
AI ถูกมองว่าเป็นจุดเปลี่ยนสำคัญที่ช่วยเปลี่ยนธุรกิจให้มีประสิทธิภาพและสร้างนวัตกรรมใหม่ ๆ อย่างไรก็ตามการนำ AI จากการทดลองไปสู่การใช้งานในระดับองค์กรกลับไม่ใช่เรื่องง่าย — หลายองค์กรพบว่าปัญหาไม่ได้อยู่ที่ความแม่นยำของโมเดลเพียงอย่างเดียว แต่เป็นข้อจำกัดด้านข้อมูล กระบวนการแมชชีนเลิร์นนิงที่ไม่เป็นระบบ และการขาดมาตรฐานในการวัดผลเมื่อระบบเริ่มใช้งานจริง ทำให้โครงการ AI จำนวนมากหยุดชะงักหรือให้ผลลัพธ์ไม่สอดคล้องกับเป้าหมายทางธุรกิจ
บทความนี้จะชี้ให้เห็นเหตุผลว่าทำไมความสามารถด้านข้อมูล (data capabilities) และกระบวนการแมชชีนเลิร์นนิงแบบเป็นระบบ (MLOps และ ML lifecycle) จึงเป็นหัวใจของการพัฒนา AI ในองค์กร พร้อมเสนอกรอบปฏิบัติที่ช่วยปรับโครงสร้างข้อมูล การวัดผลที่ชัดเจน เช่น KPI ด้านคุณภาพข้อมูล การติดตามประสิทธิภาพโมเดล และตัวอย่างกรณีศึกษาเชิงปฏิบัติ เพื่อให้ผู้บริหารและทีมงานสามารถวางแผนขยาย AI อย่างยั่งยืน มั่นคง และสอดคล้องกับเป้าหมายเชิงธุรกิจ
ภาพรวม: ทำไมองค์กรต้องลงทุนในความสามารถด้านข้อมูลและ ML
ภาพรวม: ทำไมองค์กรต้องลงทุนในความสามารถด้านข้อมูลและแมชชีนเลิร์นนิง
การลงทุนในความสามารถด้านข้อมูล (data capabilities) และแมชชีนเลิร์นนิง (ML) เป็นเรื่องเชิงกลยุทธ์ที่ขับเคลื่อนมูลค่าทางธุรกิจทั้งในระยะสั้นและระยะยาว ไม่ควรถูกมองว่าเป็นการลงทุนแค่ในทีมโมเดลหรือการทดลองวิจัยชั่วคราว แต่เป็นการสร้างสถาปัตยกรรมข้อมูล กระบวนการจัดการคุณภาพข้อมูล และการบูรณาการผลลัพธ์สู่การปฏิบัติงานจริง McKinsey Global Institute ประเมินว่าศักยภาพเชิงเศรษฐกิจจาก AI สามารถเพิ่มมูลค่าทั่วโลกได้มากถึงประมาณ $13 ล้านล้านภายในปี 2030 ซึ่งสะท้อนว่าผลกระทบไม่ได้จำกัดเพียงเทคโนโลยี แต่เกี่ยวข้องกับการเปลี่ยนแปลงกระบวนการธุรกิจและโมเดลรายได้
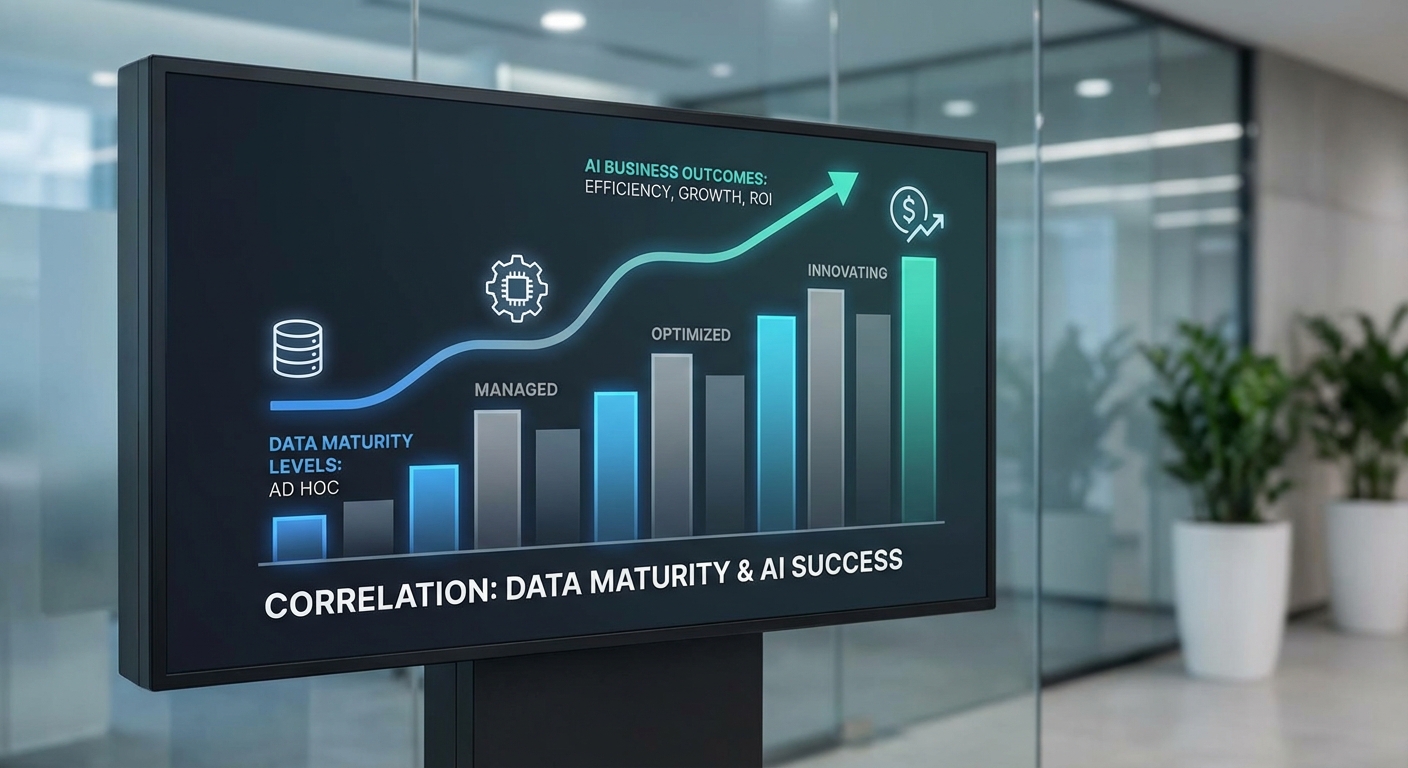
AI ไม่ใช่แค่โมเดล แต่เริ่มจากคุณภาพและการเข้าถึงข้อมูล — หลายกรณีที่โครงการ AI ล้มเหลวไม่ได้เกิดจากอัลกอริทึมที่อ่อนด้อย แต่เกิดจากข้อมูลที่ไม่ครบถ้วน แขกเจอความไม่สอดคล้องของแหล่งข้อมูล หรือการขาดมาตรฐานในการจัดเก็บและนิยามข้อมูล องค์กรที่ลงทุนในแพลตฟอร์มข้อมูลที่เข้าถึงง่าย มีการทำ metadata และ data governance ที่ชัดเจนจะมีอัตราการย้ายโมเดลจากการทดลองสู่การใช้งานจริงสูงกว่าอย่างมีนัยสำคัญ (ตามการสังเกตจากงานวิจัยของ Gartner และ McKinsey)
สัดส่วนองค์กรที่ได้ผลจริงจาก AI เพิ่มตามระดับความพร้อมของข้อมูล — รายงานจากสถาบันวิจัยหลายแห่งชี้ตรงกันว่าองค์กรที่มีความพร้อมด้านข้อมูล (data maturity) สูงจะเห็นผลตอบแทนจากโครงการ AI เป็นรูปธรรมเร็วกว่า ตั้งแต่การคืนทุนภายใน 12–24 เดือน ไปจนถึงการสร้างรายได้และลดต้นทุนอย่างต่อเนื่อง (ตัวเลขเชิงตัวอย่างจากรายงานของ Gartner/IDC/McKinsey ระบุว่าองค์กรที่มี data maturity สูงมีแนวโน้มที่จะรายงานผลกระทบเชิงธุรกิจภายใน 1–2 ปี มากกว่าองค์กรที่ยังอยู่ในระดับเริ่มต้น)
เพื่อให้เห็นภาพชัดขึ้น ต่อไปนี้เป็นกรอบความสัมพันธ์ระหว่างระดับความพร้อมของข้อมูลกับโอกาสความสำเร็จของโครงการ AI (เชิงแนวคิด):
- ระดับต่ำ (Low) — ข้อมูลกระจัดกระจาย ไม่มีมาตรฐาน ขาด governance: โครงการ AI มักติดปัญหาในการนำไปใช้จริงหรือให้ผลไม่สม่ำเสมอ
- ระดับปานกลาง (Medium) — มีการรวมข้อมูลบางส่วน มีมาตรฐานขั้นต้น: สามารถสร้าง Proof-of-Value ได้ แต่มักต้องใช้เวลาปรับปรุงสภาพแวดล้อมก่อนจะขยายผลได้
- ระดับสูง (High) — ข้อมูลคุณภาพดี เข้าถึงได้ตามสิทธิ์ มีแพลตฟอร์มและการปกครองข้อมูลที่ชัดเจน: มีโอกาสเห็น ROI ภายใน 12–24 เดือน และสามารถสเกลผลลัพธ์ไปยังหน่วยงานอื่นได้
ผลทางธุรกิจที่คาดหวัง — เมื่อองค์กรมีความสามารถด้านข้อมูลและ ML ที่เหมาะสม ผลที่เห็นได้ชัดเจนประกอบด้วย:
- ลดเวลาและต้นทุนการดำเนินงาน — การอัตโนมัติ (process automation & decision automation) รวมถึงการปรับปรุงกระบวนการสามารถลดเวลาและต้นทุนการดำเนินงานได้อย่างมีนัยสำคัญ (รายงานจาก IDC/Gartner ระบุช่วงตัวอย่างการลดต้นทุนระหว่าง 20–40% ขึ้นกับกรณีใช้งานและระดับการอัตโนมัติ)
- เพิ่มรายได้และสร้างผลิตภัณฑ์ใหม่ — โมเดลที่ขับเคลื่อนด้วยข้อมูลสามารถปรับปรุงการขายแบบเฉพาะบุคคล เพิ่มอัตราการรักษาลูกค้า และเปิดบริการหรือผลิตภัณฑ์ใหม่ที่อิงข้อมูลเชิงลึก (McKinsey พบว่าบริษัทที่ใช้ AI เชิงกลยุทธ์หลายแห่งรายงานการเพิ่มรายได้หรือคุณค่าทางธุรกิจอย่างมีนัย)
- การตัดสินใจแบบอัตโนมัติและขับเคลื่อนด้วยข้อมูล — การผสาน ML เข้ากับกระบวนการตัดสินใจช่วยให้การตัดสินใจรวดเร็ว มีความสอดคล้อง และลดความผิดพลาดจากมนุษย์ โดยเฉพาะในงานที่มีปริมาณข้อมูลมาก
สรุปคือ การลงทุนในความสามารถด้านข้อมูลและ ML ไม่ใช่ค่าใช้จ่ายเพื่อทดลอง แต่เป็นการลงทุนเชิงโครงสร้างที่สร้างพื้นฐานให้เทคโนโลยีสร้างมูลค่าได้จริง องค์กรที่ให้ความสำคัญกับการจัดการคุณภาพข้อมูล governance และสถาปัตยกรรมข้อมูล มีแนวโน้มที่จะได้รับผลตอบแทนทั้งในรูปแบบการลดต้นทุน เพิ่มรายได้ และการสร้างนวัตกรรมอย่างต่อเนื่อง (ตามรายงานเชิงนโยบายและการสำรวจจาก McKinsey, Gartner และ IDC)
ความสามารถด้านข้อมูล (Data Capabilities): พื้นฐานที่ขาดไม่ได้
ความสามารถด้านข้อมูล (Data Capabilities): พื้นฐานที่ขาดไม่ได้
ในการพัฒนา AI ภายในองค์กร ความสามารถด้านข้อมูลเป็นรากฐานที่ต้องมีความพร้อมทั้งในเชิงเทคนิคและการบริหารจัดการ ขาดขั้นตอนใดขั้นตอนหนึ่ง เช่น การนำเข้าข้อมูล (data ingestion) หรือการควบคุมคุณภาพข้อมูล (data quality) จะทำให้โมเดลแมชชีนเลิร์นนิงไม่สามารถให้ผลลัพธ์ที่เชื่อถือได้ องค์ประกอบหลักที่องค์กรควรสร้างและดูแลอย่างเป็นระบบได้แก่ data ingestion, data engineering, data catalog, metadata management, data quality และการเลือกสถาปัตยกรรมการจัดเก็บข้อมูลที่เหมาะสม เช่น data lake, data warehouse, หรือ lakehouse เพื่อสนับสนุนทั้งการวิเคราะห์เชิงธุรกิจและการให้บริการ AI/ML
องค์ประกอบเหล่านี้ควรถูกวางเป็นโครงสร้างที่เชื่อมต่อกันอย่างชัดเจน ตัวอย่างเทคโนโลยีที่ใช้งานทั่วไปในสแต็กขององค์กร ได้แก่ Kafka (event streaming), Airflow (workflow/orchestration), Delta Lake หรือ Apache Iceberg (transactional lake storage), และ Snowflake (cloud data warehouse) — ซึ่งเมื่อนำมาประสานกันจะช่วยให้ระบบรองรับการประมวลผลทั้งแบบเรียลไทม์และแบบแบตช์ ตัวอย่างเชิงสถิติแสดงให้เห็นว่าองค์กรที่ลงทุนใน data catalog และ metadata management มักลดเวลาที่นักวิเคราะห์ใช้ค้นหาข้อมูลได้ประมาณ 30–70% ทำให้ระยะเวลานำไปสู่การใช้งานจริงของโมเดลลดลงอย่างมีนัยสำคัญ

สถาปัตยกรรมข้อมูล: รองรับทั้งเรียลไทม์และแบตช์
สถาปัตยกรรมข้อมูลสมัยใหม่ต้องรองรับการเข้าถึงข้อมูลทั้งแบบ real-time และแบบ batch เพื่อให้ use case ต่าง ๆ ขององค์กรได้รับข้อมูลที่มีความสดและความครบถ้วนตามความต้องการ สำหรับการสตรีมมิ่งใช้แนวทาง event-driven ด้วย Kafka, Pulsar หรือ Debezium (CDC) ร่วมกับกรอบการประมวลผลเช่น Flink หรือ Spark Structured Streaming ส่วนงานแบตช์มักใช้ Airflow, Prefect หรือ Databricks Jobs ในการจัดตารางและ orchestration การออกแบบที่ดีมักใช้รูปแบบ Lambda หรือ Kappa architecture ให้สามารถรวมผลลัพธ์จากทั้งสองช่องทางได้อย่างสอดคล้อง
การเลือกสตอเรจมีผลต่อประสิทธิภาพและต้นทุน: data lake เหมาะกับการเก็บข้อมูลปริมาณมากและแบบไม่เป็นระเบียบ, data warehouse เหมาะกับการคิวรีเชิงวิเคราะห์ที่ต้องการความเร็ว, ส่วน lakehouse (เช่น Delta Lake บน S3 หรือ Iceberg) ผสานข้อดีของทั้งสอง ทำให้รองรับการทำงานทั้งสำหรับงาน BI และ ML ได้ดี โดยเทคโนโลยีเช่น Snowflake ยังให้ความสามารถในการแชร์ข้อมูลและการบริหารจัดการคอนโซลที่เอื้อต่อองค์กร
การจัดการ Metadata และ Data Catalog: ลดเวลา ควบคุมความเสี่ยง
การมีระบบ metadata management และ data catalog ที่เป็นระเบียบจะช่วยลดเวลาการค้นหาข้อมูลและเพิ่มความน่าเชื่อถือให้กับทีม Data/ML ตัวชี้วัดที่สะท้อนคุณค่าของ catalog ได้แก่ อัตราการนำมาใช้ (catalog adoption), เวลาเฉลี่ยในการค้นหาชุดข้อมูล (time-to-discovery) และจำนวนข้อมูลที่มีคำอธิบายเชิงธุรกิจ (business glossary coverage) โดยการศึกษาเชิงอุตสาหกรรมชี้ว่าการใช้ data catalog ที่ดีสามารถลด time-to-insight ได้อย่างมีนัยสำคัญ และลดความเสี่ยงจากการใช้ข้อมูลผิดชุดหรือข้อมูลที่ไม่มีสิทธิ์
KPI และตัวชี้วัดสำคัญที่ต้องเฝ้าติดตาม
- Data freshness: เวลาไปจนถึงการที่ข้อมูลใหม่พร้อมใช้งาน (เช่น streaming < 5 นาที, batch < 24 ชั่วโมง)
- Data latency: ความล่าช้าจากแหล่งถึงการใช้งาน (ตั้งเป้า SLA ตาม use case เช่น ≤ 1 นาที สำหรับการแจ้งเตือน)
- Data completeness: สัดส่วนของข้อมูลที่ครบถ้วนตาม schema หรือ business rules (เป้าหมาย ≥ 99%)
- Data accuracy: อัตราความถูกต้องเทียบกับแหล่งข้อมูลอ้างอิง
- Data quality score: ดัชนีรวบยอดที่รวม completeness, accuracy, conformity และ timeliness (ตัวอย่างเป้าหมาย score ≥ 0.95)
- Catalog adoption & time-to-discovery: เปอร์เซ็นต์ผู้ใช้ที่ค้นหาข้อมูลผ่าน catalog และเวลาที่ใช้ค้นหาเฉลี่ย
ปัญหาที่พบบ่อยและแนวทางแก้ไข
- ข้อมูลกระจัดกระจาย (data silos) — แนวทาง: กำหนด data contracts และสร้างแพลตฟอร์มกลาง (data platform) ที่มี APIs/stream เพื่อรวบรวมข้อมูล; ใช้ Snowflake / Delta Lake ในการรวมและจัดการสิทธิ์การเข้าถึง
- schema drift และ inconsistent formats — แนวทาง: ใช้ schema registry (เช่น Confluent Schema Registry), automated validation และ versioning; ใช้ ETL ที่รองรับการแปลงรูปแบบอัตโนมัติ (dbt, Spark)
- คุณภาพข้อมูลต่ำ — แนวทาง: ติดตั้ง data quality tests ใน pipeline (ตัวอย่างเครื่องมือ: Great Expectations, Deequ), ตั้ง thresholds และ alerting พร้อม corrective workflows
- latency สูง / การประมวลผลเรียลไทม์ไม่เสถียร — แนวทาง: ใช้ระบบ streaming ที่เหมาะสม (Kafka + Flink/Spark), ปรับ partitioning และ resource autoscaling, แยก workload ระหว่างการอ่านเขียนให้เหมาะสม
- ต้นทุนการเก็บข้อมูลสูง — แนวทาง: เลือก storage tiering, compaction (Delta/Iceberg), lifecycle policies และใช้ compute-storage separation เช่น Snowflake เพื่อควบคุมค่าใช้จ่าย
- การค้นพบข้อมูลใช้เวลานาน — แนวทาง: ลงทุนใน data catalog และ metadata enrichment (business glossary, lineage) เพื่อให้ผู้ใช้ค้นหาและเข้าใจข้อมูลได้เร็วขึ้น
สรุปคือ องค์กรที่ต้องการผลลัพธ์จาก AI อย่างยั่งยืน จำเป็นต้องลงทุนสร้างความสามารถด้านข้อมูลแบบครบวงจร ทั้งในเชิงเทคนิคและการบริหารจัดการ โดยยึด KPI ที่ชัดเจน เช่น data quality score และ data latency เพื่อวัดความพร้อมของข้อมูล และใช้สแต็กเทคโนโลยีที่เหมาะสม (Kafka, Airflow, Delta Lake, Snowflake เป็นต้น) ร่วมกับแนวปฏิบัติด้าน metadata และ data governance เพื่อให้ข้อมูลพร้อมใช้งาน ปลอดภัย และเชื่อถือได้สำหรับการนำไปใช้ในโครงการ AI/ML
ความสามารถด้านแมชชีนเลิร์นนิงและการปฏิบัติ (ML Capabilities & MLOps)
ภาพรวมวงจรการพัฒนา ML ในองค์กร
การพัฒนาโมเดลแมชชีนเลิร์นนิงในองค์กรต้องครอบคลุมตั้งแต่การสำรวจและเตรียมข้อมูล (data exploration & preprocessing) ไปจนถึงการนำขึ้นระบบและบำรุงรักษาในระยะยาว การทำงานแบบ ad-hoc ของงานวิจัยเพียงอย่างเดียวไม่เพียงพอเมื่อโมเดลต้องให้บริการผู้ใช้งานจริง MLOps เข้ามาเป็นกรอบปฏิบัติที่เปลี่ยนงานวิจัยให้กลายเป็นการผลิตอย่างปลอดภัยและต่อเนื่อง ด้วยการประยุกต์ใช้กระบวนการเช่น CI/CD สำหรับโมเดล, การจัดการเวอร์ชัน (model versioning) และ Model Registry องค์กรสามารถลดเวลาในการนำโมเดลขึ้นสู่ production และลดความเสี่ยงจากข้อผิดพลาดที่เกิดจากการแยกสภาพแวดล้อมการทดลองและการให้บริการจริง งานวิจัยและกรณีศึกษาจากตลาดชี้ให้เห็นว่าองค์กรที่ลงทุนใน MLOps สามารถลดเวลาในการนำโมเดลขึ้นระบบลงได้ครั้งละหลายสิบเปอร์เซ็นต์และเพิ่มความถี่ของการปล่อยโมเดลจากรายไตรมาสเป็นรายสัปดาห์หรือรายวันได้ในบางกรณี
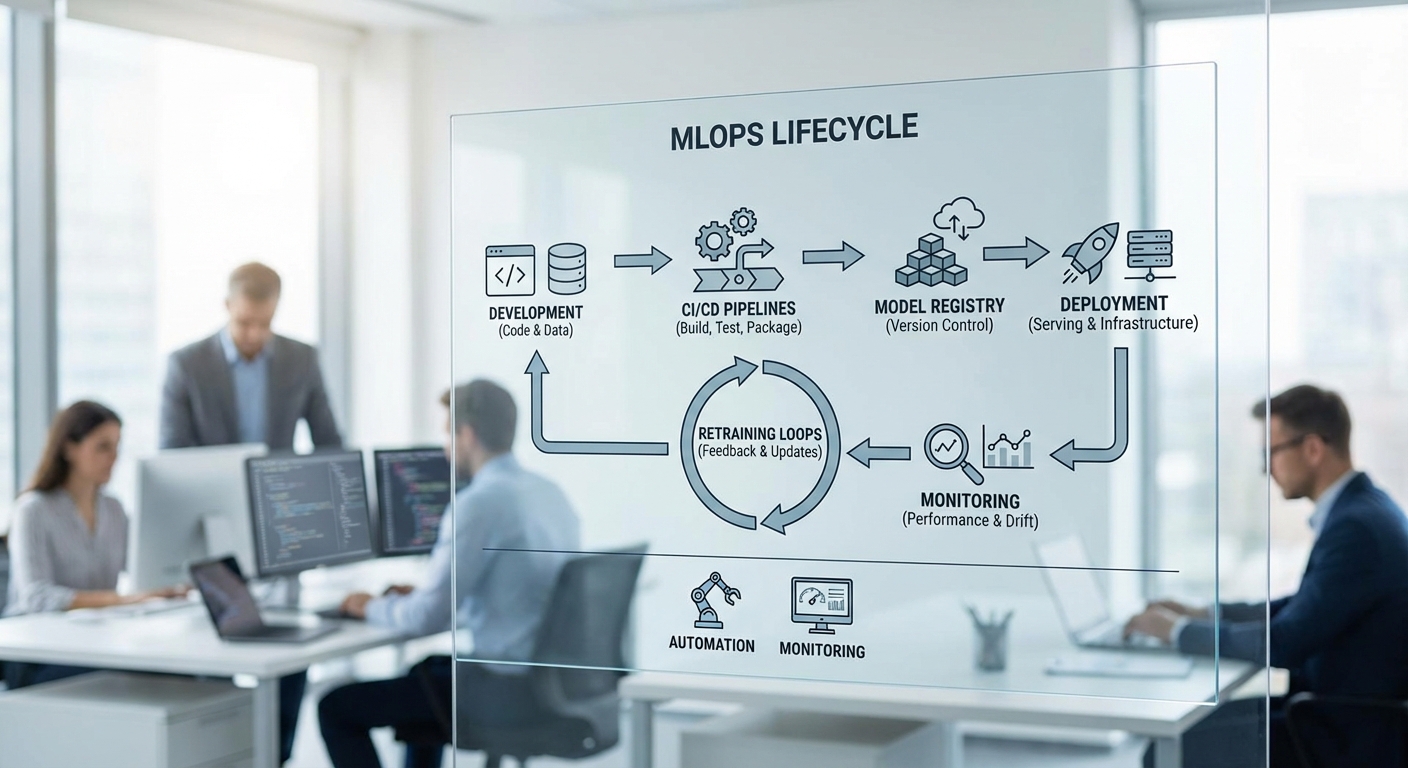
ขั้นตอนสำคัญของวงจร ML และแนวปฏิบัติที่แนะนำ
วงจรพื้นฐานประกอบด้วยขั้นตอนต่อไปนี้ ซึ่งแต่ละขั้นตอนต้องมีมาตรฐานและเครื่องมือรองรับเพื่อให้เกิดการทำซ้ำและตรวจสอบได้:
- Data Exploration & Validation: ตรวจสอบคุณภาพข้อมูล, การกระจายของตัวแปร, การจัดการค่า missing และการตรวจจับ outlier พร้อมการสร้าง data schema และ data quality checks ก่อนเข้าสู่ pipeline
- Model Development & Training: ใช้การทดลองแบบมีการติดตาม (experiment tracking) เพื่อเก็บ hyperparameters, metric และโค้ดที่ใช้ ตัวอย่างเครื่องมือ: MLflow, TensorBoard, Weights & Biases
- Testing & Version Control: ทดสอบ unit test สำหรับ pre-processing, integration test สำหรับ pipeline และ regression test สำหรับ performance พร้อมระบบ version control สำหรับโค้ดและโมเดล (Git + Model Registry เช่น MLflow Model Registry หรือ TFX Metadata)
- Deployment & CI/CD: ใช้แพลตฟอร์ม CI/CD เพื่อ build, test และ deploy โมเดลไปสู่ staging/production อัตโนมัติ (เช่น GitHub Actions, Jenkins, ArgoCD ร่วมกับ Kubeflow Pipelines หรือ TFX)
- Monitoring & Observability: ติดตาม metric ทั้งทางเทคนิคและเชิงธุรกิจ เช่น latency, throughput, error rate, และ model performance (precision/recall, AUC) รวมถึงการตรวจจับ data drift และ concept drift
- Retraining & Rollback: กำหนด workflow สำหรับ retraining แบบอัตโนมัติหรือกึ่งอัตโนมัติเมื่อพบ degradation และมีกลไก rollback ชัดเจนหากเวอร์ชันใหม่แย่ลง
ตัวชี้วัดสำคัญและการตรวจจับ drift หลังการนำขึ้นระบบ
หลังนำโมเดลขึ้นระบบ การติดตามอย่างต่อเนื่องเป็นสิ่งจำเป็น ตัวชี้วัดควรครอบคลุมทั้งด้านระบบและด้านโมเดล เช่น:
- Latency: เวลาตอบสนองเฉลี่ยและเปอร์เซ็นไทล์ (เช่น p95, p99) — สำหรับระบบเรียลไทม์ทั่วไปเป้าหมายอาจอยู่ที่ 50–200 ms ขึ้นกับบริบท
- Throughput: คำขอต่อวินาที (requests/sec) และการใช้ทรัพยากร เพื่อวางแผน scaling
- Model Performance: Metrics ทางธุรกิจและทาง ML เช่น accuracy, precision, recall, AUC, F1 ที่ต้องเปรียบเทียบกับ baseline
- Data / Concept Drift Detection: ใช้สถิติความแตกต่างของ distribution (e.g., KS test, population stability index) หรือโมเดลตรวจจับ drift โดยอัตโนมัติ เพื่อเตือนเมื่อข้อมูลเข้าใช้งานไม่สอดคล้องกับ training distribution
การตรวจจับ drift ที่รวดเร็วช่วยลดความเสี่ยงของการเสื่อมสภาพของโมเดล ตัวอย่างเช่น หากค่า PSI > 0.2 หรือตรวจพบการลดลงของความแม่นยำมากกว่า 5–10% ควรกระตุ้น workflow สำหรับ retraining หรือ rollback
Workflow สำหรับ Retraining, A/B Testing และการ Rollback
องค์กรควรมี workflow ที่กำหนดขั้นตอนชัดเจนเมื่อโมเดลต้องถูกปรับปรุงหรือทดแทน ดังนี้:
- Triggering: การ retraining อาจถูกทริกเกอร์โดยเงื่อนไขอัตโนมัติ เช่น detection ของ drift, การลดลงของ metric เชิงธุรกิจ หรือกำหนดตามรอบเวลา
- Training Pipeline: pipeline อัตโนมัติที่ดึงข้อมูลใหม่, ทำ feature engineering, ฝึกโมเดล และบันทึกผลการทดลอง โดยมีการบันทึกเวอร์ชันใน Model Registry (ตัวอย่าง tools: Kubeflow Pipelines, TFX, MLflow)
- Validation & Staging: ทดสอบโมเดลใหม่ใน environment แยก ตรวจสอบ performance เทียบกับ production baseline และเรียกใช้ canary หรือ A/B testing เพื่อตรวจสอบผลกระทบเชิงธุรกิจ
- Promotion & Deployment: หากผ่านเกณฑ์ให้ promote เวอร์ชันใหม่จาก registry ไปสู่ production ผ่านกระบวนการ CI/CD ที่สามารถ rollback ได้ทันที
- Rollback Plan: มี playbook ที่ระบุเงื่อนไข rollback (เช่น degradation เกิน threshold), ขั้นตอนการสับกลับไปยังเวอร์ชันก่อนหน้า และการแจ้งเตือนผู้เกี่ยวข้อง
การใช้ A/B testing และ progressive rollout (canary deployments) ช่วยให้ทีมมั่นใจได้ว่าเวอร์ชันใหม่ไม่ทำให้ประสบการณ์ผู้ใช้งานหรือเมตริกธุรกิจแย่ลง ก่อนจะเปิดใช้งานแบบเต็มระบบ
เครื่องมือที่เป็นประโยชน์และแนวทางปฏิบัติ
เครื่องมือยอดนิยมในระบบ MLOps ได้แก่ Kubeflow (สำหรับ orchestration และ pipeline บน Kubernetes), MLflow (สำหรับ experiment tracking, model registry และการ deploy แบบง่าย), และ TFX (TensorFlow Extended สำหรับ production pipelines) การเลือกเครื่องมือควรพิจารณาโครงสร้างพื้นฐานขององค์กร ความสามารถของทีม และความสามารถในการผสานกับระบบเดิม
แนวปฏิบัติที่แนะนำ: เริ่มจากการสร้าง data contracts และ schema validation, บังคับใช้ experiment tracking และ model registry ตั้งแต่ต้น, ออกแบบ CI/CD สำหรับโมเดลแยกจากแอปพลิเคชัน และตั้งค่า monitoring ที่รวมทั้ง metrics ระบบ, logs และข้อมูลเชิงธุรกิจเข้าด้วยกัน เพื่อให้การตัดสินใจ retraining และ rollback มีหลักฐานรองรับ
สรุป
MLOps ไม่ใช่เพียงชุดเครื่องมือแต่เป็นวินัยในการทำงานที่เชื่อมโยงงานวิจัยกับการผลิตอย่างปลอดภัยและต่อเนื่อง การติดตาม performance และการตรวจจับ data/concept drift เป็นสิ่งจำเป็นหลัง deployment และองค์กรต้องมี workflow สำหรับ retraining และ rollback ที่ชัดเจนเพื่อรักษาความน่าเชื่อถือของระบบ AI ในระยะยาว
การกำกับดูแล ความปลอดภัย และจริยธรรมของ AI
การกำกับดูแล ความปลอดภัย และจริยธรรมของ AI
การกำกับดูแล (Governance) เป็นกรอบพื้นฐานที่องค์กรต้องวางไว้เพื่อให้การพัฒนาและใช้งาน AI สอดคล้องกับนโยบายภายใน กฎหมาย และมาตรฐานสากล กรอบนี้ควรรวมถึงนโยบายการใช้งานข้อมูล (data usage policy), การจัดการสิทธิ์ (access control), นโยบายความเป็นส่วนตัวแบบออกแบบล่วงหน้า (privacy by design) และกระบวนการประเมินความเสี่ยงด้านจริยธรรมและอคติ (ethical & bias assessment) ตัวอย่างเช่น องค์กรควรกำหนดชัดเจนว่าข้อมูลใดใช้ได้เพื่อการฝึกโมเดล การเก็บรักษาอยู่ได้นานเท่าใด และการอนุญาตให้ใช้งานข้อมูลต้องผ่านขั้นตอนใดบ้าง งานสำรวจเชิงอุตสาหกรรมชี้ว่าองค์กรจำนวนมากกว่า 50% พบความท้าทายในการจัดตั้งนโยบายกำกับดูแลที่เป็นระบบ ซึ่งสะท้อนความจำเป็นที่ต้องมีกรอบที่ชัดเจนและปฏิบัติได้จริง
การจัดตั้งคณะกรรมการ AI และบทบาทการอนุมัติ การตั้งคณะกรรมการ AI (AI Governance Committee) ที่มีตัวแทนจากฝ่ายต่าง ๆ เช่น ผู้บริหาร (CIO/CTO), เจ้าหน้าที่ข้อมูล (CDO), ฝ่ายกฎหมาย, ฝ่ายคอมไพลแอนซ์, เจ้าหน้าที่ความปลอดภัยสารสนเทศ, นักวิทยาศาสตร์ข้อมูล และตัวแทนธุรกิจ เป็นสิ่งจำเป็น คณะกรรมการนี้ควรมีหน้าที่กำหนดนโยบายระดับสูง ตรวจสอบการประเมินความเสี่ยง และอนุมัติการใช้งานโมเดล โดยเฉพาะโมเดลที่จัดว่าเป็นความเสี่ยงสูง (high-risk) ซึ่งควรผ่านขั้นตอนต่อไปนี้ก่อนนำสู่การใช้งานจริง:
- การจัดหมวดความเสี่ยงของโมเดล (risk classification) — ตัวอย่าง: ต่ำ กลาง สูง
- การประเมินผลกระทบความเป็นส่วนตัว (DPIA / Privacy Impact Assessment)
- การทดสอบอคติและความยุติธรรม (bias & fairness testing) พร้อมแผนแก้ไข
- การตรวจสอบความโปร่งใส เช่น Model Card / Datasheet for Datasets
- การอนุมัติจากคณะกรรมการและบันทึกการตัดสินใจ (approval record)
นโยบายการใช้ข้อมูลและการตรวจสอบอคติของโมเดล ควรมีการบันทึกแหล่งที่มาของข้อมูล (data provenance), การทำความสะอาดและแปลงข้อมูล (data preprocessing) รวมถึงมาตรการลดอคติ เช่น การรีสมเพล (resampling), การถ่วงน้ำหนัก (re-weighting) หรือการใช้เทคนิคปรับแก้โมเดล นอกจากนี้ ควรกำหนด KPI และเมตริกสำหรับการตรวจจับอคติ เช่น ความแตกต่างของอัตราการผิดพลาด (error rates) ข้ามกลุ่มประชากร และการทดสอบด้วยชุดข้อมูลที่เป็นตัวแทนประชากรจริง ตัวอย่างเหตุการณ์ที่เป็นที่รู้จัก เช่น กรณีระบบคัดกรองซ้ำที่ทำให้เกิดการเลื่อนตำแหน่งหรือปฏิเสธกลุ่มคนบางกลุ่ม แสดงให้เห็นถึงความเสี่ยงทางธุรกิจและชื่อเสียงหากไม่จัดการอคติอย่างเป็นระบบ
การจัดการสิทธิ์และการเข้ารหัสเป็นพื้นฐานด้านความปลอดภัย ระบบควรใช้หลักการสิทธิ์ขั้นต่ำสุด (least privilege), การควบคุมการเข้าถึงแบบบทบาท (RBAC) และการเข้ารหัสข้อมูลทั้งขณะเก็บ (encryption at rest) และขณะส่ง (encryption in transit) รวมถึงการบริหารจัดการคีย์ (key management) อย่างเข้มงวด การติดตามและบันทึกการเข้าถึงข้อมูล (access logs), การแยกสิ่งแวดล้อมการพัฒนาและการใช้งานจริง (dev/test vs production) และการทดสอบด้านความปลอดภัย เช่น penetration testing และ red-team exercises ช่วยป้องกันการรั่วไหลและการโจมตีที่มุ่งเป้าไปยังโมเดลและข้อมูล
กระบวนการ audit, documentation และการลดความเสี่ยงทางกฎหมาย เอกสารที่ครบถ้วนและการทำ audit เป็นเครื่องมือสำคัญสำหรับการแสดงความรับผิดชอบต่อหน่วยงานกำกับดูแลและผู้มีส่วนได้เสีย ได้แก่ บันทึกการประมวลผลข้อมูล (ROPA), Model Cards, Datasheets, รายงาน DPIA, ขั้นตอนการตรวจสอบอคติ, ผลการทดสอบความปลอดภัย และบันทึกการตัดสินใจของคณะกรรมการ AI การมี checklist สำหรับการตรวจสอบ (audit checklist) ช่วยให้การประเมินเป็นระบบ ตัวอย่าง checklist ที่ควรมี:
- ข้อมูลต้นทางและสิทธิ์การใช้งาน (data provenance & consent)
- การเข้ารหัสและการจัดการคีย์ (encryption & key management)
- การควบคุมการเข้าถึงและการพิสูจน์ตัวตน (RBAC, MFA)
- Model documentation: สถาปัตยกรรม, เวอร์ชัน, ข้อมูลฝึก, hyperparameters
- ผลการทดสอบอคติและมาตรการบรรเทา (bias tests & mitigation)
- ผลการทดสอบความปลอดภัยและความทนทานต่อการโจมตี (security & adversarial tests)
- แผนการตรวจสอบต่อเนื่อง: monitoring, drift detection, retraining criteria
- การปฏิบัติตาม PDPA / GDPR: ข้อกำหนดการแจ้งสิทธิ์, การจัดเก็บจำกัดเวลา, การถ่ายโอนข้อมูลข้ามพรมแดน
การปฏิบัติตาม PDPA/GDPR และข้อกำหนดทางกฎหมาย องค์กรที่ใช้ AI ต้องคำนึงถึงกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ในประเทศไทย และ GDPR ในสหภาพยุโรป ซึ่งกำหนดหลักการสำคัญ เช่น ฐานทางกฎหมายในการประมวลผลข้อมูล (lawful basis), สิทธิของเจ้าของข้อมูล (data subject rights), การแจ้งการละเมิดข้อมูล (breach notification) และข้อกำหนดสำหรับ DPIA กับการประมวลผลที่มีความเสี่ยงสูง การจัดทำบันทึกการประมวลผลและแต่งตั้งเจ้าหน้าที่คุ้มครองข้อมูล (DPO) เมื่อจำเป็น จะช่วยลดความเสี่ยงทางกฎหมายและค่าปรับจากการไม่ปฏิบัติตาม
สรุปคือ การกำกับดูแลที่แข็งแกร่ง ประกอบกับการจัดการสิทธิ์และการเข้ารหัสที่เข้มงวด การประเมินอคติอย่างต่อเนื่อง และการจัดทำเอกสารเพียงพอ จะช่วยให้องค์กรสามารถนำ AI มาใช้อย่างปลอดภัย ถูกต้องตามจริยธรรม และสอดคล้องกับข้อกำหนดทางกฎหมาย ช่วยลดความเสี่ยงด้านชื่อเสียงและความรับผิดชอบทางกฎหมายในระยะยาว
การเปลี่ยนแปลงองค์กรและการพัฒนาทักษะ (People & Process)
การเปลี่ยนแปลงองค์กร: คนและกระบวนการสำคัญพอ ๆ กับเทคโนโลยี
การลงทุนในเครื่องมือ AI และโครงสร้างพื้นฐานเพียงอย่างเดียวไม่เพียงพอ การขับเคลื่อนโครงการ AI ให้เกิดมูลค่าทางธุรกิจต้องอาศัย คน และ กระบวนการ ที่ออกแบบมาอย่างเป็นระบบ ตั้งแต่การกำหนดบทบาทชัดเจน การจัดตั้งทีมข้ามสายงาน ไปจนถึงการวัดและพัฒนาทักษะอย่างต่อเนื่อง องค์กรหลายแห่งพบว่าอุปสรรคที่ใหญ่ที่สุดไม่ใช่เทคโนโลยี แต่เป็นการขาดความสามารถด้านข้อมูลและการประสานงานระหว่างฝ่าย IT, Data และธุรกิจ การวางโครงสร้างองค์กรที่รองรับ AI จึงต้องเดินควบคู่กับการเปลี่ยนแปลงกระบวนการทำงานและวัฒนธรรมภายใน
บทบาทสำคัญและการทำงานข้ามสายงาน
การพัฒนา AI ในระดับองค์กรจำเป็นต้องมีบทบาทที่ชัดเจนทั้งในระดับเชิงเทคนิคและเชิงธุรกิจ เพื่อให้กระบวนการตั้งแต่การเก็บข้อมูลจนถึงการนำโมเดลไปใช้เป็นไปอย่างราบรื่น ตัวอย่างบทบาทที่จำเป็นได้แก่:
- Data Engineers — รับผิดชอบการออกแบบและดูแลท่อข้อมูล (data pipelines), การจัดการคลังข้อมูล และการรับประกันคุณภาพข้อมูล
- Data Scientists — วิเคราะห์ข้อมูล ออกแบบฟีเจอร์ และสร้างต้นแบบโมเดลเชิงสถิติหรือแมชชีนเลิร์นนิง
- ML Engineers — นำโมเดลสู่สภาพแวดล้อมการผลิต ปรับแต่งประสิทธิภาพ และทำงานร่วมกับ MLOps ในการติดตั้งระบบ
- MLOps Engineers — สร้างกระบวนการ CI/CD สำหรับโมเดล ดูแลการวางโมเดล การตรวจสอบ และการจัดการวงจรชีวิตของโมเดล
- Product Managers (AI/Product) — เชื่อมโยงความต้องการเชิงธุรกิจกับทีมเทคนิค กำหนดวิสัยทัศน์ ผลลัพธ์ทางธุรกิจ และตัวชี้วัด (KPIs)
การทำงานข้ามสายงาน (cross-functional collaboration) ควรถูกกำหนดเป็นรูปแบบปฏิบัติการ เช่น squad หรือ guild ที่มีผู้นำทางธุรกิจเป็นเจ้าของเป้าหมาย และมีทีม Data/ML เป็นผู้รับผิดชอบทางเทคนิค นอกจากนี้ควรกำหนด RACI matrix สำหรับกิจกรรมสำคัญ เช่น การอนุมัติข้อมูล การทดสอบโมเดล และการเปิดใช้งานทางธุรกิจ เพื่อหลีกเลี่ยงความซ้ำซ้อนและช่องว่างความรับผิดชอบ
แผนฝึกอบรมและการวัดทักษะลดความเสี่ยงจากการขาดแคลนบุคลากร
การสรรหาอย่างเดียวไม่เพียงพอ — องค์กรต้องมีแผนพัฒนาทักษะภายในเพื่อเพิ่มความสามารถของพนักงานเดิมและลดความเสี่ยงจากการขาดแคลนบุคลากร โปรแกรมที่ได้ผลมักประกอบด้วยองค์ประกอบต่อไปนี้:
- โปรแกรมพื้นฐาน (Data Literacy) — การอบรมความเข้าใจข้อมูลและหลักการวิเคราะห์สำหรับพนักงานทุกระดับ (เช่น 8–16 ชั่วโมง ของคอร์สพื้นฐาน)
- เส้นทางการฝึกเฉพาะบทบาท — Bootcamp สำหรับ Data Engineers, ML Engineers และ Data Scientists (ตัวอย่าง: 12 สัปดาห์ แบบผสมผสานระหว่างคอนเทนต์และโปรเจ็กต์จริง รวมประมาณ 120–240 ชั่วโมง)
- โปรเจ็กต์ภายใน (Practicum) — ให้ทีมทำโปรเจ็กต์ต้นแบบจริงที่เชื่อมโยงกับ KPI ธุรกิจ ภายใต้การมอบหมายผู้เชี่ยวชาญเป็นพี่เลี้ยง
- Mentorship และ Rotation — การหมุนเวียนพนักงานระหว่างทีม Data, IT และธุรกิจเป็นเวลา 3–6 เดือน เพื่อสร้างความเข้าใจแบบข้ามสายงาน
- การรับรองและการยอมรับ — ให้รางวัลในรูปแบบเงินเดือน ปรับตำแหน่ง หรือโบนัสเมื่อผ่านการประเมินตาม skill matrix
การวัดความก้าวหน้าควรใช้ skill matrix ที่แบ่งระดับทักษะเป็นกลุ่ม (เช่น Novice / Developing / Competent / Advanced / Expert) โดยกำหนดเกณฑ์ชัดเจนสำหรับแต่ละทักษะ เช่น ความสามารถในการเขียน SQL, การออกแบบสถาปัตยกรรมข้อมูล, การปรับแต่งโมเดล ML และการใช้งาน MLOps สถานะพื้นฐานและเป้าหมายควรถูกทบทวนทุกไตรมาส ตัวชี้วัดเชิงปฏิบัติการสามารถรวมถึง:
- สัดส่วนพนักงานที่บรรลุระดับ "Competent" ขึ้นไปในทักษะหลัก (% เป้าหมายเช่น 60% ภายใน 12 เดือน)
- จำนวนชั่วโมงการฝึกอบรมต่อคน (เป้าหมายเช่น 120 ชั่วโมง/ปี)
- อัตราการย้ายตำแหน่งภายใน (internal mobility rate) และอัตราการเติมตำแหน่งจากภายใน
- เวลาเฉลี่ยในการนำโมเดลขึ้นสู่ production (time-to-deploy) และความสำเร็จของโมเดลต่อธุรกิจ
กรณีตัวอย่างการเปลี่ยนบทบาทของพนักงาน
ตัวอย่างการเปลี่ยนบทบาทจริง: องค์กรแห่งหนึ่งตั้งโปรแกรม "AI Fellowship 9 เดือน" สำหรับพนักงานฝ่ายวิเคราะห์ธุรกิจและ BI analyst ที่ต้องการเปลี่ยนไปทำงานด้าน ML ผลลัพธ์ที่ออกมารวมถึง:
- การอบรม 140 ชั่วโมง (พื้นฐานข้อมูล, Python, ML fundamentals, MLOps เบื้องต้น)
- การทำโปรเจ็กต์จริง 2 โปรเจ็กต์ ภายใต้การเป็นพี่เลี้ยงของ Data Scientist และ ML Engineer
- การประเมินตาม skill matrix ทุก 3 เดือน แสดงให้เห็นว่าสัดส่วนผู้เข้าร่วมที่ขึ้นสู่ระดับ "Competent" เพิ่มจาก 10% เป็น 65% ภายใน 9 เดือน
- ผลเชิงธุรกิจ: โปรเจ็กต์อย่างน้อยหนึ่งโปรเจ็กต์ถูกนำขึ้น production ภายใน 6 เดือน ลดเวลาในการตัดสินใจของธุรกิจ 20% และช่วยลดต้นทุนการดำเนินงานในส่วนนั้น
กรณีเช่นนี้แสดงให้เห็นว่าเมื่อมีแผนฝึกอบรมที่เป็นระบบ การให้โอกาสและมาตรการประเมินที่ชัดเจน องค์กรสามารถเปลี่ยนบทบาทของพนักงานเดิมไปสู่บทบาท AI/ML ได้อย่างมีประสิทธิภาพ และลดความเสี่ยงจากการขาดแคลนบุคลากรภายนอก
สรุปคือการนำ AI สู่การปฏิบัติได้จริงต้องอาศัยการออกแบบคนและกระบวนการควบคู่ไปกับเทคโนโลยี โดยบทบาทที่ชัดเจน การทำงานข้ามสายงาน และแผนพัฒนาทักษะที่มีการวัดผลอย่างเป็นระบบ จะเป็นตัวแปรสำคัญที่กำหนดความสำเร็จของโครงการ AI ในองค์กร
กรณีศึกษา ตัวเลขผลลัพธ์ และการวัดผล (Metrics & ROI)
กรณีศึกษา: ผลลัพธ์เชิงตัวเลขจากการนำ AI ไปใช้ในอุตสาหกรรมต่าง ๆ
1) โลจิสติกส์ — การใช้ Machine Learning ในการคาดการณ์สต็อก
บริษัทผู้ให้บริการอีคอมเมิร์ซขนาดกลางได้นำโมเดลทำนายความต้องการ (demand forecasting) และการจัดสต็อกแบบอัตโนมัติไปใช้ ผลลัพธ์ที่รายงานในเชิงตัวเลข ได้แก่ อัตราการเติมคำสั่งซื้อ (fill rate) เพิ่มจาก 82% เป็น 95%, ลดวันหมุนเวียนของสต็อก (inventory days) ลง จาก 45 วันเป็น 36 วัน (-20%) ส่งผลให้ค่าใช้จ่ายในการถือครองสต็อกลดลงประมาณ 0.8 ล้านบาทต่อปี และรายได้ที่ไม่ได้สูญเสียจากสินค้าขาดสต็อกเพิ่มขึ้นราว 6% ของยอดขาย ในปีแรก
2) การเงิน — ระบบตรวจจับการฉ้อโกงด้วย AI
ธนาคารรายใหญ่ได้นำระบบตรวจจับการฉ้อโกงด้วยการเรียนรู้ของเครื่องมาใช้ควบคู่กับกฎธุรกิจ ผลลัพธ์ที่วัดได้รวมถึงการเพิ่มอัตราการจับการฉ้อโกงจริง (true positive rate) ขึ้น 30% ในขณะที่อัตราบวกเท็จ (false positive rate) ลดลง 45% ส่งผลให้ต้นทุนการไต่สวนลดลงประมาณ 1.2 ล้านบาทต่อปี และการสูญเสียจากการฉ้อโกงโดยตรงลดลง ประมาณ 3% ของมูลค่าที่เสี่ยง
3) การผลิต — Predictive Maintenance
โรงงานที่นำระบบทำนายความล้มเหลวของเครื่องจักรไปใช้ พบว่าเวลาหยุดการผลิตที่ไม่ได้วางแผนลดลง 40% และอายุใช้งานชิ้นส่วนเพิ่มขึ้นโดยเฉลี่ย 20% ส่งผลให้ค่าใช้จ่ายด้านบำรุงรักษาต่อปีลดลงราว 15–25% และเพิ่มความพร้อมใช้งานของอุปกรณ์ (availability) ที่ส่งผลต่อปริมาณการผลิตเพิ่มขึ้น 5–8%
วิธีการคำนวณ ROI และตัวอย่างเชิงตัวเลข
การประเมิน ROI ของโครงการ AI ควรพิจารณาทั้งต้นทุนเริ่มต้นและต้นทุนต่อเนื่องเทียบกับประโยชน์ที่วัดได้ในหน่วยเงิน (monetized benefits) เช่น เพิ่มรายได้โดยตรง ลดค่าใช้จ่ายดำเนินงาน หรือลดการสูญเสีย ตัวชี้วัดพื้นฐานที่ใช้คือ:
- ROI (พื้นฐาน) = (Total Benefits − Total Costs) / Total Costs × 100%
- Payback Period = Total Initial Cost / Annual Net Benefit
- NPV / IRR = การคิดมูลค่าปัจจุบันของกระแสเงินสดในอนาคต (เมื่อโครงการมีวงชีพหลายปี)
ตัวอย่างเชิงตัวเลข (สมมติ): ต้นทุนติดตั้งและพัฒนา = 5,000,000 บาท, ต้นทุนการดำเนินการประจำปี = 500,000 บาท, ประโยชน์ที่วัดได้ต่อปี = ลดต้นทุน 2,000,000 บาท + เพิ่มรายได้ 1,000,000 บาท = 3,000,000 บาท/ปี
- Annual Net Benefit = 3,000,000 − 500,000 = 2,500,000 บาท
- Payback Period = 5,000,000 / 2,500,000 = 2.0 ปี
- 3-year cumulative ROI = (Total Benefits 9,000,000 − Total Costs 6,500,000) / 6,500,000 = 38.46%
หมายเหตุ: ควรปรับสมมติฐาน (growth, churn, ค่าเสื่อมราคา, discount rate) เพื่อคำนวณ NPV และ IRR ที่แม่นยำยิ่งขึ้น โดยเฉพาะสำหรับโครงการที่มีผลกระทบยาวนาน
KPI ที่ควรติดตามตามระยะการเติบโตของโครงการ (Pilot → Scale → Enterprise)
การเลือก KPI ควรผสมผสานตัวชี้วัดทางเทคนิคกับตัวชี้วัดทางธุรกิจ เพื่อวัดความสำเร็จทั้งในเชิงคุณภาพของโมเดลและผลกระทบทางการเงิน ดังนี้
- Pilot (Proof of Value)
- Model performance: Accuracy, Precision, Recall, F1-score, AUC
- Business signal: Uplift in conversion (%) หรือ reduction in error rate (%) เทียบกับ baseline
- Operational feasibility: Time-to-predict (latency), latency SLA, integration time
- Time-to-value: ระยะเวลาจากการเริ่มโครงการจนเห็นผลเงินสดหรือ KPI ที่สำคัญ
- Scale (Operationalization)
- Throughput: จำนวนคำทำนาย/การประมวลผลต่อวัน
- Cost metrics: Cost per inference, ค่าใช้จ่ายคลาวด์/ฮาร์ดแวร์ต่อเดือน
- Business impact: Cost savings per month, Revenue uplift per quarter, Reduction in manual work-hours
- Adoption: % ผู้ใช้งานธุรกิจที่ยอมรับระบบ (user adoption rate)
- Enterprise-wide (Governance & Optimization)
- Financial KPIs: Total Cost of Ownership (TCO), Payback period, 1–5 year NPV
- Risk & Quality: Model drift rate, % of models requiring retraining, False positive/negative impact cost
- Operational resilience: Mean time to detect (MTTD) model issues, Mean time to recover (MTTR)
- Strategic KPIs: % รายได้ที่มาจากผลิตภัณฑ์/บริการที่ปรับปรุงด้วย AI, Business process automation rate
สรุป: การวัดผลโครงการ AI ต้องมีทั้งตัวชี้วัดเชิงเทคนิคและเชิงธุรกิจ พร้อมกรอบการคำนวณ ROI ที่ชัดเจน (รวมทั้ง Payback, NPV/IRR) และ KPI ที่แตกต่างตามระยะของโครงการเพื่อให้การตัดสินใจทางธุรกิจมีข้อมูลรองรับและสามารถขยายผลได้อย่างยั่งยืน
แผนปฏิบัติการและ checklist สำหรับเริ่มต้นถึงขยายโครงการ AI
แผนปฏิบัติการ (Roadmap) สำหรับเริ่มต้นถึงขยายโครงการ AI
การวางแผนปฏิบัติการสำหรับโครงการ AI ควรเริ่มจากการประเมินความพร้อมด้านข้อมูลและความเป็นไปได้ของกรณีการใช้งาน โดยยึดหลักเลือก use case ที่ให้ประโยชน์สูงแต่ความเสี่ยงต่ำ และแบ่งงานเป็นขั้นตอนย่อย (increments) เพื่อลดความเสี่ยงและเพิ่มความเร็วในการสร้างมูลค่า ตัวอย่างแผนแบ่งตามช่วงเวลาที่แนะนำมีดังนี้
ระยะเวลา 0–3 เดือน: ประเมิน เตรียม และเลือก use case
เป้าหมายในช่วงแรกคือการทำ data maturity assessment และเลือก use case เริ่มต้นที่ชัดเจนและเป็นไปได้จริง โดยขั้นตอนสำคัญได้แก่:
- Data maturity assessment: ตรวจสอบคุณภาพข้อมูล (completeness, accuracy, timeliness), การจัดเก็บ, metadata, และความสามารถในการเข้าถึงข้อมูล
- Data inventory: รวบรวมรายการแหล่งข้อมูล (systems, tables, schemas, owners) และจัดทำ data catalog เบื้องต้น
- Prioritization ของ use case: เลือกกรณีที่มี ROI ชัดเจน ผลลัพธ์วัดได้ (เช่นลดเวลาการทำงาน 20%, เพิ่มอัตราการขาย 5%) และมีความเสี่ยงด้านข้อมูล/กฎระเบียบต่ำ
- ตั้งทีมและ governance พื้นฐาน: ระบุเจ้าของข้อมูล (Data Owner), เจ้าของผลิตภัณฑ์ (Product Owner), และหัวหน้าทีม ML พร้อมกำหนดนโยบายเบื้องต้นเรื่องความเป็นส่วนตัวและการเข้าถึงข้อมูล
- กำหนด metrics เริ่มต้น: KPIs สำหรับ business (ROI, conversion uplift) และ technical metrics (data quality score, baseline model accuracy)
ระยะเวลา 3–9 เดือน: PoC, พิสูจน์คุณค่า และเตรียมโครงสร้างพื้นฐาน
ในช่วงกลางโครงการให้เน้นการพัฒนา Proof of Concept (PoC) และการวัดผลเชิงปริมาณ พร้อมเตรียมสถาปัตยกรรมที่รองรับการขยายต่อ:
- พัฒนา PoC แบบเร็ว (fast iterations): สร้างโมเดลต้นแบบในสภาพแวดล้อมที่ควบคุมได้ ทดสอบกับชุดข้อมูลจริงและวัดเทียบกับ baseline
- เกณฑ์ความสำเร็จ: กำหนด thresholds ทางเทคนิคและธุรกิจ (เช่น precision ≥ 0.75, latency ≤ 200ms, หรือ uplift ทางธุรกิจ ≥ 10%) ก่อนตัดสินใจขยาย
- เตรียม infrastructure: วางแผนงบประมาณฮาร์ดแวร์/คลาวด์, storage, และ MLOps pipeline (CI/CD, model registry, automated testing)
- Pilot แบบควบคุม: นำ PoC ไปทดสอบในกลุ่มผู้ใช้จำกัดเพื่อเก็บ feedback และประเมินผลกระทบด้านการดำเนินงาน
- เริ่มจัดทำแผนการฝึกอบรมบุคลากร: ทั้งทีมเทคนิค ฝ่ายธุรกิจ และผู้ใช้งาน เพื่อรองรับการนำระบบไปใช้จริง
ระยะเวลา 9–24 เดือน: Productionize, ขยาย และดูแลรักษาอย่างต่อเนื่อง
เมื่อ PoC ผ่านเกณฑ์ ให้ดำเนินการผลิตจริงและขยายการใช้งานอย่างมีควบคุม โดยโฟกัสที่ความมั่นคง ความโปร่งใส และการติดตามผลอย่างต่อเนื่อง:
- Production deployment และ MLOps: ติดตั้ง pipeline สำหรับ deployment อัตโนมัติ การทดสอบหลัง deployment และระบบ rollback
- Monitoring & observability: ติดตามทั้ง business metrics (e.g., revenue impact, error rates) และ model metrics (e.g., drift, degradation, inference latency)
- Governance ขั้นสูง: จัดทำ model registry, audit trail, access control, และกระบวนการรีวิวด้านจริยธรรม/ความเอนเอียงของโมเดล
- กระบวนการ retraining & lifecycle management: กำหนดนโยบายเมื่อใดต้อง retrain model, วิธีการรวบรวม label ใหม่ และ testing ก่อนนำขึ้น production ใหม่
- การขยายแบบค่อยเป็นค่อยไป: เพิ่มจำนวน use case หรือตลาดเป้าหมายตามความสามารถของทีมและระบบ เพื่อรักษาคุณภาพและลดความเสี่ยง
Checklist รายการสำคัญสำหรับแต่ละช่วง
รายการตรวจสอบ (checklist) ต่อไปนี้เป็นสิ่งที่องค์กรควรเตรียมเพื่อให้โครงการ AI มีโอกาสสำเร็จสูงสุด:
- Data inventory & catalog — แหล่งข้อมูล, เจ้าของ, ตัวชี้วัดคุณภาพ
- Data quality report — ความครบถ้วน ความถูกต้อง และการจัดการ missing values
- Use case brief — วัตถุประสงค์ ทางธุรกิจ KPI และเกณฑ์ความสำเร็จ
- Infrastructure budget — ประมาณการค่าใช้จ่ายคลาวด์/เซิร์ฟเวอร์, storage, และเครื่องมือ MLOps
- Team & roles — Data Engineer, ML Engineer, Data Scientist, Product Owner, Compliance/Legal
- Training plan — แผนอบรมสำหรับทีมเทคนิคและผู้ใช้งานธุรกิจ
- Risk mitigation plan — แผนรับมือ data breaches, model bias, regulatory compliance, และ failover strategy
- Monitoring & alerting spec — รายการ metrics ที่ต้องติดตามและ threshold สำหรับแจ้งเตือน
- Governance documents — นโยบายการใช้งานข้อมูล การกำกับดูแลโมเดล และกระบวนการอนุมัติ
- Rollback and contingency plans — ขั้นตอนเมื่อโมเดลทำงานผิดพลาดหรือมีผลกระทบทางลบ
Metrics ที่ควรกำหนดตั้งแต่แรก
การกำหนด metrics ตั้งแต่ขั้นต้นช่วยให้การตัดสินใจขยายเป็นระบบและโปร่งใส โดยควรรวมทั้ง:
- Business metrics: ROI, revenue uplift, cost savings, time-to-value
- Technical metrics: accuracy, precision/recall, F1-score, latency, throughput
- Data metrics: data freshness, completeness rate, label coverage
- Operational metrics: deployment frequency, mean time to recover (MTTR), model drift rate
- Governance metrics: number of audits passed, incidents logged, compliance adherence
ข้อเสนอแนะเชิงปฏิบัติ
เพื่อให้โครงการมีความยั่งยืน ควรยึดหลักทำเป็นขั้นตอนเล็ก ๆ (small increments), วัดผลบ่อย ๆ (frequent pilots), และตั้ง governance/metrics ตั้งแต่ต้น การศึกษาพบว่าองค์กรที่ลงทุนในกระบวนการ MLOps และการควบคุมคุณภาพข้อมูลตั้งแต่ต้นมีโอกาสนำโมเดลขึ้น production สูงกว่าและลดค่าใช้จ่ายระยะยาว อีกทั้งควรเตรียมแผนการสื่อสารกับผู้มีส่วนได้ส่วนเสียเพื่อบริหารความคาดหวังและผลกระทบเชิงธุรกิจอย่างต่อเนื่อง
บทสรุป
ความสามารถด้านข้อมูล (data capabilities) และแมชชีนเลิร์นนิงเป็นรากฐานสำคัญในการนำปัญญาประดิษฐ์มาใช้ให้ได้ผลในองค์กร ความสำเร็จเชิงปฏิบัติการต้องอาศัยการลงทุนแบบครบวงจรทั้งเทคโนโลยี (ข้อมูลที่มีคุณภาพ, สถาปัตยกรรมข้อมูล, แพลตฟอร์มการเรียนรู้ของเครื่อง), บุคลากรที่มีทักษะ (data engineers, ML engineers, data scientists) และการกำกับดูแลที่ชัดเจน (data governance, model governance, นโยบายความเป็นส่วนตัวและความโปร่งใส) การเริ่มต้นจากกรณีใช้งานที่ชัดเจน เช่น การคาดการณ์ความต้องการลูกค้า การลดการฉ้อโกง หรือการเพิ่มประสิทธิภาพการผลิต จะช่วยให้กำหนด KPI ที่เหมาะสมและวัดผลได้จริง จากนั้นต้องสร้างกระบวนการ MLOps และกรอบการควบคุมเพื่อให้โมเดลถูกนำไปใช้จริงอย่างสม่ำเสมอ ปรับปรุง และตรวจสอบได้ ซึ่งเป็นเงื่อนไขสำคัญในการเปลี่ยนผลวิจัยไปสู่ผลลัพธ์เชิงธุรกิจที่ยั่งยืน
มุมมองอนาคตชี้ให้เห็นว่าองค์กรที่ผสานโครงสร้างข้อมูลที่ยืดหยุ่น การทำงานแบบอัตโนมัติของวงจร ML (Automated MLOps) และการกำกับดูแลที่รับผิดชอบ จะมีความได้เปรียบเชิงแข่งขันมากขึ้น แนวทางที่ควรเตรียมคือการลงทุนต่อเนื่องในฝึกอบรมบุคลากร การนำแนวคิดเช่น data mesh มาใช้เมื่อองค์กรเติบโต และการบูรณาการมาตรการด้านจริยธรรม ความเป็นส่วนตัว และการติดตามผลของโมเดลแบบเรียลไทม์ สุดท้าย ความสำเร็จของ AI จะขึ้นกับความสามารถในการเชื่อมโยงกลยุทธ์ธุรกิจกับสถาปัตยกรรมข้อมูลและการปฏิบัติการ ML ในระดับองค์กรอย่างต่อเนื่องและมีการกำกับดูแลที่เหมาะสม
📰 แหล่งอ้างอิง: PR Newswire



