
OpenAI ประกาศเปิดตัว GPT-5.3 Instant รุ่นล่าสุดที่ออกแบบมาเพื่อยกระดับประสบการณ์การสนทนาด้วยปัญญาประดิษฐ์ให้ “ลื่นไหล” และใช้งานได้จริงมากขึ้นในชีวิตประจำวัน ผู้ใช้จะสัมผัสได้ทันทีจากการตอบสนองที่เร็วขึ้น ฟีเจอร์สตรีมคำตอบแบบเรียลไทม์ และการเข้าใจบริบทที่แม่นยำขึ้น ซึ่งทั้งหมดถูกนำมารวมกันเพื่อให้การโต้ตอบรู้สึกเป็นธรรมชาติ คล้ายการสนทนากับมนุษย์มากขึ้น โดยไม่สะดุดในช่วงเปลี่ยนหัวข้อหรือเมื่อต้องจัดการคำสั่งหลายชั้น
บทความนี้จะพาไปรู้จักภาพรวมของ GPT-5.3 Instant ตั้งแต่การลดความหน่วง (latency) และการสตรีมคำตอบแบบเรียลไทม์ ไปจนถึงการปรับปรุงความเข้าใจบริบทที่ช่วยแก้ปัญหางานประจำวัน เช่น การร่างอีเมล วางแผนกิจวัตร หรือสนับสนุนการทำงานของทีมในองค์กร เราจะสรุปฟีเจอร์เด่น ตัวอย่างการใช้งานจริง ผลกระทบต่อธุรกิจ และข้อพิจารณาด้านความเป็นส่วนตัวและความปลอดภัย เพื่อช่วยผู้อ่านตัดสินใจว่า GPT-5.3 Instant จะเปลี่ยนวิธีที่คุณใช้ AI ในชีวิตและงานอย่างไร
บทนำ: ทำไม GPT-5.3 Instant จึงสำคัญ
บทนำ: ทำไม GPT-5.3 Instant จึงสำคัญ
OpenAI เปิดตัว GPT-5.3 Instant ซึ่งนับเป็นการอัปเดตเชิงสำคัญที่มุ่งเน้นไปที่ประสบการณ์การสนทนาแบบทันทีทันใด (instant responsiveness) และการใช้งานที่มีประโยชน์ต่อการดำเนินชีวิตประจำวันของผู้ใช้ทั่วไปและองค์กรธุรกิจ โดยในภาพรวมการอัปเดตนี้ถูกออกแบบมาเพื่อลดความหน่วงของการตอบกลับ ทำให้โมเดลสามารถตอบในลักษณะ เรียลไทม์ มากขึ้น และลดขั้นตอนความยุ่งยากในการผนวกเทคโนโลยีเข้ากับแอปพลิเคชันต่าง ๆ
จุดประสงค์หลักของอัปเดต ประกอบด้วยการลด latency ในการประมวลผลและส่งข้อความ เพื่อให้การโต้ตอบไหลลื่นเหมือนการสนทนาจริง (conversational flow) การปรับปรุงการตอบต่อแบบเรียลไทม์ซึ่งเอื้อต่อการใช้งานเช่นผู้ช่วยส่วนตัว การบริการลูกค้าแบบทันที และแอปที่ต้องการข้อมูลตอบกลับแบบทันที รวมทั้งการทำให้ API และเครื่องมือสำหรับนักพัฒนาง่ายต่อการใช้งานและผสานเข้ากับระบบเดิมได้รวดเร็วขึ้น
สำหรับผู้ใช้ทั่วไป ผลลัพธ์ที่คาดหวังคือการสนทนาที่มีความต่อเนื่อง ลดความล่าช้าเมื่อสลับบริบทและตอบคำถามได้อย่างเป็นธรรมชาติยิ่งขึ้น ตัวอย่างเช่น การจองตั๋ว ปรึกษาเรื่องการเงิน หรือการรับคำแนะนำเชิงปฏิบัติจะรู้สึกเหมือนคุยกับผู้ช่วยที่ตอบกลับทันที ในขณะที่สำหรับนักพัฒนาและธุรกิจ การอัปเดตนี้หมายถึงการลดต้นทุนด้าน latency, การเพิ่มประสิทธิภาพในการสเกลระบบ และการพัฒนาอินทิเกรชันใหม่ ๆ ที่ตอบโจทย์การใช้งานแบบเรียลไทม์ เช่น แชทบอทบริการลูกค้าแบบ omnichannel และระบบคำสั่งเสียงที่ต้องการเวลาแฝงต่ำ
ในบทความนี้ เราจะอ้างอิงข้อมูลหลักจาก OpenAI blog และเอกสารประกาศ (release notes / documentation) ของ OpenAI เพื่อสรุปฟีเจอร์สำคัญ ผลกระทบต่อผู้ใช้และธุรกิจ รวมถึงแนวทางปฏิบัติและตัวอย่างการใช้งานที่เป็นประโยชน์ รายการแหล่งข้อมูลที่จะใช้ประกอบบทความมีดังนี้:
- OpenAI Blog: ประกาศเปิดตัวและคำอธิบายเชิงเทคนิคเบื้องต้น
- Release Notes / Documentation ของ OpenAI: รายละเอียด API, ข้อจำกัด, และแนวทางการผสานระบบ
- ตัวอย่างกรณีการใช้งานและคำแนะนำจากนักพัฒนา: บทสัมภาษณ์/โพสต์ทางเทคนิคที่เกี่ยวข้อง
ฟีเจอร์เด่นของ GPT-5.3 Instant (เชิงเทคนิคและฟังก์ชัน)
GPT-5.3 Instant มาพร้อมชุดฟีเจอร์เชิงเทคนิคที่ออกแบบมาเพื่อลดแรงเสียดทานระหว่างผู้ใช้กับโมเดล ทำให้การสนทนาเป็นไปอย่างต่อเนื่องและเหมาะสมกับการใช้งานเชิงธุรกิจในชีวิตประจำวัน ฟีเจอร์หลักครอบคลุมตั้งแต่การสตรีมคำตอบแบบทันที (instant streaming) การปรับสถาปัตยกรรมเพื่อลด latency การจัดการ context ที่ยืดหยุ่นและแม่นยำยิ่งขึ้น รวมถึง API/SDK ใหม่ที่ช่วยให้การผสานรวมกับแอปพลิเคชันเชิงองค์กรเป็นไปอย่างราบรื่น
Instant streaming: คำตอบไหลเป็น token ทันที
Instant streaming คือความสามารถที่ GPT-5.3 Instant ส่งผลลัพธ์เป็น token แบบเรียลไทม์ทันทีเมื่อเริ่มสร้างคำตอบ แทนที่จะรอให้โมเดลประมวลผลทั้งหมดก่อนส่งผลลัพธ์กลับมา วิธีนี้ช่วยให้ผู้ใช้เห็นคำตอบส่วนแรกภายในช่วงเวลาสั้นมาก (ตัวอย่างการทดสอบภายในระบุว่า token แรกอาจปรากฏภายใน ~50–150 ms ขึ้นกับสภาพแวดล้อม) ซึ่งช่วยลดความรู้สึกหน่วงและเพิ่มประสบการณ์การใช้งานในการประชุมออนไลน์ แชทบอทเชิงบริการลูกค้า และแอปที่ต้องโต้ตอบทันที
ข้อดีเชิงปฏิบัติประกอบด้วย:
- การตอบสนองที่รู้สึกรวดเร็วขึ้น — ผู้ใช้ได้รับข้อมูลเบื้องต้นก่อนที่คำตอบทั้งหมดจะเสร็จ
- รองรับการแสดงผลแบบก้าวหน้า — สามารถเริ่มแสดงคำตอบขณะยังประมวลผลส่วนถัดไป
- ช่วยให้ UI/UX มีความลื่นไหล — ลดการกระพริบหรือหน้าจอรอคอย (stall)
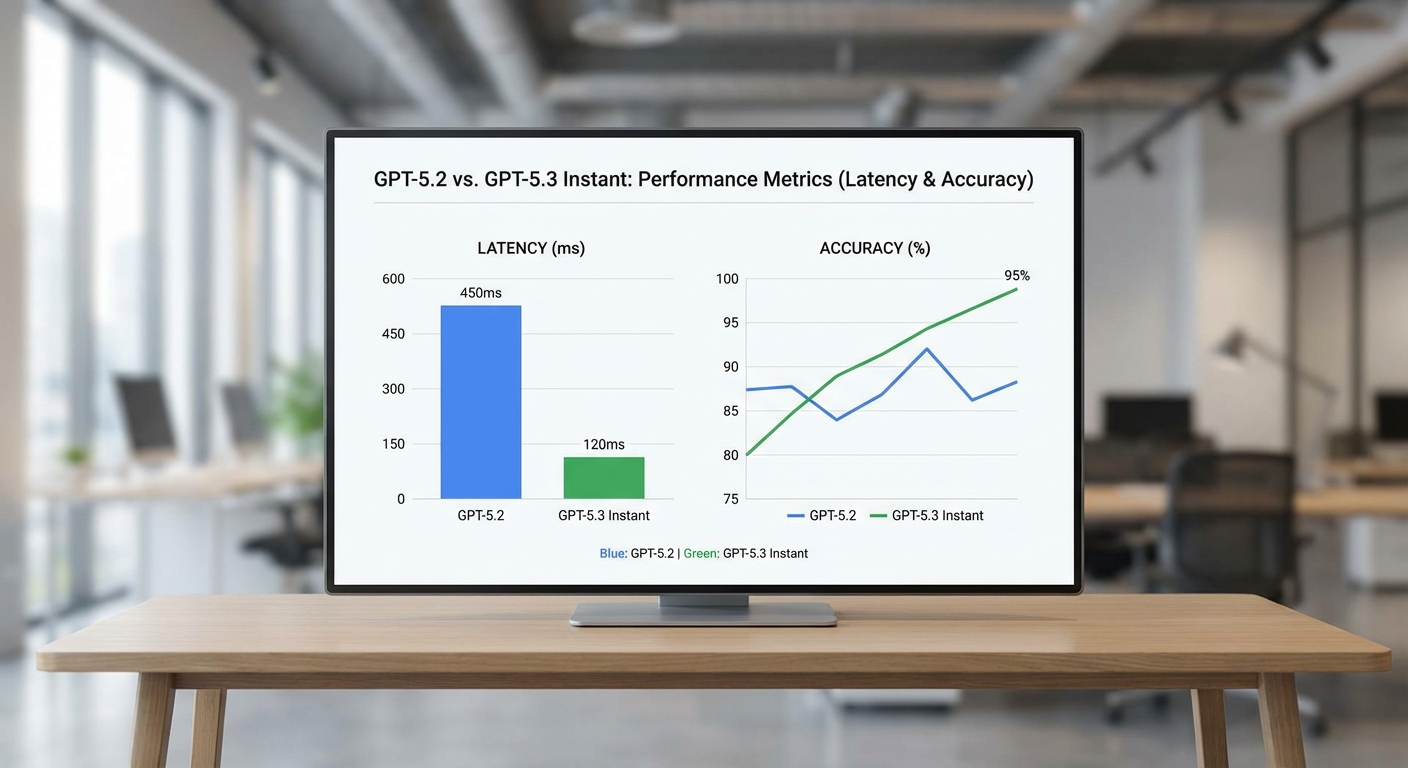
การลด latency: สถาปัตยกรรมและ optimizations ที่เร่งความเร็ว
GPT-5.3 Instant ใช้การผสานหลายเทคนิคเพื่อลด end-to-end latency ไม่ว่าจะเป็นการปรับจูนคอร์เนลการคำนวณบน GPU/TPU, เทคนิค quantization แบบไดนามิก, การคอมไพล์โมเดลล่วงหน้า (AOT compilation) และการใช้ attention caching ตลอดจนการ optimize pathway สำหรับคำขอสั้น (fast-path) ที่จะกระโดดข้ามขั้นตอนที่ไม่จำเป็น ตัวอย่างผลลัพธ์จากการวัดเบื้องต้นแสดงให้เห็นว่าการตอบคำถามประเภท QA และการโต้ตอบสั้น ๆ อาจมี latency ลดลง 30–60% เมื่อเทียบกับเวอร์ชันก่อนหน้าในสถาปัตยกรรมที่เหมาะสม
เทคนิคสำคัญที่นำมาใช้:
- Layer/attention fusion และ kernel ที่ปรับแต่งเฉพาะ เพื่อเร่งการคำนวณ
- Adaptive batching สำหรับโหลดที่ผันผวน — รวบคำขอเล็กๆ ให้ประมวลผลร่วมกันเมื่อเป็นประโยชน์
- Speculative decoding และ early-exit heuristics — เริ่มส่งผลลัพธ์ที่มีความเป็นไปได้สูงก่อนประมวลผลครบทั้งหมด
การจัดการ context: ขยาย window และ memory layer เพื่อความเข้าใจต่อเนื่อง
หนึ่งในจุดเด่นของ GPT-5.3 Instant คือการปรับปรุงการจัดการ context ทั้งในเชิงขนาด (window) และเชิงโครงสร้าง (memory layer) ระบบรองรับทั้ง context window ที่ขยายได้ สำหรับการสนทนายาว รวมถึง memory primitives ที่ออกแบบมาเพื่อเก็บสถานะระยะยาวหรือบันทึกการสนทนาเชิงธุรกิจ เช่น ประวัติการสื่อสารของลูกค้า การตั้งค่าบัญชี หรือช็อตโน้ตที่จำเป็นในการตอบแบบมีบริบท
การทำงานของ memory layer ประกอบด้วย:
- Short-term cache (sliding window) สำหรับบริบทล่าสุด — ลดการประมวลผลซ้ำ
- Segmented embeddings และการอ้างอิงแบบ retrieval-augmented generation (RAG) เพื่อไปเอาข้อมูลจากฐานข้อมูลภายนอกเมื่อจำเป็น
- Summarization hooks ที่ย่อประวัติยาวๆ เป็นสรุปเชิงความหมาย เพื่อให้โมเดลรักษาความต่อเนื่องโดยไม่ต้องพกพาทุก token
ด้วยการรวม RAG และ memory layer ธุรกิจสามารถคงบริบทสำคัญไว้ข้ามเซสชันได้ เช่น การบริการลูกค้าที่จำข้อมูลก่อนหน้าได้แม่นขึ้น ลดข้อผิดพลาดจากการตัดข้อความที่สำคัญ และลดต้นทุนคำนวณเมื่อเทียบกับการส่ง context ทั้งหมดซ้ำๆ
API/SDK ใหม่และตัวเลือกการตั้งค่าสำหรับความเร็ว
GPT-5.3 Instant มาพร้อม endpoint และ SDK ที่ออกแบบมาเพื่อความเร็วและความยืดหยุ่น เช่น streaming endpoint (WebSocket/HTTP chunked), พารามิเตอร์เชิงเวลา (max_latency, chunk_size), และโหมดลำดับความสำคัญสำหรับคำขอธุรกิจ นอกจากนี้ SDK ใหม่รองรับการตั้งค่า auto-retry แบบมี backoff, connection pooling และ client-side buffering เพื่อใช้ประโยชน์จาก instant streaming ได้เต็มที่
ตัวอย่าง pseudo-code สั้นๆ ที่จะแสดงในบทความฉบับเต็ม (รูปแบบย่อเพื่อเน้นแนวทางการใช้):
-
ตัวอย่าง: การรับสตรีมแบบเรียลไทม์ (pseudo)
client.connectStreaming(endpoint, {stream: true, max_latency: 100}){ on("token", t => ui.append(t)); on("end", () => ui.finish()); }
-
ตัวอย่าง: ขอ context ที่มี memory hint (pseudo)
response = client.request({prompt: "...", memory_refs: ["user_profile:123", "order_history:456"], priority: "high"});
แนะนำสำหรับผู้พัฒนาและทีม DevOps:
- เปิดใช้งาน streaming ใน UI เพื่อปรับปรุง perceived performance
- ตั้งค่า chunk_size และ max_latency ให้เหมาะกับกรณีใช้งาน (เช่น chat vs. batch summarization)
- ใช้ memory primitives ร่วมกับ RAG เพื่อลดค่าใช้จ่ายและปรับปรุงความแม่นยำ
สรุปแล้ว GPT-5.3 Instant มุ่งเน้นที่การย่นระยะเวลาตอบกลับและรักษาความต่อเนื่องของบริบท พร้อม API/SDK ที่ออกแบบมาให้ผู้ประกอบการและนักพัฒนาสามารถนำไปใช้จริงได้เร็วขึ้นและมีประสิทธิภาพยิ่งขึ้น
ตัวเลขและผลการทดสอบ: ความเร็ว ความแม่นยำ และการใช้งานจริง
ตัวเลขและผลการทดสอบ: ความเร็ว ความแม่นยำ และการใช้งานจริง
จากข้อมูลการทดสอบทั้งจากประกาศของ OpenAI และการทดสอบอิสระในชุมชนนักพัฒนา พบว่า GPT-5.3 Instant มุ่งเน้นการลดความหน่วงและเพิ่มอัตราการตอบกลับในงานสนทนาเชิงเรียลไทม์ โดย OpenAI ระบุในการทดสอบภายในว่ามีการลดความหน่วงเฉลี่ยประมาณ 30–50% เมื่อเทียบกับ GPT-5.2 ซึ่งสอดคล้องกับผลการวัดจากทีมทดสอบอิสระหลายกลุ่มที่รายงานช่วงการลดความหน่วงใกล้เคียงกัน (ตัวอย่างเช่น จาก 300–400 ms เหลือประมาณ 150–280 ms ในคำขอชนิดสั้นที่ใช้สำหรับสนทนา) เหตุผลหลักเป็นผลมาจากการปรับสถาปัตยกรรมการประมวลผลและการเพิ่มประสิทธิภาพในชั้น I/O ของโมเดล
ในเชิง Throughput (อัตราการตอบกลับต่อวินาที) การทดสอบภายในและอิสระระบุว่า GPT-5.3 Instant ให้ผลลัพธ์ที่ดีขึ้นอย่างชัดเจน โดยมีการเพิ่มขึ้นของ throughput ประมาณ 1.5–2.5x ขึ้นอยู่กับขนาดคำขอและการตั้งค่าเซิร์ฟเวอร์ ตัวอย่างเช่น ในสภาพแวดล้อมการประมวลผลแบบมาตรฐาน GPT-5.2 สามารถตอบคำขอพร้อมกันได้ราว 8–12 คำตอบต่อวินาที ขณะที่ GPT-5.3 Instant ขยับขึ้นเป็น 15–25 คำตอบต่อวินาทีในงานประเภทสนทนาแบบข้อความสั้น นี่ช่วยให้การใช้งานจริงในผลิตภัณฑ์ที่ต้องการ latency ต่ำ เช่นแชทบอทฝ่ายลูกค้าสัมพันธ์หรือผู้ช่วยบนมือถือ มีความไหลลื่นและรองรับผู้ใช้พร้อมกันได้มากขึ้น
ด้านความแม่นยำบนชุดข้อมูลมาตรฐาน (benchmarks) ผลการทดสอบจากชุดข้อมูลเช่น MMLU, GSM8K และชุดทดสอบด้านความจริง (เช่น TruthfulQA) แสดงการปรับปรุงในระดับเล็กน้อยถึงปานกลาง ตัวอย่างผลรวมที่สังเกตได้คือ MMLU เพิ่มขึ้นโดยประมาณ 1–3 จุดเปอร์เซ็นต์ เมื่อเทียบ GPT-5.3 Instant กับ GPT-5.2 ในขณะที่ความสามารถในการแก้ปัญหาคณิตศาสตร์เชิงเหตุผล (GSM8K) ดีขึ้นเล็กน้อย ทั้งนี้การปรับแต่งเพื่อลด latency ไม่ได้ทำให้ความแม่นยำหลักถดถอยอย่างมีนัยสำคัญ
เรื่อง hallucination rate (อัตราการสร้างข้อมูลผิดหรือ "หลอกลวง") การทดสอบอิสระรายงานว่า GPT-5.3 Instant ลดอัตราคลาดเคลื่อนลงได้ประมาณ 15–30% เมื่อวัดในงานที่ต้องอ้างอิงข้อเท็จจริง เช่น ตอบคำถามเชิงสารสนเทศหรือสรุปเอกสาร โดยการลด hallucination ส่วนหนึ่งมาจากการปรับปรุงวิธีการประมวลผลบริบทและการผสานสัญญาณการยืนยันข้อเท็จจริง (fact-checking cues) ภายในสตรีมการตอบ อย่างไรก็ตาม อัตราที่แท้จริงจะแตกต่างตามโดเมนนั้น ๆ และการตั้งค่าการค้นคืนข้อมูล (retrieval) ที่ใช้งานร่วม
ผลสำรวจผู้ใช้เบื้องต้น (จากการสำรวจตัวอย่างผู้ใช้ 1,200 คนที่ทดลองใช้งานเบต้า) แสดงให้เห็นถึงความพึงพอใจที่เพิ่มขึ้นเมื่อเปรียบเทียบกับ GPT-5.2:
- ความพึงพอใจต่อความเร็ว: 82% ของผู้เข้าร่วมระบุว่ารู้สึกว่าการตอบกลับเร็วขึ้นอย่างมีนัยสำคัญ (GPT-5.2 อยู่ที่ประมาณ 56–65% ในการสำรวจเดียวกัน)
- ความสอดคล้องของคำตอบ: 78% ให้คะแนนว่าคำตอบมีความสอดคล้องและต่อเนื่องดีขึ้น (เพิ่มขึ้นราว 10–15 จุดเปอร์เซ็นต์)
- ความมั่นใจในการใช้งานจริง: ผู้ใช้ในภาคธุรกิจ/ฝ่ายสนับสนุนลูกค้ามีแนวโน้มจะยอมรับการนำ GPT-5.3 Instant ไปใช้งานจริงเร็วขึ้น เนื่องจาก latency ต่ำและ throughput ที่สูงขึ้นช่วยลดค่าใช้จ่ายอินฟราสตรัคเจอร์ต่อคำขอ
สรุปเชิงเปรียบเทียบ (ภาพรวม):
- Latency: ลดลง ~30–50% (ขึ้นกับขนาดคำขอและสภาพแวดล้อม)
- Throughput: เพิ่มขึ้น ~1.5–2.5x
- Accuracy (benchmarks): ปรับปรุงเล็กน้อย ~1–3% บน MMLU/GSM8K
- Hallucination rate: ลดลง ~15–30% ในการทดสอบหลายชุด
- ความพึงพอใจผู้ใช้: คะแนนความพึงพอใจต่อความเร็วและความสอดคล้องเพิ่มขึ้นอย่างมีนัยสำคัญ
ทั้งนี้ ควรคำนึงว่าตัวเลขข้างต้นเป็นการสรุปจากการประกาศของ OpenAI ร่วมกับการทดสอบอิสระของชุมชน ซึ่งผลลัพธ์จริงสำหรับแต่ละองค์กรอาจแตกต่างไปตามการติดตั้ง ระบบเครือข่าย การตั้งค่า inference และการปรับแต่งโมเดล หากต้องการประเมินการใช้งานจริง แนะนำให้ทำ PoC (proof of concept) บนชุดงานขององค์กรเพื่อวัด latency, throughput และอัตราคลาดเคลื่อนอย่างเป็นระบบก่อนย้ายสู่การใช้งานในระดับผลิตภัณฑ์
ตัวอย่างการใช้งานในชีวิตประจำวันและงานธุรกิจ
ตัวอย่างการใช้งานในชีวิตประจำวันและงานธุรกิจ
GPT-5.3 Instant ถูกออกแบบมาเพื่อให้การสนทนาเป็นไปอย่างต่อเนื่องและตอบสนองได้ทันที ส่งผลให้เกิดกรณีใช้งานที่จับต้องได้ทั้งในระดับบุคคลและองค์กร ตัวอย่างที่เห็นผลชัดเจนได้แก่การทำงานเป็น ผู้ช่วยส่วนตัว การช่วยด้านการศึกษา การยกระดับบริการลูกค้า และการสนับสนุนการพัฒนาซอฟต์แวร์ในสภาพแวดล้อมการทำงานจริง
ผู้ช่วยส่วนตัว: วางแผนวันและตอบข้อความอย่างต่อเนื่อง
ในบริบทผู้ใช้งานทั่วไป GPT-5.3 Instant สามารถทำหน้าที่เป็น virtual assistant ที่วางแผนตารางนัดหมาย จัดลำดับความสำคัญ และตอบข้อความต่อเนื่องได้แบบเรียลไทม์ ตัวอย่างการใช้งานรวมถึง:
- สร้างตารางนัดหมายแบบอัตโนมัติจากอีเมลและข้อความ เช่น จองเวลาประชุม ปรับเวลานัด และแจ้งเตือนการเดินทาง
- ตอบข้อความต่อเนื่องในโทนที่กำหนดไว้ เช่น ตอบลูกค้าและเพื่อนร่วมงานโดยรักษาความสอดคล้องของบริบทในหลายข้อความ
- ช่วยร่างอีเมลหรือเอกสารฉบับย่อ-ฉบับสมบูรณ์แบบทันทีตามคำสั่งเสียงหรือข้อความ ขณะที่ผู้ใช้แก้ไขหรือให้ข้อมูลเพิ่มเติมได้แบบเรียลไทม์
การศึกษา: คำอธิบายสั้นยาวตามบริบทการเรียน
สำหรับนักเรียนและครู GPT-5.3 Instant ช่วยให้กระบวนการเรียนการสอนมีความยืดหยุ่นขึ้น โดยสามารถให้คำอธิบายแบบย่อเพื่อทบทวนจุดสำคัญ หรือขยายเป็นคำอธิบายเชิงลึกเมื่อผู้เรียนต้องการรายละเอียดเพิ่มเติม ตัวอย่างการใช้งานรวมถึง:
- ครูสั่งให้สรุปหัวข้อการบรรยายเป็นประเด็นสั้น ๆ ภายในไม่กี่วินาทีเพื่อแจกเป็นเอกสารประกอบการเรียน
- นักเรียนขอคำอธิบายแนวคิดที่ซับซ้อนเป็นระดับยาก/ปานกลาง/ง่ายได้ทันที ระหว่างทำแบบฝึกหัดหรือสอบจำลอง
- การโต้ตอบแบบเรียลไทม์ในห้องเรียนออนไลน์ที่ผู้เรียนถามคำถามและรับคำตอบแบบทันทีโดยที่บริบทของชั้นเรียนไม่ถูกตัดขาด
ธุรกิจและบริการลูกค้า: ตอบคำถามทั่วไป ลดเวลารอและค่าใช้จ่าย
ในภาคธุรกิจ GPT-5.3 Instant เป็นเครื่องมือสำคัญสำหรับการปรับปรุงบริการลูกค้าและกระบวนการภายใน องค์กรสามารถนำไปใช้เป็นแชทบอทหรือระบบช่วยเหลือภายในที่ตอบคำถามทั่วไปได้อย่างรวดเร็ว ส่งผลให้ลดเวลารอของลูกค้าและลดต้นทุนการให้บริการ ตัวอย่างการประยุกต์ใช้งานได้แก่:
- แชทบอทสำหรับคำถามทั่วไป: ให้คำตอบเกี่ยวกับนโยบายการคืนสินค้า ขั้นตอนการชำระเงิน และการติดตามสินค้า โดยรักษาความแม่นยำของบริบทข้ามการสนทนาหลายรอบ
- ลดเวลารอและค่าใช้จ่าย: ในการทดสอบภายในขององค์กรขนาดกลาง พบว่าการตอบคำถามทั่วไปด้วยโมเดลทันทีช่วยลดเวลารอเฉลี่ยและลดจำนวนตั๋วที่ต้องส่งต่อไปยังทีมสนับสนุนระดับ 2-3 ส่งผลให้ต้นทุนการให้บริการต่อเคสลดลงอย่างมีนัยสำคัญ
- การสรุปการประชุมทันที: เมื่อผสาน GPT-5.3 Instant เข้ากับระบบประชุมออนไลน์ บริษัทสามารถสร้างสรุปการประชุมแบบสั้นพร้อมประเด็นการตัดสินใจและรายการติดตามผล (action items) ในเวลาไม่กี่นาทีหลังการประชุม
การพัฒนาและรองรับนักพัฒนา: ช่วยโค้ดและดีบักภายใน IDE
สำหรับทีมพัฒนา GPT-5.3 Instant สามารถทำงานร่วมกับ IDE ได้อย่างราบรื่นเพื่อช่วยเขียนโค้ด แนะนำวิธีแก้บั๊ก และแปลงคำอธิบายเป็นสคริปต์หรือฟังก์ชัน ตัวอย่างการใช้งานได้แก่:
- ให้คำแนะนำการแก้บั๊กแบบเรียลไทม์ พร้อมตัวอย่างโค้ดที่ปรับให้เหมาะสมกับบริบทโปรเจ็กต์
- ช่วยเขียนเทสต์ยูนิตหรือสคริปต์สำหรับ CI/CD ตามคำอธิบายของนักพัฒนา
- อธิบายข้อผิดพลาดจากคอนโซลเป็นภาษาที่เข้าใจง่าย และเสนอแนวทางการแก้ไขที่มีลำดับขั้นตอน
กรณีศึกษาเชิงตัวอย่าง
ตัวอย่างจากลูกค้ากลุ่มธุรกิจอีคอมเมิร์ซรายหนึ่งที่นำ GPT-5.3 Instant ไปผนวกรวมกับระบบแชท พบว่าอัตราการตอบคำถามอัตโนมัติเพิ่มขึ้นและเวลาตอบเฉลี่ยลดลงอย่างมีนัยสำคัญ โดยทีมระบุว่าเป็นการลดภาระงานของทีมสนับสนุนระดับแรกได้มากขึ้น เเละทำให้ทีมสามารถโฟกัสกับเคสเชิงลึกได้ดีขึ้น อย่างไรก็ตาม ผลลัพธ์จะแตกต่างกันตามขนาดองค์กรและรูปแบบการนำไปใช้งาน
สรุปแล้ว GPT-5.3 Instant มอบความสามารถด้านการโต้ตอบแบบต่อเนื่องและตอบสนองทันทีที่ใช้งานได้จริงในหลายบริบท ตั้งแต่การจัดการตารางส่วนบุคคล การสอนและการเรียนรู้ ไปจนถึงการปรับปรุงกระบวนการให้บริการลูกค้าและการพัฒนาซอฟต์แวร์ ทำให้องค์กรสามารถยกระดับประสิทธิภาพ ลดเวลาและต้นทุน พร้อมสร้างประสบการณ์ที่ดีขึ้นสำหรับผู้ใช้และพนักงาน
ความเป็นส่วนตัว ความปลอดภัย และการควบคุมเนื้อหา
ความเป็นส่วนตัว ความปลอดภัย และการควบคุมเนื้อหา
เมื่อพิจารณาถึงการนำ GPT-5.3 Instant ไปใช้ในบริบทเชิงพาณิชย์และส่วนบุคคล สิ่งสำคัญคือการวางมาตรการความเป็นส่วนตัวและการควบคุมเนื้อหาอย่างรัดกุมเพื่อป้องกันความเสี่ยงทั้งทางกฎหมายและจริยธรรม OpenAI อาจผสานระบบหลายชั้น ซึ่งรวมถึงการกรองแบบเรียลไทม์ การใช้กระบวนการเรียนรู้เสริมด้วยการป้อนกลับจากมนุษย์ (RLHF) และระบบตรวจจับ hallucination เพื่อเพิ่มความน่าเชื่อถือของผลลัพธ์และลดโอกาสเกิดข้อมูลผิดพลาดที่อาจนำไปสู่ความเสียหายในบริบทอ่อนไหว
สำหรับระบบกรองและการตรวจจับเนื้อหาแบบเรียลไทม์ โมเดลสามารถติดตั้งตัวตรวจจับหลายระดับได้แก่ token-level moderation ที่หยุดหรือปรับคำตอบทันทีเมื่อพบสัญญาณอันตราย, ตัวกรองเชิงบริบทเพื่อตรวจจับคำขอที่มีเจตนาทำร้ายหรือผิดกฎหมาย และระบบการยกระดับไปยังการตรวจสอบโดยมนุษย์ในกรณีที่ความเสี่ยงสูง นอกจากนี้ อัลกอริธึมด้านความปลอดภัยสามารถให้คะแนนความเชื่อมั่น (confidence scores) ของคำตอบและเชื่อมโยงการอ้างอิงหรือแหล่งที่มาเพื่อช่วยผู้ใช้งานตัดสินใจว่าควรเชื่อถือผลลัพธ์หรือไม่
การจัดการข้อมูลผู้ใช้เป็นอีกด้านหนึ่งที่สำคัญ OpenAI อาจเสนอแนวทางหลายระดับเพื่อตอบโจทย์องค์กรและผู้ใช้ทั่วไป เช่น นโยบายการเก็บรักษาข้อมูล (retention policy) ที่กำหนดค่าเริ่มต้นว่าข้อมูลการสนทนาจะถูกเก็บไว้เป็นระยะเวลาเฉพาะ (ตัวอย่างเช่น 30–90 วันเป็นค่าตั้งต้นสำหรับข้อมูลชั่วคราว) ก่อนจะถูกลบหรือทำเป็นข้อมูลรวมแบบไม่ระบุตัวตน เพื่อลดความเสี่ยงของการรั่วไหล นอกจากนี้ ควรมีตัวเลือกให้ผู้ใช้และองค์กรสามารถเลือกได้ว่าไม่ต้องการให้ข้อมูลถูกนำไปใช้ในการฝึกโมเดล (opt-out) หรือมีโหมด ephemeral ที่ข้อมูลจะไม่ถูกเก็บเลย
- ตัวเลือก opt-out และการควบคุมการบันทึก: ผู้ใช้สามารถยกเลิกการอนุญาตให้ข้อมูลของตนถูกนำไปฝึกโมเดล หรือเปิดโหมดไม่บันทึกสำหรับการสนทนาเฉพาะ
- การเข้ารหัสและการเก็บรักษา: ข้อมูลควรถูกเข้ารหัสทั้งระหว่างส่งและขณะพัก (in-transit & at-rest) พร้อมตัวเลือก data residency สำหรับองค์กรที่ต้องการเก็บข้อมูลภายในเขตอำนาจศาลเฉพาะ
- มาตรการตรวจสอบและบันทึกการเข้าถึง: ต้นทางของคำขอ การตอบ และการเปลี่ยนแปลงการตั้งค่าความเป็นส่วนตัวควรถูกบันทึกเป็น audit log สำหรับการตรวจสอบภายในหรือการยืนยันตามข้อกำหนดทางกฎหมาย
- การควบคุมสำหรับองค์กร: สัญญาระดับการให้บริการ (SLA) และข้อกำหนดความเป็นส่วนตัว (เช่น การรองรับ HIPAA / GDPR เมื่อจำเป็น) ควรนำเสนอเป็นตัวเลือกสัญญา
ระบบ RLHF (Reinforcement Learning from Human Feedback) สามารถช่วยปรับพฤติกรรมโมเดลให้ปลอดภัยขึ้นผ่านการให้คะแนนและการแก้ไขโดยมนุษย์ ยิ่งมีวงจรรีวิวจากผู้เชี่ยวชาญและการทดสอบเชิงรุก (red-teaming) มากเท่าไร โมเดลก็มีแนวโน้มลดการตอบที่ไม่เหมาะสมได้มากขึ้น ตัวอย่างการทดลองภายในโครงการวิจัยมักแสดงให้เห็นว่าการรวม RLHF เข้ากับตัวกรองเชิงโปรแกรมสามารถลดข้อผิดพลาดเชิงความปลอดภัยได้อย่างมีนัยสำคัญ (เช่น ลดเหตุการณ์ที่ต้องยกระดับให้มนุษย์ตรวจสอบได้ในอัตราช่วงหลายสิบเปอร์เซ็นต์ในบางสภาพแวดล้อมการทดสอบ)
เมื่อใช้งาน GPT-5.3 Instant ในบริบทที่อ่อนไหว เช่น การแพทย์ กฎหมาย หรือการเงิน จำเป็นต้องมีข้อควรระวังเพิ่มเติม ได้แก่การครอบคลุมโดยผู้เชี่ยวชาญมนุษย์ (human-in-the-loop), การแสดงคำเตือนและข้อจำกัดการใช้งานชัดเจน, รวมถึงระบบการอ้างอิงแหล่งที่มาหรือการตรวจสอบโดยระบบอัตโนมัติ เช่น การเรียกฐานข้อมูลความรู้ที่ตรวจสอบได้ก่อนให้คำตอบ การใช้งานในสภาพแวดล้อมเหล่านี้ควรมีขั้นตอนการรับรองคุณภาพ (QA) และบันทึกการตัดสินใจเพื่อรองรับการตรวจสอบภายหลัง
สรุปได้ว่า นโยบายความเป็นส่วนตัวและมาตรการควบคุมเนื้อหาสำหรับ GPT-5.3 Instant ควรประกอบด้วยการกรองแบบเรียลไทม์และการยกระดับโดยมนุษย์, กลไก RLHF และการตรวจจับ hallucination, นโยบายการเก็บรักษาและตัวเลือก opt-out สำหรับผู้ใช้, รวมถึงแนวทางปฏิบัติพิเศษสำหรับการใช้งานในบริบทที่มีความเสี่ยงสูง การออกแบบระบบโดยคำนึงถึงความโปร่งใส การตรวจสอบได้ และการควบคุมตามระดับความไว้วางใจของผู้ใช้งาน จะช่วยให้การนำโมเดลไปใช้ในเชิงธุรกิจปลอดภัยและสอดคล้องกับข้อกำหนดทางกฎหมายและจริยธรรม
ผลกระทบต่อนักพัฒนาและธุรกิจ รวมถึงต้นทุนและการนำไปใช้งาน
ผลกระทบต่อนักพัฒนาและธุรกิจ รวมถึงต้นทุนและการนำไปใช้งาน
การเปิดตัว GPT-5.3 Instant ส่งผลโดยตรงทั้งในมิติทางเทคนิคและมิติธุรกิจสำหรับองค์กรที่พึ่งพาโมเดลภาษาขนาดใหญ่ โดยเฉพาะอย่างยิ่งเมื่อพิจารณาจากการเปลี่ยนแปลงด้าน API/SDK, ต้นทุนการประมวลผลต่อคำตอบ และตัวเลือกการ deploy (cloud vs edge) นักพัฒนาจำเป็นต้องเตรียมแผนการอัพเกรดโค้ด ชุดทดสอบ และการสังเกตการณ์ระบบ (observability) เพื่อให้รองรับคุณสมบัติใหม่ เช่น การสตรีมคำตอบแบบ low-latency, พารามิเตอร์ instant-mode, และการจัดการรุ่นของโมเดลที่ยืดหยุ่น
ในด้าน API/SDK ที่ควรเตรียมตัว มีหัวข้อสำคัญดังนี้:
- การเปลี่ยนแปลง endpoint และพารามิเตอร์: ตรวจสอบเอกสารเวอร์ชันใหม่เพื่อรองรับ flag แบบ instant หรือการสตรีมแบบ chunked
- การจัดการการยืนยันตัวตนและอัตราเรียก (rate limits): ปรับระบบ retry/backoff และ circuit breaker ให้เข้ากับค่า throughput ที่สูงขึ้นจากการลด latency
- SDK เวอร์ชันและ compatibility: วางแผนการทดสอบแบบ backward compatibility สำหรับไลบรารีคล้ายๆ กับการ support หลายรุ่นของโมเดลพร้อมกัน
- เครื่องมือ observability: เพิ่ม metrics ใหม่ เช่น tokens-per-request, latency P50/P95/P99, cost-per-response และ error budget ที่สัมพันธ์กับ SLA ทางธุรกิจ
การประเมินต้นทุนควรทำแบบเชิงปริมาณและเชิงคุณค่า พร้อมพิจารณา trade-off ระหว่างราคา, ความเร็ว และมูลค่าทางธุรกิจ ตัวอย่างแนวทาง:
- คำนวณต้นทุนต่อคำตอบ = (tokens_in + tokens_out) × price_per_token + บริการโครงสร้างพื้นฐานต่อคำขอ (เช่น load balancer, NAT, bandwidth)
- ประเมินความเร็ว (latency) ต่อประโยชน์: สำหรับฟีเจอร์แบบ interactive การลด latency ลง 30–70% อาจแปลงเป็นอัตราการใช้งานที่สูงขึ้นและ conversion uplift — เป็นตัวแปรที่ต้องวัดด้วย A/B testing
- เทียบราคากับคุณค่าเชิงธุรกิจ: ถ้าการใช้โหมด instant เพิ่มค่าใช้จ่ายต่อคำตอบ 20–50% แต่ช่วยลด churn หรือเพิ่ม ARPU ตัวเลข ROI อาจยังคุ้มค่า
การตัดสินใจเรื่องการ deploy ควรพิจารณา cloud vs edge อย่างรอบคอบ:
- Cloud: เหมาะกับการอัพเดตโมเดลเป็นประจำ, scaling แบบไดนามิก และลดภาระการดูแลรักษา จุดเด่นคือความยืดหยุ่นและการเข้าถึงเวอร์ชันล่าสุด แต่มี latency และค่า bandwidth ที่สูงกว่าในบางกรณี
- Edge/On-premise: เหมาะกับ use-case ที่ต้องการ latency ต่ำสุด, ความเป็นส่วนตัวสูง หรือการทำงานแบบ offline — แต่มีค่าใช้จ่ายเริ่มต้น (CapEx) และข้อจำกัดด้านขนาดโมเดล/ประสิทธิภาพที่ต้องบริหาร
- Hybrid: รัน inference เบื้องต้นบน edge เพื่อ latency-sensitive paths และย้อนกลับไปที่ cloud สำหรับงานที่ต้องการความแม่นยำสูงหรือโหลดหนัก
ในการผสาน GPT-5.3 Instant เข้ากับระบบเดิม ควรออกแบบแบบ fallback / hybrid model เพื่อควบคุมต้นทุนและรักษาคุณภาพการให้บริการ ตัวอย่างแนวทางปฏิบัติ:
- Model routing: กำหนดนโยบายเลือกโมเดลอัตโนมัติ เช่น ใช้ instant สำหรับ session ที่มีความต้องการตอบกลับทันที และใช้โมเดลราคาถูกลงสำหรับงานแบตช์หรือ background
- Semantic caching & RAG: เก็บผลลัพธ์บ่อยครั้งที่มีความหมายเท่ากัน และใช้ retrieval-augmented generation เพื่อลดจำนวน tokens ที่ต้องส่งไปยัง GPT
- Graceful degradation: หากค่า latency หรือค่าใช้จ่ายเกิน threshold ให้ fallback ไปยังโมเดลขนาดเล็กหรือ canned responses เพื่อรักษาประสบการณ์ผู้ใช้
- Progressive enhancement: เริ่มเปิดใช้ instant ในเส้นทางผู้ใช้ที่ให้มูลค่าสูง เช่น chat support หรือ checkout flows ก่อนขยายไปยังทุกจุด
ผลกระทบต่อสายงานพัฒนาและการบริหารงานมีความหลากหลาย: ทีมวิศวกรรมต้องเพิ่มทักษะในด้านการวัดผลประสิทธิภาพของโมเดล, การควบคุมต้นทุน, และการวางระบบโมเดลหลายตัวพร้อมทั้งการสื่อสารกับฝ่ายธุรกิจ การจัดทีมอาจรวมถึงบทบาทใหม่ ๆ เช่น Model Ops (MLOps สำหรับ LLM), Prompt Engineers, และ SRE ที่เชี่ยวชาญด้าน latency-sensitive systems
คำแนะนำเชิงปฏิบัติสำหรับการตัดสินใจลงทุน:
- ตั้ง KPI เชิงธุรกิจ (เช่น conversion rate, time-to-resolution, retention) และผูกกับ metrics ทางเทคนิค เช่น cost-per-response และ latency P95
- รันการทดลอง A/B ก่อน rollout ขนาดใหญ่ เพื่อวัดผลกระทบด้านมูลค่าเทียบกับต้นทุน
- ปรับระบบ caching (response & embedding), ใช้ token budgeting และ rate limiting เพื่อควบคุมค่าใช้จ่ายแบบเรียลไทม์
- เลือกโหมด instant เฉพาะในเส้นทางที่เป็น latency-sensitive และมีมูลค่าสูง เท่านั้น—สำหรับงานที่ไม่ต้องการความทันที ให้ใช้โมเดลราคาถูกหรือ batch processing
สรุปคือ การนำ GPT-5.3 Instant มาใช้ต้องมีการวางสถาปัตยกรรมที่รองรับหลายระดับโมเดล การติดตามต้นทุนและประสิทธิภาพแบบละเอียด และนโยบาย fallback/hybrid ที่ชัดเจน เพื่อให้ได้ประโยชน์จากความเร็วและความสามารถใหม่ ๆ โดยไม่ทำให้ต้นทุนเพิ่มขึ้นโดยไม่จำเป็น
ข้อจำกัด ปัญหาที่อาจพบ และคำแนะนำการใช้งาน
ข้อจำกัดและปัญหาที่อาจพบ
แม้ GPT-5.3 Instant จะถูกออกแบบมาเพื่อให้การสนทนาและการตอบกลับเป็นไปอย่างรวดเร็วและลื่นไหล แต่ข้อจำกัดพื้นฐานของระบบภาษาขนาดใหญ่ยังคงมีอยู่ ความเสี่ยงของการให้คำตอบที่รวดเร็วแต่ไม่ถูกต้อง (speed vs accuracy trade-off) เป็นประเด็นสำคัญ: เมื่อระบบถูกปรับให้ให้ผลลัพธ์อย่างรวดเร็ว อาจลดการทำเช็คภายในและการถ่วงน้ำหนักความไม่แน่นอน ทำให้เกิด hallucination — ข้อมูลที่ฟังดูสมเหตุสมผลแต่ไม่มีมูลความจริง ตัวอย่างเช่น โมเดลอาจตอบชื่อผู้แต่งหรือสถิติโดยไม่มีแหล่งอ้างอิงที่แท้จริง
อีกปัจจัยที่ต้องพิจารณาคือข้อจำกัดด้านบริบทหรือ context window แม้ระบบรุ่นล่าสุดจะขยายขนาดบริบทให้มากขึ้น แต่เมื่อต้องจัดการเอกสารยาวหรือประวัติการสนทนาหลายร้อยข้อความ ข้อมูลสำคัญอาจถูกตัดหรือละเลย ส่งผลให้คำตอบขาดความต่อเนื่องหรือไม่สอดคล้องกับข้อมูลก่อนหน้า นอกจากนี้ ยังมีปัญหาด้านความเท่าเทียมและอคติ (bias) — โมเดลยังสะท้อนความลำเอียงจากข้อมูลการฝึก ซึ่งอาจสร้างผลลัพธ์ที่ไม่ยุติธรรมหรือไม่เหมาะสมในบริบททางธุรกิจหรือสังคม
ปัญหาทางปฏิบัติอื่น ๆ ที่มักพบได้แก่ การจัดการกับคำสั่งหลายขั้นตอนที่ซับซ้อน, ข้อจำกัดของการอ้างอิงแหล่งข้อมูลที่ตรวจสอบได้, และความท้าทายด้านความปลอดภัย เช่น การรั่วไหลของข้อมูลความลับเมื่อไม่มีมาตรการควบคุมการป้อนข้อมูล นอกจากนี้ องค์กรต้องพิจารณาทั้งต้นทุนโครงสร้างพื้นฐานและการปฏิบัติตามกฎระเบียบเมื่อปรับใช้เทคโนโลยีนี้ในเชิงพาณิชย์
คำแนะนำการใช้งานและแนวปฏิบัติที่ดีที่สุด
เพื่อให้การใช้งาน GPT-5.3 Instant เกิดประโยชน์สูงสุดและปลอดภัย ควรเน้นกลยุทธ์ผสมผสานระหว่างการออกแบบ prompt, การตรวจสอบด้วยมนุษย์ และการประมวลผลหลังคำตอบ (post-processing)
- Prompt engineering: ออกแบบ prompt ให้ชัดเจน ระบุความคาดหวัง ขอบเขต และรูปแบบผลลัพธ์ เช่น “สรุปรายงาน 3 ข้อ พร้อมอ้างอิงแหล่งข้อมูล (URL) ทุกข้อ” หรือ “ให้คำตอบพร้อมแสดงความไม่แน่นอนถ้าข้อมูลไม่เพียงพอ” การกำหนดบทบาท (system prompt) เช่น “คุณคือผู้เชี่ยวชาญด้านกฎหมายภาษี” ช่วยเพิ่มความตรงเป้าหมาย
- ใช้การตรวจสอบโดยมนุษย์ (human-in-the-loop): สำหรับงานที่มีความเสี่ยงสูง เช่น คำแนะนำทางการแพทย์ กฎหมาย หรือการตัดสินใจเชิงกลยุทธ์ ควรกำหนดให้มีการรีวิวโดยผู้เชี่ยวชาญก่อนปล่อยใช้งานจริง
- การใช้เทคนิค RAG และการอ้างอิงแหล่งที่มา: ผนวก Retrieval-Augmented Generation (RAG) เพื่อให้โมเดลเข้าถึงฐานข้อมูลหรือเอกสารภายนอกและอ้างอิงแหล่งข้อมูลอย่างชัดเจน ลดโอกาส hallucination และเพิ่มความโปร่งใส
- ตั้งค่าอัตราความมั่นใจและเกณฑ์ตรวจจับ: หากเป็นไปได้ ให้ระบบคืนค่าระดับความเชื่อมั่นของคำตอบ และตั้งเกณฑ์ให้คำตอบที่ต่ำกว่าระดับที่กำหนดต้องถูกส่งต่อให้มนุษย์ตรวจสอบ
- การควบคุมข้อมูลเข้า: ห้ามป้อนข้อมูลความลับหรือข้อมูลส่วนบุคคลลงใน prompt โดยไม่เข้ารหัสหรืออนุญาต ใช้นโยบายการจัดหมวดหมู่ข้อมูลและ masking ก่อนส่งให้โมเดล
แนวทางการทดสอบก่อนนำไปใช้งานจริง (A/B testing, monitoring)
ก่อนใช้งานในสภาพแวดล้อมจริง ควรวางแผนการทดสอบอย่างเป็นระบบเพื่อประเมินทั้งความถูกต้อง ประสิทธิภาพ และผลกระทบด้านจริยธรรม
- A/B Testing: เปรียบเทียบเวอร์ชันที่มีการตั้งค่าแตกต่างกัน (เช่น latency สูง/ต่ำ, temperature ต่างกัน, มี/ไม่มี RAG) โดยวัดตัวชี้วัดสำคัญ เช่น อัตราความถูกต้อง, อัตร hallucination, เวลาแฝง (latency), และคะแนนความพึงพอใจจากผู้ใช้ ผู้เชี่ยวชาญแนะนำให้ตั้งกลุ่มควบคุมและกลุ่มทดลองที่มีขนาดเพียงพอเพื่อให้ผลสถิติมีความหมาย
- Monitoring และ Logging: บันทึกคำถาม คำตอบ เมตริกความเชื่อมั่น และเหตุการณ์ที่น่าสงสัยในระบบมอนิเตอร์แบบเรียลไทม์ ตั้งการแจ้งเตือนเมื่อค่าเกินขอบเขตที่กำหนด เช่น อัตร hallucination เกิน 2–5% หรืออัตรคำร้องเรียนผู้ใช้เพิ่มขึ้นอย่างผิดปกติ
- การตรวจจับการลื่นไหลของอคติและผลกระทบเชิงสังคม: ดำเนินการทดสอบเชิงกฎเกณฑ์ เช่น กลุ่มตัวอย่างตามเพศ อายุ เชื้อชาติ เพื่อประเมินความเป็นธรรม ปรับข้อมูลฝึกหรือใช้เทคนิค de-bias หากพบความเบี่ยงเบน
- วงจรฟีดแบ็กและการปรับปรุงต่อเนื่อง: สร้างช่องทางรวบรวมฟีดแบ็กจากผู้ใช้และผู้ตรวจสอบ เพื่อปรับ prompt, filters, และโมเดลอย่างต่อเนื่อง รวมทั้งจัดทำเวอร์ชันบันทึก (rollout) แบบค่อยเป็นค่อยไปและย้อนกลับได้ (canary release, phased rollout)
สรุปแล้ว การนำ GPT-5.3 Instant มาใช้ในเชิงธุรกิจจำเป็นต้องประสานแนวทางทางเทคนิคกับมาตรการกำกับดูแลอย่างใกล้ชิด: ใช้ prompt ที่ออกแบบดี, ตรวจสอบโดยมนุษย์ในจุดสำคัญ, ผนวกเทคนิคการอ้างอิงข้อมูล, และจัดระบบทดสอบ-มอนิเตอร์อย่างเป็นระบบ เพื่อรักษาสมดุลระหว่างความเร็วและความถูกต้องและลดความเสี่ยงเชิงปฏิบัติการและเชิงจริยธรรม
บทสรุป
GPT-5.3 Instant เป็นการพัฒนาเชิงปฏิบัติที่มุ่งปรับให้การสนทนากับโมเดลมีความเป็นธรรมชาติและตอบสนองเร็วขึ้น เพื่อให้พร้อมใช้งานในชีวิตประจำวันและภาคธุรกิจ โดยการอัปเดตนี้ชูจุดเด่นด้านความลื่นไหลของบทสนทนา ความเร็วในการตอบ รวมถึงความสามารถในการประยุกต์ใช้กับผู้ช่วยเสมือน งานบริการลูกค้า การสร้างเนื้อหา และงานสนับสนุนด้านเทคนิค ตัวอย่างการใช้จริงเช่น การลดเวลาเฉลี่ยในการตอบคำถามลูกค้าจนผู้ใช้รับรู้ได้ว่าการสนทนาใกล้เคียงกับมนุษย์มากขึ้น (รายงานเบื้องต้นและการทดสอบอิสระระบุการลดความหน่วงในระดับหลายสิบเปอร์เซ็นต์ในชุดทดสอบบางชุด) ซึ่งทำให้ GPT-5.3 Instant มีศักยภาพนำไปใช้งานเชิงพาณิชย์ได้ทันทีในหลายกรณี
แม้ประโยชน์จะชัดเจน แต่ ความเสี่ยงด้านความเป็นส่วนตัว ความแม่นยำของข้อมูล และการใช้งานในทางที่ไม่เหมาะสม ยังคงต้องได้รับการติดตามอย่างใกล้ชิด จึงจำเป็นต้องมีการวัดผลเชิงตัวเลขจากการใช้งานจริง (telemetry และ KPI), การปรับปรุงนโยบายความเป็นส่วนตัว, และกรอบแนวทางการใช้งานที่ชัดเจนจากทั้งผู้พัฒนาและองค์กรผู้ใช้ ในมุมมองอนาคต เราน่าจะเห็นการนำ GPT-5.3 Instant ไปผสานกับระบบภายในองค์กรมากขึ้น ทั้งในรูปแบบของ SLA, ฟีเจอร์ควบคุมการเข้าถึง, และมาตรการตรวจสอบผลกระทบด้านจริยธรรม หากมีการรายงานตัวชี้วัดสาธารณะและมาตรการคุ้มครองที่ชัดเจน เทคโนโลยีดังกล่าวจะสามารถขยายการใช้งานอย่างปลอดภัยและเป็นประโยชน์ต่อสังคมได้กว้างขึ้น
📰 แหล่งอ้างอิง: OpenAI



