
เมื่อโรงงานไทยต้องเผชิญกับแรงกดดันทั้งด้านต้นทุนพลังงานและความต่อเนื่องของการผลิต การผสานเทคโนโลยี Reinforcement Learning (RL) เข้ากับ Digital‑Twin ของสายการผลิตแบบเรียลไทม์กลายเป็นทางเลือกที่น่าจับตามอง บทความนี้นำเสนอกรณีศึกษาจากโรงงานในประเทศไทยที่ใช้ RL ควบคุม Digital‑Twin เพื่อปรับค่าพารามิเตอร์การทำงานแบบ closed‑loop ส่งผลให้การใช้พลังงานลดลงอย่างมีนัยสำคัญและ downtime ของเครื่องจักรลดลงอย่างเป็นรูปธรรม — ตัวอย่างภาคสนามในบทความนี้แสดงผลลัพธ์พลังงานลดลงในช่วงประมาณ 15–30% และ downtime ลดลง 20–50% ขึ้นกับประเภทกระบวนการและเงื่อนไขการติดตั้ง
บทนำนี้จะชี้ให้เห็นประเด็นสำคัญที่บทความจะขยายความ ได้แก่ สถาปัตยกรรมระบบที่รองรับการควบคุมแบบเรียลไทม์ (edge inference + cloud training), การออกแบบ Digital‑Twin เพื่อรองรับการตัดสินใจของ RL, การประเมินประสิทธิภาพเชิงตัวเลข และแผนการย้ายจาก PLC แบบเดิมสู่การควบคุมโดย RL อย่างปลอดภัยและเป็นขั้นตอน (phased migration, safety wrappers, validation-in-the-loop) ผู้ชมจะได้รับทั้งมุมมองเชิงเทคนิคและกลยุทธ์เชิงธุรกิจเพื่อนำไปใช้จริงในบริบทของโรงงานไทย
คำนำและบริบท: ทำไมโรงงานไทยต้องจับคู่ Reinforcement Learning กับ Digital Twin

ภาพรวมความท้าทายของโรงงานไทย
ภาคการผลิตของไทยเผชิญความกดดันหลายด้าน ทั้งต้นทุนพลังงานที่เพิ่มขึ้นจากราคาพลังงานโลก ภาระค่าดำเนินการที่มาจากระบบผลิตต่อเนื่อง และความคาดหวังของตลาดที่ต้องการความยืดหยุ่นและคุณภาพที่สม่ำเสมอ ในหลายโรงงาน ค่าใช้จ่ายด้านพลังงานมีสัดส่วนเป็นตัวแปรสำคัญที่ผลักดันต้นทุนต่อหน่วยให้สูงขึ้น และ downtime แบบไม่คาดคิด ย่อมส่งผลกระทบต่อผลงานทั้งเชิงการผลิตและเชิงการเงิน โดยเฉพาะกับสายการผลิตที่ทำงานแบบ 24/7 เช่น อุตสาหกรรมอาหาร เครื่องดื่ม อิเล็กทรอนิกส์ และปิโตรเคมี
ตามการสำรวจและกรณีศึกษาหลายแห่ง พบว่าโรงงานที่มีปัญหา downtime และการใช้พลังงานไม่คุ้มค่ามักมี OEE (Overall Equipment Effectiveness) ที่ต่ำกว่ามาตรฐานอุตสาหกรรม ซึ่งนำไปสู่โอกาสสูญเสียรายได้และความสามารถในการแข่งขัน การบริหารจัดการพลังงานและการลดเวลาเครื่องหยุดทำงานจึงกลายเป็นประเด็นเชิงยุทธศาสตร์ที่ต้องการเทคโนโลยีควบคู่เพื่อให้เกิดการตัดสินใจเชิงปฏิบัติการแบบเรียลไทม์
บทบาทของ Digital Twin ในการจำลองสถานะและคาดการณ์
Digital Twin ทำหน้าที่เป็นแบบจำลองดิจิทัลของกระบวนการผลิตหรืออุปกรณ์จริง ซึ่งสามารถรับข้อมูลจากเซนเซอร์และระบบ OT (Operational Technology) แบบเรียลไทม์ ทำให้ผู้ปฏิบัติงานและระบบวิเคราะห์สามารถเห็นภาพสถานะของสายการผลิตแบบไทม์ไลน์ จำลองสภาวะต่าง ๆ ทดสอบนโยบายการควบคุม และคาดการณ์ปัญหาก่อนที่จะเกิดขึ้นจริง ตัวอย่างการใช้งานรวมถึง:
- การจำลองสภาวะการสึกหรอเพื่อวางแผน predictive maintenance
- ทดสอบการตั้งค่าพารามิเตอร์เพื่อหาค่าที่ลดการใช้พลังงานโดยไม่ลด Throughput
- การวิเคราะห์สาเหตุราก (root cause analysis) โดยใช้ข้อมูลประวัติและสัญญาณเรียลไทม์
การมี Digital Twin ที่แม่นยำช่วยให้การทดลองนโยบายการควบคุมเป็นไปได้ในสภาพแวดล้อมเสมือน (safe sandbox) ลดความเสี่ยงต่อการทำงานจริง และเป็นฐานข้อมูลสำคัญสำหรับการฝึกสอนโมเดลการเรียนรู้เชิงลึกหรือการควบคุมอัตโนมัติ
ข้อดีของ Reinforcement Learning สำหรับการควบคุมเชิงปรับตัวแบบเรียลไทม์
Reinforcement Learning (RL) เป็นแนวทางการเรียนรู้ที่ออกแบบมาเพื่อค้นหานโยบายการตัดสินใจที่ให้ผลตอบแทนรวมสูงสุดภายใต้สภาพแวดล้อมที่เปลี่ยนแปลงได้อย่างต่อเนื่อง เมื่อจับคู่กับ Digital Twin แล้ว RL สามารถ:
- เรียนรู้นโยบายการควบคุมที่เพิ่มประสิทธิภาพพลังงาน โดยคำนึงถึงข้อจำกัดด้าน Throughput และคุณภาพผลิตภัณฑ์
- ปรับตัวแบบเรียลไทม์ต่อการเปลี่ยนแปลงของกระบวนการ เช่น ความผันผวนของวัตถุดิบหรือการสึกหรอของเครื่องจักร
- ทดสอบและยืนยันนโยบายในสภาพแวดล้อมจำลองก่อนนำไปใช้งานจริง ลดความเสี่ยงจากการทดลองบนสายการผลิตจริง
- สนับสนุนกลยุทธ์การควบคุมเชิงคาดการณ์ (predictive control) ซึ่งผสมผสานการตัดสินใจเชิงค่าใช้จ่ายพลังงานและการลด downtime ได้อย่างสมดุล
สรุปข้อดีและข้อจำกัดเบื้องต้น
โดยสรุป การผสาน Digital Twin กับ Reinforcement Learning ช่วยให้โรงงานไทยมีความสามารถในการควบคุมเชิงปรับตัวที่เหนือกว่า สามารถลดการใช้พลังงาน ลด downtime และเพิ่ม OEE ได้ในระยะยาว ทั้งยังรองรับการทดลองนโยบายใหม่ ๆ อย่างปลอดภัย อย่างไรก็ตาม มีข้อจำกัดที่ต้องพิจารณา เช่น คุณภาพและความต่อเนื่องของข้อมูล, ความแม่นยำของ Digital Twin (model mismatch), ความปลอดภัยและความเชื่อถือได้ของนโยบายที่ได้จาก RL, ต้นทุนด้านคอมพิวติ้งและการบูรณาการกับระบบ PLC แบบเดิม รวมถึงทักษะของบุคลากรที่ต้องการการฝึกอบรม
การนำแนวทางนี้ไปปฏิบัติควรเริ่มด้วยการตั้งกรอบการทำงานที่ปลอดภัย เช่น การใช้โหมด shadow/testing, การจำกัดขอบเขตการควบคุมในช่วงแรก และการใช้มาตรการ safe RL เพื่อให้เกิดการยอมรับจากฝ่ายปฏิบัติการและลดความเสี่ยงต่อการผลิตจริง
พื้นฐานทางเทคนิค: RL, Digital Twin และการวัดผลเชิงตัวเลข
หลักการพื้นฐานของ Reinforcement Learning ในงานอุตสาหกรรม
Reinforcement Learning (RL) เป็นกรอบการเรียนรู้ที่มุ่งสอนตัวแทน (agent) ให้ตัดสินใจเพื่อเพิ่มค่าคะแนนรวม (cumulative reward) ผ่านการโต้ตอบกับสภาพแวดล้อม โดยในบริบทอุตสาหกรรม สภาพแวดล้อมนี้มักถูกจำลองด้วย Digital Twin หรือเชื่อมต่อกับระบบจริงแบบเรียลไทม์ แนวคิดหลักประกอบด้วย state (สถานะของระบบ), action (การกระทำที่สามารถสั่งให้ระบบเปลี่ยนแปลง) และ reward (ค่าวัดผลตอบแทนที่สะท้อนเป้าหมายเชิงธุรกิจ เช่น ลดพลังงาน, ลด downtime, ลด defect) ตัวอย่างการใช้งานจริงได้แก่ การปรับความเร็วสายพาน การควบคุมอุณหภูมิของเตา และการจัดลำดับการผลิตเพื่อเพิ่ม OEE
การออกแบบ State / Action / Reward สำหรับสายการผลิต
การนิยาม state, action และ reward อย่างรอบคอบเป็นหัวใจของระบบ RL ในโรงงาน ตัวอย่างเชิงปฏิบัติที่สามารถนำไปใช้งานได้จริง ได้แก่:
- ตัวอย่าง State (เวกเตอร์สถานะ): อุณหภูมิชิ้นงาน (°C), ความเร็วสายพาน (m/s), กำลังไฟฟ้ารวม (kW), สถานะเครื่องจักร (on/off/idle), อัตราการเกิดชิ้นเสีย (%) และคิวคำสั่งผลิต (หน่วยค้าง)
- ตัวอย่าง Action: ปรับความเร็วสายพาน (ต่อเนื่อง), เปลี่ยน setpoint อุณหภูมิ (ต่อเนื่อง), ส่งคำสั่ง stop/start, เลือกโหมดการทำงาน (เช่น energy‑saving vs high‑throughput)
- ตัวอย่าง Reward (ฟังก์ชันการให้รางวัล): ค่าลบของพลังงานต่อชิ้น (kWh/ชิ้น) ผนวกกับค่าลงโทษสำหรับ downtime และ defect เช่น reward = - (α * kWh_per_piece + β * downtime_hours + γ * defect_rate) โดย α, β, γ เป็นสัมประสิทธิ์น้ำหนักที่ตั้งตามนโยบายธุรกิจ
ตัวอย่างเชิงตัวเลข: หากเป้าหมายคือเน้นลดพลังงานแต่ต้องรักษา throughput ≥ 1000 ชิ้น/วัน อาจตั้ง reward ที่ลงโทษเมื่อ throughput ต่ำกว่าเกณฑ์ และให้บวกเมื่อพลังงานเฉลี่ยต่อชิ้นลดลง 0.01 kWh เป็นต้น
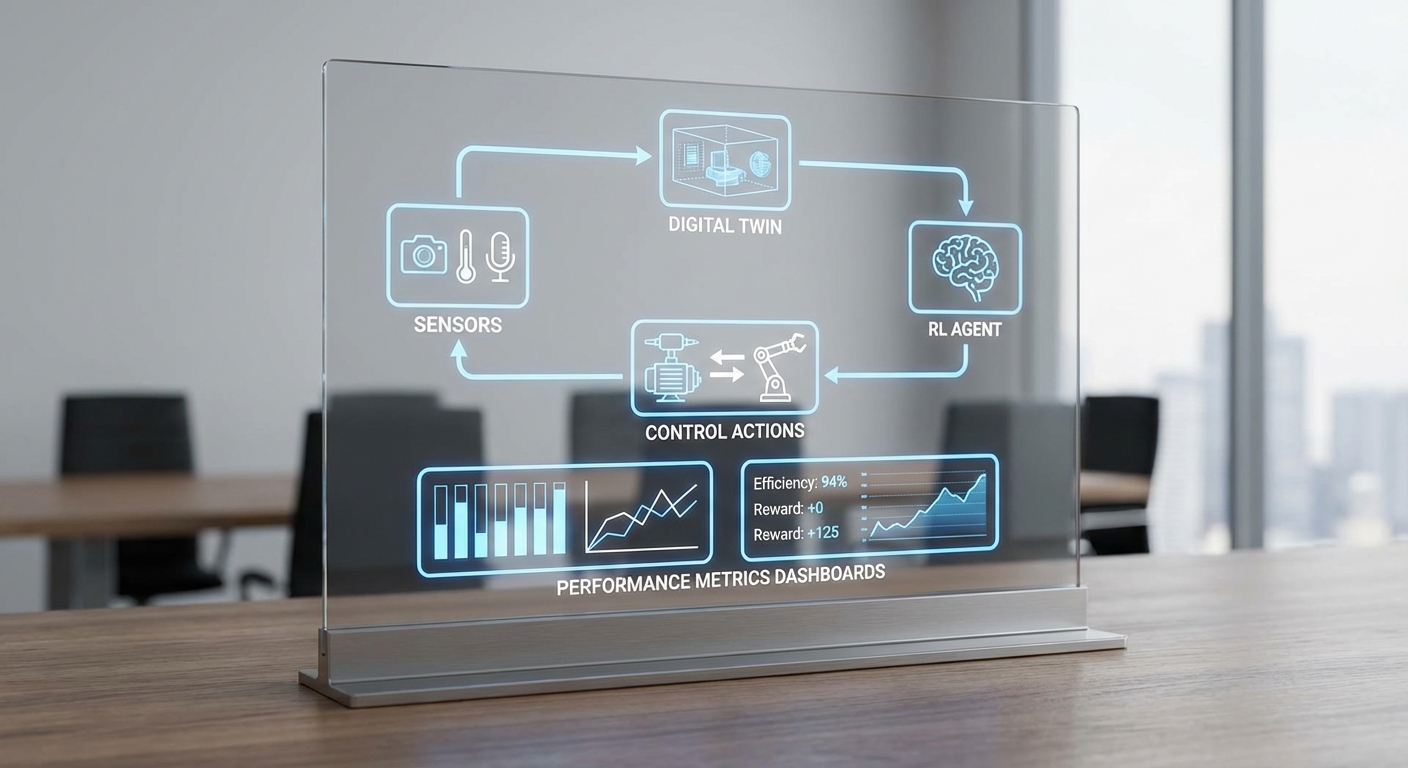
การเลือกอัลกอริทึม RL ที่เหมาะสม: PPO, SAC และ DDPG
เมื่อระบบโรงงานต้องการการควบคุมแบบต่อเนื่องและเรียลไทม์ การเลือกอัลกอริทึม RL ควรคำนึงถึงลักษณะของ action space, ความต้องการ sample efficiency และความเสถียรด้านการเรียนรู้ ต่อไปนี้เป็นข้อสรุปข้อดีข้อเสียของสามตัวอย่างที่นิยมใช้ในงานอุตสาหกรรม:
- PPO (Proximal Policy Optimization)
- ข้อดี: มีความเสถียรสูง, ตัดการแกว่งของ policy ด้วย clipping, ติดตั้งและปรับใช้ได้ง่ายในหลายกรณี
- ข้อเสีย: เป็น on‑policy จึงต้องใช้ข้อมูลจากการทดลองจริง/จำลองมากกว่า (sample inefficient) ถ้าใช้กับสภาพแวดล้อมที่จำลองช้าอาจเกิดค่าใช้จ่ายเวลาสูง
- เหมาะกับ: ปัญหาที่ต้องการความเสถียรของนโยบายและสามารถให้ตัวอย่างจำนวนมากจาก Digital Twin
- SAC (Soft Actor‑Critic)
- ข้อดี: เป็น off‑policy และ sample‑efficient, รองรับ continuous action ได้ดี และมีความสามารถ exploration ที่ดีเพราะเพิ่ม entropy term ใน objective
- ข้อเสีย: การปรับพารามิเตอร์และ tuning อาจซับซ้อนกว่า PPO เล็กน้อย, ความซับซ้อนในการติดตั้งสูงขึ้น
- เหมาะกับ: ปัญหาที่ต้องการเรียนรู้จากข้อมูลที่ถูกเก็บสะสม และต้องการประสิทธิภาพการสำเร็จในสภาพแวดล้อมต่อเนื่อง
- DDPG (Deep Deterministic Policy Gradient)
- ข้อดี: เหมาะกับ continuous action, ออกแบบมาให้มี sample efficiency เพราะเป็น off‑policy
- ข้อเสีย: มักไม่เสถียรเท่า SAC หรือ PPO, เสียง่ายต่อการ overfit หรือ divergence ต้องใช้เทคนิคเพิ่มเสถียรภาพเช่น target networks, replay buffer
- เหมาะกับ: กรณีที่ระบบมี action ต่อเนื่องที่ซับซ้อนและผู้พัฒนามีความชำนาญในการ tuning
ในทางปฏิบัติ โรงงานมักเริ่มจากการทดลองบน Digital Twin ด้วย SAC หรือ PPO แล้วเมื่อได้พฤติกรรมที่มั่นคงจึงนำมาทดสอบแบบออนไลน์ การใช้ hybrid approach (เช่น เรียนด้วย off‑policy แล้ว fine‑tune ด้วย on‑policy) เป็นกลยุทธ์ที่พบได้บ่อย
รูปแบบ Digital Twin: physics‑based vs data‑driven และแนวทางผสม
Digital Twin มีแนวทางสร้างหลักๆ สองแบบ: physics‑based ซึ่งอาศัยสมการทางฟิสิกส์และความเข้าใจเชิงกลไกของกระบวนการ กับ data‑driven ที่อาศัยโมเดลเชิงสถิติหรือแมชชีนเลิร์นนิงจากข้อมูลประวัติ ทั้งสองแบบมีข้อดีข้อจำกัด:
- Physics‑based: ให้ความแม่นยำเชิงสาเหตุ สามารถจำลองเงื่อนไขนอกช่วงข้อมูลได้ดี แต่การพัฒนาและการคาลิเบรตต้องการความรู้โดเมนสูงและเวลา
- Data‑driven: พัฒนาได้เร็วเมื่อมีข้อมูลเพียงพอและจับความซับซ้อนได้ดี แต่เสี่ยงต่อการ extrapolate นอกช่วงข้อมูล และต้องการข้อมูลที่สะอาดและครอบคลุม
- Hybrid (แนะนำ): ผสม physics‑based กับ data‑driven เพื่อได้ทั้งความแม่นยำเชิงสาเหตุและความยืดหยุ่นจากข้อมูล ตัวอย่างการใช้งานคือใช้โมเดลฟิสิกส์เป็น baseline แล้วให้ RL ฝึกบน residual model ที่เรียนจากข้อมูลจริง
จากงานวิจัยและการใช้งานเชิงอุตสาหกรรม พบว่า hybrid twin สามารถลดความคลาดเคลื่อนในการจำลองได้ถึง 30–70% เมื่อเทียบกับโมเดล data‑driven ล้วนในบางกรณีการผลิตที่มีการเปลี่ยนโหมดบ่อย
ตัวชี้วัดเชิงตัวเลข (KPIs) ที่ควรใช้วัดความสำเร็จ
การประเมินประสิทธิภาพของระบบ RL + Digital Twin ต้องใช้ KPI เชิงปริมาณที่สอดคล้องกับวัตถุประสงค์ธุรกิจ ตัวชี้วัดหลักได้แก่:
- พลังงาน (kWh/ชิ้น หรือ kWh/ชั่วโมง): วัดการใช้พลังงานเฉลี่ยต่อหน่วยผลิต ตัวอย่างเป้าหมายการปรับปรุง 5–20% ขึ้นอยู่กับกระบวนการ
- Downtime (ชั่วโมง/เดือน): จำนวนชั่วโมงที่สายการผลิตไม่ทำงาน อาจแยกเป็น planned vs unplanned downtime การลด downtime ที่สำคัญจะสะท้อนความต่อเนื่องการผลิต
- MTTR (Mean Time To Repair): เวลาซ่อมเฉลี่ยเมื่อเกิดความล้มเหลว การบูรณาการ RL กับ predictive maintenance สามารถลด MTTR ได้จากการเตรียมอะไหล่และขั้นตอนการแก้ปัญหา
- OEE (Overall Equipment Effectiveness): การรวมตัวของ Availability, Performance และ Quality เป็นตัวชี้วัดเชิงรวม เป้าหมายการปรับปรุงเชิงนโยบายอาจตั้งไว้ที่ +5–15% ภายใน 6–12 เดือนขึ้นกับสภาพเริ่มต้น
- Defect rate / Yield (%): เปอร์เซ็นต์ของชิ้นงานที่ไม่ผ่านมาตรฐาน ควรวัดแบบ real‑time และใช้เป็นส่วนหนึ่งของ reward เพื่อป้องกันการ trade‑off ระหว่างพลังงานกับคุณภาพ
การวัดผลเชิงตัวเลขควรมี baseline (เช่นค่าเฉลี่ย 6–12 เดือนก่อนการใช้ RL) และใช้การทดสอบ A/B หรือ phased rollout เพื่อประเมินผลทางสถิติ ในกรณีศึกษาที่คล้ายกัน โรงงานที่นำ RL ควบคุม Digital Twin รายงานการลดพลังงานเฉลี่ย 10–25% และลด downtime 15–40% ภายในไตรมาสแรกของการใช้งานจริง ทั้งนี้ผลลัพธ์จะแปรผันตามคุณภาพของ Digital Twin และการเลือก reward function
ภาพรวมกรณีศึกษา: โรงงานไทยที่นำไปใช้งานจริง
ภาพรวมกรณีศึกษา: โรงงานไทยที่นำไปใช้งานจริง
กรณีศึกษานี้มาจากโรงงานผลิต อะไหล่ยานยนต์ (Automotive parts) ขนาดกลาง-ใหญ่ ตั้งอยู่ในนิคมอุตสาหกรรมภาคตะวันออกของประเทศไทย โรงงานมีสายการผลิตหลัก 2 สายและเครื่องจักรรวมประมาณ 120 หน่วย ประกอบด้วยเครื่องปั๊มขึ้นรูป (press), เครื่อง CNC, สายลำเลียงอัตโนมัติ และเครื่องทดสอบคุณภาพ ผลิตในรูปแบบการทำงาน 3 กะตลอด 24 ชั่วโมงเพื่อรองรับคำสั่งซื้อจากผู้ผลิตยานยนต์ระหว่างประเทศ ระบบควบคุมเดิมเป็น PLC แบบดั้งเดิม เชื่อมต่อกับ SCADA กลางเพื่อการมอนิเตอร์และการควบคุมขั้นพื้นฐาน แต่ขาดความสามารถด้านการปรับจูนแบบเชิงคาดการณ์และการปรับตัวแบบเรียลไทม์ตามสภาวะโหลดไฟฟ้าและลักษณะการสึกหรอของเครื่องจักร
ก่อนการนำระบบ Digital Twin ที่ควบคุมโดย Reinforcement Learning มาใช้งาน โรงงานเผชิญกับปัญหาหลักสองประการ ได้แก่ ต้นทุนพลังงานสูง และ ชั่วโมง downtime ที่ไม่คาดคิดบ่อยครั้ง โดยข้อมูลพื้นฐานจากการวัดก่อนโครงการสรุปได้ว่า โรงงานใช้พลังงานเฉลี่ยประมาณ 3.6 GWh ต่อปี (ประมาณ 300,000 kWh ต่อเดือน) ซึ่งคิดเป็นค่าไฟฟ้าประมาณ 1.2–1.6 ล้านบาทต่อเดือน ขึ้นกับอัตราไฟฟ้าและชั่วโมงการทำงาน ส่วนชั่วโมง downtime เฉลี่ยอยู่ที่ประมาณ 70–90 ชั่วโมงต่อเดือน ที่เกิดจากการเปลี่ยนแม่พิมพ์ การปรับตั้งค่าเครื่องจักร และการหยุดชะงักจากสาเหตุเชิงเครื่องกล/ไฟฟ้า ส่งผลให้ OEE ของสายการผลิตอยู่ในระดับกลาง (ประมาณ 65–75%) และมีอัตราการผลิตที่ไม่เสถียรเมื่อเทียบกับแผนการผลิต
เป้าหมายเชิงธุรกิจของโครงการมีการกำหนดอย่างชัดเจนเพื่อให้สอดคล้องกับตัวชี้วัดทางการเงินและการผลิต ได้แก่
- ลดการใช้พลังงานอย่างน้อย 15% ต่อสายการผลิตภายในระยะเวลาพิสูจน์แนวคิด (pilot) 6 เดือน
- ลดชั่วโมง downtime อย่างน้อย 40% โดยมุ่งลดการหยุดไม่คาดคิดและลดเวลาการเปลี่ยนสภาพการทำงาน (changeover)
- เพิ่ม OEE ให้ได้อย่างน้อย 10–15 จุดเปอร์เซ็นต์ และปรับปรุงความสม่ำเสมอของ Throughput เพื่อลดต้นทุนการผลิตต่อหน่วย
- คาดหวังระยะเวลาคืนทุน (payback period) ภายใน 12–18 เดือน ผ่านการประหยัดค่าไฟและลดต้นทุนจาก downtime
สำหรับการทดลองระบบจริง ทีมงานเลือกทำ pilot กับ 1 สายการผลิต ที่ประกอบด้วยเครื่องจักรหลัก 10 หน่วย ซึ่งเป็นเส้นที่มีปัญหาด้านการเปลี่ยนแม่พิมพ์และจุดควบคุมแรงดัน/ความเร็วบ่อยที่สุด โดยติดตั้ง Digital Twin เพื่อจำลองพฤติกรรมเชิงกายภาพของสายและเชื่อมต่อกับ PLC ผ่านเกตเวย์ OPC‑UA/Edge เพื่อให้ RL agent สามารถปรับ setpoint ได้แบบเรียลไทม์ภายในขอบเขตที่กำหนด ขั้นตอนการย้ายจากการพึ่งพา PLC แบบเดิมประกอบด้วยกลยุทธ์สำคัญ เช่น การรักษา PLC สำหรับฟังก์ชันด้านความปลอดภัยและ interlock, การเพิ่มชั้นควบคุมแบบซูเปอร์ไวเซอร์ที่รันบน Edge, การทดสอบ fallback และการตั้งเงื่อนไขการล็อกค่าเมื่อพบความผิดปกติ ทั้งนี้มีการกำหนดขอบเขตการทดลองที่ปลอดภัยเพื่อให้การใช้งานเชิงปฏิบัติการสามารถขยายผลได้เมื่อพิสูจน์ผลลัพธ์ตาม KPI ที่ตั้งไว้
สถาปัตยกรรมแบบเรียลไทม์: การเชื่อมต่อ PLC, Edge, Cloud และ RL Agent
ภาพรวมสถาปัตยกรรมแบบชั้น (Layered Architecture)
สถาปัตยกรรมที่แนะนำสำหรับการนำ Reinforcement Learning (RL) มาควบคุม Digital‑Twin ของสายการผลิตแบบเรียลไทม์ ประกอบด้วยสามชั้นหลัก ได้แก่ PLC/RTU (Field Layer), Edge Controller ที่รัน Digital Twin และ RL inference (Edge Layer) และ Cloud สำหรับ training, analytics และการจัดการโมเดล (Cloud Layer) แต่ละชั้นมีบทบาทชัดเจน: PLC ทำงานเป็นวงปิดความเร็วสูง รับ/ส่งสัญญาณจากเซ็นเซอร์และ actuator; Edge ทำหน้าที่เป็นตัวกลางเชิงตรรกะ รับข้อมูลดิบจาก PLC แปลงเป็นสเตทของ Digital Twin และรัน RL inference เพื่อให้คำสั่งเชิงนโยบายแบบเรียลไทม์; Cloud รับข้อมูลสรุป (summaries, trajectories, metrics) เพื่อทำการฝึก (training) เพิ่มเติม วิเคราะห์เชิงธุรกิจ และจัดการ lifecycle ของโมเดล
รายละเอียดเชิงเทคนิค: โปรโตคอลการสื่อสารและ gateway
การเชื่อมต่อระหว่างชั้น field กับ edge มักใช้โปรโตคอลที่เป็นมาตรฐานอุตสาหกรรมเพื่อความเข้ากันได้และความเสถียร ตัวอย่างโปรโตคอลที่นิยมใช้ได้แก่:
- OPC UA — เหมาะสำหรับข้อมูลโครงสร้าง (meta-data, historical) และรองรับ security (certificates, TLS)
- MQTT — น้ำหนักเบา เหมาะกับการส่ง telemetry แบบ asynchronous ระหว่างอุปกรณ์และ edge/cloud
- Modbus TCP — โปรโตคอล legacy ที่พบได้ทั่วไปในอุปกรณ์ PLC/RTU รุ่นเก่า
เมื่อต้องผสานอุปกรณ์หลากหลายยุคสมัย จะใช้ gateway/protocol translator ระหว่าง PLC กับ Edge เพื่อทำหน้าที่แปลง Modbus → OPC UA/MQTT, buffer ข้อมูล, ทำ compression และรักษา session-level security (mutual TLS, client certs) โดยทั่วไป gateway ยังสามารถทำ edge‑level filtering เพื่อลดแบนด์วิดท์ไปยัง cloud ประมาณ 70–95% ขึ้นกับนโยบายการส่งข้อมูล (เช่นส่งเฉพาะ summary/episodic data แทน raw sensor stream)
Edge: Digital Twin แบบเรียลไทม์ และ RL Inference
Edge controller ควรรัน Digital Twin แบบกะทันหัน (real‑time/incremental state update) เพื่อสะท้อนสภาพจริงของสายการผลิตภายในวงจรการควบคุม (control loop) โดยข้อกำหนดเชิงเวลาต้องระบุ latency และ determinism — สำหรับการควบคุมระดับกระบวนการทั่วไป latency เป้าหมายมักอยู่ที่ 10–200 ms ขึ้นกับชนิดของระบบ (servo motor vs. batch process)
การใช้งาน RL ใน Edge มักแบ่งเป็นสองชั้นย่อย: (1) inference แบบเรียลไทม์ซึ่งตอบสนองการตัดสินใจระยะสั้น และ (2) shadow/parallel mode ที่รันทดสอบนโยบายใหม่โดยไม่ส่งผลต่อระบบจริงก่อนอนุมัติ การรันโมเดลควรอยู่ภายใต้สภาพแวดล้อมที่ถูกจำกัดด้วย sandboxing (เช่น container, WASM runtime) และ run-time enforcers เพื่อบังคับใช้ข้อจำกัดด้านการกระทำ (action bounds, rate limits)
Cloud: Training, Analytics และการจัดการโมเดล
Cloud เป็นแหล่งสำหรับการฝึก (re‑training), การเก็บรักษา logged experiences (experience replay), การวิเคราะห์ประสิทธิภาพระยะยาว และการจัดการ lifecycle ของโมเดล เช่นการทำ canary rollout หรือ A/B testing กับ fleet ของสายการผลิต ข้อมูลที่ส่งขึ้นมาควรเป็น summaries, episodic traces, feature snapshots เพื่อรักษาแบนด์วิดท์และความเป็นส่วนตัวของข้อมูล ตัวอย่างเช่น การส่งเฉพาะ trajectory summary สามารถลดปริมาณข้อมูลได้กว่า 80% เมื่อเทียบกับการส่ง raw telemetry ทั้งหมด
แนวทางที่นิยมใช้รวมถึงการฝึกแบบผสม (hybrid training) — บางส่วนฝึกบน Cloud ด้วยข้อมูลรวมจากหลายไซต์ และบางส่วนฝึกบน Edge เพื่อปรับให้เข้ากับบริบทเฉพาะของโรงงาน (federated learning หรือ local fine‑tuning)
มาตรการความปลอดภัยและกลไก fallback (Safety & Fallback)
ระบบควบคุมอุตสาหกรรมที่ผสาน RL ต้องมีมาตรการด้านความปลอดภัยหลายชั้นเพื่อป้องกันความเสี่ยงทางปฏิบัติการและเชิงไซเบอร์ ตัวอย่างมาตรการสำคัญ:
- Heartbeats และ Watchdogs — แต่ละโมดูล (PLC, Gateway, Edge, RL Agent) ส่ง heartbeat เป็นช่วงเวลา หากขาดติดต่อเกิน threshold ระบบจะเข้าสู่ปลอดภัย (safe mode) อัตโนมัติ
- Safe‑actions / Action bounding — ก่อนส่งคำสั่งจาก RL ให้ผ่าน safety filter ที่ตรวจสอบขอบเขต, ความต่อเนื่องเชิงฟิสิกส์ และข้อจำกัดของอุปกรณ์ เช่น หาก RL พยายามตั้ง setpoint นอกช่วงที่ยอมรับได้ ให้ปรับเป็น max/min ที่ปลอดภัย
- Fallback to PLC local control — เมื่อเกิดข้อผิดพลาดใน Edge หรือ RL Agent ระบบต้องสลับกลับไปใช้ PID/local logic บน PLC โดยอัตโนมัติ เพื่อรักษา stability และลด downtime
- Sandboxing และ Staging — การทดสอบนโยบาย RL ใน sandbox environment หรือ shadow mode ก่อน production deployment ช่วยป้องกัน action ที่เป็นอันตราย
- Secure communication — ใช้ TLS/mutual TLS, certificate management, network segmentation และ least‑privilege access เพื่อป้องกันการโจมตีจากภายนอก
กลไก fallback ที่ดีรวมถึงการกำหนด SLA สำหรับการตอบสนอง เช่น หาก heartbeat หายไปเกิน 2–5 วินาที (สำหรับ loop ที่เร็ว) หรือ 30–120 วินาที (สำหรับการตัดสินใจช้าลง) ให้สลับไปยัง safe control และแจ้งเตือนผู้ปฏิบัติการพร้อม log เหตุการณ์สำหรับการ forensic
บทสรุปเชิงปฏิบัติ
การนำ RL เข้ากับ Digital‑Twin ในการควบคุมสายการผลิตแบบเรียลไทม์ต้องออกแบบสถาปัตยกรรมแบบหลายชั้นที่ชัดเจน ใช้โปรโตคอลอุตสาหกรรม (OPC UA, MQTT, Modbus TCP) ด้วย gateway สำหรับการแปลงและกรองข้อมูล, วาง Edge เป็นจุดปฏิบัติการเชิงกายภาพสำหรับ Digital Twin และ RL inference, และใช้ Cloud เป็นศูนย์กลางสำหรับ training และ orchestration การผสานมาตรการความปลอดภัยเช่น heartbeats, watchdogs, safe‑actions และ sandboxing เป็นสิ่งจำเป็นเพื่อให้เกิดการใช้งานเชิงพาณิชย์ที่เชื่อถือได้ ลด downtime และรักษาความปลอดภัยของโรงงาน
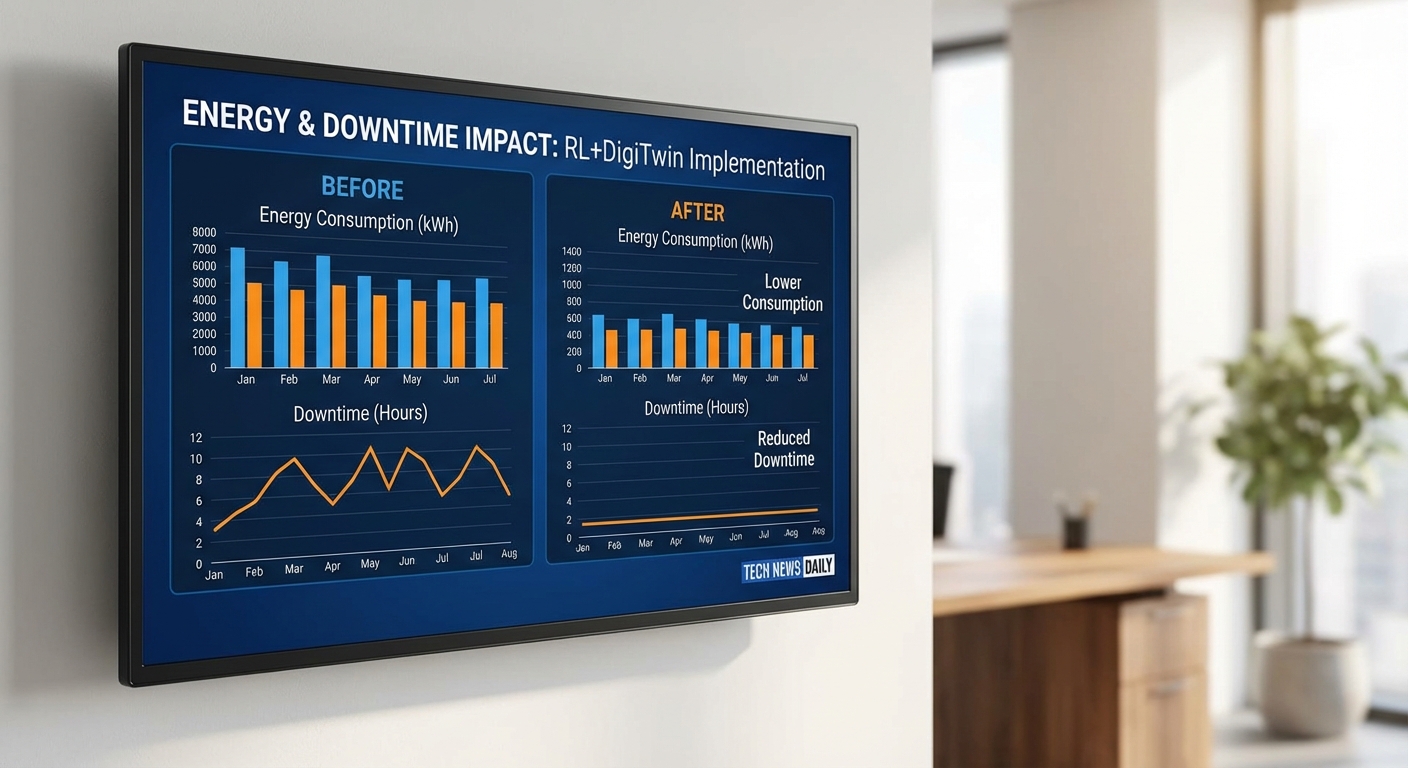
ผลลัพธ์เชิงตัวเลขจากโครงการ: ลดพลังงาน ลด downtime และค่า OEE
ภาพรวมเชิงปริมาณ (ก่อน‑หลังโครงการ)
ผลการทดลองและการนำ Reinforcement Learning (RL) ควบคุม Digital‑Twin ในสายการผลิตแบบเรียลไทม์ แสดงให้เห็นผลลัพธ์เชิงตัวเลขที่ชัดเจนเมื่อเปรียบเทียบกับการควบคุมแบบเดิม (PLC แบบสแตทิก) ในช่วงทดลองเบื้องต้น พบการลดการใช้พลังงานเฉลี่ยอยู่ระหว่าง 12–28% ขึ้นกับลักษณะของไลน์การผลิตและความซับซ้อนของกระบวนการ นอกจากนี้ยังสังเกตการลด downtime อยู่ในช่วง 30–60% เนื่องจากระบบสามารถตอบสนองแบบเรียลไทม์และดำเนินการเชิงคาดการณ์ (predictive actions) เพื่อลดระยะเวลาหยุดทำงาน
รายละเอียดผลลัพธ์ตามประเภทสายการผลิต
การแจกแจงตัวอย่างตามประเภทไลน์ผลิตที่ศึกษาให้ภาพแตกต่างชัดเจนระหว่างกรณีสแตทิก (Static PLC) และระบบ Adaptive (RL + Digital‑Twin):
- ไลน์บรรจุภัณฑ์ความเร็วสูง: ลดพลังงาน 12–18%; downtime ลด 30–45%; OEE ปรับปรุงจาก 68% → 78–84%
- ไลน์กระบวนการต่อเนื่อง (Continuous process): ลดพลังงาน 20–28%; downtime ลด 40–60%; OEE ปรับปรุงจาก 60% → 75–88%
- ไลน์แบบ Batch/เปลี่ยนสูตรบ่อย: ลดพลังงาน 14–22%; downtime ลด 35–50% (ลดเวลาตั้งค่าและ prevent start‑up failures); OEE ปรับปรุงจาก 55% → 70–82%
- คุณภาพผลิตภัณฑ์ (Defect rate): อัตราข้อบกพร่องลดลงอย่างมีนัยสำคัญ เช่น จากเฉลี่ย 4.5% → 1.2–2.8% ขึ้นกับการปรับพารามิเตอร์แบบเรียลไทม์และการป้องกันการเบี่ยงเบนกระบวนการ
การเปรียบเทียบ: Static PLC vs Adaptive RL (สรุปเชิงตัวเลข)
เมื่อสรุปเป็นตัวเลขก่อน‑หลังเพื่อให้ผู้บริหารเห็นภาพชัดเจน ผลลัพธ์แบบเฉลี่ยจากหลายไลน์ผลิตมีดังนี้:
- การใช้พลังงาน: Static control: ลดได้ ~5–10% (โดยอาศัยการตั้งค่าคงที่และ tuning ระยะสั้น) / Adaptive RL: ลดได้ 12–28%
- Downtime: Static control: ลดได้ ~10–25% (ส่วนใหญ่จากการวางแผนบำรุงรักษา) / Adaptive RL: ลดได้ 30–60% (การตอบสนองแบบเรียลไทม์ + predictive intervention)
- OEE: Static control: เพิ่มขึ้นเฉลี่ย 3–8 percentage points / Adaptive RL: เพิ่มขึ้นเฉลี่ย 8–25 percentage points ขึ้นกับประเภทไลน์
- Defect rate: ลดจากช่วง 3–6% → เหลือ 1–3% ในหลายกรณีศึกษา (การควบคุมแบบ adaptive ลดการเกิด out‑of‑spec events)
ข้อสังเกตเชิงตัวเลขและช่วงค่าที่พบ
ผลลัพธ์มีความแปรผันตามปัจจัยพื้นฐานของแต่ละไลน์ เช่น อายุของอุปกรณ์ ความถี่การเปลี่ยนสูตร และความผันผวนของวัตถุดิบ โดยภาพรวมสามารถสรุปเป็นข้อสังเกตเชิงตัวเลขได้ดังนี้:
- สายที่มีการเปลี่ยนเงื่อนไขบ่อย (high variability) มักเห็นประโยชน์จาก RL มากขึ้น — พลังงานลดได้สูงสุด ~25–28% และ downtime ลดได้ใกล้ 60%
- สายที่มีสภาวะค่อนข้างคงที่ (low variability) จะได้ประโยชน์น้อยกว่าเล็กน้อย แต่ยังคงเห็นการปรับปรุง OEE อย่างมีนัยสำคัญ ~8–12 percentage points
- การวัดผลในระยะทดลอง (pilot) 3‑6 เดือนให้ความเชื่อมั่นพอสมควร แต่การคาดการณ์ผลในระยะยาวควรรวมการปรับ model, drift detection และการรีเทรนเพื่อรักษาช่วงค่าดังกล่าว
บทสรุปเชิงตัวเลขสำหรับผู้บริหาร
สรุปเชิงตัวเลขการนำ RL ควบคุม Digital‑Twin แบบเรียลไทม์ในโรงงานไทยชี้ชัดว่าเป็นกลยุทธ์ที่ให้ผลตอบแทนเชิงประสิทธิภาพ: ลดการใช้พลังงาน 12–28%, ลด downtime 30–60%, และ เพิ่ม OEE อย่างมีนัยสำคัญ พร้อมลด defect rate จนเห็นการประหยัดวัตถุดิบและต้นทุนการผลิตโดยรวม การตัดสินใจย้ายจาก PLC แบบเดิมมาสู่สถาปัตยกรรมที่รองรับ RL ควรคำนึงถึงความพร้อมด้านข้อมูล โครงสร้าง Digital‑Twin และแผนการบำรุงรักษาเชิงคาดการณ์เพื่อให้สามารถรักษาช่วงผลลัพธ์เชิงตัวเลขเหล่านี้ในเชิงต่อเนื่อง
ความท้าทาย ปัญหาและบทเรียนที่สำคัญ
ความท้าทาย ปัญหาและบทเรียนที่สำคัญ
การนำ Reinforcement Learning (RL) มาควบคุม Digital‑Twin ของสายการผลิตแบบเรียลไทม์ในโรงงานไทย เผชิญกับความท้าทายเชิงวิศวกรรมและเชิงองค์กรที่หลากหลาย โดยประเด็นสำคัญที่เกิดขึ้นบ่อยคือการรวมระบบกับ PLC แบบเดิม (legacy PLC), ปัญหา latency และความไม่สอดคล้องของข้อมูลเซ็นเซอร์, คุณภาพข้อมูลสำหรับการฝึกโมเดล, ความเสี่ยงด้านความปลอดภัยไซเบอร์ และการยอมรับจากพนักงานและฝ่ายปฏิบัติการ การวางแผนเชิงรุกและการออกแบบสถาปัตยกรรมแบบ hybrid เป็นบทเรียนสำคัญที่ช่วยลดความเสี่ยงและเพิ่มโอกาสสำเร็จของโครงการ
การรวมระบบกับ PLC เก่าและแนวทางแบบ hybrid — PLC แบบเดิมมักไม่รองรับโปรโตคอลสมัยใหม่หรือมีข้อจำกัดด้านความสามารถในการตอบสนอง การออกแบบเป็น hybrid ที่นิยมใช้มีสองแนวทางหลักคือ read‑only และ pass‑through gateway เพื่อให้ RL/ Digital‑Twin สามารถสังเกตและแนะนำได้โดยไม่รบกวนการควบคุมจริงทันที:
- Read‑only mode: ใช้ตัวเกตเวย์แบบอ่านข้อมูล (เช่น OPC-UA/MQTT gateway) เพื่อดึงค่าจาก PLC โดยไม่ส่งคำสั่งกลับโดยตรง ช่วยลดความเสี่ยงต่อระบบการผลิตและเหมาะสำหรับเฟสการทดลองและการเก็บข้อมูล
- Pass‑through gateway / shadow control: ใช้เกตเวย์ที่สามารถเปลี่ยนเส้นทางคำสั่งแบบมีเงื่อนไข (pass‑through) เมื่อผ่านการทดสอบและได้รับการอนุมัติ พร้อมกลไกการสลับกลับอัตโนมัติ (fail‑safe) หากพบค่าผิดปกติ
- การใช้ edge computing เพื่อลด latency — ย้ายการคำนวณเชิงควบคุมบางส่วนไปยังอุปกรณ์ขอบเครือข่ายที่ติดตั้งใกล้กับ PLC ทำให้สามารถตอบสนองภายในมิลลิวินาทีที่ยอมรับได้
คุณภาพข้อมูลและการทำ clean/labeling สำหรับ training — โมเดล RL และ Digital‑Twin ต้องการข้อมูลที่มีคุณภาพสูง ทั้งในแง่ความถูกต้องของ timestamp, การซิงโครไนซ์สัญญาณ, การจัดการ missing values และการตรวจจับ drift ของเซ็นเซอร์ ปัญหาที่พบรวมถึงข้อมูลขาดหายเป็นช่วง ๆ, สัญญาณรบกวน (noise), และความไม่สอดคล้องระหว่างแหล่งข้อมูล ซึ่งมีผลโดยตรงต่อความเสถียรของนโยบายการควบคุม
- สร้าง pipeline สำหรับ cleaning อัตโนมัติ เช่นการเติมค่าแบบอิงบริบท (contextual imputation), การกรองสัญญาณ และการ normalise ตามสถานะเครื่องจักร
- ใช้กลยุทธ์ human‑in‑the‑loop labeling เพื่อจัดป้ายกำกับเหตุการณ์สำคัญ (เช่น transient faults, maintenance events) โดยเฉพาะอย่างยิ่งกรณีแรร์อีเวนต์ที่ต้องการตัวอย่างจากผู้เชี่ยวชาญ
- กำหนดมาตรฐานข้อมูล (metadata, units, sampling rate) และใช้การตรวจสอบความต่อเนื่องของข้อมูล (data provenance) — ตัวอย่างเช่น โครงการที่ประสบความสำเร็จมักต้องการอย่างน้อย 10^5–10^6 ตัวอย่าง (samples) หรือการเก็บข้อมูลในช่วงเวลาที่ครอบคลุมการเปลี่ยนโหมดการทำงานของเครื่องจักรหลายรอบก่อนการฝึกโมเดลเชิงควบคุม
- วางแผนการจัดการ concept drift ด้วยการตรวจจับความเปลี่ยนแปลงของ distribution และตารางการ retrain อย่างสม่ำเสมอ (เช่น monthly หรือเมื่อพบการลดลงของ performance เกินค่าที่กำหนด)
การจัดการความเสี่ยงด้านความปลอดภัยและการฝึกอบรมบุคลากร — การเชื่อมต่อระบบ OT (Operational Technology) กับแพลตฟอร์ม AI/IT เพิ่มความเสี่ยงด้านไซเบอร์ที่อาจนำไปสู่การหยุดการผลิตหรือความเสียหายต่ออุปกรณ์ แนวปฏิบัติที่จำเป็นต้องนำมาใช้ประกอบด้วยการแบ่งโดเมนเครือข่าย, การทำ VPN/secure tunnels, การใช้ certificate‑based authentication และการตรวจสอบแบบเรียลไทม์ (SIEM):
- ออกแบบเครือข่ายแบบ segmented (VLAN/air‑gapped segments) ระหว่าง PLC กับระบบ AI และกำหนด firewall rule แบบยิบย่อยเพื่อลดพื้นที่โจมตี
- ใช้มาตรฐานความปลอดภัยใน OT เช่นการตั้งค่า OPC‑UA security, signed firmware และการอัปเดตแพตช์อย่างมีการควบคุม เพื่อป้องกันช่องโหว่จากอุปกรณ์ legacy
- เตรียมแผนตอบสนอง (incident response) และทดสอบการ rollback ของ Digital‑Twin/RL ในกรณีที่เกิดผลลัพธ์ไม่พึงประสงค์ รวมถึงการตั้งค่า kill‑switch เพื่อคืนการควบคุมกลับสู่ PLC ทันที
- การฝึกอบรมบุคลากรเชิงปฏิบัติการและ IT — ไม่เพียงแต่สอนการใช้งานระบบ แต่ต้องรวมการอบรมด้านความเสี่ยงไซเบอร์, การตีความ output ของโมเดล และขั้นตอนการยกเลิกการใช้งาน (override) เพื่อให้ทีมปฏิบัติการมีความมั่นใจและสามารถจัดการเหตุการณ์ฉุกเฉินได้
บทเรียนที่ได้รับจากการนำไปใช้งานจริงสรุปได้ว่า เริ่มจาก pilot ขนาดเล็ก และใช้สถาปัตยกรรม hybrid ที่ปลอดภัยเป็นรากฐาน จะช่วยลด downtime และความเสี่ยงได้มากที่สุด นอกจากนี้การลงทุนใน data‑ops (cleaning, labeling, provenance) และการมีทีมข้ามสายงาน (OT/IT/AI/Operations) ที่สื่อสารกันได้ดี เป็นปัจจัยสำคัญในการไปสู่การย้ายจาก PLC แบบเดิมสู่การควบคุมแบบอัตโนมัติเต็มรูปแบบอย่างมีประสิทธิผล
กลยุทธ์การย้ายจาก PLC แบบเดิมสู่สถาปัตยกรรมที่ขับเคลื่อนด้วย RL
บทนำสั้น ๆ
ส่วนนี้นำเสนอ กลยุทธ์การย้ายจาก PLC แบบเดิมสู่สถาปัตยกรรมที่ขับเคลื่อนด้วย Reinforcement Learning (RL) โดยมีแผนปฏิบัติการ 6 ขั้นตอน พร้อมทางเลือกการย้ายระบบ (retrofit vs soft PLC vs new PLC + OPC UA), checklist การทดสอบ (simulation sandbox, shadow mode, A/B testing), แนวทางด้านคน (retraining workforce), งบประมาณเชิงประมาณการ และ KPI/Governance ที่ต้องกำหนดก่อนเริ่มโครงการ การนำเสนอเน้นเชิงปฏิบัติที่โรงงานไทยสามารถนำไปปรับใช้ได้ทันที
แผน 6‑ขั้นตอน (Roadmap ที่ปฏิบัติได้จริง)
- 1. วิจัย & PoC (4–12 สัปดาห์)
สำรวจกระบวนการที่จะได้รับประโยชน์สูงสุด (bottlenecks, energy hotspots) สร้าง PoC บน digital twin ในระดับโมดูลเดียว เป้าหมายคือยืนยันความเป็นไปได้ทางเทคนิคและวัดตัวชี้วัดสำคัญ (เช่น ลดพลังงาน 5–15% ในโมดูลทดลอง) โดยงบประมาณ PoC ทั่วไปอยู่ในช่วง ประมาณ 0.5–3 ล้านบาท ขึ้นกับความซับซ้อน
- 2. Pilot ในสายเล็ก (3–6 เดือน)
ขยาย RL ไปยังสายการผลิตย่อยที่สามารถวัดผลได้ชัดเจน กำหนด KPI ชั่วคราว เช่น ลด downtime 10–30% และทดสอบอินทิเกรชันกับ PLC จริงในรูปแบบ shadow หรือ soft-control เพื่อประเมินเสถียรภาพ
- 3. Shadow mode (1–3 เดือน)
ให้ RL รันแบบคู่ขนานกับ PLC โดยไม่ควบคุมจริง (shadow) เพื่อเก็บข้อมูลพฤติกรรมและประสิทธิภาพ สร้าง baseline เปรียบเทียบแบบเรียลไทม์ และทดสอบกรณีขอบ (edge cases) ก่อนเปิดให้ RL ควบคุม
- 4. Gradual control handover (2–6 เดือน)
เริ่มโอนหน้าที่ควบคุมเป็นระดับขั้น (per-station, per-line) พร้อมเงื่อนไขความปลอดภัย เช่น watchdog timers, hard PLC overrides และเกณฑ์ performance acceptance (เช่น reward convergence ภายใน X ชั่วโมง/สัปดาห์)
- 5. Full deployment
เมื่อผ่าน acceptance criteria ให้ขยายสู่ทั้งโรงงาน พร้อมแผนสำรอง (rollback) และการทำ document เวอร์ชันที่ชัดเจน รวมถึงการอนุมัติจากฝ่ายความปลอดภัยและ regulatory
- 6. Continuous monitoring & improvement
ติดตั้งระบบ monitoring แบบเรียลไทม์ (dashboards, alerts), ตั้ง cadence สำหรับ retraining โมเดล (เช่น ทุก 1–3 เดือนหรือเมื่อเกิด concept drift) และวางแผน lifecycle ของ model/PLC/firmware
ทางเลือกการย้ายระบบ: retrofit, soft PLC, หรือ new PLC พร้อม OPC UA
- Retrofit gateway — ติดตั้งอุปกรณ์เชื่อมต่อระหว่าง PLC เดิมกับ Digital‑Twin/RL เหมาะกับโรงงานที่ต้องการลดความเสี่ยงและค่าใช้จ่ายเริ่มต้น ข้อดีคือการทำงานร่วมกับอุปกรณ์เดิมได้รวดเร็ว ข้อจำกัดคือ latency และขีดจำกัดการควบคุมเชิงลึก
- Soft PLC — รัน logic บน PC/edge device ให้ความยืดหยุ่นสูงและอัปเดตง่าย เหมาะกับการทดลองคอนโทรลเชิงนวัตกรรม แต่ต้องวางแผนเรื่อง redundancy และ determinism
- New PLC พร้อม OPC UA — ลงทุนสูงสุดแต่ให้ความเป็นมาตรฐาน, ความปลอดภัย, และ interoperability ที่ดีที่สุด OPC UA ช่วยให้ข้อมูลสื่อสารกับ Digital Twin และระบบ MES/SCADA ได้อย่างราบรื่น เหมาะกับการย้ายแบบ long‑term modernization
Checklist การทดสอบและ Validation
- Simulation sandbox / Digital Twin — ทดสอบ RL บน twin ด้วย workload scenarios อย่างน้อย 100–1,000 episodic runs รวมกรณีผิดปกติ (power-fluctuations, sensor faults)
- Shadow mode — รัน RL คู่กับ PLC อย่างน้อย 2–8 สัปดาห์ เพื่อตรวบบันทึกการตัดสินใจและวัด delta ของ KPI
- A/B testing — แบ่งสายเป็นกลุ่มควบคุมและกลุ่มที่ RL ควบคุม เพื่อวัดสถิติที่มีนัยสำคัญ เช่น p‑value < 0.05 สำหรับการลด downtime/energy
- Stress & safety tests — ทดลอง fault injection, emergency stop, network-loss scenarios เพื่อตรวจสอบ rollback time และ safe state transitions
- Acceptance criteria — กำหนด thresholds ชัดเจน เช่น energy reduction ≥10% หรือ MTTR ลดลง ≥20% เป็นเกณฑ์ผ่านก่อน go‑live
แนวทางด้านคน (Retraining & Change Management)
- แผนฝึกอบรม — แบ่งเป็นระดับ: operators (การใช้งาน UI, manual override), control engineers (integration, tuning), data/ML engineers (model lifecycle, validation). ระยะเวลาฝึกอบรม 1–4 สัปดาห์ล่วงหน้าและ follow‑up ทุก 3 เดือน
- บทบาทใหม่ที่ต้องตั้ง — ML Ops, Model Validation Engineer, Digital Twin Steward, Cybersecurity Officer เพื่อดูแลโมเดลและระบบเชิงผลิต
- การจัดการการเปลี่ยนแปลง — สื่อสาร KPI, success metrics, และ timeline ให้ชัดเจน ใช้ workshop และ on‑the‑job training เพื่อลดความต้านทานและสร้างความเชื่อมั่น
งบประมาณและ KPI ที่ต้องกำหนดก่อนเริ่มโครงการ
- งบประมาณเชิงประมาณการ — PoC: 0.5–3 ล้านบาท; Pilot: 1–8 ล้านบาท; Full deployment: ขึ้นกับ scale อาจ 5–50+ ล้านบาท ขึ้นกับจำนวนสายการผลิตและอุปกรณ์ที่ต้องเปลี่ยน ข้อควรทำคือทำ TCO และ NPV ก่อนตัดสินใจ
- KPI เบื้องต้น
- Energy consumption (kWh/ชิ้น) — เป้าหมายลด 10–25%
- Downtime (%) หรือ MTTR — ลด 20–60%
- Throughput / cycle time — เพิ่ม 5–15%
- Model metrics — average reward, convergence time, rate of safe-action selection
- ROI / payback period — เป้าหมาย 6–24 เดือนหลัง full deployment
- การวัดและรายงาน — ตั้ง dashboard รายวัน/สัปดาห์ และรายงาน executive summary รายเดือนเพื่อติดตาม KPI และ drift
Governance, Safety Thresholds และแผน Rollback
- Safety thresholds — กำหนด hard limits เช่น max motor current, max temperature, max cycle time ที่เมื่อถึงจะต้อง trigger safe‑stop และสลับกลับไปใช้ PLC เดิมทันที
- Rollback plans — ต้องมี automatic failover (hardware watchdog), manual override buttons, และ scripted rollback procedures ที่สามารถคืนค่า control logic ภายในเวลาที่กำหนด (เช่น ≤60 วินาที สำหรับ critical lines)
- Legal / Compliance checks — ตรวจสอบข้อกำหนดความปลอดภัยเชิงฟังก์ชัน เช่น IEC 61508/ISO 13849 และมาตรฐานไซเบอร์สำหรับอุตสาหกรรมเช่น ISA/IEC 62443 รวมถึงข้อกำหนดด้านแรงงานและสิทธิส่วนบุคคลเมื่อใช้งานข้อมูลพนักงาน
- Audit & Documentation — เก็บ log การตัดสินใจของ RL, versioning ของโมเดล, และกระบวนการตรวจสอบ (model card, validation report) เพื่อการตรวจสอบภายในและการปฏิบัติตามกฎหมาย
สรุป: การย้ายจาก PLC แบบเดิมสู่สถาปัตยกรรม RL‑driven ต้องทำตาม roadmap ขั้นตอนชัดเจน ตั้ง KPI และ governance ที่เข้มงวด เลือกทางเลือกเชิงเทคนิคให้เหมาะสมกับสภาพโรงงาน และลงทุนด้านคนควบคู่ไปด้วย เพื่อให้การเปลี่ยนแปลงลดความเสี่ยง, เพิ่มประสิทธิภาพ และสร้างมูลค่าในระยะยาว
บทสรุป
การประยุกต์ Reinforcement Learning ร่วมกับ Digital Twin ในสายการผลิตแบบเรียลไทม์ แสดงผลลัพธ์เชิงบวกในหลายกรณีศึกษา โดยรายงานภาคสนามจากโรงงานไทยและต่างประเทศชี้ว่า สามารถลดการใช้พลังงานได้ในช่วงประมาณ 10–25% และลด downtime ได้ราว 20–40% ขึ้นกับลักษณะการผลิตและคุณภาพของแบบจำลองดิจิทัล ปัจจัยสำคัญที่กำหนดความสำเร็จคือการออกแบบ state/action/reward อย่างรัดกุม (เช่น การเลือกตัวแทนสถานะที่รวมทั้งข้อมูลเซนเซอร์ ความหนาแน่นการผลิต และสถานะอุปกรณ์), การนิยามรางวัลที่สะท้อนทั้งประสิทธิภาพและความปลอดภัย, รวมทั้งสถาปัตยกรรมการเชื่อมต่อที่มั่นคง (เช่น การใช้ OPC-UA, edge inference, และการซิงก์แบบ deterministic ระหว่าง Digital Twin กับ PLC/SCADA) เพื่อหลีกเลี่ยงการหน่วงเวลาและข้อมูลผิดพลาดที่อาจนำไปสู่การตัดสินใจไม่ถูกต้อง
การย้ายจาก PLC แบบเดิมไปสู่ระบบที่ใช้ AI/RT Digital Twin ควรทำเป็นขั้นตอนโดยยึดหลักการ hybrid approach และ sandboxing: เริ่มจากการรันนโยบาย RL ในสภาพแวดล้อมจำลองหรือโหมด monitoring ก่อน (shadow mode) แล้วค่อยเปิดใช้แบบขั้นบันไดสำหรับสายการผลิตที่มีความเสี่ยงต่ำ โดยตั้ง KPI ชัดเจน เช่น อัตราการลดพลังงาน เปอร์เซ็นต์การลด downtime และจำนวนเหตุการณ์แจ้งเตือนความปลอดภัยเพื่อเป็นเกณฑ์ยอมรับ ทางเทคนิคควรรวมกระบวนการทดสอบความปลอดภัยไซเบอร์ การสำรองโปรไฟล์ PLC เดิม และแผน fallback อัตโนมัติ นอกจากนี้ในระยะยาวควรเตรียมความพร้อมด้านบุคลากร (reskilling), มาตรฐานข้อมูลและโมเดล (interoperability), และการประสานกับมาตรการกำกับดูแลเพื่อให้การเปลี่ยนผ่านเป็นไปอย่างยั่งยืนและคุ้มทุน



