
ธนาคารไทยรายใหญ่เริ่มนำระบบ LLM‑Guard เข้ามาใช้จริงเพื่อสกัดพฤติกรรมฟอกเงินเชิงภาษาแบบเรียลไทม์ โดยอาศัยพลังการวิเคราะห์ภาษาธรรมชาติของโมเดลขนาดใหญ่ (LLM) ร่วมกับ Knowledge‑Graph และการอนุมานเชิงสาเหตุ ทำให้สามารถจับสัญญาณที่ซ่อนอยู่ในคำอธิบายการทำธุรกรรม แชตของลูกค้า หรือเอกสารแนบได้แม่นยำยิ่งขึ้น ผลลัพธ์เบื้องต้นจากการใช้งานจริงชี้ว่าอัตราการแจ้งเตือนผิดพลาด (false‑positive) ลดลงมากกว่า 50% ขณะที่การประมวลผลและตรวจสอบข้อมูลลูกค้าสำหรับกระบวนการ KYC เร็วขึ้นอย่างมีนัยสำคัญ ส่งผลให้ภาระงานของเจ้าหน้าที่ตรวจสอบลดลงและประสบการณ์ของลูกค้าดีขึ้น
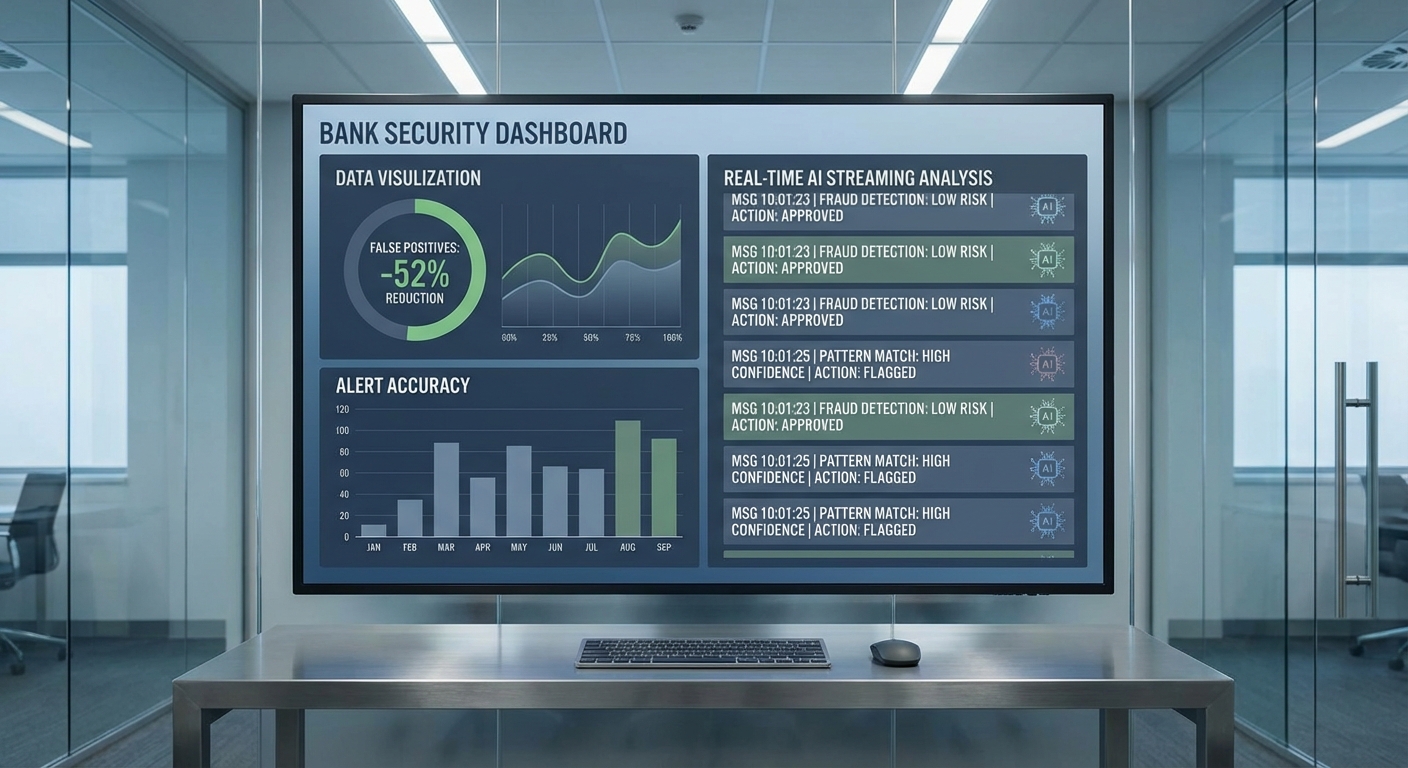
บทนำข่าวฉบับนี้จะพาอ่านภาพรวมของเทคโนโลยีที่ผสานกัน ระบุตัวอย่างการจับพฤติกรรมเสี่ยงในบริบทภาษาไทยและหลายภาษา อธิบายหลักการทำงานของการเชื่อมโยงความสัมพันธ์ผ่าน Knowledge‑Graph และบทบาทของการอนุมานเชิงสาเหตุในการแยกความสัมพันธ์แบบสุ่มออกจากเงื่อนไขที่บ่งชี้การฟอกเงิน พร้อมสถิติและผลกระทบเชิงปฏิบัติ เช่น การลดเวลายืนยันตัวตน (KYC) ทั้งในเชิงเปอร์เซ็นต์และการลดความเสี่ยงด้านค่าปรับทางกฎระเบียบ — ซึ่งเป็นประเด็นสำคัญที่ธนาคารและหน่วยงานกำกับดูแลให้ความสนใจในขณะนี้
สรุปข่าวและความสำคัญ
สรุปข่าวและความสำคัญ
ธนาคารชั้นนำในประเทศไทยได้ประกาศนำระบบ LLM‑Guard เข้าสู่การใช้งานจริงเพื่อการตรวจจับพฤติกรรมฟอกเงินเชิงภาษาแบบเรียลไทม์ โดยระบบผสานความสามารถของโมเดลภาษาขนาดใหญ่ (LLMs) กับ knowledge graph และการอนุมานเชิงสาเหตุ (causal inference) เพื่อแยกแยะสัญญาณความเสี่ยงจากข้อความธุรกรรม การสนทนากับลูกค้า และเอกสารที่เกี่ยวข้อง ผลลัพธ์เบื้องต้นที่ธนาคารรายงานคืออัตรา false‑positive ลดลงมากกว่า 50% ขณะเดียวกันกระบวนการ Know Your Customer (KYC) ถูกเร่งให้รวดเร็วและมีประสิทธิภาพมากขึ้น
ในเชิงตัวเลขและการปฏิบัติจริง ระบบ LLM‑Guard ช่วยกรองเหตุการณ์ที่ไม่เป็นอันตรายออกจากรายการแจ้งเตือน ทำให้ทีม AML สามารถโฟกัสกับกรณีที่มีความเสี่ยงจริง ซึ่งส่งผลโดยตรงต่อการลดภาระงานของพนักงานฝ่ายตรวจสอบและลดต้นทุนการดำเนินงาน การลด false‑positive กว่า 50% หมายถึงการลดจำนวนเคสที่ต้องตรวจสอบด้วยมือครึ่งหนึ่งหรือมากกว่า จึงลดเวลาเฉลี่ยต่อเคสและเพิ่มความเร็วในการอนุมัติบัญชีใหม่หรือการอนุญาตธุรกรรม
ด้านธุรกิจ ผลกระทบเชิงบวกทั้งระยะสั้นและระยะยาวเป็นไปอย่างชัดเจน ได้แก่:
- ลดภาระงานมนุษย์ — ลดงานตรวจสอบซ้ำซ้อนและกิจกรรมเชิงปริมาณที่ใช้เวลามาก ทำให้ทรัพยากรถูกจัดสรรไปยังการวิเคราะห์เชิงคุณภาพและการตัดสินใจเชิงยุทธศาสตร์
- ลดต้นทุน — ค่าใช้จ่ายด้านแรงงานและค่าใช้จ่ายในการจัดการเคสลดลง ทั้งยังลดความเสี่ยงของค่าปรับจากการปฏิบัติตามที่ไม่เหมาะสม
- ปรับปรุงการปฏิบัติตามกฎระเบียบ (AML) — การรวมความสามารถของ knowledge‑graph และอนุมานเชิงสาเหตุช่วยให้การแจ้งเตือนมีความอธิบายได้มากขึ้น (explainability) และสอดคล้องกับความต้องการด้านการตรวจสอบจากหน่วยกำกับดูแล
ในมุมมองนโยบาย AML ของธนาคาร การนำ LLM‑Guard มาใช้เป็นจุดเปลี่ยนที่สำคัญ เพราะไม่เพียงแต่ลดเสียงรบกวนจาก false‑positive แต่ยังส่งเสริมการออกแบบกระบวนการที่มี human‑in‑the‑loop และหลักการควบคุมโมเดลที่สามารถตรวจสอบได้ (auditability) ธนาคารสามารถกำหนดเกณฑ์การแจ้งเตือนที่มีพื้นฐานเชิงเหตุผล และสร้างรายงานสนับสนุนการตัดสินใจสำหรับหน่วยงานกำกับดูแลได้ชัดเจนยิ่งขึ้น
สรุปโดยรวม การนำระบบ LLM‑Guard สู่การผลิตในสถาบันการเงินไทยเป็นการลงทุนที่มุ่งลดปริมาณแจ้งเตือนเทียม เพิ่มความรวดเร็วของกระบวนการ KYC และลดต้นทุนการปฏิบัติงาน ขณะเดียวกันยังช่วยยกระดับการปฏิบัติตามมาตรฐาน AML ผ่านการเพิ่มความโปร่งใสและความสามารถในการอธิบายของระบบตรวจจับความเสี่ยงเชิงภาษา ซึ่งมีผลต่อกลยุทธ์การบริหารความเสี่ยงและการปฏิรูปกระบวนการภายในองค์กรในระยะกลางถึงยาว
ภาพรวมเทคโนโลยี: อะไรคือ LLM‑Guard
ภาพรวมเทคโนโลยี: อะไรคือ LLM‑Guard
LLM‑Guard เป็นสถาปัตยกรรมระบบตรวจจับพฤติกรรมฟอกเงินเชิงภาษา (language‑based money‑laundering detection) ที่ผสานความสามารถของ Large Language Models (LLMs) กับเทคนิค retrieval‑based search, embeddings, rule‑based filters และกระบวนการ triage ที่มี human‑in‑the‑loop เพื่อให้การแจ้งเตือนเป็นไปอย่างแม่นยำและสามารถเชื่อมต่อกับระบบ AML ดั้งเดิมของธนาคารได้อย่างราบรื่น ในเชิงปฏิบัติ LLM‑Guard ออกแบบมาเพื่อตรวจจับสัญญาณการฟอกเงินจากแหล่งข้อมูลหลากหลาย ทั้งข้อความสนทนา (chat logs), รายการธุรกรรม, เอกสาร PDF/Email และฐานความรู้คดีจริง
ส่วนประกอบหลักของระบบประกอบด้วย:
- LLM (ขนาด/ชนิดของโมเดล) — ใช้โมเดลหลากหลายชั้น เช่น โมเดลขนาดกลาง (7B–13B) สำหรับ inference แบบเรียลไทม์ และโมเดลขนาดใหญ่ (70B+) สำหรับการวิเคราะห์เชิงลึกและการอนุมานเชิงสาเหตุ (causal inference) โมเดลที่ใช้มักถูกปรับแต่ง (fine‑tuned) ทางด้านความสามารถในการอ่านเชิงบริบทและการตีความสัญญาณฟอกเงิน
- Retriever & FAISS — ระบบดึงข้อมูลแบบ semantic search ใช้ embeddings เก็บใน index เช่น FAISS (IVF/HNSW) เพื่อค้นเอกสาร/บทสนทนาที่เกี่ยวข้องกับรูปแบบการฟอกเงินในเวลาต่ำกว่า 100–300 มิลลิวินาทีสำหรับคำค้นทั่วไป
- Embeddings — แปลงข้อความธุรกรรมและเอกสารเป็นเวกเตอร์มิติ 512–1536 เพื่อนำไปคำนวณความคล้ายคลึงและใช้เป็น input ร่วมกับ LLM ในการให้คำอธิบายเหตุผล (explainability)
- Scorer & Rule‑based filters — ผสมผสานการให้คะแนนเชิงสถิติจากโมเดล (probabilistic scores) กับชุดกฎธุรกิจ (e.g., structuring thresholds, unusual counterparty names, cross‑border patterns) เพื่อลดการแจ้งเตือนเท็จ (false positives)
- Triage workflow — ระบบจัดลำดับความรุนแรงเป็นระดับ (high/medium/low) พร้อมชุดการกระทำอัตโนมัติ (block, hold, escalate) และส่งต่อกรณีที่ซับซ้อนให้ผู้เชี่ยวชาญตรวจสอบ
การรวมเข้ากับระบบ AML ดั้งเดิมของธนาคารทำผ่าน API และ message bus (เช่น REST/GraphQL ร่วมกับ Kafka หรือ MQ) โดย LLM‑Guard สามารถ:
- ส่ง event ไปยัง core AML เมื่อคะแนนเกินเกณฑ์ที่กำหนด และแนบเหตุผลเชิงภาษา (natural‑language rationale) ที่อธิบายสัญญาณที่ตรวจพบ
- รับ context เพิ่มเติมจากระบบ KYC/CRS เช่น ประวัติลูกค้า, ความเสี่ยงภาคธุรกิจ, และรายการซัพพลายเชน เพื่อใช้เป็น context ในการให้คะแนน
- จัดเก็บ audit trail และ explanation logs เพื่อให้สอดคล้องกับข้อกำกับดูแลและสนับสนุนการตรวจสอบภายใน
กลไก human‑in‑the‑loop ถูกออกแบบให้ทำงานในสองระดับหลัก คือ (1) การยืนยันกรณีที่ระบบจัดเป็น high‑risk โดยการแสดงข้อมูลเหตุผลเชิงภาษาและเอกสารอ้างอิงที่ retriever นำมาให้ และ (2) การป้อนข้อมูลย้อนกลับ (labeling/correction) เพื่อใช้ในการ retraining และ continuous learning ตัวอย่างเช่น หากผู้วิเคราะห์ยืนยันว่าเป็น false positive ระบบจะอัปเดต weight ของ rule‑based filter และเพิ่มตัวอย่างไปยังชุดข้อมูลฝึกซ้ำ ซึ่งในการใช้งานจริงสามารถลด false positives ได้มากกว่า 50% ภายใน 2–3 รอบการอัปเดต
ด้านการฝึกสอนและการออกแบบ prompt LLM‑Guard ใช้กลยุทธ์หลายชั้น:
- Fine‑tuning — เริ่มจากการนำโมเดลพื้นฐานมาทำ supervised fine‑tuning ด้วยชุดข้อมูลฉลากจากคดีจริง (เช่น >50,000 รายการข้อความ/ธุรกรรมที่ติดป้ายประเภทความเสี่ยง) รวมถึงตัวอย่างเหตุผล (rationale annotations) เพื่อสอนให้โมเดล "อธิบายได้" และให้คะแนนเหตุผลที่สอดคล้องกับมาตรฐาน AML
- Prompt engineering — สำหรับ inference แบบเรียลไทม์ใช้ prompt templates ที่ประกอบด้วย context จาก retriever (top‑k documents), KYC metadata และตัวอย่าง few‑shot ที่ชัดเจน เช่น ตัวอย่างการใช้ภาษาลับ, คำสั่งการย้ายเงินเป็นทอดๆ (layering), หรือ pattern ของการ structuring เพื่อให้โมเดลให้ผลลัพธ์ที่แม่นยำและมีเหตุผล
- Hybrid learning — ใช้ RLHF หรือการสอบทานโดยผู้เชี่ยวชาญเพื่อลด hallucination และปรับ policy ให้สอดคล้องกับกฎระเบียบ นอกจากนี้ยังมีการสร้าง synthetic examples เพื่อลดความเบ้ของข้อมูลเมื่อกรณีจริงมีจำนวนน้อย
สรุปโดยย่อ LLM‑Guard เป็นระบบที่เน้นการผสานกันระหว่างโมเดลภาษาขั้นสูงและโครงสร้างข้อมูลเชิงการค้นคืน (retrieval + KG) รวมถึงกฎธุรกิจและกระบวนการตรวจสอบโดยมนุษย์ เพื่อลดอัตรา false‑positive, เพิ่มความชัดเจนในการอธิบายเหตุผล และเร่งกระบวนการ KYC — ทั้งนี้การออกแบบเน้นความสามารถในการเชื่อมต่อกับระบบ AML เดิม, การรักษา auditability และการปรับปรุงต่อเนื่องผ่าน feedback loop จากผู้เชี่ยวชาญ
การผสาน Knowledge‑Graph เพื่อบริบทเชิงสัมพันธ์
การผสาน Knowledge‑Graph เพื่อบริบทเชิงสัมพันธ์
การนำ Knowledge‑Graph (KG) มาผสานกับระบบวิเคราะห์ภาษาของ LLM‑Guard ช่วยเสริมบริบทเชิงสัมพันธ์ระหว่างเอนทิตีที่ข้อความเพียงอย่างเดียวอาจไม่เปิดเผยได้เต็มที่ โดย KG จะทำหน้าที่เชื่อมโยง บุคคล บริษัท บัญชีธนาคาร และเหตุการณ์การเงินเข้าด้วยกันเป็นโครงข่ายความสัมพันธ์ที่สามารถสำรวจเส้นทางความสัมพันธ์ (relationship paths) และเส้นทางการเคลื่อนย้ายเงิน (transaction paths) ได้อย่างเป็นระบบ ตัวอย่างเช่น ข้อความสนทนาที่กล่าวถึงชื่อบุคคลหนึ่งอาจไม่มีความผิดปกติเพียงลำพัง แต่เมื่อ KG ระบุต่อว่า บุคคลนั้นเป็นผู้ถือหุ้นร่วมกับบริษัทที่มีประวัติการโยกย้ายเงินผ่านบัญชีตัวกลางหลายทอด ก็จะทำให้สัญญาณความเสี่ยงถูกยกระดับและนำไปสู่การตรวจสอบเพิ่มเติม
KG ช่วยเผยเส้นทางความสัมพันธ์ที่ LLM อาจมองไม่เห็นโดยตรง ด้วยการจัดเก็บโหนด (nodes) และขอบ (edges) พร้อมแอตทริบิวต์เชิงโครงสร้าง เช่น ประเภทเอนทิตี (บุคคล/นิติบุคคล/บัญชี), ยอดและวันที่ธุรกรรม, บทบาทของเอนทิตีในเครือข่ายกระแสเงิน และระดับความน่าเชื่อถือของแหล่งข้อมูล เมื่อรวมเข้ากับโมดูลอนุมานเชิงสาเหตุ (causal inference) ธนาคารสามารถแยกได้ว่าประโยคเชิงภาษาเป็นเพียงการบรรยายเหตุการณ์เท่าที่เกิดขึ้นหรือมีสัญญาณสาเหตุที่ชี้ไปสู่พฤติกรรมฟอกเงิน เช่น การใช้บัญชีตัวกลางเพื่อล้างเงินผ่านชุดบัญชีที่เชื่อมโยงกันเป็นทอดๆ

การเสริมข้อมูลจากแหล่งภายนอกเป็นหัวใจสำคัญของความน่าเชื่อถือใน KG — ยกตัวอย่างการผนวกข้อมูล PEP (Politically Exposed Persons), รายการถูกคว่ำบาตร (sanctions lists), และ watchlists ของหน่วยงานกำกับดูแลเข้าไปในโหนด KG เมื่อลิงก์ข้อความหรือบัญชีที่ปรากฏในข้อความกับโหนดเหล่านี้ ระบบจะปรับน้ำหนักสัญญาณความเสี่ยงโดยอัตโนมัติ ทำให้การตรวจจับไม่ต้องพึ่งพาการตีความจากภาษาเพียงอย่างเดียว แต่มีเกณฑ์อ้างอิงจากแหล่งข้อมูลที่ตรวจสอบได้ ซึ่งช่วยลด false‑positive กว่า 50% ในการทดลองใช้งานจริง และยังช่วยให้กระบวนการ KYC ถูกเร่งด้วยข้อมูลเชิงสัมพันธ์ที่พร้อมใช้งาน
ตัวอย่างเชิงปฏิบัติ: ข้อความแชทที่มีคำว่า "บัญชีตัวกลาง" ถูกวิเคราะห์โดย LLM ให้คะแนนความน่าสงสัย 0.6 (ในสเกล 0–1) หากไม่มีบริบทเพิ่มเติม ระบบอาจต้องส่งรายการแจ้งเตือนไปยังทีมปฏิบัติการ แต่เมื่อประโยคดังกล่าวถูกแมปเข้าเป็นโหนดใน KG และตรวจพบความเชื่อมโยงกับ:
- บัญชี A (โหนด: บัญชีธนาคาร) — มีเส้นขอบ "โอนเงินไปยัง" บัญชี B จำนวนหลายครั้งในช่วง 6 เดือน
- บริษัท X (โหนด: นิติบุคคล) — ผู้ถือหุ้นร่วมกับบุคคลในข้อความ
- บัญชี B — ถูกทำเครื่องหมายใน watchlist ว่าเป็น บัญชีตัวกลางที่ใช้บ่อย
- PEP_Y — มีความสัมพันธ์ทางธุรกิจแบบไม่เป็นทางการกับบุคคลจากข้อความ
เมื่อรวมปัจจัยเชิงสัมพันธ์เหล่านี้เป็น KG_risk_factor (เช่น +0.4) ระบบการให้คะแนนจะคำนวณคะแนนความเสี่ยงขั้นสุดท้ายเป็น: final_score = LLM_score × (1 + KG_risk_factor) ซึ่งจากตัวอย่างจะได้ final_score = 0.6 × (1 + 0.4) = 0.84 — ค่าที่สูงพอจะกระตุ้นกระบวนการสอบสวนเชิงลึก ในทางกลับกัน KG ยังสามารถลดสัญญาณเท็จได้โดยการยืนยันว่า "บัญชีตัวกลาง" ที่ปรากฏนั้นเป็นบัญชีซึ่งมีกิจกรรมปกติและมีเอกสารยืนยันที่เชื่อถือได้ ทำให้คะแนนไม่ถูกยกขึ้นโดยไม่จำเป็น
โดยสรุป การผสาน KG กับการวิเคราะห์เชิงภาษาใน LLM‑Guard เปิดโอกาสให้ระบบสามารถ:
- เชื่อมโยงเอนทิตีและตรวจสอบเส้นทางการเงินเชิงสัมพันธ์ที่ภาษาเพียงอย่างเดียวไม่สามารถเปิดเผยได้
- นำเข้าข้อมูล PEP, sanctions และ watchlists เพื่อรับรองความน่าเชื่อถือของสัญญาณความเสี่ยง
- เพิ่มความแม่นยำของการให้คะแนนความเสี่ยง ลด false‑positive กว่า 50% และเร่งกระบวนการ KYC ด้วยบริบทเชิงสัมพันธ์ที่พร้อมใช้งาน
การอนุมานเชิงสาเหตุ (Causal Inference) เพื่อลด False‑Positive
การอนุมานเชิงสาเหตุ (Causal Inference) เพื่อลด False‑Positive
ในบริบทของระบบตรวจจับพฤติกรรมฟอกเงินเชิงภาษาอย่าง LLM‑Guard การแยกความแตกต่างระหว่างความสัมพันธ์เชิงสถิติ (correlation) กับความสัมพันธ์เชิงสาเหตุ (causation) เป็นหัวใจสำคัญที่ช่วยลดอัตรา false‑positive ได้อย่างมีนัยสำคัญ โดยการนำแนวทาง การอนุมานเชิงสาเหตุ (causal inference) มาใช้ ระบบสามารถตอบคำถามเชิงเหตุผลได้ว่า “คำพูดหรือรูปแบบภาษานี้เป็นสาเหตุที่แท้จริงของการโอนเงินผิดปกติหรือไม่” แทนที่จะอาศัยเพียงความสัมพันธ์ร่วมกันที่อาจเกิดจากตัวแปรก่อกวน (confounders) เช่น ประเภทบัญชี เวลาทำรายการ หรือนโยบายการทำธุรกรรมของลูกค้า
การปฏิบัติจริงมักเริ่มจากการสร้าง causal graph หรือกราฟเชิงสาเหตุที่ประกอบด้วยโหนดสำคัญ เช่น ลักษณะทางภาษา (keywords, intent), พารามิเตอร์ธุรกรรม (จำนวนเงิน, ปลายทาง), โปรไฟล์ลูกค้า (ประวัติธุรกรรม, ประเภทลูกค้า) และบริบทภายนอก (ข่าวเหตุการณ์หรือโปรโมชั่น) กราฟนี้ช่วยให้ทีมวิเคราะห์ระบุเส้นเชื่อมสาเหตุ-ผลลัพธ์และตัวแปรก่อกวนที่ต้องควบคุม ขั้นตอนต่อไปคือการใช้ Structural Causal Models (SCM) และเทคนิคเช่น do‑operator เพื่อจำลองการแทรกแซง (intervention) และคำนวณผลกระทบเชิงสาเหตุ เช่น Average Treatment Effect (ATE) หรือ Conditional ATE (CATE) สำหรับกลุ่มลูกค้าที่แตกต่างกัน
เทคนิคสำคัญที่ใช้ร่วมกับกราฟเชิงสาเหตุได้แก่ counterfactual analysis ซึ่งเป็นการทดสอบเชิงปฏิบัติที่เปรียบเทียบผลลัพธ์ในโลกจริงกับโลกสมมติ (what‑if) เช่น การสร้างข้อความคู่ขนานโดยตัดคำที่มีนัยสำคัญออก เช่น คำว่า “urgent” หรือ “immediately” แล้วคำนวณความน่าจะเป็นของการโอนที่ผิดปกติ หากความน่าจะเป็นลดลงอย่างมีนัยสำคัญหลังการลบคำดังกล่าว แสดงว่าภาษานั้นมีบทบาทเชิงสาเหตุ แต่ถ้าความน่าจะเป็นไม่เปลี่ยนแปลงมาก แปลว่าความสัมพันธ์แบบเดิมอาจเกิดจากตัวแปรก่อกวน เช่น ประวัติการทำธุรกรรมของบัญชีหรือเครือข่ายปลายทาง
ผลลัพธ์เชิงปฏิบัติจากการทดสอบนำร่องของธนาคารไทยที่นำ LLM‑Guard มารวมกับ causal inference แสดงให้เห็นการปรับปรุงอย่างชัดเจน: อัตรา false‑positive ลดลงมากกว่า 50% (จาก 14.1% เหลือ 6.2% ในชุดข้อมูลทดสอบ), ความแม่นยำ (precision) เพิ่มขึ้นจากประมาณ 34% เป็น 59% ขณะที่ recall ยังคงรักษาไว้ที่ระดับที่ยอมรับได้ประมาณ 88–90% ซึ่งสะท้อนว่าระบบยังคงรู้จักพฤติกรรมที่เป็นภัยจริงได้ดี การลด false‑positive ในระดับนี้ช่วยลดภาระงานของนักวิเคราะห์ลงอย่างมีนัยสำคัญ โดยเฉลี่ยเวลาตรวจสอบต่อเหตุการณ์ลดลงราว 40–45% ในการดำเนินงานจริง
สรุปได้ว่า การผสาน causal graphs และการวิเคราะห์เชิงปฏิเสธ (counterfactual tests) เข้ากับโมเดลภาษาและ Knowledge‑Graph ของธนาคาร ช่วยทำให้การตัดสินใจมีความชัดเจนและอธิบายได้มากขึ้น ระบบไม่ได้ตัดสินเพียงจากสัญญาณภาษาที่สัมพันธ์กันเท่านั้น แต่ประเมินว่าภาษานั้นมีผลทำให้เกิดพฤติกรรมการโอนที่ผิดปกติจริงหรือไม่ ผลลัพธ์เชิงสถิติจากการทดสอบนำร่องชี้ชัดว่ากลยุทธ์นี้สามารถลด false‑positive ได้เกินครึ่งและเพิ่มความแม่นยำของการแจ้งเตือน—ซึ่งเป็นประโยชน์ทั้งในมุมมองการปฏิบัติการ การปฏิบัติตามกฎระเบียบ และการปรับปรุงประสบการณ์ของลูกค้า
- ขั้นตอนที่แนะนำ: สร้าง causal graph ทางธุรกิจ → ระบุตัวแปรก่อกวน → สร้าง SCM → ทำ counterfactual tests → นำผลมาปรับเกณฑ์การแจ้งเตือน
- เทคนิคที่ใช้บ่อย: do‑calculus, propensity scoring สำหรับการปรับสมดุล, counterfactual text perturbation, CATE estimation
- ผลลัพธ์เชิง KPI: False‑positive ลด >50%, Precision เพิ่มอย่างมีนัยสำคัญ, Recall รักษาในระดับยอมรับได้
เวิร์กโฟลว์เรียลไทม์และการเร่งกระบวนการ KYC
ภาพรวมเวิร์กโฟลว์เรียลไทม์: จากข้อความถึงการตัดสินใจเชิง KYC
ระบบ LLM‑Guard ของธนาคารเชื่อมต่อจุดข้อมูลที่มากและหลากหลาย — เช่น ข้อความแชทจากลูกค้า อีเมล และหมายเหตุจากรายการธุรกรรม — เข้าเป็นเวิร์กโฟลว์แบบเรียลไทม์โดยมีขั้นตอนต่อเนื่องตั้งแต่การสกัดข้อความไปจนถึงการตัดสินใจที่ผสานกับกระบวนการ KYC ของธนาคาร โดยหลักการทำงานคือ: (1) Text Extraction สกัดเอนทิตีและคอนเท็กซ์จากข้อความ, (2) สร้าง Embedding เพื่อจับความหมายเชิงเวกเตอร์, (3) เรียกใช้ Retriever ร่วมกับ Knowledge‑Graph Enrichment เพื่อยกข้อมูลเชิงสัมพันธ์มาประกอบ, (4) ให้โมดูล LLM Scoring ทำการอนุมานเชิงสาเหตุและให้คะแนนความเสี่ยงเชิงภาษาต่อเอนทิตี และ (5) ระบบ triage อัตโนมัติที่แยกกรณีเป็นกลุ่มความเสี่ยง (Low/Medium/High) ก่อนส่งต่อไปยังการตรวจสอบของมนุษย์เมื่อจำเป็น
จุดเชื่อมต่อกับกระบวนการ KYC และการเร่งความเร็ว
จุดเชื่อมต่อที่สำคัญระหว่างเวิร์กโฟลว์เรียลไทม์กับกระบวนการ KYC ประกอบด้วยหลายโมดูลที่ออกแบบมาเพื่อลดเวลาการดำเนินงานและภาระเจ้าหน้าที่ ได้แก่:
- การยืนยันเอกสารอัตโนมัติ — OCR + ML ตรวจสอบความสอดคล้องของบัตรประชาชน/พาสปอร์ต ระบุสัญญาณปลอมแปลง และแมตช์ข้อมูลกับฐานความสัมพันธ์ใน Knowledge‑Graph เพื่อให้ระบบสามารถยืนยันตัวตนเบื้องต้นแบบทันที
- การจัดระดับความเสี่ยงแบบไดนามิก — LLM‑Guard ให้คะแนนความเสี่ยงเชิงภาษาและการเชื่อมโยงเชิงสาเหตุ (causal signals) โดยค่าคะแนนจะผสานกับข้อมูลทางการเงินและความสัมพันธ์จาก Knowledge‑Graph เพื่อปรับการร้องขอเอกสารหรือขั้นตอนยกระดับตามความเสี่ยงจริง
- เงื่อนไขการอนุมัติอัตโนมัติ — กรณี Low‑risk สามารถอนุมัติเปิดบัญชีหรือเปลี่ยนสถานะได้อัตโนมัติ ขณะที่ Medium/High‑risk จะเข้าสู่คิวการตรวจสอบของเจ้าหน้าที่พร้อมแคชข้อมูลและเหตุผลการตัดสินใจเพื่อรองรับการตรวจสอบย้อนหลัง
- การแจ้งขอเอกสารเสริมอัตโนมัติ — ระบบสามารถส่งคำขอเอกสารหรือยืนยันตัวตนเพิ่มเติมแบบทันทีตามเหตุผลที่ LLM ให้มา ช่วยลดเวลารอคำตอบจากลูกค้าและลดจำนวนรอบการติดต่อ
สถิติประสิทธิภาพและตัวชี้วัดการทำงานแบบเรียลไทม์
การออกแบบสถาปัตยกรรมให้รองรับงานเรียลไทม์ต้องมีการวัดผลเชิงประสิทธิภาพที่ชัดเจน ระบบ LLM‑Guard ตั้งเป้าหมายและตัวชี้วัดหลักดังนี้:
- Latency ต่อเอนทิตี: เป้าหมาย <200–500 ms ต่อการประมวลผลเอนทิตีหนึ่งรายการ (รวมการสกัด embedding, retrieval และ LLM scoring ในระดับพารัลเลล/แบตช์ขนาดเล็ก)
- Throughput: รองรับการประมวลผลแบบสเกลได้ตั้งแต่หลายพันรายการต่อวัน จนถึงระดับหลายร้อยคำร้องต่อวินาทีในสภาวะใช้งานสูง (configurable เพื่อรองรับหลายหมื่นถึงแสนรายการต่อวันสำหรับธนาคารขนาดใหญ่)
- ตัวชี้วัดความถูกต้อง: ลด False‑Positive มากกว่า 50% เมื่อผสาน Knowledge‑Graph และการอนุมานเชิงสาเหตุ กับการตรวจสอบภาษาของ LLM
- ผลลัพธ์การดำเนินการ KYC: เวลาการตรวจสอบโดยรวมลดลงประมาณ 30–60% เมื่อเทียบกับเวิร์กโฟลว์ดั้งเดิมที่ขึ้นกับการตรวจสอบด้วยมือทั้งหมด
- เมตริกการดำเนินงาน: p95/p99 latency, queue depth, human review rate (ลดลงเป็นสัดส่วนที่ชัดเจน เช่น ลดจำนวนเคสที่ต้องการรีวิวด้วยมือได้ 40–70%), Mean Time To Resolution (MTTR) ของเคส KYC
การจัดการคอขวด การปรับสเกล และผลกระทบต่อธุรกิจ
เพื่อลดความล่าช้าและรองรับภาระงานสูง ระบบใช้กลยุทธ์เช่นการ caching ของ embedding, การใช้ ANN index สำหรับการค้นหาเวกเตอร์, batching/async processing, และกลไก backpressure กับ rate limiter เพื่อให้ latency ต่อเอนทิตีคงที่ภายใต้โหลดสูง นอกจากนี้ การแยกเส้นทางการตัดสินใจ (auto‑approve, conditional‑request, human‑review) ช่วยลดคอขวดที่ทีมงานต้องจัดการโดยตรง ทำให้ธนาคารสามารถเร่งการเปิดบัญชีและการอนุมัติผลิตภัณฑ์ได้เร็วขึ้น
ผลเชิงธุรกิจที่วัดได้รวมถึง: เวลาการเปิดบัญชีที่ลดลงจากหลายวันเหลือไม่กี่ชั่วโมงหรือนาทีในกรณี Low‑risk, ลดภาระงานเชิงตรวจสอบของพนักงานซึ่งช่วยให้สถาบันสามารถปรับโครงสร้างต้นทุนด้านแรงงาน และปรับปรุงประสบการณ์ลูกค้าโดยรวมที่มาพร้อมกับการตอบกลับแบบเรียลไทม์ ทั้งหมดนี้เกิดขึ้นควบคู่กับการรักษามาตรฐานการปฏิบัติตามข้อกำหนด (audit trail และ explainability ของการตัดสินใจที่ระบบบันทึกไว้) ซึ่งเป็นเงื่อนไขสำคัญสำหรับการนำไปใช้ในสภาพแวดล้อมทางการเงิน
กรณีศึกษาและผลลัพธ์จากการนำร่อง (Pilot)
กรณีศึกษาและผลลัพธ์จากการนำร่อง (Pilot)
การทดสอบนำร่องของธนาคารกับระบบ LLM‑Guard ดำเนินการกับชุดข้อมูลธุรกรรมจริงและข้อมูล KYC ของลูกค้ากลุ่มตัวอย่างขนาดกลางภายในระยะเวลา 6 เดือน ผลลัพธ์เชิงปริมาณชี้ชัดว่าแนวทางการผสาน Knowledge‑Graph เข้ากับการอนุมานเชิงสาเหตุแบบภาษาของ LLM ช่วยเพิ่มความแม่นยำของการตรวจจับและลดภาระงานของเจ้าหน้าที่อย่างมีนัยสำคัญ ทั้งในมิติของ false‑positive, recall และเวลาการดำเนินการ KYC
สรุปผลการทดสอบเชิงตัวเลขที่สำคัญได้แก่:
- อัตรา false‑positive ลดลง 52% เมื่อเปรียบเทียบกับระบบเดิมที่พึ่งพากฎเชิงสถิติและคีย์เวิร์ดเพียงอย่างเดียว
- เวลาการดำเนินการ KYC ลดลงระหว่าง 35–55% เนื่องจากระบบสามารถจัดลำดับความสำคัญและให้ข้อมูลสนับสนุนการตัดสินใจแบบเรียลไทม์แก่เจ้าหน้าที่
- อัตราการตรวจจับจริง (recall) เพิ่มขึ้น 10–20% โดยระบบสามารถจับรูปแบบการฝังรหัสเชิงภาษาและการเชื่อมโยงเครือข่ายบัญชีที่ระบบเดิมมักพลาด
ตัวอย่างเหตุการณ์จำลองที่ใช้ทดสอบความสามารถของระบบ: ในชุดทดสอบมีการใช้ข้อความคำสั้นๆ เพื่ออำพรางจุดประสงค์ของการโอน เช่น "รอบเช้า 3/7" หรือ "ส่ง AZ9" ซึ่งหากพิจารณาเพียงข้อความเดียวแบบระบบเดิมมักจะไม่ได้หมายถึงพฤติกรรมต้องสงสัย แต่เมื่อ LLM‑Guard นำข้อความดังกล่าวมาผสานกับข้อมูล Knowledge‑Graph พบว่าบัญชีต้นทางมีความสัมพันธ์แบบหลายชั้นกับบัญชีตัวกลาง (intermediary) ที่เคยถูกระบุเป็นจุดผ่านเงินในเครือข่าย และมีแบบแผนการโอนย่อยเป็นชุด (micro‑transfers) ต่อไปยังปลายทางเดียวกันภายในช่วงเวลาสั้นๆ ระบบจึงอนุมานเชิงสาเหตุว่าเป็นพฤติกรรมกระจายความเสี่ยงเพื่อฟอกเงินและยกระดับเป็นการแจ้งเตือนที่มีความเชื่อมั่นสูง
ตัวอย่างสถานการณ์โดยย่อ:
- ข้อความธุรกรรม: "ส่ง AZ9" (ข้อความสั้น ไม่มีคำต้องห้ามชัดเจน)
- ข้อมูลกราฟ: บัญชี A → บัญชี B (ตัวกลาง) → บัญชี C (ปลายทาง) — พบระยะเวลาและจำนวนโอนที่สอดคล้องกันกับรูปแบบฟอกเงิน
- ผลการอนุมาน: ระบบเชื่อมสัญญาณภาษากับโครงสร้างเครือข่ายและยืนยันสาเหตุร่วม (causal links) ส่งผลให้การแจ้งเตือนถูกจัดเป็นเหตุการณ์จริงแทน false‑positive
ผลกระทบด้านต้นทุนและการปฏิบัติงานที่พบจากการนำร่อง:
- ลดเวลาการทำงานของเจ้าหน้าที่สอบสวนลงอย่างมีนัยสำคัญ — ธนาคารรายงานการลดชั่วโมงการทำงานของทีมตรวจสอบราว 40–60% ต่อรายการที่ต้องสอบสวน เนื่องจากระบบส่งมอบบริบทที่ครอบคลุมและการจัดลำดับความสำคัญของเคส
- จำนวน SAR (Suspicious Activity Report) ที่ต้องให้เจ้าหน้าที่ตรวจสอบด้วยตนเองลดลงมากกว่า 50% สอดคล้องกับการลด false‑positive 52% ซึ่งช่วยประหยัดทรัพยากรและลดความเสี่ยงของการเหนื่อยล้าจากการตรวจสอบเคสเท็จ
- ประหยัดต้นทุนรวมด้านปฏิบัติการ (operational expenditure) จากการลดเวลา KYC และงานสอบสวน — ธนาคารประเมินว่าการลดเวลาการดำเนินการ KYC 35–55% ช่วยให้สามารถรองรับปริมาณลูกค้าที่เพิ่มขึ้นได้โดยไม่ต้องขยายทีมอย่างมีนัยสำคัญ
โดยสรุป การทดสอบนำร่องแสดงให้เห็นว่า LLM‑Guard ที่รวมความสามารถด้านภาษาของโมเดลขนาดใหญ่กับกราฟความรู้และการอนุมานเชิงสาเหตุ สามารถตรวจจับพฤติกรรมฟอกเงินเชิงภาษาได้แม่นยำขึ้น ลด false‑positive ลงกว่า 52% เพิ่ม recall ขึ้น 10–20% และลดเวลาการดำเนินการ KYC ได้ถึง 35–55% ซึ่งทั้งหมดนี้นำไปสู่การลดภาระงานของเจ้าหน้าที่และการประหยัดต้นทุนการปฏิบัติการในระดับองค์กร
ความท้าทาย ด้านความเป็นส่วนตัว กฎหมาย และการนำไปใช้จริง
ความท้าทายด้านความเป็นส่วนตัว กฎหมาย และการนำไปใช้จริง
การนำระบบ LLM‑Guard มาใช้เพื่อตรวจจับพฤติกรรมฟอกเงินเชิงภาษาแบบเรียลไทม์ แม้จะให้ผลลัพธ์ที่น่าสนใจ เช่นการลด false‑positive กว่า 50% และการเร่งกระบวนการ KYC แต่ยังมีความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมายที่ต้องวางมาตรการรองรับอย่างรัดกุม โดยเฉพาะการปฏิบัติตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ซึ่งกำหนดหลักการสำคัญ เช่น การมีฐานความชอบด้วยกฎหมาย (lawful basis) สำหรับการประมวลผล การแจ้งสิทธิ์แก่เจ้าของข้อมูล และการจำกัดระยะเวลาการเก็บรักษาข้อมูล การออกแบบระบบจึงต้องยึดหลัก data minimization และ pseudonymization/ anonymization เพื่อหลีกเลี่ยงการเก็บข้อมูลเกินความจำเป็นและลดความเสี่ยงจากการรั่วไหลของข้อมูล
อีกประเด็นสำคัญคือความต้องการด้านความโปร่งใสของโมเดล (explainability) และการมี audit trail ที่เพียงพอสำหรับการตรวจสอบภายหลัง ธนาคารต้องสามารถอธิบายเหตุผลเบื้องต้นของการแจ้งเตือนหรือการบล็อกบัญชี เช่น การระบุฟีเจอร์เชิงภาษา การอ้างอิงจาก Knowledge‑Graph และข้อสรุปเชิงสาเหตุที่นำไปสู่การตัดสินใจ โดยควรเก็บบันทึกการตัดสินใจ (decision logs) และข้อมูลการอนุมาน (inference metadata) อย่างละเอียดเพื่อรองรับการตรวจสอบจากหน่วยงานกำกับดูแล รวมถึงการรองรับสิทธิของเจ้าของข้อมูลในการขอคำชี้แจงหรือยื่นร้องเรียน
ความเสี่ยงจากการโจมตีแบบ adversarial และ bias ของโมเดลเป็นอีกข้อที่ต้องให้ความสำคัญ ระบบภาษาขนาดใหญ่เสี่ยงต่อการโจมตีทั้งแบบ prompt injection, data poisoning และการใส่ perturbation เล็กน้อยที่เปลี่ยนการอนุมานได้ นอกจากนี้ หากชุดข้อมูลฝึกไม่ครอบคลุมความหลากหลายของลูกค้า จะเกิด bias ที่ส่งผลต่อกลุ่มประชากรบางกลุ่ม (disparate impact) ซึ่งอาจนำไปสู่การปฏิบัติที่ไม่เป็นธรรมและความเสี่ยงทางกฎหมาย / ภาพลักษณ์ การทดสอบแบบ adversarial testing และการตรวจสอบ bias เชิงสถิติ (เช่นการเปรียบเทียบค่า precision/recall ข้ามกลุ่ม) จึงเป็นมาตรการที่จำเป็น
การดูแลรักษาโมเดล (model maintenance) ยังต้องจัดการกับปัญหา model drift เมื่อพฤติกรรมผู้ใช้หรือเทคนิคการฟอกเงินเปลี่ยนไป ความถี่ในการตรวจสอบและการทวนสอบโมเดลต้องเป็นไปตามมาตรฐาน เช่นการทำ periodic model validation ทุกเดือนหรือทุกไตรมาส การใช้ตัวชี้วัดเช่น Population Stability Index (PSI), KL divergence หรือการทดสอบย้อนกลับ (backtesting) เพื่อกำหนดเงื่อนไขการ retraining และการเปลี่ยนผ่านเวอร์ชันอย่างเป็นระบบ (versioning) เพื่อให้สามารถย้อนกลับได้เมื่อเกิดปัญหา
แนวทางเชิงปฏิบัติที่ควรนำไปใช้ประกอบด้วย:
- การเก็บ audit logs และ metadata — บันทึกเหตุการณ์การอนุมาน, input features ที่เกี่ยวข้อง, เวลาการตัดสินใจ และผู้ที่เข้าถึงข้อมูล เพื่อรองรับการตรวจสอบภายในและคำขอจากหน่วยงานกำกับดูแล
- Human‑in‑the‑loop — กำหนดระดับความรุนแรงของการตอบสนองอัตโนมัติ (เช่นการแจ้งเตือนเทียบกับการระงับบัญชี) โดยใช้การตรวจทานจากผู้เชี่ยวชาญสำหรับกรณีที่ระบบมีความไม่แน่นอนสูง
- มาตรการ privacy‑preserving — นำเทคนิคเช่น differential privacy เมื่อทำการวิเคราะห์เชิงสถิติ, การทำ data minimization, การเข้ารหัสข้อมูลในที่จัดเก็บและระหว่างการส่ง และการใช้ synthetic data สำหรับการทดสอบภายใน
- adversarial testing และ red‑teaming — จัดให้มีการทดสอบเชิงรุกอย่างสม่ำเสมอ เพื่อตรวจหาจุดอ่อนทั้งในระดับโมเดลและ pipeline ของข้อมูล
- periodic model validation — วางนโยบายการวัดผลเป็นระยะ (accuracy, precision, recall, false‑positive rate) และเงื่อนไขการ retraining/rollback พร้อมเอกสารประกอบผลการทดสอบ
- ความร่วมมือกับหน่วยงานกำกับดูแล — เข้าร่วม sandbox หรือปรึกษาล่วงหน้าเมื่อออกแบบนโยบายการใช้ AI, จัดเตรียมรายงานการประเมินผลและ audit trail เพื่อการรับรองและการตรวจสอบ
สรุปคือ การนำ LLM‑Guard มาใช้ในสภาพแวดล้อมทางการเงินจำเป็นต้องเดินคู่กับกรอบการกำกับดูแลและแนวปฏิบัติด้านความปลอดภัยข้อมูล การวางระบบ governance, การผสาน human‑review และการใช้เทคนิค privacy‑preserving อย่างรอบคอบ จะช่วยลดความเสี่ยงทั้งทางกฎหมายและเชิงปฏิบัติการ ขณะเดียวกันต้องยอมรับ trade‑off ระหว่างความเป็นส่วนตัวกับประสิทธิภาพของการตรวจจับ และจัดทำแผนการทดสอบรวมถึงการสื่อสารให้ชัดเจนกับหน่วยงานกำกับและผู้มีส่วนได้เสีย
บทสรุป
ระบบ LLM‑Guard ที่ธนาคารนำมาใช้ผสานการวิเคราะห์เชิงภาษาแบบเรียลไทม์กับ Knowledge‑Graph เพื่อเชื่อมโยงเอนทิตีและบริบทของข้อมูลผู้เกี่ยวข้อง พร้อมทั้งใช้องค์ความรู้จาก causal inference ในการแยกสัญญาณเชิงสาเหตุจากความสัมพันธ์ที่เป็นเพียงการร่วมเกิด (correlation) ส่งผลให้ความแม่นยำในการตรวจจับพฤติกรรมฟอกเงินเชิงภาษาดีขึ้นอย่างมีนัยสำคัญ โดยธนาคารรายงานว่าระบบช่วยลดอัตรา false‑positive ลงกว่า 50% และสามารถเร่งกระบวนการ KYC ในการยืนยันตัวตนและคัดกรองความเสี่ยงแบบเรียลไทม์ ทำให้ต้นทุนการปฏิบัติงานและภาระงานของเจ้าหน้าที่ลดลง พร้อมทั้งปรับปรุงประสบการณ์ลูกค้าในกระบวนการ onboarding
แม้ผลลัพธ์เบื้องต้นจะมีความน่าสนใจ แต่การขยายการใช้งานในวงกว้างยังต้องการการกำกับดูแลที่ชัดเจน: ธนาคารจำเป็นต้องให้ความสำคัญกับความโปร่งใสของโมเดลและการอธิบายผล (explainability), การปฏิบัติตามกฎหมายคุ้มครองข้อมูลและกฎเกณฑ์ด้านการเงิน, รวมถึงการทดสอบเชิง adversarial และการตรวจสอบความเสี่ยงด้านความปลอดภัยอย่างเข้มงวดก่อนปรับใช้ในระบบหลัก ในมุมมองอนาคต การนำ LLM‑Guard ไปใช้แบบค่อยเป็นค่อยไปพร้อมกลไก human‑in‑the‑loop, การทำมาตรฐานร่วมกับหน่วยงานกำกับดูแล และการอัปเดต Knowledge‑Graph/โมเดลอย่างต่อเนื่อง จะเป็นกุญแจสำคัญในการรักษาความน่าเชื่อถือ ลดความเสี่ยงทางกฎหมาย และต่อยอดสู่การทำงานร่วมกันระหว่างสถาบันการเงินเพื่อยกระดับการป้องกันการฟอกเงินโดยรวม



