
การทดสอบจริงของธนาคารไทยรายหนึ่งที่นำเทคโนโลยี Graph Neural Network (GNN) มาสแกนเครือข่ายธุรกรรม เปิดผลลัพธ์ที่น่าสนใจว่าเทคโนโลยีเชิงกราฟสามารถลดอัตรา False‑Positive ได้ถึง 70% เมื่อเทียบกับระบบตรวจจับแบบกฎเกณฑ์หรือโมเดลเชิงสถิติแบบดั้งเดิม ผลลัพธ์นี้ไม่เพียงลดปริมาณสัญญาณเตือนที่ผิดพลาดเท่านั้น แต่ยังช่วยลดภาระการสืบสวนของทีมปฏิบัติการ ปรับปรุงความแม่นยำในการระบุพฤติกรรมฟอกเงินเชิงสัมพันธ์ และสนับสนุนการปฏิบัติตามกฎระเบียบอย่างมีประสิทธิภาพยิ่งขึ้น
ความแตกต่างสำคัญของ GNN คือการวิเคราะห์ความสัมพันธ์เชิงโครงข่ายระหว่างบัญชีและการทำธุรกรรม ทำให้สามารถจับกลุ่ม (cluster) ของการโอนเงินที่มีรูปแบบซับซ้อน เช่น การใช้บัญชีตัวกลางหลายทอด หรือการกระจายเงินเป็นวงจร ที่ระบบเดิมอาจมองว่าเป็นเหตุการณ์แยกชิ้น การลด False‑Positive ถึง 70% ในการทดสอบจริงจึงหมายความว่าเวลาทำงานและต้นทุนในการตรวจสอบจะลดลงอย่างมีนัยสำคัญ ขณะเดียวกันจะช่วยให้ธนาคารโฟกัสทรัพยากรไปยังเหตุการณ์ความเสี่ยงสูงได้มากขึ้น บทความนี้จะพาไปสำรวจรายละเอียดของการทดสอบ วิธีการทำงานของ GNN และผลกระทบเชิงปฏิบัติการต่อการต่อต้านการฟอกเงินในระบบธนาคารไทย
สรุปข่าวเด่น
สรุปข่าวเด่น
ธนาคารพาณิชย์รายใหญ่ในประเทศไทย (ไม่เปิดเผยชื่อ) ได้ทดสอบการนำเทคโนโลยี Graph Neural Network (GNN) มาประยุกต์ใช้กับข้อมูลธุรกรรมจริงเพื่อสแกนและวิเคราะห์เครือข่ายความสัมพันธ์เชิงการเงินในเชิงลึก ผลการทดลองในสภาพแวดล้อมการทำงานจริงแสดงให้เห็นว่าระบบ GNN สามารถลดอัตรา False‑Positive ของการแจ้งเตือนการฟอกเงินได้ถึง 70% เมื่อเทียบกับกฎการตรวจจับแบบดั้งเดิมที่ใช้หลักการตรวจจับรายการผิดปกติรายบุคคลเพียงอย่างเดียว

การทดสอบดำเนินการบนชุดข้อมูลธุรกรรมหลายล้านรายการที่ครอบคลุมการเคลื่อนไหวของบัญชีและความสัมพันธ์ระหว่างผู้เกี่ยวข้อง โดยใช้โมเดล GNN ในการเรียนรู้โครงสร้างเครือข่ายและรูปแบบการเชื่อมโยงที่บ่งชี้ความเสี่ยง ผลลัพธ์เบื้องต้นจากทีมปฏิบัติตามกฎหมายของธนาคารระบุว่า การลด False‑Positive ดังกล่าวส่งผลโดยตรงต่อประสิทธิภาพการปฏิบัติงาน ดังนี้:
- ลดเวลาสืบสวน — รายงานภายในชี้ว่าเวลาการตรวจสอบและสืบสวนเฉลี่ยของกรณีที่ส่งต่อให้ทีมลดลงอย่างมีนัยสำคัญ (ตัวอย่างเช่น ประมาณ 30–50% ขึ้นอยู่กับประเภทเคสและระดับการปรับแต่งโมเดล)
- เพิ่มความแม่นยำของการแจ้งเตือน AML — อัตราการแจ้งเตือนที่สอดคล้องกับความเสี่ยงจริงเพิ่มขึ้น ทำให้ทีมสามารถโฟกัสทรัพยากรไปยังเคสที่มีความสำคัญสูงได้มากขึ้น
- ปรับปรุงกระบวนการคัดกรองเชิงสัมพันธ์ — GNN ช่วยเปิดเผยกลุ่มบัญชีที่มีรูปแบบเชื่อมโยงซับซ้อน เช่น เครือข่ายการโอนแบบหมุนเวียนหรือบัญชีที่ทำหน้าที่เป็น "สะพาน" ระหว่างกลุ่ม ซึ่งกฎแบบเดิมมักตรวจไม่พบ
ผลกระทบต่อการปฏิบัติงานของทีมปฏิบัติตามกฎหมายจึงค่อนข้างชัดเจน — นอกจากจะลดงานตรวจสอบที่ไม่จำเป็นลง ยังช่วยเพิ่มประสิทธิภาพในการจัดลำดับความสำคัญของเคสและการใช้ทรัพยากรบุคคล รวมถึงลดความเสี่ยงจากการพลาดการแจ้งเคสที่มีความเสี่ยงจริง เนื่องจากโมเดลเน้นวิเคราะห์บริบทเชิงเครือข่ายมากกว่าการมองเพียงรายการเดี่ยว
ภูมิหลัง: ปัญหา False‑Positive ในระบบ AML แบบเดิม
ภูมิหลัง: ปัญหา False‑Positive ในระบบ AML แบบเดิม
ระบบตรวจจับการฟอกเงิน (Anti‑Money Laundering, AML) แบบดั้งเดิมของธนาคารไทยและสถาบันการเงินทั่วโลกส่วนใหญ่ยังอาศัยหลักการ rule‑based เป็นหลัก โดยตั้งกฎเตือนจากเงื่อนไขเช่น ขีดจำกัดยอดโอน (thresholds), ความถี่การทำรายการ (velocity rules), การจับคู่กับรายชื่อใน watchlist และรูปแบบธุรกรรมที่มีความเสี่ยงตามที่กำหนดไว้ล่วงหน้า วิธีการเหล่านี้สามารถจับพฤติกรรมที่ชัดเจนว่าเบี่ยงเบนจากค่าเฉลี่ยได้ แต่มีข้อจำกัดเมื่อเผชิญกับเครือข่ายธุรกรรมที่มีความสัมพันธ์ซับซ้อนหรือเมื่อต้องพิจารณาบริบทเชิงสัมพันธ์ของผู้ทำธุรกรรมหลายบัญชีพร้อมกัน
ตามรายงานอุตสาหกรรมหลายฉบับ อัตราการแจ้งเตือนที่เป็น false‑positive ในระบบ rule‑based มักอยู่ในช่วงกว้าง — โดยทั่วไปรายงานชี้ให้เห็นว่า % ของการแจ้งเตือนทั้งหมดที่กลายเป็น false‑positive อาจสูงถึงระหว่าง 70% ถึง 95% ขึ้นกับขอบเขตของกฎและความละเอียดของการตั้งค่าของสถาบัน การแจ้งเตือนจำนวนมากที่ไม่ใช่กรณีฉาวโฉ่นี้สร้างภาระด้านการปฏิบัติงานอย่างหนัก: ทีมสืบสวนต้องใช้เวลาตรวจสอบเอกสาร ติดตามแหล่งที่มาของเงิน และทำการยืนยันเพิ่มเติม ซึ่งส่งผลให้ต้นทุนการปฏิบัติตามกฎ (compliance cost) เพิ่มสูง ทั้งในด้านเวลาและทรัพยากรบุคคล รวมถึงหน่วงเวลาในการให้บริการลูกค้า
ผลกระทบจาก false‑positive มีหลายมิติ ตั้งแต่ค่าใช้จ่ายที่เพิ่มขึ้น เช่น ชั่วโมงงานของนักสืบสวนที่เพิ่มขึ้น การต้องจัดตั้งทีมเฉพาะทาง และระบบ workflow ที่ซับซ้อน ไปจนถึงความเสี่ยงด้านประสบการณ์ลูกค้าที่แย่ลงเมื่อบัญชีถูกระงับหรือธุรกรรมถูกกีดกันโดยไม่จำเป็น นอกจากนี้ false‑positive ยังอาจทำให้สถาบันพลาดสัญญาณเตือนจริง (false‑negative) เนื่องจากทรัพยากรถูกผูกไว้กับการตอบสนองต่อแจ้งเตือนที่ไม่มีนัยสำคัญ
ความท้าทายยิ่งซับซ้อนเมื่อขยายการวิเคราะห์ไปสู่เครือข่ายธุรกรรมข้ามบัญชีและข้ามประเทศ ปัจจัยที่เพิ่มความยุ่งยากได้แก่
- ข้อมูลกระจัดกระจายและรูปแบบข้อมูลต่างกัน: ธนาคารแต่ละแห่งและแต่ละเขตอำนาจศาลมีมาตรฐานการเก็บข้อมูลและฟิลด์ข้อมูลที่แตกต่างกัน ทำให้การรวมข้อมูลเพื่อวิเคราะห์เครือข่ายเป็นไปได้ยาก
- การเชื่อมโยงบัญชีแบบซับซ้อน (aliasing & layering): ผู้กระทำความผิดมักใช้บัญชีหลายบัญชีและตัวกลาง (correspondent banks, remitters) เพื่อซ่อนต้นตอของเงิน ทำให้กฎแบบเดิมมองไม่เห็นความสัมพันธ์เชิงสาเหตุ
- กฎกติกาทางกฎหมายและการแบ่งปันข้อมูลข้ามพรมแดน: ข้อจำกัดด้านความเป็นส่วนตัวและกฎหมายแต่ละประเทศจำกัดการเข้าถึงข้อมูลเชิงลึก ทำให้การติดตามเส้นทางเงินข้ามประเทศทำได้ช้าและไม่สมบูรณ์
- ความผันผวนของสกุลเงินและช่องทางทางการเงินใหม่ๆ: การเปลี่ยนแปลงค่าเงิน การใช้บริการดิจิทัลหรือผู้ให้บริการทางการเงินนอกระบบ ทำให้รูปแบบการฟอกเงินเปลี่ยนรวดเร็วเกินกว่าการปรับกฎแบบแมนนวล
ผลรวมของปัจจัยเหล่านี้ทำให้สถาบันการเงินต้องเผชิญกับสภาพแวดล้อมที่เต็มไปด้วยการแจ้งเตือนเกินจริง ซึ่งส่งผลทั้งต่อประสิทธิภาพการปฏิบัติงาน ต้นทุนการปฏิบัติตามกฎหมาย และความสามารถในการตรวจจับกรณีฟอกเงินที่แท้จริง จึงเกิดความต้องการแนวทางใหม่ๆ ที่สามารถวิเคราะห์บริบทเชิงสัมพันธ์ของเครือข่ายธุรกรรมได้ดีกว่าระบบ rule‑based แบบเดิม
หลักการทำงานของ Graph Neural Network ในการสแกนเครือข่ายธุรกรรม
หลักการทำงานของ Graph Neural Network ในการสแกนเครือข่ายธุรกรรม
การนำ Graph Neural Network (GNN) มาใช้สแกนเครือข่ายธุรกรรมเริ่มจากการแปลงข้อมูลเชิงธุรกรรมให้เป็นรูปแบบกราฟเชิงสัมพันธ์ โดยบัญชีผู้ใช้หรือหน่วยงานต่าง ๆ จะถูกแทนเป็น node และการโอนเงินหรือการทำธุรกรรมระหว่างบัญชีจะถูกแทนเป็น edge ซึ่ง edge เหล่านี้สามารถมีทิศทาง (direction), ค่าน้ำหนัก (เช่น ยอดเงิน) และคุณลักษณะเชิงเวลา (timestamp, channel) ได้ กระบวนการนี้ทำให้เครือข่ายความสัมพันธ์ระหว่างบัญชีปรากฏเป็นโครงสร้างที่ GNN สามารถเรียนรู้ได้โดยตรง

หัวใจของ GNN คือกลไกที่เรียกว่า message passing หรือการส่งผ่านข้อความระหว่างโหนดในกราฟ โดยในแต่ละชั้นของโมเดล โหนดแต่ละตัวจะรวบรวมข้อมูลจากเพื่อนบ้าน (neighborhood aggregation) เช่น ยอดรวมของเงินที่รับจากเพื่อนบ้าน ความถี่ของการโอน และคุณลักษณะช่องทางการโอน ข้อมูลที่รวบรวมนี้จะถูกผนวกรวม (aggregate) และผ่านการแปลงเชิงเส้น (linear transformation) ตามด้วย non-linearity เพื่ออัปเดต embedding ของโหนดนั้น ทำซ้ำเป็นชั้น ๆ (มักเป็น 2–3 hop) ทำให้ embedding ที่ได้สะท้อนทั้งคุณลักษณะเฉพาะของบัญชีและบริบทเชิงโครงสร้างของเครือข่าย
ผลลัพธ์คือ embedding เชิงสัมพันธ์ ซึ่งเป็นเวกเตอร์ความยาวคงที่ (ปกติ 64–256 มิติ ขึ้นกับงาน) ที่จับทั้งรูปแบบพฤติกรรมและตำแหน่งเชิงโครงสร้างของโหนดในกราฟ Embedding เหล่านี้สามารถนำไปใช้ในการทำ clustering เพื่อค้นหา “กลุ่มพฤติกรรม” ที่ผิดปกติ เช่น รูปแบบ hub‑and‑spoke, cascade payments หรือวงจรการโอนกลับ (money layering) ซึ่งในกรณีทดสอบจริงของบางธนาคารพบว่าการใช้ GNN ร่วมกับกลไกการจัดลำดับเหตุการณ์ (temporal encoding) ช่วยลดอัตรา False‑Positive ได้สูงถึง 70% เมื่อเทียบกับกฎระบุ (rule‑based) แบบเดิม
มีสถาปัตยกรรม GNN หลายแบบที่นิยมใช้ในงานตรวจจับการฟอกเงิน ได้แก่
- GCN (Graph Convolutional Network) — เหมาะสำหรับการจับสัญญาณเชิงโครงสร้างแบบทั่วถึง โดยใช้การเฉลี่ยน้ำหนักจากเพื่อนบ้าน
- GraphSAGE — ออกแบบมาเพื่อความสามารถในการสเกล โดยใช้การสุ่มตัวอย่างเพื่อนบ้านและฟังก์ชันการรวบรวมที่ยืดหยุ่น (mean, LSTM, pooling)
- GAT (Graph Attention Network) — ใช้กลไก attention เพื่อให้น้ำหนักที่แตกต่างกันกับเพื่อนบ้านแต่ละตัว เหมาะสำหรับกรณีที่ความสำคัญของเพื่อนบ้านไม่เท่ากัน เช่น บัญชีที่เป็นตัวกลางสำคัญ
การเลือกฟีเจอร์ของ node และ edge เป็นปัจจัยสำคัญที่จะทำให้ GNN ตรวจจับพฤติกรรมเสี่ยงได้แม่นยำ โดยตัวอย่างฟีเจอร์ที่มักใช้ได้แก่
- ฟีเจอร์ของ node: อายุบัญชี, ประเภทบัญชี, จำนวนธุรกรรมต่อช่วงเวลา, คะแนนความเสี่ยงจาก Know‑Your‑Customer (KYC)
- ฟีเจอร์ของ edge: ยอดเงิน (amount), เวลาที่ทำธุรกรรม (timestamp), ช่องทางการโอน (online, branch, ATM), ความถี่ของการติดต่อกัน
- ฟีเจอร์เชิงเวลา/เชิงลำดับ: เวกเตอร์แสดงลำดับเหตุการณ์หรือการเข้ารหัสเวลา (positional/temporal encoding) เพื่อจับ pattern ที่เปลี่ยนแปลงตามเวลา
ในแง่การฝึกสอน (training) สามารถใช้หลายแนวทางตามข้อมูลที่มีและเป้าหมายการค้นหา:
- Supervised learning — เมื่อมีป้ายกำกับ (label) เช่น ธุรกรรมที่ตรวจสอบแล้วว่าเป็นฟอกเงินหรือไม่ โมเดลจะเรียนรู้แบบจำแนกคลาสโดยตรง
- Semi‑supervised learning — ใช้ป้ายกำกับบางส่วนควบคู่กับข้อมูลกราฟทั้งหมด เพื่อขยายสัญญาณการเรียนรู้ไปยังโหนดที่ไม่มีป้ายกำกับ
- Contrastive learning (self‑supervised) — สร้าง representation โดยการเรียนรู้ให้คู่ตัวอย่างที่ “ใกล้เคียง” กัน (เช่น โหนดที่มีบริบทคล้ายกัน) อยู่ใกล้ใน space ของ embedding ขณะที่ตัวอย่างที่ต่างกันอยู่ห่าง ซึ่งมีประโยชน์เมื่อข้อมูลป้ายกำกับจำกัด
การใช้งานจริงยังต้องคำนึงถึงประเด็นด้านสเกลและความเป็นไปได้ในการนำไปใช้ เช่น การใช้ GraphSAGE หรือ mini‑batch sampling เพื่อลดการคำนวณเมื่อกราฟมีจำนวนโหนดหลายล้านตัว, การเข้ารหัสเวลาแบบ streaming สำหรับข้อมูลธุรกรรมเรียลไทม์, และการรวมระบบ explainability เพื่อให้แอนาลิสต์สามารถตรวจสอบว่าทำไมโมเดลจึงยกธงเตือน (เช่น เน้น edge ใดหรือ neighborhood แบบไหน) ซึ่งช่วยให้การนำ GNN ไปใช้ในสายงาน Compliance และ Fraud Investigation มีความน่าเชื่อถือและลด False‑Positive ได้อย่างเป็นรูปธรรม
การออกแบบทดสอบจริงของธนาคาร: ข้อมูลและการผสานระบบ
ขอบเขตการทดสอบและรายละเอียดของชุดข้อมูล (Dataset)
การทดสอบเชิงปฏิบัติการของธนาคารถูกออกแบบให้สะท้อนสภาพแวดล้อมการปฏิบัติงานจริง โดยใช้ชุดข้อมูลการทำธุรกรรมระยะเวลา 12 เดือน (มกราคม–ธันวาคม 2024) ประกอบด้วยประมาณ 28 ล้านรายการธุรกรรม ที่เกี่ยวข้องกับผู้ใช้งานและนิติบุคคลราว 4.1 ล้านหน่วยงาน ระบบได้สร้างกราฟความสัมพันธ์โดยมีเส้นเชื่อม (edges) ประมาณ 14 ล้านเส้น เพื่อแทนการเคลื่อนย้ายเงินและความสัมพันธ์เชิงธุรกิจ/บุคคลที่เกี่ยวข้อง สำหรับฉลากพื้นฐาน (ground truth) ใช้บันทึกการสืบสวนย้อนหลังประมาณ 18,500 กรณีที่ยืนยันเป็น SARs เพื่อฝึกและประเมินโมเดล
การทดลองถูกตั้งเป็นการทดสอบแบบ A/B: ระบบ Graph Neural Network (GNN) ถูกนำไปรันควบคู่กับระบบกฎเดิม (rules engine) บนปริมาณข้อมูลจริงเป็นเวลา 6 สัปดาห์ในช่วงไตรมาสที่ 4 โดยครอบคลุมธุรกรรมประมาณ 4 ล้านรายการ ซึ่งแบ่งเป็นกลุ่มทดลอง (GNN-assist) และกลุ่มควบคุม (legacy-only) เพื่อวัดผลเชิงปริมาณของการลด False‑Positive และผลกระทบต่อ KPI การสืบสวน
กระบวนการเตรียมข้อมูลและการแก้ปัญหา Entity Resolution
ก่อนการสร้างกราฟ มีการดำเนินกระบวนการเตรียมข้อมูลเชิงลึก ได้แก่:
- การทำความสะอาดข้อมูล (data cleaning): กำจัดรายการซ้ำ กรอกค่าที่หายไป เทียบรูปแบบวันที่และสกุลเงิน รวมทั้งตรวจสอบความสมบูรณ์ของ metadata เช่น หมายเลขบัญชี หมายเลขบัตรประจำตัว และสถานะบัญชี
- การรวมหน่วยข้อมูล (entity resolution): ใช้เทคนิคผสมผสานระหว่างกฎเชิงธุรกิจ (เช่น matching หมายเลขภาษี, ชื่อบริษัท) และโมเดล ML สำหรับ fuzzy matching (เช่น string similarity, embedding ของชื่อ) เพื่อรวมบัญชี/ช่องทางที่แท้จริงเข้ากับตัวแทน (node) เดียว ผลลัพธ์คือการลดความแตกกระจัดกระจายของเอนทิตีและให้กราฟมีความชัดเจนยิ่งขึ้น (~ลดความซ้ำซ้อนของ node ลง 18%)
- การสร้างฟีเจอร์เชิงกราฟและเชิงเวล่า: สร้างฟีเจอร์ระดับโหนดและระดับขอบ เช่น ความถี่การโอนในช่วง 7/30/90 วัน, ปริมาณเฉลี่ยต่อการทำรายการ, ค่า centrality, และคุณลักษณะเชิงบริบท (ธุรกิจ/บุคคล) รวมทั้งใช้ time-windowing เพื่อรักษาลักษณะเชิงเวลา
- การนิรนามและปกป้องข้อมูล: ทำ tokenization/Hashing ของข้อมูล PII และรันกระบวนการในสภาพแวดล้อมที่ได้มาตรฐาน (ISO27001/Local Compliance) เพื่อลดความเสี่ยงทางกฎหมาย
การผสานโมเดลเข้ากับระบบแจ้งเตือนและการสืบสวนจริง
การนำ GNN เข้าสู่ระบบปฏิบัติการจริงถูกออกแบบในลักษณะผสานแบบค่อยเป็นค่อยไป (phased integration) เพื่อรักษาเสถียรภาพของงานปกติ:
- สถาปัตยกรรมการรันคู่ (parallel-run): ในช่วงทดสอบ โมเดลจะรันควบคู่กับ rules engine เดิม โดยผลลัพธ์ของ GNN จะถูกส่งเข้าคิวการแจ้งเตือนและบันทึกในระบบเท่านั้น — ยังไม่แทนที่การแจ้งเตือนอัตโนมัติของระบบเดิม
- การเชื่อมต่อผ่าน API/Event Bus: โมเดลให้คะแนนความเสี่ยงผ่าน API และผลจะส่งเข้าระบบบริหารคดี (case management) พร้อม metadata ของ subgraph ที่เกี่ยวข้อง เพื่อให้ผู้ตรวจสอบเห็นบริบทเชิงความสัมพันธ์ได้ทันที
- การจัดลำดับความสำคัญ (prioritization): หากคะแนนของ GNN สูงเกินเกณฑ์ที่กำหนด ระบบจะรวมคะแนนเข้ากับผลจาก rules engine โดยใช้กลยุทธ์ weighted fusion และจัดคิวให้ผู้สืบสวนก่อนทำการตรวจสอบ
- รันเวลา (latency) และโหมดการประมวลผล: ตั้งค่าให้โมเดลรันเป็นทั้งแบบ batch รายวันสำหรับการวิเคราะห์กราฟขนาดใหญ่ และแบบ near‑real‑time สำหรับธุรกรรมที่ต้องการการตอบสนองทันที โดยรักษาเวลาแฝงต่อการให้คะแนนเฉลี่ยไม่เกิน 8–12 วินาทีในโหมด near‑real‑time
กลไก Human‑in‑the‑loop และการปรับเกณฑ์เพื่อลดความเสี่ยง
เพื่อให้การตัดสินใจมีความน่าเชื่อถือและสามารถควบคุมความเสี่ยงได้ มีการออกแบบกระบวนการ human‑in‑the‑loop ดังนี้:
- การจัดตารางการตรวจสอบและเกณฑ์การคัดกรอง: ทีมสืบสวนได้รับเฉพาะเคสที่ผ่านเกณฑ์ความเสี่ยงแบบผสม (hybrid threshold) — ได้แก่คะแนน GNN สูงสุดระดับบน และ/หรือสอดคล้องกับกฎเดิม โดยระบบอนุญาตให้ปรับ thresholds แบบ dynamic ตามปริมาณงานและ SLA ของทีม
- อินเทอร์เฟซการสืบสวนที่เน้นบริบท: ผู้ตรวจสอบเห็น subgraph ที่แสดงโหนดและเส้นเชื่อมที่ส่งผลต่อคะแนน พร้อมคำอธิบายสั้น (feature importance / attention weights) เพื่อให้สามารถตัดสินใจได้เร็วขึ้นและมีเหตุผลประกอบ
- ฟีดแบ็กย้อนกลับและการเรียนรู้ต่อเนื่อง: การตัดสินใจของมนุษย์ (ยืนยัน/ปฏิเสธ) ถูกบันทึกและนำเป็นฉลากเพื่ออัปเดตโมเดลแบบ cyclical (retraining รายสัปดาห์หรือรายเดือน) และใช้กลยุทธ์ active learning เลือกตัวอย่างที่โมเดลไม่แน่นอนมากที่สุดให้ผู้ตรวจสอบช่วยติดป้าย
- การกำกับดูแลความเสี่ยง: ระดับการยอมรับความเสี่ยงและนโยบายการแจ้งหน่วยงานภายนอกถูกตั้งเป็นกฎเพิ่มเติมในการผสานผล ทำให้การตัดสินใจเชิงอัตโนมัติจะต้องผ่านการอนุมัติเมื่อคะแนนสูงแต่บริบทมีความซับซ้อน
การประเมินผล (KPIs) และผลลัพธ์เชิงตัวเลข
การประเมินประสิทธิภาพใช้ KPI หลัก ได้แก่ False‑Positive Rate, Precision, Recall และ เวลาเฉลี่ยต่อการสืบสวน โดยนิยามและวิธีวัดเป็นไปตามมาตรฐานปฏิบัติการ:
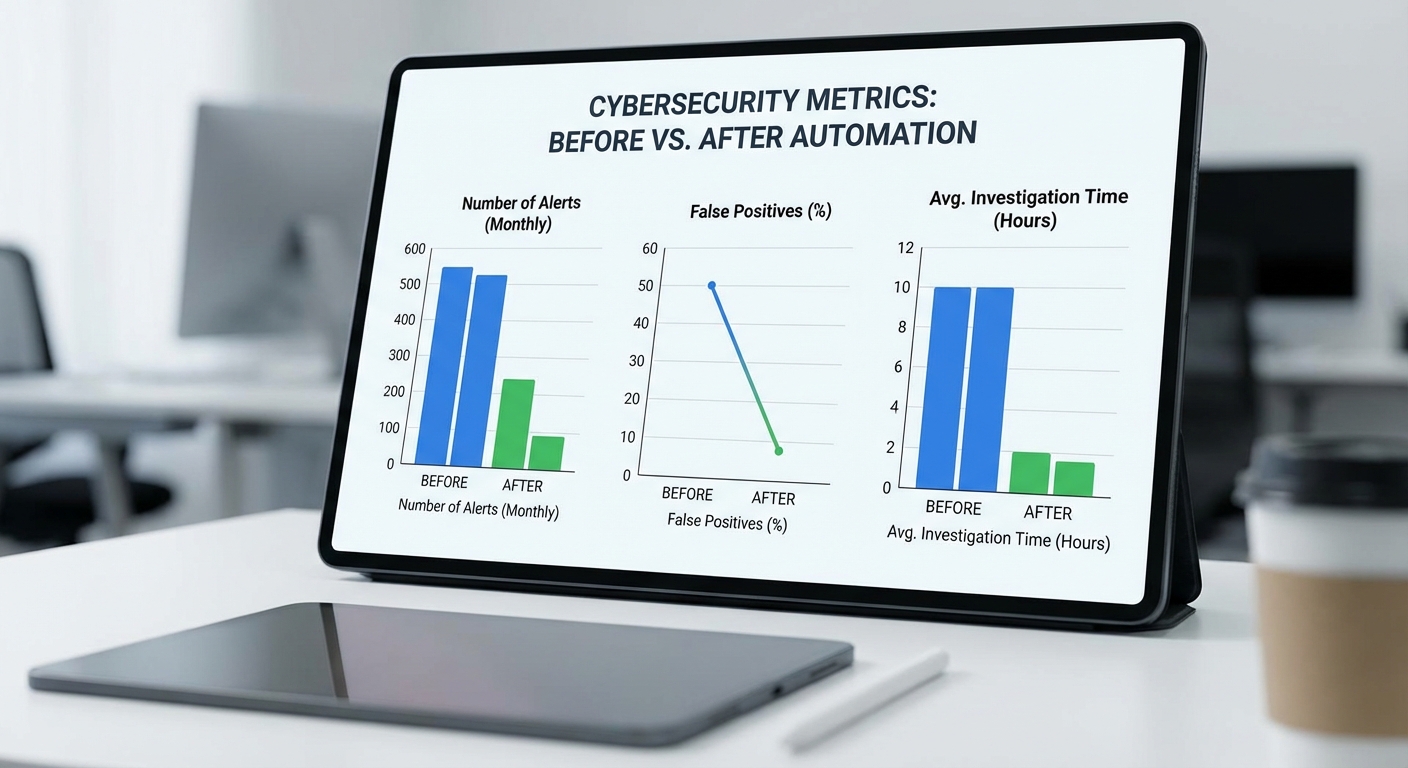
- False‑Positive Rate (FPR): สัดส่วนการแจ้งเตือนที่ถูกปฏิเสธโดยผู้ตรวจสอบต่อจำนวนการแจ้งเตือนทั้งหมด ในการทดสอบ A/B ระยะ 6 สัปดาห์ พบว่า FPR ลดลงประมาณ 70% เมื่อเทียบกับระบบเดิม (จากอัตรา FPR ประมาณ 24% เหลือ ~7.2%)
- Precision: อัตราส่วนของการแจ้งเตือนที่ถูกยืนยันว่าเป็น SARs ต่อการแจ้งเตือนทั้งหมด — เพิ่มจาก ~38% ในระบบเดิมเป็น ~72% ในระบบที่มี GNN ช่วยสนับสนุน
- Recall: อัตราการจับการทุจริตที่แท้จริง ระบบ GNN ถูกตั้งให้รักษา recall ไว้ที่ระดับสูง (ประมาณ 82–88%) เพื่อหลีกเลี่ยงการลดการตรวจจับที่สำคัญ แม้ว่าจะมีการลด FP อย่างมาก
- เวลาเฉลี่ยต่อการสืบสวน: เวลาที่ทีมใช้ในการประเมินเคสจากการแจ้งเตือนจนสรุปผล — ลดลงจากเฉลี่ย ~5.2 ชั่วโมงต่อเคส เหลือ ~2.1 ชั่วโมงต่อเคส (ลดลง ~60%) เนื่องจากการจัดลำดับความสำคัญที่ดีขึ้นและอินเทอร์เฟซที่ให้บริบทเชิงกราฟ
การวัดผลดำเนินการทั้งในเชิงปริมาณ (ตัวเลข A/B) และเชิงคุณภาพ (survey ความพึงพอใจของทีมสืบสวน) — ทีมรายงานว่าจำนวนเคสที่ต้องใช้การสอบสวนเชิงลึกลดลง จึงสามารถโฟกัสกับกรณีที่มีความเสี่ยงจริงได้มากขึ้น นอกจากนี้ การเก็บฟีดแบ็กจากผู้ใช้ช่วยให้การปรับเกณฑ์ (threshold tuning) เป็นไปอย่างมีหลักการและลดโอกาสเกิด bias จากโมเดล
ผลลัพธ์เชิงปริมาณและกรณีตัวอย่าง
ผลลัพธ์เชิงปริมาณ
จากการทดสอบจริงในสภาพแวดล้อมของธนาคารไทยรายใหญ่ พบว่าโมเดล Graph Neural Network (GNN) สามารถลดอัตรา False‑Positive ได้ถึง 70% เมื่อเทียบกับระบบ rule‑based เดิม ซึ่งสอดคล้องกับการลดปริมาณแจ้งเตือนที่ต้องตรวจสอบด้วยมืออย่างมีนัยสำคัญ ตัวอย่างในการทดสอบภายในแสดงให้เห็นว่าแจ้งเตือนที่ทีมสืบสวนต้องประเมินลดลงจากประมาณ 1,200 รายการต่อสัปดาห์ เหลือประมาณ 360 รายการต่อสัปดาห์ หลังนำ GNN มาใช้งาน

ผลเชิงประสิทธิภาพเพิ่มเติมที่สังเกตได้ ได้แก่ Precision เพิ่มขึ้นอย่างมีนัยสำคัญ เนื่องจากระบบสามารถจัดลำดับความเสี่ยงของเครือข่ายธุรกรรมได้ละเอียดขึ้น ตัวอย่างการทดสอบภายในระบุว่า precision ขยับขึ้นประมาณ 2–3 เท่าเมื่อเทียบกับค่าเดิม ขณะที่ Recall ถูกรักษาไว้ในระดับใกล้เคียงหรือเพิ่มขึ้นเล็กน้อย (ขึ้นกับการปรับ threshold ของโมเดล) ซึ่งหมายความว่า GNN ลดการแจ้งเตือนปลอมโดยไม่ลดความสามารถในการจับพฤติกรรมต้องสงสัยจริง ๆ
ในมิติของเวลาทำงาน ทีมสืบสวนระบุว่าประหยัดเวลาเฉลี่ยได้ประมาณ 140 ชั่วโมงต่อสัปดาห์ (คำนวณจากการลดจำนวนแจ้งเตือนและเวลาเฉลี่ยในการตรวจสอบต่อแจ้งเตือน) ส่งผลให้สามารถจัดสรรทรัพยากรไปยังเคสที่มีความเสี่ยงสูงและการสืบสวนเชิงลึกได้มากขึ้น นอกจากนี้ธนาคารยังรายงานการลดค่าใช้จ่ายด้านการดำเนินงานและความเครียดของพนักงานจากการไหลของแจ้งเตือนที่ลดลงอย่างต่อเนื่อง
สรุปตัวชี้วัดสำคัญ (ตัวอย่างเชิงตัวเลข)
- ลด False‑Positive: ถึง 70% ในช่วงทดลอง
- ปริมาณแจ้งเตือนที่ต้องตรวจสอบ: ลดจาก ~1,200 → ~360 ต่อสัปดาห์
- Precision: เพิ่มขึ้นประมาณ 2–3 เท่า (ขึ้นกับกลุ่มข้อมูลและการปรับ threshold)
- Recall: รักษาหรือเพิ่มเล็กน้อย — ไม่ลดทอนความสามารถในการจับพฤติกรรมต้องสงสัย
- เวลาที่ทีมสืบสวนประหยัด: ประมาณ 140 ชั่วโมงต่อสัปดาห์ (ตัวอย่างการคำนวณจากกรณีทดสอบ)
กรณีตัวอย่างเชิงคุณภาพ (ไม่ระบุตัวตน)
กรณีที่ 1: เครือข่ายพ่อค้ารวบรวมยอด (merchant aggregation) — ระบบ rule‑based มักจะระบุการโอนหลายรายการไปยังพ่อค้าคนเดียวเป็นเหตุต้องสงสัย และทำให้เกิดแจ้งเตือนจำนวนมากเป็นรายธุรกรรม แต่ GNN สามารถมองเห็นรูปแบบเครือข่ายได้ว่าแอคเคานต์หลายรายการมีลักษณะการโอนแบบซ้ำซ้อนผ่านช่องทางกลางเดียวกันและมีลำดับการโอนแบบ multi‑hop ซึ่งชี้ไปยังการจัดชั้นเงิน (layering) ของกลุ่มเดียวกัน ผลคือ GNN รวมเหตุเหล่านี้เป็นคลัสเตอร์เดียวที่มีความเสี่ยงสูงแทนที่จะสร้างแจ้งเตือนแยกเป็นจำนวนมาก ทำให้ทีมสืบสวนโฟกัสไปที่เครือข่ายที่มีความเชื่อมโยงจริง ๆ
กรณีที่ 2: วงจรบัญชีเชื่อมโยงแบบซ่อนเร้น — ในกรณีหนึ่ง GNN ตรวจพบกลุ่มบัญชีที่มีการโอนผ่านกันแบบวนซ้ำและมีบัญชีตัวกลางหลายชั้นซึ่ง rule‑based ที่พึ่งพากฎเช่นจำนวนการโอนหรือมูลค่าต่อรายการเพียงอย่างเดียวมองข้ามไป เนื่องจากแต่ละการโอนอาจมีมูลค่าต่ำหรือแยกกระจาย การวิเคราะห์เครือข่ายทางกราฟช่วยเชื่อมโยงเส้นทางการเงินหลายจุดเข้าด้วยกันและยกระดับความเสี่ยงของทั้งคลัสเตอร์ ผลลัพธ์คือการตรวจจับเครือข่ายฟอกเงินเชิงสัมพันธ์ที่มีความซับซ้อนมากขึ้นซึ่งระบบกฎไม่สามารถจับได้
กรณีที่ 3: แยกความแตกต่างระหว่าง hub ถูกต้องตามกฎหมายกับ hub ที่น่าสงสัย — ธนาคารพบว่าหลายครั้งแจ้งเตือนจากระบบเดิมเกิดจากบัญชี hub ที่ถูกต้องตามกฎหมาย เช่น บัญชีจ่ายเงินเดือนหรือผู้ให้บริการจ่ายบิลซ้ำ ๆ แต่ GNN สามารถเรียนรู้ลักษณะเชิงโครงสร้างของ hub เหล่านั้น (เช่น โปรไฟล์ลูกค้า, รูปแบบเวลาการโอน, ความสัมพันธ์กับบัญชีอื่น) และลดการแจ้งเตือนปลอมได้อย่างมีนัยสำคัญ โดยยังคงจับ hub ที่มีพฤติกรรมผิดปกติได้อย่างแม่นยำ
โดยสรุป ผลการทดสอบเชิงปริมาณและกรณีตัวอย่างชี้ว่า GNN ช่วยยกระดับความแม่นยำในการตรวจจับความเสี่ยงทางการเงิน ลดภาระงานทีมสืบสวน และเพิ่มความสามารถในการค้นหาเครือข่ายฟอกเงินเชิงสัมพันธ์ที่ซับซ้อน ซึ่งเป็นประโยชน์เชิงปฏิบัติที่ชัดเจนสำหรับธนาคารที่ต้องการลด false‑positive และเพิ่มประสิทธิภาพการปฏิบัติการด้านการป้องกันการฟอกเงิน
ประเด็นกฎระเบียบ ความเป็นส่วนตัว และการอธิบายผล (Explainability)
ประเด็นกฎระเบียบ ความเป็นส่วนตัว และการอธิบายผล (Explainability)
การนำ Graph Neural Network (GNN) มาใช้สแกนเครือข่ายธุรกรรมเพื่อตรวจจับกลุ่มฟอกเงินต้องสอดคล้องกับกรอบกฎหมายทั้งด้านการป้องกันการฟอกเงิน (AML) และการคุ้มครองข้อมูลส่วนบุคคล (PDPA พ.ศ. 2562) ของไทย โดยธนาคารต้องพิจารณาแหล่งข้อมูลและฐานทางกฎหมายในการประมวลผลข้อมูลส่วนบุคคล เช่น การประมวลผลเพื่อปฏิบัติตามหน้าที่ตามกฎหมาย/ข้อบังคับ (compliance with legal obligation) หรือเหตุผลชอบด้วยกฎหมายในการปฏิบัติการป้องกันการฟอกเงิน นอกจากนี้การจัดเก็บและเผยแพร่ข้อมูลต้องปฏิบัติตามหลัก data minimization, purpose limitation และมาตรการรักษาความมั่นคงปลอดภัย เช่น การเข้ารหัส การจำกัดสิทธิ์เข้าถึง และการทำ pseudonymization/anonimization เมื่อเป็นไปได้
ในมุมของหน่วยงานกำกับ เช่น ธนาคารแห่งประเทศไทยและสำนักงานป้องกันและปราบปรามการฟอกเงิน (AMLO) แนวทางปฏิบัติที่คาดหวังคือระบบตรวจจับต้องสามารถอธิบายเหตุผลของการแจ้งเตือนได้เมื่อต้องชี้แจงต่อผู้ตรวจสอบภายในหรือหน่วยงานกำกับดูแล การอธิบายนี้ควรรวมทั้งข้อมูลเชิงสถิติ (เช่น คะแนนความผิดปกติ, ฟีเจอร์สำคัญ, ความเชื่อมโยงของโหนด/เอดจ์ที่นำไปสู่การตัดสินใจ) และหลักฐานประกอบเพื่อให้การดำเนินการแจ้งเตือน (SAR) มีความน่าเชื่อถือ ตัวอย่างเช่น หากระบบรายงานว่า "กลุ่มบัญชี A มีคะแนนความเสี่ยงสูงเนื่องจากการส่งเงินไปยังเครือข่ายที่มีลักษณะ circular transaction และการเชื่อมโยงกับบัญชีที่ถูกปิดก่อนหน้า" คำอธิบายควรชัดเจนและสามารถแสดง subgraph ที่เกี่ยวข้องพร้อมหลักฐานการทำธุรกรรมได้
เพื่อให้การอธิบายผลมีความน่าเชื่อถือ ควรนำเทคนิค Explainable AI ที่เหมาะกับกราฟมาใช้ เช่น GNNExplainer, การวัดความสำคัญของขอบ (edge importance), การใช้ attention weights, หรือการใช้แนวทางทั่วไปอย่าง SHAP และ Integrated Gradients ที่ปรับให้เข้ากับข้อมูลกราฟ ทั้งนี้ผลการอธิบายควรถูกแปลเป็นภาษาที่ผู้สืบสวนและผู้บริหารเข้าใจได้ พร้อมภาพแผนภาพ subgraph หรือรายงานสรุปเชิงคุณภาพ-เชิงปริมาณ เพื่อช่วยให้การตัดสินใจต่อไป (เช่น การยกระดับเป็นการสอบสวนเชิงลึก หรือการปิดเคส) เป็นไปอย่างมีเหตุผล
ด้าน model governance ระบบต้องมีกรอบการควบคุมที่ชัดเจนตั้งแต่การพัฒนา จนถึงการนำไปใช้งานจริง ประกอบด้วยการจัดการเวอร์ชันโมเดล (model versioning), การทดสอบย้อนหลัง (backtesting) และการตรวจสอบความคงที่ของประสิทธิภาพ (performance monitoring & drift detection) โดยต้องกำหนดบทบาทหน้าที่ที่ชัดเจน เช่น เจ้าของโมเดล (model owner), หน่วยงานควบคุมความเสี่ยงของโมเดล (model risk management), เจ้าหน้าที่คุ้มครองข้อมูล (DPO) และทีมปฏิบัติการ AML
- Audit trail และการบันทึก (Logging): บันทึกต้องครอบคลุมข้อมูลนำเข้า (input snapshot), ผลลัพธ์ของโมเดล (prediction score), ฟีเจอร์ที่สำคัญ (feature attributions), เวอร์ชันของโมเดล, เวลาและผู้ใช้งานที่เข้าดูหรือแก้ไขข้อมูล การเก็บ log เหล่านี้ช่วยให้สามารถตรวจสอบย้อนหลังและตอบคำถามทางกฎระเบียบได้อย่างโปร่งใส
- นโยบายการเก็บรักษา: ควรกำหนดระยะเวลาการเก็บรักษาให้สอดคล้องกับข้อกำหนดด้าน AML (เช่น การเก็บเอกสารธุรกรรมและบันทึกการตรวจสอบอย่างน้อยตามที่กฎหมายกำหนด—โดยทั่วไปมักอยู่ที่ระยะเวลาเช่น 5 ปีเป็นตัวอย่าง) และ PDPA โดยต้องมีขั้นตอนลบหรือทำให้ไม่ระบุตัวตนเมื่อพ้นระยะเวลา
- การประเมินผลกระทบต่อความเป็นส่วนตัว (DPIA): สำหรับระบบที่มีความเสี่ยงสูงต่อสิทธิของเจ้าของข้อมูล ควรดำเนิน DPIA ก่อนใช้งานและทบทวนเป็นระยะ
- การตรวจสอบภายนอกและการรับรอง: ควรมีการตรวจสอบโมเดลจากหน่วยงานอิสระเป็นระยะ รวมถึงการจัดทำ model card และเอกสารรับรองความโปร่งใสสำหรับผู้ควบคุมดูแล
สุดท้าย ธนาคารต้องจัดสมดุลระหว่างความโปร่งใสกับการป้องกันการล้วงข้อมูลและการโจมตีระบบ กล่าวคือ การให้คำอธิบายแก่ผู้สืบสวนและหน่วยงานกำกับควรมีความละเอียดเพียงพอ แต่การเผยแพร่รายละเอียดเชิงเทคนิคต่อสาธารณะอาจต้องควบคุมเพื่อป้องกันการใช้ช่องโหว่โจมตีระบบ การจัดการสิทธิการเข้าถึง (RBAC), การเข้ารหัสข้อมูลขณะพักและขณะส่ง, และนโยบายการเปิดเผยข้อมูลเชิงสรุปต่อเจ้าของข้อมูลหรือสาธารณะ จึงเป็นองค์ประกอบสำคัญของการนำ GNN มาใช้ในบริบท AML อย่างปลอดภัยและสอดคล้องกฎหมาย
หมายเหตุเชิงตัวอย่าง: หากธนาคารเคยมีการแจ้งเตือน 10,000 รายการต่อเดือนและใช้เวลาสืบสวนเฉลี่ย 30 นาทีต่อรายการ การลด False‑Positive 70% จะลดจำนวนแจ้งเตือนได้ 7,000 รายการ ซึ่งเท่ากับการประหยัดเวลาประมาณ 3,500 ชั่วโมงต่อเดือน นอกจากนี้การมี audit trail ที่ดีช่วยให้เวลาตอบคำถามจากหน่วยงานกำกับสามารถลดลงอย่างมีนัยสำคัญและเพิ่มความโปร่งใสในการปฏิบัติตามกฎระเบียบ
ข้อท้าทาย การพัฒนาและแนวโน้มในอนาคต
ข้อท้าทาย การพัฒนาและแนวโน้มในอนาคต
แม้ผลการทดสอบแสดงให้เห็นว่าการนำ Graph Neural Network (GNN) มาใช้สแกนเครือข่ายธุรกรรมสามารถลดอัตรา False‑Positive ได้ถึง 70% ในสภาพแวดล้อมการทดสอบจริง แต่การยกระดับเทคโนโลยีนี้สู่การใช้งานเชิงพาณิชย์แบบเรียลไทม์ยังเผชิญกับข้อท้าทายเชิงวิศวกรรมและเชิงนโยบายหลายประการ หนึ่งในความท้าทายสำคัญคือการสเกลระบบให้รองรับปริมาณธุรกรรมมหาศาลของธนาคารพาณิชย์ไทยที่อาจประมวลผล หลายล้านรายการต่อวัน พร้อมกับเครือข่ายความสัมพันธ์ที่ขยายตัวเป็นกราฟขนาดใหญ่ การคำนวณคุณลักษณะเชิงกราฟและการทำ inference บน GNN ขนาดใหญ่มีความซับซ้อนทั้งด้านเวลาและหน่วยความจำ ดังนั้นการจัดการ latency เพื่อให้การแจ้งเตือนการฟอกเงินทำได้แบบ near‑real‑time จึงเป็นโจทย์ที่ต้องการโซลูชันระดับระบบ เช่น การทำ graph sampling แบบออนไลน์, incremental/streaming inference, และการใช้ฮาร์ดแวร์เร่งความเร็ว (เช่น GPUs, TPUs หรือ NPU) พร้อมกับสถาปัตยกรรม micro‑batching เพื่อลดเวลาแฝงในการตัดสินใจ
ด้านความมั่นคงของโมเดลเป็นอีกมิติที่ต้องให้ความสำคัญ—GNN ไม่ได้ปลอดภัยต่อการโจมตีรูปแบบใหม่ๆ โดยเฉพาะ adversarial attacks บนกราฟ เช่น การแทรกหรือปรับโครงสร้างการเชื่อมโยง (edge perturbation), การปลอมแปลงคุณลักษณะของโหนด (feature manipulation), หรือการโจมตีแบบ poisoning ที่มุ่งเป้าไปยังข้อมูลฝึกฝน ผลกระทบคือโมเดลอาจจะไม่สามารถตรวจจับเครือข่ายฟอกเงินที่ถูกออกแบบมาเพื่อลวงระบบได้ การป้องกันจึงต้องผสานทั้งการเสริมความทนทานของโมเดล (adversarial training, robust aggregation), ระบบตรวจจับพฤติกรรมผิดปกติประเภท meta‑graph (graph integrity monitoring), และการทดสอบความปลอดภัยด้วยชุดโจมตีจำลอง (red‑teaming) อย่างต่อเนื่อง เพื่อให้มั่นใจว่าการใช้งานจริงไม่ได้ถูกหลอกลวงโดยกลุ่มอาชญากรที่ปรับกลยุทธ์ได้รวดเร็ว
อีกข้อจำกัดที่เด่นชัดคือการตรวจจับเครือข่ายข้ามสถาบัน—การฟอกเงินมักกระจายตัวผ่านบัญชีของธนาคารหลายแห่ง การแลกเปลี่ยนข้อมูลธุรกรรมดิบระหว่างธนาคารจึงมีอุปสรรคทั้งด้านกฎหมาย ความเป็นส่วนตัว และการแข่งขันในเชิงธุรกิจ การแก้ไขปัญหานี้ในเชิงเทคนิคและนโยบายจำเป็นต้องมีกรอบการทำงานร่วมกันที่ชัดเจน เช่น การใช้ federated learning ในรูปแบบแนวตั้ง (vertical federated learning) หรือแนวนอนที่ปรับให้เข้ากับโครงสร้างกราฟ เพื่อให้แต่ละสถาบันสามารถฝึกโมเดลร่วมกันโดยไม่ต้องเปิดเผยข้อมูลดิบ นอกจากนั้นเทคโนโลยีที่รักษาความเป็นส่วนตัว (privacy‑preserving) อย่าง secure multi‑party computation (MPC), homomorphic encryption, และ differential privacy จะเป็นองค์ประกอบสำคัญของระบบที่ช่วยให้การแชร์ข้อมูลเชิงสถิติหรือ embeddings ของกราฟทำได้โดยไม่ละเมิดข้อบังคับความเป็นส่วนตัว
แนวโน้มในอนาคตรวมถึงการผสาน GNN กับเทคนิคเสริมเพื่อขยายขีดความสามารถและความทนทานของระบบ ตัวอย่างแนวทางที่ธนาคารและผู้พัฒนาอาจลงทุนคือ:
- Hybrid architectures: ผสาน GNN กับโมดูลเชิงกฎ (rule‑based engines) และโมเดลเชิงเวลา (temporal graph networks) เพื่อจับทั้งสัญญาณเชิงสัมพันธ์และลำดับเหตุการณ์
- Self‑supervised / contrastive learning: ใช้การเรียนรู้แบบไม่ต้องการป้ายกำกับจำนวนมากเพื่อสร้าง representations ของโหนด/กลุ่มที่ทนต่อการเปลี่ยนแปลงและลดการพึ่งพาข้อมูลที่ติดฉลาก
- Federated & privacy‑preserving ML: ขยายการฝึกแบบร่วมมือด้วยเทคนิค MPC, HE และเทคโนโลยี Trusted Execution Environments (เช่น TEE, confidential computing) เพื่อให้สามารถร่วมมือข้ามธนาคารได้ภายใต้ข้อกำหนดทางกฎหมาย
- Online and continual learning: รองรับ concept drift ของพฤติกรรมการฉ้อโกงด้วยการอัปเดตโมเดลแบบออนไลน์ ลดเวลาในการตรวจพบกลยุทธ์ใหม่
- Explainability and compliance: เพิ่มความโปร่งใสของการตัดสินใจ (XAI) เพื่อช่วยนักวิเคราะห์ปฏิบัติตามข้อกำหนดด้านการรายงานและการสอบสวน
สรุปแล้ว การนำ GNN มาใช้ในบริบทการต่อต้านการฟอกเงินของธนาคารไทยมีศักยภาพสูง แต่ความสำเร็จเชิงปฏิบัติการต้องการการออกแบบสถาปัตยกรรมที่สามารถสเกลแบบเรียลไทม์ ปรับตัวต่อการโจมตีเชิงโมเดล และวางกรอบความร่วมมือข้ามสถาบันที่คำนึงถึงความเป็นส่วนตัวและกฎระเบียบ การลงทุนในโครงสร้างพื้นฐาน การทดสอบความปลอดภัยอย่างต่อเนื่อง และการบูรณาการเทคโนโลยี privacy‑preserving ร่วมกับนโยบายส่งเสริมความร่วมมือ จะเป็นตัวขับเคลื่อนให้ระบบตรวจจับเชิงสัมพันธ์นี้บรรลุผลในเชิงปฏิบัติและยั่งยืน
บทสรุป
ธนาคารไทยที่นำ Graph Neural Network (GNN) มาสแกนเครือข่ายธุรกรรม พบผลลัพธ์เชิงปริมาณที่ชัดเจน โดยการทดสอบภาคปฏิบัติแสดงให้เห็นว่าสามารถลด False‑Positive ได้ถึง 70% เมื่อเทียบกับระบบแบบเดิม การลดอัตราแจ้งเตือนที่เป็นเท็จเช่นนี้ช่วยลดภาระการสืบสวนของทีมปฏิบัติตามกฎระเบียบอย่างมีนัยสำคัญ — ลดจำนวนเคสที่ต้องตรวจสอบด้วยแรงงานมนุษย์ เพิ่มความแม่นยำในการจัดลำดับความเสี่ยง และทำให้กระบวนการปฏิบัติตามกฎระเบียบ (AML/KYC) มีความเป็นไปได้ในเชิงปฏิบัติยิ่งขึ้น ตัวอย่างเช่น GNN สามารถจับกลุ่มเครือข่ายความสัมพันธ์ของบัญชีที่มีพฤติกรรมกระจุกตัวหรือเป็นศูนย์กลางได้ดีขึ้น จึงช่วยเน้นเคสที่มีความเสี่ยงจริงและลดเวลาที่ต้องใช้ตรวจสอบเคสที่เป็น false alarm
ขณะที่ผลลัพธ์ในเบื้องต้นน่าสนับสนุนการนำไปใช้เชิงพาณิชย์และข้ามสถาบัน แต่ต้องให้ความสำคัญกับการควบคุมโมเดลและความโปร่งใสด้านการตัดสินใจก่อนขยายการใช้งาน ทั้งการอธิบายเหตุผล (explainability), การตรวจสอบความลำเอียงและความมั่นคงของโมเดล, การบันทึก audit trail และการกำกับดูแลโดยภายนอกเป็นสิ่งจำเป็น นอกจากนี้มาตรการคุ้มครองข้อมูลส่วนบุคคลและเทคนิคความเป็นส่วนตัวแบบกระจาย (เช่น federated learning, differential privacy หรือ secure multiparty computation) จะช่วยให้สามารถแลกเปลี่ยนสัญญาณความเสี่ยงข้ามสถาบันได้โดยไม่ละเมิดกฎ PDPA หรือข้อกำหนดด้านความปลอดภัย สรุปคือเทคโนโลยี GNN มีศักยภาพสูงในการยกระดับการตรวจจับฟอกเงิน แต่การขยายผลต้องเดินควบคู่ไปกับกรอบกำกับดูแล เทคนิคคุ้มครองข้อมูล และมาตรการตรวจสอบอย่างต่อเนื่องเพื่อให้การใช้งานปลอดภัยและยั่งยืน



