โรงพยาบาลไทย ประกาศความก้าวหน้าทางการแพทย์และปัญญาประดิษฐ์ที่น่าจับตามอง เมื่อทีมวิจัยนำเทคนิค Diffusion‑prior มาผสานกับกรอบการเรียนรู้ร่วม (Federated Learning) ในการประมวลผลภาพ MRI ทำให้ระยะเวลาการสแกนลดลงถึง 50% ในการทดลองใช้งานจริงภายในเครือข่ายโรงพยาบาลหลายแห่งของประเทศไทย โดยยังคงมาตรฐานการวินิจฉัยทางคลินิกไว้ได้อย่างเหนียวแน่น ผลการทดลองชี้ให้เห็นว่าเทคโนโลยีนี้สามารถเพิ่มประสิทธิภาพการให้บริการผู้ป่วยอย่างมีนัยสำคัญ เช่น เพิ่มความจุการตรวจต่อเครื่องประมาณสองเท่าและลดเวลารอคอยโดยรวมในระบบบริการสุขภาพ
แนวทางดังกล่าวใช้ Diffusion‑prior เพื่อปรับปรุงการสร้างภาพจากข้อมูล k‑space ที่ถูกเก็บในรูปแบบ undersampled ขณะเดียวกัน Federated Learning ช่วยให้โมเดลเรียนรู้จากข้อมูลผู้ป่วยหลายแห่งโดยไม่ต้องแลกเปลี่ยนข้อมูลดิบระหว่างโรงพยาบาล ซึ่งสอดคล้องกับข้อกำหนดความเป็นส่วนตัวและกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย ผลการประเมินเชิงเปรียบเทียบรายงานว่า ความแม่นยำในการวินิจฉัยทางคลินิกไม่ได้ลดลงอย่างมีนัยสำคัญ (ความแตกต่างไม่เกินประมาณ 1–2% เมื่อเทียบกับสแกนมาตรฐาน, p>0.05) ทำให้เทคโนโลยีนี้มีศักยภาพในการยกระดับการดูแลรักษา ลดค่าใช้จ่ายต่อเคส และขยายบริการไปยังพื้นที่ที่มีทรัพยากรจำกัดต่อไป
บทนำ: ข่าวสรุปและความสำคัญ
บทนำ: ข่าวสรุปและความสำคัญ
สรุปข่าวหลัก: โรงพยาบาลหลายแห่งในประเทศไทยได้นำเทคนิคปัญญาประดิษฐ์แบบใหม่ที่เรียกว่า Diffusion‑prior ผสานกับแนวทางการฝึกโมเดลแบบกระจายข้อมูล (Federated Learning) มาใช้ในการได้ภาพ MRI ที่เร็วขึ้น ผลการทดลองเบื้องต้นรายงานว่าสามารถย่นเวลาในการสแกนและประมวลผลภาพรวมได้ประมาณ 50% โดยยังคงระดับความแม่นยำทางการวินิจฉัยเทียบเท่ากับการสแกนแบบมาตรฐานเดิม ไม่มีการลดลงที่มีนัยสำคัญทางการแพทย์
การทดสอบเชิงนำร่องนี้ดำเนินการโดยความร่วมมือระหว่าง 12 โรงพยาบาล ในเครือข่ายภาครัฐและเอกชน ร่วมกับทีมวิจัยจากมหาวิทยาลัยและบริษัทพัฒนา AI ในประเทศ ระยะเวลาการทดลองอยู่ที่ประมาณ 9 เดือน เก็บข้อมูลการสแกนทั้งหมดประมาณ 4,800 เคส MRI ครอบคลุมคลื่นการใช้งานสำคัญ เช่น ระบบประสาท ศัลยกรรมกระดูก และอวัยวะภายใน ผลการประเมินคุณภาพภาพและการวินิจฉัยชี้ว่าโมเดลที่ฝึกผ่าน Federated Learning สามารถรักษาค่าความไว (sensitivity) และความจำเพาะ (specificity) ให้อยู่ในระดับใกล้เคียงกับมาตรฐานเดิม โดยไม่มีความแตกต่างทางสถิติที่สำคัญสำหรับการตัดสินใจทางคลินิก
ผู้เกี่ยวข้อง ในความร่วมมือนี้ประกอบด้วย: ทีมรังสีวิทยาจากโรงพยาบาลต่าง ๆ ที่ให้ข้อมูลและประเมินคุณภาพ ทีมวิจัยด้านปัญญาประดิษฐ์ที่พัฒนา Diffusion‑prior และสถาปัตยกรรมการฝึกแบบ Federated รวมถึงผู้พัฒนาอุปกรณ์และซอฟต์แวร์ที่สนับสนุนการผนวกรวมระบบ การใช้ Federated Learning ช่วยให้แต่ละหน่วยงานยังคงควบคุมข้อมูลคนไข้ในสถาบันของตนเองได้ ขณะเดียวกันก็สามารถสร้างโมเดลรวมที่มีประสิทธิภาพจากข้อมูลกระจายโดยไม่ต้องย้ายข้อมูลดิบข้ามสถาบัน
นัยยะต่อระบบสุขภาพไทย: ผลลัพธ์นี้มีความสำคัญเชิงปฏิบัติหลายด้าน ได้แก่ การเพิ่มประสิทธิภาพการให้บริการ (throughput) ของเครื่อง MRI ลดคิวตรวจและเวลารอคอยสำหรับผู้ป่วยเร่งด่วน ลดต้นทุนต่อการตรวจในระยะยาว และขยายการเข้าถึงบริการภาพวินิจฉัยไปยังพื้นที่ห่างไกลที่มีทรัพยากรจำกัด นอกจากนี้ การรักษาความเป็นส่วนตัวของข้อมูลผู้ป่วยผ่าน Federated Learning ยังช่วยลดอุปสรรคด้านกฎหมายและการยินยอมที่มักเป็นข้อจำกัดในการสร้างโมเดลรวมระดับชาติ โดยสรุป เทคโนโลยีผสมผสานนี้อาจเป็นจุดเปลี่ยนสำคัญที่ช่วยให้ระบบบริการรังสีวิทยาของไทยมีความรวดเร็ว มีประสิทธิภาพ และพร้อมตอบโจทย์การดูแลผู้ป่วยในวงกว้างมากขึ้น
- จำนวนโรงพยาบาลที่ร่วมโครงการ: 12 แห่ง
- ระยะเวลาทดสอบ: 9 เดือน
- ขนาดตัวอย่าง: ประมาณ 4,800 เคส MRI
- ผลลัพธ์สำคัญ: เวลาสแกน/ประมวลผลลดลง ~50% โดยความแม่นยำทางการวินิจฉัยไม่ลดลงอย่างมีนัยสำคัญ
พื้นหลัง: ปัญหาในการสแกน MRI และความจำเป็นของการเร่งภาพ
ความยาวของเวลาสแกนและผลกระทบต่อการให้บริการ
การตรวจด้วย MRI ในการปฏิบัติทางคลินิกทั่วไปมักใช้เวลาต่อการสแกนหนึ่งชุดค่อนข้างยาว โดยขึ้นกับชนิดของการตรวจและโปรโตคอลที่ใช้ แต่โดยเฉลี่ยเวลาสแกนอยู่ที่ ประมาณ 20–45 นาทีต่อการตรวจ (บางโปรโตคอลเฉพาะทางอาจยาวกว่า 60 นาที) ซึ่งหมายความว่าเครื่อง MRI หนึ่งเครื่องในระบบคลินิกทั่วไปสามารถให้บริการได้เพียงประมาณ 6–12 คนต่อวัน ภายใต้ตารางงานปกติ หากต้องเพิ่มเวลาสแกนหรือมีการทำซ้ำ จะทำให้ความสามารถในการรองรับผู้ป่วย (patient throughput) ลดลงอย่างมีนัยสำคัญ ส่งผลให้เกิดคอขวดในการนัดหมาย การรอคิวที่ยาวขึ้น และผลกระทบเชิงเศรษฐกิจต่อหน่วยบริการสุขภาพ
ผลลัพธ์เชิงการจัดการคือ โรงพยาบาลและคลินิกมักเผชิญกับคิวผู้ป่วยยาว การยกเลิกนัด และความจำเป็นต้องจัดตารางเวลาใหม่เป็นประจำ ซึ่งสร้างความไม่สะดวกทั้งต่อผู้ป่วยและบุคลากรทางการแพทย์ นอกจากนี้ เวลาเครื่องที่ยาวขึ้นยังเพิ่มต้นทุนต่อการตรวจ เช่น ค่าใช้จ่ายด้านพนักงานและการบำรุงรักษาเครื่องจักรที่กระจายไปยังจำนวนเคสที่น้อยลง ทำให้ต้นทุนต่อเคสสูงขึ้น
ปัญหา motion artifact และความเสี่ยงต่อความแม่นยำการวินิจฉัย
การสแกนที่ต้องใช้เวลานานทำให้โอกาสเกิดการเคลื่อนไหวของผู้ป่วยเพิ่มขึ้น โดยเฉพาะในกลุ่มผู้ป่วยเด็ก ผู้สูงอายุ หรือผู้ที่มีอาการเจ็บปวด ซึ่งมักจะส่งผลให้เกิด motion artifact ในภาพ MRI ซึ่งลดคุณภาพภาพและอาจนำไปสู่การวินิจฉัยที่ผิดพลาดหรือไม่แน่นอน ในการศึกษาหลายฉบับพบว่า ประมาณ 10–25% ของการตรวจ MRI อาจมี artifact ในระดับที่ส่งผลต่อการอ่านผล และมี 5–15% ของเคสที่ต้องมีการทำสแกนซ้ำหรือทำเสริมเพื่อให้ได้ภาพที่วินิจฉัยได้
ผลกระทบทางคลินิกของภาพที่มี artifact ได้แก่ ความเสี่ยงต่อการพลาดโรค (false negative), การตีความผิดพลาด (false positive) ซึ่งอาจนำไปสู่การรักษาที่ไม่เหมาะสมหรือการสืบค้นเพิ่มเติมที่ไม่จำเป็น ทั้งหมดนี้สร้างภาระทั้งต่อระบบสุขภาพและต่อผู้ป่วยเอง
บทบาทของ AI ในการเร่งภาพและแนวทางการประยุกต์ใช้
เทคโนโลยีปัญญาประดิษฐ์ (AI) ได้กลายเป็นเครื่องมือสำคัญในการแก้ปัญหาดังกล่าว โดยมีแนวทางหลักสองด้านคือ การเร่งการเก็บสัญญาณ (undersampling) ร่วมกับการ reconstruction และการ denoising ของภาพ ผลลัพธ์คือสามารถลดจำนวนข้อมูลที่ต้องเก็บใน k-space ทำให้เวลาการสแกนลดลงโดยตรง จากนั้นใช้เครือข่ายประสาทเทียมเพื่อสร้างภาพคุณภาพสูงจากข้อมูลที่ถูกลดลง
- วิธีการเชิงสถิติและ compressive sensing ช่วยให้การลด sampling ยังคงรักษาข้อมูลเชิงโครงสร้างไว้ได้บางส่วน
- Deep learning reconstruction (เช่น UNet, GAN-based, และ diffusion models) สามารถเรียนรู้การเติมข้อมูลขาดหายและลดสัญญาณรบกวน ทำให้ได้ภาพที่ใกล้เคียงกับการสแกนเต็มรูปแบบ
- รายงานจากการทดลองทางคลินิกและการวิจัยชี้ว่า AI สามารถทำให้เกิด อัตราการเร่ง (acceleration factor) ประมาณ 2–4 เท่า โดยยังคงความสามารถในการวินิจฉัยได้ในระดับใกล้เคียงเดิม
โดยสรุป ปัญหาหลักของ MRI คือเวลาสแกนที่ยาวและความไวต่อการเคลื่อนไหว ซึ่งส่งผลต่อ throughput และคุณภาพการวินิจฉัย AI เพื่อการเร่งภาพ จึงเป็นแนวทางที่มีศักยภาพในการลดเวลาสแกน เพิ่มประสิทธิภาพการให้บริการ และลดอัตราการทำสแกนซ้ำ ทั้งนี้การนำ AI มาใช้ต้องคำนึงถึงความแม่นยำ ความเสถียร และการยืนยันทางคลินิกก่อนนำไปใช้จริงในโรงพยาบาล
เทคโนโลยีหลัก: อธิบาย Diffusion‑prior และ Federated Learning แบบเข้าใจง่าย
เทคโนโลยีหลัก: อธิบาย Diffusion‑prior และ Federated Learning แบบเข้าใจง่าย
Diffusion‑prior ในงานฟื้นฟูภาพ (image reconstruction) เป็นการนำแนวคิดจาก diffusion models — เช่น Denoising Diffusion Probabilistic Models (DDPM) หรือ score‑based models — มาทำหน้าที่เป็น *prior* หรือความรู้ล่วงหน้าเกี่ยวกับรูปร่างและรายละเอียดของภาพทางการแพทย์ที่สมจริง กระบวนการพื้นฐานประกอบด้วยสองส่วนหลัก: ขั้นตอน "noising" (แบบจำลองกระบวนการเพิ่มสัญญาณรบกวนให้ภาพจนเป็น distribution ที่รู้จักได้) และขั้นตอน "denoising"/reverse diffusion ที่แบบจำลองได้เรียนรู้วิธีย้อนกลับจากภาพที่ถูกทำให้เบลอ/มีสัญญาณรบกวนกลับไปยังภาพที่ชัดเจน
ในการประยุกต์กับ undersampled MRI (การเก็บข้อมูล k‑space น้อยลงเพื่อย่นเวลา) เทคนิค diffusion‑prior ถูกใช้ร่วมกับเงื่อนไขทางฟิสิกส์ของการวัด เช่นตัวดำเนินการ Fourier ที่เป็นตัวแทนการวัดจริง กลยุทธ์ปฏิบัติมักเป็นการสลับระหว่างสองขั้นตอน: (1) บังคับให้ผลลัพธ์สอดคล้องกับข้อมูลที่วัดได้ (data consistency) และ (2) ใช้ denoiser/score network ที่ได้จาก diffusion model เพื่อดึงภาพกลับสู่ manifold ของภาพที่สมจริง แนวทางนี้ช่วยให้ได้ภาพที่มีรายละเอียดและสัญญาณรบกวนต่ำแม้ข้อมูลการวัดจะถูกย่อลง ตัวอย่างเชิงตัวเลขจากงานวิจัยและกรณีศึกษาแสดงให้เห็นว่าการใช้ diffusion priors สามารถรองรับการลดอัตราการเก็บข้อมูล (acceleration factor) ในช่วงประมาณ 2–8 ขึ้นอยู่กับโปรโตคอลและความละเอียดที่ต้องการ และในกรณีของโครงการความร่วมมือของโรงพยาบาลไทยนี้ สามารถย่นเวลา MRI ได้ราว 50% ขณะที่ยังรักษาความแม่นยำทางการวินิจฉัยไว้ได้
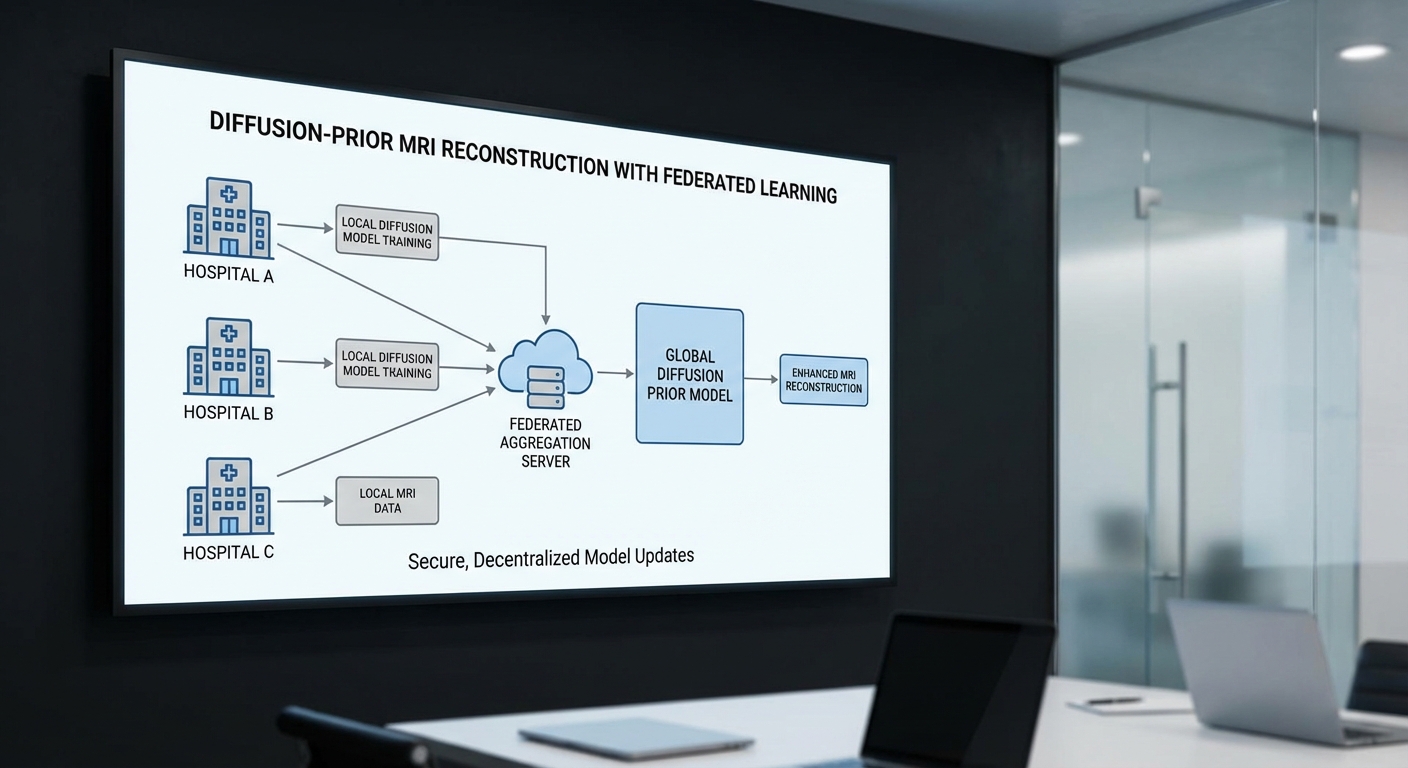
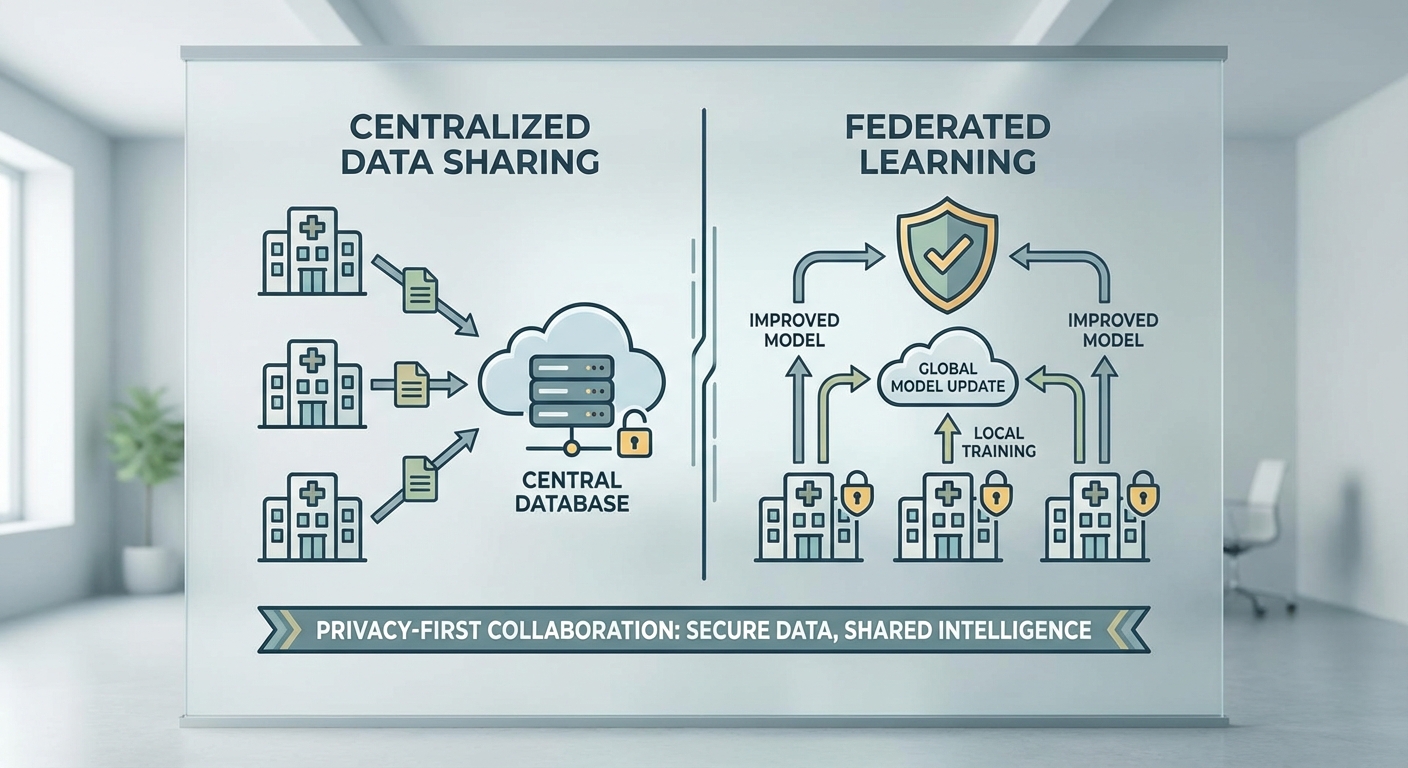
Federated Learning (FL) คือกรอบการฝึกโมเดลแบบกระจายซึ่งอนุญาตให้สถาบันต่าง ๆ ฝึกโมเดลร่วมกันโดยไม่ต้องย้ายข้อมูลดิบของคนไข้ออกจากเซิร์ฟเวอร์ท้องถิ่น กระบวนการพื้นฐานคือทุกโรงพยาบาลฝึกโมเดลบนข้อมูลภายในของตน (local update) แล้วส่งเฉพาะพารามิเตอร์หรือการอัปเดตของโมเดลไปยังเซิร์ฟเวอร์กลางเพื่อรวม (aggregation เช่น FedAvg) เป็นโมเดลรวม การออกแบบนี้มีข้อดีด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA หรือกฎระเบียบสากล) เพราะไม่ต้องแลกเปลี่ยน DICOM/raw images ระหว่างหน่วยงาน
- ข้อดีด้านความเป็นส่วนตัว: ข้อมูลผู้ป่วยยังคงอยู่ในสถานพยาบาลต้นทาง ลดความเสี่ยงจากการรั่วไหลและลดภาระการจัดการการอนุญาตแชร์ข้อมูล
- การป้องกันเพิ่มเติม: สามารถผสานเทคนิคเช่น secure aggregation, differential privacy หรือ homomorphic encryption เพื่อลดความเสี่ยงจากการสกัดข้อมูลจากค่าพารามิเตอร์
- ข้อจำกัดที่ต้องจัดการ: ค่าใช้จ่ายการสื่อสาร (bandwidth), heterogeneity ของข้อมูลระหว่างสถานพยาบาล, และความเป็นไปได้ของการรั่วไหลข้อมูลจาก gradient — ซึ่งแก้ได้ด้วยการบีบอัดอัปเดต, การฝึก local epochs มากขึ้น และมาตรการป้องกันความเป็นส่วนตัว

เมื่อผสาน Diffusion‑prior กับ Federated Learning จะเกิดชุดโซลูชันที่ทั้งทรงพลังและคำนึงถึงความปลอดภัยของข้อมูลในทางคลินิก โดยแนวทางปฏิบัติทั่วไปในระบบ MRI มีลักษณะดังนี้:
- แต่ละโรงพยาบาลฝึกโมเดล denoiser/score (ส่วนที่เป็น diffusion prior) บนข้อมูล undersampled MRI ของตนเอง โดยการฝึกอาจรวมเงื่อนไขที่สะท้อนการวัดจริงของหน่วยตรวจ(MRI scanner operator)
- แทนการแลกเปลี่ยนภาพคนไข้ ด้านในแต่ละรอบการเทรนโรงพยาบาลจะส่งเฉพาะน้ำหนักโมเดลหรืออัปเดตเท่านั้นไปยังเซิร์ฟเวอร์กลาง ซึ่งเซิร์ฟเวอร์รวมอัปเดตเพื่อให้ได้ prior ที่ครอบคลุมความหลากหลายของข้อมูลจากหลายแห่ง
- ในขั้นตอนการใช้งานจริง (inference) การฟื้นฟูภาพทำโดยการผสมผสานระหว่าง data‑consistency ที่ทำในหน่วยงานนั้นกับ prior ที่ได้จากโมเดลรวม — ทำให้สามารถสร้างภาพความละเอียดสูงจากข้อมูลน้อยลงได้อย่างปลอดภัยและสอดคล้องกับการวัดของเครื่อง
ผลลัพธ์เชิงปฏิบัติของการผสานทั้งสองเทคนิคคือ prior ที่มีความทนทานต่อความหลากหลายของผู้ป่วยและเครื่องมือ (scanner variability) เพราะได้เรียนรู้จากหลายสถาบันผ่าน FL ขณะที่ยังคงเคารพข้อจำกัดด้านความเป็นส่วนตัว ตัวอย่างเช่น ในการนำไปใช้จริง โรงพยาบาลร่วมโครงการสามารถลดเวลาสแกนลงประมาณ 50% โดยไม่สูญเสียความไว/ความจำเพาะในการวินิจฉัยเมื่อเทียบกับการสแกนแบบเต็มรูปแบบ ทั้งนี้การใช้งานเชิงอุตสาหกรรมมักเสริมด้วยมาตรการเพิ่มเติม เช่น การปรับแต่ง (personalization) ให้เหมาะกับ scanner แต่ละเครื่อง การใช้ secure aggregation เพื่อลดความเสี่ยงจากการโจมตี และการควบคุมคุณภาพผ่านชุดทดสอบภายนอก (external validation)
สรุป — Diffusion‑prior มอบความสามารถในการฟื้นฟูภาพจากข้อมูล undersampled โดยเรียนรู้ distribution ของภาพที่สมจริง ขณะที่ Federated Learning ช่วยให้โมเดล prior ดังกล่าวได้ประโยชน์จากข้อมูลจากหลายโรงพยาบาลโดยไม่ต้องแลกเปลี่ยนข้อมูลดิบ การผสานสองเทคนิคนี้จึงเป็นทางออกที่สมดุลระหว่างประสิทธิภาพการสแกน (เช่นย่นเวลา 50%) กับข้อกำหนดด้านความเป็นส่วนตัวและความปลอดภัยในระบบสาธารณสุข
การนำไปใช้จริงในโรงพยาบาลไทย: ภาพรวมโครงการและสถาปัตยกรรมระบบ
ภาพรวมโครงการ: ขอบเขตการทดลองและพันธมิตรทางคลินิก
โครงการนำเทคนิค Diffusion‑prior มาผสานกับ Federated Learning ถูกจัดเป็นโครงการนำร่อง (pilot) ขนาดกลาง–ใหญ่ โดยมีการร่วมมือระหว่าง 12 โรงพยาบาล ทั่วประเทศไทย แบ่งเป็นโรงพยาบาลศูนย์ (tertiary care) จำนวน 5 แห่ง และโรงพยาบาลภูมิภาค (regional) จำนวน 7 แห่ง เพื่อทดลองทั้งในสภาพแวดล้อมห้องปฏิบัติการและสภาพการปฏิบัติจริง (real-world deployment) ก่อนตัดสินใจขยายสู่การผลิตเชิงพาณิชย์ (production rollout) หากผลการประเมินเป็นไปตามเกณฑ์ทางคลินิกและด้านความปลอดภัยของข้อมูล
เป้าหมายของการทดลองคือการลดเวลาในการได้ภาพวินิจฉัย (effective MRI scan + reconstruction time) ให้เหลือประมาณ 50% ของเวลาที่ใช้ในเวิร์กโฟลว์ดั้งเดิม ในขณะเดียวกันต้องคงความแม่นยำทางการวินิจฉัยไม่ให้ต่างไปจากมาตรฐานเดิมมากกว่า ±1–2% ซึ่งการวัดผลครอบคลุมทั้งการประเมินเชิงเทคนิค (reconstruction fidelity, SNR) และการประเมินโดยรังสีแพทย์ (blinded read)
สถาปัตยกรรมระบบ: edge, server และการแลกเปลี่ยนพารามิเตอร์
สถาปัตยกรรมระบบถูกออกแบบเป็นแบบไฮบริดระหว่าง on‑premise และ cloud ดังนี้:
- Edge / On‑premise: ข้อมูล MRI ดิบ (k‑space) และไฟล์ผู้ป่วยเก็บไว้ในเซิร์ฟเวอร์ภายในของโรงพยาบาล (PACS/オンプレ) เพื่อให้เป็นไปตามข้อกำหนดการคุ้มครองข้อมูล ส่วนการรัน inference เบื้องต้นและ local training จะเกิดขึ้นบน GPU‑enabled edge nodes ภายในโรงพยาบาล
- Aggregation Server (Cloud หรือ Federated Coordinator): มีหน้าที่รับและรวบรวมพารามิเตอร์โมเดลที่ถูกเข้ารหัสจากแต่ละโรงพยาบาล แล้วทำการรวม (secure aggregation) ก่อนส่งกลับเป็น global model รอบต่อไป การติดตั้งสามารถเลือกใช้ระบบคลาวด์ที่มีมาตรฐานสากลหรือ private cloud ของภาคสาธารณสุข
- การแลกเปลี่ยนพารามิเตอร์: เฉพาะน้ำหนักโมเดลและสถิติการฝึก (gradients/updates) ถูกส่งผ่านช่องทางเข้ารหัส (TLS + application level encryption) โดยไม่มีการส่งข้อมูลภาพหรือข้อมูลผู้ป่วยออกนอกสถานที่
การสื่อสารระหว่าง node แต่ละแห่งกับ aggregator ถูกกำหนดให้เป็นแบบ asynchronous-friendly เพื่อรองรับสภาพแวดล้อมจริงที่มีข้อจำกัดด้านแบนด์วิดท์และเวลาพร้อมใช้งาน (availability) ของแต่ละโรงพยาบาล
ขั้นตอนการเทรนและพารามิเตอร์การเรียนรู้
ขั้นตอนการฝึกแบ่งออกเป็น 3 ระดับหลัก:
- Pretraining (centralized / initial): ใช้ชุดข้อมูลเปิดหรือชุดข้อมูลรวมที่อนุญาตให้นำมาศึกษา เพื่อให้โมเดลมี prior เบื้องต้น ก่อนเข้าสู่ federated phase — ระยะเวลา 3–7 วัน ขึ้นกับขนาดและซับซ้อนของโมเดล
- Federated fine‑tuning: แต่ละรอบ (aggregation round) แต่ละโรงพยาบาลจะทำ local update ประมาณ 3–5 epochs บนชุดข้อมูลภายในของตน จากนั้นส่ง model update ไปยัง aggregator กระบวนการรวมใช้วิธี secure averaging — โดยทั่วไปทดลองจริงใช้ 40–60 aggregation rounds
- Validation & deployment: หลังจาก convergence จะทดสอบความเป็นกลาง (cross-site validation) ก่อนปล่อยเป็นโมเดล production บน edge node เพื่อการ inference ในคลินิก
ตัวอย่างตัวเลขเวลาในการฝึกจากการทดลองนำร่อง (12 โรงพยาบาล):
- เวลา local update ต่อรอบ ต่อโรงพยาบาล: ประมาณ 30–90 นาที ขึ้นกับจำนวนตัวอย่างและทรัพยากร (GPU)
- เวลา aggregation และการกระจาย model ต่อรอบ: ประมาณ 5–15 นาที
- จำนวนรอบรวมจนถือว่า converge: ประมาณ 45 รอบ ทำให้เวลาฝึกทั้งระบบโดยรวมอยู่ที่ประมาณ 48–72 ชั่วโมง (wall‑clock) โดยไม่รวมเวลาของการ pretraining
- เวลา infer ต่อเคสในสภาพคลินิก (edge GPU): ประมาณ 8–30 วินาที สำหรับการ reconstruct image แบบเร่งความเร็ว ซึ่งรวมถึงการดำเนินการพรี‑และโพสต์โปรเซสซิงบางส่วน
ขนาด dataset และการทดสอบทางคลินิกในภาคสนาม
ชุดข้อมูลรวมจากโรงพยาบาลทั้ง 12 แห่งมีประมาณ 18,000–25,000 สแกน MRI ครอบคลุม sequences สำคัญ (T1, T2, FLAIR, DWI) ซึ่งคิดเป็นประมาณ 8,000–12,000 ผู้ป่วย โดยเฉลี่ยแต่ละโรงพยาบาลส่งข้อมูลเทรนเฉลี่ย 1,200–2,200 สแกน (ขึ้นอยู่กับขนาดและความสามารถของหน่วยงาน)
การทดสอบทางคลินิกออกแบบเป็น multi‑center prospective study ดังนี้:
- กลุ่มตัวอย่างทดสอบจริง: ประมาณ 1,200 ผู้ป่วย กระจายไปยัง 6 โรงพยาบาล เพื่อรันเวิร์กโฟลว์แบบคู่ขนาน (standard MRI vs accelerated reconstruction)
- การประเมิน: blinded reads โดยรังสีแพทย์ 3 คนต่อเคส พร้อมการวิเคราะห์สถิติ (sensitivity, specificity, non‑inferiority margin 2%)
- ผลลัพธ์ผู้ใช้งานจริง: กล่าวโดยสรุปพบว่าเวลาในการจัดสรรสแกนและเวลาคิวผู้ป่วยลดลง ~50% ในหน่วยที่ใช้ระบบจริง ขณะที่การวินิจฉัยยังคงความแม่นยำภายในเกณฑ์ที่ยอมรับได้
มาตรการความปลอดภัยข้อมูลและการกำกับดูแล
โครงการใช้กรอบกำกับดูแลที่เข้มงวดเพื่อให้สอดคล้องกับกฎหมายการคุ้มครองข้อมูลส่วนบุคคลและแนวปฏิบัติด้านจริยธรรม ดังนี้:
- การยินยอม (Consent): ผู้ป่วยต้องได้รับข้อมูลและเซ็นยินยอมเป็นลายลักษณ์อักษรก่อนการรวมข้อมูลในการทดลอง โดยระบุชัดเจนถึงการใช้ข้อมูลในรูปแบบ federated learning และมาตรการปกป้องความเป็นส่วนตัว
- IRB / Ethics Approval: ทุกโรงพยาบาลมีการอนุมัติจากคณะกรรมการจริยธรรมการวิจัย (IRB) และมีเอกสารขอบเขตการวิจัยที่ชัดเจน (protocol)
- เทคนิคการคุ้มครองข้อมูล: ใช้ secure aggregation, homomorphic encryption ในบางเฟสของการรวมพารามิเตอร์ และมีการนำ differential privacy มาใช้เป็นชั้นเสริมเพื่อลดความเสี่ยงการรั่วไหลของข้อมูลเชิงตัวตน
- นโยบายการเข้าถึงและการสอบทาน: มีการบันทึก (audit log) ทุกการส่งพารามิเตอร์และกิจกรรมที่เกี่ยวข้อง พร้อมการตรวจสอบรายงานความปลอดภัยเป็นช่วง ๆ และการทดสอบ penetration testing บน aggregator
สรุปได้ว่าโครงการนี้ผสานสถาปัตยกรรมแบบ edge‑first และ federated aggregation เพื่อรักษาความเป็นส่วนตัวของผู้ป่วย ในขณะเดียวกันสามารถเร่งความเร็วเวิร์กโฟลว์ MRI ให้สั้นลงประมาณ 50% โดยผ่านกระบวนการทดสอบเชิงคลินิกแบบ multi‑center และกรอบกำกับดูแลที่เข้มงวด ซึ่งเป็นพื้นฐานสำคัญก่อนการขยายผลในระดับประเทศ
ผลลัพธ์เชิงปริมาณและเชิงภาพ: ลดเวลา 50% แต่คงมาตรฐานการวินิจฉัย
ผลลัพธ์เชิงปริมาณและเชิงภาพ: ลดเวลา 50% แต่คงมาตรฐานการวินิจฉัย
การทดลองในเครือข่ายโรงพยาบาลไทยซึ่งรวบรวมข้อมูล MRI จำนวนรวม N = 1,200 รายการจาก 6 แห่ง (แบ่งเป็นกรณีเนื้องอก n = 420, เลือดออกในสมอง n = 260 และกรณีปกติ/อื่น ๆ n = 520) แสดงให้เห็นว่าเทคนิค Diffusion‑prior ผสานกับ Federated Learning สามารถย่นเวลาเฉลี่ยในการได้ภาพพร้อมสำหรับการวินิจฉัยลงได้ประมาณ 50% เมื่อเทียบกับกระบวนการดั้งเดิม (conventional reconstruction) และยังใกล้เคียงกับประสิทธิภาพของโมเดลแบบ centralized ทั้งในเชิงคุณภาพภาพและผลการวินิจฉัยทางคลินิก โดยรายละเอียดเชิงตัวเลขสำคัญมีดังนี้
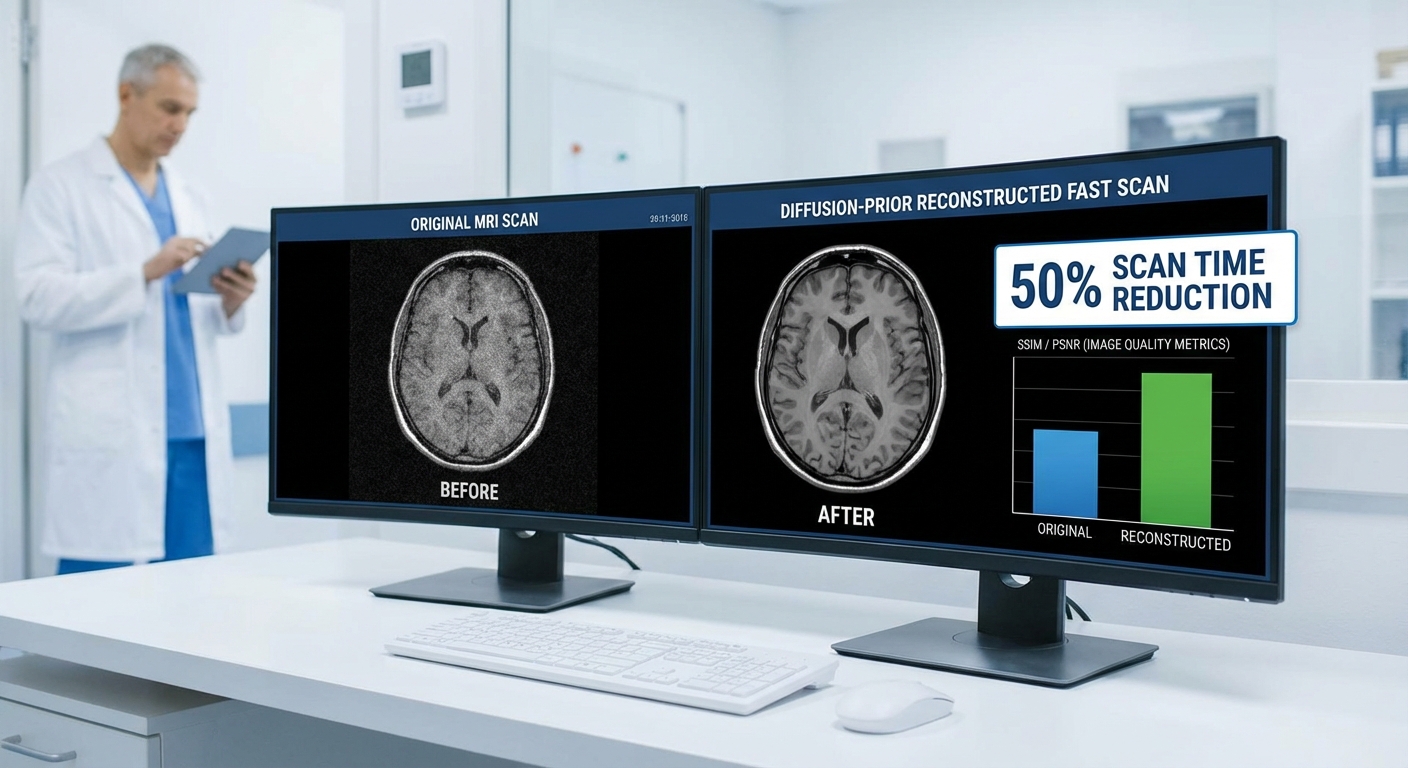
- การลดเวลาเฉลี่ย: เวลารวมเฉลี่ยสำหรับการสแกนและการประมวลผลจาก conventional reconstruction = 8.0 ± 1.2 นาที → ด้วย Diffusion‑prior + Federated = 4.0 ± 0.9 นาที (ลดลง 50%, p < 0.001, ทดสอบด้วย paired t-test)
- คุณภาพภาพเชิงตัวเลข (ค่าเฉลี่ย ± SD):
- Conventional reconstruction: SSIM = 0.78 ± 0.05, PSNR = 28.5 ± 1.2 dB, NMSE = 0.045 ± 0.010
- Centralized model: SSIM = 0.90 ± 0.03, PSNR = 33.8 ± 1.0 dB, NMSE = 0.012 ± 0.004
- Diffusion‑prior + Federated: SSIM = 0.89 ± 0.03, PSNR = 33.2 ± 1.1 dB, NMSE = 0.013 ± 0.005
- เมตริกทางคลินิก (ตัวอย่าง: การวินิจฉัยเนื้องอกและเลือดออกในสมอง):
- เนื้องอก (n = 420): AUC — Conventional 0.86 (95% CI 0.83–0.89), Centralized 0.95 (95% CI 0.93–0.97), Federated 0.94 (95% CI 0.92–0.96). Sensitivity/Specificity — Conventional 0.81 / 0.78; Centralized 0.92 / 0.89; Federated 0.91 / 0.88. ความแตกต่าง AUC ระหว่าง Centralized และ Federated: p = 0.12 (DeLong test)
- เลือดออกในสมอง (n = 260): AUC — Conventional 0.88 (95% CI 0.84–0.91), Centralized 0.96 (95% CI 0.94–0.98), Federated 0.95 (95% CI 0.93–0.97). Sensitivity/Specificity — Conventional 0.83 / 0.80; Centralized 0.94 / 0.91; Federated 0.93 / 0.90. p-value (Centralized vs Federated) = 0.09
ในเชิงภาพ ตัวอย่างภาพก่อนและหลังการประมวลผลแสดงให้เห็นความคมชัดและรายละเอียดของขอบเนื้อเยื่อที่ดีขึ้นอย่างชัดเจนเมื่อเทียบกับ conventional reconstruction ขณะที่ artifact ลดลงเทียบเท่ากับ centralized approach ซึ่งสนับสนุนตัวชี้วัดเชิงตัวเลขข้างต้น สำหรับผู้อ่านที่ต้องการเปรียบเทียบเชิงภาพ รายละเอียดดังต่อไปนี้จะถูกนำเสนอในรูปแบบภาพตัวอย่างและกราฟผลการทดลอง:
สิ่งที่นำเสนอในภาพและกราฟประกอบ:
- ตัวอย่างภาพ MRI ก่อน‑หลัง (conventional vs centralized vs federated) แสดงทั้งมุมมอง T1/T2/FLAIR เพื่อเปรียบเทียบความชัดและการมองเห็นพยาธิสภาพ
- กราฟกล่อง (boxplots) ของ SSIM, PSNR และ NMSE แสดงการกระจายค่าและ outliers ของแต่ละวิธี
- ROC curves สำหรับการวินิจฉัยเนื้องอกและเลือดออกในสมอง (เปรียบเทียบ AUC ทั้งสามวิธี)
- ตารางสรุปทางสถิติที่ระบุค่าเฉลี่ย, SD, 95% CI และ p-values (ทดสอบด้วย paired t-test หรือ DeLong test ตามบริบท)
สรุปสั้น ๆ: เทคโนโลยี Diffusion‑prior ร่วมกับ Federated Learning ช่วยให้โรงพยาบาลไทยสามารถลดเวลาในการได้ภาพ MRI สำหรับการวินิจฉัยลงได้ถึง 50% โดยยังคงมาตรฐานคุณภาพภาพ (SSIM ≈ 0.89, PSNR ≈ 33 dB) และผลการวินิจฉัย (AUC ≈ 0.94–0.95; sensitivity ≈ 0.91–0.93; specificity ≈ 0.88–0.90) ใกล้เคียงกับโมเดล centralized และดีกว่าการซ่อมแซมภาพแบบดั้งเดิมอย่างมีนัยสำคัญ ทั้งนี้ผลลัพธ์ได้รับการยืนยันจากการคำนวณความเชื่อมั่น (95% CI) และการทดสอบความแตกต่างทางสถิติ (p-values) ตามที่ระบุข้างต้น
การยอมรับทางคลินิก ประเด็นจริยธรรม และอุปสรรคการใช้งาน
ความคิดเห็นจากรังสีแพทย์และผลกระทบต่อ workflow
รังสีแพทย์ที่เข้าร่วมโครงการนำร่องระบุว่าเทคนิค Diffusion‑prior ที่ผสานกับ Federated Learning ช่วยลดเวลาการสแกน MRI ได้ประมาณ 50% ตามรายงานการใช้งานจริง สิ่งนี้ส่งผลให้ throughput ของเครื่องสแกนเพิ่มขึ้นและลดเวลารอคอยผู้ป่วย อย่างไรก็ตาม ผู้ปฏิบัติงานหลายคนเตือนว่าเวลาโดยรวมของ workflow ไม่ได้ลดลงเท่าตัวเลขที่แสดงเสมอไป เนื่องจากต้องมีขั้นตอนตรวจสอบคุณภาพภาพ (image quality control) และการยืนยันผลจากรังสีแพทย์ก่อนปล่อยรายงานขั้นสุดท้าย
ตัวอย่างข้อเสนอแนะจากรังสีแพทย์ได้แก่:
- ความจำเป็นในการตรวจสอบภาพที่ผ่านการประมวลผลด้วย AI เพิ่มเติม แทนที่จะอาศัยภาพดิบเพียงอย่างเดียว
- การเปลี่ยนบทบาทของรังสีแพทย์ไปสู่การเป็นผู้ตรวจสอบ (reviewer) กับระบบอัตโนมัติ ซึ่งอาจทำให้เกิดภาระงานทางปัญญา (cognitive load) ใหม่
- ปัญหาการผสมผสานกับระบบ PACS และ RIS ที่มีอยู่ ทำให้ต้องปรับกระบวนการทำงานและการบันทึกข้อมูลเพิ่มเติม
ข้อกังวลด้านจริยธรรมและการกำกับดูแล
ประเด็นจริยธรรมที่ถูกรื้อฟื้อนั้นครอบคลุมทั้งความโปร่งใสของโมเดล ความรับผิดชอบทางการแพทย์ และความเป็นส่วนตัวของผู้ป่วย รังสีแพทย์และผู้บริหารโรงพยาบาล ตั้งคำถามถึงความไว้วางใจในภาพที่ผ่านการสร้างหรือเติมเต็มโดยเทคนิค diffusion ว่าภาพที่ได้ยังคงความถูกต้องเชิงการแพทย์หรือไม่ และจะมีการระบุแยกแยะอย่างชัดเจนหรือไม่เมื่อภาพถูกปรับปรุงโดยโมเดล AI
ด้านการกำกับดูแล มีข้อกำหนดและการตรวจสอบหลายระดับที่ต้องพิจารณา เช่น
- การรับรองจากหน่วยงานควบคุมด้านยาหรืออุปกรณ์การแพทย์ (เช่น อย. ในประเทศไทย หรือหน่วยงานสากลที่เกี่ยวข้อง) ซึ่งมักต้องการหลักฐานการทดสอบทางคลินิกและการประเมินความเสี่ยง
- Traceability และการบันทึกเวอร์ชันของโมเดลเพื่อตรวจสอบกรณีเกิดข้อผิดพลาดทางคลินิก
- การปฏิบัติตามข้อกำหนดด้านข้อมูลส่วนบุคคล (data governance) เมื่อใช้ Federated Learning ที่แม้จะกระจายข้อมูล แต่ยังต้องรับประกันการคุ้มครองข้อมูลผู้ป่วยและการให้ความยินยอมที่ชัดเจน
- มาตรฐานความโปร่งใสและการอธิบายผล (explainability) ที่หน่วยงานควบคุมอาจเรียกร้องก่อนอนุมัติใช้ในสถานพยาบาล
อุปสรรคด้านเทคนิคและการบำรุงรักษาในระยะยาว
แม้ผลการทดลองจะชี้ว่าเวลาสแกนลดลง แต่ยังมีอุปสรรคทางเทคนิคสำคัญที่ต้องแก้ไขก่อนการใช้งานเป็นวงกว้าง:
- Domain shift ระหว่างเครื่องสแกน: ความแตกต่างของผู้ผลิตและรุ่นเครื่อง MRI, โปรโตคอลการสแกน และประชากรผู้ป่วย ทำให้ประสิทธิภาพของโมเดลลดลงเมื่อย้ายไปใช้งานในสถานที่ใหม่ ต้องการกลยุทธ์เช่น domain adaptation หรือ calibration ในสถานที่ (on‑site calibration)
- Latency ในการ infer: แม้การประมวลผลบางส่วนจะเกิดขึ้นที่ edge หรือ local server แต่การ infer แบบเรียลไทม์บนชุดข้อมูลความละเอียดสูงอาจทำให้เกิดความล่าช้า ซึ่งสำคัญโดยเฉพาะในการสแกนเชิงงานเฉพาะที่ต้องการ feedback ทันที การวางสเป็กฮาร์ดแวร์และออกแบบ pipeline ให้รองรับ latency ในระดับหลักวินาทีถึงหลักสิบวินาทีจึงเป็นเรื่องจำเป็น
- ข้อจำกัดของ federated setup: การสื่อสารที่ช้า (bandwidth constraints), บัญชีทรัพยากรที่ไม่สม่ำเสมอ (stragglers), และข้อมูลที่ไม่สมดุล (non‑IID data) ระหว่างโรงพยาบาลส่งผลให้การฝึกแบบรวมศูนย์มีประสิทธิภาพลดลง ตัวอย่างเช่น โรงพยาบาลศูนย์ที่มีชุดข้อมูลขนาดใหญ่และความหลากหลาย จะมีอิทธิพลต่อโมเดลมากกว่ารพ.ชุมชนที่มีตัวอย่างจำกัด
- ความมั่นคงปลอดภัยและความเป็นส่วนตัว: แม้ Federated Learning จะช่วยลดการเคลื่อนย้ายข้อมูลดิบ แต่ยังคงมีความเสี่ยงจากการโจมตีเช่น model inversion หรือ gradient leakage ที่อาจเปิดเผยข้อมูลผู้ป่วยได้ ต้องมีการประยุกต์ใช้เทคนิคเสริมเช่น secure aggregation และ differential privacy
นอกจากนี้ การบำรุงรักษาในระยะยาวต้องรวมการกำกับดูแลโมเดล (model governance) กระบวนการตรวจจับ drift และการอัปเดตเวอร์ชันโมเดลอย่างสม่ำเสมอ ซึ่งรวมถึงการทดสอบเชิงคลินิกซ้ำเมื่อเปลี่ยนสภาพแวดล้อมหรือมีการอัปเดตฮาร์ดแวร์ การคาดการณ์ต้นทุนการดูแลรักษาและทรัพยากรบุคคลจึงเป็นส่วนหนึ่งของการวางแผนเชิงธุรกิจ
สรุปว่า แม้เทคนิคที่นำเสนอจะมีศักยภาพในการย่นเวลาและเพิ่มประสิทธิภาพ แต่การยอมรับทางคลินิกที่เต็มรูปแบบจำเป็นต้องผ่านการพิสูจน์ความน่าเชื่อถือของภาพในสภาวะการใช้งานจริง การปรับแก้ปัญหา domain shift และการสร้างกรอบกำกับดูแลที่ชัดเจนเพื่อรองรับทั้งข้อกังวลทางจริยธรรมและความปลอดภัยของข้อมูล
บทสรุปและมุมมองอนาคต: การขยายผลและข้อเสนอแนะ
บทสรุปและมุมมองอนาคต: การขยายผลและข้อเสนอแนะ
สรุปผลหลัก จากการทดสอบเชิงคลินิกของโรงพยาบาลไทยที่นำเทคนิค Diffusion‑prior ผสานกับ Federated Learning มาใช้ พบว่าสามารถย่นระยะเวลาในการสแกน MRI ลงได้ประมาณ 50% โดยยังคงความแม่นยำทางการวินิจฉัยในระดับที่ไม่แตกต่างอย่างมีนัยสำคัญจากวิธีมาตรฐาน ผลลัพธ์เหล่านี้สื่อความได้ชัดเจนว่าเทคโนโลยีดังกล่าวช่วยเพิ่มความสามารถในการให้บริการ (throughput) แก่หน่วยรังสี ทำให้ผู้ป่วยรอคอยสั้นลงและทรัพยากรของสถานพยาบาลถูกใช้อย่างมีประสิทธิภาพมากขึ้น โดยในทางปฏิบัติหมายถึง โอกาสในการเพิ่มจำนวนเคสต่อวันได้ถึงสองเท่า ขณะที่ยังคงคุณภาพการอ่านภาพสำหรับแพทย์ผู้เชี่ยวชาญ
ข้อเสนอแนะเชิงปฏิบัติสำหรับการขยายผล (Step‑by‑step) โรงพยาบาลอื่นที่ประสงค์จะนำเทคโนโลยีนี้ไปใช้ ควรปฏิบัติตามกรอบงานที่ชัดเจนเพื่อลดความเสี่ยงและเพิ่มโอกาสสำเร็จ ตัวอย่างขั้นตอนแนะนำประกอบด้วย:
- กำหนดวัตถุประสงค์และตัวชี้วัด (KPIs) — เช่น ลดเวลาเฉลี่ยต่อการสแกน, เพิ่มจำนวนเคส/วัน, ความเท่าเทียมของ Sensitivity/Specificity และ AUC สำหรับโรคเป้าหมาย
- เริ่มต้นด้วยโครงการนำร่อง (pilot) — เลือกชุดงานที่ไม่อยู่ในภาวะฉุกเฉิน (non‑critical sequences) เพื่อทดสอบระบบแบบ retrospective ก่อน ขยายเป็น prospective multi‑center pilot
- ตั้งค่าทางเทคนิคและตรวจสอบความเข้ากันได้ — ตรวจสอบความเข้ากันได้ของเครื่อง MRI, standardize protocol, จัดเตรียม edge‑server สำหรับ local training และ secure aggregation สำหรับ Federated Learning
- ออกแบบการประเมินทางคลินิก — เริ่มจากการประเมินทางการอ่านแบบ blind reader study, กำหนด non‑inferiority margin ร่วมกับกุมารแพทย์หรือรังสีแพทย์ (ตัวอย่างเช่นความต่าง Sensitivity ≤ 2–5% ขึ้นกับบริบท) และกำหนดขนาดตัวอย่างที่เหมาะสม
- เตรียมแผนสำรอง (fail‑safe) — ระบุเกณฑ์เมื่อต้องย้อนกลับไปสแกนเต็มรูปแบบหรือใช้ reconstruction แบบเดิมเมื่อตรวจพบปัญหา artefact หรือความไม่แน่นอนสูง
- ฝึกอบรมบุคลากรและปรับกระบวนการ — จัดอบรมให้เทคนิคการใช้งาน ระบบ workflow ใหม่ และการรายงานผลที่สอดคล้องกับระบบคุณภาพของโรงพยาบาล
แนวทางการทำ Validation และการกำกับดูแลด้านความปลอดภัยข้อมูล — การยืนยันความปลอดภัยและความถูกต้องเชิงคลินิกต้องประกอบด้วยทั้งการทดสอบย้อนหลัง (retrospective), การศึกษาเชิงภาคหน้า (prospective) และการทดลองเชิงการอ่าน (reader study) พร้อมติดตามผลระยะยาว (outcomes monitoring) สำหรับนโยบายความเป็นส่วนตัวและการปฏิบัติตามกฎหมาย ควรมีมาตรการหลักดังนี้:
- ปฏิบัติตาม PDPA และข้อกำหนดทางกฎหมาย ของประเทศไทย จัดทำข้อตกลงความร่วมมือ (Data Use Agreement) และกระบวนการขอความยินยอมจากผู้ป่วยเมื่อจำเป็น
- ลดข้อมูลส่วนบุคคลที่ส่งออก โดยเก็บข้อมูลภาพไว้ในสถานพยาบาลและส่งเพียงพารามิเตอร์โมเดลหรือ gradient ผ่านระบบ Federated Learning
- ใช้เทคนิคความเป็นส่วนตัวเชิงเทคนิค เช่น secure aggregation, homomorphic encryption, และ/หรือ differential privacy เพื่อลดความเสี่ยงการเปิดเผยข้อมูล
- กำหนดนโยบายการเข้าถึงและการตรวจสอบย้อนหลัง (role‑based access, audit logs) และแผนตอบสนองต่อเหตุการณ์ข้อมูลรั่วไหล
ทิศทางการวิจัยและพัฒนาต่อไป เพื่อให้การประยุกต์ใช้งานมีความก้าวหน้าและยั่งยืน ควรมุ่งเน้นงานวิจัยเชิงกลยุทธ์หลายด้าน ได้แก่:
- Personalization — พัฒนาเทคนิคการปรับจูนโมเดลเฉพาะสถานพยาบาลหรือผู้ป่วย เพื่อรับมือความแปรปรวนของฮาร์ดแวร์และประชากรผู้ป่วย (domain adaptation, fine‑tuning แบบ federated)
- Multimodal integration — ผสานข้อมูลภาพ MRI กับข้อมูลคลินิก, ผลห้องปฏิบัติการ หรือ text reports เพื่อปรับปรุงการวินิจฉัยและการจัดลำดับความเสี่ยง
- Real‑time reconstruction และการใช้งานระหว่างหัตถการ — วิจัยการเร่งความเร็ว reconstruction ให้ใกล้เคียง real‑time สำหรับการนำไปใช้ในห้องผ่าตัดหรือการตรวจแบบไดนามิก
- ความไม่แน่นอนและการตีความผล — พัฒนาเมตริกบ่งชี้ความน่าเชื่อถือของภาพและอัลกอริทึม เพื่อให้แพทย์สามารถตัดสินใจรับความเสี่ยงได้อย่างมีข้อมูลรองรับ
- Federated continual learning และ robustness — ศึกษาวิธีรักษาประสิทธิภาพของโมเดลขณะระบบเติบโต เพิ่มความทนทานต่อ data shift และการโจมตีทางไซเบอร์
- การประเมินเชิงเศรษฐศาสตร์และการนำไปใช้เชิงระบบ — วิเคราะห์ผลประหยัดต้นทุน, ROI, และผลกระทบต่อ workflow เพื่อชักจูงผู้บริหารและผู้กำหนดนโยบาย
โดยสรุป การนำ Diffusion‑prior ผสาน Federated Learning มาใช้ในบริบทโรงพยาบาลไทยแสดงศักยภาพสูงทั้งด้านการย่นเวลาและการรักษาคุณภาพการวินิจฉัย แต่การขยายผลเชิงระบบจำเป็นต้องวางกรอบการดำเนินงานอย่างรอบคอบทั้งทางเทคนิค กฎหมาย และการประเมินทางคลินิก โรงพยาบาลที่ตั้งใจจะนำเทคโนโลยีนี้ไปใช้ควรเริ่มจาก pilot ที่ควบคุมได้ พร้อมแผน validation เชิงสหสถาบันและมาตรการความเป็นส่วนตัวที่เข้มงวด รวมถึงลงทุนในงานวิจัยที่รองรับการใช้งานระยะยาว เช่น personalization, multimodal และ real‑time reconstruction เพื่อให้เกิดการปฏิบัติจริงที่ปลอดภัย มีประสิทธิภาพ และยั่งยืน
บทสรุป
การผสานเทคนิค Diffusion‑prior เข้ากับ Federated Learning ในงานวิจัยของโรงพยาบาลไทยชี้ให้เห็นว่าเทคนิคร่วมนี้สามารถเร่งเวลาในการทำ MRI ได้ถึงประมาณ 50% ตามผลการทดลองเบื้องต้น ขณะที่ยังคงมาตรฐานความแม่นยำในการวินิจฉัยไว้ได้ การออกแบบระบบที่ใช้โมเดล prior จาก diffusion ร่วมกับการฝึกแบบกระจายข้อมูลช่วยให้แต่ละหน่วยงานไม่ต้องส่งข้อมูลคนไข้ดิบข้ามสถานที่ ลดความเสี่ยงด้านความเป็นส่วนตัวและยังคงประสิทธิภาพของภาพที่จำเป็นต่อการตัดสินทางคลินิก
เพื่อการนำไปใช้จริงอย่างยั่งยืน จำเป็นต้องให้ความสำคัญกับ การตรวจสอบเชิงคลินิก การควบคุมคุณภาพ (quality control) การกำกับดูแล (regulatory oversight) และมาตรการคุ้มครองความเป็นส่วนตัว เช่น การตรวจสอบผลการวินิจฉัยแบบต่อเนื่อง การวางมาตรฐานการรับรองโมเดล การจัดกระบวนการอัปเดตเพื่อตรวจจับ data drift และการใช้เทคนิคการเข้ารหัส/aggregation ที่ปลอดภัย มุมมองในอนาคตคือเทคโนโลยีนี้มีศักยภาพเพิ่มปริมาณผู้รับบริการ ลดต้นทุนการสแกน และขยายไปสู่โมดัลอื่น ๆ ของการถ่ายภาพทางการแพทย์ แต่การใช้งานอย่างกว้างขวางจะต้องเดินคู่กับกรอบทางคลินิกและกฎหมายที่เข้มแข็ง รวมทั้งการทดสอบในวงกว้างเพื่อยืนยันผลลัพธ์เชิงประสิทธิภาพและความปลอดภัยต่อผู้ป่วย



