
ในยุคที่ความคาดหวังของผู้ใช้ต่อบริการลูกค้าแบบดิจิทัลสูงขึ้นอย่างรวดเร็ว องค์กรไทยเริ่มหันมาใช้แนวทางใหม่ในการสร้างแชทบอทที่เชื่อถือได้มากขึ้น—Adaptive‑RAG—ซึ่งผสานการค้นหาข้อมูลแบบเวกเตอร์เรียลไทม์เข้ากับฐานความรู้ที่เปลี่ยนแปลงได้ (mutable knowledge base) เพื่อแก้ปัญหา Hallucination หรือการสร้างคำตอบที่ผิดพลาดของโมเดลภาษาขนาดใหญ่ เทคนิคนี้ไม่เพียงช่วยเพิ่มความถูกต้องของคำตอบ แต่ยังตอบโจทย์การอัปเดตข้อมูลแบบทันที เช่น สถานะการสั่งซื้อ โปรโมชั่น และนโยบายที่เปลี่ยนแปลงบ่อย โดยไม่ต้องฝึกโมเดลใหม่ทั้งหมด
บทความฉบับนี้จะพาเจาะลึกสถาปัตยกรรมของ Adaptive‑RAG ที่รวมเวกเตอร์เรียลไทม์ การจัดการความรู้แบบเปลี่ยนแปลงได้ และกลไกการยืนยันแหล่งข้อมูล พร้อมยกตัวอย่างกรณีศึกษาจากองค์กรไทยที่เริ่มนำไปใช้จริง ผลลัพธ์เบื้องต้นชี้ให้เห็นการลด Hallucination การเพิ่มความพึงพอใจของลูกค้า และการลดการส่งต่อไปยังเจ้าหน้าที่มนุษย์ เราจะสรุปข้อดี ความเสี่ยง เทคนิคการติดตั้งในสภาพแวดล้อมองค์กรไทย และแนวทางปฏิบัติที่ควรคำนึงถึงเมื่อนำ Adaptive‑RAG ไปใช้จริง
บทนำ: ทำไม Adaptive‑RAG ถึงเป็นประเด็นที่องค์กรไทยให้ความสนใจ
บทนำ: ทำไม Adaptive‑RAG ถึงเป็นประเด็นที่องค์กรไทยให้ความสนใจ
ในช่วงไม่กี่ปีที่ผ่านมา การนำแชทบอทที่ขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ (LLM) มาใช้ในงานบริการลูกค้าขององค์กรไทยให้ประโยชน์ด้านการตอบสนองทันทีและการรองรับปริมาณคำถามจำนวนมาก แต่ระบบเหล่านี้ยังเผชิญปัญหาที่เป็นอุปสรรคสำคัญต่อการนำไปใช้ในเชิงพาณิชย์ ได้แก่ การให้คำตอบที่ไม่แม่นยำหรือเกิด hallucination ข้อมูลที่ถูกฝังอยู่ในโมเดลหรือฐานความรู้กลายเป็น ข้อมูลล้าสมัย และการตอบคำถามที่ไม่สอดคล้องกับบริบทหรือกฎธุรกิจขององค์กร ตัวอย่างที่พบได้บ่อย เช่น แชทบอทแนะนำสินค้าที่หมดสต็อก แจ้งโปรโมชั่นที่สิ้นสุดไปแล้ว หรือให้คำแนะนำทางการเงินที่ขัดกับข้อกำหนดภายใน ซึ่งนำไปสู่ความไม่พอใจของลูกค้าและภาระการแก้ไขที่เพิ่มขึ้นสำหรับทีมงานมนุษย์
ผลกระทบทางธุรกิจจากปัญหาเหล่านี้มีความชัดเจน ทั้งในแง่ของความเชื่อมั่นของลูกค้า (customer trust) และต้นทุนการดำเนินงาน การสำรวจจากผู้ให้บริการและผู้ใช้งานในตลาดพบว่าองค์กรจำนวนหนึ่งเจออัตราการยกขึ้นให้เจ้าหน้าที่มนุษย์ (escalation rate) สูงขึ้นเมื่อคำตอบจากบ็อตไม่สอดคล้องหรือมีข้อมูลผิดพลาด นอกจากนี้ ยังมีความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ (compliance) เมื่อข้อมูลที่ใช้ตอบคำถามไม่ทันสมัยหรือไม่ได้ผ่านการจัดการเวอร์ชันอย่างเป็นระบบ
Adaptive‑RAG ถูกเสนอเป็นวิวัฒนาการของแนวทาง Retrieval‑Augmented Generation (RAG) แบบดั้งเดิม โดยเพิ่มเติมความสามารถสำคัญสองประการ: คือการอัปเดตเวกเตอร์ (vector embeddings) แบบเรียลไทม์เพื่อสะท้อนเหตุการณ์และข้อมูลใหม่ ๆ และการออกแบบฐานความรู้ให้เป็น mutable (สามารถเปลี่ยนแปลงและจัดการเวอร์ชันได้อย่างต่อเนื่อง) แทนการอาศัยดัชนีคงที่เพียงครั้งเดียว กระบวนการนี้ทำให้ระบบสามารถดึงหลักฐาน (evidence) ที่สดใหม่และเกี่ยวข้องมาสนับสนุนการสร้างข้อความของโมเดล ลดโอกาสที่โมเดลจะคาดเดาหรือสร้างข้อมูลที่ไม่มีหลักฐาน (hallucinate) เพราะคำตอบถูกอ้างอิงจากชิ้นข้อมูลที่ถูกตรวจสอบว่ามีอยู่จริงในขณะนั้น
เหตุผลที่ทำให้องค์กรไทยเริ่มให้ความสนใจทดลองใช้ Adaptive‑RAG มีทั้งด้านปฏิบัติการและกลยุทธ์เชิงธุรกิจ ดังนี้
- เพิ่มความน่าเชื่อถือของบริการ: การตอบคำถามโดยยึดกับหลักฐานที่เป็นปัจจุบันช่วยลดข้อผิดพลาดที่กระทบภาพลักษณ์และความเชื่อมั่นของลูกค้า
- ลดภาระงานของพนักงาน: การลดอัตราการยกเคสให้เจ้าหน้าที่มนุษย์ ทำให้ทีมบริการลูกค้าจัดการเคสเชิงซับซ้อนได้มีประสิทธิภาพมากขึ้น ลดต้นทุนแรงงานระยะยาว
- ปรับปรุงประสบการณ์ลูกค้า: คำตอบที่สอดคล้องกับนโยบาย บริษัท และสถานะปัจจุบัน (เช่น สต็อก ราคา โปรโมชั่น) ช่วยลดเวลาในการแก้ปัญหาและเพิ่มความพึงพอใจของผู้ใช้
- รองรับการเปลี่ยนแปลงเชิงกฎระเบียบและธุรกิจได้รวดเร็ว: สำหรับธุรกิจเช่นการเงิน โทรคมนาคม และอีคอมเมิร์ซ ที่ข้อมูลเปลี่ยนบ่อย การมีระบบที่อัปเดตฐานความรู้แบบ mutable ช่วยให้ตอบสนองต่อการเปลี่ยนแปลงได้ทันเวลา
ด้วยปัจจัยเหล่านี้ Adaptive‑RAG จึงไม่เพียงเป็นการปรับปรุงเชิงเทคนิค แต่ยังเป็นกลไกสำคัญที่ช่วยให้องค์กรไทยยกระดับความน่าเชื่อถือของช่องทางดิจิทัล ลดต้นทุนการให้บริการ และสร้างประสบการณ์ลูกค้าที่สอดคล้องกับบริบทและนโยบายขององค์กรในโลกที่ข้อมูลเคลื่อนไหวอย่างรวดเร็ว
Adaptive‑RAG คืออะไร: คำนิยามและองค์ประกอบหลัก
Adaptive‑RAG คืออะไร: คำนิยามและองค์ประกอบหลัก
Adaptive‑RAG (Adaptive Retrieval‑Augmented Generation) คือกรอบการทำงานสำหรับระบบตอบข้อความหรือแชทบอทที่ผสานการค้นคืนข้อมูลเชิงสาระด้วยเวกเตอร์แบบเรียลไทม์เข้ากับฐานความรู้ที่สามารถเปลี่ยนแปลงได้ (mutable knowledge base) และมีกลไกการตรวจสอบ (scoring/verification) ก่อนจะให้คำตอบโดยโมเดลภาษาขนาดใหญ่ (LLM) เป้าหมายหลักคือเพิ่มความแม่นยำและความสอดคล้องของคำตอบในบริบทที่ข้อมูลเปลี่ยนเร็ว เช่น ข้อมูลคำสั่งซื้อ ข้อมูลนโยบายโปรโมชั่น หรือสถานะการคืนเงิน การออกแบบแบบ Adaptive‑RAG จึงเน้นทั้งความสดใหม่ของข้อมูล (freshness), การตรวจสอบเชิงตรรกะ (verifiability) และการลดการสร้างข้อมูลผิดพลาดหรือ hallucination
องค์ประกอบสำคัญของ Adaptive‑RAG ประกอบด้วยหลายชั้นที่ทำงานสอดประสานกันดังนี้:
-
Encoder / Embedding (การเข้ารหัสและแปลงข้อความเป็นเวกเตอร์แบบเรียลไทม์)
บทบาท: เมื่อมีข้อความใหม่เข้ามา—เช่น คำถามลูกค้า หรือบันทึกธุรกรรม—ระบบจะเรียกใช้งาน encoder เพื่อแปลงข้อความนั้นเป็นเวกเตอร์เชิงตัวเลขทันที เวกเตอร์เหล่านี้เป็นตัวแทนเชิงความหมายที่ใช้สำหรับการค้นคืนเชิง semantic
ข้อสังเกตเชิงเทคนิค: encoder ที่รองรับการประมวลผลแบบเรียลไทม์มักต้องมีความรวดเร็วและทดแทนได้ (low-latency, stateless) เช่น ใช้หลากหลายรุ่น embedding ที่ออกแบบมาสำหรับงานเรียลไทม์ และมักจะทำงานพร้อมกันกับเมตริกซ์ normalization เพื่อให้การค้นหาเวกเตอร์มีความสอดคล้อง
-
Real‑time Vector Index (ดัชนีเวกเตอร์ที่อัปเดตและค้นหาได้ทันที)
บทบาท: เวกเตอร์ที่ได้จาก encoder จะถูกป้อนเข้าไปยังตัวจัดเก็บเวกเตอร์ที่รองรับการอัปเดตแบบทันที ตัวอย่างเทคโนโลยีที่ใช้งานได้แก่ Milvus, FAISS, Weaviate หรือ Pinecone โดยสำหรับกรณีใช้งานที่ต้องการความสดใหม่ของข้อมูลสูง ดัชนีต้องรองรับการ insert/update/delete แบบ online และยังต้องให้ latency ในการค้นหาเป็นมิลลิวินาที
ตัวอย่างเชิงตัวเลข: ในงานบริการลูกค้าระดับองค์กร การใช้ Milvus/FAISS เวอร์ชันที่ปรับแต่งแล้วสามารถให้เวลาค้นหา (nearest neighbor search) ในช่วง 5–50 ms ต่อคำค้นเมื่อดัชนีมีขนาดระดับล้านรายการ ขึ้นกับการตั้งค่าและทรัพยากร
-
Retriever แบบไฮบริด (semantic + sparse)
บทบาท: เพื่อให้การค้นคืนครอบคลุมทั้งความหมาย (semantic) และสัญกรณ์ที่ชัดเจน (keyword/sparse) ระบบ Adaptive‑RAG มักผสานการค้นหาด้วยเวกเตอร์ (semantic) ร่วมกับการค้นหาแบบ sparse เช่น BM25 หรือ Elasticsearch hybrid query การผสมผสานนี้ช่วยให้ตอบคำถามที่ต้องการการจับคู่แบบตรงตัว (เช่น หมายเลขคำสั่งซื้อ) และยังคงความเข้าใจเชิงบริบทได้ดี
ผลลัพธ์: การใช้ retriever แบบไฮบริดมักเพิ่มความครอบคลุม (recall) และความแม่นยำเชิงบริบท (precision) โดยเฉพาะเมื่อแหล่งความรู้มีทั้งเอกสารยาว ๆ และข้อมูลโครงสร้าง
-
Mutable Knowledge Base (ฐานความรู้ที่เปลี่ยนแปลงได้)
บทบาท: เป็นการรวมแหล่งข้อมูลหลายประเภทเข้าด้วยกัน เช่น หน้า FAQ, เอกสารนโยบาย, ฐานข้อมูลธุรกรรม (transactional DB), feed ของเหตุการณ์ (events) และกฎการดำเนินงาน (policy) ฐานความรู้ชนิดนี้ต้องสามารถอัปเดตได้ทันทีเมื่อตัวธุรกรรมเกิดขึ้น เช่น การเปลี่ยนสถานะคำสั่งซื้อ การคืนเงิน หรือการปรับโปรโมชั่น
ความท้าทาย: ต้องจัดการประเด็นความสอดคล้องของข้อมูล (consistency), การจัดสิทธิ์เข้าถึงข้อมูล (access control) และการประทับเวลาของแหล่งข้อมูล (provenance/timestamps) เพื่อให้โมเดลสามารถอ้างอิงแหล่งที่มาและเวลาของข้อมูลได้ถูกต้อง
-
LLM ที่ทำหน้าที่ Generate พร้อมกลไก Scoring / Verification
บทบาท: โมเดลภาษายังทำหน้าที่สร้างข้อความตอบ แต่ใน Adaptive‑RAG จะมีชั้นการประเมินและยืนยันก่อนนำคำตอบออกสู่ผู้ใช้ กลไกนี้อาจประกอบด้วย reranker, entailment verifier, fact‑checking model หรือการใช้ external tool เพื่อยืนยันค่าจากฐานข้อมูลจริง (grounded lookup)
วิธีการลด Hallucination: ก่อนส่งคำตอบจริง ระบบจะทำการให้คะแนนความสอดคล้องของแหล่งข้อมูล (source scoring), ตรวจสอบความขัดแย้งกับข้อมูล transactional และหากคะแนนต่ำหรือพบความไม่สอดคล้อง ระบบอาจเลือกที่จะคืนคำตอบที่มีความระมัดระวังมากขึ้น (e.g., ให้ลิงก์แหล่งอ้างอิง, ขอข้อมูลเพิ่มจากผู้ใช้, หรือส่งต่อไปยังมนุษย์)
ความแตกต่างจาก RAG แบบดั้งเดิม
RAG แบบดั้งเดิมมักขึ้นกับดัชนีเวกเตอร์ที่ถูกสร้างขึ้นแบบครั้งเดียวหรืออัปเดตเป็นงวด (batch) และเน้นการดึงข้อมูลเชิง semantic เป็นหลัก โดยทั่วไปจะใช้เอกสารคงที่เป็นแหล่งข้อมูลหลัก ข้อจำกัดนี้ส่งผลให้ RAG แบบเดิมตอบสนองต่อข้อมูลที่เปลี่ยนเร็วได้ไม่ดีและมีโอกาสเกิด hallucination สูงเมื่อบริบทเปลี่ยนไป ในทางตรงกันข้าม Adaptive‑RAG ถูกออกแบบมาให้รองรับการอัปเดตข้อมูลแบบทันที (real‑time ingestion), ผสานข้อมูลธุรกรรมและนโยบายเข้ากับฐานความรู้ และเพิ่มชั้นการตรวจสอบคำตอบก่อนเผยแพร่ ทำให้ความสดใหม่ (freshness) และความถูกต้องของคำตอบสูงขึ้น โดยตัวอย่างการประเมินภายในองค์กรพบว่าการนำกลไก verification มาช่วยร่วมกับดัชนีแบบเรียลไทม์สามารถลดอัตรา hallucination ได้ในช่วงประมาณ 30–60% ขึ้นกับลักษณะข้อมูลและการตั้งค่า retriever
นอกจากนี้ Adaptive‑RAG ยังให้ความสำคัญกับการอ้างอิงแหล่งที่มา (provenance) และการจัดการสิทธิ์ข้อมูล ซึ่งสำคัญต่อการปฏิบัติตามกฎระเบียบและการตรวจสอบภายในองค์กร เช่น เมื่อตอบคำถามเกี่ยวกับสถานะคำสั่งซื้อ ระบบสามารถแนบข้อมูลอ้างอิงที่ดึงจาก transactional DB แบบเรียลไทม์ ทำให้คำตอบมีความน่าเชื่อถือมากขึ้น
สรุปคือ Adaptive‑RAG เป็นวิวัฒนาการของ RAG ที่มุ่งเน้นการใช้งานในสภาพแวดล้อมที่ข้อมูลเปลี่ยนรวดเร็วและต้องการการรับรองความถูกต้องของข้อมูล เหมาะสำหรับแชทบอทบริการลูกค้าที่ต้องผสานทั้ง FAQ, นโยบายบริษัท และข้อมูลธุรกรรมแบบเรียลไทม์ เพื่อลดความเสี่ยงจากการให้ข้อมูลผิดพลาดและเพิ่มความพึงพอใจของผู้ใช้
สถาปัตยกรรมเชิงเทคนิค: ผสานเวกเตอร์เรียลไทม์กับฐานความรู้ที่เปลี่ยนแปลงได้
ส่วนนี้อธิบายสถาปัตยกรรมเชิงเทคนิคของระบบ Adaptive‑RAG ที่ออกแบบมาเพื่อลดปัญหา hallucination ในแชทบอทบริการลูกค้าโดยผสานการค้นหาเวกเตอร์เรียลไทม์กับฐานความรู้ที่สามารถเปลี่ยนแปลงได้ (mutable knowledge base) ระบบนี้เน้นกระแสข้อมูลแบบต่อเนื่อง (data flow) ตั้งแต่การรับข้อความลูกค้า การสร้าง embedding เรียลไทม์ การดึงข้อมูลร่วมกับฐานความรู้ การทำ reranking/verification การส่งบริบทให้ LLM และการวนลูปบันทึกผลเพื่อนำไปอัปเดตเวกเตอร์และฐานความรู้แบบ near‑real‑time
ภาพรวม Data Flow
Data flow หลักของระบบสามารถสรุปเป็นลำดับดังนี้: ingestion → embed → retrieve → verify → generate → feedback loop โดยมีคอมโพเนนต์สำคัญคือ Ingest pipeline, Real‑time Embedding service, Hybrid Retriever (dense + sparse), Reranker/Verifier, LLM serving และ Feedback/Indexer สำหรับอัปเดตข้อมูล
ขั้นตอนทีละขั้นตอน
- 1) การรับข้อความลูกค้าและการ preprocess
เมื่อระบบรับข้อความจากช่องทางต่าง ๆ (เว็บแชท, แอปมือถือ, โทลเซ็นเตอร์) ข้อความจะเข้าสู่ Ingestion layer ที่ทำหน้าที่ normalize, language detection, PII redaction, และการดึงเมตาดาต้าเช่น customer_id, session_id, channel, และ transaction references กระบวนการนี้อาจทำงานผ่าน event stream (เช่น Kafka) และใช้ CDC (change data capture) จากระบบธุรกรรมเพื่อให้บริบทถูกต้องก่อนส่งต่อไปยังโมดูล embedding
- 2) การสร้าง embedding เรียลไทม์จากข้อความใหม่และข้อมูลธุรกรรม
ข้อความที่ผ่านการ preprocess จะถูกส่งไปยัง Real‑time Embedding service ซึ่งใช้โมเดล embedding ขนาดเล็กถึงกลาง (เช่น bi‑encoder) เพื่อให้ได้เวกเตอร์เชิงความหมาย และในกรณีที่ข้อความอ้างอิงถึงรายการธุรกรรม ระบบจะดึงข้อมูลธุรกรรมที่เกี่ยวข้อง (เช่นคำสั่งซื้อ สถานะการส่ง การคืนสินค้า) แล้วสร้าง embeddings สำหรับ transaction snippet ร่วมด้วย การคำนวณนี้ต้องทำแบบเรียลไทม์หรือเกือบเรียลไทม์ (target: embedding latency 10–50 ms ต่อข้อความในระบบที่ปรับขนาด)
- 3) การค้นหาใน real‑time vector index ร่วมกับฐานความรู้แบบ mutable
การ Retrieve จะใช้กลยุทธ์แบบ hybrid: ทำ sparse retrieval (เช่น BM25) บนฐานความรู้เชิงข้อความเพื่อจับคำสำคัญ และ dense retrieval บน vector index (เช่น FAISS, Milvus, Vespa) เพื่อจับความหมายเชิงบริบท เทคนิคนี้ช่วยเพิ่ม recall ในกรณีที่ข้อความลูกค้ามีการสะกดหรือเรียบเรียงที่หลากหลาย โดยตัวเก็บข้อมูลจะประกอบด้วยสองชั้นคือ
- Vector store สำหรับเอกสาร/สไนปเพ็ตที่สามารถอัปเดตแบบ near‑real‑time (append/partial‑reindex, segment merge)
- Mutable knowledge base (metadata store / RDB) สำหรับเก็บสถานะปัจจุบันของข้อมูลธุรกรรม ข้อมูลราคา และนโยบายที่เปลี่ยนแปลงได้
การอัปเดต index แบบ near‑real‑time จะใช้ micro‑batch หรือ streaming upserts เพื่อให้ freshness อยู่ในระดับวินาทีถึงนาที ขึ้นกับ SLA ของธุรกิจ (ตัวอย่าง: freshness target = 30 วินาที – 5 นาที)
- 4) การทำ reranking/verification
หลังจากดึง candidate contexts มาจาก retriever ขั้นแรก ระบบจะใช้ reranker แบบ cross‑encoder (เช่น BERT/DeBERTa cross‑encoder) เพื่อประเมินความสอดคล้องเชิงบริบทและปรับลำดับผลลัพธ์ โดยพิจารณาระดับความมั่นใจ (score) และ provenance ของแหล่งที่มา (เช่น document id, timestamp, source type)
เพิ่มเติมเพื่อป้องกัน hallucination จะมีชั้น Verification ดังนี้:
- Fact‑checking retriever: ดึงหลักฐานที่เป็นข้อเท็จจริงจาก authoritative sources (เช่น policy DB, transaction ledger) และเปรียบเทียบกับคำตอบที่ LLM อาจสร้าง
- Entailment/Consistency model: ใช้โมเดลตรวจสอบ entailment ระหว่าง candidate evidence กับ generated claim หากคะแนน entailment ต่ำกว่า threshold ระบบจะปฏิเสธการใช้บริบทนั้นหรือเพิ่มข้อความ disclaimers
- Confidence thresholding: หากการยืนยันหลักฐานไม่ผ่าน ระบบจะเลือก fallback strategy เช่นส่งการตอบกลับแบบ template, ขอข้อมูลเพิ่มจากผู้ใช้ หรือยกระดับให้พนักงานดูแล
ตัวอย่างจากการนำร่องภายในพบว่า การเพิ่ม cross‑encoder reranker ร่วมกับ entailment verification สามารถลดอัตรา hallucination ได้ประมาณ 30–60% ขึ้นกับโดเมนและคุณภาพฐานความรู้
- 5) การส่ง context ที่ผ่านการคัดกรองให้ LLM
บริบทที่ผ่านการ rerank และ verification จะถูกจัดเป็น prompt template ที่มี bounding constraints เพื่อจำกัด token budget และลดความเสี่ยงในการสร้างข้อมูลนอกหลักฐาน (grounded prompt) ก่อนส่งให้ LLM กำเนิดข้อความ ระบบจะแนบ metadata เช่น provenance, evidence snippets, confidence score และลิงก์กลับไปยังแหล่งข้อมูลเมื่อต้องการให้ผู้ใช้ตรวจสอบ
Latency เป้าหมายสำหรับ end‑to‑end interaction ควรอยู่ที่ 300–1000 ms ขึ้นกับความซับซ้อนของ verification และขนาดของ LLM (สำหรับงาน customer service มาตรฐานมักตั้งเป้าไม่เกิน 1 วินาที)
- 6) การบันทึกผลเพื่ออัปเดตเวกเตอร์/ฐานความรู้ต่อเนื่อง
หลังการโต้ตอบ ระบบจะบันทึกเหตุการณ์ทั้งหมด (user utterance, selected evidence, generated reply, user_feedback, human review) ลงใน event store เพื่อใช้ในหลายงาน:
- อัปเดต vector index: สร้าง embedding จากข้อความใหม่หรือหลักฐานที่ได้รับการยอมรับและ upsert เข้าสตอร์เพื่อให้ค้นหาได้ทันที
- อัปเดต mutable knowledge base: หากการโต้ตอบยืนยันการเปลี่ยนแปลงสถานะธุรกรรมหรือ policy ระบบจะทำ CDC/transactional update เพื่อให้ฐานความรู้สะท้อนสถานะจริง
- Training loop: เก็บตัวอย่างสำหรับการ fine‑tuning reranker, verifier และ LLM calibration โดยมี human‑in‑the‑loop สำหรับ label คุณภาพ
กลไกนี้สร้าง feedback loop ที่ทำให้ความสด (freshness) และความแม่นยำของเวกเตอร์เพิ่มขึ้นเมื่อเวลาเดินหน้า
จุดวัด KPI ที่สำคัญ
- Latency (ms): embedding latency per request (10–50 ms), retrieval + rerank (50–200 ms), end‑to‑end (300–1000 ms)
- Retrieval accuracy: recall@k, precision@k, MRR — ตัวชี้วัดต้องวัดแยกระหว่าง dense, sparse และ hybrid retrieval
- Freshness / Staleness: เวลาตั้งแต่ข้อมูลเปลี่ยนแปลงจนไปถึงการปรากฏใน index (target: 30s–5min ตาม SLA)
- Hallucination rate: % ของคำตอบที่ไม่สอดคล้องกับหลักฐานหรือจริง (วัดผ่าน human labeling/entailment checks) — ตัวอย่างเป้าหมายหลังใช้ Adaptive‑RAG: ลดลง 30–60%
- Fallback / Escalation rate: % ของการตอบที่ต้องยกระดับไปยังมนุษย์หรือใช้ template
สรุปและแนวปฏิบัติที่แนะนำ
สถาปัตยกรรม Adaptive‑RAG ที่ผสานเวกเตอร์เรียลไทม์กับฐานความรู้แบบ mutable ต้องการการออกแบบที่คำนึงถึงความแม่นยำของ retrieval, กลไก reranker/verification ที่เข้มงวด และ pipeline สำหรับการอัปเดตข้อมูลแบบ near‑real‑time เพื่อให้เกิดความสดและลด hallucination ในเชิงปฏิบัติ แนะนำให้ใช้ hybrid retrieval ร่วมกับ cross‑encoder reranker, entailment/consistency checks, provenance tracking และ feedback loop ที่ผสานการอัปเดตทั้ง vector store และ metadata DB เพื่อรักษาค่า KPI ในระดับที่รับได้สำหรับงานบริการลูกค้า
ประโยชน์เชิงธุรกิจและเมตริกที่ควรติดตาม
ประโยชน์เชิงธุรกิจจากการปรับใช้ Adaptive‑RAG
การผสานการดึงเวกเตอร์เรียลไทม์เข้ากับฐานความรู้ที่เปลี่ยนแปลง (Adaptive‑RAG) ช่วยให้องค์กรสามารถลดการเกิด hallucination ของโมเดลภาษาในระบบแชทบอทบริการลูกค้าได้อย่างมีนัยสำคัญ โดยการให้บริบทที่สดใหม่และตรงกับคำถามจริงของผู้ใช้ ระบบจะอ้างอิงข้อมูลธุรกรรม นโยบาย หรือสถานะคำสั่งซื้อที่อัปเดต ทำให้คำตอบมีความถูกต้องมากขึ้นและลดการสร้างข้อมูลผิดๆ ที่อาจสร้างความเสียหายหรือความไม่พอใจของลูกค้า
ผลเชิงปฏิบัติการที่องค์กรจะสังเกตเห็นได้ภายในช่วงการทดสอบและใช้งานจริง ได้แก่ อัตราการ hallucination ลดลง ตัวอย่างจากงานวิจัยเชิงทดลองและกรณีใช้งานจริงชี้ว่าอาจลดได้ในช่วงประมาณ 30–70% ขึ้นกับคุณภาพของข้อมูลที่เก็บเข้าเวกเตอร์ กลยุทธ์การดึงข้อมูล (retrieval) และพารามิเตอร์ของระบบ ในทางปฏิบัติ การลด hallucination ส่งผลโดยตรงต่อความน่าเชื่อถือของแบรนด์และลดจำนวนการโอนต่อให้เจ้าหน้าที่มนุษย์เมื่อต้องตรวจสอบหรือแก้ไขคำตอบที่ผิด
นอกจากนี้ Adaptive‑RAG ยังช่วยปรับปรุง freshness ของคำตอบโดยเฉพาะเมื่อระบบต้องอ้างอิงข้อมูลที่เปลี่ยนบ่อย เช่น ยอดเงิน คำสั่งซื้อ สถานะการจัดส่ง หรือนโยบายโปรโมชั่น การอัปเดตเวกเตอร์เรียลไทม์ทำให้คำตอบสะท้อนสถานะปัจจุบัน ลดการให้ข้อมูลล้าสมัย และช่วยให้ KPI ทางธุรกิจ เช่น CSAT (Customer Satisfaction) และ NPS (Net Promoter Score) ดีขึ้น ตัวอย่างค่าประเมินจากการทดลองมักพบว่า CSAT อาจเพิ่มขึ้นได้ประมาณ +2–10 จุด ขึ้นกับประเภทการสนับสนุนและฐานลูกค้า
เมตริกเชิงปฏิบัติการที่ควรติดตาม
- Hallucination rate — สัดส่วนของคำตอบที่ผิดหรือสร้างข้อมูลที่ไม่มีในแหล่งอ้างอิง (เป้าหมายเชิงปฏิบัติการหลังใช้งาน Adaptive‑RAG: ลดลง 30–70% เมื่อเทียบกับ baseline)
- Retrieval precision@k — ความแม่นยำของเอกสาร/ชิ้นข้อมูลที่ดึงมาเมื่อใช้ k ตัวอย่าง (เช่น precision@5 ควรอยู่ในช่วง 60–90% ขึ้นกับคุณภาพดัชนีเวกเตอร์และการทำ embedding)
- End‑to‑end latency — เวลาตอบสนองตั้งแต่รับคำถามจนส่งคำตอบ (การออกแบบระบบที่เหมาะสมคาดว่า latency รวมอาจอยู่ในช่วง 300–1,200 ms สำหรับงานบริการลูกค้าแบบข้อความ แต่ตัวเลขขึ้นกับสถาปัตยกรรมและขนาดโมเดล)
- Cost per interaction — ต้นทุนต่อการโต้ตอบหนึ่งครั้ง (เมื่อลดการโอนต่อให้เจ้าหน้าที่มนุษย์และลดการแก้ไขด้วยมือ ต้นทุนต่ออินเทอร์แอคชันอาจลดลงประมาณ 10–40% ขึ้นกับค่าโฮสติ้งและราคาการเรียกใช้โมเดล)
- Transfer rate to human agents — สัดส่วนการย้ายเคสจากบอทไปยังเจ้าหน้าที่มนุษย์ (เป้าหมายหลังนำ Adaptive‑RAG มาใช้มักลดลง 20–50%)
- CSAT / NPS — ดัชนีความพึงพอใจและความจงรักภักดีของลูกค้า (คาดหวังการเพิ่มขึ้นตามความแม่นยำและความรวดเร็วของคำตอบ เช่น CSAT เพิ่ม +2–10 จุด และ NPS ดีขึ้นในระดับที่สอดคล้องกัน)
เพื่อให้การวัดผลมีความชัดเจน แนะนำให้ตั้งกรอบการทดลองแบบ A/B testing โดยเปรียบเทียบกลุ่มที่ใช้ Adaptive‑RAG กับระบบเดิมเป็นระยะ 4–12 สัปดาห์ ระหว่างการทดสอบติดตามเมตริกดังกล่าวทุกวันหรือทุกสัปดาห์ และรวบรวมตัวอย่างกรณีที่ระบบยังเกิด hallucination เพื่อนำมาปรับฐานความรู้และพารามิเตอร์ของ retrieval loop
โดยสรุป Adaptive‑RAG ให้ประโยชน์ทั้งในแง่การลดความเสี่ยงจากคำตอบผิด เพิ่มความถูกต้องของคำตอบ ลดเวลาตอบสนองและการพึ่งพามนุษย์ ตลอดจนผลบวกทางธุรกิจต่อ CSAT/NPS และต้นทุนการให้บริการ แต่ตัวเลขที่นำเสนอเป็น ช่วงค่าประมาณจากงานวิจัยและกรณีจริง ซึ่งองค์กรควรทดสอบในบริบทของตนเองเพื่อกำหนดค่าเป้าหมายเชิงปฏิบัติการที่เหมาะสม
การใช้งานจริงในองค์กรไทย: กรณีศึกษาและตัวอย่างเชิงตัวเลข
การใช้งานจริงในองค์กรไทย: กรณีศึกษาและตัวอย่างเชิงตัวเลข
ในภาพรวมของการทดลองใช้งาน Adaptive‑RAG ในองค์กรไทย ผลลัพธ์ที่เกิดขึ้นสะท้อนถึงความสามารถของการผสานเวกเตอร์เรียลไทม์เข้ากับฐานความรู้ที่เปลี่ยนแปลงได้ (dynamic knowledge base) เพื่อแก้ปัญหา hallucination ของโมเดลและเพิ่มความแม่นยำของการตอบในระบบแชทบอทบริการลูกค้า ตัวอย่างเชิงปฏิบัติการที่นำเสนอด้านล่างเป็นกรณีศึกษาสมมติหรือสรุปผลจากการทดลองภายในที่ไม่ระบุนาม ที่แสดงตัวชี้วัดก่อน‑หลังและคำอธิบายเชิงปฏิบัติการอย่างชัดเจน
ตัวอย่างธนาคาร (กรณีศึกษา)
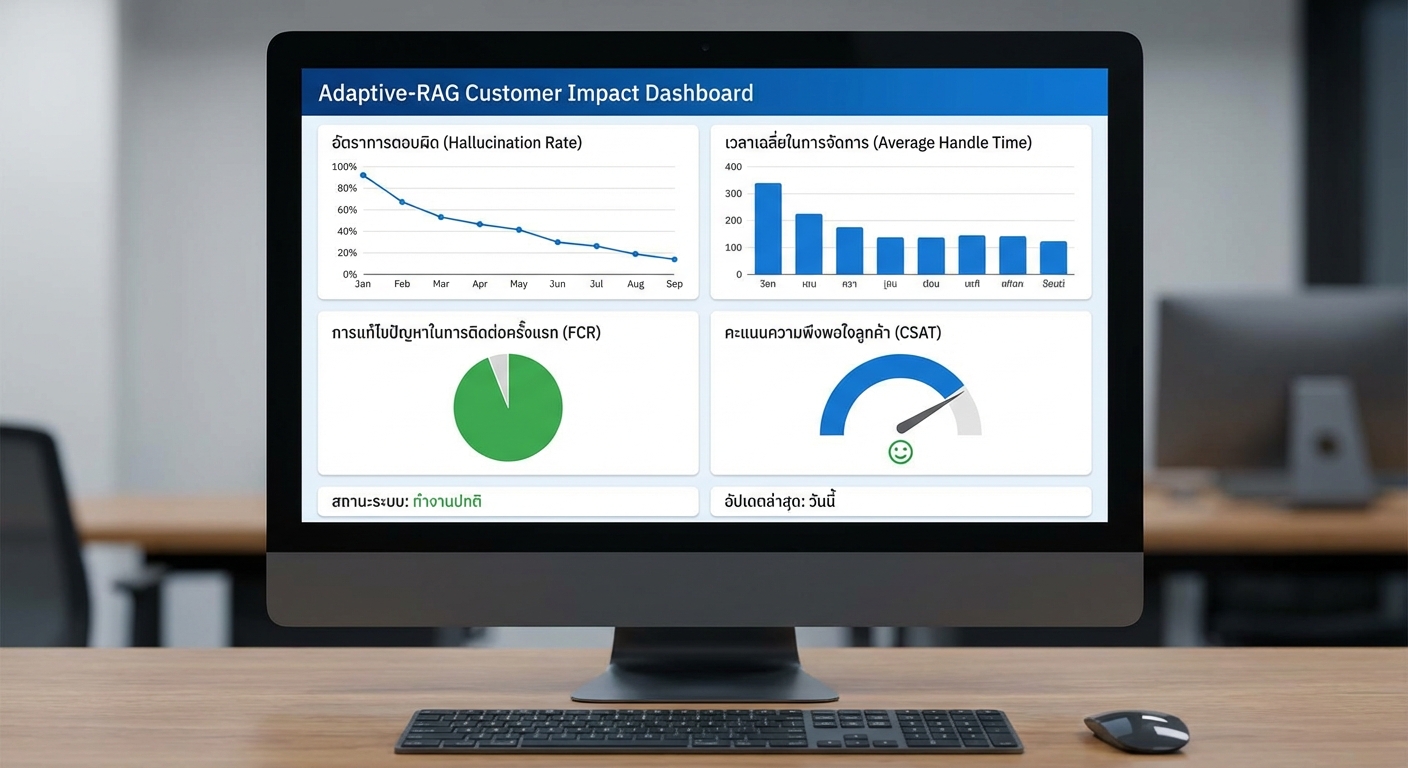
ธนาคารขนาดใหญ่ในไทยได้ทดลองนำ Adaptive‑RAG ไปใช้กับแชทบอทตอบคำถามด้านบัญชีและธุรกรรม ดำเนินการเป็นระยะเวลา 1 เดือนในรูปแบบ A/B test กับส่วนควบคุม ผลการทดลองพบว่า อัตราการเกิด hallucination ลดจาก 12% → 3% ในเดือนทดลอง (ตัวอย่างสมมติอิงข้อมูลสาธารณะและผลการทดสอบเชิงภายใน) โดยมีข้อมูลสนับสนุนดังนี้:
- ตัวอย่างการทดสอบ: วิเคราะห์ข้อความลูกค้าจำนวนประมาณ 120,000 ครั้งในช่วงทดลอง
- ปัจจัยเชิงปฏิบัติการ: การใช้เวกเตอร์เรียลไทม์ในการดึงเอกสารล่าสุด (เช่น นโยบายดอกเบี้ย ข้อกำหนดผลิตภัณฑ์) ร่วมกับการกรอง metadata เพื่อให้ retriever เลือกเนื้อหาที่เชื่อถือได้
- กลไกที่ช่วยลด hallucination: grounding คำตอบด้วยเอกสารต้นทาง และการให้คะแนนความเชื่อมั่น (confidence score) ก่อนส่งคำตอบให้ลูกค้า หากความเชื่อมั่นต่ำกว่าเกณฑ์ จะส่งต่อไปยังพนักงานมนุษย์
เชิงปฏิบัติการเพิ่มเติมที่ทำควบคู่กัน เช่น การตั้ง TTL ของเวกเตอร์สำหรับเอกสารที่เปลี่ยนบ่อย (เช่น โปรโมชั่น) เพื่อให้ฐานข้อมูลเวกเตอร์อัพเดตภายในไม่กี่นาที และการใช้ feedback loop จากผู้ใช้งานจริงเพื่อรีเทรนหรือรีแร้งกิ้งผลการดึงข้อมูลอย่างต่อเนื่อง ซึ่งลดกรณีที่โมเดลให้ข้อมูลล้าสมัยหรือผิดพลาด
ตัวอย่างผู้ให้บริการโทรคมนาคม
ผู้ให้บริการโทรคมนาคมรายหนึ่งนำ Adaptive‑RAG ไปผสานกับระบบเรียกดูธุรกรรมและสถานะเครือข่ายแบบเรียลไทม์ โดยเชื่อมต่อกับ event stream ของระบบบิลและการเรียกใช้งานบริการ ผลลัพธ์เชิงตัวเลขที่สำคัญคือ AHT (Average Handle Time) ลดลงประมาณ 15–25% และ FCR (First Contact Resolution) เพิ่มขึ้นอย่างมีนัยสำคัญ เนื่องจากแชทบอทสามารถดึงข้อมูลธุรกรรมล่าสุดและสเตตัสบริการเพื่อตอบแบบเฉพาะบุคคล
- สถิติภายใน: AHT ลดจากค่าเฉลี่ย 420 วินาที → ประมาณ 315–357 วินาที (ลด 15–25%)
- FCR: เพิ่มจากประมาณ 72% → ประมาณ 84–88% (ขึ้นอยู่กับกลุ่มเคสและช่วงเวลา)
- ปฏิบัติการเชิงเทคนิค: การผสาน API เรียลไทม์กับ vector store ทำให้ retriever คืนเอกสารที่ตรงประเด็นภายใน 150–300 ms พร้อม metadata ระบุเวอร์ชันของข้อมูล
แง่มุมเชิงปฏิบัติการที่ทำให้สำเร็จ
องค์ประกอบสำคัญที่องค์กรไทยใช้เพื่อให้ Adaptive‑RAG ได้ผลจริง ได้แก่ การกำหนดนโยบายการอัปเดตข้อมูล (ingestion pipelines), การกำหนด threshold ของ confidence/completeness ก่อนปล่อยคำตอบ, การตั้ง fallback routing ไปยัง human agent และการติดตั้งระบบ logging เพื่อวิเคราะห์เหตุการณ์ hallucination แบบเรียลไทม์ นอกจากนี้ยังมีการจัดอบรมพนักงานฝ่ายสนับสนุนให้เข้าใจการทำงานของ RAG เพื่อให้การยกระดับการบริการเกิดขึ้นอย่างราบรื่น
KPI และ dashboard ที่ควรติดตามหลังนำไปใช้
- Hallucination Rate — เปอร์เซ็นต์คำตอบที่ถูกตัดสินว่าไม่สอดคล้องกับเอกสารต้นทาง (เป้าหมาย ลดลงอย่างต่อเนื่อง)
- AHT (Average Handle Time) — เวลาเฉลี่ยต่อเคส (เป้าหมาย: ลดลง 10–25% ขึ้นกับประเภทบริการ)
- FCR (First Contact Resolution) — อัตราการแก้ปัญหาได้ในครั้งแรก (เป้าหมาย: เพิ่มขึ้นอย่างมีนัย)
- NPS / CSAT — ดัชนีความพึงพอใจของลูกค้า (ติดตามการเปลี่ยนแปลงก่อน‑หลังการใช้งาน)
- Retrieval Latency — เวลาการดึงเอกสารจาก vector store (ควร น้อยกว่า 300 ms ในระบบเรียลไทม์)
- Vector Freshness / Ingestion Lag — เวลาที่ข้อมูลใหม่ปรากฏใน index (ควรตั้งเป้าเป็นนาทีสำหรับข้อมูลธุรกรรม)
- RAG Hit Rate — สัดส่วนของคำถามที่ระบบสามารถหาเอกสารรองรับได้โดยไม่ต้อง escalate
- Escalation Rate — สัดส่วนเคสที่ต้องส่งต่อไปยังมนุษย์ (ใช้เพื่อตั้ง policy และปรับ threshold)
- Cost per Resolution — ต้นทุนต่อการแก้ไขปัญหาหนึ่งเคส (ประเมินการประหยัดหลังลด AHT และเพิ่ม automation)
การตั้ง dashboard ที่ดีควรมีทั้งมุมมองเชิงเวลาจริง (real‑time) สำหรับการตอบสนองต่อปัญหา และมุมมองเชิงวิเคราะห์ (weekly/monthly trends) เพื่อใช้ตัดสินใจเชิงกลยุทธ์ ตัวอย่างการแสดงผลใน dashboard ได้แก่ กราฟ Hallucination Rate รายวัน, Heatmap ของประเภทคำถามที่ยังมี FCR ต่ำ, และตารางการเปรียบเทียบ AHT/FCR/NPS ก่อน‑หลังการใช้ Adaptive‑RAG
สรุปเชิงปฏิบัติการ
กรณีศึกษาดังกล่าวชี้ให้เห็นว่า Adaptive‑RAG สามารถลดความเสี่ยงของ hallucination และปรับปรุงประสิทธิภาพการให้บริการลูกค้าได้จริงในบริบทองค์กรไทย หากออกแบบกระบวนการ ingestion การจัดการ metadata และ feedback loop อย่างเหมาะสม พร้อมการตั้ง KPI ที่ชัดเจน องค์กรจะเห็นผลเป็นตัวเลขที่จับต้องได้ เช่น การลด Hallucination จาก 12% → 3%, การลด AHT 15–25% และการเพิ่ม FCR ซึ่งสะท้อนถึงการยกระดับคุณภาพการบริการและความพึงพอใจของลูกค้า (NPS) อย่างเป็นรูปธรรม
อุปสรรค ความเสี่ยง และแนวทางปฏิบัติที่ดีที่สุด
ภาพรวมความเสี่ยงเชิงปฏิบัติการและการปฏิบัติตามกฎระเบียบ
การผสานเวกเตอร์เรียลไทม์กับฐานความรู้ที่เปลี่ยนแปลงได้ (Adaptive‑RAG) ช่วยลด Hallucination ได้อย่างมีนัยสำคัญ แต่ในทางปฏิบัติองค์กรต้องพิจารณาความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎข้อมูลเป็นอันดับแรก ตัวอย่างข้อปฏิบัติที่จำเป็นได้แก่การมาสก์ข้อมูลระบุตัวบุคคล (PII masking), การทำ pseudonymization, และนโยบายการเก็บรักษาข้อมูล (data retention) ที่ชัดเจนตาม PDPA ของไทยหรือ GDPR หากมีการให้บริการข้ามพรมแดน ข้อมูลสนทนาลูกค้าที่เก็บเป็นเวกเตอร์อาจยังคงสื่อถึงข้อมูลที่ละเอียดอ่อน จึงต้องมีการเข้ารหัสทั้งขณะเก็บ (at‑rest) และขณะส่ง (in‑transit) พร้อมสิทธิการเข้าถึงและการบันทึก Audit Log เพื่อให้ตอบคำถามการตรวจสอบได้
ค่าใช้จ่าย การสเกล และผลกระทบเชิงเทคนิค
การอัปเดตเวกเตอร์แบบเรียลไทม์เพิ่มความต้องการด้านทรัพยากรทั้งเก็บข้อมูลและคำนวณ ตัวอย่างเชิงตัวเลขเพื่อประกอบการวางแผน: เวกเตอร์ขนาด 1,536 มิติ หากเก็บเป็น float32 จะใช้พื้นที่ประมาณ 6 KB ต่อเวกเตอร์ ดังนั้นฐานข้อมูลเวกเตอร์ขนาด 100 ล้านรายการจะใช้พื้นที่เก็บข้อมูลประมาณ 600 GB (ไม่รวมดัชนีและเมตาดาต้า) นอกจากนี้การทำอินเด็กซ์และรีคัลคิวเลตเพื่อรองรับการอัปเดตเรียลไทม์อาจต้องใช้ CPU/GPU และ I/O สูงขึ้น ซึ่งมีผลต่อค่าใช้จ่ายคลาวด์และต้นทุนปฏิบัติการ
เพื่อควบคุมต้นทุนองค์กรควรพิจารณาแนวทางเช่นการจัดลำดับความสำคัญข้อมูล (priority tiers), การทำ micro‑batching ของการอัปเดต, การกำหนด TTL (time‑to‑live) สำหรับเวกเตอร์ที่เปลี่ยนบ่อย และการออกแบบสถาปัตยกรรมแบบไฮบริดที่ผสานฐานความรู้สแตติกกับเวกเตอร์เรียลไทม์เฉพาะส่วนที่จำเป็น
การควบคุมคุณภาพข้อมูลและการวัด Hallucination
การลด Hallucination อย่างยั่งยืนจำเป็นต้องมีมาตรฐานการประเมินที่ชัดเจน ไม่ควรวัดเพียงความพึงพอใจของผู้ใช้เท่านั้น แต่ต้องมีเมตริกเชิงเทคนิคร่วมด้วย เช่น precision@k, MRR (Mean Reciprocal Rank), % of responses with factual citations, และ Hallucination Rate (อัตราคำตอบที่ไม่มีแหล่งยืนยัน) โดยกำหนดเกณฑ์ยอมรับได้ (เช่น Hallucination Rate ต่ำกว่า 2–5% สำหรับคำถามเชิงข้อมูลสำคัญ) พร้อมชุดทดสอบ Golden Dataset ที่มีทั้งกรณีปกติและกรณีเชิงลบ เพื่อให้สามารถทำ Continuous Evaluation และตรวจจับการเปลี่ยนแปลงเชิงคุณภาพได้อย่างรวดเร็ว
แนวปฏิบัติที่ดีที่สุด (Best Practices)
- การมาสก์และนโยบาย retention: มาสก์ PII ก่อนส่งเข้าเวกเตอร์ไดเรกทอรี และกำหนดนโยบายเก็บรักษา เช่น เก็บโทเค็นสนทนาแบบละเอียดไม่เกิน 30–90 วัน ยกเว้นมีเหตุผลทางกฎหมายหรือการให้บริการที่ต้องยาวกว่า
- Data governance และ metadata catalog: สร้างระบบ catalog/lineage ของข้อมูล ระบุแหล่งที่มา เวอร์ชัน และระดับความไวต่อความเป็นส่วนตัว (sensitivity labels) เพื่อควบคุมการเข้าถึงและการใช้งาน
- Data labeling และ Golden Datasets: ลงทุนในการติดป้ายข้อมูลคุณภาพสูง (human‑annotated labels) สำหรับเทรนนิงและประเมินผล ใช้มาตรฐานการติดป้ายที่ชัดเจนและการตรวจสอบข้ามทีม (inter‑annotator agreement)
- Human‑in‑the‑loop (HITL): วางกลไกตรวจสอบโดยมนุษย์สำหรับคำตอบที่เสี่ยงหรือมี Confidence ต่ำ เช่น การส่งต่อให้เจ้าหน้าที่ตรวจทานก่อนส่งให้ลูกค้า ซึ่งช่วยลดความเสี่ยงจาก Hallucination และปรับปรุงชุดฝึกสอนอย่างต่อเนื่อง
- Continuous evaluation และ Canary testing: ทดสอบการเปลี่ยนแปลงบนกลุ่มผู้ใช้ย่อยก่อนเลื่อนเป็น Production (เช่น canary 1–5% ของทราฟฟิก) พร้อมเก็บ KPI เช่น latency, accuracy, hallucination rate เพื่อเปรียบเทียบก่อน‑หลัง
- Versioning ของฐานความรู้และเวกเตอร์: ใช้การทำเวอร์ชันทั้งของเอกสารต้นทางและของอินเด็กซ์เวกเตอร์ (semantic versioning, changelogs) เพื่อให้สามารถ rollback เมื่อเกิดปัญหา และบันทึกการเปลี่ยนแปลงเพื่อการตรวจสอบ
- SLA ด้าน latency และความพร้อมใช้งาน: กำหนด SLA ทางธุรกิจ เช่น latency retrieval สำหรับการบริการลูกค้าเชิงโต้ตอบ ควรอยู่ในช่วง 100–500 ms สำหรับขั้นตอนค้นหาและนำเสนอคำตอบ (ขึ้นอยู่กับความซับซ้อน) พร้อม SLA ทางธุรกิจสำหรับ uptime/availability
- การจัดการ Model Drift และการรีเทรน: ติดตามการเปลี่ยนแปลงของ distribution ของเวกเตอร์และผลลัพธ์ (drift detection), ตั้งกฎการรีอินเด็กซ์หรือรีเทรนเป็นรอบ (เช่นรายสัปดาห์หรือรายเดือน) และมีกระบวนการแจ้งเตือนเมื่อความแม่นยำลดลงเกินเกณฑ์ที่ยอมรับได้
การปฏิบัติในมุมธุรกิจและตัวอย่างเชิงปฏิบัติ
ตัวอย่างเชิงปฏิบัติ เช่น ธนาคารที่ให้บริการแชทบอทด้านการเงิน อาจตั้งกฎว่าเวกเตอร์ที่มาจากข้อความที่มีเลขบัญชีหรือเลขบัตรจะถูกมาสก์และเก็บเป็นเวกเตอร์เฉพาะเมตาดาต้าที่ไม่สามารถย้อนกลับเป็นข้อมูลดิบได้ โดยจำกัด retention เป็น 30 วันและสำรองเฉพาะค่าเชิงสรุปเพื่อนำไปวิเคราะห์เชิงเทรนด์ นอกจากนี้การโรลเอาต์ฟีเจอร์ใหม่ควรใช้ Canary testing ร่วมกับ HITL ในช่วงแรกเพื่อลดความเสี่ยงต่อแบรนด์และลูกค้า
บทสรุปและข้อเสนอแนะ
Adaptive‑RAG ให้ประโยชน์ชัดเจนด้านความแม่นยำและการลด Hallucination แต่ต้องแลกมาด้วยภาระด้านการกำกับดูแลข้อมูล ค่าใช้จ่าย และการจัดการคุณภาพข้อมูลที่เข้มงวด องค์กรที่ประสบความสำเร็จมักปฏิบัติตามหลักการผสมผสานคือ: ปกป้องความเป็นส่วนตัวตั้งแต่ต้นทาง, ให้ความสำคัญกับ data governance และ metadata, ลงทุนใน data labeling และ HITL, ทำ continuous evaluation พร้อมเวอร์ชันนิ่งและกลไก Canary สำหรับการเปลี่ยนแปลง ทุกหน่วยงานควรกำหนด KPI ที่จับต้องได้ เช่น Hallucination Rate, precision@k, และ latency SLA เพื่อให้การดำเนินงานเชิงเทคนิคสอดคล้องกับความเสี่ยงเชิงธุรกิจ
แนวทางการนำไปใช้จริง: Roadmap, Checklist และเครื่องมือแนะนำ
Roadmap การนำ Adaptive‑RAG ไปใช้จริง (PoC → Pilot → Production)
การนำ Adaptive‑RAG (ผสานเวกเตอร์เรียลไทม์กับฐานความรู้ที่เปลี่ยนแปลง) ควรถูกออกแบบเป็นเฟสเชิงทดลองและขยายผลอย่างเป็นระบบ เพื่อจำกัดความเสี่ยงและวัดผลอย่างมีหลักฐาน โดยแนะนำเฟสตามลำดับต่อไปนี้:
- PoC (4–8 สัปดาห์)
- วัตถุประสงค์: ยืนยันความเป็นไปได้ทางเทคนิค (feasibility) และคาดการณ์ผลกระทบด้านคุณภาพ (relevance / hallucination reduction)
- กิจกรรมสำคัญ: คัดเลือกแหล่งข้อมูลตัวอย่าง (50–500 เอกสาร), สร้างเวกเตอร์เบื้องต้น, เชื่อมต่อ retriever + LLM แบบเรียลไทม์, ตั้งชุดทดสอบเบื้องต้น (golden set)
- ตัวอย่างเกณฑ์ความสำเร็จ: Precision@5 ≥ 0.7 หรือการลดอัตรา hallucination ประมาณ 20–40% เมื่อเทียบกับ baseline
- Pilot (2–3 เดือน)
- วัตถุประสงค์: ทดสอบในขอบเขตกว้างขึ้น (หลายช่องทาง / แผนก) วัดผลเชิงธุรกิจและความคงทนของระบบ
- กิจกรรมสำคัญ: ขยายข้อมูลจริง (หมื่น–แสนเอกสาร), ติดตั้ง monitoring/alert, เปิดให้ผู้ใช้จริงบางส่วน (beta users) และทำ Human‑in‑the‑Loop (HITL) เพื่อเก็บ feedback
- ตัวอย่างเกณฑ์ความสำเร็จ: CSAT เพิ่มขึ้น ≥ 10% ภายใน 8–12 สัปดาห์, latency ของ retrieval < 300–500 ms (P95)
- Production rollout
- วัตถุประสงค์: ขยายสู่การให้บริการจริงทุกช่องทางพร้อม SLA และ governance ครบถ้วน
- กิจกรรมสำคัญ: จัดตั้ง pipeline สำหรับ embedding refresh แบบอัตโนมัติ, ระบบ verification/approval ก่อนปรับปรุงฐานความรู้, จัดการสิทธิ์และการ audit log
- เป้าหมายเชิงปฏิบัติการ: SLA uptime 99.9% ขึ้นไป, Hallucination rate ≤ เป้าหมายที่ตกลงกัน (ตัวอย่างเช่น ≤ 5–10% ขึ้นกับโดเมน)
Checklist สำคัญก่อนและระหว่างการนำไปใช้
รายการตรวจสอบ (checklist) ต่อไปนี้ช่วยให้ทีมมั่นใจว่าพื้นฐานข้อมูลและโครงสร้างพื้นฐานพร้อมรองรับ Adaptive‑RAG อย่างปลอดภัยและยืดหยุ่น:
- Data mapping & readiness
- ระบุแหล่งข้อมูลและเจ้าของข้อมูล (owners) ของแต่ละ dataset
- จัดหมวดหมู่เอกสาร: รูปแบบ (PDF, HTML, DB), ภาษา, ความอ่อนไหว (PII/PCI)
- กำหนดนโยบาย chunking (ตัวอย่าง: 200–800 tokens ต่อ chunk), metadata schema (source, timestamp, version)
- ตรวจสอบคุณภาพข้อมูล: deduplication, canonicalization, timestamping
- Embedding refresh policy
- กำหนดความถี่การรีเฟรชตามประเภทข้อมูล เช่น เอกสารนโยบายรีวิวรายเดือน, ข้อมูลโปรโมชั่นรีวิวรายวัน
- รองรับ incremental updates: upsert/delete แทน reindex ทั้งหมดเมื่อเป็นไปได้
- เวอร์ชันของ embedding model และการบันทึก metadata ของเวอร์ชัน
- Retriever / encoder selection
- เลือกระหว่าง sparse (BM25), dense embeddings หรือ hybrid ตามประสิทธิภาพกับโดเมน
- ทดสอบหลาย encoder (เช่น sentence-transformers, OpenAI embeddings) และวัดความแม่นยำ (Recall@k, MRR, nDCG)
- ตั้งค่า ANN index parameters (เช่น HNSW ef/search, M) เพื่อแลกเปลี่ยนความแม่นยำกับ latency
- Verification pipeline
- สร้าง golden dataset สำหรับการประเมินอัตโนมัติและการตรวจสอบด้วยมนุษย์
- ระบบ human review workflow สำหรับกรณีที่ confidence ต่ำหรือมีการแก้ไขเนื้อหา
- logging รายละเอียดของ retriever hits และ prompt/response เพื่อการวิเคราะห์หลังเหตุการณ์
- Evaluation & monitoring
- กำหนด offline metrics: Recall@k, Precision@k, MRR, nDCG
- กำหนด online metrics: CSAT, First Response Resolution, percentage of answers requiring escalation
- ตั้งการแจ้งเตือน (alerts) สำหรับ latency spike, index freshness lag, ความเปลี่ยนแปลงของ hallucination rate
- Governance & compliance
- นโยบายการเข้าถึงข้อมูลและ encryption at rest / in transit
- กระบวนการ audit trail และ change management สำหรับฐานความรู้และ model
- การตรวจสอบ bias และการเก็บ consent ของผู้ใช้ (ถ้ามี)
เครื่องมือและแพลตฟอร์มแนะนำ
การเลือกเครื่องมือควรพิจารณาจากข้อกำหนดเรื่องความสามารถในการ scale, latency, การรองรับการอัปเดตแบบเรียลไทม์ และการผสานกับ LLM ที่ใช้:
- Open‑source / self‑hosted:
- FAISS — เป็นไลบรารี ANN จาก Facebook เหมาะสำหรับการค้นหาเวกเตอร์ขนาดใหญ่ หากต้องการความคุ้มค่าในการจัดเก็บแบบ on‑premise
- Milvus — vector DB ที่รองรับการจัดการดัชนีหลายแบบและ scale ได้ง่าย เหมาะสำหรับกรณีใช้งานที่ต้องการ high availability
- Haystack — framework สำหรับ RAG, มี pipeline สำหรับ retriever/reader และรองรับการเชื่อมต่อกับ vector stores หลายตัว
- LangChain — library สำหรับสร้างแอปพลิเคชันที่เชื่อม LLM กับ retriever/chain ต่างๆ มี connector ไปยัง vector DB และ LLM หลายราย
- บริการคลาวด์ / Managed services:
- Pinecone, Qdrant, Weaviate — managed vector DB ที่ลดภาระการดูแลโครงสร้างพื้นฐาน
- AWS Kendra, Azure Cognitive Search, Google Vertex AI Matching Engine — สำหรับองค์กรที่ต้องการผสานการค้นหากับบริการคลาวด์ของตน
- LLM vendors และการควบคุม context:
- OpenAI, Anthropic, Cohere, Mistral — เลือกผู้ให้บริการที่มีฟีเจอร์การควบคุม prompt/context, streaming, rate limit และการตั้งค่า temperature/penalty
- เลือกผู้ให้บริการที่รองรับการตั้งค่าความเป็นส่วนตัวและการไม่เก็บข้อมูล (data residency / opt‑out) หากต้องการ
KPI & SLA ที่ควรตั้งค่าในแต่ละเฟส — ตัวอย่างเชิงปฏิบัติการ
ตัวอย่าง KPI และ SLA ที่ชัดเจนช่วยกำหนดความคาดหวังและวัดผลสำเร็จของแต่ละเฟส:
- PoC (4–8 สัปดาห์)
- KPI ตัวอย่าง: Recall@5 ≥ 0.7, Precision@5 ≥ 0.6, Hallucination reduction ≥ 20% เมื่อเทียบกับ baseline
- Latency target: retrieval + re‑rank ≤ 500 ms (P95)
- Success criteria: demo กับตัวอย่างเคสจริง 10–20 เคสที่ผ่านการตรวจสอบโดย SME
- Pilot (2–3 เดือน)
- KPI ตัวอย่าง: CSAT เพิ่มขึ้น ≥ 10%, Resolution rate on first contact เพิ่มขึ้น ≥ 8–15%
- Operational SLA: system availability ≥ 99%, P95 end‑to‑end response time ≤ 700 ms
- Quality SLA: Human escalation rate ≤ 15% (สามารถปรับลดเมื่อระบบดีขึ้น)
- Production
- KPI ตัวอย่าง: Hallucination rate ≤ 5–10% (โดเมนที่มีความเสี่ยงต่ำอาจตั้งได้ต่ำกว่า), CSAT ≥ เป้าหมายองค์กร
- SLA เชิงปฏิบัติการ: availability 99.9%+, P95 latency ≤ 500 ms, MTTD (Mean Time To Detect) ≤ 15 นาที, MTTR ≤ 2 ชั่วโมง
- Data freshness SLA: critical content refresh latency ≤ X นาที/ชั่วโมงตามชนิดข้อมูล (ตัวอย่าง: ข้อเสนอโปรโมชั่นควรรีเฟรชภายใน 15 นาที)
หมายเหตุ: ตัวเลขในตัวอย่างเป็นแนวทางเริ่มต้น — ควรปรับตามโดเมนธุรกิจ ความเสี่ยงด้านข้อมูล และทรัพยากรขององค์กร ทั้งนี้ ควรดำเนินการ A/B testing และติดตาม trend เป็นระยะเพื่อปรับ KPI/SLA ให้สมเหตุสมผลและยั่งยืน
บทสรุป
Adaptive‑RAG ช่วยลดความเสี่ยงของ hallucination โดยผสานการค้นคืนข้อมูลแบบเวกเตอร์เรียลไทม์กับฐานความรู้ที่เปลี่ยนแปลงได้ (dynamic knowledge base) ทำให้องค์กรสามารถส่งมอบคำตอบที่สดใหม่และสอดคล้องกับบริบทของธุรกิจ เช่น ข้อมูลสต็อก สถานะการสั่งซื้อ หรือโปรโมชั่นที่เพิ่งอัพเดต การรวมข้อมูลเวกเตอร์จากแหล่งข้อมูลสดเข้ากับการค้นคืนความรู้ที่อัปเดตได้ ช่วยจำกัดการคาดเดาที่ไม่ถูกต้องของโมเดล และเพิ่มความแม่นยำของคำตอบในแชทบอทบริการลูกค้า ส่งผลให้ประสบการณ์ผู้ใช้ดีขึ้นและลดความเสี่ยงด้านความน่าเชื่อถือของระบบตอบข้อความอัตโนมัติ
การนำ Adaptive‑RAG ไปใช้จริงต้องมีการวางแผนทั้งเชิงเทคนิคและเชิงนโยบายอย่างรอบคอบ ได้แก่ การออกแบบสถาปัตยกรรมข้อมูล การตั้งค่าเวกเตอร์สโตร์แบบเรียลไทม์ การผสานงานกับฐานข้อมูลภายใน และการกำหนดเกณฑ์การควบคุมคุณภาพข้อมูลอย่างชัดเจน ตัวอย่าง KPI ที่ควรวัดได้แก่ อัตราการเกิด hallucination, ความแม่นยำและความเกี่ยวข้องของคำตอบ, CSAT (Customer Satisfaction), เวลาเฉลี่ยในการแก้ปัญหา (MTTR) และความหน่วงของการตอบกลับ องค์กรควรตั้งกระบวนการตรวจสอบและ feedback loop แบบมีมนุษย์ร่วม (human‑in‑the‑loop) เพื่อปรับปรุงข้อมูลและโมเดลอย่างต่อเนื่อง ในอนาคตการปรับใช้ Adaptive‑RAG จะขยายตัวในภาคบริการลูกค้าเมื่อองค์กรที่มีการควบคุมคุณภาพและ KPI ชัดเจนสามารถลดข้อผิดพลาด เพิ่มความโปร่งใส และตอบสนองต่อการเปลี่ยนแปลงของธุรกิจได้รวดเร็วขึ้น ทั้งยังต้องให้ความสำคัญกับการกำกับดูแลข้อมูลและการสอดคล้องกับกฎระเบียบเพื่อความยั่งยืนของผลลัพธ์



