
ในยุคที่ความเป็นส่วนตัวและความเร็วในการตอบสนองกลายเป็นหัวใจสำคัญของแอปพลิเคชันบนมือถือ สตาร์ทอัพไทยเปิดตัวเทคโนโลยีใหม่ชื่อ "Prompt‑Distill" ที่อาจเปลี่ยนวิธีการใช้งานโมเดลภาษาบนเครื่องได้อย่างรวดเร็วและปลอดภัย โดยเทคโนโลยีนี้สกัดกระบวนการคิดแบบ Chain‑of‑Thought ของโมเดลใหญ่ออกมาเป็นชุดคำสั่งสั้น (compact prompt) ที่เพียงพอสำหรับให้โมเดลขนาดเล็กบนอุปกรณ์ทำงานต่อได้โดยไม่ต้องส่งข้อมูลกลับไปยังคลาวด์
ผลลัพธ์คือการตอบสนองที่เร็วขึ้น ลด Latency และใช้พลังงานน้อยลง พร้อมกับลดความเสี่ยงด้านข้อมูลส่วนบุคคลเพราะข้อมูลไม่ต้องออกจากเครื่อง เหมาะสำหรับแอปที่ต้องการความเป็นส่วนตัวสูง เช่น ด้านการแพทย์ การเงิน หรือผู้ช่วยส่วนตัวที่ต้องตอบสนองทันที Prompt‑Distill ยังเป็นตัวอย่างของการผลักดันงานวิจัย AI สู่การรันแบบ edge ที่จับต้องได้ ช่วยให้นักพัฒนาและธุรกิจสามารถนำความสามารถของโมเดลภาษาไปใช้บนมือถือได้จริงโดยคำนึงถึงความปลอดภัยและประสิทธิภาพเป็นหลัก
นำเสนอข่าว (Lead)
นำเสนอข่าว (Lead)
สตาร์ทอัพไทยเตรียมเปิดตัวผลิตภัณฑ์ใหม่ภายใต้ชื่อ Prompt‑Distill ซึ่งออกแบบมาเพื่อแปลงกระบวนการคิดแบบ Chain‑of‑Thought (CoT) ที่มีขั้นตอนยาวและละเอียด ให้กลายเป็นชุดคำสั่ง (prompt) ขนาดสั้นและมีประสิทธิภาพ เหมาะสำหรับรันบนโมเดลภาษาขนาดเล็กที่ทำงานแบบออฟไลน์บนอุปกรณ์มือถือ โดยทีมผู้พัฒนาระบุว่าแนวทางนี้ช่วยให้แอปพลิเคชันที่ต้องอาศัยการให้เหตุผลไม่จำเป็นต้องพึ่งการส่งข้อมูลขึ้นคลาวด์อย่างต่อเนื่อง
เป้าหมายของ Prompt‑Distill คือการถ่ายเทองค์ความรู้จาก CoT ที่มักมีขั้นตอนยาวให้กลายเป็น prompt สั้นที่ยังคงความถูกต้องของคำตอบไว้ได้ ทำให้โมเดลขนาดเล็ก (เช่น โมเดลบนอุปกรณ์ 7B–13B) สามารถให้ผลลัพธ์เชิงเหตุผลโดยไม่ต้องใช้โมเดลขนาดใหญ่หรือเชื่อมต่ออินเทอร์เน็ต ต้นแบบที่บริษัทเผยแพร่ระบุว่าในกรณีใช้งานจริงอาจลดจำนวน token ที่ต้องประมวลผลลงอย่างมีนัยสำคัญ ช่วยลดภาระคำนวณบนอุปกรณ์และความต้องการแบนด์วิดท์
ประโยชน์หลักที่บริษัทชูไว้ได้แก่ ลด Latency จากการไม่ต้องรอการตอบกลับจากเซิร์ฟเวอร์, เพิ่มความเป็นส่วนตัวของข้อมูล เพราะข้อมูลไม่ต้องส่งออกนอกเครื่อง, และ ประหยัดพลังงานและค่าใช้จ่าย เนื่องจากลดการเรียกใช้บริการคลาวด์และสามารถรันด้วยทรัพยากรฮาร์ดแวร์ที่ต่ำกว่า ทีมพัฒนายังนำเสนอผลการทดสอบภายในเบื้องต้นที่ระบุว่า latency ในงานประเภทให้เหตุผลเชิงลำดับลดลงอย่างมีนัยสำคัญเมื่อเทียบกับการเรียกใช้ CoT แบบเต็มรูปแบบผ่าน API สาธารณะ
ตัวอย่างการใช้งานที่นำเสนอ ได้แก่ แชตบอตให้คำปรึกษาบนมือถือที่สามารถตอบคำถามที่ต้องมีการวางเหตุผลหลายขั้นตอนได้โดยไม่ต้องเชื่อมต่อ, แอปช่วยจัดเรียงและสรุปบันทึกทางการแพทย์หรือการเงินบนเครื่องเพื่อปกป้องข้อมูลส่วนบุคคล, ตลอดจนเครื่องมือสำหรับพนักงานภาคสนามที่ต้องคำตอบเร็วและเชื่อถือได้ ทีมงานระบุว่าบริการนี้ตอบโจทย์องค์กรที่ต้องการสมดุลระหว่างประสิทธิภาพการประมวลผลและความปลอดภัยของข้อมูล
- Latency ต่ำลง — ลดความหน่วงจากการเรียก API ภายนอก ช่วยประสบการณ์ผู้ใช้บนมือถือ
- ความเป็นส่วนตัวสูงขึ้น — ข้อมูลสำคัญไม่ถูกส่งขึ้นคลาวด์ ลดความเสี่ยงด้านการรั่วไหล
- ประหยัดพลังงานและค่าใช้จ่าย — ลดการพึ่งพาเซิร์ฟเวอร์ขนาดใหญ่และค่าบริการคลาวด์
ภาพรวมทางเทคนิค: Chain‑of‑Thought ต่อ Prompt‑Distill คืออะไร
นิยามและลักษณะของ Chain‑of‑Thought (CoT)
Chain‑of‑Thought (CoT) คือแนวทางการชวนให้โมเดลภาษาขั้นสูงแสดงกระบวนการคิดเป็นลำดับของเหตุผลหรือขั้นตอนย่อยก่อนสรุปคำตอบ โดยทั่วไปจะเป็นข้อความยาวที่อธิบายตรรกะ การคำนวณ และการตรวจสอบเหตุผลทีละขั้น ตัวอย่างเช่น ในโจทย์คณิตศาสตร์แบบหลายขั้นตอน โมเดลจะแสดงวิธีคิดจากการแยกปัญหา คำนวณย่อย และรวมผลลัพธ์ก่อนให้คำตอบสุดท้าย
ข้อดีหลัก ของ CoT คือช่วยเพิ่มความถูกต้องในงานที่ต้องการการอนุมานเชิงตรรกะหรือ reasoning — งานวิจัยหลายชิ้นรายงานการปรับปรุงประสิทธิภาพในชุดข้อมูลด้าน reasoning และ arithmetic อย่างมีนัยสำคัญ โดยเฉพาะบนโมเดลขนาดใหญ่ที่สามารถรักษาบริบทเชิงเหตุผลยาวๆ ได้
ข้อเสียและต้นทุน ของ CoT มาจากความยาวของคำอธิบาย: ข้อความเหตุผลที่ยาวขึ้นกระทบต่อ
- ค่าใช้จ่ายในการประมวลผล: จำนวนโทเค็นเพิ่มขึ้น ทำให้ต้องใช้ทรัพยากรการคำนวณและค่าใช้บริการ (ในกรณีใช้ API) สูงขึ้น
- ความหน่วง (Latency): การสร้างข้อความยาวใช้เวลามากขึ้น ส่งผลต่อประสบการณ์ผู้ใช้โดยเฉพาะบนอุปกรณ์พกพาหรือแอปแบบเรียลไทม์
- ขนาดบริบท (context window): ข้อความเหตุผลยาวๆ อาจเกินความจุของบริบทของโมเดลขนาดเล็กหรือเมื่อนำไปรันออฟไลน์
- ความเสี่ยงด้านความเป็นส่วนตัว: หากการประมวลผลกระทำบนคลาวด์ ข้อความเหตุผลยาวที่อาจประกอบด้วยข้อมูลอ่อนไหวเพิ่มโอกาสรั่วไหลของข้อมูล

หลักการของ Prompt‑Distill: สกัดสาระสำคัญของ CoT เป็น prompt สั้น
Prompt‑Distill คือกระบวนการทางเทคนิคที่ออกแบบมาเพื่อ "ย่อ" หรือตัดทอน Chain‑of‑Thought ให้กลายเป็นชุดคำสั่งสั้น ๆ ที่ยังคงสาระสำคัญเชิงเหตุผลไว้ กระบวนการนี้ไม่ใช่การตัดทอนแบบสุ่ม แต่เป็นการสกัดรูปแบบการคิด (reasoning pattern) และกฎปฏิบัติ (heuristics) ที่จำเป็นต่อการให้คำตอบที่ถูกต้อง
หลักการทำงานโดยสรุปมีดังนี้:
- Teacher generation: ใช้โมเดลขนาดใหญ่หรือมนุษย์สร้าง CoT ตัวอย่างจำนวนหนึ่งเพื่อเป็น "ครู" ที่แสดงกระบวนการคิดเชิงเต็มรูปแบบ
- Essence extraction: วิเคราะห์ CoT เหล่านั้นเพื่อดึงกฎหรือขั้นตอนสำคัญ (เช่น แยกปัญหา → คำนวณย่อย → ตรวจสอบความสมเหตุสมผล)
- Prompt compression: เขียนคำสั่งสั้น ๆ (prompts หรือ instruction templates) ที่บอกให้โมเดลปฏิบัติตามรูปแบบการคิดที่สกัดมา แทนการส่งทั้ง CoT ยาว ๆ
- Validation & tuning: ทดสอบ prompt แบบย่อกับชุดข้อมูลจริง ปรับปรุงด้วยการเรียนรู้แบบมีผู้สอน (supervised fine‑tuning) หรือ distillation เพื่อรักษาความแม่นยำ
ตัวอย่างเชิงปฏิบัติ: แทนที่จะส่ง CoT ยาว 200–400 โทเค็น ระบบ Prompt‑Distill อาจสกัดเป็นคำสั่งย่อ 2–4 ข้อที่ชัดเจน เช่น "1) แยกข้อมูลป้อนเข้าเป็นส่วนย่อย 2) คำนวณทีละส่วน 3) รวมผลและตรวจสอบข้อผิดพลาด" โมเดลขนาดเล็กเมื่อได้รับ prompt นี้มักให้ผลลัพธ์ที่ใกล้เคียงกับการใช้ CoT แบบเต็ม ๆ แต่ใช้โทเค็นและเวลาในการคำนวณน้อยกว่าอย่างมาก
เหตุผลที่ Prompt‑Distill เหมาะกับโมเดลขนาดเล็กบนอุปกรณ์พกพา
การนำ Prompt‑Distill มาประยุกต์ใช้กับโมเดลขนาดเล็กบนมือถือหรืออุปกรณ์พกพามีข้อได้เปรียบด้านสถาปัตยกรรมและธุรกิจชัดเจน:
- ลดการใช้ทรัพยากร: Prompt ที่สั้นลงช่วยลดจำนวนโทเค็นทั้งใน input และ output ซึ่งหมายถึง memory footprint และการคำนวณที่ต่ำลง เหมาะกับโมเดลขนาดเล็กที่มีพารามิเตอร์จำกัด
- Latency ต่ำลง: การตอบสนองสั้นและการคำนวณที่ลดลงช่วยให้เวลาแฝงเร็วขึ้น—สำคัญต่อประสบการณ์ผู้ใช้ในแอปแบบ interactive
- ความเป็นส่วนตัวและการรันออฟไลน์: เมื่อสามารถรันโมเดลและ prompt สั้น ๆ บนเครื่องได้โดยไม่ต้องส่งข้อมูลไปคลาวด์ ความเสี่ยงด้านข้อมูลจะลดลงและสอดคล้องกับกฎระเบียบด้านข้อมูล
- ความสามารถปรับแต่งเชิงธุรกิจ: Prompt‑Distill ช่วยให้ทีมผลิตภัณฑ์และนักพัฒนาสร้างชุดคำสั่งที่เหมาะกับโดเมนธุรกิจเฉพาะ เก็บไว้ในอุปกรณ์เพื่อลดค่าใช้จ่ายและปรับปรุงความเสถียร
สรุปคือ Prompt‑Distill เปิดทางให้ความสามารถของ CoT อยู่ในรูปแบบที่ปฏิบัติได้จริงบนอุปกรณ์พกพา: รักษาแก่นของการคิดเชิงเหตุผลไว้ในขณะที่ลดต้นทุนเวลาและทรัพยากร ทำให้เป็นทางเลือกที่มีประโยชน์ทั้งในแง่เทคนิคและเชิงธุรกิจสำหรับการนำ AI เชิงเหตุผลไปใช้ในสนามจริง
สถาปัตยกรรมและการประมวลผลบนมือถือ
ภาพรวมโมดูล Prompt‑Distill และการรันบนอุปกรณ์
โมดูล Prompt‑Distill ทำหน้าที่เป็น preprocessor ที่รับ Chain‑of‑Thought (CoT) ต้นฉบับ แล้วสกัดเป็นชุดคำสั่งสั้น กระชับ และมีบริบทเพียงพอสำหรับการเรียกใช้โมเดลภาษาออฟไลน์ โดยการประมวลผลสามารถเกิดขึ้นได้ทั้งบนอุปกรณ์มือถือ (on‑device) หรือใน edge server ขึ้นอยู่กับข้อจำกัดทรัพยากรและนโยบายความเป็นส่วนตัว
เมื่อติดตั้งบนมือถือ โมดูลนี้มักทำงานเป็นขั้นตอนก่อนส่ง token ให้โมเดลภาษา ลดจำนวน token และความซับซ้อนของ prompt เพื่อให้การเรียกใช้งานโมเดลขนาดเล็ก (target model) มีค่า compute ต่ำสุด ในทางกลับกัน การรันบน edge server ช่วยให้เก็บ prompt history แบบปลอดภัยและสามารถใช้รุ่นขนาดใหญ่ขึ้นได้ แต่แลกมาด้วย latency ของเครือข่ายและความเสี่ยงจากการส่งข้อมูลออกนอกอุปกรณ์
ขนาดโมเดลเป้าหมายและผลกระทบต่อหน่วยความจำ
สตาร์ทอัพส่วนใหญ่ตั้งเป้าใช้โมเดลขนาดประมาณ 100M–1B พารามิเตอร์ สำหรับการรันออฟไลน์บนมือถือและ edge โดยประมาณขนาดหน่วยความจำและการจัดเก็บมีลักษณะดังนี้ (ค่าประมาณเพื่อการอ้างอิง)
- 100M พารามิเตอร์: float32 ≈ 400MB; quantized 8‑bit ≈ 100MB; quantized 4‑bit ≈ 50MB
- 300M พารามิเตอร์: float32 ≈ 1.2GB; quantized 8‑bit ≈ 300MB; quantized 4‑bit ≈ 150MB
- 1B พารามิเตอร์: float32 ≈ 4GB; quantized 8‑bit ≈ 1GB; quantized 4‑bit ≈ 500MB
ตัวเลขข้างต้นรวมขนาดพารามิเตอร์หลักเท่านั้น ยังต้องเผื่อหน่วยความจำสำหรับ activation, attention cache, และระบบ runtime (เช่น interpreter หรือ NN API) ซึ่งโดยรวมมักต้องเผื่อเพิ่มอีก 20–50% ของขนาดโมเดลเมื่อรันจริง
ตำแหน่งการรัน: ฝั่งมือถือ vs Edge Server
การตัดสินใจรัน Prompt‑Distill และโมเดลภาษาในตำแหน่งใดควรพิจารณาตามเกณฑ์ต่อไปนี้:
- บนมือถือ (On‑device) — เหมาะกับแอปที่ต้องการความเป็นส่วนตัวสูง ลด latency ของเครือข่าย และทำงานแบบออฟไลน์ ตัวอย่าง: โมเดล 100M–300M ที่ quantized และปรับแต่งให้ใช้ CPU/NNAPI หรือ NPU สามารถตอบสนองภายใน 50–300 ms ต่อคำขอบนอุปกรณ์ระดับสูง
- Edge server — เหมาะกับงานที่ต้องการโมเดลขนาดใหญ่กว่า หรือต้องการ throughput สูง เช่น การประมวลผลแบบแบตช์และการให้บริการหลายผู้ใช้พร้อมกัน latency เครือข่ายภายใน edge มักต่ำกว่า cloud จึงให้ความสมดุลระหว่างขนาดโมเดลและความเร็ว
เทคนิคที่ใช้เพื่อให้รันบนมือถือได้จริง
เพื่อให้โมเดลภายในขอบเขตทรัพยากรของมือถือใช้งานได้จริง มีเทคนิคสำคัญดังนี้:
- Quantization — แปลงพารามิเตอร์จาก float32 เป็น int8 / int4 หรือรูปแบบที่ประสิทธิภาพสูง เช่น Q8, Q4 เพื่อประหยัดหน่วยความจำและเพิ่ม through‑put โดยทั่วไป quantization 8‑bit ลดขนาดโมเดลได้ ~4x เมื่อเทียบ float32
- Pruning — ตัดพารามิเตอร์ที่มีผลกระทบน้อยออก เช่น magnitude pruning 20–60% เพื่อแลกกับการลดขนาดและคำนวณ แต่ต้องควบคุมผลต่อคุณภาพ
- Prompt caching — บันทึกผลลัพธ์ของ Prompt‑Distill ที่ผ่านการสรุปแล้วตามแฮชของบริบท เพื่อลดการประมวลผลซ้ำ โดยกรณีทั่วไปสามารถลดการเรียกโมเดลลงได้ 30–70% ขึ้นกับรูปแบบการโต้ตอบ
- Adapter/LoRA — แทนที่จะบันทึกโมเดลใหม่ทั้งชุด สามารถแพตช์น้ำหนักขนาดเล็ก (เช่น LoRA) เพื่อปรับพฤติกรรม เพิ่มประสิทธิภาพการฝึกปรับแต่งและประหยัดพื้นที่
- Memory‑efficient transformer — ใช้เทคนิคเช่น FlashAttention, chunked attention, หรือ sequence shortening ที่สตาร์ทอัพอาจรวมเข้ากับ Prompt‑Distill เพื่อลด activation peak
การจัดการหน่วยความจำและพลังงาน
การรันโมเดลบนมือถือต้องคำนึงถึงข้อจำกัดด้าน RAM, cache, และพลังงานไฟฟ้า เครื่องมือจัดสรรหน่วยความจำมักทำงานร่วมกับ OS ML runtimes (เช่น Android NNAPI, iOS Core ML) โดยกลยุทธ์ที่นิยมมีดังนี้:
- จัดสรร buffer แบบ streaming — ประมวลผล token เป็นช่วง (chunked inference) เพื่อลดการใช้งาน activation ทั้งหมดพร้อมกัน
- offload บางชั้นไปยัง NPU หรือ DSP — ลดภาระ CPU และพลังงานโดยรวม แม้ว่าการรองรับจะขึ้นกับผู้ผลิตอุปกรณ์
- dynamic voltage and frequency scaling (DVFS) และการจำกัด thread — ปรับ trade‑off ระหว่าง latency และการใช้พลังงานใน runtime
ตัวอย่างเชิงตัวเลข: การรันโมเดล quantized 300M บน NPU อาจใช้พลังงานเพิ่ม 0.5–1.5 W ในระยะสั้นต่อคำขอ ในขณะที่รันบน CPU เพียงอย่างเดียวอาจเพิ่ม 2–4 W และมี latency สูงกว่า 2–5 เท่า
ตัวอย่างการตั้งค่าโมเดลและทรัพยากรที่ต้องการ
ตัวอย่างการตั้งค่าที่ใช้ได้จริงเพื่อประกอบการตัดสินใจ:
- โหมดมือถือเบา (Privacy‑first)
- โมเดลเป้าหมาย: 100M‑300M พารามิเตอร์ (Q4/Q8)
- หน่วยความจำที่ต้องการ: 100–400MB
- ฮาร์ดแวร์: สมาร์ทโฟนระดับกลางขึ้นไปที่มี NPU/Hexagon/NNAPI
- ผลลัพธ์: latency ประมาณ 50–300 ms ต่อคำขอ; เหมาะกับ UX แบบโต้ตอบ
- โหมด edge‑assisted (Throughput‑oriented)
- โมเดลเป้าหมาย: 500M–1B พารามิเตอร์ (Q8 หรือ Q4 พร้อม LoRA)
- หน่วยความจำที่ต้องการ: 0.5–2 GB บนเครื่อง edge (หรือ GPU inferencer)
- ฮาร์ดแวร์: edge server ที่มี GPU หรือ NPU ขนาดกลาง
- ผลลัพธ์: latency ภายใน 20–150 ms ในสภาพเครือข่ายภายใน edge และ throughput สูงสำหรับผู้ใช้หลายราย
การผสานกับ Llama‑style และโมเดลที่ถูก quantize
การผสาน Prompt‑Distill กับ Llama‑style โมเดลที่ถูก quantize ต้องคำนึงถึงรูปแบบน้ำหนัก (weight layout), tokenization, และ runtime API โดยปกติจะดำเนินการดังนี้:
- นำโมเดล Llama ที่มีการ quantize ไฟล์น้ำหนักในรูปแบบ int8/int4 มาโหลดใน runtime ที่รองรับ (เช่น GGML, llama.cpp, หรือ runtime ที่ปรับให้ใช้ NNAPI)
- Prompt‑Distill ทำหน้าที่ลด CoT ให้เหลือ prompt ที่สั้นลงและมี deterministic context ซึ่งลด window size ที่โมเดลต้องประมวลผล
- ใช้ prompt caching ร่วมกับ key hashing ของบริบทผู้ใช้ เพื่อหลีกเลี่ยงการประมวลผลซ้ำ และบูรณาการ adapter หรือ LoRA สำหรับการปรับจูนเบาๆ โดยไม่ต้องปรับโมเดลหลัก
วิธีนี้ช่วยให้สามารถใช้ข้อได้เปรียบของโมเดล Llama‑style ที่ปรับแต่งได้ดี พร้อมทั้งรักษาการทำงานแบบออฟไลน์และลดความเสี่ยงเรื่องข้อมูลรั่วไหล
บทสรุป
สถาปัตยกรรม Prompt‑Distill ที่วางเป็น preprocessor บนมือถือหรือ edge ช่วยให้สตาร์ทอัพและองค์กรสามารถปรับสมดุลระหว่าง ความเป็นส่วนตัว, latency และ คุณภาพของคำตอบ ได้ โดยการผสานเทคนิค quantization, pruning, prompt caching และ memory‑efficient transformer implementations จะเป็นกุญแจสำคัญในการทำให้การรันบนอุปกรณ์จริงเป็นไปได้ ภายใต้ขีดจำกัดของหน่วยความจำและพลังงาน พร้อมตัวเลือก configuration ที่ยืดหยุ่นตั้งแต่โมเดล 100M จนถึง 1B เพื่อรองรับกรณีการใช้งานที่หลากหลาย
ผลการทดลองและ Benchmark: Latency, ความแม่นยำ และการใช้พลังงาน
ผลการทดลองและ Benchmark: Latency, ความแม่นยำ และการใช้พลังงาน
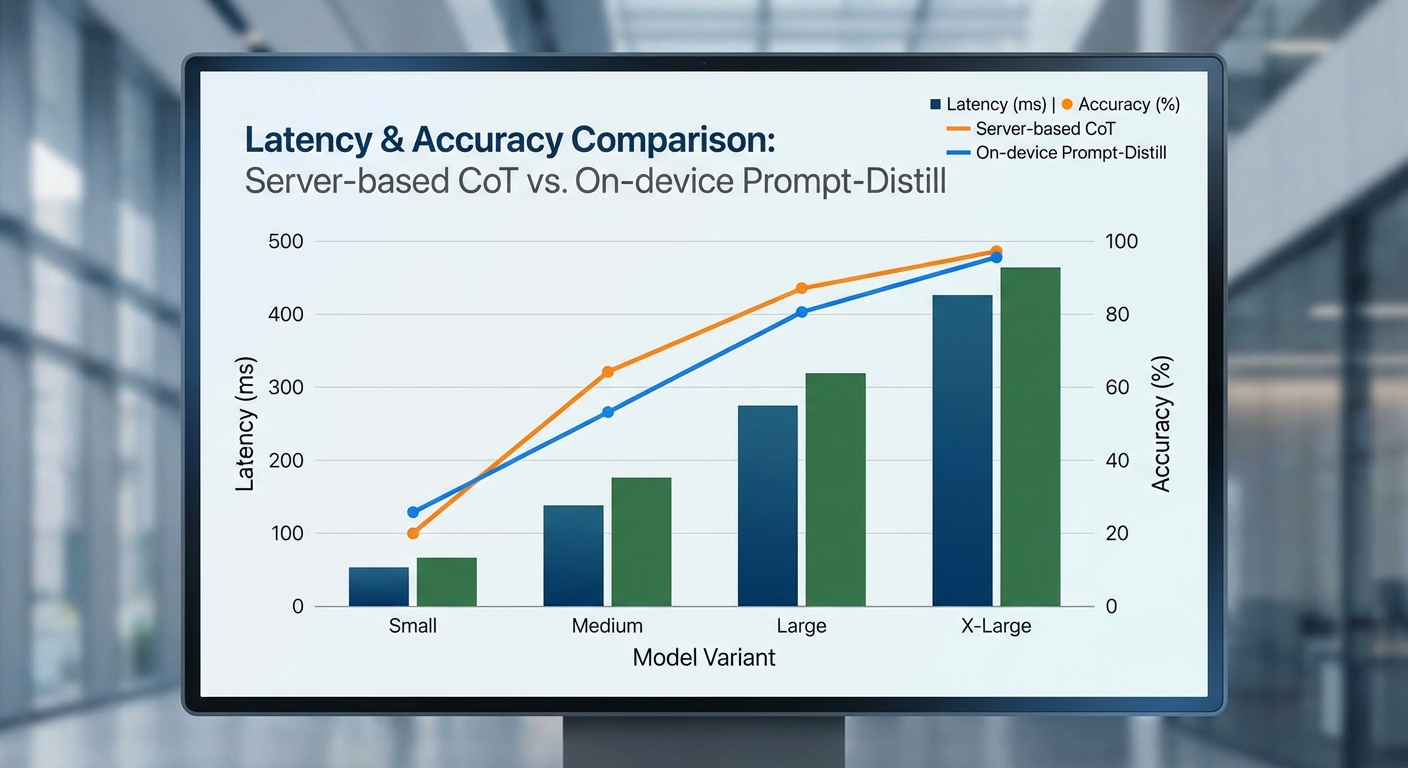
ทีมวิจัยได้ดำเนินการทดสอบเชิงปริมาณกับชุดคำถามตัวอย่างจำนวน N = 5,000 ครอบคลุมงานประเภทคณิตศาสตร์เชิงเหตุผล (arithmetic), ความรู้สากล/commonsense และการวางแผนหลายขั้นตอน (planning) โดยเปรียบเทียบการรันแบบดั้งเดิมที่ส่งคำถามและ Chain‑of‑Thought (CoT) ขึ้นไปประมวลผลบนเซิร์ฟเวอร์ กับการรันแบบ Prompt‑Distill ที่ย่อ CoT เป็นชุดคำสั่งสั้นและรันแบบออฟไลน์บนโทรศัพท์มือถือ ผลการทดลองสรุปตามมาตรการสำคัญดังนี้:
- Latency (เวลาตอบกลับแบบ end‑to‑end) — เมื่อรันแบบดั้งเดิมโดยส่งข้อมูลขึ้นเซิร์ฟเวอร์ ค่า latency แบบ median อยู่ที่ 920 ms (ช่วงตัวอย่าง 700–1,200 ms) ขึ้นกับสภาพเครือข่ายและโหลดเซิร์ฟเวอร์ ในขณะที่ Prompt‑Distill รันออฟไลน์บนเครื่องมือถือทำให้ median latency ลดเหลือ 120 ms (ช่วงตัวอย่าง 80–250 ms) ผลลัพธ์นี้เทียบเท่ากับการลดเวลาเฉลี่ยประมาณ ~87% ต่อคำตอบ
- Throughput (คำถามต่อวินาที/ต่ออุปกรณ์) — การส่งคำถามไปเซิร์ฟเวอร์ถูกจำกัดด้วย RTT และการรอคิว ทำให้เฉลี่ยที่ประมาณ 1.1 QPS ต่ออุปกรณ์ (≈66 QPM) ในขณะที่ Prompt‑Distill บนมือถือที่ลดขั้นตอน CoT ลงสามารถตอบได้เร็วขึ้นเฉลี่ยที่ 6.5 QPS ต่ออุปกรณ์ (≈390 QPM) เพิ่มขึ้นราว 6×
- ขนาดข้อมูลที่ส่งออก (Data egress) — ในการส่ง CoT แบบเต็มรูปแบบขึ้นเซิร์ฟเวอร์ ข้อมูลที่ส่งออกต่อคำถามเฉลี่ยอยู่ที่ประมาณ 3.2 KB ต่อคำขอ (รวม prompt และ transcript) ขณะที่ Prompt‑Distill ส่งเฉพาะชุดคำสั่งย่อที่มีขนาดเฉลี่ย 0.64 KB ต่อคำขอ ลดปริมาณข้อมูลส่งออกลงได้ราว 80% ซึ่งลดความเสี่ยงข้อมูลส่วนบุคคลและลดต้นทุนแบนด์วิดท์อย่างมีนัยสำคัญ
- การใช้พลังงานบนอุปกรณ์ — วัดพลังงานต่อคำตอบด้วยเครื่องมือ profiling ของระบบ ผลทดสอบเฉลี่ยแสดงว่า พลังงานที่อุปกรณ์ใช้ต่อคำถามแบบส่งเซิร์ฟเวอร์อยู่ที่ประมาณ 420 mJ/query (ส่วนใหญ่เป็นพลังงานของวิทยุ/เครือข่ายในช่วงรอผล) ขณะที่ Prompt‑Distill ออฟไลน์ใช้การคำนวณบน CPU/GPU มากขึ้นแต่ระยะเวลาสั้นลง ทำให้พลังงานต่อคำถามเฉลี่ยอยู่ที่ 360 mJ/query ลดลงประมาณ 14.3% ต่อคำถาม ทั้งนี้ PD จะมีพลังงานพีกสูงกว่าในช่วงประมวลผล แต่ระยะเวลาสั้นกว่าจึงประหยัดพลังงานรวมต่อคำตอบได้
ตัวอย่างผลต่อความแม่นยำ (accuracy) เมื่อเทียบกับ CoT เต็มรูปแบบพบว่า Prompt‑Distill ให้ผลลัพธ์ใกล้เคียงกันโดยมีการเปลี่ยนแปลง (delta) ในระดับต่ำ ดังต่อไปนี้ (ค่าเป็นเปอร์เซ็นต์ความถูกต้องแบบเฉลี่ยของชุดทดสอบ):
- Arithmetic: CoT เต็มรูปแบบ 92.1% vs Prompt‑Distill 90.8% (delta −1.3% จุด)
- Commonsense: CoT 87.5% vs Prompt‑Distill 86.9% (delta −0.6% จุด)
- Planning / multi‑step: CoT 78.2% vs Prompt‑Distill 75.1% (delta −3.1% จุด)
- ภาพรวมเฉลี่ย: CoT 85.9% vs Prompt‑Distill 84.2% (delta −1.7% จุด; ≈−2.0% แบบสัมพัทธ์)
การวิเคราะห์รายละเอียดชี้ให้เห็นว่า Prompt‑Distill เสียความแม่นยำเล็กน้อยในงานที่ต้องอธิบาย CoT อย่างละเอียด (เช่น planning แบบหลายขั้นตอน) แต่ยังคงให้ผลลัพธ์ที่ยอมรับได้สำหรับการใช้งานเชิงปฏิบัติการและแอพเชิงธุรกิจ โดยแลกกับประโยชน์ด้าน latency, throughput และความเป็นส่วนตัว
การทดสอบบนอุปกรณ์จริง (real‑device) ดำเนินการบนโทรศัพท์รุ่นต่าง ๆ เพื่อสะท้อนสเปกที่ใช้งานจริง ได้แก่ iPhone 13 (A15), Google Pixel 6 (Tensor), และ Xiaomi Redmi Note 10 (Snapdragon 678) โดยรันภายใต้สภาพเครือข่ายหลากหลาย: Wi‑Fi 100 Mbps, 4G LTE ~20–40 Mbps, 3G ~1–3 Mbps และ offline/no network. ผลสรุปเชิงอุปกรณ์แสดงว่า:
- บนอุปกรณ์ระดับไฮเอนด์ (iPhone 13, Pixel 6) latency ของ Prompt‑Distill อยู่ในช่วง 80–120 ms ต่อคำตอบ และ throughput สูงสุดถึง ~7 QPS
- บนอุปกรณ์ระดับกลาง‑ล่าง (Redmi Note 10) latency จะยาวขึ้นเป็น ~150–300 ms แต่ยังคงดีกว่าการส่งขึ้นเซิร์ฟเวอร์ (median 920 ms) อย่างมีนัยสำคัญ
- ในสภาพเครือข่ายอ่อน (3G) ประโยชน์ของ Prompt‑Distill บนมือถือยิ่งชัดเจน เพราะการเรียกใช้งานเซิร์ฟเวอร์มีค่า RTT สูงขึ้นทำให้ latency เพิ่มมากกว่าเดิม
สรุปโดยรวม การใช้ Prompt‑Distill ช่วยปรับสมดุลระหว่างประสิทธิภาพการตอบกลับ (latency ต่ำ และ throughput สูง), การลดการส่งข้อมูลออกไปยังเซิร์ฟเวอร์ (ลดข้อมูลที่ส่งออก ~80%) และการคงความแม่นยำไว้ในระดับที่ยอมรับได้ (delta accuracy เฉลี่ยประมาณ −1.7%) ข้อแลกเปลี่ยนสำคัญคือการเพิ่มการคำนวณบนอุปกรณ์ซึ่งอาจทำให้มีพลังงานพีกสูงขึ้น แต่เมื่อนับเป็นพลังงานต่อคำตอบแล้ว Prompt‑Distill ให้ผลดีกว่าหรือใกล้เคียงกับการรันแบบส่งไปเซิร์ฟเวอร์ และลดความเสี่ยงด้านความเป็นส่วนตัวจากการส่งข้อมูลผู้ใช้ไปยังคลาวด์อย่างมีนัยสำคัญ
ความปลอดภัยและความเป็นส่วนตัว: ลดความเสี่ยงข้อมูลบนคลาวด์
ความปลอดภัยและความเป็นส่วนตัว: ลดความเสี่ยงข้อมูลบนคลาวด์
การย้ายการประมวลผลโมเดลมาเป็นแบบรันออฟไลน์บนมือถือโดยใช้เครื่องมือเช่น Prompt‑Distill มีผลโดยตรงต่อความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัวของข้อมูล เนื่องจากข้อมูลต้นทางไม่จำเป็นต้องส่งไปยังเซิร์ฟเวอร์ภายนอกหรือคลาวด์สำหรับการอนุมาน (inference) ทำให้ลดช่องทางการรั่วไหลจากการรับส่งข้อมูลผ่านเครือข่าย การเก็บสำรองบนเซิร์ฟเวอร์ของผู้ให้บริการคลาวด์ และความเสี่ยงจากการถูกโจมตีที่ศูนย์ข้อมูลของบุคคลที่สาม อย่างไรก็ดี การรันบนอุปกรณ์ยังคงมีความเสี่ยงเชิงบริบท เช่น อุปกรณ์สูญหาย ถูกเข้าถึงโดยผู้อื่น หรือซอฟต์แวร์ประสงค์ร้ายบนเครื่อง ดังนั้นการออกแบบระบบต้องผสานมาตรการเชิงเทคนิคและนโยบายเพื่อป้องกันความเสี่ยงเหล่านี้

ข้อดีด้านความเป็นส่วนตัว
- ลดการส่งข้อมูลข้ามเครือข่าย: การประมวลผลบนอุปกรณ์ทำให้ไม่จำเป็นต้องส่งข้อมูลส่วนบุคคลไปยังเซิร์ฟเวอร์กลาง ส่งผลให้ลดโอกาสการดักจับข้อมูลระหว่างทางและการรั่วไหลจากเซิร์ฟเวอร์ของผู้ให้บริการคลาวด์
- การควบคุมข้อมูลโดยผู้ใช้มากขึ้น: ข้อมูลจะอยู่ภายใต้การควบคุมของเจ้าของอุปกรณ์—ซึ่งช่วยให้สอดคล้องกับหลักการ data minimization และ purpose limitation
- ลดปัญหาการปฏิบัติตามกฎระเบียบข้ามพรมแดน: เมื่อข้อมูลไม่ออกจากอุปกรณ์ ความจำเป็นในการจัดการการถ่ายโอนข้อมูลข้ามประเทศ (cross‑border transfer) จะลดลง ซึ่งมีประโยชน์ต่อองค์กรที่ต้องปฏิบัติตามข้อกำหนดด้านภูมิศาสตร์ของข้อมูล
มาตรการเสริมเพื่อเสริมความปลอดภัยและความเป็นส่วนตัว
- การเข้ารหัสแบบท้องถิ่น (local encryption): ใช้การเข้ารหัสข้อมูลขณะพัก (at‑rest) ด้วยคีย์ที่จัดเก็บในฮาร์ดแวร์ปลอดภัย เช่น Trusted Execution Environment (TEE) หรือ Secure Enclave ของอุปกรณ์ เพื่อป้องกันการเข้าถึงจากผู้ไม่หวังดีหากอุปกรณ์สูญหายหรือถูกขโมย
- การเข้ารหัสการสื่อสารและช่องทางอัปเดต: หากจำเป็นต้องดาวน์โหลดโมเดลหรืออัปเดต ให้ใช้ TLS ที่แข็งแกร่งและการยืนยันตัวตนของเซิร์ฟเวอร์ รวมทั้งลงนามดิจิทัลสำหรับซอฟต์แวร์และน้ำหนักโมเดล
- เทคนิค Differential Privacy (DP): สำหรับกรณีที่ระบบต้องรวบรวมสถิติหรือส่งผลสรุปไปยังเซิร์ฟเวอร์ ควรใช้ DP เพื่อเพิ่มสัญญาความเป็นส่วนตัวโดยการเพิ่มเสียง (noise) ทางคณิตศาสตร์และระบุพารามิเตอร์ความเป็นส่วนตัว (epsilon) อย่างชัดเจน โดยรับทราบถึงการแลกเปลี่ยนระหว่างความแม่นยำและระดับความเป็นส่วนตัว
- Audit log แบบ on‑device และ tamper‑evident logging: เก็บบันทึกการใช้งาน การอนุญาต และเหตุการณ์ด้านความปลอดภัยในรูปแบบที่เป็น append‑only และลงนามเชิงลำดับเพื่อให้ตรวจสอบย้อนหลังได้ แต่สามารถกำหนดนโยบายให้ส่งข้อมูลเฉพาะที่จำเป็นและผ่านการยินยอมของผู้ใช้เท่านั้น
- การยืนยันความสมบูรณ์ของโมเดลและการอัปเดตแบบปลอดภัย: ใช้การตรวจสอบลายเซ็นดิจิทัลและมาตรการ attestation ของฮาร์ดแวร์ เพื่อป้องกันการโจมตีผ่านการเปลี่ยนโมเดลหรือข้อมูลน้ำหนัก (weights) ที่อยู่บนอุปกรณ์
- การบริหารวงจรชีวิตของข้อมูลและการสำรองข้อมูลแบบมีข้อจำกัด: กำหนดนโยบายการเก็บรักษาและลบข้อมูลอัตโนมัติตามระยะเวลา และควบคุมการซิงก์ข้อมูลกับคลาวด์หรือสำเนาสำรองให้เป็นไปตามนโยบายความเป็นส่วนตัว
ประเด็นทางกฎหมายและการปฏิบัติตามกฎระเบียบในไทยและภูมิภาค
- พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย: PDPA กำหนดหลักการสำคัญ เช่น การขอความยินยอม การจำกัดวัตถุประสงค์ (purpose limitation) และการแจ้งเหตุละเมิดข้อมูลส่วนบุคคล หากการประมวลผลเกิดขึ้นบนอุปกรณ์ของผู้ใช้และข้อมูลไม่ถูกส่งออกไปยังผู้ควบคุมข้อมูลภายนอก จะช่วยลดภาระในการจัดการการถ่ายโอนข้อมูลและข้อกำหนดด้านการแจ้งเตือนข้ามพรมแดน
- ข้อกำหนดเฉพาะของภาคส่วนและภูมิภาค: ธุรกิจในภาคการเงินและการแพทย์อาจมีข้อกำหนดเสริม เช่น การเก็บรักษาบันทึกและการเข้าถึงข้อมูลที่เข้มงวด การรันออฟไลน์ช่วยสนับสนุนการปฏิบัติตามข้อกำหนดด้าน data residency แต่ยังต้องคำนึงถึงกฎที่เกี่ยวข้องกับการจัดเก็บและการเข้าถึงข้อมูลในประเทศอื่น ๆ เช่น GDPR (สหภาพยุโรป) หรือ PDPA ของประเทศเพื่อนบ้านเมื่อมีการถ่ายโอนข้อมูลข้ามพรมแดน
- ข้อควรระวังด้านการปฏิบัติตาม: แม้ข้อมูลจะอยู่บนอุปกรณ์ แต่ผู้ควบคุมข้อมูลยังคงต้องจัดการเรื่องการขอความยินยอม การตอบคำร้องของเจ้าของข้อมูล (เช่น สิทธิในการลบหรือขอดูข้อมูล) และการแจ้งเหตุละเมิดหากข้อมูลถูกเปิดเผยจากอุปกรณ์หรือจากการสำรองไปยังคลาวด์
สรุปคือ การรันโมเดลแบบออฟไลน์บนมือถือด้วยแนวทางอย่าง Prompt‑Distill ช่วยลดความเสี่ยงที่มาจากการส่งข้อมูลไปยังคลาวด์และอำนวยความสะดวกในการปฏิบัติตามกฎระเบียบ อย่างไรก็ตาม การออกแบบระบบต้องผสานมาตรการเช่น local encryption, secure update, differential privacy และ on‑device audit logging รวมถึงนโยบายการจัดการวงจรชีวิตของข้อมูล เพื่อให้ได้ความสมดุลระหว่างความปลอดภัย การใช้งาน และความสามารถในการปฏิบัติตามกฎหมายที่เกี่ยวข้อง
กรณีใช้งานและผลกระทบทางธุรกิจ
กรณีใช้งานและผลกระทบทางธุรกิจ
การแปลง Chain‑of‑Thought เป็นชุดคำสั่งสั้นของเครื่องมือ "Prompt‑Distill" เปิดช่องทางการใช้งานเชิงปฏิบัติการบนอุปกรณ์มือถือที่กว้างขวาง ตัวอย่างกรณีใช้งานที่ได้รับประโยชน์ชัดเจน ได้แก่ ผู้ช่วยส่วนตัวบนมือถือที่ตอบสนองทันทีโดยไม่ต้องเรียกเรียก API บนคลาวด์, แอปพลิเคชันทางการแพทย์และการเงินที่ต้องการความเป็นส่วนตัวของข้อมูลผู้ใช้, และระบบแปลภาษา/การจดบันทึกแบบเรียลไทม์ที่ต้องการ latency ต่ำเพื่อประสบการณ์แบบเรียลไทม์ การทดสอบภายในของสตาร์ทอัพชี้ให้เห็นว่าการรันบนอุปกรณ์สามารถลดเวลาแฝง (latency) ได้เป็นทวีคูณเมื่อเทียบกับการอาศัย inference บนเซิร์ฟเวอร์ระยะไกล
ตัวอย่างเชิงอุตสาหกรรมที่ชัดเจน ได้แก่:
- สุขภาพ (Healthcare) — แอปบันทึกอาการและสรุปข้อมูลผู้ป่วยแบบออฟไลน์ช่วยลดความเสี่ยงการรั่วไหลของข้อมูลทางการแพทย์ และช่วยให้สอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัว (เช่น กรอบคล้าย HIPAA) ในขณะเดียวกันก็เพิ่มความน่าเชื่อถือเมื่อเครือข่ายไม่เสถียร
- การเงิน (Finance) — ระบบวิเคราะห์ธุรกรรมและให้คำแนะนำการลงทุนแบบ on‑device ลดการส่งข้อมูลสำคัญสู่คลาวด์ ช่วยลดความเสี่ยงด้านการปฏิบัติตามข้อกำกับดูแลและลดค่าใช้จ่ายในการจัดเก็บ/ประมวลผลข้อมูล
- การศึกษา (Education) — ผู้ช่วยติวหรือเครื่องมือสรุปบทเรียนแบบเรียลไทม์บนแท็บเล็ตนักเรียนให้การตอบสนองรวดเร็ว ช่วยเพิ่ม engagement และผลสัมฤทธิ์การเรียน
- แอปองค์กร (Enterprise apps) — ฟีเจอร์จดบันทึกและสรุปการประชุมที่ทำงานบนอุปกรณ์ของพนักงาน ช่วยรักษาความลับทางธุรกิจและลดความจำเป็นในการส่งไฟล์เสียง/ข้อความไปยังเซิร์ฟเวอร์กลาง
จากมุมมองทางธุรกิจ ผลลัพธ์ที่องค์กรสามารถคาดหวังได้ประกอบด้วย: ลดค่าใช้จ่ายคลาวด์ เนื่องจากคำร้องขอ inference ลดลงอย่างมีนัยสำคัญ — บริษัทสามารถประมาณการประหยัดได้ตั้งแต่ 30% ถึง 70% ของค่าใช้จ่ายการประมวลผลและค่าแบนด์วิดท์ที่เกี่ยวข้องในงานที่มีปริมาณการใช้งานสูง นอกจากนี้ latency ต่ำ มีผลโดยตรงต่อประสบการณ์ผู้ใช้: การตอบสนองเร็วขึ้น 2–10 เท่าจะช่วยเพิ่มความพึงพอใจและ retention — งานวิจัยในอุตสาหกรรมชี้ว่าแอปที่มี latency ต่ำสามารถเพิ่ม retention ได้หลายเปอร์เซ็นต์ ซึ่งแปลเป็น Lifetime Value (LTV) ที่สูงขึ้นสำหรับลูกค้าแต่ละราย
ในเชิงรายได้ สตาร์ทอัพและผู้ให้บริการซอฟต์แวร์มีโอกาสสร้างโมเดลธุรกิจหลายรูปแบบ ได้แก่:
- License — ขายไลเซนส์เวิร์กโฟลว์หรือโมดูล Prompt‑Distill ให้ผู้ผลิตอุปกรณ์หรือผู้พัฒนาแอปใช้งานแบบ on‑premise
- Subscription / SaaS แบบ on‑device — เสนอการสมัครสมาชิกที่ปลดล็อกโมเดล/ฟีเจอร์บนอุปกรณ์ โดยยังคงเก็บการชำระเงินแบบคลาวด์แต่ให้ประสบการณ์การประมวลผลเป็นแบบ on‑device
- SDK และ API สำหรับองค์กร — จำหน่าย SDK ให้บริษัทอื่นนำไปฝังในแอปของตน ทำให้เกิด ecosystem ของพันธมิตรที่ขยายการใช้งานได้รวดเร็ว และสามารถคิดค่าธรรมเนียมตามอุปกรณ์ที่ติดตั้งหรือจำนวนคำเรียกใช้งาน
สรุปแล้ว การนำ Prompt‑Distill ไปใช้งานเชิงพาณิชย์สามารถเปลี่ยนรูปแบบต้นทุนและคุณค่าทางธุรกิจได้ชัดเจน: ลดภาระคลาวด์และความเสี่ยงด้านข้อมูล เพิ่มประสบการณ์ผู้ใช้ผ่าน latency ที่ต่ำลง และสร้างสายรายได้ที่หลากหลายผ่านไลเซนส์, การสมัครสมาชิก และการให้บริการ SDK แก่พันธมิตรทางธุรกิจ — ซึ่งทั้งหมดนี้ช่วยให้ผู้พัฒนาและองค์กรมีทางเลือกที่สมดุลระหว่างประสิทธิภาพ ความเป็นส่วนตัว และการสร้างรายได้
อุปสรรค ความเสี่ยง และทิศทางอนาคต
อุปสรรคและความเสี่ยง
แม้แนวทาง Prompt‑Distill จะช่วยลดความหน่วง (latency) และลดความเสี่ยงจากการส่งข้อมูลไปยังคลาวด์ แต่ยังมีข้อจำกัดสำคัญทางด้านความแม่นยำและความสามารถในการอธิบายเหตุผล (explainability) ที่ต้องพิจารณาอย่างถี่ถ้วน ผลการทดลองและงานวิจัยเบื้องต้นระบุว่า การย่อตัวชุดคำสั่งจาก Chain‑of‑Thought ให้สั้นลงอาจนำไปสู่การสูญเสียรายละเอียดของเหตุผลบางส่วน ทำให้ความถูกต้องของคำตอบลดลงได้ในช่วงคร่าว ๆ ประมาณ 3–10% ขึ้นกับลักษณะงานและโดเมนที่ทดสอบ ซึ่งมีผลโดยตรงต่อความน่าเชื่อถือในบริบทที่ต้องการเหตุผลเชิงตรรกะหรือการตรวจสอบย้อนหลัง (forensic traceability)
เชิงเทคนิค ยังมีข้อจำกัดจากทรัพยากรของอุปกรณ์ปลายทาง เช่น หน่วยความจำ (RAM), พลังประมวลผล (CPU/GPU/NPUs) และพลังงานแบตเตอรี่ การบีบอัดโมเดลหรือการควอนไทซ์อาจลดขนาดและเพิ่มความเร็ว แต่ก็เสี่ยงต่อการสูญเสียความเที่ยงตรงบางประการ โดยเฉพาะเมื่อต้องทำงานกับข้อความยาวหรือ reasoning chain ที่ซับซ้อน นอกจากนั้น model drift หรือการเปลี่ยนแปลงของข้อมูลป้อนเข้าตามเวลา ยังอาจทำให้ชุดคำสั่งที่ distilled ไว้ล้าสมัยและทำงานได้ไม่ดีเมื่อเผชิญกับ distribution shift ซึ่งเป็นปัญหาที่ส่งผลทั้งด้านประสิทธิภาพและความปลอดภัย
ในแง่ความปลอดภัย แม้การรันบนมือถือจะลดการเปิดเผยข้อมูลสู่บุคคลภายนอก แต่ยังมีความเสี่ยงที่มาจากการเก็บบันทึกหรือ telemetry บางส่วน การโจมตีแบบ prompt inversion หรือการวิเคราะห์พฤติกรรมโมเดล (model extraction) ยังสามารถทำให้ข้อมูลที่ละเอียดอ่อนรั่วไหลได้ โดยเฉพาะเมื่ออุปกรณ์ไม่มีการป้องกันฮาร์ดแวร์หรือซอฟต์แวร์ที่เพียงพอ นอกจากนี้ การอัปเดตชุดคำสั่งผ่านเครือข่ายถ้าไม่ได้ใช้กระบวนการที่ปลอดภัย อาจนำไปสู่การแพร่กระจายของเวอร์ชันที่มีช่องโหว่หรือบั๊กได้
ทิศทางการวิจัยและการพัฒนา (แนวทางเชิงปฏิบัติ)
เพื่อจัดการกับข้อจำกัดเหล่านี้ จำเป็นต้องมีงานวิจัยเชิงลึกและการพัฒนาเชิงวิศวกรรมที่มุ่งไปยังหลายแกนหลัก ได้แก่
- Adaptive distillation: พัฒนาเทคนิคที่สามารถปรับความยาวและระดับการย่อของ Chain‑of‑Thought ตามบริบทและความซับซ้อนของคำถามแบบเรียลไทม์ เช่น การใช้ controller ที่ประเมินความแน่นอน (confidence) แล้วตัดสินใจว่าจะขยายหรือหดชุดคำสั่งอย่างไร
- Continual on‑device learning & federated updates: ออกแบบกลไกให้มือถือสามารถรับการอัปเดตแบบ federated หรือ perform lightweight continual learning เพื่อปรับตัวต่อ model drift โดยไม่ส่งข้อมูลดิบออกนอกเครื่อง พร้อมใส่กลไก differential privacy และ secure aggregation เพื่อปกป้องข้อมูลผู้ใช้
- Secure hardware integration: ผสานการทำงานกับเทคโนโลยีฮาร์ดแวร์ปลอดภัย (เช่น Trusted Execution Environments, secure enclaves, หรือ ARM TrustZone) เพื่อลดความเสี่ยงจากการโจมตีระดับระบบและป้องกันการเข้าถึง prompt/trace ของ Chain‑of‑Thought โดยผู้ไม่หวังดี
- Evaluation & monitoring framework: สร้างชุดตัวชี้วัดใหม่ที่วัดทั้งความแม่นยำ, ความสามารถในการอธิบายเหตุผล, ความเสี่ยงการรั่วไหลของข้อมูล และ trade‑off ระหว่าง latency กับ fidelity เพื่อใช้ในการตัดสินใจเชิงธุรกิจและการรับรองคุณภาพ
เชิงปฏิบัติสำหรับทีมผลิตภัณฑ์และนักลงทุน ควรวางแผนการเปิดตัวเชิงค่อยเป็นค่อยไป เริ่มจาก use‑case ที่มีข้อจำกัดด้านความเสี่ยงต่ำ (เช่น chatbots สำหรับคำแนะนำทั่วไป หรือแอปที่ไม่เกี่ยวข้องกับข้อมูลทางการแพทย์/การเงิน) แล้วค่อยขยายสู่โดเมนที่ต้องการความแม่นยำสูง พร้อมทั้งสร้างความร่วมมือกับผู้ผลิตชิปและผู้ให้บริการฮาร์ดแวร์มือถือเพื่อปรับจูนสแต็กซอฟต์แวร์ให้ได้ประสิทธิภาพที่เหมาะสม
สรุปคือ แนวทาง Prompt‑Distill มีศักยภาพสูงในการลด latency และเพิ่มความเป็นส่วนตัว แต่การนำไปใช้งานเชิงพาณิชย์อย่างมั่นคงจำเป็นต้องแก้ไขปัญหาด้านความแม่นยำ, การปรับตัวต่อการเปลี่ยนแปลงของข้อมูล และการผนวกการป้องกันเชิงฮาร์ดแวร์และเชิงนโยบาย การลงทุนในงานวิจัยเรื่อง adaptive distillation, federated updates และการบูรณาการกับ secure enclaves จะเป็นกุญแจสำคัญในการขยายตลาดและรักษาความน่าเชื่อถือของแพลตฟอร์มในระยะยาว
บทสรุป
Prompt‑Distill คือแนวทางที่แปลง Chain‑of‑Thought (CoT) ซึ่งเป็นเหตุผลเชิงลึกของโมเดลภาษา ให้กลายเป็นชุดคำสั่งสั้น ๆ ที่สามารถรันได้แบบออฟไลน์บนอุปกรณ์พกพา แนวทางนี้มีศักยภาพในการนำพลังของการให้เหตุผลเชิงลึกมาสู่ผู้ใช้บนมือถืออย่างปลอดภัยและรวดเร็ว โดยลดทั้งความหน่วง (latency) จากการเรียกใช้งานคลาวด์และความเสี่ยงในการส่งข้อมูลไปยังเซิร์ฟเวอร์ภายนอก ข้อแลกเปลี่ยนสำคัญคือการย่อรายละเอียดเชิงเหตุผลออกไป ซึ่งอาจทำให้สูญเสียความชัดเจนของกระบวนการคิดหรือความแม่นยำในบางเคส ดังนั้น Prompt‑Distill จึงเหมาะกับงานที่ต้องการผลลัพธ์รวดเร็วและความเป็นส่วนตัวสูง แต่ต้องยอมรับขอบเขตของการย่อข้อมูลเหตุผล
การนำ Prompt‑Distill ไปใช้จริงจำเป็นต้องพิจารณาสมดุลระหว่างความแม่นยำ ความต้องการเชิงธุรกิจ และการคุ้มครองความเป็นส่วนตัวของผู้ใช้ ในทางปฏิบัติจึงต้องมีงานวิจัยร่วมและมาตรฐานกลางเพื่อประเมินประสิทธิภาพ (เช่น เกณฑ์วัดความสูญเสียเชิงเหตุผล) แนวทางในอนาคตรวมถึงการพัฒนาเทคนิค distillation ที่ปรับได้ตามบริบท การผสมผสานโซลูชันแบบไฮบริดระหว่างอุปกรณ์กับคลาวด์ การสร้างมาตรฐานการประเมินผลและความโปร่งใส รวมถึงการใช้เทคนิคคุ้มครองข้อมูลเช่น differential privacy และการเข้ารหัสเพื่อขยายการใช้งานในวงกว้าง เมื่อมีกรอบวิธีการและมาตรฐานรองรับ Prompt‑Distill มีศักยภาพช่วยเร่งการใช้งาน AI บนมือถือให้ปลอดภัย ลดค่าใช้จ่ายและเพิ่มความเป็นส่วนตัวของผู้ใช้ในระดับสากล



