
ห้องสมุดมหาวิทยาลัยฮาร์วาร์ดก้าวสู่การทดลองนำเทคโนโลยีปัญญาประดิษฐ์มาเสริมประสิทธิภาพการค้นคว้าวิจัย ด้วยโครงการนำร่องที่ตั้งเป้าสำรวจการใช้งาน AI ในการค้นข้ามคอลเลกชันกว่า 20 ล้านชิ้น — ครอบคลุมหนังสือ ต้นฉบับ วารสาร ข้อมูลชุด และเอกสารภายในห้องสมุด การเคลื่อนไหวครั้งนี้สื่อถึงความพยายามลดเวลาที่นักวิจัยต้องใช้ในการรวบรวมข้อมูลเชิงลึกซึ่งมักกินเวลาตั้งแต่หลายชั่วโมงจนถึงหลายสัปดาห์ และเปิดโอกาสให้ผู้ใช้เข้าถึงทรัพยากรที่อาจถูกซ่อนอยู่ในคอลเลกชันขนาดใหญ่ได้ง่ายขึ้น
แม้โครงการจะมุ่งเน้นผลประโยชน์ด้านความเร็วและการขยายการเข้าถึงงานวิจัย แต่ฮาร์วาร์ดยังให้ความสำคัญกับกรอบการคุ้มครองความเป็นส่วนตัวและสิทธิ์ในการเข้าถึงข้อมูล โดยตั้งเป้าทดสอบความแม่นยำของผลการค้นหา การจัดการสิทธิ์ใช้งาน ตลอดจนการป้องกันการละเมิดลิขสิทธิ์และความลำเอียงของโมเดล AI โครงการนำร่องนี้จะเป็นตัวชี้วัดสำคัญว่าการผสาน AI ในห้องสมุดระดับโลกสามารถเพิ่มประสิทธิภาพงานวิจัยได้จริงเพียงใด พร้อมทั้งต้องรักษามาตรฐานจริยธรรมและกฎระเบียบด้านข้อมูลควบคู่ไปด้วย
ภาพรวมโครงการทดลอง AI ของห้องสมุดฮาร์วาร์ด
ภาพรวมโครงการทดลอง AI ของห้องสมุดฮาร์วาร์ด
โครงการนำร่องการทดลองใช้ปัญญาประดิษฐ์ (AI) ของห้องสมุดฮาร์วาร์ดเป็นความริเริ่มเชิงปฏิบัติการที่ออกแบบมาเพื่อยกระดับกระบวนการค้นหา สรุป และนำทางทรัพยากรทั้งเชิงดิจิทัลและสิ่งพิมพ์ โครงการนี้มุ่งทดสอบเทคโนโลยีการประมวลผลภาษาธรรมชาติ (NLP) และระบบแนะนำ (recommendation) ที่สามารถเชื่อมโยงข้อมูลเมตา (metadata) เอกสารฉบับเต็ม และคอลเลกชันดิจิทัล เพื่อช่วยให้นักวิจัยเข้าถึงข้อมูลสำคัญได้รวดเร็วขึ้นและมีความแม่นยำสูงขึ้น โดยคำนึงถึงข้อจำกัดด้านทรัพย์สินทางปัญญาและความเป็นส่วนตัวของผู้ใช้เป็นสำคัญ

บริบทของโครงการต้องเข้าใจว่า Harvard Library เป็นระบบห้องสมุดขนาดใหญ่ที่มีคอลเลกชันเชิงกายภาพและดิจิทัลจำนวนมหาศาล โดยรวมมีทรัพยากรประมาณ 20 ล้านชิ้น/รายการ รวมถึงเอกสารที่ถูกสแกนเป็นดิจิทัล เอกสารเกิดใหม่ในรูปแบบดิจิทัล ฐานข้อมูลเชิงวิชาการ และคอลเลกชันพิเศษ เมตาดาต้าและรูปแบบไฟล์ที่หลากหลายทำให้การค้นพบ (discoverability) เป็นความท้าทายสำคัญ อีกทั้งยังมีความต้องการให้บริการแบบทันทีและเป็นมิตรกับผู้ใช้มากขึ้นเพื่อรองรับนักวิจัยจากหลายสาขาวิชา
ขอบเขตเบื้องต้นของโครงการนำร่องครอบคลุมฟังก์ชันหลักหลายด้านที่ออกแบบมาเพื่อลดความซับซ้อนของการค้นคว้า ตัวอย่างฟังก์ชันที่กำลังทดสอบ ได้แก่
- การค้นหาเชิงบริบท: ระบบ AI รองรับการค้นหาแบบภาษาธรรมชาติ สามารถตีความคำถามเชิงวิชาการและคืนผลลัพธ์ที่เกี่ยวข้องทั้งจากแค็ตตาล็อกและเอกสารฉบับเต็ม
- การสรุปเอกสารอัตโนมัติ: สร้างสรุปใจความสำคัญของบทความหรือเอกสารยาว เพื่อช่วยนักวิจัยตัดสินใจว่าควรอ่านฉบับเต็มหรือไม่
- การนำทางคอลเลกชัน: แนะนำแหล่งข้อมูลที่เกี่ยวข้อง เช่น งานวิจัยที่เชื่อมโยง อ้างอิงที่เกี่ยวข้อง และคอลเลกชันพิเศษที่อาจถูกมองข้าม
- การปรับปรุงเมตาดาต้า: ใช้ AI ในการสกัดคีย์เวิร์ด ชื่อบุคคล วันที่ และลิงก์อ้างอิงจากเอกสารเพื่อเพิ่มคุณภาพของข้อมูลเมตา
เหตุผลหลักในการริเริ่มโครงการนี้มาจากความต้องการแก้ปัญหาความซับซ้อนของการค้นคืนข้อมูลในระบบที่มีขนาดและรูปแบบเนื้อหาหลากหลาย ห้องสมุดต้องการลดเวลาในการค้นคว้า เพิ่มอัตราการค้นพบแหล่งข้อมูลที่เกี่ยวข้อง และสนับสนุนการทำงานข้ามสหวิทยาการของนักวิจัย ในระยะยาว ความสามารถของ AI ที่สรุปเนื้อหาและเชื่อมโยงบริบทจะช่วยเพิ่มประสิทธิภาพการทำงานวิจัยและสร้างคุณค่าแก่คอลเลกชันที่มีอยู่
สถานะของโครงการขณะนี้คือการดำเนินงานในรูปแบบ โครงการนำร่องภายใน (internal pilot) โดยมีการทดสอบกับกลุ่มนักวิจัยจำกัดเป็นระยะเวลาหลายเดือน ทีมงานกำลังประเมินผลการใช้งานตามตัวชี้วัดที่ชัดเจน เช่น เวลาที่ใช้ในการค้นพบแหล่งข้อมูล ความแม่นยำของผลลัพธ์ ความพึงพอใจของผู้ใช้ และความสอดคล้องกับข้อกำหนดทางลิขสิทธิ์ การทดสอบในช่วงนี้ยังมุ่งเน้นการตรวจสอบความปลอดภัยของข้อมูล การลดอคติในโมเดล และการปรับแต่งกระบวนการทำงานร่วมกับระบบแค็ตตาล็อกเดิมของห้องสมุด
ผลการประเมินจากโครงการนำร่องนี้จะเป็นปัจจัยสำคัญในการตัดสินใจว่าจะขยายการใช้งานไปยังผู้ใช้กลุ่มกว้างขึ้นอย่างไร โดยคำนึงถึงประสิทธิภาพ ค่าใช้จ่าย และแนวทางการกำกับดูแล (governance) ของการใช้ AI ในสภาพแวดล้อมห้องสมุดสาธารณะและสถาบันวิจัยในอนาคต
รายละเอียดเทคโนโลยีและการทำงานของระบบ AI
รายละเอียดเทคโนโลยีและการทำงานของระบบ AI
ระบบที่ห้องสมุดฮาร์วาร์ดทดลองใช้งานเป็นการผสานกันระหว่าง โมเดลภาษาขนาดใหญ่ (Large Language Models — LLM) กับระบบดัชนีการค้นหา (search index) และเครื่องมือการเรียกคืนเอกสาร (retrieval) แบบสมัยใหม่ เพื่อให้การค้นข้อมูลสำหรับนักวิจัยมีความเป็นธรรมชาติมากขึ้นและได้ผลลัพธ์ที่ตรงตามบริบทมากขึ้น ในภาพรวมสถาปัตยกรรมจะประกอบด้วยส่วนสำคัญ 3 ชั้น ได้แก่ ชั้นดัชนี (indexing layer), ชั้นการเรียกคืนเบื้องต้น (retrieval layer) และชั้นการประมวลผลด้วยภาษา (LLM / re-ranker) โดยระบบมักใช้วิธีการผสมผสานระหว่างการค้นหาข้อความเชิงสถิติ (เช่น BM25) กับการค้นหาเชิงเวกเตอร์ (vector/semantic retrieval) เพื่อให้ครอบคลุมทั้งความตรงตัวของคำค้นและความหมายเชิงบริบท
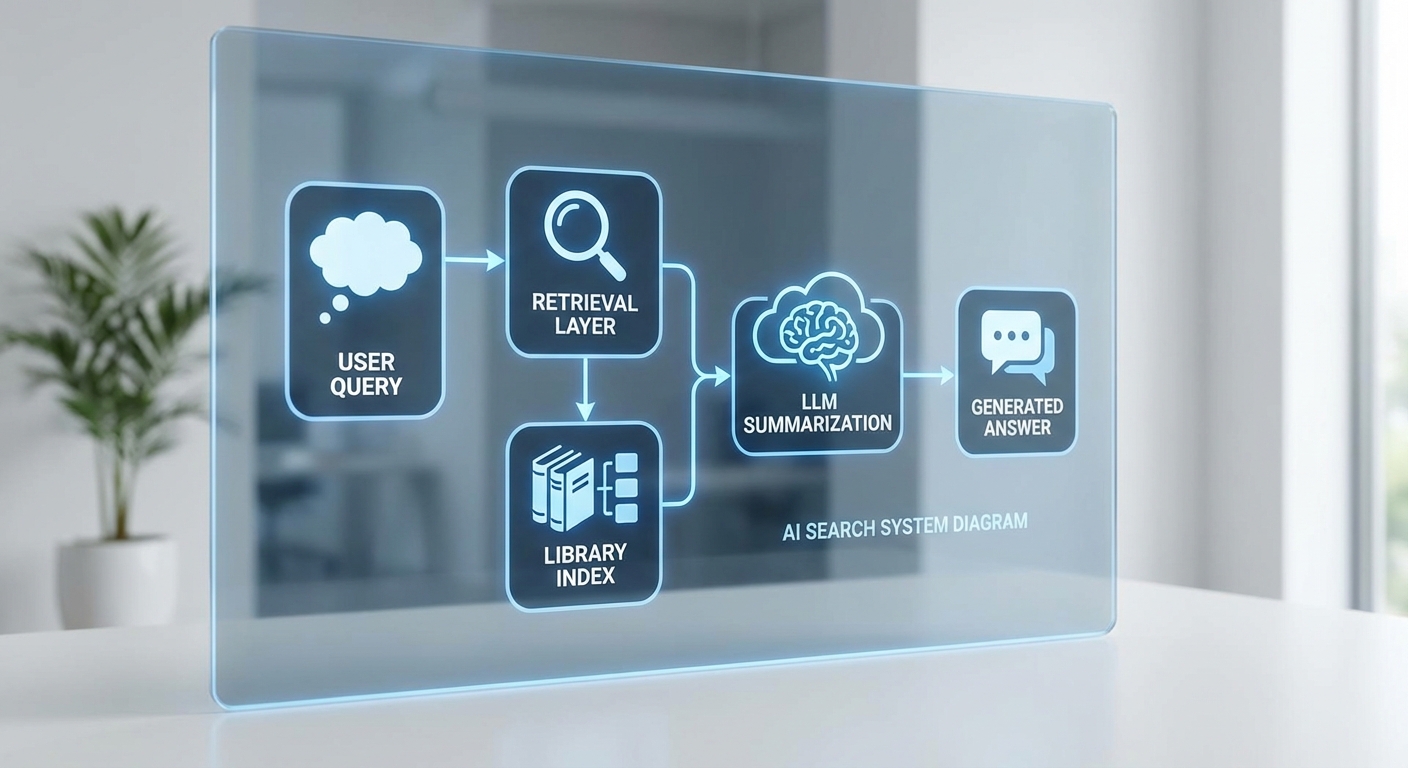
เชิงเทคนิค ระบบมักทำงานตามลำดับดังนี้: ก่อนอื่นเอกสารและเมตาดาทาจะถูก chunk หรือแยกเป็นชิ้นย่อย (passages) แล้วสร้างทั้งดัชนีดั้งเดิมสำหรับการค้นด้วยคำ (inverted index/BM25) และ embedding สำหรับการค้นเชิงความหมาย (vector embeddings) โดย embeddings เหล่านี้อาจสร้างจากโมเดลขนาดเล็กหรือโมเดลเฉพาะงาน แล้วจัดเก็บในฐานข้อมูลเวกเตอร์ (เช่น FAISS, HNSW หรือฐานข้อมูลเวกเตอร์เชิงพาณิชย์) เมื่อผู้ใช้ส่งคำค้นเป็นภาษาธรรมชาติ ระบบจะส่งคำค้นทั้งไปยังตัวค้นหาดัชนีแบบคำและตัวค้นหาเชิงเวกเตอร์ จากนั้นนำผลลัพธ์เริ่มต้นมารวม (hybrid retrieval) แล้วใช้ LLM ทำหน้าที่ re-ranking เพื่อจัดลำดับความเกี่ยวข้องใหม่และสกัดข้อความสรุปหรือประเด็นสำคัญ (summary/snippet)
ฟีเจอร์เด่นที่ผู้ใช้จะเห็นได้ชัดเจนคือ: ค้นด้วยภาษาธรรมชาติ ซึ่งผู้ใช้พิมพ์คำถามเป็นประโยคยาวได้ เช่น “ขอหลักฐานงานวิจัยเกี่ยวกับการเปลี่ยนแปลงสภาพภูมิอากาศที่ใช้ข้อมูลดาวเทียมในทศวรรษที่ผ่านมา” ระบบจะตีความเจตนารวมทั้งบริบทของคำค้นและส่งไปยังกระบวนการ retrieval แบบผสม นอกจากนี้ยังมีฟังก์ชัน สรุปผลอัตโนมัติ (automated summarization) สำหรับบทความหรือไฟล์ยาว ๆ และ การแนะนำทรัพยากรข้ามคอลเลกชัน (cross-collection recommendation) โดยใช้ความคล้ายคลึงเชิงความหมายของ embeddings เพื่อแนะนำงานวิจัย หนังสือ หรือชุดข้อมูลจากคอลเลกชันต่าง ๆ ที่สัมพันธ์กัน
การเชื่อมต่อกับระบบเดิมเป็นหัวใจสำคัญของการนำไปใช้ในสถาบันขนาดใหญ่ ระบบจึงออกแบบให้ใช้ API/connector แบบมาตรฐานเพื่อดึงเมตาดาท้าและไฟล์ดิจิทัลโดยไม่จำเป็นต้องย้ายข้อมูลทั้งหมด ตัวอย่างของ connector ที่ใช้ได้แก่ OAI-PMH สำหรับการเก็บ metadata harvesting, connectors ไปยังระบบจัดการห้องสมุดเช่น Alma/Primo, DSpace, Fedora หรือผ่าน REST/GraphQL API ของระบบภายใน โดยทั่วไปจะดึงเฉพาะเมตาดาท้าและ pointer (เช่น URL หรือ storage reference) พร้อมกับตัวอย่างหรือ excerpt สำหรับการสร้าง embeddings ทำให้ข้อมูลต้นทางยังคงอยู่ในที่จัดเก็บเดิมและลดความเสี่ยงด้านการคัดลอกข้อมูลทั้งหมด
เชิงปฏิบัติยังมีการออกแบบอินเทอร์เฟซที่รองรับการใช้งานของนักวิจัยและผู้บริหาร ดังนี้:
- ค้นด้วยภาษาธรรมชาติ — ช่องค้นหาที่รองรับคำถามเชิงบริบท และระบบจะแสดงคำตอบสรุปพร้อม citation และลิงก์สู่เอกสารต้นฉบับ
- การสรุปเอกสาร — สรุปย่อ (abstract) แบบอัตโนมัติ, ประเด็นสำคัญ และ bullet points ที่ช่วยให้ผู้ใช้ประเมินความเกี่ยวข้องได้เร็วขึ้น
- ค้นข้ามคอลเลกชัน — ฟีเจอร์แนะนำทรัพยากรที่เชื่อมโยงกันทั้งในคอลเลกชันหนังสือ, บทความวารสาร, ดาต้าเซ็ต และเอกสารเก่า โดยใช้การแมป embedding ข้ามสคีมา
- โปร่งใสและอธิบายได้ — ระบบแสดงแหล่งที่มาของข้อมูล (provenance), คะแนนความเชื่อมั่น (confidence score) และ snippets ที่ใช้เป็นหลักฐานสำหรับคำตอบ
ข้อพิจารณาทางเทคนิคและการปฏิบัติการที่สำคัญ ได้แก่ latency กับต้นทุนการเรียกใช้โมเดลขนาดใหญ่ ซึ่งมักแก้ไขด้วยการใช้โมเดลขนาดกลางสำหรับการตอบทันทีและเรียกใช้โมเดลขนาดใหญ่แบบ on-demand สำหรับการสรุปเชิงลึกหรือ re-ranking ขั้นสูง ระบบยังใช้เทคนิค caching ของผลการค้นและการจัดลำดับล่วงหน้า (pre-computed embeddings และ re-rank candidates) เพื่อรักษาความเร็ว นอกจากนี้การประเมินผลใช้ตัวชี้วัดเช่น precision@k, recall, MRR และการทดสอบผู้ใช้จริง (user satisfaction surveys) เพื่อปรับจูนพารามิเตอร์การค้นและการแสดงผล
สุดท้าย นโยบายความปลอดภัยและการควบคุมการเข้าถึงเป็นองค์ประกอบที่สำคัญสำหรับสถาบันวิชาการ: ระบบมักสนับสนุนการทำงานในรูปแบบไฮบริด (on-premise หรือ VPC ในคลาวด์), การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง, การจัดการสิทธิ์แบบละเอียด (RBAC) และการเก็บบันทึกการเข้าถึงเพื่อการตรวจสอบ ทั้งนี้เพื่อให้มั่นใจว่างานวิจัยและทรัพยากรทางปัญญาของสถาบันได้รับการคุ้มครองในขณะที่ยังคงเพิ่มความสะดวกและประสิทธิภาพในการค้นข้อมูลให้แก่นักวิจัย
ผลการทดสอบเบื้องต้นและสถิติสำคัญ
ผลการทดสอบเบื้องต้นและสถิติสำคัญ
การทดลองนำร่องของห้องสมุดฮาร์วาร์ดที่ผสานระบบปัญญาประดิษฐ์ในการค้นคืนและสรุปข้อมูลสำหรับนักวิจัยแสดงผลเริ่มต้นที่โดดเด่นทั้งเชิงปริมาณและเชิงคุณภาพ โดยการทดสอบดำเนินการกับกลุ่มผู้ใช้หลากหลายสาขาจำนวนรวมประมาณ 120 ราย (ตัวเลขเบื้องต้น) ในช่วงทดลอง 8 สัปดาห์ ผลลัพธ์ชี้ให้เห็นว่าระบบช่วยลดภาระเวลาและเพิ่มความเกี่ยวข้องของผลการค้นหาอย่างมีนัยสำคัญ โดยตัวเลขทั้งหมดยังถือเป็นการประเมินเบื้องต้นและอาจเปลี่ยนแปลงเมื่อนำไปใช้ในวงกว้างและในระยะยาว

ในเชิงปริมาณ ทีมวิจัยบันทึกการลดลงของเวลาเฉลี่ยที่นักวิจัยใช้ในการค้นหาข้อมูลที่ตอบโจทย์งานวิจัย จากการวัดครั้งแรกพบว่าระยะเวลาเฉลี่ยลดลงประมาณ 30–40% เมื่อเปรียบเทียบกับกระบวนการค้นหาดั้งเดิม ตัวอย่างเช่น กลุ่มตัวอย่างบางกลุ่มรายงานว่าเวลาเฉลี่ยต่อการค้นหาลดจากประมาณ 8.0 นาทีต่อคำค้น เป็นประมาณ 4.8–5.6 นาทีต่อคำค้น (ค่านี้เป็นการประมาณการเบื้องต้น) ซึ่งสะท้อนถึงการลดขั้นตอนการกรองผลลัพธ์และการสรุปข้อมูลที่ระบบ AI ทำให้
ด้านความแม่นยำและความเกี่ยวข้องของผลการค้นหา ทีมประเมินโดยใช้มาตรฐานการให้คะแนนภายในและแบบสำรวจความเกี่ยวข้องจากผู้เชี่ยวชาญ พบว่า คะแนนความเกี่ยวข้องอยู่ในช่วงประมาณ 80–85% ซึ่งถูกจัดอยู่ในระดับ “สูง” ตามเกณฑ์ของนักวิจัย (ตัวเลขเบื้องต้น) การประเมินนี้รวมทั้งการจับคู่คำสำคัญ (keyword matching) การให้ความสำคัญกับบริบทเชิงสาขา และการตรวจสอบว่าลิงก์หรือเอกสารที่ระบบแนะนำมีความสัมพันธ์กับคำถามวิจัยหรือไม่
ผลเชิงคุณภาพจากแบบสัมภาษณ์เชิงลึกและแบบสอบถามเปิดเผยว่าผู้ใช้หลายคนพบประโยชน์เชิงปฏิบัติ เช่น การค้นพบแหล่งข้อมูลเสริมที่ไม่เคยสังเกตมาก่อน ตัวอย่างการค้นพบ ได้แก่ รายงานภาคผนวก ข้อมูลชุดข้อมูลย่อย (datasets) และบทความประชากรศาสตร์เก่าที่ไม่ได้ขึ้นอันดับการค้นหาแบบเดิม ผู้เข้าร่วมราว 15–25% รายงานว่าพบทรัพยากรใหม่ที่มีคุณค่าในช่วงทดลอง (ตัวเลขคาดการณ์เบื้องต้น) นอกจากนี้ผู้ใช้ยังให้คะแนนความพึงพอใจโดยรวมเฉลี่ยประมาณ 4.2/5 ต่อความสามารถของระบบในการสรุปบทความและแยกประเด็นสำคัญจากภาคผนวก
นอกเหนือจากสถิติแล้ว ข้อสังเกตเชิงคุณภาพชี้ว่า AI มีบทบาทสำคัญในการสรุปบทความวิจัยและภาคผนวกให้เป็นย่อหน้าเชิงสรุปที่ช่วยให้ผู้วิจัยตัดสินใจได้เร็วขึ้น ผู้ทดสอบรายหนึ่งระบุว่ากระบวนการสรุปของระบบช่วยลดเวลาที่ใช้ในการอ่านเอกสารยาวลงมาก ทำให้สามารถประเมินความเกี่ยวข้องเบื้องต้นก่อนเจาะลึกได้อย่างมีประสิทธิภาพ อย่างไรก็ดี นักวิจัยเน้นย้ำว่าเป็นผลลัพธ์เบื้องต้น จึงต้องมีการทดสอบเพิ่มเติมเพื่อยืนยันความเสถียรของตัวเลขเหล่านี้ในบริบทและสาขาวิชาต่าง ๆ
- การลดเวลาเฉลี่ยในการค้นหา: ประมาณ 30–40% (ข้อมูลเบื้องต้น)
- คะแนนความเกี่ยวข้องของผลลัพธ์: อยู่ในช่วงประมาณ 80–85% (จัดเป็นระดับสูง; ตัวเลขเบื้องต้น)
- อัตราการค้นพบทรัพยากรใหม่: ประมาณ 15–25% ของเซสชันทดสอบรายงานพบแหล่งข้อมูลเพิ่มเติมที่ไม่เคยปรากฏมาก่อน (คาดการณ์เบื้องต้น)
- ความพึงพอใจโดยรวม: ค่าเฉลี่ยประมาณ 4.2/5 ต่อความสามารถด้านสรุปและการแนะนำแหล่งข้อมูล (ตัวเลขเบื้องต้น)
ตัวอย่างการใช้งานจริง (use cases) ของนักวิจัย
ตัวอย่างการใช้งานจริง (use cases) ของนักวิจัย
การนำระบบปัญญาประดิษฐ์มาใช้ในห้องสมุดฮาร์วาร์ดเปิดช่องทางใหม่ให้กับนักวิจัยที่ต้องการค้นข้อมูลเชิงลึกภายใต้กรอบเวลาจำกัด หนึ่งในกรณีที่เห็นผลได้ชัดคือการ ค้นข้ามคอลเลกชัน (cross-collection search) ซึ่งช่วยให้นักประวัติศาสตร์สามารถสืบค้นเอกสารหอจดหมายเหตุ รายงานภายใน สิ่งพิมพ์ทางวิชาการ และบทความข่าว ได้พร้อมกันโดยไม่ต้องสลับฐานข้อมูล ตัวอย่างเช่น นักวิจัยที่ศึกษาการเคลื่อนไหวทางสังคมในศตวรรษที่ 20 สามารถค้นหาจดหมายเหตุส่วนตัวพร้อมกับบทความข่าวและโสตทัศนวัถตุที่มีการทำดัชนีไว้ ผลลัพธ์ที่ได้ถูกจัดลำดับตามความเกี่ยวข้องและมีการเชื่อมโยงเอนทิตี (ชื่อบุคคล สถานที่ เหตุการณ์) ทำให้การเชื่อมบริบทข้ามแหล่งข้อมูลรวดเร็วยิ่งขึ้น
นอกจากนี้ ระบบ AI ช่วยในด้านการ สรุปและจัดลำดับวรรณกรรม ซึ่งเป็นงานสำคัญก่อนการเขียนข้อเสนอวิจัยหรือการยื่นทุน โดยโมดูลสรุปอัตโนมัติสามารถดึงประเด็นสำคัญจากบทความจำนวนมาก สร้างตารางสรุปวิธีการวิจัย ผลลัพธ์หลัก และช่องว่างขององค์ความรู้ ทำให้นักวิจัยสามารถเตรียมทบทวนวรรณกรรมได้รวดเร็วขึ้น ในการทดลองภายในบางโครงการพบว่า AI ช่วยลดเวลาการทบทวนวรรณกรรมพื้นฐานลงได้ประมาณ 50–70% ในกรณีที่ต้องการภาพรวมกว้าง ๆ และจัดลำดับความสำคัญของงานที่ต้องอ่านอย่างละเอียด เพื่อใช้เป็นรากฐานร่างข้อเสนอวิจัยที่มีเหตุผลเชิงวิชาการชัดเจน
อีกประเด็นสำคัญคือการ ช่วยแปลและค้นหาเชิงภาษาศาสตร์ โดยเฉพาะเมื่อเผชิญกับคำที่มีรูปแบบเก่า คำเลือกใช้ที่ไม่เป็นมาตรฐาน หรือเอกสารที่เขียนด้วยภาษาหลากหลาย ระบบ AI สามารถทำ mapping ของรูปคำเก่า-ใหม่ ทำ transliteration และรองรับการค้นด้วยความคลาดเคลื่อนของสระ วรรณยุกต์ หรือการสะกดที่แตกต่างกัน ตัวอย่างเช่น งานวิจัยด้านชาติพันธุ์ศึกษาอาจต้องค้นคำที่มีการสะกดแบบเดิมในบันทึกยุคอาณานิคม ระบบจะช่วยแมปคำเหล่านั้นกับรูปแบบปัจจุบันและแสดงผลที่เกี่ยวข้องทั้งหมด นอกจากนี้ ยังสามารถแปลสรุปย่อจากภาษาต้นฉบับเป็นหลายภาษา ทำให้ทีมวิจัยข้ามชาติสามารถประเมินความเกี่ยวข้องก่อนจะลงมือแปลเชิงลึก
ในเชิงการปฏิบัติ การใช้งานเหล่านี้มักรวมถึงฟีเจอร์ย่อยที่ตอบโจทย์นักวิจัยภายใต้ความกดดันด้านเวลา เช่น การจัดอันดับความสำคัญของเอกสาร การสร้างบรรณานุกรมอัตโนมัติ การสกัดคำค้นเชิงแนวคิด (concept extraction) และการแปะแท็กเชิงบริบทเพื่อการนำเสนอแนวทางวิจัยอย่างรวดเร็ว ขณะเดียวกัน การใช้ AI ในขั้นตอนเหล่านี้ควรมี มนุษย์ตรวจสอบ เพื่อยืนยันความถูกต้องของข้อมูลและตีความเชิงวิชาการอย่างรอบคอบ ซึ่งเป็นกฎพื้นฐานเมื่อใช้เครื่องมือเพื่อเร่งงานวิจัยและร่างข้อเสนอที่มีคุณภาพสูง
- ค้นข้ามคอลเลกชัน: นักประวัติศาสตร์ค้นจดหมายเหตุและสิ่งพิมพ์พร้อมกัน พร้อมการเชื่อมโยงเอนทิตีและบริบท
- สรุปและจัดลำดับวรรณกรรม: สร้างสรุปเชิงโครงสร้างและจัดลำดับงานวิจัยเพื่อลดเวลาทบทวนก่อนยื่นข้อเสนอ
- การช่วยแปล/ค้นหาเชิงภาษาศาสตร์: รองรับรูปคำเก่า คำเลือกใช้ไม่เป็นมาตรฐาน และการแปลสรุปข้ามภาษาเพื่อการประเมินความเกี่ยวข้อง
ความเสี่ยงด้านความเป็นส่วนตัว ลิขสิทธิ์ และความเอนเอียงของข้อมูล
ความเสี่ยงด้านความเป็นส่วนตัว ลิขสิทธิ์ และความเอนเอียงของข้อมูล
การนำระบบปัญญาประดิษฐ์มาใช้ในห้องสมุด เช่น โครงการทดลองของห้องสมุดฮาร์วาร์ด เพื่อช่วยนักวิจัยค้นและสรุปเอกสาร ช่วยเพิ่มประสิทธิภาพอย่างมาก แต่ก็ยกปัญหาด้านจริยธรรมและกฎหมายที่ต้องจัดการอย่างรอบคอบ โดยเฉพาะเรื่อง ความเป็นส่วนตัวของข้อมูล, ลิขสิทธิ์และสิทธิ์การใช้งาน และ ความเอนเอียงของโมเดล ซึ่งหากละเลยอาจสร้างความเสี่ยงทางกฎหมายและบั่นทอนความน่าเชื่อถือของผลการค้นหาได้
การปกป้องข้อมูลส่วนบุคคล: เมื่อระบบสามารถเข้าถึงบันทึกการยืม เอกสารวิจัยที่ยังไม่เผยแพร่ หรือเมตาดาต้าของผู้ใช้งาน จะต้องระบุขอบเขตการเข้าถึงอย่างชัดเจน (scope of access) และลงนามในข้อตกลงด้านการใช้ข้อมูลที่สอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล ตัวอย่างมาตรการที่ควรบังคับใช้ได้แก่ role-based access control, การเข้ารหัสข้อมูลขณะพักและขณะส่ง, การทำ anonymization หรือ pseudonymization ของข้อมูลที่ระบุตัวบุคคล และนโยบายการเก็บรักษาข้อมูล (retention) ที่จำกัดเวลาเพื่อหลีกเลี่ยงการเก็บข้อมูลเกินจำเป็น นอกจากนี้ ควรบันทึก audit logs ที่ตรวจสอบได้เพื่อติดตามการเข้าดูและการประมวลผลข้อมูล — ซึ่งเป็นหลักฐานสำคัญหากเกิดเหตุละเมิดหรือข้อร้องเรียน
ลิขสิทธิ์และสิทธิ์การใช้งาน: เมื่อ AI เข้าถึงคอลเลกชันเอกสาร ห้องสมุดต้องพิจารณาข้อจำกัดสัญญาและสิทธิ์การเผยแพร่ก่อนเปิดให้โมเดลสรุปหรือเผยแพร่เนื้อหา ตัวอย่างความเสี่ยงได้แก่ การสร้างสรุปที่มีเนื้อหาใกล้เคียงต้นฉบับจนละเมิดลิขสิทธิ์ การเผยแพร่เอกสารที่ผู้แต่งยังไม่อนุญาต หรือการใช้ข้อมูลจากฐานข้อมูลเชิงพาณิชย์โดยไม่ชอบตามสัญญา แนวทางป้องกันรวมถึงการทำ metadata-based filtering เพื่อตรวจสอบสิทธิ์ก่อนให้โมเดลเข้าถึง การบังคับใช้ข้อตกลงการใช้ข้อมูล (data use agreements) กับผู้พัฒนาโมเดล และการให้เครดิตหรืออ้างอิงแหล่งที่มาเมื่อระบบสร้างสรุป ซึ่งเป็นแนวปฏิบัติที่ช่วยลดความเสี่ยงด้านสิทธิ์การใช้งาน
ความเอนเอียงของโมเดลและผลกระทบต่อการค้นหา: โมเดลภาษาถูกฝึกจากชุดข้อมูลที่สะสมมา ซึ่งอาจมีช่องว่างหรืออคติ (bias) ต่อชนิดของเอกสาร ภาษา หรือมุมมองทางวิชาการบางประเภท ผลลัพธ์ที่ได้อาจทำให้แหล่งข้อมูลบางประเภทถูกข้ามเสียงหรือถูกให้คะแนนต่ำกว่าความเป็นจริง — ตัวอย่างเช่น งานทดสอบบางชิ้นพบความแตกต่างของอัตราความถูกต้องระหว่างกลุ่มเอกสารที่มีตัวแทนเพียงเล็กน้อยกับกลุ่มที่ถูกแทนมากถึงระดับที่มีนัยสำคัญ (เช่น >20% ในการประเมินบางกรณี) ซึ่งชี้ให้เห็นความเสี่ยงต่อความหลากหลายของมุมมองในการค้นคว้าวิจัย
เพื่อบรรเทาความเสี่ยงด้านเอนเอียง ควรมีการตรวจสอบเชิงสถิติและกระบวนการปรับปรุงโมเดลอย่างต่อเนื่อง เช่น การวัด fairness metrics (เช่น demographic parity, equalized odds) การวิเคราะห์ distributional shift ระหว่างชุดฝึกกับคอลเลกชันของห้องสมุด และการทดสอบผลกระทบต่อกลุ่มเอกสารต่างๆ นอกจากนี้ การออกแบบระบบให้มี human-in-the-loop โดยนักบรรณารักษ์หรือผู้เชี่ยวชาญด้านสาขาจะช่วยตรวจสอบและแก้ไขข้อผิดพลาดหรืออคติที่ระบบสร้างขึ้นได้
- มาตรการเชิงปฏิบัติสำหรับความเป็นส่วนตัว: กำหนดขอบเขตการเข้าถึงข้อมูล เป็นไปตามหลักความจำเป็น (least privilege), ใช้การทำ anonymization/differential privacy ในการเผยแพร่สรุปเชิงสถิติ, เปิดเผยนโยบายการเก็บข้อมูลและวงจรชีวิตของข้อมูลต่อผู้ใช้ และใช้ audit logs ที่สามารถตรวจสอบย้อนหลังได้
- มาตรการด้านลิขสิทธิ์: ตรวจสอบสิทธิ์การใช้งานก่อนอนุญาตให้โมเดลเข้าถึง (rights clearance), บังคับใช้การอ้างอิงแหล่งที่มาเมื่อมีการสรุปหรือคัดลอกเนื้อหา, สร้างกลไกสำหรับ handling takedown requests และทำข้อตกลงการใช้ข้อมูลกับผู้ให้บริการภายนอกอย่างชัดเจน
- มาตรการลดความเอนเอียง: ดำเนิน bias audits เป็นประจำ, ใช้เทคนิคการรีเวตติ้ง (reweighting) หรือการปรับสมดุลชุดฝึก, ประยุกต์ use-case specific evaluation metrics, และรักษากระบวนการตรวจสอบโดยผู้เชี่ยวชาญก่อนเผยแพร่ผลสรุปสำคัญ
- นโยบายการมีส่วนร่วมของชุมชน: เปิดช่องทางให้ผู้ใช้รายงานปัญหา ความไม่สมดุล หรือข้อผิดพลาด (feedback loop) และเผยแพร่รายงานความโปร่งใสเกี่ยวกับแหล่งข้อมูลที่ใช้ นโยบายการอัปเดตโมเดล และผลการประเมินความเสี่ยงเป็นระยะ
โดยสรุป การนำ AI มาเพิ่มความสะดวกในการค้นคว้าของห้องสมุดต้องมาพร้อมกับกรอบการกำกับดูแลที่ชัดเจน ครอบคลุมทั้งการปกป้องข้อมูลส่วนบุคคล การเคารพสิทธิ์ทางปัญญา และการจัดการความเอนเอียงของโมเดล เพื่อให้การใช้งานช่วยส่งเสริมการวิจัยอย่างรับผิดชอบและยั่งยืน
ปฏิกิริยาและมุมมองจากผู้มีส่วนได้ส่วนเสีย
ปฏิกิริยาและมุมมองจากผู้มีส่วนได้ส่วนเสีย
การประกาศทดลองใช้ AI ในห้องสมุดฮาร์วาร์ดได้รับความสนใจและข้อเสนอแนะจากหลายฝ่ายอย่างรวดเร็ว โดยภาพรวมแสดงทั้งความคาดหวังและความกังวลที่ชัดเจน ในฝั่งนักวิจัย มีเสียงตอบรับเชิงบวกในระดับสูงโดยเฉพาะเรื่อง ความเร็วในการค้นหา และความสามารถในการค้นพบทรัพยากรที่ไม่ปรากฏในผลการค้นแบบเดิม ตัวอย่างเช่น การสำรวจภายในกลุ่มตัวอย่างนักวิจัยเบื้องต้นระบุว่า ร้อยละ 68 คาดหวังว่าเครื่องมือ AI จะลดเวลาในการค้นเอกสารฉบับเต็ม (full-text retrieval) ลงอย่างมีนัยสำคัญ อย่างไรก็ดี นักวิจัยส่วนใหญ่ออกข้อเรียกร้องสำคัญเรื่อง ความโปร่งใสของกระบวนการค้น—ต้องการเห็นแหล่งข้อมูลอ้างอิง (provenance), วิธีการคัดเลือกผลลัพธ์, และการประเมินความเชื่อถือได้ของคำตอบที่ AI ให้มา
สำหรับเจ้าหน้าที่ห้องสมุด มุมมองค่อนข้างผสมระหว่างโอกาสและความห่วงกังวล เจ้าหน้าที่เห็นว่า AI สามารถเป็นตัวเร่งให้การเข้าถึงทรัพยากรวิชาการขยายออกไปสู่ผู้ใช้กลุ่มใหม่ ๆ เช่น นักศึกษาปริญญาเอกและนักวิจัยสหสาขา แต่ขณะเดียวกันมีคำถามเชิงปฏิบัติ เช่น การจัดการสิทธิ์ในการเข้าถึงเนื้อหาเชิงพาณิชย์, การป้องกันการละเมิดลิขสิทธิ์เมื่อ AI สร้างสรุปจากเอกสาร, และภาระงานในการบำรุงรักษาเมตาดาต้า (metadata) เพื่อให้ระบบสามารถทำงานได้อย่างมีประสิทธิภาพ เจ้าหน้าที่บางส่วนเตือนว่าหากไม่มีการจัดสรรทรัพยากรบุคคลและงบประมาณที่เหมาะสม การนำ AI มาใช้จริงอาจสร้างช่องว่างระหว่างผู้ใช้ที่ได้รับประโยชน์กับผู้ใช้ที่ไม่ได้รับ
ผู้พัฒนาเทคโนโลยีและนักนโยบายเสนอข้อเรียกร้องเชิงโครงสร้างเพื่อให้การทดลองนำร่องมีความน่าเชื่อถือและสามารถขยายผลได้ พวกเขาเน้นความจำเป็นของ มาตรฐานการทดสอบ และการรายงานผลที่เป็นระบบ เช่น การกำหนดเกณฑ์การประเมิน (KPIs) เพื่อวัดความแม่นยำของการค้นหา, อัตราการคืนแหล่งข้อมูลที่ถูกต้อง, เวลาตอบสนองระบบ และอัตราการเกิดคำตอบผิดพลาดเชิงเนื้อหา (hallucination rate) นอกจากนี้ยังเรียกร้องให้มีการเผยแพร่รายงานความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมายลิขสิทธิ์ เพื่อเป็นแนวทางสำหรับห้องสมุดอื่น ๆ ที่กำลังพิจารณานำระบบ AI มาใช้
เมื่อพิจารณาร่วมกัน ประเด็นสำคัญที่ผู้มีส่วนได้ส่วนเสียทั้งหลายเห็นร่วมกันคือความจำเป็นของการสื่อสารเชิงรุกและต่อเนื่องกับชุมชนผู้ใช้ เพื่อสร้างความเชื่อมั่นและลดความไม่แน่นอน คำแนะนำเชิงปฏิบัติในการสื่อสารประกอบด้วย:
- ความโปร่งใสเชิงเทคนิค: รายงานสรุปวิธีการทำงานของโมเดล ช่องทางการอ้างอิงข้อมูลต้นทาง และข้อจำกัดที่รู้จัก เพื่อให้นักวิจัยเข้าใจขอบเขตการใช้งาน
- การฝึกอบรมและเวิร์กช็อป: จัดหลักสูตรสั้น ๆ และเซสชันสาธิตการใช้งานสำหรับกลุ่มผู้ใช้ต่างระดับ ตั้งแต่ผู้เริ่มต้นจนถึงผู้มีความเชี่ยวชาญ
- ช่องทางรับฟังความคิดเห็น: ตั้งคณะกรรมการที่ปรึกษาจากตัวแทนนักวิจัย เจ้าหน้าที่ห้องสมุด และผู้เชี่ยวชาญด้านจริยธรรม เพื่อรวบรวมฟีดแบ็กและปรับปรุงโครงการแบบวงจรปิด
- การรายงานผลเชิงสาธารณะ: เผยแพร่รายงานการทดสอบและผลการประเมินเป็นระยะ พร้อมดัชนีชี้วัดที่ชัดเจน เพื่อให้สถาบันอื่น ๆ สามารถอ้างอิง
- นโยบายสิทธิ์และการคุ้มครองข้อมูล: ชี้แจงนโยบายการจัดการสิทธิ์การเข้าถึงและการคุ้มครองข้อมูลส่วนบุคคล รวมถึงกลไกการยืนยันสิทธิ์ (authentication/authorization)
- มาตรการรับมือปัญหา: ประกาศช่องทางการรายงานข้อผิดพลาด (error reporting) และกระบวนการแก้ไข เพื่อสร้างความมั่นใจว่าข้อผิดพลาดจะได้รับการจัดการอย่างรวดเร็ว
สรุปแล้ว การทดลอง AI ของห้องสมุดฮาร์วาร์ดถูกมองว่าเป็นโอกาสสำคัญในการยกระดับการค้นคว้าวิจัย แต่การประสบความสำเร็จในระยะยาวจะขึ้นกับการตอบโจทย์ด้าน ความโปร่งใส, การจัดการทรัพยากรและสิทธิ์, และการวางกรอบมาตรฐานการทดสอบที่ชัดเจน ซึ่งต้องอาศัยความร่วมมืออย่างใกล้ชิดระหว่างนักวิจัย เจ้าหน้าที่ห้องสมุด และผู้พัฒนาระบบ รวมถึงการสื่อสารเชิงรุกกับชุมชนผู้ใช้เพื่อสร้างการยอมรับและการใช้งานที่ยั่งยืน
แผนการขยายผลและข้อเสนอเชิงนโยบาย
การประเมินผลเชิงสถิติและเชิงคุณภาพก่อนขยายการให้บริการสู่สาธารณะ
ก่อนขยายการใช้งานจากรอบทดลองสู่การให้บริการสาธารณะ จำเป็นต้องดำเนินการประเมินผลทั้งเชิงปริมาณและเชิงคุณภาพอย่างเป็นระบบ โดยกำหนดเกณฑ์วัดผล (KPIs) ที่ชัดเจน เช่น ความแม่นยำของผลการค้นหา (precision), อัตราการค้นพบที่ถูกต้อง (recall), เวลาเฉลี่ยในการค้นพบข้อมูล (time-to-find), อัตราการเกิดข้อผิดพลาดหรือการสร้างข้อมูลเท็จที่เรียกว่า hallucination และดัชนีความพึงพอใจของผู้ใช้ (SUS หรือ NPS)
ขั้นตอนเชิงสถิติควรรวมการออกแบบการทดลองแบบ A/B หรือการสุ่มควบคุม (randomized controlled trial) โดยตั้งเป้าตัวอย่างที่มีความเพียงพอ (เช่น ผู้ใช้ตั้งแต่ 500–2,000 คน ขึ้นอยู่กับขนาดของสถาบัน) และระยะเวลาพิสูจน์ผลไม่น้อยกว่า 3–6 เดือน เพื่อเก็บข้อมูลพฤติกรรมการใช้งานแบบมีฤดูกาล ตลอดจนการวิเคราะห์เชิงสถิติที่ชี้ชัด (เช่น p-value, confidence interval, effect size) เพื่อยืนยันความแตกต่างที่มีนัยสำคัญก่อนการขยายบริการ
ในส่วนเชิงคุณภาพ ควรดำเนินการสัมภาษณ์เชิงลึก (in-depth interviews), กลุ่มสนทนา (focus groups) และการทดสอบความสามารถใช้งาน (usability testing) กับกลุ่มเป้าหมายหลายมิติ (อาจรวมถึงนักศึกษาปริญญาเอก อาจารย์ นักวิจัย และประชาชนทั่วไป) เพื่อเก็บความคิดเห็นเชิงบริบท ปัญหาด้านความเข้าใจผลลัพธ์ และข้อกังวลเชิงจริยธรรม ข้อมูลเชิงคุณภาพเหล่านี้มีความสำคัญในการตีความผลเชิงสถิติและออกแบบการแก้ไขก่อนขยายระบบ
การจัดทำนโยบายภายใน: Data Governance, Access Control, Copyright Compliance
การนำ AI มาใช้ในห้องสมุดต้องมาพร้อมกับกรอบนโยบายภายในที่รัดกุม โดยเริ่มจาก Data Governance ที่ประกอบด้วยการจัดทำทะเบียนข้อมูล (data inventory), การจำแนกประเภทข้อมูล (classification), นโยบายการเก็บรักษา (retention policy), การเข้ารหัสข้อมูลขณะพักและระหว่างส่ง (encryption), การทำ pseudonymization/anonymization สำหรับข้อมูลผู้ใช้ และการประเมินผลกระทบด้านความเป็นส่วนตัว (Privacy Impact Assessment)
ในด้าน Access Control ควรกำหนดหลักการ least privilege โดยใช้ระบบการยืนยันตัวตนแบบรวมศูนย์ (SSO) และการยืนยันตัวตนหลายปัจจัย (MFA) สำหรับเจ้าหน้าที่ ติดตั้งระบบบทบาทและสิทธิ์ (RBAC) สำหรับการเข้าถึงชุดข้อมูลและโมเดล รวมถึงการบันทึกและตรวจสอบ (audit logs) ทุกการเรียกใช้งานเพื่อรองรับการตรวจสอบย้อนหลังและการตอบสนองต่อเหตุการณ์ความปลอดภัย
ด้าน Copyright Compliance นโยบายต้องระบุแนวทางชัดเจนเกี่ยวกับการนำเนื้อหามาใช้ฝึกโมเดลหรือเพื่อการให้บริการ ได้แก่ การจัดการสิทธิ์ของเอกสารที่มีลิขสิทธิ์ การจัดทำเมตาดาต้าระบุแหล่งที่มา (provenance), การสร้างระบบอ้างอิงอัตโนมัติเมื่อคืนผลการค้นพบเนื้อหาที่มีลิขสิทธิ์ และกระบวนการจัดการคำขอถอนเนื้อหา (takedown) รวมถึงการทบทวนเงื่อนไขการใช้งานจากผู้ให้บริการบุคคลที่สามเพื่อให้สอดคล้องกับกฎหมายลิขสิทธิ์และข้อกำหนดสัญญา
การสร้างโครงการฝึกอบรมและช่องทางสื่อสารกับผู้ใช้เพื่อรับข้อเสนอแนะต่อเนื่อง
การฝึกอบรมและการสื่อสารเป็นหัวใจของการขยายผลอย่างยั่งยืน ควรออกแบบโปรแกรมการฝึกอบรมสำหรับกลุ่มเป้าหมายต่าง ๆ ประกอบด้วยหลักสูตรระยะสั้น (workshops) สำหรับเจ้าหน้าที่ห้องสมุด หลักสูตรเชิงปฏิบัติการ (hands-on) สำหรับนักวิจัย และเนื้อหาออนไลน์ (e-learning modules) สำหรับผู้ใช้ทั่วไป โดยกำหนดมาตรฐานเนื้อหาเช่น การตีความผลการค้นหา การประเมินความเชื่อถือของผลลัพธ์ และการใช้งานอย่างรับผิดชอบ
ควรจัดตั้งช่องทางการสื่อสารหลายระดับ ได้แก่
- ระบบรับข้อเสนอแนะในตัวแอป (in-app feedback) และแบบสำรวจผู้ใช้อัตโนมัติหลังการใช้งาน
- กระดานชุมชนออนไลน์และฟอรัมสำหรับแลกเปลี่ยนข้อเสนอแนะและกรณีใช้งาน
- คณะกรรมการที่ปรึกษาประกอบด้วยตัวแทนผู้ใช้หลากหลายกลุ่ม (user advisory board)
- บริการช่วยเหลือแบบเรียลไทม์ (helpdesk/office hours) และรายงานสรุป KPI รายไตรมาส
ข้อเสนอเชิงนโยบายสำหรับห้องสมุดสถาบันอื่น ๆ ที่สนใจนำ AI มาใช้
สำหรับสถาบันอื่นที่กำลังพิจารณาการนำ AI มาใช้ ขอแนะนำแนวปฏิบัติเป็นขั้นตอนเพื่อจำกัดความเสี่ยงและเพิ่มโอกาสความสำเร็จ ได้แก่
- การนำแบบค่อยเป็นค่อยไป (phased rollout): เริ่มจากการใช้งานภายใน (staff-only) ขยายสู่กลุ่มทดลองทางวิชาการ ก่อนเปิดสู่ประชาชน เพื่อลดความเสี่ยงและสะสมบทเรียนเชิงปฏิบัติการ
- เกณฑ์ขั้นต่ำด้านประสิทธิภาพและความปลอดภัย: กำหนดค่าเป้าหมายเช่น precision ≥ 85%, ลดเวลาในการค้นหา ≥ 30%, อัตรา hallucination น้อยกว่า 2% และมาตรการสอดส่องทางความปลอดภัยก่อนเปิดใช้สาธารณะ
- การร่วมมือในระดับเครือข่าย: จัดตั้งกลุ่มร่วมมือระหว่างห้องสมุดสถาบันเพื่อแลกเปลี่ยนนโยบาย templates, เครื่องมือประเมิน และต้นทุนการพัฒนา รวมถึงการแบ่งปันชุดข้อมูลที่ได้รับอนุญาตเพื่อเพิ่มความสามารถของโมเดลอย่างถูกต้องตามกฎหมาย
- ความโปร่งใสและการตรวจสอบภายนอก: เปิดเผยรายงานประจำปีเกี่ยวกับการประเมินผลด้านความเป็นธรรม ความปลอดภัย และการปฏิบัติตามลิขสิทธิ์ โดยอาจเชิญผู้ตรวจสอบอิสระหรือคณะกรรมการภายนอกมาประเมินเป็นระยะ
- งบประมาณและแผนความยั่งยืน: วางแผนงบประมาณระยะยาวสำหรับการบำรุงรักษา การปรับปรุงโมเดล การฝึกอบรม และการปฏิบัติตามกฎระเบียบ รวมถึงพิจารณารูปแบบความร่วมมือเชิงพาณิชย์หรือเชิงสังคมเพื่อกระจายต้นทุน
โดยสรุป แผนการขยายผลต้องผสานการประเมินเชิงสถิติและเชิงคุณภาพ นโยบายภายในที่รัดกุม และโครงการฝึกอบรมพร้อมช่องทางรับฟังผู้ใช้ เพื่อให้การนำ AI มาช่วยการค้นคว้าวิจัยของห้องสมุดเป็นไปอย่างมีความน่าเชื่อถือ ปลอดภัย และยั่งยืน ทั้งนี้ การแลกเปลี่ยนแนวปฏิบัติกับสถาบันอื่นจะช่วยยกระดับมาตรฐานรวมของระบบสารสนเทศทางวิชาการในวงกว้าง
บทสรุป
การทดลองใช้ปัญญาประดิษฐ์ในห้องสมุดฮาร์วาร์ดเป็นก้าวสำคัญที่อาจยกระดับการค้นพบและการเข้าถึงทรัพยากรการวิจัย โดยเทคโนโลยีสามารถเร่งกระบวนการค้นหา แยกสาระสำคัญจากเอกสารจำนวนมาก และเชื่อมโยงข้อมูลข้ามสาขาวิชาได้ดียิ่งขึ้น ซึ่งหากการทดสอบนำไปสู่ผลลัพธ์ที่เป็นประโยชน์และสามารถควบคุมความเสี่ยงได้อย่างมีประสิทธิภาพ ผลลัพธ์ดังกล่าวมีโอกาสขยายตัวสู่ระบบห้องสมุดและศูนย์ความรู้ทั่วโลก ช่วยลดเวลาการสืบค้นและเพิ่มการเข้าถึงทรัพยากรสำหรับนักวิจัยทั้งในสถาบันขนาดใหญ่และชุมชนนักวิจัยที่มีทรัพยากรจำกัด
อย่างไรก็ตาม การนำ AI มาใช้ต้องมาพร้อมมาตรการด้านความเป็นส่วนตัว ลิขสิทธิ์ และการตรวจสอบความเอนเอียงเป็นเงื่อนไขสำคัญเพื่อให้การใช้งานเกิดประโยชน์อย่างยั่งยืน ได้แก่ การคุ้มครองข้อมูลผู้ใช้ การจัดการสิทธิ์เข้าถึงและการอนุญาตใช้งานเนื้อหา การตรวจสอบและประเมินความเอนเอียงของโมเดลอย่างสม่ำเสมอ การระบุแหล่งที่มาของข้อมูล (provenance) และกลไกมนุษย์เป็นส่วนร่วมในการตรวจทาน ผลักดันแนวทางกำกับดูแลที่โปร่งใสและมีมาตรฐานร่วมของชุมชนวิชาการจะช่วยให้ AI กลายเป็นเครื่องมือสนับสนุนการวิจัยที่เชื่อถือได้ หากปฏิบัติตามเงื่อนไขเหล่านี้ อนาคตของระบบค้นคว้าด้วย AI อาจนำไปสู่การสังเคราะห์ความรู้ข้ามวินัย การเข้าถึงทรัพยากรอย่างเป็นธรรม และการเพิ่มประสิทธิภาพงานวิจัยในวงกว้าง
📰 แหล่งอ้างอิง: The Harvard Crimson



