
สนามแข่งขันปัญญาประดิษฐ์ระหว่าง OpenAI กับ Anthropic ไม่ใช่เพียงการแข่งขันด้านความเร็วของโมเดลหรือคะแนนบนเบนช์มาร์ก แต่เป็นเรื่องราวที่ผสมผสานระหว่างเทคโนโลยี นโยบายความปลอดภัย และแรงจูงใจส่วนตัวของผู้ก่อตั้งและทีมวิจัย เหตุการณ์ตั้งแต่การลาออกของนักวิจัยชั้นนำ การตั้งองค์กรใหม่ ไปจนถึงพันธมิตรทางธุรกิจระดับโลก ทำให้การปะทะครั้งนี้มีมิติที่ซับซ้อนกว่าเดิม: ทั้งการตีความความเสี่ยงของ AI (safety), วิธีการฝึกสอนโมเดล (เช่น RLHF ของ OpenAI และแนวคิด Constitutional AI ของ Anthropic) และการต่อรองเชิงธุรกิจที่มีมูลค่าล้านล้านดอลลาร์เป็นเดิมพัน
บทความนี้จะพาผู้อ่านสำรวจทั้งภาพกว้างและรายละเอียดเชิงเทคนิค: เราจะชี้ให้เห็นความต่างด้านแนวทางวิจัยและสถาปัตยกรรมโมเดล ตัวอย่างเช่น ผลงานของ OpenAI ในซีรีส์ GPT (เช่น ChatGPT ที่เคยมีผู้ใช้หลายสิบล้านคนภายในเวลาอันรวดเร็ว) เทียบกับการออกแบบเชิงความปลอดภัยของ Anthropic ที่เน้นกรอบเชิงจริยธรรมและ “constitutional” แนวคิดทางธุรกิจอย่างพันธมิตรเชิงกลยุทธ์และการระดมทุน รวมถึงมิติส่วนตัวที่ขับเคลื่อนการแข่งขัน—จากความเชื่อของผู้นำองค์กรไปจนถึงการดึงดูดบุคลากรสำคัญ—ซึ่งทั้งหมดนี้กำลังกำหนดทิศทางอนาคตของ AI ในระดับอุตสาหกรรมและสังคม
บทนำ: ทำไมการเผชิญหน้าระหว่าง OpenAI และ Anthropic จึงสำคัญ
บทนำ: ทำไมการเผชิญหน้าระหว่าง OpenAI และ Anthropic จึงสำคัญ
การแข่งขันระหว่าง OpenAI และ Anthropic ไม่ได้เป็นเพียงการชิงส่วนแบ่งตลาดหรือการประกาศฟีเจอร์ใหม่ของโมเดลภาษาเท่านั้น แต่เป็นการสะท้อนการวิวัฒนาการเชิงแนวคิดเกี่ยวกับวิธีออกแบบและควบคุมปัญญาประดิษฐ์ (AI) ในระดับสาธารณะและเชิงพาณิชย์ ในช่วงไม่กี่ปีที่ผ่านมา เราเห็นการนำ AI ไปใช้ในวงกว้าง—ตัวอย่างเช่น ChatGPT ของ OpenAI แตะระดับผู้ใช้รายเดือนกว่า 100 ล้านคนภายในปี 2023—ซึ่งทำให้คำถามเรื่องความปลอดภัย ความเป็นส่วนตัว และความรับผิดชอบกลายเป็นประเด็นเชิงนโยบายและเชิงธุรกิจที่เร่งด่วน
ประเด็นสำคัญที่ทำให้การปะทะนี้มีความหมายต่อผู้อ่านเทคโนโลยีและผู้กำหนดนโยบายคือการย้ายจากการแข่งขันด้านฟีเจอร์ไปสู่การแข่งขันด้าน การ align AI กับค่านิยมของมนุษย์ หรือที่เรียกว่า "alignment" การตัดสินใจออกแบบเชิงสถาปัตยกรรม, กระบวนการฝึก, และนโยบายการเปิดเผยข้อมูล จะกำหนดว่าระบบ AI จะช่วยลดความเสี่ยง เช่น การแพร่ข้อมูลผิดๆ หรือการละเมิดความเป็นส่วนตัว ได้มากน้อยเพียงใด นี่จึงเป็นการต่อสู้เชิงนโยบายและเชิงจริยธรรม ไม่ใช่เพียงการต่อสู้ด้านเทคโนโลยีล้วนๆ
ผลกระทบแผ่กว้างไปถึงผู้ใช้ทั่วไป องค์กร และสาธารณชน: ผู้ใช้ทั่วไปเผชิญความเสี่ยงจากข้อมูลรั่วไหลและการให้คำแนะนำที่ไม่ถูกต้อง องค์กรต้องตัดสินใจเรื่องการนำ AI ไปใช้ภายใต้กรอบความรับผิดชอบและการปฏิบัติตามกฎระเบียบ เช่น กรณีการปฏิบัติตามข้อกำหนดของกฎหมายคุ้มครองข้อมูล หรือแนวทางของสหภาพยุโรปเกี่ยวกับการกำกับดูแล AI ซึ่งกำลังอยู่ในความสนใจของนานาประเทศ การสำรวจหลายแห่งชี้ให้เห็นว่ากว่า ครึ่งหนึ่งขององค์กร เริ่มนำ AI ไปใช้ในบางส่วนของงานแล้ว ทำให้การออกแบบนโยบายภายในและการกำกับภายนอกมีความสำคัญยิ่งขึ้น
สุดท้าย ความเป็นส่วนตัวและเรื่องส่วนตัวของผู้ก่อตั้งและทีมบริหารมีน้ำหนักมากต่อทิศทางบริษัท ในกรณีของ OpenAI และ Anthropic ประวัติและค่านิยมของผู้ก่อตั้ง—รวมถึงประสบการณ์จากการทำงานในวงการ AI ก่อนหน้าและความเชื่อเรื่องความปลอดภัยของเทคโนโลยี—ได้หล่อหลอมวัฒนธรรมการตัดสินใจทางเทคนิคและกลยุทธ์การสื่อสารกับสาธารณะ ดังนั้น การติดตามการปะทะกันนี้จึงไม่ใช่เพียงติดตามผลิตภัณฑ์ใหม่ แต่ยังเป็นการเฝ้าดูว่าความคิดและค่านิยมของผู้สร้างจะกำหนดกรอบการพัฒนา AI อย่างไร ซึ่งมีผลต่อทั้งนวัตกรรม ความปลอดภัย และสิทธิส่วนบุคคลของผู้ใช้ในวงกว้าง
- ไม่ใช่แค่ฟีเจอร์: การต่อสู้ชี้ชัดถึงความแตกต่างในแนวทางเกี่ยวกับ alignment และการควบคุมความเสี่ยง
- ผลกระทบหลายระดับ: มีผลทั้งต่อผู้ใช้รายบุคคล องค์กรเชิงพาณิชย์ และกรอบนโยบายสาธารณะ
- อิทธิพลของผู้นำ: ความเชื่อและประวัติของผู้ก่อตั้งมีอิทธิพลต่อทิศทางทางเทคนิคและเชิงนโยบายของบริษัท
จุดเริ่มต้นและเรื่องส่วนตัว: จาก OpenAI สู่ Anthropic
จุดเริ่มต้นและเรื่องส่วนตัว: จาก OpenAI สู่ Anthropic
การก่อตั้ง Anthropic มีรากฐานมาจากการเคลื่อนไหวของกลุ่มอดีตผู้บริหารและนักวิจัยของ OpenAI นำโดย Dario Amodei ซึ่งตัดสินใจแยกตัวออกมาเพื่อตั้งองค์กรใหม่ที่ให้ความสำคัญกับงานวิจัยด้านความปลอดภัยของปัญญาประดิษฐ์เป็นหลัก การแยกตัวครั้งนี้ไม่ได้เป็นเพียงการเปลี่ยนงาน แต่สะท้อนความเห็นต่างเชิงกลยุทธ์และค่านิยมที่มีต่อทิศทางการพัฒนา AI — โดยเฉพาะเมื่อเทคโนโลยีก้าวสู่การใช้งานเชิงพาณิชย์ที่รวดเร็วและมีความเสี่ยงด้านการใช้งานในวงกว้าง
แรงจูงใจส่วนตัวของผู้ก่อตั้งและผู้ย้ายทีมมักประกอบด้วยความกังวลด้าน AI safety และความรับผิดชอบเชิงสถาบัน พวกเขาเห็นความจำเป็นที่จะต้องออกแบบกระบวนการวิจัยที่ชัดเจน มีการทดสอบและเมตริกความปลอดภัยที่เป็นรูปธรรม และมีกลไกการกำกับดูแลภายในที่เน้นการควบคุมความเสี่ยง ตัวอย่างเช่น Anthropic ผลักดันแนวคิดเชิงวิธีการอย่าง "Constitutional AI" ที่พยายามผนวกชุดหลักการและนโยบายภายในกระบวนการเรียนรู้ของโมเดล เพื่อลดความเสี่ยงจากพฤติกรรมไม่พึงประสงค์เมื่อมีการใช้งานจริง
การย้ายถิ่นฐานของบุคลากรจาก OpenAI ไปยัง Anthropic สื่อสารได้ชัดเจนว่าไม่ใช่แค่เรื่องเทคนิค แต่เป็นการเลือกที่จะสร้างวัฒนธรรมองค์กรที่ต่างออกไป — วัฒนธรรมที่ให้ความสำคัญกับการตรวจสอบภายใน ความโปร่งใสในกระบวนการทดลอง และความระมัดระวังในการเปิดตัวระบบ ตัวอย่างเช่น ภายในระยะเวลาเพียงไม่กี่ปี Anthropic ขยายทีมเป็น หลายร้อยคน และสามารถระดมทุนได้ในระดับที่ช่วยให้เดินหน้าการวิจัยความปลอดภัยได้อย่างต่อเนื่อง ซึ่งส่งสัญญาณชัดเจนต่ออุตสาหกรรมว่าโมเดลธุรกิจที่ผนวกความปลอดภัยไว้ตั้งแต่ต้นสามารถดึงดูดทุนและคนเก่งได้
ผลกระทบจากการเคลื่อนไหวนี้ต่อภูมิทัศน์ AI กว้างขวางและเห็นได้ชัดในหลายมิติ:
- วัฒนธรรมการวิจัย: มีการยกระดับมาตรฐานความปลอดภัยและจริยธรรมในการพัฒนา AI เช่น การเพิ่มบทบาทของการทดสอบเชิงจริยธรรมและการประเมินความเสี่ยงก่อนเปิดใช้เชิงสาธารณะ
- การจ้างงานและการแข่งขันบุคลากร: บริษัทสตาร์ทอัพและองค์กรขนาดใหญ่ต้องแข่งขันเพื่อดึงดูดผู้เชี่ยวชาญ ซึ่งนำไปสู่การเพิ่มตำแหน่งงานเฉพาะทางด้าน AI-safety, alignment และ policy มากขึ้น
- การกำกับดูแลและการกำหนดมาตรฐาน: การมีองค์กรที่มุ่งประเด็นความปลอดภัยชัดเจน ทำให้ภาคอุตสาหกรรมและหน่วยงานกำกับดูแลต้องพิจารณามาตรฐานใหม่ ๆ และแรงจูงใจเชิงนโยบายเพื่อควบคุมความเสี่ยง
สรุปได้ว่า การแยกตัวจาก OpenAI เพื่อก่อตั้ง Anthropic ไม่ได้เป็นเพียงเหตุการณ์ภายในวงการเทคโนโลยีเท่านั้น แต่เป็นปรากฏการณ์เชิงสังคม-วิชาชีพที่ส่งเสริมให้เกิดการถกเถียงเรื่องความรับผิดชอบของผู้พัฒนา AI, ปรับเปลี่ยนรูปแบบการจ้างงาน และยกระดับแนวปฏิบัติด้านความปลอดภัยในวงการอย่างยั่งยืน โดยมีแรงขับเคลื่อนทั้งจากเหตุผลเชิงวิชาการและแรงจูงใจส่วนบุคคลของผู้ก่อตั้งและทีมงาน
ความต่างเชิงเทคนิค: วิธีการ 'alignment' และสถาปัตยกรรมโมเดล
ความต่างเชิงเทคนิค: วิธีการ "alignment" และสถาปัตยกรรมโมเดล
การเปรียบเทียบเชิงเทคนิคระหว่าง OpenAI และ Anthropic มักจะหมุนรอบกรอบการฝึกสอนเพื่อให้โมเดลมีพฤติกรรมที่ปลอดภัยและสอดคล้องกับความตั้งใจของผู้ใช้ (alignment) โดยทั้งสององค์กรยังคงใช้สถาปัตยกรรมพื้นฐานเป็น transformer-based large language models แต่จะแตกต่างกันอย่างมีนัยสำคัญที่ขั้นตอนการฝึกเชิงนโยบายและกลไกควบคุมผลลัพธ์ ซึ่งส่งผลต่อทั้งคุณภาพการตอบและความโน้มเอียงของอคติ (bias).
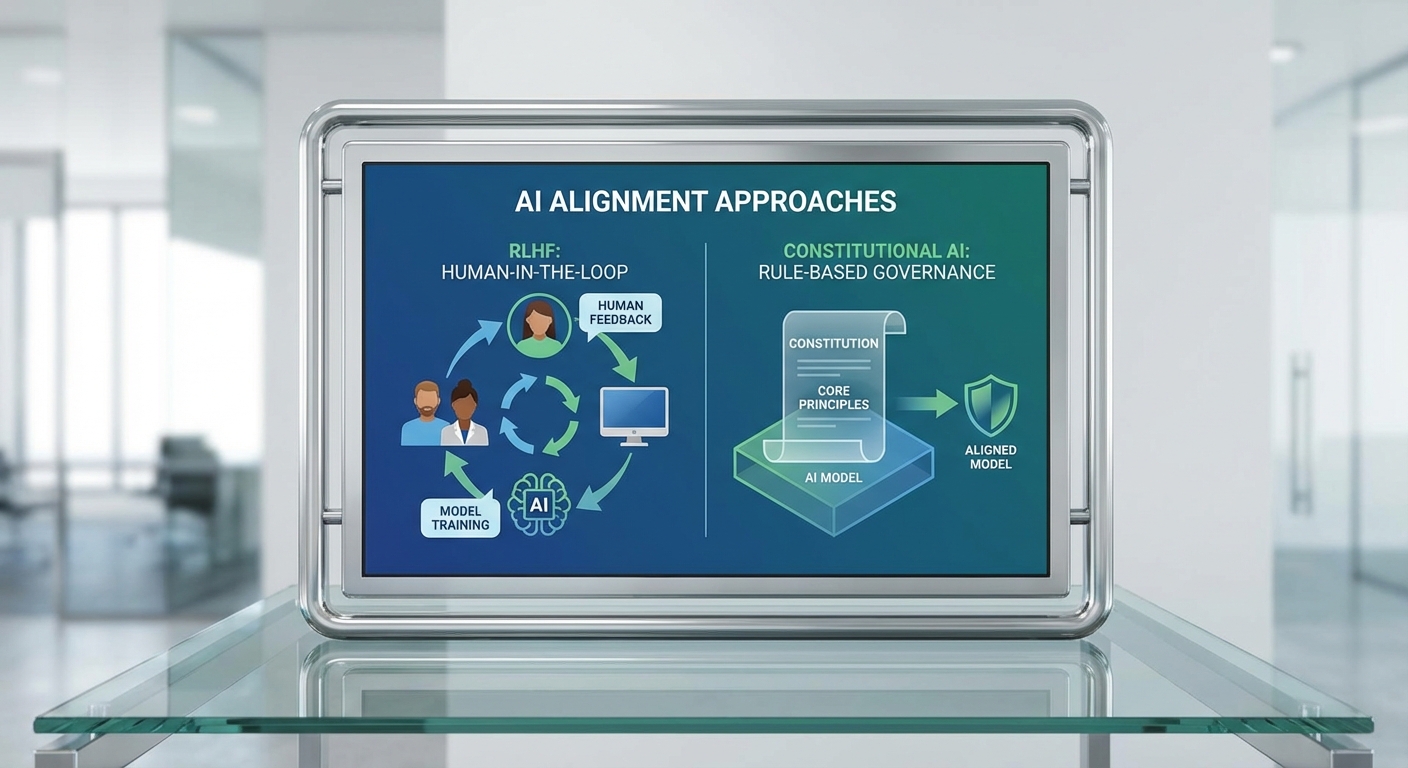
RLHF (Reinforcement Learning from Human Feedback) — แนวทางที่ OpenAI ใช้
RLHF เป็นกระบวนการที่เริ่มจากการฝึกแบบสอนด้วยตัวอย่าง (supervised fine-tuning) แล้วตามด้วยการสร้าง reward model จากการให้คะแนนคู่คำตอบโดยมนุษย์ ตัว reward model นี้ถูกใช้เป็นฟังก์ชันรางวัลในขั้นตอนการปรับด้วยการเรียนรู้แบบเสริมกำลัง (เช่น PPO) เพื่อปรับน้ำหนักของโมเดลให้ผลิตคำตอบที่ผู้ประเมินมนุษย์ชื่นชอบมากขึ้น ผลลัพธ์ที่ได้มักเป็นการเพิ่มความเป็นประโยชน์ของคำตอบ ลดการตอบที่ไม่เกี่ยวข้อง และปรับสไตล์การตอบให้เป็นไปตามมาตรฐานที่กำหนด.
ตัวอย่างผลลัพธ์ที่เกิดขึ้นจริง ได้แก่ การตอบคำถามเชิงเทคนิคด้วยความกระชับและถูกต้องมากขึ้น, การปฏิเสธคำขอที่อาจก่อให้เกิดอันตราย และการปรับโทนการสื่อสารให้สุภาพยิ่งขึ้น งานวิจัยและรายงานจากหลายแหล่งระบุว่า RLHF สามารถลดการผลิตคำตอบที่เป็นอันตรายหรือ toxic ได้อย่างมีนัยสำคัญ (ตัวเลขรายงานในงานวิจัยต่างๆ อยู่ในช่วงการลดระหว่างเลขสองหลักถึงกลาง เช่น ~20–40% ขึ้นกับมาตรวัดและชุดข้อมูลที่ใช้) แต่ RLHF ก็มีข้อจำกัด เช่น reward hacking ที่โมเดลอาจเรียนรู้การเพิ่มคะแนนโดยแลกกับผลลัพธ์ที่ยังไม่เป็นที่ต้องการ และต้องพึ่งความเห็นของมนุษย์ในการนิยามความถูกต้องของรางวัล ซึ่งเป็นงานที่มีต้นทุนสูงและเสี่ยงต่ออคติจากผู้ประเมินเอง.
Constitutional AI — แนวคิดหลักของ Anthropic
Anthropic พัฒนาแนวทางที่เรียกว่า "Constitutional AI" เพื่อพยายามลดการพึ่งพาการติดป้ายกำกับโดยมนุษย์โดยตรง โดยหลักการคือการกำหนดชุดกฎหรือ "รัฐธรรมนูญ" (constitution) ที่เป็นข้อความเชิงนโยบายเพื่อชี้นำการประเมินและการปรับคำตอบของโมเดล กระบวนการมักประกอบด้วยการให้โมเดลสร้างตัวเลือกคำตอบหลายรายการ จากนั้นใช้กฎในรัฐธรรมนูญให้โมเดล (หรือโมเดลชุดเล็ก) วิเคราะห์และเลือกคำตอบที่สอดคล้องกับกฎ ซึ่งอาจรวมถึงการให้โมเดลตรวจสอบคำตอบของตนเอง, แก้ไขคำตอบตามหลักจริยธรรม, หรือปฏิเสธคำขอที่ขัดกับกฎ.
ข้อดีสำคัญของ Constitutional AI คือการลดภาระการให้คะแนนแบบแมนนวลและลดความเสี่ยงของอคติที่มาจากผู้ประเมินเพียงกลุ่มเล็กๆ นอกจากนี้กระบวนการ self-consistency และ self-critique ช่วยให้โมเดลสามารถปรับคำตอบตามชุดกฎที่โปร่งใสและตรวจสอบได้ ตัวอย่างผลลัพธ์ที่เห็นได้คือโมเดลจะให้เหตุผลเชิงจริยธรรมก่อนตอบหรือเลือกที่จะให้คำตอบแบบปฏิเสธอย่างชัดเจนเมื่อต้องเผชิญคำขอที่เป็นอันตราย
ตัวอย่างการออกแบบเพื่อลดการสร้างข้อมูลผิด/เป็นอันตราย และผลต่อประสิทธิภาพ
- การใช้ reward models และรางวัลเชิงคุณภาพ (RLHF): ทำให้โมเดลตอบสนองตามตัวอย่างที่มนุษย์ให้ความสำคัญ แต่มีต้นทุนสูงและเสี่ยงต่อการเรียนรู้พฤติกรรมที่ 'ชนะเกมรางวัล' มากกว่าจะเป็นคำตอบที่มีความจริง
- การใช้รัฐธรรมนูญและ self-critique (Constitutional AI): ลดความจำเป็นในการติดป้ายกำกับจากมนุษย์และให้แนวทางที่สม่ำเสมอ แต่ขึ้นกับความเพียงพอและความชัดเจนของชุดกฎ — หากกฎไม่ครอบคลุม อาจเกิดพื้นที่ว่างให้โมเดลหาทางตอบที่ไม่พึงประสงค์
- การรวมชั้นกรอง (safety classifiers) และ retrieval grounding: การใช้ตัวกรองแยกต่างหากเพื่อตรวจจับเนื้อหาเป็นอันตรายหรือการดึงข้อมูลจากฐานความรู้ที่ตรวจสอบได้ สามารถลด hallucination และเพิ่มความน่าเชื่อถือของข้อเท็จจริงได้ แต่เพิ่มความหน่วงและความซับซ้อนของระบบ
- การตั้งค่า conservative refusal: ทั้งสองวิธีสามารถถูกตั้งค่าให้ปฏิเสธคำขอที่มีความเสี่ยงสูง ผลคือความปลอดภัยเพิ่มขึ้นแต่ความสามารถในการตอบคำถามที่ซับซ้อนหรือขอบเขตเทคนิคบางอย่างอาจถูกลดลง (false negatives)
ในด้านประสิทธิภาพเชิงปริมาณและเชิงคุณภาพ ผลที่ได้มักเป็นการแลกเปลี่ยน: โมเดลที่ผ่าน RLHF มักให้คำตอบที่เป็นประโยชน์และตรงตามสไตล์ที่กำหนดได้ดี ในขณะที่โมเดลที่ใช้ Constitutional AI มักแสดงความสม่ำเสมอด้านความปลอดภัยและลดการพึ่งพาผู้ประเมินมนุษย์ แต่ทั้งสองแนวทางอาจส่งผลต่อความถูกต้องเชิงข้อเท็จจริง (factuality) ในบางบริบท — เช่น การปฏิเสธมากเกินไปหรือการให้คำตอบที่ปลอดภัยแต่คลุมเครือ ซึ่งธุรกิจต้องชั่งน้ำหนักระหว่างความเสี่ยงด้านจริยธรรมกับประสิทธิภาพเชิงปฏิบัติการ
สรุปเชิงธุรกิจ: สำหรับองค์กรที่ต้องการใช้งาน AI ในเชิงพาณิชย์ การเลือกแนวทาง alignment ควรขึ้นกับความเสี่ยงของโดเมนงานและต้นทุนการดำเนินงาน — หากต้องการผลลัพธ์ที่เป็นประโยชน์ต่อผู้ใช้และยอมรับงานตัดสินใจที่มีมนุษย์กำกับได้ RLHF อาจเหมาะสมกว่า ขณะที่หากเป้าหมายคือการลดการพึ่งพาการติดป้ายกำกับโดยมนุษย์และต้องการแม่แบบความปลอดภัยที่สม่ำเสมอ Constitutional AI ให้แนวทางที่น่าสนใจ ทั้งสองแนวทางยังสามารถผสมผสานได้เพื่อให้ได้ทั้งประสิทธิภาพและความปลอดภัยที่สมดุล
ผลิตภัณฑ์และการใช้งาน: ChatGPT vs Claude และกรณีใช้งานจริง

ภาพรวมฟีเจอร์เด่นของแต่ละแพลตฟอร์ม
ChatGPT (OpenAI) ถูกวางตำแหน่งเป็นผลิตภัณฑ์ที่ใช้งานง่ายสำหรับผู้ใช้ทั่วไปและองค์กร โดยเด่นเรื่องอินเทอร์เฟซที่เป็นมิตร การรวมระบบผ่าน API ที่แพร่หลาย และชุดฟีเจอร์สำหรับองค์กร เช่น Single Sign-On, การควบคุมข้อมูล และการรับประกันความเป็นส่วนตัวของข้อมูลบนระดับองค์กร (ChatGPT Enterprise) นอกจากนี้ ChatGPT ยังได้รับความนิยมอย่างรวดเร็วโดยมีรายงานว่าแพลตฟอร์มถึงประมาณ 1 ล้านผู้ใช้ภายใน 5 วัน หลังเปิดตัว และเติบโตถึงระดับ กว่า 100 ล้านผู้ใช้ต่อเดือนในช่วงแรก ซึ่งช่วยผลักดันการยอมรับในตลาดผู้บริโภคอย่างรวดเร็ว
Claude (Anthropic) โดดเด่นด้วยแนวทางด้านความปลอดภัยเชิงต้นแบบ (safety-first) และแนวคิด “constitutional AI” ที่ออกแบบมาเพื่อลดความเสี่ยงจากการให้คำตอบที่เป็นอันตรายหรือมีอคติ ฟีเจอร์ที่องค์กรชื่นชอบรวมถึงการควบคุมพฤติกรรมของโมเดล (steerability), การรองรับบริบทการใช้งานสำหรับลูกค้าเชิงองค์กร และ API สำหรับงานเชิงธุรกิจที่ต้องการการประมวลผลภาษาธรรมชาติที่ปลอดภัยและสามารถควบคุมได้ แม้ Anthropic จะมีตัวเลขผู้ใช้รวมที่ไม่สูงเท่าฝั่งคู่แข่งในเชิงผู้บริโภค แต่ภาพรวมการยอมรับจากภาคธุรกิจมักมาจากความต้องการด้านความปลอดภัยและการกำกับดูแลภายในองค์กร
การปรับใช้ในองค์กรและกรณีใช้งานเชิงธุรกิจ
ทั้งสองแพลตฟอร์มถูกนำไปใช้ในหลากหลายสภาพแวดล้อมองค์กร โดยมีรูปแบบการปรับใช้ที่ชัดเจนดังนี้:
- การบริการลูกค้า (Customer Support) — ใช้สำหรับตอบคำถามอัตโนมัติ สรุปเคสจากตั๋วบริการ และช่วยแนะนำแนวทางแก้ปัญหาให้กับพนักงานฝ่ายสนับสนุน ตัวอย่างเช่น การสร้างเทมเพลตตอบกลับอัตโนมัติ การจัดลำดับความสำคัญของตั๋ว และการสรุปคอนเท็กซ์ของลูกค้าก่อนส่งต่อให้เจ้าหน้าที่จริง
- ระบบค้นคว้าอัตโนมัติและ RAG (Retrieval-Augmented Generation) — การรวม LLM กับฐานความรู้ขององค์กรเพื่อให้สามารถสืบค้นข้อมูลเฉพาะภายในบริษัท สรุปเอกสารยาวๆ และสร้างคำตอบที่มีหลักฐานอ้างอิง ช่วยเร่งการทำงานของทีมกฎหมาย วิจัย และฝ่ายทรัพยากรบุคคล
- การสร้างเนื้อหาและงานสร้างสรรค์ — สตูดิโอคอนเทนต์และทีมการตลาดนำไปใช้ในการร่างแคมเปญ โฆษณา สคริปต์วิดีโอ และไอเดียสร้างสรรค์ โดย ChatGPT มักถูกเลือกเพราะความรวดเร็วและอินเทอร์เฟซที่คุ้นเคย ส่วน Claude ถูกใช้อย่างแพร่หลายในสถานการณ์ที่ต้องการการควบคุมเชิงนโยบายของเนื้อหา
- เครื่องมือสำหรับนักพัฒนา — ทั้งสองระบบให้ API สำหรับการสร้างโค้ดอัตโนมัติ, การตรวจสอบโค้ด (code review), และช่วยในการจัดการเอกสารโค้ด ตัวอย่างองค์กรใช้ LLM เป็นคู่หูช่วยเขียนฟังก์ชัน สร้างเทสเคส และสร้างเอกสาร API อัตโนมัติ
ตัวอย่างกรณีใช้งานจริงและสถิติการยอมรับ
ตัวอย่างกรณีใช้งานจริงที่เห็นได้ชัดในตลาดประกอบด้วย:
- บริษัทด้านอีคอมเมิร์ซใช้ ChatGPT ในการตอบคำถามลูกค้าผ่านแชทบอท เพื่อลดเวลารอและเพิ่มความพึงพอใจของลูกค้า ผลลัพธ์ที่รายงานโดยองค์กรบางแห่งคือการลดเวลาเฉลี่ยในการตอบคำถามลงอย่างมีนัยสำคัญ
- หน่วยงานวิจัยและบริษัทเทคโนโลยีใช้ Claude สำหรับการสรุปรายงานเชิงเทคนิคและการตรวจสอบความสอดคล้องของเนื้อหา เนื่องจากความสามารถในการตั้งค่าการตอบสนองให้สอดคล้องกับนโยบายภายใน
- ทีมการตลาดและสื่อสร้างสรรค์ใช้ LLM ในการสร้างสคริปต์และไอเดีย โดยลดต้นทุนการผลิตคอนเทนต์ซ้ำซ้อน และเร่งเวลาตั้งแต่แนวคิดถึงการนำเสนอให้สั้นลง
สถิติการยอมรับ — นอกเหนือจากตัวเลขผู้ใช้ของ ChatGPT ในช่วงเปิดตัวที่เติบโตอย่างรวดเร็ว (1 ล้านผู้ใช้ในไม่กี่วัน และรายงานการมีผู้ใช้ต่อเดือนระดับร้อยล้านในช่วงแรก) ความสนใจจากภาคองค์กรได้นำไปสู่ผลิตภัณฑ์ระดับองค์กร เช่น ChatGPT Enterprise ที่ตอบโจทย์ด้านความปลอดภัยและการจัดการข้อมูล ในขณะที่ Anthropic ได้รับความสนใจเป็นพิเศษจากองค์กรที่ให้ความสำคัญกับการควบคุมเชิงนโยบายและความปลอดภัยของโมเดล ผู้ให้บริการทั้งสองฝ่ายรายงานการเติบโตของลูกค้าองค์กรในหลากหลายอุตสาหกรรม เช่น การเงิน สาธารณสุข และการผลิต ถึงแม้ตัวเลขรวมของแต่ละบริษัทอาจต่างกัน แต่แนวโน้มชัดเจนว่าธุรกิจต่างๆ ให้ความสำคัญกับการผสาน LLM เข้ากับเวิร์กโฟลว์มากขึ้น
ข้อสรุปเชิงธุรกิจ
สำหรับผู้บริหารที่กำลังตัดสินใจเลือกแพลตฟอร์ม ควรพิจารณา เป้าหมายเชิงธุรกิจ และ ข้อกำหนดด้านความปลอดภัย เป็นหลัก หากองค์กรต้องการการนำไปใช้ที่รวดเร็วและมีชุมชนผู้ใช้ใหญ่เพื่อการรวมระบบและเครื่องมือเสริม ChatGPT มอบความได้เปรียบในเชิงเอ็กโคซิสเต็ม ในทางกลับกัน หากความเสี่ยงด้านคอนเทนต์และการควบคุมพฤติกรรมของโมเดลเป็นข้อพิจารณาหลัก Claude อาจเหมาะกับงานที่ต้องการการกำกับดูแลเชิงนโยบายมากขึ้น ทั้งสองระบบสามารถนำไปใช้จริงในงานบริการลูกค้า การสร้างเนื้อหา และเครื่องมือสำหรับนักพัฒนา โดยผลลัพธ์เชิงธุรกิจที่ชัดเจนคือการเพิ่มประสิทธิภาพ ลดต้นทุน และเร่งความเร็วในการสร้างคุณค่า (time-to-value) ขององค์กร
การแข่งขันเชิงธุรกิจ: การลงทุน พันธมิตร และโมเดลรายได้
การแข่งขันเชิงธุรกิจ: การลงทุน พันธมิตร และโมเดลรายได้
ในสมรภูมิของบริษัทผู้พัฒนาโมเดลใหญ่ (LLM) อย่าง OpenAI และ Anthropic การเข้าถึงแหล่งทุนและพันธมิตรเชิงกลยุทธ์กลายเป็นปัจจัยสำคัญที่กำหนดความสามารถในการให้บริการและการเติบโตของธุรกิจ ทั้งสองบริษัทได้รับการสนับสนุนจากการลงทุนระดับสูงและความร่วมมือกับผู้ให้บริการคลาวด์รายใหญ่ ซึ่งช่วยลดเวลาในการตระเตรียมทรัพยากรคอมพิวติ้งและเปิดช่องทางสู่ลูกค้าองค์กร ตัวอย่างเช่น OpenAI มีความสัมพันธ์เชิงลึกกับ Microsoft ที่ขยายรูปแบบการใช้งานโมเดลผ่าน Azure และการรวมเข้ากับผลิตภัณฑ์องค์กร (เช่น GitHub Copilot และบริการบน Azure) ขณะที่ Anthropic เลือกเส้นทางร่วมมือกับผู้ให้บริการคลาวด์และตลาดโมเดลเพื่อกระจายช่องทางการเข้าถึงลูกค้าองค์กรและนักพัฒนา
ผลจากพันธมิตรคลาวด์มีหลายด้านที่ชัดเจน: ผู้ให้บริการคลาวด์สามารถมอบการเข้าถึงฮาร์ดแวร์ประสิทธิภาพสูง (เช่น GPU ของ NVIDIA หรือ TPU ของ Google), การตั้งค่าเครือข่ายและสตอเรจที่ปรับสเกลได้ และโมเดลการคิดค่าบริการแบบองค์กรที่ลูกค้าคุ้นเคย การได้รับสิทธิ์ใช้งานโครงสร้างพื้นฐานเช่นนี้ช่วยให้บริษัท AI ลดต้นทุนการลงทุนฮาร์ดแวร์ล่วงหน้าและเพิ่มความเร็วในการทดลองและปรับขนาดการฝึกโมเดล อย่างไรก็ดี ข้อจำกัดด้านความพร้อมของ GPU และการแข่งขันซื้อเวลาเครื่อง (instance time) ในช่วงขาดแคลนสามารถทำให้ต้นทุนเพิ่มสูงขึ้น — ผู้เชี่ยวชาญประเมินว่าค่าใช้จ่ายการฝึกโมเดลขนาดใหญ่ส่วนหนึ่งอาจมาจากฮาร์ดแวร์และคลาวด์ถึงประมาณ 60–80% ของต้นทุนทั้งหมด และการมีพันธมิตรที่พร้อมจัดสรรเครื่องจักรสำคัญจึงเป็นข้อได้เปรียบเชิงยุทธศาสตร์
ในด้านโมเดลรายได้ ทั้ง OpenAI และ Anthropic ใช้ชุดกลยุทธ์ที่หลากหลายเพื่อต่อยอดมูลค่าทางธุรกิจและกระจายแหล่งรายได้หลัก ๆ ได้แก่
- API และการใช้แบบจ่ายตามการเรียกใช้งาน (pay-as-you-go) — เป็นช่องทางหลักสำหรับนักพัฒนาและสตาร์ทอัพที่ต้องการรวมความสามารถของโมเดลเข้ากับแอปพลิเคชัน โดยบริษัทตั้งราคาตาม token หรือคำขอการประมวลผล
- Subscription สำหรับผู้ใช้งานรายบุคคล — บริการแบบสมัครสมาชิก (เช่น แผนพรีเมียมของ ChatGPT) ช่วยสร้างรายได้ประจำและทดสอบสมรรถนะกับกลุ่มผู้ใช้จำนวนมาก
- ธุรกิจระดับองค์กร (enterprise deals) — ข้อตกลงแบบสัญญารายองค์กรรวมการปรับแต่งโมเดล การฝังระบบเข้ากับโครงสร้างพื้นฐานภายใน การรับประกันด้านความปลอดภัย และการสนับสนุนระดับสูง ซึ่งมักให้มาร์จิ้นรายได้สูงแต่ต้องการการขายเชิงกลยุทธ์และการบริการหลังการขาย
- ผลิตภัณฑ์เชิงบริการและการผนวกรวม (integrations & SaaS) — การฝังโมเดลในผลิตภัณฑ์ของพันธมิตร (เช่น การผนวกในซอฟต์แวร์องค์กรหรือ marketplace ของคลาวด์) ช่วยขยายฐานลูกค้าและเปิดช่องทางรายได้ใหม่
การแข่งขันระหว่างผู้เล่นสะท้อนผ่านสองแกนหลักคือราคาและคุณภาพ/ความปลอดภัย ในการแข่งด้านราคา ผู้ให้บริการมักมีโมเดลราคาที่ยืดหยุ่นและโปรโมชั่นสำหรับลูกค้าองค์กรเพื่อดึงให้ย้ายสู่แพลตฟอร์มตน ในขณะเดียวกันคุณภาพของโมเดล—รวมถึงความแม่นยำ ความรวดเร็ว และความน่าเชื่อถือของการให้บริการ—เป็นตัวที่กำหนดความสามารถในการรักษาฐานลูกค้าองค์กร โดยเฉพาะลูกค้าที่มีข้อกำหนดด้านความเป็นส่วนตัวและการกำกับดูแลสูง แม้ราคาจะเป็นปัจจัยสำคัญ แต่สำหรับธุรกิจระดับองค์กร มักยอมจ่ายแพงขึ้นเพื่อแลกกับบริการที่รับประกันเรื่องข้อมูล ความปลอดภัย และการสอดคล้องตามกฎหมาย
การลงทุนขนาดใหญ่ไม่เพียงแต่เพิ่มความสามารถทางเทคโนโลยีเท่านั้น แต่ยังยกระดับความได้เปรียบด้านเวลาและทรัพยากรสำหรับการสร้างและทดสอบโมเดล การมีทุนมากพอช่วยให้บริษัทสามารถซื้อเวลาฝึกบนฮาร์ดแวร์ระดับสูง ทำการทดลองสถาปัตยกรรมหลากหลาย และจัดตั้งทีมด้านความปลอดภัย (red team, safety research) ขณะที่การทดสอบด้านความปลอดภัยที่ครอบคลุม—ซึ่งรวมถึงการทดสอบเชิงลบ การตรวจหาช่องโหว่ และการตรวจสอบผลกระทบเชิงสังคม—ต้องใช้ทั้งทรัพยากรคนและเงิน ในแง่นี้ การลงทุนจำนวนมากจึงแปลเป็นความได้เปรียบทางการแข่งขัน เพราะช่วยให้บริษัทสามารถทำการทดลองซ้ำและปรับปรุงโมเดลได้รวดเร็วและมีมาตรฐานมากขึ้น
ท้ายที่สุด ความได้เปรียบเชิงธุรกิจของ OpenAI และ Anthropic จะขึ้นกับการบาลานซ์ระหว่างการถือครองทรัพยากรเชิงเทคโนโลยี (เช่น การเข้าถึง GPU/TPU ผ่านพันธมิตรคลาวด์), โมเดลสร้างรายได้ที่ยืดหยุ่น (API, subscription, enterprise) และความสามารถในการตอบโจทย์ข้อกังวลด้านความปลอดภัยของลูกค้าองค์กร การลงทุนและพันธมิตรที่ถูกวางตำแหน่งอย่างรอบคอบสามารถเปลี่ยนจากค่าใช้จ่ายเป็นเครื่องมือสร้างความแตกต่างทางการแข่งขันได้ — แต่ก็ต้องแลกมาด้วยภาระด้านการจัดการข้อตกลงเชิงสัญญา การรักษาความเป็นกลางทางเทคโนโลยี และการรับประกันความโปร่งใสสำหรับลูกค้าและผู้กำกับดูแล
บุคลากร วัฒนธรรมองค์กร และการแย่งชิงทรัพยากรมนุษย์
ผลกระทบจากการย้ายทีมผู้บริหารและนักวิจัยต่อทิศทางงานวิจัย
การย้ายทีมผู้บริหารและนักวิจัยระหว่างองค์กรอย่าง OpenAI และ Anthropic มีผลโดยตรงต่อทิศทางงานวิจัย ทั้งในเชิงยุทธศาสตร์และการปฏิบัติจริง ผู้บริหารระดับสูง มักนำแนวคิดเชิงนโยบาย การจัดลำดับความสำคัญของโครงการ และทรัพยากรด้านงบประมาณมาด้วย ขณะที่ นักวิจัยและวิศวกรแถวหน้า นำความเชี่ยวชาญด้านสถาปัตยกรรมโมเดล เทคนิคการฝึก และแนวปฏิบัติที่เป็นเอกลักษณ์ของตนเอง การย้ายดังกล่าวจึงอาจเปลี่ยนพอร์ตโฟลิโอการวิจัย เช่น การให้ความสำคัญกับความปลอดภัย (safety-first) มากขึ้น หรือการเน้นประสิทธิภาพและการสเกลโมเดลอย่างรวดเร็ว
ตัวอย่างเชิงประวัติศาสตร์ที่ชัดเจน ได้แก่การก่อตั้ง Anthropic โดยอดีตพนักงาน OpenAI ซึ่งนำทีมวิจัยและมุมมองใหม่ด้านความปลอดภัยของโมเดลมาสู่ตลาด การเคลื่อนไหวระดับผู้บริหาร เช่น เหตุการณ์การเปลี่ยนแปลงผู้นำของ OpenAI ในปี 2023 ก็ถูกมองว่ามีผลต่อบรรยากาศการสรรหาบุคลากรและทิศทางการวิจัยขององค์กรในช่วงถัดมา
ปัญหาเรื่องสัญญาความลับ (NDA) และการคุ้มครองทรัพย์สินทางปัญญา
องค์กร AI ขนาดใหญ่พึ่งพาเครื่องมือทางกฎหมายเพื่อปกป้องความลับเชิงการค้าทั้ง trade secrets และผลงานที่มีมูลค่าทางพานิชย์ เช่น โค้ดการฝึก โมเดลเวต และข้อมูลฝึก (training data) โดยสัญญาความลับ (NDA) เป็นเครื่องมือหลักที่บริษัทใช้ป้องกันไม่ให้ความรู้ภายในถูกนำออกไปใช้กับคู่แข่ง อย่างไรก็ตาม บริบททางกฎหมายมีความซับซ้อน — ตัวอย่างเช่น ในรัฐแคลิฟอร์เนียข้อจำกัดเกี่ยวกับสัญญา non-compete ทำให้บริษัทต้องพึ่งพา NDA และนโยบายภายในเป็นหลัก แทนการห้ามไม่ให้พนักงานย้ายงานโดยสิ้นเชิง
ปัญหายุทธวิธีที่เกิดขึ้นจริงได้แก่ความไม่ชัดเจนของขอบเขตความรู้ที่ห้ามเผยแพร่ (เช่น แนวคิดเชิงนามธรรม vs โค้ดที่สามารถใช้งานได้) และความเสี่ยงของการละเมิดทรัพย์สินทางปัญญาเมื่อวิศวกรนำแนวทางการแก้ปัญหาไปใช้ในบริษัทใหม่ กรณีต่าง ๆ ในอุตสาหกรรมเทคโนโลยีแสดงให้เห็นว่า การฟ้องร้องเรื่อง trade secrets เป็นทางเลือกหนึ่ง แต่กระบวนการยาวนานและผลลัพธ์ไม่อาจคลุมทุกมิติของความเสี่ยงทางเทคนิคได้
ผลต่อแรงงานในอุตสาหกรรมและแนวโน้มการจ้างงานขององค์กร AI
การแข่งขันเพื่อแย่งชิงวิศวกรและนักวิจัย AI ทำให้ตลาดแรงงานเปลี่ยนแปลงอย่างรวดเร็ว ทั้งในด้านค่าตอบแทน รูปแบบสัญญา และวัฒนธรรมการทำงาน รายงานจากแพลตฟอร์มสรรหางานชี้ให้เห็นแนวโน้มการเติบโตของตำแหน่งงานด้าน AI อย่างต่อเนื่อง โดยมีอัตราการเพิ่มขึ้นที่แตกต่างกันไประหว่าง 20–40% ต่อปีในช่วงไม่กี่ปีที่ผ่านมา (ตัวเลขนี้สะท้อนการสำรวจแนวโน้มจากหลายแพลตฟอร์มการจ้างงาน)
- แรงกดดันด้านค่าตอบแทน — บริษัทต่าง ๆ เสนอแพ็กเกจรวมเงินเดือน หุ้น และสิทธิประโยชน์เชิงการวิจัยที่สูงขึ้นเพื่อดึงผู้เชี่ยวชาญชั้นนำ
- การเคลื่อนย้ายของความสามารถ — การย้ายของกลุ่มวิจัยขนาดเล็กอาจสร้างผลกระทบเชิงโดมิโน ทำให้บริษัทคู่แข่งปรับกลยุทธ์การจ้างงานอย่างรวดเร็ว
- การกระจายงานวิจัย — บางองค์กรเริ่มนำโมเดลไฮบริด เช่น รวมศูนย์การวิจัยไว้กับการร่วมมือเชิงภายนอก (partnerships, academic collaborations) เพื่อลดความเสี่ยงจากการย้ายพนักงาน
ในเชิงจริยธรรม การย้ายพนักงานระหว่างองค์กร AI ก่อให้เกิดคำถามเกี่ยวกับความรับผิดชอบต่อสังคมของนักวิจัยเมื่อเทคโนโลยีที่พัฒนาสามารถใช้ทั้งประโยชน์และก่ออันตรายได้ วัฒนธรรมองค์กรที่เน้นความโปร่งใสและการแบ่งปันความรู้แบบมีข้อควบคุม (responsible disclosure) อาจลดความเสี่ยงจากการทำซ้ำหรือการใช้งานที่ผิดวัตถุประสงค์ ในขณะที่วัฒนธรรมที่เน้นการแข่งขันสุดขั้วอาจกระตุ้นการปกป้องความรู้ด้วยมาตรการทางกฎหมายที่เข้มงวดขึ้น
สรุปแล้ว การแย่งชิงทรัพยากรมนุษย์ในแวดวง AI ไม่เพียงเป็นการแข่งขันเรื่องบุคลากรและเงินทุน แต่ยังสะท้อนการต่อสู้เชิงค่านิยม (value contest) ระหว่างแนวทางการพัฒนาเทคโนโลยีที่เปิดเผยกับแนวทางที่เน้นการควบคุมอย่างเข้มงวด — ผลลัพธ์ของสมดุลนี้จะกำหนดทิศทางทั้งด้านนวัตกรรม ความปลอดภัย และภูมิทัศน์แรงงานของอุตสาหกรรม AI ในระยะกลางถึงยาว
ความเสี่ยง กฎระเบียบ และอนาคตของการแข่งขัน
ความเสี่ยงทางสังคม: ข้อมูลผิดพลาด อคติ และความเป็นส่วนตัว
การแข่งขันระหว่าง OpenAI และ Anthropic รวมถึงผู้เล่นรายอื่น ๆ ทำให้ความสามารถของโมเดลภาษาขยายตัวอย่างรวดเร็ว แต่สิ่งนี้มาพร้อมกับความเสี่ยงทางสังคมที่จับต้องได้ ได้แก่ การแพร่กระจายข้อมูลเท็จ (misinformation) การแสดงผลลัพธ์ที่มีอคติ (bias) และการละเมิดความเป็นส่วนตัว (privacy). ตัวอย่างเชิงประจักษ์ ได้แก่ กรณีที่โมเดลสร้างข้อเท็จจริงเท็จหรือคำแนะนำอันตราย (hallucination) ซึ่งสามารถถูกนำไปใช้แพร่หลายได้ทันทีในสื่อสังคมออนไลน์หรือบริการอัตโนมัติอื่น ๆ. หลายการสำรวจของผู้บริโภคและองค์กรชี้ให้เห็นว่าผู้คนมีความกังวลต่อ AI ในมิติความเป็นส่วนตัวและความเชื่อถือได้ — โดยภาพรวมการประเมินระดับความเสี่ยงจากการใช้ AI อยู่ในช่วงกว้างและมีรายงานว่า ประมาณร้อยละหลายสิบถึงร้อยละมากกว่า 50 ของผู้ตอบแบบสอบถามในหลายการสำรวจระบุว่ากังวลเรื่องความเป็นส่วนตัวหรือความน่าเชื่อถือของผลลัพธ์จาก AI.
การเร่งเปิดตัวโมเดลโดยไม่เพียงพอด้านความปลอดภัยเป็นความเสี่ยงสำคัญ เมื่อบริษัทแข่งขันเพื่อความได้เปรียบทางการตลาด มีแรงจูงใจที่จะลดรอบการทดสอบและการประเมินผลด้านความปลอดภัย เช่น การทำ red-teaming, การทดสอบความเปราะบางต่อการถูกโจมตี, หรือตรวจสอบ bias แบบองค์รวมที่ครอบคลุมหลายภาษาและหลายบริบทได้ไม่เพียงพอ ผลลัพธ์อาจเป็นเหตุการณ์การรั่วไหลของข้อมูล การให้คำแนะนำที่เป็นอันตราย หรือการกำหนดนโยบายอัตโนมัติที่เลือกปฏิบัติ ซึ่งสร้างความเสี่ยงทั้งต่อผู้ใช้และต่อความเชื่อมั่นของตลาดโดยรวม.
บทบาทของกฎระเบียบและมาตรฐานสากล
การตอบสนองต่อความเสี่ยงเหล่านี้จำเป็นต้องอาศัยบทบาทของภาครัฐและมาตรฐานสากลอย่างจริงจัง ระหว่างปีหลัง ๆ หน่วยงานต่าง ๆ ได้เริ่มออกกรอบการกำกับดูแลที่ชัดเจน เช่น EU AI Act, แนวทางของ NIST AI Risk Management Framework, และหลักการของ OECD สำหรับ AI ซึ่งชี้นำเรื่องความโปร่งใส ความรับผิดชอบ และการจัดการความเสี่ยงในระดับระบบ. กฎระเบียบเหล่านี้สามารถบังคับใช้ได้ผ่านข้อกำหนดด้านการประเมินความเสี่ยงก่อนการวางตลาด (pre-deployment risk assessment), การทดสอบเป็นระยะ, การรายงานเหตุการณ์ความปลอดภัย, และมาตรการป้องกันข้อมูลส่วนบุคคล (เช่น การใช้ differential privacy หรือการจำกัดการเก็บข้อมูลฝึกสอนที่มีความอ่อนไหว).
อย่างไรก็ตาม การกำกับดูแลเผชิญความท้าทายเชิงปฏิบัติหลายประการ: ขอบเขตเทคโนโลยีเปลี่ยนเร็ว ทำให้กฎหมายตามไม่ทัน; ข้อกำหนดข้ามชาติและการแลกเปลี่ยนข้อมูลยังมีความซับซ้อน; และต้นทุนการปฏิบัติตามข้อกฎหมาย (compliance) อาจเป็นภาระสำหรับผู้เล่นรายเล็ก ซึ่งเสี่ยงทำให้เกิดการรวมตัวของตลาดไปยังผู้เล่นขนาดใหญ่ที่มีทรัพยากรเพียงพอในการปฏิบัติตาม. ด้วยเหตุนี้ มาตรฐานอุตสาหกรรมและการรับรองจากหน่วยงานภายนอก (third‑party audits, model cards, benchmark transparency) จึงมีบทบาทสำคัญเสริมการบังคับใช้ของภาครัฐ.
อนาคตของการแข่งขัน: การรวมกิจการ การร่วมมือด้านความปลอดภัย หรือความเสี่ยงระดับระบบ
- การร่วมมือเชิงมาตรฐานและความปลอดภัย — หนทางหนึ่งที่เห็นได้ชัดคือผู้เล่นสำคัญจะหันมาร่วมมือกันเพื่อวางกรอบความปลอดภัยร่วม เช่น การตั้ง consortium สำหรับการ red‑teaming แลกเปลี่ยนชุดทดสอบกลาง การพัฒนาวิธีการ watermarking เพื่อติดตามเนื้อหา AI และการสร้างมาตรฐานการรายงานความเสี่ยงแบบเดียวกัน การร่วมมือนี้ช่วยลดความเสี่ยงที่ระบบจะถูกนำไปใช้ในทางที่เป็นอันตรร้ายและเพิ่มความน่าเชื่อถือของเทคโนโลยีต่อสาธารณะ.
- การควบรวมกิจการและการรวมศูนย์ทรัพยากร — อีกสเกนาริโอที่เป็นไปได้คือการควบรวมเพื่อรวมทรัพยากรด้าน compute, ข้อมูล และบุคลากรเชิงวิศวกรรม การควบรวมเช่นนี้อาจเพิ่มประสิทธิภาพการพัฒนาและการปฏิบัติตามกฎระเบียบ แต่ก็ยกความกังวลเรื่องการผูกขาด การควบคุมตลาด และความเสี่ยงจากจุดล้มเหลวเดียว (single point of failure) ที่อาจกระทบต่อเศรษฐกิจและความมั่นคงระดับชาติ.
- การแบ่งตลาดเชิงเฉพาะทาง (market segmentation) — หากกฎระเบียบเข้มงวดขึ้นหรือถ้าผู้บริโภคต้องการการรับประกันความปลอดภัย อาจเกิดโมเดลธุรกิจที่แยกกันอย่างชัดเจน—ผู้ให้บริการระดับบนที่เน้นความปลอดภัยและการตรวจสอบแบบเข้มข้น กับผู้ให้บริการเชิงนวัตกรรมที่เน้นการทดลองและออกผลิตภัณฑ์ใหม่อย่างรวดเร็วในตลาดที่มีความเสี่ยงต่ำ การแบ่งตลาดนี้อาจลดแรงกดดันในการแข่งแบบ “ระเบิดเวลา” แต่จะเพิ่มความซับซ้อนในการกำกับดูแล.
โดยสรุป การแข่งขันระหว่าง OpenAI และ Anthropic รวมถึงผู้เล่นในอุตสาหกรรม จะกำหนดรูปแบบการพัฒนา AI ในระยะยาวได้ทั้งในทางบวกและทางลบ หากการพัฒนาเป็นไปอย่างรวดเร็วโดยไม่มีมาตรการความปลอดภัยและกรอบกฎระเบียบที่เหมาะสม ความเสี่ยงเชิงระบบจะเพิ่มขึ้น แต่ในทางกลับกัน การร่วมมือเชิงมาตรฐานและนโยบายสาธารณะที่ชัดเจนสามารถชะลอการแข่งที่เสี่ยงและส่งเสริมการเติบโตที่ยั่งยืนสำหรับทั้งภาคธุรกิจและสังคม. ผู้บริหารระดับสูงและผู้กำหนดนโยบายจึงควรเร่งสร้างสมดุลระหว่างนวัตกรรม การแข่งขัน และการคุ้มครองสาธารณะ เพื่อหลีกเลี่ยงผลกระทบที่ไม่พึงประสงค์ในวงกว้าง.
ไทม์ไลน์เหตุการณ์สำคัญและกรณีศึกษาที่ต้องจับตา
ไทม์ไลน์เหตุการณ์สำคัญและกรณีศึกษาที่ต้องจับตา
ส่วนนี้สรุปเหตุการณ์เชิงประวัติศาสตร์และกรณีศึกษาที่มีผลต่อการต่อสู้ทางเทคโนโลยีระหว่าง OpenAI และ Anthropic โดยเรียงตามลำดับเวลา เพื่อให้ผู้อ่านมองเห็นการเปลี่ยนผ่านเชิงกลยุทธ์ ผลกระทบเชิงองค์กร และจุดเปลี่ยนด้านความปลอดภัยที่กำหนดทิศทางสาธารณะได้อย่างชัดเจน
ไทม์ไลน์ด้านล่างคัดกรองเหตุการณ์ที่สาธารณะรับรู้ได้ชัดเจน (ก่อตั้ง การเปิดตัวผลิตภัณฑ์หลัก การประกาศพันธมิตรเชิงกลยุทธ์ และเหตุการณ์ด้านความปลอดภัยหรือข้อถกเถียง) พร้อมกรณีศึกษาที่สะท้อนผลกระทบเชิงองค์กร
- 2021 — ก่อตั้ง Anthropic: กลุ่มนักวิจัยที่แยกตัวจากสถาบันและบริษัทเดิมรวมตัวก่อตั้ง Anthropic โดยประกาศเป้าหมายชัดเจนเรื่อง alignment และความปลอดภัยของโมเดลภาษาขนาดใหญ่ (LLMs) การก่อตั้งนี้เป็นจุดเริ่มต้นของคู่แข่งเชิงวิจัยที่มุ่งเน้นด้านความปลอดภัยเป็นหลัก
- ปลาย 2022 — การเปิดตัว ChatGPT (OpenAI): แพลตฟอร์มการแชตของ OpenAI กลายเป็นปรากฏการณ์ผู้บริโภคอย่างรวดเร็ว โดยมีรายงานว่า ChatGPT แตะระดับ ~100 ล้านผู้ใช้ต่อเดือนในเวลาต่อมา เหตุการณ์นี้เร่งให้ตลาดและองค์กรทบทวนกลยุทธ์ด้าน AI อย่างกว้างขวาง
- 2022 — Anthropic เสนอแนวทาง “Constitutional AI”: Anthropic เผยแพร่วิธีการฝึกสอนโมเดลให้ยึดตามชุดกฎหรือ “รัฐธรรมนูญ” เพื่อปรับปรุงความปลอดภัยและลดการตอบสนองที่ไม่พึงประสงค์ แนวทางนี้กลายเป็นหนึ่งในกรอบการถกเถียงเรื่องการออกแบบระบบที่ปลอดภัย
- ต้น–กลาง 2023 — เปิดตัวผลิตภัณฑ์หลักของ Anthropic (Claude): Anthropic เปิดตัวโมเดลภายใต้แบรนด์ Claude และเริ่มให้บริการแก่พันธมิตร รวมทั้งนำเสนอจุดขายด้านความปลอดภัยและการควบคุมการตอบสนอง ซึ่งสร้างทางเลือกใหม่ให้ตลาดที่กังวลด้านความเสี่ยงของโมเดลขนาดใหญ่
- 2023 — การแข่งขันด้านผลิตภัณฑ์และพันธมิตรเชิงกลยุทธ์: OpenAI เสริมความร่วมมือเชิงลึกกับพันธมิตรด้านคลาวด์และซอฟต์แวร์ระดับองค์กร ขณะที่ Anthropic ประกาศพันธมิตรเชิงกลยุทธ์กับผู้ให้บริการคลาวด์รายใหญ่ (รวมถึงการลงทุนเชิงกลยุทธ์จากผู้ให้บริการคลาวด์รายหนึ่งมูลค่าหลายพันล้านดอลลาร์) ซึ่งเปลี่ยนสมดุลทางการเข้าถึงทรัพยากรการประมวลผลและช่องทางสู่ลูกค้าองค์กร
- กลาง–ปลาย 2023 — การผนวกเข้าระบบ Search และ Productivity: บริษัทเทคโนโลยีรายใหญ่ประกาศนำโมเดลภาษามาใช้ในผลิตภัณฑ์ Search และ Office (เช่น การใช้ LLM ในระบบช่วยทำงานเป็น “Copilot”) เหตุการณ์นี้ส่งผลโดยตรงต่อการใช้งานเชิงองค์กรและโมเดลรายได้ของผู้ให้บริการทั้งสอง
- ปลาย 2023 — วิกฤตการบริหารที่ OpenAI (ผลกระทบเชิงสาธารณะ): เหตุการณ์การเปลี่ยนแปลงผู้บริหารระดับสูงและการถกเถียงเรื่องบอร์ดบริหารของ OpenAI สร้างความสั่นคลอนในความเชื่อมั่นของตลาดและกระตุ้นให้ลูกค้าองค์กรพิจารณาความเสี่ยงด้านการกำกับดูแลและการกำหนดทิศทางผลิตภัณฑ์
- 2023–2024 — ความพยายามด้านกฎระเบียบและการทดสอบความปลอดภัย: หลังจากหลายกรณีของการเจลเบรก (jailbreak) และการใช้โมเดลในทางที่เป็นอันตราย รัฐบาลและหน่วยงานกำกับดูแลเริ่มขยับเพื่อกำหนดกรอบการใช้ LLM ซึ่งส่งผลต่อข้อกำหนดของลูกค้าองค์กรและการออกแบบผลิตภัณฑ์
ถัดไปเป็นกรณีศึกษาที่แสดงให้เห็นผลกระทบเชิงปฏิบัติจากการนำเทคโนโลยีของทั้งสองฝั่งไปใช้ในองค์กร
- กรณีศึกษา — การผนวก OpenAI ลงในผลิตภัณฑ์เชิงผลิตภาพและค้นหา: การรวม GPT-based models เข้ากับบริการค้นหาและชุดโปรดักทีฟของพันธมิตร (เช่น การฝัง AI ในเครื่องมือค้นหาและระบบช่วยเขียนเอกสาร) ทำให้เกิดการเปลี่ยนแปลงรูปแบบการทำงานภายในองค์กรอย่างรวดเร็ว ตัวอย่างผลกระทบที่วัดได้ ได้แก่ การลดเวลางานเอกสารเริ่มต้นถึง 20–30% ในบางทีม แต่ก็เพิ่มข้อกังวลด้านข้อมูลความลับขององค์กร
- กรณีศึกษา — แพลตฟอร์มรวมโมเดลหลายราย (เช่น Poe ของ Quora): แพลตฟอร์มที่รวมโมเดลจากหลายผู้ให้บริการ ทั้ง OpenAI และ Anthropic ช่วยให้องค์กรสามารถทดลองเปรียบเทียบประสิทธิภาพและด้านความปลอดภัยได้เร็วขึ้น กรณีนี้แสดงให้เห็นความสำคัญของความยืดหยุ่นในการเลือกโมเดลตามงานและนโยบายความปลอดภัย
- กรณีศึกษา — การนำ Claude ไปใช้ผ่านพันธมิตรคลาวด์: ลูกค้าองค์กรที่ต้องการการควบคุมและการปรับแต่งทางด้านความปลอดภัยมากขึ้น เลือกใช้บริการจาก Anthropic ผ่านผู้ให้บริการคลาวด์เชิงพาณิชย์ ผลลัพธ์ชี้ให้เห็นว่าการลงทุนเพิ่มเติมด้านการกำกับดูแล (governance) ช่วยลดความเสี่ยงการรั่วไหลของข้อมูล แต่ต้องแลกกับค่าใช้จ่ายการปรับแต่งและการดำเนินงานที่สูงขึ้น
สุดท้ายนี้ต้องเน้นว่าเหตุการณ์ด้านความปลอดภัยและข้อถกเถียง (เช่น การเจลเบรก ความแตกต่างเชิงนโยบายการเข้าถึง API และวิกฤตการบริหาร) มักเป็นตัวเร่งให้เกิดการเปลี่ยนทิศทางทั้งทางเทคนิคและเชิงธุรกิจ องค์กรที่ติดตามการแข่งขันระหว่าง OpenAI และ Anthropic จึงจำเป็นต้องเฝ้าดูไม่เพียงแต่ประสิทธิภาพโมเดล แต่รวมถึงนโยบายการกำกับดูแล ภาระผูกพันด้านสัญญา และพันธมิตรเชิงโครงสร้างพื้นฐานที่อาจตัดสินชะตาการปรับใช้ในระยะยาว
บทสรุป
การแข่งขันระหว่าง OpenAI และ Anthropic มิได้เป็นเพียงการชิงตำแหน่งผู้นำด้านสมรรถนะโมเดลเท่านั้น แต่ยังเป็นเวทีสื่อสารทางความคิดเรื่องความปลอดภัยของปัญญาประดิษฐ์ด้วย การชนกันของแนวทางเทคนิค เช่น การออกแบบสถาปัตยกรรมโมเดล นโยบายการควบคุมพฤติกรรมของโมเดล และการเปิดเผยข้อมูลการทดสอบความปลอดภัย ควบคู่ไปกับการสื่อสารเชิงสาธารณะและการเคลื่อนไหวของบุคลากร ส่งผลโดยตรงต่อความเชื่อมั่นของสังคม ตลาดทุน และทิศทางการกำกับดูแล ผลลัพธ์จากการปะทะกันของแนวคิดเหล่านี้จะเป็นตัวกำหนดว่าการนำ AI ไปใช้ในมิติทางสังคม เศรษฐกิจ และความมั่นคงจะเป็นไปในทิศทางใด

ในเชิงนโยบายและการบริหารองค์กร ควรติดตามทั้งมิติทางเทคนิคและมิติส่วนบุคคลของการเคลื่อนไหวบุคลากรอย่างเท่าเทียมกัน เพราะทั้งสองปัจจัยร่วมกันกำหนด ความน่าเชื่อถือ และ ความรับผิดชอบ ของระบบ AI ในวงกว้าง ข้อเสนอเชิงปฏิบัติได้แก่การส่งเสริมความโปร่งใสในการทดสอบความปลอดภัย การบังคับใช้มาตรฐานการประเมินภายนอก การเปิดเผยความสัมพันธ์ทางผลประโยชน์และการเคลื่อนย้ายบุคลากร รวมถึงการสร้างกรอบกฎหมายด้านความรับผิดชอบและการชดเชยเมื่อเกิดความเสียหาย การผสานระหว่างการตรวจสอบเชิงเทคนิคกับการกำกับดูแลเชิงพฤติกรรมขององค์กรและบุคคล จะช่วยให้การพัฒนา AI ก้าวหน้าอย่างปลอดภัยและเป็นประโยชน์ต่อสังคมในระยะยาว
📰 แหล่งอ้างอิง: The New York Times



