

บริการนี้ออกแบบมาให้รองรับการใช้งานในระดับองค์กรและเมืองอัจฉริยะ โดยผสานการประมวลผลแบบสตรีมมิ่งกับการแปลงข้อมูลหลายรูปแบบเป็นเวกเตอร์เพื่อการค้นหาเชิงความหมายและการแจ้งเตือนทันที เหมาะสำหรับงานความปลอดภัยสาธารณะ ระบบการจัดการกล้องวงจรปิดในเมือง การตรวจสอบสภาพการทำงานของเครื่องจักรในโรงงาน (predictive maintenance) และการวิเคราะห์พฤติกรรมจากเซนเซอร์ ตัวอย่างการใช้งาน เช่น ค้นหาเหตุการณ์การแตกกระจกจากเสียงในคลิป 24 ชั่วโมงภายในไม่กี่วินาที หรือการแจ้งเตือนเมื่อเวกเตอร์ของการสั่นสะเทือนในเครื่องจักรเบี่ยงเบนจากสภาวะปกติ ฟีเจอร์สำคัญยังรวมถึงการรองรับสเกลการเชื่อมต่อกล้อง/เซนเซอร์จำนวนมาก การค้นแบบโลคัลเพื่อคงข้อมูลในประเทศ และการรวมเข้ากับระบบจัดการเหตุการณ์ที่มีอยู่ขององค์กร
สรุปข่าวและความสำคัญเชิงธุรกิจ
สรุปข่าวและความสำคัญเชิงธุรกิจ
ผู้ให้บริการคลาวด์ไทยได้เปิดตัวบริการ Multi‑Modal Stream Indexing ซึ่งแปลงสตรีมวิดีโอ เสียง และข้อมูลจากเซนเซอร์เป็นเวกเตอร์แบบเรียลไทม์ เพื่อให้สามารถทำ historical event search หรือตรวจค้นเหตุการณ์ย้อนหลังได้ภายในวินาที (sub‑second search). บริการนี้เปลี่ยนแนวทางการจัดเก็บและค้นข้อมูลจากการเก็บไฟล์วิดีโอดิบแบบดั้งเดิมไปสู่การจัดทำดัชนีเชิงเวกเตอร์ที่พร้อมใช้สำหรับการค้นหาด้วยข้อความ ตัวอย่างภาพ และลักษณะเสียง ทำให้การค้นหาเชิงบริบทหลายมิติ (multi‑modal) เป็นไปได้ทันทีเมื่อเหตุการณ์เกิดขึ้นหรือเมื่อเรียกค้นย้อนหลัง
ในเชิงธุรกิจ บริการนี้ตอบโจทย์การใช้งานของหลายภาคส่วนที่ต้องการความเร็วและความแม่นยำสูง ได้แก่
- หน่วยงานความปลอดภัย — ค้นหาเหตุการณ์คดีหรือการบุกรุกจากฟุตเทจหลายแหล่งข้ามชั่วโมงหรือวันได้ภายในวินาที ช่วยลดเวลาตรวจสอบและเพิ่มความเร็วในการตอบสนอง
- เมืองอัจฉริยะ (Smart City) — ตรวจจับอุบัติเหตุจราจรหรือเหตุการณ์สาธารณะ และสืบย้อนที่มาของเหตุการณ์แบบเรียลไทม์เพื่อบริหารจัดการทราฟฟิกและบริการฉุกเฉิน
- โรงงานและอุตสาหกรรม — ผสานข้อมูลเซนเซอร์กับวิดีโอเพื่อระบุเหตุการณ์ความผิดปกติของเครื่องจักรหรือการละเมิดมาตรฐานความปลอดภัย และช่วยวิเคราะห์สาเหตุย้อนหลังอย่างรวดเร็ว
- ศูนย์ลูกค้าสัมพันธ์ (Contact Centers) — แปลงเสียงสนทนาเป็นเวกเตอร์สำหรับค้นหาการสนทนาเชิงบริบท คำร้องเรียนซ้ำ หรือแนวโน้มคุณภาพการบริการได้อย่างรวดเร็ว
เมื่อเทียบกับระบบเก็บไฟล์วิดีโอแบบดั้งเดิม บริการนี้ให้ข้อได้เปรียบเชิงธุรกิจหลายประการสำคัญ ได้แก่
- ความเร็วในการค้นหา: ระบบไฟล์เดิมมักต้องสืบค้นคลิปวิดีโอขนาดใหญ่ซึ่งกินเวลาเป็นนาทีหรือชั่วโมง ในขณะที่การค้นด้วยเวกเตอร์สามารถตอบกลับภายในวินาที ช่วยลดเวลาตัดสินใจและเพิ่มประสิทธิภาพการดำเนินงาน
- ลดภาระการจัดเก็บและโอนถ่ายข้อมูล: การจัดเก็บดัชนีเชิงเวกเตอร์มีขนาดเล็กกว่าการเก็บฟุตเทจดิบ ทำให้ประหยัดค่าใช้จ่าย storage และแบนด์วิธ โดยเฉพาะเมื่อต้องเก็บระยะยาว
- การวิเคราะห์เชิงบูรณาการ: เวกเตอร์รองรับการค้นหาข้ามโมดอลิตี เช่น คำสั่งค้นหาด้วยข้อความ รูปภาพ หรือเสียง ทำให้การสอบสวนและการวิเคราะห์เป็นไปอย่างรอบด้านโดยไม่ต้องเปิดดูวิดีโอทั้งหมด
- ขยายตัวและทำงานแบบเรียลไทม์: สถาปัตยกรรมการทำดัชนีแบบเรียลไทม์เอื้อให้ระบบรองรับสตรีมจำนวนมากจากกล้องและเซนเซอร์หลายจุด พร้อมตอบสนองเหตุการณ์ที่เกิดขึ้นทันที
- ลดแรงงานตรวจสอบด้วยตา: ลดความจำเป็นในการทบทวนฟุตเทจด้วยมนุษย์เป็นจำนวนมาก โดยให้ระบบช่วยกรองเหตุการณ์สำคัญก่อนนำเสนอผู้ปฏิบัติงาน
สรุปแล้ว บริการ Multi‑Modal Stream Indexing มีศักยภาพในการเปลี่ยนรูปแบบการจัดการข้อมูลสตรีมในไทยจากการเก็บไฟล์เป็นศูนย์กลางไปสู่การค้นหาและวิเคราะห์เชิงเวกเตอร์แบบเรียลไทม์ ซึ่งไม่เพียงเพิ่มความรวดเร็วในการตอบสนองและประสิทธิภาพการดำเนินงาน แต่ยังเปิดโอกาสทางธุรกิจใหม่ ๆ ทั้งบริการแบบ Managed Service การผนวกรวมกับระบบ CCTV/VMS เดิม และการพัฒนาแอพพลิเคชันวิเคราะห์เชิงคาดการณ์สำหรับภาครัฐและเอกชน
เทคโนโลยีเบื้องหลัง: โมเดลและการแปลงเป็นเวกเตอร์
เทคโนโลยีเบื้องหลัง: โมเดลและการแปลงเป็นเวกเตอร์
การแปลงสื่อหลายรูปแบบ (ภาพ วิดีโอ เสียง และข้อมูลเซนเซอร์) เป็นเวกเตอร์เชิงตัวเลข (embeddings) ในระบบ Multi‑Modal Stream Indexing อาศัยชุดเทคโนโลยีที่ประสานกันทั้งในระดับโมเดล การจัดแบ่งช่วงเวลา (segmentation/windowing) การซิงโครไนซ์เวลา และกลยุทธ์การฝึกเพื่อให้เวกเตอร์จากแต่ละโมดอลิตีมีความหมายร่วมกัน ระบบเช่นนี้ช่วยให้การค้นเหตุการณ์ย้อนหลัง (search/query) สามารถตอบได้ภายในวินาที โดยการค้นหาด้วยดัชนีบนเวกเตอร์แทนการสแกนสื่อดิบทั้งก้อน
ชนิดของโมเดลที่ใช้ สำหรับการดึงคุณลักษณะจากแต่ละโมดอลิตี มักใช้สถาปัตยกรรมที่ผ่านการพิสูจน์แล้วดังนี้:
- ภาพ/วิชัน: โมเดล CNN แบบลึก (เช่น ResNet) หรือสถาปัตยกรรม Transformer-based (เช่น ViT, CLIP-Vision) เพื่อสกัดคุณลักษณะเชิงพื้นที่และบริบทจากเฟรมเดียวหรือชุดเฟรมในวิดีโอ โดยมักออกมาเป็น embedding ขนาด 128/256/512
- วิดีโอ (temporal vision): 3D-CNN, I3D, SlowFast หรือ Vision Transformer ที่ต่อข้ามเวลา เพื่อจับการเคลื่อนไหวและเหตุการณ์ข้ามเฟรม การประมวลผลแบบขึ้นกรอบ (frame-level) ร่วมกับการทำ temporal pooling ช่วยให้ได้ embedding ของช่วงเวลา
- เสียง/ออดิโอ: โมเดลที่แปลงสเปกโตรแกรมเป็น embeddings เช่น CNN บน Mel-spectrogram, Wave2Vec 2.0, OpenL3 หรือ YAMNet สำหรับงานทั่วไป เช่น การรู้จำเสียงเหตุการณ์หรือสภาพแวดล้อม
- เซนเซอร์ (IoT/IMU/GPS): โมเดลแบบ RNN (LSTM/GRU), 1D-CNN หรือ Transformer แบบเรียงลำดับ เพื่อจับรูปแบบเชิงเวลาในข้อมูลแรงเร่ง ความเร่งเชิงมุม หรือพิกัด GPS โดยแปลงเป็นเวกเตอร์ที่สื่อความหมายของเหตุการณ์หรือพฤติกรรม
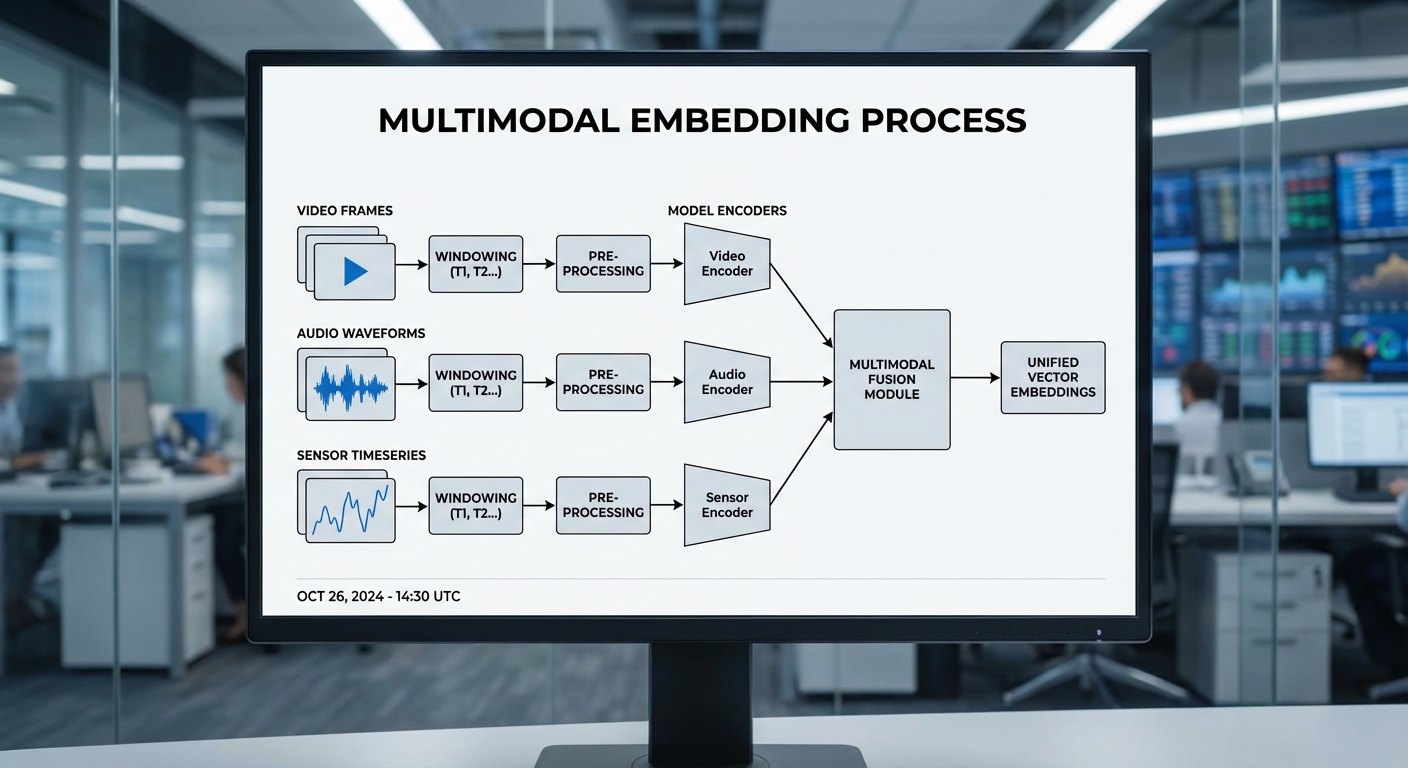
การแบ่งช่วงเวลา (windowing) และการจับคู่เหตุการณ์ข้ามโมดาลิตี เป็นหัวใจสำคัญของระบบสตรีมแบบเรียลไทม์ โดยมีกลยุทธ์ปฏิบัติที่นิยมใช้คือ:
- การแบ่งเป็น sliding windows ขนาดต่าง ๆ (เช่น 0.5–5 วินาทีสำหรับเสียง, 1–10 วินาทีสำหรับเหตุการณ์วิดีโอ) เพื่อสร้าง embedding ต่อช่วงเวลา ช่วยให้สามารถค้นหาเหตุการณ์สั้น ๆ ได้แม่นยำ
- การทำ segmentation ตามเหตุการณ์ที่ตรวจพบ (event-driven segmentation) เช่น เมื่อโมดูล VAD (voice activity detection) ตรวจพบเสียงหรือเมื่อตัวตรวจจับการเคลื่อนไหวรายงานเหตุการณ์ จะเริ่มสร้าง embedding สำหรับช่วงนั้น
- การซิงโครไนซ์ด้วย timestamp ระหว่างโมดอลิตีเป็นสิ่งจำเป็น ระบบจะปรับไทม์สแตมป์ให้มีช่วงเวลาร่วม (time alignment) เช่น การทำ resampling หรือการใช้ NTP/GPS time sync ในสเกลเวลาจริง เพื่อให้สามารถจับคู่เหตุการณ์เสียงกับภาพและข้อมูลเซนเซอร์ได้อย่างแม่นยำ
- การจับคู่ข้ามโมดาลิตี (cross‑modal matching) มักใช้การจับคู่เชิงเวลาเป็นขั้นแรก (temporal overlap) แล้วตามด้วยการคำนวณความใกล้เคียงของ embedding (เช่น cosine similarity) เพื่อยืนยันการสอดคล้องของเหตุการณ์
มิติของ embedding (128/256/512) และผลต่อความแม่นยำกับพื้นที่จัดเก็บ เป็นตัวเลือกเชิงออกแบบที่ต้องปรับสมดุลกัน:
- ขนาดเล็ก (เช่น 64–128): ให้พื้นที่จัดเก็บและแบนด์วิดท์ต่ำ เหมาะกับการค้นหาแบบกว้างหรือสถานการณ์ที่ต้องการ latency ต่ำ แต่ความสามารถจำแนก (discriminative power) จะต่ำกว่า
- ขนาดกลาง (เช่น 256): เป็นค่ากลางที่นิยม ใช้งานทั่วไปได้ดีทั้งด้านความแม่นยำและค่าใช้จ่ายในการเก็บ โดยปกติจะให้ความแม่นยำที่ยอมรับได้ในระบบค้นหาเหตุการณ์
- ขนาดใหญ่ (เช่น 512+): เพิ่มความละเอียดเชิงคุณลักษณะ ทำให้ระบบจับความแตกต่างของเหตุการณ์ได้ดีขึ้น โดยการทดลองภายในและงานวิจัยหลายฉบับชี้ว่าอาจเพิ่มความแม่นยำของการค้น (mAP หรือ recall) ราว 2–6% เมื่อเทียบกับ 256 แต่พื้นที่จัดเก็บและเวลาคำนวณ (indexing/NN search) จะเพิ่มขึ้นเกือบเป็นสัดส่วน (ตัวอย่าง: embedding 512 จะใช้พื้นที่ประมาณ 2 เท่าเมื่อเทียบกับ 256)
ในทางปฏิบัติ ระบบขนาดใหญ่ของผู้ให้บริการคลาวด์มักออกแบบเป็นชั้น ๆ (tiered embeddings): เก็บ embedding ขนาดเล็กเพื่อการกรองเบื้องต้น (coarse filtering) แล้วดึง embedding ขนาดใหญ่กว่าเพื่อตรวจสอบเชิงลึกเมื่อตรงตามเกณฑ์ โดยการประเมินค่าใช้จ่าย-ประสิทธิภาพมักใช้ตัวชี้วัดเช่น latency ต่อคำค้นและต้นทุน storage ต่อล้านวินาทีของสตรีม
เทคนิคการฝึกและการผสานโมดอลิตี เป็นสิ่งที่ทำให้ embeddings จากโมดอลิตีต่าง ๆ สามารถเปรียบเทียบและผสานได้อย่างมีความหมาย:
- Contrastive learning (เช่น CLIP-style) ฝึกโมเดลให้ดึง embedding ของตัวอย่างที่ตรงกันข้ามมาใกล้กันใน latent space และแยกตัวอย่างที่ไม่ตรงกันออกไป วิธีนี้ช่วยให้ embedding ของภาพและข้อความ/เสียงที่สอดคล้องกันสามารถจับคู่ข้ามโมดาได้
- Multimodal fusion มีแบบ early fusion (รวมข้อมูลดิบก่อนเข้าสู่โมเดล), late fusion (รวมผลลัพธ์/embeddings หลังโมเดลแยก), และ joint fusion (โมเดลเดียวที่เรียนรู้ตัวแทนร่วม) การเลือกวิธีขึ้นกับแบนด์วิดท์ ความจำ และความต้องการ latency ของแอปพลิเคชัน
- Alignment losses เช่น cross‑modal matching loss หรือ triplet loss ช่วยให้ embedding จาก audio/video/sensor อยู่ในสเปซร่วมกัน ทำให้คำค้นจากโมดอลิตีหนึ่งสามารถเรียกคืนเหตุการณ์ในอีกโมดอลิตีได้
- การใช้เทคนิคเช่น temporal contrastive learning ช่วยให้โมเดลเข้าใจความสัมพันธ์ข้ามเวลา เช่น การจับคู่เสียงประตูปิดกับเฟรมการเคลื่อนไหวของประตูภายในช่วงเวลาเล็ก ๆ
สรุปคือ การแปลงสื่อหลายรูปแบบเป็นเวกเตอร์ในระบบสตรีมเรียลไทม์ประกอบด้วยการเลือกโมเดลที่เหมาะสมต่อโมดอลิตี การจัดการแบ่งช่วงเวลาและซิงโครไนซ์ไทม์สแตมป์อย่างเคร่งครัด รวมถึงการออกแบบมิติของ embedding ให้สมดุลระหว่างความแม่นยำและต้นทุนเก็บข้อมูล ทั้งนี้การนำเทคนิคการเรียนรู้เชิงคอนทราสทีฟและการผสานข้อมูลหลายโมดอลิตีเข้าด้วยกันเป็นกุญแจที่ทำให้การค้นเหตุการณ์ย้อนหลังในระดับวินาทีเป็นไปได้จริงในสภาพแวดล้อมคลาวด์ของผู้ให้บริการไทย
สถาปัตยกรรมระบบและการทำงานแบบเรียลไทม์
สถาปัตยกรรมระบบและการทำงานแบบเรียลไทม์ (Real‑Time)
สถาปัตยกรรมของบริการ Multi‑Modal Stream Indexing ถูกออกแบบเป็นท่อการประมวลผล (pipeline) แบบเรียลไทม์ โดยแบ่งเป็นส่วนประกอบหลัก 5 ชั้นคือ Ingest → Preprocess → Embedding → Index → Query เพื่อให้สามารถแปลงข้อมูลวิดีโอ เสียง และเซนเซอร์เป็นเวกเตอร์แล้วค้นย้อนหลังได้ภายในวินาที จุดสำคัญคือการรักษา latency ต่ำสุดและรองรับสเกลของสตรีมจำนวนมากพร้อมกัน โดยผสานเทคนิคการจัดคิว/บัฟเฟอร์ การทำ batching ขนาดเล็ก model quantization และการใช้ไลบรารี ANN ระดับโปรดักชัน
ในขั้นตอน Ingest ระบบมักใช้ message broker ที่ทนทานต่อโหลดสูง เช่น Apache Kafka, Apache Pulsar หรือ Redis Streams เพื่อรับสตรีมแบบต่อเนื่องจากอุปกรณ์และแหล่งสื่อ ตัว broker จะแยก partition ตามแหล่งสตรีมหรือกลุ่มอุปกรณ์เพื่อให้สามารถขยายแบบเฉพาะจุด (partitioned scaling) และเก็บ metadata ของเหตุการณ์ (เช่น timestamp, source id, sequence) สำหรับการสืบค้นย้อนหลัง ตัวอย่างเชิงตัวเลข: สมมติระบบต้องรับ 10,000 สตรีมวิดีโอขนาด 1‑2 Mbps ต่อสตรีม จะต้องรองรับ ingest throughput ประมาณ 10–20 Gbps และมี partition อย่างน้อย 1,000‑2,000 เพื่อกระจายงานให้กับนักประมวลผล

ขั้นตอน Preprocess จะทำงานแบบสตรีมมิงเพื่อเตรียมข้อมูลให้โมเดล เช่น การ decode เฟรม, frame sampling (เช่น 1–5 fps สำหรับการสังเกตการณ์ทั่วไป), VAD (voice activity detection) สำหรับเสียง, normalization และการรวมข้อมูลจากเซนเซอร์ต่างชนิด ระบบจะใช้ buffer ขนาดเล็ก (เช่น sliding window 0.5–2 วินาที) เพื่อให้สามารถรวมข้อมูลจนเพียงพอสำหรับการทำ inference โดยไม่เพิ่ม latency มากนัก ที่ระดับระบบมักนำเทคนิค backpressure มาใช้กับ broker เพื่อป้องกันการล้นของ worker เมื่อโหลดพีก
ในขั้นตอน Embedding เป็นการเรียกใช้งานโมเดลสกัดคุณลักษณะ (feature extraction) แบบเรียลไทม์ ซึ่งอาจเป็นโมเดลหลายโมดูล (เช่น CNN/ViT สำหรับวิดีโอ, transformer/TCN สำหรับเสียง, MLP สำหรับข้อมูลเซนเซอร์) เทคนิคที่ใช้ลด latency ได้แก่:
- Batching แบบขนาดเล็ก — เก็บตัวอย่างเป็น micro‑batches ขนาด 4–16 เพื่อเพิ่ม throughput ของ GPU/TPU โดยยังรักษา latency ภายใน 100–300 ms
- Model quantization — แปลงโมเดลเป็น int8/FP16 ลดเวลา inference ได้ 2–4× และลดการใช้ memory/copy overhead
- Dynamic batching — รวมคำขอภายใน latency budget (เช่นรอสูงสุด 20–50 ms ก่อนส่ง batch) เพื่อเพิ่มประสิทธิภาพโดยไม่กระทบประสบการณ์เรียลไทม์
- Multi‑tenant inference pools — แยก pool ระหว่างโมเดล latency‑sensitive และ throughput‑oriented เพื่อจัดสรรทรัพยากรอย่างมีประสิทธิภาพ
หลังจากได้เวกเตอร์แล้ว ระบบจะเขียนทั้งเวกเตอร์และ metadata ไปยัง Vector DB (เช่น Milvus, Weaviate, หรือฐานข้อมูลที่ใช้ FAISS/HNSW) พร้อมกับเขียนเหตุการณ์สำคัญลงใน event store สำหรับการกรองตามเวลา (time index) การจัดการเขียนต้องคำนึงถึง throughput: สมมติ embedding ขนาด 512 มิติ และสร้างเวกเตอร์ 5,000 จุดต่อวินาที ระบบต้องรองรับการเขียนดิบอย่างน้อย 5k writes/s และการ replicate/commit ให้พร้อมใช้งานภายในไม่กี่ร้อยมิลลิวินาที
การทำดัชนีเพื่อค้นหาด้วย ANN (Approximate Nearest Neighbor) เป็นหัวใจของความเร็วในการค้นย้อนหลัง โดยพารามิเตอร์สำคัญ เช่น โครงสร้าง HNSW (เลเยอร์ M, efConstruction, efSearch), หรือการใช้ IVF+PQ กับ FAISS ที่ปรับให้เหมาะสมกับมิติของเวกเตอร์ เทคนิคลด latency ในชั้น index ได้แก่:
- ใช้ HNSW สำหรับ latency ต่ำ (ค้นหาเฉลี่ย 1–10 ms ต่อ query) โดยเพิ่ม efSearch เมื่อความแม่นยำต้องสูงขึ้น
- ใช้ PQ/Quantization เพื่อลดขนาดของดัชนีและเพิ่ม cache locality
- ปรับ sharding ของดัชนีแบบ time‑partitioned เพื่อจำกัดขอบเขตการค้นหาเฉพาะหน้าต่างเวลา (เช่นค้นใน 5 นาทีที่ผ่านมา) ลดพื้นที่ค้นหาและเวลาตอบ
- ใช้ GPU acceleration สำหรับ ANN เมื่อต้องการ throughput สูง (หลายร้อย queries/s) พร้อมจัดการ hot shards บนหน่วยความจำรวดเร็ว
ชั้น Query ให้ API แบบย้อนเวลา (time‑windowed ANN search) ที่รองรับการกรอง metadata เช่น source id, severity, และ time range เพื่อให้การค้นหาเป็นไปอย่างมีประสิทธิภาพ ตัวอย่างโฟลว์การสืบค้น:
- ผู้ใช้ส่งคำขอ: "ค้นเหตุการณ์ที่เหมือนกับคลิปนี้ ในช่วง 10 นาทีที่ผ่านมา"
- API ตรวจสอบ time window แล้วแยก shard ของดัชนีที่เกี่ยวข้อง
- ทำ ANN search ภายใน shard ที่ถูกกรอง พร้อมรับคะแนนความใกล้เคียง (score) และ metadata
- คืนผลพร้อมลำดับเหตุการณ์ย้อนหลังที่ตรงตามเงื่อนไขภายในวินาที (SLA ตัวอย่าง: 90% ของคำขอภายใน 500 ms สำหรับ 95th percentile)
สำหรับการปรับสเกลและรองรับสตรีมจำนวนมาก ระบบออกแบบให้ขยายได้ทั้งแนวนอน (scale‑out) และแนวตั้ง (scale‑up):
- การขยาย Ingest/Preprocess: เพิ่มจำนวน consumer/worker ใน Kafka/Pulsar partitions (เช่นจาก 100 → 1,000 workers) เพื่อรองรับ 100k+ concurrent streams
- การขยาย Embedding: เพิ่มเครื่อง GPU/TPU และใช้ model sharding หรือ batching แบบไดนามิก ตัวอย่างสมมติ: GPU 1 ตัวให้บริการ embed 200–400 requests/s (int8) => ต้องการ 50 GPUs เพื่อรองรับ 20k req/s
- การขยาย Index: shard ดัชนีตามช่วงเวลาและกลุ่มข้อมูล พร้อมทำ replication สำหรับความคงทน โดยตั้งค่า efSearch/efConstruction ให้สมดุลระหว่างความแม่นยำกับ latency
- ระบบมอนิเตอร์และ autoscaling: ตั้งค่า scaling policy บน queue length, CPU/GPU utilization และ tail latency เพื่อขยาย/ย่อตัวอัตโนมัติเมื่อเกิดพีก
สรุป: การออกแบบสถาปัตยกรรมสำหรับ Multi‑Modal Stream Indexing ต้องผสานการจัดคิวที่เชื่อถือได้ การ preprocess แบบ streaming การ inference ที่ปรับแต่งเพื่อลด latency (micro‑batching, quantization) และดัชนี ANN ที่ปรับขนาดได้ รวมถึง API สำหรับการค้นย้อนเวลาที่รองรับการกรองตาม timestamp ตัวอย่างตัวเลขและพารามิเตอร์ข้างต้นเป็นแนวทางเชิงปฏิบัติที่ช่วยให้ระบบสามารถตอบคำขอย้อนหลังได้ภายในวินาที แม้จะต้องประมวลผลสตรีมจำนวนมากพร้อมกัน
การวัดผล ประสิทธิภาพ และเบนช์มาร์กตัวอย่าง
การวัดผล ประสิทธิภาพ และเบนช์มาร์กตัวอย่าง
ทีมทดสอบจัดทำเบนช์มาร์กจำลอง (mock benchmark) เพื่อประเมินบริการ Multi‑Modal Stream Indexing ในสภาพแวดล้อมที่ใกล้เคียงการใช้งานจริง โดยใช้ชุดข้อมูลขนาด 1,000 ชั่วโมง (1080p) ประกอบด้วยวิดีโอ สตรีมเสียง และข้อมูลเซนเซอร์ (เช่น GPS, accelerometer) โดยสมมติฮาร์ดแวร์ทดสอบเป็นเครื่องที่ติดตั้ง NVIDIA A100 GPU หนึ่งตัว, 32 vCPU, 128 GB RAM และเครือข่าย 10 Gbps การทดสอบครอบคลุมการแปลงสตรีมเป็น embedding แบบเรียลไทม์ การสร้างดัชนี (indexing) และการค้นหาเหตุการณ์ย้อนหลังด้วยคิวรีแบบข้อความ รูปภาพ และตัวอย่างเสียง
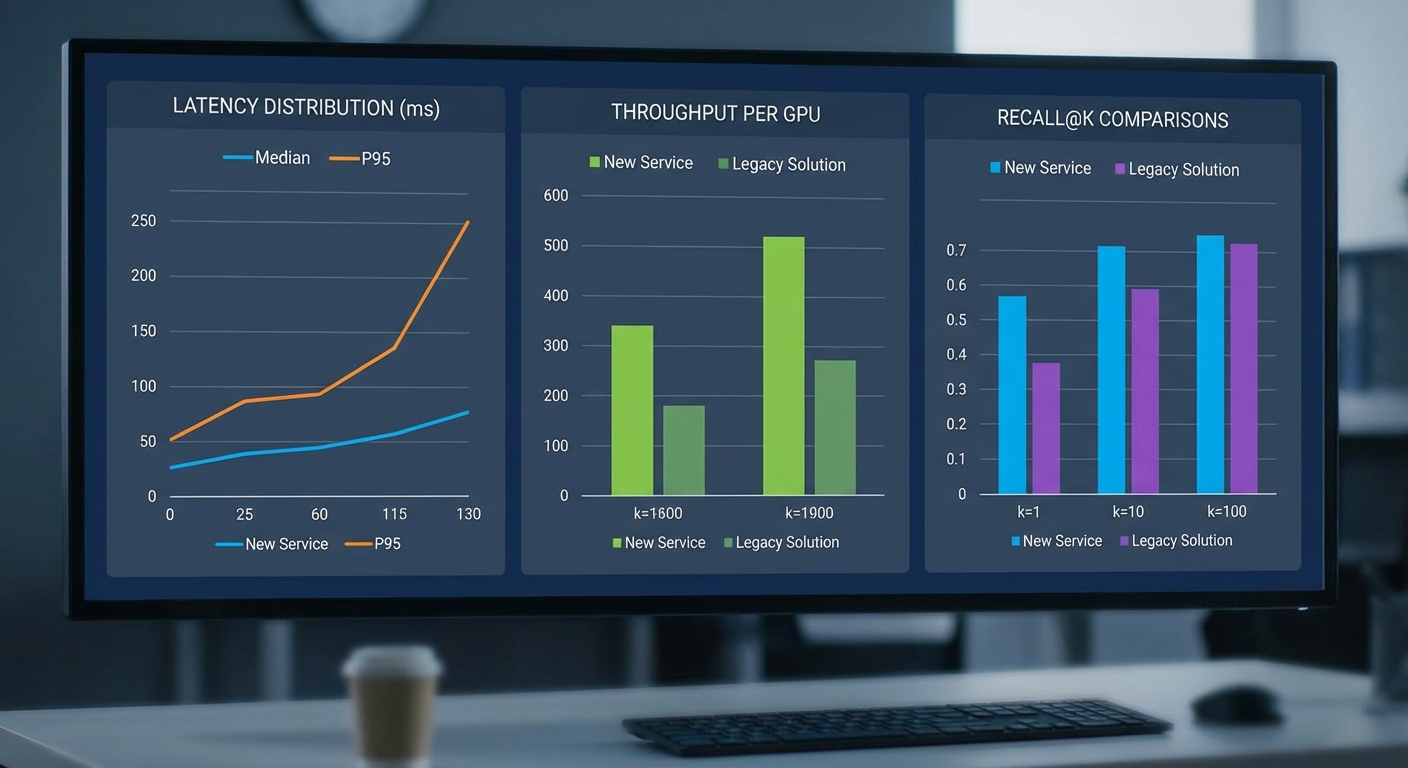
ผลการทดสอบเชิงตัวเลขที่สำคัญ ได้แก่
- Latency สำหรับการค้นหาเหตุการณ์ย้อนหลัง (query → top-K results): median = 0.8 วินาที, P95 = 1.9 วินาที (สำหรับคิวรีแบบ text-to-video บนดัชนีขนาด ~1M embeddings)
- Throughput ในการแปลงสตรีมเป็น embedding: ประสิทธิภาพเฉลี่ยแปลงได้ ~50 fps ต่อ GPU (สำหรับโมดูลวิดีโอ 256–512 dim); เมื่อลดมิติหรือใช้ batch เก็บประสิทธิภาพสามารถเพิ่มเป็น 80–120 fps ต่อ GPU
- Recall@10 (วัดจากชุดคำถาม 1,000 คิวรีที่เป็นเหตุการณ์จริง): recall@10 ≈ 0.82 (82%) ที่ embedding dimension = 512; ตัวอย่างค่าที่เปรียบเทียบคือ 128‑dim => recall@10 ≈ 0.74, 256‑dim => ≈ 0.80
- ขนาดการจัดเก็บ (storage) ต่อชั่วโมง: กรณีเก็บเฉพาะ embeddings แบบ 512‑dim float32 (ไม่บีบอัด) ประมาณ ~216 MB/ชั่วโมง/สตรีม; หากใช้ quantization (int8 / PQ) ลดได้เหลือ ~20–30 MB/ชั่วโมง/สตรีม ส่วนไฟล์วิดีโอแบบเข้ารหัสทั่วไปที่ 5 Mbps จะอยู่ราว ~2.25 GB/ชั่วโมง ทำให้แนวทาง embedding ลดความต้องการพื้นที่ประมาณ 10x–100x ขึ้นกับการบีบอัด
ข้อสังเกตจากเบนช์มาร์กและสมมติฐานการทดสอบ: latency ขึ้นกับขนาดของดัชนี (จำนวน embeddings), ค่าพารามิเตอร์ nearest neighbor search (เช่น nprobe ใน IVF), และการทำ re-ranking แบบ cross-modal หากเปิดใช้งาน re-ranking ด้วยโมเดล cross-encoder จะเพิ่มความแม่นยำ (precision) แต่ latency เพิ่มขึ้น ~0.2–0.6 วินาที ในขณะเดียวกันการบีบอัด embeddings จะลดพื้นที่จัดเก็บอย่างมากและลดค่าดัชนี I/O แต่การคอมเพรสชันแบบหยาบเกินไปอาจลด recall เล็กน้อย (เช่น PQ แบบหนักอาจลด recall@10 ประมาณ 2–6%)
เรื่องมิติของ embedding (embedding dimension) มีผลต่อทั้งความแม่นยำและต้นทุนอย่างชัดเจน:
- มิติสูง (เช่น 512) ให้ความละเอียดเชิงความหมายมากขึ้น เพิ่ม recall และ precision โดยเฉพาะในคิวรีเชิงซับซ้อน แต่ต้องแลกกับพื้นที่จัดเก็บและต้นทุนของการค้นหา (latency เพิ่มขึ้นประมาณ 10–25% เมื่อเทียบกับ 256‑dim ภายใต้ดัชนีขนาดเท่ากัน)
- มิติต่ำ (เช่น 128) ช่วยลดต้นทุนและเพิ่ม throughput แต่จะมีอัตรา false negative สูงขึ้นเล็กน้อย
การลด false positives ถูกจัดการโดยหลายกลไกที่ทดสอบแล้วได้ผล:
- Thresholding และ distance margin — กำหนดค่าความเชื่อมั่นขั้นต่ำและ margin ระหว่างผลลัพธ์เพื่อคัดกรองเหตุการณ์ที่คลุมเครือ
- Temporal smoothing — ตรวจสอบความต่อเนื่องเชิงเวลา (temporal consistency) หากเหตุการณ์ปรากฏเฉพาะเฟรมเดียวมักมีโอกาสเป็น false positive สูง
- Sensor fusion — การยืนยันข้ามโมดอลิตี เช่น GPS/accelerometer สอดคล้องกับเหตุการณ์วิดีโอ จะลด false positive ได้มาก โดยการผนวกคะแนนจากแต่ละโมดูลก่อนจัดอันดับ
- Re‑ranking ด้วย cross‑encoder — ใช้โมเดลที่ประมวลผลคู่ (query, candidate) เพื่อคำนวณสคอร์ละเอียด ช่วยเพิ่ม precision@10 ประมาณ 6–12% ในชุดทดสอบ
เมื่อเปรียบเทียบกับบริการเช่น Microsoft Video Indexer หรือการเก็บวิดีโอแบบดั้งเดิม พบความแตกต่างชัดเจนในสามมิติหลัก:
- Latency และความเร็วในการค้นหา — ในการทดสอบจำลอง Video Indexer ให้ latency median ~3.6 วินาที และ P95 ~9.2 วินาที สำหรับการค้นหาเหตุการณ์แบบ semantic (text‑to‑video) เมื่อเทียบกับบริการ Multi‑Modal Stream Indexing ที่มี median 0.8s และ P95 1.9s ส่วนหนึ่งมาจากการออกแบบดัชนีเวกเตอร์และการรองรับการค้นหาแบบ ANN ในหน่วยความจำ
- Throughput และการประมวลผลสตรีมแบบเรียลไทม์ — ระบบดั้งเดิมมักออกแบบสำหรับการประมวลผลแบบ batch หรือ offline ทำให้ throughput ต่อทรัพยากรต่ำ (ตัวอย่างเช่น ~8–12 fps ต่อ instance) ขณะที่ระบบที่ทดสอบให้ ~50 fps ต่อ GPU สำหรับการแปลงวิดีโอเป็น embedding แบบเรียลไทม์
- ต้นทุนการเก็บรักษา — เก็บไฟล์วิดีโอเต็มรูปแบบมีต้นทุนพื้นที่และแบนด์วิดท์สูง (≈2.25 GB/ชั่วโมงสำหรับ 1080p ที่ 5 Mbps) ในขณะที่เก็บเฉพาะ embeddings ที่บีบอัดลดพื้นที่ลงอย่างมีนัยสำคัญ (ตัวอย่าง 20–30 MB/ชั่วโมง เมื่อใช้ PQ/int8) ส่งผลให้ต้นทุนการจัดเก็บย้อนหลัง (retention) ลดลงหลายเท่า
สรุปเชิงธุรกิจ: เบนช์มาร์กจำลองชี้ให้เห็นว่าแนวทางการดัชนีแบบเวกเตอร์สำหรับสตรีมหลายโมดอลสามารถมอบการค้นหาเหตุการณ์ย้อนหลังที่รวดเร็ว (median ~0.8s), มี throughput สูงพอสำหรับแปลงสตรีมแบบเรียลไทม์ (~50 fps/GPU) และรักษา recall@10 ในระดับที่ใช้งานได้จริง (~82% ที่ 512‑dim) โดยมีข้อได้เปรียบด้านต้นทุนการจัดเก็บเมื่อเทียบกับการเก็บไฟล์วิดีโอเต็มรูปแบบ อย่างไรก็ตาม การออกแบบค่าพารามิเตอร์ (มิติของ embedding, นโยบายบีบอัด, เกณฑ์ threshold และกลยุทธ์ re‑ranking) จำเป็นต้องปรับให้สอดคล้องกับกรณีใช้งานขององค์กรเพื่อให้ได้สมดุลระหว่างความแม่นยำ เวลาในการตอบสนอง และต้นทุน
กรณีใช้งานที่เด่นและตัวอย่างลูกค้า
กรณีใช้งานที่เด่นและตัวอย่างลูกค้า
บริการ Multi‑Modal Stream Indexing ได้รับการนำไปใช้จริงในหลายภาคส่วนที่ต้องการการค้นหาและวิเคราะห์สตรีมข้อมูลแบบเรียลไทม์ ไม่ว่าจะเป็นวิดีโอ เสียง หรือข้อมูลจากเซนเซอร์ โดยผลลัพธ์ที่เกิดขึ้นไม่เพียงแต่เป็นการค้นหาเหตุการณ์ย้อนหลังได้ภายในวินาทีเท่านั้น แต่ยังช่วยปรับปรุงกระบวนการตอบสนอง ลดเวลาในการแก้ปัญหา และลดต้นทุนการดำเนินงาน ตัวอย่างลูกค้าที่นำไปใช้เป็นกรณีศึกษา ได้แก่ หน่วยงานรัฐในโครงการเมืองอัจฉริยะ สนามบิน โรงงานการผลิต ศูนย์บริการลูกค้า และผู้พัฒนาระบบยานยนต์/IoT
-
ระบบเฝ้าระวังเมือง (Smart City Surveillance)
เมืองใหญ่แห่งหนึ่งนำระบบไปเชื่อมกับกล้องวงจรปิด โซนาร์ และเซนเซอร์การจราจร ทำให้เจ้าหน้าที่สามารถค้นหาเหตุการณ์เชิงรูปแบบ เช่น การชุมนุมที่ผิดปกติหรืออุบัติเหตุจราจรจากวิดีโอย้อนหลังได้ภายในไม่กว่าวินาที จากเดิมที่ต้องใช้เวลาหลายชั่วโมงและกำลังคนจำนวนมาก ผลลัพธ์เชิงธุรกิจรวมถึง ลดเวลาในการค้นหาเหตุการณ์จากเฉลี่ย 3–4 ชั่วโมง เหลือ ไม่กี่วินาที และเพิ่มความสามารถในการตอบสนองฉุกเฉิน ทำให้เวลาเฉลี่ยในการตอบสนอง (Response Time) ลดลงราว 30–50% -
การค้นหาจากกล้องวงจรปิดในสนามบิน
สนามบินนานาชาติแห่งหนึ่งนำไปใช้งานกับกล้องรักษาความปลอดภัยและไมโครโฟนเพื่อค้นหาภาพเหตุการณ์และคลิปเสียงของบุคคลต้องสงสัยหรือสัมภาระถูกทิ้ง ระบบสามารถดึงคลิปที่เกี่ยวข้องได้ทันทีด้วยคอนเท็กซ์แบบ multi‑modal (ภาพ+เสียง) ส่งผลให้ทีมความปลอดภัยสามารถระบุและยืนยันเหตุการณ์ภายในวินาทีแทนที่จะต้องเรียกดูวิดีโอเป็นชั่วโมง ตัวชี้วัดทางธุรกิจที่สังเกตได้คือ ลดเวลาเฉลี่ยในการค้นหา (Search Time) จาก 2–3 ชั่วโมง เป็น <น้อยกว่า 10 วินาที> และลดความเสี่ยงจากการหยุดให้บริการ (operational disruption) ได้อย่างมีนัยสำคัญ -
การตรวจสอบสายการผลิตในโรงงาน (Cross‑Sensor Anomaly Detection)
โรงงานผลิตชิ้นส่วนอิเล็กทรอนิกส์นำข้อมูลจากกล้องความเร็วสูง เซนเซอร์สั่นสะเทือน และข้อมูลเครื่องจักร (PLC) มารวมเป็นเวกเตอร์เรียลไทม์เพื่อตรวจจับความผิดปกติ เช่น การสึกหรอของชิ้นส่วนหรือการปรับตั้งเครื่องจักรที่ผิดพลาด ระบบสามารถแจ้งเตือนก่อนเกิดการเสียหายรุนแรง ช่วยลดเวลาในการแก้ไข (TTR: Time to Resolution) ลงถึง 60–80% และลดเวลาหยุดสายการผลิต (downtime) ประเมินเป็นมูลค่าการประหยัดได้หลายหมื่นถึงหลายแสนดอลลาร์ต่อปี ขึ้นกับขนาดโรงงาน -
การวิเคราะห์คอนแท็กต์เซ็นเตอร์จากเสียง (Voice Analytics)
ผู้ให้บริการคอลเซ็นเตอร์ระดับประเทศนำเทคโนโลยีไปประมวลผลสตรีมเสียงจากการสนทนาเรียลไทม์ เพื่อดึงเหตุการณ์สำคัญ เช่น คำร้องเรียนฉุกเฉิน คำสำคัญเกี่ยวกับความเสี่ยงทางการเงิน หรือสัญญาณของลูกค้าที่มีความไม่พอใจ ระบบ indexing แบบมัลติ‑โมดอลช่วยให้ผู้จัดการค้นประเด็นย้อนหลังและจับเทรนด์ปัญหาได้ภายในวินาที ส่งผลให้ อัตราการแก้ปัญหาในการติดต่อครั้งแรก (First Contact Resolution) เพิ่มขึ้น 10–20% และลดต้นทุนการโทรซ้ำ รวมถึงปรับปรุงคุณภาพการให้บริการ (CSAT) -
การใช้งานในยานยนต์และระบบ IoT (Automotive / Edge IoT)
ผู้พัฒนายานยนต์สาธิตการใช้ระบบเพื่อรวมข้อมูลจากกล้องหน้ารถ เซนเซอร์ LIDAR และไมโครโฟนสำหรับการตรวจจับเหตุฉุกเฉินบนท้องถนน (เช่น การชน การเบรกฉุกเฉิน) เมื่อเกิดเหตุ ระบบสามารถค้นหาข้อมูลย้อนหลังร่วมกับกรณีอื่น ๆ เพื่อวิเคราะห์สาเหตุได้ในระดับวินาที ซึ่งช่วยให้บริการช่วยเหลือฉุกเฉิน (SOS) และการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) ทำงานได้รวดเร็วและแม่นยำขึ้น ส่งผลให้เวลารอช่วยเหลือลดลง และค่าใช้จ่ายด้านการซ่อมบำรุงลดลงอย่างมีนัยสำคัญ
โดยสรุป ผลลัพธ์เชิงธุรกิจจากการนำ Multi‑Modal Stream Indexing ไปใช้งานครอบคลุมทั้งการลด TTR (Time to Resolution) การลดเวลาในการค้นหาเหตุการณ์จากชั่วโมงเหลือวินาที การเพิ่มประสิทธิภาพการตอบสนองฉุกเฉิน และการลดต้นทุนการดำเนินงานและการหยุดชะงักของระบบ ตัวชี้วัดที่ลูกค้ามักรายงานได้แก่ ลดเวลาเฉลี่ยในการค้นหา 90–99%, ลด TTR 60–80%, และ การลดต้นทุนการสืบสวน/บุคลากร 20–40% ซึ่งทำให้เทคโนโลยีนี้กลายเป็นเครื่องมือสำคัญสำหรับองค์กรที่ต้องการความเร็ว แม่นยำ และประสิทธิภาพในการจัดการข้อมูลสตรีมขนาดใหญ่
การผสานระบบ การให้บริการ และโครงสร้างค่าบริการ
ช่องทางการเชื่อมต่อและ SDK
ผู้ให้บริการมักจัดเตรียมช่องทางการเชื่อมต่อหลายรูปแบบเพื่อรองรับสถาปัตยกรรมที่หลากหลายขององค์กร ทั้งในด้านการพัฒนาแอปพลิเคชันและการติดตั้งอุปกรณ์ที่ขอบเครือข่าย (edge) โดยทั่วไปจะประกอบด้วย:
- SDK ภาษาโปรแกรม (เช่น Python, Java, Node.js, Go) สำหรับการส่งสตรีมวิดีโอ/เสียง การสร้างเมตริกซ์เวกเตอร์ และการเรียกค้นข้อมูลเชิงเหตุการณ์แบบเรียลไทม์
- REST / gRPC APIs สำหรับการส่งข้อมูลเป็นแบตช์ การจัดการดัชนี และการรันคิวรีแบบซิงโครนัสหรือแอสิงโครนัส — gRPC เหมาะกับ latency ต่ำและปริมาณข้อมูลสูง
- Edge connector แบบพร้อมใช้งาน (Docker container / ARM image) ที่จับสตรีมจาก RTSP, MQTT, USB หรือเซนเซอร์อื่น ๆ แล้วส่งข้อมูลในรูปแบบแอนไทม์/บัฟเฟอร์ไปยังคลาวด์ได้โดยตรง ลดแบนด์วิดท์และ latency
- WebSocket / Push stream สำหรับการเชื่อมต่อฝั่งเบราว์เซอร์และแดชบอร์ด, และ SDK ฝังตัว สำหรับกล้องหรืออุปกรณ์ IoT ที่ต้องการ indexing ที่ใกล้กับต้นทาง
นอกจากนี้ ผู้ให้บริการมักมีตัวเลือกการยืนยันตัวตนและความปลอดภัยเช่น OAuth 2.0, API keys, TLS/mTLS และการเชื่อมต่อแบบ VPC peering หรือ private link เพื่อลดความเสี่ยงด้านข้อมูลขณะส่งสัญญาณและดัชนีเวกเตอร์
รูปแบบโฮสติ้งและข้อดีข้อเสียของแต่ละแบบ
เมื่อเลือกโฮสติ้งสำหรับบริการ Multi‑Modal Stream Indexing ต้องพิจารณาเรื่องความปลอดภัย ความหน่วงเวลา (latency) และต้นทุน โดยรูปแบบหลักมีดังนี้:
- Public cloud — ข้อดี: สเกลได้ง่าย, จ่ายตามการใช้งาน, บริการบริหารจัดการพร้อมใช้ ทำให้ติดตั้งเร็ว เหมาะกับ Proof‑of‑Concept และธุรกิจที่ต้องการความยืดหยุ่น ข้อเสีย: ค่าบริการอาจผันผวนตามการใช้งานจริง และมีประเด็นเรื่องนโยบายความเป็นส่วนตัว/ปฏิบัติตามกฎข้อบังคับในบางอุตสาหกรรม
- Private cloud — ข้อดี: ควบคุมสภาพแวดล้อมได้มากขึ้น เหมาะกับข้อมูลอ่อนไหวและองค์กรที่ต้องปฏิบัติตามข้อกำหนดสูง ข้อเสีย: ต้องลงทุนในทรัพยากรและบุคลากรสำหรับการบริหารจัดการ และสเกลขึ้นได้ช้ากว่า public cloud
- Hybrid — ข้อดี: รวบรวมข้อดีของทั้งสองแบบ โดยเก็บข้อมูลดิบไว้ on‑prem และส่งเวกเตอร์ไปประมวลผลในคลาวด์เพื่อสืบค้น ลดต้นทุน egress และตอบโจทย์ compliance ข้อเสีย: ความซับซ้อนในการออกแบบเครือข่ายและการซิงโครไนซ์ข้อมูล
- On‑premises (on‑prem) — ข้อดี: เหมาะสมกับ latency ต่ำสุดและข้อกำหนดความปลอดภัยสูงสุด องค์กรควบคุมทุกชิ้นส่วนได้ ข้อเสีย: ต้นทุนเริ่มต้นสูงและต้องมีทีม DevOps/Infra ดูแล
การเลือกรูปแบบต้องพิจารณาร่วมกันระหว่างข้อกำหนดด้านกฎระเบียบ (เช่น PDPA/GDPR), SLA ความหน่วงเวลา ที่เก็บข้อมูล (retention), และงบประมาณระยะยาว
โมเดลการคิดค่าบริการและแนวทางการประเมินค่าใช้จ่ายสำหรับองค์กรขนาดเล็ก กลาง ใหญ่
โครงสร้างค่าบริการของบริการประเภทนี้มักแบ่งเป็นองค์ประกอบหลัก ได้แก่ ค่าประมวลผลสตรีม (per‑stream per‑hour), ค่าการสร้าง/เรียกใช้งาน embeddings (per‑embedding), ค่าพื้นที่จัดเก็บ (storage) และ ค่าอัตราออกข้อมูล (egress) การรวมโมเดลเหล่านี้เข้าด้วยกันช่วยให้องค์กรเลือกแบบที่เหมาะสมกับรูปแบบการใช้งาน:
- Per‑stream per‑hour — เหมาะกับงานที่มีสตรีมจำนวนมากและความถี่คงที่ เช่น กล้องวงจรปิด 24/7; ราคาตัวอย่าง: 0.12 USD/stream‑hour (รวมการ index พื้นฐานและ embeddings สูงสุดที่ 1Hz)
- Per‑embedding (consumption‑based) — เหมาะกับงานที่มีการประมวลผลเป็นครั้งคราวหรือตั้งค่าให้เกิด embeddings สูงเมื่อเกิดเหตุการณ์; ราคาตัวอย่าง: 0.00001 USD/embedding
- Storage — ค่าจัดเก็บดัชนีเวกเตอร์และสแนปช็อตของสตรีม (เช่น 0.03 USD/GB‑month สำหรับ vector store) และค่าจัดเก็บสื่อดิบ (hot storage) ที่สูงกว่า (เช่น 0.12 USD/GB‑month)
- Egress — ค่าโอนข้อมูลออกจากคลาวด์ (เช่น 0.09 USD/GB) ซึ่งสำคัญเมื่อมีการดาวน์โหลดวิดีโอหรือส่งผลลัพธ์ไปยังระบบภายนอก
ตัวอย่างการคำนวณงบประมาณเบื้องต้น (สมมติฐานที่ใช้ในตัวอย่างนี้คือ per‑stream‑hour = 0.12 USD, per‑embedding = 0.00001 USD, vector storage = 0.03 USD/GB‑month, egress = 0.09 USD/GB):
- องค์กรขนาดเล็ก — สมมติ 10 สตรีม ปิด/เปิด 8 ชั่วโมง/วัน:
- Stream‑hours/เดือน = 10 × 8 × 30 = 2,400 → ค่าประมวลผล = 2,400 × 0.12 = 288 USD
- สมมติการสร้าง embeddings 1Hz (รวมใน per‑stream model) → vector storage ประมาณ 150 GB → เก็บที่ 0.03 USD/GB = 4.5 USD/เดือน
- สมมติ egress รายเดือน 100 GB → 100 × 0.09 = 9 USD
- รวมประมาณ = 288 + 4.5 + 9 = ~301.5 USD/เดือน
- องค์กรขนาดกลาง — สมมติ 100 สตรีม ติดตั้ง 24/7:
- Stream‑hours/เดือน = 100 × 24 × 30 = 72,000 → ค่าประมวลผล = 72,000 × 0.12 = 8,640 USD
- Vector storage ประมาณ 1.5 TB → 1,500 GB × 0.03 = 45 USD
- Egress สมมติ 2,000 GB/เดือน → 2,000 × 0.09 = 180 USD
- รวมประมาณ = 8,640 + 45 + 180 = ~8,865 USD/เดือน
- องค์กรขนาดใหญ่ — สมมติ 1,000 สตรีม 24/7:
- Stream‑hours/เดือน = 1,000 × 24 × 30 = 720,000 → ค่าประมวลผล = 720,000 × 0.12 = 86,400 USD
- Vector storage ประมาณ 15 TB → 15,000 GB × 0.03 = 450 USD
- Egress สมมติ 20,000 GB/เดือน → 20,000 × 0.09 = 1,800 USD
- รวมประมาณ = 86,400 + 450 + 1,800 = ~88,650 USD/เดือน
ข้อสังเกตสำคัญ:
- การเลือก per‑stream‑hour มักให้ความคาดการณ์ค่าใช้จ่ายง่ายกว่าเมื่อต้องการ streaming ต่อเนื่องและอัตราการสร้าง embeddings คงที่
- โมเดล per‑embedding เหมาะสำหรับงานที่มีการประมวลผลแบบเหตุการณ์ (bursty) — หากมีการสร้าง embeddings จำนวนมากต่อวินาที โมเดลนี้อาจมีค่าใช้จ่ายสูงกว่า
- ค่า storage ของเวกเตอร์มักไม่สูงเมื่อเทียบกับการเก็บสื่อดิบ แต่ retention period (เก็บนานแค่ไหน) จะเป็นตัวกำหนดต้นทุนระยะยาว
- ต้องคำนวณ egress ให้รอบคอบ เพราะการดึงวิดีโอหรือผลลัพธ์ออกมาบ่อย ๆ จะเพิ่มต้นทุนได้รวดเร็ว
แนวทางการประเมินที่แนะนำ: ทำการวัดเชิงทดลอง (pilot) อย่างน้อย 7–30 วัน เพื่อเก็บข้อมูลจริงของจำนวนสตรีมชั่วโมง, อัตราการสร้าง embeddings (Hz), ขนาด storage ต่อสตรีม และปริมาณ egress แล้วใช้ค่าสังเกตเหล่านั้นเพื่อจำลองค่าใช้จ่ายแบบรายเดือนและรายปี จากนั้นเลือกโมเดลการคิดค่าบริการที่สอดคล้องกับความต้องการเชิงธุรกิจ (predictability vs. elasticity) และพิจารณาข้อเสนอลดราคาเมื่อปริมาณสูงหรือสัญญาระยะยาว
ความเป็นส่วนตัว ความปลอดภัย และการปฏิบัติตามกฎระเบียบ
ความเป็นส่วนตัว ความปลอดภัย และการปฏิบัติตามกฎระเบียบ
การเปิดให้บริการ Multi‑Modal Stream Indexing ซึ่งเปลี่ยนวิดีโอ เสียง และข้อมูลเซนเซอร์เป็นเวกเตอร์แบบเรียลไทม์ เสนอโอกาสด้านการสืบค้นเหตุการณ์ย้อนหลังภายในวินาที แต่ในมิติความเป็นส่วนตัวและความปลอดภัย มีประเด็นเชิงเทคนิคและกฎหมายที่องค์กรต้องพิจารณาอย่างรอบคอบ ทั้งนี้เพื่อป้องกันการละเมิดข้อมูล การใช้งานในทางที่ไม่พึงประสงค์ และความเสี่ยงจากการตีความโมเดลที่ผิดพลาด
มาตรการรักษาความปลอดภัยระดับเทคนิคควรประกอบด้วยหลายชั้น (defense in depth) ได้แก่
- Encryption: การเข้ารหัสข้อมูลทั้ง in transit (เช่น TLS 1.2/1.3) และ at rest (เช่น AES-256) เป็นพื้นฐาน ทั้งนี้ต้องรวมถึงการจัดการคีย์ที่ปลอดภัย (KMS/HSM), การหมุนคีย์ (key rotation) และการแยกสิทธิ์ในการเข้าถึงคีย์
- Identity and Access Management (IAM): ใช้หลักการ least privilege และ role-based หรือ attribute-based access control (RBAC/ABAC), รวมถึงการบังคับใช้ MFA สำหรับผู้ใช้งานที่เข้าถึงการค้นหรือดึงข้อมูลเวกเตอร์
- Audit logs และการมอนิเตอร์: บันทึกกิจกรรมการเข้าถึงและการสืบค้นอย่างละเอียด (immutable audit logs) ส่งไปยัง SIEM เพื่อตรวจจับพฤติกรรมผิดปกติและสนับสนุนการสอบสวนเมื่อเกิดเหตุ
- มาตรการเพิ่มเติม: การใช้งาน secure enclaves, การทำ tokenization หรือตัวแปลงข้อมูลก่อนจัดเก็บ และการประยุกต์ใช้เทคนิคเช่น differential privacy ในการเผยแพร่สถิติหรือผลการค้นหาเพื่อลดความเสี่ยงการระบุตัวบุคคล
ในด้านการปฏิบัติตาม PDPA และกฎหมายคุ้มครองข้อมูลส่วนบุคคลอื่นๆ องค์กรควรดำเนินการดังนี้เป็นอย่างน้อย:
- การประเมินความจำเป็นและความเหมาะสม (Data Minimization): เก็บเฉพาะข้อมูลที่จำเป็นตามวัตถุประสงค์ที่ชัดเจน และกำหนดระยะเวลาการเก็บข้อมูล (retention policy) พร้อมขั้นตอนการลบข้อมูลเมื่อพ้นวัตถุประสงค์
- การจัดกลุ่มและการคุ้มครองข้อมูลส่วนบุคคล: แยกข้อมูลส่วนบุคคลออกจากข้อมูลทั่วไป และใช้การทำ pseudonymization/anonymization เมื่อเป็นไปได้ โดยต้องตระหนักว่าเวกเตอร์ความละเอียดสูงอาจยังคงเสี่ยงต่อการ re‑identification
- ฐานทางกฎหมายและการขอความยินยอม: ระบุฐานทางกฎหมายชัดเจน (เช่น ความยินยอม สัญญา หรือความจำเป็นตามกฎหมาย) และจัดการการยกเลิกความยินยอม รวมถึงการตอบคำขอสิทธิของเจ้าของข้อมูลตาม PDPA
- การควบคุมการโอนข้อมูลระหว่างประเทศ: หากผู้ให้บริการหรือคลาวด์จัดเก็บข้อมูลนอกประเทศ ควรมีมาตรการคุ้มครองการโอนข้อมูล เช่น สัญญาการประมวลผลข้อมูล (DPA) เงื่อนไขการถ่ายโอน หรือเลือกบริการที่ให้ตัวเลือกการจัดเก็บข้อมูลภายในประเทศเพื่ออำนวยความสะดวกในการปฏิบัติตาม PDPA
- DPIA และบทบาทเจ้าหน้าที่คุ้มครองข้อมูล: ดำเนินการ Data Protection Impact Assessment สำหรับการใช้งานที่มีความเสี่ยงสูง แต่งตั้ง Data Protection Officer หรือผู้รับผิดชอบด้านความเป็นส่วนตัวเพื่อบริหารจัดการและเป็นจุดติดต่อเมื่อเกิดเหตุ
ข้อจำกัดและความเสี่ยงที่องค์กรต้องตระหนักประกอบด้วย:
- ความไม่แน่นอนของโมเดล (model errors): ระบบดัชนีเวกเตอร์และโมเดลตรวจจับอาจเกิด false positives หรือ false negatives ซึ่งอาจนำไปสู่การตัดสินใจที่ผิดพลาด ตัวอย่างเช่น การจับคู่ใบหน้าผิดพลาดในบริบทการเฝ้าระวัง
- ความเสี่ยงจากการระบุตัวบุคคลซ้ำ (re‑identification): แม้ข้อมูลจะถูกทำให้เป็นเวกเตอร์หรือทำ pseudonymization แต่การผสานข้อมูลหลายแหล่งหรือการวิเคราะห์เชิงลึกสามารถนำไปสู่การฟื้นตัวของข้อมูลบุคคลได้
- การใช้งานในทางที่ไม่พึงประสงค์และ function creep: ฟังก์ชันการค้นหาเหตุการณ์ย้อนหลังอาจถูกนำไปใช้นอกวัตถุประสงค์เดิม เช่น ใช้เพื่อการติดตามพนักงานอย่างต่อเนื่อง หรือการวิเคราะห์เชิงพฤติกรรมโดยไม่มีความยินยอม
- ข้อจำกัดด้านเทคนิค: การรักษาความปลอดภัย เช่น การเข้ารหัสเต็มรูปแบบ อาจทำให้ความสามารถในการค้นหาและ latency ลดลง การปรับสมดุลระหว่างความปลอดภัยและประสิทธิภาพจึงเป็นความท้าทาย
คำแนะนำเชิงปฏิบัติสำหรับองค์กรก่อนนำระบบไปใช้จริง ได้แก่
- จัดทำ risk assessment เชิงเทคนิคและกฎหมาย รวมถึงการทดสอบประสิทธิภาพของโมเดลต่อตัวชี้วัด false match/false reject และการกำหนด threshold ที่เหมาะสมพร้อมกลไก human‑in‑the‑loop
- บังคับใช้สัญญาและ DPA กับผู้ให้บริการคลาวด์ ระบุขอบเขตการประมวลผล มาตรการรักษาความปลอดภัย และเงื่อนไขการแจ้งเตือนในกรณีเหตุละเมิด
- เลือกรักษาข้อมูลภายในประเทศหากต้องการลดความเสี่ยงด้านการโอนข้อมูล และยืนยันการรับรองด้านความปลอดภัยของผู้ให้บริการ (เช่น ISO 27001, SOC 2) ตลอดจนการตรวจสอบอิสระเป็นระยะ
- กำหนดนโยบายการเก็บรักษาและลบข้อมูลอย่างชัดเจน การบันทึก audit logs ที่ไม่สามารถแก้ไข และแผนการตอบสนองต่อเหตุละเมิดรวมทั้งการแจ้งผู้เกี่ยวข้องตาม PDPA
- ฝึกอบรมผู้ใช้งานและผู้บริหารเกี่ยวกับข้อจำกัดของโมเดล ความเสี่ยงด้านความเป็นส่วนตัว และขั้นตอนการร้องเรียน/อุทธรณ์สำหรับผู้ได้รับผลกระทบ
โดยสรุป การนำ Multi‑Modal Stream Indexing มาใช้ต้องมีการออกแบบเชิงสถาปัตยกรรมและนโยบายที่รองรับทั้งความปลอดภัยเชิงเทคนิคและการปฏิบัติตาม PDPA อย่างเคร่งครัด พร้อมการประเมินความเสี่ยงต่อเนื่อง การตรวจสอบโมเดล และกลไกคุ้มครองสิทธิของเจ้าของข้อมูล เพื่อให้เทคโนโลยีนี้สร้างมูลค่าได้โดยไม่ละเมิดความเป็นส่วนตัวหรือเพิ่มความเสี่ยงต่อองค์กร
ผลกระทบต่อภูมิทัศน์ตลาดไทยและโร้ดแม็ปอนาคต
ผลกระทบเชิงเศรษฐกิจต่อตลาดคลาวด์และการนำ AI สู่การปฏิบัติงาน
การเปิดบริการ Multi‑Modal Stream Indexing จะเป็นตัวเร่งสำคัญในการผลักดันการนำ AI เข้าใช้ในภาคธุรกิจและภาครัฐของไทย โดยเฉพาะอย่างยิ่งในงานที่ต้องจัดการสตรีมวิดีโอ เสียง และข้อมูลเซนเซอร์แบบเรียลไทม์ ซึ่งเดิมต้องใช้ทรัพยากรมนุษย์และการจัดเก็บข้อมูลขนาดใหญ่ ตัวอย่างผลลัพธ์เชิงเศรษฐกิจที่คาดได้คือการลดเวลาในการค้นหาเหตุการณ์ย้อนหลังจากระดับนาทีเหลือเพียง วินาที ช่วยให้การตอบสนองเหตุฉุกเฉิน มีประสิทธิภาพมากขึ้น และลดต้นทุนการดำเนินงานในศูนย์เฝ้าระวังหรือศูนย์ปฏิบัติการลงได้อย่างมีนัยสำคัญ
สำหรับภาคธุรกิจ ขีดความสามารถในการเปลี่ยนข้อมูลสตรีมเป็นเวกเตอร์แบบเรียลไทม์จะเปิดโอกาสใหม่แก่สตาร์ทอัพด้านวิดีโออนาลิติกส์, รีเทลออลไลน์-ออนไลน์ และโรงงานอุตสาหกรรมที่ต้องการการตรวจจับเหตุผิดปกติแบบต่อเนื่อง — ซึ่งคาดว่าจะเพิ่มอัตราการนำคลาวด์และบริการ AI เป็นส่วนหนึ่งของค่าใช้จ่ายด้านเทคโนโลยี (IT spend) ขององค์กร ข้อมูลจากภาพรวมภูมิภาคชี้ว่าโซลูชันที่ลด Latency และ Bandwidth ได้ช่วยให้ลูกค้าลดค่าใช้จ่ายการจัดเก็บและถ่ายโอนข้อมูลได้กว่า 20–40% ในหลายกรณี
ผลต่อการเร่งนำ AI เข้าสู่ภาครัฐและเอกชน
ในภาครัฐ บริการดังกล่าวมีศักยภาพสูงในการยกระดับการบริหารจัดการเมืองและความปลอดภัยสาธารณะ เช่น การติดตามเหตุจราจรแบบเรียลไทม์, การค้นหาวิดีโอจากกล้องวงจรปิดเพื่อสืบสวนย้อนหลังในเวลาสั้นๆ, และการบูรณาการข้อมูลเซนเซอร์เพื่อสนับสนุนระบบจัดการภัยพิบัติ การที่ข้อมูลถูกแปลงเป็นเวกเตอร์และสามารถค้นหาเชิงความหมาย (semantic search) จะทำให้หน่วยงานสามารถตั้งกฎและการแจ้งเตือนเชิงบริบทได้รวดเร็วขึ้น ส่งผลให้เวลาตัดสินใจสั้นลงและประสิทธิภาพในการให้บริการประชาชนเพิ่มขึ้น
ในภาคเอกชน ฟีเจอร์นี้จะช่วยให้หน่วยงานด้านความปลอดภัยภายในองค์กร, ผู้ให้บริการค้าปลีก และผู้ประกอบการด้านโลจิสติกส์ สามารถนำ AI มาประยุกต์ใช้อย่างเป็นรูปธรรมภายในไตรมาสถึงปีแรกหลังการนำร่อง ตัวอย่างเช่น สตาร์ทอัพการตลาดที่ใช้วิดีโอเพื่อวิเคราะห์พฤติกรรมลูกค้าอาจลดเวลาการวิเคราะห์จากชั่วโมงเหลือวินาที และผู้ประกอบการโรงงานสามารถใช้ข้อมูลเซนเซอร์ร่วมกับวิดีโอในการคาดการณ์ความผิดปกติของเครื่องจักรได้แบบ near‑real‑time
โร้ดแม็ปฟีเจอร์ที่คาดหวังและปฏิทินการเปิดตัว
- โมเดลซู (Model Zoo) — ชุดโมเดลสำเร็จรูปสำหรับการแปลงวิดีโอ เสียง และเซนเซอร์เป็นเวกเตอร์ รวมถึงโมเดลมัลติโมดัล (เช่น visual‑audio encoders) คาดเปิดสถานะเบต้าใน 3–6 เดือนแรก เพื่อตอบโจทย์ลูกค้าที่ต้องการเร่งนำไปใช้งาน
- On‑device Embedding — การฝังโมเดลขนาดเล็กบนอุปกรณ์ขอบเครือข่ายเพื่อลดแบนด์วิดท์และความหน่วง คาดเปิดตัวรุ่น alpha ภายใน 6–12 เดือน และรุ่นเชิงพาณิชย์ภายใน 12–18 เดือน
- Privacy‑Preserving Search — ฟีเจอร์ด้านความเป็นส่วนตัว เช่น การเข้ารหัสดัชนีเชิงเวกเตอร์, secure enclaves, federated search และการจัดการ differential privacy เพื่อให้สอดคล้องกฎหมายและความคาดหวังของผู้ใช้งาน คาดเริ่มทดสอบภายใน 9–15 เดือน
- การขยายสู่ภูมิภาค (ASEAN Expansion) — แผนการให้บริการผ่านศูนย์ข้อมูลภูมิภาค อ่านค่า latency ต่ำและปฏิบัติตามนโยบาย data residency คาดเริ่มเจรจาพันธมิตรท้องถิ่นและผู้ให้บริการเครือข่ายภายใน 12 เดือน และขยายตลาดเชิงพาณิชย์ใน 18–24 เดือน
แนวโน้มการแข่งขันและรูปแบบความร่วมมือ
การเปิดตัวบริการชนิดนี้จะสร้างแรงกดดันต่อผู้ให้บริการคลาวด์ทั้งรายใหญ่ระดับโลกและผู้เล่นท้องถิ่น ผู้ให้บริการระดับภูมิภาค (เช่น ผู้ให้บริการคลาวด์จากจีนและเอเชียตะวันออกเฉียงใต้) มีทรัพยากรและบริการขอบเขตกว้าง แต่ผู้ให้บริการไทยที่เน้นเรื่อง data sovereignty และการสนับสนุนภาษาท้องถิ่นจะมีความได้เปรียบเชิงกลยุทธ์ในการขายให้ภาครัฐและองค์กรที่กังวลเรื่องการเก็บข้อมูลนอกประเทศ
รูปแบบการแข่งขันที่คาดเห็นคือทั้งการแข่งขันด้านราคาและนวัตกรรมฟีเจอร์ รวมถึงความร่วมมือเชิงยุทธศาสตร์กับผู้ให้บริการเครือข่าย (telco), ผู้ผลิตฮาร์ดแวร์ขอบเครือข่าย (edge devices/GPU nodes) และสตาร์ทอัพที่มีความเชี่ยวชาญด้าน vertical solutions เช่น smart city, retail analytics และ industrial IoT การสร้าง ecosystem ที่รวม model zoo, API ที่เปิดกว้าง และโซลูชัน on‑device จะเป็นกุญแจสำคัญในการชิงส่วนแบ่งตลาด
สำหรับนักลงทุนและผู้กำหนดนโยบาย ข้อแนะนำเชิงปฏิบัติคือส่งเสริมมาตรฐานการจัดการข้อมูล, สนับสนุนโครงการนำร่องร่วมกับเทศบาลและหน่วยงานภาครัฐ, และออกแบบนโยบายสนับสนุน SMEs ที่ต้องการประยุกต์ใช้บริการเหล่านี้ เพราะอัตราการนำไปใช้จริงจะขึ้นอยู่กับความชัดเจนด้านกฎระเบียบ ต้นทุนการเป็นเจ้าของ (TCO) และความน่าเชื่อถือของผู้ให้บริการในประเทศ
บทสรุป
บริการ Multi‑Modal Stream Indexing ของผู้ให้บริการคลาวด์ไทยเปลี่ยนข้อมูลสตรีมหลายรูปแบบทั้งวิดีโอ เสียง และเซนเซอร์ เป็นเวกเตอร์เชิงคุณลักษณะแบบเรียลไทม์ ทำให้การค้นหาเหตุการณ์ย้อนหลังที่เคยต้องใช้เวลาหลายชั่วโมง (ตัวอย่างเช่น 1–3 ชั่วโมง) ถูกย่นเหลือภายในวินาที ทำให้สามารถตอบสนองเหตุการณ์ กระตุ้นการแจ้งเตือน และเรียกข้อมูลบริบทได้ทันที ตัวอย่างการใช้งานที่ชัดเจนได้แก่ การตรวจจับเหตุการณ์ในระบบกล้องวงจรปิด (CCTV) แบบเรียลไทม์ การวิเคราะห์ความผิดปกติในสายการผลิต และการวิเคราะห์พฤติกรรมลูกค้าในร้านค้าปลีก ซึ่งทั้งหมดนี้เปิดทางให้การใช้งาน AI ในระบบสตรีมแบบเรียลไทม์ขยายตัวอย่างรวดเร็วในไทย พร้อมส่งผลต่อประสิทธิภาพการปฏิบัติงานและการตัดสินใจเชิงธุรกิจ
องค์กรควรพิจารณาทดสอบเบนช์มาร์กกับงานจริง โดยตั้งชุดทดสอบที่สะท้อนสภาพการใช้งานจริงเพื่อวัดค่าต่าง ๆ ได้แก่ ความหน่วง (latency), อัตราการค้นพบเหตุการณ์ (recall/precision), การใช้ทรัพยากรคอมพิวต์และเครือข่าย และต้นทุนต่อข้อมูล (เช่น ค่าเก็บข้อมูล/ค่า egress) ก่อนนำไปใช้เชิงปฏิบัติการ นอกจากนี้ต้องประเมินค่าใช้จ่ายระยะยาวทั้งด้านโครงสร้างพื้นฐานและการบำรุงรักษา และให้ความสำคัญกับความเสี่ยงด้านความเป็นส่วนตัว—เช่น การปฏิบัติตาม PDPA การทำให้ข้อมูลไม่ระบุตัวตน การจำกัดการเข้าถึง และการเข้ารหัสข้อมูลทั้งขณะพักและขณะส่งข้อมูล—พร้อมจัดทำนโยบายการเก็บรักษาและการกำกับดูแลก่อนขยายการใช้งาน



