
ธนาคารกลางได้เปิดเผยผลการทดสอบการใช้งานโมเดลภาษาขนาดใหญ่ (Large Language Models: LLM) เพื่องานด้านกำกับดูแลที่สำคัญ โดยรายงานชี้ว่า LLM สามารถสรุปรายงานความเสี่ยงและร่างคำแนะนำเชิงนโยบายอัตโนมัติ ทำให้เวลาในการรีวิวเอกสารลดลงจากระดับสัปดาห์เหลือเพียงไม่กี่ชั่วโมง—หรือกล่าวได้ว่าเป็นการลดเวลาในการประมวลผลและตรวจทานมากกว่า 80% ในกรณีศึกษาที่นำร่องกับเอกสารการกำกับดูแลของสถาบันการเงิน การทดลองครั้งนี้ไม่ได้เป็นเพียงการทดสอบประสิทธิภาพเชิงเทคนิคเท่านั้น แต่ยังแสดงภาพว่าเทคโนโลยี LLM อาจเปลี่ยนโฉมกระบวนการตรวจสอบกฎระเบียบและการตอบสนองต่อความเสี่ยงอย่างมีนัยสำคัญ
นอกเหนือจากผลลัพธ์ด้านความรวดเร็ว รายงานยังนำเสนอกรอบการประเมินความเสี่ยงที่ชัดเจน ซึ่งครอบคลุมประเด็นหลักทั้งความเป็นส่วนตัวของข้อมูล ความปลอดภัย ความโปร่งใส ความลำเอียงของโมเดล และกลไกการควบคุมโดยมนุษย์ พร้อมข้อเสนอเชิงนโยบายเพื่อการใช้งานจริง เช่น การบังคับใช้การตรวจทานโดยผู้เชี่ยวชาญ (human-in-the-loop), ระบบบันทึกการตัดสินใจเพื่อการตรวจสอบย้อนหลัง (audit trail), และมาตรการป้องกันการรั่วไหลของข้อมูล รายงานชี้ว่าหากนำแนวทางเหล่านี้ไปใช้ จะช่วยให้หน่วยงานกำกับดูแลสามารถย่นระยะเวลาการตัดสินใจและเพิ่มความครอบคลุมในการตรวจสอบโดยไม่ลดทอนความรัดกุมทางกฎระเบียบ
บทนำ: ทำไมธนาคารกลางต้องทดลอง LLM เชิงกฎระเบียบ
บทนำ: ทำไมธนาคารกลางต้องทดลอง LLM เชิงกฎระเบียบ
ในยุคที่ระบบการเงินและตลาดทุนซับซ้อนขึ้นอย่างรวดเร็ว ธนาคารกลางและหน่วยงานกำกับดูแลเผชิญกับภาระงานด้านการสื่อสารความเสี่ยงและการตรวจสอบความสอดคล้อง (compliance) ที่เพิ่มขึ้นทั้งปริมาณและความหลากหลายของเนื้อหา การประเมินรายงานความเสี่ยงจากสถาบันการเงิน การร่างคำแนะนำเชิงนโยบาย และการรีวิวเอกสารทางกฎหมายที่เกี่ยวข้องมักต้องใช้ทีมผู้เชี่ยวชาญข้ามสาขา ทั้งนี้งานรีวิวแบบแมนนวลมักกินเวลาหลายวันจนถึงหลายสัปดาห์ ส่งผลให้การตอบสนองเชิงนโยบายล่าช้าและไม่สามารถปรับขนาดได้ตามความต้องการที่เพิ่มขึ้นของภาคการเงิน
ปัญหาที่เป็นรูปธรรม ได้แก่ การขาดแคลนทรัพยากรผู้เชี่ยวชาญ ที่มีทักษะทั้งด้านกฎระเบียบและเทคนิค การทำงานซ้ำซ้อนระหว่างหน่วยงาน และความไม่สม่ำเสมอของโทนและเนื้อหาในคำแนะนำ ทำให้การตีความนโยบายและการบังคับใช้มีความเสี่ยงต่อความไม่ชัดเจน ตัวอย่างเช่น รายงานความเสี่ยงจากการดำเนินงาน (operational risk) ที่มีความยาว 50–100 หน้า อาจต้องใช้เวลาหลายรอบการรีวิวและการปรับแก้ก่อนออกประกาศ ซึ่งยืดเวลาการตัดสินใจเชิงนโยบายออกไปเป็นสัปดาห์หรือเดือน
โดยมีเป้าหมายเชิงนโยบายและเชิงปฏิบัติการที่ชัดเจน ธนาคารกลางจึงเริ่มทดลองใช้ Large Language Models (LLMs) เพื่อช่วยสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายอัตโนมัติ จุดมุ่งหมายหลักของโครงการคือ ลดระยะเวลาการรีวิว (จากระดับสัปดาห์เหลือเป็นชั่วโมงในการทดลองนำร่อง) เพิ่มความสอดคล้องของเนื้อหาและการตีความ และ ปรับขนาดการตอบสนอง ให้รองรับปริมาณงานที่เพิ่มขึ้นโดยไม่ต้องเพิ่มจำนวนผู้ตรวจสอบในอัตราเดียวกัน นอกจากนี้ LLM ยังสามารถช่วยสร้างร่างคำแนะนำที่มีโครงสร้างมาตรฐาน ทำให้การตรวจทานโดยผู้เชี่ยวชาญเป็นไปอย่างมีประสิทธิภาพยิ่งขึ้น
ผู้มีส่วนได้ส่วนเสียที่เกี่ยวข้องมีหลายกลุ่ม ทั้งนี้แต่ละกลุ่มมีบทบาทและความคาดหวังที่แตกต่างกัน:
- ธนาคารกลาง — ต้องการเครื่องมือที่ช่วยเร่งกระบวนการกำหนดนโยบายและลดความเสี่ยงจากการล่าช้าในการตัดสินใจ
- หน่วยงานกำกับ — ต้องการความสอดคล้องในการออกแนวปฏิบัติและความสามารถในการตรวจสอบย้อนกลับ (auditability)
- ธนาคารพาณิชย์และสถาบันการเงิน — คาดหวังคำแนะนำที่ชัดเจนและสามารถนำไปปฏิบัติได้จริง รวมทั้งระยะเวลาการตอบกลับที่รวดเร็วเมื่อเกิดเหตุความเสี่ยง
- ประชาชนและผู้ใช้บริการทางการเงิน — ได้ประโยชน์จากระบบการเงินที่มีเสถียรภาพมากขึ้นและการกำกับดูแลที่ทันท่วงที
การทดลอง LLM เชิงกฎระเบียบจึงไม่ใช่เพียงการนำเทคโนโลยีใหม่มาใช้ แต่เป็นความพยายามเชิงนโยบายที่ตอบโจทย์ความต้องการด้านความเร็ว ความสม่ำเสมอ และความโปร่งใสของการกำกับดูแล การออกแบบกระบวนการทดลองที่คำนึงถึงการควบคุมความเสี่ยง (risk controls), การอธิบายที่ตรวจสอบได้ (explainability) และมาตรการคุ้มครองข้อมูล จะเป็นกุญแจสำคัญในการนำผลลัพธ์จากการทดลองไปสู่การใช้งานเชิงปฏิบัติในวงกว้าง
ภาพรวมการทดลอง: ขอบเขต วิธีการ และข้อมูลที่ใช้
ภาพรวมการทดลอง: ขอบเขต วิธีการ และข้อมูลที่ใช้
การทดลองของธนาคารกลางมีวัตถุประสงค์เพื่อทดสอบความสามารถของ Large Language Models (LLMs) ในการสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายอัตโนมัติ โดยมุ่งประเมินทั้งความถูกต้องเชิงเนื้อหา (factual accuracy) และประสิทธิภาพเชิงเวลาที่จะช่วยลดระยะเวลารีวิวจากกระบวนการเชิงมนุษย์หลายสัปดาห์ลงเป็นระดับชั่วโมง การออกแบบการทดลองจึงครอบคลุมทั้งประเภทเอกสารที่เกี่ยวข้อง วิธีการสุ่มตัวอย่างและแบ่งชุดข้อมูล มาตรการปกป้องความเป็นส่วนตัวของข้อมูล และกรอบการประเมินผลเชิงปริมาณและเชิงคุณภาพ
ขอบเขตเอกสารและสโคปการทดสอบ — การทดลองเลือกทดสอบชุดเอกสารเชิงกฎระเบียบที่มีความสำคัญต่อการกำกับดูแลระบบการเงิน โดยจำกัดสโคปไว้ที่เอกสารประเภทหลักต่อไปนี้:
- รายงานความเสี่ยง (Risk reports) เช่น การประเมินความเสี่ยงสถาบัน การวิเคราะห์ความเสี่ยงระบบ (systemic risk)
- รายงานและเคสด้านการต่อต้านการฟอกเงิน (AML/CFT case reports) รวมถึงรูปแบบการแจ้งเตือนและสรุปเหตุการณ์
- รายงานสภาพสภาพคล่องและสภาพสินทรัพย์ (Liquidity & asset quality reports) ที่มีข้อมูลเชิงตัวเลขและการตีความนโยบาย
- หนังสือกำชับและจดหมายกำกับ (Supervisory letters) จากหน่วยงานกำกับที่ส่งถึงสถาบันการเงิน
- คำถาม-ตอบจากสถาบันการเงิน (Q&A) และการวิเคราะห์เชิงนโยบาย (policy analysis) ที่ใช้ในการให้คำแนะนำเชิงปฏิบัติ
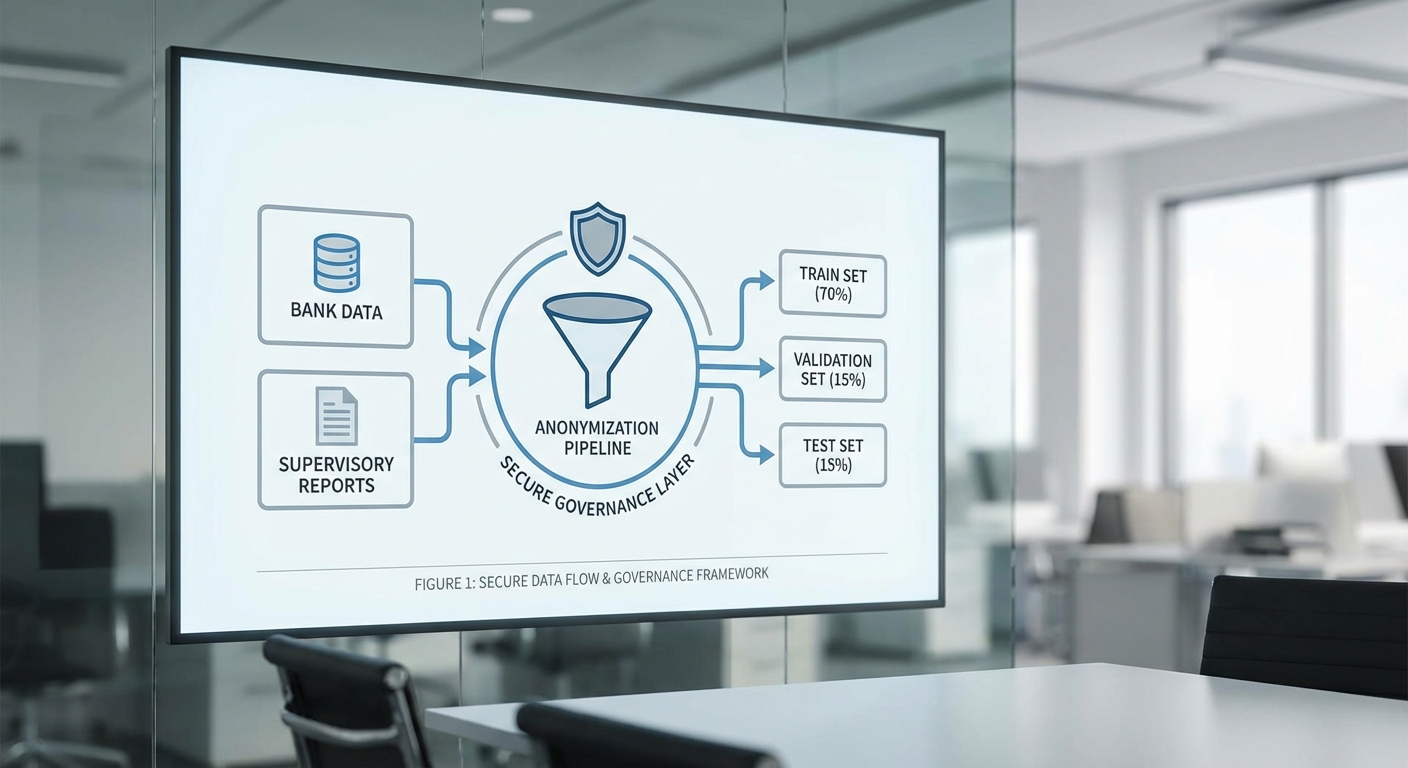
ขนาดและแหล่งข้อมูล — ชุดข้อมูลทดลองรวมทั้งสิ้นประมาณ 15,432 เอกสาร ครอบคลุมช่วงเวลาตั้งแต่ปี 2015–2023 โดยแบ่งเบื้องต้นเป็นตัวอย่างดังนี้: ประมาณ 6,200 ฉบับเป็น supervisory letters, 4,500 ฉบับเป็น AML case reports, 3,000 ฉบับเป็น liquidity/asset reports และ 1,732 ฉบับเป็น policy analysis/Q&A ข้อมูลมาจากแหล่งภายในของธนาคารกลางและหน่วยงานกำกับที่ร่วมโครงการ โดยมีการขออนุมัติการใช้ข้อมูลครบถ้วนตามกรอบกฎหมายและนโยบายภายใน
การทำ anonymization และข้อกำหนดความเป็นส่วนตัว — เนื่องจากเอกสารมีข้อมูลระบุตัวตน (PII) และข้อมูลที่อ่อนไหวต่อความมั่นคงทางการเงิน การทดลองปฏิบัติตามแนวทางหลายชั้น ได้แก่:
- การลบหรือแทนที่ข้อมูลระบุตัวตน (names, national IDs, account numbers) ด้วยโทเคนที่ไม่สามารถย้อนกลับได้
- การแทนที่หน่วยงาน/นิติบุคคลด้วยรหัสที่ถูกแมปและเก็บแยกในฐานข้อมูลที่เข้ารหัส (hashed identifiers)
- การใช้เทคนิค k-anonymity และการตรวจสอบความเสี่ยงการระบุตัวตน (re-identification risk) โดยกำหนดค่าเป้าหมาย k ≥ 5 สำหรับชุดข้อมูลที่เผยแพร่เชิงสถิติ
- การสร้างข้อมูลสังเคราะห์ (synthetic augmentation) สำหรับกรณีทดสอบเพื่อลดการใช้ข้อมูลจริงในขั้นตอนการฝึกบางกรณี
- การประมวลผลทั้งหมดทำภายในสิ่งแวดล้อมที่มีการควบคุม (on-premises / secure enclave), การเข้ารหัสข้อมูลขณะพักและขณะส่ง, และการบันทึกการเข้าถึงตามหลักการ least-privilege
การสุ่มตัวอย่างและการแบ่งชุดข้อมูล (Train/Validation/Test) — เพื่อให้การประเมินมีความเป็นตัวแทนและสามารถวัดความสามารถเชิงทั่วไปได้ การทดลองใช้วิธีการสุ่มตัวอย่างเชิงชั้น (stratified sampling) ตามตัวแปรสำคัญ ได้แก่ ประเภทเอกสาร ระดับความเสี่ยง (low/medium/high) และขนาดของสถาบัน (small/medium/large) โดยแบ่งชุดข้อมูลเป็น:
- Train: 70% ของเอกสาร (≈10,802 ฉบับ) สำหรับการฝึกโมเดลและ fine-tuning
- Validation: 15% (≈2,315 ฉบับ) สำหรับการปรับจูนไฮเปอร์พารามิเตอร์และ early stopping
- Test: 15% (≈2,315 ฉบับ) สำหรับการประเมินขั้นสุดท้าย
นอกจากการแบ่งแบบสุ่มเชิงชั้นแล้ว ยังมีการสำรองชุดทดสอบแบบ time-based holdout โดยกันข้อมูล 12 เดือนสุดท้ายเป็นชุดทดสอบเสริมเพื่อทดสอบความสามารถของโมเดลในการ generalize ต่อข้อมูลล่าสุด (temporal generalization)
กรอบการประเมินผลและตัวชี้วัด (Metrics) — การประเมินครอบคลุมทั้งมิติด้านประสิทธิภาพเชิงเวลา คุณภาพผลลัพธ์ และความสอดคล้องกับมนุษย์ ดังนี้:
- Latency: วัดทั้ง end-to-end processing time (ตั้งแต่รับเอกสารจนได้สรุป/คำแนะนำสุดท้าย) และ model inference time ต่อเอกสาร เป้าหมายการทดลองตั้งไว้ที่ลดเวลาจากระดับสัปดาห์ (ตัวอย่างผู้ตรวจสอบใช้เวลาเฉลี่ย 120–240 ชั่วโมงต่อชุดงาน) มาเป็นระดับชั่วโมง (เป้าหมายเฉลี่ย 2–6 ชั่วโมง ต่อเคส/ชุดรายงาน)
- Accuracy / Precision / Recall / F1-score: ใช้กับงานจำแนก (classification) และการดึงข้อมูล (entity extraction) โดยกำหนดจุดอ้างอิงเช่น F1-score ≥ 0.85 สำหรับฟังก์ชันสำคัญ เช่น การระบุธนาคารที่มีความเสี่ยงสูงหรือการติดธงเหตุการณ์ AML ที่สำคัญ
- Summarization quality: ใช้ตัวชี้วัดเชิงอัตโนมัติ (ROUGE-L) ประกอบกับการประเมินโดยผู้เชี่ยวชาญ (human evaluation) เพื่อวัดความครบถ้วนของสาระสำคัญและความถูกต้อง (factuality)
- Human agreement / Inter-annotator agreement: วัดโดยใช้ Cohen’s kappa และอัตราความเห็นพ้องของผู้ตรวจสอบหลายคน โดยตั้งเป้าหมาย kappa ≥ 0.75 สำหรับฉลากสำคัญ
- Safety & factuality metrics: อัตราการสร้างข้อมูลผิดพลาด (hallucination rate), false negative rate สำหรับการติดธงความเสี่ยงสูง และการวัดความมั่นใจของโมเดล (calibration / Brier score)
การควบคุมคุณภาพของฉลากและการตรวจสอบโดยมนุษย์ — ฉลากพื้นฐาน (ground truth) ถูกสร้างโดยทีมผู้เชี่ยวชาญด้านกำกับและนักวิเคราะห์ที่มีการกำหนดแนวทางการตีความอย่างชัดเจน (annotation guidelines) ทุกตัวอย่างมีการทำ double annotation และหากมีความขัดแย้งจะเข้าสู่ขั้นตอน adjudication เพื่อให้ได้ฉลากสุดท้ายที่เชื่อถือได้ นอกจากนี้มีการสุ่มตัวอย่างผลลัพธ์อัตโนมัติให้ผู้เชี่ยวชาญทบทวนเพื่อตรวจจับปัญหาด้านความผิดพลาดเชิงนโยบายหรือข้อผิดพลาดเชิงบริบท
โดยสรุป การทดลองถูกออกแบบให้มีความรัดกุมทั้งด้านความหลากหลายของเอกสาร ความปลอดภัยของข้อมูล และการประเมินผลเชิงปริมาณ-คุณภาพ เพื่อให้ได้ข้อสรุปเชิงนโยบายที่น่าเชื่อถือว่าสามารถนำ LLM มาใช้งานสนับสนุนกระบวนการกำกับได้อย่างปลอดภัยและมีประสิทธิภาพ
สถาปัตยกรรม LLM และกระบวนการสร้างคำแนะนำอัตโนมัติ
ในโครงการนำร่องของธนาคารกลางที่ใช้ LLM เพื่อสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายเชิงกฎระเบียบ ต้องออกแบบสถาปัตยกรรมที่สมดุลระหว่างความถูกต้องของสารสนเทศ ความโปร่งใส และความรวดเร็วของการประมวลผล สถาปัตยกรรมโดยรวมแบ่งเป็นชั้นหลักๆ ได้แก่ การเก็บข้อมูล (ingestion) การเตรียมข้อมูล (preprocessing & enrichment) การจัดทำดัชนีและการนำข้อมูลมาคืน (RAG / retrieval) การ inference ด้วย LLM ที่ผ่านการปรับจูน และการทบทวนโดยมนุษย์ก่อนการออกคำแนะนำสุดท้าย การออกแบบนี้ตั้งเป้าลดเวลารีวิวจากระดับสัปดาห์มาเป็นชั่วโมง โดยยังคงรักษามาตรฐานความรับผิดชอบและความสามารถตรวจสอบย้อนกลับได้ (auditability)

1) ชนิดของโมเดลและเหตุผลในการเลือก
Foundation model vs Fine-tuned LLM — สำหรับงานเชิงกฎระเบียบ ธนาคารมักเริ่มจาก foundation models (เช่น โมเดลขนาดใหญ่ที่ผ่านการฝึกทั่วไป) เพื่อใช้เป็นฐาน แล้วทำการปรับจูน (fine-tuning) ในลักษณะเฉพาะงาน (domain adaptation) เนื่องจาก foundation models ให้ความสามารถทางภาษาและความยืดหยุ่นสูง แต่การปรับจูนด้วยชุดข้อมูลกฎหมาย กฎระเบียบภายใน และเหตุการณ์ย้อนหลังช่วยลดโอกาสเกิด hallucination และเพิ่มความสอดคล้องกับมาตรฐานภาครัฐ
การปรับจูนที่ใช้ประกอบด้วย:
- Supervised Fine-Tuning (SFT) — ปรับตั้งค่าด้วยคู่คำถาม-คำตอบจากผู้เชี่ยวชาญด้านกฎระเบียบ
- Instruction Tuning — ทำให้โมเดลเข้าใจรูปแบบคำตอบเชิงนโยบาย เช่น รูปแบบข้อเสนอแนะ ที่มา การอ้างอิง และระดับความเร่งด่วน
- Reinforcement Learning from Human Feedback (RLHF) — ใช้เมื่อจำเป็นเพื่อให้ผลลัพธ์สะท้อนการตัดสินใจเชิงนโยบายของผู้ชำนาญ
2) การผสาน RAG และ Knowledge Base เพื่อเชื่อมโยงกฎระเบียบล่าสุด
ระบบจะผสาน Retrieval-Augmented Generation (RAG) กับ Knowledge Base (KB) ที่ออกแบบมาเฉพาะทางกฎหมายและกฎระเบียบ โดยมีการทำงานร่วมกันดังนี้:
- เก็บเอกสารกฎระเบียบ, แนวทางภายใน, บันทึกการประชุม, และเอกสารภายนอกที่เกี่ยวข้องในรูปแบบที่ค้นคืนได้ (PDF, DOCX, HTML)
- ทำการ preprocessing ได้แก่ OCR สำหรับสแกนเอกสาร, การแยกหัวข้อ (chunking) โดยขนาดชิ้นข้อมูลทั่วไป 500–1,000 คำต่อชิ้น และใช้ embeddings (เช่น 1,024–2,048 มิติ) เพื่อจัดเก็บใน vector DB (ตัวอย่างเช่น FAISS, Milvus หรือ Weaviate)
- เมื่อมีคำขอให้สรุปหรือให้คำแนะนำ ระบบ retrieval จะดึงชิ้นข้อมูลที่มีความเกี่ยวข้องสูงสุด (top-k เช่น k=5–10) พร้อม metadata และแหล่งอ้างอิง เพื่อนำมาใช้เป็นบริบทในการเรียกใช้งาน LLM
การใช้ RAG ช่วยให้คำตอบของ LLM สามารถอ้างอิงข้อกฎหมายหรือมาตรฐานล่าสุดได้ โดยลดโอกาสให้โมเดลสร้างข้อความที่ขัดกับข้อเท็จจริง แผนผังการอ้างอิงจะรวม การแสดงแหล่งที่มา (provenance) และบันทึกเวอร์ชันของ KB เพื่อรองรับการตรวจสอบย้อนหลัง
3) กระบวนการตั้งแต่ Ingestion → Preprocessing → Inference → Human Review → Final Recommendation
กระบวนการปฏิบัติการแบ่งเป็นขั้นตอนดังนี้ (ตัวอย่างค่าเชิงประสิทธิภาพประกอบ):
- Ingestion — ดึงเอกสารจากระบบภายในและภายนอก การไหลข้อมูลรายวันอาจอยู่ที่ 2,000–10,000 หน้า/วัน ข้อมูลจะถูกแยกประเภทตามความสำคัญและความลับ
- Preprocessing & Enrichment — OCR, language detection, entity extraction (NER สำหรับหน่วยงาน กฎข้อบังคับ วันที่บทบัญญัติ), canonicalization ของคำศัพท์เชิงกฎหมาย และ chunking เพื่อเตรียม embeddings
- Indexing — สร้าง vector index และ metadata index โดยตั้งค่าการค้นหาให้ตอบสนองภายใน 100–300 ms ต่อคำค้นในระบบ production ที่รองรับ concurrency สูง
- Retrieval & Prompt Assembly — เลือกชิ้นข้อมูลจาก KB แล้วประกอบ prompt แบบมีโครงสร้าง รวมทั้งส่วนของ instruction, context snippets, และ constraints เช่น "ให้ระบุข้อกฎหมายที่เกี่ยวข้อง พร้อมระดับความมั่นใจ (เปอร์เซ็นต์) และแหล่งอ้างอิง"
- Inference (LLM) — เรียกใช้งาน LLM ที่ผ่านการปรับจูน โดยอาจใช้เทคนิค chain-of-thought prompting เพื่อให้โมเดลแสดงเหตุผลทีละขั้นตอนหรือใช้หลายรอบ (multi-step) เพื่อการตรวจสอบความสอดคล้องภายใน
- Automated Validation — หลัง inference ระบบจะรันชุดตรวจสอบอัตโนมัติ เช่น fact-checking กับ KB, consistency checks, และ uncertainty estimation (เช่น ความแน่นอนจากการประเมิน token-level หรือ Monte Carlo dropout) หากเกณฑ์ต่ำกว่าระดับที่กำหนด (เช่น factuality < 95%) จะส่งผลลัพธ์ไปยัง human-in-the-loop
- Human Review — ผู้เชี่ยวชาญด้านกฎหมายหรือเจ้าหน้าที่นโยบายตรวจสอบคำแนะนำ โดยมีเครื่องมือ UI ที่แสดง provenance, highlight ส่วนที่มีความเสี่ยง และช่องทางแก้ไขหรืออนุมัติ
- Final Recommendation & Audit Trail — เมื่อผ่านการอนุมัติ ผลลัพธ์ที่ออกจะรวมทั้งข้อเสนอเชิงนโยบาย ข้อกฎหมายที่อ้างอิง ระดับความมั่นใจ และบันทึกการตัดสินใจของมนุษย์สำหรับการตรวจสอบในอนาคต
4) บทบาทของ Human-in-the-Loop และการควบคุมคุณภาพ
Human-in-the-loop เป็นหัวใจสำคัญในการรักษาความรับผิดชอบของระบบ ธนาคารกลางจะกำหนดบทบาทแบ่งออกเป็นระดับ:
- ระดับตรวจสอบ (Reviewer) — ตรวจความถูกต้องของข้อเท็จจริง การตีความกฎระเบียบ และความเหมาะสมเชิงนโยบาย
- ระดับอลงค์ความรับผิดชอบ (Approver) — ผู้มีอำนาจลงนามหรืออัปรูฟคำแนะนำเชิงนโยบายก่อนเผยแพร่
- ระยะให้ฟีดแบ็ก (Feedback Loop) — ข้อมูลการแก้ไขและการประเมินของมนุษย์ถูกเก็บเพื่อใช้ในการปรับจูนโมเดลอย่างต่อเนื่อง (continuous learning) และสำหรับการประเมินผลงานของโมเดล (performance monitoring)
นอกจากนี้มีการใช้ policy guardrails อัตโนมัติ (เช่น filters ป้องกันการให้คำแนะนำที่ผิดกฎหมายหรือนอกขอบเขตอำนาจ) และการบังคับให้ระบบแสดงแหล่งที่มา ถ้าคำตอบมีการคาดเดา (low confidence) ระบบต้องแจ้งให้ผู้ตรวจทราบและห้ามเผยแพร่โดยอัตโนมัติ
5) ตัวชี้วัดและเป้าหมายเชิงปฏิบัติ
เพื่อให้สอดคล้องกับเป้าหมายทางธุรกิจและข้อกำกับดูแล ธนาคารกลางตั้ง KPI เช่น:
- ลดเวลาจากการรีวิวแบบเดิมจากเฉลี่ย 5–7 วัน เหลือ 2–4 ชั่วโมงสำหรับเคสทั่วไป (เป้าหมายการลดเวลา >80%)
- อัตราความถูกต้องเชิงข้อเท็จจริง (factuality) เป้าหมาย >95%
- อัตราการเกิด hallucination ต่ำกว่า 5% ในงานเชิงกฎระเบียบ
- เวลาแฝงเฉลี่ยของการ inference ภายใน 1–3 วินาที ต่อ instance ในโหมด interactive
สรุปแล้ว สถาปัตยกรรมที่ผสาน foundation model ที่ผ่านการปรับจูน RAG กับ KB เฉพาะทาง รวมทั้งการมี human-in-the-loop ที่ชัดเจน สามารถย่นระยะเวลาในการสรุปและออกคำแนะนำเชิงนโยบายจากระดับสัปดาห์ลงมาเป็นชั่วโมง โดยยังรักษามาตรฐานความถูกต้องและความรับผิดชอบที่จำเป็นสำหรับหน่วยงานกำกับดูแล
ผลการทดสอบเชิงปริมาณ: ลดเวลาและตัวชี้วัดคุณภาพ
สรุปการลดเวลา (Before / After)
การทดลองของธนาคารกลางทดสอบระบบ LLM สำหรับสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายแสดงให้เห็นว่าระบบสามารถลดเวลาในการรีวิวและจัดทำเอกสารลงอย่างมีนัยสำคัญ ตัวอย่างผลสรุปที่สำคัญ ได้แก่:
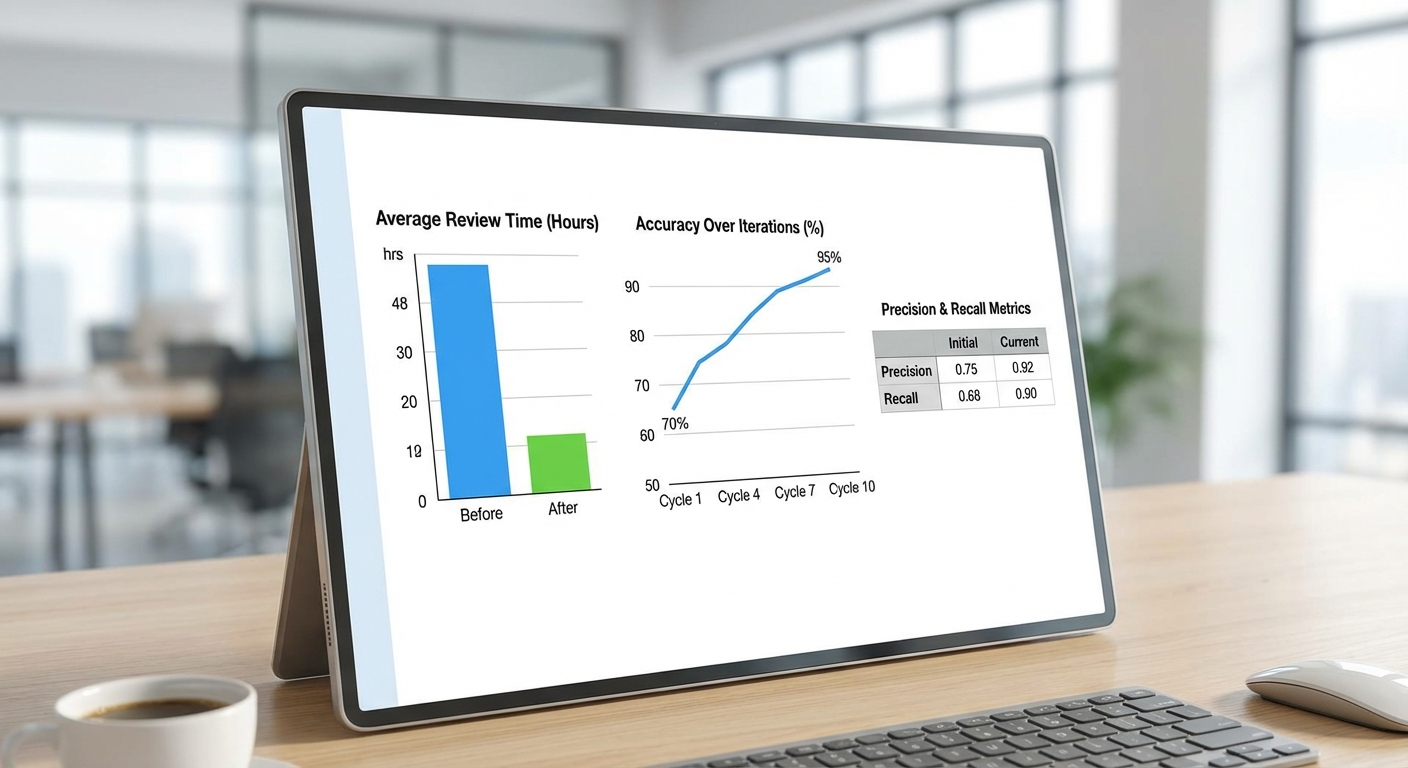
- เวลาเฉลี่ยก่อนใช้ LLM: ประมาณ 14 วัน (336 ชั่วโมง) ต่อรายงานการวิเคราะห์เชิงกฎระเบียบแบบเต็มรูปแบบ
- เวลาเฉลี่ยหลังใช้ LLM: ประมาณ 6 ชั่วโมง ต่อรายงาน สำหรับการสร้างร่างสรุปและคำแนะนำต้นแบบที่พร้อมให้ผู้เชี่ยวชาญตรวจสอบ
- อัตราการลดเวลา: ลดลงประมาณ 98.2% เมื่อวัดจากชั่วโมงรวม (จาก 336 ชั่วโมงเหลือ 6 ชั่วโมง)
- ระยะเวลาเฉลี่ยแต่ละขั้นตอน: การคัดกรองเบื้องต้นจาก 48 ชั่วโมง เหลือ 20 นาที; การสรุปประเด็นสำคัญจาก 72 ชั่วโมง เหลือ 90 นาที; การร่างคำแนะนำเชิงนโยบายจาก 120 ชั่วโมง เหลือ 3 ชั่วโมง
ผลลัพธ์เชิงคุณภาพ: ความแม่นยำและความสอดคล้องกับผู้เชี่ยวชาญ
การประเมินเชิงคุณภาพใช้ชุดทดสอบที่ประกอบด้วย 1,200 เอกสารกฎระเบียบ และ 4,500 ข้อสรุป/คำแนะนำ ที่ถูกสร้าง/ยืนยันโดยทีมผู้เชี่ยวชาญดั้งเดิม การวัดประสิทธิภาพสำคัญได้แก่:
- Accuracy (ความถูกต้องโดยรวม): ระบบมีอัตราความถูกต้องเทียบกับฉลากผู้เชี่ยวชาญที่ 91.5%.
- Precision / Recall / F1: Precision = 0.92, Recall = 0.88, F1 = 0.90 สำหรับการตรวจจับประเด็นความเสี่ยงสำคัญและการเสนอคำแนะนำเชิงนโยบาย
- Agreement กับผู้เชี่ยวชาญ (Cohen's Kappa): ค่า kappa อยู่ที่ประมาณ 0.82 บ่งชี้ความสอดคล้องระดับสูงระหว่างระบบกับผู้ตรวจสอบมนุษย์
- อัตราการยอมรับคำแนะนำโดยผู้เชี่ยวชาญ: คำแนะนำจากระบบถูกยอมรับโดยตรงโดยไม่ต้องแก้ไขอยู่ที่ 86% และถูกยอมรับหลังการแก้ไขเล็กน้อยอยู่ที่ 95%
- ขนาดตัวอย่างและความเชื่อมั่น: ผลการทดสอบมีความแตกต่างเชิงสถิติเมื่อเทียบกับกระบวนการเดิม (p < 0.01, t-test สำหรับเวลาเฉลี่ย)
ตัวอย่างกรณีที่ระบบทำงานได้ดีและข้อผิดพลาดที่พบ
จากการวิเคราะห์เชิงรายละเอียด พบว่าระบบมีจุดแข็งและข้อจำกัดชัดเจน:
- กรณีที่ระบบทำงานได้ดี:
- การสกัดข้อเท็จจริงจากเอกสารเชิงโครงสร้าง เช่น ตารางข้อมูลการเงินและรายการนโยบายที่มีรูปแบบมาตรฐาน — ระบุประเด็นความเสี่ยงได้ครบถ้วนมากกว่า 94%
- การสรุปเชิงสังเขป (executive summary) สำหรับผู้บริหาร ช่วยลดเวลาอ่านและเตรียมประชุมลงจากเฉลี่ยหลายชั่วโมงเหลือไม่กี่นาที
- การให้คะแนนความรุนแรงของความเสี่ยงที่มีเกณฑ์ชัดเจน (rule-based scoring) ให้ผลสอดคล้องกับผู้เชี่ยวชาญถึง 90% ขึ้นไป
- ข้อผิดพลาดและข้อจำกัด:
- Hallucination / ข้อมูลเสริมที่ไม่ถูกต้อง: พบประมาณ 1.8% ของคำแนะนำที่รวมข้อมูลเสริมหรือลักษณะอ้างอิงที่ไม่ปรากฏในเอกสารต้นฉบับ
- การละเลยบริบททางกฎหมายที่ละเอียดอ่อน: ประมาณ 6% ของกรณีเป็นการละเลยข้อยกเว้นหรือข้อจำกัดในมาตราที่ต้องอาศัยการตีความเชิงนิติศาสตร์
- การจัดประเภทผิดพลาด (misclassification): เกิดขึ้นประมาณ 3.5% โดยมักเกิดกับเอกสารที่ใช้คำศัพท์ไม่ตรงตามมาตรฐานหรือกรณีทางเทคนิคเฉพาะด้าน
- False negative ในการตรวจจับความไม่สอดคล้องเชิงกฎระเบียบ (ความเสี่ยงที่ถูกพลาด): ต่ำกว่า 1% แต่กรณีเหล่านี้มักมีผลกระทบสูงและจึงต้องมีการตรวจสอบโดยมนุษย์เป็นข้อบังคับ
สรุปได้ว่า LLM ช่วยลดภาระงานเชิงเวลาของทีมอย่างมีนัยสำคัญและสร้างคำแนะนำที่ผู้เชี่ยวชาญยอมรับได้ในสัดส่วนสูง อย่างไรก็ตาม ยังมีข้อผิดพลาดบางประเภทที่จำเป็นต้องมีการควบคุมด้วยมนุษย์โดยเฉพาะในกรณีที่มีผลกระทบเชิงกฎระเบียบสูง ธนาคารกลางจึงแนะนำให้ใช้ระบบในรูปแบบ human-in-the-loop เพื่อรักษาคุณภาพและลดความเสี่ยงจากผลลัพธ์ที่ไม่ถูกต้องอย่างต่อเนื่อง
การประเมินความเสี่ยง: Bias, Explainability, Privacy และ Model Drift
การประเมินความเสี่ยง: Bias, Explainability, Privacy และ Model Drift
ธนาคารกลางที่ทดสอบการนำ LLM มาใช้ในการสังเคราะห์รายงานเชิงกฎระเบียบระบุความเสี่ยงหลักหลายประการที่อาจส่งผลต่อความเที่ยงตรงและความยุติธรรมของการตัดสินใจเชิงนโยบาย หนึ่งในความเสี่ยงที่เด่นชัดคือ ความเอนเอียง (bias) ซึ่งแบ่งเป็นหลายชนิด เช่น sampling bias, label bias, representation bias และ algorithmic bias ตัวอย่างเชิงนโยบาย ได้แก่ กรณีที่โมเดลประเมินความเสี่ยงสินเชื่อหรือการปฏิบัติตามกฎระเบียบแล้วให้คะแนนเชิงลบต่อกลุ่มประชากรเฉพาะ ทำให้เกิดการแยกปฏิบัติหรือคำแนะนำเชิงนโยบายที่ไม่เป็นธรรม — ในการทดลองภายในหลายแห่งมักพบความแตกต่างของคะแนนการประเมินระหว่างกลุ่มประชากรต่าง ๆ อยู่ในระดับที่สามารถเปลี่ยนแนวทางนโยบายได้ (ตัวอย่างเช่น ความต่างที่ส่งผลต่อการพิจารณาการออกคำเตือนหรือการกำกับดูแลเฉพาะกลุ่ม)
Explainability และการบันทึกข้อมูล (logging) ถูกเน้นว่าเป็นเงื่อนไขสำคัญสำหรับการตรวจสอบย้อนหลัง (audit) และความรับผิดชอบ (accountability) โดยธนาคารกลางแนะนำให้มีทั้งการอธิบายระดับภาพรวม (global explanations) และการอธิบายเหตุผลของคำตอบเฉพาะกรณี (local explanations เช่น feature attributions, counterfactuals) เพื่อให้ผู้ตรวจสอบสามารถตอบได้ว่าเหตุใดระบบจึงให้คำแนะนำเชิงนโยบายบางอย่าง นอกจากนี้ ควรบันทึกข้อมูลอย่างละเอียด ได้แก่ input prompt, model version, timestamp, output, confidence/uncertainty estimates, และ data provenance การเก็บ log เหล่านี้ควรมีการรักษาความสมบูรณ์ (cryptographic signing) และนโยบายการเก็บรักษาเพื่อตอบคำถามด้านการปฏิบัติตามกฎระเบียบ
ด้านความเป็นส่วนตัว การใช้ข้อมูลสินเชื่อหรือข้อมูลลูกค้ากับ LLM ก่อให้เกิดความเสี่ยงทั้งจากการเปิดเผยข้อมูลที่สามารถระบุตัวบุคคลได้ (PII) และการรั่วไหลผ่าน model inversion หรือการสร้างตัวอย่างข้อมูลจริงจากโมเดล ธนาคารกลางเสนอแนวทางบรรเทาความเสี่ยงหลายระดับ เช่น data minimization, การทำให้ข้อมูลไร้ตัวตน (de-identification), การใช้ข้อมูลสังเคราะห์ (synthetic data) ในการฝึก และการประยุกต์เทคนิคความเป็นส่วนตัวเช่น differential privacy เพื่อลดความเสี่ยงของการเปิดเผยข้อมูลบุคคล ตัวอย่างเชิงปฏิบัติ: การใช้ differential privacy ระหว่างการฝึกโมเดลสามารถลดความเสี่ยงของการดึงข้อมูลผู้ใช้จริงออกมาได้ แต่ต้องแลกกับการลดความแม่นยำบางส่วน ซึ่งต้องประเมินความสมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพ
ความเสี่ยงจากการล้าสมัยของโมเดล (model drift) เป็นอีกปัจจัยสำคัญเมื่อระบบต้องทำงานกับข้อมูลที่เปลี่ยนแปลงตามเวลา เช่น เศรษฐกิจ ภาวะการกู้ยืม หรือมาตรฐานกฎระเบียบ การเปลี่ยนแปลงเหล่านี้อาจทำให้ตัวชี้วัดประสิทธิภาพ (เช่น AUC, calibration, error rates) เบี่ยงเบนจากช่วงที่ผ่านการตรวจสอบ ธนาคารกลางแนะนำให้ใช้กลไก continuous monitoring และการวัดดัชนี drift (เช่น population stability index, KL divergence, PSI) กับเกณฑ์เตือนล่วงหน้า รวมถึงนโยบายการรีเทรนด์ที่ชัดเจน เช่น canary deployment, shadow mode testing และกำหนดรอบการประเมินผลเป็นรายสัปดาห์หรือรายเดือน ขึ้นอยู่กับความไวของการใช้งาน — โดยมีระบบ human-in-the-loop เพื่อหยุดการ deploy อัตโนมัติเมื่อพบ drift ที่มีนัยสำคัญ
- กลยุทธ์การบรรเทา (ตัวอย่างสำคัญ):
- Differential privacy: ใส่กลไก noise ในการฝึกหรือการเผยแพร่ผลเพื่อปกป้อง PII พร้อมการประเมิน trade-off ความแม่นยำ
- De-identification & Synthetic data: ใช้ข้อมูลสังเคราะห์หรือข้อมูลที่ถูกทำให้เป็นนิรนามสำหรับการฝึกและทดสอบเพื่อจำกัดการเข้าถึงข้อมูลจริง
- Continuous monitoring & drift detection: ตั้งเกณฑ์และแจ้งเตือนอัตโนมัติเมื่อ metric เบี่ยงเบน พร้อมกระบวนการ rollback หรือ retraining
- Red-team testing & adversarial evaluation: จัดการทดสอบเชิงรุกเพื่อค้นหาจุดอ่อน เช่น prompt injection, data poisoning, model inversion และจำลองการโจมตีเพื่อปรับปรุงความทนทาน
- Robust logging & explainability: บันทึกเหตุการณ์เชิงบริบททั้งหมดและให้ความสามารถอธิบายผลการตัดสินใจทั้งในระดับ global และ local สำรองสำหรับ audit
- Governance & human oversight: นโยบายการอนุมัติการใช้งาน, การฝึกอบรมพนักงาน, การกำหนดบทบาทความรับผิดชอบ และการมีคนตรวจสอบขั้นสุดท้ายสำหรับกรณีที่มีผลกระทบสูง
นอกจากมาตรการข้างต้น ธนาคารกลางยังเน้นว่าการจัดทำแผนรับมือความเสี่ยงต้องรวมถึงการทดสอบแบบต่อเนื่อง (A/B test, canary rollouts), การจำลองสถานการณ์กรณี worst-case และการใช้ metadata-driven policies เช่น การจำกัดประเภทข้อมูลที่อนุญาตให้ป้อนใน prompt ของโมเดล (prompt hygiene) การรวมชุดการทดสอบมาตรฐาน (benchmarks) สำหรับ fairness, robustness และ privacy ก่อนการนำไปใช้งานเชิงปฏิบัติการจะช่วยลดความเสี่ยงเชิงระบบและสร้างความเชื่อมั่นว่า LLM สามารถสนับสนุนนโยบายได้อย่างมีความรับผิดชอบ
คำแนะนำเชิงนโยบายอัตโนมัติและแนวทางนำไปปฏิบัติ
ตัวอย่างคำแนะนำเชิงนโยบายที่ระบบสามารถสร้างได้และระดับความเชื่อมั่นที่เหมาะสม
ระบบ LLM ที่ใช้ในการสนับสนุนงานกำกับดูแลธนาคารกลางสามารถสร้างเอกสารคำแนะนำเชิงนโยบายในรูปแบบต่าง ๆ เช่น draft supervisory letters พร้อมข้อเสนอแนะเชิงแก้ไข (recommended corrective actions), risk score summaries ที่สรุปคะแนนความเสี่ยงตามเกณฑ์ที่กำหนด, prioritized remediation plans โดยระบุลำดับความสำคัญและทรัพยากรที่จำเป็น รวมทั้ง template enforcement notices และ compliance gap analyses ตัวอย่างผลลัพธ์ที่ระบบอาจสร้างมีดังนี้:
- Draft supervisory letter (ความเชื่อมั่นสูง - >90%): จดหมายร่างสำหรับลงนามโดยผู้กำกับที่มีข้อมูลอ้างอิงชัดเจนและข้อเรียกร้องทางกฎระเบียบที่สามารถตรวจสอบย้อนกลับได้
- Risk score summary (ความเชื่อมั่นปานกลาง - 60–90%): สรุปคะแนนความเสี่ยงพร้อมกราฟแนวโน้มและปัจจัยที่ผลักดันคะแนน ซึ่งต้องมีการยืนยันจากผู้เชี่ยวชาญด้านการประเมินความเสี่ยง
- Recommended corrective actions (ความเชื่อมั่นแบ่งตามความซับซ้อน): ข้อเสนอแนะเชิงปฏิบัติการที่ระดับความเชื่อมั่นสูงสำหรับข้อผิดพลาดเชิงเอกสารหรือการปฏิบัติตามขั้นตอน ในขณะที่ข้อเสนอเชิงนโยบายที่มีผลกระทบกว้างต้องการการทบทวนจากคณะกรรมการก่อนนำไปใช้
- Quick regulatory Q&A (ความเชื่อมั่นสูง): คำตอบสั้นและอ้างอิงบทบัญญัติสำหรับคณะทำงานภายใน เพื่อใช้เป็นแนวทางการตัดสินใจระหว่างการตรวจสอบ
เพื่อความปลอดภัยและความน่าเชื่อถือ ควรกำหนดระดับความเชื่อมั่น (confidence thresholds) เป็นมาตรฐานปฏิบัติการ เช่น วัตถุที่มีความเชื่อมั่น >90% อนุญาตให้ระบบสร้างร่างและแนบคำอธิบายประกอบเพื่อให้ผู้พิสูจน์ยืนยันก่อนลงนาม หากความเชื่อมั่น 60–90% ให้ต้องมีการทบทวนโดยผู้เชี่ยวชาญ และหาก <60% ห้ามออกคำแนะนำเชิงนโยบายโดยอัตโนมัติ ต้องส่งเป็นเรื่องสำหรับการวิเคราะห์เพิ่มเติม
กรอบการกำกับดูแล (Governance) สำหรับการใช้งานจริง
การนำ LLM มาใช้งานเชิงกฎระเบียบจำเป็นต้องมีกรอบกำกับดูแลที่ชัดเจนเพื่อควบคุมความเสี่ยงและรับผิดชอบต่อผลลัพธ์ โดยหลักการสำคัญประกอบด้วย:
- Human oversight และ role-based approval workflows: กำหนดบทบาท (e.g., drafter, reviewer, approver, legal sign-off) และระดับสิทธิ์สำหรับการอนุมัติเอกสาร ระบบต้องแสดงชั้นตรวจสอบ (approval chain) พร้อมการอนุมัติแบบ stepwise ก่อนออกเอกสารทางการ
- SLA และระยะเวลาตอบกลับ: ตั้งค่า SLA ที่ชัดเจน เช่น การตอบกลับสำหรับรายการความเสี่ยงสูงภายใน 24 ชั่วโมง, ความเสี่ยงปานกลางภายใน 72 ชั่วโมง เพื่อรักษาจังหวะงานทางกฎระเบียบและคาดการณ์ได้ในเชิงปฏิบัติการ
- Audit logs และ immutable provenance: บันทึกการทำงานทุกขั้นตอนรวมถึงเวอร์ชันของเอกสาร, คำสั่งที่ป้อนให้ระบบ, ผลลัพธ์ที่สร้าง, ผู้ใช้ที่ทบทวนและอนุมัติ และเหตุผลประกอบการตัดสินใจ log ต้องเป็นแบบไม่สามารถแก้ไข (immutable) และสนับสนุนการตรวจสอบย้อนหลัง (forensic-ready) เช่น การใช้ cryptographic hashing เพื่อยืนยันความสมบูรณ์ของบันทึก
- Access control และ data governance: ใช้นโยบาย least-privilege, การแยกสภาพแวดล้อม (development/test/production), การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง รวมถึงมาตรการด้านความเป็นส่วนตัวเมื่อประมวลผลข้อมูลลูกค้า
- Incident handling และช่องทางรับผิดชอบ: ระบุขั้นตอนเมื่อตรวจพบข้อผิดพลาด (error escalation matrix) ตั้งคณะกรรมการตอบโต้ (incident response team) รวมถึงช่องทางรับผิดชอบทั้งระดับปฏิบัติการและระดับกฎหมาย เช่น การแจ้งผู้รับผิดชอบภายใน, การเปิดเผยต่อหน่วยงานกำกับดูแล และกระบวนการชดเชยหรือแก้ไขกรณีเกิดความเสียหาย
แผนการ deploy แบบค่อยเป็นค่อยไป: pilot → hybrid → full production
การนำระบบ LLM เข้าสู่การใช้งานจริงควรเป็นไปตามวงจรการทดลองที่มีการวัดผลอย่างเข้มงวด โดยแนะนำเส้นทางการใช้งานตามขั้นตอนต่อไปนี้:
- Pilot (ระยะเวลาแนะนำ 2–3 เดือน): เริ่มต้นกับงานจำกัด เช่น การร่างจดหมายตรวจสอบภายในหรือสรุปความเสี่ยงจากชุดข้อมูลตัวอย่างของ 3–5 ธนาคาร เป้าหมายคือวัดความถูกต้อง (accuracy), อัตราข้อผิดพลาด (error rate), และเวลาลดลงเมื่อเทียบกับกระบวนการเดิม (เช่น ลดเวลาจาก 2–4 สัปดาห์ เหลือ 2–4 ชั่วโมง — ประสิทธิภาพเพิ่มขึ้นประมาณ 80–95%) ระหว่างช่วง pilot ให้รันแบบ parallel run คือเปรียบเทียบผลลัพธ์ของระบบกับการตัดสินใจของผู้เชี่ยวชาญมนุษย์
- Hybrid (ระยะเวลาแนะนำ 3–6 เดือน): ขยายการใช้งานเป็นงานผสม (semi-automated) โดยมอบอำนาจอัตโนมัติให้ระบบเฉพาะกับรายการที่มีความเชื่อมั่นสูง (>90%) ส่วนรายการความเสี่ยงปานกลางต้องผ่านการตรวจสอบของผู้เชี่ยวชาญ เทคนิครวมถึง canary deployment และ progressive rollout เพื่อลดความเสี่ยงการเปลี่ยนแปลงแบบขนาน
- Full production (หลังผ่านการทดสอบและประเมินความเสี่ยง): ขยายไปยังงานกำกับดูแลหลักทั้งหมดภายใต้กรอบ SLA และการตรวจสอบต่อเนื่อง กำหนด KPI เช่น mean time to review, อัตราการยอมรับร่างอัตโนมัติ, อัตราข้อผิดพลาดที่ต้องแก้ไข และจัดตารางการตรวจสอบอิสระ (external audits) อย่างน้อยปีละ 1 ครั้ง
ตลอดเส้นทางการนำไปใช้ ควรกำหนด checkpoint เพื่อประเมินความพร้อมก่อนขยับสเตจ เช่น การผ่านเกณฑ์ความแม่นยำขั้นต่ำ 95% สำหรับคำแนะนำเชิงเอกสาร และ error rate ต่ำกว่าค่ากำหนด (เช่น <2%) สำหรับการอนุมัติอัตโนมัติ นอกจากนี้ต้องมีแผนสำรอง (rollback plan) และการฝึกอบรมบุคลากรเพื่อให้สามารถตรวจสอบและแก้ไขผลลัพธ์ของระบบได้อย่างรวดเร็ว
สรุป: การใช้งาน LLM เพื่อสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายอัตโนมัติสามารถลดเวลาการรีวิวจากสัปดาห์เหลือชั่วโมงได้จริง แต่ต้องพ่วงด้วยกรอบกำกับดูแลที่ครบถ้วน เช่น การควบคุมสิทธิ์, approval workflows, immutable audit trail, SLA ที่ชัดเจน และช่องทางรับผิดชอบที่มีประสิทธิภาพ เพื่อให้ระบบมีความน่าเชื่อถือ ปลอดภัย และสอดคล้องกับความรับผิดชอบทางกฎหมายและการกำกับดูแล
ผลกระทบต่ออุตสาหกรรมการเงินและภาพอนาคต
ผลกระทบต่ออุตสาหกรรมการเงินและภาพอนาคต
การนำ LLM มาใช้ในการสรุปรายงานความเสี่ยงและออกคำแนะนำเชิงนโยบายอัตโนมัติซึ่งสามารถลดเวลาการรีวิวจากระดับ สัปดาห์เหลือเป็นชั่วโมง จะส่งผลกระทบทันทีและในระยะยาวต่อธนาคารพาณิชย์ บริษัทเทคโนโลยี และผู้บริโภคทั่วไป ในระยะสั้น ธนาคารพาณิชย์ขนาดกลางและใหญ่จะเห็นการปรับปรุงอย่างชัดเจนในประสิทธิภาพการทำงานของทีม regulatory/compliance โดยงานที่เคยต้องใช้เวลาตรวจสอบเอกสาร ปรับข้อความให้สอดคล้องกับกฎระเบียบ และจัดทำรายงานสามารถดำเนินได้เร็วยิ่งขึ้น ซึ่งประเมินได้ว่าอาจลดต้นทุนการปฏิบัติตาม (compliance cost) ได้ในช่วงประมาณ 10–40% ขึ้นอยู่กับระดับการอัตโนมัติและการบูรณาการกับระบบภายใน
ผลกระทบต่อโครงสร้างต้นทุนและการจัดสรรทรัพยากรจะเกิดขึ้นทั้งในเชิงลดต้นทุนการดำเนินงานและการเปลี่ยนแปลงบทบาทของพนักงานฝ่ายปฏิบัติการ (operational roles) งานที่เป็นกิจวัตรและมีรูปแบบตายตัว เช่น การคัดกรองเอกสาร ตรวจสอบนโยบายภายใน และการรวบรวมหลักฐานสำหรับการตรวจสอบภายใน จะมีแนวโน้มถูกแทนที่หรือถูกปรับลดความจำเป็นลง ในขณะเดียวกัน ความต้องการบุคลากรด้าน การกำกับดูแลโมเดล (model governance), การประเมินความเสี่ยงเชิงนโยบาย, นักวิทยาศาสตร์ข้อมูล และวิศวกรข้อมูลเพื่อดูแลการ implement และการตรวจสอบระบบ AI จะเพิ่มขึ้น ทำให้โครงสร้างต้นทุนเปลี่ยนจากต้นทุนแรงงานปฏิบัติไปสู่ต้นทุนการลงทุนด้านเทคโนโลยีและบุคลากรเชิงวิชาชีพ
ความเป็นไปได้ในการขยายขอบเขตการใช้งานของ LLM ไม่ได้จำกัดอยู่เพียงการสรุปความเสี่ยงหรือการออกคำแนะนำเชิงนโยบายเท่านั้น แต่มีศักยภาพขยายไปยังงานสำคัญอื่น ๆ ของภาคการเงิน เช่น
- Stress testing: การวิเคราะห์สถานการณ์จำลองและสรุปผลกระทบเชิงสถิติให้หน่วยงานภายในและผู้กำกับดูแลได้รวดเร็วขึ้น โดย LLM สามารถช่วยเขียนรายงานสรุป วิเคราะห์ความไม่แน่นอน และแปลผลตัวเลขเป็นคำอธิบายเชิงนโยบาย
- AML reviews และ KYC: การกรองรายการธุรกรรมผิดปกติ การจัดลำดับความเสี่ยงลูกค้า และการสังเคราะห์ข้อมูลจากแหล่งข้อมูลหลากหลายเพื่อลด false positives และให้ผู้ตรวจสอบมนุษย์มุ่งเน้นกรณีที่มีความซับซ้อนสูง
- การจัดการเอกสารด้านการกำกับดูแลและการรายงานแบบอัตโนมัติ: ช่วยให้การปฏิบัติตามข้อกำหนดรายงานต่อหน่วยงานกำกับเร็วขึ้นและสอดคล้องมากขึ้น ลดเวลาในการเตรียมแบบฟอร์มและการแปลความหมายเชิงกฎระเบียบ
ในมิติระดับประเทศและระหว่างประเทศ มีความจำเป็นอย่างยิ่งสำหรับการประสานงานระหว่างหน่วยงานกำกับดูแลและการกำหนดมาตรฐานร่วม เพื่อจัดการประเด็นเชิงนโยบายที่เกิดขึ้นจากการใช้งาน LLM ในบริบทของการเงิน ประเด็นสำคัญได้แก่ความโปร่งใสของโมเดล (model explainability), traceability ของคำแนะนำที่สร้างโดยโมเดล, การกำกับดูแลความเสี่ยงเชิงโมเดล (model risk management) และการคุ้มครองข้อมูลส่วนบุคคล นอกจากนี้ การประสานงานกับกรอบการกำกับดูแลระหว่างประเทศ เช่น แนวทางของ Basel Committee on Banking Supervision (BCBS) และหลักการของ Financial Action Task Force (FATF) จะช่วยลดความเสี่ยงเรื่องความไม่สอดคล้องของกฎระเบียบข้ามพรมแดน ซึ่งสำคัญต่อการแลกเปลี่ยนข้อมูลการค้นหาพฤติกรรมฟอกเงินและการตรวจสอบข้ามประเทศ
ในภาพรวม ผลกระทบต่อประชาชนและผู้บริโภคมีทั้งด้านบวกและด้านที่ต้องระวัง ด้านบวกคือการตอบสนองและการให้บริการที่รวดเร็วขึ้น ความสอดคล้องของการคุ้มครองผู้บริโภคที่ดีขึ้น และต้นทุนบริการการเงินที่อาจลดลง แต่ด้านที่ต้องบริหารจัดการรวมถึงความเสี่ยงจากข้อผิดพลาดของโมเดล การลำเอียงในข้อมูลที่ใช้ฝึกสอน และเรื่องความเป็นส่วนตัวของข้อมูล ผู้กำกับดูแลจึงควรกำหนดมาตรการบังคับใช้ เช่น การทดสอบย้อนกลับ (backtesting) ของระบบ, การจัดทำ audit trail ที่สามารถตรวจสอบต้นทางของคำแนะนำ และการกำหนดมาตรฐานการรายงานเมื่อมีการใช้ AI ในกระบวนการกำกับดูแล
สุดท้าย ภาพอนาคตที่เป็นไปได้คือระบบนิเวศการกำกับดูแลที่ผสมผสานระหว่างความสามารถของ LLM กับการกำกับดูแลที่เข้มแข็งและความร่วมมือระดับนานาชาติ ธนาคารพาณิชย์จะกลายเป็นผู้ซื้อเทคโนโลยีที่เน้นการบริหารความเสี่ยงของโมเดล ขณะที่บริษัทเทคโนโลยีจะขยายข้อเสนอไปยังบริการการตรวจสอบและการทำตามข้อกำหนดแบบครบวงจร หากหน่วยงานกำกับดูแลออกหลักเกณฑ์และมาตรฐานร่วมที่ชัดเจน เราอาจเห็นการนำเทคโนโลยีไปใช้ในวงกว้างสำหรับงานเช่น stress testing และ AML โดยคงไว้ซึ่งความมั่นคงของระบบการเงินและการคุ้มครองผู้บริโภค
บทสรุป
การทดลองของธนาคารกลางชี้ให้เห็นศักยภาพของ Large Language Models (LLMs) ในการลดระยะเวลารีวิวงานเชิงกฎระเบียบจากระดับสัปดาห์ลงมาเหลือเพียงชั่วโมง โดยผลการทดลองระบุว่าเวลากลาง (median) ของกระบวนการที่เคยใช้ 7–14 วัน ถูกย่นเหลือเพียง 2–6 ชั่วโมงเมื่อผนวกการประมวลผลเชิงภาษาอัตโนมัติและการคัดกรองเชิงนโยบาย ซึ่งเทียบได้กับการลดเวลาได้ประมาณ 80–95% ในการทดสอบเชิงปฏิบัติจริง LLM ถูกใช้ในกรณีใช้งานสำคัญ เช่น การสกัดประเด็นความเสี่ยงจากเอกสารยาว การสรุปผลกระทบเชิงนโยบาย การสร้างร่างคำแนะนำเชิงกฎระเบียบ และการตรวจจับข้อไม่สอดคล้องกับมาตรฐาน ตัวอย่างเชิงตัวเลขรวมถึงอัตราความถูกต้องของการคัดกรองเบื้องต้นที่ระดับ 85–92% (ขึ้นกับโดเมนและข้อมูลฝึกอบรม) ซึ่งช่วยให้ทีมผู้ตรวจสอบมนุษย์มุ่งเน้นการตัดสินใจเชิงนโยบายที่สำคัญมากขึ้น แทนการใช้เวลาตรวจสอบเชิงเอกสารที่ใช้เวลามาก
อย่างไรก็ดี การนำ LLM ไปใช้จริงในงานกำกับดูแลต้องมากับกรอบกำกับดูแลที่เข้มงวด การทดสอบความเสี่ยงอย่างต่อเนื่อง และการผสานระบบ human-in-the-loop ในจุดตัดสินใจเชิงนโยบายเพื่อรับประกันความน่าเชื่อถือและความรับผิดชอบ โดยข้อเสนอเชิงปฏิบัติรวมถึงการตั้งมาตรการตรวจสอบแบบต่อเนื่อง (continuous monitoring), adversarial testing และ backtesting, การบันทึก audit trail และเวอร์ชันของโมเดล, มาตรฐานการอธิบายผล (explainability) และการจัดการสิทธิ์เข้าถึงข้อมูล ในมุมมองอนาคต คาดว่าใน 2–5 ปีข้างหน้า LLM จะกลายเป็นเครื่องมือช่วยงานที่ทำให้กระบวนการกำกับดูแลเป็นกึ่งอัตโนมัติ (semi-automated) โดยผสมผสานการตัดสินใจของมนุษย์และการตรวจสอบอัตโนมัติอย่างต่อเนื่อง ขณะที่หน่วยงานกำกับควรเร่งพัฒนามาตรฐานร่วมกัน การรับรองโมเดล และ sandbox สำหรับการทดสอบเพื่อให้การนำเทคโนโลยีนี้ไปใช้เป็นไปอย่างปลอดภัย โปร่งใส และรับผิดชอบต่อสาธารณะ



