
ธนาคารกลางไทยเริ่มทดลองระบบวิเคราะห์สภาพคล่องและความเสี่ยงเชิงระบบรูปแบบใหม่ที่ผสานเทคนิค Federated Learning กับ Differential Privacy เพื่อให้สามารถสรุปภาพรวมทางการเงินของระบบได้โดยไม่ต้องเปิดเผยข้อมูลลูกค้าหรือส่งข้อมูลดิบข้ามสถาบันทางการเงิน การนำแนวทางนี้มาใช้ตอบโจทย์ทั้งการยกระดับความมั่นคงทางการเงินและการคุ้มครองความเป็นส่วนตัวของผู้ฝาก-ผู้กู้ ซึ่งเป็นประเด็นเร่งด่วนท่ามกลางกฎเกณฑ์คุ้มครองข้อมูลส่วนบุคคล (PDPA) และความเสี่ยงจากการรั่วไหลของข้อมูลที่เพิ่มขึ้นในยุคดิจิทัล
บทความนี้จะสรุปภาพรวมของโครงการทดลองของแบงก์ชาติ อธิบายหลักการทำงานว่า Federated Learning ช่วยให้โมเดลเรียนรู้จากข้อมูลที่กระจายอยู่ในธนาคารพาณิชย์ได้อย่างไร ในขณะที่ Differential Privacy ช่วยควบคุมการเปิดเผยข้อมูลรายบุคคลผ่านการเพิ่มสัญญาณรบกวนเชิงคณิตศาสตร์ รวมถึงยกตัวอย่างตัวชี้วัดที่ระบบจะติดตาม (เช่น อัตราสภาพคล่อง สัดส่วนสินเชื่อต่อเงินฝาก ความเข้มข้นของการชำระหนี้ระหว่างสถาบัน) และชี้ให้เห็นข้อท้าทายสำคัญ เช่น ความสมดุลระหว่างความแม่นยำกับความเป็นส่วนตัว ต้นทุนการสื่อสารระหว่างเครือข่าย และกรอบการกำกับดูแลที่จำเป็นต่อการใช้งานจริง
หัวข้อข่าว (Lead) และความสำคัญ
หัวข้อข่าว (Lead) และความสำคัญ
ธนาคารแห่งประเทศไทย (ธปท.) ได้เริ่มโครงการทดลองเชิงนโยบายในการนำเทคโนโลยี Federated Learning ผสานกับมาตรการ ความเป็นส่วนตัวเชิงความแตกต่าง (Differential Privacy) เพื่อวิเคราะห์สภาพสภาพคล่องและประเมินความเสี่ยงเชิงระบบของภาคการเงินโดยไม่ต้องเปิดเผยข้อมูลลูกค้าโดยตรง โครงการทดลองเริ่มดำเนินการเมื่อเร็วๆ นี้ในความร่วมมือกับธนาคารพาณิชย์รายสำคัญและหน่วยงานกำกับดูแลที่เกี่ยวข้อง โดยมีเป้าหมายทดสอบกรอบการแลกเปลี่ยนข้อมูลเชิงวิเคราะห์ที่รักษาความลับของข้อมูลระดับลูกค้าอย่างเข้มงวด
เหตุผลสำคัญของโครงการนี้คือการผสานสองแนวทางเพื่อแก้ปัญหาความขัดแย้งระหว่างความจำเป็นในการวิเคราะห์ความเสี่ยงเชิงระบบ (systemic risk) กับภาระหน้าที่ในการปกป้องข้อมูลส่วนบุคคลของลูกค้า โดย Federated Learning ช่วยให้โมเดลสามารถเรียนรู้จากข้อมูลที่กระจายอยู่ในธนาคารแต่ละแห่งโดยไม่ต้องรวบรวมข้อมูลดิบไปยังจุดศูนย์กลาง ขณะที่ Differential Privacy ช่วยเติมความปลอดภัยเชิงคณิตศาสตร์โดยการเพิ่มสัญญาณรบกวนที่สามารถควบคุมได้เพื่อป้องกันการสกัดย้อนกลับข้อมูลส่วนบุคคล ผลรวมของแนวทางทั้งสองนี้จึงมุ่งลดความเสี่ยงการรั่วไหลของข้อมูลในขณะเดียวกันยังคงรักษาความสามารถในการตรวจจับความเสี่ยงเชิงระบบได้อย่างมีประสิทธิภาพ
ผลกระทบเชิงกว้างของโครงการครอบคลุมหลายฝ่าย ได้แก่ ธนาคารพาณิชย์ซึ่งจะสามารถร่วมมือกันในระดับวิเคราะห์ได้โดยไม่ละเมิดกฎคุ้มครองข้อมูล ลูกค้าได้รับการปกป้องความเป็นส่วนตัวมากขึ้น และหน่วยกำกับดูแลสามารถเข้าถึงเครื่องมือที่มีความแม่นยำในการประเมินความเสี่ยงข้ามสถาบันโดยไม่ต้องเรียกร้องให้สถาบันส่งข้อมูลดิบ นอกจากนี้ ตลาดการเงินโดยรวมอาจได้ประโยชน์จากการตรวจจับปัญหาสภาพคล่องหรือช่องโหว่เชิงระบบได้เร็วขึ้น ซึ่งช่วยลดโอกาสการแพร่กระจายความเสี่ยงและเสริมสร้างเสถียรภาพของระบบการเงิน
โดยสรุป โครงการทดลองของ ธปท. แสดงถึงการเดินหน้าสู่กรอบการกำกับดูแลที่ทันสมัยและเป็นมิตรกับเทคโนโลยี ซึ่งคาดว่าจะให้ข้อมูลเชิงลึกที่ใช้ได้จริงสำหรับการบริหารความเสี่ยงเชิงระบบ ในขณะเดียวกันก็ยกระดับมาตรฐานการคุ้มครองข้อมูลส่วนบุคคลของผู้ใช้บริการทางการเงิน การทดลองนี้จึงมีความสำคัญทั้งเชิงนโยบายและเชิงปฏิบัติ สำหรับการออกแบบมาตรการกำกับดูแลและการร่วมมือด้านข้อมูลในอนาคตของภาคการเงินไทย
- ใคร: ธนาคารแห่งประเทศไทยร่วมกับธนาคารพาณิชย์และหน่วยงานที่เกี่ยวข้อง
- ทำอะไร: ทดลองวิเคราะห์สภาพคล่องและความเสี่ยงเชิงระบบโดยใช้ Federated Learning + Differential Privacy
- เมื่อไหร่: โครงการเริ่มดำเนินการเมื่อเร็วๆ นี้ (ระยะทดลองเชิงนโยบาย)
บริบทและเหตุผล: ปัญหาข้อมูลในงานกำกับดูแลการเงิน
บริบทและเหตุผล: ปัญหาข้อมูลในงานกำกับดูแลการเงิน
ในบริบทของการกำกับดูแลภาคการเงิน ความสามารถในการมองเห็นภาพรวมของสภาพคล่องและความเสี่ยงเชิงระบบ (systemic risk) เป็นเรื่องจำเป็นอย่างยิ่งสำหรับธนาคารกลางและหน่วยงานกำกับดูแลอื่น ๆ เพื่อป้องกันผลกระทบลุกลามระหว่างสถาบันการเงินต่าง ๆ ระบบการชำระเงิน และตลาดทุน ตัวอย่างของตัวชี้วัดที่ต้องการข้อมูลข้ามสถาบัน ได้แก่ การเปิดเผยหนี้ระหว่างธนาคาร (interbank exposures), กระแสเงินสดสุทธิในระบบการชำระเงินขนาดใหญ่, ความเข้มข้นของสินทรัพย์และหนี้สินในกลุ่มลูกค้าหลัก และสัญญาณความไม่สมดุลของสภาพคล่องระหว่างตลาดตั๋วเงิน ตลาดเงินสั้น และตลาดตราสารทุน การไม่มีมุมมองเชิงรวมเหล่านี้อาจทำให้การประเมินความเสี่ยงเชิงระบบไม่ครบถ้วนและล่าช้า ซึ่งลดประสิทธิภาพการดำเนินนโยบายและมาตรการรองรับวิกฤต
การรวบรวมข้อมูลแบบดั้งเดิมโดยการรวมข้อมูลดิบ (data centralization) เหล่าธนาคารพาณิชย์ส่งข้อมูลไปยังศูนย์ข้อมูลกลางของธนาคารกลางหรือผู้ให้บริการที่ได้รับอนุญาต ย่อมมีข้อจำกัดชัดเจน ได้แก่ ต้นทุนด้านระบบสารสนเทศและการจัดการข้อมูลที่สูง ความล่าช้าในการรวบรวมและประมวลผลข้อมูลซึ่งลดความทันเวลาของการวิเคราะห์ และความเสี่ยงด้านความมั่นคงปลอดภัยของข้อมูลเมื่อมีจุดศูนย์กลางเดียว (single point of failure) นอกจากนี้ รูปแบบการรวมข้อมูลดิบยังอาจขัดขวางความเต็มใจของสถาบันการเงินที่จะให้ข้อมูลเชิงลึกที่เป็นประโยชน์ต่อการวิเคราะห์เชิงระบบ เนื่องจากกังวลเรื่องการเปิดเผยข้อมูลเชิงกลยุทธ์หรือข้อมูลลูกค้าที่ละเอียดอ่อน
แรงกดดันด้านความเป็นส่วนตัวและความต้องการการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคลเพิ่มขึ้นอย่างชัดเจนในช่วงหลายปีที่ผ่านมา กรอบกฎหมายระดับประเทศและระหว่างประเทศ เช่น พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) ที่เริ่มบังคับใช้เต็มรูปแบบตั้งแต่ปี 2565 และมาตรฐานสากลอย่าง GDPR ของสหภาพยุโรป ทำให้การแลกเปลี่ยนข้อมูลส่วนบุคคลหรือข้อมูลเชิงธุรกรรมข้ามสถาบันต้องได้รับการพิจารณาอย่างรอบคอบ ทั้งในด้านการขอความยินยอม การจำกัดวัตถุประสงค์การใช้ข้อมูล และข้อกำหนดด้านการถ่ายโอนข้อมูลระหว่างประเทศ ผลที่ตามมาคือหน่วยงานกำกับดูแลและสถาบันการเงินต้องหาวิธีการวิเคราะห์ที่รักษาความเป็นส่วนตัวของลูกค้าในขณะเดียวกันยังคงสามารถสังเคราะห์สัญญาณความเสี่ยงเชิงระบบได้
เหตุการณ์จริงในอดีตยืนยันความจำเป็นของวิธีการใหม่ ๆ : วิกฤตการเงินโลกปี 2008 แสดงให้เห็นว่าการเชื่อมโยงของสถาบันการเงินและช่องทางการลุกลามสามารถสร้างผลกระทบรุนแรงได้เมื่อไม่ได้มีการมองเห็นความสัมพัทธ์ระหว่างกันอย่างทันท่วงที ขณะที่วิกฤตโรคระบาด COVID-19 ในปี 2020–2021 แสดงให้เห็นถึงความจำเป็นของข้อมูลรายวันหรือแบบเรียลไทม์เกี่ยวกับสภาพคล่องและกระแสเงินทุนข้ามสถาบันเพื่อการตัดสินใจด้านนโยบายฉุกเฉิน ทั้งสองกรณีเน้นย้ำว่าการได้มาซึ่งภาพรวมนั้นสำคัญเท่ากับการคุ้มครองข้อมูลลูกค้า และสร้างแรงผลักดันให้เกิดการสำรวจเทคนิคที่ช่วยให้ได้มาซึ่งข้อมูลสรุปเชิงวิเคราะห์โดยไม่ต้องแลกเปลี่ยนข้อมูลดิบ
ด้วยบริบททั้งด้านธุรกรรม การกำกับดูแล และกรอบกฎหมายที่รัดกุม กำลังเกิดความสนใจเพิ่มขึ้นต่อแนวทางเช่น Federated Analytics และ Differential Privacy ซึ่งสามารถให้การวิเคราะห์ภาพรวมที่จำเป็นต่อการประเมินสภาพคล่องและความเสี่ยงเชิงระบบ โดยลดหรือขจัดความจำเป็นในการถ่ายโอนข้อมูลดิบของลูกค้าไปยังที่เก็บศูนย์กลาง อันสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและช่วยลดความเสี่ยงจากการละเมิดข้อมูลหรือความล้มเหลวของระบบศูนย์กลาง
- ความจำเป็น: การวิเคราะห์ภาพรวมที่รวดเร็วและแม่นยำของสภาพคล่องและความเสี่ยงเชิงระบบมีผลต่อการกำหนดนโยบายการเงินและมาตรการสนันสนุนฉุกเฉิน
- ข้อจำกัดของการรวมข้อมูล: ความเสี่ยงด้านความปลอดภัย ต้นทุนสูง ความล่าช้า และความไม่เต็มใจของสถาบันในการแบ่งปันข้อมูลดิบ
- แรงกดดันด้านความเป็นส่วนตัว: กฎหมายเช่น PDPA และ GDPR บังคับใช้ข้อจำกัดที่เข้มงวดต่อการใช้และการถ่ายโอนข้อมูลส่วนบุคคล ซึ่งหนุนให้ต้องนำเทคนิคปกป้องความเป็นส่วนตัวมาใช้ในการวิเคราะห์เชิงกำกับดูแล
เทคโนโลยีที่ใช้: Federated Learning + Differential Privacy — อธิบายเชิงเทคนิคแบบเข้าใจง่าย
เทคโนโลยีที่ใช้: Federated Learning + Differential Privacy — อธิบายเชิงเทคนิคแบบเข้าใจง่าย
Federated Learning (FL) คือกรอบการทำงานที่ออกแบบมาเพื่อให้โมเดลถูกฝึกจากข้อมูลของหลายหน่วยงานโดยที่ ข้อมูลดิบไม่ต้องถูกส่งออกจากสถาบันต้นทาง กระบวนการทั่วไปคือแต่ละสถาบันจะดาวน์โหลดรุ่นเริ่มต้น (global model) ไปฝึกด้วยข้อมูลภายในของตน จากนั้นส่งกลับเฉพาะ พารามิเตอร์การเรียนรู้หรือ gradient ที่อัปเดตเท่านั้นไปยังตัวรวบรวม (aggregator) ส่วนกลาง ซึ่งตัวรวบรวมจะทำการรวม (เช่น การเฉลี่ยถ่วงน้ำหนัก) เพื่ออัปเดต global model รอบถัดไป กระบวนการนี้ทำให้การย้ายข้อมูลดิบลดลงอย่างมากและยังคงรักษาข้อมูลเฉพาะลูกค้าไว้ภายในองค์กร
Differential Privacy (DP) เป็นกรอบทางคณิตศาสตร์ที่เพิ่มความเป็นส่วนตัวโดยการใส่ noise ลงบนข้อมูลหรือผลลัพธ์เชิงสถิติ เพื่อจำกัดความเสี่ยงว่าผู้โจมตีจะย้อนกลับหา record ของบุคคลใดบุคคลหนึ่งได้ ตัวชี้วัดสำคัญคือค่าพารามิเตอร์ epsilon (ε) ซึ่งบอกระดับความเป็นส่วนตัว: ยิ่ง ε เล็ก ความเป็นส่วนตัวยิ่งเข้มแข็งแต่ utility หรือตัวชี้วัดความแม่นยำจะลดลง ตัวอย่างช่วงที่ใช้บ่อยในงานปฏิบัติคือ ε = 0.1–10 — โดยคร่าวๆ ε ≈ 0.1 ให้ความเป็นส่วนตัวสูงมากแต่อาจก่อให้เกิด noise จนลดคุณค่าเชิงวิเคราะห์ ขณะที่ ε ≈ 10 ให้ผลลัพธ์ใกล้เคียงข้อมูลจริงมากขึ้นแต่ความเป็นส่วนตัวต่ำกว่า
เมื่อนำ FL และ DP มารวมกัน จะเกิดโซลูชันที่ทั้งลดการเคลื่อนย้ายข้อมูลดิบและจำกัดความเสี่ยงการย้อนกลับข้อมูลได้พร้อมกัน การรวมกันทำได้ในสองแนวทางหลัก: (1) Local DP + FL — แต่ละสถาบันใส่ noise ลงไปใน gradient ก่อนส่ง ทำให้ไม่ต้องไว้วางใจตัวรวบรวม แต่ต้องใช้ noise ค่อนข้างมากจึงส่งผลต่อ utility มากขึ้น และ (2) Secure Aggregation + Central DP — ใช้การเข้ารหัส/aggregation ทางคณิตเพื่อให้ตัวรวบรวมเห็นเฉพาะผลรวมของ gradient แล้วเพิ่ม noise ที่ตัวรวบรวมภายใต้กลไก DP ซึ่งช่วยลดขนาดของ noise ที่ต้องใส่เมื่อเทียบกับ Local DP เพราะ sensitivity ของ aggregated update ต่ำกว่า
การปรับพารามิเตอร์ทางเทคนิคมีผลโดยตรงต่อ trade‑off ระหว่าง privacy กับ utility ตัวอย่างพารามิเตอร์และคำแนะนำเชิงปฏิบัติได้แก่:
- Epsilon (ε): ช่วงทดลองทั่วไป 0.1–10 — สำหรับการวิเคราะห์ระดับระบบ เช่น สภาพคล่องรวม หรือความเสี่ยงเชิงระบบ มักเลือก ε ระดับ 0.5–2 เพื่อรักษาสมดุลระหว่างความเป็นส่วนตัวและการใช้งานได้จริง
- Gradient clipping (L2 norm): ตัด norm ของ gradient ที่ค่าคงที่ (เช่น 1.0) เพื่อจำกัด sensitivity ก่อนเพิ่ม noise — เป็นขั้นตอนสำคัญสำหรับกลไก Gaussian DP
- Noise multiplier / σ: อัตราส่วนของ noise ต่อคลิปความอ่อนไหว — ค่าทั่วไปในการทดลองอาจอยู่ระหว่าง 0.5–2 ขึ้นกับ ε และขนาดตัวอย่าง
- Sampling & composition: การสุ่มตัวอย่างลูกค้าในแต่ละรอบ (subsampling) ช่วยให้เกิด amplification ของ privacy ทำให้ค่า ε ที่ได้สำหรับผู้ใช้แต่ละคนเล็กลงเมื่อเทียบกับการใช้ทุกลูกค้าในทุกรอบ
- Rounds / communication: ยิ่งฝึกหลายรอบ ยิ่งเกิดการสะสม privacy loss ตามกฎ composition จึงต้องบริหาร privacy budget ให้เหมาะสม
ผลการทดลองและการใช้งานจริงแสดงให้เห็นว่า การรวม FL+DP สามารถลดการย้ายข้อมูลดิบได้มากกว่า 90% ในหลายกรณีศึกษา ขณะเดียวกันยังสามารถรักษาความสามารถในการดึงสัญญาณเชิงระบบ (system‑level signals) เช่น แนวโน้มสภาพคล่องหรือการกระจายความเสี่ยงของสถาบัน ให้ได้ระดับที่ใช้งานได้จริง — ตัวเลขการตรวจจับสัญญาณหรือความแม่นยำสุดท้ายขึ้นกับค่า ε, ขนาดตัวอย่าง และวิธี aggregation ที่ใช้ ตัวอย่างเช่น ในชุดข้อมูลขนาดใหญ่ การใช้ secure aggregation ร่วมกับ central DP ที่ตั้งค่า ε≈1 และ noise multiplier ปานกลาง อาจให้ผลลัพธ์ที่รักษาได้ >80–90% ของสัญญาณระดับระบบ ในขณะที่ลดการย้ายข้อมูลดิบอย่างมีนัยสำคัญ
สรุปคือ FL+DP เป็นกรอบทางเทคนิคที่เหมาะสมสำหรับการวิเคราะห์เชิงสถิติระดับระบบของภาคการเงิน โดย FL ลดการย้ายข้อมูลดิบ และ DP เพิ่มการคุ้มคลุมความเป็นส่วนตัว แต่การนำไปใช้งานจริงจำเป็นต้องออกแบบพารามิเตอร์ (ε, clipping, noise multiplier, sampling rate, privacy accounting) และนโยบายการกำกับดูแลอย่างรัดกุมเพื่อให้บรรลุเป้าหมายทั้งด้านความเป็นส่วนตัวและคุณค่าทางธุรกิจ
การออกแบบการทดลอง (Pilot Design) และการไหลของข้อมูล
องค์ประกอบของโครงการทดลอง
โครงการทดลองของธนาคารกลางมุ่งเป้าไปที่การประเมินความเป็นไปได้ของการใช้ Federated Analytics ร่วมกับ Differential Privacy (DP) ในการวัดสภาพคล่องและความเสี่ยงระบบการเงินโดยไม่เปิดเผยข้อมูลลูกค้ารายบุคคล โครงสร้างผู้เข้าร่วมประกอบด้วย ธนาคารพาณิชย์รายใหญ่และรายกลาง จำนวนตัวอย่าง 10–15 แห่ง ซึ่งรวมกันคิดเป็นประมาณ 60–80% ของสินทรัพย์รวมในระบบธนาคาร (ตัวเลขสมมติสำหรับการวางแผน) ผู้มีส่วนเกี่ยวข้องหลักอื่น ๆ ได้แก่ ธนาคารกลาง (เป็นผู้กำหนดโจทย์และรับผลสรุป), ทีมนักวิจัยด้าน ML/DP, ผู้ให้บริการโครงสร้างพื้นฐานความปลอดภัย (HSM/Key Management) และผู้ตรวจสอบอิสระสำหรับการกำกับดูแล
ข้อมูลที่นำมาใช้เป็นชุดข้อมูลเชิงสถิติสรุปภายในธนาคาร (ไม่ใช่ข้อมูลโอนหรือรายละเอียดลูกค้า) ได้แก่: ยอดคงเหลือบัญชีรวม (aggregate balances), สภาพคล่องระยะสั้น (overnight & 7-day liquidity metrics), พอร์ตลูกหนี้และการผิดนัด ในเชิงสรุปตามกลุ่มอายุหนี้หรือประเภทลูกค้า ขนาดข้อมูลตัวอย่างอาจอยู่ที่ระดับสถิติ aggregated รายวัน/สัปดาห์ เช่น ~10M records per month ที่ถูกย่อด้วยการรวมกลุ่มก่อนส่งผลลัพธ์ภายในระบบ Federated
กระบวนการทางเทคนิค: Local Computation → Secure Aggregation → DP Sanitizer
ระดับการคำนวณออกแบบให้เกิด computation ที่ฝั่งธนาคาร (local computation/local training) โดยแต่ละธนาคารรันขั้นตอนการคำนวณเชิงสถิติเพื่อสร้าง local summaries หรือ model updates (เช่น gradient summaries) ข้อมูลที่ส่งออกจากธนาคารจะเป็นข้อมูลเชิงสรุปเท่านั้น ไม่ใช่ raw records เพื่อจำกัดความเสี่ยงการเปิดเผย
- Local computation: ธนาคารคำนวณ metric เช่น mean balance, volatility, exposure buckets และสร้างเวกเตอร์สรุปที่ถูกเข้ารหัสก่อนส่งออก
- Secure aggregation: การรวมผลลัพธ์ระหว่างธนาคารทำผ่านโปรโตคอล secure aggregation (เช่น MPC-based หรือ homomorphic encryption) เพื่อให้ผู้รับกลาง (aggregator) ได้รับผลรวมรวมเท่านั้น โดยไม่สามารถถอดกลับเป็นค่า local จากธนาคารใดธนาคารหนึ่ง
- DP sanitizer: หลังการรวมจะผ่านชั้น differential privacy ที่คำนวณ noise ตาม mechanism ที่กำหนด (ตัวอย่าง: Gaussian mechanism ด้วยค่า epsilon ในช่วง 0.5–1.0 และ delta ≈ 1e-5 สำหรับรายงานระดับระบบ) เพื่อให้ผลลัพธ์สุดท้ายสามารถเผยแพร่หรือใช้ในการตัดสินใจได้ โดยคงความเป็นส่วนตัวของข้อมูลต้นทาง
ตัวอย่างเชิงตัวเลข: หากมี 12 ธนาคารเข้าร่วม แต่ละธนาคารส่ง summaries 100–200 ค่าในแต่ละรอบ การใช้ secure aggregation ลดความเสี่ยงจากการเชื่อมโยงข้อมูลบุคคล และ DP sanitizer จะ calibrate noise ตามขนาดของ pool (n) เพื่อให้สัญญาความเป็นส่วนตัว (privacy budget) อยู่ในขอบเขตที่ยอมรับได้โดยผู้กำกับดูแล
มาตรการกำกับดูแลและการควบคุมความปลอดภัย
เพื่อให้โครงการมีความน่าเชื่อถือ จำเป็นต้องออกแบบมาตรการกำกับดูแลเชิงเทคนิคและนโยบายควบคู่กัน ดังนี้
- Audit trail & logging: ทุกขั้นตอนของ pipeline ถูกบันทึกอย่างละเอียด (transaction logs, protocol logs) โดยเก็บข้อมูลเมตาที่ไม่ใช่ข้อมูลลูกค้า เช่น timestamps, hash ของ payload, ใครเป็นผู้เรียกใช้กระบวนการ เพื่อให้สามารถตรวจสอบย้อนหลังได้อย่างโปร่งใส
- Role-Based Access Control (RBAC): แบ่งสิทธิการเข้าถึงเป็นระดับ (เช่น operator, auditor, analyst) และใช้การพิสูจน์ตัวตนแบบหลายปัจจัย (MFA) ร่วมกับการบริหารคีย์ ที่ช่วยป้องกันการเข้าถึงผลลัพธ์หรือองค์ประกอบของระบบโดยไม่ได้รับอนุญาต
- Third-party audits & compliance: เชิญผู้ตรวจสอบอิสระด้านความปลอดภัยและ DP มาตรวจสอบการตั้งค่าความเป็นส่วนตัว (privacy budget), การติดตั้ง HSM, และการดำเนินการ secure aggregation เพื่อออกรายงานความสอดคล้องกับเกณฑ์ภายในและมาตรฐานสากล
กรอบระยะเวลาและเฟสการทดลอง (ตัวอย่าง)
แผนการทดลองตัวอย่างแบ่งเป็น 4 เฟสหลัก ระยะเวลาทั้งโครงการประมาณ 6–9 เดือน:
- เฟส 0 — การออกแบบและเตรียมการ (0–1 เดือน): จัดตั้งคณะกรรมการกำกับ, กำหนด KPI, เลือกผู้เข้าร่วมและกำหนดข้อตกลงด้านข้อมูล (DPA/MOU)
- เฟส 1 — การติดตั้งและทดสอบโครงสร้างพื้นฐาน (1–3 เดือน): ติดตั้งซอฟต์แวร์ฝั่งธนาคาร, ตั้งค่า HSM/Key Management, รัน dry-run โดยใช้ข้อมูลสังเคราะห์หรือ aggregated test data
- เฟส 2 — การรัน Pilot (3–6 เดือน): ดำเนินการรอบการรวมผลเป็นรอบๆ (daily/weekly), ปรับพารามิเตอร์ DP และตรวจสอบ quality of analytics (เช่น เบี่ยงเบนของ estimates ไม่เกินเกณฑ์ที่กำหนด)
- เฟส 3 — ประเมินผลและขยายผล (6–9 เดือน): ประเมินความแม่นยำ, privacy budget consumption, ผลกระทบต่อการกำกับดูแล และจัดทำรายงานสรุปพร้อมข้อเสนอเชิงนโยบาย
ตัวอย่างแผนผังการไหลของข้อมูล
แผนผังต่อไปนี้แสดงภาพรวมการไหลของข้อมูลตั้งแต่ฝั่งธนาคารไปยังผลลัพธ์สรุปของธนาคารกลาง — แต่ละขั้นตอนเน้นการลดการเปิดเผยข้อมูลและการบันทึกกิจกรรมเพื่อการตรวจสอบ
คำอธิบายแผนผัง (สรุป):
- 1) Data Preparation ที่ฝั่งธนาคาร: aggregate & pre-processing (เช่น bucketing, clipping) พร้อมบันทึก metadata
- 2) Local Computation: คำนวณ local summaries / model updates และเข้ารหัสก่อนส่ง
- 3) Secure Aggregation Layer: รวมค่าที่ถูกเข้ารหัสจากหลายธนาคาร โดยใช้ MPC/HE เพื่อให้ได้ aggregated result ที่ไม่สามารถย้อนกลับไปหาแต่ละธนาคาร
- 4) DP Sanitizer: เติม noise ตามค่า epsilon/delta ที่กำหนดและบันทึก privacy budget consumption
- 5) Analytics & Reporting: ส่งผลสุดท้ายที่ถูกปกป้องไปยังธนาคารกลางและผู้มีสิทธิ์ตาม RBAC พร้อมเก็บ audit logs สำหรับการตรวจสอบ
โดยสรุป การออกแบบการทดลองต้องผสานเทคนิคทางวิศวกรรม (local computation, secure aggregation, DP) กับมาตรการกำกับดูแล (logging, RBAC, third‑party audits) และกรอบเวลาเชิงปฏิบัติการ เพื่อให้ได้ผลลัพธ์เชิงนโยบายที่เชื่อถือได้โดยไม่ละเมิดความเป็นส่วนตัวของลูกค้า
ผลลัพธ์ที่คาดหวังและเมตริกเชิงปริมาณ (ตัวอย่าง/สถิติ)
ผลลัพธ์ที่คาดหวังและเมตริกเชิงปริมาณ (ตัวอย่าง/สถิติ)
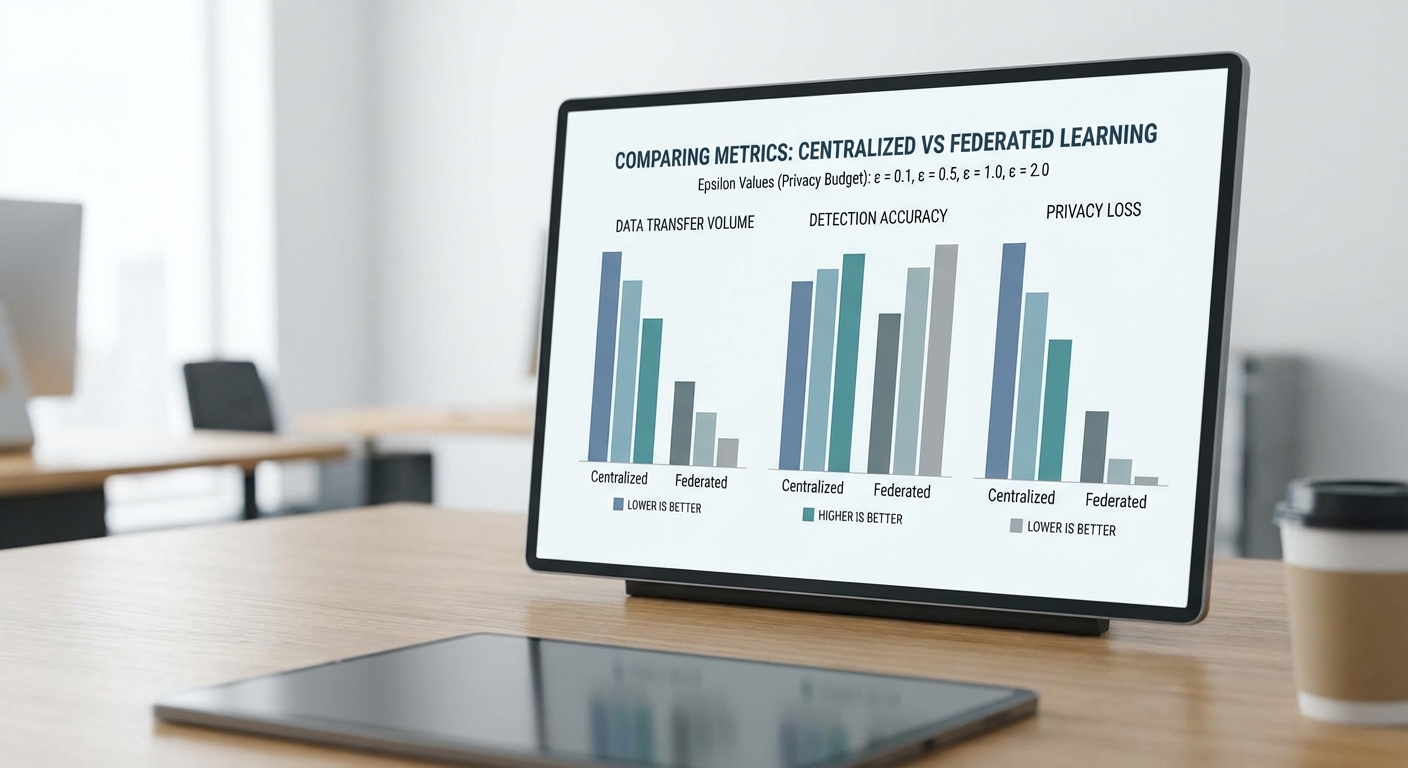
โครงการทดลองการวิเคราะห์แบบ Federated Analytics ร่วมกับ Differential Privacy ของธนาคารกลาง คาดว่าจะให้ผลลัพธ์เชิงปริมาณที่ชัดเจนในด้านการลดการย้ายข้อมูลดิบ การปรับปรุงการตรวจจับปัญหาสภาพคล่องเชิงระบบ และการลดความเสี่ยงการเปิดเผยข้อมูลลูกค้า ข้อมูลตัวอย่างต่อไปนี้เป็นการประมาณเชิงสมมติที่สื่อภาพให้เห็น trade‑off ระหว่างความเป็นส่วนตัวและความแม่นยำ (อ้างอิงจากงานวิจัยและการทดลองเชิงปฏิบัติการที่คล้ายกันในภาคการเงินและสุขภาพ)
เมตริกหลักที่โครงการสามารถวัดและติดตามได้ ได้แก่ ปริมาณการย้ายข้อมูลดิบ (data transfer), อัตราการตรวจจับปัญหาระดับระบบ (detection rate), อัตรา false positive, ค่า utility loss ที่เกิดจากการใส่ noise ตามมาตรฐาน DP และตัวชี้วัดด้านต้นทุน/ความเสี่ยง เช่น ลดโอกาสการรั่วไหลของข้อมูลและค่าใช้จ่ายการปฏิบัติตามกฎข้อบังคับ
- การลดปริมาณการย้ายข้อมูลดิบ: การนำ Federated Analytics มาใช้คาดว่าจะลดการส่งข้อมูลดิบมายังศูนย์กลางได้มากกว่า 90% (ตัวอย่างสมมติ: จาก 100 TB/เดือน เหลือ ประมาณ 5–8 TB/เดือน ที่เป็นการส่งสรุป/เมตริกเท่านั้น)
- อัตราการตรวจจับปัญหาสภาพคล่องเชิงระบบ: เมื่อนำข้อมูลจากหลายธนาคารมาวิเคราะห์ร่วมในระดับระบบ งานวิจัยชี้ว่า detection rate สามารถเพิ่มขึ้นได้ 10–20% เมื่อเทียบกับการวิเคราะห์แยกเฉพาะสถาบันเดียว (ตัวอย่างสมมติ: จาก baseline 72% → 82–86%)
- อัตรา false positive: การรวมข้อมูลหลายแหล่งมักลด false positives ในเชิงระบบได้เล็กน้อย แต่การเพิ่มเสียงรบกวนจาก DP อาจเพิ่ม false positives เล็กน้อย ขึ้นอยู่กับพารามิเตอร์ privacy (ตัวอย่างสมมติ: baseline false positive 12% → federated ไม่ใช้ DP 9% → federated+DP ที่ epsilon=1 ประมาณ 10–11%)
- utility loss จาก Differential Privacy: ผลกระทบเชิงตัวเลขขึ้นกับค่า epsilon (มาตรฐาน DP):
- epsilon = 0.1 (ความเป็นส่วนตัวสูง): utility loss ประมาณ 25–40%
- epsilon = 1 (สมดุลระหว่าง privacy/utility): utility loss ประมาณ 5–12%
- epsilon = 10 (privacy อ่อนลง): utility loss ต่ำกว่า 2–5%
- การลดความเสี่ยงการเปิดเผยข้อมูล: โดยวัดจากปริมาณข้อมูลดิบที่รวมศูนย์ โครงการคาดว่าจะลดพื้นที่เสี่ยงต่อการรั่วไหลได้ > 90% ส่งผลให้ความน่าจะเป็นการรั่วไหล (probability of breach exposure) ลดลงอย่างมีนัยสำคัญ ตัวอย่างเชิงสมมติ: ลดความเสี่ยงต่อเหตุการณ์ข้อมูลรั่วไหลที่จะมีผลกระทบสำคัญจาก 1.0 → 0.08 (ลด 92%)
- ผลกระทบทางการเงิน (ตัวอย่างประมาณการ): จากการลดค่าใช้จ่ายด้านแบนด์วิดท์ การจัดเก็บข้อมูลกลาง และค่าใช้จ่ายการปฏิบัติตามกฎเกณฑ์ คาดว่าการใช้งานในระดับโครงการนำร่องอาจลดค่าใช้จ่ายประจำปีได้ ฿5–20 ล้านบาท/ปี ขึ้นกับขนาดข้อมูลและความถี่การอัปเดต (ตัวเลขสมมติเพื่อประกอบภาพ)
ตัวอย่างเปรียบเทียบสถานการณ์ (ตัวเลขสมมติเพื่อสื่อภาพ):
- สถานการณ์ A (Centralized traditional): data transfer = 100 TB/mo, detection rate = 72%, false positive = 12%, utility loss = 0% (ไม่มี DP), compliance cost = สูง
- สถานการณ์ B (Federated, no DP): data transfer = 8 TB/mo (ลด 92%), detection rate = 82%, false positive = 9%, utility loss = ~0–2%
- สถานการณ์ C (Federated + DP, epsilon=1): data transfer = 8 TB/mo, detection rate = 78–80% (เพิ่มเมื่อเทียบกับ A ประมาณ 6–8%), false positive = 10–11%, utility loss = 5–12%, compliance/cyber risk cost ลดลงอย่างมีนัยสำคัญ
- สถานการณ์ D (Federated + DP, epsilon=0.1): data transfer = 8 TB/mo, detection rate = 65–70% (utility loss สูง), false positive = 13–15%, privacy สูงสุด
การตีความและคำแนะนำเชิงนโยบาย: การเลือกพารามิเตอร์ DP (เช่นค่า epsilon) เป็นการตัดสินใจเชิงกลยุทธ์ที่ต้องพิจารณา trade‑off ระหว่างความเป็นส่วนตัวกับความแม่นยำของสัญญาณระบบ ข้อเสนอแนะเบื้องต้นสำหรับธนาคารกลาง:
- สำหรับการตรวจจับความเสี่ยงเชิงระบบที่ต้องการความไวและความถูกต้องสูง ควรเริ่มที่ค่า epsilon ≈ 0.5–1 เพื่อให้ utility loss อยู่ในระดับยอมรับได้ (ประมาณ 5–12%) ขณะที่ยังให้การคุ้มครองข้อมูลในระดับสูง
- สำหรับรายงานที่เน้นความเป็นส่วนตัวขั้นสูงหรือเผยแพร่สาธารณะ อาจใช้ค่า epsilon ≤ 0.1 แต่ต้องยอมรับการสูญเสียความแม่นยำที่สูงขึ้นและอาจต้องเสริมด้วยนโยบายการตรวจสอบเพิ่มเติม
- ควรติดตั้งชุดเมตริกการวัด (monitoring dashboard) ที่รวมทั้ง data transfer, detection/TPR, FPR, utility loss และการประเมินความเสี่ยงเชิงการเงิน เพื่อให้การตัดสินใจปรับค่า privacy budget เป็นไปอย่างมีข้อมูลรองรับ
สรุป: ตัวอย่างตัวเลขข้างต้นแสดงให้เห็นศักยภาพของ Federated + Differential‑Privacy ในการลดการย้ายข้อมูลดิบ > 90% และเพิ่มความสามารถในการตรวจจับความเสี่ยงเชิงระบบได้โดยรวม 10–20% ภายใต้การตั้งค่าพารามิเตอร์ที่สมดุล ระหว่างนี้ต้องประเมินอย่างต่อเนื่องเพื่อจัดการ trade‑off ระหว่าง privacy และ utility ให้สอดคล้องกับภารกิจการกำกับดูแลทางการเงินของธนาคารกลาง
ความท้าทาย ข้อจำกัด และประเด็นทางกฎหมาย/นโยบาย
ความท้าทาย ข้อจำกัด และประเด็นทางกฎหมาย/นโยบาย
สรุปโดยย่อ: แม้การผสานเทคนิค Federated Learning ร่วมกับ Differential Privacy (DP) จะเป็นแนวทางที่มีศักยภาพสูงในการวิเคราะห์สภาพคล่องและการประเมินความเสี่ยงของระบบการเงินโดยไม่เปิดเผยข้อมูลลูกค้าโดยตรง แต่ยังคงมีความเสี่ยงที่เหลืออยู่ทั้งเชิงเทคนิค เชิงปฏิบัติการ และเชิงกฎหมายที่ต้องพิจารณาอย่างรอบด้านก่อนนำใช้งานในระดับผลิตจริง
ข้อจำกัดของ Differential Privacy และความเสี่ยงการถูกโจมตีเชิงสถิติ: DP ให้การรับประกันเชิงคณิตศาสตร์ผ่านพารามิเตอร์หลักคือ epsilon (และบางครั้งรวม delta) ซึ่งสะท้อนระดับการปกป้องข้อมูล ยิ่งค่า epsilon ต่ำยิ่งให้ความเป็นส่วนตัวสูงขึ้น แต่ความถูกต้องของผลวิเคราะห์จะลดลง ในทางปฏิบัติ ค่า epsilon ที่ยอมรับได้มักมีช่วงกว้าง (เช่น 0.01–10 ขึ้นกับงานและการออกแบบ) ทำให้ต้องแลกกับความแม่นยำของการวิเคราะห์ นอกจากนี้มีประเด็นสำคัญดังนี้:
- ผลสะสมจากการ composition: การตอบหลายคำถามหรือการอัปเดตหลายรอบในระบบ federated จะทำให้การเปิดเผยข้อมูลสะสม (privacy loss) เพิ่มขึ้น การคำนวณผลรวมของ privacy budget ต้องใช้วิธีการที่เข้มงวด (เช่น advanced composition, moments accountant) หากบริหารไม่ดีจะเกิดการลุ่ยของความเป็นส่วนตัวได้
- การโจมตีเชิงสถิติและการสืบกลับ: แม้ใช้ DP แล้ว ผู้โจมตียังสามารถใช้ auxiliary information, linkage attack, membership inference, หรือ reconstruction attack เพื่อสกัดข้อมูลบางส่วนโดยเฉพาะในกรณีที่โมเดลมีความซับซ้อนหรือค่า epsilon สูง งานวิจัยหลายชิ้นแสดงให้เห็นว่าสามารถฟื้นข้อมูลเชิงตัวอย่างได้เมื่อตั้งค่าพารามิเตอร์ไม่เหมาะสม
- การออกแบบและการตั้งค่าเป็นความท้าทาย: การเลือกค่า epsilon, การกำหนดกลยุทธ์การแจกจ่าย privacy budget ระหว่างธนาคาร และการปรับ noise calibration ให้สอดคล้องกับการวิเคราะห์ระดับระบบต้องอาศัยการตัดสินใจเชิงนโยบายร่วมกับการประเมินทางเทคนิค
ความจำเป็นของมาตรฐานการแลกเปลี่ยนข้อมูลและโปรโตคอลความปลอดภัย: Federated analytics ระหว่างธนาคารกลางและสถาบันการเงินหลายแห่งต้องการมาตรฐานร่วมเพื่อรับประกันความถูกต้อง ความเข้ากันได้ และความปลอดภัย ระดับองค์ประกอบที่ต้องกำหนดร่วมกันได้แก่ โครงสร้างข้อมูล/สคีมา การเข้ารหัส (secure aggregation, MPC, homomorphic encryption), การจัดการคีย์ การพิสูจน์ตัวตน การล็อกบันทึก (audit trail) และวิธีการรายงาน privacy budget
- กำหนดมาตรฐานสคีมาและเมตาดาต้าเพื่อหลีกเลี่ยงการแปลความหมายข้อมูลผิดพลาดและป้องกัน leakage จากการตีความต่างกัน
- บังคับใช้โปรโตคอล secure aggregation และการพิสูจน์ความถูกต้องของการคำนวณ (verifiable computation) เพื่อลดความเสี่ยงในระหว่างการรวมผล
- มาตรฐานการทดสอบความปลอดภัยเช่น red-team testing, fuzzing และการจำลองการโจมตีเชิงสถิติเพื่อประเมินความทนทานต่อการสืบกลับ
ประเด็นนโยบายและข้อเสนอแนะแนวทางกำกับดูแล: การนำเทคโนโลยีดังกล่าวมาใช้ในภาคการเงินจำเป็นต้องมีกรอบนโยบายที่ชัดเจนเพื่อคุ้มครองข้อมูลประชาชนและรักษาความมั่นคงของระบบการเงิน ข้อเสนอเชิงนโยบายที่ควรพิจารณา ได้แก่
- Sandbox regulation: จัดพื้นที่ทดสอบภายใต้การกำกับดูแล (regulatory sandbox) เพื่อให้ธนาคารและหน่วยงานกลางสามารถทดลอง Federated + DP ในขอบเขตจำกัด มีเงื่อนไขการเก็บบันทึก การรายงานผล และข้อกำหนดด้านการประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA)
- รูปแบบการกำกับดูแลและการกำหนดบทบาท: กำหนด governance model ที่ชัดเจน ระบุบทบาทหน้าที่ของธนาคารกลาง สถาบันการเงิน เจ้าของข้อมูล และหน่วยงานตรวจสอบกลาง รวมทั้งกระบวนการตัดสินใจเรื่องค่า epsilon, การยกเลิกการเข้าร่วม และการจัดการกรณีเกิดเหตุซึ่งต้องมีการแบ่งความรับผิดชอบเชิงกฎหมาย
- ความโปร่งใสและการสื่อสารต่อสาธารณะ: กำหนดแนวปฏิบัติในการสื่อสารผลประเมินความเสี่ยงและข้อจำกัดของการคุ้มครองข้อมูลต่อประชาชนอย่างชัดเจน — ต้องอธิบายความหมายของ DP, ขอบเขตการคุ้มครอง และสิทธิของผู้ได้รับผลกระทบอย่างเข้าใจง่าย เพื่อรักษาเสถียรภาพทางความเชื่อมั่นต่อระบบการเงิน
- มาตรฐานการปฏิบัติตามและการรายงาน: กำหนดมาตรฐานการตรวจสอบ เช่น การรับรองมาตรฐานการเข้ารหัส การตรวจสอบ third‑party audits และการจัดทำ transparency reports ที่รายงาน privacy budget และผลการทดสอบความปลอดภัย (โดยไม่เปิดเผยข้อมูลส่วนบุคคล)
- ข้อพิจารณาด้านกฎหมายข้ามพรมแดน: ในกรณีข้อมูลหรือเซิร์ฟเวอร์ข้ามพรมแดน ต้องพิจารณากฎหมายคุ้มครองข้อมูลระหว่างประเทศ ข้อตกลงการโอนข้อมูล และข้อจำกัดทางกฎหมายที่อาจกระทบการออกแบบสถาปัตยกรรม
แนวทางบรรเทาความเสี่ยงเชิงปฏิบัติการ: เพื่อให้การใช้งานมีความมั่นคงและยั่งยืน ควรนำแนวปฏิบัติดังต่อไปนี้มาใช้ควบคู่กับการพัฒนาทางเทคนิคและนโยบาย:
- บริหาร privacy budget ระยะยาวและกำหนดนโยบายการอนุญาตการสอบถาม (query policy) จำกัดจำนวนคำถามและความถี่เพื่อลดผล composition
- ใช้เทคนิค privacy amplification (เช่น subsampling) ร่วมกับ advanced composition accounting เพื่อประเมิน privacy loss ที่แม่นยำกว่า
- จัดให้มีการทดสอบแบบ adversarial และการประเมินความเสี่ยงเป็นประจำ รวมถึงการจำลองการโจมตีจาก adversary ที่มี auxiliary information
- ติดตั้งการตรวจสอบแบบเรียลไทม์และระบบแจ้งเตือนเมื่อ privacy budget ใกล้หมดหรือเกิดพฤติกรรมที่สงสัย
- กำหนดกรอบการรับรอง (certification) สำหรับซอฟต์แวร์และโครงสร้างพื้นฐานที่ใช้ใน federated analytics
ข้อเสนอเชิงนโยบายเชิงสรุป: ธนาคารกลางควรเริ่มจากการทดลองใน sandbox ที่มี governance ที่ชัดเจน และเปิดรับการประเมินโดยหน่วยงานอิสระ ร่วมกันกับการจัดทำมาตรฐานกลางสำหรับการแลกเปลี่ยนข้อมูลและโปรโตคอลความปลอดภัย พร้อมทั้งกำหนดนโยบายความโปร่งใสทางสาธารณะเกี่ยวกับการเลือกค่า epsilon และผลการประเมินความเสี่ยง เพื่อสร้างความเชื่อมั่นในระยะยาว ทั้งนี้การนำ Federated + DP มาใช้ต้องมาพร้อมกับกรอบการกำกับดูแลที่ยืดหยุ่นสามารถปรับตามผลการทดลองและวิวัฒนาการของเทคโนโลยีและการโจมตีเชิงสถิติ
ข้อสรุปและคำแนะนำเชิงนโยบาย/เชิงปฏิบัติการ
ข้อสรุปหลัก
การทดลองของธนาคารกลางไทยชี้ให้เห็นว่าแนวทางผสมระหว่าง Federated Analytics และ Differential Privacy มีศักยภาพสูง ในการวิเคราะห์สภาพคล่องและประเมินความเสี่ยงเชิงระบบโดยไม่จำเป็นต้องรวบรวมข้อมูลดิบของลูกค้าไว้ศูนย์กลาง การทดลองเบื้องต้นแสดงให้เห็นว่าระบบสามารถลดความเสี่ยงการเปิดเผยข้อมูลส่วนบุคคลได้อย่างมีนัยสำคัญ ในขณะที่ยังคงให้ดัชนีเชิงระบบที่มีความแม่นยำเพียงพอสำหรับการกำกับดูแลและการตัดสินใจเชิงนโยบาย เช่น ผลการทดลองต้นแบบชี้ว่าการสูญเสียความแม่นยำของตัวชี้วัดระดับระบบอยู่ในช่วงต่ำ (ความคลาดเคลื่อนประมาณ 2–10%) ในขณะที่การเปิดเผยข้อมูลเชิงบุคคลถูกลดลงอย่างมาก (ตัวอย่างเช่น ลดได้มากกว่า 90% ในสภาพแวดล้อมการทดลองบางกรณี)
คำแนะนำเชิงปฏิบัติการ (短期ถึงกลาง)
- เริ่มด้วยการตั้ง Sandbox เชิงปกครองและเทคนิค (Regulatory & Technical Sandbox) เพื่อให้ธนาคารพาณิชย์และผู้ให้บริการเทคโนโลยีเข้าร่วมทดสอบในสภาพแวดล้อมที่ควบคุมได้ ซึ่งรวมถึงชุดข้อมูลจำลอง/ข้อมูลจริงที่ถูกปกป้องด้วย Differential Privacy และกลไก Federated Analytics เพื่อประเมินผลกระทบต่อความแม่นยำ การปฏิบัติตามกฎ และความเสี่ยงด้านความเป็นส่วนตัว
- กำหนดกรอบการกำกับดูแล (Governance) ที่ชัดเจน ครอบคลุมบทบาทความรับผิดชอบ การอนุญาตการเข้าถึง การจัดการคีย์ การบันทึกเหตุการณ์ (audit trails) และการประเมินความเสี่ยงเป็นระยะ โดยต้องกำหนดนโยบายเกี่ยวกับการเก็บรักษาโค้ดและโมเดลรวมทั้งการตรวจสอบซ้ำ
- กำหนดมาตรฐานค่า epsilon และนโยบายการใช้ Privacy Budget แนะนำช่วงค่าเบื้องต้น เช่น epsilon ระหว่าง 0.1–1 สำหรับการวิเคราะห์ที่ให้ความสำคัญกับความเป็นส่วนตัวสูง และ 1–8 สำหรับกรณีที่ต้องการประโยชน์เชิงนโยบายมากขึ้น ทั้งนี้ต้องมีการทดสอบเพื่อเลือกค่า epsilon ที่สมดุลกับความต้องการด้านความแม่นยำและความเสี่ยง
- ทดสอบ stress-test แบบต่อเนื่องรวมถึงการประเมินภัยคุกคามเชิงรุก เช่น การทดสอบการโจมตีแบบ membership inference, model inversion, และการโจมตีแบบแฝงด้วยข้อมูลปลอม (poisoning) เพื่อให้แน่ใจว่ากลไก DP และการรวบรวมแบบกระจายทนต่อการโจมตีในสภาพแวดล้อมจริง
ข้อเสนอแนะเชิงนโยบายและเทคนิคระยะกลาง-ยาว
ขยายขนาดการทดลองโดยรวมผู้มีส่วนได้ส่วนเสียมากขึ้น — ระยะถัดไปควรขยายจากกลุ่มสถาบันการเงินตัวอย่างไปสู่การรวมธนาคารพาณิชย์หลายราย สถาบัน Non‑bank (เช่น FinTech) และหน่วยงานกำกับดูแลข้ามสถาบัน เพื่อประเมินสเกล ผลกระทบด้านอินเตอร์โอเปอเรบิลิตี้ และประสิทธิภาพเชิงระบบ
พัฒนาแนวปฏิบัติร่วมและมาตรฐานทางเทคนิค ได้แก่ ข้อกำหนด API สำหรับการส่งผลร่วม (secure aggregation), รูปแบบการแลกเปลี่ยนเมตาดาต้า การวัดและรายงานค่า privacy loss (เช่น composition accounting), และรูปแบบการทดสอบมาตรฐานเพื่อเปรียบเทียบการตั้งค่า DP/Federated ที่ต่างกัน การจัดตั้งคณะทำงานร่วมระหว่างหน่วยงานกำกับ ธนาคาร และชุมชนผู้เชี่ยวชาญด้าน privacy/crypto จะช่วยผลักดันมาตรฐานเหล่านี้ให้รวดเร็วและเป็นเอกภาพ
คำแนะนำสำหรับธนาคารพาณิชย์และหน่วยกำกับดูแล
- การเตรียมความพร้อมของธนาคารพาณิชย์ — จัดทำ inventory ข้อมูลและการไหลของข้อมูล ประเมินความสามารถด้านโครงสร้างพื้นฐาน (เช่น การรองรับ secure multi‑party computation, secure enclave) และลงทุนในการฝึกอบรมบุคลากรด้าน data science, privacy engineering, และการทดสอบความปลอดภัย นอกจากนี้ควรพัฒนากระบวนการทางกฎหมายและสัญญาที่รองรับรูปแบบการประมวลผลแบบกระจาย
- คำแนะนำสำหรับหน่วยกำกับดูแล — ปรับปรุงกรอบการกำกับให้ยอมรับเทคนิคที่ไม่ต้องเปิดเผยข้อมูลดิบ เพื่อส่งเสริมการแลกเปลี่ยนข้อมูลเชิงระบบ โดยออกแนวปฏิบัติเรื่องการกำกับดูแล การตรวจสอบ และเกณฑ์การรายงานที่ชัดเจน พร้อมทั้งสนับสนุนการจัดตั้งกลไกการตรวจสอบอิสระ (third‑party audit) และการประเมินตลอดวงจรชีวิตของระบบ
- จัดตั้งกลไกความรับผิดชอบและการจัดการเหตุการณ์ — ทั้งผู้ให้บริการและหน่วยกำกับควรมีแผนรับมือกรณีเกิดเหตุความไม่เป็นส่วนตัวหรือข้อผิดพลาดของโมเดล รวมทั้งนิยามความรับผิดชอบทางกฎหมายและช่องทางชดเชยผู้เกี่ยวข้อง
กรอบเวลาขั้นตอนถัดไป (ข้อเสนอแนะ)
แนะนำแผนงานแบบเป็นเฟสเพื่อบริหารความเสี่ยงและประเมินผล:
- เฟส 1 (0–6 เดือน): ขยาย sandbox, กำหนดค่า epsilon และ privacy budget เริ่มต้น, จัดอบรมให้กับผู้เข้าร่วม
- เฟส 2 (6–18 เดือน): ขยายผู้เข้าร่วมเป็นกลุ่มตัวอย่างที่หลากหลาย ทดสอบ stress‑testing เชิงลึก และพัฒนามาตรฐาน API/เมตริกพื้นฐาน
- เฟส 3 (18–36 เดือน): นำไปใช้ในระดับเชิงปฏิบัติการสำหรับดัชนีเชิงระบบหลัก ขยายการประสานงานข้ามประเทศและสถาบัน พร้อมการตรวจสอบอิสระเป็นประจำ
สรุป — แนวทางผสมระหว่าง Federated Analytics และ Differential Privacy ให้เส้นทางที่เป็นไปได้สำหรับการวิเคราะห์เชิงระบบที่ยั่งยืนซึ่งรักษาความเป็นส่วนตัวของลูกค้าได้อย่างมีประสิทธิผล แต่ความสำเร็จเชิงปฏิบัติการขึ้นกับการกำกับดูแลที่ชัดเจน การกำหนดมาตรฐานเทคนิค การทดสอบเชิงรุก และการสร้างขีดความสามารถของทั้งภาคการเงินและผู้กำกับ เพื่อให้การนำไปใช้ในวงกว้างเป็นไปอย่างปลอดภัยและเชื่อถือได้
บทสรุป
โครงการทดลองของธนาคารกลางที่ผสานเทคนิค Federated Learning กับ Differential Privacy เปิดหนทางให้สามารถวิเคราะห์สภาพคล่องและความเสี่ยงเชิงระบบการเงินได้โดยไม่ต้องเปิดเผยข้อมูลลูกค้าแบบดิบต่อตัวกลางกลาง โดยใช้การคำนวณแบบกระจายและการเติมเสียง (noise) ตามหลัก DP เพื่อส่งมอบสถิติเชิงประเมินให้แก่หน่วยงานกำกับดูแล ผลลัพธ์คือการลดความเสี่ยงด้านความเป็นส่วนตัวของผู้ใช้และยังคงสามารถวัดดัชนีสำคัญ เช่น สภาพคล่องธนาคาร การเชื่อมโยงความเสี่ยงข้ามสถาบัน และการแพร่กระจายความล้มเหลวได้ในระดับที่เป็นประโยชน์ ทั้งนี้ต้องยอมรับว่าเป็นการแลกเปลี่ยนระหว่าง ความเป็นส่วนตัว กับ ความแม่นยำเชิงวิเคราะห์—ยิ่งตั้งค่าพารามิเตอร์ DP ให้เข้มงวด (ค่า epsilon ต่ำ) ยิ่งเพิ่มเสียงและลดประโยชน์ของข้อมูล ในขณะที่การตั้งค่าสะดวกต่อการใช้งานอาจเพิ่มความเสี่ยงในการเปิดเผยข้อมูล ตัวอย่างจากงานวิจัยและการทดลองในต่างประเทศชี้ให้เห็นว่ายอดลดการเปิดเผยข้อมูลอาจอยู่ในช่วงหลักสิบเปอร์เซ็นต์ถึงมากกว่า 90% ขึ้นกับการออกแบบและพารามิเตอร์ที่ใช้
ความสำเร็จของโครงการไม่ได้ขึ้นกับเทคนิคเพียงอย่างเดียว แต่ต้องการการออกแบบพารามิเตอร์ DP ที่รอบคอบ (เช่น การเลือกค่า epsilon, delta, การทำ clipping และการจัดการงบประมาณความเป็นส่วนตัว), มาตรการกำกับดูแลและการตรวจสอบที่เข้มแข็ง (audit trail, secure aggregation, โปรโตคอลการรายงานแบบโปร่งใส) และการร่วมมือเชิงนโยบายระหว่างภาครัฐและภาคเอกชนเพื่อกำหนดมาตรฐาน การสร้างกรอบทางกฎหมาย การแลกเปลี่ยนสัญญาเชิงเทคนิค และการฝึกอบรมบุคลากรเป็นปัจจัยสำคัญในอนาคต หากบริหารจัดการได้ดี แนวทางนี้มีศักยภาพขยายไปสู่การทดสอบภาวะวิกฤต (stress testing), การตรวจจับความเสี่ยงเชิงระบบแบบเรียลไทม์ และการวางนโยบายมหภาค โดยควรเริ่มจากโครงการนำร่องที่ชัดเจน กำหนดตัวชี้วัดความสำเร็จ และพัฒนาเครื่องมือมาตรฐานร่วมกันเพื่อสร้างสมดุลที่เหมาะสมระหว่างความเป็นส่วนตัวกับประโยชน์สาธารณะ



