
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มใหม่ "CodeSBOM" ที่ผสานพลังของ Large Language Models (LLMs) เข้ากับการวิเคราะห์แบบ Static และ Binary เพื่อสร้างและยืนยัน Software Bill of Materials (SBOM) อัตโนมัติ ซึ่งออกแบบมาเพื่อลดความเสี่ยงในซัพพลายเชนซอฟต์แวร์ขององค์กรต่าง ๆ โดยรองรับมาตรฐานสากลอย่าง SPDX และ CycloneDX จุดเด่นของแพลตฟอร์มอยู่ที่การรวมความสามารถเชิงภาษาของ LLM ในการทำความเข้าใจโค้ดและไลบรารี เข้ากับเครื่องมือวิเคราะห์โค้ดและไบนารีเพื่อยืนยันส่วนประกอบจริงที่ประกอบอยู่ในซอฟต์แวร์ ทำให้กระบวนการจัดทำ SBOM ที่เคยใช้เวลานานและเสี่ยงต่อความผิดพลาดจากการตรวจสอบด้วยมือ ถูกเร่งและเป็นระบบมากขึ้น

ความสำคัญของเทคโนโลยีนี้ยิ่งชัดเจนหลังเหตุการณ์โจมตีซัพพลายเช่น SolarWinds และช่องโหว่ที่กระทบองค์ประกอบภายนอกเช่น Log4Shell ซึ่งกระตุ้นให้หน่วยงานและองค์กรต้องให้ความสำคัญกับการมองเห็นส่วนประกอบซอฟต์แวร์อย่างเป็นระบบ CodeSBOM ตั้งเป้าช่วยองค์กรในการเร่งกระบวนการตรวจสอบความปลอดภัย ฝังการสร้าง SBOM ใน CI/CD pipeline สำหรับการตรวจสอบแบบต่อเนื่อง และลดความเสี่ยงจากส่วนประกอบที่ไม่ได้รับการยืนยันหรือมีช่องโหว่ ทั้งยังช่วยให้การปฏิบัติตามข้อกำหนดด้านความปลอดภัยและการรายงานเป็นไปได้รวดเร็วขึ้นสำหรับทีมฝ่ายรักษาความปลอดภัยและการปฏิบัติการขององค์กร
บทนำ: ทำไม SBOM ถึงสำคัญ และภาพรวมของ CodeSBOM
บทนำ: ทำไม SBOM ถึงสำคัญ และภาพรวมของ CodeSBOM
SBOM (Software Bill of Materials) คือรายการรายละเอียดของส่วนประกอบซอฟต์แวร์ทั้งหมดที่ประกอบกันเป็นผลิตภัณฑ์หนึ่ง ๆ ซึ่งรวมถึงไลบรารีโอเพนซอร์ส, โมดูล, ไบนารี่ และข้อมูลเมตาเช่นเวอร์ชัน ผู้พัฒนา และที่มา ในบริบทของการจัดการความเสี่ยงซัพพลายเชนซอฟต์แวร์ SBOM ทำหน้าที่เป็นเอกสารอ้างอิงเชิงปริมาณที่ช่วยให้องค์กรสามารถระบุส่วนประกอบที่อาจมีช่องโหว่ การละเมิดลิขสิทธิ์ หรือการขึ้นต่อกันของแพ็กเกจที่ไม่ปลอดภัยได้อย่างรวดเร็วและมีความชัดเจน
ความสำคัญของ SBOM ถูกเน้นย้ำขึ้นหลังจากเหตุการณ์การละเมิดซัพพลายเชนหลายกรณีที่เกิดความเสียหายต่อองค์กรจำนวนมาก โดยเฉพาะในระดับองค์กรและภาครัฐ การมี SBOM ช่วยให้องค์กรสามารถตอบสนองต่อการแจ้งเตือนช่องโหว่ (vulnerability disclosures) ได้เร็วขึ้น ลดพื้นที่ในการค้นหา และเพิ่มความโปร่งใสต่อผู้มีส่วนได้ส่วนเสีย กระบวนการนี้จึงกลายเป็นหัวใจสำคัญของนโยบายการบริหารจัดการความเสี่ยงด้านไอทีและความปลอดภัยไซเบอร์
CodeSBOM เป็นแพลตฟอร์มที่เปิดตัวโดยสตาร์ทอัพไทยชื่อเดียวกันในเดือนมีนาคม 2026 ซึ่งพัฒนาโดยทีมวิศวกรซอฟต์แวร์และนักวิจัยด้านความปลอดภัยไซเบอร์ของไทย จุดประสงค์หลักของแพลตฟอร์มคือการผสานความสามารถของ Large Language Models (LLMs) กับเทคนิคการวิเคราะห์ซอฟต์แวร์ทั้งแบบ static analysis และ binary analysis เพื่อสร้างและยืนยัน SBOM อย่างอัตโนมัติและเชื่อถือได้ โดยมุ่งเป้าไปที่องค์กรที่ต้องการลดความเสี่ยงจากซัพพลายเชนซอฟต์แวร์และปรับปรุงกระบวนการปฏิบัติการด้านความปลอดภัยอย่างครบวงจร
ฟีเจอร์หลักและข้อเสนอคุณค่าของ CodeSBOM ได้แก่:
- การสร้าง SBOM อัตโนมัติ — สแกนซอร์สโค้ดและอาร์ติแฟ็กต์ไบนารี่เพื่อสกัดรายการส่วนประกอบและเมตาดาต้าแบบเรียลไทม์ ลดการพึ่งพาการบันทึกด้วยมือที่มักนำมาซึ่งความผิดพลาด
- การยืนยันความถูกต้อง — ครอส-เช็กข้อมูลจากหลายแหล่ง (manifest, package manager, binary signatures) เพื่อลด false positives และยืนยันที่มาของส่วนประกอบ
- การผสาน LLM กับ Static/Binary Analysis — ใช้ LLM ในการตีความบริบทเชิงภาษาที่ซับซ้อน เช่น license text, change logs และ dependency graphs ร่วมกับ static/binary analysis เพื่อให้การระบุส่วนประกอบมีความแม่นยำสูงขึ้น
- การรายงานเชิงธุรกิจ — สร้างรายงานสรุปความเสี่ยงที่เหมาะกับผู้บริหาร ลดความซับซ้อนในการสื่อสารระหว่างทีมเทคนิคและทีมบริหาร
การอัตโนมัติของการสร้างและยืนยัน SBOM ช่วยลดเวลาและความผิดพลาดได้อย่างมีนัยสำคัญ ตัวอย่างเช่น องค์กรที่ยังคงจัดทำ SBOM ด้วยมืออาจใช้เวลาหลายวันหรือสัปดาห์ในการตรวจสอบซอฟต์แวร์แต่ละรุ่น ขณะที่ระบบอัตโนมัติสามารถย่อเวลานั้นลงเหลือเป็นชั่วโมงหรือไม่ก็นาที นอกจากนี้ การลดขั้นตอนที่ต้องทำด้วยมือยังช่วยลดความเสี่ยงจาก human error เช่น การละเลย dependency ย่อยหรือการบันทึกเวอร์ชันผิด ข้อมูลเชิงประเมินแสดงให้เห็นว่าองค์กรที่นำกระบวนการอัตโนมัติด้าน SBOM มาใช้ สามารถปรับปรุงความรวดเร็วในการตอบสนองต่อช่องโหว่และการตรวจสอบการปฏิบัติตามนโยบายได้อย่างมีนัยสำคัญ (ในบางกรณีรายงานว่าลดเวลาถึงกว่า 50%)
โดยรวมแล้ว CodeSBOM เสนอโซลูชันที่รวบรวมความสามารถเชิงเทคนิคและการตีความเชิงบริบทไว้ด้วยกัน ทำให้องค์กรสามารถมีภาพรวมของซัพพลายเชนซอฟต์แวร์ที่ชัดเจนและเชื่อถือได้ ลดภาระงานเชิงปฏิบัติการ และเพิ่มความมั่นใจในการจัดการความเสี่ยงสำหรับการพัฒนาและการนำส่งซอฟต์แวร์ในระดับองค์กร
บริบท: ความเสี่ยงของซัพพลายเชนซอฟต์แวร์และสถิติที่เกี่ยวข้อง
บริบท: ความเสี่ยงของซัพพลายเชนซอฟต์แวร์และสถิติที่เกี่ยวข้อง
ซัพพลายเชนของซอฟต์แวร์ในปัจจุบันมีความซับซ้อนขึ้นอย่างมาก แอปพลิเคชันสมัยใหม่ส่วนใหญ่ประกอบด้วยคอมโพเนนต์จากบุคคลที่สาม ไลบรารีโอเพนซอร์ส และไบนารีที่ถูกดัดแปลงซ้ำหลายชั้น ส่งผลให้ความเสี่ยงไม่ได้จำกัดอยู่ที่ซอฟต์แวร์ที่องค์กรเขียนขึ้นเองแต่เพียงอย่างเดียว เมื่อคอมโพเนนต์ภายนอกเหล่านี้มีช่องโหว่ ผู้โจมตีสามารถใช้เป็นทางเข้าไปยังระบบของผู้ใช้งานได้ในวงกว้าง ความท้าทายสำหรับองค์กรคือการมองเห็น (visibility) และการยืนยัน (verification) ว่าซอฟต์แวร์แต่ละชิ้นประกอบด้วยส่วนประกอบใดบ้าง และส่วนประกอบเหล่านั้นมีสถานะความปลอดภัยอย่างไร
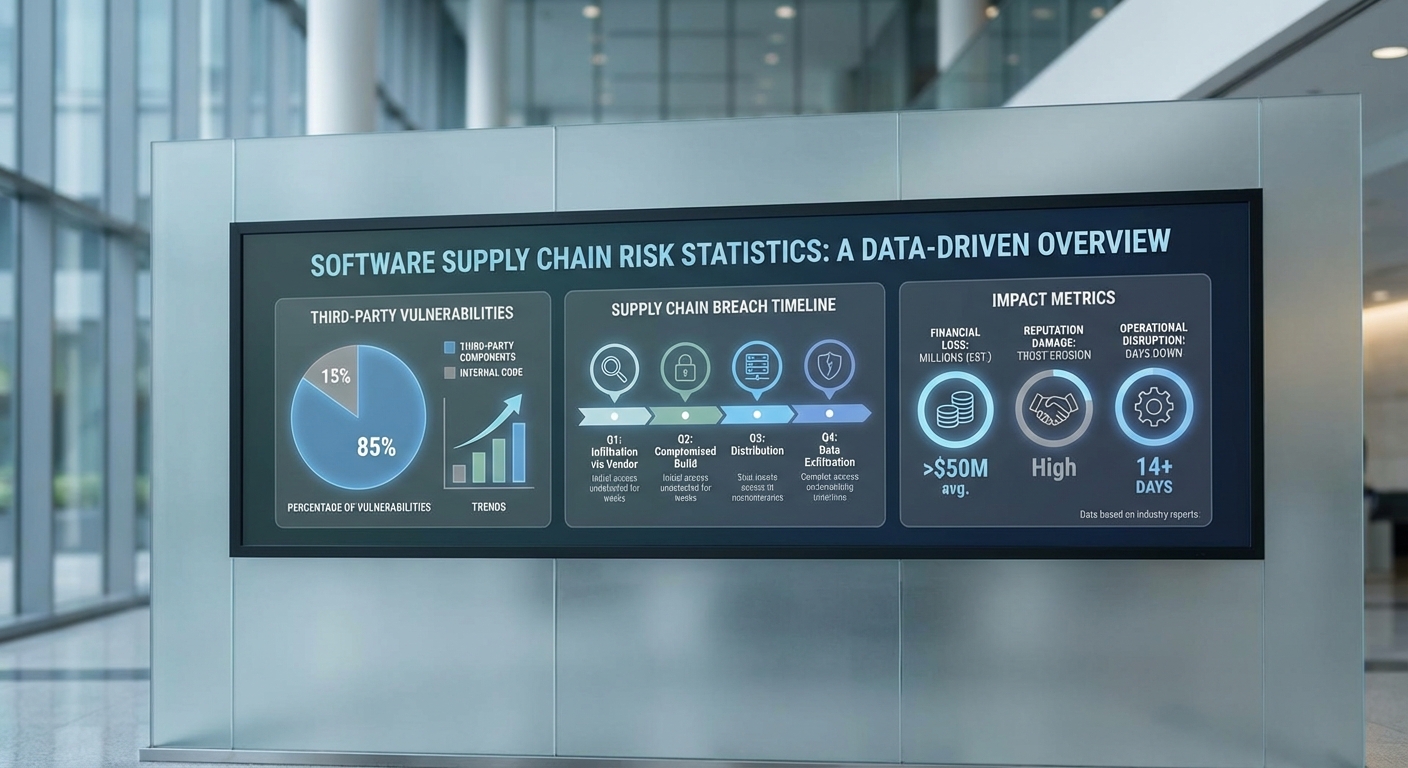
จากงานศึกษาต่าง ๆ และรายงานอุตสาหกรรม พบสถิติที่ชี้ให้เห็นความรุนแรงของปัญหา ตัวอย่างสถิติที่น่าสังเกตได้แก่
- สัดส่วนการใช้โอเพนซอร์สสูง: มากกว่า 90% ของซอฟต์แวร์สมัยใหม่ประกอบด้วยไลบรารีโอเพนซอร์สอย่างน้อยหนึ่งตัว ทำให้ความเสี่ยงจากคอมโพเนนต์ภายนอกเป็นเรื่องปกติในวงการ
- สัดส่วนช่องโหว่จากบุคคลที่สาม: ข้อมูลจากรายงานหลายฉบับชี้ว่าระหว่าง 60–80% ของช่องโหว่ที่ตรวจพบบนแอปพลิเคชันมักมีต้นกำเนิดมาจากไลบรารีหรือคอมโพเนนต์ของบุคคลที่สาม (third‑party/OSS)
- เวลาที่ใช้ในการแก้ไข (MTTR): องค์กรมักใช้เวลาหลายสิบถึงหลายร้อยวันในการตรวจจับและแพตช์ช่องโหว่ที่เกี่ยวข้องกับคอมโพเนนต์ภายนอก — งานศึกษาบางชิ้นรายงานค่ากลางในช่วง 60–120 วัน ขึ้นอยู่กับความซับซ้อนของซัพพลายเชนและการมองเห็นภายใน
- ผลกระทบเชิงธุรกิจสูง: เหตุการณ์ซัพพลายเชนระดับโลกหลายครั้งทำให้ธุรกิจต้องหยุดชะงัก เกิดความสูญเสียเชิงการเงินและชื่อเสียงอย่างรวดเร็ว
เหตุการณ์จริงที่มองเห็นได้ชัด เช่น การโจมตีซัพพลายเชน SolarWinds (2020) ที่ผู้โจมตีแฝงโค้ดอันตรายในอัปเดตของผู้ขาย ทำให้ระบบของหน่วยงานภาครัฐและองค์กรขนาดใหญ่หลายแห่งได้รับผลกระทบ หรือช่องโหว่ Log4j (2021) ซึ่งเป็นไลบรารีโอเพนซอร์สที่ถูกใช้งานอย่างแพร่หลาย ส่งผลให้ระบบทั่วโลกต้องแข่งกันตรวจสอบและแพตช์คอมโพเนนต์ที่ได้รับผลกระทบ เหตุการณ์เหล่านี้เป็นตัวอย่างชัดเจนที่แสดงให้เห็นว่า การไม่รู้จักหรือไม่สามารถยืนยันส่วนประกอบภายในซอฟต์แวร์ของตนเอง สามารถกลายเป็นความเสี่ยงระดับองค์กรได้ทันที
นอกเหนือจากความเสี่ยงด้านเทคนิคแล้ว ความต้องการด้านกฎระเบียบและการปฏิบัติตามมาตรฐานก็ผลักดันให้ SBOM (Software Bill of Materials) กลายเป็นสิ่งจำเป็น ตัวอย่างเช่น คำสั่งของรัฐบาลสหรัฐฯ และแนวทางของหน่วยงานความมั่นคง ทางการแพทย์ และอุตสาหกรรมต่าง ๆ เริ่มบังคับให้ผู้ขายซอฟต์แวร์ต้องเสนอข้อมูลเกี่ยวกับส่วนประกอบซอฟต์แวร์ ในสภาพแวดล้อมที่มีกฎระเบียบเหล่านี้ การมี SBOM ที่ถูกต้องและได้รับการยืนยันช่วยให้องค์กรสามารถแสดงความสอดคล้อง (compliance), ลดความเสี่ยงจากข้อบังคับ และตอบสนองต่อเหตุการณ์ความปลอดภัยได้รวดเร็วขึ้น
ดังนั้นการสร้างและยืนยัน SBOM อย่างอัตโนมัติ พร้อมกับการวิเคราะห์เชิงสถิตและการตรวจสอบไบนารี ถือเป็นกลยุทธ์เชิงป้องกันที่สำคัญสำหรับองค์กรที่ต้องการลดเวลาในการตรวจพบและแก้ไขช่องโหว่ ปรับปรุงการควบคุมซัพพลายเชน และปฏิบัติตามข้อกำหนดทางกฎหมายและมาตรฐานสากล
เทคโนโลยีเบื้องหลัง: การผสาน LLM กับ Static และ Binary Analysis
ภาพรวมของ Pipeline การวิเคราะห์
แพลตฟอร์ม CodeSBOM ใช้สถาปัตยกรรมการประมวลผลเป็นลำดับขั้น (pipeline) เพื่อสร้างและยืนยัน SBOM อัตโนมัติ โดยครอบคลุมตั้งแต่การเก็บข้อมูลไปจนถึงการลงนามยืนยันความถูกต้อง กระบวนการหลักแบ่งเป็น: ingestion → static analysis → binary analysis → LLM-assisted interpretation → SBOM generation & attestation ซึ่งแต่ละขั้นตอนมีเทคนิคและเครื่องมือเฉพาะที่ทำงานร่วมกันเพื่อเพิ่มความแม่นยำและความน่าเชื่อถือของผลลัพธ์
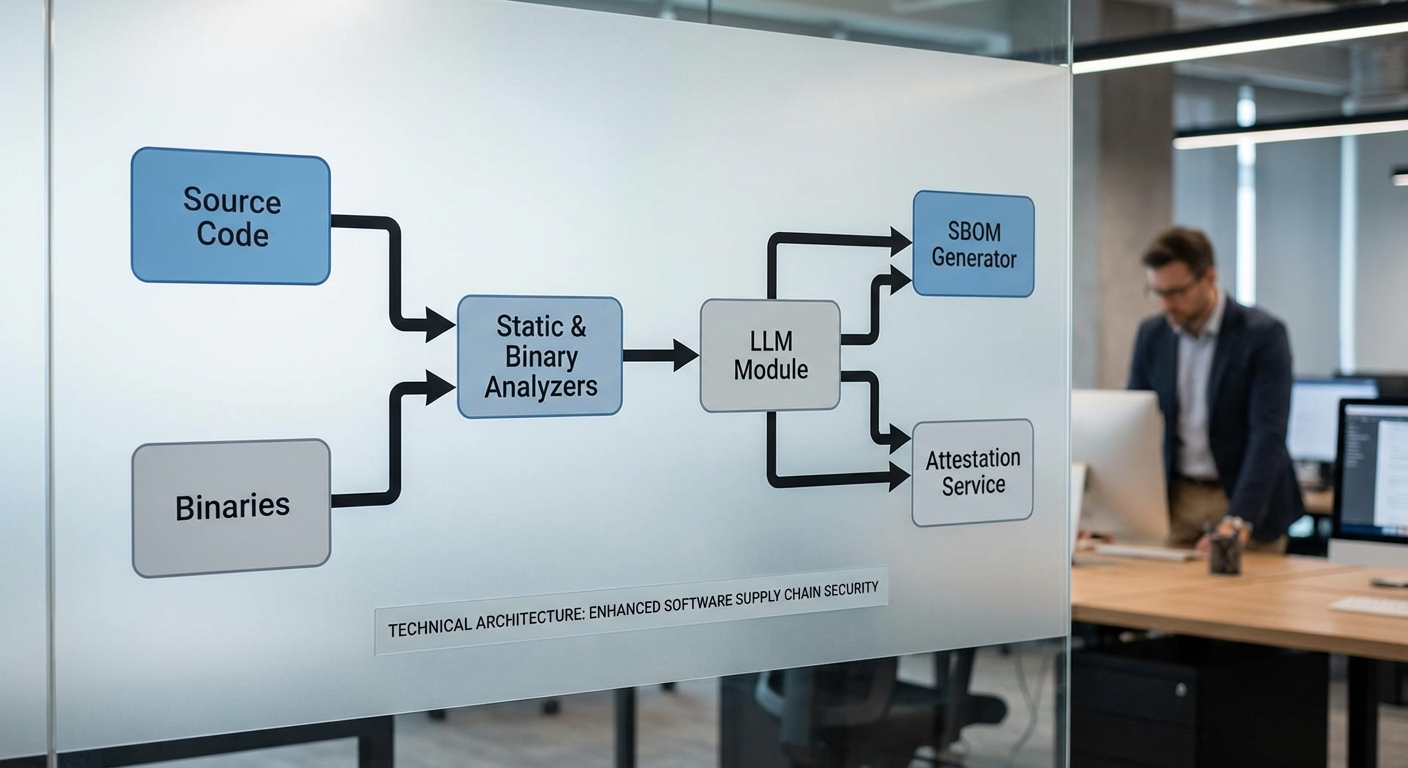
1) การเก็บข้อมูล (Ingestion)
ขั้นตอนแรกคือการรวบรวมแหล่งข้อมูลหลากหลายรูปแบบ เช่น source code repositories (Git), package manifests (package.json, pom.xml, go.mod), container images (OCI layers), และ binary blobs (executables, libraries, firmware). ระบบจะเก็บเมตาดาต้าเบื้องต้น เช่น ชื่อไฟล์, hash (SHA-256), ข้อมูล manifest, build metadata และ timestamps เพื่อสร้างฐานข้อมูลสำหรับการวิเคราะห์ต่อไป
2) Static Analysis
Static analysis บนโค้ดและซอร์สไฟล์ใช้ทั้งเทคนิคแบบดั้งเดิมและแบบสมัยใหม่ ได้แก่:
- การ parse AST และการสร้าง dependency graph เพื่อระบุการอ้างอิงไลบรารี, เวอร์ชันที่ถูกอ้างถึง และ call graph ที่สำคัญ
- การสแกน manifest และ lockfile เพื่อดึงข้อมูล dependency ที่ชัดเจน (เช่นชื่อแพ็กเกจและเวอร์ชัน)
- การวิเคราะห์ไลเซนส์ด้วย signature matching และ heuristic rules เพื่อตรวจหาไฟล์ LICENSE และ header comment
- การจัดทำ fingerprint ของโค้ดเพื่อจับ pattern ของซอร์สโค้ดที่อาจบ่งชี้ซอฟต์แวร์ third‑party หรือโค้ดที่ reuse
ในกรณีที่ metadata ขาดหรือไม่สมบูรณ์ (เช่น binary ที่ไม่มี source mapping) static analysis อาจได้ข้อมูลที่จำกัด ซึ่งเป็นจุดที่ LLM เข้ามาช่วยเติมช่องว่าง
3) Binary Analysis
Binary analysis จะทำงานกับ artifacts ที่เป็นไบนารีโดยตรง โดยใช้เทคนิคเช่น:
- การสกัด symbol table, exported/imported functions และ dynamic dependencies (เช่น ldd, objdump, readelf ใน ELF / dumpbin ใน PE)
- string analysis เพื่อค้นหา URL, version strings, build IDs หรือคำสั่งที่ฝังอยู่ในไบนารี
- fuzzy hashing (เช่น ssdeep) และ similarity clustering เพื่อแมปลักษณะใกล้เคียงระหว่างไบนารีและโค้ดต้นทาง
- การแยก resource/section เพื่อตรวจหาไฟล์ภายใน (เช่น embedded JARs, native libs) และการดึง manifest/metadata ที่ฝังมา
การรวมผลจาก static และ binary analysis ช่วยให้ระบบสามารถจับคู่ไลบรารีที่มีการเปลี่ยนชื่อหรือถูกบีบอัดได้แม้ไม่มี metadata สมบูรณ์
4) LLM-assisted Interpretation
บทบาทของ Large Language Models (LLMs) ใน pipeline ไม่ใช่การแทนที่ static/binary tools แต่เป็นการ ตีความเมตาดาต้า และ เติมช่องว่างข้อมูลเชิงบริบท ที่เครื่องมือดั้งเดิมอาจพลาด โดยฟังก์ชันสำคัญได้แก่:
- การเชื่อมโยงข้อมูลเชิงบริบท — LLM สามารถอ่าน comment, commit message, build logs และอธิบายความสัมพันธ์ระหว่างโค้ดกับ dependency เช่น สาเหตุที่มีการใช้ไลบรารีบางตัว
- การตีความไลเซนส์ — นอกเหนือจากการแมทช์ signature, LLM ช่วยสรุปข้อจำกัดของไลเซนส์และแจ้งความเสี่ยงเชิงสัญญาต่อธุรกิจ (เช่น copyleft implications)
- การเติมข้อมูลที่ขาดหาย — เมื่อเวอร์ชันหรือชื่อแพ็กเกจขาดหาย LLM สามารถคาดการณ์เวอร์ชันหรือแม้แต่แมปฟังก์ชันในไบนารีไปยังไลบรารีที่เป็นไปได้ โดยให้คะแนนความเชื่อมั่น (confidence score) ประกอบ
- การจับ pattern ของโค้ด — LLM ถูกฝึกให้จดจำ idioms, boilerplate หรือ template code ที่บ่งชี้ถึงแหล่งที่มา เช่น โค้ดที่คัดลอกจากโปรเจกต์โอเพนซอร์สที่มีชื่อเสียง
- การเชื่อมโยงกับ CVE/Security Advisory — LLM สามารถแมปฟิงเกอร์พรินต์หรือฟังก์ชันที่ตรวจพบกับฐานข้อมูลช่องโหว่ เพื่อให้รายการแสดงความเสี่ยงเชิงปฏิบัติได้ทันที
ผลลัพธ์จาก LLM จะถูกเก็บเป็น structured assertions (เช่น JSON-LD claim) ที่ระบุแหล่งที่มา (evidence) และระดับความเชื่อมั่น เพื่อให้ผู้ใช้งานและระบบอัตโนมัติสามารถตัดสินใจได้
5) การสร้าง SBOM และการยืนยัน (Attestation & Provenance)
หลังจากรวมผลจากทุกขั้นตอน ระบบจะสร้าง SBOM ในรูปแบบมาตรฐาน เช่น SPDX หรือ CycloneDX ซึ่งประกอบด้วยรายการคอมโพเนนต์, เวอร์ชัน, ไลเซนส์, hashes และข้ออ้างอิง (evidence links) ที่มาจาก static/binary analysis และ LLM assertions
เพื่อให้ SBOM มีความน่าเชื่อถือเชิงพิสูจน์ (provenance) แพลตฟอร์มใช้กลไกการยืนยันดังนี้:
- cryptographic signing — SBOM และ attestation envelope ถูกลงนามด้วยคีย์ส่วนตัวของผู้สร้าง (หรือของระบบ CI/CD) โดยใช้มาตรฐานเช่น X.509, PGP หรือ JSON Web Signatures (JWS)
- content-addressable storage & Merkle trees — การจัดเก็บ artifact และ SBOM ด้วย hash-based identifiers ช่วยให้สามารถพิสูจน์ว่า SBOM อ้างถึงเนื้อหาเฉพาะได้อย่างไม่เปลี่ยนแปลง
- in-toto / SLSA-style provenance — บันทึกขั้นตอนการ build (who, what, when, how) และสร้าง attestations ที่เชื่อมโยงกับ SBOM เพื่อยืนยันแหล่งที่มาและกระบวนการผลิต
- timestamping และ certificate transparency — การเพิ่ม timestamp ที่ตรวจสอบได้และการเผยแพร่ hash ลงในระบบที่ตรวจสอบได้สาธารณะ ช่วยป้องกันการเปลี่ยนแปลงย้อนหลัง
- TPM / HSM-backed keys — สำหรับลูกค้าที่ต้องการระดับความมั่นใจสูง คีย์สำหรับลงนามสามารถเก็บใน HSM หรือ TPM เพื่อป้องกันการถูกขโมยหรือปลอมแปลง
ตัวอย่างผลลัพธ์เชิงปฏิบัติ
จากการทดสอบภายในของ CodeSBOM พบว่า การผสาน LLM เข้ากับ static/binary analysis ช่วยเพิ่มอัตราการระบุคอมโพเนนต์ที่ไม่มี metadata ได้ราว 10–30% เมื่อเทียบกับ static/binary tools เพียงอย่างเดียว และช่วยลดเวลาการตรวจสอบด้วยมือจากหลายชั่วโมงเหลือเป็นนาทีสำหรับไลบรารีทั่วไป นอกจากนี้ การใส่ attestations และการลงนามทางคริปโตกราฟิกทำให้ลูกค้าสามารถตรวจสอบความถูกต้องของ SBOM ได้แบบปลายทางต่อปลายทาง (end‑to‑end)
สรุปแล้ว การรวม LLM กับ static และ binary analysis ภายใน pipeline ของ CodeSBOM ไม่เพียงแต่ช่วยให้การสร้าง SBOM เป็นไปอย่างอัตโนมัติและครอบคลุมมากขึ้น แต่ยังเพิ่มมิติของความเชื่อมั่น (confidence & provenance) ผ่านการตีความเชิงบริบทโดย LLM และการยืนยันด้วยกลไกทางคริปโตกราฟิก ทำให้องค์กรสามารถบริหารความเสี่ยงซัพพลายเชนซอฟต์แวร์ได้อย่างเป็นระบบและตรวจสอบได้
ฟีเจอร์หลักและ workflow ของ CodeSBOM
ฟีเจอร์หลักของ CodeSBOM
CodeSBOM เป็นแพลตฟอร์มที่ออกแบบมาเพื่อตอบโจทย์ความต้องการด้านการจัดการซัพพลายเชนซอฟต์แวร์โดยเฉพาะ โดยผสานความสามารถของ Static Analysis, Binary Analysis และ Large Language Models (LLMs) เพื่อเพิ่มความแม่นยำในการระบุส่วนประกอบซอฟต์แวร์ (components) ไลบรารี และไบนารีที่ฝังมากับแอปพลิเคชัน ฟีเจอร์หลักรวมถึงการสแกนอัตโนมัติผ่าน pipeline, การตรวจจับไลเซนส์และช่องโหว่, การสร้าง SBOM ในรูปแบบมาตรฐาน และความสามารถในการยืนยัน (signing/attestation) เพื่อให้ข้อมูลมีความน่าเชื่อถือและตรวจสอบได้
แพลตฟอร์มรองรับมาตรฐาน SBOM สำคัญ ได้แก่ SPDX และ CycloneDX พร้อมตัวเลือกการส่งออกเป็น JSON, XML, และรูปแบบอื่นที่องค์กรต้องการ ทำให้สามารถผสานกับระบบเดิม เช่น asset inventory, vulnerability management หรือ GRC ได้อย่างราบรื่น นอกจากนี้ CodeSBOM ยังมีความสามารถในการแปลงระหว่างฟอร์แมตเพื่อรองรับระบบภายนอกและการรายงานที่หลากหลาย

ฟีเจอร์เชิงปฏิบัติการและการแจ้งเตือน
ในเชิงการใช้งาน CodeSBOM ให้ชุดฟีเจอร์ที่ตอบโจทย์องค์กรขนาดกลางถึงใหญ่ ได้แก่
- การสแกนอัตโนมัติแบบ CI/CD integration — ติดตั้งเป็นขั้นตอนใน pipeline (เช่น GitHub Actions, GitLab CI, Jenkins) เพื่อสร้าง SBOM ทุกครั้งเมื่อเกิดการ build หรือ merge ทำให้เกิด SBOM แบบต่อเนื่อง (continuous) ที่ผูกกับแต่ละเวอร์ชันของซอฟต์แวร์
- การตรวจจับไลเซนส์และช่องโหว่ — ผสานฐานข้อมูล CVE, NVD และแหล่งข้อมูลไลเซนส์ เพื่อระบุความเสี่ยงทางกฎหมายและความปลอดภัย รวมทั้งให้คะแนนความร้ายแรงและคำแนะนำการแก้ไข
- การวิเคราะห์ Static/Binary ที่เสริมด้วย LLM — ใช้ static analysis เพื่อแยก dependency tree และ binary analysis เพื่อตรวจหาไลบรารีฝังตัว พร้อมให้ LLM ช่วยตีความข้อสรุปในกรณีความคลุมเครือ เช่น การแมปชื่อไลบรารีที่ถูกย่อหรือการจัดกลุ่มเวอร์ชันที่ไม่ชัดเจน
- การยืนยัน (signing/attestation) — รองรับการลงนามดิจิทัลของ SBOM (e.g., X.509, Sigstore-style) และการออกใบรับรองการตรวจสอบ (attestation) เพื่อใช้ในกระบวนการจัดส่งซอฟต์แวร์ที่ต้องการความเชื่อถือ
- การแจ้งเตือนและการรายงาน — ส่งการแจ้งเตือนเมื่อพบความเสี่ยงที่ต้องการการตอบสนองทันที หรือเมื่อ dependency มีการอัปเดตสำคัญ พร้อมแดชบอร์ดและรายงานเชิงสรุปสำหรับผู้บริหาร
- API สำหรับองค์กร — มี REST/GraphQL API สำหรับดึงข้อมูล SBOM, คิวรีความเสี่ยง, เรียกใช้งานการสแกน และผสานเข้ากับระบบ CI/CMDB/Vulnerability Management ภายใน
ตัวอย่าง workflow: จาก commit ถึง SBOM ที่ลงนามและจัดเก็บได้
ตัวอย่าง workflow ของ CodeSBOM ถูกออกแบบให้ใช้งานจริงในสภาพแวดล้อมการพัฒนาอย่างต่อเนื่อง โดยมีขั้นตอนหลักดังนี้
- 1. Commit & Push — นักพัฒนาทำการ commit โค้ดและ push ไปยัง repository เช่น GitHub/GitLab
- 2. CI/CD Trigger — ระบบ CI/CD ตรวจจับการเปลี่ยนแปลงแล้วเรียกใช้ขั้นตอน build รวมถึงสเต็ปของ CodeSBOM ที่ฝังอยู่ใน pipeline
- 3. Static + Binary Analysis — CodeSBOM สแกนโค้ดซอร์สและไบนารี ตรวจหา dependencies, สืบค้นไลเซนส์, วิเคราะห์สัญญาณของ third-party code และใช้ LLM เพื่อช่วยตีความกรณีพิเศษ
- 4. SBOM Generation — สร้างเอกสาร SBOM ตามมาตรฐานที่กำหนด (SPDX/CycloneDX) พร้อม metadata ของเวอร์ชัน, commit hash, build ID และข้อมูลแวดล้อม
- 5. Attestation & Signing — SBOM ถูกลงนามดิจิทัลโดยคีย์ขององค์กรหรือผ่านบริการ signing ภายนอก เพื่อยืนยันความถูกต้องของแหล่งที่มาและขั้นตอนการ build
- 6. Storage & Verification — SBOM ที่ลงนามจะถูกจัดเก็บในระบบที่ตรวจสอบได้ (เช่น artifact registry, internal SBOM database หรือ transparency log) พร้อมให้ API/แดชบอร์ดเรียกดูและตรวจสอบย้อนหลัง
- 7. Notification & Remediation — หากพบช่องโหว่หรือปัญหา CodeSBOM จะส่งการแจ้งเตือนไปยังทีมที่เกี่ยวข้อง พร้อมลิงก์ไปยัง SBOM เวอร์ชันที่เกี่ยวข้องและคำแนะนำการแก้ไข
จากการทดสอบเบื้องต้นในสภาพแวดล้อมจริง พบว่าองค์กรสามารถลดเวลาในการผลิตและตรวจสอบ SBOM จากขั้นตอนที่เคยใช้เวลาหลายชั่วโมงเหลือเพียงไม่กี่นาทีในแต่ละ build และช่วยลดความเสี่ยงจากส่วนประกอบที่ไม่ทราบแหล่งที่มาหรือไลเซนส์ที่ไม่สอดคล้องกันได้อย่างมีนัยสำคัญ ตัวอย่างเช่น ในกรณีตัวอย่างของโปรเจกต์ขนาดกลาง CodeSBOM สามารถระบุ dependency ได้มากกว่า 90% และช่วยให้ทีมตอบสนองต่อช่องโหว่ที่สำคัญเร็วขึ้น
โดยสรุป CodeSBOM ทำหน้าที่เป็นศูนย์กลางสำหรับการสร้าง ตรวจสอบ และยืนยัน SBOM ในรูปแบบที่สอดคล้องกับมาตรฐานสากล ตอบโจทย์ทั้งกระบวนการพัฒนาแบบ CI/CD และความต้องการด้านการตรวจสอบเชิงองค์กร ผ่านการผสานเทคโนโลยีวิเคราะห์โค้ดและความสามารถของ LLM เพื่อเพิ่มความแม่นยำและความเชื่อถือได้ในทุกขั้นตอนของ supply chain ซอฟต์แวร์
ประโยชน์ด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ
ประโยชน์ด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ
การนำแพลตฟอร์ม CodeSBOM ไปใช้ช่วยลดความเสี่ยงด้านซัพพลายเชนซอฟต์แวร์ทั้งในเชิงป้องกัน (preventive) และเชิงตรวจจับ (detective) โดยอาศัยการผสานกันระหว่าง Large Language Models (LLMs) กับเทคนิคการวิเคราะห์แบบ static และ binary analysis เพื่อสร้าง ตรวจสอบ และยืนยันความถูกต้องของ SBOM อัตโนมัติ ซึ่งผลลัพธ์คือการลดความผิดพลาดจากการทำด้วยมือ (human error), การค้นพบส่วนประกอบที่ไม่ได้ประกาศ, การตรวจจับการเปลี่ยนแปลงหรือการฝังโค้ดที่เป็นอันตรายในไบนารี และการเชื่อมโยงรายการคอมโพเนนต์กับช่องโหว่ที่ทราบแล้วอย่างรวดเร็ว ทำให้ทีมความปลอดภัยสามารถมองเห็นพื้นฐานความเสี่ยงได้ชัดเจนขึ้นตั้งแต่ต้นน้ำของกระบวนการพัฒนา
ในมิติของการตรวจสอบและ audit แพลตฟอร์มอัตโนมัติอย่าง CodeSBOM ช่วยลดเวลาและต้นทุนอย่างมีนัยสำคัญ โดยการสร้าง SBOM ในรูปแบบเครื่องอ่านได้ (machine-readable) และมีการยืนยันความสอดคล้องระหว่างซอร์สโค้ดกับไบนารี ทำให้งาน audit ที่เดิมต้องใช้เวลาตรวจสอบด้วยมือจำนวนมากถูกย่นระยะ ตัวอย่างการประเมินเชิงอุตสาหกรรมชี้ว่าองค์กรที่ใช้กระบวนการ SBOM อัตโนมัติสามารถลดเวลาในการเตรียมข้อมูลสำหรับการตรวจสอบลงได้ประมาณ 30–60% โดยในทางปฏิบัติสำหรับองค์กรขนาดใหญ่ การตรวจสอบแต่ละ release ที่เคยใช้เวลาเป็นร้อยชั่วโมงอาจลดลงเหลือประมาณ 80–120 ชั่วโมง และสำหรับองค์กรขนาดกลาง/เล็กอาจเห็นการประหยัดทรัพยากรด้านบุคลากรและค่าใช้จ่ายได้ในสัดส่วนที่เทียบเท่าหรือมากกว่า
ด้านการตอบสนองต่อช่องโหว่ (vulnerability response) และการจัดการแพตช์ CodeSBOM ช่วยให้การเชื่อมโยงช่องโหว่กับคอมโพเนนต์จริงในระบบเป็นไปอย่างอัตโนมัติและแม่นยำ ส่งผลให้การตั้งลำดับความสำคัญ (prioritization) และการแพตช์ทันท่วงทีดีขึ้น การประเมินทั่วไประบุว่าแพลตฟอร์มที่รวมการตรวจจับ SBOM อัตโนมัติสามารถลด Mean Time To Remediate (MTTR) ได้ถึง 40–70% เมื่อเทียบกับการจัดการแบบแมนนวล นั่นหมายความว่าเวลาที่ระบบเปราะบางเปิดให้อาศัยโจมตีในสภาพแวดล้อมการผลิตลดลงอย่างมีนัยสำคัญ
ในด้านการปฏิบัติตามกฎระเบียบ CodeSBOM ออกแบบมาให้สอดคล้องกับกรอบงานและแนวทางสากลที่เกี่ยวข้อง เช่น US Executive Order on Improving the Nation’s Cybersecurity (Executive Order 14028) และแนวทางการใช้งาน SBOM ของหน่วยงานที่เกี่ยวข้องในสหรัฐอเมริกา (เช่น NTIA/NIST) รวมทั้งแนวทางของสหภาพยุโรปและ ENISA ตลอดจนมาตรฐานสากลที่เกี่ยวข้องกับการจัดการความปลอดภัยของระบบสารสนเทศ (เช่น ISO/IEC 27001) และรูปแบบมาตรฐานของ SBOM อย่าง SPDX และ CycloneDX CodeSBOM สามารถส่งออกข้อมูลในรูปแบบที่เป็นที่ยอมรับต่อการตรวจสอบและจัดเก็บเป็นหลักฐานการปฏิบัติตามข้อกำหนด ทำให้การจัดซื้อซอฟต์แวร์ การประเมินความเสี่ยงของผู้ขาย (vendor risk assessment) และการตอบข้อเรียกร้องด้านกฎระเบียบมีความราบรื่นยิ่งขึ้น
นอกจากนี้การใช้งาน CodeSBOM ยังเสริมการทำงานร่วมกับทีมความปลอดภัย (SecOps) และซัพพลายเออร์ โดยสามารถผสานเข้ากับเครื่องมือ CI/CD, ระบบติดตามช่องโหว่ (Vulnerability Management), และระบบ Ticketing เพื่อให้เกิดวงจรการตอบสนองแบบอัตโนมัติ (automated workflows) ระหว่างทีมพัฒนา ทีมรักษาความปลอดภัย และผู้จัดส่งซอฟต์แวร์ ตัวอย่างผลลัพธ์เชิงธุรกิจที่สามารถคาดการณ์ได้รวมถึงการลดอุบัติการณ์ที่เกี่ยวข้องกับซัพพลายเชนลงประมาณ 30–50% จากการลดช่องโหว่ที่ไม่ได้ถูกตรวจพบและลดเวลาตอบสนอง รวมถึงการปรับปรุงความโปร่งใสและความเชื่อมั่นระหว่างองค์กรกับซัพพลายเออร์ ซึ่งเป็นปัจจัยสำคัญในการลดความเสี่ยงรวมของระบบ
สรุปแล้ว CodeSBOM ให้ทั้งการป้องกันเชิงรุกโดยการยกระดับการมองเห็นและความสอดคล้องของคอมโพเนนต์ซอฟต์แวร์ และการตรวจจับเชิงลึกผ่านการยืนยันไบนารีและการจับคู่ช่องโหว่อัตโนมัติ ซึ่งผลรวมของประสิทธิภาพที่เพิ่มขึ้นนี้นำไปสู่การลดเวลา audit, การลด MTTR, และการช่วยให้การปฏิบัติตามข้อกำหนดเป็นไปได้อย่างมีประสิทธิผลและตรวจสอบได้ตามมาตรฐานสากล
ผลกระทบทางธุรกิจ ตลาด และการยอมรับจากองค์กร
ผลกระทบทางธุรกิจ ตลาด และการยอมรับจากองค์กร
ภาพรวมกลุ่มลูกค้าเป้าหมาย
แพลตฟอร์ม CodeSBOM มีศักยภาพตอบโจทย์ลูกค้าหลัก 3 กลุ่ม ได้แก่ องค์กรไอทีขนาดใหญ่และหน่วยงานภาครัฐ ที่ต้องบริหารความเสี่ยงเชิงซัพพลายเชน, ผู้ผลิตอุปกรณ์ (OEM) ที่ต้องการการรับรองความถูกต้องของซอฟต์แวร์บนฮาร์ดแวร์เชิงพาณิชย์ และ ผู้ให้บริการซอฟต์แวร์และผู้พัฒนา (ISV/DevOps) ที่ต้องการอัตโนมัติในการสร้าง SBOM และยืนยันไดเร็กทอรีไบนารี/โค้ดที่ถูกใช้งานจริง การใช้งานของลูกค้าแต่ละกลุ่มมีลักษณะต่างกัน เช่น องค์กรขนาดใหญ่สนใจความสามารถเชิงกฎหมาย การตรวจสอบย้อนกลับ และการผสานกับกระบวนการ GRC ขณะที่ OEM ต้องการการรองรับแบบ on-premise และการพิสูจน์ความสมบูรณ์ของเฟิร์มแวร์
โมเดลธุรกิจที่เป็นไปได้
CodeSBOM สามารถนำเสนอโมเดลรายได้แบบผสมที่สอดคล้องกับความต้องการตลาด ดังนี้
- SaaS Subscription — การสมัครเป็นรายปี/รายเดือน สำหรับการสแกนต่อเนื่อง, การจัดเก็บ SBOM ในคลาวด์, การอัปเดตฐานข้อมูลความเสี่ยง และแดชบอร์ดการปฏิบัติตามข้อกำหนด
- On‑premise / Private Cloud — ไลเซนส์สำหรับองค์กรที่มีข้อจำกัดด้านความปลอดภัยหรือข้อกำหนดทางกฎหมาย เช่น ภาครัฐและสถาบันการเงิน
- Hybrid — การผสมผสานระหว่าง SaaS และ on‑premise สำหรับลูกค้าที่ต้องการการประมวลผลภายในแต่ใช้บริการคลาวด์ในบางส่วน
- Per‑scan / Consumption Pricing — เหมาะกับลูกค้าที่มีสแกนครั้งคราวหรือโครงการเฉพาะ โดยคิดค่าบริการตามจำนวนไฟล์/ไบนารีหรือขนาดซอร์สโค้ด
- Professional Services และ Integration — รายได้จากการติดตั้ง, การฝึกอบรม, การปรับแต่งการผสานกับ CI/CD และการทำ penetration testing ที่เกี่ยวข้อง
การประมาณขนาดตลาดและแนวโน้มการยอมรับ
ตลาดความปลอดภัยซอฟต์แวร์และการป้องกันซัพพลายเชนคาดว่าจะเติบโตอย่างต่อเนื่อง โดยรายงานหลายแหล่งประมาณการว่าตลาด SCA (Software Composition Analysis) และซอฟต์แวร์สำหรับความปลอดภัยซัพพลายเชนอาจมีมูลค่าหลายพันล้านดอลลาร์ในช่วงปลายทศวรรษนี้ และเติบโตด้วย CAGR ประมาณ 10–15% ต่อปี นอกจากนี้ หลังคำสั่งและแนวทางเชิงนโยบายในหลายประเทศ (เช่น การผลักดัน SBOM ในการจัดซื้อภาครัฐของสหรัฐฯ และยุโรป) ทำให้องค์กรระดับองค์กรโดยรวมให้ความสนใจใน SBOM มากขึ้น: องค์กรจำนวนมากกว่า 50% ในกลุ่มผู้ใช้ระดับองค์กรมีแผนหรือโครงการที่เกี่ยวข้องกับ SBOM ภายใน 2–3 ปีข้างหน้า ซึ่งเปิดโอกาสสำหรับโซลูชันอัตโนมัติอย่าง CodeSBOM
การเปรียบเทียบกับคู่แข่งทั้งในและต่างประเทศ
การแข่งขันประกอบด้วยผู้เล่นระดับโลก เช่น Snyk, Sonatype, Synopsys/Black Duck และโซลูชันโอเพนซอร์สอย่าง Syft/SPDX ซึ่งมีจุดแข็งด้านฐานข้อมูลภัยคุกคามขนาดใหญ่และการยอมรับในตลาดสากล อย่างไรก็ดี CodeSBOM สามารถสร้างความแตกต่างได้จากการผสาน LLM กับ Static และ Binary Analysis เพื่อเพิ่มความแม่นยำในการจับคอมโพเนนต์ที่ซับซ้อนและลด false positives นอกจากนี้ยังมีข้อได้เปรียบเชิงภูมิภาคเมื่อเปรียบเทียบกับผู้ให้บริการต่างประเทศ ดังนี้:
- ความเข้าใจบริบทด้านกฎหมายและมาตรฐานท้องถิ่น รวมถึงการรองรับภาษา/เอกสารในระดับภูมิภาค
- ต้นทุนการให้บริการที่อาจแข่งขันได้เมื่อเทียบกับผู้ให้บริการสหรัฐฯ/ยุโรป
- ความยืดหยุ่นในการเสนอโมเดล on‑premise สำหรับลูกค้าที่มีข้อกำหนดด้านความลับสูง
โอกาสส่งออกเทคโนโลยีและการสร้างความเชื่อมั่นสาธารณะ
การส่งออก CodeSBOM ไปยังตลาดภูมิภาคอาเซียนและตลาดเกิดใหม่มีโอกาสสูงเนื่องจากหลายประเทศกำลังเพิ่มความเข้มงวดด้านซัพพลายเชนซอฟต์แวร์และยังมีช่องว่างด้านท้องถิ่นสำหรับบริการที่ปรับให้เข้ากับภาษาหรือกรอบกฎหมายเฉพาะประเทศ นโยบายการส่งเสริมจากภาครัฐไทย (เช่น โครงการสนับสนุนสตาร์ทอัพและดิจิทัลทรานส์ฟอร์มเมชัน) จะช่วยลดอุปสรรคการเข้าสู่ตลาดต่างประเทศได้ การสร้างความเชื่อมั่นสาธารณะสำคัญมาก — CodeSBOM ควรลงทุนในมาตรฐานและการรับรอง (เช่น การตรวจรับรองมาตรฐาน SBOM, ผลการตรวจสอบอิสระ, การเปิดเผยกระบวนการทำงาน) เพื่อให้ผู้ซื้อระดับองค์กรมั่นใจ นอกจากนี้การสร้างพันธมิตรกับผู้ให้บริการระบบคลาวด์ ผู้ให้บริการความปลอดภัย และหน่วยงานภาครัฐ จะเร่งการยอมรับและขยายฐานลูกค้าได้รวดเร็วขึ้น
สรุปเชิงธุรกิจ
โดยสรุป CodeSBOM อยู่ในตำแหน่งที่ดีที่จะตอบโจทย์ความต้องการที่เพิ่มขึ้นของตลาดทั้งในประเทศและภูมิภาค หากสามารถนำเสนอโมเดลรายได้ที่ยืดหยุ่น, ข้อได้เปรียบด้านเทคนิคที่ชัดเจนจากการผสาน LLM กับการวิเคราะห์ไบนารี, และแผนการรับรองความน่าเชื่อถือระดับสากล ก็มีโอกาสสูงในการขยายธุรกิจ ทั้งในแง่การรักษาฐานลูกค้าองค์กรขนาดใหญ่และการส่งออกเทคโนโลยีไปยังตลาดเพื่อนบ้าน
ข้อจำกัด ความท้าทาย และแผนพัฒนาต่อไป
ข้อจำกัด ความท้าทาย และแผนพัฒนาต่อไป
แม้แพลตฟอร์ม CodeSBOM จะผสานความสามารถของ Large Language Models (LLMs) ร่วมกับเทคนิค Static และ Binary Analysis เพื่อสร้างและยืนยัน SBOM อัตโนมัติ แต่ก็ยังมีข้อจำกัดเชิงเทคนิคที่ต้องยอมรับและจัดการอย่างเป็นระบบ ประการแรก LLMs มีแนวโน้มที่จะเกิด hallucination หรือการสรุปข้อมูลผิดพลาด โดยเฉพาะเมื่อนำมาใช้ตีความข้อมูลซอฟต์แวร์ที่มีรูปแบบเฉพาะ เช่น ข้อความในเอกสารประกอบซอร์สโค้ด หรือ metadata ของไลบรารี งานวิจัยและการประเมินภาคสนามชี้ว่าอัตราความผิดพลาดของการอนุมานเชิงความหมายอาจแปรผันอย่างมาก ขึ้นกับการเทรนและโดเมนข้อมูล ซึ่งส่งผลให้เกิด false positives (ระบุ component ที่ไม่มีจริง) หรือ false negatives (พลาดการระบุ component สำคัญ) ซึ่งมีผลต่อความน่าเชื่อถือของ SBOM ในการบริหารความเสี่ยงของซัพพลายเชนซอฟต์แวร์
ประการที่สอง การวิเคราะห์ไบนารีมีความท้าทายเมื่อเผชิญกับเทคนิคการออฟฟัสเคชัน (obfuscation) และการป้องกันเช่น packers, runtime encryption, anti-debug/anti-tamper หรือการโหลดโค้ดแบบ dynamic ที่ทำให้สัญญาณเชิงสถาปัตยกรรมและลายนิ้วมือของ component ถูกเบลอหรือถูกทำให้เปลี่ยนแปลง ตัวอย่างเช่น ไลบรารีที่ถูกบรรจุด้วย UPX หรือใช้การเข้ารหัสส่วนหนึ่ง จะทำให้การจับสัญญาณเวอร์ชันและการแมปไปยังแหล่งที่มาถูกบั่นทอน ส่งผลให้เกิดการอนุมานผิดพลาดเมื่อนำ LLM มาช่วยตีความผลวิเคราะห์แบบ static เท่านั้น ซึ่งเป็นเหตุผลที่ระบบต้องอาศัยข้อมูลเชิงไดนามิกและ heuristics เดิมร่วมด้วย
นอกจากนี้ ความท้าทายด้านความเป็นส่วนตัวและกฎหมายเป็นปัจจัยสำคัญที่ไม่อาจมองข้าม การสแกนโค้ดหรือไบนารีของลูกค้าอาจสัมผัสข้อมูลอ่อนไหว เช่น คีย์ลับ ข้อมูลรับรอง (credentials) หรือโค้ดกรรมสิทธิ์ ซึ่งเกี่ยวข้องกับข้อกำหนดด้านกฎหมายเช่น PDPA ของไทย, GDPR ในยุโรป และข้อจำกัดการส่งออกเทคโนโลยี ทีมพัฒนา CodeSBOM ต้องออกแบบการจัดการข้อมูลด้วยนโยบายการเข้าถึงแบบละเอียด (RBAC), การเข้ารหัสทั้งขณะส่งและจัดเก็บ, การเก็บบันทึกการเข้าถึง (audit logs) และตัวเลือกการปรับใช้แบบ on-premises/air-gapped เพื่อให้ลูกค้าควบคุมข้อมูลได้ นอกจากนี้ยังต้องจัดเตรียมข้อตกลงด้านสัญญา (SLA/NDA) และกระบวนการลบข้อมูลตามข้อกำหนดทางกฎหมาย
เพื่อรับมือกับข้อจำกัดเหล่านี้ ทีม CodeSBOM วางแผนพัฒนาระยะสั้น กลาง และยาว ดังนี้:
- ระยะสั้น (0–6 เดือน)
- ปรับปรุงกระบวนการทำงานแบบไฮบริด โดยรวมผลจาก Static Analysis, Binary Heuristics และ LLM ensemble เพื่อลดอัตรา false inference เบื้องต้น
- พัฒนาเครื่องมือวิเคราะห์ pre-processing สำหรับไบนารีที่ถูกบรรจุ (unpackers) และ signature-based detection ของ packers/obfuscators เพื่อลดการเบลอข้อมูล
- ระยะกลาง (6–18 เดือน)
- เพิ่มโมดูลตรวจจับมัลแวร์และพฤติกรรมอันตรายที่ใช้ร่วมกับผล SBOM โดยผสานผลจาก sandboxing และการวิเคราะห์ไดนามิกเพื่อลด false negatives
- พัฒนาการยืนยัน provenance ด้วยเทคนิคเชิงเข้ารหัส (เช่น การเซ็นดิจิทัลของแหล่งที่มา, การรวมกับโครงการอย่าง sigstore และ in-toto) เพื่อติดตามแหล่งที่มาของ component
- ขยายไลบรารีของแพลตฟอร์มให้รองรับแพ็กเกจเมเนเจอร์หลายภาษา (npm, PyPI, Maven, NuGet) และสถาปัตยกรรมไบนารีเพิ่มเติม เพื่อเพิ่ม coverage ของการแมป component
- วางมาตรวัดเชิง KPI เช่น เป้าหมายลดอัตรา false positives/negatives และเพิ่ม precision/recall ของการแมป component ที่ชัดเจน (ตัวอย่างเช่นตั้งเป้าปรับปรุงความแม่นยำรวมขึ้นอย่างน้อยระดับหลักสิบเปอร์เซ็นต์เมื่อเทียบกับ baseline)
- ระยะยาว (18 เดือนขึ้นไป)
- พัฒนาโซลูชันเชิง provenance ขั้นสูงรวมถึงการสนับสนุน reproducible builds และการสร้างแถวประวัติที่ตรวจสอบได้ตั้งแต่ซอร์สโค้ดถึงไบนารี เพื่อให้ SBOM เป็นแหล่งความจริง (single source of truth)
- นำวิธีการเรียนรู้แบบกระจาย (federated learning) และเทคนิค differential privacy มาใช้เพื่อปรับปรุงโมเดลโดยไม่ต้องส่งข้อมูลลูกค้ากลับสู่คลาวด์ ลดความเสี่ยงด้านข้อมูลอ่อนไหว
- ผสานการตรวจสอบเชิงนโยบายอัตโนมัติ (policy-as-code) และการเชื่อมต่อกับระบบจัดการเหตุการณ์ด้านความปลอดภัย (SIEM/SOAR) เพื่อให้การตอบสนองต่อความเสี่ยงของซัพพลายเชนเป็นไปอย่างต่อเนื่องและอัตโนมัติ
- ร่วมมือกับหน่วยงานมาตรฐานและชุมชนโอเพนซอร์สเพื่อผลักดันการยอมรับมาตรฐาน SBOM ที่เข้มแข็งและ interoperable ในระดับสากล
โดยสรุป แม้จะมีข้อจำกัดทั้งจากด้านโมเดลภาษาขนาดใหญ่ การออฟฟัสเคชันของไบนารี และประเด็นความเป็นส่วนตัวและกฎหมาย ทีมพัฒนา CodeSBOM วางแผนใช้แนวทางผสมผสานระหว่างเทคนิคต่าง ๆ ทั้งการปรับปรุงโมเดล การเสริมการวิเคราะห์เชิงไดนามิก การใช้มาตรการคุ้มครองข้อมูล และการยืนยันที่มาด้วยคริปโตกราฟี เพื่อยกระดับความแม่นยำและความเชื่อถือได้ของ SBOM ในการลดความเสี่ยงของซัพพลายเชนซอฟต์แวร์สำหรับองค์กรทั้งในระดับท้องถิ่นและสากล
บทสรุป
CodeSBOM เป็นตัวอย่างที่ชัดเจนของการประยุกต์ใช้ปัญญาประดิษฐ์โดยเฉพาะ LLM ร่วมกับการวิเคราะห์ซอฟต์แวร์เชิงสถิติกับไบนารี (static/binary analysis) เพื่อแก้ปัญหาจริงในซัพพลายเชนซอฟต์แวร์ แพลตฟอร์มนี้ช่วยเร่งกระบวนการสร้างและยืนยัน Software Bill of Materials (SBOM) ให้สอดคล้องกับมาตรฐานที่เป็นที่ยอมรับ เช่น SPDX และ CycloneDX โดยอัตโนมัติ ประกอบกับการจับคู่องค์ประกอบจากโค้ด ไบนารี และเมตาดาต้า ทำให้สามารถค้นหาการพึ่งพาเครือข่ายที่ซ่อนอยู่ ลดเวลาการตรวจสอบด้วยมือ และลดข้อผิดพลาดจากการจัดทำ SBOM แบบแมนนวล องค์กรที่นำแนวทางแบบอัตโนมัติเช่นนี้ไปใช้งานมักรายงานผลเป็นการลดเวลาตรวจสอบและความไม่สอดคล้องของข้อมูลอย่างมีนัยสำคัญ ซึ่งนำไปสู่การ ลดความเสี่ยงของซัพพลายเชน และเพิ่มความน่าเชื่อถือของซอฟต์แวร์ในภาพรวม
แม้จะมีข้อดีชัดเจน แต่การใช้งานยังเผชิญข้อจำกัดทางเทคนิคและความท้าทายด้านความเป็นส่วนตัว เช่น ความเสี่ยงจากการทำงานของ LLM ที่อาจสร้างคำตอบคลาดเคลื่อน (hallucination), ขีดจำกัดการวิเคราะห์ไบนารีเมื่อมีการออฟัสเคตหรือไม่มีสัญลักษณ์, และความเสี่ยงด้านข้อมูลเมตาที่อาจรั่วไหลหากส่งข้อมูลไปยังบริการคลาวด์ ภายใต้กรอบการจัดการที่เข้มงวด เช่น การรันโมเดลในสภาพแวดล้อมภายในองค์กร (on‑prem), การใช้แนวทางไฮบริดในการวิเคราะห์, การผนวกการตรวจสอบใน CI/CD, การเซ็นรับรองทางคริปโต และนโยบายการเข้าถึงข้อมูลที่ชัดเจน แพลตฟอร์มอย่าง CodeSBOM สามารถลดความเสี่ยงได้อย่างมีนัยสำคัญและเป็นเครื่องมือสำคัญในการยกระดับความโปร่งใสของซัพพลายเชนซอฟต์แวร์ แนวโน้มในอนาคตคือการผนวกเทคโนโลยีเหล่านี้เข้ากับมาตรฐานการปฏิบัติงานและกฎระเบียบมากขึ้น ส่งผลให้องค์กรที่บริหารจัดการอย่างรัดกุมมีความได้เปรียบทั้งด้านความมั่นคงและความน่าเชื่อถือของผลิตภัณฑ์ดิจิทัล



