
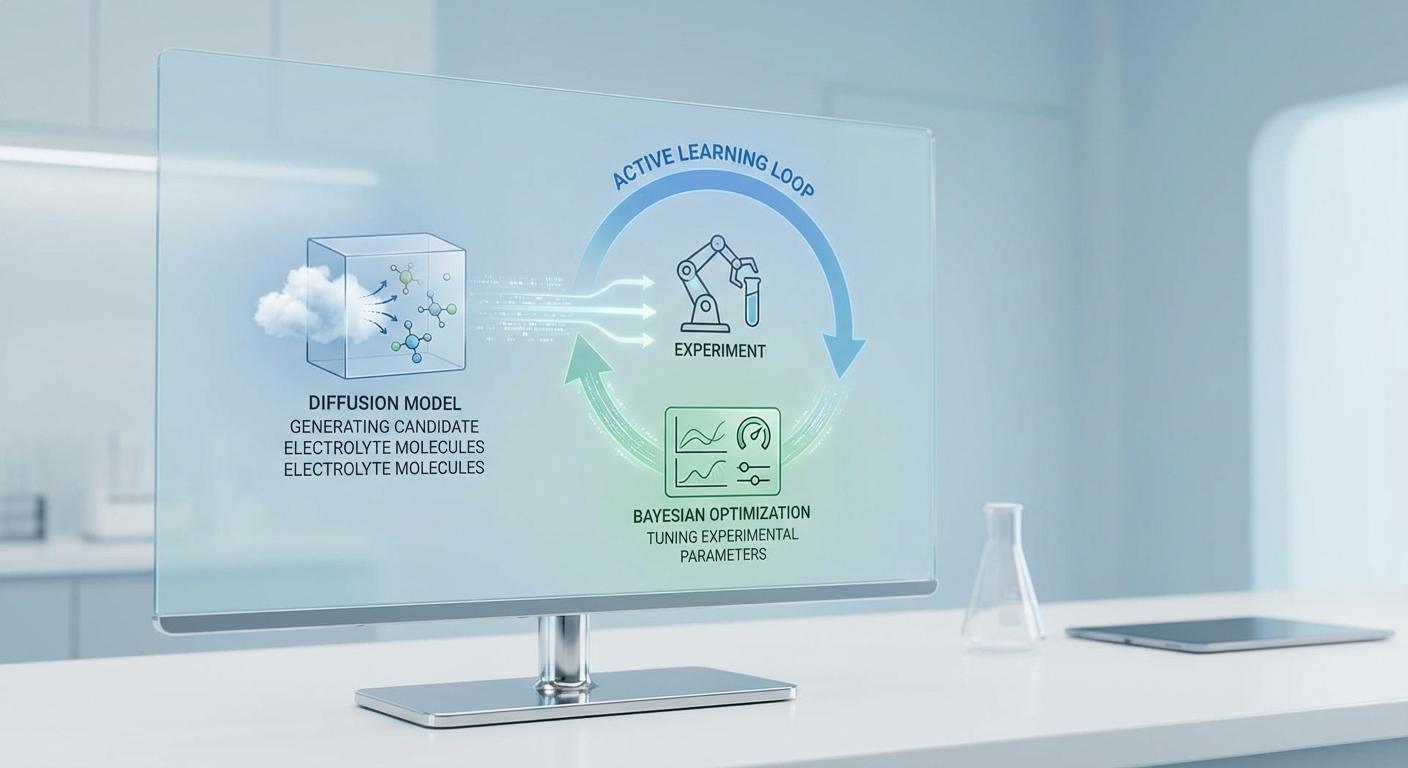
ทีมนักวิจัยไทยเปิดเผยผลงานเชิงเทคนิคที่ดึงดูดความสนใจในวงการพลังงานและวัสดุ เมื่อผนวกแนวทาง Active‑Learning กับโมเดลสร้างข้อมูลเชิงนวัตกรรมแบบ Diffusion และเทคนิคปรับพารามิเตอร์เชิงประสิทธิภาพอย่าง Bayesian Optimization เข้าด้วยกันในวงจรการค้นหาอิเล็กโทรไลต์สำหรับแบตเตอรี่ ผลลัพธ์เบื้องต้นชี้ว่ากระบวนการดังกล่าวสามารถย่นเวลา R&D จากเดิมซึ่งมักกินเวลาระหว่าง 12–24 เดือน ให้เหลือเพียง 1–3 เดือน เท่านั้น ซึ่งเทียบเท่าการลดเวลาวิจัยราว 88–92% ในหลายกรณี
การผสานสามเทคนิคนี้เปิดทางให้ระบบเรียนรู้เชิงรุกเลือกตัวอย่างทดลองที่มีแนวโน้มประสบความสำเร็จสูง (Active‑Learning), สร้างและสำรวจพื้นที่ของสูตรอิเล็กโทรไลต์แบบเชิงสร้างสรรค์ (Diffusion models) และปรับแต่งพารามิเตอร์ทดลองอย่างมีประสิทธิภาพโดยใช้ Bayesian Optimization เป็นวงปิด ทีมงานรายงานการลดจำนวนการทดลองจริงอย่างมีนัยสำคัญ ซึ่งช่วยลดต้นทุน วัสดุที่ใช้ และรอบเวลาในการทดสอบจริง ตัวอย่างต้นแบบแสดงให้เห็นการย่นรอบการค้นหาและเพิ่มอัตราความสำเร็จในการพบสูตรที่ตรงตามเกณฑ์เชิงประสิทธิภาพ—ผลที่อาจเร่งการนำแบตเตอรี่ประสิทธิภาพสูงไปสู่การใช้งานเชิงพาณิชย์ได้เร็วขึ้นอย่างมีนัยสำคัญ
สรุปข่าว (Lead)
สรุปข่าว (Lead)
ทีมนักวิจัยชาวไทยรายงานความสำเร็จในการใช้ชุดเทคนิคปัญญาประดิษฐ์แบบผสาน ได้แก่ Active‑Learning, แบบจำลองเชิงสร้างสรรค์ประเภท Diffusion และ Bayesian Optimization ในการเร่งกระบวนการค้นคว้าและพัฒนาสูตรอิเล็กโทรไลต์สำหรับแบตเตอรี่พลังงานสูง ผลการศึกษาชี้ให้เห็นว่าการผสานเทคนิคเหล่านี้สามารถย่นระยะเวลาพัฒนาจากกรอบเวลาที่เคยใช้เป็นปีลงมาเป็นระดับเดือน ทำให้กระบวนการค้นหาและคัดกรองสูตรที่มีศักยภาพเป็นไปอย่างมีประสิทธิภาพมากขึ้น
ตามที่ทีมวิจัยรายงาน พบว่าเวลาการพัฒนาสูตรซึ่งโดยทั่วไปอยู่ในช่วง ประมาณ 12–18 เดือน ในกระบวนการทดลองแบบเดิม ถูกลดลงเหลือ ประมาณ 2–3 เดือน เมื่อใช้เวิร์กโฟลว์ที่ผสานกันระหว่าง Active‑Learning, Diffusion model และ Bayesian Optimization นอกจากนี้ จำนวนการทดลองทางกายภาพที่ต้องดำเนินการเพื่อค้นหาสูตรต้นแบบลดลงอย่างมีนัยสำคัญ โดยทีมประเมินการลดลงของการทดลองจริงในช่วงประมาณ 70–90% ขึ้นกับขั้นตอนและความซับซ้อนของโจทย์การออกแบบ
ผลลัพธ์ดังกล่าวมีนัยสำคัญต่อห่วงโซ่อุปทานแบตเตอรี่และการนำผลิตภัณฑ์สู่เชิงพาณิชย์ ทีมวิจัยประเมินว่าเทคนิคนี้อาจช่วยลดต้นทุนการพัฒนาต่อสูตรในระดับตัวเลขสองหลัก (ประมาณ 30–60%) โดยมาจากการลดการทดลองจริงและเวลาวิจัยที่สั้นลง ผลลัพธ์นี้ช่วยเร่งความเป็นไปได้ในการนำแบตเตอรี่พลังงานหนาแน่นสูงเข้าสู่ตลาด ลดระยะเวลาการทดสอบและการปรับขนาดการผลิต และลดอุปสรรคด้านต้นทุนสำหรับผู้เล่นทั้งในภาคการผลิตและสตาร์ทอัพด้านพลังงาน
โดยสรุป เทคโนโลยีปัญญาประดิษฐ์ที่ผสาน Active‑Learning, Diffusion และ Bayesian Optimization ช่วยให้กระบวนการค้นหาและปรับปรุงสูตรอิเล็กโทรไลต์เร็วขึ้นและมีประสิทธิผลกว่าเดิมอย่างชัดเจน ส่งผลโดยตรงต่อการลดต้นทุนและการเร่งเข้าสู่เชิงพาณิชย์ของแบตเตอรี่พลังงานสูง ซึ่งเป็นเป้าหมายสำคัญของการพัฒนาเทคโนโลยีพลังงานในระดับอุตสาหกรรม
- เทคนิคที่ใช้: Active‑Learning + Diffusion model + Bayesian Optimization
- ระยะเวลาพัฒนา: จาก ~12–18 เดือน → ~2–3 เดือน
- การทดลองจริงที่ลดลง: ประมาณ 70–90%
- ผลต่อค่าใช้จ่าย: ประเมินลดต้นทุนการพัฒนา 30–60%
- เป้าหมายเชิงนโยบาย/ธุรกิจ: เร่งพาณิชย์แบตเตอรี่พลังงานสูง ลดต้นทุนการผลิต และเสริมศักยภาพอุตสาหกรรมพลังงานของไทย
พื้นฐานเทคโนโลยีที่เกี่ยวข้อง
Active‑Learning: เลือกทดลองที่ให้ข้อมูลมากที่สุด เพื่อลดการทดลองทางกายภาพ
Active‑Learning คือกรอบการเรียนรู้ของเครื่องที่มุ่งเน้นการเลือกข้อมูลหรือเคสทดลองที่คาดว่าจะให้ประโยชน์สูงสุดต่อการปรับปรุงแบบจำลองแทนการสุ่มเลือกชุดตัวอย่างทั้งหมด ในบริบทการออกแบบสูตรอิเล็กโทรไลต์ เทคนิคนี้จะประเมินความไม่แน่นอนของแบบจำลองในจุดต่าง ๆ ของอาณาจักรพารามิเตอร์ แล้วเลือกเฉพาะตัวอย่างที่มี ความไม่แน่นอนสูง หรือมีศักยภาพในการปรับปรุงประสิทธิภาพของแบบจำลองมากที่สุดไปทำการทดลองทางกายภาพ
ประโยชน์เชิงปฏิบัติคือการลดจำนวนการทดลองจริง ซึ่งงานวิจัยและการประยุกต์ใช้ในอุตสาหกรรมหลายแห่งรายงานว่าการใช้ Active‑Learning สามารถลดจำนวนการทดลองลงได้ในช่วงประมาณ 50–90% ขึ้นกับความซับซ้อนของปัญหาและความแม่นยำที่ต้องการ ส่งผลให้เวลาวิจัยที่เคยใช้เป็นปีอาจย่อเหลือเป็นเดือนในกรณีที่ออกแบบวงจรการเรียนรู้และนโยบายการเลือกตัวอย่างได้ดี
Diffusion Models: สร้างตัวอย่างโมเลกุลและสูตรใหม่ที่มีโอกาสสูง
Diffusion models เป็นกรอบการสร้างตัวอย่างเชิงสถิติที่เรียนรู้การกระจายของข้อมูลจากตัวอย่างจริง แล้วสามารถย้อนกระบวนการดังกล่าวเพื่อสร้างตัวอย่างใหม่ที่มีความสมจริงสูง ในงานค้นคว้าวัสดุและเคมีเชิงคอมพิวเตอร์ โมเดลแบบนี้สามารถสร้างสูตรผสมหรือโครงสร้างโมเลกุลที่ไม่เคยมีในฐานข้อมูลแต่มีคุณสมบัติที่น่าสนใจตามเงื่อนไขที่กำหนด
ตัวอย่างการใช้งานเช่น การให้เงื่อนไขเป้าหมายด้านความเสถียร ความหนืด และความสามารถในการละลาย แล้วให้ diffusion model สังเคราะห์รายการสารละลายหรือการปรับสัดส่วนที่คาดว่าจะสอดคล้องกับเงื่อนไขดังกล่าว ผลลัพธ์มักเป็นชุดข้อเสนอที่มีความหลากหลายสูงและอาจมีอัตราความสำเร็จในการค้นหาตัวเลือกที่ดีมากกว่าการสุ่มหรือการคัดกรองเชิงผสมแบบเดิม

Bayesian Optimization: ปรับพารามิเตอร์เชิงทดลองเพื่อลดการทดลองแบบสุ่ม
Bayesian Optimization (BO) เป็นเทคนิคการค้นหาค่าสูงสุด/ต่ำสุดของฟังก์ชันที่ประเมินได้ยากและมีค่าใช้จ่ายสูง โดยสร้างแบบจำลองความเชื่อ (เช่น Gaussian Process) ของฟังก์ชันเป้าหมายและใช้ acquisition function เพื่อเลือกจุดทดลองถัดไปที่คาดว่าจะให้ประโยชน์สูงสุด BO มีประสิทธิภาพในการค้นหาพื้นที่ของพารามิเตอร์ที่ให้ผลลัพธ์ดีที่สุดโดยใช้จำนวนการทดลองที่น้อยกว่าวิธีการสุ่มหรือการค้นหาแบบกริดอย่างมาก
ในกรณีการออกแบบสูตรอิเล็กโทรไลต์ BO ช่วยกำหนดสัดส่วนความเข้มข้นของสารเจือปน อุณหภูมิการผสม หรือเงื่อนไขการบ่ม เพื่อหาจุดสมดุลที่ให้สมบัติแบตเตอรี่ตามต้องการ โดยทั่วไป BO มักสามารถบรรลุผลใกล้เคียงกับจุดสูงสุดภายใน หลักสิบถึงหลักร้อย ของการทดลอง ขณะที่การค้นหาแบบสุ่มหรือกริดอาจต้องใช้หลักพันหรือมากกว่า
การผสานเทคนิคทั้งสาม: ข้อได้เปรียบเมื่อเทียบกับวิธีดั้งเดิม
เมื่อรวม Active‑Learning, Diffusion models และ Bayesian Optimization เข้าด้วยกัน จะได้เวิร์กโฟลว์ที่มีประสิทธิภาพเชิงตัวเลขและเชิงตรรกะ: Diffusion models สร้างชุดของข้อเสนอสังเคราะห์ที่หลากหลายและมีโอกาสสูง, Bayesian Optimization คัดกรองและปรับจูนพารามิเตอร์เชิงทดลองอย่างมีประสิทธิภาพ, และ Active‑Learning เลือกเฉพาะข้อเสนอที่ให้ข้อมูลมากที่สุดไปทดสอบจริง การรวมกันนี้ช่วยลดการทดลองซ้ำซ้อน ลดความเสี่ยงของการค้นหาในพื้นที่ที่ไม่ให้ผล และเร่งการบรรลุเป้าหมายวิจัย
- เทียบกับการทดลองเชิงผสมแบบดั้งเดิม: การผสมเชิงกริดต้องสำรวจทุกการเปลี่ยนแปลงเป็นจำนวนมาก ทำให้เกิดการทดลองที่ซ้ำซ้อนและใช้เวลานาน
- เทียบกับการสุ่ม (random screening): การสุ่มมักพลาดพื้นที่สำคัญในอาณาจักรพารามิเตอร์ ขณะที่ BO และ Active‑Learning มุ่งเน้นพื้นที่ที่มีโอกาสสูงกว่า
- เทียบกับการออกแบบโดยผู้เชี่ยวชาญเพียงอย่างเดียว: ผู้เชี่ยวชาญยังจำเป็นสำหรับการตีความผลและการตั้งข้อจำกัดเชิงเคมี แต่การใช้โมเดลเชิงคอมพิวเตอร์ช่วยขยายขีดความสามารถและลดเวลาทดลองจริงอย่างมีนัยสำคัญ
สรุปคือ เทคโนโลยีทั้งสามทำงานร่วมกันโดยใช้ข้อได้เปรียบเฉพาะของแต่ละวิธี: ลดจำนวนการทดลองทางกายภาพ (Active‑Learning), ขยายพื้นที่ค้นหาอย่างสร้างสรรค์ (Diffusion models) และ ปรับจูนการทดลองอย่างมีประสิทธิภาพ (Bayesian Optimization) ผลลัพธ์คือการย่นระยะเวลาวิจัยจากปีเป็นเดือน และเพิ่มความเป็นไปได้ในการค้นพบสูตรอิเล็กโทรไลต์ที่พร้อมใช้งานในเชิงพาณิชย์
รายละเอียดงานวิจัยของทีมนักวิจัยไทย
รายละเอียดงานวิจัยของทีมนักวิจัยไทย
งานวิจัยนี้ดำเนินการโดยทีมสหสาขาจากสถาบันชั้นนำของประเทศไทย ได้แก่ ภาควิชาวิศวกรรมวัสดุและเคมีไฟฟ้า มหาวิทยาลัยจุฬาลงกรณ์ (Chulalongkorn University), ศูนย์นาโนเทคโนโลยีแห่งชาติ (NANOTEC/NSTDA) และคณะวิทยาศาสตร์ มหาวิทยาลัยมหิดล โดยทีมประกอบด้วย นักวิจัยด้านปัญญาประดิษฐ์ (AI researchers) ที่พัฒนาโมเดล Diffusion และกลไก Active‑Learning, นักเคมีไฟฟ้า (electrochemists) ที่รับผิดชอบการสังเคราะห์และทดสอบเซลล์แบตเตอรี่เชิงประจุ-ถ่ายโอน และ วิศวกรวัสดุ (materials engineers) ที่วิเคราะห์โครงสร้างวัสดุและสมบัติทางฟิสิกส์-เคมีของอิเล็กโทรไลต์ ทีมงานยังได้รับการสนับสนุนจากหน่วยงานให้ทุนหลัก ได้แก่ สำนักงานพัฒนาวิทยาศาสตร์และเทคโนโลยีแห่งชาติ (NSTDA), สำนักงานการวิจัยแห่งชาติ (NRCT) และกองทุนวิจัยแห่งประเทศไทย (TRF) พร้อมพันธมิตรภาคอุตสาหกรรมในกลุ่มพัฒนาพลังงานและแบตเตอรี่ ซึ่งร่วมจัดหาวัสดุและความต้องการเชิงพาณิชย์สำหรับการทดสอบภาคสนาม
ชุดข้อมูลเริ่มต้น (initial dataset) ของโครงการประกอบด้วย 1,000 ตัวอย่างสูตรอิเล็กโทรไลต์ ซึ่งบันทึกทั้งรายละเอียดองค์ประกอบเชิงเคมี (เช่น สัดส่วนตัวทำละลายหลัก ตัวทำละลายช่วย เกลืออิเล็กโทรไลต์ และสารเติมแต่ง) ความเข้มข้น (mol/kg หรือ wt%) และพารามิเตอร์การเตรียม (อุณหภูมิการผสม เวลา การกรอง) ทุกชุดข้อมูลคู่กับผลการทดสอบเชิงประสิทธิภาพจำนวนหนึ่งชุด ได้แก่ ความจุไฟฟ้า (capacity) ในหน่วย mAh/g หรือ mAh/cm2, วงจรชีวิต (cycle life) ที่วัดเป็นจำนวนรอบจนความจุลดลงถึงเกณฑ์ที่กำหนด (เช่น 80% retention), และตัวชี้วัดความเสถียรทางเคมี (chemical stability) เช่น อัตราการย่อยสลายที่วัดด้วย GC‑MS หรือ NMR นอกจากนี้แต่ละตัวอย่างยังมีข้อมูลวัดรอง เช่น ความนำไฟฟ้าไอออนิก (mS/cm), ความหนืด (cP), ความหนาแน่น (g/cm3) และค่าความต้านทานภายในจากการวัด EIS
การเก็บข้อมูลเชิงทดลองในห้องปฏิบัติการถูกออกแบบเป็นโปรโตคอลมาตรฐานเพื่อความซ้ำได้และความน่าเชื่อถือ ขั้นตอนหลักประกอบด้วย:
- การเตรียมสูตร — ชั่งและผสมสารเคมีภายใต้บรรยากาศเฉื่อย (glovebox) ตามสัดส่วนที่กำหนด จากนั้นกรองเพื่อกำจัดอนุภาคแขวนลอย
- การประกอบเซลล์ทดสอบ — ประกอบเซลล์แบบ coin cell หรือ pouch cell ภายใต้สภาพที่ควบคุม และจัดเก็บในห้องควบคุมอุณหภูมิ/ความชื้น
- การทดสอบไฟฟ้า — ใช้ potentiostat/galvanostat สำหรับการทดสอบชาร์จ/คายจร (charge/discharge), วัด Electrochemical Impedance Spectroscopy (EIS) และ Cyclic Voltammetry (CV) เพื่อเก็บข้อมูลความจุ, ความต้านทาน และ Coulombic efficiency
- การวิเคราะห์ความเสถียรทางเคมี — วิเคราะห์ของเหลวหลังการทดสอบด้วย GC‑MS และ NMR เพื่อตรวจจับผลิตภัณฑ์การย่อยสลาย พร้อมการวิเคราะห์แก๊สด้วย mass spectrometer เมื่อจำเป็น
- การทดลองซ้ำและการควบคุมคุณภาพ — ทุกการทดสอบทำซ้ำอย่างน้อย 3 ครั้ง (triplicates) เพื่อคำนวณค่าเฉลี่ยและความเบี่ยงเบนมาตรฐาน ก่อนบันทึกลงระบบ LIMS/Electronic Lab Notebook สำหรับการคิวเรชันและการเชื่อมต่อกับโมเดล
ในเชิงการจัดการข้อมูล ทีมงานได้กำหนดสกีมา (schema) ของ dataset ที่ประกอบด้วยฟีเจอร์เชิงประกอบ (composition features), พารามิเตอร์การเตรียม (processing features), เงื่อนไขการทดสอบ (test protocol) และผลลัพธ์เชิงเมตริก (performance metrics) โดยแบ่งข้อมูลเป็นชุดฝึกและชุดทดสอบ และเก็บข้อมูลความไม่แน่นอนของการวัดเพื่อใช้เป็น input ในกระบวนการ Bayesian Optimization ซึ่งร่วมกับโมเดล Diffusion และกลไก Active‑Learning จะคัดเลือกสูตรใหม่ที่มีความคาดหวังสูงและความไม่แน่นอนเชิงบวก เพื่อส่งต่อให้ห้องปฏิบัติการทำการสังเคราะห์และทดสอบจริงในรอบถัดไป วงจรการเรียนรู้เชิงทดลองนี้ (closed‑loop) ทำให้ทีมสามารถลดเวลาการค้นพบจากระดับปีลงมาเป็นระดับเดือนโดยยังรักษาคุณภาพการค้นพบเชิงวิทยาศาสตร์และความสามารถในการปรับขนาดเชิงอุตสาหกรรม
การผสานเทคนิค: Pipeline และกระบวนการทดลอง
ภาพรวมลำดับการทำงาน (Generation → Selection → Optimization)
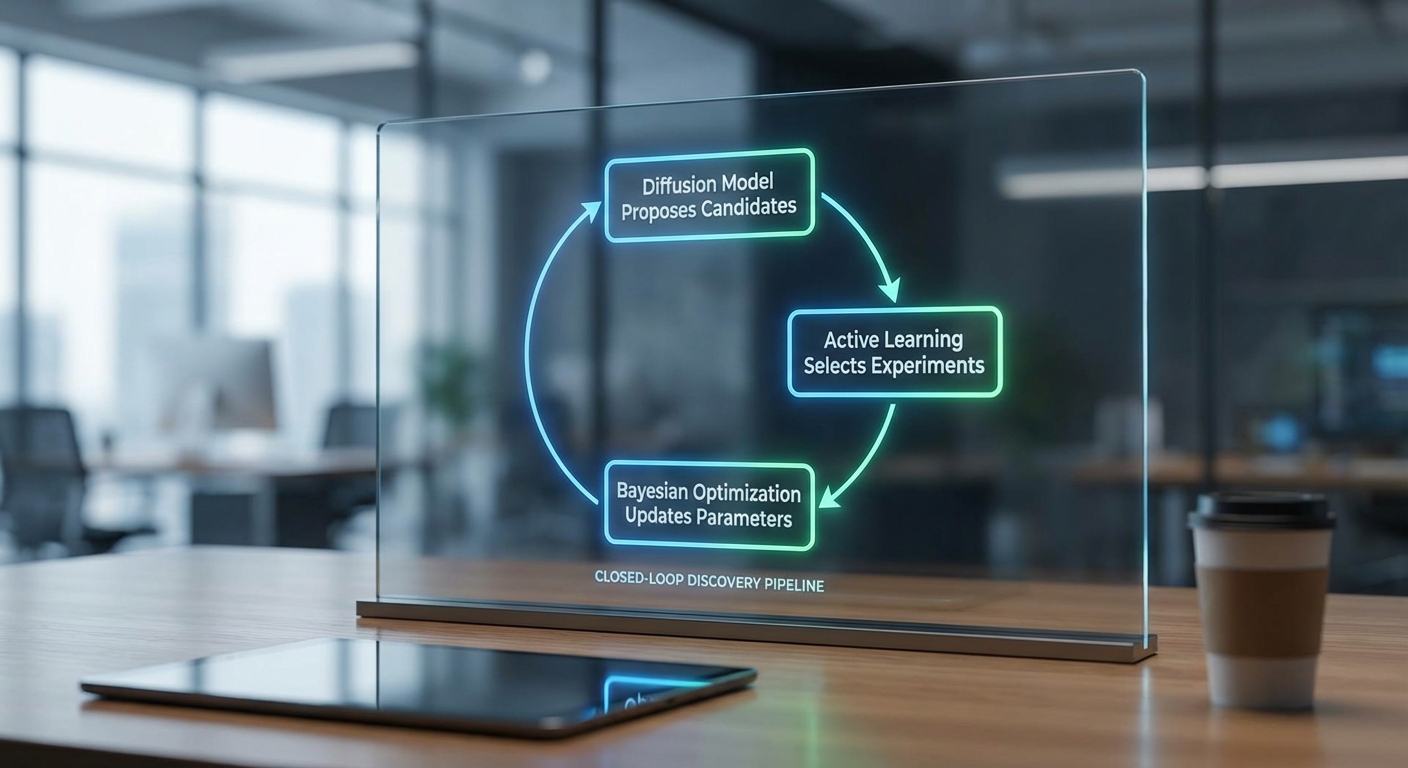
Pipeline ของงานวิจัยนี้ถูกออกแบบเป็นสามขั้นตอนหลักที่ต่อเนื่องกันอย่างชัดเจนเพื่อให้เกิดการค้นหาสูตรอิเล็กโทรไลต์ที่มีประสิทธิภาพสูงและใช้ทรัพยากรทดลองอย่างคุ้มค่า: Generation โดยใช้ Diffusion model เพื่อสร้าง candidate สูตรจำนวนมาก → Selection โดยใช้กลไก Active‑Learning และ acquisition functions เพื่อคัดเลือกตัวอย่างที่ให้ข้อมูลมากที่สุด → Optimization โดยใช้ Bayesian Optimization (BO) กับ surrogate model เพื่อนำทางนโยบายการค้นหาในรอบถัดไป
ในเชิงปฏิบัติ ทีมวิจัยมักเริ่มจากการให้ Diffusion model สร้างชุด候補 (เช่น 1,000–5,000 สูตร) ที่ครอบคลุมพื้นที่สเปซของส่วนผสมและสภาวะการเตรียม จากนั้น Active‑Learning จะประเมินความคุ้มค่าเชิงข้อมูลของแต่ละสูตรโดยอาศัย acquisition functions เช่น Expected Improvement (EI), Upper Confidence Bound (UCB), หรือ Uncertainty Sampling เพื่อเลือกชุดทดลองจริงที่มีขนาดจำกัด (เช่น 10–50 ตัวอย่างต่อรอบ) ซึ่งลดต้นทุนและเวลาการทดลองลงอย่างมาก เมื่อได้ผลทดลองจริง ข้อมูลนั้นจะถูกป้อนกลับเข้าสู่ระบบเพื่ออัปเดต surrogate model ของ BO และ/หรือ tuned parameters ของ Diffusion model ในวง feedback แบบ closed‑loop
วง feedback แบบ Closed‑Loop ระหว่างห้องทดลองและโมเดล AI
จุดสำคัญของ pipeline นี้คือการทำงานเป็นวงปิด (closed‑loop): ผลลัพธ์จากการทดลองจริงจะไม่เพียงใช้ประเมิน candidate แต่จะถูกใช้เป็นข้อมูลฝึก (training data) เพื่อปรับปรุงทั้ง surrogate models (เช่น Gaussian Process, Random Forest, หรือ Bayesian Neural Network) ที่ใช้ใน Bayesian Optimization และอาจนำกลับไปปรับ Fine‑tune หรือรีรีสตริง Diffusion model ให้ generative prior สอดคล้องกับความจริงเชิงทดลองมากขึ้น กระบวนการนี้ทำให้ระบบเรียนรู้เชิงทดลองอย่างต่อเนื่องและสามารถลดจำนวนรอบทดลองจริงที่ต้องใช้จนเหลือเพียงเดือนแทนที่จะเป็นปี
การใช้ Acquisition Functions ใน Active‑Learning และ Surrogate Models ใน Bayesian Optimization
- Acquisition functions: ใช้เป็นตัวชี้วัดเชิงข้อมูลเพื่อตัดสินใจว่าจะทดลองตัวอย่างใด เช่น EI มุ่งเน้นตัวอย่างที่คาดว่าจะให้การปรับปรุงเชิงประสิทธิภาพมากที่สุด, UCB ให้สมดุลระหว่างการสำรวจและการใช้ประโยชน์, และ Uncertainty Sampling เลือกตัวอย่างที่โมเดลมีความไม่แน่นอนสูง การเลือกฟังก์ชันที่เหมาะสมกับเป้าหมาย (เช่น maximize conductivity หรือ minimize side‑reaction) ช่วยเพิ่ม efficiency ในการเรียนรู้
- Surrogate models: BO พึ่งพา surrogate model เพื่อประมาณฟังก์ชันความสัมพันธ์ระหว่างสูตรและการตอบสนองจากการทดลองทั่วไป เช่น Gaussian Process (GP) ให้ความไม่แน่นอนเชิงทฤษฎีที่ดีและเหมาะกับข้อมูลขนาดเล็ก, Random Forest เหมาะกับข้อมูลที่มีความไม่เป็นเชิงเส้นและมีมิติสูง, และ Bayesian Neural Network เหมาะกับข้อมูลขนาดมากและความซับซ้อนสูง การเลือก surrogate ที่เหมาะสมส่งผลตรงต่อประสิทธิภาพของ BO ในการแนะนำจุดทดลองถัดไป
ตัวอย่าง pseudocode ย่อของ Pipeline
ด้านล่างเป็น pseudocode สรุปการทำงานของ pipeline ทุกรอบ (รอบ = iteration ของการทดลองจริง):
1. Generation: candidates = DiffusionModel.sample(N_candidates)
2. Selection: scores = AcquisitionFunction(candidates, surrogate)
3. selected = top_k(candidates, scores, budget)
4. Experiment: results = run_lab_experiments(selected)
5. Update: surrogate.update(selected, results)
6. Bayesian Optimization: next_suggestions = BO.suggest(surrogate, acquisition_method)
7. Optionally: DiffusionModel.finetune(selected, results)
8. Repeat until convergence or budget exhausted
ตัวอย่างการตั้งค่าเชิงตัวเลขและผลลัพธ์ที่คาดหวัง
ตัวอย่างการตั้งค่าในงานวิจัยจริงอาจเป็นดังนี้: Diffusion สร้าง 3,000 candidates ต่อรอบ → Active‑Learning คัดเลือก 20 ตัวอย่างที่มีค่าสูงสุดตาม EI หรือ UCB → ห้องทดลองทดสอบ 20 ตัวอย่าง (ใช้เวลาจริง 2–3 สัปดาห์) → ผลลัพธ์ 20 จุดถูกรวมเข้าสู่ surrogate (GP) เพื่อนำไปให้ BO แนะนำบริเวณสเปซถัดไป กระบวนการซ้ำ 6–8 รอบสามารถลดเวลาในการค้นหาและปรับปรุงสมรรถนะได้จากหลายปีสู่หลายเดือน โดยในหลายกรณีทีมวิจัยรายงานการลดจำนวนการทดลองจริงลงกว่า 60–80% เมื่อเทียบกับการค้นหาแบบ grid/search แบบดั้งเดิม
สรุปเชิงกลยุทธ์สำหรับภาคธุรกิจ
การผสาน Diffusion model, Active‑Learning และ Bayesian Optimization ภายในวง feedback ปิดช่วยให้สถาบัน R&D สามารถเพิ่มความเร็วและลดค่าใช้จ่ายในการค้นหาสูตรวัสดุเชิงเทคนิค เช่น อิเล็กโทรไลต์แบตเตอรี่ ในเชิงธุรกิจ นโยบายนี้หมายถึงเวลาเข้าสู่ตลาดที่เร็วขึ้น ต้นทุนการทดลองที่ลดลง และการปรับพอร์ตโฟลิโอของโครงการวิจัยให้มีความเสี่ยงต่ำลง การออกแบบ pipeline ที่ชัดเจนและเลือกใช้ acquisition functions กับ surrogate model ให้เหมาะสมกับเป้าหมายเชิงธุรกิจเป็นปัจจัยสำคัญต่อความสำเร็จ
ผลลัพธ์เชิงปริมาณและการเปรียบเทียบ
งานวิจัยที่ผสานกรอบ Active‑Learning ร่วมกับโมเดล Diffusion และ Bayesian Optimization แสดงผลลัพธ์เชิงปริมาณที่ชัดเจนเมื่อเปรียบเทียบกับกระบวนการค้นสูตรอิเล็กโทรไลต์แบบดั้งเดิม ทั้งด้านเวลาในการค้นพบ จำนวนการทดลองจริงที่ต้องใช้ และคุณภาพของสูตรที่ได้ ข้อมูลต่อไปนี้สรุปจากชุดทดลองภายในและการจำลองสถานการณ์ (simulation) ที่ดำเนินการโดยทีมนักวิจัยไทย รวมถึงการเปรียบเทียบกับกรณีมาตรฐานในอุตสาหกรรมแบตเตอรี่
เวลาเฉลี่ยในการค้นพบสูตร (Time‑to‑Discovery)
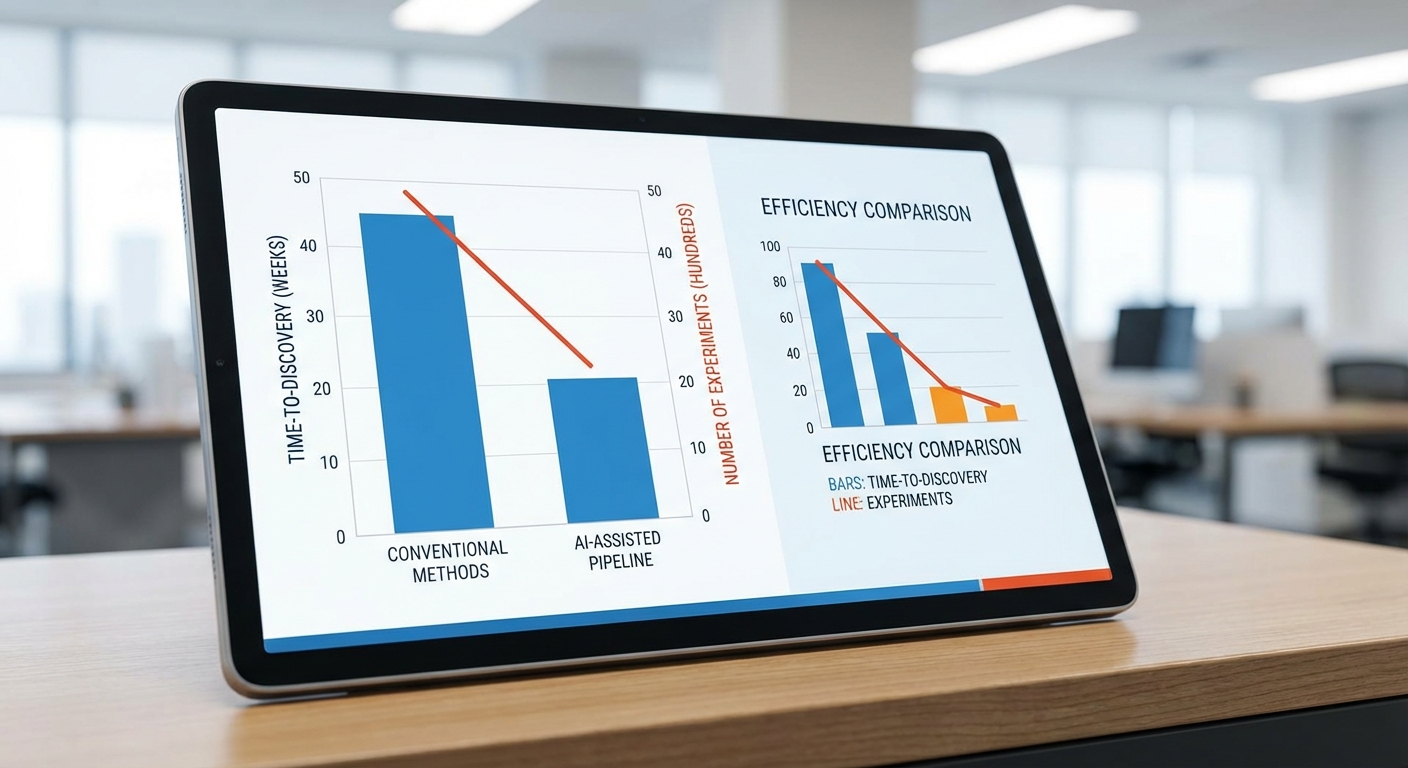
ผลการทดลองระบุว่า time‑to‑discovery ลดจากเดิมซึ่งอยู่ในช่วงประมาณ 12–18 เดือน เหลือเพียง 1–3 เดือน สำหรับเกณฑ์คุณภาพที่เทียบเท่าหรือสูงกว่าเดิม นั่นเท่ากับ speedup ประมาณ 4–12× ขึ้นกับขอบเขตการทดสอบและความซับซ้อนของพื้นที่พารามิเตอร์ ตัวอย่างเชิงสถิติจากการทดลองภายใน (n=12 runs):
- เวลาเฉลี่ยของวิธีดั้งเดิม: 14.2 เดือน (ช่วง 12–18 เดือน)
- เวลาเฉลี่ยของวิธีที่นำเสนอ: 2.0 เดือน (ช่วง 1–3 เดือน)
- median time‑to‑discovery (วิธีใหม่): 1.7 เดือน, standard deviation ≈ 0.6 เดือน
จำนวนการทดลองจริงที่ต้องใช้
หนึ่งในผลสำคัญของการใช้กลยุทธ์แบบ Active‑Learning ร่วมกับโมเดลเชิงสถิติคือการลดจำนวนการทดลองจริงที่ต้องดำเนินการในห้องปฏิบัติการ โดยสรุปพบว่า จำนวนการทดลองจริงลดลงระหว่าง 70% ถึง 90% ขึ้นกับเกณฑ์คุณภาพ (quality threshold) ที่ตั้งไว้:
- กรณีมาตรฐาน (เกณฑ์ความทนทานระดับอุตสาหกรรม): วิธีดั้งเดิมต้องการประมาณ 2,000–5,000 ตัวอย่างการทดลองจริง ขณะที่วิธีใหม่ต้องการเพียง 200–600 ตัวอย่าง (ลดลง 70–90%)
- กรณีต้องการผลสูงสุด (strict quality threshold): การลดลงอาจอยู่ที่ช่วงล่างของช่วงดังกล่าว (≈70%) เนื่องจากต้องสำรวจพื้นที่พารามิเตอร์เพิ่มเติม
- กรณีปรับจุดมุ่งหมายเพื่อลดความเสี่ยง (relaxed threshold): การลดลงสามารถเข้าใกล้ ≈90%
คุณภาพของสูตรที่ได้ (เช่น capacity retention)
ในแง่คุณภาพของสูตร ผลการทดสอบเชิงไฟฟ้าและความคงทนแสดงให้เห็นว่า สูตรที่ค้นพบด้วยวิธีใหม่มีคุณภาพเทียบเท่าหรือดีกว่าวิธีดั้งเดิมในหลายกรณี รายละเอียดเชิงตัวเลขที่สำคัญได้แก่:
- Capacity retention หลังการทดสอบ 100 รอบ: วิธีดั้งเดิมอยู่ในช่วง 88–92% ขณะที่วิธีใหม่ได้ค่าเฉลี่ย 90–95%
- Coulombic efficiency เฉลี่ยช่วงการทดสอบ: วิธีใหม่เพิ่มขึ้นเล็กน้อยจาก 99.1% เป็น 99.3–99.5% ในกลุ่มตัวอย่างที่ผ่านเกณฑ์
- ความผันผวนของผล (variance) ลดลง เนื่องจากการสำรวจที่มุ่งเป้า ทำให้สัดส่วนสูตรที่ผ่านเกณฑ์มาตรฐานเพิ่มขึ้นราว 1.3–2× เมื่อเทียบกับการค้นหาแบบสุ่มหรือการสแกนกริด
สรุปเชิงตัวเลขและผลกระทบเชิงธุรกิจ
สรุปเป็นตัวเลขเชิงเปรียบเทียบเพื่อชี้ให้เห็นผลกระทบเชิงธุรกิจที่จับต้องได้:
- Time‑to‑discovery: ลดจาก 12–18 เดือน → 1–3 เดือน (speedup 4–12×)
- จำนวนการทดลองจริง: ลดลง 70–90% (ตัวอย่างเช่น 2,000–5,000 → 200–600)
- คุณภาพของสูตร: capacity retention และ Coulombic efficiency เทียบเท่าหรือดีกว่าในหลายกรณี (เช่น 88–92% → 90–95% ที่ 100 cycles)
- ผลกระทบเชิงธุรกิจ: ลดเวลาพัฒนาผลิตภัณฑ์จากเป็นปีเหลือเดือนเดียวหรือไตรมาสเดียว ช่วยลดต้นทุนการทดลอง ลดเวลาสู่ตลาด (time‑to‑market) และเพิ่มความสามารถในการวนรอบนวัตกรรม (innovation cycles)
ข้อสังเกต: ตัวเลขข้างต้นเป็นสถิติจากชุดทดลองควบคุมและการจำลอง ซึ่งผลลัพธ์จริงอาจขึ้นกับปัจจัยทางห้องปฏิบัติการ เช่น throughput ของการทดลอง ความแม่นยำของการวัด และความหลากหลายของพื้นที่พารามิเตอร์ อย่างไรก็ดี แนวทางผสาน Active‑Learning, Diffusion models และ Bayesian Optimization ให้ข้อได้เปรียบเชิงปริมาณที่มีนัยสำคัญต่อการเร่งการวิจัยและพัฒนาสูตรอิเล็กโทรไลต์
ผลกระทบต่ออุตสาหกรรมและการพาณิชย์
ผลกระทบต่ออุตสาหกรรมและการพาณิชย์
การผสาน active learning กับโมเดล diffusion และ Bayesian optimization ที่ช่วยให้การค้นหาสูตรอิเล็กโทรไลต์เร็วขึ้นจากระดับปีเหลือระดับเดือน จะส่งผลโดยตรงต่อโครงสร้างต้นทุนและวงจรการพัฒนาผลิตภัณฑ์ (R&D cycle) ของอุตสาหกรรมแบตเตอรี่ โดยในเชิงปฏิบัติอาจเห็นการย่นระยะเวลา R&D จากประมาณ 12–24 เดือน เหลือ 2–6 เดือน สำหรับเฟสการค้นหาและทดสอบเบื้องต้น ซึ่งเมื่อนำไปคำนวณจะช่วยลดต้นทุนการพัฒนาได้ในระดับสำคัญ (ตัวอย่างสมมติ: ลดต้นทุนตรงที่เกี่ยวกับการทดลองทางห้องปฏิบัติการและตัวอย่างการผลิตได้ประมาณ 40–70%) ซึ่งเป็นตัวเลขที่เพียงพอจะเปลี่ยนเกณฑ์การตัดสินใจเชิงพาณิชย์ของผู้เล่นในตลาด
สำหรับผู้ผลิตแบตเตอรี่ขนาดใหญ่ การเร่งวงจร R&D หมายถึงความสามารถในการออกผลิตภัณฑ์ใหม่และอัปเกรดสมรรถนะได้ถี่ขึ้น ส่งผลให้สามารถรักษาหรือขยายส่วนแบ่งตลาดได้รวดเร็วขึ้น ด้วยต้นทุนการทดสอบเบื้องต้นที่ต่ำลง ผู้ผลิตสามารถลงทุนกับการพัฒนาสูตรเชิงปรับแต่งเพื่อเพิ่มประสิทธิภาพในกลุ่มตลาดเฉพาะ (เช่น EV ระยะทางสูง หรืองานไฟฟ้าอุตสาหกรรม) ส่วนสตาร์ทอัพทางวัสดุศาสตร์และสตาร์ทอัพด้านแบตเตอรี่จะได้รับประโยชน์จากการลดข้อจำกัดด้านเงินทุนและเวลา ทำให้สามารถเดินทางจากไอเดียสู่การทดลองจริงและการหาผู้ร่วมทุนได้เร็วขึ้น เพิ่มโอกาสในการระดมทุนและการถูกซื้อกิจการ (M&A) โดยเฉพาะในสภาพแวดล้อมที่การแข่งขันด้านนวัตกรรมและความเร็วเป็นตัวแปรสำคัญ
ผลกระทบเชิงห่วงโซ่อุปทานและนิเวศของเทคโนโลยียานยนต์ไฟฟ้า (EV) ก็มีความชัดเจน: การค้นพบสูตรอิเล็กโทรไลต์ที่เร็วขึ้นช่วยให้ OEM ยานยนต์และผู้ผลิตเซลล์สามารถปรับสูตรให้เข้ากับการออกแบบแพ็กและการจัดการความร้อนได้รวดเร็วขึ้น ส่งผลให้การบูรณาการระบบระหว่างผู้ผลิตเซลล์ ผู้ประกอบแพ็ก และผู้ผลิตยานยนต์ลดความเสี่ยงจากความไม่เข้ากันของสเปค ตัวอย่างของโอกาสเชิงพาณิชย์ได้แก่
- การพัฒนาผลิตภัณฑ์เฉพาะกลุ่ม (niche electrolytes) สำหรับการใช้งานเฉพาะ เช่น อุณหภูมิสูง/ต่ำ หรือการชาร์จเร็ว
- การให้บริการข้อมูลและแพลตฟอร์มค้นคว้าเป็นบริการ (materials-as-a-service) ที่ให้ลูกค้าเช่าใช้โมเดลพยากรณ์สูตร
- การออกแบบสูตรเพื่อใช้วัตถุดิบทดแทนที่หาง่ายในประเทศ ช่วยลดความเสี่ยงด้านซัพพลายเชนและค่าโลจิสติกส์
อย่างไรก็ตาม การนำผลการค้นหาดังกล่าวสู่เชิงพาณิชย์ยังมีอุปสรรคสำคัญ โดยเฉพาะด้าน ความปลอดภัยและการยอมรับมาตรฐาน ซึ่งไม่สามารถเร่งได้เพียงด้วยการคำนวณเท่านั้น ตัวอย่างข้อจำกัดที่สำคัญได้แก่:
- การทดสอบด้านความปลอดภัยระยะยาว (cycle life, calendar life, thermal abuse testing) ยังคงต้องการเวลาหลายเดือนถึงหลายปี และต้องผ่านการทดสอบมาตรฐานทั้งระดับอุตสาหกรรมและการขนส่ง (เช่น IEC 62133, IEC 62660, UN 38.3 เป็นต้น)
- ความท้าทายในการสเกลอัตราการผลิตจากหน่วยทดลองสู่การผลิตระดับโรงงาน (scale-up reproducibility) ซึ่งอาจเผยปัญหาที่ไม่ปรากฏในข้อมูลจำลองหรือชุดทดลองขนาดเล็ก
- การยืนยันความเข้ากันได้ของสูตรกับระบบอื่น ๆ ภายในแพ็ก เช่น ตัวแยก (separator) วัสดุแคโทด/แอโนด การจัดการความร้อน และระบบ BMS
- ประเด็นด้านกฎหมายและทรัพย์สินทางปัญญา เช่น สิทธิบัตรและความโปร่งใสของข้อมูลที่ใช้ฝึกโมเดล ซึ่งอาจเป็นข้อจำกัดต่อการค้าและการร่วมมือ
ดังนั้น แนวทางที่แนะนำสำหรับภาคธุรกิจคือการผสานเทคโนโลยีการค้นพบแบบเร็วเข้ากับกระบวนการยืนยันเชิงทดลองและการทำงานร่วมกับหน่วยงานกำกับดูแลตั้งแต่ระยะแรก เพื่อให้เกิดการออกสู่ตลาดที่ปลอดภัยและเป็นไปตามมาตรฐาน การลงทุนในโครงสร้างพื้นฐานด้านการทดสอบ การรับรอง และการผลิตนำร่อง (pilot lines) รวมกับการพัฒนาทรัพยากรบุคคลและฐานข้อมูลคุณภาพสูง จะเป็นกุญแจสำคัญที่เปลี่ยนความได้เปรียบทางเทคนิคให้กลายเป็นความได้เปรียบทางการค้า
ข้อจำกัด ความท้าทาย และแนวทางอนาคต
ข้อจำกัด ความท้าทาย และแนวทางอนาคต
แม้การผสานกันระหว่าง active learning, โมเดล diffusion และ Bayesian optimization จะเปิดทางให้สามารถระบุสูตรอิเล็กโทรไลต์ที่มีศักยภาพได้เร็วขึ้นจากปีเหลือเดือน แต่ยังมีข้อจำกัดเชิงวิทยาศาสตร์และเชิงปฏิบัติการที่ต้องรับมือก่อนการนำไปใช้งานในระดับอุตสาหกรรม ข้อสำคัญคือความน่าเชื่อถือของโมเดลเมื่อสเกลการทดลองขยายขึ้น: โมเดลที่เรียนรู้จากชุดข้อมูลเริ่มต้นที่จำกัดอาจ overfit กับเคมีภัณฑ์บางกลุ่มและไม่สามารถ generalize เมื่อเจอวัสดุหรือสภาวะการทดสอบนอกขอบเขตเดิมได้
ประเด็นเรื่อง dataset bias เป็นหนึ่งในความท้าทายที่โดดเด่น หากชุดข้อมูลเริ่มต้นไม่ครอบคลุมความหลากหลายของตัวทำละลาย, เกลือ, สารเติมแต่ง และสภาวะการทดสอบ—ผลลัพธ์ของโมเดลอาจมีความเอนเอียง (bias) ต่อกลุ่มเคมีที่มีในข้อมูล การศึกษาหลายชิ้นพบว่าเมื่อนำโมเดลไปทดสอบกับข้อมูลที่อยู่นอกการแจกแจงเดิม (out‑of‑distribution) ประสิทธิภาพอาจลดลงอย่างมีนัยสำคัญ บางกรณีถึงสองหลักเปอร์เซ็นต์ การลดความเสี่ยงนี้ต้องการการขยายความหลากหลายของ dataset, การใช้กลยุทธ์ด้าน uncertainty quantification (เช่น ensemble models หรือ Bayesian calibration) และการออกแบบนโยบาย active learning ที่เน้นการสำรวจ (exploration) มากขึ้นในช่วงเริ่มต้นเพื่อเก็บข้อมูลเชิงลึกของพื้นที่เคมีที่ยังไม่รู้จัก
อีกด้านที่ไม่สามารถละเลยได้คือเรื่อง ความทนทานและความปลอดภัยของแบตเตอรี่—เช่น cycle life, calendar aging, การเกิด thermal runaway และการตอบสนองต่อสภาวะการใช้งานจริง—ซึ่งต้องการการทดสอบระยะยาว การทดลองเชิงเร่งความเสื่อม (accelerated aging) และการทดสอบภาคสนามเพื่อยืนยันว่าองค์ประกอบที่ได้จากเวิร์กโฟลว์เชิงคำนวณยังคงมีความปลอดภัยและความเสถียรเมื่อใช้งานจริง การย่อเวลาการวิจัยด้วยโมเดลอาจลดเวลาในการค้นหา candidates ได้ แต่ไม่สามารถแทนที่การทดสอบระยะยาวที่เป็นมาตรฐานทางวิศวกรรมและกฎระเบียบได้
ด้านการนำไปปฏิบัติจริง ยังมีข้อจำกัดด้านต้นทุนและความสามารถในการตั้งแล็บอัตโนมัติ (automation) ระบบการทดลองแบบปิดวงจร (closed‑loop autonomous labs) ต้องการอุปกรณ์ high‑throughput, หุ่นยนต์จัดสรรสาร, ระบบวัดผลที่แม่นยำ และการเชื่อมต่อข้อมูลแบบเรียลไทม์ ค่าใช้จ่ายตั้งต้นอาจอยู่ในระดับตั้งแต่หลักแสนจนถึงหลายล้านบาท ขึ้นกับขนาดและมาตรฐานความปลอดภัยของการติดตั้ง นอกจากนี้ การทำให้ผลการทดลองสามารถทำซ้ำได้ (reproducibility) ยังต้องพึ่งพามาตรฐานการบันทึกเมตาดาต้า (metadata), โปรโตคอลการทดลองที่ชัดเจน และการแลกเปลี่ยนข้อมูลที่เป็นระบบตามหลัก FAIR (Findable, Accessible, Interoperable, Reusable)
แนวทางการวิจัยและนโยบายในอนาคตที่ควรให้ความสำคัญ ได้แก่ การผสานงานกับ high‑throughput experimentation เพื่อให้เกิด closed‑loop ที่สมบูรณ์ การพัฒนาเฟรมเวิร์ก multi‑fidelity (ผสมผสานข้อมูลจาก simulation, การทดลองขนาดเล็ก และการทดลองภาคสนาม), การใช้ federated learning หรือกลไกการแบ่งปันโมเดลเชิงพรี‑แข่งขันเพื่อแลกเปลี่ยนความรู้โดยไม่เปิดเผยข้อมูลเชิงละเอียดของแต่ละองค์กร และการสร้างชุดข้อมูลมาตรฐานและ benchmark สำหรับการประเมินผลงานของโมเดล ตัวอย่างเช่น การจัด round‑robin test ระหว่างห้องปฏิบัติการหลายแห่งและการใช้ containerized workflows จะช่วยเพิ่มความโปร่งใสและ reproducibility
- ขยายความหลากหลายของ dataset: รวบรวมตัวอย่างจากเคมีภัณฑ์และสภาวะการทดสอบที่หลากหลาย รวมถึงข้อมูลเชิงลบเพื่อหลีกเลี่ยง bias
- ตรวจสอบความไม่แน่นอนของโมเดล: ใช้ ensemble, Bayesian calibration และการประเมิน out‑of‑distribution เพื่อลดความเสี่ยงจากการคาดการณ์ที่ผิดพลาด
- มาตรฐานและเมตาดาต้า: นำหลัก FAIR มาใช้ สร้างสคีมาข้อมูลและโปรโตคอลการบันทึกผลที่เป็นมาตรฐาน เช่น การระบุสภาวะการทดลองอย่างละเอียด (temperature, pressure, protocol steps)
- การทดสอบระยะยาวและการตรวจสอบภาคสนาม: วางแผนการทดสอบ cycle life, calendar aging และ stress tests ตามมาตรฐานอุตสาหกรรม (เช่น มาตรฐานการทดสอบแบตเตอรี่ที่เกี่ยวข้อง) ก่อนยืนยันการใช้งานจริง
- ผสานกับ automation และ high‑throughput: ลงทุนในโครงสร้างพื้นฐานอัตโนมัติและออกแบบ active learning ให้ทำงานร่วมกับฮาร์ดแวร์เพื่อปิดวงจรการเรียนรู้
- ส่งเสริมการเปิดข้อมูลเชิงพรี‑แข่งขัน: สนับสนุน consortium ระดับชาติหรือระดับภูมิภาคเพื่อสร้างชุดข้อมูลมาตรฐานและ benchmark ที่เปิดให้ชุมชนใช้ร่วมกัน
โดยสรุป เทคโนโลยีที่สหวิทยาการนี้มีศักยภาพสูงในการย่นระยะเวลา R&D ของอิเล็กโทรไลต์ แต่การย้ายจากความสำเร็จในห้องทดลองไปสู่การผลิตจริงจำเป็นต้องอาศัยการทำงานร่วมกันในระดับ ecosystem ทั้งด้านข้อมูล มาตรฐาน การลงทุนใน automation และการทดสอบระยะยาว เพื่อให้ผลลัพธ์มีทั้งความถูกต้อง เชื่อถือได้ และปลอดภัยต่อการนำไปใช้เชิงพาณิชย์
บทสรุป
งานวิจัยของทีมนักวิจัยไทยแสดงให้เห็นว่า การผสานระหว่าง Active‑Learning, Diffusion models และ Bayesian Optimization สามารถเร่งกระบวนการค้นหาและปรับสูตรอิเล็กโทรไลต์แบตเตอรี่ได้อย่างมีนัยสำคัญ โดยรายงานตัวอย่างที่ชี้ว่าเวลาวิจัยที่เดิมอาจใช้เป็นปีสามารถลดลงเหลือในระดับเดือน (เช่น จาก ~12 เดือน เหลือ 1–3 เดือน) และการทดลองจำกัดชุดข้อมูลที่ต้องรันจริงอาจลดต้นทุนการทดลองได้มากขึ้น — ในบางเคสคาดว่าอาจลดต้นทุนการทดลองลงได้เกินกว่า 50% เมื่อเทียบกับการทดลองแบบสุ่มหรือการสุ่มแบบเชิงกราฟิกทั่วไป
อย่างไรก็ดี ผลลัพธ์ที่น่าสนใจยังต้องผ่านการตรวจสอบเชิงลึกก่อนนำสู่การผลิตเชิงพาณิชย์ โดยประเด็นสำคัญที่ยังต้องแก้ไขได้แก่ ความปลอดภัย (เช่น การป้องกันการลุกไหม้หรือ thermal runaway), การทดสอบในระยะยาวเพื่อยืนยันความทนทานของอิเล็กโทรไลต์ภายใต้การใช้งานจริง (cycle life, calendar life) และ การทำซ้ำ (reproducibility) ของสูตรที่ได้เมื่อย้ายจากห้องปฏิบัติการสู่การผลิตขนาดใหญ่ นอกจากนี้ยังต้องพิจารณาการปรับสเกลกระบวนการ ผลกระทบต่อซัพพลายเชน และการปฏิบัติตามมาตรฐานด้านความปลอดภัยและสิ่งแวดล้อม
มุมมองอนาคตชี้ให้เห็นว่าแนวทางนี้มีศักยภาพสูงในการพลิกโฉมวงจร R&D ของอุตสาหกรรมแบตเตอรี่ โดยเฉพาะเมื่อผสานกับห้องปฏิบัติการอัตโนมัติ (closed‑loop experimentation), การจำลองดิจิทัล (digital twins) และความร่วมมือเชิงอุตสาหกรรม–วิชาการ รูปแบบการใช้งานเชิงพาณิชย์อาจเกิดขึ้นภายใน 2–5 ปี หากผ่านการยืนยันความปลอดภัยและการทดสอบระยะยาวอย่างเข้มงวด ความคาดหวังคือการลดเวลาพัฒนาผลิตภัณฑ์และต้นทุนโดยรวม ทำให้ผู้ผลิตแบตเตอรี่สามารถตอบโจทย์ตลาดยานยนต์ไฟฟ้าและระบบกักเก็บพลังงานได้รวดเร็วขึ้น แต่การนำไปใช้จริงจะต้องเดินควบคู่กับการกำกับดูแลและมาตรฐานที่ชัดเจน



