
ในยุคที่การผลิตยานยนต์ต้องการความแม่นยำระดับสูงและการตรวจจับข้อบกพร่องแบบเรียลไทม์ กลยุทธ์สำคัญไม่ได้อยู่ที่ฮาร์ดแวร์อย่างเดียวอีกต่อไป แต่รวมถึงคุณภาพของข้อมูลที่ใช้ฝึกโมเดลด้วย สตาร์ทอัพไทยเปิดตัวแพลตฟอร์มใหม่ชื่อ Defect‑Forge ซึ่งใช้เทคนิค diffusion ในการสังเคราะห์ภาพข้อบกพร่องบนชิ้นส่วนยานยนต์—จากรอยขีดข่วนและฟองในสี ไปจนถึงรอยร้าวบนคาร์บอนไฟเบอร์—เพื่อแก้ปัญหาการขาดแคลนภาพข้อบกพร่องจริงและการเสียเวลาค่าใช้จ่ายในการเก็บข้อมูลและติดป้ายกำกับแบบแมนนวล บริษัทระบุว่าการทดลองภายในแสดงผลเบื้องต้นว่าการเสริมชุดข้อมูลด้วยภาพสังเคราะห์สามารถช่วยเพิ่มความแม่นยำของโมเดลตรวจจับได้อย่างมีนัยสำคัญ และลดเวลาและต้นทุนการเก็บข้อมูลจริงได้เป็นอย่างมาก
จุดเด่นของ Defect‑Forge อยู่ที่การนำ diffusion models มาใช้แทนเทคนิคเดิม เช่น GANs เพื่อให้ได้ภาพที่สมจริงและควบคุมลักษณะข้อบกพร่องได้ละเอียด — เช่น การปรับมุมกล้อง แสง เงา และความรุนแรงของความเสียหาย ทำให้สามารถจำลองสถานการณ์บนสายการผลิตจริงได้หลากหลาย ตัวอย่างการใช้งานครอบคลุมทั้งการฝึกโมเดลตรวจจับบนสายประกอบ สีตัวถัง และชิ้นส่วนคอมโพสิต โดยแพลตฟอร์มสามารถผสานเข้ากับเวิร์กโฟลว์การทำงานของโรงงานและระบบ MLOps ที่มีอยู่ได้ ในบทความนี้เราจะพาไปเจาะลึกเทคโนโลยี diffusion ที่ใช้ ผลลัพธ์การทดสอบเชิงปริมาณ และผลกระทบที่อาจเกิดขึ้นต่อการยกระดับคุณภาพและประสิทธิภาพบนสายการผลิตยานยนต์ไทย
บทนำ: ทำไมการสังเคราะห์ภาพข้อบกพร่องถึงสำคัญต่ออุตสาหกรรมยานยนต์
บทนำ: ทำไมการสังเคราะห์ภาพข้อบกพร่องถึงสำคัญต่ออุตสาหกรรมยานยนต์
ในสายการผลิตยานยนต์ การตรวจจับข้อบกพร่องตั้งแต่ขั้นตอนการประกอบจนถึงการตรวจสอบคุณภาพสุดท้ายเป็นหัวใจสำคัญของการควบคุมคุณภาพและการลดค่าใช้จ่ายจากการเรียกคืนสินค้า อย่างไรก็ตาม การเก็บตัวอย่างภาพข้อบกพร่องจริงเพื่อใช้ฝึกสอนระบบตรวจจับด้วยคอมพิวเตอร์วิชั่นมีต้นทุนสูงและใช้เวลานาน—เริ่มตั้งแต่การบันทึกภาพภายใต้เงื่อนไขการผลิตที่หลากหลาย การรวบรวมข้อบกพร่องที่เกิดขึ้นจริงที่มีความถี่ต่ำ ไปจนถึงกระบวนการติดป้าย (labeling) เชิงมนุษย์ที่ต้องอาศัยผู้เชี่ยวชาญด้านคุณภาพ การดำเนินการเหล่านี้ทำให้การสร้างชุดข้อมูลคุณภาพสูงเป็นอุปสรรคสำคัญต่อการนำโมเดล AI มาใช้อย่างแพร่หลายในโรงงาน

ปัญหาที่ตามมาคือ ความไม่สมดุลของข้อมูล (class imbalance) — ข้อบกพร่องบางประเภทเช่น รอยขีดข่วนเล็ก ๆ หรือความผิดรูปที่เกิดขึ้นครั้งคราวอาจปรากฏน้อยกว่า 1% ของชิ้นงานทั้งหมด ทำให้โมเดลที่ฝึกด้วยข้อมูลเชิงประวัติศาสตร์มีแนวโน้มที่จะ overfit กับกลุ่มข้อมูลที่พบบ่อยและพลาดการตรวจจับข้อบกพร่องหายาก ผลลัพธ์คือค่า recall ต่ำสำหรับข้อบกพร่องที่สำคัญและความเสี่ยงด้านความปลอดภัยหรือต้นทุนการซ่อมบำรุงที่ยังคงหลบอยู่ในสายการผลิต นอกจากนี้ การติดฉลากเชิงละเอียดสำหรับงานตรวจจับและการเซกเมนเทชันอาจใช้เวลาหลายนาทีถึงชั่วโมงต่อภาพ ขึ้นกับความซับซ้อน ทำให้ต้นทุนรวมของการเตรียมข้อมูลพุ่งสูง
การสังเคราะห์ภาพด้วยเทคโนโลยี AI โดยเฉพาะเทคนิคสมัยใหม่อย่าง diffusion models เข้ามาเป็นทางออกที่สำคัญ เพราะสามารถช่วยขยายชุดข้อมูลและจำลองกรณีที่หายากได้ในลักษณะที่ควบคุมได้ ตัวอย่างประโยชน์ที่ชัดเจน ได้แก่:
- การขยายชุดข้อมูล — สร้างตัวอย่างข้อบกพร่องในมุมมอง แสง และพื้นผิวต่าง ๆ เพื่อให้โมเดลได้เรียนรู้ความแปรผันที่หลากหลาย
- การแก้ปัญหาความไม่สมดุล — เติมตัวอย่างสำหรับคลาสที่หายากเพื่อลด bias และเพิ่มความสามารถในการตรวจจับของโมเดล
- การจำลองกรณีฉุกเฉิน — สร้างข้อบกพร่องในสภาวะที่ยากต่อการเก็บข้อมูลจริง เช่น บนพื้นผิวสะท้อนแสงสูงหรือมุมมองที่ไม่ปกติ
- ลดต้นทุนและเวลาการเตรียมข้อมูล — ลดความต้องการเก็บตัวอย่างจริงจำนวนมากและลดภาระการติดป้ายด้วยมือ
ในบริบทนี้ แพลตฟอร์มใหม่อย่าง Defect‑Forge ซึ่งพัฒนาโดยสตาร์ทอัพไทย ถูกนำเสนอเป็นหนึ่งในทางเลือกที่น่าสนใจ โดยใช้ diffusion-based synthesis เพื่อสร้างภาพข้อบกพร่องสังเคราะห์ที่มีความสมจริงและปรับแต่งได้ตามสเปกของสายการผลิต ช่วยให้ผู้ผลิตสามารถเติมเต็มช่องว่างของข้อมูลและปรับสมดุลชุดข้อมูลโดยไม่ต้องพึ่งพาการเก็บตัวอย่างจริงเพียงอย่างเดียว ตัวอย่างการทดสอบเบื้องต้นในอุตสาหกรรมชิ้นส่วนยานยนต์แสดงให้เห็นว่าการเสริมด้วยภาพสังเคราะห์สามารถปรับปรุงความแม่นยำและ recall ของโมเดลตรวจจับได้อย่างมีนัยสำคัญ (เช่น เพิ่มขึ้นในช่วงตัวอย่าง 10–30% ขึ้นกับกรณีใช้งาน) ซึ่งสะท้อนถึงศักยภาพของการสังเคราะห์ภาพในการลดความเสี่ยงและต้นทุนให้กับโรงงาน
ภาพรวมเทคโนโลยี: Diffusion Models ทำงานอย่างไรในการสร้างข้อบกพร่องสังเคราะห์
Diffusion Models เป็นกรอบการสร้างภาพที่อาศัยกระบวนการสองทิศทาง: ทิศทางแรกเป็นการเติม noise ลงบนภาพจริงอย่างเป็นระบบ (forward/noising) จนได้เป็น distribution ของสัญญาณรบกวนเชิงสุ่ม ส่วนทิศทางที่สองคือการเรียนรู้ฟังก์ชันย้อนกลับ (reverse/denoising) เพื่อคืนภาพที่สมจริงจากตัวอย่าง noisy นั้น กระบวนการนี้ต่างจากการเรียนรู้เชิงชนิดที่พยายามสร้างภาพโดยตรง เพราะโมเดลจะเรียนรู้การลด noise ทีละขั้นตอน จนสามารถกู้คืนรายละเอียดและโครงสร้างของข้อบกพร่องบนวัสดุได้อย่างแม่นยำ
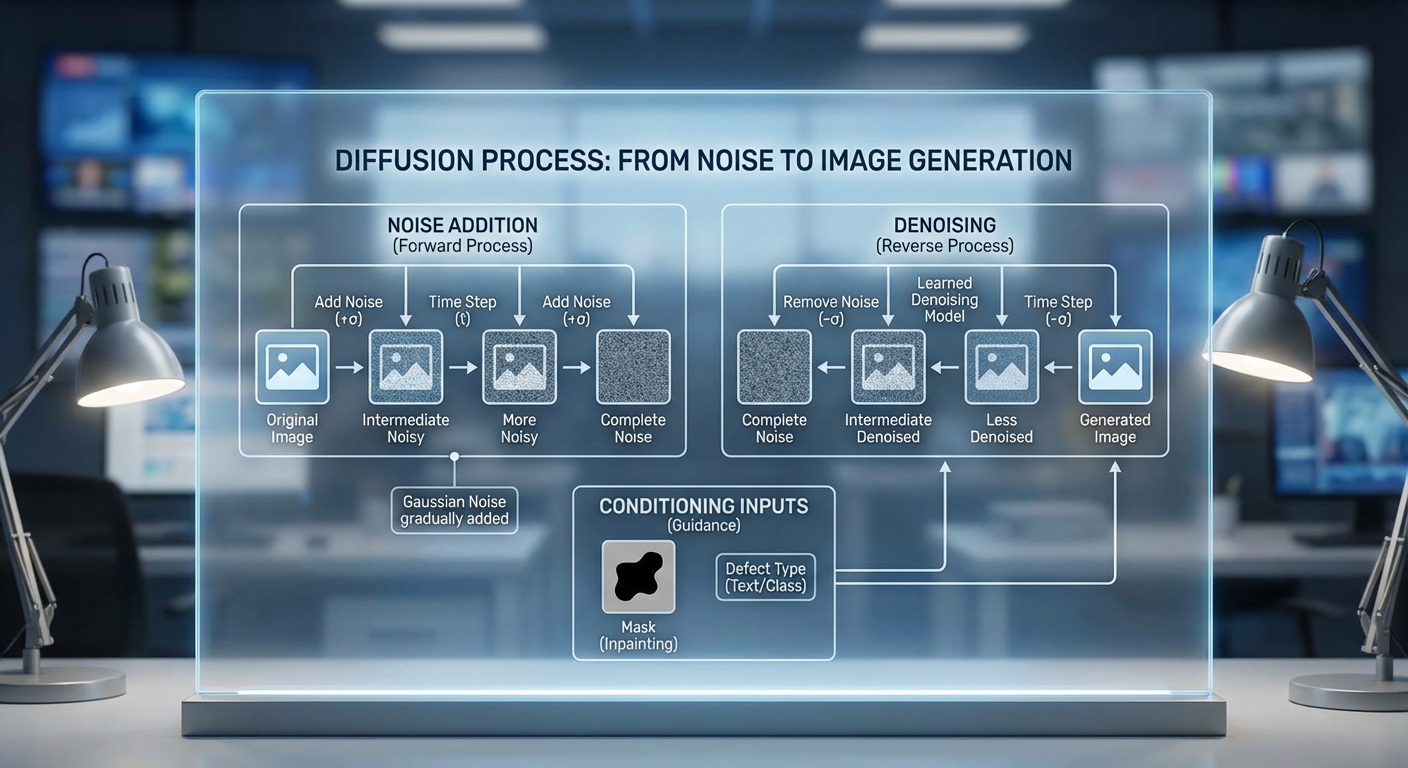
หลักการทำงานพื้นฐาน (สรุปเชิงเทคนิค)
โดยสรุป กระบวนการพื้นฐานประกอบด้วย:
- Forward process (noising): เริ่มจากภาพจริง x_0 และเพิ่ม noise ทีละขั้นตอนตามสัดส่วน β_t เพื่อให้ได้ x_1, x_2, …, x_T โดยทั่วไป q(x_t | x_{t-1}) = N(x_t; sqrt(1-β_t) x_{t-1}, β_t I)
- Reverse process (denoising): โมเดลพารามิเตอร์ θ จะประมาณ p_θ(x_{t-1} | x_t) ซึ่งมักนิยามเป็น Gaussian เช่น p_θ(x_{t-1}|x_t) = N(x_{t-1}; μ_θ(x_t, t), σ_t^2 I) และฝึกโดยใช้ loss ที่เทียบกับ noise จริง (predict-ε objective)
- การฝึก: โมเดล (ส่วนใหญ่เป็น U-Net หรือสถาปัตยกรรมที่ปรับแล้ว) จะถูกเทรนให้ทำนาย noise ε จาก x_t โดย loss = E[||ε - ε_θ(x_t, t)||^2] ซึ่งสอดคล้องกับการแมปความหนาแน่นและ score matching
- การสุ่มตัวอย่าง: หลังฝึกแล้ว เริ่มจากตัวอย่างสุ่มจาก Gaussian และทำ denoise ย้อนกลับเป็นลำดับ (ancestral sampling) หรือใช้เทคนิคความเร็วสูงเช่น DDIM/denoising diffusion implicit models เพื่อลดจำนวนขั้นตอน
ตัวอย่างเชิงเทคนิค: ในการใช้งานบนภาพความละเอียดสูง มักใช้ latent diffusion — ย่อภาพเข้าสู่ latent space ผ่าน encoder ก่อนแล้วรัน diffusion ใน latent space เพื่อให้ sampling เร็วขึ้นและลดความต้องการหน่วยความจำ
การควบคุมลักษณะข้อบกพร่อง (Conditioning) เพื่อให้ได้ภาพตรงตามความต้องการ
ความสามารถในการควบคุม (conditioning) เป็นจุดเด่นสำคัญของ diffusion เมื่อเทียบกับการสร้างภาพแบบทั่วไป สำหรับงานสร้างข้อบกพร่องบนสายการผลิต สามารถควบคุมปัจจัยสำคัญได้อย่างละเอียด ได้แก่ ตำแหน่ง ขนาด สี และพื้นผิวของ defect
- การระบุตำแหน่งและขอบเขต (mask / bounding box): ป้อน mask ของตำแหน่งที่ต้องการให้เกิด defect เป็นช่องข้อมูลเพิ่มเติมให้กับ U-Net (concatenate เป็น channel หรือใช้ cross-attention) ทำให้โมเดลสร้างข้อบกพร่องเฉพาะบริเวณที่กำหนด
- การควบคุมขนาดและความรุนแรง: ใช้ embedding ที่แทนค่าพารามิเตอร์เช่น diameter, depth หรือ severity แล้วรวมเข้ากับ embedding ของ timestep เพื่อให้ผลลัพธ์สะท้อนขนาด/ความรุนแรงที่ต้องการ
- การกำหนดสีและพื้นผิว: ป้อนตัวอย่าง texture map หรือ histogram ของสีเป็นเงื่อนไข (conditioning) เพื่อชี้นำลักษณะพื้นผิว เช่น รอยสนิม รอยถลอก หรือรอยขีดข่วน
- เทคนิค guidance: ใช้ classifier guidance หรือ classifier‑free guidance เพื่อยกระดับการสอดคล้องกับเงื่อนไข เช่น eps_final = eps_uncond + w * (eps_cond - eps_uncond) โดย w เป็น guidance scale ที่ปรับความเข้มของเงื่อนไข
ตัวอย่างเชิงเทคนิค: หากต้องการให้มีรอยแตกขนาด 5–10 มม. ที่ตำแหน่งด้านซ้ายบนของชิ้นส่วน สามารถส่ง bounding-box coordinate + scalar severity embedding เข้าร่วมกับ x_t เพื่อให้ U-Net สร้างสัญญาณ noise ที่เมื่อ denoise แล้วจะก่อตัวเป็นรอยแตกตามขนาดและตำแหน่งที่กำหนดได้อย่างแม่นยำ
ความได้เปรียบเมื่อเทียบกับเทคนิคสังเคราะห์แบบเก่า (GANs, augmentations)
เมื่อเปรียบเทียบกับ GANs และการทำ data augmentation แบบดั้งเดิม Diffusion Models ให้ข้อได้เปรียบหลายประการที่สำคัญต่อการใช้งานในอุตสาหกรรมยานยนต์และการตรวจจับข้อบกพร่อง:
- ความเสถียรและการครอบคลุมโหมด (mode coverage): Diffusion มีแนวโน้มหลีกเลี่ยงปัญหา mode collapse ของ GANs และสามารถสร้างตัวอย่างที่หลากหลายครอบคลุมรูปแบบข้อบกพร่องที่หาได้ยาก
- การควบคุมที่ละเอียด: Conditioning ทำให้สามารถสังเคราะห์ข้อบกพร่องตามสเป็กทางวิศวกรรม (ตำแหน่ง ขนาด สี พื้นผิว) ได้ดีกว่าการปรับแต่งด้วย augmentations แบบเดิม
- คุณภาพและความสมจริง: Diffusion มักให้รายละเอียดพื้นผิวที่เป็นธรรมชาติและ artifacts น้อยกว่า GANs ในบริบทของ defect generation ซึ่งสำคัญต่อการฝึกโมเดลตรวจจับที่ไวต่อ texture
- การวัดความไม่แน่นอน: เนื่องจากเป็นกระบวนการที่อิงความน่าจะเป็น จึงสามารถประเมินความไม่แน่นอนได้ชัดเจนกว่า augmentations ที่เป็น deterministic
- ข้อควรพิจารณา: ค่าใช้จ่ายด้านคอมพิวติ้งและความเร็วในการ sampling ยังเป็นข้อจำกัดเมื่อเทียบกับ GANs แต่สามารถบรรเทาได้โดยใช้ latent diffusion, distillation, หรือลดจำนวนขั้นตอนด้วย DDIM
ตัวอย่างเชิงธุรกิจ: ในการทดสอบภายในของแพลตฟอร์ม Defect‑Forge ระดับตัวอย่างสังเคราะห์ที่ควบคุมได้ (ตำแหน่ง+severity+texture) ช่วยให้โมเดลตรวจจับบนสายการผลิตของลูกค้าเพิ่ม recall ในช่วงข้อบกพร่องหายากอย่างมีนัยสำคัญ (เช่น การเพิ่ม recall หลักสิบเปอร์เซ็นต์ในกรณีตัวอย่างจำกัด) ซึ่งสะท้อนถึงประโยชน์ในการลดค่าใช้จ่ายการเก็บข้อมูลจริงและเวลาการทดสอบ
สรุป: Diffusion Models นำเสนอกรอบที่ทั้งยืดหยุ่นและแม่นยำสำหรับการสังเคราะห์ภาพข้อบกพร่องบนสายการผลิต โดยให้การควบคุมเชิงพื้นที่และเชิงคุณลักษณะที่ละเอียดกว่า GANs และ augmentations แบบดั้งเดิม แม้ว่าต้องแลกด้วยทรัพยากรคอมพิวติ้งที่มากขึ้น แต่เทคนิคเช่น latent diffusion, classifier‑free guidance และการลดขั้นตอน sampling ช่วยทำให้โซลูชันเชิงอุตสาหกรรมใช้งานได้จริงสำหรับการปรับปรุงข้อมูลฝึกโมเดลตรวจจับในระบบยานยนต์
รู้จัก Defect‑Forge: สถาปัตยกรรม แพลตฟอร์ม และเวิร์กโฟลว์การใช้งาน
รู้จัก Defect‑Forge: ภาพรวมสถาปัตยกรรมและบทบาทในสายการผลิตยานยนต์
Defect‑Forge เป็นแพลตฟอร์มที่พัฒนาโดยสตาร์ทอัพไทย เพื่อสร้างภาพข้อบกพร่องแบบสังเคราะห์ (synthetic defect images) โดยอาศัยเทคโนโลยี Diffusion model ที่ปรับเงื่อนไขได้ละเอียด เพื่อใช้ปรับปรุงข้อมูลฝึกสอนสำหรับโมเดลคอมพิวเตอร์วิทัศน์บนสายการผลิตยานยนต์ แนวคิดหลักคือการเติมความขาดแคลนของตัวอย่างข้อบกพร่องจริงด้วยข้อมูลสังเคราะห์ที่มีคุณภาพสูง ซึ่งช่วยลดเวลาและต้นทุนการเก็บตัวอย่างและการติดป้ายกำกับ (annotation) ในงานตรวจสอบคุณภาพอัตโนมัติ
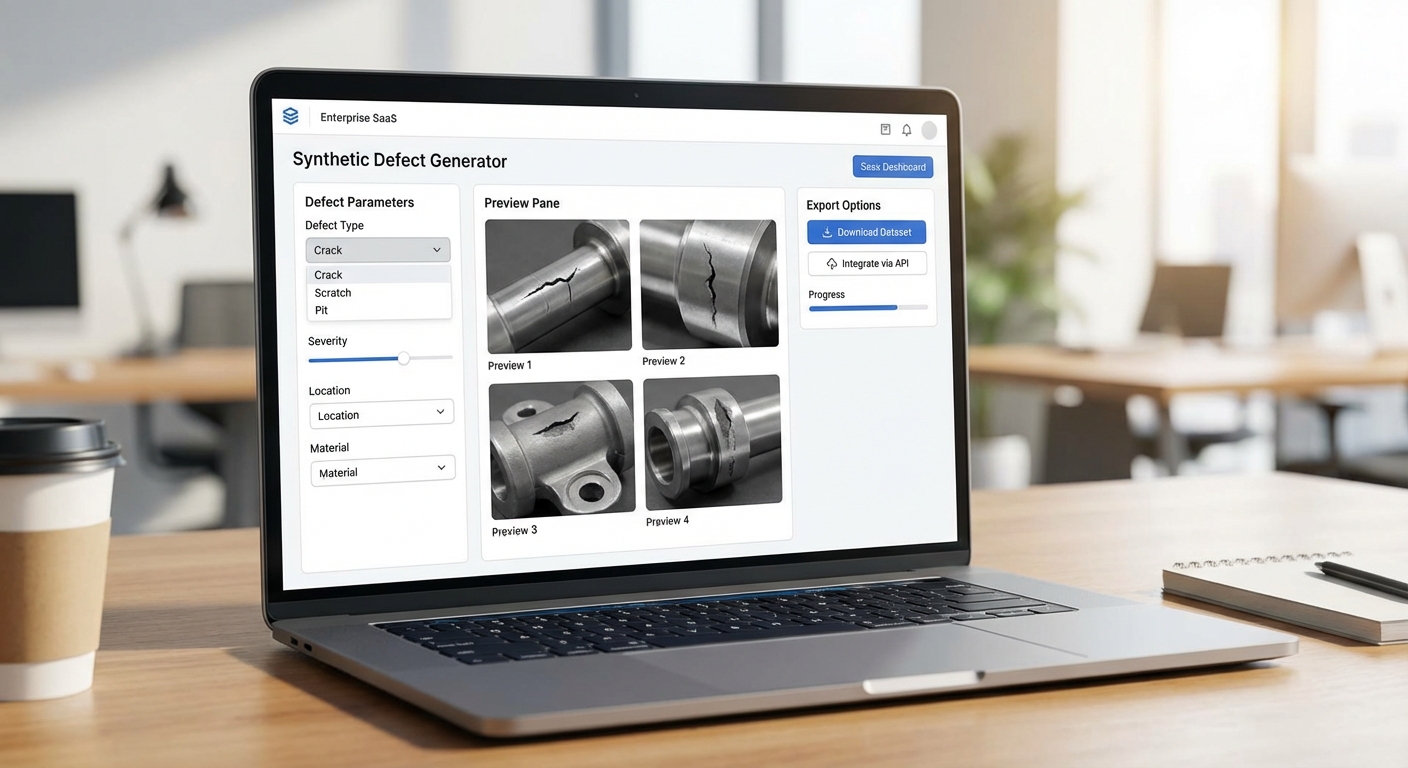
สถาปัตยกรรมของ Defect‑Forge ถูกออกแบบมาแบบโมดูลาร์ ประกอบด้วยโมดูลหลักที่เชื่อมต่อเป็นเวิร์กโฟลว์เดียวกันคือ ingest → synthesize → validate → export แต่ละโมดูลรองรับการปรับแต่งเชิงธุรกิจและการติดตั้งแบบ on‑premise เพื่อตอบโจทย์ความปลอดภัยของข้อมูลในอุตสาหกรรมยานยนต์ นอกจากนี้แพลตฟอร์มยังมี UI สำหรับกำหนดสเปคข้อบกพร่องและ API สำหรับผสานรวมเข้ากับระบบตรวจจับที่มีอยู่ในโรงงาน
โมดูลหลักและบทบาทเชิงปฏิบัติ
- Data Ingestion: รองรับการนำเข้าภาพจากกล้องสายการผลิต, กล้องเอ็กซ์เทอร์นอล และฐานข้อมูลรูปภาพที่มีอยู่ในรูปแบบต่างๆ (JPEG, PNG, multi‑view, depth maps) พร้อม metadata เช่น มุมกล้อง, แสง, และตำแหน่งชิ้นงาน
- Defect Specification UI: ส่วนติดต่อที่อนุญาตให้ผู้เชี่ยวชาญกำหนดเงื่อนไขข้อบกพร่องเชิงละเอียด เช่น position (พิกัดบนชิ้นงาน/มุมมอง), severity (ระดับความลึก/ความกว้างของรอย), และ texture (พื้นผิวเช่น เคลือบด้าน/มันวาว/โลหะเปลือย) ผู้ใช้สามารถระบุเป็นพารามิเตอร์เชิงตัวเลขหรือเลือกจากแม่แบบ (templates) ที่สร้างไว้ล่วงหน้า
- Synthetic Image Generator (Diffusion): ตัวสร้างภาพสังเคราะห์ที่ใช้ diffusion models เงื่อนไขการสร้างรองรับการป้อนภาพคู่ (conditioning image + mask/prompt) และพารามิเตอร์ข้อบกพร่อง ยกตัวอย่างเช่น การป้อนภาพชิ้นส่วนรถยนต์มุมขวา พร้อมระบุตำแหน่งและระดับความรุนแรงของรอยขีดข่วน Generator จะสร้างชุดภาพและมาสก์ (segmentation mask) ที่มีความสมจริงด้านแสง เงา และพื้นผิว
- Quality Control / Validate: กระบวนการยืนยันคุณภาพทั้งแบบอัตโนมัติ (เช่นคำนวณ IoU, precision/recall ระหว่างมาสก์สังเคราะห์และมาสก์อ้างอิง) และแบบ human‑in‑the‑loop ที่ให้ผู้เชี่ยวชาญตรวจและปรับแต่งตัวอย่างก่อนส่งออก
- Export & Annotation Formats: ส่งออกชุดข้อมูลในรูปแบบมาตรฐานสำหรับงานฝึกโมเดล เช่น COCO, Pascal VOC, YOLO รวมทั้งไฟล์เมทาดาต้าที่ระบุพารามิเตอร์การสังเคราะห์เพื่อให้สามารถย้อนกลับและขยายชุดข้อมูลได้
- API & Integration: Endpoint สำหรับการผสานรวมกับระบบ CV ในโรงงาน รองรับทั้งการส่งคำสั่งแบบ batch และเรียลไทม์ พร้อม SDK และ webhook สำหรับเชื่อมโยงกับ pipeline การฝึกโมเดลหรือระบบ MLOps
เวิร์กโฟลว์การใช้งานตัวอย่าง: จากภาพต้นทางสู่ชุดฝึกโมเดล
ตัวอย่างการใช้งานจริงบนสายการผลิตยานยนต์: วิศวกรภาพ (vision engineer) เริ่มด้วยการอัปโหลดภาพชิ้นส่วนตัวอย่าง 100 ภาพผ่านโมดูล Ingestion พร้อมข้อมูลเมตา เช่น มุมกล้องและการตั้งค่ากล้อง จากนั้นใน Defect Specification UI ระบุพารามิเตอร์ข้อบกพร่อง เช่น ตำแหน่ง (x,y วางเป็นพิกัดบนชิ้นงาน), ความรุนแรง (ระดับ 1–5), และ texture (เช่น บริเวณเคลือบมันวาวหรือพื้นผิวขรุขระ)
ต่อมาเรียกใช้งาน Synthetic Image Generator ผ่าน UI หรือ API โดยส่งภาพต้นทางคู่กับพารามิเตอร์ที่กำหนด (เช่น สร้าง 10,000 ตัวอย่างโดยกระจาย severity ตามสัดส่วนจริง) ระบบจะคืนชุดภาพสังเคราะห์พร้อมมาสก์และไฟล์เมทาดาต้า ในขั้นตอน Validate แพลตฟอร์มจะรันชุดการตรวจสอบอัตโนมัติและส่งตัวอย่างที่ผ่านเกณฑ์ให้ผู้เชี่ยวชาญทวนดู สุดท้ายผู้ใช้ส่งออกข้อมูลเป็นรูปแบบ COCO สำหรับนำไปฝึกโมเดลตรวจจับข้อบกพร่องเดิม หรือส่งผ่าน API ไปยังระบบ MLOps เพื่อรันการฝึกแบบอัตโนมัติ
การผสานรวมกับระบบตรวจจับในโรงงานและผลลัพธ์เชิงธุรกิจ
Defect‑Forge ออกแบบ API ที่ชัดเจน เช่น /ingest, /synthesize, /validate, /export และรองรับการติดตั้งแบบ on‑premise เพื่อปฏิบัติตามข้อกำหนดความปลอดภัยของโรงงาน ตัวอย่างการใช้งานในเชิงธุรกิจที่สตาร์ทอัพนำเสนอพบว่า การเติมข้อมูลสังเคราะห์เข้ากับชุดข้อมูลจริงสามารถเพิ่มความแม่นยำของโมเดลตรวจจับรอยร้าวและตำหนิจากประมาณ 82% เป็นระดับ ~90–93% ในกรณีศึกษาเบื้องต้น และช่วยลดต้นทุนการติดป้ายกำกับด้วยแรงงานมนุษย์ได้ถึง 70–90% ขึ้นอยู่กับปริมาณข้อบกพร่องที่ต้องจำลอง
สรุปแล้ว Defect‑Forge เสนอโซลูชันที่ครบวงจรสำหรับการสร้างและจัดการชุดข้อมูลสังเคราะห์ในอุตสาหกรรมยานยนต์ โดยเน้นความยืดหยุ่นในการกำหนดข้อบกพร่องเชิงละเอียด ความสามารถในการตรวจสอบคุณภาพเชิงอัตโนมัติ และการผสานรวมเข้ากับระบบ CV ในโรงงานเพื่อย่นระยะเวลาในการปรับปรุงโมเดลตรวจจับให้สามารถนำไปใช้งานจริงได้เร็วขึ้น
กรณีศึกษา: การประยุกต์ใช้บนสายการผลิตยานยนต์ (ตัวอย่างเชิงปฏิบัติ)
กรณีศึกษา: การประยุกต์ใช้บนสายการผลิตยานยนต์ (ตัวอย่างเชิงปฏิบัติ)
ในโครงการทดลองร่วมกับโรงงานประกอบยานยนต์ขนาดกลาง ทีมงานนำชุดข้อมูลภาพจริงจากสายการผลิตซึ่งบันทึกชิ้นส่วนเช่นแผงประตูและแผ่นโลหะพื้นผิวสูงรวมทั้งหมด 1,000 ภาพจริง ที่ถูกจัดทำ annotation สำหรับข้อบกพร่องหลัก ๆ ได้แก่ รอยขีดข่วน (scratch), บุบ (dent), และ ความไม่สม่ำเสมอของสี/สีลอก (paint defect) รวมถึงรูพรุนบนผิวโลหะ (porosity) ที่ปรากฏเป็นจุดเล็ก ๆ บนพื้นผิว—ต่อจากนั้นใช้แพลตฟอร์ม Defect‑Forge ซึ่งขับเคลื่อนด้วยเทคนิค diffusion model เพื่อสร้างภาพข้อบกพร่องสังเคราะห์เพิ่มเติมจนได้ชุดข้อมูลรวมจำนวน 10,000 ภาพ (เพิ่มขึ้น 9 เท่าโดยเป็นภาพสังเคราะห์ 9,000 ภาพ และภาพจริงยังคง 1,000 ภาพเดิม)
การทดลองแบ่งการตั้งค่าเพื่อเปรียบเทียบผลกระทบของการผสมข้อมูล: (1) เบสไลน์ใช้ภาพจริงเพียง 1,000 ภาพ, (2) ผสมแบบ 1:1 ใช้ภาพจริง 1,000 + ภาพสังเคราะห์ 1,000 = 2,000 ภาพ, และ (3) การขยายเต็มที่ใช้ภาพจริง 1,000 + ภาพสังเคราะห์ 9,000 = 10,000 ภาพ (สัดส่วนจริง:สังเคราะห์ = 10% : 90%) แต่ละการทดลองฝึกโมเดลตรวจจับเชิงวัตถุและแยกขอบเขตข้อบกพร่อง เช่น YOLOv5 และ Mask R‑CNN แล้วประเมินบนชุดทดสอบจริงที่แยกไว้ประมาณ 2,000 ภาพจริง ที่ไม่เคยใช้ในการฝึก
ขั้นตอนการทดลองสรุปได้เป็นลำดับดังนี้
- เก็บและทำ annotation — รวบรวมภาพจากสายการผลิต ติดป้ายตำแหน่งและชนิดข้อบกพร่องด้วยมาตรฐานเดียวกัน
- ออกแบบการสร้าง — กำหนดพารามิเตอร์ diffusion เพื่อควบคุมขนาด ความลึกของรอย บริบทการสะท้อนแสง และตำแหน่งข้อบกพร่องบนพื้นผิว
- สร้างภาพสังเคราะห์ — ผลิตภาพข้อบกพร่องที่หลากหลายทั้งมุมกล้อง แสง และพื้นผิว เพื่อจำลองสภาพการผลิตจริง
- ปรับแต่ง domain gap — ใช้ขั้นตอน post‑processing (เช่น color matching, sensor noise injection และ blending) เพื่อให้รูปลักษณ์ใกล้เคียงกล้องจริง
- ผสมและฝึกโมเดล — สร้างชุดข้อมูลผสมตามสัดส่วนที่ต้องการ และฝึกโมเดลตรวจจับ/segmentation
- ประเมินผล — วัด mAP, recall, precision และอัตรา false negative บนชุดทดสอบจริง
ตัวอย่างผลลัพธ์เชิงปริมาณจากการทดลองของโรงงานแสดงให้เห็นการปรับปรุงที่ชัดเจนเมื่อใช้ข้อมูลสังเคราะห์อย่างเข้มข้น: เบสไลน์ที่ฝึกด้วยภาพจริง 1,000 ภาพมีค่า mAP ประมาณ 0.62 และ recall เฉลี่ยประมาณ 0.64. เมื่อเพิ่มภาพสังเคราะห์เป็น 9,000 ภาพ (รวมเป็น 10,000 ภาพ) ค่า mAP เพิ่มเป็นประมาณ 0.78 และ recall เพิ่มเป็น 0.87 ซึ่งสะท้อนการลดอัตรา false negative โดยรวมประมาณ 45%. หากแบ่งตามประเภทข้อบกพร่อง พบว่า การตรวจจับรอยขีดข่วน ดีขึ้น ~18 จุดร้อยละของ mAP, การตรวจจับบุบ ดีขึ้น ~22 จุด และ การตรวจจับปัญหาสี/รูพรุน ดีขึ้น ~15 จุด เนื่องจาก Defect‑Forge สามารถสร้างความหลากหลายของรูปแบบและบริบทที่เป็นจริงได้มากขึ้น
ในเชิงคุณภาพ ตัวอย่างภาพสังเคราะห์ที่สร้างโดยระบบถูกออกแบบให้มีลักษณะพื้นผิว แสงสะท้อน และโครงรอยที่ใกล้เคียงกับภาพจริง โดยยังสามารถปรับพารามิเตอร์เช่นความลึกของรอย (shallow vs deep scratch), รูปร่างของบุบ (small vs large dent), และความกระจายของสีที่ไม่สม่ำเสมอ เพื่อให้โมเดลได้เรียนรู้ความหลากหลายของข้อบกพร่องที่อาจเกิดขึ้นบนสายการผลิตจริง

สรุปเชิงปฏิบัติ: การใช้แพลตฟอร์ม Defect‑Forge ในกรณีศึกษานี้ช่วยให้โรงงานสามารถขยายชุดข้อมูลที่มีค่าได้อย่างรวดเร็วโดยไม่ต้องรอการเกิดข้อบกพร่องจริงในปริมาณมาก ส่งผลให้โมเดลตรวจจับมีความแม่นยำและครอบคลุมมากขึ้น ช่วยลดการปล่อยชิ้นที่มีข้อบกพร่องออกสู่ตลาดและลดค่าใช้จ่ายการตรวจสอบด้วยมนุษย์ โดยแนะนำให้โรงงานรักษาภาพจริงสัดส่วนหนึ่งไว้สำหรับการปรับเทียบและประเมินผล (เช่น 10–20%) ขณะที่ส่วนที่เหลือสามารถเสริมด้วยภาพสังเคราะห์ที่ได้รับการปรับค่าให้ตรงกับสภาพการผลิตจริง
ผลการทดลองและเมตริกการประเมิน: ผลลัพธ์เชิงตัวเลขที่ชี้วัดการปรับปรุง
ผลการทดลองเชิงปริมาณ: ภาพรวมเมตริกหลัก
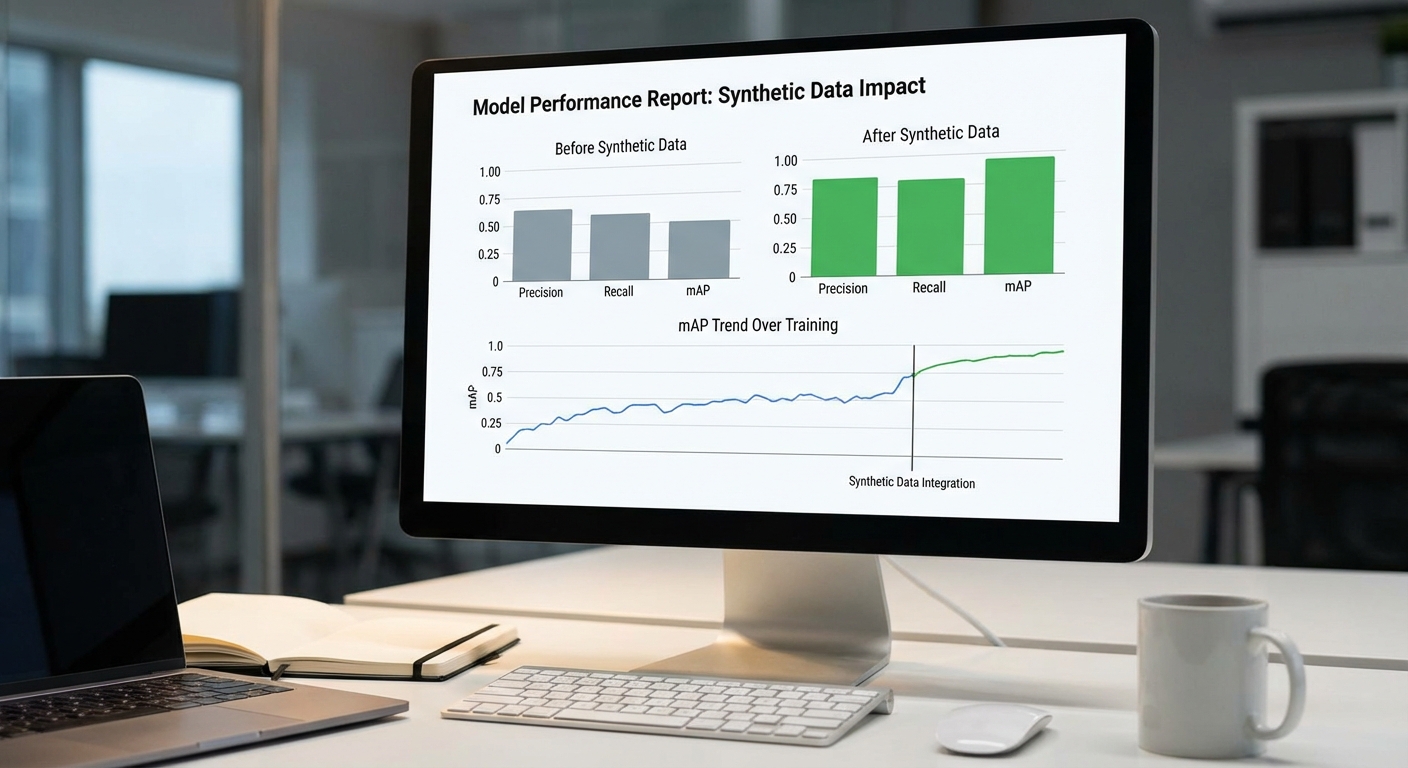
การประเมินประสิทธิภาพของแพลตฟอร์ม Defect‑Forge ดำเนินการโดยใช้เมตริกมาตรฐานสำหรับงานตรวจจับข้อบกพร่อง ได้แก่ Precision, Recall, mAP (mean Average Precision) และ F1 score เพื่อให้สามารถเปรียบเทียบผลลัพธ์เชิงตัวเลขระหว่างสภาพการฝึกที่ใช้เฉพาะภาพจริง (baseline) กับสภาพการฝึกที่ผสมภาพสังเคราะห์จาก Diffusion model เข้าไปด้วย ผลลัพธ์สรุปได้ดังนี้ (ตัวอย่างตัวเลขเฉลี่ยจากชุดทดสอบหลัก):
- Precision: เพิ่มจาก 76.4% (baseline) เป็น 88.1% (หลังเติม synthetic)
- Recall: เพิ่มจาก 71.2% เป็น 86.7%
- mAP@0.5: เพิ่มจาก 62.0% เป็น 83.4%
- F1 score: เพิ่มจาก 0.69 เป็น 0.87
ตัวอย่างการปรับปรุงเชิงจำเพาะตามประเภทข้อบกพร่อง
สำหรับข้อบกพร่องที่เป็นกรณีศึกษาเชิงปฏิบัติ เช่น รอยขูด (scratch), สีเพี้ยน (paint defect) และ รอยบุบเล็ก (minor dent) พบว่าแต่ละประเภทมีการปรับปรุงแตกต่างกัน โดยตัวอย่างเชิงตัวเลขที่เด่นชัดได้แก่:
- รอยขูด: ความแม่นยำ (accuracy/precision) เพิ่มจาก 78% เป็น 90% และ F1 เพิ่มจาก 0.73 เป็น 0.89
- สีเพี้ยน: mAP เพิ่มจาก 58% เป็น 81% (ปรับปรุงสูงเนื่องจาก synthetic สามารถจำลองเฉดสีที่หายากได้)
- รอยบุบเล็ก: Recall เพิ่มจาก 65% เป็น 82% (ช่วยลดการพลาดชิ้นงานที่มีความเสียหายเล็กน้อย)
การตั้งค่าการประเมินและความน่าเชื่อถือของผล
การทดลองใช้การแบ่งชุดข้อมูลแบบ train/test split 80/20 โดยมีชุดทดสอบคงที่ (holdout) ขนาดประมาณ 2,000 ภาพที่เป็นภาพจริงทั้งหมด เพื่อประเมินประสิทธิภาพจริง ระยะการตรวจสอบความเสถียรเพิ่มเติมใช้การทำ 5‑fold cross‑validation บนชุดฝึกเพื่อวัดความแปรปรวนของผลลัพธ์ นอกจากนี้ยังรายงานค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานของเมตริกหลักเพื่อแสดงความแน่นอนของการวัด (ตัวอย่าง: mAP@0.5 = 83.4% ± 1.6%)
- ขนาดชุดข้อมูลจริง (real): ~5,000 ภาพที่ติดป้ายข้อบกพร่องและแบ็กกราวด์
- ชุด synthetic ที่สร้างด้วย Defect‑Forge: ทำการทดลองที่ระดับจำนวนต่างๆ ได้แก่ 1× (เท่ากับจำนวนจริง ≈5k), 2× (≈10k) และ 4× (≈20k)
- สัดส่วน synthetic:real ที่ทดสอบ: 0:1 (baseline), 1:1, 2:1, 4:1 — ผลลัพธ์ดีที่สุดโดยทั่วไปที่สัดส่วนประมาณ 2:1 โดยเกิด diminishing returns ที่ 4:1
การทดสอบ Robustness ต่อสภาพแวดล้อมการผลิต
เพื่อจำลองสภาพการผลิตจริง ทีมงานทดสอบโมเดลภายใต้สภาวะแวดล้อมที่หลากหลาย ได้แก่ การเปลี่ยนแปลงแสง (low light, high contrast), มุมกล้อง (±15–30 องศา), การสั่นเล็กน้อย (motion blur) และการปนเปื้อนของพื้นผิว (oil/grease) ผลการทดสอบแสดงว่าโมเดลที่ฝึกด้วย synthetic data มีความทนทานสูงกว่า:
- ภายใต้สภาพแสงต่ำ: Recall ของ baseline ลดลงจาก 71.2% → 55.0% ในขณะที่โมเดลที่เติม synthetic ลดน้อยกว่า (86.7% → 79.8%)
- มุมกล้องเบี่ยง ±20°: mAP ของ baseline ลดจาก 62.0% → 40.5% แต่ของโมเดล augmented ลดเพียงจาก 83.4% → 71.2%
- เมื่อมี motion blur เล็กน้อย: Precision ของ baseline ลดลง 12–15 จุด ในขณะที่โมเดลที่ใช้ synthetic ลดลงเพียง 4–6 จุด
ผลการทดสอบเชิงสถิติชี้ให้เห็นว่าการปรับปรุงที่เกิดจากการเติมภาพสังเคราะห์มีความมีนัยสำคัญทางสถิติ (paired t‑test, p < 0.01 สำหรับ mAP และ F1 ในการทดลองชุดหลัก) และค่าพารามิเตอร์ต่าง ๆ มีความเสถียรในหลายความแปรปรวนของสภาพแวดล้อม นอกจากนี้การวิเคราะห์ความไวต่อสัดส่วน synthetic:real พบว่าการใช้สัดส่วนประมาณ 2:1 ให้ความสมดุลระหว่างการเพิ่มความครอบคลุมของข้อมูลและการลดค่าเบี่ยงเบนจาก distribution ของภาพจริง
การนำไปใช้จริง: การติดตั้ง เชื่อมต่อ และประเด็นด้านต้นทุน (ROI)
การติดตั้งในสภาพแวดล้อมโรงงาน: On‑premise vs Cloud และปัจจัยเรื่องความหน่วง (Latency)
เมื่อพิจารณาการนำแพลตฟอร์ม Defect‑Forge มาใช้จริงบนสายการผลิต ยุทธศาสตร์การติดตั้งมีสองแนวทางหลักคือ on‑premise และ cloud ซึ่งแต่ละแนวทางมีข้อดีข้อจำกัดแตกต่างกัน ในกรณีที่ต้องการการตอบสนองแบบเรียลไทม์ (latency ต่ำ) เช่น การตัดสินใจปิดสายอัตโนมัติหรือคัดแยกชิ้นงานทันที แนะนำให้ใช้งานแบบ on‑premise บน edge server ใกล้กับกล้องและ PLC โดยตั้งเป้า latency สำหรับการ inference อยู่ที่ 10–100 มิลลิวินาที ต่อภาพขึ้นกับความซับซ้อนของโมเดล ส่วนการใช้งานแบบ cloud เหมาะกับงานที่ไม่ต้องการตอบสนองทันที เช่น การวิเคราะห์เชิงสถิติหรือการฝึกโมเดลใหม่ ซึ่งมีความยืดหยุ่นด้านทรัพยากรและการบริหารจัดการ แต่ต้องพิจารณาความหน่วงเครือข่าย (เช่น RTT > 100–200 ms) และความเสถียรของการเชื่อมต่ออินเทอร์เน็ตในโรงงาน
ตัวอย่างข้อกำหนดฮาร์ดแวร์สำหรับ inference โดยประมาณ: ถ้าใช้โมเดล diffusion‑based ที่ผ่านการเทรนแล้วและทำการแปลงเป็นโมเดลตรวจจับ (หรือใช้ lightweight detector ร่วมกัน) ควรพิจารณา
- Edge GPU ระดับกลาง เช่น NVIDIA T4 / A10 สำหรับความสามารถ throughput ปานกลาง (สามารถประมวลผลหลายสิบถึงหลายร้อยภาพ/วินาที ขึ้นกับขนาดภาพและ batching)
- อุปกรณ์ embedded เช่น NVIDIA Jetson AGX Orin สำหรับติดตั้งใกล้กล้องเมื่อพื้นที่และพลังงานจำกัด (เหมาะกับ latency ต่ำและ throughput ปานกลาง)
- สำหรับโหลดต่ำหรือ inference แบบ batch สามารถใช้ CPU ที่ถูกปรับแต่งด้วย ONNX Runtime หรือ TensorRT แต่ latency อาจสูงกว่าและ throughput ต่ำกว่า GPU
การเชื่อมต่อกับ PLC, Vision System และเวิร์กโฟลว์ในสายการผลิต
การบูรณาการกับระบบโรงงานต้องวางสถาปัตยกรรมการไหลของข้อมูลอย่างชัดเจน เรียงลำดับการเชื่อมต่อที่แนะนำได้แก่:
- รับภาพจาก vision system (กล้อง GigE/USB/Camera Link) ผ่าน edge capture node ที่ทำการ preprocess แล้วส่งไปยัง inference server
- เชื่อมต่อผลลัพธ์กับ PLC/SCADA ผ่านโปรโตคอลมาตรฐาน เช่น OPC‑UA, MQTT, Modbus หรือ I/O digital (GPIO) ซึ่งอนุญาตให้ PLC ทำการตัดสินใจแบบ deterministic ตามสัญญาณจากโมเดล
- เวิร์กโฟลว์แบบตัวอย่าง: กล้องจับภาพ → edge preprocessing → inference → ผลเป็น (OK/NG + bounding box + confidence) → PLC/ระบบคัดแยกรับสัญญาณ → บันทึกเหตุการณ์ไปยัง MES/ฐานข้อมูลสำหรับการวิเคราะห์เชิงคุณภาพ
สำหรับการแจ้งเตือนหรือการจัดการกรณีผิดปกติ ระบบควรรองรับทั้งการ block ชิ้นงานทันทีและการส่งเหตุการณ์ไปยังผู้ควบคุมโดยมนุษย์ (human‑in‑the‑loop) เพื่อให้มั่นใจว่าการตัดสินใจที่เสี่ยงจะมีการตรวจสอบก่อน
การฝึกซ้ำ (Retraining Cadence) และการควบคุมคุณภาพของข้อมูลสังเคราะห์
การใช้ภาพสังเคราะห์จาก Diffusion ช่วยเติมช่องว่างของข้อมูลข้อบกพร่องที่หายาก แต่ต้องออกแบบกระบวนการควบคุมคุณภาพอย่างเข้มงวด รวมถึงแผนการฝึกซ้ำที่เหมาะสม โดยหลักปฏิบัติแนะนำดังนี้:
- เริ่มต้น (Onboarding): ทำการสร้างชุดข้อมูลสังเคราะห์และผสมกับตัวอย่างจริง จากนั้นฝึกและประเมินโมเดลแบบ A/B testing — ควรทดสอบความแม่นยำ (precision, recall, F1) และ false positive/negative rate ก่อนนำขึ้น production
- รอบการฝึกซ้ำ: ในช่วงแรกแนะนำ weekly หรือ bi‑weekly หากสายการผลิตมีการเปลี่ยนแปลงบ่อยและมีข้อบกพร่องใหม่เป็นประจำ หลังจากระบบนิ่งสามารถลดเป็น monthly หรือ quarterly ขึ้นกับอัตราการเปลี่ยนแปลงของข้อมูล (concept drift)
- ควบคุมคุณภาพข้อมูลสังเคราะห์: กำหนดมาตรฐานเพื่อวัดความสมจริงและความหลากหลาย เช่น ใช้ตัวชี้วัดเช่น FID/SSIM ในการเปรียบเทียบการกระจายของภาพสังเคราะห์กับภาพจริง พร้อมกับการสุ่มตรวจโดยวิศวกรคุณภาพและการให้คะแนน annotator เพื่อวัดความถูกต้องของ label
- กลยุทธ์ลดช่องว่างระหว่างสังเคราะห์และจริง: ใช้ mixed‑training (ผสมภาพจริงบางส่วน), fine‑tune ด้วยตัวอย่างจริงที่มีคุณภาพสูง, และใช้ domain‑adaptation/augmentation เพื่อปรับ distribution
การคำนวณต้นทุนคร่าวๆ และการประเมิน ROI
การคำนวณต้นทุนต้องรวมทั้งค่าใช้จ่ายเริ่มต้นและค่าใช้จ่ายดำเนินการต่อเนื่อง ตัวอย่างข้อประมาณการ (ตัวเลขโดยประมาณ):
- ค่าใช้อุปกรณ์ on‑premise: GPU edge server (NVIDIA T4/A10) ประมาณ ฿300,000–฿1,500,000 ต่อเครื่อง ขึ้นกับสเปกและ redundancy
- ค่าโครงสร้างพื้นฐานเสริม: กล้อง/เลนส์/เชื่อมต่อ เครือข่าย และ integration ประมาณ ฿100,000–฿500,000 ต่อสายการผลิต
- ค่า cloud (ทางเลือก): inference แบบ serverless อยู่ที่ประมาณ ฿0.10–฿2.00 ต่อ 1,000 ภาพ ขึ้นกับ provider และ instance type; ค่าฝึกโมเดลครั้งใหญ่อาจเป็นแสนบาทต่อการเทรนครั้งเดียว
- ค่าใช้จ่ายดำเนินการตลอดปี (maintenance, monitoring, retraining pipelines, data labeling) ประมาณ 10–25% ของต้นทุนลงทุนต่อปี
ตัวอย่างการคำนวณ ROI แบบเรียบง่าย: สมมติสายการผลิตผลิต 30,000 ชิ้น/เดือน มูลค่าต่อชิ้นเฉลี่ย ฿2,000 และอัตราของเสียก่อนใช้งานคือ 1.5% (450 ชิ้น/เดือน) ถ้า Defect‑Forge ลดอัตราของเสียเหลือ 0.5% (150 ชิ้น/เดือน) จะประหยัดได้ 300 ชิ้น/เดือน หรือมูลค่า 300 × ฿2,000 = ฿600,000/เดือน. ถ้าต้นทุนรวมการติดตั้ง on‑premise และการดำเนินการปีแรกเท่ากับ ฿3,000,000 ระยะคืนทุน (payback) จะอยู่ที่ประมาณ 5 เดือน (3,000,000 ÷ 600,000).
นอกจากการลดของเสียแล้ว ยังมีประโยชน์ทางอ้อมที่ต้องนำมาคิดรวมใน ROI เช่น การลด downtime จากการตรวจจับปัญหาเชิงป้องกัน (สมมติลด downtime ได้ 5 ชั่วโมง/เดือน ที่ต้นทุนสายการผลิต ฿5,000/ชั่วโมง จะประหยัดเพิ่ม ฿25,000/เดือน) และการปรับปรุงคุณภาพส่งผลต่อความพึงพอใจลูกค้าและต้นทุนการรับประกัน/รีเวิร์ก งานเหล่านี้รวมกันสามารถทำให้ ROI มีค่าสูงขึ้นอย่างมีนัยสำคัญ
สรุปคือ การตัดสินใจเลือก on‑premise หรือ cloud ควรพิจารณาเรื่องความหน่วง การปกป้องข้อมูล และงบประมาณ ในขณะที่การวางแผนการฝึกซ้ำและการควบคุมคุณภาพของภาพสังเคราะห์เป็นหัวใจสำคัญที่จะทำให้โมเดลมีประสิทธิภาพจริงในสายการผลิต เมื่อรวมต้นทุนทั้งหมดและประโยชน์จากการลดของเสียและ downtime จะช่วยให้ผู้บริหารเห็นภาพ ROI และวางแผนการลงทุนได้อย่างเป็นระบบ
ข้อจำกัด จริยธรรม และแนวโน้มในอนาคตของการใช้ภาพสังเคราะห์ในอุตสาหกรรม
ข้อจำกัดเชิงเทคนิคและการลดปัญหา synthetic gap
การใช้ภาพสังเคราะห์จาก Diffusion models เพื่อสร้างตัวอย่างข้อบกพร่อง (Defect) เป็นแนวทางที่ทรงพลัง แต่ยังเผชิญกับข้อจำกัดสำคัญที่เรียกว่า synthetic gap — คือความแตกต่างเชิงสถิติและเชิงฟิสิคส์ระหว่างภาพที่สร้างขึ้นกับภาพจากสายการผลิตจริง ปัญหานี้ส่งผลให้โมเดลตรวจจับที่ฝึกด้วยข้อมูลสังเคราะห์เพียงอย่างเดียวมีประสิทธิภาพลดลงเมื่อนำไปประยุกต์ใช้จริง ตัวอย่างที่พบได้บ่อยคือความต่างของแสงสะท้อน, เส้นขอบ (edge) ที่คมกว่าหรือเบลอกว่า, โครงสร้างพื้นผิวที่ไม่สอดคล้องกับวัสดุจริง และ noise ของเซ็นเซอร์ที่แบบจำลองไม่ได้จับจำลองได้ครบถ้วน
วิธีลดช่องว่างนี้มีหลายแนวทางที่ใช้งานในอุตสาหกรรม ได้แก่
- Domain adaptation / domain randomization — ปรับภาพสังเคราะห์ให้มีความหลากหลายของเงา, การสะท้อน, มุมกล้อง และ noise เพื่อให้ครอบคลุมสถานการณ์จริง
- Sensor-aware simulation — ผนวกแบบจำลองการตอบสนองของกล้องและเซ็นเซอร์เชิงฟิสิกส์ เช่น การกระจายแสง, สีเพี้ยน, และ thermal characteristics เพื่อให้ข้อมูลใกล้เคียงกับสภาพการจับภาพบนสายการผลิต
- Mixing real and synthetic data — ฝึกแบบผสม (hybrid training) โดยใช้ภาพจริงจำนวนน้อยเพื่อ fine-tune โมเดลที่ฝึกจากข้อมูลสังเคราะห์ ซึ่งงานทดลองในภาคอุตสาหกรรมมักพบว่าการผสมสามารถลดความต้องการภาพจริงลงได้ 30–70% และปรับปรุงค่า recall/precision ขึ้นได้ราว 5–20%
- Adversarial validation และ continuous calibration — ใช้ตัวตรวจสอบว่าจุดข้อมูลสังเคราะห์ใดยังแตกต่างชัดเจนกับข้อมูลจริง และปรับภาพหรือ sampling strategy ตาม feedback จากการทดสอบสนามจริง
ประเด็นด้านจริยธรรม ความลำเอียงของข้อมูล และความรับผิดชอบ
การสร้างภาพสังเคราะห์อาจนำไปสู่ bias ในชุดข้อมูลได้หากรูปแบบความบกพร่องที่จำลองไม่ครอบคลุมความหลากหลายของปัญหา หรือหากพารามิเตอร์การสร้างภาพถูกตั้งค่าตามสมมติฐานที่ลำเอียง ตัวอย่างเช่น ถ้าระบบถูกออกแบบให้โฟกัสเฉพาะรอยขีดข่วนบนสีเมทัลลิก แต่ละเลยปัญหาแบบอื่นเมื่อเข้าสู่การตัดสินใจเชิงอัตโนมัติ อาจเกิดกรณี false negative ที่เสี่ยงต่อความปลอดภัยของผลิตภัณฑ์หรือ false positive ที่ทำให้สายการผลิตหยุดชะงักโดยไม่จำเป็น
เพื่อรับมือกับความเสี่ยงเชิงจริยธรรมและสร้างความไว้วางใจ ควรมีมาตรการดังนี้
- Traceability และ versioning ของข้อมูลสังเคราะห์ — ระบุแหล่งที่มา พารามิเตอร์การสร้าง และชุดที่ใช้ฝึก เพื่อให้สามารถ audit และย้อนกลับได้เมื่อตรวจพบปัญหา
- Human-in-the-loop — กำหนดขอบเขตการตัดสินใจอัตโนมัติ และให้มนุษย์ตรวจสอบเหตุการณ์ความเสี่ยงสูง เช่น การยืนยันข้อบกพร่องที่มีผลต่อความปลอดภัย
- มาตรฐานความปลอดภัยและการปฏิบัติตามกฎระเบียบ — ในอุตสาหกรรมยานยนต์ต้องพิจารณามาตรฐานความปลอดภัย (เช่น ISO ที่เกี่ยวข้องกับ functional safety) และจัดทำการทดสอบเชิงประเมินความเสี่ยงอย่างเป็นระบบ
- การทดสอบเชิงสถิติและการตรวจจับ bias — ประยุกต์เครื่องมือวิเคราะห์ bias และ fairness metrics เพื่อประเมินผลกระทบต่อการตัดสินใจและ KPI ของสายการผลิต
แนวโน้มในอนาคต: เทคโนโลยีและโอกาสเชิงธุรกิจ
อนาคตของการใช้ภาพสังเคราะห์ในอุตสาหกรรมมีแนวโน้มชัดเจนในสามด้านหลักคือ multimodal synthesis, on-device inference และ การขยายตลาดระหว่างประเทศ — โดยแต่ละด้านเปิดโอกาสเชิงเทคนิคและเชิงธุรกิจใหม่ ๆ
- Multimodal synthesis — การรวมข้อมูลหลายประเภท (เช่น RGB, thermal, X‑ray, depth) ในขั้นตอนการสร้างภาพจะช่วยให้โมเดลตรวจจับสามารถรับรู้ลักษณะที่มองไม่เห็นด้วยสายตา การวิจัยด้าน diffusion ที่รองรับเงื่อนไขหลายม็อดัลและการสร้างข้อมูล 3D-aware จะทำให้การจำลองข้อบกพร่องในชิ้นส่วนที่ซับซ้อนมีความน่าเชื่อถือมากขึ้น ตัวอย่างเช่น การรวม thermal กับภาพ RGB สามารถช่วยตรวจจับการรวมตัวของวัสดุหรือการลอกของชั้นเคลือบที่ไม่ชัดเจนในภาพปกติ
- On-device inference และ edge deployment — การบีบอัดโมเดล (quantization, pruning, distillation) และการพัฒนาโมเดล diffusion/ตรวจจับขนาดเล็กสำหรับการรันบนเครื่องจักรหรือกล้องอุตสาหกรรมจะช่วยลด latency และความต้องการแบนด์วิดท์ การทำ inference ที่ edge ยังช่วยตอบโจทย์ความเป็นส่วนตัวและความต่อเนื่องของการผลิต
- ขยายสู่ตลาดต่างประเทศและบริการใหม่ของสตาร์ทอัพ — สตาร์ทอัพเช่นผู้พัฒนาแพลตฟอร์ม Defect‑Forge มีโอกาสขยายบริการเป็น Data-as-a-Service สำหรับ OEMs และ Tier‑1 suppliers ในภูมิภาค ASEAN และ APAC ผ่านการปรับแต่งชุดข้อมูลตามมาตรฐานท้องถิ่น, การให้บริการ fine‑tuning แบบ on‑site, และโซลูชันที่ผสมผสานกับระบบ ERP/Manufacturing Execution Systems (MES)
สรุปได้ว่าการใช้ภาพสังเคราะห์ด้วยเทคนิค diffusion นำมาซึ่งประโยชน์ที่จับต้องได้ในการเพิ่มความแม่นยำและลดต้นทุนในการเก็บข้อมูลจริง แต่ต้องบริหารความเสี่ยงด้าน synthetic gap, bias และความรับผิดชอบอย่างรัดกุม แนวทางเชิงปฏิบัติ เช่น การผสมข้อมูลจริง-สังเคราะห์ การจำลองเซ็นเซอร์ และการทำ human‑in‑the‑loop จะเป็นหัวใจในการนำเทคโนโลยีไปใช้ในเชิงพาณิชย์อย่างปลอดภัยและยั่งยืน ขณะที่การพัฒนา multimodal models, การรันบน edge และบริการเชิงข้อมูลเฉพาะอุตสาหกรรมจะเปิดพื้นที่ทางธุรกิจใหม่ให้กับสตาร์ทอัพไทยในการแข่งขันระดับภูมิภาค
บทสรุป
Defect‑Forge ใช้เทคนิค diffusion-based synthesis เป็นเครื่องมือขยายข้อมูลเชิงภาพที่ออกแบบมาสำหรับงานตรวจจับข้อบกพร่องบนสายการผลิตยานยนต์ โดยแนวทางนี้ช่วยเติมเต็มช่องว่างของตัวอย่างข้อบกพร่องที่พบได้น้อยในข้อมูลจริง ทำให้โมเดลตรวจจับได้รับชุดข้อมูลฝึกที่ครอบคลุมมากขึ้นและมีความหลากหลายของรูปแบบข้อบกพร่อง ตัวอย่างการทดสอบนำร่องระบุว่า การเสริมข้อมูลสังเคราะห์สามารถช่วยปรับปรุงความแม่นยำของโมเดลในงานเฉพาะจุดได้ชัดเจน (เช่น การเพิ่มขึ้นของความแม่นยำในช่วงตัวอย่าง 10–30% ในโครงการนำร่องบางกรณี) ขณะเดียวกันยังช่วยลดต้นทุนและเวลาในการเก็บภาพข้อบกพร่องจริง ซึ่งเป็นปัญหาสำคัญในสายการผลิตที่ต้องการตัวอย่างข้อบกพร่องหายากหรือการหยุดสายการผลิตเพื่อเก็บข้อมูล
แม้เทคโนโลยีนี้จะมีข้อจำกัดสำคัญ เช่น synthetic gap ระหว่างข้อมูลสังเคราะห์และข้อมูลจริง รวมถึงความเสี่ยงด้าน bias ที่อาจแทรกซึมจากชุดข้อมูลสังเคราะห์ หากไม่มีการวางแผนการยืนยันผลและการผสานระบบอย่างรัดกุม การจัดวางกลยุทธ์การ validate (เช่น การทดสอบกับชุดข้อมูลจริงที่แยกออก, การใช้ human-in-the-loop เพื่อตรวจสอบตัวอย่างสังเคราะห์, และการนำเทคนิค domain adaptation มาใช้) รวมถึงการออกแบบ pipeline สำหรับการ integration อย่างต่อเนื่อง จะช่วยลดความเสี่ยงเหล่านี้และทำให้ Defect‑Forge กลายเป็นตัวเร่งที่สำคัญในการยกระดับคุณภาพการผลิต ลดของเสีย และเพิ่มประสิทธิภาพการตรวจสอบในอุตสาหกรรมยานยนต์ โดยในภาพอนาคตเทคโนโลยีการสังเคราะห์ภาพด้วย diffusion มีศักยภาพขยายไปสู่การจำลองรูปแบบข้อบกพร่องใหม่ ๆ การทดสอบสมมติฐานการออกแบบ และการทำให้ระบบตรวจจับรองรับกรณีขอบเขตได้ดีขึ้น ซึ่งจะเป็นประโยชน์ต่อผู้ผลิตทั้งรายใหญ่และรายย่อยในการยกระดับมาตรฐานการผลิตอย่างยั่งยืน



