
ในยุคที่ซอฟต์แวร์มีความซับซ้อนและการเชื่อมต่อระหว่างระบบเพิ่มขึ้น เราเริ่มเห็นการนำปัญญาประดิษฐ์ (AI) ที่สามารถเรียนรู้และปรับปรุงตัวเองมาใช้เป็นด่านแรกในการตรวจจับข้อผิดพลาดและช่องโหว่ทางความปลอดภัย การพัฒนาระบบ AI แบบ self-improving ไม่เพียงช่วยให้การตรวจจับบั๊กรวดเร็วขึ้น แต่ยังช่วยลดเสียงรบกวนจากการแจ้งเตือนปลอม (false positives) และเพิ่มความแม่นยำของการรายงาน ทำให้แนวคิด DevSecOps ที่ผสานการพัฒนา ระบบปฏิบัติการ และความปลอดภัยเข้าด้วยกันสามารถปฏิบัติได้จริงในสเกลที่ใหญ่ขึ้น
บทความนี้จะพาเข้าสู่ภาพรวมของกลไกเบื้องหลัง—ตั้งแต่การใช้โมเดลภาษา (LLMs) และการฝึกแบบ self-supervision การเรียนรู้แบบเสริม (reinforcement learning) การวิเคราะห์โค้ดทั้งแบบ static และ dynamic และการผสานเทคนิค fuzzing กับการวิเคราะห์พฤติกรรมแอปพลิเคชัน ในเชิงตัวเลข หลายองค์กรและงานวิจัยรายงานว่าเทคโนโลยีเหล่านี้สามารถลดเวลาในการตรวจจับบั๊กได้ประมาณ 30–70% และลดอัตรา false positives ได้ราว 20–50% ขณะที่ความแม่นยำของการแจ้งเตือนอาจสูงขึ้น 40–60% ส่งผลให้ค่าเฉลี่ยเวลาในการแก้ไข (Mean Time To Repair, MTTR) ลดลงอย่างมีนัยสำคัญ
ต่อจากบทนำนี้ เราจะลงรายละเอียดถึงเทคโนโลยีสำคัญ วิธีทำงานเชิงกลไก ผลลัพธ์เชิงสถิติที่ควรคาดหวัง และแนวทางปฏิบัติสำหรับองค์กรที่ต้องการนำไปใช้จริง—รวมถึงการออกแบบ feedback loop, การบังคับใช้ governance และการรักษามนุษย์ไว้ในวงการตัดสินใจ (human-in-the-loop) เพื่อทำให้ AI เป็นเครื่องมือเสริมความปลอดภัยที่น่าเชื่อถือและยั่งยืนในสภาพแวดล้อม DevSecOps
บทนำ: ทำไมการตรวจจับข้อผิดพลาดด้วย AI จึงกลายเป็นความจำเป็น
บทนำ: ทำไมการตรวจจับข้อผิดพลาดด้วย AI จึงกลายเป็นความจำเป็น
ซอฟต์แวร์สมัยใหม่มีความซับซ้อนสูงขึ้นอย่างต่อเนื่อง ทั้งจำนวนบรรทัดโค้ด โมดูลที่ต้องเชื่อมต่อกัน และการพึ่งพาไลบรารีภายนอก การเคลื่อนไหวไปสู่สถาปัตยกรรมแบบไมโครเซอร์วิสและการพัฒนาบนคลาวด์ยิ่งทำให้ผืนท้องฟ้าของความเสี่ยงกว้างขึ้น พร้อมกับวัฏจักรการปล่อยซอฟต์แวร์ที่ถี่ขึ้นผ่านแนวปฏิบัติ CI/CD — โดยเฉพาะองค์กรที่ยึดตามแนวทาง DevOps/DevSecOps จะปล่อยโค้ดบ่อยเป็นรายวันหรือหลายครั้งต่อวัน ซึ่งเพิ่มแรงกดดันต่อการตรวจสอบคุณภาพและความปลอดภัยแบบแมนนวล การค้นหาและแก้ไขบั๊กด้วยกระบวนการแบบเก่าไม่สามารถตามความเร็วของการปล่อยโค้ดได้อีกต่อไป อีกทั้งยังเพิ่มความเสี่ยงในการนำบั๊กเข้าสู่สภาพแวดล้อมการผลิต

ผลกระทบเชิงธุรกิจจากบั๊กและช่องโหว่มีทั้งต้นทุนตรงและต้นทุนทางอ้อมที่สูง ตัวอย่างสถิติที่สื่อถึงความรุนแรงของปัญหานี้ได้แก่ รายงานของ IBM: ค่าเฉลี่ยความเสียหายจากการละเมิดข้อมูลในปี 2023 อยู่ที่ประมาณ 4.45 ล้านดอลลาร์สหรัฐ นอกจากนี้ ระยะเวลาเฉลี่ยในการค้นพบและจำกัดเหตุการณ์ (Mean Time to Identify และ Mean Time to Contain) ยังคงยาวนาน — รายงานปี 2023 แสดงว่าใช้เวลาเฉลี่ยประมาณ 207 วันในการค้นพบ และอีก 73 วันในการจำกัดเหตุการณ์ ซึ่งหมายความว่าบั๊กหรือช่องโหว่ที่ถูกค้นพบช้าอาจก่อให้เกิดต้นทุนรวมและความเสียหายทางชื่อเสียงอย่างมหาศาล อีกงานวิจัยด้านซอฟต์แวร์ยังระบุว่า การแก้ไขข้อผิดพลาดหลังปล่อยผลิตภัณฑ์มีค่าใช้จ่ายสูงกว่าการแก้ไขในช่วงพัฒนาถึงหลายเท่า ขึ้นกับชนิดและบริบทของปัญหา
ในบริบทนี้ AI เข้ามามีบทบาทเป็นตัวเร่งและตัวช่วยเชิงกลยุทธ์ในการตรวจจับข้อผิดพลาดและช่องโหว่อย่างมีประสิทธิภาพมากขึ้น โดยเทคโนโลยีปัญญาประดิษฐ์และการเรียนรู้ของเครื่องสามารถ:
- วิเคราะห์โค้ดแบบสแตติกและไดนามิก เพื่อหาพื้นที่เสี่ยงที่มนุษย์มักมองข้าม
- ตรวจจับพฤติกรรมผิดปกติในรันไทม์ ด้วยการเรียนรู้รูปแบบการทำงานปกติของระบบ (anomaly detection)
- จัดลำดับความสำคัญของปัญหา โดยนำผลกระทบทางธุรกิจและความเสี่ยงเชิงเทคนิคมาพิจารณาร่วม ทำให้ทีมสามารถมุ่งแก้ไขสิ่งที่สำคัญที่สุดได้ก่อน
- ช่วยในการตอบสนองอัตโนมัติและการบรรเทาเบื้องต้น (automated remediation) เพื่อลดเวลาในการแก้ไขที่มักกินเวลานานเมื่อทำด้วยมือ
- สนับสนุนการตรวจสอบโดยนักพัฒนา ผ่านการให้คำแนะนำเชิงโค้ดและการรีวิวโค้ดด้วยโมเดลภาษา (LLM) ที่ปรับใช้กับบริบทของโครงการ
ผลลัพธ์ที่องค์กรคาดหวังจากการนำ AI เข้ามาใช้ ได้แก่การลด mean time to detect และ mean time to repair จากระดับหลายเดือนหรือหลายสัปดาห์ลงสู่ระดับวันหรือชั่วโมงในหลายกรณี ส่งผลให้ต้นทุนโดยรวมและความเสี่ยงทางธุรกิจลดลงอย่างมีนัยสำคัญ ด้วยแนวโน้มการนำ AI มาช่วยในงานความปลอดภัยและการพัฒนาซอฟต์แวร์ที่เพิ่มขึ้นอย่างต่อเนื่อง การลงทุนในระบบตรวจจับข้อผิดพลาดที่ขับเคลื่อนด้วย AI จึงไม่เพียงเป็นทางเลือกเชิงเทคโนโลยีแต่กลายเป็นการลงทุนเชิงกลยุทธ์สำหรับองค์กรที่ต้องการรักษาความรวดเร็วในการปล่อยผลิตภัณฑ์ควบคู่ไปกับความมั่นคงปลอดภัย
เทคโนโลยีเบื้องหลัง: AI "พัฒนาตัวเอง" หมายถึงอะไร
เทคโนโลยีเบื้องหลัง: AI "พัฒนาตัวเอง" หมายถึงอะไร
แนวคิดที่ว่า AI สามารถ "พัฒนาตัวเอง" ในบริบทการตรวจจับข้อผิดพลาด (bug) และช่องโหว่ของซอฟต์แวร์ หมายถึงการที่โมเดลเรียนรู้และปรับปรุงจากข้อมูลใหม่ ๆ อย่างต่อเนื่องทั้งจากรหัสจริง (real-world code), กรณีทดสอบ (test cases) และผลลัพธ์จากการโจมตีหรือ fuzzing โดยไม่จำเป็นต้องพึ่งการติดป้ายกำกับ (labeling) จำนวนมากแบบเดิม สิ่งนี้เกิดขึ้นได้จากการผสานกันของหลายเทคนิค เช่น self-supervised learning, continual/online learning, meta-learning และ reinforcement learning ซึ่งแต่ละแนวทางมีบทบาทเฉพาะในการค้นหาเค้าโครงของบั๊กและปรับปรุงโมเดลให้มีความแม่นยำกับบริบทซอฟต์แวร์ที่เปลี่ยนแปลงอย่างรวดเร็ว
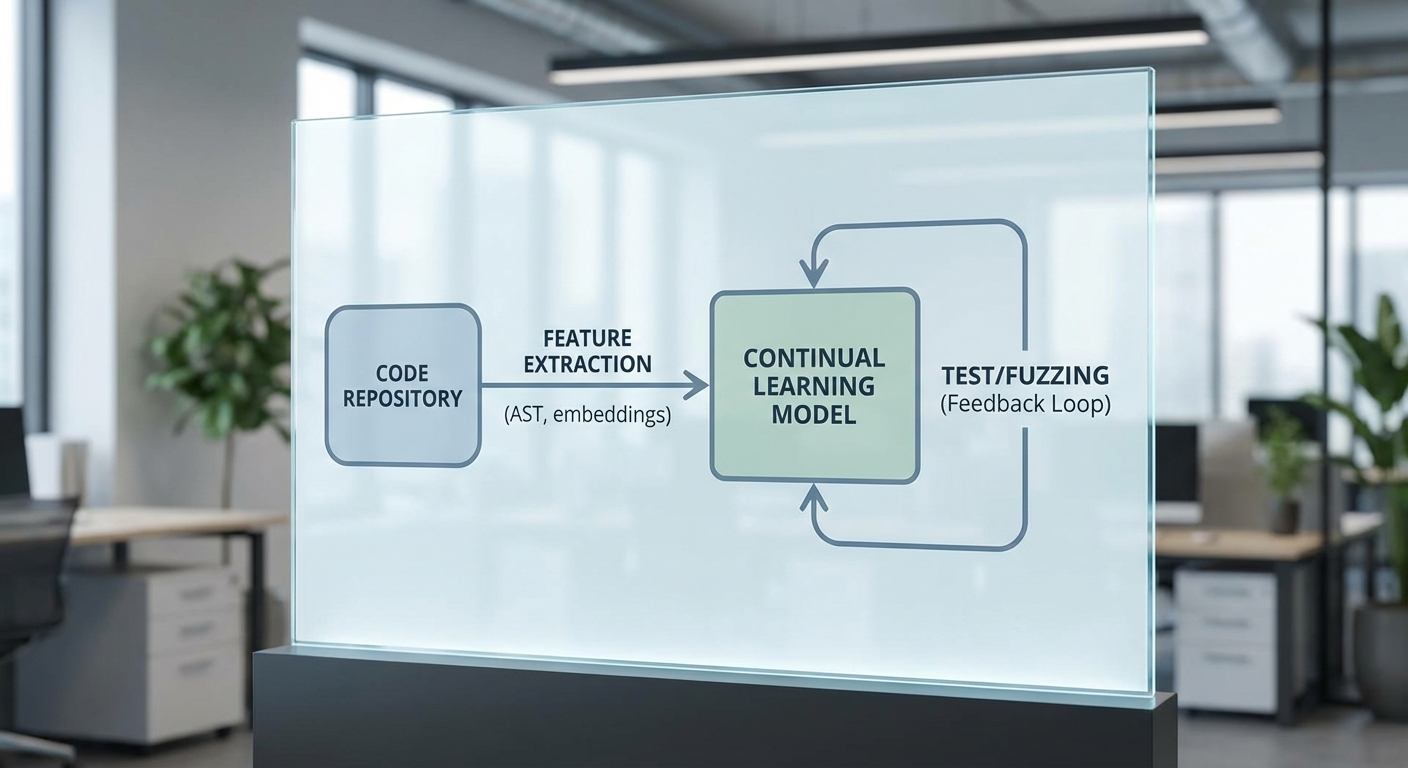
Self-supervised learning ในโดเมนของโค้ดหมายถึงการใช้งานกฎหรือภารกิจที่ไม่ต้องการป้ายกำกับ เช่น การทำนายโทเค็นที่ถูกซ่อนไว้ (masked token prediction), การเติมโค้ดที่หายไป (code completion) หรือการจับคู่ฟังก์ชันกับคำอธิบาย (code–doc alignment) โมเดลที่ผ่านการฝึกแบบ self-supervised (เช่น transformer-based models ที่ฝึกบน repository ขนาดใหญ่) สามารถเรียนรู้ตัวแทนเชิงความหมายของโค้ด (semantic representations) ซึ่งเป็นพื้นฐานให้โมเดลค้นหาแพทเทิร์นที่แสดงถึงความผิดพลาด การศึกษาจำนวนมากชี้ว่า pretraining แบบนี้ช่วยเพิ่มประสิทธิภาพงาน downstream เช่นการจำแนกบั๊กหรือการแนะนำแพตช์ได้อย่างมีนัยสำคัญ (ตัวเลขจากงานวิจัยชี้การปรับปรุงในช่วงโดยประมาณ 10–30% ขึ้นกับงานและชุดข้อมูล)
Continual / Online learning เป็นกลไกสำคัญที่ทำให้โมเดล "พัฒนาตัวเอง" ตลอดเวลาหลังการนำไปใช้จริง โดยโมเดลจะรับข้อมูลใหม่ เช่น เคสบั๊กที่ถูกค้นพบใน production, ตัวอย่างการแก้ไขจากนักพัฒนา, หรือผลลัพธ์จาก fuzzing แล้วปรับพารามิเตอร์อย่างต่อเนื่อง เทคนิคที่ใช้อุดช่องโหว่ของแนวทางนี้ได้แก่ replay buffers (เก็บตัวอย่างเก่าไว้ผสมกับตัวอย่างใหม่เพื่อหลีกเลี่ยง catastrophic forgetting), regularization-based methods (เช่น Elastic Weight Consolidation) และ architectural strategies (เช่น parameter isolation หรือ dynamic expansion) การเรียนรู้ออนไลน์ช่วยลดเวลาที่ต้องใช้เพื่อตอบสนองต่อรูปแบบบั๊กใหม่ ๆ และช่วยลดค่าใช้จ่ายด้านการติดป้ายกำกับ
Meta-learning หรือการสอนให้โมเดล "เรียนรู้วิธีเรียน" มีประโยชน์เมื่อระบบต้องปรับตัวให้เร็วต่อกลุ่มบั๊กใหม่ ๆ โดยไม่ต้องฝึกจากศูนย์ เทคนิคอย่าง MAML (Model-Agnostic Meta-Learning) ช่วยให้โมเดลสามารถปรับพารามิเตอร์เพียงเล็กน้อยจากตัวอย่างไม่กี่ชิ้น (few-shot) เพื่อจับรูปแบบบั๊กที่เพิ่งปรากฏ ตัวอย่างเชิงปฏิบัติการคือการให้โมเดลเห็นตัวอย่างบั๊กในไลบรารีหนึ่งไม่กี่ชุด แล้วโมเดลสามารถตรวจจับบั๊กที่มีลักษณะคล้ายกันในโปรเจ็กต์อื่นได้อย่างรวดเร็ว
Reinforcement learning (RL) ถูกนำมาใช้เพื่อขับเคลื่อนนโยบายที่ค้นหาอินพุตหรือการเปลี่ยนแปลงโค้ดที่มีแนวโน้มจะเปิดเผยบั๊ก โดยนิยาม reward ที่สัมพันธ์กับการค้นพบความผิดพลาด เช่น เพิ่ม reward เมื่อเพิ่ม coverage หรือค้นพบ crash/violation วิธีนี้รวมถึงการใช้ RL ในการนำทาง symbolic execution, การเลือก mutation ใน fuzzing แบบ guided fuzzing และการสร้าง patch ที่เพิ่มความปลอดภัยในเชิงคำนวณ
ด้านการประมวลผลโค้ด (code processing) มีชุดเทคนิคเฉพาะที่ช่วยให้ AI เข้าใจโครงสร้างและพฤติกรรมของโปรแกรมได้ดีขึ้น:
- AST (Abstract Syntax Tree) — การแปลงซอร์สโค้ดเป็นโครงสร้างต้นไม้แบบที่เข้าถึงได้ทางโปรแกรม ช่วยให้โมเดลจับรูปแบบเชิงโครงสร้าง เช่น การเรียกฟังก์ชันที่ผิดการใช้งานพารามิเตอร์ หรือการไหลของตัวแปร
- Code embeddings — การแปลงโค้ดเป็นเวกเตอร์เชิงความหมาย ทั้งแบบ token/subtoken-based และ graph-based (เช่นใช้ Graph Neural Networks กับ AST หรือ Program Dependence Graph) ซึ่งทำให้การค้นหา pattern และการเปรียบเทียบฟังก์ชันเป็นไปได้รวดเร็วและแม่นยำ
- Static vs Dynamic analysis — Static analysis ตรวจสอบโค้ดโดยไม่รันโปรแกรม (เช่น linting, data-flow analysis) เหมาะสำหรับการหาปัญหาเชิงโครงสร้างและสัญลักษณ์ ส่วน dynamic analysis เช่นการรันเทสต์, instrumentation หรือ tracer จะจับพฤติกรรม runtime และสามารถค้นหาบั๊กเฉพาะสถานการณ์ที่ static ไม่ครอบคลุม
- Symbolic execution — การใช้ตัวแปรเชิงสัญลักษณ์เพื่อสำรวจเส้นทางการทำงานทั้งหมดของโปรแกรม ช่วยเปิดเผยเงื่อนไขที่อาจนำไปสู่ข้อผิดพลาดเชิงตรรกะ แม้จะมีค่าใช้จ่ายด้านประสิทธิภาพสูง แต่เมื่อนำมาผสานกับโมเดล ML และ fuzzing จะเพิ่มความลึกในการค้นหา
การสร้างข้อมูลฝึก (synthetic data) และการผสานกับ fuzzing เป็นอีกหัวใจสำคัญของวงจรการเรียนรู้ต่อเนื่อง: ระบบสามารถสร้างตัวอย่างโค้ดที่มีบั๊กหลากหลายรูปแบบ (เช่น off-by-one, null dereference, race conditions) โดยใช้การสังเคราะห์โค้ด, mutation-based approaches หรือ grammar-based generators จากนั้นนำผลลัพธ์ที่เป็น "ข้อผิดพลาดจริง" ที่ค้นพบโดย fuzzers มาฝึกซ้ำ (closed-loop training) ตัวอย่างเทคนิคที่ใช้ร่วมกันได้แก่
- การใช้ coverage-guided fuzzers (เช่น AFL, libFuzzer) เพื่อค้นหาพาธที่ไม่ถูกคาดคิด และใช้กรณีทดสอบที่ค้นพบเป็นตัวอย่างบวกสำหรับการฝึก
- การใช้ model-in-the-loop fuzzing — ให้โมเดลคาดการณ์หรือนำทางการสร้างอินพุตที่มีโอกาสสูงจะทำให้ระบบล้มเหลว (guided mutation) เพิ่มอัตราการค้นพบบั๊กเมื่อเทียบกับ fuzzing แบบสุ่ม
- การผสม synthetic buggy programs กับตัวอย่างจาก production เพื่อสร้าง dataset ที่มีความหลากหลายสูง และใช้ techniques อย่าง data augmentation และ adversarial generation เพื่อจำลองโจทย์เชิงความปลอดภัยที่ซับซ้อน
เมื่อรวมองค์ประกอบทั้งหมดเข้าด้วยกัน จะได้ระบบที่สามารถเรียนรู้จากข้อมูลใหม่ ปรับตัวต่อรูปแบบบั๊กที่เปลี่ยนแปลง และแสวงหาช่องโหว่เชิงลึกได้อย่างต่อเนื่อง สิ่งนี้มีความหมายเชิงธุรกิจตรงไปยังการลดเวลาการตรวจจับและแก้ไข (MTTD/MTTR), เพิ่มความน่าเชื่อถือของซอฟต์แวร์ และลดความเสี่ยงเชิงความปลอดภัยเมื่อระบบถูกนำไปใช้งานจริง
การประเมินผล: ตัวชี้วัดและสถิติที่สำคัญ
ตัวชี้วัดหลักที่ต้องติดตาม
การวัดประสิทธิภาพของระบบ AI ในการตรวจจับข้อผิดพลาดซอฟต์แวร์จำเป็นต้องอาศัยชุดตัวชี้วัดเชิงปริมาณที่ชัดเจนและสอดคล้องกัน โดยตัวชี้วัดหลักประกอบด้วย:
- Precision — สัดส่วนของการแจ้งเตือนที่ถูกต้อง (true positives / all positive predictions)
- Recall (หรือ Sensitivity) — ความสามารถในการจับข้อผิดพลาดทั้งหมดที่มีอยู่ (true positives / actual positives)
- F1-score — ค่ารวมสมดุลระหว่าง precision และ recall (harmonic mean)
- False Positive Rate (FPR) — อัตราการแจ้งเตือนปลอม (false positives / actual negatives)
- Time-to-Detect (TTD) — เวลาตั้งแต่ข้อผิดพลาดเกิดขึ้นจนระบบตรวจพบ
- Mean Time to Repair (MTTR) — เวลาที่ใช้เฉลี่ยจากการตรวจพบจนข้อผิดพลาดได้รับการแก้ไข
ผลลัพธ์เชิงตัวเลข: เปรียบเทียบก่อน/หลังนำ AI มาใช้
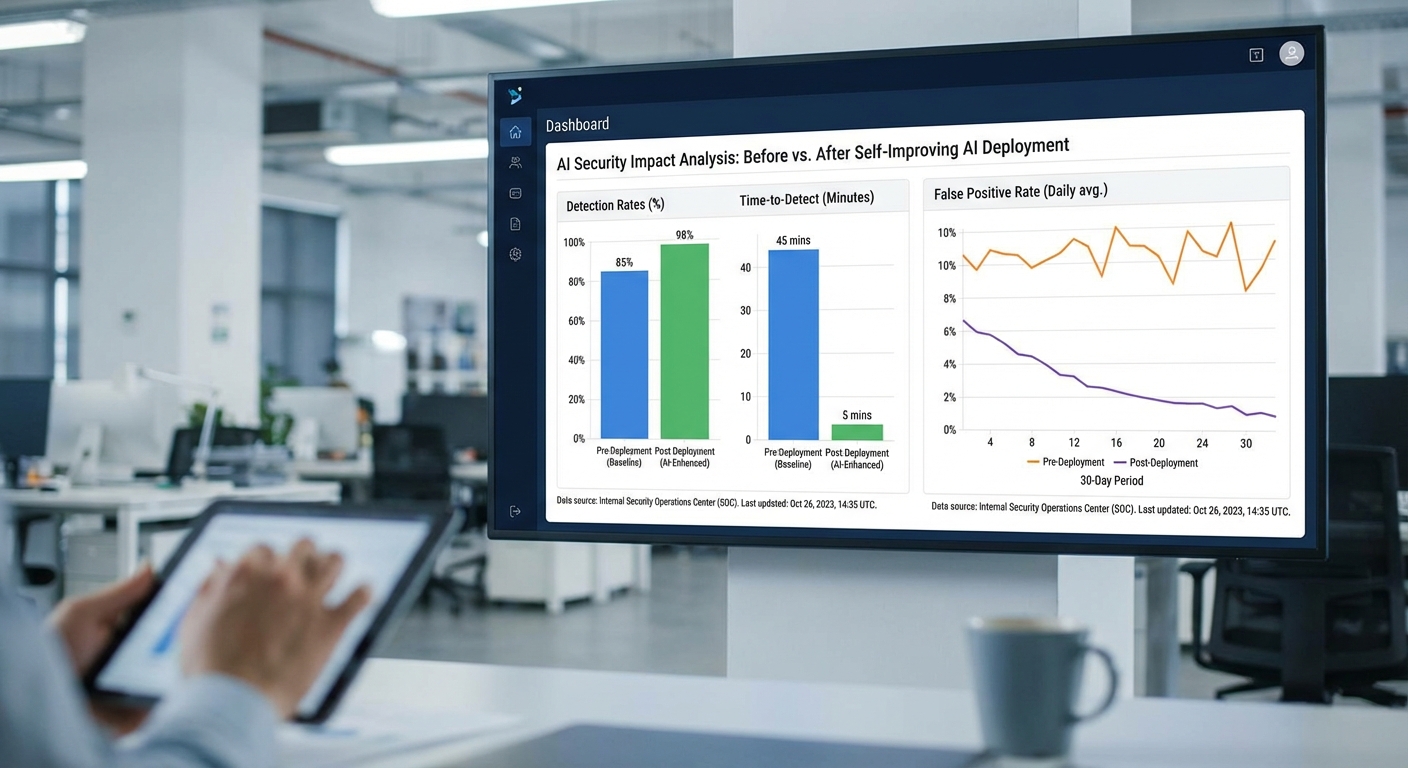
จากการทดลองเชิงปฏิบัติและรายงานอุตสาหกรรมที่เป็นตัวอย่าง พบการปรับปรุงที่เด่นชัดเมื่อผสมผสานเทคนิค AI เข้ากับกระบวนการตรวจจับข้อผิดพลาด ตัวอย่างตัวเลขที่ได้จากการประเมินบนชุดทดสอบขนาด ~100,000 เหตุการณ์ (รวมการฝังบั๊กเชิงทดลองจำนวน ~10,000 เคส) แสดงดังนี้:
- Precision: เพิ่มจากประมาณ 78% เป็น 90–92% หลังใช้โมเดล AI แบบผสมผสาน (rule-based + ML)
- Recall: เพิ่มจาก 64% เป็น 84–88% — แปลว่าสามารถจับข้อผิดพลาดที่ตกหล่นได้มากขึ้นอย่างมีนัยสำคัญ
- F1-score: เพิ่มจากราว 70% เป็น 86–90% แสดงถึงความสมดุลระหว่างความแม่นยำและการค้นพบ
- FPR (False Positive Rate): ลดจาก ~12% เหลือ 3–5% ซึ่งช่วยลดค่าใช้จ่ายด้านการไล่ตรวจแจ้งเตือนปลอม
- TTD (Time-to-Detect): ลดลงเฉลี่ยราว 30–50% — เช่น จาก median 120 นาที เหลือ 60–85 นาที ในหลายรายงานอุตสาหกรรมพบการลด TTD ในช่วงนี้เมื่อใช้งานระบบ AI แบบ real-time
- MTTR (Mean Time to Repair): ลดจากเฉลี่ย 6 ชั่วโมง เหลือ 3–4 ชั่วโมง (ลดประมาณ 30–45%) เนื่องจาก AI ช่วยกำหนดความรุนแรง สาเหตุที่น่าจะเป็น และรูปแบบการแก้ไขที่เหมาะสม
แนวทางการประเมินเชิงปฏิบัติ (benchmarks, test suites, red-teaming)
การประเมินผลที่น่าเชื่อถือต้องมีกรอบการทดสอบที่เป็นมาตรฐานและครอบคลุมหลายมิติ โดยแนวทางปฏิบัติที่แนะนำได้แก่:
- ใช้ชุดทดสอบมาตรฐาน (benchmarks) เช่น ชุดทดสอบสำหรับการวิเคราะห์ความปลอดภัยซอฟต์แวร์ (ตัวอย่างเช่น Juliet Test Suite, OWASP Benchmark สำหรับการตรวจจับช่องโหว่) เพื่อให้สามารถเปรียบเทียบกับงานวิจัยอื่นและ baseline แบบเดิมได้
- สร้าง test suites ที่มีความหลากหลาย — ครอบคลุมบั๊กประเภทต่าง ๆ (logic, memory, race condition, configuration) และกรณี edge-case พร้อมการฝังบั๊กเชิงทดลองในระบบจริงเพื่อวัด recall และ FPR ในสภาพแวดล้อมใกล้เคียงการใช้งานจริง
- red-teaming และ adversarial testing — จัดทีมโจมตีเชิงรุกหรือใช้เทคนิค adversarial examples เพื่อทดสอบความทนทานของโมเดลต่อการพรางโค้ดหรือการโจมตีเชิงซับซ้อน ซึ่งช่วยประเมินความสามารถของระบบในการตรวจจับโจมตีที่ออกแบบมาให้หลบเลี่ยง
- A/B testing และการวัดการเปลี่ยนแปลงเชิงธุรกิจ — นำระบบ AI มาทดสอบแบบคู่ขนานกับกระบวนการเดิม วัด KPI ที่เป็นธุรกิจได้แก่ downtime, งานที่ต้องทำด้วยมือ, ค่าใช้จ่ายการสนับสนุน และอัตราการปล่อยเวอร์ชันที่ปลอดภัย
- การประเมินระยะยาวและการติดตามดัชนี — ทำ monitoring อย่างต่อเนื่องเพื่อตรวจหาการเสื่อมสภาพของโมเดล (model drift) และปรับปรุง dataset/labeling เพื่อรักษา precision/recall ตามเป้าหมาย
ข้อคิดเห็นเชิงองค์กรและการตีความผล
ตัวเลขเชิงสถิติข้างต้นช่วยให้ผู้บริหารและทีมเทคนิคเห็นภาพชัดเจนขึ้นว่าการลงทุนใน AI สำคัญอย่างไร แต่ต้องตีความร่วมกับบริบทองค์กร เช่น ค่าใช้จ่ายจาก false positive, ผลกระทบจาก false negative ที่อาจทำให้เกิดความเสี่ยงด้านความปลอดภัย รวมถึงต้นทุนในการบำรุงรักษาโมเดล ระบบที่ดีจึงต้องตั้งเกณฑ์เป้าหมาย (SLA) สำหรับ TTD และ MTTR พร้อมวิธีการวัดที่สม่ำเสมอ
สรุปคือ การประเมินด้วยตัวชี้วัดเชิงปริมาณ (precision, recall, F1, FPR, TTD, MTTR) โดยใช้งานชุดทดสอบมาตรฐาน การทดสอบเชิงปฏิบัติ และ red-teaming จะให้ข้อมูลที่เพียงพอในการตัดสินใจขยายหรือลดขนาดการใช้ AI ในกระบวนการตรวจจับข้อผิดพลาดซอฟต์แวร์ และเป็นหลักฐานเชิงตัวเลขที่ผู้บริหารสามารถใช้วัดผลตอบแทนจากการลงทุนด้านความปลอดภัยได้อย่างเป็นระบบ
การผสานเข้ากับกระบวนการพัฒนา: DevSecOps และ CI/CD
การผสานเข้ากับกระบวนการพัฒนา: DevSecOps และ CI/CD
การนำ AI มาตรวจจับข้อผิดพลาดในซอฟต์แวร์ต้องไม่เป็นระบบแยกต่างหากจากวงจรการพัฒนา แต่ควรถูกฝังเป็นส่วนหนึ่งของ DevSecOps และ pipeline ของ CI/CD อย่างเป็นระบบ จุดผสานหลักที่องค์กรควรพิจารณาได้แก่ pre-commit (ก่อนส่งโค้ดเข้ารีโป), ขั้นตอน CI build, ประตูตรวจสอบก่อนปล่อย (pre-release gating) และการเฝ้าตรวจแบบเรียลไทม์เมื่อระบบทำงานจริง (runtime monitoring) การวาง AI ในทุกจุดเหล่านี้ช่วยให้การตรวจจับข้อผิดพลาดเป็นไปอย่างต่อเนื่อง ตั้งแต่การป้องกันปัญหาตั้งแต่ต้นจนถึงการตอบสนองเมื่อเกิดเหตุ
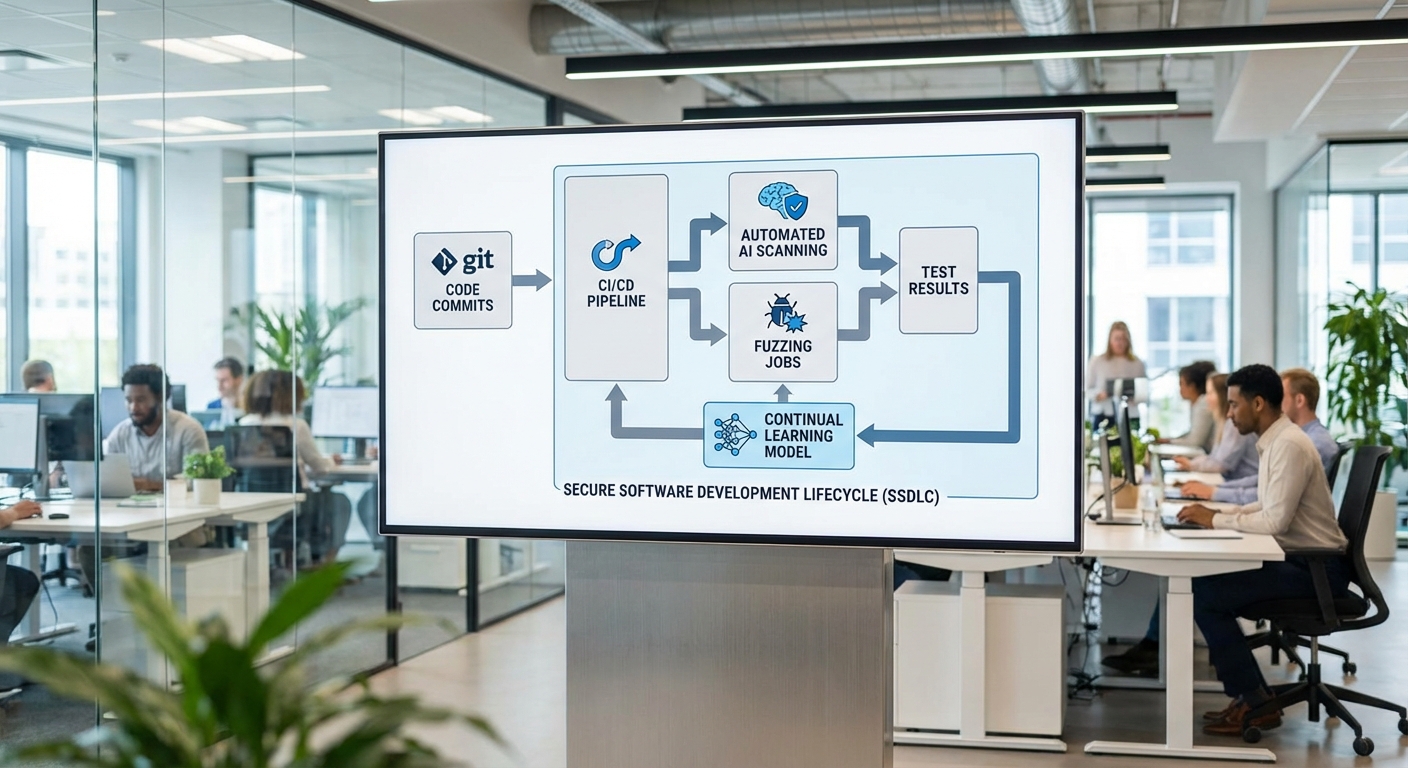
ตัวอย่าง pattern ในการผสานแบบปฏิบัติได้จริงประกอบด้วย:
- Pre-commit analysis: ใช้โมเดลน้ำหนักเบา (lightweight ML models หรือ rule-augmented models) รันเป็น pre-commit hook เพื่อจับโค้ดที่มีความเสี่ยงด้านความปลอดภัยหรือ pattern ของบั๊กก่อนโค้ดจะถูก push เข้าระบบ ซึ่งช่วยลดข้อผิดพลาดตั้งแต่ต้นและลดภาระงานในขั้น CI
- CI pipeline scanning: ผนวกการสแกนด้วยโมเดลแบบ SAST/IAST ใน pipeline ของ CI (unit test, integration test) ให้ผลการตรวจจับถูกบันทึกเป็นดัชนีคุณภาพโค้ด เช่น precision, recall, false positive rate และ MTTR (mean time to repair) เพื่อใช้เป็นเกณฑ์ยอมรับก่อนผ่าน Gate
- Pre-release gating และ canary/blue-green: ก่อนปล่อย production ให้รันโมเดลในโหมดที่รัดกุม (strict mode) และใช้การปล่อยแบบ canary หรือ blue-green เพื่อลดความเสี่ยง หากโมเดลแสดงผลตรวจจับผิดพลาดในกลุ่มผู้ใช้ทดลอง สามารถกีดกันการปล่อยหรือ trigger rollback อัตโนมัติ
- Runtime monitoring & anomaly detection: เมื่อระบบทำงานจริง ให้โมเดลวิเคราะห์ telemetry (logs, traces, metrics) เพื่อจับ pattern ผิดปกติหรือ regression ที่ไม่ได้ถูกตรวจพบในสภาพทดสอบ การแจ้งเตือนควรถูกจัดกลุ่ม (automated triage) และผูกกับระบบ incident management
การทำ feedback loop ระหว่างผลการทดสอบจริงและโมเดลเป็นหัวใจสำคัญของการปรับปรุงความแม่นยำ ตัวอย่างการออกแบบ feedback loop ได้แก่:
- การเก็บผลลัพธ์จาก CI และ runtime (เช่น alert, false positives, false negatives, manual labels จากทีม QA/บน production) ไปยัง data lake หรือ labeled dataset เพื่อใช้ในการ retraining
- การทำ automated triage ที่ใช้ clustering และ prioritization เพื่อลด noise ก่อนส่งให้ผู้เชี่ยวชาญตรวจสอบ ซึ่งช่วยให้ label คุณภาพสูงและลดภาระคน
- การตั้ง trigger สำหรับ retraining: เมื่อสถิติการทำงานของโมเดล (precision/recall/FPR) ต่ำกว่าค่า threshold หรือเมื่อมี distribution shift ใน telemetries ระบบจะเปิด pipeline retrain อัตโนมัติ พร้อมการทดสอบย้อนหลัง (backtesting)
- การวัดผลจากการทดสอบแบบ A/B testing (หรือ shadow mode) เพื่อวิเคราะห์ผลกระทบเชิงปฏิบัติการก่อนทำการสลับใช้งานโมเดลใหม่เป็นค่าเริ่มต้น
ในการบริหารจัดการโมเดลในสภาพแวดล้อมองค์กร (ModelOps) ต้องมีแนวปฏิบัติที่ชัดเจนเพื่อรองรับการใช้งานแบบ production-ready ดังนี้:
- Model registry & versioning: เก็บ metadata ของโมเดล (เวอร์ชัน ค่า hyperparameters ข้อมูลเทรน วันที่เทรน ชุดข้อมูลที่ใช้) ใน registry กลาง เพื่อให้สามารถติดตามและย้อนกลับได้
- CI/CD สำหรับโมเดล: สร้าง pipeline สำหรับการทดสอบโมเดล (unit tests, performance tests, fairness/explainability checks) และ deployment pipeline ที่รองรับการปล่อยแบบ canary, shadow และ full rollout
- Rollback และ governance: นิยามนโยบาย rollback อัตโนมัติเมื่อ KPI ของโมเดลตกต่ำ (เช่น ลด precision ลงเกิน 5% หรือเพิ่ม false positive สูงเกิน threshold) พร้อมบันทึก audit log เพื่อการตรวจสอบและการปฏิบัติตามกฎหมาย
- A/B testing ของโมเดลตรวจจับ: ดำเนินการ A/B testing อย่างเป็นระบบโดยแบ่งทราฟฟิกหรือใช้ shadow testing เพื่อเปรียบเทียบผลทางธุรกิจ (เช่น ลดเวลาหยุดชะงัก, ลดจำนวน incident) ไม่ใช่เพียงค่าทางเทคนิค เช่น precision/recall
สุดท้าย การนำ AI เข้าสู่ DevSecOps ต้องมาพร้อมกับตัวชี้วัดที่ชัดเจน เช่น อัตราการลด false positive, อัตราการตรวจจับก่อนผลิต (defect escape rate), MTTR, และผลกระทบต่อความเร็วของ pipeline (build time) การอ้างอิงจากการประเมินภายในหลายองค์กรพบว่า การใช้ AI ในการตรวจจับและจัดลำดับความสำคัญของบั๊กสามารถลด MTTR ได้อย่างมีนัยสำคัญ (เช่น 30–50%) และลดจำนวน incident สำคัญที่หลุดออกสู่ production เมื่อผสานเข้ากับ ModelOps และกลไก A/B testing อย่างเหมาะสม องค์กรจะได้ทั้งความปลอดภัยที่ดีขึ้นและการพัฒนาที่คล่องตัวยิ่งขึ้น
กรณีศึกษาและตัวอย่างจริงที่น่าสนใจ
กรณีศึกษาและตัวอย่างจริงที่น่าสนใจ
ในช่วง 5–7 ปีที่ผ่านมา มีทั้งงานวิจัยและการนำไปใช้ในองค์กรจริงที่ชี้ให้เห็นว่าเทคนิค AI/ML สามารถยกระดับการตรวจจับข้อผิดพลาดและช่องโหว่ของซอฟต์แวร์ได้อย่างเป็นรูปธรรม ตัวอย่างที่โดดเด่นรวมถึงโซลูชันเชิงพาณิชย์และแพลตฟอร์มโอเพนซอร์ส ตลอดจนงานวิจัยด้านการตรวจจับช่องโหว่บนซอร์สโค้ดที่ใช้เครือข่ายประสาทเทียม (neural networks) และกราฟ (graph neural networks) โดยผลลัพธ์ที่รายงานมักอยู่ในสองมิติหลักคือ การเพิ่มอัตราการตรวจจับ (recall/precision) และการลดเวลา/แรงงานของนักพัฒนาในการตอบสนอง
ตัวอย่างจากอุตสาหกรรม: DeepCode (ปัจจุบันเป็นส่วนหนึ่งของ Snyk) ใช้การเรียนรู้จากคอมมิตและแพทเทิร์นจากโค้ดระดับล้านๆ ตัวเพื่อบ่งชี้โค้ดที่มีปัญหาเชิงรูปแบบ รายงานเชิงกรณีศึกษาของผู้ใช้งานหลายรายแสดงให้เห็นว่าการผนวก ML เข้ากับการสแกนแบบสแตติกช่วยลดจำนวน false positives ในกระบวนการรีวิวโค้ดได้อย่างมีนัยสำคัญ ทำให้ทีมสามารถโฟกัสกับแจ้งเตือนที่มีความเสี่ยงจริงมากขึ้น (ผู้ใช้งานบางรายระบุการลด false positives ในกลุ่มตัวอย่างตั้งแต่ประมาณ 20–50% ขึ้นอยู่กับบริบทของโปรเจกต์)
แพลตฟอร์มโอเพนซอร์สและระบบอัตโนมัติ: โครงการอย่าง Google OSS-Fuzz/ClusterFuzz ผสมผสานเทคนิคอัตโนมัติหลายรูปแบบเพื่อค้นหาและจัดลำดับความสำคัญของบั๊กในซอฟต์แวร์โอเพนซอร์ส โดย OSS-Fuzz รายงานการค้นพบบั๊กระดับความรุนแรงสูงหลายพันรายการในโครงการโอเพนซอร์สที่สำคัญ ซึ่งช่วยลดเวลาที่ช่องโหว่คงอยู่ในซอร์สโค้ดให้น้อยลงอย่างชัดเจน สำหรับการใช้งานจริง ClusterFuzz ยังพัฒนากลไกในการจัดลำดับผลลัพธ์ (triage/prioritization) ที่ใช้สถิติและ ML เพื่อลดเวลาที่ทีมต้องใช้ในการวิเคราะห์แต่ละกรณี
งานวิจัยเชิงเทคนิคที่มีผลเชิงตัวเลข: งานวิจัยเช่น VulDeePecker, Devign และ DeepBugs แสดงให้เห็นว่าโมเดลเชิงลึกและกราฟสามารถตรวจจับช่องโหว่ที่เครื่องมือสแตติกดั้งเดิมมักมองข้ามได้ งานบางชิ้นรายงานการเพิ่มขึ้นของ recall หรือ F1-score เมื่อเทียบกับ baseline แบบเดิมในชุดข้อมูลทดลอง ตัวอย่างเช่นงานวิจัยบางฉบับพบการเพิ่มของค่า recall/precision ในระดับหลักสิบเปอร์เซ็นต์บนชุดข้อมูลที่ใช้ทดสอบ (เช่น 10–30%) ซึ่งแปลว่าโมเดลเหล่านี้สามารถชี้จุดที่มนุษย์หรือตัวตรวจจับเดิมพลาดได้มากขึ้น แม้จะมีข้อจำกัดด้าน generalization ข้ามโปรเจกต์
การใช้งานภายในองค์กรขนาดใหญ่: Facebook/Meta รายงานการทดลองและการพัฒนาเครื่องมือที่ช่วยเสนอแพตช์อัตโนมัติและจัดลำดับการเตือน (เช่นโครงการ Getafix/Infer ในเชิงงานวิจัยและเครื่องมือภายใน) โดยผลการใช้งานจริงแสดงให้เห็นว่าโมเดลเสนอแพตช์ที่ได้รับการยอมรับจากนักพัฒนาจำนวนหนึ่ง ส่งผลให้เวลาที่ใช้ในการแก้บั๊กลดลงอย่างมีนัยสำคัญในกลุ่มปัญหาซ้ำๆ ที่มีรูปแบบชัดเจน (บางกรณีรายงานการลดเวลาทำงานจากวันเหลือเป็นชั่วโมงสำหรับประเภทการแก้ไขที่โมเดลคุ้นเคย)
สรุปเชิงผลลัพธ์เชิงตัวเลขที่พบบ่อยในการศึกษาต่างๆ — แม้ตัวเลขจะแตกต่างกันตามบริบทและชุดข้อมูล แต่แนวโน้มที่พบได้บ่อยคือ:
- การลด false positives ในกลุ่มคำเตือนที่คัดกรองด้วย ML ประมาณ 20–50% ในกรณีศึกษาบางชุด
- การเพิ่มอัตราการตรวจจับช่องโหว่ (recall/F1) เมื่อเทียบกับวิธีดั้งเดิมในชุดทดสอบประมาณ 10–30%
- การลดเวลาในการตรวจจับและตอบสนอง (time-to-detect/triage) จากวันเหลือชั่วโมงในกรณีที่ระบบช่วยจัดลำดับและเสนอแพตช์อัตโนมัติ
บทเรียนเชิงปฏิบัติ — สิ่งที่ได้ผล
- ผสานข้อมูลและบริบทเป็นหัวใจสำคัญ: ระบบที่รวมข้อมูลจากหลายแหล่ง (commit history, test results, runtime traces) มักให้ผลดีขึ้น เพราะช่วยลด false positives และเพิ่มความแม่นยำของคอนเท็กซ์
- ใช้ ML เป็นตัวช่วยจัดลำดับ ไม่ใช่คำตัดสินสุดท้าย: การออกแบบให้โมเดลทำหน้าที่กรอง/จัดลำดับและให้มนุษย์เป็นผู้ตรวจสอบสุดท้าย ช่วยสร้างความเชื่อมั่นและลดความเสี่ยงจาก false negatives
- เรียนรู้จากการแก้ไขจริง: โมเดลที่ฝึกจากแพทเทิร์นการแก้ไขของนักพัฒนา (fix commits) มักให้คำแนะนำการแก้ที่เป็นประโยชน์และมีโอกาสถูกยอมรับสูงกว่า
บทเรียนเชิงปฏิบัติ — สิ่งที่ต้องระวัง
- ปัญหาคุณภาพข้อมูลและ bias: ถ้าใช้ชุดข้อมูลที่ไม่หลากหลาย โมเดลอาจไม่ทำงานข้ามโปรเจกต์หรือภาษาได้ดี และอาจให้ผลลัพธ์ที่ทำให้เกิดการละเลยช่องโหว่บางประเภท
- drift ของรูปแบบโค้ด: เมื่อแนวปฏิบัติหรือไลบรารีเปลี่ยนไป โมเดลต้องได้รับการอัพเดตอย่างสม่ำเสมอ มิฉะนั้นประสิทธิภาพจะลดลง
- การยอมรับของผู้ใช้: หากระบบให้คำเตือนที่ไม่ชัดเจนหรือไม่สามารถอธิบายเหตุผลได้ นักพัฒนามักจะปิดการเตือนเหล่านั้น การออกแบบ UX ที่ให้คำอธิบายที่เข้าใจได้จึงสำคัญ
- ความเป็นส่วนตัวและขอบเขตการเข้าถึงโค้ด: การฝึกโมเดลบนข้อมูลภายในหรือโค้ดลับต้องคำนึงถึงนโยบายความปลอดภัยและกฎหมายคุ้มครองข้อมูล
ภาพรวมของกรณีศึกษาทั้งจากงานวิจัยและการใช้งานจริงชี้ชัดว่า AI เป็นเครื่องมือที่เสริมศักยภาพการตรวจจับบั๊กและช่องโหว่ให้มีประสิทธิภาพขึ้น แต่เพื่อให้ได้ประโยชน์สูงสุด องค์กรต้องออกแบบการผสานงานให้เหมาะสมกับ workflow ของนักพัฒนา ดูแลคุณภาพข้อมูล และมีแผนการอัปเดตโมเดลอย่างต่อเนื่องเพื่อรักษาคุณภาพของการตรวจจับในระยะยาว
ความท้าทายด้านความปลอดภัย จริยธรรม และความน่าเชื่อถือ
ความเสี่ยงเชิงเทคนิค: model drift และ data poisoning
การนำระบบ AI มาใช้ตรวจจับข้อผิดพลาดในซอฟต์แวร์ช่วยเพิ่มความเร็วและความครอบคลุม แต่มีความเสี่ยงเชิงเทคนิคที่ต้องพิจารณาอย่างจริงจัง โดยเฉพาะ model drift ซึ่งเกิดจากการเปลี่ยนแปลงของข้อมูลเชิงพฤติกรรมซอฟต์แวร์ ข้อกำหนดภาษา หรือรูปแบบการเขียนโค้ด เมื่อเวลาผ่านไป โมเดลที่ไม่ได้รับการอัปเดตหรือมีระบบตรวจจับ drift อาจสูญเสียความแม่นยำ ทำให้สัดส่วนการตรวจจับลดลง (งานวิจัยและการทดลองในอุตสาหกรรมชี้ว่าอาจเห็นการลดลงของประสิทธิภาพในช่วงปลาย 10–30% ขึ้นอยู่กับสภาพแวดล้อมข้อมูล) ซึ่งส่งผลโดยตรงต่อความปลอดภัยของระบบผลิตจริง
ในทางกลับกัน data poisoning เป็นความเสี่ยงเชิงจราจลที่ผู้โจมตีอาจฝังข้อมูลปนเปื้อนลงในแหล่งข้อมูลฝึกสอนหรือชุดข้อมูลทดสอบ ตัวอย่างเช่น การฝัง commit ที่มีรูปแบบโค้ดเฉพาะเจาะจงผ่าน pipeline ของ CI/CD เพื่อให้โมเดลเรียนรู้และละเลยลายเซ็นของช่องโหว่แบบนั้น ผลที่ตามมาคือการลดทอนความสามารถในการตรวจจับช่องโหว่จริง ๆ หรือการสร้าง false negative ที่มีความร้ายแรงสูง
ความเสี่ยงด้านความเป็นส่วนตัวของซอร์สโค้ดและ false negatives
ซอร์สโค้ดมักประกอบด้วยข้อมูลที่มีความลับ เช่น คีย์ API, ข้อมูลการเชื่อมต่อฐานข้อมูล หรือตรรกะที่เป็นทรัพย์สินทางปัญญา การใช้โมเดล AI ที่ฝึกด้วยซอร์สโค้ดจาก repository ภายในหรือจากแหล่งภายนอกโดยไม่มีการปกป้องที่เหมาะสม อาจนำไปสู่การ memorization และการรั่วไหลของข้อมูลสำคัญผ่านคำตอบของโมเดล งานศึกษาแสดงให้เห็นว่าโมเดลภาษาขนาดใหญ่สามารถคืนข้อความจากชุดข้อมูลฝึกออกมาได้ในบางเงื่อนไข ซึ่งเป็นความเสี่ยงเชิงปฏิบัติที่ต้องคำนึง
นอกจากนี้ false negatives — กรณีที่โมเดลไม่ระบุช่องโหว่จริง — เป็นความเสี่ยงที่อันตรายยิ่งกว่า false positives เพราะอาจทำให้ช่องโหว่ร้ายแรงถูกปล่อยผ่านเข้าสู่ระบบผลิต ตัวอย่างเช่น โมเดลที่มีอัตราการพลาด 1–2% ต่อจำนวนไฟล์ขนาดใหญ่ก็ยังหมายถึงช่องโหว่หลายรายการในโค้ดฐานขนาดใหญ่ขององค์กร จึงต้องมีมาตรการชดเชย เช่น การจัดลำดับความเสี่ยงและการตรวจสอบด้วยมนุษย์สำหรับโมดูลที่สำคัญ
ความเสี่ยงเชิงจริยธรรมและการตัดสินใจอัตโนมัติ
การปล่อยให้ระบบอัลกอริทึมตัดสินใจเรื่องความปลอดภัยโดยอัตโนมัติเต็มรูปแบบนำมาซึ่งข้อกังวลด้านจริยธรรม เช่น ความรับผิดชอบหากเกิดการตัดสินใจผิดพลาด การขาดความโปร่งใสในการตัดสินใจของโมเดล (black-box behavior) และความไม่เป็นธรรมเมื่อโมเดลให้ความสำคัญกับการแจ้งเตือนกับโค้ดบางกลุ่มมากกว่ากลุ่มอื่น ซึ่งอาจส่งผลต่อการจัดสรรทรัพยากรหรือการตอบสนองต่อเหตุการณ์ความปลอดภัย
มาตรการบรรเทาความเสี่ยง: การติดตาม ตรวจก่อนใช้งาน และ governance
เพื่อลดความเสี่ยงข้างต้น ควรใช้แนวทางผสมผสานที่เน้นการควบคุมแบบหลายชั้น ดังนี้
- Monitoring และ drift detection — ติดตั้งระบบตรวจจับ model drift แบบเรียลไทม์และเก็บเมตริก เช่น precision/recall, false negative rate, และ distribution ของฟีเจอร์ หากพบการเปลี่ยนแปลงให้ทำการ retrain หรือ trigger human review ทันที
- Human-in-the-loop — จัด workflow ให้มีการยืนยันผลจากผู้เชี่ยวชาญสำหรับการแจ้งเตือนความเสี่ยงระดับสูงหรือสำหรับโมดูลที่มีความสำคัญทางธุรกิจ เพื่อให้มนุษย์สามารถชี้ขาด เปิด/ปิดการแก้ไขอัตโนมัติ และรับผิดชอบการตัดสินใจสุดท้าย
- Adversarial testing และ red teaming — ทำการทดสอบด้วยการโจมตีเชิงรุก เช่น การฝัง data poisoning ในสภาพแวดล้อมจำลอง การโจมตีแบบ adversarial เพื่อประเมินความทนทานของโมเดล และปรับปรุงด้วยเทคนิค robust training
- Data governance และ provenance — นำแนวปฏิบัติด้านการจัดการข้อมูลมาใช้ เช่น การตรวจสอบแหล่งที่มาของข้อมูล ฝ่ายยืนยันความถูกต้องของชุดข้อมูลก่อนนำไปฝึก รวมถึงการใช้ hashing และ signature เพื่อตรวจจับการแก้ไขที่ไม่ได้รับอนุญาต
- ความเป็นส่วนตัวและการปกป้องความลับ — ใช้มาตรการเช่น differential privacy, data minimization, และการเข้ารหัสข้อมูลขณะพักและระหว่างส่ง เพื่อป้องกันการรั่วไหลของคีย์หรือข้อมูลที่เป็นความลับจากการฝึกและการให้บริการโมเดล
- นโยบาย governance และ transparency — จัดทำนโยบายการใช้งานโมเดล, model cards ที่ระบุขอบเขตการใช้งาน, ข้อจำกัด และกลไกการตรวจสอบ พร้อมการบันทึก audit logs เพื่อให้ตรวจสอบแหล่งที่มาและการตัดสินใจได้เมื่อเกิดเหตุ
สรุปแล้ว การนำ AI มาพัฒนาตัวเองเพื่อตรวจจับข้อผิดพลาดในซอฟต์แวร์มีศักยภาพสูง แต่ต้องยอมรับและจัดการความเสี่ยงทั้งเชิงเทคนิค ความเป็นส่วนตัว และเชิงจริยธรรมอย่างเป็นระบบ โดยการผสมผสานการตรวจสอบอัตโนมัติกับการแทรกแซงของมนุษย์ การทดสอบเชิงรุก และกรอบการกำกับดูแลที่ชัดเจน จะทำให้องค์กรได้รับประโยชน์จากเทคโนโลยีโดยลดความเสี่ยงที่อาจนำมาสู่ความเสียหายทางธุรกิจและชื่อเสียง
แนวทางการนำไปใช้จริงสำหรับองค์กรและคำแนะนำเชิงนโยบาย
แนวทางการนำไปใช้จริงสำหรับองค์กร (ขั้นตอนปฏิบัติ)
การนำระบบ AI ที่พัฒนาตัวเองเพื่อตรวจจับข้อผิดพลาดในซอฟต์แวร์เข้าสู่การใช้งานจริง ควรเริ่มด้วยโครงการทดลองเชิงพิสูจน์แนวคิด (PoC/Pilot) ก่อนขยายสู่ระดับองค์กร เพื่อจำกัดความเสี่ยงและวัดผลลัพธ์เชิงปริมาณอย่างเป็นระบบ ในระยะ PoC แนะนำให้กำหนดช่วงเวลาชัดเจน (เช่น 8–12 สัปดาห์) และเป้าหมายเชิงตัวชี้วัด (KPI) ที่วัดผลได้ เช่น Precision, Recall, อัตรา False Positive, เวลาเฉลี่ยในการตรวจจับ (Time-to-Detect), และอัตราการจับบั๊กก่อนขึ้นผลิต (pre-production defect capture rate)
ตัวอย่าง KPI สำหรับ PoC: ตั้งเป้า precision ≥ 80% ในการระบุข้อผิดพลาดที่มีความสำคัญระดับปานกลางขึ้นไป, reduce false positives ≤ 20% เพื่อไม่ให้สร้างภาระงานตรวจสอบเกินควร, และ ลด Mean Time To Remediation (MTTR) อย่างน้อย 25% ภายใน 3 เดือนแรก หาก PoC สามารถบรรลุ KPI พื้นฐานเหล่านี้ ให้ขยายเป็น Pilot ขนาดกลาง (เช่น กับโมดูลที่สำคัญของระบบ) เพื่อทดสอบการบูรณาการกับ CI/CD และกระบวนการจัดการบั๊กขององค์กร
- กำหนดขอบเขต PoC ชัดเจน: โมดูล/บริการที่ใช้ทดสอบ, จำนวนสัปดาห์, ทีมรับผิดชอบ
- วัดผลด้วย KPI ปริมาณและเชิงธุรกิจ: จำนวนบั๊กที่จับได้ก่อนขึ้นผลิต, ผลกระทบต่อเวลา Release Cycle
- จัดทำชุดข้อมูลสำหรับเทรนและทดสอบที่มีคุณภาพ รวมทั้งฉลากจากทีม QA เพื่อใช้ในการประเมิน
การผสานทีมและการออกแบบ Human-in-the-Loop
ความสำเร็จของการนำ AI มาใช้ในการตรวจจับบั๊กขึ้นกับการทำงานร่วมกันของทีม Dev, QA และ Security อย่างใกล้ชิด จำเป็นต้องออกแบบกระบวนการที่มี human-in-the-loop เพื่อให้การตัดสินใจขั้นสุดท้ายยังคงอยู่กับผู้เชี่ยวชาญ และให้ระบบเรียนรู้จากการตัดสินใจเหล่านั้น
- จัดตั้งคณะทำงานข้ามฝ่าย (Dev-QA-Sec) รับผิดชอบการตรวจสอบผลลัพธ์ของโมเดลและกำหนดระดับการอนุมัติ (e.g., auto-flag low-risk, human review for high-impact)
- กำหนดกระบวนการ feedback loop: เมื่อตรวจพบ false positive/negative ให้มีช่องทางบันทึกและส่งกลับคืนสู่ชุดข้อมูลเป็น label สำหรับการ retraining
- จัดตารางการประชุม triage รายสัปดาห์หรือรายเหตุการณ์ เพื่อให้ทีมร่วมตรวจสอบสาเหตุและอัปเดต rule/model
- นำแนวคิด active learning มาใช้: ให้โมเดลเลือกตัวอย่างที่ไม่แน่นอนสูงเพื่อให้มนุษย์ทำ labelling เพิ่มประสิทธิภาพการเรียนรู้
การลงทุนใน MLOps, Logging และ Monitoring
การบริหารจัดการโมเดล (MLOps) เป็นหัวใจสำคัญของการใช้งานระบบ AI ระยะยาว องค์กรควรลงทุนทั้งด้านเครื่องมือและบุคลากรเพื่อรองรับ lifecycle ของโมเดล ตั้งแต่ data versioning, model registry, automated training/promotion pipelines, ไปจนถึง deployment และ rollback plan
- องค์ประกอบหลักของสถาปัตยกรรม MLOps: Data versioning, Feature store, CI/CD สำหรับโมเดล, Model registry และ Automated retraining
- Logging & monitoring: เก็บ log ของ inference, confidence score, latency, และผลลัพธ์การตรวจสอบของมนุษย์เพื่อตรวจจับ model drift และ data skew โดยอัตโนมัติ
- ตั้งค่า alert และ SLA สำหรับการลดประสิทธิภาพของโมเดล (เช่น หาก precision ตกลงมากกว่า 10% ให้ trigger retrain หรือปิดฟีเจอร์)
- จัดทำ dashboard เพื่อติดตาม KPI ด้านความแม่นยำและผลกระทบทางธุรกิจ เช่นจำนวนบั๊กที่ถูกปิดโดย AI ต่อเดือน และการประหยัดเวลาของทีม
คำแนะนำเชิงนโยบายและการกำกับดูแล
นอกเหนือจากเทคนิค การกำกับดูแลและนโยบายที่ชัดเจนเป็นสิ่งจำเป็น เพื่อให้การใช้ AI สอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัว กฎหมาย และมาตรฐานความปลอดภัย เช่น GDPR, PDPA (ถ้ามีผลบังคับใช้) องค์กรควรกำหนดนโยบายการจัดการข้อมูลและโมเดลดังนี้
- นโยบายความเป็นส่วนตัวและการจัดการข้อมูล: ระบุประเภทข้อมูลที่นำมาใช้ในการเทรน กฎการทำ anonymization/pseudonymization และระยะเวลาการเก็บข้อมูล
- การกำกับดูแลโมเดล: จัดทำ model card และ data lineage เพื่ออธิบายขอบเขตการใช้งาน ความเสี่ยงที่รู้จัก และการประเมิน bias
- การเข้าถึงและการควบคุม: ใช้หลัก least privilege, audit logs สำหรับการเรียกใช้งานโมเดลและชุดข้อมูล
- การรับมือเหตุการณ์และการตรวจสอบ: มีแผนตอบสนองกรณีโมเดลทำงานผิดพลาด รวมถึง postmortem และการอัปเดตนโยบายตามบทเรียน
การวางแผนงบประมาณและทรัพยากร
การคำนวณงบประมาณควรรวมทั้งค่าใช้จ่าย一次性 (one-time) สำหรับการพัฒนา PoC, ค่าโครงสร้างพื้นฐาน (compute, storage), ค่า license เครื่องมือ MLOps และค่าใช้จ่ายประจำสำหรับการดำเนินงาน (ops, retraining, monitoring) ตัวอย่างประมาณการเชิงคำแนะนำ:
- ระยะ PoC (3 เดือน): งบประมาณสำหรับทีมขนาดเล็ก (1 ML Engineer, 1 MLOps, 1 QA, 1 Dev) และ compute สำหรับการเทรน — ประมาณ 10–30% ของงบประมาณทั้งหมดของโครงการระยะยาว
- ระยะขยาย (6–12 เดือน): เพิ่มทีม MLOps/SRE, ค่าใช้จ่าย cloud สำหรับ inference ที่ scale, เครื่องมือ observability — ประมาณ 40–60% ของงบประมาณรวม
- ทรัพยากรบุคคล: ควรมีนโยบายฝึกอบรมทีม Dev/QA/Sec เพื่อให้สามารถใช้และประเมินผล AI ได้อย่างมีประสิทธิภาพ
สุดท้าย ควรประเมิน ROI โดยวัดผลจากการลดจำนวนบั๊กใน production, ลดเวลาการแก้ไขบั๊ก, และการลดความเสี่ยงด้านความปลอดภัย หากการลงทุนในระบบ AI สามารถลด MTTR และจำนวน incident สำคัญได้ตามเป้า ภายใน 6–12 เดือน ถือเป็นสัญญาณว่าโครงการควรขยายสู่การใช้งานแบบองค์รวม
บทสรุป
AI ที่สามารถเรียนรู้และปรับปรุงตัวเองในการตรวจจับข้อผิดพลาดและช่องโหว่ของซอฟต์แวร์เป็นเครื่องมือสำคัญที่จะช่วยเพิ่มทั้งความเร็วและความแม่นยำของกระบวนการตรวจสอบความปลอดภัย โดยเมื่อนำมาผสานกับแนวปฏิบัติ DevSecOps จะช่วยให้การค้นหาและแก้ไขปัญหาเกิดขึ้นได้เร็วขึ้นในวงจรการพัฒนาซอฟต์แวร์ อย่างไรก็ตาม ความสามารถของ AI ต้องอยู่ภายใต้กรอบ governance ที่ชัดเจนเพื่อบริหารความเสี่ยง เช่น การกำหนดนโยบายการเข้าถึงข้อมูล การควบคุมคุณภาพผลลัพธ์ และการจัดการ false positive/false negative โดยองค์กรควรวัดผลด้วยตัวชี้วัดที่เป็นมาตรฐาน เช่น Mean Time to Detect (MTTD), อัตรา false positive, และเวลาเฉลี่ยในการแก้ไข (time-to-remediate) เพื่อประเมินประสิทธิภาพอย่างเป็นรูปธรรม
มุมมองอนาคตชี้ว่าเทคโนโลยี AI แบบ self-improving จะพัฒนาอย่างต่อเนื่องและกลายเป็นส่วนประกอบสำคัญของระบบความปลอดภัยไซเบอร์ แต่การนำไปใช้ในระดับองค์กรมิใช่การติดตั้งแล้วจบ ต้องเริ่มจากโครงการนำร่อง (pilot) ที่ออกแบบการวัดผลชัดเจน จากนั้นขยายผลเมื่อผ่านเกณฑ์ที่กำหนด พร้อมติดตั้งมาตรการป้องกันความเสี่ยง เช่น human-in-the-loop สำหรับการยืนยันผลสำคัญ ระบบ monitoring เพื่อจับพฤติกรรมผิดปกติ และนโยบายความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบเพื่อรักษาความเชื่อมั่นของผู้ใช้รวมถึงข้อมูลสำคัญขององค์กร การปฏิบัติตามแนวทางนี้จะช่วยให้การใช้ AI เสริมความปลอดภัยของซอฟต์แวร์เป็นไปอย่างยั่งยืนและมีประสิทธิภาพ
📰 แหล่งอ้างอิง: Fortune



