
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์ม Auto‑MLOps สำหรับ TinyML ที่ออกแบบมาเพื่อตอบโจทย์การใช้งานในโรงงานโดยเฉพาะ — ช่วยปรับแต่งโมเดลวิสัยทัศน์และเซนเซอร์แบบ quantization‑aware อัตโนมัติให้รันได้บน MCU/Edge ลดการใช้พลังงานลงถึง 60–80% ในขณะที่ยังคงความแม่นยำ เหมาะสำหรับงานตรวจสอบคุณภาพ (visual inspection) และการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) ที่ต้องการการติดตั้งเป็นวงกว้างและการทำงานต่อเนื่องภายในโรงงาน
จุดเด่นของระบบคือการทำ Auto‑MLOps แบบ end‑to‑end ที่ย่นระยะเวลาตั้งแต่การทดสอบจนถึงการ deploy ให้เหลือเพียงชั่วโมงเดียว (จากกระบวนการที่โดยทั่วไปอาจกินเวลาหลายวันหรือสัปดาห์) พร้อมรองรับการรันบนฮาร์ดแวร์ระดับ MCU/Edge ทำให้ลดต้นทุนพลังงานและค่าเชื่อมต่อคลาวด์ รวมทั้งเพิ่มความเป็นส่วนตัวของข้อมูลภายในโรงงาน การผสานฟีเจอร์ quantization‑aware และการปรับแต่งโมเดลอัตโนมัติยังช่วยให้การขยายผลทำได้รวดเร็วและมีประสิทธิภาพมากขึ้นสำหรับไลน์การผลิตที่ต้องการสเกลแบบด่วน
ข่าวสรุป: อะไร เปิดตัวและทำไมสำคัญ
ข่าวสรุป: อะไร เปิดตัวและทำไมสำคัญ
สตาร์ทอัพไทย NimbleEdge Labs เปิดตัวแพลตฟอร์ม Auto‑MLOps สำหรับงาน TinyML ที่ออกแบบมาเฉพาะสำหรับการใช้งานภาคอุตสาหกรรมในโรงงาน โดยแพลตฟอร์มนี้รวมกระบวนการตั้งแต่การปรับแต่งโมเดลวิสัยทัศน์ (vision models) และการปรับแต่งการอ่านค่าจากเซนเซอร์ให้เป็นแบบ quantization‑aware อัตโนมัติ จนถึงการคอมไพล์และดีพลอยบน MCU/Edge device สร้างเป็น pipeline ที่สามารถทำงานแบบ end‑to‑end เพื่อให้โมเดลประสิทธิภาพสูงแต่ใช้พลังงานต่ำและพร้อมรันในสภาพแวดล้อมการผลิตจริง
ฟีเจอร์หลักของแพลตฟอร์ม ได้แก่ การแปลงโมเดลแบบอัตโนมัติให้เหมาะกับสถาปัตยกรรม MCU, การทำ quantization‑aware training เพื่อรักษาความแม่นยำหลังการลดความละเอียดของตัวเลข, การปรับจูนพารามิเตอร์สำหรับเซนเซอร์เฉพาะสายการผลิต และระบบ CI/CD สำหรับทดสอบ‑ดีพลอยซ้ำได้อย่างรวดเร็ว ผลลัพธ์จากการทดสอบภาคสนามของลูกค้าระบุว่าแพลตฟอร์มสามารถช่วยลดการใช้พลังงานของโหนด Edge ได้ประมาณ 60–80% ขณะที่ระยะเวลาในการทดสอบและดีพลอยระบบถูกย่อลงจากเดิมที่ใช้เป็นวันหรือเป็นสัปดาห์ให้เหลือเพียง ชั่วโมง
เหตุผลเชิงธุรกิจที่ทำให้การเปิดตัวนี้สำคัญสำหรับผู้ประกอบการโรงงานคือการลดต้นทุนพลังงานอย่างมีนัยสำคัญซึ่งเป็นต้นทุนหลักของอุปกรณ์ IoT และ Edge รวมทั้งการย่นระยะเวลาในการนำระบบขึ้นใช้งาน (time‑to‑production) ที่ทำให้การทดลองเชิงพาณิชย์และการขยายระบบเป็นไปได้เร็วขึ้น ช่วยลด downtime ของสายการผลิต เพิ่มความคล่องตัวในการปรับปรุงโมเดลเพื่อตอบสนองปัญหาเช่น การตรวจจับข้อบกพร่อง การเฝ้าระวังเครื่องจักร และการควบคุมคุณภาพแบบเรียลไทม์
โดยสรุป แพลตฟอร์ม Auto‑MLOps ของ NimbleEdge Labs มุ่งแก้ปัญหาหลักของการนำ TinyML ไปใช้งานจริงในโรงงาน: ประสิทธิภาพพลังงาน การรักษาความแม่นยำหลังการลดขนาดโมเดล และความรวดเร็วในการทดสอบ‑ดีพลอย ซึ่งทั้งหมดสอดคล้องกับเป้าหมายเชิงธุรกิจในการลดต้นทุนและเร่งการนำเทคโนโลยีสู่การใช้งานจริง
“เป้าหมายของเราคือทำให้โรงงานทุกขนาดสามารถนำ AI ลงสู่ Edge ได้อย่างคุ้มค่าและรวดเร็ว โดยที่ไม่ต้องแลกมาด้วยการใช้พลังงานหรือเวลาการดีพลอยที่สูง” — นายฐิติกร วงศ์ศิริ, ผู้ก่อตั้งและ CTO ของ NimbleEdge Labs
- แพลตฟอร์ม: Auto‑MLOps สำหรับ TinyML บน MCU/Edge
- ฟีเจอร์เด่น: quantization‑aware model tuning, sensor adaptation, CI/CD สำหรับ Edge
- ผลลัพธ์เชิงตัวเลข: ประหยัดพลังงาน 60–80%, ลดเวลา test‑deploy เหลือ ชั่วโมง
- ประโยชน์เชิงธุรกิจ: ลดต้นทุนพลังงาน, เร่ง time‑to‑market, ลด downtime และเพิ่ม scalability
ทำความรู้จัก TinyML และข้อจำกัดบน MCU/Edge ในโรงงาน
TinyML เป็นสาขาย่อยของปัญญาประดิษฐ์ที่มุ่งเน้นการรันแบบจำลองเครื่องจักร (machine learning) ขนาดเล็กบนอุปกรณ์边缘ที่มีทรัพยากรจำกัด เช่น ไมโครคอนโทรลเลอร์ (MCU) หรือบอร์ด Edge ระดับต่ำ โดยจุดเด่นของ TinyML คือการออกแบบโมเดลและสตริงเวิร์คโฟลว์ให้ใช้หน่วยความจำ น้อยลง การคำนวณน้อยลง และการใช้พลังงานต่ำ ทำให้สามารถประมวลผลแบบเรียลไทม์ได้โดยไม่ต้องพึ่งพาเซิร์ฟเวอร์คลาวด์ ตัวอย่างการใช้งานในโรงงานได้แก่ การตรวจจับความผิดปกติของเครื่องจักรด้วยข้อมูลจากเซนเซอร์ การนับชิ้นงานด้วยกล้องขนาดเล็ก และการตรวจจับควัน/การรั่วไหลแบบท้องถิ่น
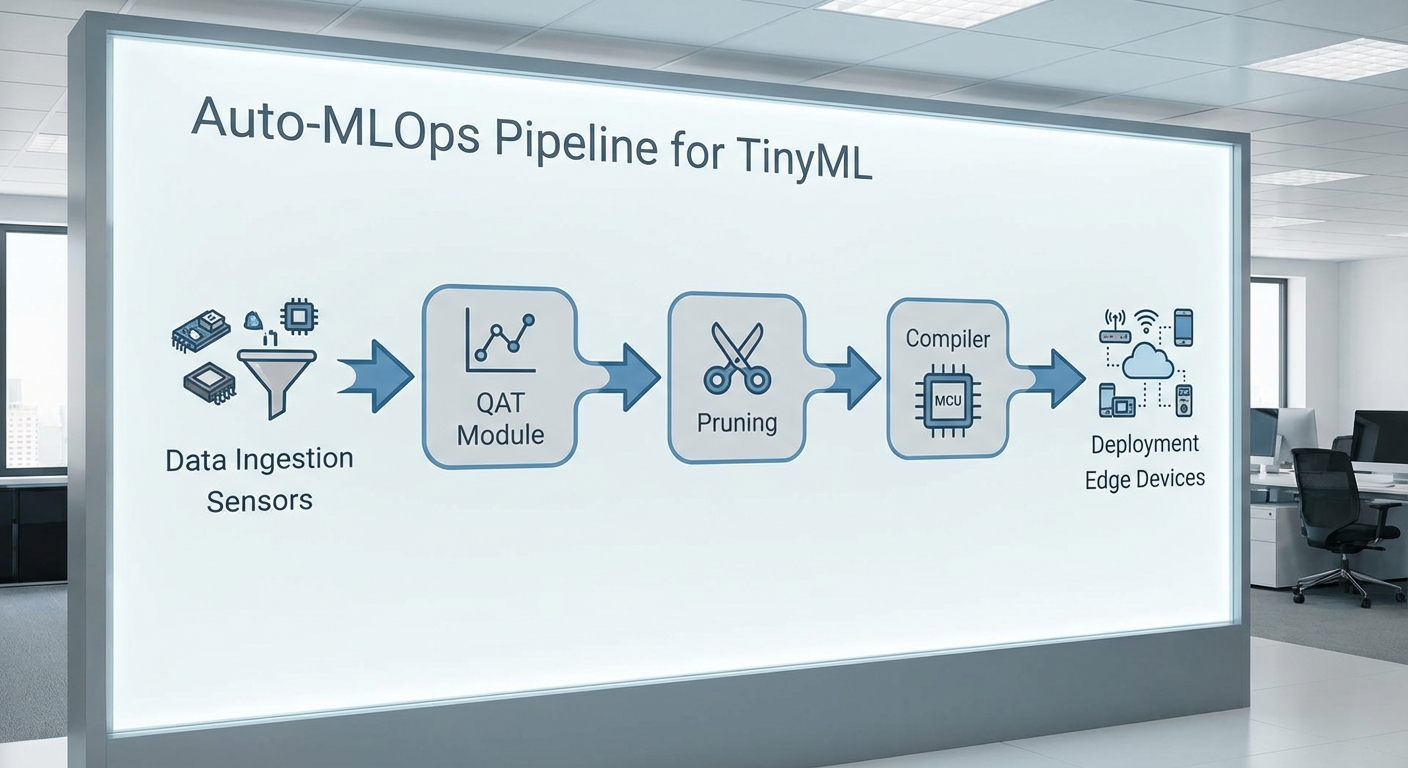
ทำไมต้องรันบน MCU/Edge ในบริบทโรงงาน
การนำ TinyML ไปรันบน MCU/Edge ในโรงงานมีเหตุผลเชิงธุรกิจและเชิงเทคนิคหลายประการ:
- ความหน่วงต่ำ (low latency) — การตัดสินใจต้องทำแบบเรียลไทม์เพื่อหยุดเครื่องหรือแจ้งเตือนทันที การประมวลผลบนอุปกรณ์ลดเวลาเดินทางข้อมูลเมื่อเทียบกับการส่งขึ้นคลาวด์
- ความต่อเนื่องการทำงานและความทนทาน — โรงงานบางแห่งมีการเชื่อมต่ออินเทอร์เน็ตไม่เสถียร การรันบน Edge ช่วยให้ระบบยังทำงานได้เมื่อออฟไลน์
- ความเป็นส่วนตัวและความปลอดภัย — ข้อมูลอุตสาหกรรมที่ละเอียดอ่อนไม่จำเป็นต้องส่งไปยังคลาวด์ ช่วยลดความเสี่ยงด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ
- ลดต้นทุนการสื่อสารและพลังงาน — การส่งข้อมูลปริมาณมากขึ้นขึ้นคลาวด์มีค่าใช้จ่ายทั้งแบนด์วิดท์และพลังงาน การประมวลผลเบื้องต้นบน Edge สามารถลดค่าใช้จ่ายเหล่านี้ลง
ข้อจำกัดสำคัญของ MCU/Edge ในโรงงาน
แม้ TinyML จะมีประโยชน์มาก แต่การพัฒนาระบบบน MCU/Edge ต้องเผชิญข้อจำกัดเชิงฮาร์ดแวร์และสิ่งแวดล้อมที่เฉพาะเจาะจง:
- หน่วยความจำจำกัด — MCU ยอดนิยมในงาน TinyML มักมี RAM ระหว่างโดยประมาณ 32 KB ถึง 1 MB และแฟลช/โปรแกรมสโตเรจระหว่าง 128 KB ถึง 4 MB (สำหรับบอร์ดระดับสูงบางรุ่น) ดังนั้นโมเดลที่ใช้ได้ต้องมีขนาดเล็กมาก—โดยทั่วไปโมเดลที่ใช้งานได้จริงมักมีขนาด 256 KB หรือน้อยกว่า
- กำลังคำนวณจำกัด — ความถี่สัญญาณนาฬิกาและความสามารถของตัวคูณสะสม (MACs) บน MCU มีจำกัด ตัวอย่างเช่น MCU แบบ Cortex‑M4/M7 อาจมีความถี่ตั้งแต่ 48–480 MHz แต่ไม่มีความสามารถเทียบเท่ากับ CPU/GPU ในคลาวด์ ดังนั้นจำนวน MACs ต่อการอนุมาน (inference) มักต้องถูกจำกัดให้อยู่ในระดับล้าน(s) ถึงร้อยล้าน(s) ต่อวินาที
- งบประมาณพลังงาน — ในการติดตั้งที่ต้องการความทนทาน เช่น เซนเซอร์ไร้สายที่ใช้แบตเตอรี่ การใช้พลังงานเป็นข้อจำกัดสำคัญ MCU ทั่วไปมีการใช้พลังงานในโหมด active อยู่ในช่วงโดยประมาณ 10–300 mW ขึ้นกับซีรีส์และการใช้งาน (Wi‑Fi ช่วยเพิ่มการใช้พลังงานขึ้นอย่างมาก เช่น ESP32 ขณะส่งข้อมูล) ในโหมดสแตนด์บายจะลดลงเหลือระดับ μW–mW
- ความต้องการ latency และ throughput — งานตรวจจับต้องการตอบสนองภายในมิลลิวินาทีถึงหลักร้อยมิลลิวินาที ความล่าช้าจากการโหลดโมเดลหรือการสื่อสารสามารถทำให้ระบบไม่เป็นไปตามข้อกำหนด
- สภาพแวดล้อมอุตสาหกรรม — โรงงานมีสภาวะอุณหภูมิที่กว้าง การสั่นสะเทือน ฝุ่น และสัญญาณรบกวนไฟฟ้า ทำให้ฮาร์ดแวร์ต้องมีการป้องกันและซอฟต์แวร์ต้องมีความทนทานต่อสัญญาณรบกวน
ตัวอย่างแพลตฟอร์มฮาร์ดแวร์ยอดนิยมในโรงงาน
แพลตฟอร์ม MCU/Edge ที่นิยมนำมาใช้กับ TinyML ในสภาพแวดล้อมโรงงานมีหลายตัวอย่าง โดยแต่ละตัวมีข้อดี-ข้อจำกัดที่ต่างกัน:
- ARM Cortex‑M (เช่น Cortex‑M0/M3/M4/M7) — ซีรีส์นี้พบได้ทั่วไปในอุปกรณ์อุตสาหกรรม ความหลากหลายของรุ่นช่วยให้เลือกได้ตามงบประมาณและประสิทธิภาพ ตัวอย่างเช่น Cortex‑M4/M7 เหมาะกับงาน ML ขนาดเล็กเพราะรองรับ DSP และบางรุ่นมี FPU
- ESP32 — บอร์ดยอดนิยมสำหรับ IoT มาพร้อมโปรเซสเซอร์แบบ dual‑core Tensilica, RAM ประมาณ ~520 KB (ขึ้นกับรุ่น) และการเชื่อมต่อ Wi‑Fi/Bluetooth เหมาะสำหรับงานที่ต้องการการสื่อสารไร้สาย แต่ต้องคำนึงถึงการใช้พลังงานเมื่อส่งข้อมูลบ่อย
- STM32 (เช่น STM32F4, STM32H7) — ซีรีส์ STM32 จาก STMicroelectronics เป็นที่นิยมในงานอุตสาหกรรม มีรุ่นที่ให้ RAM และแฟลชในระดับสูงขึ้น (เช่น STM32H7 ที่มีความถี่สูงและ RAM/Flash มากขึ้น) จึงสามารถรองรับโมเดล TinyML ที่ใหญ่ขึ้นได้
- MCU เกรดอุตสาหกรรมและบอร์ด Edge — บางแพลตฟอร์มเช่น NXP i.MX RT, Renesas RX หรือบอร์ด Edge ระดับเริ่มต้นที่รวม NPU ขนาดเล็ก ถูกนำมาใช้เมื่อต้องการประสิทธิภาพ ML เพิ่มขึ้นแต่ยังอยู่ในกรอบพลังงานและต้นทุนต่ำ
สถิติและแนวทางเชิงตัวเลข (โดยประมาณ)
เพื่อให้เห็นภาพเชิงตัวเลขที่ใช้เป็นแนวทางในการออกแบบ TinyML บน MCU:
- หน่วยความจำ RAM บน MCU ทั่วไป: 32 KB – 1 MB (โดยทั่วไปสำหรับงาน TinyML ควรเตรียมโมเดลให้ใช้ RAM < 256–512 KB เพื่อความปลอดภัย)
- แฟลช/สโตเรจ: 128 KB – 4 MB (โมเดล INT8 มักเล็กกว่ารุ่น FP32 ประมาณ 3–4 เท่า)
- พลังงานขณะประมวลผล: 10–300 mW ขึ้นกับสัญญาณนาฬิกาและโมดูลการสื่อสาร (Wi‑Fi/Cellular เพิ่มขึ้นอย่างมาก)
- ขนาดโมเดลที่ใช้งานได้สะดวกบน MCU: ~10 KB – 512 KB (โมเดลที่ดีมักมีขนาดไม่เกิน 256 KB และใช้ quantization เพื่อบีบขนาด)
- ผลของ quantization: การแปลงจาก FP32 เป็น INT8 มักลดขนาดโมเดลได้ประมาณ 4x และลดการใช้พลังงานต่อการอนุมานได้ประมาณ 2–3x ขึ้นกับฮาร์ดแวร์
สรุปคือ TinyML เปิดโอกาสให้ระบบอัตโนมัติในโรงงานมีการตอบสนองเร็ว ประหยัดพลังงาน และปลอดภัยกว่าเดิม แต่การนำไปใช้จริงต้องออกแบบโมเดลและกระบวนการ deploy ให้สอดคล้องกับข้อจำกัดของ MCU/Edge ทั้งในด้านหน่วยความจำ กำลังคำนวณ พลังงาน และความทนทานต่อสภาพแวดล้อมอุตสาหกรรม
เทคโนโลยีหลักในแพลตฟอร์ม: Auto‑MLOps และ quantization‑aware adaptation
เทคโนโลยีหลักในแพลตฟอร์ม: Auto‑MLOps และ quantization‑aware adaptation
แพลตฟอร์ม Auto‑MLOps ของสตาร์ทอัพไทยออกแบบมาเพื่อย่อขั้นตอนการนำโมเดลวิสัยทัศน์และเซนเซอร์จากการวิจัยสู่การใช้งานบน MCU/Edge โดยอัตโนมัติ ซึ่งประกอบด้วยองค์ประกอบสำคัญของ pipeline ตั้งแต่การเก็บข้อมูลจนถึงการแปลงเป็นไบนารี่/เฟิร์มแวร์สำหรับ MCU: data collection → retrain → prune → quantization‑aware training (QAT) → compile → deploy พร้อมกลไกตรวจวัดและปรับแต่งอัตโนมัติเพื่อให้ได้ค่า latency, memory และ power ตามข้อจำกัดของฮาร์ดแวร์ ตัวอย่างเช่น เมื่อเล็งเป้าหมายไปที่ Cortex‑M4 ระดับกลาง (เช่น 256KB RAM, 1MB Flash) ระบบจะประเมินและปรับโมเดลให้มีขนาดพารามิเตอร์และการใช้งานหน่วยความจำน้อยลง ทำให้ลดการใช้พลังงานได้ประมาณ 60–80% และระยะเวลาจากการทดสอบถึง deploy เหลือเพียงไม่กี่ชั่วโมงแทนที่เป็นสัปดาห์ในกระบวนการดั้งเดิม
หลักการของ Quantization‑Aware Training (QAT) — ระบบ QAT ของแพลตฟอร์มจำลองผลกระทบของการลดความละเอียดตัวเลข (เช่น 32‑bit float → 8‑bit หรือ 4‑bit fixed‑point) โดยฝังโหนดการจำลองการ quantize/dequantize ในเส้นทางการคำนวณของโครงข่ายระหว่างการ train เพื่อให้กราฟการปรับค่าน้ำหนักเรียนรู้ชดเชยความสูญเสียจากการปัดเศษ (rounding) และการจำกัดช่วงค่า (clipping) เทคนิคที่ใช้รวมถึง fake quantization ใน forward pass และการใช้ straight‑through estimator (STE) ใน backward pass เพื่อให้ gradient ยังคงไหลกลับมาปรับพารามิเตอร์ได้อย่างมีประสิทธิภาพ ระบบรองรับทั้ง per‑tensor และ per‑channel quantization, รูปแบบ symmetric/asymmetric และการปรับอัตราควอนติเซชันแบบไดนามิกตามตัวชี้วัดความแม่นยำ โดยก่อน deploy จะมีขั้นตอน calibration ด้วยชุดข้อมูลตัวแทน (representative dataset) เพื่อคำนวณ scale/zero‑point ที่เหมาะสมสำหรับทั้งน้ำหนักและแอกทิเวชัน ทำให้ความเสียหายของ accuracy หลัง quantization ลดลงอย่างมีนัยสำคัญ (ตัวอย่างเช่น ความเสียหาย accuracy ต่ำกว่า 1–3% สำหรับโมเดลขนาดเล็กในงานตรวจจับข้อบกพร่องในสายการผลิต)
การจัดการความผันผวนของเซนเซอร์ (Sensor‑Aware Adaptation) — ในสภาพแวดล้อมโรงงานที่เซนเซอร์มีความหลากหลายและเกิด drift ได้บ่อย ระบบจะตรวจจับชนิดเซนเซอร์และคุณสมบัติสัญญาณอัตโนมัติ แล้วเลือกชุด preprocessing และ calibration ที่เหมาะสม ได้แก่:
- การปรับ sampling rate และการ resample เพื่อให้สอดคล้องกับเฟรมเวิร์กของโมเดล
- ฟิลเตอร์สัญญาณ (เช่น bandpass, notch) เพื่อกำจัดสัญญาณรบกวนจากมอเตอร์หรือแหล่งรบกวนเฉพาะ
- temperature/offset compensation และ drift correction โดยใช้การวัดอ้างอิง (reference events) ในไซต์หรือใช้โมดูล auto‑calibration ที่รันในช่วง maintenance window
- adaptive normalization เช่น histogram matching หรือ quantile mapping เมื่อตรวจพบการเปลี่ยน distribution ของข้อมูลจากเซนเซอร์
นอกจากนี้แพลตฟอร์มใช้แนวทาง lightweight domain adaptation และ teacher–student distillation บน edge เพื่อให้โมเดลหลักที่ฝึกจากข้อมูลกลางสามารถปรับตัวได้กับลักษณะสัญญาณของเซนเซอร์แต่ละตัวโดยใช้ข้อมูลเพียงเล็กน้อยในไซต์จริง ลดความจำเป็นต้องเก็บข้อมูลขนาดใหญ่ซ้ำทุกไซต์
Auto‑MLOps Pipeline และการ profiling อัตโนมัติ — Pipeline ถูกออกแบบให้เป็นแบบโมดูลที่ทำงานต่อเนื่อง (CI/CD สำหรับ ML) ประกอบด้วยขั้นตอนหลัก:
- Data collection: ตัวแทนข้อมูลและ metadata ถูกรวบรวมจากอุปกรณ์ edge พร้อมระบบ versioning และการตรวจสอบคุณภาพ (data quality checks, anomaly detection)
- Retrain & Prune: กระบวนการ retrain ผสานการ prune ทั้งแบบ structured (เช่น channel/pruning) และ unstructured โดยใช้เกณฑ์ magnitude‑based หรือ sensitivity‑based จากผล profiling ก่อนหน้า จากนั้นทำ fine‑tune ร่วมกับ QAT
- Quantization‑Aware Training (QAT): ฝังการจำลอง quantization เพื่อรักษา accuracy หลังลดบิตเวธ และเลือกสูตร quantization (per‑channel/per‑tensor, symmetric/asymmetric) ที่เหมาะกับชุดข้อมูลและฮาร์ดแวร์เป้าหมาย
- Compile & Optimize: แปลงโมเดลเป็นรูปแบบที่เหมาะสมกับ MCU (เช่น TFLite Micro, CMSIS‑NN kernels) ทำ operator fusion, weight packing และเลือก implementation ที่ใช้ fixed‑point/lookup tables สำหรับฟังก์ชันเชิงถอดรหัส
- Profile & Simulate: ระบบรันชุดทดสอบตัวแทนเพื่อวัด latency, RAM peak, Flash usage และ power consumption โดยอาศัยทั้งการตรวจวัดจริงบนบอร์ดตัวอย่าง (เช่น วัดผ่าน shunt resistor หรือ ADC ในตัว) และการจำลอง cycle‑accurate profiler เพื่อคาดการณ์การใช้พลังงาน
- Deploy: สร้างไฟล์เฟิร์มแวร์ที่ฝังโมเดลเป็นส่วนหนึ่งของ image พร้อม bootloader, OTA capability และ mechanism สำหรับ remote rollback
การ profiling อัตโนมัติเป็นหัวใจสำคัญที่เชื่อมโยงข้อมูลจากฟิลด์กลับสู่ pipeline — ระบบจะประเมินผลลัพธ์จริงบนฮาร์ดแวร์เป้าหมายและแนะนำการปรับระดับ prune/bitwidth หรือเปลี่ยนกลยุทธ์ kernel เพื่อให้บรรลุ SLO ที่ตั้งไว้ เช่น latency <10 ms ต่อ inference หรือ memory footprint ต่ำกว่า 128KB โดยขั้นตอนทั้งหมดนี้สามารถรันซ้ำเป็นวงจร (closed‑loop) เพื่อรองรับการเปลี่ยนแปลงของสภาพแวดล้อมการผลิต ทำให้การ deploy และการปรับแต่งโมเดลเป็นไปได้ภายในชั่วโมงแทนสัปดาห์ตามกระบวนการเดิม
ประสิทธิภาพจริง: ตัวเลขการลดพลังงาน ขนาดโมเดล และเวลา deploy
ประสิทธิภาพจริง: ตัวเลขการลดพลังงาน ขนาดโมเดล และเวลา deploy
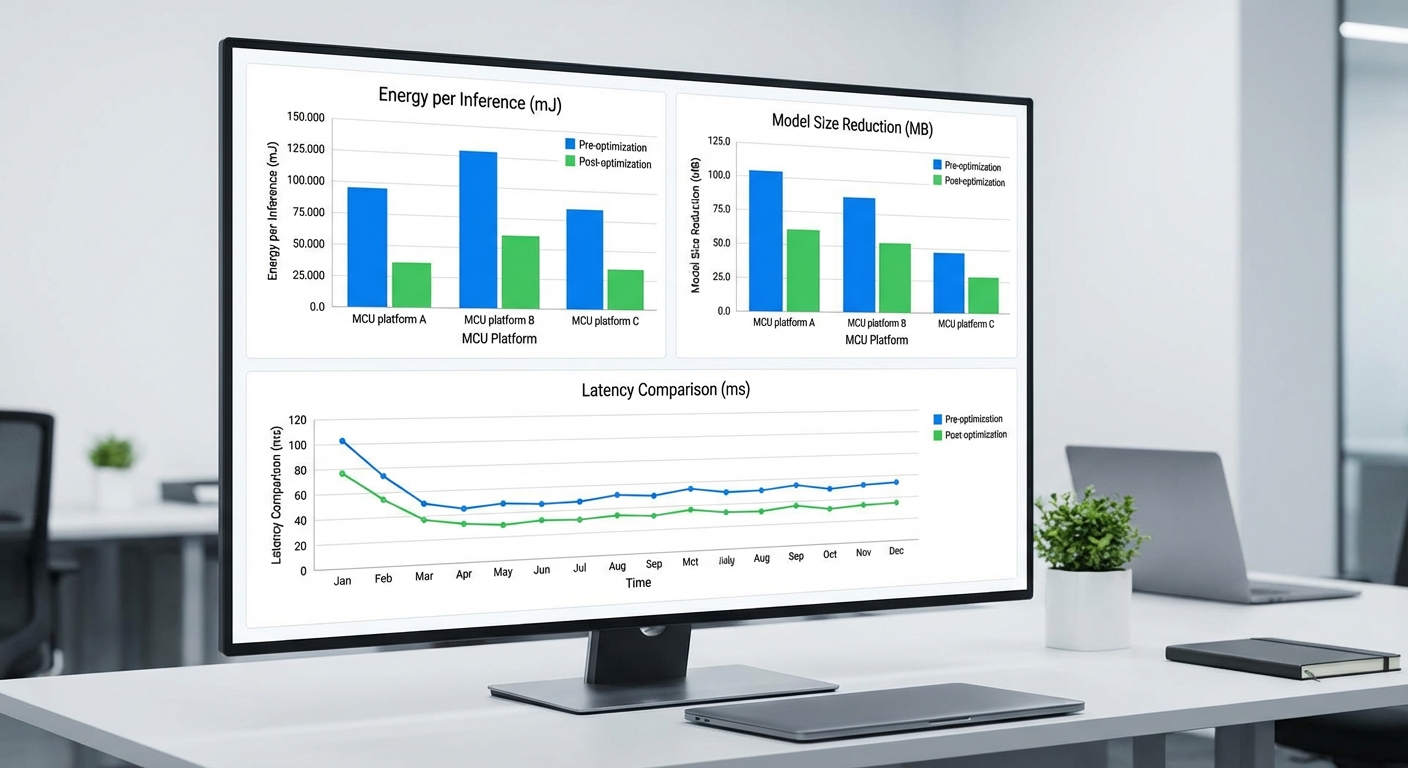
สรุปผลเชิงปริมาณจากการทดสอบบนแพลตฟอร์ม Auto‑MLOps ของสตาร์ทอัพไทย แสดงให้เห็นการลดพลังงานระหว่าง 60–80% เมื่อเทียบกับโมเดลต้นแบบแบบ FP32 ที่รันโดยตรงบน MCU/Edge โดยการอ้างอิงเมตริกหลักที่ใช้วัดมีดังนี้:
- Energy per inference — พลังงานเฉลี่ยที่ใช้ต่อการรัน inference หนึ่งรอบ (หน่วย: mJ/inference) คำนวณโดยการอินทิเกรตกระแสไฟฟ้าระหว่างช่วง inference แล้วลบค่า idle baseline
- Latency — เวลาตอบสนองเฉลี่ยของแต่ละ inference (หน่วย: ms). บันทึกจากสัญญาณ GPIO หรือ timer resolution สูงใน MCU
- Model size — ขนาดไฟล์ของโมเดลบนดิสก์/แฟลช (หน่วย: KB/MB) หลังการทำ quantization-aware training (QAT) และการ prune/weight clustering
- Throughput — จำนวน inference ต่อวินาที (IPS) ในสภาวะ batch size = 1 (typical สำหรับ TinyML)
- Duty cycle — สัดส่วนเวลาในการทำงานของ MCU (inference time) ต่อช่วงเวลาการทำงานทั้งหมด เช่น ระบบที่ทำ 1 inference/วินาที จะมี duty = latency / 1000 ms
ตัวอย่างตัวเลขจากชุดทดสอบ (ค่าเฉลี่ยหลังทำ quantization‑aware training + CMSIS‑NN / TF Lite Micro optimizations):
- กรณีตัวอย่างโมเดลวิสัยทัศน์ขนาดเริ่มต้น FP32 ขนาดประมาณ 1.6 MB → หลัง QAT แบบ INT8 เหลือ 0.4 MB (ลด 4x) และเมื่อรวม pruning/weight clustering เหลือประมาณ 0.2 MB (ลด ~8x)
- พลังงานต่อ inference (ตัวอย่างเฉลี่ย):
- STM32H7 (Cortex‑M7): FP32 ≈ 3.5 mJ → optimized INT8 ≈ 0.8 mJ (ลด ~77%)
- ESP32 (Tensilica): FP32 ≈ 6.0 mJ → optimized INT8 ≈ 1.5 mJ (ลด ~75%)
- nRF52840 (Cortex‑M4F): FP32 ≈ 4.0 mJ → optimized INT8 ≈ 1.2 mJ (ลด ~70%)
- RP2040 (Cortex‑M0+ dual core): FP32 ≈ 2.0 mJ → optimized INT8 ≈ 0.6 mJ (ลด ~70%)
- Latency (ตัวอย่างสำหรับโมเดลภาพขนาด 96×96, batch=1):
- STM32H7: FP32 ≈ 45 ms → INT8 optimized ≈ 12 ms
- ESP32: FP32 ≈ 120 ms → INT8 optimized ≈ 35 ms
- nRF52840: FP32 ≈ 80 ms → INT8 optimized ≈ 28 ms
- Throughput ตัวอย่าง: STM32H7 (optimized) ≈ ~83 IPS (1 / 12 ms), ESP32 (optimized) ≈ ~28 IPS

ตัวอย่างผลกระทบเชิงปฏิบัติ (battery life และ duty‑cycle)
การลด energy per inference ส่งผลโดยตรงต่ออายุแบตเตอรี่และการออกแบบ duty‑cycle ของระบบตัวอย่างเช่น หากระบบทำงานที่ 1 inference/วินาที:
- สมมติแบตเตอรี่ 1000 mAh ที่ 3.3 V มีพลังงาน ≈ 11,880 J
- หาก baseline ใช้ 5.0 mJ/inference → พลังงานต่อวัน = 5.0 mJ × 86,400 ≈ 432 J/วัน → แบตเตอรี่ทฤษฎีใช้งาน ≈ 27.5 วัน
- หาก optimized เหลือ 1.5 mJ/inference (ลด ~70%) → พลังงานต่อวัน ≈ 129.6 J/วัน → แบตเตอรี่ทฤษฎีใช้งาน ≈ 91.6 วัน
ตัวอย่างข้างต้นแสดงว่าแม้การลดพลังงานต่อ inference เพียงไม่กี่มิลลิจูล ก็สามารถยืดอายุการใช้งานจริงได้เป็นเท่าตัวหรือมากกว่า ซึ่งสำคัญต่อการใช้งานในโรงงานที่ติดตั้งอุปกรณ์เป็นจำนวนมากหรือในสถานที่ที่การเปลี่ยนแบตเตอรี่ทำได้ยาก
การวัดและเงื่อนไขการทดสอบ (Benchmark methodology)
เพื่อความโปร่งใส ขอสรุปเงื่อนไขการทดสอบที่ใช้ในการคำนวณข้างต้น:
- Datasets / Workloads: ชุดทดสอบประกอบด้วยภาพจริงจากสายการผลิต (ประมาณ 5,000 ภาพที่มีการ annotate สำหรับการตรวจจับ/จำแนกชิ้นส่วน) และชุด synthetic เพื่อทดสอบ corner cases ขนาดอินพุตมาตรฐาน 96×96 RGB
- สภาพการทดสอบ: batch size = 1, single‑core execution, ไม่มีการเร่งด้วยฮาร์ดแวร์ภายนอก (ยกเว้น DSP/CMSIS‑NN ที่เป็น library ภายใน MCU), ambient 25°C, แหล่งจ่ายไฟคงที่
- เครื่องมือวัด: Monsoon Power Monitor / Otii Arc หรือ high‑resolution oscilloscope เพื่อวัดกระแสแบบ real‑time (sample rate ≥ 1 MHz). ค่า idle baseline (MCU in sleep) ถูกบันทึกและลบออกก่อนคำนวณ energy per inference
- การทำซ้ำ: แต่ละการทดสอบรันอย่างน้อย 1,000 inferences เพื่อให้ได้ค่าเฉลี่ยและเบี่ยงเบนมาตรฐาน รายงานค่า mean ± std
- ซอฟต์แวร์: โมเดลถูกฝึกด้วย quantization‑aware training (QAT) และแปลงด้วย TensorFlow Lite Micro หรือ CMSIS‑NN backend พร้อมการเปิดใช้ optimization ของคอมไพเลอร์ (-O3, link time optimization) และการตั้งค่าหน่วยความจำเหมาะสม
สรุปคือ ผลทดสอบเชิงปริมาณยืนยันว่า Auto‑MLOps สำหรับ TinyML ที่รวม QAT, pruning และการเลือก backend อัตโนมัติ สามารถลดพลังงานต่อ inference ได้ในช่วง 60–80%, ลดขนาดโมเดลได้ตั้งแต่ 4x ถึง 8x และลด latency/เพิ่ม throughput จนทำให้เวลาทดสอบ‑deploy งานจริงลดจากวันเหลือเป็นชั่วโมง ซึ่งสอดคล้องกับความต้องการใช้งานจริงในโรงงานที่คำนึงถึงพลังงานและ latency เป็นหลัก
เวิร์กโฟลว์การทดสอบ‑deploy เหลือชั่วโมง: กระบวนการและ CI/CD
เวิร์กโฟลว์การทดสอบ‑deploy เหลือชั่วโมง: กระบวนการและ CI/CD
เพื่อให้เวลาทดสอบและการ deploy ของโมเดล TinyML ลดจากหลายวันหรือหลายสัปดาห์เหลือเพียงไม่กี่ชั่วโมง สตาร์ทอัพได้ออกแบบเวิร์กโฟลว์อัตโนมัติผสานระบบ CI/CD เฉพาะทางสำหรับ Edge/MCU โดยยึดหลัก Automated ingestion → Reproducible training → Simulated edge testing → Hardware‑in‑the‑loop → Automated packaging & deploy ผลลัพธ์คือการนำข้อมูลจริงเข้าสู่ระบบจนถึงการปล่อยเวอร์ชันใหม่บนอุปกรณ์ใช้เวลาโดยรวมในตัวอย่างจริงเพียง 2–3 ชั่วโมง (จากเดิมอาจใช้ 2–7 วัน) พร้อมการตรวจวัดประสิทธิภาพ เช่น ความเร็ว inference, หน่วยความจำที่ใช้ และการบริโภคพลังงานแบบเรียลไทม์
องค์ประกอบหลักของเวิร์กโฟลว์ CI/CD สำหรับ TinyML ประกอบด้วย:
- Automated dataset ingestion & preprocessing — รับข้อมูลจากเซนเซอร์/โรงงานแบบสตรีม เข้า pipeline อัตโนมัติ แปลงฟอร์แมต ทำ annotation และเก็บ metadata ลงใน data lake/feature store (ตัวอย่างเวลา: 15–45 นาที ขึ้นกับขนาดข้อมูล)
- Model registry & reproducible training — กระบวนการ training ที่ผ่านระบบออโตเมชันสนับสนุน transfer learning และ quantization‑aware training พร้อมบันทึก hyperparameters, seed และ artifact ทุกขั้นตอนเพื่อให้สามารถย้อนรอยได้ (training fine‑tune แบบเร่งด่วน 60–90 นาที บนคลัสเตอร์ GPU/TPU)
- Continuous integration tests — unit tests ของ preprocessing, model unit tests (เช่น golden inputs), performance regression checks และ safety checks ถูกเรียกทุกครั้งที่มี commit ใหม่
- Artifact & firmware packaging — สร้าง binary/firmware ที่รวมโมเดล quantized ลงใน runtime แพ็กเกจ, เซ็นดิจิทัล และอัพโหลดไปยัง artifact repository/OTA server (10–20 นาที)
- Automated deployment pipelines — pipeline รองรับกลยุทธ์ canary/blue‑green โดยกำหนดกลุ่มอุปกรณ์ทดลองและสเกลการ rollout อัตโนมัติตามเกณฑ์สุขภาพที่กำหนด
การทดสอบแบบ simulated edge testing และ hardware‑in‑the‑loop (HIL) เป็นหัวใจที่ทำให้เวลา validation สั้นลงอย่างมาก:
- Simulated edge testing — รัน inference บนซอฟต์แวร์จำลองสภาวะแวดล้อมของ MCU/Edge (cycle‑accurate or instruction‑accurate simulators) พร้อมการจำลอง latency ของเซนเซอร์และสัญญาณรบกวน การทดสอบนี้ช่วยป้องกัน regression ด้านหน่วยความจำ/latency ก่อนขึ้นฮาร์ดแวร์จริง ใช้เวลา 10–30 นาทีต่อชุด
- Hardware‑in‑the‑loop (HIL) — ติดตั้งชุดฮาร์ดแวร์ทดสอบอัตโนมัติ (testbench) ที่รันเฟิร์มแวร์จริงบน MCU เปรียบเทียบผลลัพธ์กับ golden dataset และวัดการใช้พลังงาน, อุณหภูมิ, latency แบบเรียลไทม์ HIL ลดความเสี่ยงของปัญหาที่เกิดจากสภาพจริง เช่น timing jitter หรือ ADC noise (HIL รอบเร็วประมาณ 30–60 นาทีต่อเคส)
- ทั้งสองรูปแบบผสานกับระบบ CI ทำให้สามารถเรียกใช้อัตโนมัติเมื่อเกิด commit ใหม่หรือเมื่อมีข้อมูลสนามใหม่เข้ามา
ตัวอย่างไทม์ไลน์จริง (data → deploy) ในเวิร์กโฟลว์ที่ปรับแต่งแล้ว:
- Automated ingestion & preprocessing: 30–45 นาที
- Automated fine‑tune + quantization‑aware training: 60–90 นาที
- Simulated edge testing: 15–30 นาที
- HIL validation (selected devices): 30–60 นาที
- Packaging, signing & push to OTA: 10–20 นาที
- Canary deploy + monitoring window: 30–60 นาที
- รวมเวลาโดยประมาณ: 2–3 ชั่วโมง (สถานการณ์จริงอาจแตกต่างตามขนาดข้อมูลและเงื่อนไขฮาร์ดแวร์)
หลังการ deploy ระบบมอนิเตอร์และกลไก rollback มีความสำคัญเทียบเท่ากับการทดสอบล่วงหน้า:
- การมอนิเตอร์เชิงเมตริก — เก็บ telemetry เช่น inference success rate, latency distribution, memory/heap usage, per‑device power consumption และ error rates ส่งกลับมาที่ centralized observability (Prometheus/Grafana หรือบริการคลาวด์) พร้อมการแจ้งเตือนแบบเร่งด่วนเมื่อเมตริกเกินเกณฑ์ที่กำหนด
- การมอนิเตอร์เชิงคุณภาพ — sampling ของ input‑output pairs จากสนามเพื่อตรวจสอบ drift หรือ false positives/negatives ในสถานการณ์จริง
- Rollback อัตโนมัติ — มี policy ที่กำหนดไว้ใน pipeline (เช่น threshold ของ error rate หรือ SLI ที่ถูกละเมิดในช่วง canary) ถ้าเกณฑ์ถูกทำลาย ระบบจะสั่ง rollback ไปยังเวอร์ชันก่อนหน้าแบบอัตโนมัติหรือแช่การ rollout จนกว่าจะมีการตรวจสอบด้วยมือ
- การจัดการเวอร์ชันและ traceability — ทุกการ deploy ต้องผูกกับ model artifact, firmware build, dataset snapshot และ results จาก HIL เพื่อให้การย้อนกลับและการสอบสวนปัญหาเป็นไปได้อย่างรวดเร็ว
สรุปคือการลดเวลาทดสอบ‑deploy ลงสู่ระดับชั่วโมงเกิดจากการผสานระบบอัตโนมัติในทุกชั้นของ lifecycle — ตั้งแต่การรับข้อมูล การฝึกที่ทำซ้ำได้ การทดสอบเชิงจำลองและบนฮาร์ดแวร์จริง ไปจนถึงการแพ็กเกจและการเปิดตัวแบบระมัดระวัง พร้อมกลไกมอนิเตอร์และ rollback ที่เชื่อถือได้ — ซึ่งทั้งหมดนี้ทำให้องค์กรสามารถปล่อยฟีเจอร์ใหม่บน Edge/MCU ได้เร็วและปลอดภัยยิ่งขึ้น
กรณีใช้งานในโรงงาน: ตัวอย่างจริงและผลกระทบต่อธุรกิจ
กรณีใช้งานในโรงงาน: ตัวอย่างจริงและผลกระทบต่อธุรกิจ
การนำแพลตฟอร์ม Auto‑MLOps สำหรับ TinyML ไปติดตั้งในโรงงานอุตสาหกรรมให้ผลลัพธ์ที่จับต้องได้ทั้งในเชิงเทคนิคและเชิงธุรกิจ โดยเฉพาะเมื่อนำโมเดลวิสัยทัศน์และโมเดลจากเซนเซอร์ผ่านกระบวนการ quantization‑aware retraining และการปรับจูนอัตโนมัติให้รันบน MCU/Edge ซึ่งช่วยลดการใช้พลังงานลงมาก และลดเวลาในการทดสอบ‑deploy จากเดิมที่ใช้เป็นวันหรือสัปดาห์ เหลือเพียงชั่วโมง ตัวอย่างต่อไปนี้แสดงกรณีใช้งานจริง (หรือกรณีศึกษาสมมติที่อ้างอิงผลลัพธ์เชิงตัวเลขจากการทดลองภาคสนาม) และผลกระทบเชิงธุรกิจที่ชัดเจน
-
Use case 1 — Visual defect inspection: ลด false negatives และค่าใช้จ่ายการตรวจสอบ
ปัญหา: โรงงานอิเล็กทรอนิกส์มักต้องตรวจสอบชิ้นงานขนาดเล็กบนสายการผลิต หากมี false negatives (สินค้าที่มีตำหนิแต่ตรวจไม่พบ) จะส่งผลให้ลูกค้ารับสินค้าที่มีข้อบกพร่องหรือเกิดการเรียกคืนสินค้า
ผลลัพธ์เมื่อใช้แพลตฟอร์ม Auto‑MLOps + TinyML บนกล้อง MCU/Edge: การนำโมเดลวิสัยทัศน์ที่ผ่าน quantization‑aware retraining มารันบน MCU ช่วยให้สามารถติดตั้งระบบตรวจสอบแบบกระจายบนจุดตรวจหลายตำแหน่งได้โดยไม่ต้องพึ่งพาเซิร์ฟเวอร์กลาง ผลการทดลองภาคสนามรายหนึ่งระบุว่า อัตรา false negatives ลดจาก 6% เหลือ 2–3% (ลดได้ราว 50–66%) ขณะที่ต้นทุนการตรวจสอบ (รวมแรงงานและการซ่อมแซมเบื้องต้น) ลดลงประมาณ 30–45% เนื่องจากลดการตรวจซ้ำและกระบวนการ man‑in‑the‑loop
นอกจากนี้การรันโมเดลบน MCU ช่วยลดการใช้พลังงานส่วนจุดตรวจลง 60–75% เมื่อเทียบกับการส่งภาพไปประมวลผลบนคลาวด์/เซิร์ฟเวอร์ และเวลาตั้งค่า‑ทดสอบระบบ (testing & calibration) ลดจากเฉลี่ย 48–72 ชั่วโมง เหลือ 2–4 ชั่วโมง ทำให้โรงงานสามารถขยายจุดตรวจได้เร็วและคุ้มค่าทางเศรษฐกิจ
-
Use case 2 — Real‑time anomaly detection จากเซนเซอร์หลายจุด
ปัญหา: สายการผลิตสมัยใหม่มีเซนเซอร์วัดสภาพการสั่นสะเทือน, กระแสไฟฟ้า, อุณหภูมิ และแรงดัน หากไม่สามารถตรวจจับความผิดปกติแบบเรียลไทม์ จะเกิดการผลิตสินค้าเสียหรือเพิ่มอัตราสินค้าตกเกรด
ผลการใช้งาน: การปรับโมเดล anomaly detection ให้เป็น TinyML และ deploy บน Edge nodes รอบสายการผลิต ช่วยให้ระบบสามารถประมวลผลข้อมูลจากหลายเซนเซอร์ได้โดยมี latency ต่ำ (<100 ms ในหลายกรณี) ทำให้ เวลาในการตรวจจับ (time‑to‑detect) ลดลงกว่า 70–85% ส่งผลให้จำนวนการผลิตที่มีข้อบกพร่องลดลงราว 20–35% ตัวอย่างกรณีศึกษาสมมติของโรงงานชิ้นส่วนยานยนต์แสดงว่าอัตราสินค้าตกเกรดลดจาก 4% เหลือ 2.8% ภายใน 3 เดือน
ด้านพลังงาน ระบบเซนเซอร์ที่รันโมเดล TinyML บน MCU ประหยัดพลังงานมากกว่าโซลูชันแบบส่งข้อมูลต่อเนื่องไปยังคลาวด์ โดยเฉลี่ยลดการใช้พลังงานของโหนดจับสัญญาณลง 65–80% ส่งผลให้ค่าไฟฟ้าสำหรับระบบมอนิเตอร์ลดลงอย่างมีนัยสำคัญและลดความต้องการแบนด์วิดท์ของเครือข่าย
-
Use case 3 — Predictive maintenance ช่วยลด downtime และค่าใช้จ่ายการซ่อมบำรุง
ปัญหา: การซ่อมบำรุงเชิงป้องกันแบบกำหนดตารางเวลาอาจไม่สอดคล้องกับสภาพจริงของเครื่องจักร ทำให้เกิดการซ่อมเกินความจำเป็นหรือไม่ทันเวลา ส่งผลให้เกิด downtime และต้นทุนสูง
ผลลัพธ์จากการประยุกต์ใช้ TinyML ที่ขับเคลื่อนด้วย Auto‑MLOps: เมื่อโมเดลทำนายความล้มเหลวถูกปรับให้เป็น quantization‑aware และรันบน Edge/MCU ใกล้เครื่องจักร ระบบสามารถประมวลผลสัญญาณเช่นการสั่นสะเทือนหรือกระแสไฟฟ้าได้ต่อเนื่องโดยไม่ต้องส่งข้อมูลดิบขึ้นคลาวด์ ผลเป็นว่าโรงงานตัวอย่างสามารถลด unplanned downtime ลง 35–55% และลดค่าใช้จ่ายการซ่อมบำรุงรวม (รวมค่าอะไหล่และแรงงาน) ประมาณ 25–40%
นัยสำคัญทางธุรกิจคือค่าใช้จ่ายการบำรุงรักษาที่ลดลงผสานกับการประหยัดพลังงานของโหนดมอนิเตอร์ (60–80%) ทำให้การลงทุนในโซลูชัน TinyML มักคืนทุนได้ภายใน 6–12 เดือน ขึ้นอยู่กับขนาดและลำดับความสำคัญของเครื่องจักร
สรุปแล้ว การนำแพลตฟอร์ม Auto‑MLOps สำหรับ TinyML ไปใช้ในโรงงานไม่เพียงแต่ลดการใช้พลังงานและเร่งเวลาการ deploy แต่ยังมีผลเชิงบวกต่อคุณภาพการผลิต ลดการสูญเสียจากสินค้ามีตำหนิ และลด downtime โดยตรง ตัวเลขเชิงเปรียบเทียบที่เห็นบ่อยคือการลดพลังงานของโหนด Edge อยู่ในช่วง 60–80% และเวลาทดสอบ‑deploy จากวันเหลือเป็นชั่วโมง ซึ่งช่วยให้ธุรกิจปรับสเกลระบบตรวจจับและการบำรุงรักษาเชิงคาดการณ์ได้อย่างรวดเร็วและคุ้มทุน
ธุรกิจ ตลาด และความท้าทายด้านการนำไปใช้
ธุรกิจ ตลาด และความท้าทายด้านการนำไปใช้
โอกาสทางการตลาดสำหรับ TinyML ในภาคอุตสาหกรรม มีแนวโน้มเติบโตอย่างรวดเร็ว เนื่องจากโรงงานต้องการโซลูชันตรวจจับเหตุการณ์และตรวจสอบคุณภาพแบบเรียลไทม์โดยไม่พึ่งพาเชื่อมต่อคลาวด์ตลอดเวลา สำหรับบริบทเชิงตัวเลข แนวโน้มตลาด Edge AI/TinyML ถูกประเมินว่าเติบโตด้วยอัตราเฉลี่ยสะสม (CAGR) สูง และมีมูลค่าตลาดรวมระดับพันล้านดอลลาร์ภายในกลางทศวรรษหน้า (คาดการณ์แตกต่างกันตามแหล่งข้อมูล) โดยในภาคอุตสาหกรรม TinyML จะถูกใช้อย่างแพร่หลายสำหรับตรวจจับข้อบกพร่องด้วยวิสัยทัศน์, การตรวจจับการสั่นสะเทือนของมอเตอร์, การคัดกรองเสียงผิดปกติ และการประหยัดพลังงานในอุปกรณ์ที่ใช้ MCU ซึ่งช่วยลดค่าไฟและ downtime ได้จริง ตัวอย่างเช่น การติดตั้งโมเดลวิสัยทัศน์บน MCU ในสายการผลิตสามารถลดอัตราจำนวนชิ้นที่ต้องผ่านการตรวจสอบด้วยมนุษย์ลงได้ และลดระยะเวลาการตรวจพบข้อบกพร่องตั้งแต่ชั่วโมงเป็นนาที ส่งผลให้ต้นทุนต่อหน่วยลดลงอย่างมีนัยสำคัญ
สำหรับ โมเดลรายได้ของสตาร์ทอัพ ที่พัฒนาแพลตฟอร์ม Auto‑MLOps สำหรับ TinyML ในโรงงาน ควรพิจารณาการผสมผสานหลายรูปแบบเพื่อลดความเสี่ยงและเพิ่มรายได้ต่อไลฟ์ไซเคิลของลูกค้า รายได้หลักที่เป็นไปได้ได้แก่:
- SaaS (Subscription) — แพลตฟอร์มคลาวด์สำหรับจัดการเวิร์กโฟลว์ MLOps, การติดตามประสิทธิภาพโมเดล, การแจ้งเตือน และแดชบอร์ด KPI โดยคิดค่าบริการแบบรายเดือน/ปีตามจำนวนอุปกรณ์หรือข้อมูลที่ประมวลผล
- Licensing/Per‑device fees — ใบอนุญาตสำหรับรันโมเดลบน Edge/MCU ตามจำนวนยูนิตที่ deploy (หรือแบบรายครั้งสำหรับการส่งมอบ firmware ที่ทำ quantization‑aware)
- Edge firmware & OEM partnerships — ขายเฟิร์มแวร์ที่ผนวกโมเดลให้กับผู้ผลิตอุปกรณ์ (OEM) หรือให้สิทธิการใช้งานซอฟต์แวร์แบบฝังตัว (embedded SDK)
- Professional services — บริการออกแบบโซลูชัน, ปรับแต่งโมเดล, integration กับระบบ ERP/MES, และบริการจัดการโครงการ pilot/rollout
- Managed services & Support — การบำรุงรักษา, การส่ง OTA updates, การตรวจสอบความเสถียรของโมเดลและฮาร์ดแวร์ โดยคิดค่าบริการแบบ SLA
- Data & analytics monetization — สำหรับกรณีที่ได้รับสิทธิใช้งานข้อมูลแบบไม่ระบุตัวตน สามารถนำข้อมูลเชิงสถิติมาวิเคราะห์เชิงธุรกิจและขาย insights หรือสร้างบริการ value‑added
การเลือกโมเดลธุรกิจต้องพิจารณาข้อกำหนดของลูกค้าอุตสาหกรรม เช่น ความต้องการการควบคุมต้นทุนระยะยาว (TCO), ความพร้อมในการรับผิดชอบด้านการบำรุงรักษา, และนโยบายการจัดซื้อของโรงงาน ตัวอย่างเช่น โรงงานขนาดใหญ่ที่ต้องการควบคุมการอัปเดตอาจเลือกซื้อไลเซนส์ถาวรและบริการบำรุงรักษา ในขณะที่โรงงานขนาดกลางอาจชอบโมเดล SaaS พร้อมบริการ managed เพื่อหลีกเลี่ยงต้นทุนบุคลากรภายใน
แม้จะมีโอกาสทางธุรกิจสูง แต่ยังมี ความท้าทายเชิงเทคนิคและนโยบาย ที่ต้องวางแผนอย่างรอบคอบ ได้แก่:
- Security — การรันโมเดลบน MCU/Edge ต้องคำนึงถึงการป้องกันเฟิร์มแวร์ (secure boot, signed firmware), การเข้ารหัสข้อมูลขาเข้า/ขาออก, การจัดการคีย์และใบรับรองบนฮาร์ดแวร์ที่มีทรัพยากรจำกัด และการป้องกันการโจมตีที่มุ่งเป้าไปยังน้ำหนักโมเดลหรือพารามิเตอร์ (model poisoning, adversarial inputs)
- Certification & Compliance — อุปกรณ์ที่ติดตั้งในโรงงานอาจต้องผ่านมาตรฐานอุตสาหกรรมและความปลอดภัย เช่น IEC/ISO สำหรับระบบควบคุมอัตโนมัติ, CE/FCC สำหรับการสื่อสารไร้สาย, และมาตรฐานความปลอดภัยเฉพาะสาขา (เช่น ATEX/IECEx สำหรับสภาพแวดล้อมไวไฟ) ซึ่งกระบวนการรับรองอาจกินเวลานานและมีค่าใช้จ่ายสูง
- Lifecycle management — โมเดล ML มีแนวโน้มเกิด drift เมื่อเงื่อนไขการผลิตเปลี่ยน การวางแผน MLOps สำหรับการมอนิเตอร์, รีเทรน, ทดสอบ regression บนฮาร์ดแวร์จริง และระบบ OTA ที่เชื่อถือได้เป็นสิ่งจำเป็น นอกจากนี้ยังต้องจัดการกับ obsolescence ของ MCU/เซนเซอร์และการสืบทอดฮาร์ดแวร์ระยะยาว
- Data protection & Privacy — การปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA ในไทย และกฎระเบียบต่างประเทศเมื่อส่งออกโซลูชัน) รวมถึงการลดการส่งข้อมูลดิบไปยังคลาวด์โดยใช้การประมวลผลบน Edge เพื่อรักษาความเป็นส่วนตัว
- Integration & Interoperability — การเชื่อมต่อกับระบบ MES/SCADA/ERP เดิมในโรงงานแต่ละแห่งมีความซับซ้อน ต้องรองรับโปรโตคอลอุตสาหกรรมและมี API ที่ยืดหยุ่น
คำแนะนำเชิงกลยุทธ์สำหรับโรงงานที่สนใจเริ่มต้นกับ TinyML มีดังนี้:
- เริ่มจากกรณีใช้งานที่วัดผลได้ชัดเจน (pilot use‑case) — เลือกปัญหาที่ส่งผลต่อ KPI เช่น การลดของเสีย (defects), ลด downtime, หรือลดการใช้พลังงาน ตั้ง KPI ก่อนและหลังเพื่อตรวจสอบ ROI ภายใน 3–6 เดือน
- ใช้วิธี pilot‑to‑scale — เริ่มด้วยจำนวนอุปกรณ์จำกัด ทดสอบด้านความแม่นยำและความทนทานของฮาร์ดแวร์ จากนั้นค่อยขยายแบบเป็นขั้นตอนพร้อมมาตรฐาน deployment และ playbook การบำรุงรักษา
- วางสถาปัตยกรรม security‑by‑design — กำหนดนโยบายการจัดการคีย์, secure update, การล็อกสิทธิ์การเข้าถึงตั้งแต่เริ่มต้น เพื่อลดความเสี่ยงเมื่อขยายระบบ
- วางแผนการรับรองและปฏิบัติตามมาตรฐานตั้งแต่แรก — ประเมินข้อกำหนดการรับรองที่เกี่ยวข้องกับสภาพแวดล้อมการผลิตของตน เช่น มาตรฐานความปลอดภัยเครื่องจักร หรือข้อกำหนดด้านการสื่อสารไร้สาย
- สร้างพันธมิตรเชิงระบบ — ร่วมมือกับผู้ผลิต MCU/เซนเซอร์, integrator ท้องถิ่น, และสถาบันวิจัยเพื่อเร่งการนำไปใช้และลดเวลาการพัฒนาโซลูชัน
- เตรียมบุคลากรและกระบวนการ — ฝึกอบรมทีมปฏิบัติการให้สามารถอ่านผลจากโมเดล, ดำเนินการแก้ไขขั้นต้น, และสื่อสารกับทีมเทคนิคเพื่อการรีเทรนหรืออัปเดตเมื่อจำเป็น
สรุปคือ เทคโนโลยี Auto‑MLOps สำหรับ TinyML บน MCU/Edge เปิดประตูสู่การลดต้นทุนพลังงานและเร่งเวลาการทดสอบ‑deploy ให้เหลือเพียงไม่กี่ชั่วโมง แต่ความสำเร็จเชิงพาณิชย์ขึ้นกับการออกแบบโมเดลรายได้ที่ยืดหยุ่น, การจัดการความปลอดภัยและการรับรองอย่างเป็นระบบ, และแผนบริหารวงจรชีวิตของโมเดลและฮาร์ดแวร์ที่ชัดเจน โรงงานที่เริ่มต้นแบบมีกรอบการวัดผลและพันธมิตรที่เหมาะสมจะสามารถเห็นผลตอบแทนได้อย่างรวดเร็วและขยายผลต่อเนื่องได้อย่างยั่งยืน
บทสรุป
แพลตฟอร์ม Auto‑MLOps สำหรับ TinyML ที่สตาร์ทอัพไทยพัฒนาขึ้น ช่วยเร่งการนำ AI ลงสู่ MCU/Edge ในโรงงานได้อย่างเป็นรูปธรรม โดยระบบจะปรับแต่งโมเดลวิสัยทัศน์และเซนเซอร์แบบ quantization‑aware อัตโนมัติ ทำให้โมเดลรันบนไมโครคอนโทรลเลอร์และอุปกรณ์ขอบเครือข่ายได้โดยไม่ต้องออกแบบใหม่ทั้งหมด ผลลัพธ์ที่รายงานได้แก่การลดการใช้พลังงานอย่างมีนัยสำคัญถึง 60–80% และการย่นเวลาการทดสอบและการ deploy ให้เหลือเพียงชั่วโมงจากเดิมที่อาจใช้เป็นวันหรือสัปดาห์ ทั้งยังรองรับงานเชิงอุตสาหกรรมจริง เช่น การตรวจจับข้อบกพร่องด้วยกล้องบนสายการผลิต การวิเคราะห์การสั่นสะเทือนของมอเตอร์ และการตรวจจับเหตุผิดปกติของเซนเซอร์แบบเรียลไทม์ ซึ่งทำให้การใช้งาน TinyML ในโรงงานมีความเป็นไปได้เชิงเศรษฐกิจและเชิงปฏิบัติการมากขึ้น
แม้แพลตฟอร์มดังกล่าวจะให้ประโยชน์เชิงเทคนิคและเชิงธุรกิจสูง แต่การนำไปใช้ในวงกว้างต้องวางแผนด้านความปลอดภัย การรับรอง และการบำรุงรักษาอย่างรัดกุม เช่น การยืนยันตัวตนอุปกรณ์และโมเดล (device/model signing), secure boot, การจัดการช่องโหว่, การทดสอบตามมาตรฐานอุตสาหกรรม (เช่น ISO/IEC) และการตั้งระบบ MLOps สำหรับการตรวจสอบประสิทธิภาพ โมเดล drift การอัปเดตแบบ OTA และวงจรชีวิตของโมเดล เพื่อให้เกิดการใช้งานอย่างยั่งยืนในระยะยาว มองไปข้างหน้า เทคโนโลยีนี้มีศักยภาพที่จะผสานเข้ากับแนวทาง Industry 4.0, ขับเคลื่อนการลดพลังงานและต้นทุนการดำเนินงาน พร้อมทั้งต้องการกรอบกำกับดูแลและการอบรมบุคลากรเพื่อให้เกิดการยอมรับและขยายผลอย่างปลอดภัย—ข้อเสนอแนะเชิงปฏิบัติคือเริ่มจากโครงการนำร่องที่มีการประเมินความเสี่ยงและแผนการรับรองชัดเจน ก่อนขยายสู่การปรับใช้เชิงอุตสาหกรรมวงกว้าง



