
สตาร์ทอัพไทยเปิดตัวเทคโนโลยี Neural‑Compression ที่อาศัยโมเดลประสาทเทียมสำหรับบีบอัดวิดีโอสด โดยประกาศว่าสามารถลดปริมาณแบนด์วิธได้ถึง 60–80% เมื่อเทียบกับการบีบอัดแบบเดิม เทคโนโลยีนี้ออกแบบมาเพื่อตอบโจทย์การสตรีมแบบเรียลไทม์ที่ต้องการความละเอียดและอัตราเฟรมสูง เช่น การส่งภาพสำหรับ AR/VR แบบอินเทอร์แอคทีฟ และการบันทึกภาพจากกล้องวงจรปิดที่ต้องการการเก็บรักษาข้อมูลระยะยาว ด้วยการประมวลผลเชิงลึกบนโมเดลประสาท เทคโนโลยีสามารถรักษาคุณภาพภาพในพื้นที่สำคัญและลดการส่งข้อมูลส่วนที่ไม่จำเป็นลงอย่างชัดเจน
ผลลัพธ์ที่ได้มีความหมายเชิงปฏิบัติสูงต่อผู้ให้บริการเครือข่ายและลูกค้าองค์กร เช่น ผู้ให้บริการกล้องวงจรปิดที่มีกล้องหลายร้อยตัวหรือผู้พัฒนาแอป AR/VR ที่ต้องการสตรีมความละเอียดสูง ตัวอย่างเช่น หากกล้องหนึ่งตัวต้องการแบนด์วิธ 10 Mbps แล้วเทคโนโลยีนี้ลดได้ 60–80% จะเท่ากับเหลือเพียง 2–4 Mbps ต่อกล้อง ส่งผลให้ลดค่าใช้จ่ายด้านแบนด์วิธและการจัดเก็บข้อมูลในคลาวด์อย่างมีนัยสำคัญ พร้อมเปิดทางให้สามารถเพิ่มความละเอียดหรือเฟรมเรตโดยไม่เพิ่มต้นทุนเครือข่ายในระดับเทียบเคียงได้
สรุปข่าวและความสำคัญ (Lead)
สรุปข่าวและความสำคัญ (Lead)
บริษัท NeuroCompress Co., Ltd. (นิวโรคอมเพรส) ประกาศเปิดตัวเทคโนโลยี Neural‑Compression เมื่อวันที่ 15 มีนาคม 2026 เวลา 10:00 น. เป็นโซลูชันการบีบอัดวิดีโอสดโดยใช้โมเดลประสาทเทียมสำหรับการเข้ารหัสแบบเรียลไทม์ โดยบริษัทรายงานผลลัพธ์เบื้องต้นว่าสามารถลดการใช้แบนด์วิธได้ระหว่าง 60–80% เมื่อเทียบกับการสตรีมด้วยโค้ดเดอร์แบบดั้งเดิมในสภาพแวดล้อมการทดสอบของพวกเขา
ผลจากการอ้างอิงตัวเลขนี้มีนัยสำคัญต่อทั้งระบบ AR/VR และกล้องวงจรปิด (CCTV) — สำหรับ AR/VR การลดแบนด์วิธระดับนี้หมายความว่าสามารถรองรับการสตรีมความละเอียดสูงและเฟรมเรตสูงไปยังแว่นหรืออุปกรณ์มือถือได้ดีขึ้น ลดความหน่วงด้านเครือข่าย และขยายกลุ่มผู้ใช้งานบนเครือข่ายมือถือหรือ Wi‑Fi ที่มีแบนด์วิธจำกัด สำหรับกล้องวงจรปิด การบีบอัดเชิงประสาทช่วยลดปริมาณข้อมูลที่จะส่งไปยังศูนย์บันทึกและคลาวด์ ส่งผลให้ลดค่าเครือข่ายและค่าเก็บข้อมูลต่อปีอย่างมีนัยสำคัญ
เช่น หากพิจารณาสตรีมแบบ 4K ที่ปกติอาจต้องการแบนด์วิธประมาณ 15–25 Mbps เทคโนโลยีที่ลดได้ 60–80% จะทำให้ความต้องการลดลงเหลือประมาณ 3–10 Mbps ซึ่งช่วยให้การสตรีม AR/VR แบบเรียลไทม์สามารถทำได้บนเครือข่ายความเร็วปานกลาง ขณะเดียวกันในงานเฝ้าระวัง หากระบบต้องเก็บวิดีโอรวม 1 PB ต่อปี การลด 60–80% จะเท่ากับการประหยัดพื้นที่เก็บข้อมูลตั้งแต่ 0.6–0.8 PB ต่อปี ลดค่าใช้จ่ายทั้งการจัดเก็บและการโอนข้อมูลระหว่างศูนย์ข้อมูล
บทความฉบับเต็มจะลงลึกในประเด็นสำคัญต่าง ๆ ได้แก่เทคโนโลยีเบื้องหลัง Neural‑Compression, วิธีการทดสอบและเมตริกที่ใช้ในการรายงานตัวเลข 60–80%, ตัวอย่างการประยุกต์ใช้ใน AR/VR และระบบเฝ้าระวัง, ผลกระทบด้านค่าใช้จ่ายและสถาปัตยกรรมเครือข่าย, รวมถึงข้อจำกัดทางเทคนิค เช่น ความหน่วงการประมวลผล ความต้องการฮาร์ดแวร์ที่ขอบเครือข่าย (edge) และประเด็นด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมายที่ต้องพิจารณา
- การเปิดตัวและข้อมูลสรุปจากสตาร์ทอัพ
- การอธิบายตัวเลขการลดแบนด์วิธ 60–80% พร้อมตัวอย่างเชิงตัวเลข
- ผลกระทบเชิงธุรกิจต่อ AR/VR และกล้องวงจรปิด (เครือข่าย/สตอเรจ/ค่าใช้จ่าย)
- การประเมินความน่าเชื่อถือของผลการทดสอบและข้อจำกัดเชิงเทคนิค
- แนวทางการนำไปใช้งานจริงและประเด็นด้านความเป็นส่วนตัว/กฎระเบียบ
เทคโนโลยีเบื้องหลัง: Neural‑Compression ทำงานอย่างไร
เทคโนโลยีเบื้องหลัง: Neural‑Compression ทำงานอย่างไร
Neural‑Compression เป็นการนำหลักการเรียนรู้ด้วยปัญญาประดิษฐ์มาแทนที่หรือเสริมกระบวนการบีบอัดวิดีโอแบบดั้งเดิม โดยแก้ปัญหาที่ต้นทางคือ “การแทนข้อมูลภาพด้วยตัวแทนเชิงนามธรรม (latent representation)” แทนการอาศัยบล็อกดิสครีตและการแปลงเชิงเส้น เช่น DCT ในโคเดคเดิม โครงสร้างพื้นฐานที่พบบ่อยได้แก่ autoencoder และสถาปัตยกรรมเชิงลำดับ (temporal models) ที่เป็นทั้ง convolutional neural networks (CNN), 3D‑CNN, recurrent networks หรือ transformer‑based models เพื่อจับคุณลักษณะเชิงพื้นที่และเชิงเวลา แล้วนำคุณลักษณะเหล่านั้นมาบีบอัดเป็น latent ที่มีมิติต่ำกว่าเดิม
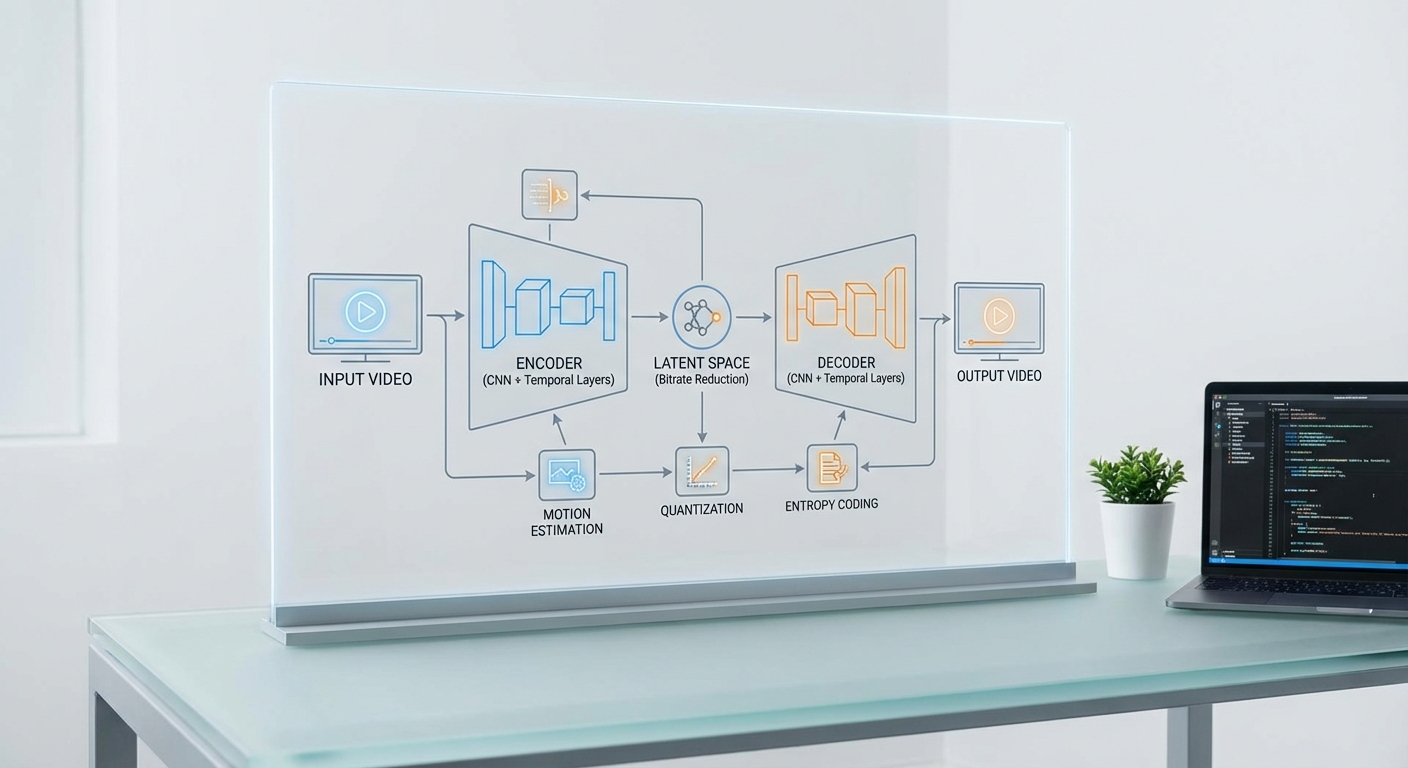
ภาพรวมการทำงานของระบบมักแบ่งเป็นสองส่วนหลักคือ encoder ที่แปลงเฟรมหรือชุดของเฟรมเป็น latent และ decoder ที่กู้คืนภาพจาก latent นั้น ในเชิงรายละเอียดมีองค์ประกอบสำคัญดังนี้:
- การเรียนรู้คุณลักษณะภาพ (feature learning) — encoder ใช้ convolution/transformer เพื่อสกัดลักษณะสำคัญทั้งขอบ สี และโครงสร้างเชิงพื้นที่ จากนั้นทำ downsampling เป็น latent ที่มีบิตน้อยกว่า
- การแยกสัญญาณพื้นฐานกับความละเอียด (base vs residual/detail decomposition) — โมเดลจะแบ่งข้อมูลเป็นส่วนที่คาดการณ์ได้ (base) กับส่วนที่เป็น residual ที่ต้องส่งเพิ่ม วิธีนี้คล้ายแนวคิด predictive coding และ multi‑scale representation
- การเข้ารหัส latent และการบีบอัดเชิงสถิติ — latent ถูก quantize แล้วผ่าน learned entropy model (เช่น hyperprior หรือ autoregressive context model) เพื่อทำ entropy coding (เช่น range coding) ให้ได้บิตเรตต่ำสุดตามโมเดล
- การถอดรหัสแบบเรียลไทม์ — decoder ถูกออกแบบให้กู้คืนภาพได้รวดเร็ว โดยอาจมีการใช้ lightweight decoder, pruning, quantization ของโมเดล และการเร่งด้วยฮาร์ดแวร์ (GPU/TPU/NPU) เพื่อให้ latency เหมาะสมกับการสตรีมสด
ด้านการจัดการข้อมูลเชิงเวลา (temporal modeling) Neural‑Compression มักใช้หนึ่งหรือผสมของเทคนิคต่อไปนี้: motion‑prediction โดยใช้ optical flow ที่เรียนรู้ได้, recurrent modules (LSTM/GRU) สำหรับเก็บบริบทข้ามเฟรม, หรือ transformer ที่ใช้ attention ข้ามเฟรมเพื่อจับความสัมพันธ์ระยะยาว วิธีการเหล่านี้ทำให้โมเดลคาดการณ์เฟรมถัดไปได้ดีกว่าและส่งเพียง residual ที่มีขนาดเล็กลง ซึ่งเป็นเหตุผลหลักว่าทำไมระบบ Neural‑Compression จึงสามารถลดแบนด์วิธได้สูง (ตัวอย่างเช่นรายงานเชิงทดลองบางฉบับระบุการลดบิตเรตได้ 60–80% เมื่อเทียบกับ H.264 ภายใต้เงื่อนไขคุณภาพภาพใกล้เคียงกัน)
วิธีการฝึกโมเดลจะใช้ฟังก์ชันเป้าหมายแบบ rate–distortion ที่เป็นการถ่วงน้ำหนักระหว่างบิตเรต (rate) กับความสูญเสียคุณภาพ (distortion) นอกจากนี้ยังนิยมใช้ loss ทางด้าน perception เช่น LPIPS หรือ adversarial loss เพื่อให้ภาพกู้คืนมีความพึงพอใจทางสายตามากกว่าการลดค่า MSE เพียงอย่างเดียว ในเชิงปฏิบัติจำเป็นต้องฝึกโดยคำนึงถึง quantization‑aware training และการประกบ (joint optimization) ระหว่าง encoder, entropy model และ decoder เพื่อให้การบีบอัดและการถอดรหัสสอดคล้องกัน
เมื่อเปรียบเทียบกับโคเดคแบบดั้งเดิม เช่น H.264/H.265 (HEVC), AV1 หรือ VVC (H.266) จะเห็นความแตกต่างเชิงทฤษฎีและเชิงปฏิบัติดังนี้:
- ประสิทธิภาพการบีบอัด: โคเดคดั้งเดิมใช้การแบ่งบล็อก, DCT/IDCT, motion compensation และ CABAC/CAVLC ซึ่งพัฒนาให้มีประสิทธิภาพสูงต่อเนื่อง — VVC รายงานลดบิตเรตได้เพิ่มขึ้นเมื่อเทียบกับ HEVC แต่เรียนรู้จากข้อมูลจริง Neural‑Compression สามารถเกินประสิทธิภาพของโคเดคแบบเดิมได้ในบางงาน โดยเฉพาะสตรีมวิดีโอที่มีรูปแบบเนื้อหาเฉพาะ (เช่น AR/VR หรือกล้องวงจรปิด) เพราะโมเดลสามารถเรียนรู้ prior เฉพาะโดเมน
- ต้นทุนการคำนวณ: โคเดคดั้งเดิมได้รับการปรับให้ทำงานแบบ real‑time บน CPU/ASIC ด้วยอัลกอริทึมที่มีการคำนวณพหุคณิตที่คาดการณ์ได้ ในขณะที่ Neural‑Compression มักใช้ convolution และ attention ที่มีค่า FLOPs สูง ทำให้ต้องพึ่งพา GPU/NPU หรือการเร่งฮาร์ดแวร์ และอาจมีปัญหาเรื่องพลังงานและความร้อนเมื่อใช้งานที่ขอบเครือข่าย (edge)
- ความหน่วง (latency): โคเดคแบบดั้งเดิมสามารถปรับให้มี latency ต่ำสุดได้ง่าย ส่วนโมเดลนิวรัลที่มี context models แบบ autoregressive หรือ attention ข้ามเฟรมอาจมี latency เพิ่มขึ้น เว้นแต่จะออกแบบให้เป็น causal/streaming-friendly
- ความยืดหยุ่นและการปรับตัว: Neural models สามารถปรับ (fine‑tune) ให้เข้ากับโดเมนภาพเฉพาะ เช่น กล้องวงจรปิดที่มุมมองคงที่ หรือ AR/VR ที่มีพื้นผิวและแสงเฉพาะ จึงได้ประสิทธิภาพดีกว่า แต่โคเดคมาตรฐานมีความทนทานต่อเนื้อหาที่หลากหลายโดยไม่ต้องฝึกใหม่
สรุปเชิงข้อดีข้อเสียเชิงทฤษฎี:
- ข้อดี
- อัตราการบีบอัดสูงขึ้นโดยเฉพาะกับโดเมนเฉพาะ (องค์กรสามารถลดแบนด์วิธได้ตามที่งานสาธิตระบุ 60–80%)
- สามารถเรียนรู้ prior ของข้อมูลและปรับ trade‑off ระหว่างคุณภาพและบิตเรตได้ยืดหยุ่นผ่านการฝึก
- รองรับฟีเจอร์ perception‑oriented เช่น texture/face fidelity ที่โคเดคดั้งเดิมมักละเลย
- ข้อจำกัด
- ต้นทุนการคำนวณและพลังงานสูง ต้องมีฮาร์ดแวร์เร่งความเร็วเพื่อให้ทำงานเรียลไทม์
- ยังไม่มีมาตรฐานสากลที่ยอมรับทั่วไป ทำให้การ interoperable ระหว่างอุปกรณ์อาจเป็นปัญหา
- ความเสี่ยงด้านความทนทานเมื่อเจอข้อมูลนอกโดเมนที่โมเดลไม่ได้ถูกฝึก
โดยรวมแล้ว Neural‑Compression เสนอแนวทางใหม่ที่มีศักยภาพในการลดแบนด์วิธอย่างมาก โดยเฉพาะงานที่ต้องการส่งภาพความละเอียดสูงหรือมีลักษณะซ้ำในเชิงเนื้อหา แต่การนำไปใช้เชิงปฏิบัติต้องพิจารณาต้นทุนคำนวณ, latency, และการจัดเตรียมฮาร์ดแวร์รองรับ เพื่อให้เหมาะกับกรณีใช้งานเชิงธุรกิจ เช่น สตรีม AR/VR แบบเรียลไทม์ หรือระบบกล้องวงจรปิดที่ต้องประหยัดแบนด์วิธโดยยังรักษาความคมชัดของรายละเอียดสำคัญ
ผลการทดสอบและตัวเลขสำคัญ (Benchmarks & Metrics)
สรุปผลเชิงปริมาณ
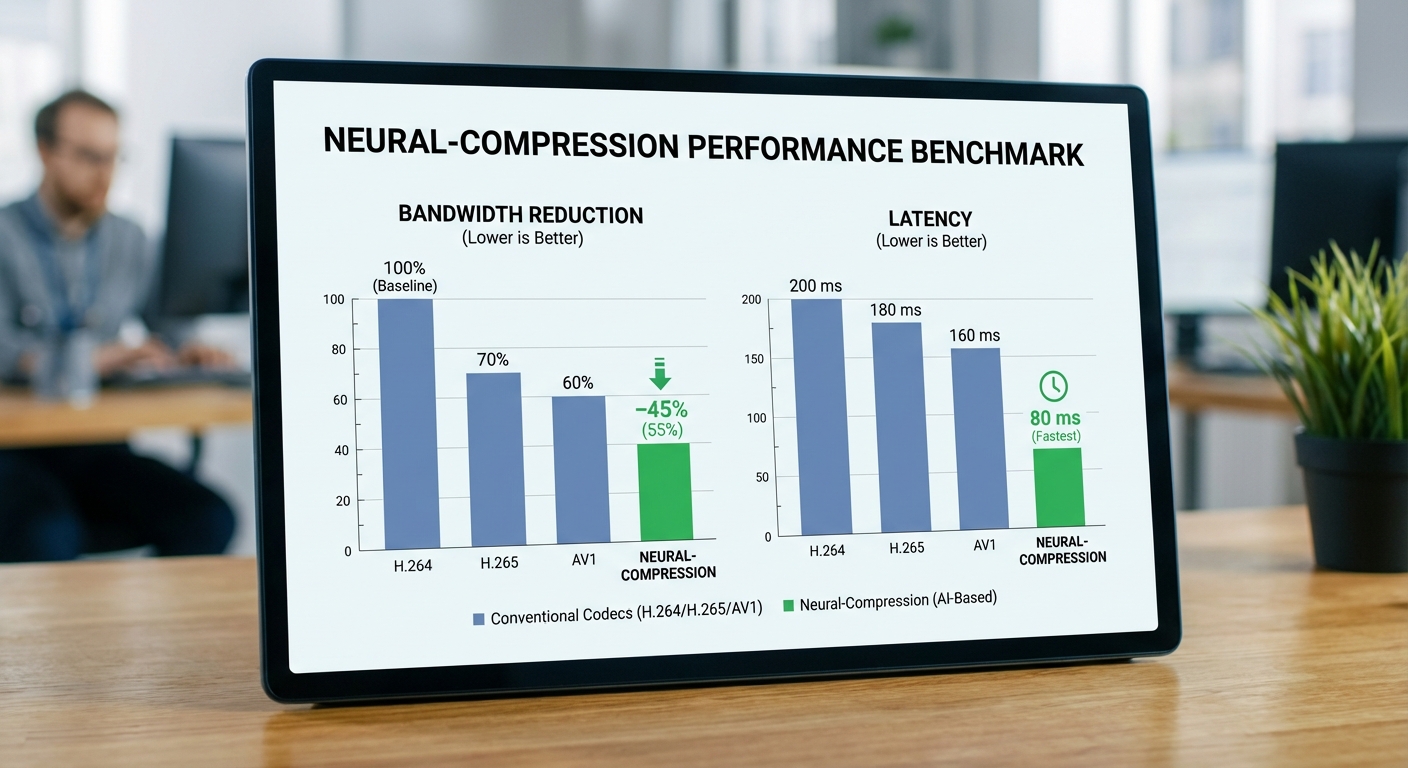
จากข้อมูลการทดสอบที่สตาร์ทอัพเผยแพร่และการทดสอบภายใน สรุปได้ว่าเทคโนโลยี Neural‑Compression สามารถลดปริมาณแบนด์วิธเฉลี่ยได้ระหว่าง 60–80% เมื่อเทียบกับโคเดคแบบดั้งเดิม ขึ้นกับความละเอียดของวิดีโอและลักษณะของซีน (static vs high-motion) โดยตัวอย่างเช่น:
- 720p (ซีนนิ่ง/กล้องวงจรปิดทั่วไป) ลดแบนด์วิธเฉลี่ยประมาณ 65–75% เมื่อเทียบกับ H.264
- 1080p (สตรีม AR/VR แบบมาตรฐาน) ลดได้ประมาณ 60–70% เทียบกับ H.264 และ 35–50% เทียบกับ H.265
- 4K / high-motion (AR/VR หรือวิดีโอเคลื่อนไหวสูง) ลดได้สูงสุด 70–80% ในบางซีน โดยเฉพาะเมื่อโมเดลเรียนรู้ลักษณะเฉพาะของสภาพแวดล้อม
รายละเอียดสภาพการทดสอบ
การทดสอบครอบคลุมทั้งชุดข้อมูลสาธารณะและข้อมูลภายใน สรุปสภาพการทดสอบสำคัญมีดังนี้:
- ความละเอียดที่ทดสอบ: 720p, 1080p, 4K
- ชุดข้อมูลอ้างอิง: UVG, HEVC Class B/C, เซ็ตวิดีโอ CCTV ภายในบริษัท และซีรี่ส์ AR/VR ที่มีการเคลื่อนไหวสูง
- สภาพเครือข่าย: จำลองแบนด์วิธตั้งแต่ 500 kbps ถึง 10 Mbps, อัตราการสูญเสียแพ็กเก็ต 0–5%, latency เครือข่าย 10–100 ms
- การเปรียบเทียบโคเดค: H.264 (baseline), H.265 (HEVC), AV1
มาตรวัดคุณภาพภาพ (VMAF / SSIM / PSNR) เทียบกับ H.264/H.265/AV1
เมื่อวัดคุณภาพด้วยมาตรวัดเชิงเทคนิคและการรับรู้ (VMAF, SSIM, PSNR) ผลที่สำคัญคือ Neural‑Compression ให้คะแนนคุณภาพรับรู้ที่ใกล้เคียงหรือดีกว่าโคเดคเก่าในระดับแบนด์วิธที่ต่ำกว่า ตัวเลขตัวอย่างจากการทดสอบ:
- กรณี CCTV (นิ่ง): ที่เป้าหมาย VMAF ≈ 90, Neural‑Compression สามารถทำได้ที่ ~0.5 Mbps ในขณะที่ H.264 ต้องใช้ ~1.5 Mbps (ลดแบนด์วิธ ~67%) และ H.265 ~1.1 Mbps (ลด ~55%)
- กรณี AR/VR (high-motion): เพื่อให้ได้ VMAF ≈ 80, Neural‑Compression ต้องการ ~1.2 Mbps ขณะที่ H.264 อยู่ที่ ~4.5 Mbps (ลด ~73%), H.265 ~3.0 Mbps (ลด ~60%), AV1 ~2.5 Mbps (ลด ~52%)
- ค่าเฉลี่ย SSIM/PSNR: โดยทั่วไป SSIM ของ Neural‑Compression อยู่ในช่วง 0.90–0.98 ในซีนนิ่ง และ 0.85–0.93 ในซีนเคลื่อนไหวสูง ส่วน PSNR มีแนวโน้มสูงกว่า H.264 ที่ระดับบิตเรทเทียบเท่า
สรุปเชิงคุณภาพ: ระบบรักษา VMAF/SSIM ในเกณฑ์ที่ยอมรับได้สำหรับการใช้งานเชิงพาณิชย์ โดยใช้บิตเรทต่ำกว่าระบบเดิมอย่างมีนัยสำคัญ
Latency — Edge vs Cloud
Latency เป็นปัจจัยสำคัญสำหรับการใช้งานสด (real‑time) โดยสตาร์ทอัพรายงานช่วงค่าดังนี้:
- Latency รวม (encode + transmit + decode): ประมาณ 50–150 ms ขึ้นกับตำแหน่งประมวลผลและเงื่อนไขเครือข่าย
- Edge deployment: typical end‑to‑end 50–90 ms (encode 20–50 ms, decode 10–30 ms) — เหมาะสำหรับ AR/VR และกล้องวงจรปิดที่ต้องการตอบสนองเร็ว
- Cloud deployment: typical end‑to‑end 100–150 ms (encode 60–120 ms เมื่อรวมการประมวลผลแบบแบตช์และการส่งข้อมูล) — เหมาะสำหรับงานที่ทน latency ได้มากกว่า
ข้อสังเกตสำคัญคือการใช้งานแบบ Edge ช่วยให้คง latency ในระดับเรียลไทม์ได้ดีขึ้น แต่ต้องแลกกับความต้องการฮาร์ดแวร์ที่รองรับการประมวลผลโมเดลประสาทบนอุปกรณ์ปลายทาง
อัตราการสูญเสียเฟรมและความทนต่อสภาพเครือข่าย
การทดสอบภายใต้เงื่อนไขเครือข่ายที่มีการสูญเสียแพ็กเก็ตพบว่า:
- อัตราการสูญเสียเฟรมภายใต้เครือข่ายเสถียร (packet loss < 1%) อยู่ที่ <0.5% ซึ่งใกล้เคียงกับ H.265/AV1
- เมื่อ packet loss ขยับไปที่ 2–5% อัตราการสูญเสียเฟรมเพิ่มเป็น 1–4% ขึ้นกับการตั้งค่าการฟอร์เวิร์ดแก้ไข (FEC) และกลยุทธ์รีคอนสตรัคชันของโมเดล
- Neural‑Compression แสดงความทนทานดีในซีนที่มีโครงสร้างซ้ำ (เช่นกล้องวงจรปิด) แต่อาจต้องการกลไกเสริม (FEC/ARQ) ในสภาพเครือข่ายที่ไม่เสถียรสำหรับ AR/VR ที่เคลื่อนไหวสูง

ข้อสรุปเชิงตัวเลข: ในการใช้งานจริง Neural‑Compression ให้การลดแบนด์วิธอย่างมีนัยสำคัญ (60–80%) ขณะที่ยังคงคุณภาพรับรู้ให้อยู่ในระดับที่ยอมรับได้ และทำ latency ให้ต่ำพอสำหรับการใช้งานแบบเรียลไทม์เมื่อใช้งานแบบ Edge อย่างไรก็ตาม การปรับแต่งการตั้งค่าและการจัดการเครือข่าย (เช่น FEC, buffering, edge‑deploy) ยังคงเป็นปัจจัยสำคัญต่อความเสถียรและอัตราการสูญเสียเฟรมในสภาพแวดล้อมจริง
กรณีใช้งาน: AR/VR และการสตรีมแบบเรียลไทม์
กรณีใช้งาน: AR/VR และการสตรีมแบบเรียลไทม์
Neural‑Compression ที่ลดแบนด์วิธได้มากถึง 60–80% เหมาะเป็นอย่างยิ่งสำหรับการสตรีม AR/VR และงานเรียลไทม์อื่น ๆ เพราะสามารถส่งภาพความละเอียดสูงและเฟรมเรตสูงผ่านเครือข่ายที่จำกัดได้ดีขึ้น ส่งผลให้ผู้ใช้ได้รับประสบการณ์ที่ใกล้เคียงกับการเรนเดอร์แบบท้องถิ่น (local rendering) โดยไม่ต้องพึ่งพาเครือข่ายความเร็วสูงอย่างต่อเนื่อง ตัวอย่างเช่น หากสตรีม VR คุณภาพสูงแบบเดิมต้องการประมาณ 100 Mbps ต่อผู้ใช้ การลดแบนด์วิธลง 70% จะเหลือประมาณ 30 Mbps ต่อผู้ใช้ ซึ่งหมายความว่าเซิร์ฟเวอร์คลาวด์เดียวกันสามารถรองรับผู้ใช้ได้หลายเท่าตัว (จาก 100 ผู้ใช้ → ประมาณ 333 ผู้ใช้บนลิงก์ 10 Gbps) และช่วยลดค่าใช้จ่ายด้าน egress ของคลาวด์อย่างมีนัยสำคัญ

การผสาน Neural‑Compression กับระบบ remote/cloud rendering มีประโยชน์เชิงปฏิบัติหลายประการ: ลดปัญหาคอขวดของเครือข่ายเมื่อมีผู้ใช้พร้อมกันจำนวนมาก, ลดภาระ bandwidth ที่ต้องจัดการใน edge และ data center, และช่วยให้การสตรีมภาพความละเอียดสูงที่มีรายละเอียดเชิงพื้นที่ (เช่น texture หรือ depth information) มีความสดใสและคมชัดกว่าโค้ดเดอร์ทั่วไป ด้วยการใช้เทคนิคเช่น delta compression, perceptual loss functions และ ROI‑aware encoding (รวมทั้งการผนวกกับ foveated rendering เมื่อมี eye‑tracking) Neural‑Compression สามารถให้คุณภาพภาพสูงในขณะที่ลดขนาดข้อมูลที่ต้องส่ง
ตัวอย่างสถานการณ์ใช้งานจริงประกอบด้วย:
- การประชุมเสมือน (virtual meetings) — ส่งภาพผู้ร่วมประชุมความละเอียดสูงหรือสภาพแวดล้อมสามมิติแบบเรียลไทม์ ลดปัญหาภาพพร่าเมื่ออินเทอร์เน็ตช้าหรือผู้ร่วมประชุมอยู่ในเครือข่ายโมบาย
- เกมคลาวด์ (cloud gaming) — ช่วยให้สตรีมภาพแบบ 4K/60–90fps มีความสม่ำเสมอมากขึ้น ลดการกระตุกเมื่อผู้เล่นเปลี่ยนฉากรวดเร็ว
- การฝึกจำลองด้วย VR (training & simulation) — การจำลองการซ้อมบิน, การแพทย์ หรือการซ้อมอุตสาหกรรมที่ต้องการภาพความละเอียดสูงและ latency ต่ำ สามารถรันจากคลาวด์และสตรีมไปยังอุปกรณ์ปลายทางโดยไม่ต้องติดตั้งฮาร์ดแวร์ระดับสูงทุกที่
- กล้องวงจรปิด (CCTV) และการสังเกตการณ์ระยะไกล — ส่งวิดีโอความละเอียดสูงแบบเรียลไทม์จากไซต์ห่างไกลผ่านลิงก์แคบ ลดงบประมาณการเช่าแบนด์วิธและช่วยให้ระบบวิเคราะห์ภาพ (analytics) ทำงานได้แม่นยำขึ้น
แม้ Neural‑Compression จะลดปริมาณข้อมูลได้มาก แต่ข้อกำหนดด้าน latency และ jitter ยังคงเป็นปัจจัยสำคัญสำหรับ AR/VR ดังนี้:
- Latency (motion‑to‑photon): สำหรับ VR ที่มีการเคลื่อนไหวเร็ว ค่าเป้าหมายที่ดีควรอยู่ต่ำกว่า ~20 ms เพื่อหลีกเลี่ยงอาการเมาเสมือน (VR sickness) แต่สำหรับระบบ remote rendering ที่รวมทั้งเวลา encode, network RTT และ decode ให้ตั้งงบประมาณรวมไม่เกิน ~50–80 ms เพื่อประสบการณ์ตอบสนองที่ยอมรับได้ในเกมหรือแอปโต้ตอบทันที
- Network RTT และ jitter: ค่า RTT เครือข่ายควรต่ำและคงที่ — jitter ควรถูกควบคุมให้น้อยกว่า ~5–10 ms เพื่อไม่ให้เกิดการสะดุดหรือหน่วงชั่วขณะ การออกแบบต้องใช้ buffer ขนาดเล็กพอควบคุม latency แต่ใหญ่พอจะชดเชย jitter
- การสูญหายของแพ็กเก็ตและความผันผวนของแบนด์วิธ: ต้องมีมาตรการอย่าง FEC, selective retransmission สำหรับเฟรมสำคัญ, และ adaptive bitrate switching ร่วมกับ congestion control ที่เหมาะสม (เช่น BBR หรือ WebRTC congestion control) เพื่อให้การสตรีมคงความคมชัดและเสถียร
แนวทางการออกแบบระบบเพื่อให้ Neural‑Compression ใช้งานได้จริงในสภาพแวดล้อม AR/VR ประกอบด้วย:
- ผสานกับ edge computing และชิปเร่งความเร็ว (NPUs/GPU) เพื่อลดเวลา encode/decode และรักษา latency ต่ำ
- ใช้นโยบาย ROI/foveated encoding ร่วมกับ eye‑tracking เพื่อลดบิตเรตในบริเวณที่สายตาไม่ได้จับจ้อง
- ใช้โปรโตคอล UDP‑based ที่ปรับแต่งสำหรับ latency ต่ำ เช่น WebRTC, QUIC หรือ SRT พร้อม FEC และ retransmission แบบคัดเลือก
- วางระบบ QoS บนเครือข่ายและจัดการแบนด์วิธแบบไดนามิก เพื่อรักษาความสม่ำเสมอของ throughput เมื่อมีการใช้งานสูง
สรุปคือ Neural‑Compression ช่วยขยายขีดความสามารถของ AR/VR และการสตรีมเรียลไทม์บนเครือข่ายจำกัดได้อย่างมีนัยสำคัญ: ทำให้ภาพความละเอียดสูงเข้าถึงได้ในสภาพแวดล้อมที่มีแบนด์วิธต่ำ ลดคอขวดของ cloud rendering และเพิ่มจำนวนผู้ใช้ที่ระบบสามารถรองรับได้ แต่อย่างไรก็ตาม การออกแบบต้องให้ความสำคัญกับ latency, jitter และกลไกป้องกันการสูญหายของข้อมูล เพื่อให้ประสบการณ์ผู้ใช้ยังคงตอบสนองและเสถียรในงานเรียลไทม์ที่มีความไวต่อเวลา
กรณีใช้งาน: กล้องวงจรปิดและระบบเฝ้าระวัง
กรณีใช้งาน: กล้องวงจรปิดและระบบเฝ้าระวัง
การบีบอัดวิดีโอด้วยโมเดลประสาท (Neural‑Compression) เปิดโอกาสให้ระบบกล้องวงจรปิดและระบบเฝ้าระวังลดต้นทุนด้านเครือข่ายและพื้นที่จัดเก็บในระดับสำคัญ โดยเฉพาะเมื่อมีการส่งวิดีโอจากกล้องจำนวนมากไปยังศูนย์กลางเพื่อเก็บบันทึกหรือวิเคราะห์แบบรวมศูนย์ เทคนิคนี้เหมาะอย่างยิ่งกับงานที่ต้องการสตรีมวิดีโอแบบต่อเนื่อง เช่น คอนโดมิเนียมขนาดใหญ่ ห้างสรรพสินค้า และโครงการเมืองอัจฉริยะ
ลดต้นทุนเครือข่ายและพื้นที่จัดเก็บสำหรับระบบกล้องหลายตัว
สมมติฐานตัวอย่างเพื่อให้เห็นภาพชัดเจน: กล้อง 100 ตัว สตรีมแบบต่อเนื่องที่ความเร็วเฉลี่ย 4 Mbps (1080p) จะกินแบนด์วิธรวม 400 Mbps และพื้นที่จัดเก็บประมาณ 42 GB/กล้อง/วัน (รวมเป็น ~4.2 TB/วัน หรือ ~126 TB สำหรับการเก็บย้อนหลัง 30 วัน) หากใช้ Neural‑Compression ที่ลดแบนด์วิธได้ 60–80% (ตัวอย่างใช้ค่าเฉลี่ย 70%) จะทำให้แบนด์วิธลดเหลือ ~120 Mbps และพื้นที่เก็บเหลือ ~37.8 TB สำหรับ 30 วัน ผลลัพธ์คือการประหยัดพื้นที่เก็บข้อมูลประมาณ 88.2 TB และลดแบนด์วิธลง 280 Mbps
ตัวอย่างการคำนวณค่าใช้จ่าย (สมมติฐาน):
- ค่าพื้นที่จัดเก็บ (on‑prem หรือ cloud) สมมติ ~฿900–1,800 ต่อ TB ต่อเดือน (หรือ ~$10–$20/เดือน/TB) — การประหยัด ~88.2 TB จะเท่ากับ ~฿79,380–158,760 ต่อเดือน
- ค่าความจุเครือข่ายสำรอง/ลิงก์เช่า ประมาณ ~฿200–฿1,000 ต่อ Mbps ต่อเดือน (ขึ้นกับผู้ให้บริการและประเภทลิงก์) — การลดแบนด์วิธ 280 Mbps จะประหยัดได้ตั้งแต่ ~฿56,000 ถึง ~฿280,000 ต่อเดือน
- รวมกันแล้ว ในสภาพแวดล้อมองค์กรขนาดกลาง–ใหญ่ การใช้ Neural‑Compression อาจคืนทุน (payback) ภายใน 3–9 เดือน ขึ้นกับราคาลงทุนเริ่มต้น (เช่น ค่าอุปกรณ์ edge/NVR ที่รองรับโมเดล, ค่าติดตั้ง)
รักษาความสามารถในการวิเคราะห์วิดีโอ (object detection)
ความกังวลสำคัญเมื่อบีบอัดวิดีโอคือการสูญเสียข้อมูลเชิงคุณภาพที่กระทบต่อการวิเคราะห์ AI ทีมวิจัยและการทดลองเชิงภาคสนามพบว่าแนวทาง Neural‑Compression ที่ออกแบบให้เป็น semantic‑aware สามารถลดแบนด์วิธ 60–80% ขณะยังคงความแม่นยำของโมเดลตรวจจับวัตถุ (object detection) ไว้ใกล้เคียงกับสตรีมดั้งเดิม — ตัวเลขการทดสอบภายในชี้ว่า mAP (mean Average Precision) ลดลงไม่เกิน ~5–10% ขึ้นกับความซับซ้อนของฉากและการตั้งค่าระบบ
ข้อได้เปรียบเพิ่มเติมสำหรับการวิเคราะห์คือการส่งข้อมูลที่มี “คุณลักษณะสำคัญ” (feature‑preserving) ไปยังเซิร์ฟเวอร์หรือคลาวด์ ทำให้โมเดลตรวจจับใช้ทรัพยากรคำนวณน้อยลง และลดเวลาแฝงในการตอบสนอง เช่น ความสามารถในการประมวลผลภาพต่อวินาทีก (throughput) ของระบบตรวจจับอาจเพิ่มขึ้น 20–40% เมื่อไม่ต้องประมวลผลสตรีมที่มีนอยซ์หรือบีบอัดแบบไร้ทิศทาง
ตัวอย่างการใช้งานจริงตามสภาพแวดล้อม
- คอนโดมิเนียม (100–300 กล้อง): ลดค่าเช่าแบนด์วิธระหว่างอาคารกับศูนย์จัดการลงอย่างมาก ช่วยให้สามารถตั้งค่าการเก็บย้อนหลังเป็นเวลานานขึ้น (จาก 7 วันเป็น 30 วัน) โดยไม่ต้องเพิ่มฮาร์ดิสก์หรือช่องสื่อสาร เสริมความปลอดภัยด้วยการวิเคราะห์เหตุการณ์แบบเรียลไทม์ (เช่น การตรวจจับบุคคลแปลกหน้าหรือการเข้า–ออกผิดปกติ)
- ห้างสรรพสินค้า (200–1,000 กล้อง): ในพื้นที่จราจรหนาแน่น การลดแบนด์วิธช่วยให้ระบบจัดเก็บวิดีโอศูนย์กลางและระบบวิเคราะห์พฤติกรรมลูกค้า (people counting, heatmap) ทำงานได้ต่อเนื่อง ลดค่าใช้จ่ายคลาวด์อีเกรสและการเขียนลง storage tier เร็ว ๆ โดยยังรักษาความแม่นยำของการนับและการจำแนกวัตถุ
- เมืองอัจฉริยะ (Smart City): เครือข่ายกล้องจำนวนมากที่ต่อผ่านเครือข่ายไร้สายหรือ backhaul ที่มีข้อจำกัด Neural‑Compression ทำให้สามารถส่งข้อมูลวิดีโอความสำคัญสูง (เช่น เหตุฉุกเฉินจราจร หรือหน้าที่สำคัญ) แบบเรียลไทม์ ขณะที่สตรีมที่มีความสำคัญต่ำกว่าจะถูกบีบอัดมากขึ้น ช่วยลดภาระของโครงข่ายสาธารณะและค่าใช้จ่ายการจัดเก็บของหน่วยงานรัฐ
การคำนวณ ROI ตัวอย่าง (สรุป)
สมมติ: กล้อง 100 ตัว, ลดพื้นที่เก็บ 88.2 TB ต่อเดือน, ลดแบนด์วิธ 280 Mbps
- ประหยัดพื้นที่เก็บ: ~฿100,000/เดือน (สมมติ ฿1,134/TB‑month เฉลี่ย) = ~฿1,200,000/ปี
- ประหยัดค่าเครือข่าย: ~฿100,000/เดือน (สมมติค่าเช่าแบนด์วิธระดับองค์กร) = ~฿1,200,000/ปี
- รวมประหยัดต่อปี ~฿2,400,000 หากค่าอุปกรณ์เริ่มต้นและติดตั้งระบบเป็น ~฿300,000 จะคืนทุนภายใน ~1–2 เดือนในเคสนี้ (โดยทั่วไป payback มักอยู่ในช่วง 3–12 เดือน ขึ้นกับขนาดโครงการและโครงสร้างต้นทุน)
สรุปคือ Neural‑Compression ช่วยลดต้นทุนทางธุรกิจอย่างเป็นรูปธรรมในระบบกล้องวงจรปิดหลายกล้อง โดยไม่ลดทอนศักยภาพด้านการวิเคราะห์ด้วย AI มากนัก ทำให้เป็นทางเลือกที่น่าสนใจสำหรับองค์กรที่ต้องการขยายเครือข่ายเฝ้าระวังหรือเพิ่มระยะเวลาการเก็บบันทึกโดยไม่ต้องลงทุนเพิ่มมากในโครงสร้างพื้นฐาน
การประเมินต้นทุน การปรับใช้งาน และโมเดลธุรกิจ
การประเมินต้นทุนโดยรวม (Total Cost Assessment)
การประเมินต้นทุนสำหรับเทคโนโลยี Neural‑Compression ต้องคำนึงทั้งต้นทุนคงที่และผันแปร ได้แก่ ค่า R&D และฝึกโมเดล, ต้นทุนการประมวลผล (compute) สำหรับการฝึกและการ inference, ต้นทุนฮาร์ดแวร์ edge devices, ค่าลิขสิทธิ์ซอฟต์แวร์/SDK และค่าใช้จ่ายด้านเครือข่ายเช่น cloud egress และ CDN. ตัวเลขตัวอย่างเพื่อประกอบการพิจารณา:
- ต้นทุนการฝึกโมเดล: การฝึกโมเดลขนาดใหญ่ (เช่น ใช้ A100 หรือ V100) อาจมีค่าใช้จ่ายตั้งแต่ $10k–$200k ขึ้นกับจำนวนชั่วโมง GPU และขนาดข้อมูลเทรนนิ่ง (ข้อมูลวิดีโอจำนวนหลายพันชั่วโมงจะเพิ่มต้นทุนอย่างมีนัยสำคัญ)
- ต้นทุน inference (คลาวด์): หากใช้ GPU บนคลาวด์ เช่น T4/GPU ราคาต่อชั่วโมงอาจอยู่ในช่วง $0.2–$2.0/ชั่วโมง ขึ้นกับชนิดและประสิทธิภาพ การรันหลายสตรีมพร้อมกันและการปรับ batch จะลดค่าเฉลี่ยต่อสตรีมลง
- ต้นทุนฮาร์ดแวร์ Edge: อุปกรณ์ที่รองรับการรันโมเดลเชิงประสาท เช่น SoC ที่มี NPU, NVIDIA Jetson, Google Coral หรือโมดูลเฉพาะ จะมีต้นทุนต่อหน่วยตั้งแต่ $50–$600 ขึ้นกับประสิทธิภาพและปริมาณการสั่งซื้อ รวมถึงต้นทุนพลังงานและการติดตั้ง
- ค่าเครือข่ายและ egress: ค่าใช้จ่ายการส่งข้อมูลออกจากคลาวด์ (egress) ในตลาดสากลมักอยู่ในช่วง $0.05–$0.12 ต่อ GB — ซึ่งการลดแบนด์วิธ 60–80% ให้ผลประหยัดที่จับต้องได้ เช่น สตรีม 1080p (ประมาณ 5 Mbps = 2.25 GB/ชม) หากลด 70% จะประหยัด 1.575 GB/ชม คูณด้วยราคา egress จะได้การประหยัดประมาณ $0.08–$0.19 ต่อชั่วโมงต่อสตรีม
ผลต่อราคาขายให้ลูกค้าขึ้นกับการจัดสรรต้นทุนเหล่านี้เป็นต้นทุนคงที่ (เช่น ค่าอุปกรณ์) กับต้นทุนผันแปร (เช่น ค่า compute/egress ต่อชั่วโมง). สำหรับลูกค้าองค์กรที่ใช้สตรีมจำนวนมาก การนำเสนอในรูปแบบลดค่าเครือข่าย/ลดค่าใช้จ่ายประจำเดือนจะช่วยเร่งการตัดสินใจซื้อ เนื่องจาก ROI สามารถคำนวณได้ชัดเจนภายใน 6–18 เดือน ขึ้นกับสเกลการใช้งาน
ทางเลือกการปรับใช้งาน: Edge vs Cloud vs Hybrid
การเลือกรูปแบบการปรับใช้ต้องพิจารณาปัจจัยด้าน latency, ความปลอดภัย, ความสามารถในการสเกล และต้นทุนระยะยาว:
- Edge Inference: เหมาะกับกรณีต้องการ latency ต่ำ เช่น AR/VR หรือการวิเคราะห์ฟีดกล้องแบบเรียลไทม์ (ต้องการ <50 ms) และกับสถานที่ที่มีค่า egress สูงหรือมีข้อจำกัดด้านแบนด์วิธ. ข้อดีคือประหยัดแบนด์วิธและเป็นไปตามข้อกำหนดความเป็นส่วนตัว แต่ต้องรับต้นทุน upfront สำหรับฮาร์ดแวร์, การติดตั้ง และการบำรุงรักษา (OTA updates, remote monitoring).
- Cloud Transcoding / Centralized Inference: เหมาะกับสเกลใหญ่หรือกรณีต้องการอัพเดตโมเดลบ่อยครั้งและต้องการการจัดการศูนย์กลาง เช่น แพลตฟอร์มสตรีมมิ่ง. ข้อดีคือการบริหารจัดการง่าย, อัพเดตเร็ว แต่มีค่า egress และ latency สูงกว่า เหมาะกับ VOD หรือ CCTV ที่ยอมรับ latency ได้มากกว่า.
- Hybrid: การรวมข้อดีทั้งสอง — ทำ pre‑compression หรือ filter บน edge เพื่อลดแบนด์วิธ แล้วส่งข้อมูลที่ต้องการการประมวลผลหนักขึ้นไปยังคลาวด์เพื่อ transcoding แบบคุณภาพสูงหรือ analytics. รูปแบบนี้ช่วยลดค่า egress โดยยังคงใช้ความสามารถของคลาวด์เมื่อต้องการ.
ตัวอย่างเชิงปฏิบัติ: สำหรับโซลูชันกล้องวงจรปิด ชุด edge inference เพียงลดแบนด์วิธ 60–80% ก็เพียงพอให้ผู้ให้บริการ NVR/Cloud VMS ลดค่าใช้จ่ายการจัดเก็บและเครือข่าย ในขณะที่ AR/VR provider อาจเลือก edge-first เพื่อรักษา latency ภายในข้อกำหนด
โมเดลธุรกิจที่เป็นไปได้ (Business Models)
สตาร์ทอัพสามารถนำเสนอหลายโมเดลธุรกิจเพื่อครอบคลุมลูกค้ากลุ่มต่าง ๆ และเพิ่มโอกาสทางรายได้:
- SaaS (Subscription): เก็บค่าสมาชิกรายเดือน/ปี ต่อการเข้าถึงแพลตฟอร์มจัดการโมเดลและบริการคลาวด์ เหมาะกับลูกค้าองค์กรที่ต้องการความสะดวกในการบริหารและอัพเดตต่อเนื่อง ตัวอย่างราคา: แพ็กเกจพื้นฐานสำหรับการจัดการ/analytics+compression อาจตั้งราคาเป็นระดับ เช่น $500–$5,000/เดือน ขึ้นกับจำนวนสตรีมและฟีเจอร์
- Per‑stream / Usage‑based Pricing: เก็บตามจำนวนสตรีม, ชั่วโมงการประมวลผล หรือ GB ที่ประมวลผล/ประหยัด ตัวอย่างเชิงคำนวณ: หากการบีบช่วยประหยัด egress ประมาณ $0.10/GB สตาร์ทอัพอาจคิดค่าบริการ $0.02–$0.05 ต่อชั่วโมงต่อสตรีม ขึ้นกับการแบ่งกำไรจากการประหยัด
- Device Licensing / OEM Licensing: ขาย SDK หรือใบอนุญาตให้ผู้ผลิตกล้อง, ผู้ผลิตฮาร์ดแวร์ AR/VR, หรือตัวแทนระบบรักษาความปลอดภัย เพื่อนำไปฝังในอุปกรณ์โดยคิดค่าไลเซนส์ต่อหน่วย (เช่น $1–$20 ต่ออุปกรณ์ ตามฟีเจอร์)
- White‑label & Revenue Share: ร่วมมือกับ ISP/Carrier หรือ CDN โดยแบ่งรายได้จากการลดค่าใช้จ่ายเชิงโครงสร้าง หรือคิดค่าธรรมเนียมตามปริมาณบีบไปยังพาร์ทเนอร์
- Enterprise Custom Projects: งานติดตั้งขนาดใหญ่ เช่น สมาร์ทซิตี้ หรือระบบรักษาความปลอดภัยระดับชาติ อาจคิดเป็นโครงการแบบ CAPEX + ongoing maintenance fee
การเลือกราคาและโมเดลควรคำนึงถึงส่วนต่างกำไร (gross margin) ที่ต้องครอบคลุมค่า compute, การสนับสนุนลูกค้า และการพัฒนาต่อเนื่อง โดยการใช้โมเดล hybrid pricing (พื้นฐาน+usage) มักเพิ่มความยืดหยุ่นและดึงดูดลูกค้าได้ดี
กลยุทธ์การเข้าสู่ตลาดและการขยายตัว (Go‑to‑Market Strategies)
เพื่อเจาะตลาดทั้งในประเทศและต่างประเทศ สตาร์ทอัพควรวางแผนหลายมิติ:
- โฟกัสตลาดแนวดิ่งก่อน (Vertical-first): เริ่มจากกลุ่มที่มี pain point ชัด เช่น ผู้ให้บริการ CCTV/ระบบรักษาความปลอดภัย, ผู้พัฒนา AR/VR, และ ISP/Carrier ที่เผชิญต้นทุน egress สูง การเสนอกรณีศึกษาพร้อมตัวเลข ROI จะช่วยปิดการขายได้เร็ว
- พันธมิตรเชิงกลยุทธ์: ร่วมมือกับผู้ผลิตกล้อง (OEM), ผู้ให้บริการ CDN, และ integrator ด้านความปลอดภัย เพื่อฝังเทคโนโลยีในฮาร์ดแวร์หรือสแต็กซอฟต์แวร์ที่มีอยู่แล้ว
- Pilot และ การพิสูจน์มูลค่า (PoC): เสนอโครงการทดลอง 3–6 เดือนพร้อมตัวชี้วัดชัดเจน (ค่าแบนด์วิธที่ประหยัด, latency, คุณภาพภาพ) เพื่อสร้าง reference customers
- การปรับตามภูมิภาค: ในตลาดต่างประเทศต้องพิจารณากฎระเบียบเรื่องข้อมูล (data residency), การรองรับเครือข่ายและมาตรฐานท้องถิ่น, และโมเดลการตั้งราคาให้เหมาะสมกับกำลังซื้อ
- การตลาดเชิงเทคนิค: สร้างเอกสารเทคนิค, benchmark เปรียบเทียบกับ H.264/H.265/AV1, และเผยแพร่ผลทดสอบคุณภาพต่อ bit-rate เพื่อโน้มน้าวฝ่ายเทคนิคของลูกค้าองค์กร
ขนาดตลาดและการแข่งขัน (Market Size & Competitors)
ตลาดคลาวด์วิดีโอ, CDN, และการประมวลผลวิดีโอยังคงมีขนาดใหญ่มาก — หากรวมมูลค่าตลาดสตรีมมิ่ง, CDN และโครงสร้างพื้นฐานวิดีโอ คาดว่ามูลค่าตลาดรวมอยู่ในระดับหลายพันล้านดอลลาร์ต่อปี ซึ่งสร้างโอกาสให้เทคโนโลยีที่ลดต้นทุนการส่งข้อมูลและการเก็บข้อมูลได้รับการยอมรับอย่างรวดเร็ว. สำหรับ niche ของ learned/neurally‑driven video compression ตลาดเริ่มก่อตัวและมีคู่แข่งทั้งจากบริษัทสตาร์ทอัพและองค์กรขนาดใหญ่
- คู่แข่งจากเทคโนโลยีดั้งเดิม: ผู้ให้บริการ transcoding คลาวด์ (เช่น AWS Elemental, Bitmovin, Wowza) และโค้ดมิจิ่วัฒนธรรม (H.264/H.265, AV1) ซึ่งมีความเชื่อถือสูงและ ecosystem ครบ
- คู่แข่งที่ใช้ ML/Neural approaches: บริษัทเช่น Beamr, V‑Nova และสตาร์ทอัพที่วิจัยการบีบอัดแบบเรียนรู้ได้ รวมถึงโครงการวิจัยจาก Google/Meta ที่อาจนำเสนอเทคโนโลยีใกล้เคียง
- ความแตกต่างเชิงการแข่งขัน: จุดแข็งของสตาร์ทอัพไทยควรเน้นที่การปรับแต่งเพื่อตลาดท้องถิ่น, ราคาแข่งขัน, ความร่วมมือเชิงภูมิภาค และบริการรองรับ/ติดตั้ง onsite ซึ่งผู้เล่นระดับโลกอาจตอบสนองได้ช้ากว่า
สรุป: การตั้งราคาที่ชัดเจนจากการคำนวณต้นทุน (โดยเฉพาะ compute และ egress) การเลือกโครงแบบปรับใช้ให้สอดรับกับกรณีใช้งาน (edge/ cloud/ hybrid) และการออกแบบโมเดลธุรกิจที่ยืดหยุ่น (SaaS + usage + OEM licensing) จะเป็นกุญแจสำคัญในการทำให้โซลูชัน Neural‑Compression ชนะการแข่งขันและขยายตลาดทั้งในประเทศและต่างประเทศ
ความท้าทายด้านเทคนิคและนโยบาย (Privacy, Compliance)
ความท้าทายด้านเทคนิคและนโยบาย (Privacy, Compliance)
แม้เทคโนโลยี Neural‑Compression จะสัญญาการลดแบนด์วิธได้ถึง 60–80% แต่การนำไปใช้ในระบบส่งวิดีโอสดเช่น AR/VR หรือกล้องวงจรปิด ยังคงเผชิญอุปสรรคเชิงเทคนิคและด้านนโยบายหลายประการที่ต้องคำนึงก่อนปรับใช้อย่างกว้างขวาง หนึ่งในข้อจำกัดเชิงเทคนิคที่เด่นชัดคือความต้องการทรัพยากรการประมวลผลสำหรับการเร่งโมเดลทั้งฝั่งเอนโค้ดเดอร์/ดีโค้ดเดอร์ การประมวลผลแบบเรียลไทม์ต้องการฮาร์ดแวร์เร่งความเร็ว (เช่น NPU, GPU, หรือ accelerator เฉพาะทาง) เพื่อรักษาเฟรมเรตและความหน่วงภายในเกณฑ์ที่ยอมรับได้ ซึ่งมีผลต่อต้นทุนการลงทุนและการบำรุงรักษาของระบบอย่างมีนัยสำคัญ
จากมุมมองความเป็นส่วนตัวและกฎหมาย ข้อกังวลสำคัญคือการเก็บและประมวลผลข้อมูลภาพที่อาจเชื่อมโยงกับบุคคล (personally identifiable information, PII) เช่น รูปหน้า พฤติกรรมการเคลื่อนไหว หรือป้ายทะเบียนยานพาหนะ การส่งข้อมูลดิบไปยังคลาวด์เพื่อบีบอัดหรือเทรนโมเดลเพิ่มความเสี่ยงต่อการละเมิดข้อมูลและปฏิบัติไม่สอดคล้องกับกฎระเบียบ เช่น พ.ร.บ. คุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) หรือข้อกำหนดระหว่างประเทศอย่าง GDPR ในกรณีที่มีการส่งข้อมูลข้ามพรมแดน จึงจำเป็นต้องออกแบบนโยบายการเก็บรักษา การขอความยินยอม และการแจ้งเหตุละเมิดให้ชัดเจน รวมถึงการพิจารณาเทคนิคเชิงความปลอดภัยเช่นการเข้ารหัสแบบ end‑to‑end, การประมวลผลบนอุปกรณ์ปลายทาง (on‑device), หรือการใช้เทคโนโลยีความเป็นส่วนตัวเสริม (เช่น differential privacy หรือ secure enclaves) เพื่อจำกัดการเปิดเผยข้อมูล
ด้านความเสถียรของโมเดลเป็นอีกประเด็นที่ต้องให้ความสำคัญ: โมเดลที่ฝึกบนชุดข้อมูลจำกัดอาจทำงานได้ดีภายในเงื่อนไขที่คุ้นเคย แต่เมื่อเจอซีนที่ไม่คาดคิด—เช่น แสงสว่างเปลี่ยนเร็ว มีการบังตัววัตถุ ภูมิทัศน์ที่ต่างจากเดิม หรือการโจมตีแบบ adversarial—คุณภาพการบีบอัดและการกู้คืนภาพอาจลดลงอย่างมาก ส่งผลต่อความถูกต้องของงานด้านความปลอดภัยหรือการวิเคราะห์วิดีโอ (เช่น การตรวจจับเหตุผิดปกติ หรือการจดจำใบหน้า)
เพื่อจัดการกับปัญหาดังกล่าว ควรนำแนวทางปฏิบัติและมาตรการรองรับดังต่อไปนี้ไปใช้ทั้งในระดับผู้พัฒนา ผู้ใช้งาน และผู้กำหนดนโยบาย:
- การประเมินฮาร์ดแวร์และต้นทุนเสมือนจริง: ทำการประเมิน TCO (total cost of ownership) และต้นทุนต่อโหนดสำหรับการเร่งโมเดลทั้งกรณีใช้งานแบบ edge และ cloud โดยคำนึงถึงค่าไฟฟ้า ความร้อน และการบำรุงรักษา เพื่อกำหนดสถาปัตยกรรมผสม (hybrid) ที่เหมาะสมกับงบประมาณ
- ออกแบบความเป็นส่วนตัวตั้งแต่ต้น (privacy by design): ใช้การประมวลผลบนอุปกรณ์เมื่อเป็นไปได้ ส่งเฉพาะฟีเจอร์หรือนามธรรมของข้อมูลแทนการส่งวิดีโอดิบ และนำเทคนิคเช่น federated learning ร่วมกับ differential privacy มาใช้เมื่อทำการอัพเดตโมเดลรวมแบบกระจาย
- ปฏิบัติตามกฎหมายและจัดทำเอกสารประกอบ: ดำเนินการ Data Protection Impact Assessment (DPIA) สำหรับการติดตั้งกล้องหรือบริการวิดีโอ เก็บบันทึกการเข้าถึงข้อมูล (audit logs) และจัดทำนโยบายการเก็บรักษา/ลบข้อมูลให้ชัดเจนเพื่อสอดคล้องกับ PDPA/GDPR
- มาตรการรับรองคุณภาพและการทดสอบภาคสนาม: นำชุดทดสอบที่ครอบคลุมสภาวะจริง (lighting, motion, occlusion, network variability) มาใช้ประเมินคุณภาพตามทั้งเกณฑ์ภาพ (PSNR, SSIM, VMAF) และผลกระทบต่องานเชิงปฏิบัติ (เช่น mAP สำหรับการตรวจจับ, อัตราการผิดพลาดของระบบระบุใบหน้า) พร้อมตั้งค่าเกณฑ์การยอมรับและกระบวนการฟอลแบ็กเมื่อคุณภาพต่ำกว่ามาตรฐาน
- ระบบมอนิเตอร์และอัปเดตโมเดลแบบต่อเนื่อง: ติดตั้งการตรวจจับความไม่แน่นอนของโมเดล (uncertainty estimation) และระบบแจ้งเตือนเมื่อเจอสถานการณ์ OOD (out‑of‑distribution) เพื่อให้สามารถสลับกลับไปใช้การบีบอัดเดิมหรือส่งวิดีโอดิบได้ชั่วคราว พร้อมกระบวนการ retraining/continuous learning ภายใต้การกำกับดูแลของนโยบายความเป็นส่วนตัว
- ข้อเสนอเชิงนโยบายสำหรับหน่วยงานกำกับดูแล: สนับสนุนหลักเกณฑ์การรับรองความปลอดภัยและความเป็นส่วนตัวสำหรับโมดูล Neural‑Compression, กำหนดมาตรฐานการวัดประสิทธิภาพและการทดสอบภาคสนาม, รวมถึงการสร้างกรอบการตรวจสอบอิสระ (third‑party audits) เพื่อเพิ่มความโปร่งใสและความไว้วางใจในเชิงสาธารณะ
สรุปแล้ว การปรับใช้ Neural‑Compression ในงานวิดีโอสดมีศักยภาพทางธุรกิจสูง แต่ต้องจับคู่กับการลงทุนด้านฮาร์ดแวร์ การออกแบบระบบที่คำนึงถึงความเป็นส่วนตัวและการปฏิบัติตามกฎหมายอย่างรัดกุม รวมถึงกระบวนการทดสอบและมอนิเตอร์เชิงรุกเพื่อรับประกันความเสถียรเมื่อระบบต้องเผชิญกับสภาพแวดล้อมที่เปลี่ยนแปลงอย่างรวดเร็ว ผู้ให้บริการและผู้กำหนดนโยบายควรร่วมมือกันวางมาตรฐานและแนวปฏิบัติเหล่านี้ก่อนขยายการใช้งานในวงกว้าง
บทสรุป
Neural‑Compression ของสตาร์ทอัพไทยแสดงศักยภาพชัดเจนในการลดปริมาณแบนด์วิธสำหรับการสตรีมวิดีโอแบบเรียลไทม์ได้ประมาณ 60–80% ซึ่งเหมาะอย่างยิ่งกับงานที่ต้องการแบนด์วิธต่ำและตอบสนองสูง เช่น AR/VR ที่ต้องการเฟรมเรตและความหน่วงต่ำ รวมถึงระบบกล้องวงจรปิดที่ต้องการส่งภาพความละเอียดสูงไปยังศูนย์กลาง การลดแบนด์วิธระดับนี้สามารถลดต้นทุนเครือข่ายและเพิ่มความครอบคลุมการใช้งานในเครือข่ายแบนด์วิธจำกัดได้อย่างเป็นรูปธรรม อย่างไรก็ตาม ผลลัพธ์เหล่านี้ต้องแลกมาด้วยต้นทุนการคำนวณที่สูงขึ้น (เช่น การเร่งด้วย GPU/NPU หรือการใช้เซิร์ฟเวอร์เพิ่มเติมสำหรับการเข้ารหัส/ถอดรหัสเชิงประสาท) และข้อพึงระวังด้านความเป็นส่วนตัว — โดยเฉพาะกรณีที่โมเดลอาจประมวลผลหรือลดรูปข้อมูลที่ยังคงมีความเสี่ยงต่อการย้อนกลับหรือการเปิดเผยข้อมูลผู้ใช้ ดังนั้นต้องพิจารณากลยุทธ์การเข้ารหัส การประมวลผลบนอุปกรณ์ (on‑device) และนโยบายการคุ้มครองข้อมูลควบคู่กันไป
การนำ Neural‑Compression ไปใช้จริงจำเป็นต้องวัดผลในสภาพแวดล้อมจริง (field trials) โดยตั้งเกณฑ์ KPI ชัดเจน เช่น อัตราการลดแบนด์วิธ, เพิ่ม/ลดความหน่วง (latency), คุณภาพภาพเชิงตัวชี้วัด (PSNR/SSIM), อัตราการสูญเฟรม และการใช้ทรัพยากรฮาร์ดแวร์ (CPU/GPU/พลังงาน) สำคัญคือต้องเลือกสถาปัตยกรรมการปรับใช้ให้เหมาะกับกรณีใช้งาน — edge deployment (ประมวลผลใกล้กับกล้องหรืออุปกรณ์ AR/VR) ช่วยลดความหน่วงและข้อกังวลด้านความเป็นส่วนตัว ขณะที่ cloud deployment เหมาะกับงานที่ต้องการกำลังประมวลผลสูงและการอัปเดตโมเดลเป็นประจำ การออกแบบแบบไฮบริด (บางการประมวลผลที่ edge และบางส่วนที่ cloud) มักเป็นทางเลือกที่สมดุล นอกจากนี้ต้องมีแผนการตรวจสอบคุณภาพอย่างต่อเนื่อง (continuous monitoring) และกลไก fallback เมื่อคุณภาพตกหรือความหน่วงเพิ่ม เช่น rollback เป็นโค้ดคอมเพรสชั่นดั้งเดิมหรือปรับพารามิเตอร์ของโมเดลแบบเรียลไทม์
มุมมองอนาคตค่อนข้างสดใส: หากมีการปรับแต่งโมเดลให้ประหยัดพลังงานมากขึ้น, ใช้การเร่งฮาร์ดแวร์เฉพาะทาง (NPU/ASIC) และมาตรฐานกลางสำหรับการประเมินคุณภาพ ผลิตภัณฑ์ประเภทนี้มีศักยภาพเปลี่ยนโครงสร้างต้นทุนของการสตรีม AR/VR และการจัดการกล้องวงจรปิดในระดับเมืองหรืออุตสาหกรรม แต่อุปสรรคด้านความเป็นส่วนตัว กฎระเบียบ และต้นทุนการลงทุนเริ่มต้นยังคงต้องได้รับการจัดการอย่างเป็นระบบ คำแนะนำเชิงปฏิบัติคือเริ่มต้นด้วยโครงการนำร่องในสภาพแวดล้อมจำลองหรือไซต์ตัวอย่าง กำหนด KPI ชัดเจน ทดลองทั้งสถาปัตยกรรม edge/cloud แบบไฮบริด และติดตั้งระบบมอนิเตอร์เชิงปริมาณเพื่อประเมิน trade‑off ระหว่างคุณภาพ เงื่อนไขเครือข่าย และต้นทุน ก่อนขยายผลในวงกว้าง



