
ศูนย์ข้อมูลในประเทศไทยกำลังก้าวสู่ยุคใหม่ของการจัดการความร้อนด้วยการผสานเทคโนโลยี Digital‑Twin และ Reinforcement Learning เพื่อควบคุมระบบคูลลิ่งแบบเรียลไทม์ — โครงการนำร่องระบุว่าสามารถลดค่า PUE ได้ราว 20% ส่งผลให้ผู้ประกอบการคาดว่าจะประหยัดค่าไฟฟ้ารวมเป็นหลักล้านบาทต่อปี โดยการลดความสูญเสียพลังงานจากระบบระบายความร้อนที่เป็นสัดส่วนใหญ่ของต้นทุนค่าไฟของศูนย์ข้อมูล ช่วงเวลาจริง (real‑time) ของการปรับแต่งพารามิเตอร์ เช่น อุณหภูมิเซ็ทพอยต์ ความเร็วพัดลม และการไหลของน้ำหล่อเย็น ช่วยให้ระบบตอบสนองต่อการเปลี่ยนแปลงภาระงานและสภาพแวดล้อมได้ทันที เพิ่มประสิทธิภาพด้านพลังงานโดยไม่ลดทอนความน่าเชื่อถือของเซิร์ฟเวอร์
บทความนี้จะสรุปประเด็นสำคัญตั้งแต่การทำงานของ Digital‑Twin ที่จำลองสภาพความร้อนภายในห้องเซิร์ฟเวอร์และการฝึก Reinforcement Learning เพื่อค้นหานโยบายควบคุมที่เหมาะสม ไปจนถึงตัวอย่างตัวเลขเชิงปฏิบัติ เช่น PUE ที่ลดลงจากประมาณ 1.8 เหลือประมาณ 1.44 (ลดราว 20%) และการประเมินผลกระทบด้านเศรษฐศาสตร์ — ผู้ประกอบการคาดว่าการลดค่าไฟฟ้าจะช่วยให้ประหยัดหลักล้านบาทต่อปี พร้อมการวิเคราะห์ความเสี่ยงและอุปสรรคทางเทคนิค เช่น ความแม่นยำของโมเดล การรวมระบบกับอุปกรณ์เดิม และประเด็นความปลอดภัยของข้อมูล ที่จะกำหนดความยั่งยืนและการขยายผลของโซลูชันนี้ต่อไป
ข่าวสรุป (Lead): ผลลัพธ์เด่นของโครงการ
ข่าวสรุป (Lead): ผลลัพธ์เด่นของโครงการ
ศูนย์ข้อมูลในไทยนำเทคโนโลยี Digital‑Twin ร่วมกับ Reinforcement Learning มาใช้ควบคุมระบบคูลลิ่งแบบเรียลไทม์จนได้ผลลัพธ์ชัดเจน — ระบบสามารถปรับพารามิเตอร์การทำงานของเครื่องปรับอากาศและระบบระบายความร้อนในระดับองค์รวม ทำให้ค่า PUE ลดลงประมาณ 20% เมื่อเปรียบเทียบกับการตั้งค่าดั้งเดิมของโรงงาน ซึ่งผู้ประกอบการประเมินว่าเทคโนโลยีดังกล่าวสามารถช่วยลดค่าไฟฟ้าประจำปีได้ตั้งแต่ หลักแสนถึงหลักล้านบาท ขึ้นกับขนาดของศูนย์ข้อมูลและอัตราค่าไฟท้องถิ่น
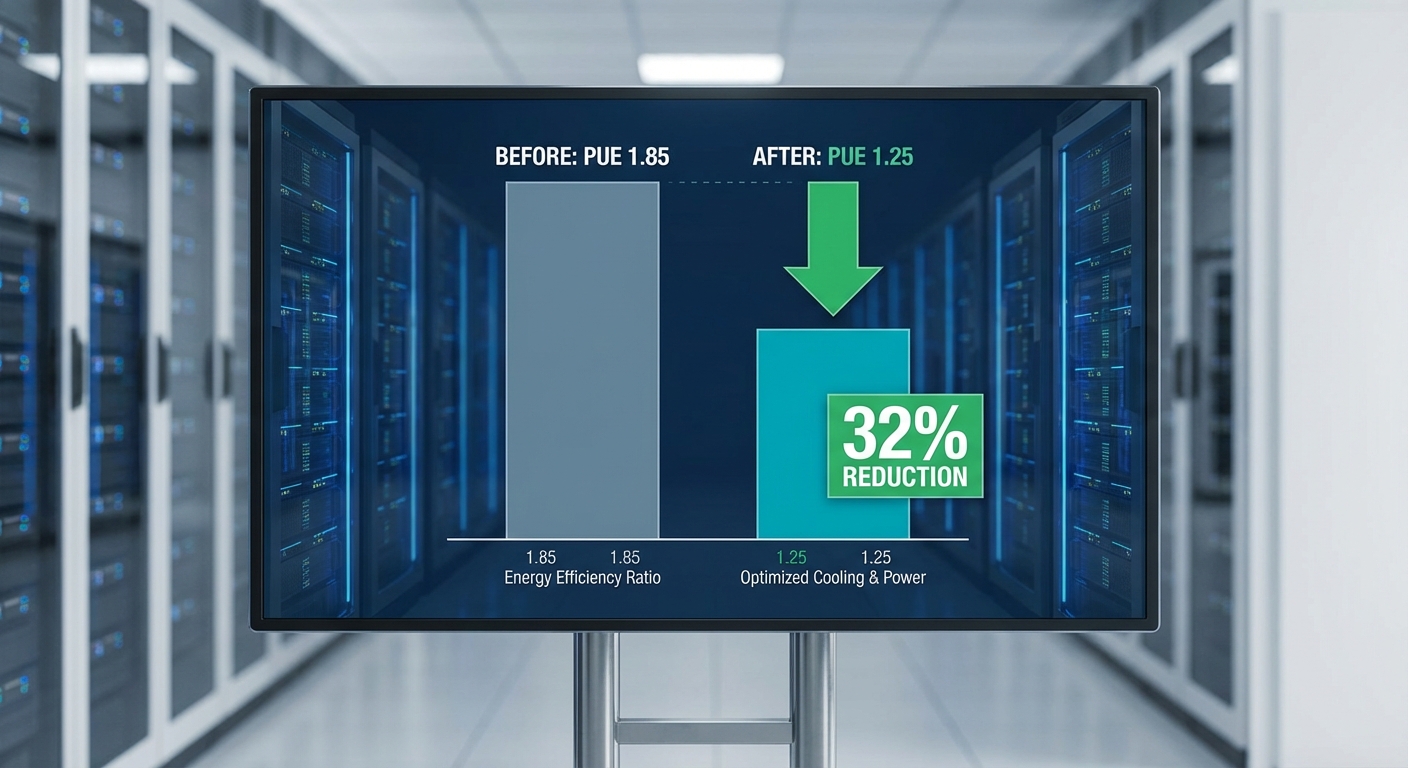
ในเชิงตัวอย่าง หากสมมติค่า PUE ก่อนปรับเท่ากับ 1.80 และลดลงประมาณ 20% จะอยู่ที่ประมาณ 1.44 ซึ่งการลด PUE ในระดับนี้สะท้อนการลดพลังงานที่ใช้โดยรวมของระบบสนับสนุน (cooling & facility) อย่างมีนัยสำคัญ — ผลโดยรวมหมายถึงลดต้นทุนการดำเนินงานและเพิ่มความคุ้มค่าของการลงทุนในระบบบริหารจัดการพลังงานแบบอัตโนมัติ
การคาดการประหยัดค่าไฟฟ้าถูกนำเสนอเป็นช่วงตามขนาดโหลดไอทีและอัตราค่าไฟที่ต่างกัน โดยใช้สมมติฐาน การใช้งาน 24/7 (8,760 ชั่วโมง/ปี) และผลต่าง PUE ราว 0.36 (1.80 → 1.44) จะให้พลังงานที่ประหยัดได้ราว 3,153.6 kWh ต่อปีต่อ 1 kW ของโหลดไอที ตัวอย่างการคำนวณเพื่อให้เห็นภาพ:
- ศูนย์ข้อมูลขนาด 50 kW (IT load): ประหยัดพลังงาน ≈ 50 × 3,153.6 = 157,680 kWh/ปี → หากค่าไฟ 3–5 บาท/kWh เท่ากับประมาณ 0.47–0.79 ล้านบาท/ปี
- ศูนย์ข้อมูลขนาด 200 kW (IT load): ประหยัดพลังงาน ≈ 200 × 3,153.6 = 630,720 kWh/ปี → หากค่าไฟ 3–5 บาท/kWh เท่ากับประมาณ 1.89–3.15 ล้านบาท/ปี
- ศูนย์ข้อมูลขนาดใหญ่กว่า (เช่น 500 kW): ในสมมติฐานเดียวกันอาจเห็นการประหยัดเป็นตัวเลขหลายล้านบาทต่อปี ขึ้นกับอัตราไฟและรูปแบบการดำเนินงาน
โครงการระบุช่วงทดลอง (pilot) เป็นระยะเวลา 3–6 เดือน บนศูนย์ข้อมูลที่มีขนาดทดสอบในช่วง ประมาณ 200–500 kW (IT load) เพื่อเก็บข้อมูลการตอบสนองแบบเรียลไทม์และปรับจูนโมเดล Digital‑Twin/ RL ก่อนขยายการใช้งานสู่ศูนย์ข้อมูลขนาดต่าง ๆ ผลลัพธ์ในช่วงพายล็อตนี้ถือเป็นสัญญาณบวกต่อความเป็นไปได้ในการนำเทคโนโลยีไปใช้เชิงพาณิชย์ ทั้งในแง่การลดค่าใช้จ่ายและการลดคาร์บอนจากการใช้พลังงานไฟฟ้า
ทำไมการคูลลิ่งเป็นปัญหาใหญ่สำหรับศูนย์ข้อมูลในไทย
ทำไมการคูลลิ่งเป็นปัญหาใหญ่สำหรับศูนย์ข้อมูลในไทย
ประเทศไทยอยู่ในเขตร้อนชื้นซึ่งมีอุณหภูมิและความชื้นสัมพัทธ์สูงตลอดทั้งปี ส่งผลให้ความต้องการด้านการระบายความร้อน (cooling) ของศูนย์ข้อมูลสูงกว่าภูมิภาคที่มีสภาพอากาศเย็นกว่า การกำจัดความร้อนจากอุปกรณ์ IT ไม่ได้หมายถึงการลดเพียงอุณหภูมิเท่านั้น แต่ยังรวมถึงการจัดการภาระความชื้น (latent load) ซึ่งต้องใช้พลังงานเพิ่มสำหรับการควบแน่นและกำจัดความชื้น ทำให้ระบบคูลลิ่งทำงานหนักขึ้นและลดประสิทธิภาพโดยรวมของระบบ
โดยทั่วไประบบคูลลิ่งมักสร้างสัดส่วนการใช้พลังงานสูงในศูนย์ข้อมูล ในหลายกรณีระบบระบายความร้อนกินสัดส่วนประมาณ 30–50% ของการใช้พลังงานทั้งหมด ซึ่งหมายความว่านโยบายหรือเทคโนโลยีที่ลดการใช้พลังงานในส่วนคูลลิ่งจะมีผลต่อค่าใช้จ่ายและประสิทธิภาพโดยรวมอย่างมีนัยสำคัญ ตัวชี้วัดสำคัญอย่าง PUE (Power Usage Effectiveness) ของศูนย์ข้อมูลในภูมิภาคเอเชียตะวันออกเฉียงใต้และไทยมักอยู่ในช่วงประมาณ 1.6–1.9 สำหรับศูนย์ข้อมูลเชิงพาณิชย์ทั่วไป (ค่าสิ่งแวดล้อมและการออกแบบของสถานที่มีผลต่อค่าเฉลี่ยนี้อย่างมาก)
ผลกระทบเชิงเศรษฐกิจและการดำเนินงานของคูลลิ่งมีความชัดเจน: ค่าไฟฟ้าที่สูงขึ้นเป็นต้นทุนการดำเนินงาน (OPEX) รายใหญ่อันดับต้น ๆ ของผู้ให้บริการศูนย์ข้อมูล ตัวอย่างเชิงตัวเลขเพื่อแสดงภาพว่าเรื่องนี้มีผลมากเพียงใด สมมติศูนย์ข้อมูลมีภาระ IT เพียง 1 เมกะวัตต์ หากค่า PUE ลดลง 20% จาก 1.8 เหลือ 1.44 จะลดการใช้ไฟฟ้าของอาคารลงประมาณ 360 กิโลวัตต์เทียบเท่า ซึ่งตลอดปีคิดเป็นพลังงานประมาณ 3.15 ล้านหน่วย หากคำนวนด้วยอัตราค่าไฟฟ้ากลางสำหรับภาคอุตสาหกรรมที่ประมาณ 4 บาท/หน่วย จะเท่ากับการประหยัดค่าไฟประมาณ กว่า 12 ล้านบาทต่อปี — ตัวอย่างนี้สะท้อนว่าการปรับปรุงระบบคูลลิ่งแม้เพียงไม่กี่เปอร์เซ็นต์ก็สามารถแปลงเป็นผลตอบแทนทางการเงินได้อย่างชัดเจน
สาเหตุหลักที่ทำให้การคูลลิ่งเป็นปัญหาเชิงโครงสร้างสำหรับศูนย์ข้อมูลในไทย ได้แก่
- อุณหภูมิและความชื้นสูงตลอดปี: ทำให้ระบบคูลลิ่งต้องทำงานต่อเนื่องและไม่สามารถพึ่งพา “free cooling” ภายนอกได้บ่อยเท่าภูมิภาคหนาว
- ภาระความชื้น (latent load): ต้องใช้พลังงานเพิ่มเติมในการลดความชื้นและหลีกเลี่ยงปัญหาการควบแน่นที่อาจทำให้อุปกรณ์เสียหาย
- ความหนาแน่นพลังงานของอุปกรณ์ IT ที่เพิ่มขึ้น: Server รุ่นใหม่และ GPU-accelerated blades สร้างความร้อนหนาแน่นสูง เกิด hot‑spot ที่ต้องการการจัดการอากาศและการระบายความร้อนที่ละเอียดขึ้น
- โครงสร้างพื้นฐานและการออกแบบอาคาร: ศูนย์ข้อมูลบางแห่งใช้งานในอาคารที่ไม่ออกแบบมาเพื่อการระบายความร้อนที่มีประสิทธิภาพ ทำให้เกิดการรั่วไหลของอากาศและการแลกเปลี่ยนความร้อนที่สูญเปล่า
- ต้นทุนพลังงานและความเสี่ยงด้านซัพพลาย: ราคาค่าไฟฟ้าและความไม่แน่นอนของแรงจ่ายไฟ ส่งผลให้อัตราคืนทุนของการลงทุนในเทคโนโลยีคูลลิ่งที่มีประสิทธิภาพสูงมีความสำคัญต่อการตัดสินใจเชิงธุรกิจ
ด้วยปัจจัยเชิงสภาพภูมิอากาศ โครงสร้างพื้นฐาน และภาระงานที่เพิ่มขึ้น การจัดการคูลลิ่งจึงไม่ใช่เพียงปัญหาทางวิศวกรรมแต่เป็นความท้าทายเชิงกลยุทธ์ของผู้ประกอบการศูนย์ข้อมูลในไทย การลงทุนในเทคโนโลยีที่เพิ่มประสิทธิภาพการระบายความร้อน เช่น การใช้ Digital‑Twin เพื่อจำลองพารามิเตอร์ความร้อนร่วมกับระบบควบคุมอัจฉริยะ จะช่วยลด PUE, ลดค่าใช้จ่ายพลังงาน และลดความเสี่ยงด้านการดำเนินงานในระยะยาว
เทคโนโลยีที่ใช้: Digital‑Twin + Reinforcement Learning อธิบายเชิงเทคนิค
เทคโนโลยีที่ใช้: Digital‑Twin + Reinforcement Learning (อธิบายเชิงเทคนิค)
ภาพรวมเชิงเทคนิคของ Digital‑Twin
Digital‑Twin ในบริบทศูนย์ข้อมูลหมายถึงแบบจำลองเสมือนที่จำลองพฤติกรรมความร้อนและการไหลของอากาศ (thermal & airflow dynamics) ภายในห้องเซิร์ฟเวอร์แบบเรียลไทม์หรือใกล้เรียลไทม์ โดยทั่วไประบบจะผสาน high‑fidelity CFD (Computational Fluid Dynamics) สำหรับการวิเคราะห์เชิงลึกแบบออฟไลน์ กับ reduced‑order models หรือ surrogate models (เช่น neural networks, POD/Galerkin models, physics‑informed neural networks) สำหรับการใช้รันแบบเรียลไทม์ การออกแบบจะรวมถึงกระบวนการ data assimilation เพื่อผสานผลวัดจากเซนเซอร์ให้แบบจำลองปรับสถานะ (state estimation) อย่างสม่ำเสมอ เช่น Kalman filter หรือ ensemble methods เพื่อรักษาความสอดคล้องระหว่างโลกจริงกับแบบจำลอง
ตัวอย่างเช่น ขั้นตอนฝั่ง Digital‑Twin อาจมีการรัน CFD แบบละเอียดเป็นชุดการทดลอง (offline) เพื่อสร้างชุดข้อมูลครอบคลุมเงื่อนไขการทำงานต่าง ๆ แล้วฝึก surrogate model (เช่น LSTM หรือ convolutional NN) ให้ทำนายการแจกจ่ายอุณหภูมิและแรงดันอากาศตามพารามิเตอร์การควบคุม เพื่อให้สามารถประเมินผลกระทบของการเปลี่ยนพารามิเตอร์ได้ภายในมิลลิวินาที–วินาทีในสภาพแวดล้อมการควบคุมจริง
สถาปัตยกรรมระบบ (จากเซนเซอร์ถึงคอนโทรลเลอร์)
- Edge sensors: อุณหภูมิ (inlet/outlet per rack, ambient), pressure differential (ระหว่างช่องทางไหล), แรงดันน้ำ/น้ำยา, กระแสไฟฟ้า (compressor, fan current), ความชื้น — ข้อมูลตัวอย่างระบบขนาดกลางอาจมีระหว่าง 500–2,000 จุดวัด ขึ้นกับขนาดและการแบ่งโซน
- ฟีดข้อมูลและ Telemetry: เซนเซอร์ส่งข้อมูลแบบ MQTT/HTTP ไปยัง edge gateway — ข้อมูลถูกเก็บแบบ time‑series ในฐานข้อมูลเช่น InfluxDB/Prometheus ที่มี retention และ downsampling, sampling rate ทั่วไป 0.2–1 Hz (1–5 วินาที) สำหรับการวัดความร้อน/แรงดัน และต่ำกว่าสำหรับเมตริกการใช้พลังงาน
- Simulation environment: ประกอบด้วย CFD engine (OpenFOAM/ANSYS หรือ in‑house), surrogate model สำหรับ inference เร็ว, และ data assimilation module ที่อัปเดตพารามิเตอร์แบบจำลองตามข้อมูลจริง
- RL Agent / Controller: เอเจนต์ RL รับสภาพ (state) จาก Digital‑Twin + telemetry แล้วเลือกการกระทำ (actions) เช่น ปรับความเร็วพัดลม (fan speed 0–100%), เปลี่ยน setpoint คอนเด็นเซอร์ (chiller setpoint ±x°C), สลับชุดคอนเด็นเซอร์/CRAC unit หรือควบคุม dampers/economizer
- Actuators & Integration: คำสั่งถูกส่งผ่าน BMS/SCADA (โปรโตคอลเช่น BACnet, Modbus) พร้อมกับกลไก fail‑safe (hardware thermostat, hard limits) เพื่อรักษา SLA
หลักการ Reinforcement Learning ในการตัดสินใจควบคุมเชิงนโยบายแบบเรียลไทม์
ระบบใช้แนวทาง Reinforcement Learning (RL) เพื่อเรียนรู้นโยบาย (policy) ที่แม็ปสถานะของศูนย์ข้อมูลไปยังการกระทำควบคุมโดยตรง โดยนิยามองค์ประกอบสำคัญดังนี้:
- State: เวกเตอร์รวมสถานะจากเซนเซอร์ (อุณหภูมิ inlet/outlet, pressure differentials, power draw per unit), สถานะอุปกรณ์ (fan RPM, compressor stage), และตัวแปรบริบท (ภาระงานเซิร์ฟเวอร์, outdoor temp)
- Action: การปรับพารามิเตอร์คูลลิ่ง เช่น fan speed (continuous), chiller setpoint (continuous/discrete), status ของชุดคอนเด็นเซอร์ (on/off, staging)
- Reward: ฟังก์ชันออกแบบเพื่อถ่วงน้ำหนักระหว่างการลดพลังงาน (เช่นลด kW หรือ PUE) กับการรักษา SLA (เช่น penalty เมื่อต่ำกว่า/เกินช่วงอุณหภูมิที่กำหนด) — ตัวอย่าง reward = −α·energy + β·(SLA‑violation_penalty)
- Constraints / Safety: ใช้ safe‑RL (เช่น Constrained Policy Optimization, Lagrangian approaches) หรือ “action shield” ที่คัดกรองคำสั่งที่อาจทำให้ค่าอุณหภูมิเกินขอบเขตทางกายภาพ
การฝึก (training) มักเริ่มในสภาพแวดล้อมจำลอง (sim‑to‑real) โดยใช้นโยบาย RL ที่ sample‑efficient (เช่น PPO, SAC สำหรับ continuous action) ผสานกับ domain randomization เพื่อให้เอเจนต์ทนต่อความไม่แน่นอนของโลกจริง เมื่อ deploy จะใช้ staged rollout (A/B testing ในโซนย่อย) พร้อมการตรวจจับ anomalous behavior และ human‑in‑the‑loop เพื่ออนุมัติการเปลี่ยนแปลงที่เสี่ยง
Loop การควบคุมและการเรียนรู้ต่อเนื่อง
วงจรการทำงานแบบครบวงจรประกอบด้วย:
- Data acquisition → state estimation → Digital‑Twin inference → policy inference → actuation → monitoring
- ความถี่การควบคุมขึ้นกับชนิดการกระทำ: สำหรับการปรับ fan speed หรือ damper อาจทำทุก 10–60 วินาที ขณะที่การเปลี่ยน setpoint ชิลเลอร์อาจรันทุก 5–15 นาที เพื่อหลีกเลี่ยงการสลับบ่อยเกินไปและป้องกันการสึกหรอ
- Continuous learning: ประสบการณ์จริงถูกบันทึกลง replay buffer หรือ event store เพื่อใช้ในการฝึกอัปเดตแบบออฟไลน์/ออนไลน์ (off‑policy updates) การอัปเดตแบบอินไลน์ช่วยให้โมเดลปรับตัวต่อแนวโน้มโหลดหรือสภาพอากาศที่เปลี่ยนแปลง แต่จะมีกลไก validation ก่อนผลักโมเดลใหม่สู่ production
นอกเหนือจากประสิทธิภาพเชิงพลังงานแล้ว ระบบต้องมีการตรวจวัดการปฏิบัติตาม SLA อย่างต่อเนื่อง ตัวอย่างเช่นการรักษา rack inlet temperature ให้อยู่ในช่วง 18–27°C และลดความผันแปรเชิงอุณหภูมิต่อเนื่อง ระบบรายงานเมตริกเช่น PUE, IT load, cooling power แบบ near‑real‑time — ในการทดลองภาคสนามที่เปิดเผย ผลลัพธ์คือ ลด PUE ประมาณ 20% และผู้ประกอบการคาดการณ์การประหยัดค่าไฟเป็นจำนวน หลักล้านบาทต่อปี ขึ้นอยู่กับขนาดและลักษณะโหลด
ประเด็นด้านปฏิบัติการและการบูรณาการ
การบูรณาการตั้งแต่ระดับ edge ถึง cloud ต้องคำนึงถึงความปลอดภัยของข้อมูล (segmentation, TLS), latency ของเครือข่าย, และการจัดการเฟลโอเวอร์ ส่วนการอธิบายการตัดสินใจ (explainability) ใช้เทคนิคเช่น feature importance หรือ sensitivity analysis เพื่อให้ผู้ดำเนินงานเข้าใจว่าทำไมเอเจนต์เลือกการกระทำใด ๆ และสามารถตั้งค่า policy‑level constraints ได้ตามนโยบายองค์กร
สรุปคือการผสาน Digital‑Twin ที่แม่นยำพอและอัปเดตตามข้อมูลจริง กับ Reinforcement Learning ที่ออกแบบอย่างระมัดระวังเรื่อง reward/constraints และการฝึกแบบ sim‑to‑real ทำให้สามารถปรับการควบคุมระบบคูลลิ่งแบบเรียลไทม์ ลดการใช้พลังงาน และยังคงรักษา SLA ได้อย่างเป็นระบบและเชื่อถือได้
การติดตั้งและกระบวนการพายล็อต (Pilot): ขั้นตอนและมาตรการวัดผล
การนำระบบ Digital‑Twin ที่ผสานกับ Reinforcement Learning (RL) เข้าสู่ศูนย์ข้อมูลจริง ต้องออกแบบกระบวนการพายล็อตที่เป็นระบบ เพื่อให้มั่นใจทั้งด้านประสิทธิภาพและความปลอดภัยของระบบ IT เป้าหมายของพายล็อตคือทดสอบเชิงปฏิบัติการในสภาพแวดล้อมจริง โดยเริ่มจากการสำรวจ สร้างแบบจำลอง ปรับแต่งในซิมูเลชัน และค่อยๆ ปรับไปสู่การควบคุมเรียลไทม์ภายใต้การเฝ้าระวังอย่างเข้มงวด
ขั้นตอนการติดตั้งและจัดเตรียมสภาพแวดล้อม (Overview ขั้นตอนหลัก)
- 1. สำรวจระบบเดิม (Assessment) — รวบรวมข้อมูลสถาปัตยกรรมศูนย์ข้อมูล, แผนผังการไหลอากาศ, รายการอุปกรณ์ (CRAC/CRAH, chillers, pumps, VFDs, PDUs), แคลมป์มิเตอร์และบันทึกการใช้พลังงานย้อนหลัง 3–12 เดือน เพื่อสร้าง baseline การทำงาน ปกติแนะนำช่วงเก็บข้อมูล baseline อย่างน้อย 2–4 สัปดาห์ เพื่อให้ค่าสถิติมีความมั่นคง
- 2. ติดตั้งเซนเซอร์และระบบการวัด (Instrumentation) — ติดตั้งเซนเซอร์วัดอุณหภูมิ inlet/outlet แต่ละแร็ค (หรือทุก 2–3 แร็ค), ความชื้น, ความดันความแตกต่าง (pressure differential), อัตราการไหล (flow), เซนเซอร์พลังงานที่ PDU และเมตริกของเครื่องทำความเย็น เช่น เซนเซอร์จุดต่างอุณหภูมิคอยล์, สัญญาณ VFD และสถานะปั๊ม จำนวนเซนเซอร์สำหรับศูนย์ข้อมูลขนาดกลางมักอยู่ระหว่าง 50–200 จุด ในเฟสพายล็อต ตัวอย่างจะเลือกกลุ่มตัวอย่าง 10–30 แร็คหรือ 10–30% ของโหลด IT เพื่อควบคุมความเสี่ยง
- 3. สร้างและปรับแบบจำลอง Digital‑Twin (Modeling & Calibration) — พัฒนาแบบจำลองเทอร์มอล (เช่น network thermal RC model หรือ CFD ระดับเหมาะสม) ที่จับพฤติกรรมการกระจายความร้อนและการไหลของอากาศ จากนั้นทำการคาลิเบรตโดยใช้ข้อมูลเซนเซอร์จริง (data assimilation) จนค่าพยากรณ์อุณหภูมิและพลังงานใกล้เคียงกับความจริงภายในเกณฑ์ความคลาดเคลื่อน เช่น MAE ของอุณหภูมิ < 0.5–1.0°C
- 4. ฝึก RL ในสภาพแวดล้อมจำลอง (Simulation Training) — ออกแบบสภาพแวดล้อมซิมูเลชันโดยใช้ Digital‑Twin เป็นสภาพแวดล้อมชั้นใน (inner-loop) เพื่อเทรนตัวแทน RL โดยกำหนดฟังก์ชันรางวัลที่สมดุลระหว่าง การลด PUE/พลังงาน กับ การรักษาอุณหภูมิและ SLA (ลงโทษรุนแรงเมื่อละเมิดขอบเขตอุณหภูมิ) ใช้เทคนิค domain randomization เพื่อลดช่องว่างระหว่างซิมกับจริง และตรวจสอบพฤติกรรมภายใต้สภาวะรบกวนหลายรูปแบบ การเทรนปกติอยู่ในช่วง 4–12 สัปดาห์ ขึ้นกับความซับซ้อนของสภาพแวดล้อม
- 5. เฟสทดลองจริง (Pilot Deployment) — เริ่มแบบขั้นบันได: (a) Shadow mode ให้ RL ทำการเสนอคำสั่งแต่ยังไม่ส่งออกไปควบคุมจริง เพื่อเปรียบเทียบกับการควบคุมเดิมเป็นเวลา 1–4 สัปดาห์, (b) Advisory mode ให้ operator สามารถยอมรับ/ปฏิเสธคำสั่ง, (c) Closed‑loop เรียลไทม์ ภายใต้ขอบเขตการทำงานที่จำกัด เริ่มด้วยบางส่วนของระบบ (subset) ก่อนขยายสู่การควบคุมทั้งกลุ่มหลังจากยืนยันความปลอดภัยและประสิทธิภาพ
มาตรการความปลอดภัยและการควบคุมความเสี่ยง
- ตั้งค่า hard limits บนคำสั่งใดๆ ที่ RL ออก หากคำสั่งจะทำให้อุณหภูมิห้องหรือแร็คร้อนเกินค่า SLA ให้ระบบไม่ยอมรับคำสั่งและสลับกลับเป็นโหมดอัตโนมัติเดิม
- มีระบบมนุษย์ควบคุม (human-in-the-loop) ตลอดเฟสพายล็อต โดยเฉพาะช่วงเปลี่ยนโหมดเป็น closed‑loop
- บันทึกทุกการตัดสินใจของ RL เพื่อการ audit และย้อนกลับ (rollback) หากพบพฤติกรรมผิดปกติ
เกณฑ์วัดผล (KPIs) และวิธีการประเมินผล
- PUE ก่อน‑หลัง — เปรียบเทียบค่า PUE รายวัน/รายสัปดาห์ ก่อนและระหว่างพายล็อต โดยคำนวณจากการวัดพลังงานรวมของสถานที่ต่อพลังงาน IT ตัวอย่างเป้าหมายคือการลด PUE ประมาณ 20% (เช่น จาก 1.80 → 1.44)
- kWh ลดลง (Annualized kWh savings) — ยกตัวอย่าง: ศูนย์ข้อมูลขนาดกลางที่มี IT load 500 kW จะใช้พลังงาน IT ประมาณ 4,380,000 kWh/ปี (500 kW × 8,760 ชม.) หาก PUE ลดลง 20% จาก 1.80 → 1.44 จะทำให้พลังงานรวมลดจาก 7,884,000 kWh เป็น 6,307,200 kWh ประหยัดประมาณ 1,576,800 kWh/ปี ซึ่งถ้าค่าไฟฟ้า 4.5 บาท/kWh จะเท่ากับประมาณ 7.1 ล้านบาท/ปี (ตัวอย่างเชิงประเมินเพื่อชี้ให้เห็นศักยภาพ)
- การรักษาอุณหภูมิภายใน SLA — วัดเปอร์เซ็นต์เวลาที่อุณหภูมิ inlet แร็คอยู่ภายในช่วงที่กำหนด (เช่น ASHRAE 18–27°C หรือ SLA เฉพาะของผู้ให้บริการ) เป้าหมายคือรักษาให้ไม่น้อยกว่า 99.9% ของเวลา ไม่ให้เกิด thermal excursions
- ความเสถียรของการควบคุม — ตรวจวัดค่า variance/oscillation ของ setpoints และความถี่ของการเปลี่ยนแปลงคำสั่ง (เพื่อหลีกเลี่ยงการสวิงบ่อยเกินไป), จำนวน alarms/incidents และ Mean Time Between Failures (MTBF) ที่เกี่ยวข้องกับระบบคูลลิ่ง
- ผลกระทบต่อ SLA ทางธุรกิจ — ตรวจสอบ event ที่อาจกระทบต่อ availability ของเซิร์ฟเวอร์ เช่น thermal throttling หรือการปิดเครื่องฉุกเฉิน ต้องไม่มีการละเมิด SLA ของลูกค้าที่เกี่ยวข้อง
- การวัดเชิงสถิติ — ใช้การทดสอบเชิงสถิติเช่น paired t‑test หรือ bootstrap confidence intervals เพื่อตรวจความมีนัยสำคัญของการลดพลังงาน ระบุระดับความเชื่อมั่น (เช่น 95% CI) และระบุขนาดตัวอย่าง (จำนวนแร็ค/ช่วงเวลา) เพื่อการสรุปผลที่น่าเชื่อถือ
ตัวอย่างระยะเวลาและขนาดตัวอย่างการทดลอง
- เตรียมการและติดตั้งเซนเซอร์: 1–3 สัปดาห์
- เก็บข้อมูล baseline: 2–4 สัปดาห์
- สร้างและคาลิเบรต Digital‑Twin: 4–8 สัปดาห์ (พร้อมการวนคาลิเบรตหลายรอบ)
- ฝึก RL ในซิมูเลชัน: 4–12 สัปดาห์ ขึ้นกับความซับซ้อนและการทดลอง hyperparameter
- เฟสพายล็อตจริง (Pilot): โดยทั่วไปแนะนำ 3–6 เดือน บนศูนย์ข้อมูลขนาดกลาง เพื่อรวมช่วงฤดูกาลและสภาวะโหลดที่หลากหลาย
- ขนาดตัวอย่าง: เริ่มจาก subset 10–30 แร็คหรือ 10–30% ของโหลด IT (ขึ้นกับสัดส่วนการกระจายความร้อน) หากสำเร็จค่อยขยายเป็นการควบคุมเต็มรูปแบบ
โดยสรุป กระบวนการพายล็อตต้องมีการวางแผนเป็นขั้นตอน ตั้งแต่การสำรวจพื้นฐาน ติดตั้งเซนเซอร์ สร้างและคาลิเบรต Digital‑Twin ไปจนถึงการฝึก RL ในซิมูเลชัน ก่อนย้ายสู่การทดสอบเรียลไทม์ภายใต้การควบคุมและมาตรการความปลอดภัยที่เข้มงวด โดยใช้เกณฑ์วัดผลที่ชัดเจนทั้งด้าน PUE, kWh savings, และการรักษาอุณหภูมิในขอบเขต SLA เพื่อให้ผลลัพธ์เชิงธุรกิจมีความน่าเชื่อถือและสามารถขยายผลได้ในเชิงพาณิชย์
ผลลัพธ์เชิงตัวเลขและตัวอย่างการประหยัดค่าไฟ
ผลลัพธ์เชิงตัวเลขเบื้องต้นจากพายล็อต
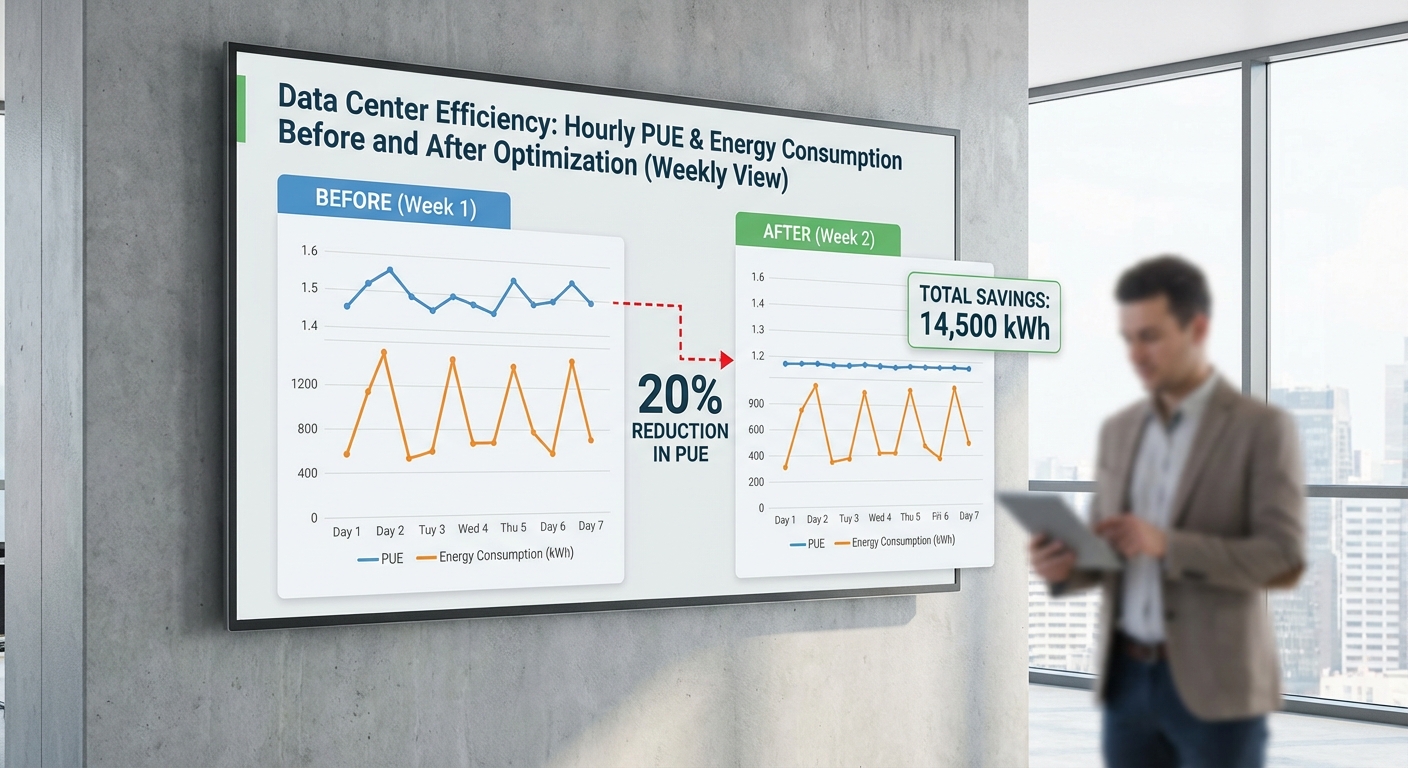
จากการทดลองพายล็อตที่ศูนย์ข้อมูลของโครงการ พบว่า PUE ลดจาก 1.60 เป็น 1.28 ซึ่งเทียบเป็นการลดสัมพัทธ์ราว 20% ของค่า PUE เดิม (คำนวณจาก (1.60−1.28)/1.60 = 0.20) การลด PUE ในลักษณะนี้สะท้อนถึงการลดพลังงานรวมที่ใช้ในส่วนระบบสาธารณูปโภคของศูนย์ข้อมูล (facility power) ขณะเดียวกันพลังงานที่ถูกใช้โดยอุปกรณ์ไอที (IT load) คงที่ตามเงื่อนไขการทดสอบ ทำให้การคำนวณการประหยัดพลังงานสามารถทำได้อย่างตรงไปตรงมา

สมมติฐานการคำนวณและวิธีการ
วิธีการคำนวณหลักใช้สมการพื้นฐาน:
- Facility Power (kW) = IT Load (kW) × PUE
- พลังงานต่อปี (kWh/ปี) = Facility Power (kW) × ชั่วโมงการใช้งานต่อปี (ปกติ 8,760 ชั่วโมง/ปี สำหรับการใช้งาน 24/7)
- การประหยัดพลังงาน (kWh/ปี) = (PUEก่อน − PUEหลัง) × IT Load × 8,760
- มูลค่าการประหยัด (บาท/ปี) = การประหยัดพลังงาน (kWh/ปี) × อัตราค่าไฟ (บาท/kWh)
สมมติฐานตัวอย่างที่ใช้คำนวณในเอกสารนี้: PUE ก่อน = 1.60, PUE หลัง = 1.28, ชั่วโมง/ปี = 8,760 และใช้ตัวอย่างอัตราค่าไฟเพื่อแสดงความไวต่ออัตราค่าไฟ ได้แก่ 3.50, 4.50, 5.00 บาท/kWh (สามารถปรับค่าได้ตามอัตราจริงของแต่ละผู้ประกอบการ)
ตัวอย่างการประหยัดตามขนาดศูนย์ข้อมูล (กรณีศึกษา)
ต่อไปนี้เป็นตัวอย่างผลลัพธ์เชิงตัวเลขสำหรับขนาดศูนย์ข้อมูล 3 ระดับ เพื่อแสดงภาพรวมการประหยัดทั้งทางพลังงานและมูลค่า
-
ขนาดเล็ก — IT load 100 kW
Facility power ก่อน = 100 × 1.60 = 160 kW
Facility power หลัง = 100 × 1.28 = 128 kW
การประหยัดกำลังไฟ = 32 kW → การประหยัดพลังงาน = 32 × 8,760 = 280,320 kWh/ปี
มูลค่าการประหยัด (ตัวอย่างอัตราไฟ):
- 3.50 บาท/kWh → 280,320 × 3.50 = 980, 0xx บาท/ปี (≈ 980,120 บาท/ปี)
- 4.50 บาท/kWh → 280,320 × 4.50 = 1,261,440 บาท/ปี
- 5.00 บาท/kWh → 280,320 × 5.00 = 1,401,600 บาท/ปี -
ขนาดกลาง — IT load 500 kW (ตัวอย่างหลักจากพายล็อต)
Facility power ก่อน = 500 × 1.60 = 800 kW
Facility power หลัง = 500 × 1.28 = 640 kW
การประหยัดกำลังไฟ = 160 kW → การประหยัดพลังงาน = 160 × 8,760 = 1,401,600 kWh/ปี
มูลค่าการประหยัด (ตัวอย่างอัตราไฟ):
- 3.50 บาท/kWh → 1,401,600 × 3.50 = 4,905,600 บาท/ปี
- 4.50 บาท/kWh → 1,401,600 × 4.50 = 6,307,200 บาท/ปี (ตัวอย่างที่แสดงว่า “ประหยัดหลักล้าน/ปี”)
- 5.00 บาท/kWh → 1,401,600 × 5.00 = 7,008,000 บาท/ปี -
ขนาดใหญ่ — IT load 2,000 kW (2 MW)
Facility power ก่อน = 2,000 × 1.60 = 3,200 kW
Facility power หลัง = 2,000 × 1.28 = 2,560 kW
การประหยัดกำลังไฟ = 640 kW → การประหยัดพลังงาน = 640 × 8,760 = 5,606,400 kWh/ปี
มูลค่าการประหยัด (ตัวอย่างอัตราไฟ):
- 3.50 บาท/kWh → 5,606,400 × 3.50 = 19,621,400 บาท/ปี (ปัดเศษ)
- 4.50 บาท/kWh → 5,606,400 × 4.50 = 25,228,800 บาท/ปี
- 5.00 บาท/kWh → 5,606,400 × 5.00 = 28,032,000 บาท/ปี
การวิเคราะห์ความไวและข้อสังเกต
จากสมการการประหยัดจะเห็นได้ว่า การประหยัดพลังงานเป็นเชิงเส้นตามขนาด IT load และแปรผันตรงกับความต่างของ PUE (PUEก่อน − PUEหลัง) รวมถึงจำนวนชั่วโมงการใช้งานต่อปีและอัตราค่าไฟ ดังนั้นตัวแปรสำคัญที่มีผลต่อมูลค่าการประหยัดคือ:
- ขนาด IT Load: ยิ่ง IT load สูง ผลรวมการประหยัด (kWh/ปี) จะยิ่งมากขึ้นเป็นสัดส่วนนตรง
- ชั่วโมงการใช้งาน/ปี: สำหรับศูนย์ข้อมูลที่ไม่ทำงาน 24/7 การคำนวณต้องปรับชั่วโมงจริง (เช่น 8,760 × อัตราการใช้งานเฉลี่ย)
- อัตราค่าไฟ (บาท/kWh): เป็นตัวแปรสำคัญในการแปลงเป็นมูลค่า — สำหรับผู้ประกอบการที่มีอัตราไฟฟ้าสูงกว่าค่าเฉลี่ย การลงทุนในระบบคูลลิ่งที่มีประสิทธิภาพจะคืนทุนเร็วขึ้น
สรุป: กรณีตัวอย่างจากพายล็อตที่แสดง PUE ลดจาก 1.60 เป็น 1.28 สามารถให้การประหยัดพลังงานตั้งแต่ระดับแสนกิโลวัตต์ชั่วโมงต่อปีจนถึงหลายล้านกิโลวัตต์ชั่วโมงต่อปี ขึ้นอยู่กับขนาดศูนย์ข้อมูล และเมื่อคำนวณเป็นมูลค่าตามอัตราค่าไฟปกติของไทย จะเห็นได้ชัดเจนว่าการลด PUE ในสัดส่วน 20% สามารถแปลเป็นการประหยัดค่าไฟได้ในระดับ หลักล้านถึงหลักสิบล้านบาทต่อปี สำหรับศูนย์ข้อมูลขนาดกลางถึงใหญ่
ผลกระทบทางธุรกิจ: ROI, ต้นทุนการลงทุน และมุมมองผู้ประกอบการ
ผลกระทบทางธุรกิจ: ROI, ต้นทุนการลงทุน และมุมมองผู้ประกอบการ
การนำระบบ Digital‑Twin ร่วมกับ Reinforcement Learning (RL) มาปรับจูนระบบคูลลิ่งของศูนย์ข้อมูลส่งผลโดยตรงต่อค่าใช้จ่ายการดำเนินงาน (OPEX) และตัวชี้วัดประสิทธิภาพอย่าง PUE ที่ลดลงประมาณ 20% ตามที่โครงการนำร่องรายงานไว้ การลด PUE ในระดับนี้แปลเป็นการลดค่าไฟฟ้าที่เกี่ยวข้องกับคูลลิ่งซึ่งศูนย์ข้อมูลทั่วไปสามารถมีค่าใช้จ่ายเป็นหลักล้านบาทต่อปีได้ — ดังนั้นมิติเชิงการเงินจึงเป็นตัวขับเคลื่อนสำคัญในการตัดสินใจลงทุน
ต้นทุนเริ่มต้นของโครงการจำแนกได้เป็นกลุ่มหลัก ดังนี้
- ฮาร์ดแวร์และเครือข่าย — คอนโทรลเลอร์ Edge, อุปกรณ์สื่อสาร, ระบบเกตเวย์ (ประมาณ 0.5–3 ล้านบาท ขึ้นกับขนาดและความซับซ้อน)
- เซนเซอร์และอุปกรณ์วัด — เทอร์โมมิเตอร์ความแม่นยำสูง, เซนเซอร์การไหล, humidity sensors และ IO modules (ประมาณ 0.2–1 ล้านบาท)
- ซอฟต์แวร์ — ไลเซนส์ Digital‑Twin, โมดูล RL/AI, แดชบอร์ดการมอนิเตอร์ และค่า Cloud compute ในช่วงฝึกโมเดล (เบื้องต้น 0.5–2 ล้านบาท รวมค่า annual subscription)
- บริการวิศวกรรมและปรับจูน — การติดตั้ง, การบูรณาการกับระบบ BMS/SCADA, การปรับจูนโมเดลและการทดสอบ (ประมาณ 0.8–3 ล้านบาท ขึ้นกับผู้ให้บริการและความซับซ้อน)
- การฝึกอบรมและบุคลากร — ค่าอบรมทีมปฏิบัติการ, วิศวกร ML/DevOps และค่าใช้จ่ายการบำรุงรักษาเพิ่มเติม (ปีแรก 0.2–0.6 ล้านบาท)
รวมกันแล้วสำหรับศูนย์ข้อมูลขนาดกลางถึงใหญ่ ต้นทุน CAPEX เบื้องต้นมักอยู่ในช่วง ประมาณ 3–12 ล้านบาท สำหรับโครงการครบวงจร ขณะที่ศูนย์ข้อมูลขนาดใหญ่อาจสูงกว่านี้ได้ ทั้งนี้ตัวเลขขึ้นกับสเกลระบบและความต้องการเชื่อมต่อกับระบบเดิม
การคำนวณระยะเวลาคืนทุน (payback) และ ROI สามารถยกตัวอย่างสมมติได้ดังนี้:
- กรณีตัวอย่าง A (ขนาดกลาง) — ติดตั้งรวม 3,000,000 บาท, ลดค่าไฟได้ 20% คิดเป็นการประหยัด 1,200,000 บาท/ปี (ก่อนหักค่าเสริม) หากมีค่าใช้จ่ายบำรุงรักษาและ cloud compute เพิ่ม 200,000 บาท/ปี => ประหยัดสุทธิ 1,000,000 บาท/ปี → ระยะเวลาคืนทุนประมาณ 3.0 ปี. ROI แบบง่าย (annual net savings / CAPEX) = 33%/ปี
- กรณีตัวอย่าง B (ขนาดใหญ่) — ติดตั้งรวม 10,000,000 บาท, ลดค่าไฟได้ 3,000,000 บาท/ปี, ค่าเสริม 400,000 บาท/ปี => ประหยัดสุทธิ 2,600,000 บาท/ปี → ระยะเวลาคืนทุนประมาณ 3.8 ปี. ROI แบบง่าย ≈ 26%/ปี
หมายเหตุ: ตัวเลขข้างต้นเป็นตัวอย่างเชิงสมมติที่สอดคล้องกับช่วงการคืนทุนที่ผู้ประกอบการคาดการณ์ไว้ (โดยทั่วไปอยู่ในช่วง 2–4 ปี) โดยปัจจัยที่ทำให้ช่วงคืนทุนสั้นลงได้แก่ ค่าลดลงของต้นทุนฮาร์ดแวร์, การต่อรองค่าไลเซนส์ซอฟต์แวร์, การมีพาร์ทเนอร์ที่ให้บริการแบบบริการ (SaaS/managed) เพื่อลด CAPEX และราคาพลังงานที่ปรับสูงขึ้น (ซึ่งทำให้การประหยัดเงินสดต่อปีเพิ่มขึ้น)
มุมมองจากผู้ประกอบการและวิศวกรที่ปฏิบัติงานจริงสะท้อนข้อดีและความท้าทาย:
- “การติดตั้งระบบนี้ช่วยลดค่าไฟฟ้าประจำปีของเราได้ราว 1–1.5 ล้านบาท ทำให้การคืนทุนเกิดขึ้นภายใน 2–3 ปี” — ผู้บริหารศูนย์ข้อมูลรายหนึ่งกล่าว
- “ทางเทคนิค เราต้องมีการบำรุงรักษาเซนเซอร์อย่างสม่ำเสมอและทีมที่เข้าใจการทำงานของ RL เพื่อรีเทรนโมเดลเมื่อเงื่อนไขเปลี่ยน” — วิศวกรระบบกล่าวเสริม โดยชี้ว่าการรักษาความปลอดภัยของวงจรการควบคุมเป็นสิ่งที่ต้องให้ความสำคัญ
- “เมื่อต้องการขยายสเกลไปยังไซต์อื่น ค่าใช้จ่ายซอฟต์แวร์และโมเดลสามารถกระจายได้ ทำให้ต้นทุนต่อไซต์ลดลงอย่างมีนัยสำคัญ” — ผู้ประกอบการที่มีหลายไซต์ระบุว่ากรณีสเกลขึ้น ROI จะดีขึ้น
สรุปเชิงกลยุทธ์: การลงทุนใน Digital‑Twin + RL สำหรับคูลลิ่งเป็นการลงทุนที่ช่วยลด OPEX อย่างมีนัยสำคัญและสนับสนุนเป้าหมายความยั่งยืนขององค์กร โดยในภาพรวม ระยะเวลาคืนทุนมักอยู่ในช่วง 2–4 ปี ขึ้นกับขนาดและรูปแบบการจัดซื้อ แต่ผู้ประกอบการต้องเตรียมพร้อมด้านการบำรุงรักษา บุคลากร และการบริหารความเสี่ยง (เช่น โซลูชันสำรองและมาตรการไซเบอร์) เพื่อให้ผลตอบแทนทางการเงินเกิดขึ้นจริงและยั่งยืนเมื่อขยายสเกล
ความเสี่ยง ข้อจำกัด และการขยายสู่ศูนย์ข้อมูลอื่น
ความเสี่ยง ข้อจำกัด และการขยายสู่ศูนย์ข้อมูลอื่น
การนำ Digital‑Twin ความร้อนผสานกับ Reinforcement Learning (RL) มาใช้เพื่อปรับระบบคูลลิ่งเรียลไทม์ในศูนย์ข้อมูลแม้มีศักยภาพในการลดค่าไฟและ PUE ได้มาก แต่ก็มีความเสี่ยงและข้อจำกัดเชิงปฏิบัติการที่ต้องพิจารณาอย่างรอบคอบก่อนการขยายผล การวิเคราะห์ต่อไปนี้สรุปประเด็นหลักทั้งด้านคุณภาพข้อมูล ความปลอดภัยของระบบอัตโนมัติ และความท้าทายเมื่อสเกลการใช้งานข้ามศูนย์ข้อมูลหรือข้ามประเทศ พร้อมแนวทางบรรเทาความเสี่ยงเชิงเทคนิคและการจัดการ
1) ปัญหาคุณภาพข้อมูลและการแปลผลสู่แบบจำลอง
คุณภาพข้อมูลจากเซนเซอร์เป็นรากฐานของทั้ง Digital‑Twin และ RL หากข้อมูลมีค่าเบี่ยง เบี้ยว (bias), หาย (missing) หรือมีสัญญาณรบกวนสูง จะส่งผลให้แบบจำลอง Digital‑Twin ทำนายสภาพความร้อนไม่แม่นยำ และทำให้นโยบาย RL เรียนรู้การกระทำที่ไม่เหมาะสม ตัวอย่างเช่น การสูญเสียข้อมูลเซนเซอร์เพียง 5–10% ในจุดสำคัญอาจทำให้การประมาณค่าอุณหภูมิภายในช่องว่าง (micro‑climates) ผิดพลาดจนระบบตัดสินใจปรับพัดลมหรือวาล์วผิดช่วงเวลา
- แหล่งปัญหา: เซนเซอร์สึกหรอ การติดตั้งผิดตำแหน่ง ระบบสื่อสารมีแพ็กเก็ตสูญหาย และการคาลิเบรตที่ไม่สม่ำเสมอ
- ผลกระทบ: Digital‑Twin มีความไม่แน่นอนสูง, RL อาจเรียนรู้พฤติกรรมที่โอเวอร์ฟิตกับความผิดพลาดของข้อมูล และการควบคุมฮาร์ดแวร์ตามคำสั่งที่ผิดพลาด
- แนวทางบรรเทา: ใช้การตรวจสอบคุณภาพข้อมูลแบบเรียลไทม์ (data validation), สำรองเซนเซอร์ในจุดสำคัญ, ใช้อัลกอริธึมเติมข้อมูล (imputation) ที่เหมาะสม และแยกชั้นความเชื่อมั่นของข้อมูลก่อนป้อนสู่โมเดล
2) ความเสี่ยงด้านความปลอดภัยเมื่อระบบอัตโนมัติควบคุมฮาร์ดแวร์
เมื่อ RL ถูกอนุญาตให้ควบคุมอุปกรณ์ทางกายภาพ เช่น พัดลม, ทิศทางการไหลของอากาศ หรือวาล์วคูลลิ่ง ความเสี่ยงทางไซเบอร์และความปลอดภัยเชิงปฏิบัติการจะเพิ่มขึ้น หากช่องทางควบคุมไม่ได้รับการป้องกันอย่างเพียงพอ ผู้ไม่หวังดีอาจเข้าถึงและสั่งให้ระบบทำงานผิดพลาด ส่งผลให้เกิดความร้อนเกิน (thermal runaway), อุปกรณ์เสียหาย หรือแม้แต่ downtime ของบริการที่เสียหายทางธุรกิจ
- กรณีตัวอย่าง: การโจมตีทาง OT/IT ที่แยกไม่ได้ชัดเจนอาจทำให้การสั่งงานพัดลมลดลงต่ำกว่าที่ปลอดภัยเป็นเวลานาน ส่งผลให้เซิร์ฟเวอร์ร้อนเกินและทำให้เกิดความเสียหายต่อฮาร์ดแวร์
- แนวทางบรรเทา:
- แยกเครือข่าย OT และ IT, ใช้นโยบาย Zero Trust สำหรับ API ที่เชื่อมต่อ Digital‑Twin กับอุปกรณ์
- บังคับใช้การยืนยันตัวตนแบบหลายปัจจัย (MFA), การเข้ารหัสช่องสื่อสาร (TLS/DTLS) และการตรวจสอบสิทธิ์ระดับบทบาท (RBAC)
- ออกแบบข้อจำกัดความปลอดภัยของนโยบาย RL (safety constraints) เช่น การกำหนดขอบเขตการเปลี่ยนแปลงต่อรอบ (rate limits), โหมด shadow/observe ก่อนอนุญาตให้เปลี่ยนแปลงจริง และกลไก rollback อัตโนมัติ
3) ความท้าทายในการปรับขนาด: บริบทท้องถิ่นและการรวมกับระบบเดิม
การนำแนวปฏิบัติที่ประสบความสำเร็จในศูนย์ข้อมูลหนึ่งไปขยายสู่ศูนย์ข้อมูลอื่นไม่ได้ทำได้โดยตรง เพราะปัจจัยท้องถิ่น เช่น สถาปัตยกรรมอาคาร พิมพ์เขียวระบบระบายความร้อน, สภาพภูมิอากาศ, อัตราค่าไฟฟ้า รวมถึงมาตรฐานอุปกรณ์และโปรโตคอลควบคุม (เช่น BACnet, Modbus, SNMP) มีความต่างกัน ยิ่งไปกว่านั้น ศูนย์ข้อมูลเกิดใหม่และศูนย์ข้อมูลที่มีระบบเดิม (legacy BMS) อาจต้องการการบูรณาการผ่าน middleware, gateway หรือการปรับเปลี่ยนฮาร์ดแวร์บางส่วน
- ความท้าทายเชิงเทคนิค: โมเดล RL ที่ฝึกในสภาพแวดล้อมหนึ่งอาจไม่ generalize ไปยังอีกสภาพแวดล้อมได้ดี (domain shift) — ตัวอย่างเช่น ศูนย์ข้อมูลในพื้นที่ชื้นสูงอาจต้องใช้นโยบายต่างจากศูนย์ข้อมูลในพื้นที่แห้งและร้อน
- ข้อจำกัดด้านปฏิบัติการ: การสื่อสารกับระบบเดิมอาจต้องการการพัฒนา connector เพิ่มเติม, การทดสอบร่วม (integration testing) และการจัดการ change management กับทีมวิศวกรรมภายใน
- ข้อเสนอแนะแนวทางขยายผล: เริ่มด้วยการปรับใช้แบบเป็นลำดับ (phased rollout): pilot → hybrid mode (human‑in‑loop) → full automation; ใช้เทคนิค transfer learning และ domain adaptation เพื่อลดความจำเป็นฝึกโมเดลจากศูนย์ข้อมูลใหม่ทั้งหมด; ออกแบบ API/adapter ให้รองรับโปรโตคอลมาตรฐานและมีชั้นการแปลแบบ plug‑and‑play
4) การบำรุงรักษาโมเดลและการจัดการความเสี่ยงเชิงต่อเนื่อง
โมเดล RL และ Digital‑Twin ต้องการการดูแลรักษาอย่างต่อเนื่อง เนื่องจากสภาวะการทำงานจะเปลี่ยนไปเมื่อมีการเพิ่มอุปกรณ์ เปลี่ยนแปลงโหลด หรือการเปลี่ยนแปลงสภาพแวดล้อม เช่น เทรนด์การใช้พลังงานที่เปลี่ยนในแต่ละฤดู หากไม่มีกลไกตรวจจับ drift และการ retrain อย่างเป็นระบบ ประสิทธิภาพที่คาดหวังในการประหยัดพลังงานอาจลดลง ตัวชี้วัดเช่น reward per episode, constraint violations และอัตราการเกิด anomaly ควรถูกมอนิเตอร์เป็น KPI
- แนวปฏิบัติที่แนะนำ: ตั้งกระบวนการ MLOps สำหรับ RL ที่รวมการมอนิเตอร์แบบเรียลไทม์, การตรวจจับ concept drift, การทดสอบความปลอดภัยก่อน deployment และตารางการ retrain เป็นประจำ
- การกำกับดูแล: จัดตั้งคณะกรรมการความเสี่ยงด้าน AI (AI Risk Committee) ประกอบด้วยวิศวกรระบบ วิศวกรความปลอดภัย และผู้บริหารเพื่อกำหนดนโยบาย SLAs, แผนฉุกเฉิน และเกณฑ์ยกเลิกการใช้งานหากโมเดลทำงานผิดพารามิเตอร์ที่ยอมรับได้
สรุปคือ การขยายการใช้ Digital‑Twin + RL ในระบบคูลลิ่งของศูนย์ข้อมูลมีศักยภาพลด PUE และค่าไฟฟ้าได้จริง แต่ต้องออกแบบมาตรการป้องกันเชิงเทคนิคและกระบวนการบริหารความเสี่ยงที่ครบถ้วน รวมถึงการทดสอบอย่างเป็นระบบ การแยกเครือข่ายและการจำกัดสิทธิ์ การมอนิเตอร์คุณภาพข้อมูลและประสิทธิภาพของโมเดล ตลอดจนแผนการสเกลแบบค่อยเป็นค่อยไป (phased, region‑aware rollout) เพื่อให้การขยายผลปลอดภัยและยั่งยืน
อนาคตและนัยต่ออุตสาหกรรม: ความยั่งยืนและการบูรณาการกับกริดไฟฟ้า
อนาคตและนัยต่ออุตสาหกรรม: ความยั่งยืนและการบูรณาการกับกริดไฟฟ้า
การนำ Digital‑Twin ร่วมกับ Reinforcement Learning มาใช้ปรับระบบคูลลิ่งจนลด PUE ได้ประมาณ 20% ไม่เพียงแต่สร้างผลประหยัดด้านต้นทุนทันที แต่ยังเป็นจุดเริ่มต้นของการบูรณาการเชิงยุทธศาสตร์กับกริดไฟฟ้าและการขับเคลื่อนความยั่งยืนวงกว้างในอุตสาหกรรมศูนย์ข้อมูล ในระยะยาว เทคโนโลยีเหล่านี้จะทำหน้าที่เป็นเลเยอร์การควบคุมอัจฉริยะที่เชื่อมโยงระหว่างโหลดความร้อนของศูนย์ข้อมูลกับสัญญาณตลาดพลังงาน อัตราไฟแบบไดนามิก และการจัดสรรพลังงานหมุนเวียน
การเชื่อมต่อกับ Demand Response (DR) และการประสานงานกับผู้ให้บริการไฟฟ้าจะเป็นหัวใจสำคัญของการบูรณาการนี้ โดยใช้กลไกดังนี้
- การตอบสนองต่อสัญญาณราคา — RL และ digital‑twin สามารถปรับจังหวะการทำงานของระบบคูลลิ่งเพื่อลดโหลดในช่วงราคาไฟสูงและเพิ่มโหลดเมื่อราคาต่ำ ทำให้ศูนย์ข้อมูลสามารถลดต้นทุนค่าไฟและรับประโยชน์จากโมเดลการตั้งราคาแบบ Time‑of‑Use ได้
- เข้าร่วมตลาดบริการเสริม (ancillary services) — ศูนย์ข้อมูลที่สามารถลดหรือเลื่อนโหลดอย่างรวดเร็วสามารถเข้าร่วมเป็นทรัพยากรให้กับระบบไฟฟ้า เช่น การจัดหาไฟฟ้าสำรองหรือการตอบสนองความถี่ ผ่านโปรโตคอลมาตรฐานอย่าง OpenADR หรือแพลตฟอร์ม VPP
- การประสานงานกับผู้ให้บริการไฟฟ้า (TSP/DSO) — การเชื่อมต่อข้อมูลเรียลไทม์และ API มาตรฐานช่วยให้การบริหารจัดการโหลดในระดับเขตและระดับภูมิภาคมีประสิทธิภาพมากขึ้น เพิ่มความสามารถในการจัดการพีคดีมานด์และลดความเสี่ยงจากการลัดวงจรของกริด
ในด้านการลดคาร์บอนและการรายงานด้าน ESG เทคโนโลยีเหล่านี้เอื้อต่อทั้งการวัดและการลดการปล่อยก๊าซเรือนกระจกอย่างเป็นรูปธรรม โดยสามารถผนวกรวมกับแนวปฏิบัติและตัวชี้วัดที่สำคัญได้ เช่น CUE (Carbon Usage Effectiveness) และ WUE (Water Usage Effectiveness) ตัวอย่างเชิงตัวเลข: หากศูนย์ข้อมูลขนาดกลางมีการใช้พลังงานรวมประมาณ 20 GWh/ปี การลด PUE 20% อาจลดการใช้พลังงานโดยรวมได้ราว 4 GWh/ปี ซึ่งหากใช้อัตราการปล่อยคาร์บอนของกริดที่ประมาณ 0.56 kgCO2/kWh จะเท่ากับการลดการปล่อย ~2,240 ตัน CO2 ต่อปี ผลลัพธ์เช่นนี้ช่วยให้การรายงาน ESG มีน้ำหนักมากขึ้นและเพิ่มโอกาสในการจัดซื้อพลังงานหมุนเวียน (PPA) หรือการได้รับเครดิตคาร์บอน
การต่อยอดทางเทคโนโลยีสู่การควบคุมเครือข่ายศูนย์ข้อมูลแบบกระจาย (distributed data center orchestration) จะเป็นก้าวสำคัญต่อไป โดยมีแนวทางปฏิบัติดังนี้
- การโยกย้ายงานอัจฉริยะ (workload shifting) — ใช้ RL และ digital‑twin ในการตัดสินใจโยกย้ายภาระงานไปยังไซต์ที่มีต้นทุนพลังงานต่ำกว่า หรือมีพลังงานหมุนเวียนเหลือใช้ในขณะนั้น
- การผสาน microgrid และ storage — ศูนย์ข้อมูลสามารถเชื่อมต่อกับไมโครกริดและแบตเตอรี่เพื่อใช้เป็น buffer ในการตอบ DR หรือรองรับการเติบโตของพลังงานหมุนเวียน
- การเรียนรู้แบบรวมศูนย์-กระจาย (federated/federated RL) — องค์กรที่มีหลายไซต์สามารถแชร์โมเดลการควบคุมที่ปรับแต่งแล้วโดยไม่ต้องเปิดเผยข้อมูลเชิงลึกของธุรกิจ ช่วยให้เกิดการปรับปรุงประสิทธิภาพแบบข้ามองค์กร
เพื่อเร่งการนำไปใช้และขยายผล เชิงนโยบายมีบทบาทสำคัญที่ควรพิจารณา ได้แก่
- มาตรฐานการสื่อสารและการเชื่อมต่อ — สนับสนุนการใช้โปรโตคอลเปิด (เช่น OpenADR, IEEE standards) เพื่อให้การเชื่อมต่อระหว่างศูนย์ข้อมูลกับผู้ให้บริการไฟฟ้าเป็นไปอย่างปลอดภัยและสอดคล้อง
- แรงจูงใจทางการเงิน — ให้สิทธิประโยชน์ทางภาษีหรือเงินอุดหนุนสำหรับการติดตั้งระบบ Digital‑Twin, AI และ storage รวมถึง PPA กับพลังงานหมุนเวียน
- การรายงานและการตรวจสอบ — กำหนดกรอบการรายงาน ESG ที่รวมทั้ง PUE, CUE และข้อมูลการตอบ DR เพื่อสร้างความโปร่งใสและมาตรฐานการประเมินผล
- การสนับสนุน R&D และโครงการนำร่อง — อนุมัติทุนสนับสนุนสำหรับโครงการร่วมระหว่างภาครัฐ ภาคเอกชน และสถาบันวิจัย เพื่อทดลองโมเดลการรวมศูนย์ข้อมูลเข้ากับกริดและตลาดพลังงาน
- ความมั่นคงปลอดภัยของไซเบอร์ — ออกแนวปฏิบัติด้านความปลอดภัยสำหรับการเชื่อมต่อระหว่างศูนย์ข้อมูลและกริด เพื่อป้องกันความเสี่ยงต่อเสถียรภาพของระบบ
สรุปแล้ว การผสาน Digital‑Twin และ Reinforcement Learning เข้ากับการจัดการพลังงานของศูนย์ข้อมูลจะเปลี่ยนบทบาทของศูนย์ข้อมูลจากผู้บริโภคพลังงานแบบพาสซีฟ เป็นผู้เล่นเชิงรุกที่ร่วมสนับสนุนความมั่นคงและความยั่งยืนของกริดได้จริง การประสานงานกับระบบ DR, การซื้อขายพลังงานหมุนเวียน และการควบคุมเครือข่ายแบบกระจาย จะทำให้ภาคศูนย์ข้อมูลมีศักยภาพลดต้นทุน ลดการปล่อย CO2 และยกระดับการรายงาน ESG ให้เทียบชั้นในเวทีสากลได้อย่างเป็นรูปธรรม
บทสรุป
การผสานเทคโนโลยี Digital‑Twin ร่วมกับ Reinforcement Learning (RL) สามารถปรับระบบคูลลิ่งของศูนย์ข้อมูลให้ทำงานแบบเรียลไทม์และมีประสิทธิภาพมากขึ้น ผลลัพธ์เชิงตัวเลขจากโครงการนำร่องชี้ว่าเป็นไปได้ที่จะลดค่า PUE ประมาณ 20% ในสภาพการใช้งานจริง ซึ่งแปลเป็นการลดการใช้พลังงานของอาคารโดยรวมอย่างมีนัยสำคัญ ตัวอย่างเช่น สำหรับศูนย์ข้อมูลขนาดกลางที่มีโหลด IT ประมาณ 500 kW การลด PUE ประมาณ 20% อาจเท่ากับการประหยัดพลังงานราว 1.6 GWh/ปี และหากค่าน้ำไฟเฉลี่ยอยู่ในระดับ 4–5 บาทต่อ kWh จะเทียบเท่าการประหยัดค่าไฟประมาณ 7–8 ล้านบาทต่อปี — ยืนยันความเป็นไปได้ของการแปลงประสิทธิภาพด้านพลังงานให้เป็นผลประหยัดทางเศรษฐกิจที่จับต้องได้สำหรับศูนย์ข้อมูลขนาดกลางถึงขนาดใหญ่
อย่างไรก็ดี แม้ว่าจะมีศักยภาพทั้งทางเทคนิคและเศรษฐศาสตร์ ความสำเร็จเชิงปฏิบัติขึ้นกับปัจจัยสำคัญหลายประการ ได้แก่ คุณภาพและความถี่ของข้อมูลเซนเซอร์ (sensor accuracy, telemetry latency), การจัดการความเสี่ยงด้านความปลอดภัยไซเบอร์และความถูกต้องของโมเดล (model drift, adversarial risks), รวมถึงการวางแผนเพื่อขยายสเกลอย่างเป็นระบบ (integration กับ BMS, governance, การทดสอบแบบ phased rollout และ human‑in‑the‑loop) หากผู้ประกอบการออกแบบกลยุทธ์นำร่องที่เข้มแข็ง มีนโยบายข้อมูลและความปลอดภัยที่ชัดเจน และเตรียมทรัพยากรสำหรับการบำรุงรักษาและ retraining ของโมเดล การผสาน Digital‑Twin + RL จะเป็นทางเลือกที่คุ้มค่าสำหรับการลดต้นทุนพลังงานและการลดคาร์บอนในระยะยาว โดยแนวโน้มอนาคตยังรวมถึงการพัฒนาอัลกอริทึม RL ที่มีความมั่นคงมากขึ้น การเชื่อมต่อกับระบบจัดการพลังงานของกริด (demand response) และการนำแนวปฏิบัติมาตรฐานของ Digital‑Twin มาใช้ร่วมกันเพื่อเร่งการยอมรับเชิงอุตสาหกรรม



