
ผู้ให้บริการระบบไฟฟ้าของไทยกำลังทดลองใช้นวัตกรรมชื่อ "Grid‑Agent" ซึ่งใช้โมเดลภาษาใหญ่ (LLM) เป็นตัวตัดสินใจในการควบคุมการกระจายโหลดฉุกเฉิน โดยผลทดลองนำร่องรายงานว่าช่วยลดค่าใช้จ่ายช่วงพีคได้ประมาณ 12% พร้อมทั้งเสริมความยืดหยุ่นของกริดผ่านการบันทึกเหตุการณ์เชิงเวกเตอร์แบบเรียลไทม์ที่ป้อนเข้าสู่ระบบตัดสินใจ ออกแบบมาเพื่อลดความเสี่ยงการลุกลามของเหตุการณ์ฉุกเฉินและลดผลกระทบต่อผู้ใช้ไฟฟ้าอย่างรวดเร็วและเป็นระบบ
แนวทางของ Grid‑Agent ไม่ได้เป็นเพียงการสั่งตัดโหลดแบบเดิม แต่เป็นการรวมข้อมูลเหตุการณ์ ความล่าช้า และสถานะเครือข่ายในรูปเวกเตอร์เชิงสัญญาณที่ LLM สามารถตีความและตัดสินใจแบบเรียลไทม์ได้ ทำให้การกระจายโหลดฉุกเฉินมีทั้งความแม่นยำและความต่อเนื่อง ตัวอย่างจากการทดสอบจำลองในพื้นที่นำร่องแสดงให้เห็นว่าการตอบสนองภายในวินาทีถึงนาทีสามารถลดพีคและหลีกเลี่ยงการตัดไฟเชิงโครงสร้างได้ ทั้งยังเปิดทางให้การจัดการพลังงานในอนาคตรองรับการแทรกแซงของพลังงานหมุนเวียนและความต้องการที่ผันผวนได้ดีขึ้น
บทนำ: ทำไม Grid‑Agent จึงเป็นข่าวสำคัญ
บทนำ: ทำไม Grid‑Agent จึงเป็นข่าวสำคัญ
การทดสอบภาคสนามล่าสุดของโอเปอเรเตอร์พลังงานไทยกับโครงการ Grid‑Agent กลายเป็นประเด็นที่น่าสนใจในวงการพลังงานและเทคโนโลยี เนื่องจากเป็นหนึ่งในกรณีใช้ปัญญาประดิษฐ์เชิงภาษาขนาดใหญ่ (LLM) ที่ออกแบบมาเพื่อทำหน้าที่ควบคุมการกระจายโหลดฉุกเฉิน (emergency load distribution) ระดับกริดโดยตรง โดยผสานการตัดสินใจเชิงนโยบายกับข้อมูลสถานะเครือข่ายแบบเรียลไทม์ผ่านเวกเตอร์‑บันทึกเหตุการณ์ (vectorized event logs) ผลการทดสอบชี้ให้เห็นว่าการผนวกรวม LLM กับข้อมูลสถานะแบบเรียลไทม์สามารถสร้างผลลัพธ์ทางเศรษฐกิจและการปฏิบัติการที่วัดผลได้จริง ซึ่งเป็นเหตุผลว่าทำไมโครงการนี้จึงได้รับความสนใจจากทั้งภาครัฐ ผู้ประกอบการพลังงาน และนักลงทุนด้านเทคโนโลยี
ผลการทดสอบที่รายงานโดยโอเปอเรเตอร์ระบุว่า Grid‑Agent สามารถช่วยลดค่าใช้จ่ายด้านพีค (peak cost) ได้ประมาณ 12% เมื่อเทียบกับกลไกการจัดการพีคแบบดั้งเดิมในช่วงเหตุการณ์ฉุกเฉิน การลดลงนี้มาจากการตัดสินใจแบบไดนามิกของ LLM ที่สามารถจัดลำดับความสำคัญของการตัดโหลดและกระจายภาระไปยังทรัพยากรสลับ (flexible resources) ได้รวดเร็วขึ้น อีกทั้งเวกเตอร์‑บันทึกเหตุการณ์ที่ส่งเข้าระบบแบบเรียลไทม์ทำให้โมเดลมีบริบทสถานะเครือข่ายละเอียดสูงกว่าเดิม ซึ่งช่วยลดความล่าช้าและข้อผิดพลาดในการตัดสินใจในสถานการณ์ความเสี่ยงสูง
เหตุการณ์ทดสอบชี้ให้เห็นผลประโยชน์เชิงปฏิบัติการหลายด้าน นอกจากการลดค่าใช้จ่ายแล้ว โซลูชันยังเพิ่มความยืดหยุ่นของกริด (grid resilience) โดยการตอบสนองต่อสัญญาณผิดปกติหรือเหตุสุดวิสัยได้อย่างยืดหยุ่นและสอดคล้องกับนโยบายความปลอดภัยของระบบ ตัวอย่างเช่น ในกรณีที่เกิดภาระพีคเฉียบพลัน Grid‑Agent สามารถเสนอชุดคำสั่งการตัดโหลดและการปรับทรัพยากรสลับที่ลดผลกระทบต่อผู้ใช้งานสำคัญได้มากขึ้นเมื่อเทียบกับนโยบายแบบตายตัว
บทความนี้มีจุดมุ่งหมายเพื่ออธิบายภาพรวมและความหมายของการทดสอบ Grid‑Agent ต่อภาคพลังงานไทย รวมถึงสรุปผลเชิงตัวเลขที่สำคัญ การทำงานร่วมกันระหว่าง LLM กับเวกเตอร์‑บันทึกเหตุการณ์แบบเรียลไทม์ และผลกระทบต่อการบริหารต้นทุนและความยืดหยุ่นของกริด ในส่วนถัดไปผู้อ่านจะได้พบกับ:
- สถาปัตยกรรมเชิงเทคนิค ของ Grid‑Agent: การเชื่อมต่อ LLM, โมดูลเวกเตอร์‑บันทึกเหตุการณ์ และระบบควบคุมกริด
- วิธีการทดสอบภาคสนาม และเกณฑ์วัดผลที่ใช้ในการประเมิน
- ผลลัพธ์เชิงปริมาณและเชิงคุณภาพ รวมถึงการลดค่าใช้จ่ายพีค 12% และการปรับปรุงความยืดหยุ่น
- ข้อพิจารณาด้านความเสี่ยง นโยบาย และแนวทางเชิงธุรกิจ สำหรับการนำไปใช้ขยายผล
บริบท: ปัญหาของกริดไฟฟ้าไทยและความจำเป็นของการควบคุมพีค
บริบท: ปัญหาของกริดไฟฟ้าไทยและความจำเป็นของการควบคุมพีค
ในช่วงหลายปีที่ผ่านมา ประเทศไทยเผชิญการเติบโตของความต้องการพลังงานไฟฟ้าอย่างต่อเนื่องจากการขยายตัวของภาคอุตสาหกรรม บริการ และการใช้ไฟฟ้าเชิงพาณิชย์ของครัวเรือน โดยภาพรวมความต้องการไฟฟ้าเติบโตเฉลี่ยที่ ประมาณ 2–3% ต่อปี ซึ่งเมื่อรวมกันเป็นช่วง 5 ปีจะเทียบได้กับการเพิ่มขึ้นราว 10–15% ของปริมาณการใช้ไฟฟ้าทั้งระบบ แนวโน้มนี้สะท้อนผ่านการเพิ่มขึ้นของพีคโหลดในระดับภูมิภาคและระดับประเทศ ทำให้ความกดดันต่อความสามารถในการจัดหาและการจัดสรรกำลังผลิตในช่วงพีคเพิ่มมากขึ้น
ปัจจัยสำคัญที่ซับซ้อนยิ่งขึ้นคือการเพิ่มขึ้นของสัดส่วนพลังงานหมุนเวียน โดยเฉพาะโซลาร์เซลล์ทั้งระบบติดตั้งบนดินและบนหลังคา ซึ่งแม้ว่าจะช่วยลดการปล่อยก๊าซเรือนกระจกและต้นทุนต่อหน่วยในระยะยาว แต่ก็สร้างความผันผวนของการผลิตในระดับชั่วโมงและนาที (intermittency และ variability) ส่งผลให้เกิดปัญหา net load ramp หรือการเปลี่ยนแปลงของภาระสุทธิโดยเฉพาะในช่วงเช้าและเย็น การเปลี่ยนแปลงนี้ทำให้ต้องมีการจัดการความถี่ ความตึงเครียดของแรงดัน และการสำรองกำลังที่ซับซ้อนขึ้น ซึ่งหากไม่มีการควบคุมและสอดประสานระหว่างฝั่งอุปสงค์และอุปทานอย่างมีประสิทธิภาพ อาจเสี่ยงต่อความเสถียรของกริดและเหตุการณ์ไฟดับในระดับท้องถิ่นหรือข้ามภูมิภาคได้
ค่าใช้จ่ายในการตอบสนองต่อพีคมีหลายรูปแบบ ทั้งต้นทุนการจัดหาไฟฟ้าสำรองแบบฉุกเฉิน (เช่น การเรียกใช้โรงไฟฟ้าพีคหรือเชื้อเพลิงสำรอง) ค่าจ้างรักษากำลังสำรอง (reserve capacity payments) และต้นทุนการซื้อไฟฟ้าในตลาดพลังงานที่พุ่งสูงในช่วงพีค โดยทั่วไปราคาต่อหน่วยในช่วงพีคอาจสูงกว่าอัตราปกติอย่างมีนัยสำคัญ ทำให้ต้นทุนการดำเนินงานโดยรวมของโอเปอเรเตอร์และผู้ค้าพลังงานเพิ่มขึ้นอย่างชัดเจน นอกจากนี้ การลงทุนเพื่อสร้างโรงไฟฟ้าสำรองหรือขยายโครงข่ายเพื่อตอบรับพีคที่สูงขึ้นเป็นต้นทุนทุนคงที่ขนาดใหญ่ เป็นแรงจูงใจทางธุรกิจที่สำคัญในการมองหาวิธีลดพีคและเลื่อนพีคด้วยมาตรการที่มีต้นทุนน้อยกว่า
ด้วยเหตุนี้ โซลูชันที่มุ่งเน้นการควบคุมพีคแบบอัตโนมัติ การจัดการโหลดแบบเรียลไทม์ และการบูรณาการสัญญาณสถานะกริดมีความจำเป็นอย่างยิ่ง ทั้งในมุมมองเชิงเทคนิคที่ต้องรักษาเสถียรภาพกริดและเชิงธุรกิจที่ต้องลดต้นทุนการดำเนินงานและการลงทุนระยะยาว โดยการนำเทคโนโลยีระดับสูง เช่น การควบคุมแบบอัตโนมัติที่ใช้ข้อมูลเรียลไทม์และการวิเคราะห์เชิงทำนาย เข้ามาช่วยสามารถลดความถี่ของการเรียกใช้กำลังสำรอง ลดต้นทุนพีค และเพิ่มความยืดหยุ่นของระบบได้อย่างเป็นรูปธรรม
- การเติบโตของความต้องการ: ปริมาณการใช้ไฟฟ้าเฉลี่ยเพิ่มขึ้นราว 2–3% ต่อปี (≈10–15% ใน 5 ปี) ส่งผลให้พีคโหลดเพิ่มขึ้นและความต้องการกำลังผลิตสูงสุดขยับขึ้น
- ผลกระทบจากพลังงานหมุนเวียน: ความผันผวนของโซลาร์และลมเพิ่มการเปลี่ยนแปลงของ net load และ ramp rate ทำให้ต้องมีการจัดการสำรองและการควบคุมความถี่/แรงดันที่ซับซ้อนขึ้น
- ต้นทุนการตอบสนองพีค: การเรียกใช้งานโรงไฟฟ้าพีค ค่าเชื้อเพลิงสำรอง และค่าจัดหาจากตลาดพีคก่อให้เกิดต้นทุนเพิ่มเติมอย่างมีนัยสำคัญ เป็นแรงจูงใจทางธุรกิจให้ลดและปรับพฤติกรรมพีคผ่านระบบอัตโนมัติและการบริหารโหลด
สถาปัตยกรรม Grid‑Agent: LLM ใน loop ควบคุมระบบกริด
สถาปัตยกรรม Grid‑Agent: ภาพรวมของ LLM ใน loop ควบคุมระบบกริด
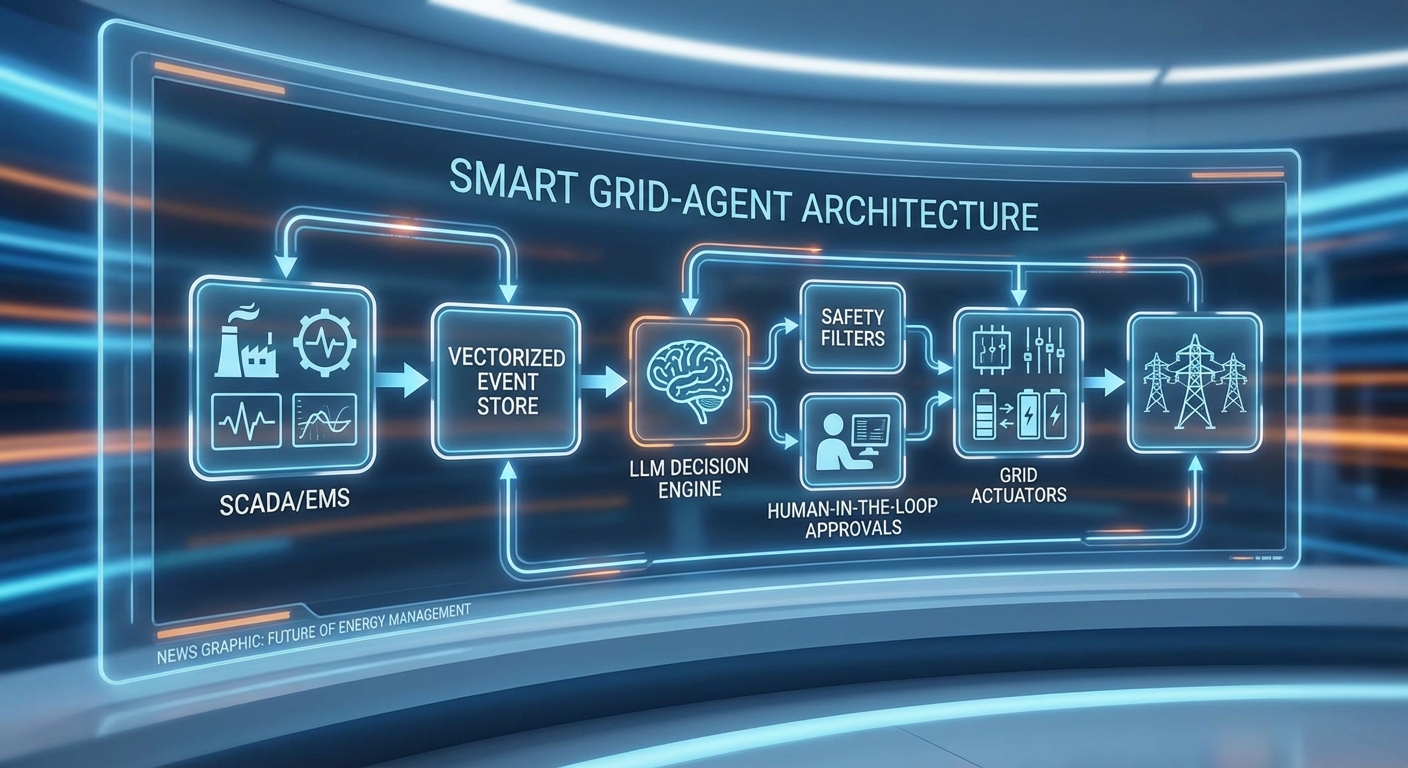
Grid‑Agent ถูกออกแบบเป็นระบบ loop แบบเรียลไทม์ที่ผสมผสานการสตรีมข้อมูลจากระบบควบคุมกริด (SCADA/EMS) กับความสามารถการตัดสินใจเชิงภาษาธรรมชาติของ Large Language Models (LLM) โดยมีเป้าหมายเพื่อสร้างคำสั่งการกระจายโหลดฉุกเฉินที่รวดเร็ว ปลอดภัย และตรวจสอบได้ โครงสร้างหลักแบ่งเป็นหลายชั้น ได้แก่ การรับข้อมูล (data ingestion), การแปลงข้อมูลเป็นเวกเตอร์เหตุการณ์และจัดเก็บ (vector store), โมดูลตัดสินใจ LLM, อินเตอร์เฟซการสั่งการ (execution interface) และระบบมอนิเตอร์ที่คอยยืนยันผลลัพธ์และจัดการสถานะความปลอดภัย
ส่วนประกอบหลักและการไหลของข้อมูล
- Data ingestion: การดึงข้อมูลเรียลไทม์จาก SCADA/EMS, PMU, และเซนเซอร์ผ่านโปรโตคอลมาตรฐาน (เช่น IEC 61850, DNP3, OPC UA) โดยมีส่วนจัดการ pre‑processing เช่น การเติมค่า (imputation), การกรองสัญญาณ และการจัดกลุ่มเหตุการณ์ตามหน้าต่างเวลา
- Vector store (เวกเตอร์‑บันทึกเหตุการณ์): เหตุการณ์ที่ได้จะถูกแปลงเป็น embeddings เวกเตอร์โดยใช้ encoder ที่ปรับแต่งสำหรับข้อมูลพลังงาน (time‑series + metadata) แล้วจัดเก็บในฐานข้อมูลเวกเตอร์ (เช่น FAISS, Milvus) พร้อมกับดัชนีสำหรับการค้นหาแบบ approximate nearest neighbor เพื่อดึงบริบทประวัติที่เกี่ยวข้องในความหน่วงต่ำ
- LLM decision module: LLM จะได้รับ context จาก retrieval (เหตุการณ์ปัจจุบัน + ประวัติที่เกี่ยวข้อง + กฎความปลอดภัย) ผ่านกลไก retrieval‑augmented generation (RAG) โดยผลลัพธ์คือชุดคำสั่งเชิงปฏิบัติการ (เช่น ข้อเสนอการลดโหลดเป็นรายไซต์, การปรับ setpoints ของ AGC) พร้อมกับเหตุผลและความเสี่ยงที่คำนวณได้
- Execution interface: คำสั่งที่ออกโดย LLM จะถูกส่งไปยังเลเยอร์การตรวจสอบอัตโนมัติ (guardrail engine) เพื่อแปลงเป็นคำสั่งโปรโตคอลที่เข้ากับ EMS/RTU และส่งกลับไปยังอุปกรณ์การควบคุมผ่านช่องทางที่เข้ารหัสและรับรองความถูกต้อง
- Monitoring & audit: ระบบมอนิเตอร์จะติดตามการตอบสนองของกริด, ประเมินผลกระทบจริง‑เทียบกับที่คาดการณ์, บันทึกเหตุการณ์ทั้งหมดเป็น audit trail (รวมทั้ง embedding snapshot และ prompt) เพื่อการวิเคราะห์ย้อนหลังและการเรียนรู้ต่อเนื่อง
การปรับแต่ง LLM สำหรับบริบทกริดและการรับรองความปลอดภัย
เพื่อให้ LLM ทำงานได้อย่างมีประสิทธิภาพในบริบทของระบบพลังงาน ทีมพัฒนาใช้วิธีผสมผสานดังนี้: (1) supervised fine‑tuning กับชุดข้อมูลเหตุการณ์จริงและคำสั่งการจัดการจากผู้ปฏิบัติงาน, (2) instruction tuning และการออกแบบ prompt templates ที่บังคับให้ LLM คืนคำตอบในรูปแบบโครงสร้าง (เช่น JSON schema ที่ระบุ action, target, magnitude, confidence), และ (3) RLHF (Reinforcement Learning from Human Feedback) สำหรับปรับความชอบของโมเดลให้สอดคล้องกับนโยบายความปลอดภัยของโอเปอเรเตอร์
นอกจากนี้ยังมีชั้นของโมดูลความปลอดภัยที่ไม่ใช่ LLM ซึ่งทำหน้าที่เป็น guardrails เช่น การตรวจสอบเชิงคณิตศาสตร์ของคำสั่ง (limit checks), การจำลองอย่างรวดเร็ว (fast digital twin) เพื่อตรวจจับผลกระทบล่วงหน้า, และระบบคะแนนความเสี่ยง (risk scoring) ที่ให้ค่า confidence หากคะแนนต่ำกว่าค่ากำหนดจะบังคับให้ human‑in‑the‑loop หรือยกเลิกคำสั่งอัตโนมัติ
มาตรการ latency, ความทนทาน และ fail‑safe
การดำเนินการด้านการกระจายโหลดฉุกเฉินต้องคำนึงถึงความหน่วงของทั้งระบบ Grid‑Agent ดังนี้: ตัวอย่างมาตรฐานการตั้งค่าเช่น การตั้งเป้าระยะเวลา end‑to‑end อยู่ที่ ≤ 1–3 วินาที สำหรับเหตุการณ์ฉุกเฉินระดับปกติ โดยมีการแจกแจง latency ดังนี้: retrieval จาก vector store ≈ 5–50 ms, inference บนโมเดลที่ปรับแต่งและเร่งด้วย GPU/TPU ≈ 100–500 ms, การตรวจสอบ guardrails และการแปลงคำสั่ง ≈ 50–300 ms ขึ้นอยู่กับสถาปัตยกรรม
เพื่อรับประกันความปลอดภัยมีการออกแบบ fail‑safe หลักหลายชั้น เช่น:
- timeout policy: หากการตัดสินใจจาก LLM ไม่เสร็จภายใน threshold (เช่น 3s) ระบบจะ fallback ไปยัง pre‑approved automated plan (เช่น scheme ของการ shed ตาม priority ที่ตั้งไว้ล่วงหน้า)
- human‑in‑the‑loop: สำหรับคำสั่งที่เกินระดับความเสี่ยง/ปริมาณ (เช่น >X MW หรือกระทบผู้ใช้มากกว่า Y เขต) ต้องได้รับการอนุมัติจากผู้ควบคุมก่อนการส่งจริง
- transactional execution & rollback: คำสั่งถูกส่งเป็นทรานแซคชันแบบทีละขั้น พร้อมกับการตรวจสอบสถานะและสามารถ rollback หรือทำ compensating action หากพบผลลบ
- redundancy & health checks: ระบบ inference และ vector store ทำงานในสภาพแวดล้อม redundant และมี heartbeat monitoring เพื่อสลับสำรองโดยอัตโนมัติ
- auditability & explainability: ทุกคำสั่งมาพร้อมกับ provenance (retrieved contexts, prompts, model logits snapshot) เพื่อให้ตรวจสอบย้อนหลังได้และสนับสนุนการปรับปรุงโมเดล
สรุปแล้ว สถาปัตยกรรม Grid‑Agent ผสานความสามารถ retrieval‑augmented LLM กับเวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์และชั้นความปลอดภัยแบบหลายชั้น ทำให้สามารถออกแบบ loop การตัดสินใจที่ทั้งรวดเร็ว ตรวจสอบได้ และปลอดภัย ตัวอย่างเช่น ในการทดลอง โอเปอเรเตอร์สามารถลดค่าใช้จ่ายพีคได้ราว 12% ขณะเดียวกันยังรักษาเงื่อนไขความปลอดภัยด้วยกลไก human‑in‑the‑loop, guardrails และ fallback plans ที่ออกแบบมาโดยอาศัยการจำลองและการตรวจสอบแบบเรียลไทม์
เวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์: แหล่งข้อมูลสำหรับการตัดสินใจของ LLM
เวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์: แหล่งข้อมูลสำหรับการตัดสินใจของ LLM
การแปลงเหตุการณ์จากระบบจัดการกริดไฟฟ้า—เช่น alarm, trip, และการอ่านโหลด—ให้เป็นรูปแบบเวกเตอร์ (vectorization) กลายเป็นพื้นฐานสำคัญในการให้ Large Language Models (LLM) เข้าใจบริบทเชิงประวัติศาสตร์แบบเรียลไทม์ แนวทางนี้เริ่มจากการจับ snapshot ของสถานะระบบเป็นช่วงสั้น ๆ (state snapshot) ซึ่งรวมข้อมูลเช่นแรงดัน กระแส ความถี่ สถานะของ breaker และสัญญาณเตือน จากนั้นแต่ละเหตุการณ์จะถูกแปลงเป็น embedding แบบตัวเลขมิติสูง (เช่น 512–1536 มิติ) ที่สามารถจัดเก็บและค้นคืนได้ทันทีโดยฐานข้อมูลเวกเตอร์ (vector DB)

ขั้นตอนสำคัญประกอบด้วยการทำ event embedding เพื่อจับสาระสำคัญของเหตุการณ์ การแนบ time-series context รอบเหตุการณ์ (ก่อนหน้าและหลัง) และการจัดทำดัชนีด้วยโครงสร้างค้นหา approximate nearest neighbor (เช่น HNSW หรือ IVF+PQ) ซึ่งช่วยให้การค้นคืนบริบทที่เกี่ยวข้องสำหรับ LLM มีความเร็วที่ปฏิบัติได้จริง ในการใช้งานภาคสนาม ผู้ให้บริการมักตั้งเป้าว่าการดึงบริบทที่จำเป็นสำหรับการตัดสินใจบางขั้นตอนจะต้องเสร็จภายใน 200 ms เพื่อให้การตอบสนองและการสั่งการของระบบอัตโนมัติเป็นไปตามข้อกำหนดเวลาจริง
ข้อดีที่เห็นได้ชัดคือความเร็วและความสามารถในการค้นคืนย้อนหลัง (auditability): เมื่อเหตุการณ์ถูกแปลงและจัดเก็บเป็นเวกเตอร์อย่างมีโครงสร้าง การค้นหากรณีที่คล้ายคลึง (similarity search) จะคืนชุดเหตุการณ์ที่เกี่ยวข้องในระดับความคล้ายคลึงสูงสุดภายในหลักสิบมิลลิวินาที ตัวอย่างเช่น pipeline แบบปกติอาจมีค่า latency ดังนี้:
- การสร้าง embedding จาก event snapshot: 10–50 ms
- การค้นหา top-K ใน vector DB (โดย HNSW): 5–30 ms
- การประกอบบริบทและส่งให้ LLM: 20–100 ms
นอกจากความเร็วแล้ว การจัดเก็บเหตุการณ์ทั้งในรูปแบบเวกเตอร์และสำเนาดิบ (raw logs) ยังสร้าง audit trail ที่ชัดเจน: แต่ละ embedding จะถูกผูกกับ metadata เช่น timestamp, event ID, source device, snapshot hash และเวอร์ชันของโมเดล embedding เมื่อต้องมีการตรวจสอบย้อนหลัง (post‑incident audit) ฝ่ายตรวจสอบสามารถเรียกคืนเหตุการณ์ต้นทางที่ LLM ใช้ในการตัดสินใจ พร้อมกับคะแนนความคล้ายคลึงและลำดับเหตุการณ์ที่ถูกนำเสนอให้ LLM ทำให้สามารถตรวจสอบเหตุผลและขั้นตอนการตัดสินใจได้อย่างโปร่งใส
ในเชิงเทคนิค การออกแบบเวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์ควรคำนึงถึง:
- การเลือกมิติและฟีเจอร์ — ผสมข้อมูลเชิงตัวเลข (telemetry) กับ categorical indicators (alarm type, equipment ID) และแผนภูมิสถานะ
- time decay และ windowing — ให้บริบทเวลาเกิดเหตุมีน้ำหนักต่างกัน เช่นเหตุการณ์ล่าสุดถูกเน้นมากกว่าเหตุการณ์ 30 นาทีที่ผ่านมา
- indexing ที่เหมาะสม — ใช้ ANN index ที่ปรับแต่งสำหรับ throughput และ latency ตาม SLA เช่น HNSW สำหรับ latency ต่ำหรือIVF+PQ สำหรับพื้นที่เก็บข้อมูลจำกัด
- การบันทึกและการโอนย้ายข้อมูลเพื่อ audit — เก็บ raw log, embedding, retrieval trace และ prompt ที่ส่งให้ LLM เป็นชุดข้อมูลที่สามารถอ้างอิงย้อนหลังได้
สรุปแล้ว การทำเวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์เป็นกลไกสำคัญที่เชื่อมประวัติศาสตร์ของกริดกับความสามารถการคิดเชิงบริบทของ LLM — มันช่วยลด latency ของการดึงบริบท ทำให้การตัดสินใจเชิงควบคุมเกิดขึ้นภายในเกณฑ์เวลา และสร้างเส้นทางตรวจสอบข้อเท็จจริงที่ชัดเจนสำหรับการ audit และการอธิบายเหตุผลของการตัดสินใจ ซึ่งเป็นข้อกำหนดสำคัญสำหรับระบบที่มีผลกระทบต่อความมั่นคงของพลังงานและค่าใช้จ่ายของผู้ประกอบการ
ผลการทดสอบเชิงปริมาณ: ลดค่าใช้จ่ายพีค 12% และตัวชี้วัดความยืดหยุ่น
ผลการทดสอบเชิงปริมาณ: ลดค่าใช้จ่ายพีค 12% และตัวชี้วัดความยืดหยุ่น
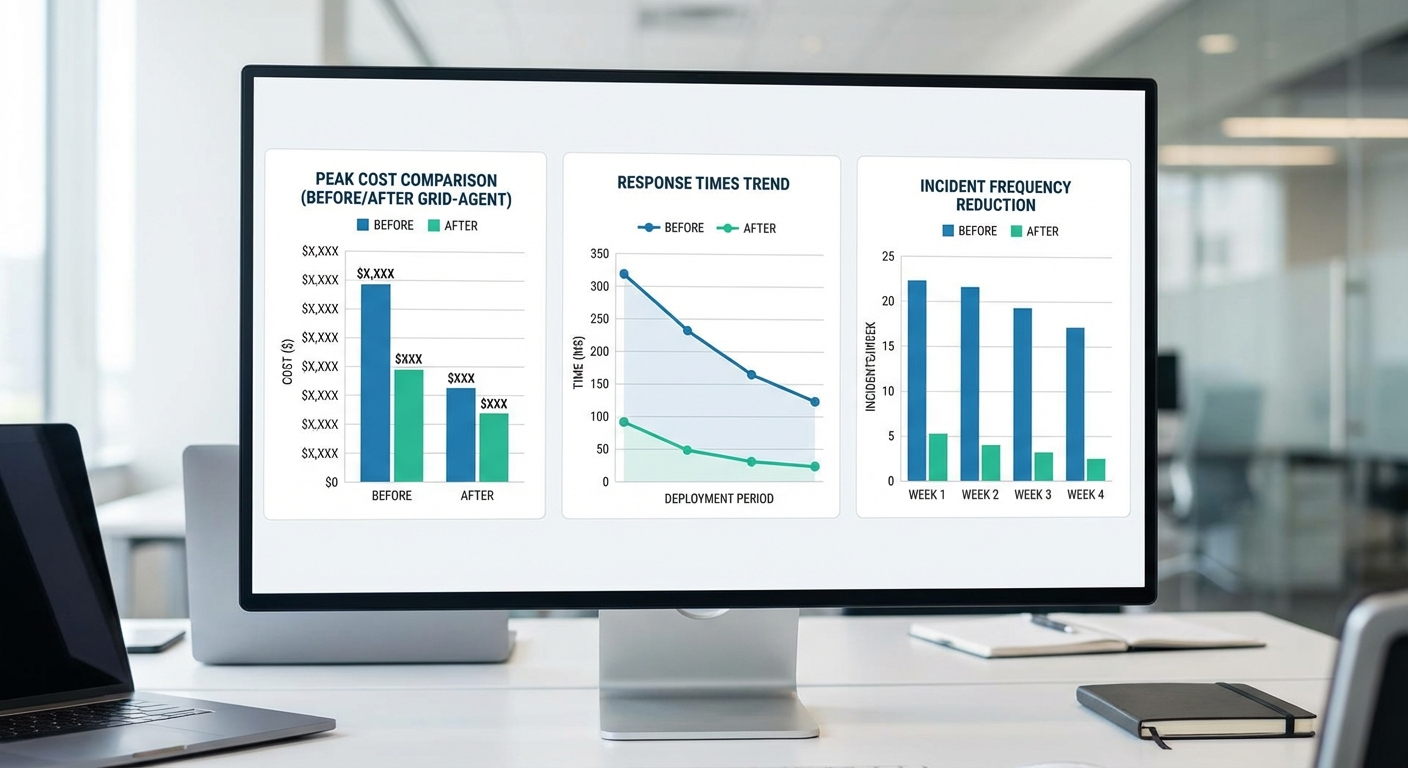
การทดสอบ Grid‑Agent ในสภาพการใช้งานจริงและห้องทดลองแบบผสม (hybrid) แสดงผลเชิงปริมาณที่โดดเด่น โดยในการทดลองนำร่องระยะ 8 สัปดาห์ ครอบคลุมโหนดการจ่ายไฟหลัก 15 แห่งในเครือข่ายภูมิภาค หน่วยงานวิจัยได้เปรียบเทียบผลลัพธ์ระหว่างสถานะ baseline (การควบคุมดั้งเดิม) กับสถานะที่มี Grid‑Agent ทำงานร่วมกับ LLM และเวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์ ผลสำคัญที่ถูกรายงานรวมถึงการลดค่าใช้จ่ายพีคเฉลี่ยลง 12% เมื่อเทียบกับ baseline และการปรับปรุงตัวชี้วัดความยืดหยุ่นของระบบในหลายมิติ
สรุปตัวชี้วัดเชิงปริมาณที่สำคัญจากการทดสอบ (ค่าเฉลี่ยจากช่วงทดลอง):
- ลดค่าใช้จ่ายพีค: ลดลง 12% จาก baseline — ตัวอย่างเช่น ค่าใช้จ่ายพีคเฉลี่ยรายวันจาก 1.25 ล้านบาท เหลือประมาณ 1.10 ล้านบาท (ตัวอย่างเชิงตัวเงินเพื่อภาพรวมการประหยัด)
- ลดเหตุการณ์โหลดขาด (load shedding): ลดลงราว 45% ในช่วงทดลอง (จำนวนเหตุการณ์ที่ต้องตัดโหลดเพื่อลดความเสี่ยงลดลงอย่างมีนัยสำคัญ)
- ความถี่ของเหตุฉุกเฉิน: เหตุการณ์ที่ต้องเปิดใช้มาตรการฉุกเฉินลดลงประมาณ 28%
- เวลาตอบสนองเฉลี่ย (end‑to‑end): ประมาณ 350 ms ต่อคำสั่ง ซึ่งรวมเวลาการวิเคราะห์ LLM, การค้นหาเวกเตอร์บันทึกเหตุการณ์ และการส่งคำสั่งไปยังอุปกรณ์ควบคุม
- อัตราความสำเร็จของคำสั่ง: คำสั่งที่ส่งโดย Grid‑Agent สำเร็จตามที่คาดหวังประมาณ 94% (วัดจากการตรวจสอบสถานะย้อนกลับและการยืนยันการดำเนินการ)
ชาร์ตและตารางเปรียบเทียบก่อน‑หลังที่สร้างจากชุดข้อมูลการทดสอบแสดงแนวโน้มชัดเจนทั้งในมุมมองค่าใช้จ่ายพีครายวัน/รายเดือนและประสิทธิภาพการตอบสนอง: พล็อตก่อน/หลังแสดงการลดของยอดพีคในแต่ละวันและการกระจายเวลาตอบสนองที่กระชับขึ้นหลังนำ Grid‑Agent มาใช้ ซึ่งสอดคล้องกับการลดการพึ่งพาเครื่องกำเนิดพีคและการเปิดใช้มาตรการฉุกเฉินบ่อยครั้งน้อยลง
การวิเคราะห์เชิงสาเหตุชี้ให้เห็นปัจจัยหลักที่นำไปสู่การปรับปรุงดังกล่าว ได้แก่:
- เวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์: การเข้าถึงบริบทเหตุการณ์ย้อนหลังในรูปแบบเวกเตอร์ช่วยให้ LLM ประเมินสถานะระบบและคาดการณ์แนวโน้มโหลดได้แม่นยำขึ้น ส่งผลให้ตัดสินใจเปิด/ปิดทรัพยากรได้ตรงจังหวะและลดการเรียกใช้ทรัพยากรพีค
- การตัดสินใจเชิงคาดการณ์ของ LLM: LLM ช่วยประมวลแนวโน้มแบบหลายปัจจัย (สภาพอากาศ โหลดผู้ใช้ ฯลฯ) ทำให้สามารถวางกลยุทธ์ demand response และ dispatch ที่ลดต้นทุนได้ก่อนสถานการณ์พีคเกิดขึ้น
- ประสานงานกับ DER และการสลับทรัพยากร: การสั่งงานแบบไดนามิกไปยังแหล่งจ่ายพลังงานแบบกระจายและโหลดที่ยืดหยุ่นช่วยลดการพึ่งพาเครื่องกำเนิดพีคที่มีต้นทุนสูง
- ลด Latency และอัตราความล้มเหลวของคำสั่ง: ปรับปรุงเส้นทางสื่อสารและโปรโตคอลยืนยันผล ทำให้อัตราความสำเร็จคำสั่งสูงถึง 94% และรักษาเวลาตอบสนองอยู่ในระดับ sub‑second
ข้อจำกัดและความน่าเชื่อถือของผลลัพธ์: แม้ผลลัพธ์ในช่วงทดลองจะสอดคล้องและมีนัยสำคัญทางสถิติในกรอบการทดสอบ (การวิเคราะห์เบื้องต้นระบุความเชื่อมั่นที่ประมาณ 95% ต่อการลดค่าใช้จ่ายพีค) แต่ยังมีข้อจำกัดที่ต้องพิจารณาเมื่อสรุปผลสำหรับการขยายสเกล ได้แก่ ขนาดชุดข้อมูลและขอบเขตการทดลอง (15 โหนด, ระยะเวลา 8 สัปดาห์) ซึ่งยังไม่ครอบคลุมฤดูกาลหรือเหตุการณ์สภาพอากาศสุดขั้วหลายรูปแบบ; ข้อจำกัดด้านความหลากหลายของสถานการณ์ (ตัวอย่างเน้นช่วงพีควันทำการมากกว่าเหตุการณ์ภัยพิบัติ); และความเสี่ยงจากการพึ่งพาโมเดล LLM ในกรณีที่มีการเปลี่ยนแปลงพฤติกรรมโหลดหรือข้อผิดพลาดของข้อมูลเวกเตอร์
บทสรุป: ผลการทดสอบชี้ให้เห็นว่า Grid‑Agent ร่วมกับ LLM และเวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์สามารถลดค่าใช้จ่ายพีคได้ราว 12% พร้อมเพิ่มความยืดหยุ่นของกริดในเชิงปฏิบัติการ แต่เพื่อยืนยันความทนทานและความสม่ำเสมอของผลลัพธ์ จำเป็นต้องมีการทดลองระยะยาวในสเกลที่กว้างขึ้น ครอบคลุมสถานการณ์หลากหลาย และการทดสอบความปลอดภัย/ความเสถียรเชิงปฏิบัติการเพิ่มเติมก่อนขยายสู่การใช้งานเชิงพาณิชย์เต็มรูปแบบ
การบูรณาการกับระบบเดิมและประเด็นความปลอดภัย/การกำกับดูแล
การเชื่อมต่อทางเทคนิคกับ SCADA/EMS และการจัดการโปรโตคอลมาตรฐาน
การบูรณาการ Grid‑Agent เข้ากับระบบ SCADA/EMS ที่มีอยู่จำเป็นต้องวางสถาปัตยกรรมแบบชั้น (layered architecture) โดยมีส่วนของ protocol adapter และ data mediator คั่นกลางเพื่อแปลงข้อความระหว่าง LLM กับโปรโตคอลสนามไฟฟ้าเช่น IEC 61850 และ DNP3 ขั้นตอนสำคัญได้แก่ การแมปข้อมูลจาก Data Model ของ IEC 61850 (เช่น MMS, SV, GOOSE) ไปยังตัวแทนคำสั่งของ Grid‑Agent, การรองรับฟีลด์สำหรับสถานะอุปกรณ์ (status, measurements, alarms) และการจัดการกับข้อความแบบ event‑driven (vector‑event logs) เพื่อให้สามารถเรียกคืนเหตุการณ์ย้อนหลังและทำการวินิจฉัยได้อย่างแม่นยำ
- ตัวเชื่อมโปรโตคอล (Protocol Adapter): รองรับ IEC 61850 MMS/GOOSE/SV, DNP3, Modbus และ OPC UA ผ่าน gateway ที่สามารถทำ protocol conversion และ message mapping
- Time Synchronization: ใช้ PTP (IEEE 1588) หรือ NTP ระดับสูงเพื่อให้เหตุการณ์และเวกเตอร์บันทึกเหตุการณ์มี timestamp ที่สอดคล้องกัน ลดปัญหาลำดับเหตุการณ์ (causality)
- Data Model Mapping: กำหนด schema สำหรับ mapping ระหว่างข้อมูลเชิงกายภาพและ token ที่ LLM ใช้ โดยรวมฟิลด์ความเชื่อมั่น (confidence), latency และ provenance ของแต่ละเหตุการณ์
- Sandboxed Command Interface: ควรออกแบบช่องทางสั่งการโดยแยกคำสั่งที่เป็น “proposal” จากคำสั่งที่เป็น “execution” — Grid‑Agent ส่งข้อเสนอคำสั่งไปยัง EMS/SCADA ผ่าน API ที่ต้องได้รับการอนุมัติหรือผ่านกลไก human‑in‑the‑loop ตามนโยบาย
มาตรการความปลอดภัยไซเบอร์และการควบคุมสิทธิ์
การนำ LLM เข้ามามีบทบาทในการควบคุมกระบวนการเชิงปฏิบัติการจำเป็นต้องใช้มาตรการด้านความปลอดภัยหลายชั้น (defense‑in‑depth) ทั้งด้าน authentication, encryption, monitoring และ recovery โดยหลักปฏิบัติที่ควรบังคับใช้คือ:
- Authentication & Authorization: ใช้ Mutual TLS สำหรับการเชื่อมต่อระหว่าง Grid‑Agent และ SCADA/EMS, ผสานกับระบบ PKI สำหรับการจัดการใบรับรองในระดับอุปกรณ์และบริการ และบังคับใช้ RBAC/ABAC เพื่อให้สิทธิ์น้อยที่สุด (least privilege)
- Encryption: ปกป้องการส่งข้อมูลด้วย TLS 1.3 หรือมาตรฐานที่เทียบเท่า รวมถึงการเข้ารหัสข้อมูลขณะพัก (at‑rest) โดยใช้ฮาร์ดแวร์ HSM สำหรับการจัดการคีย์ที่สำคัญ
- Intrusion Detection & Monitoring: ติดตั้ง IDS/IPS และ SIEM เพื่อวิเคราะห์เทเลเมทรีแบบเรียลไทม์ และใช้โมเดลตรวจจับความผิดปกติ (anomaly detection) ที่เทรนจากทราฟฟิกปกติของกริดเพื่อจับพฤติกรรมแปลกปลอม
- Command Signing & Non‑repudiation: ให้ทุกคำสั่งควบคุมมีลายเซ็นดิจิทัลและหมายเลขอ้างอิง เพื่อให้สามารถตรวจสอบแหล่งที่มาและป้องกันคำสั่งที่ถูกดัดแปลง
- Rollback & Fail‑safe Mechanisms: สร้างกลไก circuit‑breaker และ rollback อัตโนมัติเมื่อพบว่าการดำเนินการมีผลกระทบรุนแรง เช่น การคืนค่าสถานะจาก snapshot/HSM checkpoint หรือการสั่งยกเลิกการเปลี่ยนแปลงผ่าน safe‑stop procedure
- Immutable Vector‑Event Logs: เก็บบันทึกเหตุการณ์เป็นรูปแบบ immutable (เช่น WORM storage หรือ hash‑chained ledger) พร้อมการเก็บ metadata ของ LLM prompt/response เพื่อการตรวจสอบย้อนหลังและตอบสนองข้อกฎหมาย
ข้อกังวลด้านกฎระเบียบ ความรับผิดชอบ และการกำกับดูแล
การอนุญาตให้ AI ส่งคำสั่งในระบบโครงสร้างพื้นฐานที่สำคัญมีด้านกฎหมายและข้อบังคับหลายมิติ หน่วยงานกำกับดูแลมักกำหนดให้มีการควบคุมสิทธิ์การดำเนินงาน การรายงานเหตุการณ์ และแนวทางการรับผิดชอบเมื่อเกิดความเสียหาย ดังนี้:
- การกำกับดูแลและมาตรฐานที่เกี่ยวข้อง: ปฏิบัติตามมาตรฐานสากลเช่น IEC 62443 สำหรับ OT security, NERC CIP (ในกรอบสากล) และข้อกำหนดของหน่วยกำกับในประเทศ เช่น กรอบกฎระเบียบด้านพลังงานหรือไซเบอร์ของหน่วยงานรัฐ
- Human‑in‑the‑Loop versus Full Automation: กำหนดชัดเจนว่าคำสั่งประเภทใด AI สามารถสั่งโดยตรงได้ และคำสั่งใดต้องผ่านการอนุมัติของมนุษย์ (e.g., thresholds สำหรับการสลับสายส่งหรือ shed load ขนาดใหญ่) พร้อมบันทึกกระบวนการอนุมัติทุกขั้นตอน
- ความรับผิดชอบเมื่อเกิดเหตุ: ระบุความรับผิดชอบทางแพ่งและอาญาสำหรับผู้ปฏิบัติการ ผู้พัฒนาอัลกอริทึม และผู้ให้บริการคลาวด์ รวมถึงนิยามเหตุการณ์ไม่พึงประสงค์ (incident) และกรอบการแจ้งเตือนต่อหน่วยงานกำกับทันที
- ความโปร่งใสและการตรวจสอบได้: นโยบายต้องระบุการเก็บ log, การจัดเก็บ prompt/response ของ LLM, และการเปิดเผยการตัดสินใจที่สำคัญเพื่อให้ผู้ตรวจสอบ (auditors) สามารถทวนสอบได้
ข้อเสนอแนะสำหรับการทดสอบความปลอดภัยก่อนใช้งานจริง
ก่อนนำ Grid‑Agent ไปใช้งานในสภาพแวดล้อมจริง ควรทำการทดสอบหลายชั้นทั้งในเชิงเทคนิคและเชิงกำกับดูแล เพื่อความมั่นใจว่าไม่เกิดผลกระทบต่อความปลอดภัยและความมั่นคงของกริด แนวปฏิบัติที่แนะนำได้แก่:
- สร้าง Testbed และ Digital Twin: จำลองสภาพกริดจริงด้วย HIL (hardware‑in‑the‑loop) และ digital twin เพื่อทดสอบการโต้ตอบของ Grid‑Agent กับ SCADA/EMS โดยไม่กระทบระบบจริง
- End‑to‑End Functional Testing: ทดสอบ latency, throughput และความถูกต้องของคำสั่งในทุกเส้นทางการสื่อสาร (รวมทั้งการแปลงโปรโตคอล) โดยมี KPI เช่นเวลาตอบสนองเฉลี่ย, อัตราการดำเนินการสำเร็จ และอัตราการ false positive
- Red‑Team / Penetration Testing: จัดทำการทดสอบการโจมตีโดยภายนอกและภายใน พร้อมประเมินความสามารถของ IDS/IPS และ SIEM ในการตรวจจับและตอบสนอง
- Failover & Rollback Drills: ฝึกซ้อมสถานการณ์ล้มเหลว เช่น network partition, corrupted command และตรวจสอบว่า rollback mechanism, snapshot restore และ manual override ทำงานได้ตามข้อกำหนด
- Compliance & Audit Trail Review: ตรวจสอบว่า vector‑event logs และ audit trail มีความครบถ้วน ไม่สามารถแก้ไขย้อนหลังได้ และสอดคล้องกับข้อกำหนดการเก็บรักษาข้อมูลของหน่วยงานกำกับ
- Tabletop Exercises กับผู้มีส่วนได้ส่วนเสีย: จัดการซ้อมสถานการณ์ร่วมกับผู้ควบคุมระบบ ผู้บริหาร และหน่วยกำกับ เพื่อประเมินกระบวนการตัดสินใจ การสื่อสาร และบทบาทความรับผิดชอบเมื่อเกิดเหตุ
โดยสรุป การบูรณาการ Grid‑Agent เข้ากับ SCADA/EMS ต้องออกแบบสถาปัตยกรรมที่รองรับการแปลงโปรโตคอล การยืนยันตัวตนและการเข้ารหัสที่เข้มงวด พร้อมกลไกตรวจจับและฟื้นฟู เมื่อผนวกกับนโยบายกำกับดูแลที่ชัดเจน (รวมถึงข้อกำหนด human‑in‑the‑loop) และกระบวนการทดสอบที่ครอบคลุม จะช่วยให้การนำ LLM มาควบคุมการกระจายโหลดฉุกเฉินเพิ่มประสิทธิภาพของกริดได้โดยลดความเสี่ยงเชิงปฏิบัติการและกฎหมาย
ผลกระทบเชิงธุรกิจและอนาคต: การขยายผลและความเป็นไปได้เชิงพาณิชย์
ผลกระทบเชิงธุรกิจโดยรวม
การทดสอบ Grid‑Agent ที่ช่วยให้ LLM ควบคุมการกระจายโหลดฉุกเฉินและใช้เวกเตอร์‑บันทึกเหตุการณ์เรียลไทม์มีความหมายเชิงธุรกิจชัดเจน: การลดค่าใช้จ่ายพีคราว 12% ที่รายงานจากการทดลองชี้ให้เห็นถึงศักยภาพในการประหยัดค่าใช้จ่ายเชิงปฏิบัติการ (OPEX) ในระดับระบบกริด การลดพีคนี้ไม่เพียงลดต้นทุนพลังงานโดยตรง แต่ยังลดภาระการจัดหาไฟฟ้าสำรอง การชำระค่าความจุ และค่าใช้จ่ายจากการใช้เชื้อเพลิงราคาแพงในช่วงพีค ซึ่งเมื่อรวมกับเมตริกการดำเนินงานอื่น ๆ อาจแปลเป็นการปรับปรุง system marginal cost และความน่าเชื่อถือของกริดโดยรวม
โมเดลการจัดเก็บมูลค่าเชิงพาณิชย์
การแปลงประสิทธิภาพทางเทคนิคเป็นรายได้หรือการประหยัดที่จับต้องได้สามารถทำได้หลายรูปแบบ ขึ้นกับขอบเขตการใช้งานและโครงสร้างตลาดพลังงาน:
- SaaS (Software‑as‑a‑Service): ให้บริการ Grid‑Agent แบบสมัครสมาชิก พร้อมการอัปเดตโมเดล LLM และการบำรุงรักษาเวกเตอร์‑บันทึก เหมาะกับผู้ประกอบการไดนามิกที่ไม่ต้องการลงทุน CAPEX สูง
- Licensing & On‑premises: โซลูชันติดตั้งภายในสำหรับผู้ประกอบการที่มีข้อกำกับดูแลเข้มงวด ต้องการควบคุมข้อมูลและ latency ต่ำ
- Performance‑based contracts: เก็บค่าตอบแทนตามเปอร์เซ็นต์ของค่าใช้จ่ายที่ประหยัดได้หรือค่าบริการความยืดหยุ่นที่จัดหาให้ (เช่น demand response หรือ ancillary services)
- Marketplace & Aggregation: การจับคู่ความยืดหยุ่นของโหลดกับตลาดพลังงานแบบเรียลไทม์และแพลตฟอร์ม VPP เพื่อแบ่งปันรายได้จากการให้บริการความยืดหยุ่น
ตัวอย่างเชิงตัวเลข: หากโอเปอเรเตอร์มีต้นทุนพีครวม 100 ล้านบาทต่อปี การลดได้ 12% สามารถแปลเป็นการประหยัดได้ 12 ล้านบาทต่อปี — ซึ่งหากคิด ROI ในรูปแบบ SaaS ด้วยค่าบริการที่เหมาะสม สามารถคืนทุนได้ภายใน 1–3 ปีในเครือข่ายที่มีอัตราพีคสูง
โอกาสและอุปสรรคในการสเกลระบบ
การขยายผล Grid‑Agent จากการทดลองสู่การใช้งานเชิงพาณิชย์ในระดับประเทศหรือข้ามโอเปอเรเตอร์ต้องเผชิญกับปัจจัยสำคัญหลายด้าน:
- Data governance: ข้อมูลเชิงเหตุการณ์และเวกเตอร์‑บันทึกเป็นข้อมูลความละเอียดสูงที่อาจมีข้อมูลส่วนบุคคลหรือข้อมูลเชิงปฏิบัติการที่อ่อนไหว จำเป็นต้องมีกฎเกณฑ์การเข้าถึง การจัดเก็บ และการอนุญาตใช้งานที่ชัดเจน รวมถึงการปฏิบัติตามมาตรฐานความเป็นส่วนตัวและกฎระเบียบของภาครัฐ
- Interoperability: ระบบต้องทำงานร่วมกับ SCADA/EMS, AMI และโปรโตคอลระดับอุตสาหกรรม (IEC 61850, DNP3 ฯลฯ) ได้อย่างราบรื่น การมี API มาตรฐานและชั้นแปลภาษาสำหรับสัญญาณและเหตุการณ์เป็นข้อจำเป็น
- Operational readiness: การบูรณาการ LLM ในการตัดสินใจเชิงปฏิบัติการต้องมีระบบยืนยัน ผลิตภัณฑ์สำหรับการตรวจสอบย้อนกลับ (audit trail) และกลไกมนุษย์ยืนยัน (human‑in‑the‑loop) เพื่อจัดการความเสี่ยงจากความผิดพลาดของแบบจำลอง และลดความกังวลด้านความปลอดภัย
- Cybersecurity & resilience: การเปิดช่องควบคุมกริดให้กับระบบอัตโนมัติใหม่เพิ่มพื้นความเสี่ยง ต้องใช้แนวทาง defense‑in‑depth, การตรวจจับการเปลี่ยนแปลง (anomaly detection) บนเวกเตอร์‑บันทึก และการอัปเดตแพตช์อย่างต่อเนื่อง
แนวโน้มอนาคต: Multi‑agent, Edge AI และการผสาน VPP/DER
ทิศทางการวิจัยและพัฒนาที่น่าจับตามองสำหรับการต่อยอด Grid‑Agent ประกอบด้วย:
- Multi‑agent coordination: การขยายสถาปัตยกรรมจากตัวกลางเดียวไปสู่ชุดของเอเจนต์ที่ประสานงานกันจะช่วยให้สามารถจัดการความซับซ้อนและความขัดแย้งของทรัพยากรได้ดีขึ้น ตัวอย่างการใช้งานคือการประสานกันระหว่างเอเจนต์ของโซนต่าง ๆ เพื่อลดการหนาแน่นของพีคโดยไม่กระทบต่อคุณภาพไฟฟ้า
- Edge AI: การย้ายบางฟังก์ชันไปยังอุปกรณ์ขอบเครือข่าย (substation, gateway ของ VPP หรือแม้แต่ smart inverters) จะลด latency และความต้องการแบนด์วิดท์ของศูนย์ข้อมูล ในสถานการณ์ฉุกเฉิน การตัดสินใจที่เกิดขึ้นบน edge ช่วยให้ตอบสนองได้รวดเร็วและปรับตัวตามเงื่อนไขท้องถิ่น
- การผสานกับ VPP/DER: เมื่อผสานกับ Virtual Power Plants และ Distributed Energy Resources จะเพิ่มศักยภาพในการลดพีคและสร้างแหล่งรายได้ใหม่ผ่านการขายบริการ ancillary, balancing และ frequency regulation — การวิจัยที่สำคัญคือการสร้างกลไก incentive และการควบคุมเชิงเศรษฐศาสตร์ระหว่างเอเจนต์ต่าง ๆ
- มาตรฐานและตลาดสำหรับข้อมูลความยืดหยุ่น: การพัฒนามาตรฐานการแลกเปลี่ยนเวกเตอร์‑เหตุการณ์และตลาดสำหรับความยืดหยุ่น (flexibility markets) จะช่วยให้โอเปอเรเตอร์และผู้ให้บริการบันทึกมูลค่าเชิงพาณิชย์ได้ง่ายขึ้น
สรุปแล้ว การนำ Grid‑Agent เข้าสู่การใช้งานเชิงพาณิชย์มีศักยภาพสูงในการลดต้นทุนและเพิ่มความยืดหยุ่นของกริด โดยโมเดลธุรกิจที่เป็นไปได้มีตั้งแต่ SaaS ไปจนถึงสัญญาค่าตอบแทนตามผลการปฏิบัติงาน อย่างไรก็ตาม ความท้าทายด้าน governance, interoperability และ readiness ด้านปฏิบัติการต้องได้รับการจัดการควบคู่ไปกับการลงทุนในความมั่นคงปลอดภัยและการฝึกอบรมบุคลากร หากสามารถผสานแนวทาง multi‑agent, edge AI และ VPP/DER ได้สำเร็จ โอกาสในการสร้างรายได้จากบริการความยืดหยุ่นและการเพิ่มประสิทธิภาพเชิงระบบจะมีมูลค่าสูงและยั่งยืนในระยะยาว
บทสรุป
Grid‑Agent ซึ่งผสานความสามารถของ Large Language Model (LLM) เข้ากับเวกเตอร์‑บันทึกเหตุการณ์แบบเรียลไทม์ เป็นแนวทางใหม่ในการจัดการการกระจายโหลดฉุกเฉินที่เน้นทั้งการตัดสินใจเชิงบริบทและการติดตามสถานะแบบละเอียด การทดสอบเบื้องต้นของโอเปอเรเตอร์พลังงานไทยชี้ให้เห็นว่าแนวทางดังกล่าวช่วยลดค่าใช้จ่ายพีคได้ถึง 12% โดยระบบสามารถวิเคราะห์เหตุการณ์แบบต่อเนื่อง ประสานการตอบสนองของทรัพยากร (เช่น demand response, การเลื่อนโหลด, การควบคุมแหล่งกำเนิดสำรอง) และลดการพึ่งพาเครื่องกำเนิดพีกราคาแพง ผลลัพธ์เพิ่มเติมรวมถึงความยืดหยุ่นของกริดที่เพิ่มขึ้นจากการตอบสนองที่รวดเร็วและมีบริบทมากขึ้น ช่วยให้ลดความเสี่ยงต่อการล้มเหลวเป็นวงกว้างและปรับปรุงความเสถียรในช่วงพีคโหลด
ในการนำไปใช้งานจริง จำเป็นต้องพิจารณาการบูรณาการกับระบบเดิม (SCADA/DMS, ตลาดพลังงาน), มาตรการความปลอดภัยไซเบอร์และความถูกต้องของข้อมูล (authentication, encryption, anomaly detection) รวมทั้งกรอบกฎระเบียบที่เกี่ยวข้อง (grid codes, market rules, auditability) ทั้งนี้ เวกเตอร์‑บันทึกเหตุการณ์แบบเรียลไทม์ช่วยให้มีเส้นทางตรวจสอบ (traceability) และการอธิบายการตัดสินใจเพื่อรองรับการตรวจสอบและการกำกับดูแลเชิงกฎเกณฑ์ ทางธุรกิจแล้ว Grid‑Agent มีศักยภาพสูงต่อการสเกลเพื่อประหยัดต้นทุนทั้งสำหรับโอเปอเรเตอร์และผู้บริโภค (ตัวอย่างเช่นลดค่าใช้จ่าย OPEX ของโอเปอเรเตอร์และลดค่าไฟฟ้าพีคของผู้บริโภค) แนวทางต่อไปควรเป็นการขยายการทดลอง, การตั้งเกณฑ์ประเมินสมรรถนะ, การพัฒนามาตรฐานร่วม และการจัดกรอบกำกับดูแลเพื่อให้เทคโนโลยีนี้ขยายตัวได้อย่างปลอดภัยและคุ้มค่าทางเศรษฐกิจ



