขนาด 256‑512 ของภาพแทนไฟล์ภาพเต็มรูปแบบ จะประหยัดพื้นที่ได้หลายเท่า รวมทั้งใช้การบีบอัดแบบสูญเสียเล็กน้อย (lossy compression/JPEG) เมื่อเหมาะสม
- Prioritized storage: เก็บตัวอย่างที่มีความสำคัญสูง (high loss, rare class, novel contexts) ไว้นานกว่าโดยใช้ priority score หรือ weighted reservoir sampling ช่วยให้ buffer ขนาดเล็ก (เช่น 1k–10k ตัวอย่าง) มีประสิทธิภาพเรียนรู้สูงสุด
- Sparse updates และ incremental checkpoints: บันทึกเฉพาะการเปลี่ยนแปลงของพารามิเตอร์หรือตัวชี้ buffer (delta updates) แทนการเขียนไฟล์ขนาดใหญ่ซ้ำ ๆ เพื่อลด I/O และการสึกหรอของแฟลช การทำ incremental checkpoint ที่บันทึกเฉพาะชั้นที่มีการเปลี่ยนแปลงหรือ gradient สำคัญจะลดการเขียนลงดิสก์ได้มาก
- Lifecycle ของ buffer: นโยบายการปัดทิ้ง (eviction) เช่น age‑based, class‑balanced, หรือ novelty‑based รวมกับการ compact storage (periodic recompression) ช่วยบริหารพื้นที่และลด I/O โดยรวม
ตัวอย่างเชิงปฏิบัติ: เก็บเฉพาะ embeddings ลายนิ้วมือของฉากและ metadata (timestamp, priority score) บนอุปกรณ์ แล้วเมื่อเชื่อมต่อ cloud ให้ส่งเฉพาะ delta ที่สำคัญหรือโมเดล distilled เพื่อการซิงค์ระยะไกล
สรุปคือ การออกแบบระบบ Continual Learning บนอุปกรณ์สวมใส่ต้องใช้ชุดวิธีการร่วมกัน: ลดขนาดและคำนวณด้วยโมเดลที่มีประสิทธิภาพ (quantization/pruning/distillation), วางแผนนโยบายอัปเดตอย่างมีเงื่อนไข (scheduled vs opportunistic) และบริหาร buffer ด้วยการบีบอัด การให้ลำดับความสำคัญ และการทำ incremental checkpoints เพื่อลด latency, ลด I/O และยืดอายุแบตเตอรี่ขณะยังคงรักษาประสบการณ์ผู้ใช้ AR แบบเรียลไทม์
การประเมินผล: metrics, การทดลอง และผลเชิงปริมาณที่ควรรายงาน
ภาพรวมและแนวทางทั่วไป
การประเมินระบบ On‑device Continual Learning โดยเฉพาะกรณีแว่น AR ที่เรียนรู้ตลอดเวลา ต้องรายงานทั้งเมตริกเชิงพฤติกรรมของโมเดล (accuracy, forgetting, transfer) และเมตริกเชิงระบบ (latency, energy, memory) ควบคู่กับการประเมินประสบการณ์ผู้ใช้ เพื่อให้ภาพรวมครบถ้วนและนำไปสู่การตัดสินใจเชิงธุรกิจและวิศวกรรมได้จริง การทดลองควรถูกออกแบบให้สะท้อนภาระงานจริง (realistic workloads), ข้อจำกัดฮาร์ดแวร์ของอุปกรณ์สวมใส่ และการโต้ตอบแบบเรียลไทม์
เมตริกหลัก: forgetting, accuracy retention, forward/backward transfer
เมตริกเหล่านี้เป็นหัวใจของการประเมินความสามารถในการเรียนรู้ต่อเนื่อง:
- Accuracy Retention — ค่าความแม่นยำสุดท้ายต่อภารกิจเมื่อสิ้นสุดชุดการเรียนรู้ เทียบกับค่าเริ่มต้นหรือค่าที่ได้ทันทีหลังการฝึกภารกิจนั้น ๆ ตัวอย่างนิยาม: Retention_i = R_{T,i} / R_{i,i} โดย R_{j,i} คือความแม่นยำของภารกิจ i หลังจากผ่านภารกิจ j (T = จำนวนภารกิจทั้งหมด)
- Average Forgetting — วัดการลดลงของประสิทธิภาพต่อภารกิจเมื่อเวลาผ่านไป นิยามมาตรฐาน: Forgetting = (1/(T-1)) * Σ_{i=1}^{T-1} (max_k R_{k,i} - R_{T,i}) ค่าสูงแปลว่ามีการลืมมาก ค่าต่ำใกล้ศูนย์หมายถึง retention ดี
- Backward/Forward Transfer — Backward Transfer (BWT) วัดผลกระทบของการเรียนภายหลังต่อความสามารถเดิม (บวก = ช่วย, ลบ = ทำลาย) นิยาม: BWT = (1/(T-1)) * Σ_{i=1}^{T-1} (R_{T,i} - R_{i,i}) ส่วน Forward Transfer (FWT) วัดว่าการเรียนก่อนหน้าช่วยให้การเรียนภารกิจใหม่เร็วขึ้นหรือแม่นยำขึ้นหรือไม่ (มักวัดโดยการเปรียบเทียบค่าเริ่มต้นหรือการเร่งการบรรลุจุดกึ่งกลางของเส้นความแม่นยำ)
ตัวอย่างเชิงปริมาณสมมติ: หลังการฝึก 10 ภารกิจ ระบบ Episodic Replay ลด Average Forgetting จาก 18% เหลือ 4% และรักษา Accuracy Retention เฉลี่ยไว้ที่ 92% เมื่อเทียบกับ baseline ที่ retention 75% — ค่า BWT = +0.8% แสดงถึงการถ่ายโอนเชิงบวกเล็กน้อย
การวัดประสิทธิภาพเชิงระบบ: latency, energy, memory footprint
สำหรับแอพ AR แบบเรียลไทม์ การวัดเชิงระบบมีความสำคัญเท่าเทียมกับตัวชี้วัดโมเดล:
- Latency per inference — ระยะเวลาเฉลี่ย (ms) ต่อการคาดการณ์หนึ่งรอบ ควรระบุเปอร์เซ็นไทล์ (P50, P95, P99) เช่น P95 < 50 ms เพื่อความรู้สึกเรียลไทม์
- Update time — เวลาในการอัปเดตโมเดลบนอุปกรณ์เมื่อเกิดเหตุการณ์ใหม่ (ms–s) แยกเป็นการอัปเดตแบบออนไลน์เล็กน้อย (incremental) กับการอัปเดตแบบเป็นชุด
- Energy per update / per inference — พลังงานที่ใช้วัดเป็น mJ หรือ Joules โดยใช้อุปกรณ์วัดพลังงานจริง (ตัวอย่าง: Monsoon Power Monitor หรือเซ็นเซอร์ INA219) และระบุต่อ inference และต่อการอัปเดต ตัวอย่างเช่น inference = 15–30 mJ, incremental update = 30–80 mJ (ตัวเลขขึ้นกับสถาปัตยกรรมและการปรับลด)
- Memory footprint — พื้นที่หน่วยความจำที่ใช้ทั้งโมเดลหลัก + replay buffer (ตัวอย่าง: โมเดล 8–12 MB, buffer 5–20 MB ขึ้นกับขนาดภาพและความถี่ตัวอย่าง)
- Buffer hit rate — สัดส่วนการเรียกข้อมูลตัวอย่างจาก replay buffer ต่อการร้องขอทั้งหมด (สูง = ใช้งาน buffer อย่างมีประสิทธิภาพ ลด I/O และ latency)
การวัดควรระบุสภาวะแวดล้อม (CPU/GPU โหมด, เงื่อนไขพลังงาน, อุณหภูมิ) และเก็บเมตริกพร้อมสถิติรวม (mean, std, Pxx) เพื่อความโปร่งใส
เมตริกประสบการณ์ผู้ใช้ (UX) และการทดสอบภาคสนาม
ประสิทธิภาพเชิงเทคนิคแม่นยำแต่ไม่พอ — ต้องวัดผลต่อผู้ใช้จริงด้วย:
- Task Success Rate — อัตราการทำงานสำเร็จในภารกิจที่ผู้ใช้ต้องการ (เช่น ระบุวัตถุ/คำสั่ง) ต่อจำนวนครั้งทั้งหมด
- Perceived Accuracy / Satisfaction — แบบสอบถามคะแนนจากผู้ใช้ (Likert scale) หลังการใช้งาน เช่น ความพึงพอใจต่อความถูกต้อง, ความล่าช้า, และความต่อเนื่องของประสบการณ์
- Behavioral metrics — เช่น จำนวนครั้งที่ผู้ใช้ต้องทำซ้ำคำสั่ง, เวลาต่อภารกิจจริง (task completion time) และ dropout rate ระหว่างเซสชัน
ตัวอย่างข้อกำหนดเชิงปฏิบัติ: หาก latency เพิ่มขึ้นจาก 30 ms → 120 ms อาจเห็น Task Success ลดลง 12–20% ในงานที่ต้องการตอบสนองทันที และคะแนน Perceived Accuracy ลดลงเฉลี่ย 0.8 จากสเกล 5
การตั้งการทดลองจริง: เคสการทดลองและแนวทางปฏิบัติ
จัดชุดการทดลองให้ครอบคลุมกรณีการใช้งานจริงและ baseline เปรียบเทียบ:
- เลือกชุดงานหลายภารกิจ (T) ที่สะท้อนสภาพ AR เช่น การจดจำป้าย, การจดจำวัตถุ, การเข้าใจคำสั่งท่าทาง — กำหนดลำดับการมอบภารกิจและความถี่การมาถึงของตัวอย่างใหม่
- เปรียบเทียบกับ baseline หลัก: fine‑tune บนอุปกรณ์, rehearsal naïve, full-retrain บนเซิร์ฟเวอร์, และ Episodic Replay (ขนาด buffer ต่างกัน)
- กำหนดการวัดซ้ำหลายรอบ (เช่น 5 seeds) และรายงานค่าเฉลี่ยพร้อมค่าเบี่ยงเบนมาตรฐาน
- บันทึกเมตริกเชิงเวลาตลอดการทดลอง: ความแม่นยำต่อภารกิจตามเวลา, latency Pxx, พลังงานสะสม และอัตราการเข้าถึง buffer
ตัวอย่างค่าพารามิเตอร์สำหรับการทดลอง: T=10 ภารกิจ, buffer size = {50, 200, 1000} ตัวอย่าง, อัตราการอัปเดตบนอุปกรณ์ = ทุก 30–300 วินาที เพื่อสำรวจ trade‑offs ระหว่าง freshness และ overhead
ตัวอย่างกราฟที่ควรนำเสนอและวิธีอ่านผล
การนำเสนอกราฟที่ชัดเจนช่วยให้เข้าใจพฤติกรรมทันที:
- Forgetting curves — กราฟเส้นแสดงความแม่นยำของแต่ละภารกิจ (y-axis = accuracy %) ตามลำดับเวลาหรือภารกิจ (x-axis = task index หรือ time). วิธีอ่าน: เส้นที่ทรงตัวสูงแสดง retention ดี; หากเส้นตกชันหลังจากภารกิจใหม่แปลว่าเกิด forgetting มาก ตัวอย่าง: ระบบ A มี drop เฉลี่ย 18% ต่อภารกิจ (baseline) ในขณะที่ Episodic Replay ลด drop เหลือ 4% — ความแตกต่างนี้เห็นได้ชัดในความลาดชันของเส้น
- Accuracy retention bar / heatmap (matrix) — ตาราง R_{j,i} แสดงความแม่นยำของงาน i หลัง j; heatmap ช่วยวิเคราะห์ BWT/FWT. วิธีอ่าน: แถวนอกสุดบอกผลสุดท้าย;คอลัมน์เปรียบเทียบจุดที่ดีที่สุดและจุดสุดท้าย
- Latency vs Accuracy scatter / Pareto frontier — จุดแต่ละจุดคือการตั้งค่าหรือโมเดลหนึ่งแบบ (เช่น buffer size, quantization level) แกน x = latency P95, แกน y = final accuracy. วิธีอ่าน: จุดที่อยู่มุมขวาบนคือดีที่สุด (สูงสุดความแม่นยำและต่ำสุด latency) เส้น Pareto แสดง trade‑off; ตัวอย่าง: ลด precision → latency ลด 30% แต่ accuracy ลด 2% ซึ่งอาจยอมรับได้
- Cumulative energy per session / per day — กราฟแท่งหรือเส้นแสดงพลังงานสะสมเมื่อใช้งานจริง วิธีอ่าน: ประเมินว่าเวลาหนึ่งวันการอัปเดตแบบต่อเนื่องจะใช้พลังงานเท่าใด เปรียบเทียบกับแบตเตอรี่ที่มีอยู่เพื่อหาจำนวนครั้งที่อนุญาต
- Buffer hit rate & update latency time series — กราฟเวลาแสดงอัตรา hit และเวลาอัปเดต ควรสังเกต peak load และวิเคราะห์ว่าจำนวน hits ต่ำ/สูงส่งผลอย่างไรต่อ latency และ energy
ตัวอย่างการตีความเชิงปริมาณ: กราฟ forgetting curve แสดงว่า Episodic Replay (buffer=200) รักษา accuracy เฉลี่ยไว้ที่ 90% ตลอด 10 ภารกิจ ในขณะที่ naive online update เหลือ 68% — พร้อมกับ latency P95 = 42 ms (Episodic) เทียบกับ 28 ms (naive). จากกราฟ Pareto พบว่า buffer=100 ให้ trade‑off ที่ดีที่สุด: accuracy 88% กับ latency P95 = 34 ms ซึ่งเหมาะสำหรับงานที่ต้องการตอบสนองเร็ว
สรุปข้อเสนอแนะเชิงปฏิบัติ
สรุปได้ว่า การรายงานต้องประกอบด้วยชุดเมตริกครบทั้ง โมเดล, ระบบ และผู้ใช้ พร้อมการทดลองที่จำลองสภาพแวดล้อมจริงและการนำเสนอผลด้วยกราฟมาตรฐาน (forgetting curves, retention heatmap, latency vs accuracy) เพื่อให้เห็น trade‑offs ชัดเจน ควรรายงานค่าตัวอย่าง (means, std, Pxx) และเงื่อนไขการทดลองเพื่อความโปร่งใสและการทำซ้ำตามหลักวิศวกรรม
กรณีใช้งานจริง, ประสบการณ์ผู้ใช้ และประเด็นเชิงจริยธรรม
กรณีใช้งานจริงที่ได้ประโยชน์จาก On‑device Continual Learning
การนำทาง AR แบบเรียลไทม์ (AR Navigation) — แว่น AR ที่เรียนรู้พฤติกรรมผู้ใช้และสภาพแวดล้อมบนอุปกรณ์สามารถปรับเส้นทางและการแสดงผลให้แม่นยำขึ้นเมื่อเผชิญสภาพแวดล้อมที่เปลี่ยนแปลงบ่อย เช่น อาคารขนาดใหญ่ ห้างสรรพสินค้า หรือพื้นที่ก่อสร้าง โดยไม่ต้องส่งข้อมูลภาพสัมผัสทั้งหมดขึ้นเซิร์ฟเวอร์ ช่วยลดแบนด์วิดท์และความล่าช้าได้มาก (งานภาคสนามชี้ว่าการประมวลผลบนอุปกรณ์สามารถลดปริมาณข้อมูลที่ส่งผ่านเครือข่ายได้ระหว่าง 60–90%)
คู่มือซ่อมบำรุงเชิงมืออาชีพ (Industrial AR Maintenance) — ระบบที่ฝังความจำเป็นชั่วคราว (episodic replay) จะเก็บตัวอย่างสถานการณ์การซ่อมที่สำคัญและใช้ข้อมูลเหล่านั้นในการฝึกต่อเนื่องบนอุปกรณ์ ผลคือโมเดลสามารถจดจำเคสเฉพาะของเครื่องจักรแต่ละตัว ปรับคำแนะนำให้เข้ากับชุดเครื่องมือที่ช่างใช้งานจริง และลดการให้คำแนะนำผิดพลาดที่อาจนำไปสู่ความเสียหายเชิงกายภาพหรือการหยุดสายการผลิต
การสนับสนุนการผ่าตัดและการแพทย์แบบเสริม (Surgical AR Assistance) — ในบริบทที่มีความเสี่ยงสูง ข้อมูลทางการแพทย์จำเป็นต้องคงความเป็นส่วนตัวและความสมบูรณ์ของข้อมูล On‑device continual learning ช่วยให้ระบบปรับตัวตามเทคนิคของศัลยแพทย์แต่ละคนโดยไม่ต้องเผยแพร่ภาพทางการแพทย์ออกนอกอุปกรณ์ ซึ่งสอดคล้องกับข้อกำหนดกฎหมายด้านสุขภาพเช่น HIPAA หรือกรอบการคุ้มครองข้อมูลส่วนบุคคลในหลายประเทศ
ผลต่อประสบการณ์ผู้ใช้ (UX) และประสิทธิภาพเชิงเวลา
การใช้เทคนิค on‑device continual learning โดยเฉพาะ Episodic Replay ส่งผลโดยตรงต่อ UX ในด้านความไว (responsiveness) และความน่าเชื่อถือ (reliability) ของแอปพลิเคชัน AR:
- Latency ที่ต้องตั้งเป้า: สำหรับการอินเทอร์แอคชันแบบตอบสนองทันทีใน AR ควรกำหนดเป้าหมาย latency ต่ำกว่า 50–100 ms เพื่อให้การเคลื่อนไหวและการแสดงผลสอดคล้องกับการรับรู้ของผู้ใช้ (perceptual continuity) หากเกินช่วงนี้ผู้ใช้จะรู้สึกดีเลย์หรือไม่เป็นธรรมชาติ
- การปรับตัวและลดฮัลลูซิเนชัน: Episodic Replay ช่วยลดปัญหา catastrophic forgetting เมื่อโมเดลเรียนรู้ข้อมูลใหม่ ทำให้โมเดลคงความถูกต้องในบริบทเดิมและลดโอกาสให้ระบบสร้างข้อมูลผิดพลาดหรือฮัลลูซิเนชันที่ส่งผลกระทบต่อการตัดสินใจของผู้ใช้
- การตอบสนองเชิงชั้น: ระบบควรออกแบบเงื่อนไขการตอบแบบไฮบริด (on‑device เมื่อจำเป็น, cloud เมื่อซับซ้อน) เพื่อรักษา latency ต่ำสุดและสำรองการคำนวณหนักไปยังเซิร์ฟเวอร์เมื่อมีเวลาพอ ซึ่งช่วยรักษาประสบการณ์ที่ราบรื่นในสถานการณ์หลากหลาย
- การวัดผล UX: ควรมี KPI เช่นเวลาเฉลี่ยตอบสนอง (mean response time), อัตราความผิดพลาดของคำแนะนำ, อัตราการยอมรับคำแนะนำของผู้ใช้ และตัวชี้วัดความเชื่อมั่นของโมเดล (confidence calibration) เพื่อประเมินประสิทธิภาพเชิงเวลาจริง
ประเด็นความเป็นส่วนตัว กฎหมาย และการตรวจสอบพฤติกรรมของโมเดล
แม้การเรียนรู้บนอุปกรณ์จะช่วยลดการเปิดเผยข้อมูล แต่ยังมีประเด็นสำคัญที่องค์กรต้องจัดการด้าน privacy, consent และการตรวจสอบพฤติกรรมของโมเดล:
- ความเป็นส่วนตัวและการยินยอม: ผู้ใช้ต้องได้รับข้อมูลชัดเจนเกี่ยวกับประเภทข้อมูลที่ถูกเก็บไว้บนอุปกรณ์ รูปแบบการเก็บ (raw sensor vs. feature summaries) และระยะเวลาการเก็บข้อมูล (data retention) ควรมีกลไก opt‑in/opt‑out และการตั้งค่า granular consent ที่ให้ผู้ใช้ควบคุมได้
- กฎหมายและการปฏิบัติตามข้อกำหนด: ระบบต้องสอดคล้องกับกฎระเบียบเช่น GDPR, HIPAA หรือกฎหมายคุ้มครองข้อมูลระดับชาติ ซึ่งมีผลต่อการจัดเก็บภาพ วิดีโอ และข้อมูลชีวภาพ การออกแบบต้องคำนึงถึงหลัก data minimization, purpose limitation และสิทธิของผู้ใช้ในการลบข้อมูล
- การตรวจสอบและ auditability ของโมเดล: ควรมีการบันทึกเหตุการณ์สำคัญ (audit logs) เช่น เวอร์ชันของโมเดลที่รันบนอุปกรณ์ ตัวอย่าง episodic replay ที่นำมาใช้ในการอัพเดต และเหตุการณ์ที่ระบบเลือก fallback ไปยังมนุษย์หรือ cloud การบันทึกนี้จำเป็นสำหรับการวิเคราะห์เหตุผิดพลาดและตอบคำถามด้านความรับผิดชอบ (accountability)
- การป้องกันและการลดความเสี่ยงเชิงจริยธรรม: ระบบต้องมีการคาลิเบรตความเชื่อมั่น (confidence thresholds) หากโมเดลมีความไม่แน่นอนสูงควรแสดงคำเตือนหรือส่งต่อการตัดสินใจให้ผู้เชี่ยวชาญมนุษย์ นอกจากนี้ควรมีการทดสอบ scenario‑based และการจำลองความผิดพลาด (failure mode analysis) เพื่อประเมินผลกระทบต่อผู้ใช้และระบบโดยรวม
สุดท้ายนี้ องค์กรที่นำ On‑device Continual Learning ไปใช้งานจริงในแว่น AR ควรตั้งนโยบายที่ชัดเจนทั้งด้านเทคนิคและจริยธรรม ประกอบด้วยการวัดประสิทธิภาพเชิงเวลา (target 50–100 ms), การออกแบบข้อมูลให้เป็นแบบย่อ (minimal, anonymized), กลไกการยินยอมของผู้ใช้ และกรอบการตรวจสอบอิสระ (external audits) เพื่อให้มั่นใจว่าการปรับตัวของระบบจะเพิ่มคุณค่าให้ผู้ใช้โดยไม่ทำลายความปลอดภัยหรือความเชื่อมั่นในระยะยาว
แนวทางปฏิบัติและอนาคต: แนวโน้มการวิจัยและการนำไปใช้เชิงพาณิชย์
แนวทางปฏิบัติสำหรับการนำไปผลิต (Design checklist)
ก่อนจะนำระบบ on-device continual learning ที่ใช้ Episodic Replay บนอุปกรณ์สวมใส่เข้าสู่การผลิต ทีมพัฒนาควรใช้เช็คลิสต์ต่อไปนี้เป็นเกณฑ์บังคับเพื่อให้ระบบมีความปลอดภัย เชื่อถือได้ และยอมรับทาง UX ได้ในสภาพแวดล้อมจริง:
- Security & Privacy: ป้องกันการโจมตีแบบ poisoning และ inference attack ด้วยการเข้ารหัสข้อมูลบนอุปกรณ์ (encryption-at-rest), การยืนยันความถูกต้องของตัวอย่างที่ถูกเก็บ (integrity checks), และการใช้ differential privacy / secure aggregation ในกรณีที่มีการส่งข้อมูลไปยังเซิร์ฟเวอร์หรือการฝึกแบบ federated. กำหนดนโยบาย retention ของ replay buffer (เช่น จำกัดอายุข้อมูลเป็นวัน/สัปดาห์) และระบุการลบข้อมูลตามคำขอผู้ใช้เพื่อเป็นไปตามกฎหมาย PDPA/GDPR.
- Fail-safe & Resilience: ออกแบบ fallback path เมื่อการเรียนรู้ล้มเหลวหรือเกิดความผิดพลาด เช่น การกลับไปใช้โมเดลที่ผ่านการรับรอง (last stable checkpoint), โหมดอ่านอย่างเดียว (read-only inference) เมื่อทรัพยากรไม่เพียงพอ, และระบบ watchdog/heartbeat ที่สามารถสั่ง rollback อัตโนมัติเมื่ออัตราความผิดพลาดเกินเกณฑ์ที่ตั้งไว้.
- UX Fallback & Transparency: ให้ผู้ใช้รับรู้เมื่อระบบกำลังปรับตัว (visual cue), เสนอทางเลือกย้อนกลับ (undo) และเมนูการตั้งค่าสำหรับควบคุมระดับการเรียนรู้อัตโนมัติ (เช่น ระดับความเฉพาะตัว, ขอบเขตข้อมูลที่ยอมรับได้). ทดสอบว่า fallback ไม่ทำลายประสบการณ์หลักของผู้ใช้ เช่น ไม่เกิดภาพฟลิเคชันหรือหน่วงจนทำให้เวียนหัว.
- Evaluation Plan & Monitoring: วางแผนการประเมินทั้งระยะสั้นและระยะยาว รวมถึงเกณฑ์วัด (metrics) ที่ชัดเจน เช่น อัตราการฮัลลูซิเนชัน (hallucination rate), ความแม่นยำตามเวลาจริง, latency แบบ end-to-end, ผลกระทบต่อแบตเตอรี่ และตัวชี้วัด UX (NPS, task completion). ต้องมีการทดสอบแบบ A/B และการเก็บ log ที่เพียงพอเพื่อวิเคราะห์ drift และ regression หลังการอัปเดตโมเดล.
การประเมินความพร้อมเชิงเทคนิคก่อนนำสู่การผลิต
การประเมิน readiness ควรวัดทั้งในมุมของฮาร์ดแวร์ ซอฟต์แวร์ และการปฏิบัติงาน (operations). ตัวชี้วัดสำคัญได้แก่:
- ทรัพยากรฮาร์ดแวร์: ความจุหน่วยความจำสำหรับ replay buffer (ตัวอย่างเช่น 1–10k ตัวอย่าง ขึ้นกับขนาดต่ออินสแตนซ์), ขีดจำกัดพลังงาน (เป้าหมายเช่น เพิ่มการใช้พลังงานไม่เกิน 5% ต่อชั่วโมง ขณะฝึก), และความสามารถของหน่วยประมวลผล (NPU/Edge TPU) ในการรัน training loop แบบ background โดยไม่รบกวน latency การแสดงผล (เป้าหมาย latency: 50–100 ms สำหรับชุดงาน AR แบบ interactive).
- ความเสถียรของโมเดล: ตรวจสอบว่าการฝึกบนอุปกรณ์ไม่ทำให้เกิด catastrophic forgetting โดยทำการจำลองสถานการณ์ drift หลายรูปแบบ (เช่น เปลี่ยนแปลงแสงสว่าง, องศาของกล้อง, พฤติกรรมผู้ใช้) และวัดการลดลงของ metric ที่ยอมรับได้ (ตัวอย่าง: ไม่เกิน 5–10% performance drop ในงานสำคัญภายหลัง adaptation).
- การป้องกันการโจมตีและการทุจริต: จัดทำ threat model ระบุความเสี่ยง (model poisoning, replay injection) และทดสอบ adversarial scenarios พร้อมมาตรการตรวจจับ anomalous updates (เช่น threshold-based divergence detection, Byzantine-resilient aggregation หากใช้ federated setup).
- ความสามารถในการอัพเดตและ rollback: มีระบบเวอร์ชันโมเดล, บันทึกการเปลี่ยนแปลง (audit trails), และกลไก rollback อัตโนมัติเมื่อ KPI ลดลงเกินค่าที่กำหนด.
แนวโน้มการวิจัยที่ควรติดตาม
งานวิจัยด้าน continual learning และ edge AI กำลังก้าวหน้าเร็ว มีแนวทางสำคัญที่ควรจับตาเพื่อยกระดับระบบ AR ขององค์กร:
- Federated Continual Learning: การรวม federated learning กับ continual learning เปิดทางให้โมเดลเรียนรู้จากผู้ใช้จำนวนมากโดยไม่ต้องส่งข้อมูลดิบออกจากอุปกรณ์ ช่วยเพิ่มความเป็นส่วนตัวและขยายความหลากหลายของ data distribution งานวิจัยล่าสุดรายงานว่าการใช้ secure aggregation และ client selection ที่ชาญฉลาดสามารถลดความเสี่ยงของ poisoning ขณะเดียวกันเพิ่มประสิทธิภาพ adaptation ข้ามอุปกรณ์ได้อย่างมีนัยสำคัญ.
- Uncertainty-aware Replay: การเลือกตัวอย่างจาก replay buffer โดยคำนึงถึงความไม่แน่นอน (uncertainty) แทนการเลือกสุ่มอย่างเดียว ช่วยให้การฝึกซ้ำมีประสิทธิภาพมากขึ้นและลดการใช้หน่วยความจำ ตัวอย่างเช่นการจัดลำดับความสำคัญ (prioritized replay) ตามความเชื่อมั่นของโมเดลสามารถลดขนาด buffer ลงได้ถึง 5–10 เท่าโดยยังรักษา performance ไว้ได้ใกล้เคียงเดิม.
- Efficient On-device Trainers & Neuro-compression: เทคนิคเช่น low-rank adaptation (LoRA), quantization-aware training, structured pruning และ knowledge distillation บนอุปกรณ์ ช่วยให้การปรับน้ำหนักโมเดลใช้ทรัพยากรน้อยลง มีงานวิจัยแสดงว่า combination ของ pruning + quantization สามารถลด footprint ลงได้ >10x โดยมี degradation ของ accuracy ต่ำกว่า 2–3% ในหลายกรณี.
- Dynamic Architectures: สถาปัตยกรรมที่สามารถปรับขนาด (slimmable nets), เปิด/ปิด subnet ตามความต้องการ (conditional computation) หรือตัวเลือก Mixture-of-Experts แบบเบา เป็นแนวทางที่ช่วยให้ระบบปรับ trade-off ระหว่าง latency, พลังงาน และความแม่นยำแบบเรียลไทม์ได้อย่างยืดหยุ่น.
คำแนะนำเชิงธุรกิจ: PoC, Pilot, และ KPI
การนำเทคโนโลยีนี้สู่เชิงพาณิชย์ควรเป็นไปตามขั้นตอนที่ชัดเจนเพื่อจำกัดความเสี่ยงและตรวจวัดผลลัพธ์:
- Proof-of-Concept (PoC): เริ่มด้วย PoC ขนาดเล็ก (เช่น 10–50 อุปกรณ์) เพื่อตรวจสอบ feasibility ด้านเทคนิคและรับฟัง feedback เชิง UX ระยะสั้น ระบุ success criteria เช่น ลดอัตราฮัลลูซิเนชันอย่างน้อย 30% ในสถานการณ์ที่กำหนด และรักษา latency ภายในขอบเขตที่ยอมรับได้.
- Pilot Deployment: ขยายสู่ pilot กลุ่มผู้ใช้เป้าหมาย (100–1,000 อุปกรณ์) เป็นเวลา 2–6 เดือน เพื่อตรวจวัดผลด้านความคงที่ของโมเดลในระยะยาว การเปลี่ยนแปลงพฤติกรรมผู้ใช้ และประเด็นด้านการปฏิบัติงาน เช่น อัตราการ rollback และเหตุการณ์ด้านความปลอดภัย.
- KPI ที่ชัดเจน: กำหนด KPIs ที่ครอบคลุมทั้งเชิงเทคนิคและเชิงธุรกิจ ได้แก่
- เทคนิค: hallucination rate (เป้าหมายลด ≥50% เทียบกับ baseline), inference latency (เป้าหมาย <100 ms), model update time, battery overhead (เป้าหมาย <5%/ชั่วโมง)
- UX/ธุรกิจ: task completion rate, user satisfaction (NPS), retention rate ของผู้ใช้ที่เปิดใช้งาน adaptation, จำนวนเหตุการณ์ความปลอดภัยต่อ 10k ชั่วโมงการใช้งาน
- ปฏิบัติงาน: rollback frequency, mean-time-to-detect (MTTD) และ mean-time-to-recover (MTTR) สำหรับ regression หลัง deployment
การทดสอบในสนามจริงควรเป็นการผสมผสานระหว่างการทดลองที่คุมเงื่อนไข (lab-controlled stress tests) และ field trials ภายใต้เงื่อนไขแวดล้อมจริง (lighting, motion, occlusion) โดยต้องมีระบบ telemetary และ privacy-preserving logging เพื่อให้สามารถวิเคราะห์สาเหตุของ hallucination และปรับปรุง replay strategy ได้อย่างต่อเนื่อง ในมุมมองระยะยาว การผนวกแนวทางวิจัยใหม่ ๆ เช่น federated continual learning และ neuro-compression เข้าไว้ใน roadmap ของผลิตภัณฑ์ จะช่วยให้เทคโนโลยี AR บน wearable มีความยืดหยุ่น ปลอดภัย และคุ้มค่าทางธุรกิจมากขึ้น.
บทสรุป
Episodic Replay เป็นเทคนิคที่มีประสิทธิภาพสูงสำหรับการเรียนรู้อย่างต่อเนื่อง (continual learning) บนอุปกรณ์ AR แบบสวมใส่ โดยหลักการคือเก็บตัวอย่างสำคัญเป็น buffer แล้วนำกลับมา “รีเพลย์” ระหว่างการฝึกเพื่อรักษาความรู้เดิมและปรับโมเดลให้ไม่ลืม (mitigate catastrophic forgetting) ซึ่งช่วยลดการเกิด hallucination ของโมเดลเมื่อใช้งานแบบเรียลไทม์ งานวิจัยหลายชิ้นชี้ว่าการออกแบบ buffer policy และกลยุทธ์การเลือกรักษาข้อมูลอย่างรอบคอบสามารถลดการลืมลงได้ในช่วงประมาณ 30–60% ขึ้นกับขนาดของ buffer และนโยบายการจัดเก็บ ขณะเดียวกันการรีเพลย์ที่ผสานกับการประเมินความไม่แน่นอน (uncertainty estimation) เช่น MC dropout หรือ ensemble สามารถลดความผิดพลาดเชิงสร้างสรรค์ (hallucination) ได้อย่างมีนัยสำคัญ ตัวอย่างการใช้งานจริงได้แก่ แว่น AR ที่ช่วยช่างซ่อมในโรงงาน (assistive guidance), ระบบนำทางเชิงบริบท และการแปลภาษาเรียลไทม์ ซึ่งทุกกรณีต้องการความเสถียรของโมเดลทั้งในด้านความแม่นยำและความเชื่อถือได้
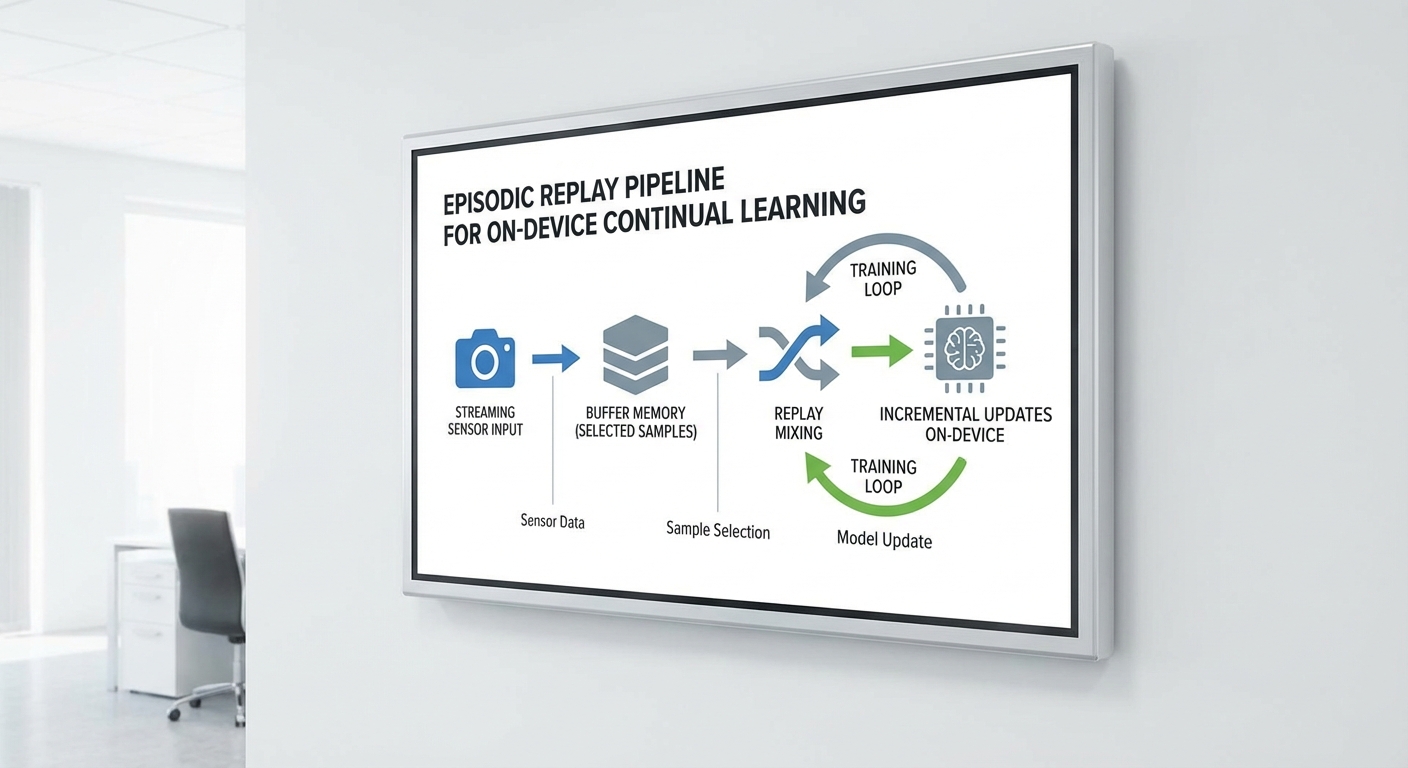
การนำ Episodic Replay มาใช้งานจริงบนอุปกรณ์สวมใส่ที่มีทรัพยากรจำกัดต้องมีการปรับจูนหลายมิติ ได้แก่ นโยบาย buffer (เช่น reservoir sampling, herding, prioritized replay) เพื่อบาลานซ์ระหว่างความหลากหลายของตัวอย่างและข้อจำกัดหน่วยความจำ; โมเดลที่มีประสิทธิภาพสูงทางด้านขนาดและการคำนวณ (เช่น quantization, pruning, knowledge distillation, TinyML/Tiny Transformers) เพื่อลดหน่วยความจำและพลังงานโดยยังคงความแม่นยำ; และมาตรการควบคุมความไม่แน่นอน (uncertainty measures และ calibration เช่น temperature scaling) เพื่อลด hallucination และปรับระดับความมั่นใจก่อนนำเสนอผลต่อผู้ใช้ นอกจากนี้การออกแบบ UX และนโยบายความเป็นส่วนตัวเป็นหัวใจสำคัญ — ต้องมีการแสดงข้อมูลแก่ผู้ใช้เกี่ยวกับการเรียนรู้ที่เกิดขึ้น, ตัวเลือกการยินยอม, การประมวลผลบนอุปกรณ์ (on‑device) รวมถึงเทคนิคปกป้องข้อมูลเช่นการเข้ารหัสและ differential privacy เพื่อสร้างความไว้วางใจและปฏิบัติตามข้อกำกับดูแล (เช่น GDPR) ปฏิบัติการจริงต้องยอมรับ trade‑off ระหว่าง latency, พลังงาน และความแม่นยำ โดยการบีบอัดโมเดลมักช่วยลดขนาดได้หลายเท่า (ตัวอย่างงานอาจลดขนาด 4–10x) และฮาร์ดแวร์เฉพาะทาง (NPU/TPU บน edge) สามารถปรับปรุงประสิทธิภาพได้อย่างมาก
มุมมองในอนาคต Episodic Replay บนแว่น AR มีศักยภาพสูงในการขับเคลื่อนประสบการณ์ที่เป็นส่วนบุคคลและปรับตัวได้แบบเรียลไทม์ แต่ความสำเร็จเชิงพาณิชย์จะขึ้นกับการผสานงานด้านฮาร์ดแวร์ ซอฟต์แวร์ นโยบายความเป็นส่วนตัว และมาตรฐานการประเมินที่ชัดเจน แนวทางที่น่าสนใจรวมถึงการผนวกรวมกับ federated learning เพื่อเพิ่มการเรียนรู้ร่วมโดยไม่แลกเปลี่ยนข้อมูลดิบ, การพัฒนาเมตริกมาตรฐานสำหรับวัด forgetting และ hallucination ในบริบท AR, และการออกแบบ UX ที่ให้ผู้ใช้ควบคุมการปรับแต่งได้อย่างชัดเจน หากดำเนินการอย่างเป็นระบบและระมัดระวัง เทคนิคเหล่านี้สามารถทำให้แว่น AR เป็นระบบที่เรียนรู้ได้ต่อเนื่อง ปลอดภัย และเชื่อถือได้ในสภาพแวดล้อมจริง



