
สตาร์ทอัพไทยประกาศเปิดตัวแพลตฟอร์มใหม่ชื่อ "Multimodal Time‑Series LLM" ซึ่งมุ่งใช้ปัญญาประดิษฐ์ระดับภาษาขนาดใหญ่ที่ปรับแต่งสำหรับข้อมูลเชิงเวลา เพื่อวิเคราะห์สัญญาณเซนเซอร์จากโรงงานแบบเรียลไทม์ โดยผสานข้อมูลหลายมิติทั้งสัญญาณสั่นสะเทือน อุณหภูมิ เสียง และภาพจากกล้องวงจรปิด เพื่อคาดการณ์ความล้มเหลวของอุปกรณ์ก่อนที่จะเกิดเหตุจริง ช่วยให้ผู้ผลิตสามารถวางแผนการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) ลดเวลาเครื่องจักรหยุดทำงาน (downtime) และเพิ่มประสิทธิภาพการผลิตในภูมิภาคได้อย่างมีนัยสำคัญ

จุดเด่นสำคัญ ของแพลตฟอร์มนี้คือการประมวลผลสตรีมข้อมูลแบบเรียลไทม์ด้วยโมเดล LLM ที่รองรับข้อมูลแบบ time‑series หลายรูปแบบ พร้อมฟีเจอร์แจ้งเตือนล่วงหน้า วิเคราะห์สาเหตุเบื้องต้น และเชื่อมต่อกับระบบบำรุงรักษาอัตโนมัติ (CMMS/ERP) ผู้พัฒนาระบุว่าในการทดสอบภาคสนามเบื้องต้น แพลตฟอร์มสามารถช่วยลด downtime ได้ถึง 30–50% และลดต้นทุนการบำรุงรักษาประมาณ 20–40% ซึ่งหากขยายการใช้งานในโรงงานขนาดใหญ่จะส่งผลต่อการลดการสูญเสียรายได้จากการหยุดเครื่องจักรและเพิ่มอัตราการใช้งานของทรัพย์สิน (asset utilization) ได้อย่างมีนัยสำคัญ บทความนี้จะพาไปทำความเข้าใจเทคโนโลยีเบื้องหลัง ตัวอย่างการใช้งานจริง และผลกระทบต่ออุตสาหกรรมการผลิตในภูมิภาค
บทนำ: ข่าวสำคัญและบริบทของสตาร์ทอัพ
บทนำ: ข่าวสำคัญและบริบทของสตาร์ทอัพ
SenseAI Labs (เซนส์เอไอ แล็บส์) สตาร์ทอัพสัญชาติไทยประกาศเปิดตัวแพลตฟอร์มใหม่ภายใต้ชื่อ “Multimodal Time‑Series LLM” ในไตรมาสแรกของปี 2026 ซึ่งออกแบบมาเพื่อวิเคราะห์สัญญาณเซนเซอร์จากโรงงานอุตสาหกรรมแบบเรียลไทม์และคาดการณ์ความล้มเหลวก่อนเกิดเหตุ โดยบริษัทระบุว่าโซลูชันนี้เป็นการผสานความสามารถด้านปัญญาประดิษฐ์เชิงลำดับเวลา (time‑series), การประมวลผลข้อมูลหลายรูปแบบ (multimodal) และโมเดลภาษาเชิงลำดับเพื่อให้คำอธิบายเชิงสาเหตุและคำแนะนำการบำรุงรักษาเชิงรุก
ความสำคัญของการเปิดตัวครั้งนี้อยู่ที่บริบทของอุตสาหกรรมการผลิตในไทยและอาเซียน ซึ่งยังเผชิญกับความท้าทายด้าน downtime ของเครื่องจักรและสายการผลิตที่สร้างผลกระทบต่อประสิทธิภาพและต้นทุนการผลิต การศึกษาหลายฉบับชี้ว่าเวลาหยุดทำงานที่ไม่คาดคิดเป็นหนึ่งในต้นทุนหลักของโรงงาน โดยสามารถลดผลผลิตและเพิ่มต้นทุนการบำรุงรักษาได้อย่างมีนัยสำคัญ ดังนั้นโซลูชันที่สามารถทำนายความผิดปกติและแนะนำการบำรุงรักษาล่วงหน้าจึงมีมูลค่าสูงต่อทั้งผู้ผลิตขนาดใหญ่และซัพพลายเชนในภูมิภาค
ตามที่ SenseAI Labs รายงาน ผลการทดสอบเบื้องต้นกับชุดข้อมูลจากโรงงานอิเล็กทรอนิกส์และโรงงานแปรรูปอาหารระบุว่าแพลตฟอร์มสามารถคาดการณ์ความล้มเหลวได้ล่วงหน้าระหว่าง 6 ชั่วโมงถึง 72 ชั่วโมง (6–72 ชั่วโมง) ขึ้นอยู่กับชนิดของเซนเซอร์และลักษณะความผิดปกติ พร้อมทั้งอ้างว่าสามารถลดช่วงเวลาหยุดทำงาน (downtime) ได้ระหว่าง 30–60% และลดต้นทุนการบำรุงรักษาเชิงป้องกันลงได้ตามลำดับ บริษัทเน้นว่าอัตราความแม่นยำและช่วงเวลาล่วงหน้าที่ได้จะขึ้นกับปริมาณข้อมูลเชิงประวัติ (historical data), คุณภาพสัญญาณเซนเซอร์ และการตั้งค่าระบบ
ความสามารถหลักของแพลตฟอร์มที่เป็นเหตุผลให้ข่าวนี้มีความสำคัญต่ออุตสาหกรรม ได้แก่
- Real‑time processing: การดึงข้อมูลและวิเคราะห์สัญญาณแบบสตรีมมิง เพื่อส่งการแจ้งเตือนทันทีเมื่อตรวจพบแนวโน้มความผิดปกติ
- Multimodal data fusion: รวมข้อมูลจากหลายแหล่ง เช่น สัญญาณสั่นสะเทือน (vibration), อุณหภูมิ, กระแสไฟฟ้า, เสียง และภาพเชิงวิชวล เพื่อให้การวิเคราะห์มีบริบทและความแม่นยำมากขึ้น
- Time‑Series LLM: ใช้สถาปัตยกรรมโมเดลเชิงลำดับที่ออกแบบพิเศษสำหรับข้อมูล time‑series ซึ่งสามารถเรียนรู้รูปแบบสาเหตุและผลลัพธ์ในช่วงเวลาต่าง ๆ และให้คำอธิบายเชิงสาเหตุพร้อมคำแนะนำการแก้ไข
- Integration & deployment: รองรับการเชื่อมต่อกับระบบ SCADA/PLC และการติดตั้งแบบ Edge หรือ Cloud เพื่อลดความหน่วงและรองรับโรงงานหลายไซต์
เทคโนโลยีเบื้องหลัง: อะไรคือ Multimodal Time‑Series LLM
เทคโนโลยีเบื้องหลัง: อะไรคือ Multimodal Time‑Series LLM
Multimodal Time‑Series LLM เป็นการผสานระหว่างแนวคิดของ Large Language Models (LLMs) กับความสามารถในการประมวลผลข้อมูลตามเวลา (time‑series) และข้อมูลจากหลายโมดัล (multimodal) เช่น สัญญาณสั่นสะเทือน (vibration), อุณหภูมิ (temperature), กระแสไฟฟ้า (current), เสียง (audio) และภาพ (image) เพื่อวิเคราะห์สภาวะของเครื่องจักรในโรงงานแบบเรียลไทม์ การรวมกันของโมดัลเหล่านี้ช่วยให้ระบบสามารถจับบริบทเชิงฟิสิกส์ได้ละเอียดกว่าการใช้โมดัลเดียว: ตัวอย่างเช่น การสั่นสะเทือนร่วมกับการเปลี่ยนแปลงกระแสไฟฟ้าอาจบ่งชี้ปัญหาทางกลไก ขณะที่การเปลี่ยนแปลงเสียงหรือภาพอาจยืนยันชนิดของความผิดปกติได้ชัดเจนขึ้น ความจำเป็นของ multimodal inputs ในสภาพแวดล้อมโรงงานมาจากความซับซ้อนของสาเหตุความล้มเหลวและเสียงรบกวน (noise) — การผสานข้อมูลหลายมิติช่วยเพิ่มความแม่นยำและลดอัตราการเตือนผิดพลาด (false alarms)
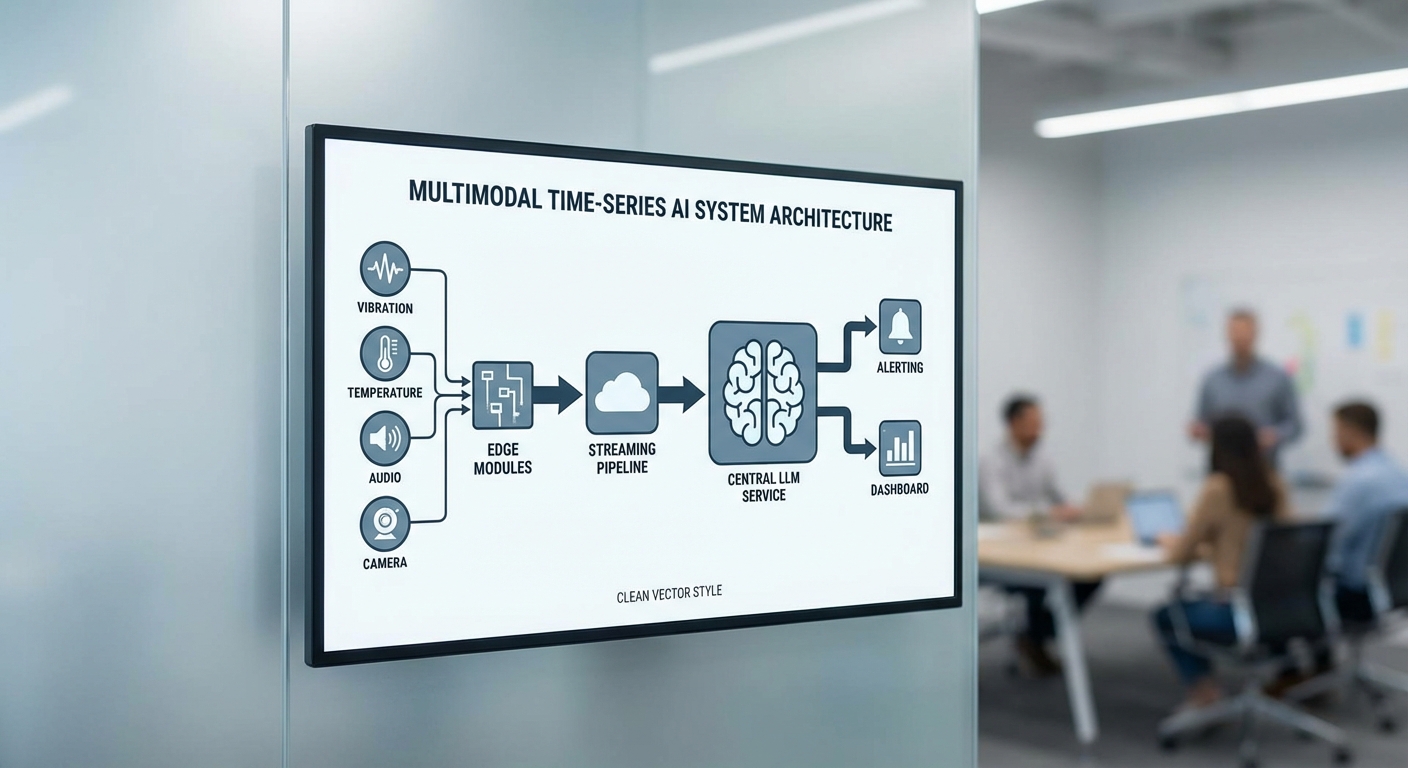
การแปลง time‑series ให้เป็น representation ที่ LLM สามารถประมวลผลได้ เป็นหัวใจสำคัญของสถาปัตยกรรมนี้ โดยทั่วไปจะประกอบด้วยชั้นของตัวเข้ารหัสเฉพาะโมดัล (modality‑specific encoders) แล้วแปลงผลออกมาเป็น token/embedding ที่เป็นมาตรฐานสำหรับตัวถอดรหัสร่วม (shared decoder) แนวทางที่ใช้บ่อยได้แก่:
- การแบ่งหน้าต่าง (windowing) และ patching: ตัดสัญญาณเวลาเป็นหน้าต่างสั้น ๆ (เช่น 100–1000 ms หรือ N ตัวอย่าง) แล้วแปลงหน้าต่างเป็น token แต่ละตัว เพื่อให้สามารถป้อนเข้าความสนใจแบบ Transformer ได้
- การแปลงสัญญาณเชิงเวลาสู่โดเมนความถี่: ใช้ STFT หรือ wavelet เพื่อแปลง audio/vibration เป็น spectrogram แล้วใช้ CNN หรือ patch‑embedding เพื่อสร้าง token ของความถี่‑เวลา
- encoder ชนิดเฉพาะโมดัล: ใช้ 1D‑CNN/TCN หรือ Transformer ย่อยสำหรับสัญญาณ time‑series, CNN/ViT สำหรับภาพ, และ CNN บน spectrogram สำหรับเสียง จากนั้นทำการแมปผลลัพธ์เป็น embedding ขนาดเดียวกัน
การจัดการ Temporal Information — เพื่อปรับ LLM ให้รองรับข้อมูลเชิงเวลา จะต้องป้อนบริบทเชิงลำดับอย่างมีประสิทธิภาพ เทคนิคหลัก ๆ ได้แก่:
- Positional encoding แบบซายนัส/โคไซน์หรือลักษณะเรียนรู้ได้ (learned positional embeddings) เพื่อให้โมเดลรับรู้ตำแหน่งเชิงเวลา
- Temporal embeddings เช่น time2vec, cyclic time features (ชั่วโมง/วันที่/ฤดูกาล) และ embedding ของเวลาอ้างอิง (timestamp) เพื่อถ่ายทอดพฤติกรรมตามรอบเวลา
- Relative positional encodings หรือ attention แบบเชิงเวลา (temporal attention) ที่ช่วยให้โมเดลจับความสัมพันธ์ระหว่างช่วงเวลาต่าง ๆ ได้แม่นยำกว่า absolute position เพียงอย่างเดียว
- Hierarchical temporal modeling โดยแยกการมองเห็นเป็นระดับสเกล (short‑term / medium‑term / long‑term) เพื่อจับทั้งสัญญาณชั่ววูบและแนวโน้มระยะยาว
กลยุทธ์การฝึกสอน (training) เพื่อให้โมเดลทนทานและใช้ได้จริงในโรงงานมักรวมหลายเทคนิค เช่น:
- Self‑supervised learning: ใช้ภารกิจเช่น masked signal modeling (ปิดข้อมูลบางส่วนแล้วให้โมเดลทำนาย), contrastive learning (จับคู่ augmentations ของสัญญาณจากเหตุการณ์เดียวกัน) และ forecasting (ทำนายหน้าต่างถัดไป) — วิธีเหล่านี้ช่วยให้เรียนรู้ representation ที่มีประโยชน์แม้ไม่มีป้ายกำกับจำนวนมาก
- Transfer learning และ fine‑tuning: ฝึกโมเดลขนาดใหญ่บนชุดข้อมูลอุตสาหกรรมข้ามโดเมน แล้วนำมา fine‑tune กับเครื่องจักรหรือไซต์เฉพาะ เพื่อเร่งเวลาในการใช้งานจริงและลดความต้องการข้อมูลป้ายกำกับ
- Data augmentation แบบเชิงสัญญาณ: เช่น การเพิ่มสัญญาณรบกวน, การเปลี่ยนช่วงความถี่, การยืด/ย่อเวลา (time‑stretch) เพื่อเพิ่มความทนทานต่อความแปรปรวนในสภาพสนามจริง
- Model compression & distillation: หลังจากฝึกบนคลาวด์ มักใช้การ distillation เพื่อย่อยโมเดลให้เล็กลงและเร็วขึ้นสำหรับ edge โดยยังคงความแม่นยำในระดับที่ยอมรับได้
การประมวลผลแบบขนานและสถาปัตยกรรมการให้บริการ (edge ↔ cloud) — ระบบที่ใช้งานจริงต้องออกแบบให้ตอบโจทย์เรียลไทม์ ปลอดภัย และคุ้มค่าทรัพยากร มาตรฐานสถาปัตยกรรมประกอบด้วยสามชั้นหลัก:
- Edge preprocessing: ทำการกรองสัญญาณ, การคำนวณฟีเจอร์เบื้องต้น (FFT, RMS, spectral features), การลดขนาดข้อมูล (compression/encoding) และการตรวจจับเหตุการณ์เบื้องต้น (lightweight anomaly detection) บนอุปกรณ์ขอบเครือข่ายเพื่อให้ลดแบนด์วิดท์และความหน่วง ตัวอย่างฮาร์ดแวร์ได้แก่ NVIDIA Jetson, Google Coral, หรือ microcontrollers ที่รองรับ NN accelerators — โดยเป้าหมาย latency ของ pipeline edge อาจต่ำกว่า 100–500 ms สำหรับการตอบสนองทันที
- Cloud aggregation & orchestration: ข้อมูลที่ผ่านการคัดกรองจะถูกส่งไปยังคลาวด์สำหรับการรวมข้อมูลจากหลายแหล่ง (site aggregation), การปรับโมเดลแบบรวม (federated aggregation / centralized retraining) และการวิเคราะห์เชิงลึก ปริมาณข้อมูลที่ส่งมักลดลงอย่างมากด้วย preprocessing — รายงานในภาคอุตสาหกรรมระบุว่าการกรองบน edge สามารถลดทราฟฟิกได้มากกว่า 90% ในบางกรณี
- Model serving & streaming inference: ให้บริการโมเดลแบบสตรีมมิงที่รองรับการประมวลผลแบบต่อเนื่อง (stateful inference) ด้วยกลยุทธ์เช่น sliding windows พร้อม overlap, recurrent memory หรือตัวจัดการสถานะ (streaming transformer) เพื่อรักษาบริบทข้ามหน้าต่าง การปรับใช้ใช้เทคนิค batching แบบไดนามิก, autoscaling และ model sharding เพื่อให้รองรับโหลดสูงในโรงงานขนาดใหญ่
ปฏิบัติการบน edge – ประสิทธิภาพและความปลอดภัย — เพื่อให้ตอบโจทย์เรียลไทม์และข้อจำกัดทรัพยากร ต้องใช้การบีบอัดโมเดล (quantization 8‑bit/4‑bit), pruning, และ lightweight attention mechanisms (เช่น Linformer, Performer) พร้อมมาตรการด้านความปลอดภัยเช่นการเข้ารหัสข้อมูลที่ถูกส่ง, การยืนยันอุปกรณ์ และนโยบายการเข้าถึงแบบ role‑based ทั้งนี้ การออกแบบต้องคำนึงว่าข้อผิดพลาดแบบ false negative มีผลทางธุรกิจสูง ดังนั้นต้องบาลานซ์ระหว่าง latency, ความแม่นยำ และความน่าเชื่อถือของระบบ
โดยสรุป Multimodal Time‑Series LLM เป็นส่วนผสมของ encoder เฉพาะโมดัล, เทคนิคการแทนค่าทางเวลา, กลยุทธ์การฝึกสอนแบบ self‑supervised/transfer learning และสถาปัตยกรรม edge‑to‑cloud ที่ออกแบบมาให้ทำงานแบบสตรีมมิงในสภาพแวดล้อมโรงงานจริง เมื่อออกแบบอย่างเหมาะสม ระบบเหล่านี้สามารถทำนายความล้มเหลวก่อนเกิดเหตุ ลด downtime และเพิ่มความต่อเนื่องของการผลิตได้ในระดับที่จับต้องได้ (ตัวอย่างเช่นการรายงานการลด downtime ระหว่าง 20–40% ในการปรับใช้งานเชิงพาณิชย์หลายกรณีศึกษา)
กรณีใช้งานจริง: ตัวอย่างการใช้งานและสถิติผลลัพธ์
กรณีใช้งานจริง: ตัวอย่างการใช้งานและสถิติผลลัพธ์
ในโครงการพิลอตที่ดำเนินการร่วมกับโรงงานอุตสาหกรรมผลิตอาหารและชิ้นส่วนยานยนต์ ทีมงานได้นำแพลตฟอร์ม Multimodal Time‑Series LLM ไปใช้งานเพื่อวิเคราะห์สัญญาณจากเซนเซอร์หลายรูปแบบ ได้แก่ สัญญาณสั่นสะเทือน (vibration), อุณหภูมิ, กระแสไฟฟ้า และสัญญาณเสียง (acoustic) บนมอเตอร์ ปั๊ม และสายพานลำเลียง ผลการประมวลผลเชิงลึกสามารถตรวจจับ pattern ของการสั่นสะเทือนที่บ่งชี้การเสื่อมสภาพของ bearing ได้และพยากรณ์ความล้มเหลวล่วงหน้า เฉลี่ย 48 ชั่วโมง (ช่วงทดสอบ 24–72 ชั่วโมง ขึ้นกับประเภทอุปกรณ์และความถี่ของการเก็บข้อมูล) ซึ่งเพียงพอสำหรับการวางแผนการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) แทนการรอให้เกิดเหตุฉุกเฉิน
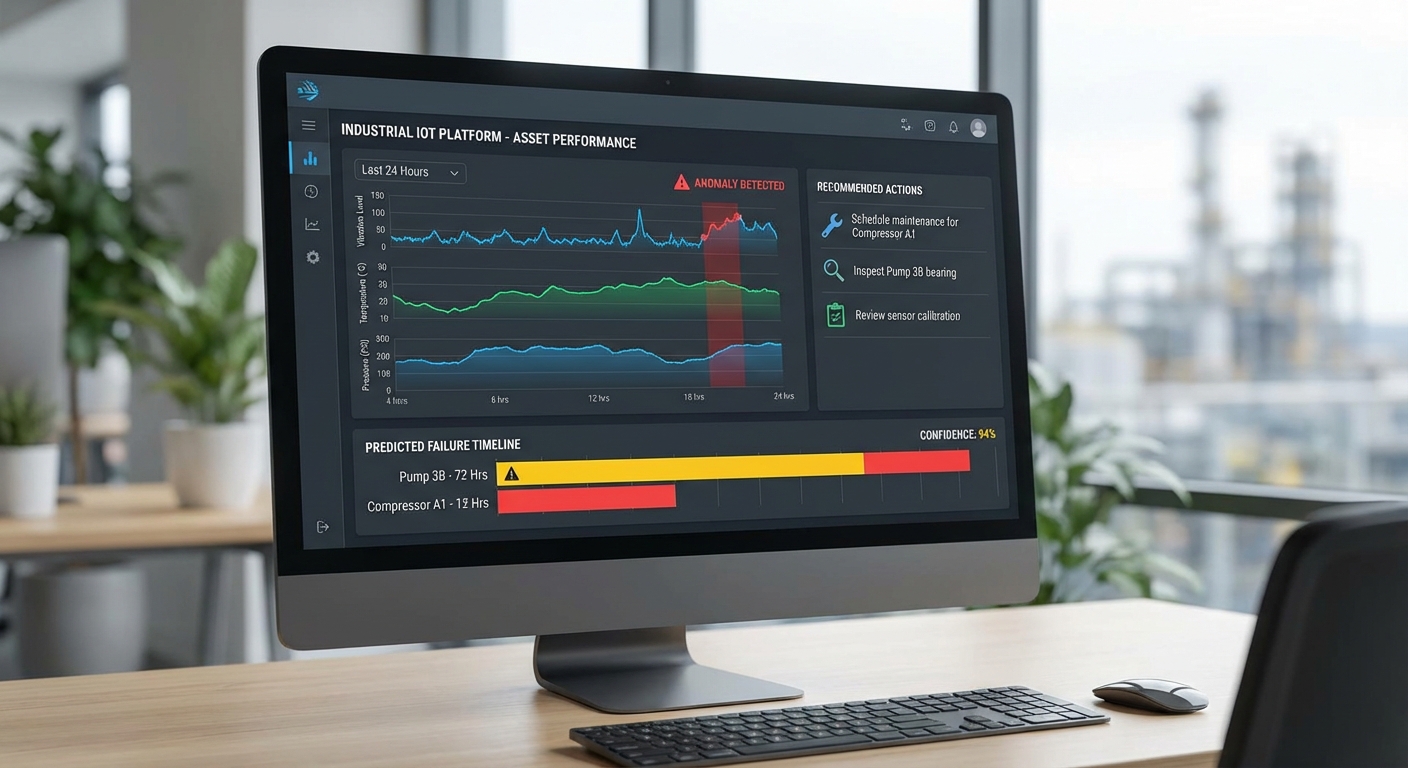
ผลลัพธ์จากการทดลองพิลอต (ระยะเวลา 6 เดือน ครอบคลุม 120 ชิ้นส่วนอุปกรณ์ใน 5 โรงงาน) สรุปได้ดังนี้:
- การลด Unplanned Downtime: ลดได้ประมาณ 30%–50% เมื่อเทียบกับช่วงก่อนติดตั้งระบบ ตัวอย่างเช่น โรงงานผลิตอาหารลดชั่วโมงการหยุดเครื่องไม่คาดคิดจากเฉลี่ย 200 ชั่วโมง/เดือน เหลือ 120–140 ชั่วโมง/เดือน
- ความแม่นยำในการพยากรณ์: อัตราความแม่นยำเฉลี่ยในการทำนายความล้มเหลวอยู่ที่ 88%–94% สำหรับมอเตอร์, 82%–90% สำหรับปั๊ม และ 85%–93% สำหรับสายพานลำเลียง (วัดจาก Precision/Recall และ F1-score ในชุดทดสอบจริง)
- เวลานำหน้าการเตือน (lead time): ค่าเฉลี่ยการเตือนล่วงหน้าที่มีนัยสำคัญคือ 48 ชั่วโมง โดยบางกรณีมีการเตือนล่วงหน้าได้สูงสุดถึง 72 ชั่วโมง ทำให้สามารถจัดลำดับงานและสต็อกอะไหล่ได้ทัน
ด้านต้นทุนและผลประโยชน์เชิงเศรษฐศาสตร์ โครงการพิลอตแสดงให้เห็นการลดค่าใช้จ่ายบำรุงรักษาแบบฉุกเฉินและค่าใช้จ่ายโดยรวม ดังนี้:
- ลดค่าใช้จ่ายบำรุงรักษาเฉลี่ย: ประมาณ 25%–40% จากการเปลี่ยนไปใช้การบำรุงรักษาเชิงคาดการณ์ ลดการเรียกช่างฉุกเฉิน และการเปลี่ยนอุปกรณ์ก่อนเวลา
- การยืดอายุการใช้งานของอุปกรณ์: ค่า MTBF (Mean Time Between Failures) เพิ่มขึ้นระหว่าง 1.2–1.8 เท่า ขึ้นกับประเภทอุปกรณ์และเงื่อนไขการใช้งาน ทำให้สามารถเลื่อนการลงทุนเพื่อเปลี่ยนอุปกรณ์ได้
- ผลกระทบเชิงการเงินโดยตรง: ตัวอย่างการประเมินจากโรงงานหนึ่งระบุว่า การป้องกันเหตุฉุกเฉิน 12 ครั้งใน 6 เดือน ประหยัดค่าเสียโอกาสและค่าแรงงานฉุกเฉินรวมประมาณ 1.6–2.4 ล้านบาท ต่อโรงงาน (ตัวเลขขึ้นกับมูลค่าการผลิตต่อชั่วโมงและค่าแรงงาน)
นอกจากตัวเลขเชิงสถิติแล้ว ยังมีกรณีตัวอย่างที่ชัดเจน เช่น ระบบได้ตรวจจับคลื่นความถี่สั่นสะเทือนเฉพาะที่สัมพันธ์กับการสึกหรอของ bearing บนมอเตอร์ไดร์ฟของสายการบรรจุ เมื่อมีการเตือนล่วงหน้า 48 ชั่วโมง ทีมบำรุงรักษาทำการเปลี่ยน bearing ในช่วงเวลาที่มีการผลิตต่ำ ส่งผลให้หลีกเลี่ยงการหยุดสายการผลิตแบบฉุกเฉินและลดค่าใช้จ่ายการซ่อมฉุกเฉินได้อย่างมีนัยสำคัญ
สรุป: การนำแพลตฟอร์ม Multimodal Time‑Series LLM มาใช้ในสภาพแวดล้อมการผลิตจริงสามารถสร้างผลลัพธ์เชิงปฏิบัติการและเชิงธุรกิจที่จับต้องได้ ได้แก่ การพยากรณ์ความล้มเหลวที่มีความแม่นยำสูงด้วย lead time ~48 ชั่วโมง, การลด unplanned downtime ประมาณ 30%–50%, และการลดต้นทุนบำรุงรักษาระหว่าง 25%–40% ซึ่งรวมกันนำไปสู่การคืนทุนในระยะสั้นและการเพิ่มประสิทธิภาพการดำเนินงานของโรงงานอย่างยั่งยืน
ความท้าทายด้านข้อมูลและการนำไปใช้จริง
ความท้าทายด้านข้อมูลและการนำไปใช้จริง
การนำระบบ AI ประเภท Multimodal Time‑Series LLM มาใช้ในสภาพแวดล้อมโรงงานเผชิญกับความท้าทายด้านข้อมูลที่ซับซ้อนตั้งแต่ต้นทางของสัญญาณจนถึงการให้บริการเชิงปฏิบัติการ ตัวอย่างสำคัญคือความหลากหลายและความไม่สอดคล้องของเซนเซอร์ที่มีทั้งอัตราการสุ่มตัวอย่าง (sampling rates) ต่างกัน, ระดับสัญญาณรบกวน (noise) ที่เปลี่ยนตามสภาพแวดล้อม, และมาตรฐานการส่งข้อมูลที่ไม่เหมือนกัน ซึ่งกรณีจริงอาจพบอัตราการสุ่มตัวอย่างต่างกันมากเป็นหลักสิบเท่าเมื่อเปรียบเทียบเซนเซอร์ชนิดวัดแรงสั่นกับเซนเซอร์อุณหภูมิ ปัญหาเหล่านี้นำไปสู่สัญญาณที่มีช่องว่าง (gaps), ข้อมูลซ้ำซ้อน หรือบิดเบือน ซึ่งถ้าไม่ได้รับการจัดการจะทำให้โมเดลเกิดการโอเวอร์ฟิตหรือคาดการณ์พลาดในงานคาดการณ์ความล้มเหลวได้ง่าย
อีกหนึ่งความท้าทายคือการขาดฉลาก (label scarcity) ในข้อมูลโรงงาน โดยทั่วไปข้อมูลเวลาจริงส่วนใหญ่เป็นข้อมูลไม่ติดฉลาก (unlabeled) — องค์กรจำนวนมากมีสัดส่วนข้อมูลติดฉลากเพียงหลักหน่วยถึงหลักสิบเปอร์เซ็นต์ของข้อมูลทั้งหมด การจัดหาฉลากการล้มเหลวต้องอาศัยผู้เชี่ยวชาญและบางครั้งต้องรอให้เกิดเหตุจริงจึงจะบันทึกได้ ทำให้การเรียนรู้แบบมีผู้สอน (supervised) มีข้อจำกัด การแก้ไขเชิงปฏิบัติการที่ได้ผลรวมถึงการใช้ self‑supervised learning (เช่น contrastive learning, masked prediction, และ sequence reconstruction) เพื่อดึงคุณลักษณะจากข้อมูลไม่ติดฉลาก, การใช้ semi‑supervised และ active learning เพื่อเลือกตัวอย่างสำคัญสำหรับการติดฉลากด้วยงบประมาณจำกัด และการใช้เทคนิค weak labeling หรือการขยายฉลาก (label propagation) เพื่อเพิ่มปริมาณข้อมูลติดฉลากเชิงมีคุณค่า
ในเชิงการใช้งานจริงยังมีปัญหาเรื่อง concept drift — พฤติกรรมของเครื่องจักรและกระบวนการผลิตเปลี่ยนแปลงเมื่อเวลาผ่านไป เช่น การสึกหรอของชิ้นส่วนหรือการปรับตั้งค่าการผลิต ทำให้โมเดลที่ฝึกไว้ล้าสมัย การจัดการต้องอาศัยระบบติดตามประสิทธิภาพ (monitoring & observability), การตรวจจับ drift แบบเรียลไทม์, และกลยุทธ์ continual learning หรือ periodic retraining โดยอาจใช้เทคนิค domain adaptation เพื่อให้โมเดลตอบสนองต่อสภาพแวดล้อมใหม่ได้โดยไม่ทำลายพฤติกรรมที่เรียนรู้เดิม
ด้าน latency และข้อจำกัดด้านฮาร์ดแวร์เป็นปัจจัยกำหนดสถาปัตยกรรมการให้บริการในไซต์งานโรงงาน ระบบตรวจจับความผิดปกติและคาดการณ์ล้มเหลวมักต้องการการตัดสินใจแบบ near‑real‑time ซึ่งเครือข่ายไปยังคลาวด์อาจมีความหน่วงสูงหรือไม่เสถียร โดยเฉพาะในไซต์ที่มีการเชื่อมต่อจำกัด การออกแบบที่มักใช้ได้ผลคือการนำการประมวลผลไปยัง edge เพื่อรันโมเดลขนาดเล็กสำหรับการแจ้งเตือนทันที ขณะที่ข้อมูลเชิงลึกแบบเชิงลึกและการฝึกซ้ำตกลงไปที่คลาวด์แบบเป็นชุด (batch) หรือแบบไฮบริด นอกจากนี้ควรใช้เทคนิค model compression เช่น quantization, pruning, และ knowledge distillation เพื่อลดขนาดและความต้องการคำนวณของโมเดล ทำให้รันบน CPU/MCU หรือ NPU ในอุปกรณ์ edge ได้จริง
- การแก้ปัญหาคุณภาพข้อมูล — ทำ normalization/resampling เพื่อปรับ sampling rate ให้สอดคล้อง, ใช้ denoising filters, anomaly‑aware preprocessing และ sensor calibration พร้อมระบบ metadata เพื่อติดตามความน่าเชื่อถือของแต่ละช่องสัญญาณ
- การใช้ข้อมูลไม่ติดฉลาก — นำ self‑supervised และ contrastive approaches มาใช้เป็นขั้นแรกเพื่อเรียนรู้ representation, ตามด้วย semi‑supervised หรือ active learning เพื่อลดต้นทุนการติดฉลากและเพิ่มประสิทธิภาพของโมเดล
- การจัดการความเปลี่ยนแปลงของระบบ — ติดตั้งระบบตรวจจับ concept drift และ pipeline สำหรับ continual learning หรือ periodic retraining โดยเก็บตัวอย่างใหม่ลงใน dataset เวอร์ชันที่มีการควบคุม (data versioning)
- สถาปัตยกรรม edge vs cloud — ใช้โมเดลขนาดกะทัดรัดบน edge สำหรับการ inference แบบเรียลไทม์ และทำ aggregation/ฝึกซ้ำบนคลาวด์หรือใช้ federated learning เมื่อมีข้อจำกัดด้านความเป็นส่วนตัวหรือแบนด์วิดท์
- การเพิ่มประสิทธิภาพฮาร์ดแวร์ — ดำเนินการ model compression, ใช้ hardware acceleration ที่มีในไซต์ (GPU/NPU/FPGA), และออกแบบ fallback strategy เมื่อเครือข่ายไม่พร้อม
การเผชิญและแก้ไขความท้าทายด้านข้อมูลเหล่านี้ต้องการทั้งกลยุทธ์ทางเทคนิคและกระบวนการเชิงองค์กร ตั้งแต่การกำหนดมาตรฐานการเก็บข้อมูล, การร่วมมือกับฝ่ายบำรุงรักษาเพื่อให้ได้ฉลากที่มีคุณภาพ, การลงทุนในโครงสร้างพื้นฐาน edge, จนถึงการสร้างวงจร feedback เพื่อให้โมเดลเรียนรู้จากเหตุการณ์จริงอย่างต่อเนื่อง เมื่อรวมแนวทางเหล่านี้เข้าด้วยกัน สตาร์ทอัพและภาคอุตสาหกรรมจะสามารถยกระดับระบบ Multimodal Time‑Series LLM ให้รับมือกับความซับซ้อนของโรงงานได้อย่างมั่นคงและเชื่อถือได้
ผลกระทบทางธุรกิจและโอกาสในตลาด
ผลกระทบทางธุรกิจและโอกาสในตลาด
แพลตฟอร์ม Multimodal Time‑Series LLM สำหรับการวิเคราะห์สัญญาณเซนเซอร์โรงงานแบบเรียลไทม์สร้างมูลค่าทางธุรกิจได้จากหลายมิติ ทั้งการลดต้นทุนการบำรุงรักษา การลดเวลาหยุดเดินเครื่องที่ไม่คาดคิด และการเพิ่มประสิทธิภาพการผลิตโดยรวม สำหรับโรงงานขนาดกลางถึงใหญ่ การป้องกันความล้มเหลวล่วงหน้าสามารถแปลงเป็นการประหยัดที่จับต้องได้ เช่น ลด downtime, ลดชิ้นส่วนสต๊อกฉุกเฉิน และยืดอายุการใช้งานอุปกรณ์ ซึ่งทั้งหมดส่งผลต่อต้นทุนต่อหน่วยและอัตราผลกำไร (margin) ของธุรกิจอย่างมีนัยสำคัญ
ในเชิงตลาด โอกาสในไทยและภูมิภาคอาเซียนยังคงกว้างใหญ่ เนื่องจากการปรับตัวสู่ Industry 4.0 ของผู้ผลิตและผู้ให้บริการโลจิสติกส์กำลังเร่งตัว สถิติหลายแหล่งชี้ว่าการลงทุนด้าน IIoT และระบบดิจิทัลในภาคการผลิตของอาเซียนมีอัตราการเติบโต (CAGR) อยู่ในช่วง 15–25% โดยเฉพาะประเทศที่มีฐานการผลิตขนาดใหญ่ เช่น ไทย อินโดนีเซีย เวียดนาม และมาเลเซีย แนวโน้มนี้สะท้อนความต้องการเทคโนโลยีที่สามารถให้การวิเคราะห์เชิงลึกจากข้อมูลเซนเซอร์หลายรูปแบบ (vibration, temperature, acoustics, electrical) แบบเรียลไทม์ ซึ่งเป็นจุดแข็งของแพลตฟอร์มดังกล่าว
โมเดลการหารายได้ที่เป็นไปได้มีความยืดหยุ่นและสามารถผสมผสานกันได้ตามกลยุทธ์การขยายตลาด ได้แก่
- SaaS (Subscription): คิดค่าบริการรายเดือน/รายปีตามจำนวนผู้ใช้หรือจำนวนอุปกรณ์ที่เชื่อมต่อ (per‑asset) โดยแพ็กเกจอาจแบ่งเป็น Basic, Pro, Enterprise เพื่อรองรับการใช้งานตั้งแต่โรงงานขนาดเล็กถึงโรงงานระดับกลุ่มบริษัท
- Per‑asset / Per‑sensor Pricing: คิดค่าบริการเป็นหน่วยต่อชิ้น เช่น 10–50 ดอลลาร์สหรัฐฯ ต่ออุปกรณ์ต่อเดือน สำหรับการดึงข้อมูลและวิเคราะห์แบบเรียลไทม์ ซึ่งช่วยให้ลูกค้าจับคู่ต้นทุนกับผลประโยชน์ได้ชัดเจน
- Licensing & On‑premises: สำหรับผู้ประกอบการที่มีข้อจำกัดด้านความมั่นคงของข้อมูลหรือเครือข่าย สามารถขายใบอนุญาตใช้งานซอฟต์แวร์แบบติดตั้งภายใน (on‑prem) พร้อมค่าบริการติดตั้งและบำรุงรักษารายปี
- Value‑added Services: บริการเสริมเช่นการปรับแต่งโมเดล, การฝึกอบรม, การวิเคราะห์เชิงลึกแบบ project‑based และการสนับสนุน 24/7 ซึ่งเป็นแหล่งรายได้ที่มีมาร์จินสูง
- Partnership & Revenue Share: โมเดลการร่วมธุรกิจกับ OEM, ผู้ผลิตเซนเซอร์ หรือ system integrator ด้วยการฝังเทคโนโลยี (embedded) หรือแบบ white‑label พร้อมแบ่งรายได้จากการขายโซลูชัน
เพื่อให้เห็นภาพทางการเงิน ตัวอย่างกรณี ROI ของลูกค้าพิลอตมีลักษณะดังนี้: โรงงานผลิตขนาดกลางมีเครื่องจักร 200 เครื่อง ค่าเฉลี่ย downtime ต่อเครื่อง 8 ชั่วโมงต่อเดือน ค่าเสียโอกาสการผลิตและการซ่อมเฉลี่ย 1,000 ดอลลาร์สหรัฐฯ ต่อชั่วโมง (รวมวัตถุดิบ แรงงาน และผลผลิตที่หายไป) แพลตฟอร์มสามารถลด downtime ลง 50% เหลือ 4 ชั่วโมงต่อเดือน ผลลัพธ์คือการประหยัดโดยประมาณ 200 เครื่อง × 4 ชั่วโมง/เดือน × 1,000 ดอลลาร์ = 800,000 ดอลลาร์/เดือน หรือ 9.6 ล้านดอลลาร์/ปี
หากคิดค่าใช้จ่ายแพลตฟอร์มแบบ per‑asset ที่ 30 ดอลลาร์ต่อเครื่องต่อเดือน ต้นทุนการใช้งานจะอยู่ที่ 200 × 30 × 12 = 72,000 ดอลลาร์/ปี ซึ่งเทียบกับการประหยัด 9.6 ล้านดอลลาร์/ปี แสดงอัตราผลตอบแทนการลงทุน (ROI) ที่สูงมาก โดยระยะเวลาคืนทุน (payback period) จะสั้นกว่า 1 เดือนในสถานการณ์นี้ แม้ในกรณีที่สมมติฐานอนุรักษ์นิยมกว่า เช่น ลด downtime เพียง 10% ก็ยังให้ผลตอบแทนเป็นบวกและคืนทุนภายใน 3–9 เดือน ขึ้นกับขนาดโรงงานและต้นทุนต่อชั่วโมงของ downtime
การเป็นพันธมิตรกับ OEM และ integrator มีบทบาทสำคัญสำหรับการขยายการใช้งานในภูมิภาค: การร่วมมือกับผู้ผลิตเครื่องจักรช่วยให้แพลตฟอร์มถูกฝังเป็นฟีเจอร์มาตรฐานตั้งแต่การขายเครื่องจักร การทำงานร่วมกับ system integrator ช่วยเร่งกระบวนการติดตั้งและเชื่อมต่อข้อมูลภายในโรงงาน รวมถึงการขายผ่านช่องทาง (channel sales) ที่มีเครือข่ายลูกค้ากระจายทั่วอาเซียน โมเดลการร่วมทุนหรือ revenue‑share agreements (เช่น แบ่งรายได้ 70/30 กับ integrator หลังหักต้นทุนการติดตั้ง) สามารถลดต้นทุนการเข้าตลาด (go‑to‑market) และเร่งการนำไปใช้งานจริงได้อย่างมีประสิทธิภาพ
โดยสรุป แพลตฟอร์ม Multimodal Time‑Series LLM มีศักยภาพสร้างมูลค่าทางธุรกิจสูงทั้งในไทยและอาเซียน โดยโมเดลการหารายได้สามารถปรับได้ตามเงื่อนไขลูกค้าและตลาด การพิสูจน์ผลลัพธ์ด้วยกรณีพิลอตที่ชัดเจนและการสถาปนาพันธมิตรเชิงกลยุทธ์กับ OEM/Integrator จะเป็นกุญแจสำคัญที่ช่วยขยายฐานลูกค้า ลดความเสี่ยงในเชิงการขาย และเพิ่มศักยภาพในการสร้างรายได้ระยะยาว
ความปลอดภัย กฎระเบียบ และประเด็นจริยธรรม
ความปลอดภัย กฎระเบียบ และประเด็นจริยธรรม
การนำแพลตฟอร์ม Multimodal Time‑Series LLM ไปใช้ในสภาพแวดล้อมโรงงานต้องคำนึงถึงมาตรการความปลอดภัยไซเบอร์และการคุ้มครองทรัพย์สินทางปัญญา (IP) อย่างเข้มงวด ข้อมูลสัญญาณเซนเซอร์มักเป็นข้อมูลเชิงเทคนิคที่สามารถเปิดเผยกระบวนการผลิตหรือสูตรการควบคุมที่เป็นความลับ ดังนั้นองค์กรควรนำข้อกำหนดมาตรฐานสากลเช่น ISO/IEC 27001, IEC 62443 และแนวทาง NIST มาใช้เป็นกรอบงาน เพื่อกำหนดนโยบายการเข้าถึงข้อมูล การจัดการช่องโหว่ และการทดสอบเชิงเจาะระบบอย่างสม่ำเสมอ การเข้ารหัสข้อมูลทั้งที่จุดปลาย (edge), ระหว่างทาง (in-transit) และขณะพัก (at-rest) เป็นมาตรฐานจำเป็น — เช่น การใช้ TLS 1.3 พร้อม mutual TLS, การเข้ารหัสแบบฮาร์ดแวร์ผ่าน HSM (Hardware Security Module), การลงนามเฟิร์มแวร์ และการใช้ data diodes ในส่วนที่ต้องการทิศทางเดียวของการไหลข้อมูลเพื่อป้องกันการรุกล้ำจากเครือข่ายภายนอก
มาตรการเพิ่มเติมที่ต้องพิจารณาได้แก่การแบ่งส่วนเครือข่าย (network segmentation), แนวทาง Zero Trust, การกำหนดสิทธิ์แบบบทบาท (RBAC), การตรวจสอบและบันทึกกิจกรรม (audit logs) พร้อมระบบ SIEM/IDS-IPS เพื่อจับสัญญาณการโจมตีเชิงพฤติกรรม (anomaly-based detection) และการบังคับใช้การอัปเดตเฟิร์มแวร์อย่างเป็นระบบ งานวิจัยเชิงอุตสาหกรรมแสดงให้เห็นว่าโรงงานที่ใช้แนวทางรักษาความปลอดภัยเชิงกระบวนการสามารถลดความเสี่ยงจากการรั่วไหลของข้อมูลเชิงอุตสาหกรรมได้อย่างมีนัยสำคัญ ระบบต้องรองรับการเข้ารหัสระดับสูง เช่น homomorphic encryption หรือ secure multi‑party computation เมื่อจำเป็นต้องประมวลผลข้อมูลที่เป็นความลับร่วมกับผู้ให้บริการภายนอก
ด้านความสามารถในการอธิบายผลลัพธ์ (explainability) เป็นปัจจัยสำคัญต่อการยอมรับผลการพยากรณ์โดยวิศวกรและทีมบำรุงรักษา โมเดลที่ให้คำทำนายว่าชิ้นส่วนใดกำลังจะล้มเหลวควรมาพร้อมกับการอธิบายเชิงสาเหตุ เช่น การใช้เทคนิค SHAP/LIME สำหรับ time‑series, visualization ของ attention maps, counterfactual explanations และตัวชี้วัดความไม่แน่นอน (prediction intervals) เพื่อให้ผู้ปฏิบัติงานสามารถตรวจสอบและตัดสินใจได้อย่างมีข้อมูล ตัวอย่างเช่น การระบุว่าเสียงสัญญาณแรงสั่นสูงขึ้น 3.2 dB ร่วมกับอุณหภูมิที่เพิ่ม 7% เป็นปัจจัยสำคัญที่ส่งผลต่อการพยากรณ์ จะช่วยให้ช่างบำรุงรักษาเข้าใจและสอดคล้องกับมาตรการที่ระบบเสนอ
การลดอัตรา false positives และ false negatives เป็นอีกหัวใจสำคัญ เพราะการแจ้งเตือนผิดพลาดอาจสร้างต้นทุนการหยุดเครื่องและลดความเชื่อมั่นของทีม ในทางปฏิบัติ ควรใช้กระบวนการต่อไปนี้: threshold tuning ตามความเสี่ยงของแต่ละเครื่องจักร, การเรียนรู้แบบ cost‑sensitive, การใช้ ensemble models เพื่อเพิ่มความเสถียร, การตั้งระบบ human‑in‑the‑loop สำหรับการยืนยันแจ้งเตือนสำคัญ และการติดตาม performance แบบเรียลไทม์ (monitoring drift) โดยใช้เมตริกเช่น precision, recall, ROC/AUC และ calibration หากเป้าหมายเชิงปฏิบัติ ตัวอย่างในงานอุตสาหกรรมมักตั้งค่าเพื่อรักษา false positive rate ต่ำสุดที่ยอมรับได้ โดยคำนึงถึงต้นทุนการหยุดผลิตและความปลอดภัย
- การประกันความโปร่งใส: กำหนดระดับ explainability ขั้นต่ำสำหรับการนำระบบไปใช้ตัดสินใจอัตโนมัติ เช่น ให้มีการอธิบายเหตุผลและข้อมูลประกอบทุกครั้งก่อนการสั่งหยุดเครื่องอัตโนมัติ
- การตรวจสอบและตรวจรับ: ทำ Audit trail ของการพยากรณ์และการตอบสนองจริง เพื่อรองรับการตรวจสอบย้อนหลังทางกฎหมายและมาตรการคุณภาพ
- การคุ้มครอง IP: ใช้นโยบายการมองเห็นข้อมูลแบบน้อยที่สุด (data minimization), การทำ anonymization/synthesis ของชุดข้อมูลสำหรับการพัฒนา และข้อตกลง NDA กับพันธมิตรภายนอก
ผลกระทบต่อแรงงานที่เกิดจากการเปลี่ยนผ่านสู่การบำรุงรักษาเชิงพยากรณ์ควรถูกจัดการอย่างรอบคอบเพื่อให้เกิดการเปลี่ยนแปลงที่ยุติธรรมและยั่งยืน ระบบดังกล่าวมักทำให้บทบาทของช่างที่เน้นการซ่อมเชิงปฏิกิริยาลดลง แต่เปิดโอกาสให้เกิดงานเชิงทักษะใหม่ เช่น การวิเคราะห์ข้อมูลเบื้องต้น, การตีความผลโมเดล, การตั้งค่าระบบและการบำรุงรักษาแบบเชิงคาดการณ์ องค์กรควรออกแบบโปรแกรมฝึกอบรมที่เป็นระบบ ครอบคลุมทักษะดังต่อไปนี้:
- พื้นฐานด้านข้อมูลและการอ่านค่า time‑series
- การตีความคำอธิบายของโมเดล (explainability tools เช่น SHAP)
- การปฏิบัติด้านความปลอดภัยไซเบอร์สำหรับช่างภาคสนาม
- การใช้เครื่องมือซอฟต์แวร์และแพลตฟอร์มการจัดการการบำรุงรักษา (CMMS/ADF)
- กระบวนการเปลี่ยนผ่านและการทำงานแบบข้ามสายงาน (cross‑functional collaboration)
การวัดผลการฝึกอบรมควรตั้ง KPI เช่น อัตราการยอมรับคำเตือนโดยมนุษย์ (human validation rate), เวลาที่ลดลงในการตอบสนองต่อเตือน (mean time to acknowledge), อัตราความถูกต้องของการดำเนินการด้านบำรุงรักษาหลังคำแนะนำของระบบ และระดับความพึงพอใจของพนักงาน โดยควรมีแผนรองรับผู้ได้รับผลกระทบ เช่น การเปลี่ยนบทบาทภายใน แผนพัฒนาทักษะ (reskilling/upskilling) และการมีส่วนร่วมของตัวแทนแรงงาน เพื่อลดความเสี่ยงด้านสังคมและคงไว้ซึ่งความรับผิดชอบตามจริยธรรมในการนำเทคโนโลยีมาใช้
มุมมองอนาคต: แผนขยายและโอกาสการเติบโต
มุมมองอนาคต: แผนขยายและโอกาสการเติบโต
สตาร์ทอัพรายนี้วางกรอบแผนขยายธุรกิจเป็นระยะสั้นถึงกลางด้วยเป้าหมายเชิงกลยุทธ์ 3 ด้านหลัก ได้แก่ การระดมทุนเพื่อเร่งพัฒนาเทคโนโลยี, การสยายปีกสู่ตลาดต่างประเทศผ่านพันธมิตรเชิงพาณิชย์ และการร่วมมือกับผู้ผลิตอุปกรณ์และผู้ให้บริการระบบอัตโนมัติเพื่อฝังโซลูชันเข้าไปในห่วงโซ่อุปทานเครื่องจักร การระดมทุนในรอบถัดไปมุ่งเป้าเป็น Series A เพื่อรวบรวมทรัพยากรทางวิศวกรรมและทีมขาย โดยแผนการระดมทุนเบื้องต้นคาดว่าอยู่ที่ประมาณ 5–10 ล้านเหรียญสหรัฐ เพื่อรองรับการขยายทีมวิจัยและตลาดต่างประเทศ
ในแง่กลยุทธ์การขยายตลาด สตาร์ทอัพมีแนวทางผสมผสานระหว่างการขายตรงและการสร้างเครือข่ายพันธมิตรเชิงนิเวศ (ecosystem partners) โดยจะมุ่งเป้าไปยังอุตสาหกรรมที่มีความต้องการแรง เช่น ยานยนต์ อิเล็กทรอนิกส์ อาหารและยา และการผลิตหนัก กลยุทธ์สำคัญ ได้แก่:
- การจับมือกับผู้ผลิตอุปกรณ์ (OEM) เพื่อฝังโมเดลแบบเรียลไทม์ลงใน PLC/edge device และขายเป็นแพ็กเกจพร้อมเครื่อง
- พันธมิตรระบบบูรณาการ (SI) เพื่อเร่งการติดตั้งในโรงงานขนาดกลางและขนาดใหญ่ ด้วยโมเดลการขายแบบ channel
- เข้าไปสู่ตลาดต่างประเทศเชิงคัดเลือก โดยเริ่มจากภูมิภาคที่มีคลัสเตอร์การผลิตหนาแน่น เช่น เอเชียตะวันออกเฉียงใต้ ญี่ปุ่น และยุโรปตะวันตก ก่อนขยายสู่สหรัฐฯ
ด้านฟีเจอร์และเทคโนโลยี ทีมพัฒนาวาง roadmap ให้ความสำคัญกับการยกระดับจากการ คาดการณ์ความล้มเหลว ไปสู่ระบบที่สามารถให้คำตอบเชิงสาเหตุและคำแนะนำปฏิบัติการได้ชัดเจนขึ้น ฟีเจอร์ที่ให้ความสำคัญใน 12–24 เดือนข้างหน้ารวมถึง:
- Auto‑diagnosis: ระบบวิเคราะห์และสรุปอาการความผิดปกติแบบอัตโนมัติ พร้อมส่งผลกระทบที่คาดว่าจะเกิดและขั้นตอนการแก้ไขเบื้องต้น
- Root‑cause analysis (RCA): การประมวลผลข้ามสัญญาณแบบมัลติโมดัลเพื่อค้นหาสาเหตุรากฐาน เช่น ความสั่นสะเทือนร่วมกับการลดแรงดันน้ำมัน
- Cross‑site learning & federated learning: ใช้ประโยชน์จากข้อมูลจากโรงงานหลายแห่งโดยไม่ละเมิดความเป็นส่วนตัวของข้อมูล เพื่อเพิ่มความแม่นยำและลดเวลาการเรียนรู้ (time‑to‑value)
- Edge inference และ hybrid cloud deployment: เพื่อให้ระบบตอบสนองแบบเรียลไทม์และลด latency ในภาคการผลิต
การนำไปใช้งานในเชิงอุตสาหกรรมคาดว่าจะเพิ่มขึ้นอย่างมีนัยสำคัญในช่วง 2–5 ปีข้างหน้า โดยประมาณการแนวโน้มเบื้องต้นมีดังนี้: ภายใน 2 ปีแรกจะเห็นการนำไปใช้ในรูปแบบ pilot และโปรเจ็กต์เชิงพาณิชย์ระดับไซต์ (site‑level) เพิ่มขึ้นอย่างรวดเร็ว ตั้งแต่โรงงานในคลัสเตอร์ยานยนต์และอิเล็กทรอนิกส์ ที่มีแรงจูงใจด้านการลด downtime และการปฏิบัติตามมาตรฐานคุณภาพ; ภายใน 3–5 ปีคาดว่าอัตราการยอมรับ (adoption rate) ของโซลูชัน multimodal time‑series AI ในโรงงานขนาดกลาง–ใหญ่ในตลาดเป้าหมายอาจขยายตัวถึง 20–40% ขึ้นกับการพิสูจน์ ROI เช่น การลด downtime ได้ 20–40% และการลดค่าใช้จ่ายการบำรุงรักษาเชิงป้องกันได้อย่างมีนัยสำคัญ
ความท้าทายที่ต้องจับตามีทั้งเรื่องการจัดการข้อมูลเชิงอุตสาหกรรมที่มีความหลากหลาย ความปลอดภัยของข้อมูล และการผสานเข้ากับระบบไอทีเดิม ซึ่งสตาร์ทอัพได้วางแนวทางรับมือด้วยการพัฒนา API มาตรฐาน การร่วมมือด้าน compliance กับผู้ให้บริการคลาวด์ และการนำกรณีศึกษา (case studies) ที่มีตัวเลขผลลัพธ์ชัดเจนออกสู่สาธารณะเพื่อสร้างความเชื่อมั่น สำหรับแผนระยะกลาง หากสามารถพิสูจน์โซลูชันเชิงพาณิชย์ได้ต่อเนื่อง บริษัทมีทางเลือกเชิงกลยุทธ์ทั้งการขยายทีมขายระดับโลก การระดมทุนรอบต่อไป หรือการเข้าร่วมกับผู้เล่นรายใหญ่ในอุตสาหกรรมเพื่อขยายการเข้าถึงตลาดอย่างรวดเร็ว
บทสรุป
Multimodal Time‑Series LLM คือเทคโนโลยีที่ผสานการวิเคราะห์สัญญาณเวลาจริงจากเซนเซอร์หลายรูปแบบ (เช่น การสั่นสะเทือน, อุณหภูมิ, กระแสไฟฟ้า, เสียง และภาพ) เข้ากับความสามารถเชิงภาษาของโมเดลขนาดใหญ่เพื่อคาดการณ์ความล้มเหลวก่อนเกิดเหตุจริง โดยใช้การประมวลผลแบบเรียลไทม์เพื่อแจ้งเตือนและชี้แนะแนวทางการบำรุงรักษาเชิงป้องกัน ตัวอย่างจากโครงการนำร่องและงานวิจัยในอุตสาหกรรมชี้ให้เห็นว่าการคาดการณ์เชิงรุกเหล่านี้สามารถลด downtime ได้อย่างมีนัยสำคัญ (ตัวอย่างเช่นการลด downtime หลายสิบเปอร์เซ็นต์ และปรับปรุงค่า MTBF/MTTR) เมื่อข้อมูลคุณภาพดีและระบบตอบสนองทันเวลา
การนำไปใช้จริงต้องให้ความสำคัญกับปัจจัยหลักสามประการคือ คุณภาพข้อมูล (data fidelity, ความครอบคลุมของเซนเซอร์), ความปลอดภัย (การเข้ารหัสข้อมูล การจัดการสิทธิ์ และการป้องกันการโจมตีต่อระบบ OT/IT) และการวัดผลเชิงธุรกิจเพื่อพิสูจน์ ROI (เช่น การลดต้นทุนบำรุงรักษา, จำนวนชั่วโมงการผลิตที่เพิ่มขึ้น, อัตราการแจ้งเตือนเท็จ) โดยการออกแบบสถาปัตยกรรมแบบ edge‑cloud, นโยบายข้อมูลที่ชัดเจน และการวัดเมตริกเช่นอัตราการพยากรณ์ถูกต้อง vs. เท็จ จะช่วยยืนยันมูลค่าทางเศรษฐกิจ หากจัดการความเสี่ยงและบูรณาการกับกระบวนการผลิตได้ดี แพลตฟอร์มนี้มีศักยภาพที่จะสร้างมูลค่าเชิงเศรษฐกิจอย่างชัดเจนและเร่งการขับเคลื่อน Industry 4.0 ในภูมิภาค ทั้งในแง่การเพิ่มประสิทธิภาพการผลิต ลดต้นทุน และยกระดับความพร้อมของภาคอุตสาหกรรม



