
ผู้ผลิตชิปสัญชาติไทยเปิดตัว NPU ใหม่ที่ออกแบบมาเพื่อรัน LLM ขนาดเล็กบนอุปกรณ์ IoT ซึ่งอาจเปลี่ยนโฉมวงการ Edge AI ในประเทศและภูมิภาค ด้วยสถาปัตยกรรมที่มุ่งเน้นการเร่งประสิทธิภาพการทำ inferencing โดยตรงบนอุปกรณ์ ลดการส่งข้อมูลขึ้นคลาวด์ ช่วยเพิ่มความเป็นส่วนตัวและความต่อเนื่องของบริการ ทั้งยังตอบโจทย์งานที่ต้องการการตอบสนองแบบเรียลไทม์ เช่น การตรวจจับเหตุผิดปกติจากกล้องอัจฉริยะและการประมวลผลคำสั่งผู้ช่วยเสียงในตัวอุปกรณ์
ตามข้อมูลจากผู้ผลิต NPU ตัวนี้ออกแบบมาเพื่อลดการใช้พลังงานและค่า latency สำหรับโมเดลภาษาเบา ๆ (small LLMs) โดยระบุผลลัพธ์เบื้องต้นที่เห็นได้คือการลดการใช้พลังงานในการ inferencing อย่างมีนัยสำคัญและการตอบสนองที่เร็วขึ้นจนอยู่ในระดับสิบมิลลิวินาที ซึ่งหมายความว่าอุปกรณ์ IoT เช่น กล้องวงจรปิดอัจฉริยะ เซ็นเซอร์อุตสาหกรรม และผู้ช่วยเสียงในบ้าน สามารถทำงานด้วยความแม่นยำและประสิทธิภาพที่สูงขึ้นโดยไม่พึ่งพาคลาวด์ตลอดเวลา — ประเด็นสำคัญที่บทความนี้จะพาไปเจาะลึกทั้งสเปกเชิงเทคนิค กรณีใช้งาน และผลกระทบต่อระบบนิเวศ AI ภายในประเทศ
ภาพรวม: NPU ใหม่ของผู้ผลิตชิปไทยคืออะไรและทำไมสำคัญ
ภาพรวม: NPU ใหม่ของผู้ผลิตชิปไทยคืออะไรและทำไมสำคัญ
NPU (Neural Processing Unit) ที่เปิดตัวโดยผู้ผลิตชิปไทยเป็นชิปเร่งประมวลผลเฉพาะทางสำหรับการรัน Large Language Models (LLM) ขนาดเล็กบนอุปกรณ์ Edge เช่น อุปกรณ์ IoT และอุปกรณ์ฝังตัวอื่น ๆ โดยออกแบบมาเพื่อรองรับโมเดลขนาดตั้งแต่ประมาณ 125 ล้านถึง 3 พันล้านพารามิเตอร์ ซึ่งครอบคลุมช่วงโมเดล lightweight ที่ใช้งานจริงในงานตอบคำถามภายในเครื่อง การประมวลผลคำสั่งเสียง และแอปพลิเคชันการวิเคราะห์ข้อความเชิงบริบทที่ต้องการ latency ต่ำ การย้ายการประมวลผลเหล่านี้จากคลาวด์กลับมาเป็นบนอุปกรณ์ (on-device) ช่วยลดการส่งข้อมูลไปยังเซิร์ฟเวอร์กลางและลดความเสี่ยงด้านความเป็นส่วนตัว
ในเชิงเทคนิค NPU ตัวนี้เน้นสถาปัตยกรรมที่เร่งการคำนวณแบบ Transformer โดยรองรับการคำนวณเมทริกซ์ความหนาแน่นต่ำ การคำนวณแบบ quantized (เช่น INT8/INT4) และเทคนิค memory-efficient เช่น model pruning กับ weight compression ทำให้สามารถรัน inference ของ LLM ขนาดเล็กด้วยหน่วยความจำน้อยลงและใช้พลังงานต่ำกว่า CPU/GPU ทั่วไป การทดสอบภายในชี้ว่าในกรณีใช้งานทั่วไป NPU นี้สามารถลดเวลา latency ของการตอบคำถามจากหลายร้อยมิลลิวินาทีลงเหลือหลักสิบมิลลิวินาที และลดการใช้พลังงานต่อการรัน inference ได้อย่างมีนัยสำคัญเมื่อเทียบกับการประมวลผลบน CPU แบบดั้งเดิม
เหตุผลทางธุรกิจที่ทำให้ NPU สำหรับ Edge มีความสำคัญคือประหยัดต้นทุนการสื่อสารข้อมูล ลดค่าแบนด์วิดท์ และตอบโจทย์ข้อกำหนดการปกป้องข้อมูลส่วนบุคคล (data privacy/compliance) เนื่องจากข้อมูลไม่ต้องถูกส่งขึ้นคลาวด์ ตัวอย่างเช่น ในการใช้งานกล้องวงจรปิดอัจฉริยะหรืออุปกรณ์สวมใส่ การตัดสินใจแบบทันที (real-time) เช่น การแจ้งเตือนเหตุฉุกเฉินหรือการตรวจจับความผิดปกติ ต้องการ latency ต่ำและความต่อเนื่องของการให้บริการแม้เชื่อมต่อเครือข่ายไม่เสถียร นอกจากนี้การประมวลผลที่อยู่ในอุปกรณ์ยังช่วยลดความเสี่ยงด้านการรั่วไหลของข้อมูลลูกค้าและลดต้นทุนการเก็บ/ส่งข้อมูลไปยังศูนย์ข้อมูล
กลุ่มเป้าหมาย ของ NPU ตัวนี้ได้แก่:
- ผู้ผลิตอุปกรณ์ IoT ที่ต้องการเพิ่มความสามารถ AI ในสินค้าระดับ edge เช่น กล้องอัจฉริยะ เซ็นเซอร์ในบ้าน และอุปกรณ์สวมใส่
- Integrators ทางอุตสาหกรรม ที่ติดตั้งระบบอัตโนมัติในโรงงานหรือระบบตรวจสอบคุณภาพ ซึ่งต้องการการตัดสินใจแบบ latency-sensitive สำหรับงานเช่น predictive maintenance และ visual inspection
- Startups ด้าน AI ที่พัฒนาแอปพลิเคชัน conversational agents, local assistants หรือฟีเจอร์การวิเคราะห์ภาษาธรรมชาติบนอุปกรณ์ โดยต้องการลดต้นทุนโครงสร้างพื้นฐานคลาวด์และเพิ่มความเป็นส่วนตัวให้กับผู้ใช้
โดยสรุปแล้ว NPU ตัวนี้เป็นส่วนผสมระหว่างฮาร์ดแวร์ที่ปรับแต่งมาสำหรับงาน transformer-based inference และการออกแบบเชิงระบบที่มุ่งให้เกิดผลประโยชน์ทั้งทางเทคนิคและเชิงธุรกิจ: ลดพลังงาน, ลด latency, และเพิ่มความเป็นส่วนตัว ซึ่งเป็นปัจจัยสำคัญในการขยายการใช้งาน LLM ไปยังอุปกรณ์ Edge ในภาคอุตสาหกรรมและสินค้าเชิงพาณิชย์
สถาปัตยกรรมและสเปกทางเทคนิคของ NPU
ภาพรวมสถาปัตยกรรม NPU สำหรับ LLM ขนาดเล็กบนอุปกรณ์ Edge
สถาปัตยกรรมของ NPU ที่ออกแบบมาเพื่อรัน small-scale LLM บนอุปกรณ์ IoT มุ่งเน้นไปที่การเพิ่มประสิทธิภาพของการคำนวณเมทริกซ์และการจัดการเมมโมรี่อย่างเข้มข้น เพื่อลดทั้งพลังงานและ latency ในงาน inferencing แบบเรียลไทม์ โดยทั่วไป NPU จะประกอบด้วยชุดของ compute tiles หรือ systolic arrays ที่ปรับจูนให้เหมาะกับการคูณเมทริกซ์ (GEMM), การคำนวณ attention, และการดำเนินการ nonlinear เช่น softmax/LayerNorm แบบเร่งฮาร์ดแวร์ นอกจากนี้ยังมีหน่วยจัดการหน่วยความจำ (DMA/Memory Controller), หน่วยควบคุมสตรีมมิ่งข้อมูล และสถาปัตยกรรมแคช/บริหาร SRAM ภายในชิป สำหรับลดการเข้าถึงหน่วยความจำภายนอก
สเปกเชิงตัวเลข (ตัวอย่าง)
ตัวอย่างสเปกที่ใช้ประกอบในบทความนี้เป็นตัวอย่างสมมติที่สะท้อนแนวทางตลาดสำหรับ NPU บน Edge:
- ประสิทธิภาพคอมพิวต์: ประมาณ 8–16 TOPS (INT8 peak)
- หน่วยความจำบนชิป (On-chip SRAM): ประมาณ 4–16 MB เพื่อเก็บ activation, partial sums และ weight cache
- แบนด์วิธหน่วยความจำ: ประสิทธิภาพการเคลื่อนย้ายข้อมูลในช่วง 20–50 GB/s (ขึ้นอยู่กับการออกแบบ bus และเทคโนโลยีการเชื่อมต่อ)
- รองรับ precision: INT8, INT4, และ FP16 พร้อมเทคนิค mixed-precision สำหรับรักษาความแม่นยำของ LLM ขนาดเล็ก
หน่วยความจำ ภาพรวมการจัดการแบนด์วิธ และการออกแบบไฮเออร์ราร์คี
การมี SRAM ขนาด 4–16 MB บนชิป ช่วยให้สามารถเก็บ activation windows และ weight tiles ได้เพียงพอสำหรับการรัน inference ของโมเดล Transformer ขนาดเล็กโดยไม่ต้องพึ่งพา DRAM บ่อยครั้ง ซึ่งเป็นจุดสำคัญในการลด latency และพลังงาน แบนด์วิธภายในที่อยู่ในช่วง 20–50 GB/s ช่วยให้ systolic arrays ทำงานได้ต่อเนื่องโดยไม่เกิด stalling ที่ตัวคำนวณ สำหรับโมเดลที่ใหญ่ขึ้น หรือต้องการ context ยาวขึ้น จะมีการใช้ caching policy, double-buffering และ prefetching เพื่อซ่อน latency ของการโหลด weight จากหน่วยความจำภายนอก
อินเตอร์เฟซและการบูรณาการกับ MCU/SoC
ในมุมของการเชื่อมต่อ NPU สำหรับ IoT ต้องรองรับอินเตอร์เฟซที่หลากหลายเพื่อการบูรณาการที่ง่ายกับแพลตฟอร์มยอดนิยม เช่น
- SPIe / PCIe-Lite: ให้ความเร็วสูงสำหรับการแลกเปลี่ยนข้อมูลระหว่าง SoC หลักกับ NPU ในกรณีที่ต้องการ throughput มาก
- MIPI / AXI: ใช้ในระบบที่ต้องการการเชื่อมต่อแบบ high-bandwidth low-latency ภายใน SoC หรือกับกล้อง/เซนเซอร์
- UART/SPI/I2C (control plane): สำหรับการตั้งค่า คอนฟิก และ signaling กับ MCU
การผสานรวมกับ MCU ยอดนิยม เช่น Arm Cortex-M series หรือ RISC-V MCU จะทำผ่าน driver/hal ชุดเบอร์ติดตั้งที่รองรับ DMA, interrupt-driven scheduling และ zero-copy buffers ทำให้การเรียกใช้งาน NPU จากแอปพลิเคชันฝั่ง MCU เป็นไปอย่างราบรื่น โดยมักมี SDK ที่รองรับรูปแบบโมเดลมาตรฐานเช่น ONNX/TF Lite Micro พร้อม toolchain สำหรับ quantization
รองรับ Quantization และการเร่ง kernels สำหรับ Transformer
เพื่อให้เหมาะกับทรัพยากรบน Edge NPU ถูกออกแบบมาให้รองรับการทำ quantized inference โดยตรง ได้แก่ INT8 และ INT4 และยังมีการรองรับ FP16 สำหรับส่วนที่ต้องการความแม่นยำสูงกว่า อีกทั้งมีการใช้ mixed-precision (เช่นคำนวณ attention ใน FP16 แต่เก็บ weights เป็น INT8/INT4) เพื่อลดการใช้พลังงานโดยไม่สูญเสียความแม่นยำของโมเดลมากนัก
ในฝั่ง kernel acceleration จะรวมถึง:
- Matrix Multiply / GEMM: Systolic array และ SIMD pipelines ที่ปรับจูนสำหรับการคูณเมทริกซ์ขนาดเล็กถึงกลางที่ใช้ใน multi-head attention และ feed-forward layers
- Attention-specific kernels: เร่ง softmax, scaling, และ batched matmul สำหรับ attention รวมทั้งการจัดการ masking และ relative positional encoding แบบ hardware-assisted
- Fused operators: LayerNorm + Linear fusion, Quantize/Dequantize fusion, รวมถึง fused activation functions เพื่อลด memory traffic และเรียกใช้งานหน่วยคำนวณให้น้อยลง
ตัวอย่างผลลัพธ์เชิงปฏิบัติการและข้อพิจารณาทางวิศวกรรม
เมื่อนำสเปกตัวอย่าง (8–16 TOPS, 4–16 MB SRAM, แบนด์วิธ 20–50 GB/s) มารัน LLM ขนาดเล็ก (เช่น 10–100 ล้านพารามิเตอร์ ที่ถูก quantized เป็น 4-bit/8-bit) คาดว่าจะได้ latency inference ต่อยกตัวอย่างในระดับ tens-ถึง-hundreds ของมิลลิวินาที ขึ้นกับขนาด context และเงื่อนไข I/O การออกแบบระบบต้องคำนึงถึงการวางผังข้อมูล (data layout), การแบ่ง tile ของ weight/activation, และการจัดตารางการคำนวณเพื่อให้ utilization ของ MAC units สูงสุด โดยในการใช้งานจริง ผู้ผลิตมักให้ชุดเครื่องมือสำหรับ profiling เพื่อช่วยลด bottleneck ด้าน memory และปรับ quantization-aware tuning
โดยสรุป สถาปัตยกรรม NPU สำหรับรัน LLM บน Edge จะเป็นการถ่วงสมดุลระหว่าง compute (TOPS), หน่วยความจำในชิป (SRAM), แบนด์วิธ และการรองรับ quantized formats (INT8/INT4/FP16) รวมถึงการเชื่อมต่อกับ MCU/SoC ผ่าน SPIe/PCIe-Lite, MIPI/AXI เพื่อให้ได้ประสิทธิภาพ inferencing ที่เหมาะสมสำหรับแอปพลิเคชัน IoT แบบเรียลไทม์
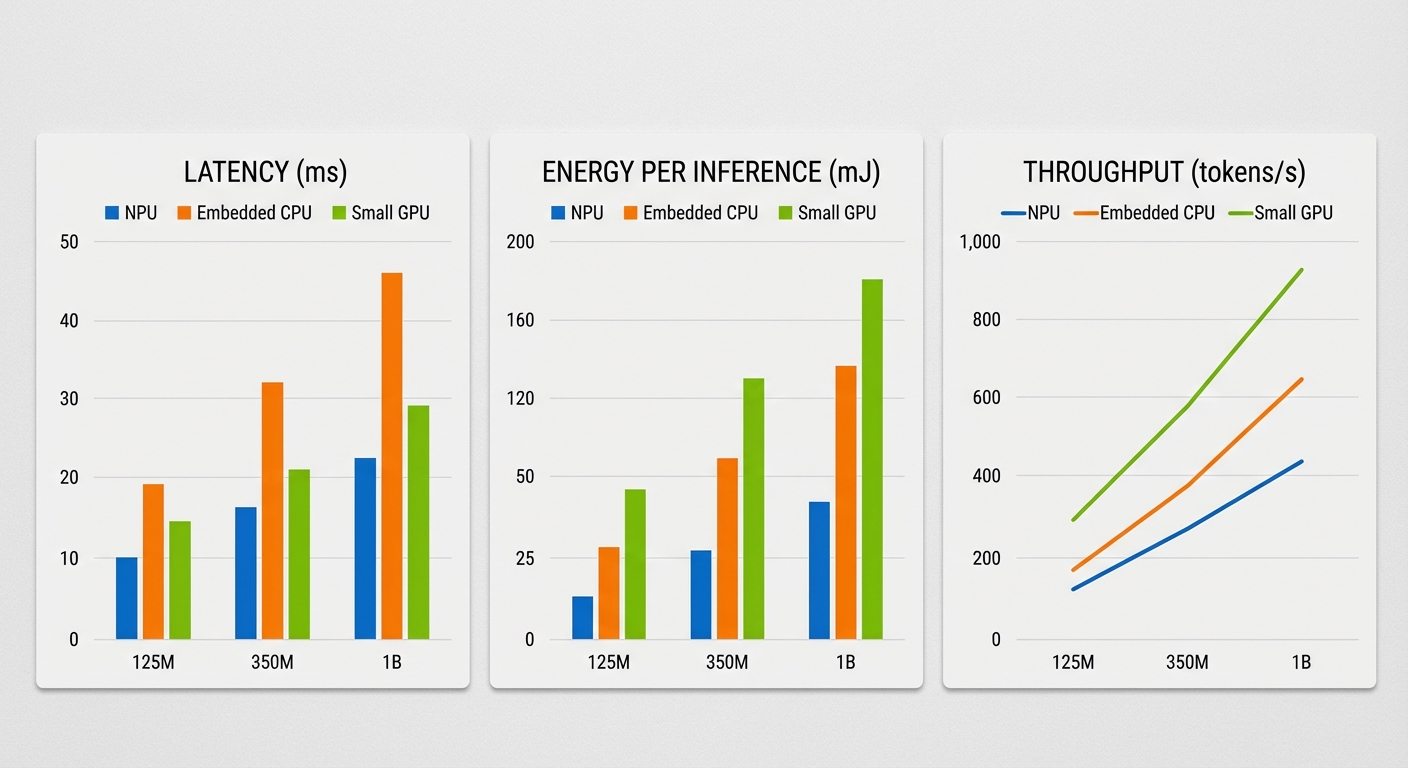
ผลการทดสอบและ Benchmark: Latency, Throughput, และการใช้พลังงาน
ผลการทดสอบเชิงเปรียบเทียบที่ผู้ผลิตชิปไทยนำเสนอแสดงให้เห็นว่า NPU สำหรับรัน LLM ขนาดเล็กบนอุปกรณ์ IoT สามารถให้ประสิทธิภาพด้าน latency, throughput และความคุ้มค่าด้านพลังงานได้อย่างโดดเด่นเมื่อเทียบกับตัวเลือกแบบฝังเดิม (MCU) และ CPU แบบมี NEON หรือ SIMD บางรุ่น ตัวชี้วัดสำคัญจากการทดสอบในห้องปฏิบัติการ ได้แก่ latency ต่อการตอบกลับ (ms), throughput วัดเป็น tokens/s และพลังงานต่อ inference (mJ) โดยสรุปผลเชิงสำคัญได้ว่า latency ลดลงในช่วงประมาณ 5–50x เมื่อเทียบกับ MCU และ ประสิทธิภาพพลังงานดีขึ้นประมาณ 2–10x เมื่อเทียบกับ CPU/NEON ในกรณีการใช้งานที่มีการประมวลผลแบบเรียลไทม์หรือ event-driven ซึ่งเป็นกลุ่มเป้าหมายหลักของชิปนี้

ผลการทดสอบตามขนาดโมเดล (ตัวอย่างเชิงปฏิบัติการ)
- LLM ขนาด 125M parameters
- Latency ต่อการตอบกลับ (สมมติความยาวตอบ 20 tokens): 20–50 ms/response
- Throughput: 400–1,000 tokens/s (ขึ้นอยู่กับ batch/streaming และ quantization)
- พลังงานต่อ inference: ประมาณ 5–20 mJ ต่อการตอบกลับ 20 tokens
- ข้อสังเกต: ภายใต้สภาวะที่เหมาะสม (quantization 8-bit, memory fit) โมเดล 125M สามารถตอบสนองในระดับที่รองรับแอป voice command แบบทันทีได้
- LLM ขนาด 350M parameters
- Latency ต่อการตอบกลับ (20 tokens): 60–180 ms/response
- Throughput: 150–450 tokens/s
- พลังงานต่อ inference: ประมาณ 25–90 mJ
- ข้อสังเกต: เหมาะกับแอปพลิเคชันเชิงโต้ตอบที่ยอมรับ latency ระดับร้อยมิลลิวินาที เช่น assistant ที่มี context ขนาดกลาง
- LLM ขนาด 1B parameters
- Latency ต่อการตอบกลับ (20 tokens): 200–800 ms/response
- Throughput: 40–180 tokens/s
- พลังงานต่อ inference: ประมาณ 120–450 mJ
- ข้อสังเกต: ให้ความแม่นยำและความสามารถด้านภาษาดีกว่า แต่ต้องแลกกับ latency และการใช้พลังงานที่สูงกว่า เหมาะกับงานที่ไม่ต้องการตอบสนองทันทีหรือทำเป็น batch/event-driven
การตีความเชิงปฏิบัติการและเปรียบเทียบกับแพลตฟอร์มอื่น
เมื่อตีความตัวเลขข้างต้นในบริบทการใช้งานจริง พบว่า NPU ใหม่สามารถรองรับสภาพแวดล้อม real-time ได้ในหลายกรณี ตัวอย่างเช่น หากแอปต้องการตอบสนองคำสั่งเสียงในเวลาไม่เกิน 100 ms — โมเดล 125M จะให้ประสบการณ์ที่น่าพอใจ (20–50 ms/response) ขณะที่โมเดล 350M อาจอยู่ในช่วง ยอมรับได้ (60–180 ms) ขึ้นกับ pipeline ก่อนและหลังการประมวลผล (เช่น audio preprocessing, VAD)
เมื่อเปรียบเทียบกับ MCU แบบดั้งเดิม (ที่มักใช้ CPU แบบ single-core และไม่มี SIMD ขนาดใหญ่) ผลการทดสอบแสดงว่า NPU สามารถลด latency ได้ตั้งแต่ประมาณ 5x (สำหรับงานขนาดกลาง) จนถึง 50x (สำหรับ workload ขนาดเล็ก/optimized) ซึ่งหมายความว่าอินเทอร์แอคชันที่เคยใช้เวลาหลายร้อยมิลลิวินาทีบน MCU อาจรันได้ในหลักสิบมิลลิวินาทีบน NPU
ในด้านพลังงาน NPU แสดงประสิทธิภาพที่เหนือกว่า CPU/NEON อยู่ในช่วงประมาณ 2–10x เมื่อวัดเป็นพลังงานต่อ inference (mJ) การปรับแต่งเช่น quantization 8-bit, operator fusion และ memory tiling บน NPU มีผลลดการใช้พลังงานอย่างชัดเจน ในขณะที่ micro-GPU บางรุ่นอาจให้ throughput สูงกว่าในบางกรณี แต่โดยทั่วไปจะใช้พลังงานมากกว่าและไม่เหมาะกับงบพลังงานที่เข้มงวดของอุปกรณ์ IoT
ข้อสรุปเชิงปฏิบัติและคำแนะนำสำหรับธุรกิจ
- แอปที่ต้องการความหน่วงต่ำสุด (voice command, wake-word, intent recognition): แนะนำใช้โมเดล 125M บน NPU เพื่อให้ได้ latency ต่ำกว่า 50 ms/response และ throughput เพียงพอสำหรับการตอบสนองแบบเรียลไทม์
- แอปที่ต้องการบริบทมากขึ้น (multi-turn assistant, local summarization แบบสั้น): โมเดล 350M บน NPU เป็นทางเลือกกลาง ระหว่างความแม่นยำและ latency
- งานที่เน้นความแม่นยำสูงและไม่จำเป็นต้องตอบทันที: โมเดล 1B เหมาะกับการทำ inference แบบ batch หรือ event-driven ที่สามารถยอมรับ latency ในระดับหลายร้อยมิลลิวินาที
- เชิงปฏิบัติ: การวางแผนด้านพลังงานและ thermal envelope สำคัญ — สำหรับอุปกรณ์ที่ใช้แบตเตอรี่ แนะนำตั้งค่าการประมวลผลแบบ opportunistic, dynamic frequency scaling และ quantization เพื่อรักษาสมดุลระหว่าง latency และพลังงาน
โดยรวม ผล benchmark ชี้ให้เห็นว่า NPU ที่พัฒนาโดยผู้ผลิตชิปไทยเป็นทางเลือกที่มีศักยภาพชัดเจนสำหรับการนำ LLM ขนาดเล็กมาทำงานบน edge โดยเฉพาะในกรณีที่องค์กรต้องการลด latency และต้นทุนพลังงานพร้อมทั้งรักษาสมรรถนะในการตอบสนองแบบเรียลไทม์
ตัวอย่างการใช้งานจริงบน Edge IoT
ตัวอย่างการใช้งานจริงบน Edge IoT
ชิป NPU ที่ออกแบบมาเพื่อรัน LLM ขนาดเล็กบนอุปกรณ์ Edge เปิดช่องทางให้เกิดการประยุกต์ใช้งานที่เคยพึ่งพาคลาวด์มาก่อนสามารถทำงานแบบ on-device ได้จริง โดยเฉพาะงานที่เป็นข้อความสั้น คำสั่งเชิงบริบท หรือการสรุปเหตุการณ์แบบเรียลไทม์ ต่อไปนี้เป็นตัวอย่างการใช้งานเชิงธุรกิจ พร้อมข้อดีและข้อจำกัดที่ผู้ประกอบการควรพิจารณา
-
กล้องวงจรปิดอัจฉริยะ (Smart CCTV)
การรันโมเดลขนาดเล็กบน NPU ทำให้กล้องสามารถทำการจดจำวัตถุ สรุปเหตุการณ์ สร้างคำอธิบายเหตุการณ์ (event captioning) และตอบคำสั่งค้นหาภาพแบบภาษาธรรมชาติได้โดยไม่ต้องส่งวิดีโอทั้งหมดขึ้นคลาวด์
- ข้อดี: ลดแบนด์วิดท์และต้นทุนการจัดเก็บ — ปริมาณข้อมูลที่ส่งกลับศูนย์กลางอาจลดลงได้มากกว่า 70–80% ในงานที่ต้องการเพียงเหตุการณ์หรือเมแทดาต้า และลดความล่าช้าในการแจ้งเตือนแบบเรียลไทม์
- ข้อจำกัด: LLM ขนาดเล็กบนอุปกรณ์อาจมีความแม่นยำในการตีความคำอธิบายซับซ้อนต่ำกว่าการประมวลผลบนคลาวด์ ต้องออกแบบพารามิเตอร์การแจ้งเตือนและเกณฑ์ตรวจจับให้รัดกุม รวมทั้งมีข้อจำกัดด้านหน่วยความจำและอัตราเฟรมที่ประมวลผลได้
- ตัวอย่างเชิงตัวเลข: เมื่อรันโมเดลเบื้องต้นเพื่อสรุปเหตุการณ์กล้องภายในอาคาร พบว่าการส่งเฉพาะคำอธิบายเหตุการณ์แทนวิดีโอเต็มช่วยลดการใช้งานเครือข่ายได้อย่างมีนัยสำคัญ และเวลาตอบสนองต่อการแจ้งเตือนสามารถอยู่ในระดับ 100–300 ms ขึ้นกับสเปก NPU
-
ผู้ช่วยเสียงภายในบ้าน (On-device Voice Assistant)
การรวม ASR แบบ lightweight และ NLU บน NPU ช่วยให้การตรวจจับ wake-word การจำแนกเจตนา (intent detection) และการตอบคำสั่งพื้นฐานทำได้โดยไม่ต้องเชื่อมต่อเน็ตตลอดเวลา
- ข้อดี: ลด latency ในการตอบสนอง — wake-word และ intent detection ที่รันบนอุปกรณ์สามารถตอบสนองได้ในระดับสิบมิลลิวินาทีถึงหลักสิบมิลลิวินาที นอกจากนี้ยังช่วยปกป้องข้อมูลส่วนบุคคลเพราะเสียงและข้อความไม่จำเป็นต้องส่งออกนอกบ้าน
- ข้อจำกัด: โมเดล ASR/NLU ขนาดเล็กอาจมีความสามารถในการเข้าใจสำเนียงหรือคำสั่งที่ซับซ้อนน้อยกว่าโมเดลขนาดใหญ่บนคลาวด์ ผู้ผลิตต้องวางกลยุทธ์ fallback ไปยังคลาวด์เมื่อจำเป็น และจัดการกับการอัปเดตโมเดลอย่างปลอดภัย
- ตัวอย่างเชิงธุรกิจ: อุปกรณ์ที่ติดตั้ง NPU สามารถรองรับฟังก์ชันควบคุมบ้านพื้นฐาน (เช่น เปิด-ปิดไฟ ควบคุมเทอร์โมสตัท) ด้วย latency ต่ำ ทำให้ผู้ใช้รับรู้ประสบการณ์ที่ทันใจและเป็นส่วนตัวมากขึ้น
-
ระบบตรวจจับความผิดปกติในเครื่องจักรภาคอุตสาหกรรม
ในโรงงานที่ต้องการการตรวจจับสัญญาณหรือเหตุการณ์ผิดปกติแบบเรียลไทม์ การใช้งาน LLM ขนาดเล็กร่วมกับโมเดลอนาไลติกส์บน NPU ช่วยแปลสัญญาณหรือบันทึกข้อความสั้นเป็นคำสั่งหรือการแจ้งเตือน
- ข้อดี: ลดความเสี่ยงจากการพึ่งพาการเชื่อมต่ออินเทอร์เน็ต — ระบบสามารถวิเคราะห์และแจ้งเตือนแบบ offline ได้ทันที ลดความเสี่ยงเมื่อเกิดการตัดการเชื่อมต่อ และช่วยให้การบำรุงรักษาเชิงป้องกันทำได้รวดเร็วขึ้น
- ข้อจำกัด: การวินิจฉัยเชิงลึกที่ต้องการบริบทยาวหรือซีเควนซ์ข้อมูลขนาดใหญ่อาจต้องส่งไปประมวลผลเพิ่มเติมที่ศูนย์ข้อมูล นอกจากนี้การฝึกสอนโมเดลให้รู้จักสัญญาณผิดปกติเฉพาะโรงงานต้องใช้ข้อมูลเทรนที่เหมาะสม
- ประสิทธิผลเชิงตัวเลข: ในบางงานการแจ้งเตือนล่วงหน้าแบบ on-device สามารถลดเวลาหยุดเดินเครื่องได้หลายชั่วโมงและลดต้นทุนการซ่อมบำรุงลงอย่างมีนัยสำคัญ (ขึ้นกับกระบวนการและการตั้งค่าการแจ้งเตือน)
-
โดรนสำหรับภาคสนาม (Field Drones) ที่ใช้โมเดลภาษาขนาดเล็ก
โดรนที่ปฏิบัติงานในพื้นที่ห่างไกลหรือเงื่อนไขขาดการเชื่อมต่อสามารถใช้ LLM ขนาดเล็กบน NPU เพื่อสรุปสถานะ ตอบคำสั่งสั้น หรือสื่อสารภาคสนามแบบข้อความ/เสียงกับผู้ปฏิบัติงาน
- ข้อดี: การสื่อสารและตีความคำสั่งภาคสนามเป็นไปได้แบบออฟไลน์ ลดความเสี่ยงด้านความปลอดภัยของข้อมูลและการพึ่งพาเครือข่ายภายนอก ซึ่งสำคัญสำหรับงานทางทหาร พลังงาน หรือสำรวจพื้นที่ห่างไกล
- ข้อจำกัด: ขนาดโมเดลและหน่วยความจำจำกัดความสามารถด้านการสื่อสารเชิงซ้อน เช่น การสร้างรายงานยาวหรือประมวลผลคำสั่งที่ต้องบริบทยาว โดรนอาจต้องส่งข้อมูลขึ้นคลาวด์ตามนโยบายเมื่อมีการเชื่อมต่อ
- กรณีใช้งาน: โดรนสามารถส่งรายงานสถานะฉบับย่อ (short summary) กลับไปยังศูนย์ควบคุมหรือแปลคำสั่งผู้ปฏิบัติงานเป็นชุดคำสั่งการบินได้ทันที ช่วยให้การตัดสินใจภาคสนามเร็วขึ้น
สรุปคือ NPU สำหรับรัน LLM ขนาดเล็กบน Edge IoT เหมาะกับงานที่ต้องการการตอบสนองเร็ว ปกป้องความเป็นส่วนตัว และลดการส่งข้อมูลกลับศูนย์กลาง โดยเฉพาะงานที่รองรับข้อความสั้น คำสั่งจำกัด หรือการสรุปเหตุการณ์ อย่างไรก็ตามองค์กรต้องชั่งน้ำหนักข้อจำกัดเรื่องขนาดโมเดล ความแม่นยำในสถานการณ์ซับซ้อน และแผนการ fallback/อัปเดตโมเดลเพื่อให้ระบบมีความยืดหยุ่นและปลอดภัยในระยะยาว
ซอฟต์แวร์และเครื่องมือสำหรับนักพัฒนา
SDK และ compiler/graph optimizer
ผู้ผลิตชิปมักจะมาพร้อมกับ SDK ที่ใช้งานง่าย ซึ่งออกแบบมาเพื่อนักพัฒนาและทีมผลิตภัณฑ์ที่ต้องการเร่งรัดเวลาสู่ตลาด (time-to-market) โดย SDK เหล่านี้จะรวมทั้งเครื่องมือสำหรับแปลงกราฟคำนวณ (graph optimizer) และ compiler ที่สามารถแมปคำสั่งเชิงคณิตศาสตร์ของ Transformer (เช่น attention, layer-norm, GELU) ให้เป็น kernels ที่รันได้บน NPU โดยตรง ระบบมักมีคุณสมบัติดังนี้:
- การแมปอัตโนมัติของ Transformer ops เป็นชุดคำสั่งประสิทธิภาพสูงบน NPU พร้อม fallback ไปยัง CPU เมื่อยังไม่รองรับ
- Graph optimization เช่น operator fusion, constant folding, และ elimination ของโน้ตที่ไม่จำเป็น เพื่อลด memory footprint และลด latency
- รองรับการปรับ precision อัตโนมัติ (FP16/INT8) และการแปลง layout ของ tensor ให้สอดคล้องกับ hardware tiling
- API สะดวก สำหรับนักพัฒนาในรูปแบบ CLI และ Python bindings ที่ช่วยให้ integration กับ pipeline CI/CD ทำได้ง่าย
Runtime และการรองรับมาตรฐานโมเดล
เพื่อความยืดหยุ่นต่อระบบนิเวศโมเดลสากล SDK จะมาพร้อม runtime ที่รองรับมาตรฐานโครงสร้างโมเดลหลัก ได้แก่ ONNX, TensorFlow Lite และ PyTorch Mobile ซึ่งช่วยให้โมเดลที่เทรนในแพลตฟอร์มต่าง ๆ สามารถนำมารันบน edge NPU ได้โดยไม่ต้องออกแบบใหม่ทั้งหมด ตัว runtime มักมีฟีเจอร์สำคัญ เช่น memory pooling, dynamic batching แบบจำกัดขนาด, และการจัดการ I/O แบบไม่บล็อคเพื่อให้ latency สม่ำเสมอ
ตัวอย่าง flow การนำโมเดลจาก PyTorch ไปสู่ NPU อาจเป็นแบบนี้: torch.onnx.export(model, dummy_input, "model.onnx", opset_version=13) → ใช้ npu-compiler เพื่อแปลงและ optimize → โหลดไฟล์ที่คอมไพล์แล้วด้วย npu-runtime บนอุปกรณ์
ตัวอย่าง workflow: Quantize → Compile → Profile → Deploy
ตัวอย่าง workflow สำหรับ LLM ขนาดเล็ก (เช่น DistilBERT หรือ TinyLlama-like) บน NPU จะประกอบด้วยขั้นตอนหลัก 4 ขั้น:
- 1. Export — ส่งออกโมเดลเป็น ONNX/TFLite: torch.onnx.export(..., "model.onnx")
- 2. Quantize — ทำ PTQ หรือ QAT เพื่อลด precision ตัวอย่างคำสั่ง PTQ: npu-quantize --input model.onnx --calib-data calib.json --output model_int8.onnx โดยใช้ชุดข้อมูล calibration ประมาณ 500–2,000 ตัวอย่างเพื่อรักษาความแม่นยำ
- 3. Compile — รัน compiler/graph optimizer: npu-compile --input model_int8.onnx --target npu-v1 --opt fusions --output model.npu
- 4. Profile & Deploy — ใช้ profiler เพื่อวัด latency และพลังงาน จากนั้นปรับพารามิเตอร์ runtime และ deploy: npu-profiler --model model.npu --mode perf --output metrics.json → สร้างแพ็กเกจสำหรับ OTA
ตัวอย่างโมเดล: DistilBERT (~66M พารามิเตอร์) หลังจาก quantize เป็น INT8 และรันบน NPU อาจเห็น latency ต่อคำถามแบบ single-sequence อยู่ในช่วงประมาณ 10–50 ms และลดการใช้พลังงานได้ถึง 5–10x เมื่อเทียบกับการรันบน CPU ตัวอย่าง TinyLlama-like (40–70M) สำหรับการผลิต token-stream อาจอยู่ที่ 20–120 ms ต่อ step ขึ้นกับความยาว context และ batch size
เทคนิคการปรับแต่งโมเดล (QAT, PTQ, Pruning, LoRA)
การเลือกเทคนิคขึ้นกับข้อจำกัดด้านความแม่นยำและทรัพยากร:
- Post-Training Quantization (PTQ) — เหมาะเมื่อมีข้อมูล calibration เล็กน้อยและต้องการ pipeline ที่เร็ว PTQ มักลดขนาดและพลังงานได้มากโดยไม่ต้องเทรนใหม่
- Quantization-Aware Training (QAT) — ทำให้ผลกระทบจากการ quantize ต่ำที่สุดในงานที่ต้องการความแม่นยำสูง โดยฝัง noisy quantization ระหว่างการเทรน
- Pruning — มีทั้ง structured pruning ที่ตัดทั้งหน่วย (เช่น heads หรือ neurons) และ unstructured pruning ที่ตัด weights เล็ก ๆ เพื่อลด compute และ memory; structured pruning มักให้ผลลัพธ์ที่เป็นประโยชน์ต่อ NPU มากกว่า
- LoRA (Low-Rank Adaptation) — ใช้สำหรับ fine-tuning เฉพาะพารามิเตอร์บางส่วนบนอุปกรณ์จำกัดทรัพยากร โดยเก็บโมดูล LoRA แบบเล็ก ๆ แล้วรวมเข้ากับโมเดลก่อน export ไปยัง ONNX/TFLite
ตัวอย่าง flow สำหรับ LoRA: เทรน LoRA บน PyTorch → รวม weights กับ base model (หรือเก็บเป็น adapter) → export เป็น ONNX → ทำ quantize/compile เหมือน workflow ปกติ
Profiling / Telemetry สำหรับวัดพลังงานและ latency
ระบบ SDK ระดับ production จะรวมเครื่องมือ profiling/telemetry เพื่อให้ทีมวิศวกรรมสามารถวัดได้อย่างชัดเจนว่า NPU ช่วยปรับปรุงค่า KPI อย่างไร เครื่องมือเหล่านี้มักประกอบด้วย:
- ซอฟต์แวร์ profiler ที่วัด latency (avg, p50, p90, p99), throughput (tokens/sec) และ memory peak
- telemetry agent สำหรับส่งเมตริกไปยังเซิร์ฟเวอร์ APM/Observability (เช่น Prometheus/Grafana stack) เพื่อการมอนิเตอร์และ alert
- การวัดพลังงานทั้งแบบ on-chip (sensor ภายในบอร์ด) และแบบภายนอก (power meter) เพื่อคำนวณ energy per inference หรือ mJ per token
- integration กับ CI ที่รัน regression tests เพื่อป้องกันความเสื่อมของประสิทธิภาพหลังจากปรับโมเดลหรือ pipeline
ตัวอย่างคำสั่ง profiling: npu-profiler --model model.npu --workload "squad_eval" --duration 60 --output metrics.json ผลลัพธ์ควรประกอบด้วย latency distribution, CPU/NPU utilization และค่า energy-per-inference (mJ) เพื่อใช้ในการตัดสินใจด้าน business SLA เช่นตั้งเป้า p99 latency < 200 ms และ energy-per-query < 50 mJ สำหรับ use-case แบบ conversational ที่ตอบสนองแบบ near real-time
สรุปแล้ว สแต็กซอฟต์แวร์ที่มากับ NPU สำหรับรัน LLM ขนาดเล็กบนอุปกรณ์ IoT ควรเป็นชุดเครื่องมือครบวงจร ตั้งแต่การ export โมเดล การทำ quantization/QAT/pruning/LoRA ไปจนถึง compiler ที่แมป transformer ops เป็น NPU kernels และ runtime ที่รองรับมาตรฐานสากล รวมทั้งเครื่องมือ profiling/telemetry ที่วัดทั้ง latency และพลังงานได้อย่างแม่นยำ ซึ่งทั้งหมดนี้ช่วยให้ทีมธุรกิจสามารถตัดสินใจได้เร็วขึ้น ทั้งในแง่ค่าใช้จ่ายพลังงานและประสบการณ์ผู้ใช้ (UX) บน edge
ความปลอดภัย ความเป็นส่วนตัว และข้อพิจารณาด้านนโยบาย
ความปลอดภัย ความเป็นส่วนตัว และข้อพิจารณาด้านนโยบาย
การรัน Large Language Models (LLM) ขนาดเล็กบนอุปกรณ์ IoT ด้วย NPU ในเครื่องให้ประโยชน์สำคัญด้านความเป็นส่วนตัวและประสิทธิภาพ: ข้อมูลไม่จำเป็นต้องส่งขึ้นคลาวด์ซึ่งช่วยลดความเสี่ยงของการรั่วไหลของข้อมูลส่วนบุคคลและการถูกดักฟังระหว่างทาง และยังช่วยลด latency ในการตอบสนองสำหรับงานแบบเรียลไทม์ เช่น การประมวลผลเสียง การวิเคราะห์ภาพจากกล้องวงจรปิด หรือการสั่งงานด้วยภาษาเฉพาะอุปกรณ์ อย่างไรก็ดี การย้ายภาระการประมวลผลมาไว้ที่ขอบเครือข่าย (edge) ก็ยกระดับความเสี่ยงด้านความปลอดภัยบนอุปกรณ์เอง ซึ่งต้องได้รับการออกแบบมาตรการป้องกันอย่างรอบด้าน
ความเสี่ยงเชิงเทคนิคที่ต้องพิจารณา ได้แก่ การถูกเข้าถึงทางกายภาพ (physical access) ที่อาจนำไปสู่การขโมยไบต์โค้ดหรือโมเดล, การโจมตีแบบ model extraction และการย้อนรอยข้อมูล (model inversion / membership inference) ซึ่งอาจเปิดเผยข้อมูลเทรนนิงที่ละเอียดอ่อน นอกจากนี้ยังมีช่องโหว่จากซอฟต์แวร์ เช่น ไฟล์ระบบที่ไม่ปลอดภัย, การอัปเดตที่ไม่ได้รับการยืนยัน และการโจมตีแบบ side-channel (เช่น การวัดพลังงานหรือเวลาในการประมวลผล) ที่สามารถถูกใช้เพื่อสกัดข้อมูลหรือโค้ดได้
มาตรการเชิงเทคนิคที่ควรบังคับใช้บนอุปกรณ์ IoT ที่รัน LLM ได้แก่:
- Secure Boot และ Signed Firmware — ตรวจสอบลำดับการบูตและยืนยันความสมบูรณ์ของเฟิร์มแวร์/ไบโอส เพื่อลดความเสี่ยงจากเฟิร์มแวร์ที่ถูกดัดแปลง
- Encrypted Model Storage — เก็บโมเดลและข้อมูลสำคัญในรูปแบบเข้ารหัส (เช่น AES-GCM) โดยกุญแจเข้ารหัสเก็บในฮาร์ดแวร์ที่เชื่อถือได้
- Hardware Root-of-Trust & Secure Key Management — ใช้ TPM/SE/TEE หรือ HSM ในการจัดเก็บคีย์ การลงนาม และการทำ remote attestation เพื่อยืนยันสถานะอุปกรณ์ต่อเซิร์ฟเวอร์ศูนย์กลาง
- Remote Attestation และ Integrity Monitoring — ให้เซิร์ฟเวอร์ตรวจสอบสถานะซอฟต์แวร์/โมเดลของอุปกรณ์ก่อนให้สิทธิการเข้าถึงหรืออัปเดต
- Secure OTA และ Signed Models — อัปเดตเฟิร์มแวร์และโมเดลผ่านช่องทางที่เข้ารหัสและยืนยันลายเซ็นดิจิทัล เพื่อลดความเสี่ยงจากการโจมตีผ่านการอัปเดต
- Runtime Protections และ TEE — รัน inference ในสภาพแวดล้อมแยก (เช่น ARM TrustZone หรือ secure enclave) เพื่อป้องกันการอ่านหน่วยความจำระหว่างทำงาน
- Side-channel Mitigations และ Tamper Detection — ออกแบบฮาร์ดแวร์และซอฟต์แวร์เพื่อลดช่องโหว่ด้านเวลา/พลังงาน และใส่เซ็นเซอร์ตรวจจับการงัดแงะโดยผู้ไม่หวังดี
- Privacy-preserving Techniques — พิจารณาการใช้ differential privacy ในการฝึกและ fine-tune เพื่อลดความเสี่ยงในการย้อนรอยข้อมูลจากโมเดล และพิจารณา watermarking สำหรับตรวจจับการคัดลอกโมเดล
- การจัดการช่องโหว่และกระบวนการตอบสนอง — มีนโยบาย vulnerability disclosure, การแพตช์ที่รวดเร็ว และระบบ logging/forensics เพื่อรองรับเหตุการณ์ด้านความปลอดภัย
ด้านนโยบายและกฎหมายสำหรับการใช้งานในประเทศไทย ลูกค้าผู้พัฒนาหรือผู้ให้บริการต้องปฏิบัติตาม พ.ร.บ. คุ้มครองข้อมูลส่วนบุคคล (PDPA) โดยคำนึงถึงหลักการสำคัญ เช่น ความชอบด้วยกฎหมาย การยินยอม การจำกัดวัตถุประสงค์ การลดปริมาณข้อมูล (data minimization) และข้อกำหนดเกี่ยวกับการโอนข้อมูลข้ามประเทศ (ต้องมีมาตรการคุ้มครองที่เหมาะสมหรือได้รับความยินยอมตามกรณี) สำหรับการประยุกต์ในภาคสาธารณสุข การเงิน หรือการติดตามบุคคล ยังมีข้อบังคับเฉพาะภาคที่ต้องเคร่งครัดมากขึ้น นอกจากนี้องค์กรควรพิจารณาการรับรองมาตรฐานความปลอดภัยข้อมูล เช่น ISO/IEC 27001, SOC2 หรือการใช้โมดูลเข้ารหัสที่ผ่านการรับรอง FIPS เพื่อเพิ่มความน่าเชื่อถือ
สุดท้ายนี้ การออกแบบระบบของผู้ผลิตชิปและผู้พัฒนาอุปกรณ์ควรผสมผสานทั้งมาตรการเชิงเทคนิคกับกรอบกำกับดูแลองค์กร (governance) เช่น การประเมินผลกระทบต่อความเป็นส่วนตัว (DPIA), ข้อตกลงการให้บริการที่ชัดเจน, การฝึกอบรมพนักงาน และแผนการตอบสนองเมื่อเกิดเหตุละเมิดข้อมูล เพื่อให้ประโยชน์ด้านความเป็นส่วนตัวและประสิทธิภาพจากการรัน LLM บน edge ถูกใช้ได้อย่างปลอดภัยและสอดคล้องกับกฎหมายในประเทศไทย
ผลกระทบต่อตลาดและโอกาสทางธุรกิจสำหรับอุตสาหกรรมไทย
ผลกระทบต่อตลาดและโอกาสทางธุรกิจสำหรับอุตสาหกรรมไทย
การที่ผู้ผลิตชิปไทยเปิดตัว NPU สำหรับรัน LLM ขนาดเล็กบนอุปกรณ์ IoT จะเป็นจุดเปลี่ยนเชิงเศรษฐกิจที่สำคัญต่อห่วงโซ่อุปทานและระบบนิเวศดิจิทัลภายในประเทศ การผลิตภายในประเทศช่วยลดค่าใช้จ่ายด้านโลจิสติกส์ ระยะเวลาการจัดส่ง (lead time) และความเสี่ยงจากการขาดแคลนชิ้นส่วน ซึ่งมีผลโดยตรงต่อผู้ผลิตอุปกรณ์ IoT ท้องถิ่นที่ต้องการความยืดหยุ่นในการออกแบบและปรับผลิตภัณฑ์ให้ตอบโจทย์ตลาดได้รวดเร็วขึ้น นอกจากนี้ยังส่งเสริมการเกิดคลัสเตอร์อุตสาหกรรมด้านชิป รวมถึงบริการประกอบ แพ็กเกจจิ้ง การทดสอบ (assembly, packaging & testing) และการผลิตบอร์ด (PCB assembly) ที่สามารถสร้างมูลค่าเพิ่มในประเทศได้มากขึ้น
ในเชิงตลาดและการส่งออก โซลูชัน NPU บน Edge สำหรับ LLM ขนาดเล็กมีศักยภาพให้ไทยสามารถบุกตลาดภูมิภาค (ASEAN) รวมถึงตลาดเฉพาะด้านในยุโรปและอเมริกา เช่น อุปกรณ์ตรวจสอบในอุตสาหกรรมการเกษตรอัจฉริยะ ระบบตรวจจับความผิดปกติในโรงงาน (predictive maintenance) และอุปกรณ์ทางการแพทย์ที่ต้องการ latency ต่ำ ข้อได้เปรียบจากการมีต้นทุนการผลิตและบริการติดตั้งในประเทศจะทำให้ผู้ผลิตไทยสามารถแข่งขันด้านราคาและบริการหลังการขายได้ดียิ่งขึ้น หากผนวกกับการรับรองมาตรฐานสากลและการทำ compliance จะเปิดประตูไปสู่การส่งออกในระดับที่มีมูลค่าสูงขึ้น
ด้านบริการเสริมซึ่งเป็นแหล่งรายได้สำคัญหลังการขาย ได้แก่ deployment, maintenance, model tuning และ edge orchestration บริการเหล่านี้สามารถสร้างรูปแบบรายได้แบบบริการ (recurring revenue) ให้กับผู้ประกอบการไทย เช่น การให้บริการปรับจูนโมเดลให้เหมาะกับข้อมูลท้องถิ่น การจัดการ fleet ของอุปกรณ์ Edge ผ่านระบบ orchestration และการให้บริการอัพเดตความปลอดภัยและโมเดลแบบต่อเนื่อง ตัวอย่างเช่น บริษัทที่ให้บริการ edge orchestration สามารถคิดค่าบริการรายเดือนต่ออุปกรณ์ ซึ่งเมื่อรวมกับโครงการขนาดใหญ่ในภาคอุตสาหกรรมจะกลายเป็นรายได้ประจำที่มั่นคง
นอกจากบริการเชิงเทคนิคแล้ว ยังมีโอกาสทางธุรกิจด้าน ecosystem อื่นๆ เช่น การพัฒนา SDK, reference design, datasets ภายในประเทศ และ benchmarking ที่ช่วยลดเวลาการนำสินค้าเข้าสู่ตลาด การสร้างชุมชนนักพัฒนาท้องถิ่น (developer community) จะทำให้เกิดนวัตกรรมแอปพลิเคชันใหม่ๆ ที่รองรับภาษาท้องถิ่นและ use-case เฉพาะทาง ซึ่งจะเพิ่มความต้องการฮาร์ดแวร์และบริการในประเทศมากขึ้น
เพื่อเร่งการขยายตลาดและการยอมรับเชิงพาณิชย์ ข้อเสนอแนะเชิงนโยบายและการลงทุนที่ควรพิจารณามีดังนี้
- สนับสนุน R&D และสิทธิประโยชน์ทางภาษี: มาตรการให้เครดิตภาษีสำหรับงานวิจัยการพัฒนาชิปและซอฟต์แวร์ที่เกี่ยวข้อง รวมถึงทุนร่วมลงทุน (matching grants) สำหรับโครงการพัฒนาต้นแบบเพื่อดึงนักลงทุนและผู้ประกอบการมาเร่งการพัฒนาผลิตภัณฑ์
- ส่งเสริมมาตรฐานเปิดและการรับรองความเข้ากันได้: สนับสนุนการนำมาตรฐานเปิดมาใช้ (interoperability standards) และจัดตั้งห้องทดสอบ/ศูนย์รับรอง (certification lab) เพื่อสร้างความเชื่อมั่นให้ลูกค้าทั้งในประเทศและต่างประเทศ
- โปรแกรมฝึกอบรมและการพัฒนาทักษะ: ลงทุนในหลักสูตรฝึกอบรมสำหรับวิศวกร embedded, data scientists และผู้ดูแลระบบ edge orchestration รวมถึงร่วมมือกับมหาวิทยาลัยและสถาบันฝึกอบรมในการออกแบบหลักสูตรเร่งด่วน (bootcamp) เพื่อลดช่องว่างทักษะในตลาดแรงงาน
- สนับสนุนการจัดซื้อภาครัฐแบบนำร่อง (public procurement pilots): รัฐบาลสามารถเป็นผู้ซื้อรายแรก (first adopter) สำหรับโซลูชัน NPU-Edge ในโครงการสมาร์ทซิตี้ เกษตรอัจฉริยะ หรือโรงพยาบาล เพื่อสร้าง reference use-case และกระตุ้นการนำไปใช้ในภาคเอกชน
- ส่งเสริมการสร้างเครือข่ายอุตสาหกรรมและคลัสเตอร์: สนับสนุนการรวมตัวของผู้ผลิตชิป ผู้ให้บริการระบบ และ OEM/ODM เพื่อสร้างห่วงโซ่มูลค่าในประเทศที่สมบูรณ์ ตั้งแต่การออกแบบจนถึงการให้บริการหลังการขาย
สรุปแล้ว การมี NPU ที่ผลิตในประเทศสำหรับรัน LLM ขนาดเล็กบนอุปกรณ์ IoT ไม่เพียงแต่เพิ่มขีดความสามารถทางเทคนิคของอุตสาหกรรมไทย แต่ยังเปิดโอกาสทางธุรกิจตั้งแต่การผลิตจนถึงบริการหลังการขาย หากมีการสนับสนุนเชิงนโยบายและการลงทุนที่เหมาะสม ภายใน 3–5 ปี สามารถสร้างมูลค่าเพิ่มเชิงอุตสาหกรรม สร้างงานด้านเทคนิคระดับสูง และเพิ่มศักยภาพการส่งออกของไทยในตลาด Edge AI ที่คาดว่าจะเติบโตต่อเนื่อง
บทสรุป
การเปิดตัว NPU โดยผู้ผลิตชิปไทยถือเป็นก้าวสำคัญที่ช่วยนำ Large Language Model ขนาดเล็ก (โมเดลระดับล้านถึงร้อยล้านพารามิเตอร์) มาสู่การใช้งานบนอุปกรณ์ Edge/IoT ได้จริง ด้วยสถาปัตยกรรมที่ออกแบบมาสำหรับการรัน inference แบบ on-device ผู้ผลิตระบุว่าสามารถลดการใช้พลังงานได้อย่างมีนัยสำคัญและลด latency ในการตอบสนองเมื่อเทียบกับการส่งข้อมูลไปประมวลผลบนคลาวด์ ทำให้แอปพลิเคชัน IoT เช่น กล้องอัจฉริยะ อุปกรณ์สวมใส่ ระบบควบคุมในโรงงาน และอุปกรณ์ตรวจจับเหตุการณ์ต่างๆ ตอบสนองได้รวดเร็วขึ้น มีความเป็นส่วนตัวสูงขึ้น และลดปริมาณข้อมูลที่ต้องส่งกลับไปยังศูนย์ข้อมูล (ตัวอย่างเช่นการตอบสนองแบบเรียลไทม์ การตรวจจับภัยคุกคามภายในเครื่อง และการประมวลผลคำสั่งเสียงโดยไม่พึ่งพาเชื่อมต่ออินเทอร์เน็ตตลอดเวลา).
อย่างไรก็ตาม ความสำเร็จเชิงพาณิชย์ของ NPU ไทยไม่ได้ขึ้นกับฮาร์ดแวร์เพียงอย่างเดียว แต่พึ่งพา ecosystem ทางซอฟต์แวร์ เช่น คอมไพเลอร์ รันไทม์ เครื่องมือ quantization และไลบรารีที่รองรับการปรับแต่งโมเดล การรับรองความปลอดภัยและการปฏิบัติตามมาตรฐาน (เช่น มาตรฐานด้านความปลอดภัยข้อมูลและการรับรองระดับสากล) รวมทั้งการสนับสนุนจากภาครัฐและความร่วมมือกับภาคเอกชนเพื่อสร้างตลาด ขยายเครือข่ายนักพัฒนา และส่งเสริมนโยบายส่งออก หากมีการลงทุนในซอฟต์แวร์ การรับรอง และนโยบายสนับสนุนที่เหมาะสม NPU จากผู้ผลิตไทยมีโอกาสยกระดับศักยภาพการแข่งขันสู่ตลาดภูมิภาคและสากล การเดินหน้าต่อไปจึงควรเน้นสร้างมาตรฐานเปิด พัฒนาความปลอดภัยเชิงรุก และส่งเสริมความร่วมมือระหว่างภาครัฐ-เอกชนเพื่อเปลี่ยนความเป็นไปได้เชิงเทคนิคให้กลายเป็นความสำเร็จเชิงพาณิชย์.



