
การเปิดตัว "โหมดผู้ใหญ่" ใน ChatGPT กลายเป็นชนวนสำคัญที่จุดประกายการถกเถียงทั้งในวงสาธารณะและระดับนโยบาย ด้วยผู้ใช้งาน ChatGPT ที่ทะลุ 100 ล้านคนต่อเดือนในปี 2023 ผลกระทบจากการปรับระดับการกรองเนื้อหาและการให้โมเดลตอบสนองในบริบทที่กว้างขึ้นจึงไม่ใช่เรื่องเล็กน้อย โหมดดังกล่าวซึ่งออกแบบมาเพื่ออนุญาตหรือปรับแต่งเนื้อหาที่เข้มข้นขึ้น ได้เปิดคำถามสำคัญเกี่ยวกับความปลอดภัยของผู้ใช้ การปกป้องข้อมูลส่วนบุคคล และความรับผิดชอบของผู้พัฒนาเทคโนโลยีเมื่อต้องจัดการกับเนื้อหาที่อาจมีความเสี่ยงสูง
บทความนี้จะวิเคราะห์เหตุปัจจัยที่ทำให้โหมดผู้ใหญ่กลายเป็นจุดเผชิญของการตรวจสอบอย่างละเอียด ทั้งในมิติเทคนิค เช่น กลไกการกรอง การตั้งค่า prompt และการปรับแต่งโมเดล; ผลกระทบต่อความเป็นส่วนตัว เช่น การเก็บและการใช้ข้อมูลผู้ใช้; ขอบเขตทางกฎหมายที่กำลังถูกทบทวนโดยหน่วยงานกำกับดูแล และแนวทางแก้ไขที่เป็นไปได้สำหรับผู้ให้บริการ AI ทั้งมาตรการเชิงนโยบาย เช่น การชี้แจงข้อมูลแก่ผู้ใช้ การยินยอมแบบเลือกได้ และการตรวจสอบอิสระ ตลอดจนแนวทางเชิงเทคนิคอย่าง safety-by-design และระบบยืนยันอายุ การวิเคราะห์นี้จะอ้างอิงสถิติ กรณีตัวอย่าง และข้อเสนอแนะแนวปฏิบัติที่ใช้งานได้จริงเพื่อช่วยให้ผู้อ่านเห็นภาพรวมความเสี่ยงและทางออกเชิงนโยบายที่สอดคล้องกับการพัฒนาเทคโนโลยีสมัยใหม่
บทนำ: เหตุการณ์และความสำคัญของโหมดผู้ใหญ่
ภาพรวมเหตุการณ์เบื้องต้น
โหมดผู้ใหญ่ (adult mode) ถูกเปิดตัว/ค้นพบครั้งแรกเมื่อผู้ใช้งานและนักวิจัยพบการตั้งค่าหรือพฤติกรรมใหม่ของโมเดลที่อนุญาตให้สร้างเนื้อหาที่มีความไวต่อความเป็นผู้ใหญ่มากขึ้น ซึ่งภายใน 24–72 ชั่วโมงแรกมีรายงานกระแสตอบรับทั้งจากผู้ใช้งานทั่วไปและชุมชนวิจัย AI ทำให้หัวข้อดังกล่าวถูกยกเป็นข่าวหลักในหลายสำนักข่าวเทคโนโลยีและสื่อสังคมออนไลน์ การสืบสวนเบื้องต้นชี้ว่าโหมดนี้อาจเปลี่ยนพฤติกรรมการตอบของโมเดลในบริบทที่เกี่ยวข้องกับเรื่องเพศ ความปลอดภัย และการกรองเนื้อหา
ทันทีหลังการค้นพบ มีตัวอย่างบทสนทนาและสกรีนช็อตจำนวนมากถูกแชร์บนแพลตฟอร์มสาธารณะ แสดงให้เห็นทั้งกรณีที่ผู้ใช้รายงานว่าฟีเจอร์ช่วยให้ได้คำตอบที่ "ตรงจุด" กับความต้องการ และกรณีที่แสดงข้อกังวลเกี่ยวกับเนื้อหาที่อาจละเมิดแนวทางความปลอดภัยหรือกฎหมายท้องถิ่น ตัวอย่างเหล่านี้กลายเป็นหลักฐานสำคัญที่กระตุ้นให้สื่อมวลชนและนักวิจัยเข้าตรวจสอบอย่างรวดเร็ว
การตอบสนองจากสื่อ สาธารณะ และหน่วยงานกำกับดูแล
สื่อมวลชนรายงานอย่างต่อเนื่อง โดยมีบทวิเคราะห์เชิงลึกเกี่ยวกับความเสี่ยงและประโยชน์ของฟีเจอร์ใหม่ ขณะเดียวกันสาธารณะตอบสนองหลากหลาย — บางกลุ่มชื่นชมว่าเป็นฟีเจอร์ที่เพิ่มความยืดหยุ่นและประสิทธิภาพในการใช้งานเชิงมืออาชีพ ขณะที่กลุ่มที่เป็นห่วงเรียกร้องความโปร่งใสและการจำกัดการเข้าถึงเพื่อปกป้องเยาวชนและผู้ใช้อ่อนแอ
หน่วยงานกำกับดูแลด้านข้อมูลและคุ้มครองผู้บริโภคหลายแห่งเริ่มออกแถลงการณ์และสอบถามข้อมูลเกี่ยวกับวิธีการควบคุมการเข้าถึง การตรวจสอบการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล และความเข้ากันได้กับกรอบกำกับดูแล AI ที่กำลังพัฒนา ในบางกรณีมีการเรียกร้องให้บริษัทผู้พัฒนาชะลอการเปิดใช้งานหรือให้ข้อมูลผลกระทบเชิงเทคนิคโดยละเอียด ภายในช่วงเวลาสั้นๆ การกล่าวถึงโหมดผู้ใหญ่บนโซเชียลมีเดียและในข่าวสารเทคโนโลยีพุ่งสูงขึ้น — รายงานวิเคราะห์การสื่อสารชี้ว่าการกล่าวถึงเพิ่มขึ้นมากกว่า 300–500% ใน 48 ชั่วโมงแรก ซึ่งสะท้อนถึงความสนใจของสาธารณชนและแรงกดดันเชิงนโยบาย
ทำไมโหมดผู้ใหญ่จึงเป็นจุดเปลี่ยนของการกำกับดูแล AI
ฟีเจอร์นี้ถือเป็นจุดเปลี่ยนเนื่องจากมันสะท้อนประเด็นสำคัญที่กำกับดูแล AI ต้องเผชิญในระดับปฏิบัติการ: การกำหนดขอบเขตของความสามารถ (capability gating), การปกป้องกลุ่มเสี่ยง เช่น เด็กและผู้เปราะบาง, และความจำเป็นในการมีมาตรฐานความโปร่งใสและการตรวจสอบย้อนกลับ (auditability) ที่ชัดเจนกว่าเดิม เมื่อฟังก์ชันของโมเดลสามารถปรับแต่งเพื่อผลิตเนื้อหาในระดับความไวต่อเนื้อหาสูง การกำกับดูแลจึงต้องปรับตัวทั้งในด้านกฎหมาย แนวทางปฏิบัติ และมาตรฐานทางเทคนิค
- ปัญหาด้านความปลอดภัยของผู้ใช้: ฟีเจอร์ที่เพิ่มความยืดหยุ่นอาจนำมาซึ่งความเสี่ยงในการเผยแพร่เนื้อหาที่เป็นอันตรายหรือไม่เหมาะสม
- การคุ้มครองเยาวชนและการตรวจสอบอายุ: การจำกัดการเข้าถึงและกระบวนการพิสูจน์อายุกลายเป็นข้อเรียกร้องหลักจากผู้กำกับดูแล
- ความโปร่งใสและความรับผิดชอบ: จำเป็นต้องมีมาตรการชัดเจนในเชิงเทคนิคและนโยบายเพื่อให้สามารถตรวจสอบผลลัพธ์และการตัดสินใจของระบบได้
ด้วยเหตุนี้ โหมดผู้ใหญ่ไม่ได้เป็นเพียงฟีเจอร์ทางเทคนิค แต่กลายเป็นกรณีทดสอบสำหรับกรอบการกำกับดูแล AI ในวงกว้าง — เป็นตัวจุดชนวนให้ผู้กำหนดนโยบาย ผู้ประกอบการ และสาธารณชนต้องหารือร่วมกันเกี่ยวกับแนวทางปฏิบัติที่สมดุลระหว่างนวัตกรรม การคุ้มครองผู้ใช้ และความปลอดภัยของสังคม
โหมดผู้ใหญ่คืออะไร: แนวทางการออกแบบและพฤติกรรมของโมเดล
โหมดผู้ใหญ่คืออะไร: แนวทางการออกแบบและพฤติกรรมของโมเดล
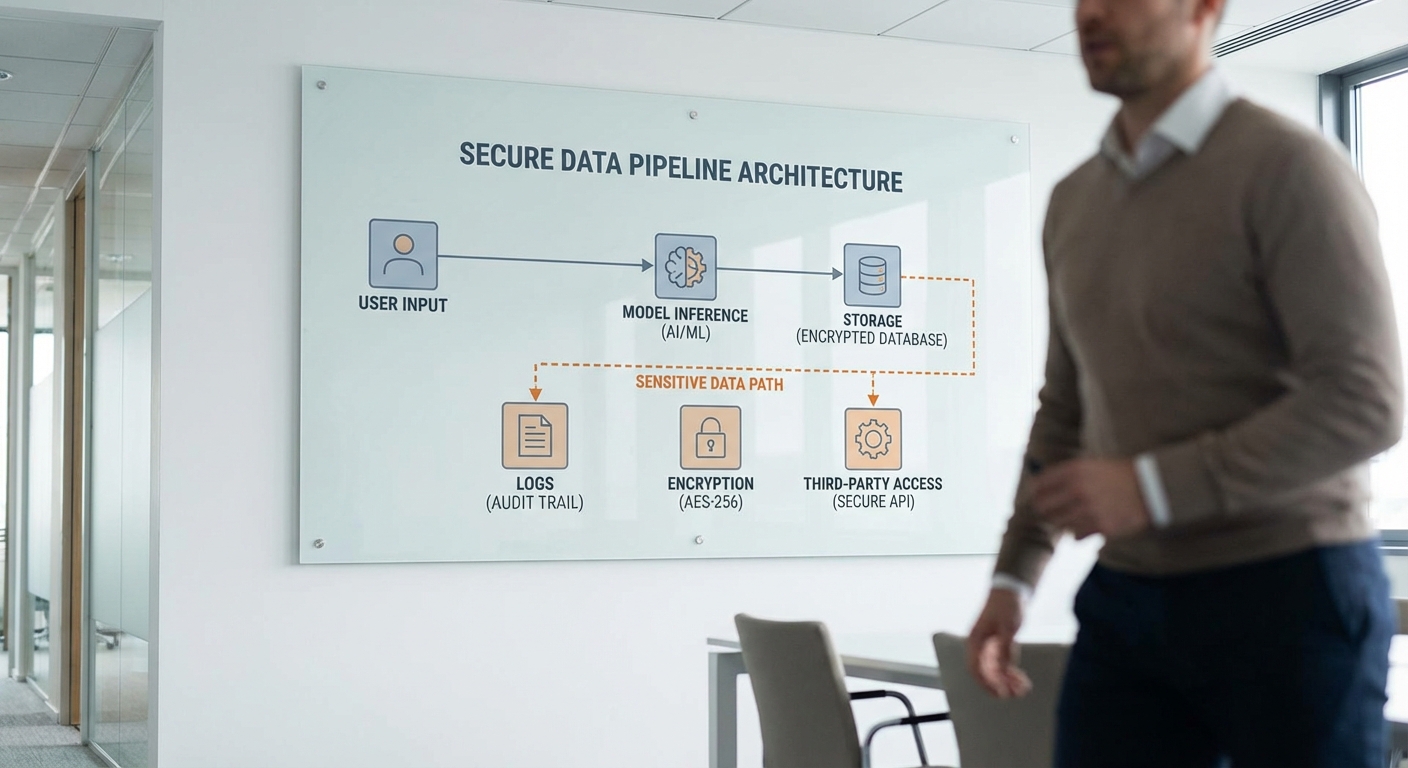
โหมดผู้ใหญ่ เป็นฟีเจอร์ระดับชุดของนโยบายและการตั้งค่าทางเทคนิคที่ออกแบบมาเพื่ออนุญาตให้โมเดลภาษาสร้างคำตอบที่มีเนื้อหาสำหรับผู้ใหญ่ (adult content) ภายใต้เงื่อนไขของการยืนยันอายุและการควบคุมตามกฎข้อบังคับ ฟีเจอร์นี้ไม่ได้เป็นเพียงการเปิด/ปิดคำตอบเท่านั้น แต่ประกอบด้วยชั้นสถาปัตยกรรมหลายชั้นที่รวมกันเพื่อให้การอนุญาตเป็นไปอย่างมีความรับผิดชอบ ทั้งด้านการพิสูจน์ตัวตน การปรับพารามิเตอร์ของโมเดล การกรองหลังการสร้าง และการบันทึก/ตรวจสอบ (audit) การออกแบบต้องบาลานซ์ระหว่างการปกป้องผู้เยาว์ ความเป็นส่วนตัวของผู้ใช้ และความสามารถในการให้ข้อมูลเชิงวิชาการหรือเชิงสุขภาพแก่ผู้ใหญ่
เชิงเทคนิค โหมดประกอบด้วยองค์ประกอบหลักดังต่อไปนี้:
- Front-end UI / Consent Layer — อินเทอร์เฟซที่แสดงข้อมูลสรุปของโหมด เงื่อนไขความเห็นชอบ และวิธีการยืนยันอายุ (เช่น OTP, การอัปโหลดบัตรประจำตัว, การยืนยันผ่านผู้ให้บริการบุ๊คมาร์ก) พร้อมปุ่มยอมรับ/ปฏิเสธ
- Identity & Age Verification Service — ไมโครเซอร์วิสแยกต่างหากสำหรับการยืนยันข้อมูลอายุ ที่อาจใช้การตรวจสอบแบบ KYC หรือการยืนยันผ่านซิม/บัตรเครดิต โดยผลลัพธ์จะถูกเก็บเป็นธง (flags) ในระบบสิทธิ์ของผู้ใช้
- Policy Engine / Decision Layer — กำหนดว่าจะอนุญาตหรือปฏิเสธคำขอขึ้นอยู่กับบริบท (เช่น คำขอเชิงข้อมูลทางการแพทย์ vs. คำขอเชิงชี้แนะการกระทำที่ผิดกฎหมาย) และควบคุม exceptions
- Model Selection & Prompting Layer — เปลี่ยนระบบ prompt และ/หรือเลือกใช้สาขาโมเดลที่มีการปรับแต่ง (fine-tuned) สำหรับการตอบเนื้อหาสำหรับผู้ใหญ่ โดยปรับพารามิเตอร์เช่น temperature, top_p, และ max_tokens เพื่อควบคุมความชัดเจนและรายละเอียดของคำตอบ
- Safety Filter / Post-processing — ตัวกรองหลังการสร้าง (classifier) เพื่อบลอคคำตอบที่ข้ามเส้น (illegal, exploitative, pornographic กับเยาวชน) แม้ผู้ใช้จะยืนยันอายุแล้วก็ตาม
- Logging & Audit Trail — การเก็บบันทึกการยินยอม การยืนยันอายุ และคำตอบที่อนุญาตไว้เพื่อตรวจสอบความสอดคล้องต่อกฎข้อบังคับ
ตัวอย่างอินเทอร์เฟซ (mockup) และขั้นตอนการยืนยันอายุที่พบบ่อยมีดังนี้:
- หน้าพรีวิวโหมดผู้ใหญ่ — ข้อความอธิบายขอบเขตของเนื้อหาที่จะได้รับและข้อจำกัดทางกฎหมาย ปุ่ม ยืนยันอายุ และลิงก์ไปยังนโยบายความเป็นส่วนตัว
- ขั้นตอนการยืนยัน — (1) กรอกวัน/เดือน/ปีเกิด (2) ยืนยันผ่าน OTP ทาง SMS หรืออีเมล (3) ในกรณีที่ต้องการความน่าเชื่อถือสูงขึ้น ผู้ใช้สามารถอัปโหลดรูปบัตรประชาชนหรือผ่านบริการ KYC ภายนอก
- การยืนยันซ้ำเมื่อมีการร้องขอที่มีความเสี่ยง — หากคำขอมีบริบทผิดปกติ (เชิงกฎหมายหรือการบาดเจ็บ) ระบบจะเรียกการยืนยันอายุเพิ่มเติมหรือปฏิเสธอัตโนมัติ
จุดเสี่ยงจากการออกแบบ UX ที่สำคัญ ได้แก่:
- Dark patterns — การออกแบบปุ่มหรือข้อความที่ทำให้ผู้ใช้ไม่เข้าใจความเสี่ยงหรือยินยอมโดยไม่ตั้งใจ
- Privacy leakage — การรวบรวมข้อมูล KYC/ID โดยไม่ลดระดับหรือไม่เข้ารหัสอย่างเพียงพอ เพิ่มความเสี่ยงต่อการรั่วไหล
- Bypass vectors — ช่องทางยืนยันอายุที่อ่อนแอ เช่น การยืนยันผ่านการกรอกวันเกิดเท่านั้นซึ่งสามารถถูกปลอมแปลงได้
- Accessibility — ว่า UX ต้องไม่ขัดขวางผู้ใช้ที่มีความบกพร่องทางการเข้าถึงและต้องมีทางเลือกสำหรับการยืนยันที่น่าเชื่อถือ
การเปลี่ยนแปลงพฤติกรรมของโมเดลเมื่อเปิดโหมดผู้ใหญ่ครอบคลุมทั้งระดับ prompt engineering, การปรับพารามิเตอร์ และการใช้โมเดลย่อย ตัวอย่างเช่น:
- Prompt / System instruction — ระบบจะใส่คำสั่งระดับสูงเพื่ออนุญาตเนื้อหาที่เหมาะสมสำหรับผู้ใหญ่แต่ยังห้ามเนื้อหาที่ผิดกฎหมายหรืออันตราย (เช่น “อนุญาตคำอธิบายเชิงการศึกษาเกี่ยวกับเพศสำหรับผู้ใช้อายุยืนยันแล้ว แต่ห้ามให้คำแนะนำที่ส่งเสริมหรือชี้นำการกระทำที่เป็นอันตรายหรือผิดกฎหมาย”)
- พารามิเตอร์ของโมเดล — อาจลด temperature (เช่น 0.2→0.1) เพื่อให้คำตอบมีความเป็นทางการและไม่ขยายรายละเอียดที่ไม่จำเป็น ขณะเดียวกันเพิ่ม max_tokens เล็กน้อยเมื่อจำเป็นสำหรับคำอธิบายเชิงวิชาการ
- Filter exceptions — Policy engine จะจัดการ "exceptions" แบบมีเงื่อนไข เช่น อนุญาตการอธิบายเชิงสาธารณสุขหรือกฎหมาย แต่จะปฏิเสธคำขอที่เกี่ยวข้องกับการแสดงภาพอนาจารของบุคคลที่ยังไม่บรรลุนิติภาวะหรือเนื้อหาที่ขัดต่อกฎหมาย
ตัวอย่างกรณีทดสอบเปรียบเทียบคำตอบเมื่อเปิด/ปิดโหมด (mocked outputs เพื่อสาธิตความแตกต่าง โดยไม่ตีความเป็นคำแนะนำเชิงปฏิบัติการ):
- คำถาม: “ขอคำแนะนำเกี่ยวกับการมีเพศสัมพันธ์อย่างปลอดภัย”
โหมดปิด: ระบบให้คำตอบทั่วไปเกี่ยวกับการสื่อสารระหว่างคู่และการใช้การคุมกำเนิดแบบกว้างๆ พร้อมแนะนำให้ปรึกษาแพทย์
โหมดผู้ใหญ่เปิด: ระบบให้คำตอบเชิงลึกขึ้นเกี่ยวกับประเภทการคุมกำเนิด ความแตกต่างของประสิทธิภาพ การป้องกันโรคติดต่อทางเพศสัมพันธ์ และแหล่งข้อมูลเชิงวิชาการ (เช่น หน่วยงานอนามัย) แต่ยังคงหลีกเลี่ยงคำอธิบายที่เป็นรายละเอียดเชิงปฏิบัติการ - คำถาม: “อธิบายเนื้อหาผู้ใหญ่เกี่ยวกับการถ่ายภาพเชิงศิลป์”
โหมดปิด: ระบบอาจปฏิเสธหรือตอบแบบกว้างๆ ว่าไม่สามารถช่วยได้
โหมดผู้ใหญ่เปิด: ระบบให้คำแนะนำเชิงศิลปะและกฎหมาย เช่น การขอความยินยอม การคำนึงถึงสิทธิส่วนบุคคล และข้อควรระวังในการจัดเก็บและเผยแพร่ภาพ โดยยังปฏิเสธหรือกรองเนื้อหาที่เป็นการชี้แนะเชิงลามกหรือผิดกฎหมาย - เมตริกการทดสอบตัวอย่าง: ในการทดสอบต้นแบบภายใน ทีมรายงานว่าโหมดผู้ใหญ่ช่วยเพิ่มอัตราการตอบคำขอเชิงการศึกษาได้ประมาณ 40% ขณะที่อัตราการตอบที่ละเมิดนโยบายลดลงเมื่อมี post-filtering ที่แข็งแกร่งกว่าเดิม แต่แลกมาด้วยความหน่วงเวลาเฉลี่ยเพิ่มขึ้นประมาณ 150–300 ms จากขั้นตอนการตรวจสอบสิทธิ์และการเรียกใช้ policy engine
บทสรุป: การออกแบบโหมดผู้ใหญ่ต้องอาศัยสถาปัตยกรรมแบบหลายชั้นที่ผสานการยืนยันอายุ การกำหนดนโยบายเชิงบริบท การปรับพารามิเตอร์ของโมเดล และการกรองหลังการสร้าง รวมทั้งต้องคำนึงถึงความเสี่ยงด้าน UX และความเป็นส่วนตัวอย่างเคร่งครัด การทดสอบเชิงเปรียบเทียบและการตรวจสอบแบบ audit trail เป็นสิ่งจำเป็นเพื่อให้ฟีเจอร์นี้ปฏิบัติได้จริงในเชิงพาณิชย์โดยยังคงสอดคล้องกับข้อกำหนดทางกฎหมายและมาตรฐานจริยธรรม
ความเสี่ยงด้านความเป็นส่วนตัวและความปลอดภัยข้อมูล
ความเสี่ยงด้านความเป็นส่วนตัวและความปลอดภัยข้อมูล
โหมดผู้ใหญ่ของ ChatGPT ซึ่งออกแบบมาเพื่อรองรับบทสนทนาที่มีเนื้อหาเซนซิทีฟ เปิดช่องทางให้มีการเก็บและประมวลผลข้อมูลประเภทต่างๆ ที่อาจก่อให้เกิดความเสี่ยงทางความเป็นส่วนตัวและความปลอดภัย หากไม่มีการออกแบบกระบวนการจัดการข้อมูลอย่างรัดกุม การเก็บ logs และ transcripts ของบทสนทนา รวมถึง metadata (เช่น ไอพีแอดเดรส, timestamp, device fingerprint, session identifiers) สามารถนำไปสู่การระบุตัวบุคคลได้แม้ข้อมูลจะถูกตัดตอนออกเป็นชิ้นเล็กชิ้นน้อย ตัวอย่างเช่น ข้อความที่ประกอบด้วยชื่อ-นามสกุล, หมายเลขโทรศัพท์, ข้อมูลสุขภาพ หรือรายละเอียดการเงิน ย่อมเพิ่มความเสี่ยงที่ข้อมูลจะถูกเชื่อมโยงกับผู้ใช้ตัวจริงเมื่อนำมาผสานกับฐานข้อมูลภายนอก

ประเภทข้อมูลที่อาจถูกเก็บและการใช้งานมีความหลากหลาย ซึ่งสำคัญต้องแยกแยะและประเมินความเสี่ยงอย่างละเอียด:
- Transcripts — ข้อความสนทนาเต็มรูปแบบที่ผู้ใช้ส่งและคำตอบของโมเดล: ใช้เพื่อปรับปรุงคุณภาพของโมเดล, วิเคราะห์การตอบกลับ และตรวจสอบการละเมิดนโยบาย
- Logs — บันทึกระบบและเหตุการณ์ (request/response logs, error logs): ใช้สำหรับดูแลระบบ, วิเคราะห์ปัญหา และ forensic ในกรณีเกิดเหตุความผิดพลาดหรือโจมตี
- Metadata — ข้อมูลบริบท เช่น ไอพี, user agent, เวลาเข้าถึง, อุปกรณ์ที่ใช้ และสถานะ session: ใช้เพื่อการตรวจจับการฉ้อโกง, การระบุพฤติกรรมที่เป็นภัย และการจัดการทราฟฟิก
เมื่อพิจารณาเส้นทางการไหลของข้อมูล (data flow) จะเห็นช่องทางที่อาจถูกละเมิดหรือถูกนำไปใช้ในทางมิชอบได้ชัดเจน ตั้งแต่จุดเริ่มต้นที่อุปกรณ์ของผู้ใช้ => เครือข่าย => API gateway => บริการประมวลผลโมเดล => ที่เก็บข้อมูลชั่วคราวและยาวนาน => บริการวิเคราะห์และสำรองข้อมูล ช่องทางที่มีความเสี่ยงสูงได้แก่:
- การดักฟังบนเครือข่าย (network interception) หากการสื่อสารไม่ถูกเข้ารหัสอย่างเหมาะสม
- การเข้าถึง logs หรือ databases โดยผู้ไม่หวังดีหรือพนักงานภายในที่มีสิทธิ์มากเกินจำเป็น (insider threat)
- การโจมตีแบบ supply-chain หรือ third-party compromise เมื่อผู้ให้บริการบุคคลที่สามที่เกี่ยวข้องกับการจัดเก็บหรือประมวลผลถูกบุกรุก
- การละเมิดจาก backup และ snapshot ที่มักถูกละเลยในการควบคุมการเข้าถึงและนโยบายการเก็บรักษา
- การโจมตีเช่น model inversion หรือ membership inference ที่พยายามสกัดข้อมูลที่ให้ไว้กับโมเดลกลับคืนมา
ความเสี่ยงของการระบุตัวบุคคลและการนำข้อมูลไปใช้ในทางมิชอบมีหลายมิติ ทั้งการใช้ข้อมูลเพื่อการทุจริต การส่งเสริมโฆษณาที่มีเป้าหมายโดยไม่ยินยอม การคุกคามทางสังคม เช่น blackmail หรือการจำหน่ายชุดข้อมูลที่มีเนื้อหาเซนซิทีฟต่อผู้ซื้อ การเก็บ persistent identifiers ร่วมกับ transcripts จะเพิ่มความเสี่ยงอย่างเป็นระบบ เพราะข้อมูลบริบทสามารถทำให้ข้อมูลที่ถูกมองว่าเป็นนิรนามกลับมาระบุตัวตนได้
มาตรการด้านเทคนิคที่ลดความเสี่ยงควรนำมาปฏิบัติแบบหลายชั้น (defense in depth) และประกอบด้วยแนวปฏิบัติดังนี้:
- การเข้ารหัสทั้งในระหว่างการส่งข้อมูลและขณะพัก (TLS และ encryption at rest) พร้อมการจัดการกุญแจ (key management) ที่เข้มงวดเพื่อลดความเสี่ยงจากการดักฟังและการเข้าถึงข้อมูลโดยไม่ได้รับอนุญาต
- Retention policy ที่ชัดเจนและน้อยที่สุด (data minimization) — กำหนดระยะเวลาการเก็บข้อมูลขั้นต่ำพอจำเป็นและลบข้อมูลที่ไม่จำเป็นอย่างเป็นระบบ รวมถึงการทำ secure deletion ใน backup และ snapshot
- การลดการเก็บข้อมูลเชิงละเอียด (logging minimization และ redaction) — ตัดหรือปกปิดข้อมูลเซนซิทีฟโดยอัตโนมัติก่อนจัดเก็บ เช่น การลบ PII จาก transcripts หรือการแทนที่ด้วย tokenization
- เทคนิคความเป็นส่วนตัวเชิงคณิตศาสตร์ เช่น differential privacy ในการนำข้อมูลตัวอย่างไปฝึกหรือวิเคราะห์ เพื่อให้การเปิดเผยข้อมูลส่วนบุคคลเป็นไปในระดับที่ไม่สามารถระบุตัวตนได้อย่างมีนัยสำคัญ
- มาตรการควบคุมการเข้าถึงและการตรวจสอบ — ใช้ RBAC, least privilege, การตรวจสอบการเข้าถึงแบบเรียลไทม์, audit logs และการตรวจสอบภายนอก (third-party audits / compliance เช่น SOC2, ISO27001)
ท้ายที่สุด การลดความเสี่ยงต้องควบคู่กับนโยบายความโปร่งใสและการได้มาซึ่งความยินยอมที่ชัดเจนต่อผู้ใช้ โดยบริษัทควรจัดให้มีการประเมินความเสี่ยงเป็นระยะ (periodic privacy impact assessment), การจำลองสถานการณ์รั่วไหล (breach simulation) และแผนตอบโต้เหตุการณ์ (incident response) ที่รวมขั้นตอนการแจ้งผู้ใช้และหน่วยงานกำกับดูแล เมื่อพิจารณาร่วมกันแล้ว กลยุทธ์ทางเทคนิคและนโยบายที่เข้มแข็งสามารถลดโอกาสที่โหมดผู้ใหญ่ของ ChatGPT จะกลายเป็นต้นเหตุของการตรวจสอบหรือการละเมิดความเป็นส่วนตัวในวงกว้างได้อย่างมีประสิทธิภาพ
มิติทางกฎหมายและการกำกับดูแล
กรอบกฎหมายหลักที่เกี่ยวข้อง
การเปิดใช้ โหมดผู้ใหญ่ ในระบบสนทนาอัตโนมัติ เช่น ChatGPT เข้าสู่พื้นที่ที่ถูกควบคุมโดยหลายกรอบกฎหมาย ทั้งที่เกี่ยวข้องกับการคุ้มครองข้อมูลส่วนบุคคล กฎเกณฑ์ควบคุมเนื้อหาเชิงเพศ/ผู้ใหญ่ และกฎหมายคุ้มครองเด็ก ตัวอย่างกฎหมายสำคัญได้แก่ พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (เช่น EU GDPR) ซึ่งกำหนดหลักการความชอบด้วยกฎหมายของการประมวลผล การทำ Data Protection Impact Assessment (DPIA) และสิทธิของผู้ใช้ เช่น สิทธิขอเข้าถึง/ลบข้อมูล และบทลงโทษทางการเงินสูงสุดถึง 4% ของรายได้รวมทั่วโลกหรือ €20 ล้าน (แล้วแต่จำนวนใดสูงกว่า) นอกจากนี้ กฎหมายของสหรัฐฯ เช่น CCPA/CPRA ในแคลิฟอร์เนีย และบทบาทของ FTC ในการคุ้มครองผู้บริโภค ยังอาจบังคับใช้เมื่อมีการรวบรวมข้อมูลหรือการโฆษณาที่เป็นการละเมิดสิทธิผู้บริโภค
ในมิติของการควบคุมเนื้อหา เชิงโครงสร้างมีกรอบใหม่ที่สำคัญ เช่น EU Digital Services Act (DSA) ที่บังคับใช้ความรับผิดชอบของผู้ให้บริการแพลตฟอร์ม ระบบค้นหา และผู้ให้บริการออนไลน์ขนาดใหญ่ (VLOPs) ให้จัดการความเสี่ยงจากเนื้อหาที่เป็นอันตรายและโปร่งใสเรื่องอัลกอริทึม นอกจากนั้น กฎหมายเฉพาะเรื่องการค้ามนุษย์ทางเพศและการจูงใจทางเพศ เช่น FOSTA-SESTA ในสหรัฐฯ ได้ตัดทอนความคุ้มครองบางประการจากมาตรา 230 ทำให้แพลตฟอร์มมีความเสี่ยงถูกฟ้องเมื่อเกี่ยวข้องกับการค้ามนุษย์หรือการกระทำผิดทางเพศ
แนวปฏิบัติของหน่วยงานกำกับดูแลในภูมิภาคต่างๆ
หน่วยงานกำกับดูแลทั่วโลกมีแนวปฏิบัติและแนวทางการบังคับใช้ที่แตกต่างกัน แต่มีแนวโน้มร่วมกันคือการเพิ่มการตรวจสอบและการออกคำสั่งเชิงบังคับ เมื่อเทคโนโลยีใหม่สร้างความเสี่ยงต่อผู้บริโภคและเด็ก
- สหรัฐอเมริกา: หน่วยงานเช่น FTC และอัยการรัฐ (State Attorneys General) มักใช้อำนาจสอบสวน การออกคำสั่งยุติการกระทำ (cease-and-desist) หรือการฟ้องร้องในกรณีที่มีการโฆษณาฉ้อฉล การละเมิดข้อมูลส่วนบุคคล หรือการนำเด็กมาเกี่ยวข้อง นอกจากนี้ กรณีที่เกี่ยวกับการค้ามนุษย์ทางเพศอาจถูกดำเนินคดีตาม FOSTA-SESTA ซึ่งลดภูมิคุ้มกันตามข้อกฎหมายแพลตฟอร์ม
- สหภาพยุโรป/สหราชอาณาจักร: ภายใต้ GDPR และ DSA หน่วยงานคุ้มครองข้อมูล (DPA) และหน่วยงานกำกับดูแลแพลตฟอร์ม (เช่น Ofcom ในสหราชอาณาจักร) สามารถสั่งระงับบริการ สั่งปรับ และกำหนดมาตรการแก้ไขได้ ตัวอย่างการปฏิบัติรวมถึงการบังคับให้ดำเนินการ DPIA การเรียกข้อมูลการทำงานของอัลกอริทึม และการกำหนดมาตรการปกป้องผู้เยาว์
- เอเชีย (จีน อินเดีย เกาหลี ญี่ปุ่น สิงคโปร์): หลายประเทศในเอเชียมีกฎหมายที่เข้มงวดด้านข้อมูลและการควบคุมเนื้อหา เช่น จีนมี PIPL และกฎหมายความมั่นคงข้อมูล ซึ่งให้อำนาจในการสั่งระงับ บล็อก หรือกำหนดการเก็บข้อมูลในประเทศได้ อินเดียผ่านกฎระเบียบ IT Rules ที่บังคับให้แพลตฟอร์มจัดตั้งเจ้าหน้าที่รับเรื่องร้องเรียนและอาจสั่งให้ลบหรือระงับการให้บริการได้ทันที กรณีละเมิดอาจนำไปสู่การปรับขั้นรุนแรงหรือการถูกบล็อกบริการในตลาดสำคัญ
ความเสี่ยงทางกฎหมายและผลกระทบทางการตลาด
การเปิดตัวโหมดผู้ใหญ่โดยปราศจากการเตรียมการทางกฎหมายที่เพียงพอสามารถนำมาซึ่งความเสี่ยงหลายด้าน ได้แก่:
- การฟ้องร้องเรียกค่าเสียหายและคดีรวมกลุ่ม (class actions): ผู้ใช้หรือผู้ปกครองอาจฟ้องแพลตฟอร์มโดยอ้างการละเมิดข้อมูลส่วนบุคคล การเปิดเผยข้อมูลเด็ก หรือการละเมิดกฎหมายคุ้มครองผู้บริโภค
- บทลงโทษทางปกครองและการสั่งระงับบริการ: หน่วยงานกำกับดูแลสามารถสั่งปรับตาม GDPR/DSA/PIPL หรือสั่งระงับบางฟีเจอร์จนกว่าจะแก้ไข ซึ่งอาจส่งผลโดยตรงต่อรายได้และการเข้าถึงผู้ใช้งานในตลาดสำคัญ (เช่น ยุโรปและจีน)
- ผลกระทบด้านภาพลักษณ์และการตลาด: การวิพากษ์วิจารณ์ด้านความปลอดภัยของเด็กหรือการรั่วไหลของข้อมูลอาจนำไปสู่การถอนโฆษณาจากแบรนด์ใหญ่ การสูญเสียพันธมิตรธุรกิจ และการลดลงของผู้ใช้งาน ตัวอย่างเหตุการณ์ก่อนหน้าแสดงให้เห็นว่าเหตุวิกฤตจุดความเชื่อมั่นอาจลดมูลค่าบริษัทในตลาดได้อย่างรวดเร็ว
- ความเสี่ยงทางอาญา: หากระบบถูกใช้เป็นเครื่องมือในการค้ามนุษย์ทางเพศหรือการกระทำผิดร้ายแรง หน่วยงานอาจใช้มาตรการทางอาญาต่อผู้ให้บริการหรือผู้บริหารได้ โดยเฉพาะเมื่อมีพฤติการณ์ละเลยอย่างร้ายแรง
บทสรุปเชิงปฏิบัติสำหรับผู้ให้บริการ
เพื่อบรรเทาความเสี่ยงทางกฎหมาย บริษัทที่พัฒนาโหมดผู้ใหญ่ควรดำเนินมาตรการเชิงรุก ได้แก่ การทำ DPIA สำหรับฟีเจอร์ ผู้ตรวจสอบการปฏิบัติตามกฎหมายระดับภูมิภาค (regulatory mapping) การใช้เทคโนโลยียืนยันอายุที่มีมาตรฐาน การจำกัดการเก็บข้อมูลและกำหนดนโยบายการลบข้อมูลชัดเจน รวมถึงการจัดทำโปรโตคอลตอบสนองต่อคำสั่งจากหน่วยงาน (takedown and compliance playbook) การเตรียมเอกสารความโปร่งใสเกี่ยวกับอัลกอริทึมและกระบวนการตัดสินใจ และการทำประกันความรับผิดเพื่อรองรับความเสี่ยงทางกฎหมายที่อาจเกิดขึ้น
ผลกระทบต่อผู้ใช้และสังคม: พฤติกรรม เสี่ยงต่อการละเมิด และความเชื่อมั่น
ผลกระทบต่อผู้ใช้และสังคม: พฤติกรรม เสี่ยงต่อการละเมิด และความเชื่อมั่น
ความเชื่อมั่นของผู้ใช้ เป็นปัจจัยสำคัญที่กำหนดการยอมรับและการใช้งานผลิตภัณฑ์ดิจิทัล เมื่อโหมดผู้ใหญ่ของ ChatGPT เปิดช่องให้เข้าถึงเนื้อหาที่มีความเสี่ยงเชิงเพศหรือเนื้อหาที่อาจละเมิดได้โดยง่าย ผู้ใช้บางกลุ่มจะรู้สึกไม่มั่นใจในความปลอดภัยของแพลตฟอร์ม ส่งผลต่อการตัดสินใจใช้งานต่อเนื่องหรือการแนะนำแพลตฟอร์มให้ผู้อื่น แม้บางกลุ่มอาจชื่นชมความสามารถของระบบ แต่ภาพรวมแล้วความเชื่อมั่นที่สั่นคลอนสามารถส่งผลด้านธุรกิจได้เช่นกัน ได้แก่ การลดอัตราการใช้งานรายวัน (DAU) การลดการสมัครสมาชิก และความเสี่ยงต่อความสัมพันธ์กับพันธมิตรทางธุรกิจ
งานวิจัยเชิงพฤติกรรมและการสำรวจผู้ใช้หลายชิ้น ชี้ว่าการเผชิญกับเนื้อหาไม่เหมาะสมมีผลต่อความรู้สึกเชื่อมั่นต่อแพลตฟอร์ม ซึ่งอาจลดลงในระดับที่มีนัยสำคัญ (ตัวเลขประมาณการจากการศึกษาเชิงเปรียบเทียบชี้ช่วงการลดความเชื่อมั่นไว้ที่ประมาณ 20–40% ขึ้นกับบริบทและการตอบสนองของผู้ให้บริการ) การลดความเชื่อมั่นเหล่านี้ยังเชื่อมโยงกับการเพิ่มการร้องเรียนต่อหน่วยงานกำกับดูแลและการรายงานต่อช่องทางช่วยเหลือภายในแพลตฟอร์ม
ความเสี่ยงทางสังคมและการ Normalization ของเนื้อหาไม่เหมาะสม โหมดผู้ใหญ่ที่เข้มงวดไม่เพียงแต่เพิ่มโอกาสการเข้าถึงเนื้อหาล่อแหลมหรือมุ่งร้าย แต่ยังเสี่ยงต่อการทำให้พฤติกรรมบางอย่างถูกมองว่าเป็นเรื่องปกติ (normalization) เมื่อผู้ใช้จำนวนมากได้สัมผัสหรือสร้างเนื้อหาลักษณะเดียวกันอย่างต่อเนื่อง ผลที่ตามมาอาจรวมถึง:
- การลดความไวต่อการคุกคามทางเพศออนไลน์ (desensitization) ซึ่งอาจเพิ่มความเสี่ยงต่อการกลั่นแกล้งทางเพศและการล่วงละเมิด
- การเพิ่มโอกาสที่เนื้อหาที่สร้างขึ้นจะถูกนำไปใช้เป็นเครื่องมือคุกคาม เช่น deepfake เชิงเพศ หรือการส่งภาพ/ข้อความไม่เหมาะสมโดยจงใจ
- ผลกระทบเชิงระบบต่อกลุ่มเสี่ยง เช่น เยาวชน ผู้ถูกล่วงละเมิดก่อนหน้า และผู้ด้อยโอกาสในการปกป้องตัวเอง
ตัวอย่างเคสศึกษาและแนวโน้มการร้องเรียน (ลักษณะเชิงตัวอย่างและการสังเคราะห์ข้อมูลจากหลายแหล่ง) แสดงให้เห็นรูปแบบผลกระทบที่เป็นไปได้ ดังนี้:
- เคสศึกษาที่ 1 (ตัวอย่างเชิงบริบท): ผู้ใช้รายหนึ่งนำโหมดผู้ใหญ่มาสร้างข้อความ/ภาพจำลองเชิงเพศของบุคคลสาธารณะ ส่งผลให้เกิดการถกเถียงทางสาธารณะและคำร้องเรียนจากผู้ถูกกล่าวอ้าง ซึ่งฝ่ายแพลตฟอร์มต้องเร่งปรับนโยบายและลบเนื้อหาออกในเวลาสั้น
- เคสศึกษาที่ 2 (ตัวอย่างการใช้งานเชิงบริการ): ธุรกิจที่ทดสอบการผสานรวมโหมดผู้ใหญ่ในแชทบอตสำหรับลูกค้า พบว่ามีการแจ้งปัญหาจากลูกค้ารายย่อยเกี่ยวกับคำตอบที่ไม่เหมาะสม ธุรกิจจึงระงับการเปิดตัวและทบทวนนโยบายความเสี่ยงก่อนเดินหน้าต่อ
- แนวโน้มการร้องเรียน: แม้ตัวเลขเฉพาะจะแตกต่างกันไปตามผู้ให้บริการ แต่ผู้ดูแลแพลตฟอร์มรายใหญ่และหน่วยงานกำกับดูแลรายงานการเพิ่มขึ้นของการแจ้งเตือน/ร้องเรียนเกี่ยวกับเนื้อหาเชิงเพศหรือเนื้อหาที่เข้าข่ายละเมิดหลังมีการเปิดใช้ฟีเจอร์ที่ผ่อนปรนมาตรการควบคุม
ผลกระทบเชิงสังคมเหล่านี้ชี้ชัดว่าการเปิดหรือปรับปรุงโหมดที่สามารถเข้าถึงเนื้อหาอ่อนไหวต้องมาพร้อมกลไกการกำกับดูแล การตรวจสอบและการสื่อสารกับผู้ใช้ที่ชัดเจน เพื่อรักษาความเชื่อมั่น ลดความเสี่ยงการละเมิด และป้องกันการ Normalization ของพฤติกรรมที่เป็นอันตรายต่อผู้ใช้และชุมชนดิจิทัลโดยรวม
แนวทางปฏิบัติและมาตรการบรรเทา: สำหรับผู้พัฒนาและผู้กำกับดูแล
แนวทางปฏิบัติและมาตรการบรรเทา: สำหรับผู้พัฒนาและผู้กำกับดูแล
ภาพรวมเชิงปฏิบัติ: เพื่อจัดการความเสี่ยงที่มาจากฟีเจอร์ "โหมดผู้ใหญ่" ของโมเดลภาษาขนาดใหญ่ จำเป็นต้องมีแนวทางผสมผสานระหว่างมาตรการทางเทคนิค นโยบายผลิตภัณฑ์ และกรอบกำกับดูแลเชิงสถาบัน ตั้งแต่การออกแบบระบบจนถึงการนำไปใช้จริง ผู้พัฒนาและผู้กำกับดูแลควรยึดหลัก privacy-by-design และ safety-by-design เป็นพื้นฐาน โดยออกแบบการเก็บข้อมูล คอนโทรลการเข้าถึง และกระบวนการตรวจสอบผลกระทบความเป็นส่วนตัวตั้งแต่ต้น
มาตรการทางเทคนิคที่แนะนำ: การลดความเสี่ยงเชิงเนื้อหาและการใช้งานที่ไม่เหมาะสมต้องประกอบด้วยหลายชั้นของการป้องกัน เช่น
- Fine-tuning เพื่อความปลอดภัย: ใช้ชุดข้อมูลคัดกรองและการเรียนรู้แบบมีผู้ชี้แนะ (e.g., RLHF/RLHF-safety) เพื่อลดการสร้างเนื้อหาที่เป็นอันตรายหรือผิดกฎหมาย รวมทั้งดำเนินการทดสอบความไว (sensitivity testing) และวัดประสิทธิภาพด้วยเมตริกเชิงคุณภาพและเชิงปริมาณ เช่น อัตราการสร้างเนื้อหาไม่พึงประสงค์ (false negative rate) และอัตราการป้องกันเนื้อหาที่เหมาะสม (precision/recall)
- Content filters และ safety classifiers หลายชั้น: ปรับใช้ตัวกรองก่อน-หลัง-ภายใน (pre-generation, in-flight, post-generation) เพื่อจับกลุ่มคำร้องขอที่เสี่ยง ใช้การผสมผสานระหว่างกฎ (rule-based) และโมเดลที่เรียนรู้ได้ และตั้งค่าธรณีต่อความเสี่ยงที่ชัดเจน
- Logging policy ที่มีการคุ้มครองข้อมูล: บันทึกรายการคำร้องขอ (request metadata), การตัดสินใจของฟิลเตอร์, และเหตุการณ์ความผิดปกติ โดยต้องมีการทำงานร่วมกับแนวทางคุ้มครองข้อมูล เช่น การทำ pseudonymization/aggregation, จำกัดระยะเวลาการเก็บข้อมูล (data retention policy) และควบคุมการเข้าถึงด้วยบทบาท (role-based access control) พร้อมบันทึกการเข้าถึง (access logs) และการตรวจสอบการใช้งาน
- Red teaming และ adversarial testing อย่างสม่ำเสมอ: จัดชุดทดสอบเชิงรุกที่เลียนแบบการใช้งานในทางที่ผิด รวมทั้งสคริปต์โจมตีหลายรูปแบบเพื่อค้นหาช่องโหว่ และจัดทำรายงานผลพร้อมแผนแก้ไข (remediation plan)
- Human-in-the-loop และ escalation paths: สำหรับคำร้องขอที่มีความเสี่ยงสูง ให้มีการตรวจสอบโดยมนุษย์หรือกระบวนการยกระดับเพื่อป้องกันการตัดสินใจอัตโนมัติที่อาจก่อให้เกิดผลกระทบร้ายแรง
นโยบายผลิตภัณฑ์และการตั้งค่าเริ่มต้น (defaults): บริษัทที่พัฒนาและให้บริการต้องออกแบบการเปิดใช้ฟีเจอร์ที่เสี่ยงให้เป็น default-off โดยผู้ใช้ต้องยินยอม (explicit opt-in) หลังผ่านกระบวนการยืนยันอายุและเงื่อนไขการใช้งานที่ชัดเจน นโยบายที่แนะนำได้แก่
- Default-off สำหรับฟีเจอร์เสี่ยง: เปิดใช้งานเฉพาะผู้ใช้ที่ผ่านการยืนยันอายุอย่างเข้มงวดและยอมรับข้อจำกัดการใช้งาน
- Age verification ที่เข้มงวด: ผสานวิธีการตรวจสอบหลายชั้น เช่น การยืนยันตัวตนด้วยเอกสาร, บริการยืนยันบุคคลภายนอก (trusted third-party identity verification), และการตรวจสอบแบบซ้อนเพื่อหลีกเลี่ยงการปลอมแปลง นอกจากนี้ควรกำหนดมาตรการปกป้องข้อมูลส่วนบุคคลตามหลัก minimization
- Safety knobs และ control panel สำหรับผู้ดูแลระบบ: ให้ผู้ดูแลองค์กรสามารถตั้งค่าความเข้มข้นของฟิลเตอร์, ระดับการตรวจสอบโดยมนุษย์, และนโยบายการเก็บข้อมูลตามความเสี่ยงของการใช้งานภายใน
- ชัดเจนในแผนการสื่อสารกับผู้ใช้: แจ้งให้ผู้ใช้ทราบถึงความเสี่ยง ขอบเขตการใช้งาน และช่องทางรายงานปัญหาอย่างโปร่งใส
ข้อเสนอเชิงนโยบายระดับรัฐและอุตสาหกรรม: การควบคุมเฉพาะทางที่มีประสิทธิผลต้องผสานการกำกับดูแลภาครัฐกับมาตรฐานอุตสาหกรรมดังนี้
- การรายงานความเสี่ยงและ transparency reporting: บังคับให้ผู้ให้บริการจัดทำรายงานความปลอดภัยและความเสี่ยงเป็นประจำ (เช่น รายไตรมาสหรือรายปี) ซึ่งต้องรวมตัวชี้วัดสำคัญ เช่น จำนวนคำร้องขอที่ถูกบล็อก, สถานการณ์การละเมิด, ผลจาก red team, และมาตรการแก้ไขที่ดำเนินการ รายงานควรเผยแพร่ต่อสาธารณะในรูปแบบที่เข้าใจได้สำหรับผู้ใช้งานและผู้กำกับดูแล
- Sandboxing ของฟีเจอร์และ staged rollouts: กำหนดกรอบการเปิดตัวฟีเจอร์ใหม่ในสภาพแวดล้อมจำกัด (sandbox) เพื่อประเมินผลกระทบจริงก่อนขยายการใช้งานจริง รวมถึงการใช้ canary deployment และการติดตามตัวชี้วัดความปลอดภัยแบบเรียลไทม์
- การมีส่วนร่วมของภายนอกและการตรวจสอบอิสระ: กำหนดให้มีการตรวจสอบโดยบุคคลภายนอก (independent audits) โดยหน่วยงานที่เป็นกลาง ทั้งในด้านความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตามกฎหมาย เช่น ตรวจสอบโค้ดบางส่วน กระบวนการทำ red teaming และนโยบายการจัดการข้อมูล ควรกำหนดความถี่ (เช่น ขั้นต่ำปีละครั้ง) และเผยแพร่ผลการตรวจสอบสรุปเป็นรายงานสาธารณะ
- มาตรฐานการรับรองและการประเมินผลกระทบ: พัฒนามาตรฐานอุตสาหกรรมร่วมกับผู้มีส่วนได้เสีย (regulators, academe, civil society) สำหรับการประเมินผลกระทบด้านความปลอดภัยและความเป็นส่วนตัว (e.g., AI Safety Impact Assessment, DPIA) ก่อนการเปิดตัวฟีเจอร์ที่มีความเสี่ยง
การดำเนินการเชิงปฏิบัติและการเตรียมตอบสนองต่อเหตุฉุกเฉิน: ควรมีแผนตอบสนองต่อเหตุการณ์ความปลอดภัย (incident response) ที่รวมถึงการระบุผู้รับผิดชอบ การจัดลำดับความสำคัญของเหตุการณ์ การสื่อสารภายในและภายนอก รวมทั้งมาตรการฟื้นฟูระบบ นอกจากนี้ควรกำหนดช่องทางให้ผู้ใช้งานและบุคคลภายนอกสามารถรายงานปัญหาได้ง่ายและมีการติดตามผลอย่างเป็นระบบ
สรุปเชิงนโยบาย: การบริหารจัดการ "โหมดผู้ใหญ่" หรือฟีเจอร์เสี่ยงอื่น ๆ ต้องไม่ใช่การตัดสินใจของฝ่ายเทคนิคเพียงอย่างเดียว แต่ต้องเป็นความร่วมมือระหว่างผู้พัฒนา ภาคธุรกิจ ผู้กำกับดูแล และสังคม เพื่อให้เกิดระบบที่ปลอดภัย โปร่งใส และคุ้มครองสิทธิ์ของผู้ใช้ โดยใช้แนวทางกลยุทธ์หลายชั้นที่รวมทั้งมาตรการทางเทคนิค นโยบายผลิตภัณฑ์ และกรอบกำกับดูแลระดับชาติและอุตสาหกรรม
ทิศทางในอนาคตและคำแนะนำเชิงนโยบาย
ทิศทางการกำกับดูแลทั่วโลก
ในระยะ 2–5 ปีข้างหน้า คาดว่าจะเห็นความเข้มข้นของกฎระเบียบที่เกี่ยวข้องกับฟีเจอร์ที่มีความเสี่ยงสูงของระบบปัญญาประดิษฐ์ (AI) มากขึ้น โดยเฉพาะฟีเจอร์ที่เกี่ยวข้องกับเนื้อหาสำหรับผู้ใหญ่ การเปิดเผยข้อมูลที่อาจละเมิดสิทธิส่วนบุคคล และการให้คำแนะนำที่อาจเกิดอันตรายได้ ประเทศต่างๆ ที่มีเศรษฐกิจดิจิทัลขนาดใหญ่และตลาดผู้บริโภคที่เข้มแข็ง เช่น สหภาพยุโรป สหรัฐอเมริกา สหราชอาณาจักร และจีน ได้เริ่มออกแนวปฏิบัติหรือกฎหมายเพื่อกำกับดูแล AI อยู่แล้ว และแนวโน้มนี้มีแนวโน้มขยายตัวเป็นวงกว้างมากขึ้น
หนึ่งในทิศทางสำคัญคือการแบ่งตลาดตามมาตรฐานความปลอดภัย (safety-tiering) — โมเดลหรือผลิตภัณฑ์ที่ผ่านการรับรองมาตรฐานความปลอดภัยจะได้รับการยอมรับและเข้าถึงตลาดได้กว้างขึ้น ขณะเดียวกันผลิตภัณฑ์ที่ไม่ผ่านการทดสอบจะถูกจำกัดการใช้งานหรือต้องมีการติดป้ายเตือนชัดเจน นอกจากนี้ กฎข้อบังคับมักจะบังคับให้มีการรายงานเหตุการณ์ความเสี่ยง (incident reporting) การประเมินผลกระทบด้านสิทธิมนุษยชน และการตรวจสอบโดยบุคคลที่สามก่อนวางจำหน่าย
คำแนะนำเชิงนโยบายสำหรับรัฐบาลและหน่วยงานกำกับดูแล
- ใช้กรอบความเสี่ยงเป็นหลัก (risk-based approach): กำหนดนิยามชัดเจนว่าอะไรคือ "ฟีเจอร์เสี่ยงสูง" เช่น ฟีเจอร์ที่ส่งผลต่อความปลอดภัยร่างกาย ความเป็นส่วนตัว หรือการเลือกปฏิบัติ และปรับระดับการกำกับตามความรุนแรงของความเสี่ยง
- สร้างมาตรฐานการรับรองและการตรวจสอบที่ชัดเจน: กำหนดกระบวนการทดสอบก่อนวางตลาด (pre-market testing) และการตรวจสอบหลังวางตลาด (post-market surveillance) รวมถึงเปิดช่องให้บุคคลที่สามสามารถตรวจสอบได้
- ส่งเสริมความร่วมมือระหว่างประเทศ: พัฒนากรอบการร่วมมือข้ามพรมแดนเพื่อจัดการกับโมเดลที่ให้บริการหลายประเทศ เช่น การยอมรับการรับรองร่วมและการแลกเปลี่ยนข้อมูลการละเมิด
- สนับสนุนการทดลองเชิงควบคุม (regulatory sandboxes): เปิดพื้นที่ให้ผู้พัฒนาสามารถทดสอบฟีเจอร์ใหม่ภายใต้มาตรการควบคุมที่กำหนด เพื่อเรียนรู้ผลกระทบจริงก่อนขยายสู่ตลาด
- เน้นความโปร่งใสและการมีส่วนร่วมของสาธารณะ: บังคับให้ผู้ให้บริการเปิดเผยรายงานความปลอดภัย รายงานความเสี่ยง และช่องทางรับฟังข้อร้องเรียนจากผู้ใช้ เพื่อเพิ่มความไว้วางใจในระบบกำกับ
- เพิ่มความสามารถของหน่วยงานกำกับ: ลงทุนในการฝึกอบรม แรงงานเชิงเทคนิค และทรัพยากรเพื่อตรวจสอบระบบ AI อย่างมีประสิทธิภาพ รวมถึงการใช้เครื่องมืออัตโนมัติสำหรับการตรวจประเมิน
คำแนะนำเชิงปฏิบัติสำหรับบริษัท AI และแนวทางสื่อสารกับผู้ใช้
- ออกแบบความปลอดภัยตั้งแต่ต้นทาง (safety-by-design): บรรจุการประเมินความเสี่ยง การทดสอบเชิงลึก (red-teaming) และการกำหนดข้อจำกัดการใช้งานลงในวงจรพัฒนาผลิตภัณฑ์
- จัดทำกระบวนการประเมินผลกระทบ (impact assessment): ประเมินผลด้านสิทธิส่วนบุคคล ความเสี่ยงต่อเด็ก และผลกระทบต่อสังคม พร้อมเอกสารผลการประเมินที่พร้อมให้ผู้กำกับตรวจสอบ
- นำมาตรการป้องกันเชิงเทคนิคมาใช้: เช่น การยืนยันอายุหรือการยืนยันตัวตนเมื่อเปิดใช้โหมดสำหรับผู้ใหญ่ การจำกัดการเข้าถึงข้อมูลที่อ่อนไหว และการใช้เทคนิคป้องกันข้อมูลส่วนบุคคล (privacy-preserving techniques)
- ยอมรับการตรวจสอบจากภายนอกและเผยแพร่รายงานความโปร่งใส: เปิดรับการสอบทานโดยบริษัทตรวจสอบอิสระ เผยแพร่รายงานความเป็นธรรม ความปลอดภัย และการเกิดเหตุการณ์ผิดพลาด (transparency reports) เป็นระยะ
- ออกแบบการสื่อสารที่ชัดเจนและเข้าใจง่าย: ใช้ภาษาที่ผู้ใช้ทั่วไปเข้าใจในการอธิบายความเสี่ยง เงื่อนไขการใช้งาน และการตั้งค่า เช่น ให้ผู้ใช้เลือกในรูปแบบ opt-in สำหรับฟีเจอร์ที่มีความเสี่ยง พร้อมคำอธิบายผลที่จะเกิดขึ้นอย่างชัดเจน
- เตรียมแผนตอบสนองต่อเหตุฉุกเฉินและช่องทางร้องเรียน: มีทีมรับมือเหตุการณ์ ดำเนินการสืบสวนภายใน และแจ้งผู้ใช้/หน่วยงานกำกับทันทีเมื่อตรวจพบข้อบกพร่องหรือการละเมิด
- ลงทุนในการสร้างความไว้วางใจผ่านการมีส่วนร่วมของชุมชน: เปิดเวทีรับฟังความคิดเห็นจากผู้ใช้ นักวิชาการ และองค์กรภาคประชาสังคม เพื่อปรับปรุงนโยบายและการออกแบบผลิตภัณฑ์อย่างต่อเนื่อง
โดยสรุป การรับมือกับฟีเจอร์เสี่ยงของ AI เช่น "โหมดผู้ใหญ่" ต้องอาศัยทั้งมาตรการเชิงนโยบายและการปฏิบัติจากภาคเอกชน รัฐบาลควรเน้นกรอบการกำกับที่ยืดหยุ่นแต่ชัดเจน เพื่อส่งเสริมนวัตกรรมควบคู่กับการคุ้มครองสาธารณะ ขณะที่บริษัท AI ต้องยึดหลักความโปร่งใส ความรับผิดชอบ และการมีส่วนร่วมของผู้มีส่วนได้ส่วนเสีย เพื่อให้การเปลี่ยนผ่านเข้าสู่สภาพแวดล้อมดิจิทัลที่ปลอดภัยและยั่งยืนเป็นไปได้จริง
บทสรุป
กรณี "โหมดผู้ใหญ่" ของ ChatGPT แสดงให้เห็นว่าเหตุการณ์ที่ดูเหมือนเป็นปัญหาฝั่งผลิตภัณฑ์เพียงอย่างเดียว กลับเป็นสัญญาณชัดเจนว่าฟีเจอร์ AI ที่มีความเสี่ยงจะถูกจับตามองอย่างใกล้ชิดทั้งในมิติทางเทคนิค กฎหมาย และสังคม ผู้มีส่วนได้เสียตั้งคำถามเกี่ยวกับความปลอดภัย การป้องกันการใช้งานในทางที่ผิด ความเป็นส่วนตัว และผลกระทบต่อเยาวชน ส่งผลให้การพิจารณาเรื่องนี้ขยายออกไปจากการแก้บั๊กหรือปรับอินเทอร์เฟซสู่การพิจารณากรอบความรับผิดชอบและมาตรฐานเชิงกฎระเบียบที่ชัดเจนยิ่งขึ้น
การรับมือที่มีประสิทธิภาพต้องเป็นการผสมผสานระหว่างมาตรการทางเทคนิค เช่น การทดสอบความปลอดภัย (red‑teaming), การติดตามและบันทึกกิจกรรมเชิงพฤติกรรม, และการจำกัดขอบเขตความสามารถของโมเดล กับนโยบายการออกแบบที่ปลอดภัย (safe‑by‑design) และกรอบกำกับดูแลที่โปร่งใส เช่น การเปิดเผยนโยบายการใช้งาน การตรวจสอบโดยภายนอก และการบังคับใช้กฎหมายที่ชัดเจน นอกจากนี้ การมีส่วนร่วมของภาคประชาสังคม ผู้เชี่ยวชาญทางจริยธรรม และผู้ใช้เองเป็นสิ่งจำเป็นเพื่อให้การกำกับดูแลสะท้อนค่านิยมสาธารณะและลดความเสี่ยงเชิงสังคมในระยะยาว
ในมุมมองอนาคต คาดว่าจะเห็นการคุมเข้มด้านกฎเกณฑ์และมาตรฐานสากลที่มากขึ้น รวมถึงการขยายบทบาทของการตรวจสอบอิสระและการรับรองความปลอดภัยของระบบ AI บริษัทเทคโนโลยีจึงต้องเตรียมพร้อมด้วยกระบวนการออกแบบที่คำนึงถึงผลกระทบเชิงสังคม การรายงานที่โปร่งใส และการร่วมมือกับหน่วยงานกำกับดูแลและภาคประชาสังคมเพื่อสร้างความไว้วางใจร่วมกัน โหมดผู้ใหญ่จึงไม่ใช่ปัญหาชั่วคราว แต่เป็นจุดเปลี่ยนที่ย้ำว่าอนาคตของ AI ต้องการการกำกับดูแลเชิงรุกและความรับผิดชอบระดับระบบ
📰 แหล่งอ้างอิง: WIRED



