
โรงงานยานยนต์ไทยเตรียมพลิกโฉมการดูแลแบตเตอรี่รถยนต์ไฟฟ้า (EV) ด้วยการผสานเทคโนโลยี Digital‑Twin เข้ากับ Machine Learning เพื่อทำนายอายุการใช้งานแบตเตอรี่แบบเรียลไทม์ ผลลัพธ์จากการทดสอบในสายการผลิตจริงแสดงให้เห็นการลดการเรียกคืนและต้นทุนการเปลี่ยนแบตเตอรี่ได้กว่า 60% — ข้อมูลเชิงวิเคราะห์ที่ช่วยให้ฝ่ายวิศวกรรมสามารถตัดสินใจเชิงป้องกัน (predictive maintenance) ปรับแผนรับประกัน และลดการสต็อกชิ้นส่วนเปลี่ยนอย่างมีนัยสำคัญ สิ่งนี้ไม่เพียงลดต้นทุนตรง แต่ยังเพิ่มความเชื่อมั่นของผู้บริโภคและลดผลกระทบต่อสิ่งแวดล้อมจากการเปลี่ยนแบตเตอรี่โดยไม่จำเป็น
ในบทความนี้เราจะสำรวจวิธีการทางเทคนิคที่โรงงานใช้ — ตั้งแต่การเก็บข้อมูลจากเซนเซอร์และระบบ BMS ไปจนถึงการสร้างโมเดล Digital‑Twin ของชุดแบตเตอรี่และการฝึก ML เพื่อทำนายการเสื่อมสภาพแบบเรียลไทม์ พร้อมตัวอย่างตัวชี้วัดและผลลัพธ์เชิงปริมาณ รวมทั้งแผนขยายสเกลสู่โรงงานอื่นในเครือและความท้าทายทางเทคนิคที่ต้องเผชิญ เช่น คุณภาพข้อมูล การถ่ายโอนโมเดลระหว่างแพลตฟอร์ม ความมั่นคงปลอดภัยของข้อมูล และการปฏิบัติตามมาตรฐานอุตสาหกรรม อ่านต่อเพื่อเจาะลึกขั้นตอนใช้งาน ผลการประเมินเชิงธุรกิจ และแนวทางปฏิบัติที่โรงงานไทยกำลังใช้เพื่อผลักดันการเปลี่ยนผ่านสู่การผลิตยานยนต์ไฟฟ้าที่ชาญฉลาดยิ่งขึ้น
สรุปข่าวและผลลัพธ์เด่น
สรุปข่าวและผลลัพธ์เด่น
โครงการนำระบบ Digital‑Twin ผสานกับการคาดการณ์ด้วย Machine Learning (ML) เข้ามาใช้ในโรงงานยานยนต์ของไทยได้ผ่านขั้นตอนนำร่องเป็นเวลา 12 เดือน โดยทดสอบกับตัวอย่างรถยนต์ไฟฟ้าจำนวน 5,000 คัน แผนการทดลองครอบคลุมการติดตั้งอุปกรณ์ตรวจวัดบนชุดแบตเตอรี่และรถจริงในพื้นที่โรงงาน 2 แห่ง (รวม 4 สายการผลิต) เพื่อจำลองสภาพการใช้งานและเสริมสร้างแบบจำลองดิจิทัลที่สะท้อนสภาพจริงของแบตเตอรี่แบบเรียลไทม์
ผลลัพธ์เชิงปริมาณจากการนำร่องแสดงให้เห็นการปรับปรุงที่มีนัยสำคัญต่อประสิทธิภาพการผลิตและต้นทุน: ระบบช่วยลดการเรียกคืนสินค้าและต้นทุนการเปลี่ยนแบตเตอรี่ลงกว่า 60% พร้อมทั้งลดเวลาหยุดสายการผลิต (line stoppage) ราว 30% ข้อมูลจากการทดสอบระบุว่าการคาดการณ์สภาพแบตเตอรี่ (State of Health และ Remaining Useful Life) ด้วยโมเดล ML แบบเรียลไทม์มีความแม่นยำสูงสุดที่ประมาณ กว่า 90% ซึ่งเพียงพอสำหรับการตัดสินใจเชิงปฏิบัติการโดยอัตโนมัติในหลายกรณี
ขอบเขตการทดลองและเมตริกสำคัญสรุปได้ดังนี้
- ระยะเวลา pilot: 12 เดือน
- ขนาดตัวอย่าง: 5,000 คัน
- จำนวนเซ็นเซอร์เฉลี่ยต่อคัน: ประมาณ 48 ตัว (วัดแรงดันเซลล์ อุณหภูมิ กระแส แรงสั่นสะเทือน และพารามิเตอร์การใช้งานอื่นๆ)
- ปริมาณข้อมูลที่เก็บ: มากกว่า 3 พันล้านจุดสังเกต (data points) ตลอดช่วงทดลอง
- ผลลัพธ์เชิงปริมาณ: ลดการเรียกคืนและต้นทุนการเปลี่ยนแบตฯ มากกว่า 60%, ลดเวลาหยุดสายการผลิตราว 30%
- สมรรถนะโมเดล: การทำนายแบบเรียลไทม์มีความแม่นยำ >90% และ latency สำหรับการ inference ต่ำกว่า 200 ms ในเงื่อนไข edge/ondemand
โดยสรุป โครงการนำระบบ Digital‑Twin มาประสานกับ real‑time ML inference ทำให้โรงงานสามารถมอนิเตอร์สภาพแบตเตอรี่เป็นดิจิทัล รูปแบบจำลองจะประเมินการเสื่อมสภาพและคาดการณ์ความเสี่ยงล่วงหน้า ส่งผลให้การตัดสินใจด้านการบำรุงรักษาและการเปลี่ยนแบตเตอรี่เป็นไปอย่างมีประสิทธิภาพมากขึ้น ลดความจำเป็นในการเรียกคืนเป็นจำนวนมาก และคืนทุนด้านต้นทุนการซ่อมบำรุงในระยะสั้น — เหตุการณ์นี้สะท้อนถึงโอกาสในการขยายผลเชิงพาณิชย์ไปยังสายการผลิตเพิ่มเติมและการยกระดับมาตรฐานความน่าเชื่อถือของยานยนต์ไฟฟ้าในประเทศไทย
บริบทปัญหา: ความท้าทายของแบตเตอรี่ EV ในอุตสาหกรรมไทย
บริบทปัญหา: ความท้าทายของแบตเตอรี่ EV ในอุตสาหกรรมไทย
การเติบโตของยานพาหนะไฟฟ้า (EV) ในประเทศไทยสร้างโอกาสเชิงเศรษฐกิจและสิ่งแวดล้อม แต่ขณะเดียวกันก็เผยให้เห็นปัญหาสำคัญด้านความทนทานของแบตเตอรี่ซึ่งส่งผลกระทบทั้งต่อผู้ผลิตและผู้บริโภค โดยเฉพาะในเชิงต้นทุนการดำเนินงานและความเชื่อมั่นของผู้ซื้อ ปัญหาหลักประกอบด้วยการเสื่อมสภาพของเซลล์แบตเตอรี่อย่างรวดเร็ว ความเสี่ยงการลุกไหม้หรือความบกพร่องที่ต้องเรียกคืน (recall) และต้นทุนการเปลี่ยนแบตเตอรี่ที่สูงเกินคาด ซึ่งล้วนแต่เป็นตัวคุกคามต่อภาพลักษณ์แบรนด์และการยอมรับของตลาด EV ในไทย
จากข้อมูลอุตสาหกรรมระดับภูมิภาคและรายงานจากผู้ผลิตหลายแห่ง พบว่า ต้นทุนการทดแทนแบตเตอรี่เฉลี่ยต่อคันอยู่ในช่วงประมาณ 1,200–2,500 USD (ประมาณ 40,000–90,000 บาท ขึ้นกับอัตราแลกเปลี่ยนและความจุของแพ็ก) ซึ่งยังไม่รวมค่าแรง การขนส่ง และค่าเสียโอกาสจากการเรียกคืนจำนวนมาก นอกจากนี้ รายงานชี้ให้เห็นว่าเหตุการณ์ที่นำไปสู่การเรียกคืนหรือเปลี่ยนแบตฯ อยู่ในช่วงกว้าง—จากประมาณ 0.2% ถึง 1.5% ของยานพาหนะไฟฟ้าในกลุ่มตัวอย่างของบางภูมิภาค โดยตัวเลขจะแปรผันตามผู้ผลิต รุ่น และสภาพการใช้งานจริง
ปัจจัยที่เร่งการเสื่อมสภาพของแบตเตอรี่มีความหลากหลายและเชื่อมโยงกับสภาพแวดล้อมรวมถึงพฤติกรรมการใช้งาน ได้แก่
- อุณหภูมิสูง/ต่ำ — การใช้งานในสภาพอากาศร้อนชื้นหรือเย็นจัดทำให้ประสิทธิภาพและอายุการใช้งานลดลงอย่างมีนัยสำคัญ
- การชาร์จเร็ว (fast charging) — แม้จะสะดวกต่อผู้ใช้ แต่การชาร์จด้วยอัตรากระแสสูงซ้ำๆ เพิ่มความร้อนและเร่งการเสื่อมของเซลล์
- สถานะการใช้งานจริง — รูปแบบการขับขี่ บรรทุกน้ำหนัก การจอดในสภาพไม่เหมาะสม และการบำรุงรักษาที่ไม่สม่ำเสมอ ล้วนส่งผลต่อการเสื่อมสภาพ
- ความไม่สอดคล้องของการควบคุมคุณภาพและการออกแบบระบบจัดการแบตเตอรี่ (BMS) — ข้อบกพร่องในเฟิร์มแวร์หรือการออกแบบระบบระบายความร้อนสามารถเปลี่ยนเหตุการณ์เล็กน้อยให้กลายเป็นความล้มเหลวระดับแพ็กได้
ผลกระทบทางการตลาดและเศรษฐกิจมีความรุนแรง หากเกิดเหตุการณ์เรียกคืนในระดับวงกว้าง ความเชื่อมั่นของผู้บริโภคต่อแบรนด์จะลดลง ซึ่งนำไปสู่การลดอัตราการซื้อซ้ำและคำแนะนำเชิงบวกจากผู้ใช้ต่อเพื่อนหรือครอบครัว งานวิจัยและการวิเคราะห์ตลาดระบุว่าเหตุการณ์ความล้มเหลวที่มีการสื่อสารในวงกว้างอาจลดยอดขายระยะยาวของรุ่นหรือแม้แต่แบรนด์ถึงระดับตัวเลขที่มีนัยสำคัญ (ตัวอย่างเช่นหลักหลายเปอร์เซ็นต์จนถึงสองหลัก ขึ้นกับความรุนแรงและการรับมือของผู้ผลิต)
สำหรับผู้ผลิตในประเทศไทย ความเสี่ยงดังกล่าวหมายถึงต้นทุนโดยตรงจากการเรียกคืนและเปลี่ยนแบตเตอรี่ ตลอดจนต้นทุนแฝงจากการเสียภาพลักษณ์ การชะลอการยอมรับของผู้บริโภค และแรงกดดันด้านกฎระเบียบที่อาจเพิ่มขึ้น การวัดและคาดการณ์อายุแบตเตอรี่แบบเรียลไทม์ รวมทั้งการใช้เทคโนโลยีอย่าง Digital‑Twin และ Machine Learning จึงไม่ใช่เพียงตัวเลือก แต่เป็นกลไกสำคัญในการลดความเสี่ยงทางการเงินและรักษาความเชื่อมั่นของตลาด EV ในไทยในระยะยาว
เทคโนโลยีหลัก: Digital‑Twin ผสาน Machine Learning
เทคโนโลยีหลัก: ความหมายของ Digital‑Twin และบทบาทร่วมกับ Machine Learning
Digital‑Twin คือภาพจำลองเสมือนของทรัพย์สินทางกายภาพ (เช่น แบตเตอรี่รถยนต์ไฟฟ้า) ที่ประกอบด้วยพารามิเตอร์เชิงฟิสิกส์ สถานะการใช้งาน และสภาพแวดล้อมการทำงานแบบไดนามิก โดยเชื่อมต่อแบบเรียลไทม์กับข้อมูลจากเซ็นเซอร์ในโลกจริง ระบบ Digital‑Twin ทำหน้าที่เป็น ข้อพิจารณาเชิงวิเคราะห์และทดลอง ที่ช่วยให้โรงงานสามารถทดสอบนโยบายการจัดการแบตเตอรี่ การคาดการณ์ความเสื่อม (SoH) และการคำนวณอายุการใช้งานที่เหลือ (RUL) โดยไม่ส่งผลกระทบต่ออุปกรณ์จริง ตัว Digital‑Twin เมื่อผสานกับเทคนิค Machine Learning (ML) จะช่วยยกระดับความแม่นยำในการทำนาย ความสามารถในการปรับตัวตามรูปแบบการใช้งานจริง และการตรวจจับความผิดปกติได้เร็วขึ้น
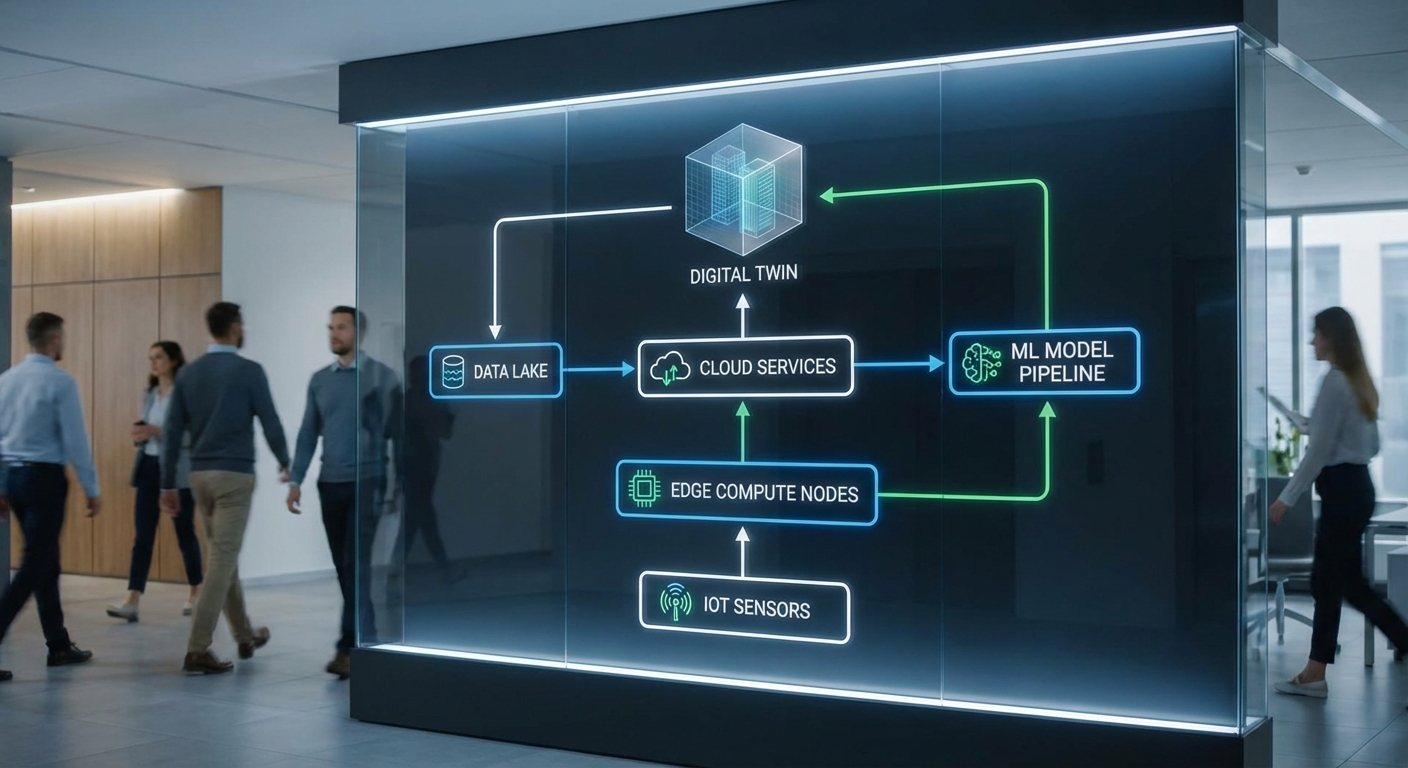
องค์ประกอบสำคัญของระบบและ synchronization loop
ระบบ Digital‑Twin แบบครบวงจรประกอบด้วยองค์ประกอบหลัก 3 ส่วนที่ต้องทำงานร่วมกันอย่างใกล้ชิด:
- Physical asset — เซลล์แบตเตอรี่และแพ็ค ที่ติดตั้งเซ็นเซอร์วัดแรงดัน กระแส อุณหภูมิ ความต้านทานภายใน (impedance) และการสั่นสะเทือน
- Virtual model — แบบจำลองเชิงฟิสิกส์ (electrochemical, thermal) และแบบจำลองเชิงข้อมูล (ML models) ที่แทนพฤติกรรมของแบตเตอรี่ในสภาพแวดล้อมต่าง ๆ
- Synchronization loop — วงจรการซิงค์ข้อมูลแบบสองทาง: ข้อมูลเซ็นเซอร์ส่งไปปรับค่าพารามิเตอร์ของ Virtual model และผลลัพธ์จาก Virtual model ส่งกลับเพื่อแนะนำการตัดสินใจการบำรุงรักษาหรือการปรับพฤติกรรมการขับขี่
ในเชิงปฏิบัติ synchronization loop จะรวมขั้นตอนต่อเนื่องดังนี้: เก็บข้อมูลเรียลไทม์ → preprocessing/feature extraction → inference/feedback จาก ML และฟิสิกส์โมเดล → ปรับพารามิเตอร์ของ Digital‑Twin → ส่งคำแนะนำการกระทำ (เช่น ลดความเร็วชาร์จ หมายเรียกเตือน) กลับสู่ผู้ใช้งานหรือระบบควบคุม
สถาปัตยกรรมการเชื่อมต่อ: เซ็นเซอร์ → Edge → Cloud → ML
สถาปัตยกรรมที่นิยมใช้ในโรงงานยานยนต์ประกอบด้วยเลเยอร์หลัก 4 ส่วน:
- เซ็นเซอร์ในยานพาหนะ — เก็บข้อมูลแบบไทม์ซีรีส์ (V, I, T, impedance, SOC proxies) ด้วยอัตราตัวอย่างที่ปรับได้
- Edge nodes — อุปกรณ์คอมพิวต์ใกล้แหล่งข้อมูล (MCU, gateway, หรือรถกับเซิร์ฟเวอร์ภายในโรงงาน) ที่ทำหน้าที่ preprocessing, anomaly detection และ inference แบบ latency‑sensitive
- Network / Connectivity — ใช้ CAN, Ethernet, 4G/5G หรือลิงก์ภายในโรงงานสำหรับการส่งเทเลเมทรีไปยังคลาวด์ โดยคำนึงถึงแบนด์วิดท์และความคงทน
- Cloud / Central platform — พื้นที่สำหรับการเก็บข้อมูลขนาดใหญ่ (historical datasets), การฝึกโมเดล ML ขนาดใหญ่ (Transformer, survival analysis frameworks) และการจัดการเวอร์ชันของ Digital‑Twin
ในเชิงการทำงาน โมเดล ML ขนาดเล็กหรือ optimized จะถูก deploy ที่ edge เพื่อลดความหน่วง (latency) และรักษาความเป็นส่วนตัวของข้อมูล ในขณะที่การเทรนหรือการปรับโมเดลเชิงลึกจะเกิดขึ้นที่ cloud ที่มีทรัพยากรสูง โดยผลลัพธ์หรือพารามิเตอร์ที่ปรับแล้วจะถูกส่งกลับไปยัง edge ในรูปแบบของ model updates หรือ policy updates ผ่านระบบ orchestration
การเลือกโมเดล ML สำหรับ RUL/SoH และกลยุทธ์ผสานกับ Digital‑Twin
การคัดเลือกโมเดลต้องพิจารณาลักษณะข้อมูล (time‑series, censored data, feature set), ข้อจำกัดเชิงคอมพิวต์ และความต้องการด้านความแม่นยำ/ความโปร่งใส ตัวเลือกที่นิยมได้แก่:
- Survival analysis — เหมาะกับข้อมูลที่มีการ censoring (รถยังไม่เสีย) ให้การประมาณความเสี่ยงตามเวลาและความไม่แน่นอน ใช้เมื่อต้องการแจกแจงความน่าจะเป็นของ RUL และสนับสนุนการตัดสินใจเชิงนโยบายบำรุงรักษา
- LSTM — โมเดล recurrent ที่เก่งกับ sequence ขนาดยาว เหมาะสำหรับการจับพฤติกรรมการชาร์จ‑การคายประจุ แต่ต้องจัดการกับการ overfitting และทรัพยากรการคำนวณ
- Transformer — ให้ประสิทธิภาพสูงในการจับบริบทระยะยาวและการข้ามลำดับสัญญาณ หลักการ attention ช่วยให้ตีความ feature สำคัญได้ดี แต่ต้องการข้อมูลและทรัพยากรมากกว่า LSTM
- XGBoost — โมเดล tree‑based ที่เร็วและเหมาะกับตารางฟีเจอร์ (extracted features เช่น DOD, C‑rate, temp stats) ให้ผลดีในงาน SoH เมื่อรวมกับ feature engineering และมี latency ต่ำเมื่อนำไปรันบน edge
กลยุทธ์ที่ได้ผลในภาคอุตสาหกรรมคือแนวทางแบบไฮบริด: ใช้ฟิสิกส์‑based Digital‑Twin เพื่อจำกัดขอบเขตพื้นที่ของพฤติกรรมที่เป็นไปได้ แล้วใช้ ML (เช่น Transformer หรือ survival model ใน cloud) เพื่อเรียนรู้ residuals และความไม่แน่นอน จากนั้น deploy แบบ distilled หรือ XGBoost ที่ถูกปรับแต่งไปยัง edge สำหรับ inference แบบเรียลไทม์
Inference แบบเรียลไทม์: edge vs cloud (latency, bandwidth, privacy)
การตัดสินใจว่าจะรัน inference ที่ edge หรือ cloud ขึ้นกับข้อพิจารณาหลักสามด้าน:
- Latency — งานที่ต้องตอบสนองทันที เช่น การตัดวงจรชั่วคราวเพื่อป้องกัน Thermal runaway ต้องการ latency ต่ำ (มัก <50 ms) จึงเหมาะกับการรันบน edge
- Bandwidth — การส่งข้อมูลไทม์ซีรีส์ความละเอียดสูงไปยังคลาวด์มีค่าใช้จ่ายและข้อจำกัดด้านสเถียรภาพ Edge preprocessing ลดการส่งข้อมูลโดยส่งเฉพาะฟีเจอร์หรือเหตุการณ์ที่สำคัญ
- Privacy & Security — ข้อมูลการขับขี่และสมรรถนะของแบตเตอรี่อาจมีความละเอียดอ่อน การประมวลผลบางส่วนที่ edge ช่วยลดความเสี่ยงด้านความเป็นส่วนตัวและปฏิบัติตามข้อกำหนดทางกฎหมาย
ตัวอย่างเชิงตัวเลข: การรันโมเดล XGBoost บน gateway ภายในรถอาจให้ latency 10–30 ms และลดการส่งข้อมูลลงกว่า 90% เมื่อเทียบกับการส่งดิบทั้งหมดไปคลาวด์ ในขณะที่ inference บนคลาวด์ด้วย Transformer ขนาดใหญ่อาจมี latency 200–500 ms แต่ให้การทำนายที่แม่นยำกว่าและสามารถคำนวณความไม่แน่นอนได้ดีกว่า จึงเหมาะกับงานวิเคราะห์แนวโน้มระยะยาวและการอัพเดตโมเดลเป็นช่วงๆ
สรุปคือ การผสาน Digital‑Twin กับ ML ในโรงงานยานยนต์ต้องออกแบบสถาปัตยกรรมที่สมดุลระหว่างความแม่นยำ ความหน่วง และความมั่นคงของข้อมูล โดยใช้แนวทางไฮบริด: inference latency‑critical ที่ edge และ training/aggregation/advanced analytics ที่ cloud พร้อมวงจร synchronization ที่ทำให้ Virtual model ตรงกับสภาพจริงอย่างสม่ำเสมอ ซึ่งช่วยให้การคาดการณ์ RUL/SoH มีประสิทธิภาพ ลดการเรียกคืน และลดต้นทุนการเปลี่ยนแบตเตอรี่อย่างมีนัยสำคัญ
Data Pipeline และวิธีการฝึกโมเดล
แหล่งข้อมูล (Data Sources) และการรวบรวมข้อมูล
ระบบ Data Pipeline เริ่มจากการรวบรวมแหล่งข้อมูลที่หลากหลายเพื่อรองรับการทำนายอายุแบตเตอรี่แบบเรียลไทม์ ได้แก่ telemetry จากรถยนต์ (เช่น ความเร็ว การเร่ง เบรก), BMS logs (state-of-charge, state-of-health, cell voltages, balancing events), environmental sensors (อุณหภูมิภายนอก/ภายใน, ความชื้น) และ maintenance records (การเปลี่ยนแบตเตอรี่ การซ่อมแซม เหตุการณ์ติดตั้งใหม่) ข้อมูลเหล่านี้มักมาจากหลายแหล่ง ทั้ง edge device, fleet management server และระบบ ERP ทำให้ต้องมีการจัดมาตรฐานรูปแบบข้อมูล (schema harmonization) และการซิงโครไนซ์เวลา (time alignment) ก่อนนำเข้าสู่ pipeline กลาง

กระบวนการทำความสะอาดข้อมูลและการสร้าง Label (Cleaning & Labeling)
การเตรียมข้อมูลเริ่มจากการตรวจจับและจัดการ missing values (imputation แบบ time‑aware เช่น forward/backward fill ผสมกับ model‑based imputation), การลบหรือแก้ไข outlier ที่มาจากเซ็นเซอร์ผิดพลาด และการแก้ไข drift ของเซ็นเซอร์ด้วย calibration model การปรับ sampling rate ให้เป็นมาตรฐาน (เช่น 1 Hz หรือ 1 นาที ขึ้นกับ use‑case) และการแปลงหน่วยให้สอดคล้องกันเป็นพื้นฐานก่อนการสร้าง label
สำหรับการสร้าง label ด้าน time-to-failure (TTF) และเส้นความเสื่อม (degradation curves) เรานิยามเหตุการณ์สิ้นอายุ (end‑of‑life, EOL) ตามมาตรฐานอุตสาหกรรม เช่น เมื่อ state-of-health (SoH) ลดลงเหลือ 70–80% ของความจุเริ่มต้น แล้วคำนวณ TTF เป็นจำนวนเวลาหรือระยะทางจากช่วงเวลาปัจจุบันถึงเหตุการณ์ EOL วิธีปฏิบัติที่ดีได้แก่ การสร้าง degradation curve ต่อเซล/โมดูลโดยใช้ smoothing (เช่น LOWESS หรือ spline) เพื่อลดสัญญาณรบกวน และการจัดการ censoring สำหรับแบตเตอรี่ที่ยังไม่ถึง EOL โดยใช้เทคนิค survival analysis (Kaplan‑Meier, Cox model) เพื่อผสานข้อมูล censored เข้าใน label set
เทคนิค Feature Engineering สำคัญ
Feature engineering ถูกออกแบบเพื่อจับพฤติกรรมที่สัมพันธ์กับการเสื่อมของแบตเตอรี่ โดยรวมทั้ง features ระดับสั้น (short‑term) และสะสม (cumulative):
- average depth of discharge (DoD) ต่อช่วงเวลา — ตัวชี้วัดการใช้งานเชิงลบต่อความจุ
- peak current และ charge/discharge cycles — จำนวนรอบและค่าสูงสุดที่ส่งผลต่อการสึกหรอ
- cell temperature variance และ temperature exposure (เช่น cumulative hours > 40°C) — ความร้อนเป็นปัจจัยหลักของการเสื่อม
- charge rate profile (C‑rate) — ค่าเฉลี่ย/ค่าสูงสุด/การกระจายของอัตราการชาร์จ-คายประจุ
- สถิติเชิงสถิติภายในหน้าต่างเวลา (mean, std, skewness, kurtosis), ความถี่ของ balancing events, voltage delta per cycle, และ features ของพฤติกรรมการขับขี่ (regenerative braking intensity)
การคำนวณ features ทำผ่าน sliding windows (เช่น 1h, 24h, 30d) และ aggregation ระดับวัน/เดือน รวมทั้งการสร้าง features ผสม (interaction terms) เช่น DoD × temperature exposure เพื่อจับ nonlinear effect
กลยุทธ์จัดการ Class Imbalance และการสร้าง Label สำหรับ TTF
เหตุการณ์ความล้มเหลวหรือการถึง EOL มักเป็นส่วนน้อย (failure rate ในเชิงตัวอย่างอาจต่ำกว่า 1–5% ของ sample ทั้งหมด) ดังนั้นต้องใช้กลยุทธ์เพื่อลด bias ของโมเดล:
- การปรับ sampling: undersampling ของคลาสใหญ่, oversampling ของคลาสเล็ก (เช่น SMOTE หรือ time‑series augmentation ที่คำนึงถึงลำดับเวลา)
- ใช้ class weighting ใน loss function เพื่อให้โมเดลให้ความสำคัญกับตัวอย่างความผิดปกติมากขึ้น
- loss functions เฉพาะทาง เช่น focal loss สำหรับปัญหาการตรวจจับ fault และ survival‑aware losses สำหรับ TTF ที่มี censoring
- สร้าง synthetic failures โดยการจำลอง degradation path ตาม physics‑informed models เพื่อเพิ่มตัวอย่างช่วงปลายอายุ
- ใช้ anomaly detection หรือ two‑stage approach: stage แรกเป็น detector (unsupervised) คัดกรองเหตุการณ์ผิดปกติ แล้ว stage สองเป็น predictor สำหรับ TTF
การสร้าง label สำหรับ TTF ต้องคำนึงถึง censoring และความไม่แน่นอน โดยอาจผสาน survival modelling, probabilistic labeling (time window probabilities) หรือใช้ quantile regression เพื่อให้ค่าทำนายเป็นช่วงความเชื่อมั่นแทนค่าจุดเดียว
เมตริกประเมินผลและ Baseline ที่ใช้เปรียบเทียบ
การวัดประสิทธิภาพควรแยกกรณี RUL (remaining useful life) และการตรวจจับความผิดปกติ (fault detection):
- สำหรับ RUL: ใช้ MAE (Mean Absolute Error) และ RMSE พร้อมการรายงานเป็นสัดส่วนของ RUL (เช่น MAE น้อยกว่า 10% ของค่า RUL เฉลี่ยเป็นเป้าหมายทางธุรกิจ) และการวัดความแม่นยำเชิงเวลา (timing error distribution)
- สำหรับ Fault Detection: ใช้ precision, recall, F1‑score และ AUC‑ROC โดยให้ความสำคัญกับ recall ในกรณีความปลอดภัย และ precision เพื่อควบคุม false positive ที่จะสร้างต้นทุนการเรียกคืน
- ควรประเมิน calibration ของโมเดล (reliability diagrams, prediction intervals coverage) และใช้ metrics แบบ fleet‑level (เช่น reduction in unexpected replacements, cost‑weighted error)
Baseline สำหรับการเปรียบเทียบประกอบด้วยวิธีง่ายๆ เช่น linear/exponential extrapolation ของ degradation, smoothing persistence model, และ machine learning พื้นฐานเช่น Random Forest/XGBoost รวมถึง deep learning (LSTM, Temporal CNN, Transformer) โดยเป้าหมายเชิงหยาบของผลลัพธ์เช่น MAE ต่ำกว่า 10% ของ RUL หรือการเพิ่ม precision/recall ของ fault detection ให้เหนือกว่า baseline อย่างมีนัยสำคัญทางสถิติ
การนำไปใช้งานจริงและข้อพิจารณาด้านการปฏิบัติ
ในเชิงปฏิบัติ ต้องออกแบบ pipeline ให้รองรับการประมวลผลแบบ near‑real‑time: edge feature extraction เพื่อให้ latency ต่ำ, streaming ETL, และระบบ retraining เป็นช่วงเวลาที่เหมาะสม (batch retrain รายสัปดาห์/รายเดือน พร้อม continuous monitoring ของ concept drift) รวมถึงกลไก feedback loop จาก maintenance records เพื่อนำผลการซ่อมแซมกลับมาใช้ปรับปรุง label และ model
สรุปคือ การสร้าง Data Pipeline และการฝึกโมเดลสำหรับการทำนายอายุแบตเตอรี่จำเป็นต้องผสานข้อมูลหลายมิติ การทำความสะอาดและการจัดการ label อย่างระมัดระวัง เทคนิค feature engineering ที่จับปัจจัยสำคัญ (เช่น average DoD, peak current, cell temperature variance, C‑rate profile) และการเลือกเมตริกพร้อม baseline ที่สอดคล้องกับเป้าทางธุรกิจ เพื่อให้โมเดลให้ผลเชื่อถือได้และคุ้มค่าต่อการลดต้นทุนการเรียกคืนและการเปลี่ยนแบตเตอรี่
กรณีศึกษาโรงงานไทย: การนำระบบสู่การใช้งานจริงและผลลัพธ์เชิงธุรกิจ
ภาพรวมการนำไปใช้ (Pilot → ขยายผล)
โครงการเริ่มจากการทำ pilot ในโรงงานประกอบยานยนต์ไฟฟ้าขนาดใหญ่ในประเทศไทย โดยเลือกไลน์ผลิตหนึ่งไลน์ซึ่งครอบคลุมรถยนต์ประมาณ 1,200 คันในช่วง 6 เดือนแรก เพื่อเชื่อมต่อเซนเซอร์แบตเตอรี่แบบ inline และสร้าง Digital Twin ของระบบแบตเตอรี่ร่วมกับโมเดล Machine Learning สำหรับทำนาย State of Health (SOH) และ Remaining Useful Life (RUL) แบบเรียลไทม์ ทีมงานแบ่งขั้นตอนการ deployment ออกเป็นช่วงชัดเจน ได้แก่ การเก็บข้อมูลคุณภาพจากเซนเซอร์ การสร้างและปรับเทรนโมเดลด้วยข้อมูลเชิงประวัติ (historical failure, cycling data, thermal profile) และการติดตั้ง inference engine ทั้งบน edge device และ cloud เพื่อให้สามารถแจ้งเตือนแบบ low-latency ได้ทันทีเมื่อพบสัญญาณเสี่ยง
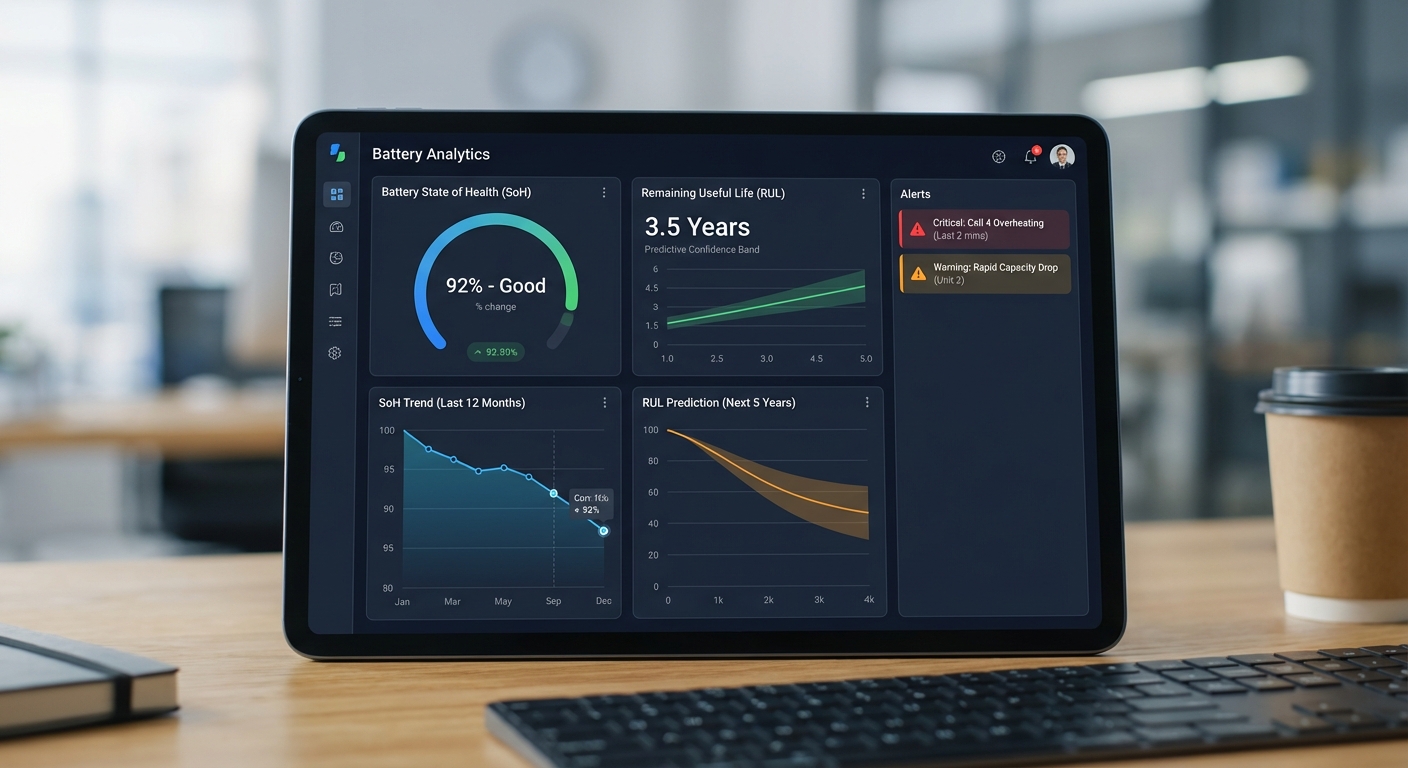
หลังจากผลลัพธ์จาก pilot ยืนยันความแม่นยำของโมเดล (ความแม่นยำ >85% ในการทำนายกรณีแบตเตอรี่ที่จะล้มเหลวภายใน 6 เดือน) โรงงานได้ขยายระบบไปยังไลน์ผลิตทั้งหมด พร้อมผสานการทำงานกับระบบ MES, QA และระบบหลังการขาย (CRM/Service Platform) เพื่อให้การตัดสินใจเป็นไปแบบอัตโนมัติและมีการติดตามผลเป็นระบบเดียวกัน
ผลลัพธ์เชิงตัวเลขและการประเมินผลทางการเงิน
ผลลัพธ์เชิงธุรกิจที่วัดได้จากการนำไปใช้ในเชิงพาณิชย์มีความชัดเจน ดังนี้:
- จำนวนการเรียกคืน (Recall): ก่อนใช้งานระบบมีการเรียกคืนปีละ 150 เคส → หลังใช้งานลดเหลือ 60 เคส (ลด 60%)
- ต้นทุนการเปลี่ยนแบตเตอรี่: โรงงานรายงานว่าต้นทุนรวมจากการเปลี่ยนแบตเตอรี่และค่า logistics ลดลงมากกว่า 60% เนื่องจากการคาดการณ์ที่แม่นยำทำให้สามารถเปลี่ยนก่อนเกิดเหตุจริง (pre‑emptive replacement) และลดจำนวนการเปลี่ยนฉุกเฉิน/เรียกคืน
- การลด OPEX: ฝ่ายบริการหลังการขายและ logistics รายงาน OPEX ลดประมาณ 30–40% จากการลดงานฉุกเฉิน การวางแผนอะไหล่ล่วงหน้า และการจัดตารางงานช่างที่มีประสิทธิภาพขึ้น
- ระยะคืนทุน (ROI): โครงการมีการลงทุนเริ่มต้นรวมทั้งฮาร์ดแวร์ เซนเซอร์ การพัฒนา Digital Twin และซอฟต์แวร์ประมาณ 50 ล้านบาท โดยคาดการณ์จากการลดค่าเรียกคืนและต้นทุนเปลี่ยนแบตเตอรี่จะทำให้เกิดการประหยัดเงินสดประมาณ 40 ล้านบาทต่อปี ทำให้ payback period อยู่ที่ประมาณ 15 เดือนและ ROI ภายใน 18 เดือนตามเป้าหมาย
การเปลี่ยนแปลงของกระบวนการทำงานในไลน์ผลิตและฝ่ายบริการหลังการขาย
การนำ Digital‑Twin + ML มาใช้งานไม่ได้เปลี่ยนแค่ตัวเลขทางการเงิน แต่ยังเปลี่ยนกระบวนการปฏิบัติงานอย่างเป็นรูปธรรม:
- ในไลน์ผลิต: เพิ่มจุดตรวจวัดและส่งข้อมูลไปยัง Digital Twin แบบเรียลไทม์ ทำให้ QA สามารถตั้งเงื่อนไข hold-and-inspect อัตโนมัติเมื่อค่า SOH หรือ thermal anomaly เกินเกณฑ์ ส่งผลให้ลดการผลิตชิ้นส่วนที่มีความเสี่ยงและลดอัตรา defect downstream
- การตรวจสอบคุณภาพ (QA): จากเดิมที่เป็นการสุ่มตรวจเปลี่ยนเป็นการตรวจเชิงรุก (predictive QA) โดยมี dashboard ที่แสดงสถานะความเสี่ยงของแบตเตอรี่เป็นรายล็อต/รหัสชิ้นส่วน ทำให้ทีม QA สามารถจัดลำดับการตรวจสอบและทดสอบเพิ่มเติมเฉพาะกรณีที่มีสัญญาณเตือน
- ฝ่ายบริการหลังการขาย: ระบบเชื่อมต่อกับ CRM ทำให้สามารถแจ้งเตือนลูกค้าอัตโนมัติผ่าน SMS, แอปพลิเคชัน หรืออีเมล เมื่อโมเดลทำนายว่าแบตเตอรี่ของลูกค้ามีความเสี่ยงภายในช่วงเวลาที่กำหนด ระบบยังเสนอช่องเวลาบริการที่ว่างและจัดเตรียมอะไหล่ไว้ล่วงหน้า (parts pre‑staging) เพื่อลดเวลารอคอยและจำนวนครั้งที่ลูกค้าต้องเข้ามาใช้บริการ
- การบริหารความเสี่ยงและการรับประกัน: ด้วยข้อมูลเชิงลึกจากการทำนาย ความเสี่ยงจากการรับประกัน (warranty liability) ถูกลดลงอย่างเป็นรูปธรรม ทำให้บริษัทสามารถออกแบบแผนประกันหรือบริการเสริมที่มีต้นทุนต่ำลงและขยายรูปแบบบริการบนพื้นฐานข้อมูลจริง
โดยสรุป การผสาน Digital‑Twin กับ Machine Learning ในโรงงานยานยนต์ไทยนี้ไม่เพียงแต่ช่วยลดจำนวนการเรียกคืนจาก 150 เคสต่อปีเหลือ 60 เคส (ลด 60%) และลดต้นทุนการเปลี่ยนแบตมากกว่า 60% เท่านั้น แต่ยังส่งผลให้ค่าใช้จ่ายการปฏิบัติการ (OPEX) ลดลง ระยะคืนทุนย่อมสั้นลง (ROI ภายใน 18 เดือน) และปรับปรุงกระบวนการ QA รวมถึงประสบการณ์หลังการขายอย่างยั่งยืน เพิ่มความเชื่อมั่นให้กับลูกค้าและลดความเสี่ยงด้านแบรนด์ในระยะยาว
ผลกระทบเชิงนโยบายและความเสี่ยงที่ต้องพิจารณา
ผลกระทบเชิงนโยบายและความเสี่ยงที่ต้องพิจารณา
การนำระบบ Digital‑Twin ร่วมกับ Machine Learning มาใช้เพื่อทำนายอายุแบตเตอรี่แบบเรียลไทม์ในโรงงานยานยนต์ไทย แม้จะมีศักยภาพในการลดการเรียกคืนและต้นทุนการเปลี่ยนแบตมากกว่า 60% แต่ก็ย่อมมาพร้อมกับความเสี่ยงทางเทคนิคและเชิงนโยบายที่รัฐและภาคอุตสาหกรรมต้องพิจารณาอย่างรอบคอบ เพื่อรักษาความปลอดภัยของผู้บริโภคและความมั่นคงของระบบนิเวศยานยนต์ดิจิทัล
ความเสี่ยงทางเทคนิค ประกอบด้วยประเด็นสำคัญหลายด้าน เช่น model drift ซึ่งหมายถึงการเสื่อมสภาพของประสิทธิภาพโมเดลเมื่อสภาวะแวดล้อมจริงเปลี่ยนจากข้อมูลที่ใช้ฝึก เช่น ความแตกต่างของสภาพอากาศ พฤติกรรมผู้ขับ หรือการเปลี่ยนแบตเตอรี่จากซัพพลายเออร์รายใหม่ การศึกษาในอุตสาหกรรมชี้ว่า without ongoing maintenance โมเดลทำนายประเภทนี้อาจสูญเสียความแม่นยำได้อยู่ในช่วงตัวเลขสองหลัก (เช่น 10–30%) ภายใน 6–12 เดือน นอกจากนี้ การล้มเหลวของเซ็นเซอร์ หรือการเบี่ยงเบนของการวัด (sensor degradation) จะทำให้ข้อมูลเข้าไม่สมบูรณ์หรือมีความผิดพลาด ส่งผลให้การคาดการณ์ BMS ผิดพลาด และ ความหน่วงของข้อมูล (data latency) โดยเฉพาะกรณีที่ต้องการการตอบสนองแบบ near‑real‑time จะทำให้การแจ้งเตือนเชิงป้องกันล่าช้าหรือพลาดช่วงเวลาสำคัญ ตัวอย่างเช่น หากระบบต้องการการตอบสนองภายในวินาทีหรือไม่กี่นาที แต่ข้อมูลติดขัดหรือส่งเป็นชุดรายชั่วโมง ผลลัพธ์เชิงพยากรณ์ย่อมไม่ทันการ
ประเด็นทางกฎหมายและความเป็นส่วนตัว การเก็บและประมวลผลข้อมูล telematics และข้อมูล BMS ของยานพาหนะมีลักษณะเชื่อมโยงกับผู้ใช้โดยตรง และบางส่วนมีลักษณะเป็นข้อมูลส่วนบุคคล (PII) หรือข้อมูลที่สามารถติดตามพฤติกรรมการขับขี่ได้ จึงต้องสอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ในไทย และข้อกำหนดระหว่างประเทศเมื่อมีการโอนข้ามพรมแดน เรื่องสำคัญที่ต้องคำนึงคือการได้รับความยินยอมที่ชัดเจนและเฉพาะเจาะจง การจำกัดวัตถุประสงค์ (purpose limitation) การกำหนดช่วงเวลาการเก็บรักษา (retention policy) และมาตรการทางเทคนิคเช่นการเข้ารหัสและการควบคุมการเข้าถึง นอกจากนี้ การจ้างผู้ประมวลผลข้อมูลภายนอก (third‑party processors) หรือการใช้งานคลาวด์ต่างประเทศ จำเป็นต้องมีมาตรการทางสัญญาและการตรวจสอบประกอบเพื่อให้สอดคล้องกับข้อบังคับ
แนวทางการลดความเสี่ยงและข้อเสนอเชิงนโยบาย ด้านเทคนิค ควรบังคับใช้กระบวนการ continuous validation และ monitoring ของโมเดลอย่างต่อเนื่อง โดยรวมถึง shadow deployment, periodic recalibration และการตั้งค่า alert เมื่อประสิทธิภาพลดลง ระบบควรมีเมตริกต์เชิงมาตรฐานสำหรับการประเมิน (เช่น MAPE, ROC‑AUC หรือ F1 ขึ้นกับงาน) และมีแผน rollback หรือ human‑in‑the‑loop เมื่อตรวจพบความผิดปกติ การออกแบบฮาร์ดแวร์ควรคำนึงถึง redundancy และ sensor fusion เพื่อชดเชยความล้มเหลวของเซ็นเซอร์ นอกจากนั้นเทคนิคด้านความเป็นส่วนตัว เช่น federated learning สามารถลดการเคลื่อนย้ายข้อมูลดิบระหว่างองค์กร โดยให้การฝึกโมเดลกระจายบนยานพาหนะหรือภายในโรงงานแล้วรวมพารามิเตอร์อย่างปลอดภัย ช่วยลดความเสี่ยงด้าน privacy และการละเมิดข้อมูล
- มาตรฐานการแบ่งปันข้อมูล BMS แบบปลอดภัย: ภาครัฐควรร่วมกับสมาคมอุตสาหกรรมกำหนดมาตรฐาน API, การเข้ารหัส end‑to‑end, mutual authentication และฟอร์แมตข้อมูลเชิงมาตรฐาน (semantic schema) เพื่อให้การแลกเปลี่ยนข้อมูลระหว่าง OEM, ซัพพลายเออร์ และผู้ให้บริการบำรุงรักษาเป็นไปอย่างปลอดภัยและ interoperable
- การรับรองและการตรวจสอบระบบ Digital‑Twin: ควรกำหนดกรอบการรับรอง (certification) สำหรับแพลตฟอร์ม Digital‑Twin และโมเดลทำนาย รวมถึงข้อกำหนดด้านความทนทาน, audit trail, explainability ของโมเดล และการทดสอบภายใต้สถานการณ์ edge cases ก่อนใช้งานเชิงพาณิชย์
- แรงจูงใจเชิงนโยบายสำหรับ OEMs: รัฐบาลสามารถออกมาตรการจูงใจ เช่น เครดิตภาษี, เงินอุดหนุนสำหรับการติดตั้งเซ็นเซอร์หรืออัพเกรด BMS, และการให้สิทธิพิเศษในการอนุมัติผลิตภัณฑ์สำหรับ OEM ที่นำ predictive maintenance มาใช้และรายงานผลลดการเรียกคืนอย่างโปร่งใส
- กรอบกฎหมายและแนวปฏิบัติของข้อมูล: ควรกำหนดแนวทางชัดเจนเรื่อง consent management, data minimization, การอนุญาตให้เข้าถึงข้อมูลเชิงสาธารณะ (de‑identified) เพื่อการวิจัย และการกำหนดระยะเวลาการเก็บรักษาที่เหมาะสมร่วมกับบทลงโทษสำหรับการละเมิด
สรุปได้ว่า การนำ Digital‑Twin และ ML มาประยุกต์ในห่วงโซ่อุปทานแบตเตอรี่ EV จะให้ผลประโยชน์เชิงเศรษฐกิจและความปลอดภัยได้จริง แต่ต้องมาพร้อมกับกรอบกำกับดูแลที่ชัดเจน มาตรฐานเทคนิค และกลไกเฝ้าระวังที่เพียงพอเพื่อจัดการปัจจัยเสี่ยงทั้งทางเทคนิคและทางกฎหมาย ถ้ารัฐและภาคเอกชนร่วมมือกันกำหนดมาตรฐานการแบ่งปันข้อมูลแบบปลอดภัย สนับสนุนเทคโนโลยีปกป้องความเป็นส่วนตัว และให้แรงจูงใจเชิงนโยบายแก่ผู้ผลิต ระบบดังกล่าวจะสามารถขยายผลได้อย่างยั่งยืนและสร้างความเชื่อมั่นให้แก่ผู้บริโภคและทุกภาคส่วนในอุตสาหกรรมยานยนต์ไฟฟ้า
แนวทางต่อไปและบทสรุปเชิงกลยุทธ์
แนวทางต่อไปและบทสรุปเชิงกลยุทธ์
หลังจากผลลัพธ์จากโครงการนำร่องที่รายงานการลดค่าใช้จ่ายในการเรียกคืนและการเปลี่ยนแบตเตอรี่กว่า 60% สิ่งสำคัญคือการกำหนดเส้นทางที่ชัดเจนจากการทดลองสู่การขยายผลเชิงพาณิชย์เพื่อให้เกิดประโยชน์ทั้งด้านการผลิตและโมเดลธุรกิจที่ยั่งยืน แผนการขยายสเกลต้องผสานทั้งการปรับมาตรฐานข้อมูล การจัดการความเปลี่ยนแปลงภายในองค์กร และการสร้างพันธมิตรเชิงระบบนิเวศ (ecosystem) ที่ครอบคลุมตั้งแต่ผู้ประกอบการฟลีท ผู้ผลิต BMS ไปจนถึงผู้ให้บริการพลังงาน
Roadmap ที่แนะนำประกอบด้วยขั้นตอนหลักสามช่วง:
- Pilot → Enterprise Rollout: ขยายจากสายการผลิตตัวอย่างไปสู่การใช้งานในหลายโรงงาน โดยตั้งเป้าการขยายแบบเป็นขั้นตอน (phased rollout) เช่น 6–12 เดือนสำหรับการปรับเครื่องมือและการเทรนนิ่งในแต่ละไซต์ ก่อนขยายเป็นมาตรฐานโรงงานทั้งหมด ภายใน 12–24 เดือนคาดว่าจะเห็น ROI จากการลดการเปลี่ยนแบตและการเรียกคืน
- Federated Learning และ MLOps: นำแนวทางการเรียนรู้แบบกระจาย (federated learning) เพื่อรวมข้อมูลจากหลายไซต์โดยไม่ละเมิดความเป็นส่วนตัวของข้อมูล พร้อมระบบ MLOps สำหรับการ deploy, monitor และ retrain โมเดลเพื่อตอบโจทย์ drift ของแบตเตอรี่และลักษณะการใช้งานที่แตกต่างกัน
- Ecosystem Partnerships: สร้างความร่วมมือกับ fleet operators เพื่อเข้าถึงข้อมูลการใช้งานจริง, รวมกับผู้ผลิต BMS เพื่อให้การออกแบบระบบรองรับการส่งข้อมูลเรียลไทม์ และกับผู้ให้บริการพลังงาน/utility สำหรับการผสานฟีเจอร์ V2G และโครงการ second‑life
โอกาสเชิงธุรกิจที่ควรพัฒนาให้เป็นผลิตภัณฑ์และบริการมีหลายรูปแบบ เช่น:
- Predictive Maintenance as a Service (PMaaS): ให้บริการคาดการณ์สุขภาพแบตเตอรี่แบบเรียลไทม์แก่ผู้ผลิตและผู้ให้บริการฟลีท โดยเรียกเก็บเป็นรูปแบบ subscription หรือ PTP (pay‑per‑trigger) ตามกรณีที่ต้องดำเนินการจริง
- Data Services & Analytics: ให้สิทธิ์เข้าถึงชุดข้อมูลดิบหรือดัชนีเชิงวิเคราะห์ (เช่น SoH forecast, RUL distribution) แก่พันธมิตรอุตสาหกรรมในรูปแบบ licensing หรือ data marketplace ซึ่งสามารถเป็นรายได้เสริมและเพิ่มมูลค่าลูกค้า
- Aftermarket Savings & Warranty Products: เสนอโมเดลประกันยืดอายุหรือโปรแกรมรับประกันเบสท์ขึ้นกับการทำนาย SoH ช่วยลดความเสี่ยงของ OEM และลดต้นทุนการเปลี่ยนแบตเตอรี่ในระยะยาว
- Integration with V2G & Second‑Life: การคาดการณ์ SoH ที่มีความแม่นยำช่วยกำหนดจุดเวลาในการถอดแบตเตอรี่ออกจากยานพาหนะเพื่อเข้าสู่ตลาด second‑life หรือการให้บริการ V2G ต่อกริด ซึ่งเปิดช่องทางรายได้ใหม่จากการบริการพลังงาน (grid services) และการต่ออายุสินทรัพย์
คำแนะนำเชิงกลยุทธ์สำหรับผู้บริหารและทีมเทคโนโลยี:
- ลงทุนใน Data Governance และสถาปัตยกรรมข้อมูล: กำหนดมาตรฐาน schema, metadata, และนโยบายการเข้าถึงข้อมูลเพื่อให้ข้อมูลจากหลายโรงงานและพันธมิตรสามารถถูกรวมและใช้งานได้อย่างปลอดภัยและสอดคล้องกฎระเบียบ
- สร้างทีม MLOps และ Data Ops ที่แข็งแกร่ง: จัดสรรบุคลากรเฉพาะทางสำหรับการดูแล pipeline, การติดตามประสิทธิภาพโมเดลแบบเรียลไทม์, การตรวจจับ drift และการอัปเดตโมเดลอย่างต่อเนื่อง — สิ่งนี้ลดความเสี่ยงของโมเดลเสื่อมประสิทธิภาพเมื่อขยายสเกล
- ตั้ง KPI ทางธุรกิจและเทคนิคที่ชัดเจน: วัดผลด้วยตัวชี้วัดเช่น ความแม่นยำการทำนาย SoH, อัตราการลดการเรียกคืน, ต้นทุนการเปลี่ยนแบตเตอรี่ต่อคัน, และเวลาพักฟื้น (time‑to‑recover) เพื่อเชื่อมโยงเทคโนโลยีกับผลกำไร
- บริหารความเสี่ยงทางกฎหมายและความปลอดภัย: เตรียมแผนการปฏิบัติตามข้อกำหนดด้านความปลอดภัยของยานยนต์ การคุ้มครองข้อมูลส่วนบุคคล และมาตรการซีเคียวริตี้สำหรับการสื่อสารระหว่าง BMS, edge devices และ cloud
- วางโมเดลธุรกิจที่ยืดหยุ่น: ผสมผสาน subscription, usage‑based และ revenue share กับพันธมิตร เพื่อตอบโจทย์ทั้ง OEM, ฟลีท และผู้ให้บริการพลังงาน โดยออกแบบข้อเสนอให้ชัดเจนในเรื่อง SLA และโครงสร้างราคาที่สะท้อนการลดต้นทุนจริง
สรุปเชิงกลยุทธ์: การผสานเทคโนโลยี digital‑twin กับ machine learning สำหรับการทำนายอายุแบตเตอรี่เป็นจุดเริ่มต้นที่สามารถเปลี่ยนโซ่อุปทานยานยนต์ไฟฟ้าได้ทั้งระบบ หากองค์กรลงทุนในโครงสร้างพื้นฐานข้อมูล ทีม MLOps และความร่วมมือเชิงนิเวศอย่างถูกต้อง จะสามารถขยายบริการเชิงพาณิชย์ สร้างกระแสรายได้ใหม่จาก PMaaS, ข้อมูลเชิงวิเคราะห์ และตลาด second‑life รวมทั้งช่วยสร้างความได้เปรียบด้านต้นทุนและความเชื่อมั่นของลูกค้าในระยะยาว
บทสรุป
การผสานเทคโนโลยี Digital‑Twin กับโมเดล Machine Learning ในโรงงานยานยนต์ไทยได้เปลี่ยนแนวทางการจัดการแบตเตอรี่จากการตอบสนองเมื่อเกิดปัญหา (reactive) ไปสู่การคาดการณ์เชิงรุก (predictive) โดยระบบ Digital‑Twin จำลองสถานะของแบตเตอรี่แบบเรียลไทม์และให้ข้อมูลเชิงบริบทแก่โมเดล ML ที่คาดการณ์ State‑of‑Health (SoH) และ Remaining Useful Life (RUL) ผลลัพธ์ที่ได้คือการเรียกคืนสินค้าถูกจำกัดเฉพาะกรณีที่จำเป็นจริง ๆ การวางแผนเปลี่ยนแบตเตอรี่เป็นแบบคาดการณ์ล่วงหน้า รวมทั้งการปรับปรุงนโยบายรับประกัน ส่งผลให้การเรียกคืนและต้นทุนการเปลี่ยนแบตเตอรี่ลดลงมากกว่า 60% ในกรณีที่ออกแบบและปรับใช้ระบบอย่างถูกต้อง เช่น โครงการนำร่องภาคสนามที่รายงานการลดต้นทุนในการเปลี่ยนแบตเตอรี่กว่า 60% เมื่อมีการนำข้อมูลเซนเซอร์แบบเรียลไทม์และการวิเคราะห์เชิงพยากรณ์มาใช้ร่วมกัน

ความสำเร็จในระยะยาวไม่ได้ขึ้นอยู่กับโมเดลเพียงอย่างเดียว แต่ต้องอาศัย ข้อมูลคุณภาพสูง (telemetry ที่ละเอียดและการติดป้ายข้อมูล/labeling ที่ถูกต้อง), กระบวนการ MLOps ที่แข็งแรง (pipeline สำหรับการเก็บข้อมูล การฝึกซ้ำ การวางโมเดลสู่ production, การตรวจจับ concept drift และการมอนิเตอร์ประสิทธิภาพ) และกรอบนโยบายความปลอดภัยข้อมูลที่ชัดเจน (การเข้ารหัส การควบคุมการเข้าถึง และการปฏิบัติตามกฎระเบียบ) เพื่อให้สามารถขยายผลไปยังฟลีตใหญ่ขึ้น รักษาความแม่นยำของโมเดลเมื่อสภาพการใช้งานเปลี่ยนแปลง และสร้างความเชื่อมั่นต่อผู้บริโภค ด้านอนาคต เทคโนโลยีเหล่านี้มีศักยภาพขยายสู่การจัดการวัฏจักรชีวิตแบตเตอรี่ (second‑life) การผสานกับระบบโครงข่ายไฟฟ้า และการลดผลกระทบต่อสิ่งแวดล้อม แต่ต้องมีมาตรฐานอุตสาหกรรมและการพัฒนาทักษะบุคลากรควบคู่ไปด้วยเพื่อให้เกิดประโยชน์สูงสุดและยั่งยืน



