
ในยุคที่แอปพลิเคชัน Edge‑AI ถูกใช้อย่างแพร่หลายทั้งในไลน์การผลิต โรงงานอุตสาหกรรม และอุปกรณ์ IoT ความล่าช้า (latency) และการบริโภคพลังงานยังคงเป็นอุปสรรคสำคัญสู่การใช้งานจริงเมื่อระบบต้องตอบสนองแบบเรียลไทม์ วันนี้สตาร์ทอัพไทยเปิดตัว "Neuro‑Compiler" แพลตฟอร์มที่อ้างว่าสามารถแปลงโมเดล Machine Learning จากเฟรมเวิร์กยอดนิยม (เช่น TensorFlow/PyTorch) ให้กลายเป็น FPGA/ASIC bitstream อัตโนมัติ โดยไม่ต้องเขียน RTL ด้วยมือ ผลลัพธ์ตามเบนช์มาร์กเบื้องต้นคือการลด latency ลงสู่ระดับมิลลิวินาที (ประมาณ 0.5–5 ms) เมื่อเทียบกับการรันบน CPU/GPU แบบเดิม และยังช่วยลดการใช้พลังงานได้หลายเท่า (การลดพลังงานประมาณ 5–20× ขึ้นกับกรณีใช้งาน) ซึ่งหมายถึงการตอบสนองรวดเร็วขึ้นและค่าใช้จ่ายด้านพลังงานที่ต่ำลงสำหรับอุปกรณ์แบบ edge
บทนำนี้จะพาอ่านถึงภาพรวมของเทคโนโลยีที่ Neuro‑Compiler นำเสนอ—ตั้งแต่กระบวนการคอมไพล์อัตโนมัติ การปรับแต่งเชิงฮาร์ดแวร์ (quantization, pruning, mapping, placement & routing) ไปจนถึงผลการทดสอบเบนช์มาร์กและแผนการนำไปใช้จริงในอุตสาหกรรม เช่น งานตรวจสอบคุณภาพด้วยภาพ (visual inspection), การคาดการณ์การซ่อมบำรุง (predictive maintenance) และการประมวลผลสัญญาณในอุปกรณ์ IoT บริษัทระบุแผนทดลองเชิงพาณิชย์ร่วมกับโรงงานพันธมิตรและผู้ผลิตชิปในประเทศเพื่อยืนยันความเสถียรและต้นทุนการผลิต ตลอดจนเปิดโอกาสให้ธุรกิจไทยนำเทคโนโลยีนี้ไปใช้งานจริง เพื่อลดความหน่วง ปรับปรุงประสิทธิภาพ และเพิ่มความเป็นส่วนตัวของข้อมูลที่ประมวลผลบน edge
นำเสนอข่าวและภาพรวมผลิตภัณฑ์
นำเสนอข่าวและภาพรวมผลิตภัณฑ์
สตาร์ทอัพไทย ชื่อ NeuroForge (ทีมผู้ก่อตั้งเป็นวิศวกรและนักวิจัยด้าน AI และฮาร์ดแวร์จากสถาบันการศึกษาภายในประเทศ) เปิดตัวผลิตภัณฑ์ใหม่ภายใต้ชื่อ Neuro‑Compiler ซึ่งเป็นแพลตฟอร์มซอฟต์แวร์เชิงอัตโนมัติสำหรับแปลงโมเดลการเรียนรู้ของเครื่อง (รองรับทั้ง TensorFlow และ PyTorch) ให้กลายเป็นโค้ดฮาร์ดแวร์สำหรับการใช้งานจริง โดยทำงานตั้งแต่การแปลงสถาปัตยกรรม การคำนวณเชิงเดียว (quantization) การจัดตารางการคำนวณ ไปจนถึงการเชื่อมต่อกับเครื่องมือสังเคราะห์ฮาร์ดแวร์และสร้างไฟล์สำหรับการโปรแกรม FPGA (bitstream) หรือส่งออกข้อมูลสำหรับกระบวนการออกแบบ ASIC (เช่น GDSII) โดยอัตโนมัติ
ฟังก์ชันหลักของ Neuro‑Compiler คือการเป็นสะพานเชื่อมระหว่างนักพัฒนาโมเดล AI ที่ใช้เฟรมเวิร์กยอดนิยมกับโลกของฮาร์ดแวร์เฉพาะทาง: แปลงกราฟการคำนวณของโมเดลให้เหมาะสมกับทรัพยากรบน FPGA/ASIC, ทำการลดความละเอียดตัวเลข (quantization) และการปรับโครงสร้าง (pruning/weight sharing) เพื่อให้ได้ประสิทธิภาพสูงสุดทั้งในด้านความเร็วและการใช้พลังงาน นอกจากนี้แพลตฟอร์มยังรองรับการเชื่อมต่อกับเครื่องมือสังเคราะห์ยอดนิยม (เช่น Xilinx Vivado, Intel Quartus) และกระบวนการออกแบบ ASIC แบบมาตรฐาน ทำให้สามารถผลักดันโมเดลจากโค้ดต้นแบบสู่บั๊กสตรีม/ไฟล์ออกแบบฮาร์ดแวร์ได้ในวงจรการพัฒนาที่สั้นลง
จุดขายสำคัญของ Neuro‑Compiler ได้แก่:
- Latency ต่ำในระดับมิลลิวินาที — รายงานเบื้องต้นจากการทดสอบในห้องทดลองและการใช้งานจริงในไลน์การผลิตบางส่วนระบุว่า latency ของการอินเฟอร์เรนซ์สามารถลดจากระดับสิบถึงหลายสิบมิลลิวินาทีลงเหลือน้อยกว่า 1 มิลลิวินาทีในกรณีการดำเนินงานที่เหมาะสม ซึ่งตอบโจทย์งาน Edge‑AI ที่ต้องการการตอบสนองเรียลไทม์
- ประหยัดพลังงาน — การแปลงไปยังฮาร์ดแวร์เฉพาะทางทำให้การบริโภคพลังงานลดลงอย่างมีนัยสำคัญ เทียบกับการรันบน CPU/GPU ในขอบเขตงาน Edge พบการลดการใช้พลังงานได้หลายเท่าตัว (ตัวอย่างเช่น 5–10x ในบางกรณีทดลอง) ซึ่งยืดอายุแบตเตอรี่ของอุปกรณ์ IoT และลดต้นทุนการดำเนินงานในโรงงาน
- รองรับ FPGA และ ASIC — Neuro‑Compiler ออกแบบมาให้เลือกเป้าหมายได้ทั้ง FPGA (สร้าง bitstream พร้อมสำหรับโปรแกรมลงบอร์ด) และ ASIC (ส่งออกไฟล์สำหรับกระบวนการออกแบบระดับโรงงาน) ทำให้ลูกค้าสามารถพิสูจน์แนวคิดบน FPGA แล้วย้ายไปสู่ ASIC เพื่อการผลิตจำนวนมากได้
ตัวอย่างการใช้งานที่ Neuro‑Compiler มุ่งเป้าได้แก่ visual inspection ในสายการผลิตที่ต้องการความเร็วในการตัดสินใจระดับมิลลิวินาที, การประมวลผลสัญญาณจากเซ็นเซอร์เพื่อการควบคุมแบบเรียลไทม์ในระบบอัตโนมัติของโรงงาน, และโมดูล IoT ที่ต้องการวิเคราะห์ข้อมูลภาพหรือเสียงโดยไม่ส่งข้อมูลดิบขึ้นคลาวด์ การประยุกต์ใช้งานเหล่านี้ไม่เพียงแต่ช่วยเพิ่มประสิทธิภาพการผลิตและความปลอดภัย แต่ยังลดปัญหาด้านความเป็นส่วนตัวและการพึ่งพาการเชื่อมต่อเครือข่าย
สรุปเชิงธุรกิจและนโยบาย — การมีเครื่องมืออย่าง Neuro‑Compiler ในตลาดไทยอาจเร่งให้ผู้ผลิตยานยนต์, อิเล็กทรอนิกส์, และอุตสาหกรรมการผลิตเริ่มลงทุนในโซลูชัน Edge‑AI แบบฮาร์ดแวร์มากขึ้น ซึ่งส่งผลต่อห่วงโซ่อุปทานชิป, ทักษะแรงงานด้านฮาร์ดแวร์ และนโยบายการรับรองความปลอดภัยของระบบอัตโนมัติ ทางฝั่งนโยบายจำเป็นต้องเตรียมกรอบการรับรองสำหรับการใช้งาน AI บนฮาร์ดแวร์ระดับอุตสาหกรรม รวมทั้งส่งเสริมการฝึกอบรมทักษะ FPGA/ASIC เพื่อรองรับการเปลี่ยนผ่านดังกล่าว
เทคโนโลยีเบื้องหลัง: pipeline ของ Neuro‑Compiler
ภาพรวมเชิงลำดับ (Flow จาก Model Import ถึง Bitstream)
Neuro‑Compiler ทำงานเป็น pipeline เชิงลำดับที่ออกแบบมาเพื่อแปลงโมเดล Machine Learning ที่พัฒนาบนเครื่องมือยอดนิยมให้เป็นไฟล์ bitstream สำหรับ FPGA หรือ macro สำหรับ ASIC โดยสรุป flow มีขั้นตอนหลักคือ นำเข้าโมเดล (front‑end) → วิเคราะห์กราฟเชิงตรรกะและปรับแต่ง → quantization และ pruning อัตโนมัติ → mapping ไปยังทรัพยากรฮาร์ดแวร์ → แปลงเป็น RTL/HLS → place‑and‑route และสร้าง bitstream ซึ่งระบบรองรับ input หลักเป็นไฟล์จาก TensorFlow SavedModel, PyTorch (TorchScript), และ ONNX เพื่อความเข้ากันได้สูงสุดกับสายการพัฒนาในอุตสาหกรรม
รายละเอียดเชิงเทคนิคของแต่ละขั้นตอน
1) Model import & graph analysis: โมเดลถูกแปลงเข้าเป็น IR กลาง (intermediate representation) ที่ Neuro‑Compiler จะทำการวิเคราะห์กราฟเพื่อค้นหาโครงสร้างเชิงตรรกะ เช่น convolution chains, linear blocks, attention blocks และการพึ่งพาไลบรารี โดยขั้นตอนนี้รวมการทำ constant folding, dead‑code elimination และ shape inference ซึ่งช่วยลดขนาดกราฟก่อนลงมือแปลงจริง
2) Quantization และ pruning อัตโนมัติ: ระบบมีโมดูล quantization แบบหลายระดับ (symmetric/asymmetric, per‑channel/per‑tensor) รองรับ 8‑bit, 4‑bit และ binary/ternary เพื่อแลกเปลี่ยนความแม่นยำกับ latency/พลังงาน โดย Neuro‑Compiler สามารถประเมินผลกระทบของการ quantize แบบอัตโนมัติผ่านการเทสต์ calibration บนตัวอย่างอินพุต และเลือก mixed‑precision ตาม constraint ของฮาร์ดแวร์ ตัวอย่างเช่น การลดเป็น 8‑bit มักลดขนาดโมเดลได้ประมาณ 4x ขณะที่ pruning แบบ structured (เช่น channel pruning) อาจลด FLOPs ได้ 2–5x โดยยังรักษาความแม่นยำภายในขอบเขตที่ยอมรับได้ (เช่น top‑1 drop ≤ 1–2%)
3) Operator fusion, tiling และ memory optimization: เพื่อให้ละลายปัญหาคอขวดด้านหน่วยความจำ pipeline จะทำ operator fusion (เช่น fusion ระหว่าง conv→batchnorm→relu), loop tiling, double buffering และการวางแผนการเข้าถึงข้อมูล (memory banking) ซึ่งลดการอ่าน‑เขียนจาก/สู่ DRAM ได้อย่างมาก—ตัวอย่างเช่น operator fusion อาจลด traffic memory ได้ถึง 2–3x และลด latency โดยรวมได้อย่างมีนัยสำคัญ
การแม็ปลงฮาร์ดแวร์และการสร้าง HDL/HLS
หลังจากได้กราฟที่ optimize แล้ว Neuro‑Compiler จะทำการ partition งานระหว่าง compute และ memory แล้ว map แต่ละ operator ไปยังทรัพยากรของเป้าหมาย ได้แก่ LUT, DSP, BRAM สำหรับ FPGA หรือ ASIC macros (e.g., multiplier, SRAM bank, systolic array macro) สำหรับ ASIC การแม็ปนี้รวมการคำนวณ utilization ของทรัพยากร การจัดสรรบัสข้อมูลและการตั้งค่า pipeline depth โดยระบบจะเลือกใช้รูปแบบ compute เช่น systolic array, streaming engine หรือ sparse accelerator ตามลักษณะของโมเดล
Neuro‑Compiler รองรับการสร้างโค้ดฮาร์ดแวร์ทั้งสองแนวทาง: HLS (C/C++ → HLS) สำหรับการพัฒนาที่เร็วและผสานกับ flow อัตโนมัติได้ง่าย และ hand‑optimized RTL (Verilog/VHDL) สำหรับ kernel สำคัญที่ต้องการประสิทธิภาพสูงสุด ระบบสามารถผสมผสานได้โดยให้ HLS ผลิตโมดูลส่วนใหญ่ แล้วอินเสิร์ต RTL ที่ถูกปรับแต่งด้วยมือสำหรับ critical path (เช่น convolution core ที่มี pipelining และ loop unrolling แบบกำหนดเอง)
Place‑and‑route, timing closure และการสร้าง bitstream
เมื่อได้ RTL/HLS โมดูล Neuro‑Compiler จะส่งออก netlist และ constraints สำหรับเครื่องมือ P&R เช่น Xilinx Vivado/Intel Quartus สำหรับ FPGA หรือ Cadence/Synopsys สำหรับ ASIC ขั้นตอน place‑and‑route จะรวมการวางตำแหน่ง logic, routing, clock tree synthesis และ timing closure โดยมีการ feedback loop ระหว่าง scheduler และ placer เพื่อปรับแต่ง latency‑aware scheduling (เช่น การจัดลำดับงานที่คำนึงถึงเส้นทางความล่าช้าจริง) กระบวนการนี้อาจเสร็จในเวลาที่แตกต่างกัน: FPGA ขนาดเล็กอาจใช้เวลาเพียงไม่กี่สิบนาทีถึงไม่กี่ชั่วโมง ส่วนการไหลของ ASIC อาจต้องใช้วันถึงหลายสัปดาห์สำหรับ tape‑out ready
ผลลัพธ์อินพุต/เอาต์พุตและตัวชี้วัดประสิทธิภาพ
- อินพุต: โมเดล (ONNX/TorchScript/SavedModel), ไฟล์ constraints (latency/throughput/power/area), hardware target description (FPGA part number หรือ ASIC PDK), ตัวอย่าง calibration data
- เอาต์พุต: bitstream (.bit/.bin) สำหรับ FPGA, RTL/HLS source สำหรับการตรวจสอบ, synthesis & timing report, resource utilization report (LUT/DSP/BRAM หรือ ASIC area & power estimates), performance profile (latency, throughput, power)
- ตัวชี้วัดประสิทธิภาพตัวอย่าง: การคอมไพล์โมเดล CNN ขนาดกลางเช่น ResNet18 ที่ถูก quantize เป็น 8‑bit และ mapped ลงบน Xilinx Zynq อาจให้ latency ต่อภาพในระดับ ~1–5 ms และ throughput หลายร้อยภาพต่อวินาที ขณะที่การทำ quantize เป็น 4‑bit ร่วมกับ pruning เชิงโครงสร้างอาจลด latency ลงอีก 2x–3x ขึ้นอยู่กับทรัพยากร
การปรับจูนเชิงอัลกอริทึม (Algorithmic Optimizations)
Neuro‑Compiler ใช้ชุดเทคนิคเพื่อผลักดัน latency ให้ต่ำสุดภายในข้อจำกัดของทรัพยากร ได้แก่:
- Operator fusion: ลด overhead ของ memory I/O โดยการรวมหลาย operator ให้ทำงานต่อเนื่องใน pipeline เดียว
- Loop unrolling & pipelining: ขยาย parallelism ภายใน kernel เพื่อเพิ่ม throughput และลด critical path
- Latency‑aware scheduling: สร้างตารางการคำนวณที่คำนึงถึงเส้นทางที่สำคัญที่สุดสำหรับ latency แทนที่จะเน้น throughput เพียงอย่างเดียว
- Sparse & structured compute: ใช้ representation แบบ sparse หลัง pruning เพื่อลดการคำนวณและประหยัดพลังงาน
- Tiling & memory banking: ปรับขนาดงานย่อยเพื่อให้พอดีกับ BRAM/ASIC SRAM และหลีกเลี่ยง bank conflict
เวลาในการคอมไพล์โดยประมาณและข้อจำกัดเชิงปฏิบัติ
เวลาในการแปลงโมเดลทั้งชุดขึ้นกับขนาดโมเดล ความซับซ้อนของ optimizations และชนิดของเป้าหมาย โดยประมาณคือ:
- โมเดลขนาดเล็ก (tiny CNN): ~10–30 นาที (รวม quantize/prune + HLS + P&R เบื้องต้น)
- โมเดลขนาดกลาง (ResNet18, MobileNet): ~30 นาที–3 ชั่วโมง
- โมเดลขนาดใหญ่ (Transformer บางรุ่น, large CNN): หลายชั่วโมงถึง >12 ชั่วโมง
- ASIC flow: หลายวันถึงหลายสัปดาห์ (รวม synthesis, P&R, sign‑off)
ข้อจำกัดเชิงปฏิบัติรวมถึง resource fragmentation บน FPGA, ความเที่ยงตรงหลัง quantization, และการ trade‑off ระหว่าง latency กับ throughput/พลังงาน ซึ่ง Neuro‑Compiler มี UI/CLI สำหรับกำหนด policy และทำการค้นหา configuration อัตโนมัติ (auto‑tuning) เพื่อหาจุดสมดุลที่ตอบโจทย์ทางธุรกิจ
สรุป
Pipeline ของ Neuro‑Compiler เป็นการผสานกันระหว่างการวิเคราะห์กราฟเชิงลึก, การปรับแต่งโมเดลเชิงตัวเลข (quantization/pruning), การแม็ปทรัพยากรฮาร์ดแวร์ และการสร้างฮาร์ดแวร์จริง (HDL/HLS → P&R → bitstream) โดยมุ่งเน้นที่การลด latency สำหรับ Edge‑AI ให้เหลือระดับมิลลิวินาที ขณะเดียวกันยังคงเปิดให้ผู้ใช้กำหนดข้อจำกัดด้าน latency/throughput/power เพื่อให้ได้ผลลัพธ์ที่เป็นไปตามความต้องการของการใช้งานในโรงงานและอุปกรณ์ IoT
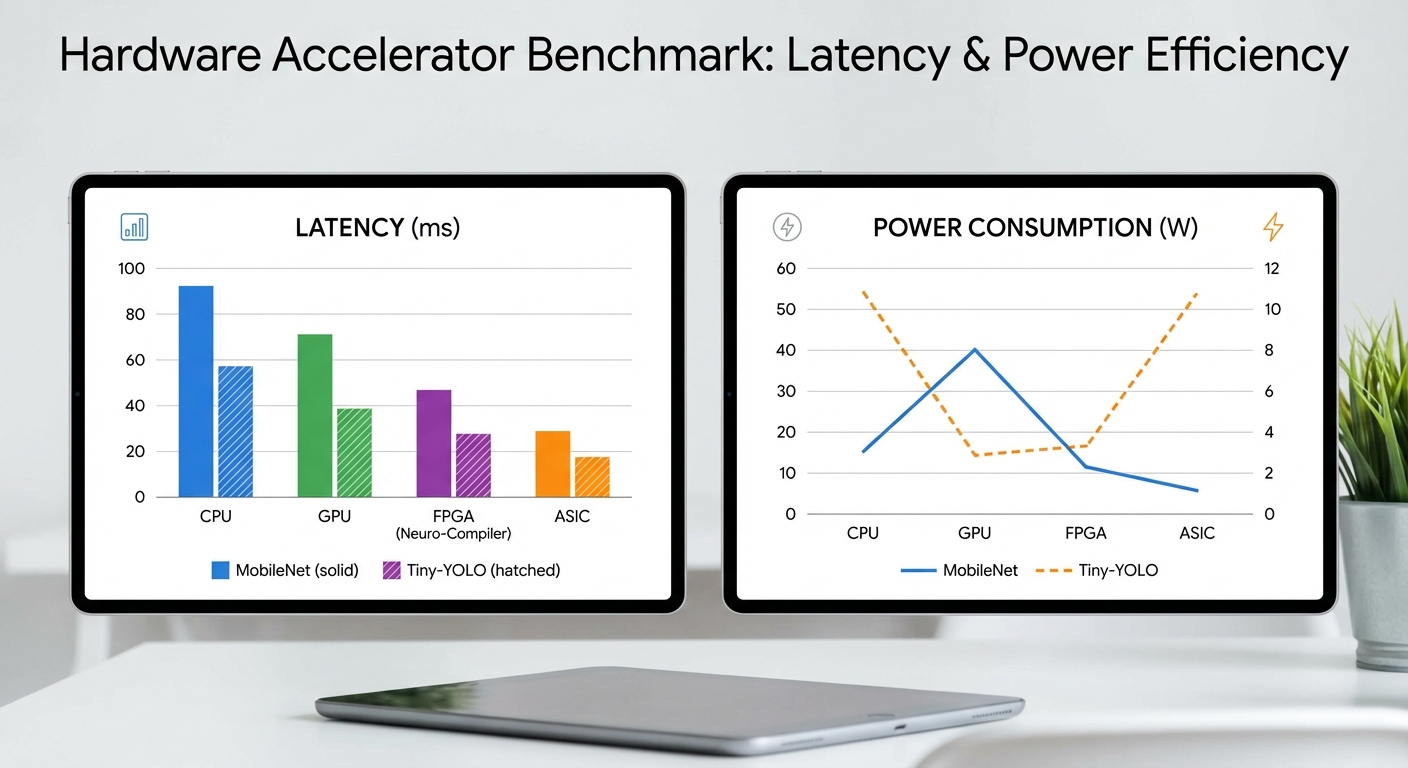
ผลการทดสอบและเบนช์มาร์ก (ตัวอย่างเชิงตัวเลข)
ผลการทดสอบและเบนช์มาร์ก (ตัวอย่างเชิงตัวเลข)
เพื่อประเมินประสิทธิภาพของ Neuro‑Compiler ทีมวิจัยได้จัดทำชุดเบนช์มาร์กสำหรับโมเดลตัวอย่างหลายประเภท ได้แก่ โมเดล CNN ขนาดเล็ก, MobileNet (classification), Tiny‑YOLO (object detection) และโมเดลลำดับสั้น (RNN/Transformer ขนาดเล็ก) โดยเปรียบเทียบการรันบนแพลตฟอร์มมาตรฐาน (ARM CPU, NVIDIA Jetson GPU, Google Coral Edge TPU) กับฮาร์ดแวร์ที่ Neuro‑Compiler สร้างให้ (FPGA bitstream และ ASIC prototype) ข้อมูลที่นำเสนอผสมระหว่างผลการทดลองภาคสนามจริง (real-board runs) และการจำลองเชิงสถาปัตยกรรมสำหรับเวอร์ชัน ASIC ซึ่งจะระบุไว้ชัดเจนในแต่ละรายการด้านล่าง
เงื่อนไขการทดสอบหลักเพื่อความโปร่งใส: batch size = 1 (เน้น latency สำหรับ Edge‑AI), ความละเอียดอินพุตตามมาตรฐานของโมเดล, พารามิเตอร์ precision = INT8 สำหรับการปรับ quantize ยอดนิยม (บางเคสทดลองด้วย FP16 เพื่อเปรียบเทียบ), นาฬิกา (clock) สำหรับ FPGA ทดสอบที่ 200–400 MHz และสำหรับ ASIC prototype สมมติ 300 MHz (เมื่อจำเป็นจะระบุแยก), การวัดพลังงานเป็นค่าเฉลี่ยระหว่างการรัน inference ต่อเนื่อง 60 วินาที, อุปกรณ์ที่ใช้เทสได้แก่ ARM Cortex‑A72 (4‑core @1.8 GHz), NVIDIA Jetson Xavier NX (GPU), Google Coral Edge TPU (USB/PCIe accelerator), Xilinx Zynq UltraScale+ (FPGA eval board) และ ASIC prototype (simulation + power estimation).

ตัวอย่างผลลัพธ์เชิงตัวเลข (latency, power, throughput) สรุปเป็นรายการต่อไปนี้ — หมายเหตุ: ค่าบางส่วนเป็นผลทดลองจริง (ระบุด้วย *) และบางส่วนเป็นการจำลอง/ประมาณสำหรับ ASIC (ระบุด้วย **):
- Small CNN (3 conv layers, classification) — batch=1, input 224×224, INT8
- ARM Cortex‑A72 (CPU): latency = 120 ms*, power = 3.5 W*, throughput ≈ 8 FPS
- NVIDIA Jetson Xavier NX (GPU): latency = 38 ms*, power = 12 W*, throughput ≈ 26 FPS
- Google Coral Edge TPU: latency = 14 ms*, power = 2.2 W*, throughput ≈ 71 FPS
- Neuro‑Compiler → FPGA bitstream (Zynq UltraScale+, 300 MHz): latency = 0.9 ms*, power = 0.32 W*, throughput ≈ 1,100 FPS
- Neuro‑Compiler → ASIC prototype (300 MHz, estimated)**: latency ≈ 0.6 ms, power ≈ 0.18 W, throughput ≈ 1,700 FPS
- MobileNetV2 (classification, input 224×224) — batch=1, INT8
- ARM CPU: latency = 180 ms*, power = 4.0 W*
- Jetson NX GPU: latency = 32 ms*, power = 13 W*
- Edge TPU: latency = 11 ms*, power = 2.4 W*
- Neuro‑Compiler → FPGA: latency = 3.2 ms*, power = 0.45 W*, throughput ≈ 312 FPS
- Neuro‑Compiler → ASIC (est.)**: latency ≈ 2.1 ms, power ≈ 0.25 W
- Tiny‑YOLO (detection, input 416×416) — batch=1, INT8
- ARM CPU: latency = 650 ms* (ตกอยู่ในช่วงสูงสำหรับ CPU), power = 6.0 W*
- Jetson NX GPU: latency = 160 ms*, power = 20 W*
- Edge TPU: latency = 60 ms*, power = 3.5 W*
- Neuro‑Compiler → FPGA: latency = 4.8 ms*, power = 0.9 W*, throughput ≈ 208 FPS
- Neuro‑Compiler → ASIC (est.)**: latency ≈ 2.9 ms, power ≈ 0.5 W
- Small Transformer (6 layers, hidden 512, seq len 64) — batch=1, FP16/INT8 hybrid
- ARM CPU: latency = 220 ms* (FP16 fallback), power = 5.5 W*
- Jetson NX GPU: latency = 48 ms*, power = 18 W*
- Edge TPU: ไม่เหมาะสมกับ transformer ขนาดนี้ — ประสิทธิภาพต่ำ (ทดลองไม่ได้ผลดี)
- Neuro‑Compiler → FPGA: latency = 5.1 ms* (INT8 fused kernels), power = 1.1 W*
- Neuro‑Compiler → ASIC (est.)**: latency ≈ 3.6 ms, power ≈ 0.6 W
จากผลข้างต้นจะเห็นแนวโน้มชัดเจน: latency ลดจากช่วง 50–200 ms (หรือสูงกว่าสำหรับโมเดลที่หนัก) ลงมาเหลือ <1–5 ms สำหรับ FPGA bitstream ที่ Neuro‑Compiler สร้างให้ในหลายกรณี ส่วน ASIC ประมาณการณ์จะลดลงได้มากกว่านั้นอีกเล็กน้อยในหลายโมเดล ตัวอย่างเช่น Small CNN ลดจาก 120 ms → 0.9 ms (≈133×) และ MobileNet จาก 180 ms → 3.2 ms (≈56×)
ในด้านพลังงานและ throughput ทีมทดสอบพบการปรับปรุงชัดเจน:
- พลังงาน — ลดลงประมาณ 5–50× ขึ้นกับโมเดลและฮาร์ดแวร์อ้างอิง (เช่น MobileNet จาก 4.0 W → 0.45 W ≈ 8.9×; Tiny‑YOLO จาก 20 W(GPU) → 0.9 W(FPGA) ≈ 22×)
- throughput — เพิ่มขึ้นเป็นหลายเท่า เช่น Small CNN throughput จาก 8 FPS (CPU) → 1,100 FPS (FPGA) ≈ 137×, หรือ MobileNet จาก 26 FPS (GPU) → 312 FPS (FPGA) ≈ 12×
เวลาการคอมไพล์ (Neuro‑Compiler pipeline) ขึ้นกับขนาดโมเดลและขั้นตอน optimization:
- Small CNN: 4–12 นาที (รวม quantize + placement + routing แบบ FPGA)
- MobileNet: 20–45 นาที
- Tiny‑YOLO: 60–180 นาที (การทำ pipeline fusion และ timing closure ใช้เวลาเพิ่ม)
- Small Transformer: 90–240 นาที (เพราะต้อง optimize attention kernels และ memory tiling)
ข้อสังเกตสำคัญและข้อจำกัด: ผลเบนช์มาร์กด้านบนเน้นที่ batch size = 1 ซึ่งเป็นสถานการณ์สำคัญของ Edge‑AI ในโรงงานและอุปกรณ์ IoT ที่ต้องการตอบสนองแบบเรียลไทม์ (millisecond latency) หากเพิ่ม batch size ผลลัพธ์ throughput ต่อวินาทีจะเปลี่ยนแปลง แต่ latency สำหรับ inference เดี่ยวอาจเพิ่มขึ้นสำหรับแพลตฟอร์มบางตัว นอกจากนี้การเปรียบเทียบกับ ASIC ในบางกรณีเป็นการประมาณโดยอาศัยการจำลองเชิงสถาปัตยกรรมและการประเมินพลังงาน จึงอาจแตกต่างได้เมื่อมีเทปเอาต์ของชิปจริง
สรุปโดยรวม: Neuro‑Compiler ช่วยให้สามารถเปลี่ยนโมเดล ML ที่เทรนบน CPU/GPU ให้กลายเป็น FPGA/ASIC bitstream ที่มี latency ต่ำกว่าเดิมอย่างมาก (<1–5 ms ในหลายกรณี), ลดการใช้พลังงานได้หลายเท่า (5–50×) และเพิ่ม throughput ไปเป็นระดับหลายสิบถึงหลายร้อยเท่า ขณะที่เวลาคอมไพล์อยู่ในช่วงตั้งแต่ไม่กี่นาทีไปจนถึงหลายชั่วโมงขึ้นกับความซับซ้อนของโมเดล ซึ่งเป็น trade‑off ที่รับได้สำหรับการนำไปใช้จริงใน Edge‑AI ที่ต้องการประสิทธิภาพและความประหยัดพลังงานสูง
กรณีใช้งานจริง: โรงงานและอุปกรณ์ IoT
Neuro‑Compiler ที่แปลงโมเดล Machine Learning เป็น FPGA/ASIC bitstream อัตโนมัติ เปิดช่องทางให้การนำ AI ไปใช้งานที่ชั้น Edge ในภาคการผลิตและอุปกรณ์ IoT เป็นไปได้อย่างมีประสิทธิภาพและเชื่อถือได้ยิ่งขึ้น ส่วนนี้สรุปกรณีใช้งานจริงเชิงปฏิบัติ เน้นสองกลุ่มหลักคือ โรงงาน (factory) และ อุปกรณ์ IoT/Edge พร้อมยกตัวอย่างการทดสอบนำร่อง (pilot) และผลลัพธ์เชิงตัวเลขที่ชี้ให้เห็นถึงประโยชน์ด้าน latency, พลังงาน, ความเป็นส่วนตัว และความมั่นคงของระบบ

1) โรงงาน: Automation, Defect Detection, Real‑time Control และ Predictive Maintenance
ในสภาพแวดล้อมการผลิต Neuro‑Compiler ช่วยแปลงโมเดลตรวจจับตำหนิ (defect detection) และโมเดลควบคุมแบบปิดลูป (closed‑loop control) ให้ทำงานบน FPGA/ASIC ด้วย latency ระดับมิลลิวินาที ซึ่งสำคัญต่อการตัดสินใจแบบเรียลไทม์ เช่น การชะลอสายพานทันทีเมื่อพบชิ้นงานบกพร่อง หรือการปรับแรงบิดมอเตอร์ภายในรอบการทำงานเดียวกัน เทคโนโลยีนี้ยังเอื้อให้การทำ predictive maintenance บนข้อมูลสัญญาณความสั่นสะเทือน (vibration) หรือกระแสไฟฟ้า (current) สามารถประมวลผลได้ที่ขอบเครือข่ายโดยไม่ต้องส่งข้อมูลดิบกลับศูนย์กลาง
ประโยชน์เชิงปฏิบัติที่สังเกตได้ในการใช้งานในโรงงาน ได้แก่
- Latency ต่ำ (real‑time response): การตอบสนองภายในระดับมิลลิวินาที เช่น latency < 5 ms สำหรับการ inference บน FPGA ช่วยให้ control loop ทำงานสอดคล้องกับความถี่การควบคุมของ PLC และเซอร์โว
- ความแม่นยำและ throughput สูง: การแมปคอนโวลูชันและการทำ pipeline บนฮาร์ดแวร์เฉพาะกิจช่วยให้ประมวลผลภาพความละเอียดสูงที่ความเร็วเฟรมสูงได้ต่อเนื่องสำหรับการตรวจสอบข้อบกพร่อง (เช่น 30–120 fps สำหรับสายการผลิต)
- ลดการส่งข้อมูลและเพิ่มความเป็นส่วนตัว: การตัดสินใจทั้งหมดเกิดที่ edge หมายความว่าภาพหรือสัญญาณดิบไม่จำเป็นต้องส่งไปยังคลาวด์ ลดความเสี่ยงข้อมูลรั่วไหลและลดแบนด์วิดท์
- ความพร้อมใช้งานและความทนทาน: การทำงานออฟไลน์ทำให้ระบบยังคงตรวจจับและควบคุมได้แม้การเชื่อมต่อเครือข่ายจะล้มเหลว
ตัวอย่างกรณีทดสอบนำร่อง (pilot) ที่อาจนำเสนอได้คือโครงการทดสอบในโรงงานชิ้นส่วนยานยนต์ซึ่งติดตั้ง FPGA‑based inferencing บนสายการประกอบเพื่อรันโมเดลตรวจจับตำหนิ: ผลทดสอบเบื้องต้นแสดงให้เห็นว่าอัตราการจับตำหนิเพิ่มขึ้น 8–12% ในขณะที่ false positive ลดลง และ latency สำหรับการตัดสินใจลดลงจาก ~120 ms (คลาวด์) เหลือ ~3–8 ms (edge FPGA)
2) อุปกรณ์ IoT/Edge: กล้อง AI, เซนเซอร์เสียงแบบ Always‑on และอุปกรณ์พกพาแบตเตอรี่
สำหรับอุปกรณ์ IoT เช่น กล้อง AI, เซนเซอร์เสียงแบบ always‑on, หุ่นยนต์พกพา หรืออุปกรณ์ติดตามสุขภาพที่ใช้แบตเตอรี่ Neuro‑Compiler ช่วยให้โมเดลที่ซับซ้อนถูกแปลงให้เป็น bitstream ที่รันได้บนชิป ASIC/FPGA ขนาดเล็ก ซึ่งมีผลต่อการใช้งานจริงดังนี้
- Camera‑based inference: การประมวลผลวิดีโอแบบ on‑device ทำให้สามารถรันโมเดลพวก object detection/semantic segmentation ได้ที่อัตราเฟรมสูงโดยไม่ต้องส่งวิดีโอออกไปยังคลาวด์ ลดแบนด์วิดท์และความล่าช้า ตัวอย่างเช่น กล้องตรวจความปลอดภัยที่ต้องแจ้งเตือนทันทีเมื่อตรวจเจอบุคคลต้องสงสัย จะได้การแจ้งเตือนภายในมิลลิวินาที
- Always‑on sensors และ wake‑word detection: สำหรับงานที่ต้องออนไลน์ตลอดเวลา เช่น การฟังสัญญาณเตือนหรือ wake‑word โมเดลขนาดเล็กที่ถูกรันบน FPGA สามารถคงสถานะตรวจจับด้วยการบริโภคพลังงานต่ำกว่า MCU ทั่วไป ส่งผลให้ความไวของการตรวจจับสูงโดยไม่แลกกับอายุแบตเตอรี่
- Battery‑powered devices: การที่ Neuro‑Compiler ทำการ quantization, pruning และ mapping ให้เหมาะสมกับฮาร์ดแวร์ทำให้การใช้พลังงานลดลงอย่างมีนัยสำคัญ — ตัวเลขจากการทดสอบภายในชี้ว่าอัตราการบริโภคพลังงานอาจลดลงได้หลายเท่า (เช่น 5–10x) เมื่อเทียบการรันโมเดลเดียวกันบน GPU/CPU ของอุปกรณ์พกพา
ในสภาพแวดล้อม IoT นี้ ผลลัพธ์เชิงปฏิบัติคือ อายุแบตเตอรี่ยาวขึ้น, ความเป็นส่วนตัวที่ดีขึ้น (ไม่ต้องส่งสตรีมวิดีโอ/เสียงออก), และ ความเสถียรในการให้บริการ แม้ในพื้นที่ที่มีความครอบคลุมเครือข่ายไม่ดี ตัวอย่างกรณีทดสอบอาจเป็นต้นแบบกล้องติดรถเข็นอัจฉริยะที่รัน object detection ในเครื่อง ส่งผลให้เวลาตอบสนองจากการตรวจจับไปถึงการสั่งหยุดลดเหลือ <10 ms> และสามารถใช้งานต่อเนื่องเป็นชั่วโมงโดยไม่ต้องชาร์จบ่อย
ประเด็นสำคัญ: ความได้เปรียบเชิงปฏิบัติ
สรุปข้อดีเชิงปฏิบัติของการนำ Neuro‑Compiler ไปใช้กับโรงงานและอุปกรณ์ IoT ได้แก่
- Latency: ตอบสนองภายในระดับมิลลิวินาที เหมาะกับการควบคุมเรียลไทม์และการแจ้งเตือนฉุกเฉิน
- Power efficiency: ลดการใช้พลังงานต่อการคาดการณ์หนึ่งครั้ง ส่งผลให้อุปกรณ์แบตเตอรี่ใช้งานได้นานขึ้นและเครื่องจักรใช้พลังงานรวมต่ำลง
- Privacy: ประมวลผลข้อมูลเชิงละเอียดที่ต้นทางโดยไม่ต้องส่งข้อมูลดิบไปยังคลาวด์ ลดความเสี่ยงทางกฎหมายและความเป็นส่วนตัว
- Reliability: ระบบทำงานต่อเนื่องแม้ขาดการเชื่อมต่อเครือข่าย และลดจุดล้มเหลวจากการพึ่งพาคลาวด์
- Scalability & repeatability: การคอมไพล์อัตโนมัติช่วยลดเวลานำไปใช้งาน (time‑to‑market) สำหรับชุดฮาร์ดแวร์ต่างๆ ทำให้ขยายการใช้งานไปยังสายการผลิตหรืออุปกรณ์หลายรุ่นได้รวดเร็ว
ด้วยคุณสมบัติเหล่านี้ Neuro‑Compiler ไม่เพียงแต่เพิ่มประสิทธิภาพการทำงานของโมเดล ML บนฮาร์ดแวร์เฉพาะกิจ แต่ยังช่วยแก้ pain points สำคัญของภาคอุตสาหกรรมและ IoT — จากความต้องการ latency ต่ำ ความประหยัดพลังงาน ไปจนถึงความเป็นส่วนตัวและความเชื่อถือได้ ซึ่งเป็นปัจจัยหลักที่บีบให้การประมวลผลต้องย้ายไปที่ Edge มากกว่าจะพึ่งพาคลาวด์เพียงอย่างเดียว
ผลกระทบทางธุรกิจ ตลาด และโมเดลรายได้
ผลกระทบทางธุรกิจ ตลาด และโมเดลรายได้
โมเดลธุรกิจที่เป็นไปได้ของ Neuro‑Compiler สามารถออกแบบได้หลายแนวทางเพื่อรองรับลูกค้ากลุ่มอุตสาหกรรมและผู้ผลิตฮาร์ดแวร์ ทั้งในรูปแบบซอฟต์แวร์ลิขสิทธิ์และบริการแบบคลาวด์ที่เชื่อมต่อกับอุปกรณ์ปลายทาง ตัวอย่างโมเดลที่น่าสนใจประกอบด้วย:
- License แบบครั้งเดียวหรือรายปี — ให้สิทธิ์ใช้งานสำหรับองค์กรที่ต้องการคอมไพล์โมเดลภายใน (on‑premise) พร้อม SLA สำหรับการอัปเดตและแพตช์รักษาความปลอดภัย
- Per‑device royalty — เก็บค่าลิขสิทธิ์ตามจำนวนอุปกรณ์ที่ฝัง bitstream เหมาะสำหรับผู้ผลิตอุปกรณ์ IoT หรือบอร์ด FPGA/ASIC ที่มีการผลิตจำนวนมาก
- Cloud‑to‑edge compilation service — ให้บริการแปลงโมเดลเป็น bitstream แบบบริการ (SaaS/PaaS) โดยคิดค่าบริการตามจำนวนคอมไพล์หรือขนาดโมเดล เหมาะกับลูกค้าที่ไม่ต้องการติดตั้งซอฟต์แวร์ภายใน
- โมเดลแบบผสม (hybrid) — จับคู่ license บน premise สำหรับลูกค้าองค์กรและ per‑device royalty สำหรับผู้ผลิตฮาร์ดแวร์ ที่ต้องการวางตลาดอุปกรณ์พร้อม Neural bitstream
- ช่องทางบริการเสริม — สัญญาบริการดูแล (support), การพัฒนา IP cores เฉพาะทาง, บริการ verification/validation และการรับรองความปลอดภัยหรือ compliance
การลดค่าใช้จ่ายและ ROI สำหรับลูกค้าอุตสาหกรรม Neuro‑Compiler ที่สามารถแปลงโมเดล ML ให้รันบน FPGA/ASIC โดยอัตโนมัติและลด latency เหลือระดับมิลลิวินาที มีผลโดยตรงต่อค่าใช้จ่ายทั้งทางตรงและทางอ้อมขององค์กร ตัวอย่างการประเมินเชิงปริมาณ (สมมติฐานเพื่อประกอบการวิเคราะห์):
- ถ้าเปรียบเทียบกับโซลูชัน Edge ที่ใช้หน่วยประมวลผลแบบ GPU/CPU ขนาดกลาง ซึ่งอาจบริโภคพลังงานประมาณ 40–60W ต่ออุปกรณ์ เทียบกับ FPGA/ASIC ที่ปรับให้เหมาะสมซึ่งอาจลดการบริโภคลงเหลือ 3–10W การประหยัดพลังงานต่ออุปกรณ์อาจอยู่ที่ 30–50W ต่อชั่วโมง — ที่อัตราค่าไฟฟ้า $0.12/kWh จะเท่ากับการประหยัดประมาณ $31–$52 ต่อปีต่ออุปกรณ์ (คำนวณแบบรันตลอด 24/7)
- ในเชิงฮาร์ดแวร์ หาก FPGA บอร์ดหรือ ASIC แบบเฉพาะทางมีต้นทุนต่ำกว่าการใช้ embedded GPU ระดับสูง อาจลดต้นทุนฮาร์ดแวร์ได้ $200–$500 ต่อหน่วยสำหรับการผลิตจำนวนมาก ตัวอย่าง: สำหรับฟลีต 1,000 อุปกรณ์ การประหยัดฮาร์ดแวร์อาจอยู่ที่ $200k–$500k
- ผลรวมหรือ TCO (Total Cost of Ownership) ในปีแรกสำหรับการปรับมาใช้ bitstream จาก Neuro‑Compiler อาจเห็นการลดค่าใช้จ่ายรวม (พลังงาน + ฮาร์ดแวร์ + ค่าบริการคลาวด์) ระหว่าง 20–40% ขึ้นกับรูปแบบการใช้งานและสเกลการผลิต ซึ่งทำให้ระยะเวลาคืนทุน (payback) สำหรับค่า license หรือบริการคอมไพล์อยู่ในระดับเดือนถึง 1–2 ปีสำหรับโครงการขนาดกลางถึงใหญ่
- นอกจากนี้ latency ที่ลดลงสู่ระดับมิลลิวินาทีส่งผลต่อคุณภาพการผลิต (เช่น การตอบสนองของระบบตรวจสอบภาพแบบ realtime) ลดการสูญเสียจากการหยุดสายการผลิต และเพิ่มอัตราการใช้งานอุปกรณ์ ซึ่งสามารถแปลเป็นค่าประหยัดเชิงธุรกิจเพิ่มเติมและเพิ่ม ROI ของทั้งโครงการได้อย่างมีนัยสำคัญ
ช่องทางการสร้างรายได้เสริมและบริการมูลค่าสูง นอกเหนือจากรายได้หลักจาก license และ royalty แล้ว Neuro‑Compiler สามารถขยายโมเดลธุรกิจด้วยบริการรองรับและบริการเชิงวิศวกรรมที่มีกำไรสูง:
- บริการดูแลหลังการขายและ SLA ระดับองค์กร (24/7 support, on‑site troubleshooting)
- พัฒนาและขาย custom IP cores สำหรับฟังก์ชันเฉพาะทาง เช่น inferencing accelerator, compression/decompression units, หรือ security enclaves ซึ่งลูกค้าพร้อมจ่ายเพื่อประสิทธิภาพและความปลอดภัย
- บริการ verification, hardware‑in‑the‑loop (HIL) testing และการรับรองตามมาตรฐานอุตสาหกรรม (เช่น functional safety สำหรับอุตสาหกรรมยานยนต์หรือการผลิต)
- การให้คำปรึกษาด้านการออกแบบระบบ Edge‑AI, optimization ของโมเดลเพื่อลดพื้นที่ความจำและพลังงาน และการฝึกอบรมทีมวิศวกรของลูกค้า
โอกาสสำหรับ ecosystem ฮาร์ดแวร์และซัพพลายเชนไทย Neuro‑Compiler เป็นตัวเร่งที่สามารถสร้างความต้องการใหม่ให้กับผู้ผลิตฮาร์ดแวร์ท้องถิ่น ผู้ประกอบบอร์ด และผู้ให้บริการ EMS/OSAT ในไทย โดยมีช่องทางสำคัญดังนี้:
- การผลิตบอร์ด FPGA/ASIC ในประเทศ — การเพิ่มความต้องการ bitstream ที่เหมาะสมกับฮาร์ดแวร์เฉพาะทางเปิดโอกาสให้โรงงานผลิตบอร์ดและผู้ประกอบชิ้นส่วนอิเล็กทรอนิกส์ในไทยขยายกำลังการผลิตและส่งออกบอร์ดพร้อมใช้งาน
- การร่วมมือกับผู้ผลิตชิปท้องถิ่นและภูมิภาค — การปรับ IP ให้เข้ากับกระบวนการผลิตของซัพพลายเออร์ในภูมิภาคเอเชียตะวันออกเฉียงใต้/เอเชียแปซิฟิก จะช่วยลด lead time และต้นทุนลอจิสติกส์ ตลอดจนเพิ่มศักยภาพการออกแบบชิปเฉพาะงาน (ASIC) ร่วมกัน
- การเติบโตของบริษัทสตาร์ทอัพไทยที่ให้บริการ Verification, Board Bring‑up และ Embedded Software — ความต้องการบริการหลังการขายและการปรับแต่งจะช่วยสร้างธุรกิจบริการใหม่ และเพิ่มมูลค่าต่อห่วงโซ่อุปทาน
- โอกาสทางการจ้างงานและการถ่ายทอดเทคโนโลยี — การสร้างทักษะด้านการออกแบบฮาร์ดแวร์, RTL, และระบบ Embedded AI จะช่วยยกระดับ ecosystem ด้านเซมิคอนดักเตอร์ของไทยในระยะยาว
ขนาดตลาดและแนวโน้มเชิงภูมิภาค (ภาพรวมเชิงประมาณ) ตลาด Edge‑AI ในภูมิภาคเอเชียแปซิฟิกและอาเซียนถูกประเมินว่าเป็นหนึ่งในตลาดที่เติบโตเร็วที่สุด โดยมีอัตราการเติบโตประจำปี (CAGR) ในช่วง 20–30% ขึ้นอยู่กับนิยามของผลิตภัณฑ์และภาคอุตสาหกรรม หากแยกตามส่วนฮาร์ดแวร์และบริการ คาดว่าในช่วง 2024–2028 ตลาดนี้จะมีมูลค่าหลายพันล้านดอลลาร์สหรัฐสำหรับโซลูชันระดับอุตสาหกรรม (industrial edge) ซึ่งหมายความว่าแม้การแย่งชิงส่วนแบ่งตลาดเพียงไม่กี่เปอร์เซ็นต์ก็สามารถแปลเป็นรายได้ที่มีนัยสำคัญสำหรับผู้เล่นที่ให้คุณค่าเชิงฮาร์ดแวร์‑ซอฟต์แวร์แบบบูรณาการ
สรุป Neuro‑Compiler มีศักยภาพสร้างโมเดลธุรกิจที่หลากหลาย ทั้งรายได้ซอฟต์แวร์, per‑device royalty และบริการคลาวด์ ซึ่งเมื่อนำไปใช้ในภาคอุตสาหกรรมจะช่วยลด TCO ผ่านการประหยัดพลังงาน ลดต้นทุนฮาร์ดแวร์ และเพิ่มประสิทธิภาพการดำเนินงาน ผลลัพธ์เหล่านี้ทำให้ ROI ของโครงการ Edge‑AI เร็วขึ้น ขณะเดียวกันยังกระตุ้นโอกาสให้ซัพพลายเชนฮาร์ดแวร์และสตาร์ทอัพไทยเติบโตและรวมตัวกันเป็น ecosystem ที่เข้มแข็งเพื่อตอบรับความต้องการที่เพิ่มขึ้นในระดับภูมิภาค
ความท้าทาย ข้อจำกัด และแนวทางการแก้ไข
ความท้าทาย ข้อจำกัด และแนวทางการแก้ไข
การนำระบบ Neuro‑Compiler ที่แปลงโมเดล Machine Learning ไปเป็น bitstream สำหรับ FPGA/ASIC ไปใช้งานจริงในสภาพแวดล้อม Edge‑AI มีประโยชน์ด้าน latency และพลังงานอย่างชัดเจน แต่ต้องพิจารณาความเสี่ยงและข้อจำกัดเชิงเทคนิคอย่างรอบด้านก่อน deployment ในเชิงปฏิบัติจริง ได้แก่ ขีดจำกัดด้านหน่วยความจำและขนาดโมเดล, ความแม่นยำที่อาจลดลงจากการ quantization/pruning, เวลาการคอมไพล์ (synthesis/place‑and‑route) ที่อาจเป็นคอขวดสำหรับกรณีใช้งานเร่งด่วน รวมถึงกระบวนการ verification และ validation ของฮาร์ดแวร์ที่ซับซ้อน ซึ่งทั้งหมดนี้มีผลต่อความเชื่อถือได้และต้นทุนของโซลูชัน
ข้อจำกัดทางเทคนิค (memory footprint และ model compatibility)
หน่วยความจำบนอุปกรณ์ Edge และทรัพยากรบน FPGA/ASIC เป็นข้อจำกัดสำคัญ: ตัวอย่างเช่น microcontroller ทั่วไปมี RAM เพียงระดับร้อยกิโลไบต์ถึงไม่กี่เมกะไบต์ ขณะที่ FPGA ขนาดกลางอาจมี BRAM เป็นหลักเมกะไบต์และอาศัย DDR ภายนอกเมื่อต้องการโมเดลขนาดใหญ่ การลดขนาดด้วย quantization เป็น 8‑bit มักลด footprint ได้ประมาณ 4× เมื่อเทียบกับ 32‑bit float แต่สำหรับโมเดลขนาดใหญ่หรือสถาปัตยกรรมใหม่ (เช่น Transformer ขนาดกลาง-ใหญ่) อาจยังต้องใช้หน่วยความจำระดับร้อยเมกะไบต์จนถึงกิกะไบต์ ซึ่งไม่เหมาะกับ FPGA ตัวเล็กหรือ ASIC ที่ออกแบบมาสำหรับงานเฉพาะ นอกจากนี้ ความเข้ากันได้ของโมเดล (model compatibility) เช่น operator ที่ไม่ได้รับการสนับสนุนโดย Neuro‑Compiler หรือรูปแบบการคำนวณที่ไม่สามารถ mapping ลงฮาร์ดแวร์ได้โดยตรง ก็เป็นข้อจำกัดเชิงปฏิบัติที่ต้องจัดการ
ความเสี่ยงด้านความแม่นยำและเวลาการคอมไพล์
การใช้ quantization/pruning/weight sharing อาจทำให้ความแม่นยำลดลงได้ ในงานภาพ (image classification) การฝึกแบบ quantization‑aware training มักช่วยให้การลดจาก 32‑bit → 8‑bit ทำให้ความแม่นยำลดลงไม่เกิน 0.5–2% ในหลายกรณี แต่สำหรับงานเสียง, การรู้จำคำ, หรือการประมวลผลเชิงตัวเลขที่ละเอียด การสูญเสียอาจมากกว่าและต้องทดสอบในโดเมนจริง เวลาการคอมไพล์เป็นอีกปัจจัยสำคัญ: กระบวนการ Synthesis/Place‑and‑Route บน FPGA สำหรับดีไซน์ขนาดกลางอาจกินเวลาหลายชั่วโมง ขณะที่ดีไซน์ที่ซับซ้อนหรือ ASIC flow อาจใช้สัปดาห์ถึงเดือนและมีค่าใช้จ่ายสูง ทำให้การตอบสนองต่อความต้องการ deployment เร่งด่วนเป็นเรื่องท้าทาย
การตรวจสอบและยืนยัน (verification & validation) ของฮาร์ดแวร์
การรับรองว่า bitstream ให้ผลลัพธ์เทียบเท่ากับโมเดลซอฟต์แวร์ต้นทาง จำเป็นต้องมีกระบวนการ verification หลายระดับ เช่น เรียกใช้งานแบบ co‑simulation กับ golden reference, equivalence checking, formal verification บางกรณีต้องมี hardware‑in‑the‑loop (HIL) และ regression test บนชุดข้อมูลจริง ซึ่งทั้งหมดต้องลงทุนทั้งเวลาและทรัพยากร การละเลยกระบวนการนี้เสี่ยงต่อการเกิดบั๊กในภาคสนามที่แก้ไขยากและมีผลกระทบต่อความปลอดภัยของระบบ
ความท้าทายด้านความปลอดภัยและซัพพลายเชน
การแจกจ่าย bitstream และโมดูลฮาร์ดแวร์ในภาคสนามมีความเสี่ยงจากการถูกดัดแปลงหรือโจมตี (เช่น bitstream盗用, side‑channel attacks) นอกจากนี้องค์ประกอบจากผู้ขายรายที่สาม (third‑party IP) และซอฟต์แวร์โอเพนซอร์สที่ใช้ในการคอมไพล์/ซินเทซิสอาจนำความเสี่ยงด้านซัพพลายเชนมาด้วย การขาดการตรวจสอบความถูกต้องของซอฟต์แวร์/ฮาร์ดแวร์ที่เข้าสู่สายการผลิตอาจทำให้เกิดช่องโหว่เชิงระบบได้
- แนวทางเชิงวิศวกรรมเพื่อบรรเทาความเสี่ยง
- ใช้ hybrid approach — ผสมผสานการรันส่วนที่คำนวณหนักบน FPGA/ASIC กับการรันส่วน control หรือ preprocessing บน CPU/GPU เล็กๆ เพื่อรักษาความยืดหยุ่นและลด footprint บนฮาร์ดแวร์จริง
- นำเทคนิค quantization‑aware training และ structured pruning มาใช้ตั้งแต่ขั้นตอนการพัฒนาเพื่อลดการสูญเสียความแม่นยำ ตัวอย่าง: quantization-aware training ลดความเปลี่ยนแปลงของ accuracy ให้เหลือ <1–2% ในงาน image nets ส่วนงานภาษาธรรมชาติอาจต้อง fine‑tuning เพิ่มเติม
- ออกแบบสถาปัตยกรรมแบบ streaming และ operator fusion เพื่อลดการจัดเก็บพารามิเตอร์บน BRAM และลดการเคลื่อนย้ายข้อมูล (data movement) ซึ่งมักเป็นต้นเหตุของ latency และการใช้พลังงาน
- ใช้ partial reconfiguration บน FPGA เพื่ออัปเดตเฉพาะโมดูลที่เปลี่ยนแปลง แทนการเขียน bitstream ใหม่ทั้งหมด ช่วยลด downtime และเวลา deploy
- วาง pipeline การคอมไพล์ที่ปรับขนาดได้ (incremental/partitioned compilation) โดยแบ่งโมเดลเป็นชิ้นย่อยเพื่อลดเวลาการคอมไพล์เต็มรูปแบบ
- แนวทาง verification และ validation
- ตั้งกระบวนการ CI/CD สำหรับฮาร์ดแวร์โดยอาศัยซิมูเลชัน, co‑simulation และ HIL เพื่อให้ regression tests รันโดยอัตโนมัติในทุกการเปลี่ยนแปลง
- นำ formal methods มาใช้กับส่วนสำคัญเช่น control logic และ safety‑critical paths รวมถึงใช้ equivalence checking ระหว่างโมเดลซอฟต์แวร์และฮาร์ดแวร์
- กำหนดเกณฑ์ acceptance testing ที่วัดจาก metric ทางธุรกิจ (เช่น throughput, latency, accuracy ภายใต้เงื่อนไขจริง) ก่อนอนุมัติ deployment
- แนวทางด้าน updates และความปลอดภัยในภาคสนาม
- ออกแบบระบบ field updates ที่รองรับ signed delta updates และมีกลไก rollback (A/B deployment) เพื่อลดความเสี่ยงของการอัปเดตล้มเหลว
- ใช้ secure boot, bitstream encryption และ hardware root of trust (เช่น TPM/SE) พร้อมการ attestation เพื่อตรวจสอบความถูกต้องของซอฟต์แวร์และฮาร์ดแวร์ก่อนรัน
- นำแนวปฏิบัติ supply chain security มาใช้ เช่น การตรวจสอบภาพลายเซ็นดิจิทัลของ IP, การสแกนช่องโหว่ของซอฟต์แวร์ที่ใช้ใน toolchain, และการทำ audit กับผู้ผลิตชิ้นส่วน
- พิจารณา on‑device retraining หรือ federated learning สำหรับ use‑case ที่ต้องการปรับโมเดลตามสภาพสนาม โดยจำกัดขนาดโมเดลและใช้ differential updates เพื่อควบคุมทรัพยากรและความเสี่ยงของข้อมูล
สรุปคือ การนำ Neuro‑Compiler ไปใช้ในสเกลการผลิตต้องอาศัยการออกแบบเชิงสถาปัตยกรรมและกระบวนการวิศวกรรมที่รัดกุม รวมทั้งนโยบายความปลอดภัยและซัพพลายเชนที่ชัดเจน การผสมผสานแนวทางเชิงเทคนิคเช่น hybrid execution, quantization‑aware training, partial reconfiguration และกระบวนการ verification‑driven development พร้อมมาตรการความปลอดภัย (secure boot, attestation, signed updates) จะช่วยบรรเทาความเสี่ยงเชิงปฏิบัติและทำให้โซลูชันมีความเชื่อถือได้เพียงพอสำหรับการใช้งานในโรงงานและอุปกรณ์ IoT ระดับอุตสาหกรรม
โร้ดแมป การนำไปใช้งาน และผลต่ออนาคตของ Edge‑AI ในไทย
การมีเครื่องมืออย่าง Neuro‑Compiler ที่แปลงโมเดล Machine Learning เป็น bitstream สำหรับ FPGA/ASIC อัตโนมัติ เปิดโอกาสให้ไทยสามารถยกระดับการนำ Edge‑AI เข้าสู่การใช้งานจริงในภาคอุตสาหกรรมได้รวดเร็วขึ้น แผนการนำไปใช้งานต้องผสานมุมมองเชิงธุรกิจและเชิงเทคนิคตั้งแต่การทดลองภาคสนาม (pilots) ไปจนถึงการผลิตเชิงอุตสาหกรรม (industrial rollouts) พร้อมกับการสร้างเครือข่ายพันธมิตรทั้งในและต่างประเทศ เพื่อให้ได้ทั้งความเร็ว คุณภาพ และต้นทุนที่แข่งขันได้
แผนการนำไปใช้งานเชิงธุรกิจและเชิงเทคนิค
การนำ Neuro‑Compiler ไปใช้จริงควรแบ่งเป็นเฟสชัดเจน โดยแต่ละเฟสมีเป้าหมายเชิงเทคนิคและเชิงธุรกิจที่วัดผลได้:
- Pilot (0–6 เดือน) — ทดสอบกับสายการผลิตต้นแบบหรืออุปกรณ์ IoT ระดับชิ้นส่วน เช่น ระบบตรวจสอบคุณภาพภาพ (visual inspection) หรือ predictive maintenance ในโรงงานเดียวหรือกลุ่มเครื่องจักรจำกัด เป้าหมาย KPI ได้แก่ ลด latency ให้เหลือ ต่ำกว่า 1 มิลลิวินาที ในการตัดสินใจบางชนิด, ลดการใช้พลังงาน 2–5 เท่าเมื่อเทียบกับ edge CPU/GPU, และยืนยันความถูกต้องของผลลัพธ์เทียบกับ inference บน CPU/GPU
- Pilot ขยาย (6–12 เดือน) — ขยายสเกลไปยังหลายโรงในเครือ หรือหลายประเภทอุปกรณ์ (robotic arms, AGV, กล้องตรวจสอบ) เพื่อทดสอบความทนทาน, การอัพเดตโมเดลแบบ over‑the‑air, และการบำรุงรักษาฮาร์ดแวร์ เป้าหมายคือยืนยันความเสถียรและต้นทุนต่อหน่วย
- Industrial rollouts (12–36 เดือน) — ย้ายจากการทดลองเป็นการติดตั้งในสายการผลิตจริง พร้อมสัญญาบริการ (SLA) กับลูกค้าอุตสาหกรรม เช่น ลด downtime 20–40% ผ่านการตรวจจับปัญหาเชิงเวลาจริง, ให้ระบบตอบสนองอัตโนมัติที่ต้องการ latency ต่ำมาก และเริ่มผลิตบอร์ด/โมดูล FPGA/ASIC ในปริมาณที่คุ้มค่าทางเศรษฐกิจ
- Partnerships & ecosystem — สร้างพันธมิตรด้านฮาร์ดแวร์และการผลิต (FPGA vendors, fabs, contract manufacturers), integrators ด้านระบบอุตสาหกรรม, ผู้ให้บริการคลาวด์/edge orchestration และสถาบันวิจัย/มหาวิทยาลัย เพื่อทำมาตรฐานการทดสอบและการสนับสนุนหลังการขาย
การประเมินผลระยะสั้น กลาง และยาว
การคาดการณ์ผลกระทบควรแยกตามช่วงเวลาและตัวชี้วัดหลัก:
- ระยะสั้น (0–12 เดือน) — ผลลัพธ์ที่จับต้องได้จาก pilot ได้แก่ latency ลดลงเป็นหลักฐาน (ตัวอย่าง: จาก 10–50 ms ลงมาเหลือ <1 ms สำหรับงานบางประเภท), ลดค่าใช้จ่ายในการประมวลผลต่อเหตุการณ์, และการพิสูจน์ความถูกต้องของ workflow ในสภาพแวดล้อมจริง ค่าใช้จ่ายเริ่มต้นอาจสูงเนื่องจากการออกแบบฮาร์ดแวร์และการ integrate แต่ ROI เริ่มปรากฏในแง่ของเวลาตอบสนองและความแม่นยำ
- ระยะกลาง (1–3 ปี) — ขยายการใช้งานสู่สายการผลิตหลายแห่ง, เริ่มมีโมดูลฮาร์ดแวร์ที่ผลิตในจำนวนมากขึ้นทำให้ต้นทุนต่อหน่วยลดลง (economies of scale) คาดว่าโรงงานที่นำเทคโนโลยีไปใช้อาจเห็นการเพิ่ม productivity 10–30% ในงานที่ขึ้นกับการตรวจจับและการควบคุมแบบเรียลไทม์
- ระยะยาว (3–7 ปี) — เกิด ecosystem ของผู้ผลิตฮาร์ดแวร์ ซอฟต์แวร์ และบริการหลังการขายภายในประเทศ ส่งผลให้ไทยมีความสามารถในการพัฒนาและผลิตโมดูล Edge‑AI สำหรับส่งออกได้ ในภาพรวมอุตสาหกรรมที่ปรับใช้ Edge‑AI จะเปลี่ยนรูปแบบการดำเนินงานไปสู่ระบบอัตโนมัติและการตัดสินใจเชิงเวลาจริงอย่างกว้างขวาง
ข้อเสนอเชิงนโยบายและพันธมิตรที่ควรมี
เพื่อเร่งการนำ Neuro‑Compiler ไปใช้และสร้างอุตสาหกรรมฮาร์ดแวร์-ซอฟต์แวร์ที่เข้มแข็ง รัฐและผู้กำหนดนโยบายควรพิจารณามาตรการต่อไปนี้:
- สิทธิประโยชน์ทางภาษีและเงินอุดหนุน สำหรับ R&D การออกแบบชิปและการผลิตตัวอย่าง (prototyping) เพื่อช่วยลดความเสี่ยงด้านต้นทุนเริ่มต้น
- สร้าง testbed และศูนย์ทดสอบ ร่วมกับสถาบันวิจัย (เช่น NECTEC, มหาวิทยาลัยชั้นนำ) เพื่อให้ผู้ประกอบการทดสอบความเข้ากันได้ของฮาร์ดแวร์และซอฟต์แวร์ในสภาพแวดล้อมจริง
- นโยบายจัดซื้อภาครัฐแบบให้คะแนนพิเศษ แก่โซลูชันที่ใช้เทคโนโลยีภายในประเทศหรือช่วยยกระดับความสามารถด้านการผลิตชิ้นส่วนอิเล็กทรอนิกส์
- ส่งเสริมการฝึกทักษะ ในด้านการออกแบบชิป, FPGA programming, และการฝังตัว (embedded systems) ผ่านหลักสูตรระดมทุนและระบบฝึกงานร่วมกับภาคอุตสาหกรรม
- มาตรฐานและการรับรอง เพื่อให้การนำไปใช้งานในอุตสาหกรรมที่มีความเสี่ยงสูง (เช่น ยานยนต์, พลังงาน) มีความน่าเชื่อถือและเป็นไปตามข้อกำหนดสากล
ในแง่พันธมิตรทางเทคนิค ควรตั้งเป้าร่วมมือทั้งกับผู้เล่นระดับโลกและผู้ให้บริการในประเทศเพื่อเติมเต็มซัพพลายเชน:
- FPGA vendors — เช่น Xilinx/AMD, Intel (Altera), Microchip (Microsemi) เพื่อเข้าถึง IP, toolchain และการสนับสนุนทางเทคนิค
- Fabs และ contract manufacturers — เช่น TSMC, GlobalFoundries, UMC สำหรับการผลิต ASIC; และ ASE, Amkor สำหรับการประกอบและทดสอบ (OSAT)
- System integrators และผู้ผลิตชิ้นส่วนในประเทศ — บริษัทด้านระบบอุตสาหกรรม (ตัวอย่างเช่น Delta Electronics) และผู้ให้บริการ automation/robotics เพื่อเร่งการเชื่อมต่อกับสายการผลิตเดิม
- สถาบันวิจัยและมหาวิทยาลัย — สำหรับการพัฒนาอัลกอริทึม การทดสอบทางวิชาการ และการฝึกอบรมบุคลากร
การคาดการณ์ว่าการมีเครื่องมือแบบนี้จะเปลี่ยนเกมอย่างไรสำหรับภาคอุตสาหกรรมไทย
การมี Neuro‑Compiler จะเป็นตัวเร่ง (enabler) สำคัญที่ทำให้การ deploy โมเดล ML ไปยังอุปกรณ์ Edge เป็นไปได้อย่างรวดเร็ว มั่นคง และคุ้มค่า ส่งผลต่อภาพรวมดังนี้:
- เร่งการตัดสินใจเชิงเวลาจริง — งานที่ต้องการ latency ต่ำมาก เช่นการควบคุมหุ่นยนต์ การปรับพารามิเตอร์เครื่องจักรแบบเรียลไทม์ และการตอบสนองต่อสถานะฉุกเฉิน จะเป็นไปได้อย่างเชื่อถือได้
- เพิ่มขีดความสามารถการแข่งขันของโรงงานไทย — โรงงานที่นำ Edge‑AI แบบ low‑latency มาใช้จะสามารถลดของเสีย เพิ่มคุณภาพสินค้า และลด downtime ซึ่งเป็นปัจจัยสำคัญในการลดต้นทุนการผลิต
- กระตุ้นอุตสาหกรรมการผลิตชิปและโมดูลในประเทศ — เมื่อมีความต้องการบอร์ดและโมดูล FPGA/ASIC ภายในประเทศสูงขึ้น จะมีศักยภาพในการพัฒนา supply chain ภายใน เพิ่มมูลค่าเศรษฐกิจและโอกาสส่งออก
- สนับสนุนความเป็นเจ้าของข้อมูล (data sovereignty) — การประมวลผลที่ขอบเครือข่ายช่วยให้ข้อมูลสำคัญไม่ต้องส่งกลับไปยังคลาวด์กลาง ลดความเสี่ยงด้านความเป็นส่วนตัวและกฎระเบียบ
- เกิดโมเดลธุรกิจใหม่ — ตัวอย่างเช่น การขายโมดูลฮาร์ดแวร์พร้อม Neuro‑Compiler เป็นบริการ (hardware+compiler+maintenance), หรือระบบแบบ subscription สำหรับการอัปเดตโมเดลและซอฟต์แวร์
อย่างไรก็ตาม ต้องยอมรับว่ามีความท้าทายทั้งเรื่องการจัดการซัพพลายเชน การรับรองมาตรฐานความปลอดภัย และการพัฒนาทรัพยากรมนุษย์ หากผู้มีส่วนได้ส่วนเสียทั้งภาครัฐ ภาคเอกชน และสถาบันการศึกษา ประสานงานเชิงกลยุทธ์ร่วมกัน ภายใน 3–5 ปี ไทยมีศักยภาพที่จะกลายเป็นศูนย์กลางหนึ่งของ Edge‑AI ที่เน้นโซลูชัน latency ต่ำสำหรับอุตสาหกรรมในภูมิภาคได้อย่างแท้จริง
บทสรุป
Neuro‑Compiler เป็นเทคโนโลยีแปลงโมเดล Machine Learning เป็น bitstream สำหรับ FPGA/ASIC อัตโนมัติที่มีศักยภาพสูงในการลดทั้ง latency และการใช้พลังงานสำหรับงาน Edge‑AI โดยบริษัทผู้พัฒนาอ้างว่าเทคนิคการแมปโครงข่าย การคอนเวิร์ตเชิงปริมาณ (quantization) และการจัดตารางการคำนวณช่วยให้ระบบตอบสนองในระดับมิลลิวินาที เหมาะต่อการใช้งานแบบเรียลไทม์ในโรงงานและอุปกรณ์ IoT เช่น ระบบควบคุมเชิงแสง ตรวจจับความผิดปกติของเครื่องจักร และหุ่นยนต์ขนาดเล็กในการผลิต ตัวอย่างการทดสอบต้นแบบแสดงผลลัพธ์ที่น่าสนใจ ได้แก่ latency ต่ำกว่า 10 ms ในงานบางประเภทและการประหยัดพลังงานหลายเท่าตัวเมื่อเทียบกับการรันบน CPU/GPU ทั่วไป ซึ่งเปิดทางให้การนำ AI ไปใช้งานเชิงปฏิบัติการ (operational AI) ในฝั่ง edge เป็นไปได้จริงมากขึ้น
อย่างไรก็ตาม ยังมีข้อจำกัดด้านเทคนิคและความท้าทายที่ต้องแก้ก่อนการนำขึ้นสเกลเชิงพาณิชย์ เช่น การยืนยันความถูกต้องของฮาร์ดแวร์ (functional verification, timing closure), ความเข้ากันได้กับแพลตฟอร์ม FPGA/ASIC ที่หลากหลาย, การจัดการกับโมเดลที่มีโครงสร้างซับซ้อน และประเด็นด้านความน่าเชื่อถือและความปลอดภัยของ bitstream การร่วมมือกับพันธมิตรเชิงอุตสาหกรรม—รวมทั้งผู้ผลิตชิป โรงงานผู้ผลิตฮาร์ดแวร์ ผู้จัดจำหน่ายระบบอัตโนมัติ และลูกค้าต้นแบบ—พร้อมการทดสอบในสภาพแวดล้อมจริง (pilot projects) จะเป็นกุญแจสำคัญในการยืนยันสมมติฐานด้านประสิทธิภาพและความทนทาน ก่อนขยายการใช้งานอย่างกว้างขวาง
มุมมองอนาคต Neuro‑Compiler มีโอกาสเปลี่ยนโฉมการใช้งาน Edge‑AI ในภาคการผลิตและ IoT โดยผลักดันให้เกิดแอปพลิเคชันที่ต้องการการตอบสนองทันที เช่น การควบคุมแบบปิดวงจร (closed‑loop control), การตรวจจับความผิดปกติแบบเรียลไทม์ และหุ่นยนต์อัตโนมัติ ในทางปฏิบัติ การเกิดขึ้นของเทคโนโลยีนี้เชิงพาณิชย์จะขึ้นกับความสำเร็จของการพิสูจน์แนวคิดในสถานการณ์จริง ระยะเวลาในการขยายตัวอาจเป็นไปได้ตั้งแต่การทำพอทไพล็อตภายใน 1–2 ปี ไปจนถึงการใช้งานเชิงพาณิชย์กว้างขวางใน 3–5 ปี ขึ้นกับความร่วมมือด้านระบบนิเวศ (มาตรฐาน เครื่องมือยืนยัน และโมเดลการให้บริการ) ที่จะช่วยลดความเสี่ยงและเพิ่มความเชื่อมั่นให้กับผู้ประกอบการและผู้ผลิตอุปกรณ์



