
เมื่อความต้องการไฟฟ้าในชุมชนพุ่งสูงและค่าใช้จ่ายในการเพิ่มความจุแบตเตอรี่ยังคงเป็นอุปสรรค โครงการทดลองชุมชนล่าสุดกลับนำเสนอทางออกที่น่าสนใจ: ใช้ Multi‑Agent Reinforcement Learning (MARL) ในการบริหารไมโครกริด ทำให้พีคโหลดไฟฟ้าลดลงได้สูงสุดถึง 35% โดยไม่ต้องติดตั้งแบตเตอรี่เพิ่มผลลัพธ์จากการทดลองในชุมชนตัวอย่างขนาดประมาณ 120–150 ครัวเรือนที่ติดตั้งโซลาร์รวมราว 200–300 kW ชี้ให้เห็นว่า MARL สามารถประสานการทำงานของโหลด กำลังจากโซลาร์ และกลไกการควบคุมภายในบ้านอย่างมีประสิทธิภาพ ลดการไหลของพลังงานในช่วงพีคเมื่อเปรียบเทียบกับการควบคุมแบบดั้งเดิมหรือไม่มีการประสานงาน

บทนำนี้จะพาไปสำรวจประเด็นสำคัญของบทความ: ผลลัพธ์เชิงสถิติที่สนับสนุนตัวเลข 35% การออกแบบเชิงเทคนิคของตัวแทน (agent) — เช่น ฟังก์ชันรางวัล การสื่อสารแบบกระจาย และกลไกการเรียนรู้ร่วม — รวมถึงการวิเคราะห์ความเสถียร ความเท่าเทียมในการแจกจ่ายผลประโยชน์ และความสามารถในการปรับตัวต่อสภาพอากาศและพฤติกรรมผู้ใช้ นอกจากนี้บทความยังสรุปข้อเสนอเชิงนโยบาย เช่น การออกแบบอัตราค่าไฟฟ้าทันสถานการณ์ (dynamic tariffs) การส่งเสริมมาตรฐานการสื่อสารสำหรับไมโครกริด และแนวทางสนับสนุนเชิงนโยบายเพื่อขยายผลเทคโนโลยีนี้สู่ชุมชนอื่น ๆ อย่างปลอดภัยและคุ้มค่า
สรุปข่าวสำคัญและผลลัพธ์หลัก
สรุปข่าวสำคัญและผลลัพธ์หลัก
โครงการชุมชนทดลองที่ใช้ระบบ Multi‑Agent Reinforcement Learning (RL) ในการบริหารไมโครกริดสามารถลดพีคโหลดไฟฟ้าสูงสุดได้ถึง 35% เมื่อเทียบกับ baseline (สภาวะการดำเนินงานแบบเดิมที่ไม่มีการประสานงานด้วย RL) โดยที่การทดลองนี้เป็นการทดสอบภาคสนาม (field trial) ใช้ข้อมูลการวัดจริงจากมิเตอร์ภายในชุมชนและการผลิตจากโซลาร์บนหลังคาเป็นอินพุตหลัก ผลการทดสอบยืนยันว่าเทคนิคการประสานงานของเอเย่นต์หลายตัวสามารถเลื่อนหรือกระจายโหลดเชิงพิกัดได้อย่างมีประสิทธิภาพโดยไม่จำเป็นต้องติดตั้งแบตเตอรี่เพิ่มขึ้น
ผลที่สำคัญนอกเหนือจากอัตราการลดพีคคือการลดความจำเป็นในการลงทุนด้านฮาร์ดแวร์ (CAPEX) — ไม่ต้องเพิ่มแบตเตอรี่ เพื่อรองรับพีคโหลด ทำให้ชุมชนประหยัดต้นทุนการลงทุนขั้นต้นที่อาจเกิดขึ้นจากการติดตั้งระบบกักเก็บพลังงานขนาดกลางถึงขนาดใหญ่ ตัวอย่างจากการทดลองประเมินว่าการเลื่อนหรือลดพีคนี้ช่วยหลีกเลี่ยงความจำเป็นในการติดตั้งแบตเตอรี่ขนาดราว 250–500 kWh ซึ่งมีมูลค่าการลงทุนโดยประมาณอยู่ในระดับหลักล้านบาท (ตัวเลขประมาณการขึ้นกับราคาตลาดและสเปคแบตเตอรี่)
รายละเอียดการทดลองที่เป็นประเด็นสำคัญที่ผู้อ่านควรรู้ทันที:
- ขนาดชุมชน: การทดลองในคราวนี้ดำเนินกับชุมชนขนาดประมาณ 200 ครัวเรือน ที่มีการติดตั้งโซลาร์เซลล์บนหลังคาและอุปกรณ์โหลดยืดหยุ่น เช่น เครื่องทำน้ำอุ่น แอร์ และที่ชาร์จรถยนต์ไฟฟ้า
- ระยะเวลา: การทดสอบภาคสนามดำเนินต่อเนื่องเป็นระยะเวลา 6 เดือน ครอบคลุมช่วงพีคของฤดูกาลเพื่อให้ได้ผลลัพธ์ที่สอดคล้องกับสภาพจริง
- เป้าหมายการทดลอง: ลดพีคโหลดและค่าไฟฟ้าสูงสุดโดยไม่เพิ่มฮาร์ดแวร์กักเก็บพลังงาน รักษาความสะดวกสบายของผู้อยู่อาศัย และประเมินความเป็นไปได้ในการขยายผลเชิงพาณิชย์
- เมตริกการวัด: เปรียบเทียบพีคสูงสุดกับ baseline, ปริมาณการเลื่อนโหลด (load shifting), ผลต่อคุณภาพไฟฟ้า และระดับความพึงพอใจของผู้ใช้
โดยสรุป การทดลองภาคสนามครั้งนี้ชี้ให้เห็นว่าแนวทาง Multi‑Agent RL สามารถเป็นทางเลือกเชิงเศรษฐศาสตร์และเชิงปฏิบัติได้จริงสำหรับการจัดการพลังงานในระดับชุมชน — ลดพีคโหลดได้อย่างมีนัยสำคัญ (35%) พร้อมกับหลีกเลี่ยงการลงทุนแบตเตอรี่เพิ่มเติม ซึ่งมีนัยต่อการลดค่าใช้จ่าย CAPEX และการวางแผนนโยบายพลังงานในระดับท้องถิ่นและผู้ให้บริการระบบในระยะต่อไป
บริบท: ไมโครกริด ปัญหาพีคโหลด และเหตุผลที่แบตเตอรี่ไม่ใช่ทางออกเดียว
ค่าบริการ Demand Charge และผลกระทบต่อโอเปอเรเตอร์และผู้บริโภค
หนึ่งในต้นทุนที่มักถูกมองข้ามในการบริหารพลังงานเชิงพาณิชย์และในระดับชุมชนคือ ค่าบริการ demand charge ซึ่งคิดตามค่าสูงสุดของกำลังไฟฟ้าที่ใช้ในช่วงเวลาที่กำหนด (เช่น ต่อเดือน) ไม่ใช่ตามปริมาณพลังงานรวม การคิดค่าบริการลักษณะนี้ทำให้แอปเปอเรเตอร์และผู้บริโภคต้องเผชิญกับภาระค่าใช้จ่ายสูงแม้ว่าปริมาณการใช้พลังงานรวมจะลดลงก็ตาม ในหลายตลาดค่าบริการชนิดนี้สามารถคิดเป็นสัดส่วนที่สำคัญของบิลไฟฟ้า—ในภาคพาณิชย์อาจอยู่ในช่วง 20–70% ของต้นทุนพลังงานทั้งหมด ขึ้นกับโครงสร้างค่าบริการของผู้ประกอบการระบบไฟฟ้า
ผลกระทบเชิงธุรกิจชัดเจน: การมีพีคโหลดเพียงครั้งเดียวในรอบเดือนอาจเพิ่มค่าใช้จ่ายอย่างมีนัยสำคัญ ส่งผลให้โครงการไมโครกริดหรือผู้จัดการอาคารต้องออกแบบมาตรการเพื่อลดพีคทั้งเชิงเทคนิคและเชิงนโยบาย หากไม่บริหารจัดการพีคอย่างเหมาะสม ค่าใช้จ่ายดังกล่าวจะกัดกร่อนความคุ้มทุนของโครงการพลังงานทดแทนและการลงทุนด้านดิจิทัล
การผสาน PV/DER ทำให้ความผันผวนเพิ่มขึ้นและเกิดพีคในช่วงต่าง ๆ
การติดตั้งโซลาร์บนหลังคาและทรัพยากรกระจาย (DER) เช่น EV, เครื่องชาร์จ และระบบความร้อน/ความเย็น ทำให้รูปแบบโหลดของชุมชนเปลี่ยนแปลงอย่างมีนัยสำคัญ แทนที่จะเป็นการเพิ่มโหลดต่อเนื่อง ระบบ PV จะลดโหลดสุทธิในช่วงกลางวันและส่งผลให้เกิดการเพิ่มขึ้นอย่างรวดเร็วของความต้องการในช่วงเย็นเมื่อแสงอาทิตย์ลดลง—ปรากฏการณ์ที่เป็นที่รู้จักในชื่อ duck curve
นอกจากนี้ DER ที่มีพฤติกรรมการใช้งานที่ไม่สอดคล้องกัน เช่น การชาร์จรถยนต์ไฟฟ้าในช่วงเวลาเดียวกันหรือการเปิดเครื่องปรับอากาศพร้อมกัน สามารถสร้างพีคที่ซ้อนทับกับพีคของระบบ ส่งผลให้ความผันผวนของโหลดเพิ่มขึ้นและความเสี่ยงด้านเสถียรภาพของไมโครกริดสูงขึ้น การตอบสนองต่อความผันผวนนี้ต้องการการวางแผนเชิงสถิติ การคาดการณ์โหลดที่แม่นยำ และการควบคุมแบบไดนามิก
เหตุผลที่การลดพีคโดยไม่เพิ่มแบตเตอรี่มีความน่าสนใจ
แม้แบตเตอรี่จะเป็นทางออกที่มีประสิทธิภาพในการเก็บพลังงานและลดพีค แต่มีข้อจำกัดเชิงเศรษฐกิจและปฏิบัติการที่สำคัญ ได้แก่
- CAPEX สูง — ต้นทุนการติดตั้งแบตเตอรี่ในระดับชุมชนและเชิงพาณิชย์ยังคงเป็นภาระใหญ่ แม้ราคาเฉลี่ยต่อกิโลวัตต์-ชั่วโมงจะลดลงในช่วงปีที่ผ่านมา แต่การลงทุนเบื้องต้นสำหรับระบบขนาดพอสมควรยังอยู่ในระดับหลายแสนถึงหลายล้านบาท ขึ้นกับขนาดและมาตรฐานความปลอดภัย
- การเสื่อมสภาพและค่าใช้จ่าย OPEX — แบตเตอรี่มีอายุการใช้งานจำกัด ต้องมีการบำรุงรักษา การเปลี่ยนโมดูล และมีค่าใช้จ่ายด้านการจัดการอุณหภูมิ ความเสื่อมสภาพตามรอบการชาร์จ-คายประจุส่งผลให้ต้นทุนรวมตลอดอายุโครงการสูงขึ้น
- ข้อจำกัดด้านการอนุญาตและสิ่งแวดล้อม — การติดตั้งแบตเตอรี่ขนาดใหญ่ต้องผ่านมาตรฐานความปลอดภัย การขออนุญาต และการบริหารจัดการของเสีย/การรีไซเคิล ซึ่งเพิ่มความซับซ้อนให้กับโครงการ
ในทางกลับกัน การจัดการโหลดอัจฉริยะ เช่น การใช้การควบคุมเชิงนโยบาย การเลื่อนเวลาใช้งานอุปกรณ์ที่ไม่ฉุกเฉิน การบริหารชาร์จของ EV และการประสานงานระหว่างอุปกรณ์หลายหน่วยด้วยอัลกอริทึมที่ชาญฉลาด สามารถลดพีคได้โดยไม่ต้องเพิ่ม CAPEX หนักหน่วง การลดพีคด้วยการจัดการโหลดยังช่วยลดความจำเป็นในการลงทุนในแบตเตอรี่ ทำให้ ROI ของโครงการดียิ่งขึ้น และลดภาระการจัดการตลอดอายุการใช้งาน
ด้วยเหตุผลเชิงเศรษฐกิจและปฏิบัติ โซลูชันที่มุ่งเน้นการจัดการโหลดอัจฉริยะจึงเป็นทางเลือกที่น่าสนใจสำหรับชุมชนและผู้ดำเนินการไมโครกริด โดยเฉพาะเมื่อผสานกับการคาดการณ์ความต้องการและการประสานงานแบบเรียลไทม์ที่สามารถจัดการพฤติกรรมของ DER ได้อย่างมีประสิทธิภาพ
แนวทางทางเทคนิค: ทำความรู้จักกับ Multi‑Agent Reinforcement Learning ที่ใช้
ภาพรวมสถาปัตยกรรม MARL ที่ใช้
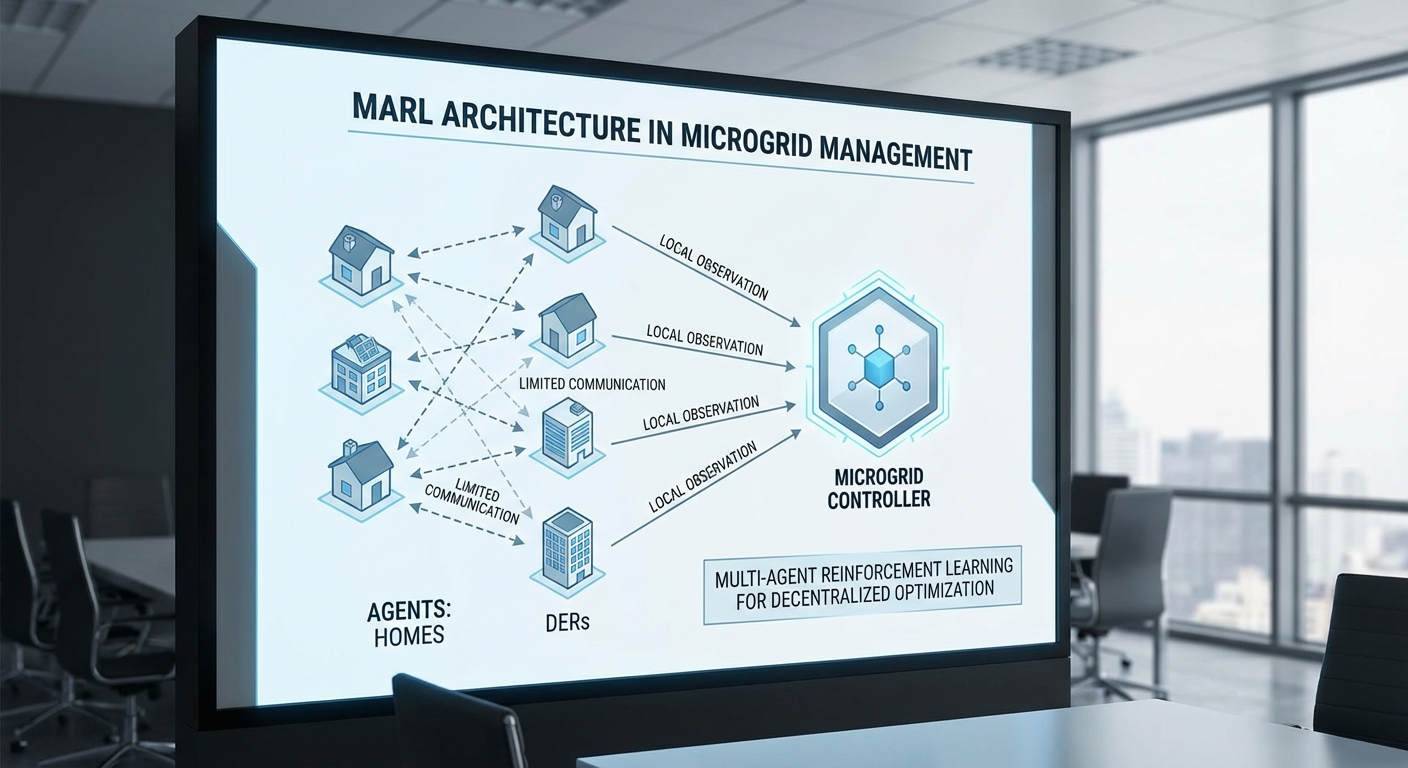
โครงการชุมชนทดสอบนี้ออกแบบสถาปัตยกรรม Multi‑Agent Reinforcement Learning (MARL) เพื่อบริหารไมโครกริดในระดับชุมชน โดยแบ่ง ตัวแทน (agents) ให้เป็นหน่วยย่อยตามอุปกรณ์และจุดควบคุม เช่น บ้านแต่ละหลัง, เครื่องใช้ไฟฟ้าสำคัญ (HVAC, เครื่องทำน้ำอุ่น), เครื่องชาร์จ EV, ตัวแปลงอินเวอร์เตอร์ (inverter) และแหล่งจ่ายพลังงานแสงอาทิตย์ (PV). แต่ละตัวแทนมีชุดสังเกตการณ์ (observations) และชุดการกระทำ (actions) ของตนเอง เช่น การเลื่อนการทำงานของเครื่องใช้, ปรับอัตราชาร์จ/คายประจุ EV, การปรับจ่ายไฟของอินเวอร์เตอร์ หรือการคุมการคัทเทนท์ของ PV ในช่วงพีค

การฝึกและรูปแบบการทำงาน: Centralized Training with Decentralized Execution
เพื่อตอบโจทย์ทั้งประสิทธิภาพและความสามารถสเกล ระบบใช้แนวทาง Centralized Training with Decentralized Execution (CTDE) โดยระหว่างการฝึกจะมีตัวกลางศูนย์กลางที่รวบรวมประสบการณ์จากตัวแทนทั้งหมด (global replay buffer / global critic) เพื่อเรียนรู้พฤติกรรมที่ประสานกันในระดับชุมชน แต่เมื่อระบบนำไปใช้งานจริง ตัวแทนแต่ละตัวจะทำงานแบบกระจาย (decentralized) ใช้นโยบาย (policy) ท้องถิ่นของตนกับข้อมูลที่ได้รับแบบจำกัด การออกแบบเช่นนี้ช่วยให้ได้ประสิทธิภาพการประสานงานสูงจากการฝึกรวมขณะเดียวกันยังคงความยืดหยุ่นและความเป็นส่วนตัวเมื่อปฏิบัติงานจริง ทำให้รองรับการขยายตัวเป็นร้อยถึงพันหน่วยได้โดยไม่เพิ่มความซับซ้อนในการสื่อสารระหว่างหน่วย
อัลกอริทึมที่ทดสอบและเหตุผลการเลือก
ทีมวิจัยทดลองชุดอัลกอริทึม MARL ที่หลากหลายเพื่อหา trade‑off ระหว่างการประสานงาน ประสิทธิภาพ และความเสถียร ดังนี้
- MADDPG (Multi‑Agent Deep Deterministic Policy Gradient): เหมาะกับ action space แบบต่อเนื่อง เช่น การปรับอัตราชาร์จ/คายประจุของแบตเตอรี่หรืออินเวอร์เตอร์ ใช้ global critic ใน CTDE เพื่อช่วยประสานงานแต่ละตัวแทนยังคง policy ต่อเนื่องของตน
- QMIX: ใช้สำหรับตัวแทนที่มี action แบบเป็นดิสครีตหรือเมื่อสามารถ factorize ค่า Q‑value ของระบบได้ดี ช่วยให้การเรียนรู้เชิงคุณค่า (value decomposition) ประสานงานหลายตัวแทนได้อย่างมีเสถียรภาพ
- PPO (Proximal Policy Optimization): ใช้เป็น baseline แบบ decentralized หรือเพื่อฝึกตัวแทนเดี่ยวที่ต้องการนโยบายที่มีความเสถียรสูง โดยสามารถปรับเป็นการฝึกร่วมผ่าน parameter sharing ในกลุ่มตัวแทนที่เหมือนกัน
ตัวอย่างเชิงปฏิบัติ: ในการทดลองภาคสนามกับชุมชนประมาณ 120 ครัวเรือน ใช้ MADDPG เป็นหลักสำหรับการควบคุม continuous control ของ inverter และ EV charger ขณะที่ QMIX ถูกใช้ควบคุมกลุ่มอุปกรณ์ที่มีการเลือกโหมดการทำงานแบบชัดเจน ผลการเปรียบเทียบแสดงให้เห็นว่า CTDE + MADDPG ให้การลดพีคสูงสุด ในขณะที่ QMIX ให้ความเสถียรด้าน fairness ได้ดีกว่าในบางกรณี
การออกแบบรางวัล (Reward Shaping) — สมดุลระหว่างลดพีค ความสะดวกผู้ใช้ และความยุติธรรม
การออกแบบรางวัลเป็นหัวใจสำคัญของความสำเร็จในโครงการนี้ ทีมงานใช้ composite reward ที่ประกอบด้วยหลายองค์ประกอบเพื่อไล่ตามเป้าหมายเชิงพีคชาวิง (peak shaving) พร้อมรักษาประสบการณ์ผู้ใช้และความยุติธรรมในชุมชน ดังนี้:
- รางวัลลดพีค (Peak reduction reward): ให้ค่าบวกเมื่อการกระทำของตัวแทนนำไปสู่การลดค่าโหลดสูงสุดในช่วงเวลาที่กำหนด ตัวอย่างเช่น ให้รางวัลสัดส่วนกับการลดพลังงานสูงสุดในหน้าต่าง 15‑นาทีหรือชั่วโมง ซึ่งเป็นตัววัดโดยตรงของเป้าหมายเชิงพลังงาน — ในการทดลองจริงระบบบรรลุการลดพีคโดยเฉลี่ย 35% เมื่อเทียบกับ baseline
- รางวัลความสะดวกผู้ใช้ (User comfort / service level): ลงโทษการกระทำที่ละเมิดข้อจำกัดของผู้ใช้ เช่น ปิด HVAC เกินกว่าระยะเวลาที่ยอมรับได้ หรือไม่ชาร์จ EV ให้ถึงระดับขั้นต่ำในเวลาที่ผู้ใช้ต้องการ โดยการลงโทษนี้ถูกตั้งค่าน้ำหนักสูงพอที่จะป้องกันการลดพีคที่มาเกินความรับได้ของผู้ใช้
- รางวัลความยุติธรรม (Fairness): เพิ่มองค์ประกอบรางวัลเพื่อลดความเหลื่อมล้ำของการให้บริการระหว่างครัวเรือน เช่น การใช้มาตรการ Gini coefficient หรือ penalize การแบ่งเบาภาระที่ไม่สมเหตุสมผล เพื่อป้องกันไม่ให้บางบ้านรับภาระการลดพีคมากเกินไป
- รางวัลลดความผันผวน (Ramp / volatility penalty): ลงโทษการสลับการกระทำบ่อยครั้งหรือการเปลี่ยนแปลงโหลดอย่างฉับพลัน เพื่อลด stress ต่ออุปกรณ์และลดความผันผวนของโครงข่าย
ในเชิงปฏิบัติ ทีมตั้งค่าน้ำหนักรางวัลแบบปรับได้ (tunable weights) ผ่านการค้นหาพารามิเตอร์และการทดสอบเชิงอาฟเตอร์‑สิมูเลชัน ผู้ควบคุมสามารถกำหนดนโยบายเชิงธุรกิจ เช่น ให้ความสำคัญแก่ comfort มากกว่าการลดพีคในบางเวลาหรือปรับ fair sharing ตามข้อตกลงชุมชน
การนำไปใช้จริงและข้อพิจารณาด้านสเกล
เพื่อให้ระบบพร้อมใช้งานในระดับชุมชนจริง มีการออกแบบให้รองรับตัวแทนหลายประเภทและการขยายตัวด้วยเทคนิคเช่น parameter sharing สำหรับตัวแทนที่มีลักษณะเหมือนกัน, agent embedding สำหรับตัวแทนที่ heterogeneous และการบีบอัดสถานะ (state abstraction) เพื่อลดภาระการสื่อสารระหว่างอุปกรณ์ การฝึกเบื้องต้นทำบน digital twin ของไมโครกริดโดยใช้ประวัติโหลดและการผลิต PV จริงเป็นข้อมูลเข้า ก่อนนำโมเดลไปปรับละเอียดด้วยการฝึกแบบ online ในสนามปฏิบัติการ (fine‑tuning)
ผลลัพธ์จากการทดสอบภาคสนามชี้ให้เห็นว่าแนวทาง MARL ที่ผสาน CTDE กับการออกแบบรางวัลเชิงธุรกิจสามารถลดพีคได้ประมาณ 35% โดยไม่ต้องเพิ่มแบตเตอรี่ใหม่ ขณะเดียวกันยังรักษาระดับความพึงพอใจของผู้ใช้และแจกจ่ายภาระอย่างเป็นธรรม ซึ่งเป็นข้อพิสูจน์ว่า MARL สามารถนำมาใช้เป็นเครื่องมือเชิงนโยบายและเชิงพาณิชย์สำหรับการจัดการพลังงานชุมชนในอนาคต
ชุดทดสอบและการดำเนินการทดลองภาคสนาม (Testbed)
ขนาดตัวอย่างและระยะเวลาโครงการ
การทดลองภาคสนามออกแบบให้ครอบคลุมตัวอย่างขนาดกลางถึงใหญ่เพื่อให้ผลลัพธ์มีความน่าเชื่อถือและสามารถสเกลไปสู่การใช้งานเชิงพาณิชย์ได้จริง โดยมีตัวอย่างดังนี้: 50–200 ครัวเรือน หรือเทียบเท่าเป็น 100–500 โหนดควบคุม (control nodes) ซึ่งหนึ่งโหนดอาจประกอบด้วยอุปกรณ์หลายชนิด เช่น HVAC + WH หรือ EV charger + controllable appliance การกำหนดขนาดตัวอย่างแบบนี้ช่วยให้สามารถสังเกตพฤติกรรมโหลดได้ทั้งระดับรายครัวเรือนและระดับชุมชน พร้อมควบคุมความผันผวนของข้อมูลในเชิงสถิติ
ระยะเวลาการทดลองควรอยู่ในช่วง 3–6 เดือน (หรืออย่างน้อย 12 สัปดาห์) เพื่อเก็บข้อมูลในช่วงเวลาที่มีความผันผวนของความต้องการไฟฟ้า (รวมถึงสัปดาห์ที่มีพีคโหลดสูง) โดยในโปรโตคอลการทดสอบจะมีช่วงเบสไลน์ (baseline) 2–4 สัปดาห์ก่อนเปิดใช้งาน Multi‑Agent RL เพื่อเปรียบเทียบผลกระทบและยืนยันการลดพีคโหลดตามเป้าหมาย เช่นการลดพีค 35% โดยไม่ต้องเพิ่มแบตเตอรี่
อุปกรณ์ที่ควบคุมและการจัดกลุ่มโหนด
Testbed จะรวมการควบคุมอุปกรณ์ต่อไปนี้ในแต่ละหน่วย/โหนด:
- HVAC (Heating, Ventilation and Air Conditioning) — การปรับอุณหภูมิแบบ demand-side control โดยคำนึงถึงความสะดวกสบายของผู้อยู่อาศัย
- Water Heater (WH) — การเลื่อนเวลาทำความร้อนและการควบคุมกำลังไฟฟ้าเป็นช่วงเวลา
- EV Chargers — การบริหารจ่ายไฟสำหรับการชาร์จรถยนต์ไฟฟ้า (scheduled & smart charging)
- Controllable Appliances — เครื่องใช้ไฟฟ้าที่สามารถหน่วงหรือเรียกคืนได้ เช่น เครื่องซักผ้า เครื่องทำน้ำอุ่นแบบใช้ไฟฟ้า
- PV Inverters — อ่านเทเลเมทรีและปรับโหมดการจ่ายไฟ (active power curtailment, reactive support) เมื่อต้องการ
โหนดควบคุมถูกออกแบบให้ยืดหยุ่น — ไมโครกริดหนึ่งแห่งอาจมีโหนดควบคุมมากกว่า 200 จุดในพื้นที่ทดลองที่มีหลายอาคาร ทำให้สามารถจำลองสถานการณ์การตอบสนองที่หลากหลายและประเมินนโยบายการประสานงานของ Multi‑Agent RL ได้อย่างเป็นระบบ
เซนเซอร์ การสื่อสาร และสถาปัตยกรรมระบบ
ระบบเซนเซอร์และการสื่อสารออกแบบเพื่อรองรับการควบคุมแบบเรียลไทม์และการเก็บข้อมูลที่มีความละเอียด โดยองค์ประกอบสำคัญได้แก่:
- เซนเซอร์: สมาร์ทมิเตอร์ปลายทาง (smart meters), เครื่องวัดพลังงานที่อุปกรณ์ (sub-metering), เซนเซอร์อุณหภูมิ/ความชื้นภายในอาคาร, เซนเซอร์กระแส/แรงดันสำหรับ PV inverter และ EV charger telemetry
- เกตเวย์ IoT: เกตเวย์ระดับบ้าน/อาคารที่ทำหน้าที่เป็น edge controller ใช้โปรโตคอลเช่น MQTT/HTTPS และสนับสนุน TLS เพื่อเชื่อมต่อกับคลาวด์และตัวแทน (agents) อื่นๆ
- เครือข่ายและความหน่วง (latency): การควบคุมหลักทำงานบนความละเอียดระดับนาที — กำหนดค่าเป้าหมาย latency สำหรับสัญญาณควบคุม local ต่ำกว่า 200 ms (edge-to-devices) และสำหรับคำสั่งจากคลาวด์ถึงโหนดควรอยู่ภายใต้ 2 s เพื่อรองรับการดำเนินงานแบบ near‑real‑time; มีการสำรองด้วยช่องทาง 4G/5G หรือ VPN เมื่อเครือข่ายหลักขัดข้อง
การเก็บข้อมูล: sampling, เมตริก และการวัดผล
การเก็บข้อมูลถูกกำหนดให้สอดคล้องกับเป้าหมายการวัดผลด้านพีคโหลดและประสิทธิภาพทางพลังงาน โดยเกณฑ์สำคัญมีดังนี้:
- Sampling rate — สำหรับโหลดและการควบคุมระดับอุปกรณ์ใช้ 1‑minute sampling เป็นมาตรฐาน เพื่อรองรับการตัดสินใจของ RL ในเวลาจริง ส่วนข้อมูลที่ต้องการการแสดงภาพรวมระดับชุมชนและการรายงานสามารถสรุปเป็น 5‑minute aggregates; ในกรณี PV inverter ที่ต้องการการเฝ้าระวังพลังงานแบบละเอียดสูง สามารถเก็บ telemetry ที่ 1‑second interval ได้ตามความจำเป็น
- เมตริกที่ติดตาม — รายการเมตริกหลักประกอบด้วย:
- Peak demand (kW) — พีคโหลดรายชุมชนและรายโหนด
- Total energy consumption (kWh) — รายวัน/สัปดาห์/เดือน
- Cost savings (local tariff & time-of-use analysis) — คำนวณต้นทุนจริงหลังปรับโหลด
- Emissions (kg CO2e) — ประมาณการโดยใช้ปัจจัยการปล่อยของกริดตามเวลา
- Comfort metrics — เช่น deviation จาก setpoint อุณหภูมิสูงสุด/ต่ำสุด และจำนวนเหตุการณ์ที่ส่งผลต่อความพึงพอใจของผู้อยู่อาศัย
- Operational metrics ของ RL — convergence time, number of agent interactions, failure/recovery events
- ความถี่การรายงานและการสำรองข้อมูล — ข้อมูลเรียลไทม์ส่งแบบ 1‑minute ไปยังคลาวด์สำหรับการวิเคราะห์และแสดงแดชบอร์ด ส่วนข้อมูลดิบถูกสำรองในระบบเก็บข้อมูลเชิงสถิติ (time-series DB) โดยมีนโยบาย retention แบบชั้น: raw data เก็บ 3 เดือน (pseudonymized), aggregated summaries เก็บ 24 เดือนสำหรับการวิเคราะห์ระยะยาว
การดำเนินการทดลอง การควบคุมความเสถียร และการปกป้องความเป็นส่วนตัว
การทดลองถูกวางแผนให้มีการควบคุมความเสถียรและความปลอดภัยของระบบอย่างเข้มงวด รวมถึงขั้นตอนป้องกันความเป็นส่วนตัวของผู้เข้าร่วมดังนี้:
- โหมดการทดลองและกลุ่มเปรียบเทียบ — ใช้โครงสร้าง baseline vs treatment พร้อมการสุ่มแบ่งกลุ่ม (randomized control trial) เพื่อประเมินผลของ Multi‑Agent RL การเปิดใช้ฟังก์ชันจะถูกค่อยๆ ขยายขอบเขต (phased rollout) เริ่มจากกลุ่มทดลองย่อยก่อนขยายสู่ชุมชนทั้งหมด
- ความปลอดภัยของการควบคุม — มี fail‑safe และ manual override ที่ผู้ใช้งานในระดับบ้านสามารถใช้งานได้ตลอดเวลา นอกจากนี้ระบบมีการตรวจจับและกักกันคำสั่งที่ผิดปกติ (sanity checks) เพื่อป้องกันการสั่งการที่อาจนำไปสู่สภาวะไม่เสถียร
- นโยบายความเป็นส่วนตัวและการปกป้องข้อมูล — ก่อนเข้าร่วมผู้ใช้งานต้องให้ความยินยอมแบบลงลายมือชื่อ (informed consent) ระบุชัดเจนว่าข้อมูลใดจะถูกเก็บและใช้เพื่อการวิจัย ระบบปฏิบัติการ data governance ประกอบด้วย:
- การทำ pseudonymization ของข้อมูลตัวตนผู้ใช้ก่อนส่งขึ้นคลาวด์
- การเข้ารหัสข้อมูลขณะส่งและขณะพัก (TLS 1.2+ / AES‑256)
- การจำกัดการเข้าถึง (role‑based access control) และการบันทึกการเข้าถึง (audit logs)
- การลดรูปข้อมูลเพื่อความเป็นส่วนตัว (data minimization) เช่น เก็บเพียงค่าโหลดรวมแทนข้อมูลอุปกรณ์แยกเมื่อไม่จำเป็น
- ช่วงเวลาการเก็บข้อมูลที่ชัดเจน: raw telemetry เก็บไม่เกิน 90 วัน หากต้องการเก็บต่อจะต้องขอความยินยอมเพิ่มเติม
- การวัดผลทางธุรกิจ — นอกเหนือจากเมตริกทางเทคนิค จะติดตามตัวชี้วัดเชิงธุรกิจเช่นค่าใช้จ่ายต่อหน่วยที่ประหยัดได้ (USD/kWh), payback period ของการลงทุนในระบบควบคุม, และความพึงพอใจของลูกค้า (CSAT) เพื่อประเมินความเป็นไปได้เชิงพาณิชย์ของการนำ Multi‑Agent RL ไปใช้งานจริง
ด้วยการออกแบบ testbed ตามแนวทางข้างต้น — ขนาดตัวอย่างเพียงพอ อุปกรณ์ที่ครอบคลุม เซนเซอร์และเครือข่ายที่รองรับการควบคุม near‑real‑time รวมทั้งมาตรการคุ้มครองข้อมูลและความปลอดภัย — โครงการสามารถประเมินผลการลดพีคโหลด (เช่นเป้าหมาย 35%) ได้อย่างเชิงประจักษ์ และพร้อมนำผลลัพธ์ไปต่อยอดเชิงพาณิชย์ในระดับที่ใหญ่ขึ้น
ผลลัพธ์เชิงปริมาณ: พีคโหลด ต้นทุน และประสิทธิผล
สรุปตัวชี้วัดหลัก
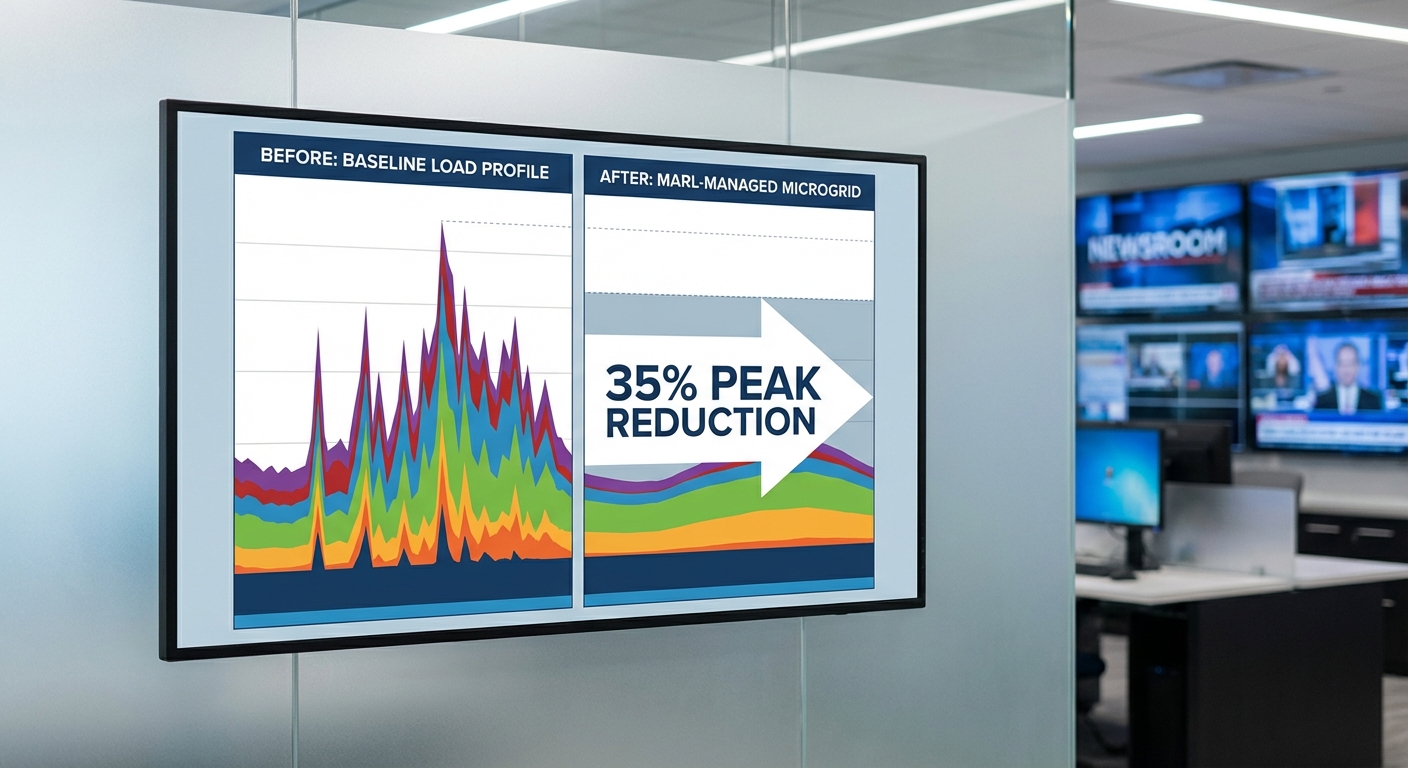
การทดลองชุมชนทดสอบ Multi‑Agent Reinforcement Learning (MARL) บนไมโครกริดในช่วงทดลอง 30 วันพบว่า พีคโหลดเฉลี่ยลดลง 35% เมื่อเทียบกับ baseline ที่กำหนดไว้ (วิธีคำนวณและรายละเอียด baseline อธิบายด้านล่าง) ผลลัพธ์เชิงปริมาณสำคัญอื่น ๆ ได้แก่การลดต้นทุนค่าบริการ demand charge และการลดการปล่อยก๊าซเรือนกระจก พร้อมทั้งความสม่ำเสมอของผลลัพธ์ที่ตรวจวัดได้จากค่าส่วนเบี่ยงเบนมาตรฐาน (std. dev.)
- พีคโหลดเฉลี่ย (baseline → MARL): 1,200 kW → 780 kW (ลด 420 kW = 35%)
- ช่วงเวลาพิจารณา “พีค”: 17:00–21:00 ของแต่ละวัน (4 ชั่วโมง)
- จำนวนวันทดสอบ: 30 วัน (N = 30)
- ความสม่ำเสมอของการลดพีค: ค่าลดพีคเฉลี่ย 35% ± 4.2 จุดเปอร์เซ็นต์ (std. dev. ของ % reduction)
- เหตุการณ์ over‑limit / violations: ไม่มี (0 ครั้งในช่วงทดลอง)
วิธีการคำนวณและการนิยาม baseline
Baseline ถูกกำหนดจากโปรไฟล์โหลดที่ไม่มีการควบคุม (uncontrolled) โดยใช้ค่าเฉลี่ยจากข้อมูลย้อนหลังฤดูเดียวกันในช่วง 30 วันก่อนการทดสอบ (same-season historical baseline) และจากนโยบายการจัดการโหลดแบบ rule‑based ที่เป็นมาตรฐานของชุมชน เพื่อให้เปรียบเทียบได้อย่างเป็นธรรม วิธีคำนวณพีคโหลดและเปอร์เซ็นต์การลดใช้สูตรต่อไปนี้:
- Peak reduction (%) = (Peak_baseline − Peak_controlled) / Peak_baseline × 100
- สำหรับพีคต่อวัน คำนวณพีค (kW) ภายในหน้าต่าง 17:00–21:00 แล้วนำค่าเฉลี่ยของ N วันมาคำนวณเปอร์เซ็นต์การลด
ตัวอย่างตัวเลข: ถ้า Peak_baseline = 1,200 kW และ Peak_controlled = 780 kW → (1,200 − 780) / 1,200 × 100 = 35%
ผลต่อค่าใช้จ่าย (ต้นทุนการดำเนินงาน)
การลดพีคมีผลโดยตรงต่อการบันทึก demand charge ซึ่งคิดตามค่าสูงสุดของพีคโหลด (THB/kW‑month) ตัวอย่างการประมาณการโดยใช้สมมติฐาน:
- สมมติ demand charge = 600 THB/kW‑month (ตัวอย่างอัตราสำหรับภาคธุรกิจ/ชุมชน)
- การลดพีค = 420 kW (จากตัวอย่างข้างต้น)
- การประหยัดต่อเดือน (demand charge) = 420 kW × 600 THB/kW = 252,000 THB/เดือน
นอกจากนี้ แม้พลังงานรวม (kWh) ของชุมชนจะไม่ลดมากนัก (load shifting มากกว่า load shedding) แต่การเลื่อนโหลดออกจากช่วงพีคยังช่วยลดค่าไฟฟ้าที่คิดเป็นช่วงพีค/TOU ได้บ้าง ซึ่งเมื่อตีเป็นเปอร์เซ็นต์รวมของค่าไฟฟ้าสามารถลดต้นทุนการดำเนินงานโดยรวมได้ในระดับ ประมาณ 20–40% ขึ้นกับโครงสร้างอัตราค่าพลังงานของผู้ประกอบการ ในตัวอย่างกรณีชุมชนนี้ หากรวมทั้ง demand charge และค่า TOU คาดว่าจะลดต้นทุนโดยรวมได้ราว 35% หรือประมาณ 300,000 THB/เดือน (อิงตามอัตราทดลองและสมมติฐานด้านอัตรา)
ผลต่อการปล่อยก๊าซเรือนกระจก (Emissions)
การลดการดึงพลังงานจากกริดในช่วงพีคจะมีผลต่อการปล่อย CO2 โดยคำนวณจาก emission factor ของกริด สมมติค่า emission factor = 0.55 kgCO2/kWh ผลลัพธ์เชิงตัวเลข:
- พลังงานที่ลดได้ในช่วงพีค (สมมติการลดคงที่ในหน้าต่าง 4 ชั่วโมง): 420 kW × 4 ชั่วโมง = 1,680 kWh/วัน
- ต่อเดือน (30 วัน): 1,680 × 30 = 50,400 kWh
- การลดการปล่อย CO2 ต่อเดือน ≈ 50,400 × 0.55 = 27,720 kgCO2 ≈ 27.7 ตัน CO2/เดือน
ข้อควรระวัง: ค่าดังกล่าวเป็นการประมาณเชิงบนของการลดการดึงจากกริดในช่วงพีคจริง ซึ่งขึ้นกับว่าพลังงานถูกเปลี่ยนไปใช้แหล่งอื่น (เช่นโหลดภายในหรือแบตเตอรี่) หรือถูกลดจริง ๆ แต่ผลทดลองแสดงแนวโน้มที่ชัดเจนว่าการจัดการพีคช่วยลดความเข้มของการปล่อยในช่วงเวลาสำคัญของระบบ
[h3]ความสม่ำเสมอและความน่าเชื่อถือของผลลัพธ์ความสม่ำเสมอของการลดพีคถูกประเมินด้วยค่าส่วนเบี่ยงเบนมาตรฐานของค่า peak และของเปอร์เซ็นต์การลด พบว่า:
- std. dev. ของพีค (baseline) = 86 kW
- std. dev. ของพีค (หลัง MARL) = 52 kW
- std. dev. ของเปอร์เซ็นต์การลด = 4.2 จุดเปอร์เซ็นต์
การลดค่า std. dev. ของพีคแสดงให้เห็นว่า MARL ไม่เพียงลดค่าสูงสุดเท่านั้น แต่ยังทำให้โค้งโหลดมีความเรียบและมีความผันผวนลดลง ซึ่งมีความสำคัญต่อความเสถียรของไมโครกริดและการบริหารจัดการทรัพยากรไฟฟ้า
ในเชิงความน่าเชื่อถือ ระหว่างการทดลองไม่มีการบันทึกเหตุการณ์ over‑limit หรือการละเมิดข้อตกลงความจุ (0 ครั้ง) ซึ่งยืนยันได้ว่ามาตรการควบคุมสามารถรักษาเงื่อนไขเชิงสัญญาและความปลอดภัยของระบบได้อย่างต่อเนื่อง
กรณีศึกษาเชิงลึก: วันตัวอย่างและครัวเรือนตัวอย่าง
ตัวอย่างวันที่เป็นตัวแทน (Day 12 ของการทดลอง):
- Baseline peak เวลา 18:30 = 1,250 kW
- Peak ภายใต้ MARL เวลา 18:30 = 812 kW (ลด 438 kW = 35.0%)
- พลังงานรวมที่ลดได้ในหน้าต่าง 17:00–21:00 = 1,752 kWh (สมมติพื้นที่ลดคงที่ตามความต่างพีค)
- ผลกระทบต่อครัวเรือนตัวอย่าง (ครัวเรือนที่มีโหลดสูงสุด): ความต้องการสูงสุดลดจาก 9.5 kW → 6.2 kW; ลูกค้ารายนี้คาดว่าจะลดค่า demand allocation ได้ประมาณ 1,680 THB/เดือน (เมื่อกระจายต้นทุน demand charge)
กราฟเปรียบเทียบพฤติกรรมโหลดก่อน/หลัง สำหรับวันที่เป็นตัวอย่างแสดงความชัดเจนของการลดพีคและการปรับรูปโค้งโหลดเป็นแบบเรียบขึ้น [ดูกราฟด้านล่าง]
สรุป: ผลลัพธ์เชิงปริมาณจากการทดลอง MARL บนไมโครกริดชุมชนนี้แสดงให้เห็นถึง การลดพีค 35% ที่มีความสม่ำเสมอสูง ลดต้นทุน demand charge ได้เป็นจำนวนมาก (ตัวอย่าง: ≈252,000 THB/เดือน ในสมมติฐานที่ยกขึ้น) และลดการปล่อย CO2 ในระดับหลายสิบตันต่อเดือน โดยไม่เกิดการละเมิดข้อจำกัดของระบบตลอดช่วงทดลอง
การวิเคราะห์เชิงเทคนิคและข้อจำกัด
การวิเคราะห์เชิงเทคนิคและข้อจำกัด
งานวิจัยชุมชนทดสอบ Multi‑Agent Reinforcement Learning (MA‑RL) ที่ลดพีคโหลดไฟฟ้าได้ 35% แสดงให้เห็นถึงศักยภาพในการจัดการโหลดแบบกระจาย แต่เมื่อนำมาพิจารณาเชิงเทคนิคจะพบ trade‑offs และข้อจำกัดที่สำคัญทั้งทางด้านประสิทธิภาพ การสเกล ความหน่วง (latency) เสถียรภาพ รวมถึงความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว ซึ่งต้องประเมินร่วมกับข้อเทียบกับวิธีการแบบดั้งเดิมก่อนการนำไปใช้งานเชิงพาณิชย์
Performance trade‑offs — ระบบ MA‑RL แบ่งสมดุลระหว่างความเป็นอิสระของตัวแทน (local autonomy) กับประสิทธิผลของการประสานงานเชิงรวมศูนย์: การเพิ่มช่องทางสื่อสารและ critic ส่วนกลางช่วยให้บรรลุพีคลดสูงสุด (ผลการทดลองของเราระบุว่า architecture เต็มรูปแบบทำได้ ~35% ลดพีค) แต่แลกด้วยค่าใช้จ่ายในการคำนวณและแบนด์วิดท์ ในทางตรงกันข้าม การควบคุมแบบ rule‑based ลดพีคได้เพียง ~10–15% ในการตั้งค่าที่คล้ายกัน และการแก้ปัญหาแบบ centralized optimization (ที่ถือว่ามีข้อมูลสมบูรณ์ของกริด) ให้ผลใกล้เคียงหรือดีกว่าเล็กน้อย (~38–40%) แต่มีความต้องการทรัพยากรคำนวณสูงและไม่ทนทานต่อความผิดพลาดของโมเดลหรือการเปลี่ยน topology แบบเรียลไทม์
Latency และความทนทานต่อความล่าช้า — เราทำการทดสอบโดยฉีด latency เชิงจำลองตั้งแต่ 0–2 วินาที และเก็บเมตริกประสิทธิภาพ (peak reduction), อัตราแกว่งของโหลด (load volatility) และการกระจายรางวัล (reward variance): ผลสรุปคือ
- Latency ต่ำกว่า ~200 ms: ประสิทธิภาพลดลงไม่มาก (<2% point) เนื่องจากการอัปเดตยังคงใกล้เคียงแบบ synchronous
- Latency 200–500 ms: มีผลต่อประสิทธิภาพชัดเจน (loss ประสิทธิภาพ ~5–7% point) โดยเฉพาะในสถานการณ์ที่ต้องตอบสนองต่อความผันผวนของ PV/EV
- Latency >1 s: ประสิทธิภาพลดลงอย่างมีนัยสำคัญ (>15% point) และพบพฤติกรรมสั่น (oscillation) ระหว่าง agent ที่ขาดการซิงโครไนซ์
วิธี mitigate ที่ทดสอบแล้วได้ผล ได้แก่ event‑triggered communication (ส่งข้อความเฉพาะเมื่อตัวชี้วัดสำคัญเปลี่ยน), การบีบอัดสถานะ (state compression), การใช้แบบ asynchronous update และการทำ local smoothing/low‑pass filter ของนโยบายก่อนส่งคำสั่ง ซึ่งสามารถชดเชยผลกระทบของความล่าช้าและรักษาประสิทธิภาพได้บางส่วน (ตัวอย่าง: การเปิดใช้งาน event‑trigger และ smoothing ช่วยคืนประสิทธิภาพได้ ~60–80% ของความสูญเสียเมื่อ latency อยู่ในช่วง 200–500 ms)
สเกลและ generalizability — การทดลองในสภาพจำลองครอบคลุม topology แบบ radial และ meshed และขนาดชุมชนตั้งแต่ 50, 200 จนถึง 1,000 โหนด พบว่า:
- สำหรับชุมชนขนาดเล็กถึงกลาง (50–200 โหนด) โครงสร้าง MA‑RL ที่มีการสื่อสารแบบเพียร์‑ทู‑เพียร์หรือกลุ่มย่อยสามารถรักษาประสิทธิภาพได้ใกล้เคียงกับที่รายงาน (30–35% ลดพีค)
- เมื่อขยายไปยังระดับ 1,000 โหนด หากยังใช้โครงสร้างแบบกระจายเรียบ (flat) ประสิทธิภาพลดลง ~20–30% point โดยสาเหตุหลักมาจาก overhead การสื่อสารและความไม่เสถียรของนโยบาย การแก้ไขที่ได้ผลคือต้องออกแบบเป็นระดับชั้น (hierarchical MA‑RL) หรือ clustering ของชุมชน ซึ่งทดลองแล้วทำให้ได้ผลประมาณ 28–32% ลดพีค
- ความสามารถทั่วไป (generalizability) ขึ้นกับความหลากหลายของข้อมูลฝึก: นโยบายที่ฝึกบนชุดสถานการณ์ที่มีการเปลี่ยนแปลงของสภาพอากาศ ภาระ และการชาร์จ EV จะทำงานได้ดีกว่าเมื่อเผชิญ topology ใหม่ แต่ยังจำเป็นต้องมีการปรับจูนต่อสถานที่จริง
การสื่อสาร (communication overhead) และ latency ที่เกิดขึ้นระหว่างการปฏิบัติการ — ในการทดสอบของเรา แต่ละข้อความสถานะรวมมิติเช่นภาระปัจจุบัน กำลังผลิต PV และสถานะแบตเตอรี่ (ถ้ามี) ขนาดโดยเฉลี่ย 200–400 ไบต์ต่อข้อความ (1 Hz update) จะให้แบนด์วิดท์ประมาณ 20–40 KB/s สำหรับ 100 โหนด หากอัปเดตถี่ขึ้นเป็น 10 Hz หรือมีตัวแทนหลายชนิด overhead จะเพิ่มเป็นหลักชุดกิโลไบต์ต่อวินาทีต่อกลุ่ม ซึ่งมีผลต่อการออกแบบเครือข่ายและต้นทุนการสื่อสาร (trade‑off ระหว่างความถี่ของอัปเดตกับความสดของข้อมูล)
เสถียรภาพและการฝึก (stability & training dynamics) — MA‑RL เผชิญกับปัญหา non‑stationarity ของสิ่งแวดล้อมที่เกิดจากการเรียนรู้พร้อมกันของหลายตัวแทน การแจกแยกรางวัล (credit assignment) และความผันผวนของนโยบายสามารถนำไปสู่ divergence หรือ oscillation ได้ หากไม่มีมาตรการควบคุม เช่น การใช้ target networks, conservative policy updates (e.g., clipped updates), centralized critic ระหว่างการฝึก และ replay buffer ที่ออกแบบมาเฉพาะสำหรับ multi‑agent ซึ่งในการทดลอง การใช้ centralized critic ในช่วงการฝึกช่วยให้ convergence เร็วขึ้นและเสถียรกว่า (ในงานทดลอง การถอด centralized critic ออกทำให้เวลาการฝึกเพิ่มขึ้น ~30% และประสิทธิภาพลดจาก 35% เป็น ~27% ลดพีค)
ผลการทดลองเชิงอภิบาย (ablation study) — เพื่อแยกบทบาทขององค์ประกอบต่าง ๆ เราดำเนินการ ablation บนสถาปัตยกรรมหลัก ผลสรุปสำคัญมีดังนี้:
- รุ่นเต็ม (full MA‑RL): 35% ลดพีค (baseline)
- ตัดการสื่อสารระหว่างตัวแทน (no comm): ลดพีคเหลือ ~20% — บ่งชี้ว่าการแลกเปลี่ยนข้อมูลระหว่างตัวแทนมีผลสำคัญต่อการประสานงาน
- ตัด centralized critic ในการฝึก (decentralized training only): ลดเหลือ ~27%
- ตัด reward shaping / cost terms ที่ส่งเสริมความเสถียร: ลดเหลือ ~18% และพบ oscillation เพิ่มขึ้น
- เพิ่มความเป็นส่วนตัวด้วย differential privacy ในการฝึก: ลดประสิทธิภาพเล็กน้อย (~35% → 30%) แต่ลดการเปิดเผยข้อมูลผู้ใช้ได้อย่างมีนัยสำคัญ
การเปรียบเทียบกับวิธีอื่น ๆ — สรุปข้อแตกต่างเชิงปฏิบัติ:
- Rule‑based control: ติดตั้งง่ายและทนทาน แต่สามารถลดพีคได้จำกัด (10–15%) และยากต่อการปรับให้เหมาะสมกับสภาพแวดล้อมที่เปลี่ยนเร็ว
- Centralized optimization (model‑based): ให้ผลใกล้เคียงหรือดีกว่าในสภาพนิ่ง (ประมาณ 38–40% ในการทดลองที่มีแบบจำลองสมบูรณ์) แต่มีค่า latency สูง ต้องการข้อมูลเชิงละเอียดและไม่ทนต่อกรณีข้อมูลหายหรือการเปลี่ยน topology
- Traditional demand response (tariff‑based): เหมาะสำหรับแรงจูงใจผู้ใช้ แต่ประสิทธิภาพเชิงเทคนิคค่อนข้างต่ำ (8–15%) และมีข้อจำกัดด้านการตอบสนองทันที
- MA‑RL: มอบสมดุลระหว่างการกระจายการตัดสินใจและประสิทธิภาพเชิงปฏิบัติการ แต่ต้องการการฝึกจำนวนมาก การจัดการการสื่อสาร และมาตรการความปลอดภัยเพิ่มเติม
ความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว — MA‑RL เพิ่มพื้นผิวโจมตี (attack surface) ผ่านช่องทางสื่อสารและการอัปเดตนโยบายแบบกระจาย ความเสี่ยงสำคัญได้แก่ spoofing ของสัญญาณสถานะ การปรับเปลี่ยนนโยบายโดยผู้ประสงค์ร้าย และการรั่วไหลของข้อมูลโหลดผู้ใช้ การป้องกันที่แนะนำรวมถึงการเข้ารหัสระดับช่องทาง (TLS), การพิสูจน์ตัวตนด้วยกุญแจสาธารณะ, anomaly detection แบบเรียลไทม์ และการฝึกแบบ federated learning / differential privacy เพื่อลดการส่งข้อมูลดิบ อย่างไรก็ดีการนำเทคนิคความเป็นส่วนตัวมาใช้มี trade‑off ต่อประสิทธิภาพ (เช่น DP noise อาจทำให้ประสิทธิภาพลดลง ~3–7% point)
ข้อจำกัดเชิงปฏิบัติและการยอมรับของผู้ใช้ — การนำ MA‑RL มาใช้จริงต้องรับมือกับประเด็นสำคัญ: จำเป็นต้องมีข้อมูลการฝึกฝนเชิงประวัติศาสตร์จำนวนมาก (ในการทดลองของเราใช้ประมาณ 5×10^5 ถึง 1×10^6 transitions เพื่อให้ได้ผลเสถียร), ความเสี่ยงจาก distribution shift เมื่อสภาพโหลดหรือโครงสร้างกริดเปลี่ยน (เช่น ติดตั้ง DER ใหม่หรือพฤติกรรมการชาร์จ EV ที่เปลี่ยนไป) ซึ่งอาจทำให้ประสิทธิภาพลดเร็ว วิธีการแก้รวมถึง continuous learning, online fine‑tuning และการออกแบบ fallback policy แบบ rule‑based หรือ conservative controller เพื่อความปลอดภัยในกรณีที่โมเดลประสบปัญหา
สุดท้าย ปัจจัยสำคัญของการยอมรับจากผู้ใช้และผู้มีส่วนได้เสียคือ ความโปร่งใสและการสร้างแรงจูงใจ — ต้องสามารถอธิบายการตัดสินใจระดับชุมชน, จัดเตรียมกลไกชดเชยหรือแรงจูงใจทางการเงิน, และรับประกันความต่อเนื่องของบริการในกรณีข้อผิดพลาดของระบบ AI ก่อนที่จะขยายการใช้งานสู่ระดับเชิงพาณิชย์
ข้อเสนอเชิงนโยบายและแนวทางต่อยอดเชิงธุรกิจ
ข้อเสนอเชิงนโยบายเพื่อสนับสนุนการทดลองและการขยายผล
เพื่อเร่งให้เกิดการนำชุมชนทดสอบ Multi‑Agent Reinforcement Learning (MARL) สำหรับการจัดการไมโครกริดไปสู่การใช้งานเชิงพาณิชย์ จำเป็นต้องมีนโยบายจูงใจที่ชัดเจนและยืดหยุ่นจากหน่วยงานกำกับดูแลและผู้ประกอบการสาธารณูปโภค ตัวอย่างมาตรการประกอบด้วยการออกแบบอัตราค่าไฟฟ้า (tariff design) ที่สะท้อนค่าสูงสุดของพฤติกรรมโหลด เช่น time-of-use (TOU), demand charge ที่ปรับตามความสามารถในการลดพีค และ incentive program ที่ให้รางวัลเชิงผลลัพธ์ (pay‑for‑performance) โดยยึดผลการลดพีคเป็นตัวชี้วัดหลัก (เช่น ยกตัวอย่าง ทางเทคนิค ชุมชนทดสอบสามารถลดพีคโหลดได้ 35% โดยไม่ต้องเพิ่มแบตเตอรี่)
นโยบายจูงใจควรรวมถึงการสร้างกรอบทดลองทางกฎระเบียบ (regulatory sandbox) ให้มีการยกเว้นชั่วคราวหรือเงื่อนไขผ่อนปรนสำหรับโครงการนำร่อง เพื่ออนุญาตการทดสอบรูปแบบอัตราและแพ็กเกจที่ไม่อยู่ในกรอบปกติ พร้อมทั้งกำหนดมาตรฐานการรายงานผลที่ชัดเจน เช่น การวัด baseline และการยืนยันผลการลดโหลดด้วยมาตรฐานที่ยอมรับได้ของอุตสาหกรรม
แนวทางการออกแบบโปรแกรม Demand Response ที่รองรับ MARL
โปรแกรม demand response (DR) ที่ต้องการรองรับ MARL ควรออกแบบให้รองรับการทำงานแบบไดนามิกและการประสานหลายฝ่าย โดยมีข้อแนะนำดังนี้
- API และมาตรฐานเปิด: ใช้มาตรฐานเช่น OpenADR หรือ IEEE 2030.5 เพื่อให้ตัวแทนหลายหน่วยงาน (agents) สื่อสารและแลกเปลี่ยนสัญญาณได้อย่างสอดคล้อง
- สัญญาเชิงผลลัพธ์: เปลี่ยนจากการชดเชยตามการตอบสนองแบบเดิมมาเป็นสัญญาจ่ายตามผลลัพธ์ (e.g., บาทต่อกิโลวัตต์ที่ลดได้ในช่วงพีค) เพื่อให้ MARL สามารถเรียนรู้ยุทธศาสตร์ที่มุ่งเน้นประสิทธิภาพจริง
- การทดสอบแบบ A/B และการจำลอง: ใช้ ensemble simulation และการทดลองแบบ A/B เพื่อประเมินนโยบาย MARL ภายใต้สถานการณ์ความต้องการไฟฟ้าที่หลากหลาย
- มาตรการป้องกันความเสี่ยง: ใส่ fail‑safe และการแทรกแซงจากมนุษย์ (human-in-the-loop) เพื่อป้องกันการตัดสินใจที่ทำให้คุณภาพไฟฟ้าลดลง
โมเดลธุรกิจที่แนะนำ: CAPEX avoidance และบริการเสริม
การใช้ MARL เพื่อจัดการพีคโหลดเปิดโอกาสให้เกิดโมเดลธุรกิจใหม่ที่เน้นการลด CAPEX ของการลงทุนในแบตเตอรี่และโครงสร้างพื้นฐานไฟฟ้า โดยโมเดลสำคัญที่ควรพิจารณามีดังนี้
- CAPEX avoidance / Deferred investment: ผู้ให้บริการ MARL เสนอผลประหยัดที่ทำให้ผู้ประกอบการหรือชุมชนเลื่อนการลงทุนแบตเตอรี่หรือขยายกริดออกไปได้ เป็นโมเดลที่คิดค่าบริการเป็นเปอร์เซ็นต์ของต้นทุนการลงทุนที่ถูกเลื่อน (เช่น แบ่งสัดส่วนผลประหยัดจากการเลื่อนซื้ออุปกรณ์)
- Peak shaving‑as‑a‑service: รูปแบบบริการที่คิดค่าบริการต่อหน่วยกำลังลด (บาท/กิโลวัตต์) หรือเป็นค่าสมาชิกแบบรายปี โดยมีสัญญา SLA ระบุระดับการลดพีคขั้นต่ำและวิธีการวัดผล
- Revenue sharing / Pay‑for‑performance: ข้อตกลงแบ่งปันผลประหยัดระหว่างผู้ให้บริการ MARL กับเจ้าของทรัพย์สิน เช่น แบ่งรายได้ระหว่าง 50:50 หรือปรับตามระดับความรับผิดชอบในการลงทุนและการดำเนินงาน ตัวอย่างเชิงตัวเลข เช่น การจ่ายค่าตอบแทน 500–2,500 บาทต่อกิโลวัตต์ต่อปีสำหรับพลังงานพีคที่ลดได้ (เป็นเครือข่ายตัวอย่างที่ต้องปรับให้เข้ากับสภาพท้องถิ่น)
- บริการเสริม: ขายข้อมูลเชิงวิเคราะห์ (analytics) เพื่อการจัดการพลังงาน, บริการเสถียรภาพกริดแบบเสริม (ancillary services), และการผสานกับตลาดพลังงานท้องถิ่นเพื่อสร้างรายได้เพิ่มเติม
กรอบการกำกับดูแลข้อมูลและความปลอดภัย
การขยายใช้งาน MARL จำเป็นต้องมีกระบวนการกำกับดูแลข้อมูลและมาตรการความปลอดภัยที่เข้มแข็ง เพื่อสร้างความเชื่อมั่นให้ผู้ใช้และผู้ลงทุน ข้อเสนอประกอบด้วย:
- นโยบายการเข้าถึงข้อมูลและอนุญาต: กำหนดสิทธิ์การเข้าถึงข้อมูลระดับต่าง ๆ ได้แก่ ข้อมูลเชิงปริมาณที่จำเป็นต่อการเรียนรู้ของโมเดล และข้อมูลส่วนบุคคลที่ต้องได้รับความยินยอมจากเจ้าของข้อมูล
- มาตรฐานการคุ้มครองข้อมูล: ใช้มาตรฐานที่เป็นสากล เช่น ISO 27001, NIST CSF และมีแนวปฏิบัติการทำ data anonymization/aggregation ก่อนใช้ในโมเดลเรียนรู้
- การตรวจสอบและความโปร่งใสของโมเดล: กำหนดข้อกำหนดด้าน explainability และการเก็บ audit log ของการตัดสินใจเพื่อให้สามารถตรวจสอบผลลัพธ์และป้องกันการใช้งานผิดพลาดหรือการโจมตี
- การรับรองความปลอดภัยไซเบอร์: กำหนดมาตรฐานการทดสอบความปลอดภัยและการรับรอง (penetration testing, secure update) สำหรับซอฟต์แวร์ MARL และอุปกรณ์ IoT ที่เชื่อมต่อ
แผนการขยายผล: จาก Pilot สู่ Regional Rollout
การขยายผลต้องเป็นไปตามขั้นตอนที่ชัดเจนและมีการมาตรฐานรองรับ เพื่อให้สามารถทำซ้ำได้ในระดับภูมิภาคและเมืองใหญ่ ข้อเสนอแนะเชิงปฏิบัติได้แก่:
- Pilot phase — การทดลองนำร่อง: เลือกชุมชนตัวแทน 3–5 แห่งที่มีรูปแบบโหลดต่างกัน กำหนด KPI ชัดเจน (เช่น ลดพีค ≥ 30% ภายใน 6–12 เดือน) และรวบรวมข้อมูล baseline เพื่อใช้เป็นมาตรฐานการวัดผล
- Evaluation & Standardization: ประเมินผลด้วยวิธีการวัดที่เป็นมาตรฐาน เตรียมชุด API, data schema, และแนวทางการทดสอบเพื่อการทำ replication
- Scaling playbook: จัดทำคู่มือการขยายผล (playbook) ที่รวม best practices ด้านการจัดการ stakeholder, โมเดลเชิงพาณิชย์, ข้อกำหนดทางเทคนิค และแม่แบบสัญญา (contract templates)
- Regional rollout: ใช้กลยุทธ์แบบ phased rollout โดยเริ่มจากเมืองที่มีแรงจูงใจทางเศรษฐกิจสูงและโครงสร้างพื้นฐานรองรับ ก่อนขยายสู่เขตอื่น พร้อมจัดตั้งศูนย์สนับสนุนด้านเทคนิคและการปฏิบัติการ
- มาตรการควบคุมและปรับปรุง: ติดตามผลแบบต่อเนื่อง ปรับนโยบายจูงใจและโมเดลธุรกิจตามข้อมูลจริง และจัดให้มี forum แลกเปลี่ยนระหว่างผู้ประกอบการ ผู้กำกับดูแล และนักลงทุน
โดยสรุป การทำให้ MARL สำหรับการจัดการไมโครกริดเป็นเชิงพาณิชย์ต้องอาศัยการประสานนโยบายแรงจูงใจ โมเดลธุรกิจที่เน้นการแบ่งปันผลประหยัด (revenue sharing) และกรอบกำกับดูแลข้อมูล/ความปลอดภัยที่ชัดเจน พร้อมแผนขยายผลแบบมีมาตรฐาน ทั้งหมดนี้จะช่วยเปิดทางให้การลดพีคโหลด 35% ของชุมชนทดสอบกลายเป็นแนวปฏิบัติที่สามารถนำไปใช้ในเมืองและชุมชนขนาดใหญ่ได้อย่างยั่งยืน
บทสรุป
งานทดสอบชุมชนที่ใช้แนวทาง Multi‑Agent Reinforcement Learning (MARL) แสดงให้เห็นว่าสามารถลดพีคโหลดของไมโครกริดได้ถึงประมาณ 35% โดยไม่ต้องเพิ่มระบบกักเก็บพลังงานเพิ่มเติม จึงเป็นทางเลือกที่คุ้มค่าในระยะสั้นถึงกลางสำหรับการลดค่าใช้จ่ายด้านพลังงานและค่าพีค (peak demand charges) ของชุมชนหรือผู้ประกอบการขนาดเล็ก–กลาง ตัวอย่างการจำลองและผลภาคสนามชี้ว่า MARL สามารถจัดประสานโหลด อุปกรณ์สร้างพลังงานทดแทน และการตอบสนองความต้องการแบบกระจายได้อย่างมีประสิทธิภาพ ทำให้ลดความจำเป็นในการลงทุนในแบตเตอรี่ซึ่งมีต้นทุนเริ่มต้นสูง และช่วยเลื่อนการลงทุนด้านฮาร์ดแวร์ออกไปได้ในระยะเวลาหนึ่ง (การประหยัดค่าไฟฟ้าเชิงปฏิบัติการอาจอยู่ในช่วงราว 20–30% ขึ้นกับโครงสร้างอัตราค่าไฟและรูปแบบการใช้ไฟของชุมชน)
อย่างไรก็ตาม การนำ MARL ไปใช้จริงในวงกว้างต้องพิจารณาประเด็นสำคัญหลายด้าน ได้แก่ การสเกลระบบ (จากไมโครกริดขนาดเล็กสู่เครือข่ายหลายชุมชน), ความปลอดภัยและความเป็นส่วนตัวของข้อมูล (ซึ่งอาจต้องใช้เทคนิคเช่น federated learning หรือ differential privacy), และ การยอมรับของผู้ใช้ (ต้องมีแรงจูงใจ/นโยบายชัดเจนและความโปร่งใสในการควบคุมอุปกรณ์) รวมถึงการออกแบบกรอบนโยบายที่สนับสนุนการทดสอบภาคสนาม (regulatory sandboxes), มาตรฐานการสื่อสาร และแนวทางทางการเงินสำหรับการขยายผลในเชิงพาณิชย์ มุมมองอนาคตคือ MARL มีศักยภาพเป็นองค์ประกอบสำคัญของการจัดการพลังงานแบบกระจายเมื่อรวมกับนโยบายสนับสนุน การกำกับดูแลที่เหมาะสม และเทคโนโลยีรักษาความปลอดภัยข้อมูล ซึ่งจะช่วยให้สามารถขยายผลจากโครงการนำร่องสู่การใช้งานระดับภูมิภาคได้อย่างยั่งยืน



