
สตาร์ทอัพไทยเปิดตัวบริการใหม่ "Model‑Tailor" ซึ่งสัญญาว่าสามารถย่อหรือปรับแต่งโมเดลภาษาใหญ่ (LLM) ให้รันได้บนคลาวด์ขนาดเล็กโดยยังคงประสิทธิภาพที่ใช้งานได้จริง ส่งผลให้ค่าใช้จ่ายด้านโครงสร้างพื้นฐานลดลงอย่างมีนัยสำคัญถึง 60–80% — ข้อเสนอที่เข้ามาตัดปมปัญหาสำคัญขององค์กรไทยที่อยากขยายการใช้ AI แต่ติดข้อจำกัดด้านงบประมาณและทรัพยากรคอมพิวติ้ง การประกาศครั้งนี้ยังมาพร้อมสัญญาระดับองค์กร (SLA) เพื่อรับประกันระดับการตอบสนองและความพร้อมใช้งาน รวมทั้งชุดเครื่องมือสำหรับวัดความเบี่ยงเบนหลังการย่อโมเดล ทำให้องค์กรสามารถประเมินความเสี่ยงด้านความแม่นยำและพฤติกรรมทางสถิติก่อนนำไปใช้งานจริง
ประเด็นสำคัญที่ผู้อ่านควรจับตามองคือความสมดุลระหว่างต้นทุนกับคุณภาพ: Model‑Tailor ไม่ได้เป็นเพียงการย่อขนาดเพื่อประหยัดทรัพยากร แต่รวมการวัดผลที่ชัดเจน เช่น การเปรียบเทียบความแม่นยำของคำตอบ, อัตราการเกิด hallucination, ค่าความหนาแน่นของการตอบ (latency/throughput) และมาตรวัดความเบี่ยงเบนเชิงสถิติหลังการย่อ เพื่อให้ผู้ประกอบการตัดสินใจได้ว่าการลดต้นทุนนั้นยังคงตอบโจทย์เชิงธุรกิจหรือไม่ ด้วยข้อเสนอ SLA ประกอบกับชุดเครื่องมือวัดผลนี้ สตาร์ทอัพรายดังกล่าวหวังช่วยให้ธุรกิจเล็ก–กลางสามารถนำปัญญาประดิษฐ์ระดับสูงมาใช้ได้อย่างคุ้มค่าและมั่นใจมากขึ้น
ภาพรวมข่าว: อะไรคือ Model‑Tailor และทำไมสำคัญ
ภาพรวมข่าว: อะไรคือ Model‑Tailor และทำไมสำคัญ
Model‑Tailor เป็นบริการด้านการย่อและปรับแต่งโมเดลภาษาใหญ่ (LLM) ที่พัฒนาโดยสตาร์ทอัพไทย ซึ่งออกแบบมาเพื่อช่วยให้องค์กรสามารถรัน LLM ได้บนคลาวด์ขนาดเล็กหรือสภาพแวดล้อม edge/cloud‑edge โดยไม่ต้องพึ่งพาโครงสร้างพื้นฐานขนาดใหญ่แบบเดิม ๆ บริการนี้รวมเทคนิคการบีบอัดและปรับประสิทธิภาพโมเดล (เช่น quantization, pruning, knowledge distillation และ optimization ด้านการรัน) พร้อมเครื่องมือทางวิศวกรรมที่ช่วยตรวจวัดและควบคุมผลลัพธ์หลังการย่อ
กลุ่มเป้าหมายหลักของ Model‑Tailor คือ องค์กรขนาดกลางถึงใหญ่ ที่ต้องการผสาน LLM เข้ากับระบบภายใน, ผู้ให้บริการซอฟต์แวร์แบบบริการ (SaaS) ที่ให้บริการผ่าน API, และผู้ให้บริการแชทบอท/บริการลูกค้าที่ต้องการรันโมเดลด้วยความหน่วงต่ำและต้นทุนที่คงที่ โดยทั่วไปลูกค้ากลุ่มนี้มีข้อกำหนดด้านความมั่นคงของข้อมูล ความน่าเชื่อถือของบริการ และความคงที่ของต้นทุนเป็นสำคัญ
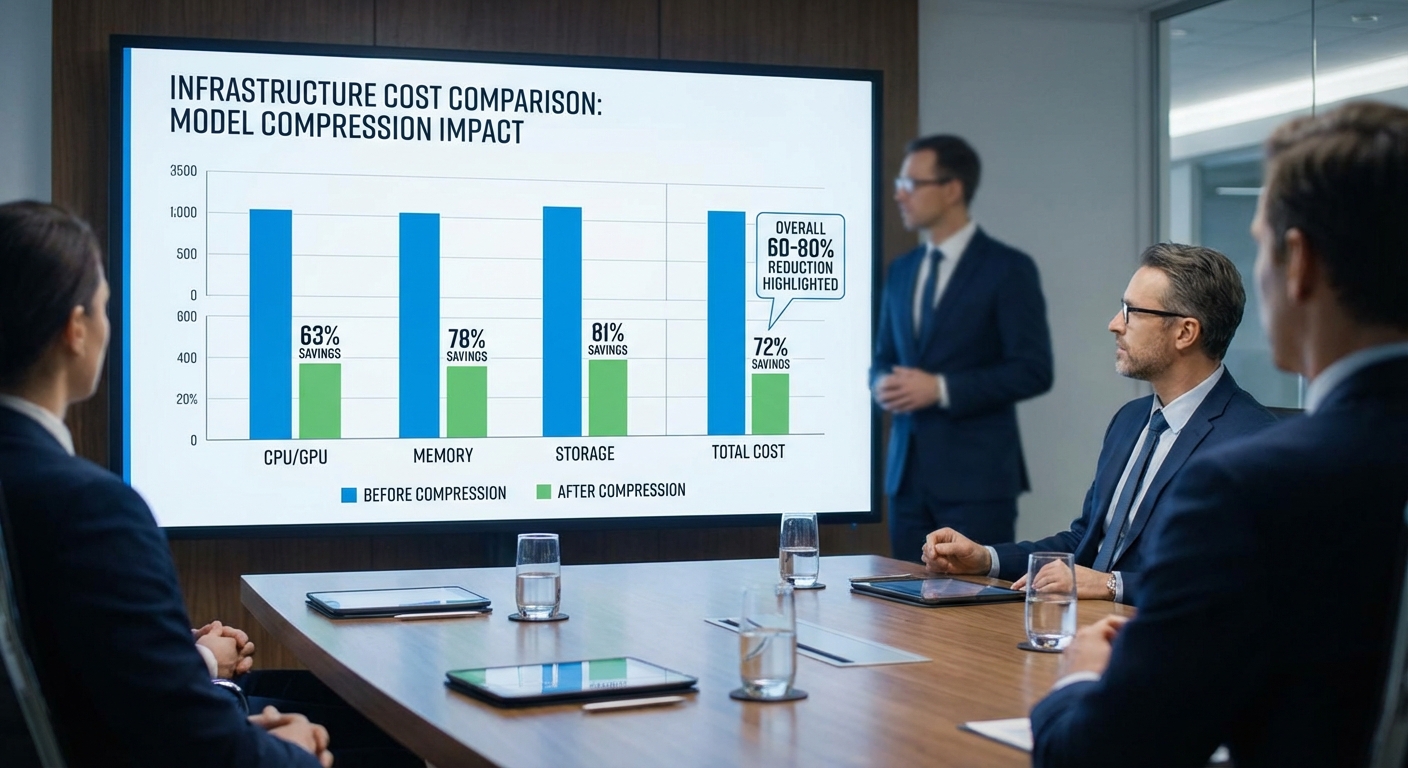
สถิติเด่นที่บริษัทประกาศคือการลด ค่าใช้จ่ายโครงสร้างพื้นฐานจริง 60–80% ตัวเลขนี้หมายถึงการลดต้นทุนปฏิบัติการ (operational infrastructure cost) ที่เกิดจากการใช้ทรัพยากรคอมพิวต์ เช่น ค่าเช่า GPU/CPU, ชั่วโมงการใช้งาน instance, ค่าพลังงานและเครือข่าย เมื่อเปรียบเทียบกับการรัน LLM รุ่นต้นแบบบนคลาวด์สาธารณะที่ใช้ instance ขนาดใหญ่ ตัวอย่างเชิงบริบท: หากองค์กรเคยต้องใช้ GPU ประสิทธิภาพสูงเป็นหลักเพื่อให้บริการ LLM แบบเรียลไทม์ การย่อโมเดลด้วยเทคนิคของ Model‑Tailor ทำให้สามารถย้ายงานไปยัง instance ที่เล็กลงหรือแม้แต่ node edge ได้ ส่งผลให้ต้นทุนต่อคำขอ (cost per inference) ลดลงอย่างมีนัยสำคัญ
ข้อเสนอที่แตกต่าง และเป็นจุดขายสำคัญของบริการนี้คือการให้ SLA ระดับองค์กร ร่วมกับชุดเครื่องมือสำหรับวัดความเบี่ยงเบนหลังการย่อ (post‑compression deviation measurement) ซึ่งรวมถึงเมตริกเชิงคุณภาพและเชิงปริมาณ เช่น อัตราความถูกต้องตามงาน (task accuracy), ค่าเบี่ยงเบนของการตอบ (semantic drift / cosine similarity), อัตราการเกิด hallucination, latency เฉลี่ยต่อคำขอ และเครื่องมือสำหรับเปรียบเทียบผลลัพธ์ก่อน/หลังย่อ นอกจากนี้ยังรองรับการมอนิเตอร์แบบเรียลไทม์ การแจ้งเตือน และกลไก rollback เพื่อให้สอดคล้องกับความต้องการทางธุรกิจและข้อบังคับด้านข้อมูล
- ความคุ้มค่า: ลดต้นทุนโครงสร้างพื้นฐาน ทำให้ธุรกิจสามารถขยายการให้บริการ LLM ได้โดยไม่ต้องเพิ่มงบประมาณโฮสติ้งในอัตราเดียวกับการเติบโตของทราฟฟิก
- ความน่าเชื่อถือ: SLA ระดับองค์กร พร้อมการมอนิเตอร์และการวัดเบี่ยงเบน ช่วยลดความเสี่ยงด้านคุณภาพของคำตอบ
- ความยืดหยุ่นทางการปรับใช้: รองรับการรันบนคลาวด์ขนาดเล็กและ edge ทำให้ตอบโจทย์ latency ต่ำและข้อกำหนดด้านความเป็นส่วนตัว/ข้อมูลท้องถิ่น
เหตุใดข่าวนี้จึงสำคัญสำหรับธุรกิจไทยและภูมิภาค: ตลาดเอเชียตะวันออกเฉียงใต้มีความต้องการใช้งานแอปพลิเคชัน AI ในภาคธุรกิจและสาธารณูปโภคเพิ่มขึ้น แต่หลายองค์กรยังถูกจำกัดด้วยงบประมาณด้านโครงสร้างพื้นฐานและข้อกำกับดูแลข้อมูล การที่มีบริการภายในประเทศที่สามารถลดต้นทุน 60–80% พร้อมมาตรฐาน SLA และเครื่องมือวัดผลเชิงวิทยาศาสตร์จะช่วยลดอุปสรรคการนำ LLM มาใช้งานจริง เพิ่มโอกาสให้สตาร์ทอัพและผู้ให้บริการท้องถิ่นแข่งขันได้ และสนับสนุนการนำเทคโนโลยีไปใช้ในภาคการเงิน การแพทย์ การศึกษา และบริการลูกค้าอย่างปลอดภัยและมีประสิทธิผล
เทคโนโลยีเบื้องหลัง: วิธีการย่อโมเดล (distillation, pruning, quantization, compilation)
ภาพรวมเทคนิคย่อโมเดลของ Model‑Tailor
Model‑Tailor ใช้ชุดเทคนิคเชิงวิศวกรรมและวิจัยเพื่อย่อลงทั้งด้านจำนวนพารามิเตอร์, ขนาดหน่วยความจำ และความยุ่งยากของคำนวณ โดยยังรักษาคุณภาพของผลลัพธ์ให้อยู่ในเกณฑ์ที่สอดคล้องกับ SLA ของลูกค้า หน่วยงานรายงานผลที่ได้จากการผสมผสานวิธีต่าง ๆ ว่าสามารถลดค่าใช้จ่ายโครงสร้างพื้นฐานได้ประมาณ 60–80% เมื่อเทียบกับการรัน LLM เต็มรูปแบบบนคลัสเตอร์ขนาดใหญ่ ตัวอย่างเช่น การย่อจากโมเดล 13B → รุ่น student 2–3B อาจลดพารามิเตอร์ลงได้ 4–6x และลด memory footprint ได้ 6–8x พร้อมลด latency ต่อคำตอบเฉลี่ย 2–4x ขึ้นกับการปรับแต่งและฮาร์ดแวร์
Knowledge Distillation: หลักการและการรักษาความแม่นยำ
Knowledge distillation เป็นกระบวนการที่ใช้โมเดลขนาดใหญ่ (teacher) ถ่ายทอดพฤติกรรมไปยังโมเดลขนาดเล็ก (student) ผ่านการเทรนให้เลียนแบบ logits หรือ distribution ของ teacher แทนที่จะเรียนจาก label ตรง ๆ เทคนิคสำคัญได้แก่การใช้ soft targets, temperature scaling และการผสม loss ระหว่าง cross‑entropy กับ distillation loss เพื่อรักษา fine‑grained knowledge
เชิงปฏิบัติ Model‑Tailor ใช้ workflow ดังนี้:
- กำหนดชุดข้อมูล validation และ held‑out ที่ครอบคลุม instruction/QA/zero‑shot เพื่อวัด divergence
- ฝึก student โดยใช้ mixture of losses (soft logits + hard labels) และใช้ temperature (T = 2–8) เพื่อปรับความเนียนของ distribution
- ใช้งานตัวชี้วัดเช่น KL divergence, Δperplexity, และ task‑specific metrics (accuracy/F1/EM) เพื่อวัดการเสื่อมลงหลัง distillation
ในสถิติทั่วไป โมเดล student ขนาดเล็กกว่าประมาณ 3–6x สามารถรักษาความแม่นยำไว้ได้ประมาณ 95–99% ของ teacher ในหลาย ๆ งาน NLP (เช่น QA, classification) ถ้ามีการคัดเลือกตัวอย่างฝึกและ fine‑tuning ขั้นต่อเนื่อง ในกรณีที่ต้องการ SLA เคร่งครัด Model‑Tailor จะตั้งค่าขีดจำกัดการยอมรับ divergence เช่นไม่ให้ Δaccuracy เกิน 1–3% หรือ Δperplexity เกินระดับที่กำหนดก่อนอนุญาตใช้งานจริง
Pruning และ Quantization: ลดพารามิเตอร์และหน่วยความจำ
Pruning แบ่งเป็นสองแบบหลักคือ unstructured และ structured pruning:
- Unstructured pruning (weight pruning) ทำให้ได้ความหนาแน่น (sparsity) สูง เช่น 70–90% sparsity ซึ่งลดพารามิเตอร์เชิงนามธรรมได้มาก แต่ต้องการเคอร์เนลแบบ sparse หรือ runtime ที่รองรับ sparse GEMM เพื่อให้ได้ speedup จริง ปกติ memory footprint ลดได้ 2–4x ขึ้นกับการเก็บข้อมูลแบบ sparse
- Structured pruning (เช่นการตัดหัว attention, ตัด neuron หรือช่องของเมทริกซ์) ทำให้ได้ speedup จริงบนฮาร์ดแวร์เชิงพาณิชย์เพราะรักษา layout เป็นแบบ dense หลังการตัด ปริมาณการตัดมีแนวโน้มทำได้ 30–70% ของพารามิเตอร์โดยที่ latency ดีขึ้น 1.5–3x
Quantization เป็นการลดความละเอียดของตัวเลขภายในโมเดลเพื่อประหยัดหน่วยความจำและเพิ่ม throughput เทคนิคที่ใช้รวมถึง:
- 8‑bit (INT8) quantization — เป็นมาตรฐานที่ได้ผลคงที่ในหลากหลายงาน โดยมักลด memory footprint ได้ 4x เมื่อเทียบกับ FP32 และ latency ลดได้ 1.5–3x โดยมีการสูญเสียความแม่นยำต่ำ (<1–2% ในหลายกรณี) หากทำ calibration และ dynamic range handling ดี
- 4‑bit (INT4) / mixed INT4 — ลดได้มากขึ้น (8x ลดจาก FP32 ทางทฤษฎี) แต่มีความเสี่ยงต่อ degradation มากขึ้น Model‑Tailor ใช้เทคนิคเช่น per‑channel quantization, outlier clipping และ quantization‑aware training (QAT) เพื่อลดผลกระทบ ในงานบางประเภทสามารถรักษาคุณภาพได้ภายใน Δ 2–5% เมื่อใช้ mixed precision (บางเลเยอร์เป็น INT8 หรือ FP16)
- Mixed precision (FP16 / BF16 + INT8/INT4) — การผสม FP16/BF16 กับ INT8/INT4 บนเลเยอร์ที่ไวต่อความแม่นยำช่วยให้ได้ trade‑off ระหว่าง throughput และ accuracy
ตัวอย่างตัวเลข: จากโมเดล 7B FP32 (ประมาณ 28GB memory) หากทำ INT8 จะเหลือ ~7GB (4x ลด) และถ้าทำ structured pruning ร่วมด้วย 50% อาจลงมาเหลือ ~3–4GB ซึ่งทำให้รันบนอินสแตนซ์ ARM Graviton ที่มีหน่วยความจำ 8–16GB ได้อย่างสบาย ๆ
Token/Attention Optimization และการคอมไพล์สำหรับคลาวด์ขนาดเล็ก
นอกจากการลดขนาดพารามิเตอร์แล้ว Model‑Tailor ยังปรับปรุงการประมวลผลระดับ token/attention เพื่อลด latency และค่าใช้จ่าย:
- Sparse / localized attention เช่น sliding window, block sparse หรือ BigBird‑style attention ลดความซับซ้อนจาก O(N^2) → O(N·window) สำหรับ sequence ยาว ๆ
- Early‑exit และ cascading decoders สำหรับกรณีที่คำตอบไม่ต้องการการถอดรหัสเต็มความลึก สามารถออกคำตอบเร็วขึ้นตามเงื่อนไขความเชื่อมั่น
- Attention caching / incremental decoding และ optimized KV‑cache layout เพื่อลดค่า memory และ I/O ของการตอบโต้แบบ streaming
ในส่วนของการคอมไพล์และการปรับให้เหมาะกับฮาร์ดแวร์แพลตฟอร์มขนาดเล็ก Model‑Tailor ใช้ toolchain และวิธีการหลากหลายเพื่อให้ได้ประสิทธิภาพสูงสุดบน ARM/Graviton และ small GPUs:
- สำหรับ ARM/Graviton CPUs: ปรับแต่ง kernel ให้ใช้ vector ISA (NEON, SVE), ใช้ quantized GEMM, cache tiling และ multi‑threading ที่เหมาะกับจำนวนคอร์จริงของอินสแตนซ์ ตัวเลขการปรับแต่งเหล่านี้มักให้ speedup 2–4x เมื่อเทียบกับการรันโมเดลไม่ผ่านการคอมไพล์เฉพาะ
- สำหรับ small GPUs (เช่น T4/RTX‑class): ใช้ TensorRT, cuBLAS/CUTLASS, Triton หรือ optimized CUDA kernels สำหรับ FP16/INT8/INT4 เพื่อเรียกใช้ block GEMM ที่มีประสิทธิภาพสูง สามารถลด latency ต่อการสร้างข้อความลง 1.5–3x และเพิ่ม throughput ได้หลายเท่าเมื่อเทียบกับ naive kernel
- Compiler stack: ใช้ ONNX Runtime + custom kernels, TVM/Apache‑NNVM สำหรับการทำ schedule แบบ auto‑tune, และ MLIR/XLA สำหรับการรวมหลาย operation เป็น fused kernels เพื่อลด memory traffic
เมื่อรวมกัน การนำ distillation + structured pruning + INT8 quantization + compiler optimizations สามารถทำให้โมเดลที่เดิมต้องการ >50GB RAM และ GPU ขนาดใหญ่ รันได้บนคลาวด์ขนาดเล็กที่มี 8–16GB RAM หรือบน instance ARM Graviton ที่มีต้นทุนต่อชั่วโมงต่ำกว่า ส่งผลให้ค่าใช้จ่ายโดยรวมลดลงตามสัดส่วน 60–80% ตามที่อ้าง
การวัดความเบี่ยงเบนและการรับประกัน SLA
เพื่อให้สอดคล้องกับ SLA ทางธุรกิจ Model‑Tailor รวมระบบวัดและรายงานที่ครอบคลุม:
- ใช้ชุดเมตริกอัตโนมัติ: KL divergence ของ logits, Δperplexity, task‑level metrics (accuracy, F1), และ human‑in‑the‑loop sampling
- การวิเคราะห์ sensitivity แบบ per‑layer/per‑head เพื่อระบุจุดที่หากย่อแล้วจะส่งผลต่อความแม่นยำมากที่สุด และกำหนด policy (เช่นไม่ย่อเลเยอร์สำคัญหรือใช้ mixed precision)
- SLA ที่กำหนดขอบเขตทางคุณภาพ เช่น maximum allowed Δaccuracy = 2% หรือ latency SLA ที่ระบุ p95/p99 response times หลังการย่อ
สรุปแล้วเทคนิคที่ Model‑Tailor ใช้เป็นการผสานระหว่างวิธีเชิงทฤษฎี (distillation) และวิศวกรรมประสิทธิภาพ (pruning, quantization, compilation และ attention optimization) เพื่อให้ได้ผลลัพธ์ที่สามารถรันบนคลาวด์ขนาดเล็กได้จริง พร้อมเครื่องมือวัดความเบี่ยงเบนที่รับประกันคุณภาพตาม SLA ของลูกค้า
ผลกระทบด้านค่าใช้จ่ายและโครงสร้างพื้นฐาน: วิธีการคำนวณ 60–80%
การอ้างอิงตัวเลขการลดค่าใช้จ่าย 60–80% ที่มักระบุในบริการ Model‑Tailor ต้องอาศัยการวัดเมตริกเชิงปริมาณที่ชัดเจนและสูตรคำนวณที่โปร่งใส เพื่อให้ผู้บริหารและทีมเทคนิคสามารถประเมินผลกระทบทางการเงินได้จริง เมตริกหลักที่นำมาประกอบการคำนวณได้แก่ vCPU/GPU hours, memory footprint, storage, network egress และค่าใช้จ่ายรวมของระบบหรือ TCO (Total Cost of Ownership) โดยทั่วไป Model‑Tailor ลดการใช้งานทรัพยากรโดยตรงผ่านการย่อโมเดล (quantization, pruning, distillation) และการปรับสถาปัตยกรรมให้เหมาะกับคลาวด์ขนาดเล็ก ส่งผลให้สามารถลดค่าใช้จ่ายด้านฮาร์ดแวร์และค่าใช้จ่ายรอง (เช่น cooling/ops) ได้อย่างมีนัยสำคัญ
เมตริกหลักและสูตรการคำนวณ
- vCPU / GPU hours: คำนวณจากจำนวนชั่วโมงที่ใช้จริงของแต่ละประเภททรัพยากร
สูตร: ค่า Compute = (GPU_hours × cost_per_GPU_hour) + (vCPU_hours × cost_per_vCPU_hour) - Memory footprint: วัดเป็น GB หรือ GB-hours ที่จองไว้หรือถูกใช้งานจริง การย่อโมเดลช่วยลดจำนวน RAM ที่จำเป็นต้องจอง (ลดขนาด instance)
ผลกระทบ: ลดขนาด instance → ลดค่า vCPU/memory ในการจองต่อเดือน - Storage: ขนาดของโมเดลและ artifact (GB) ต่อเดือน
สูตร: Storage_cost = GB_storage × cost_per_GB_month - Network egress: ปริมาณข้อมูลออกนอกคลาวด์ (GB/month)
สูตร: Egress_cost = GB_egress × cost_per_GB - Cooling / ops: ค่า overhead สำหรับการดำเนินงานศูนย์ข้อมูลและความเย็น มักคำนวณเป็นเปอร์เซ็นต์ของค่าโครงสร้างพื้นฐาน (เช่น 15–30%)
สูตร: Ops_cost = Infra_cost × ops_factor - TCO (Total Cost of Ownership):
สูตร: TCO = Compute + Storage + Network + Ops_cost + (License/Support + SRE/Management) - เปอร์เซ็นต์การลดค่าใช้จ่าย:
สูตร: Reduction% = (Baseline_TCO − Optimized_TCO) / Baseline_TCO × 100
ตัวอย่างกรณีศึกษา A (สมมติ) — การคำนวณเชิงตัวเลข
สมมติบริษัท X รัน LLM แบบอินเฟอเรนซ์เป็นหลัก โดยก่อนใช้ Model‑Tailor มีการจองทรัพยากรเพื่อตอบรับโหลดสูงสุดตลอดเวลา เราจะยกตัวเลขสมมติเพื่อแสดงวิธีคำนวณดังนี้ (ตัวเลขเป็น USD/เดือน เพื่อความเข้าใจง่าย):
- Baseline (ก่อนย่อโมเดล)
- GPU: 4 × A100 (720 ชม./เดือน) → GPU_hours = 4×720 = 2,880 GPU-hrs; cost_per_GPU_hr = $3 → GPU_cost = $8,640
- vCPU: 64 vCPU × 720 ชม. → vCPU_hours = 46,080; cost_per_vCPU_hr = $0.02 → vCPU_cost = $921.60
- Storage: 4 TB (4,096 GB) × $0.02/GB-month → Storage_cost = $81.92
- Network egress: 10 TB (10,240 GB) × $0.09/GB → Egress_cost = $921.60
- Infra_cost (Compute + Storage + Network) = $8,640 + $921.60 + $81.92 + $921.60 = $10,565.12
- Cooling/Ops (ops_factor = 20%) → Ops_cost = $2,113.02
- Baseline TCO ≈ $12,678.14 /เดือน
- Optimized (หลังใช้ Model‑Tailor)
- สมมติ Model‑Tailor ลดการใช้ GPU 70% (จากการย่อและรันบน GPU ขนาดเล็กหรือ CPU เร่งด้วย quantization) → GPU_cost = $8,640 × 0.3 = $2,592
- vCPU ลด 50% ด้วยการลด footprint ของโมเดล → vCPU_cost = $921.60 × 0.5 = $460.80
- Storage ลด 50% (โมเดลเล็กลง, artifact ลด) → Storage_cost = $81.92 × 0.5 = $40.96
- Network egress ลด 30% ด้วย caching และการลดขนาด output → Egress_cost = $921.60 × 0.7 = $645.12
- Infra_cost_optimized = $2,592 + $460.80 + $40.96 + $645.12 = $3,738.88
- Ops_cost (20%) = $747.78
- Optimized TCO ≈ $4,486.66 /เดือน
- ผลลัพธ์การลดค่าใช้จ่าย
- การลด TCO = $12,678.14 − $4,486.66 = $8,191.48
- เปอร์เซ็นต์การลด = 64.6% (อยู่ในช่วง 60–80%)
- เพิ่มเติม: ตัวอย่างนี้สอดคล้องกับข้อมูลว่า GPU cost ลด 70%, latency ลด 30% (เพราะการรันบน instance ที่ตอบสนองไวขึ้น) และ accuracy ลดไม่เกิน 2% (หลังการย่อโมเดลและ tuning)
ข้อสมมุติฐานที่อยู่เบื้องหลังตัวเลข 60–80%
- ประเภทงาน (workload type): ผลลัพธ์สูงสุดมักเป็นกับงาน inference ที่มีปริมาณคำขอสูงและ latency-sensitive ซึ่งสามารถย่อโมเดลได้มากโดยกระทบ accuracy น้อย ขณะที่งาน training จะได้รับประโยชน์น้อยกว่า
- การใช้งานจริง vs การจอง (utilization): หากองค์กรจองทรัพยากรในระดับสูงเพื่อตอบพีค (overprovisioning) การลด footprint จะให้ผลประหยัดสูงกว่ากรณีที่ใช้งานเต็มที่ตลอดเวลา
- วิธีการย่อโมเดล: การใช้ quantization (8-bit หรือน้อยกว่า), pruning และ distillation ถูกนำมาใช้ร่วมกัน จะให้การลดขนาด/เวลาอย่างมีนัยสำคัญโดยลดผลกระทบต่อ accuracy ไม่เกินที่ยอมรับได้
- สัดส่วนค่าใช้จ่ายที่เป็น compute-dominant: ถ้ารายจ่ายของระบบเป็น compute-dominant (เช่น GPU คิดเป็น >50% ของ TCO) การลด GPU-hours จะส่งผลต่อเปอร์เซ็นต์รวมได้มากขึ้น
- overhead อื่น ๆ: ค่า license, SRE และการบำรุงรักษาอาจลดลงตามการลดขนาดระบบ แต่ต้องนำมาคำนวณแยกเพื่อหาค่า TCO ที่แท้จริง
สรุป: การคำนวณ 60–80% ที่ Model‑Tailor อ้างถึงไม่ได้เป็นตัวเลขตายตัว แต่เกิดจากการรวมผลของการลด GPU/vCPU hours, การลด memory footprint, การลด storage และ network egress รวมกับการลดค่า overhead ด้านการบริหารและการระบายความร้อน ตัวอย่างเชิงตัวเลขข้างต้นแสดงให้เห็นว่าเมื่อ workload เป็นแบบ inference และมีการ overprovisioning การลดค่าใช้จ่ายแบบ 60–80% เป็นไปได้จริงภายใต้ข้อสมมุติฐานที่ชัดเจน
SLA และความน่าเชื่อถือ: สิ่งที่บริการประกาศและความหมายสำหรับองค์กร
SLA และความน่าเชื่อถือ: สิ่งที่บริการประกาศและความหมายสำหรับองค์กร
Service Level Agreement (SLA) ของบริการ Model‑Tailor ถูกออกแบบมาเพื่อให้ภาพชัดเจนทั้งด้านความพร้อมใช้งาน (availability) และคุณภาพการตอบกลับของโมเดลหลังย่อ การประกันเหล่านี้ประกอบด้วยองค์ประกอบเชิงปริมาณ เช่น uptime เป็นเปอร์เซ็นต์, ค่าความหน่วง (latency) ในระดับเปอร์เซ็นไทล์สำคัญ (P95/P99), เวลาในการตอบ (response time), error budget และระดับการสนับสนุน (support tiers) รวมทั้งตัวชี้วัดด้านการกู้คืนเมื่อเกิดเหตุ (RPO/RTO). ยกตัวอย่างเช่น Model‑Tailor อาจประกาศ SLA พื้นฐานดังนี้: uptime 99.9% (ซึ่งเทียบเท่ากับเวลา downtime ประมาณ 43.2 นาทีต่อเดือน), P95 latency < 200 ms, P99 latency < 500 ms สำหรับคำขอแบบ text generation แบบมาตรฐาน และมีการรับประกันการตอบกลับเบื้องต้นสำหรับแผนสนับสนุนระดับ Enterprise ภายใน 1 ชั่วโมง
องค์ประกอบสำคัญของ SLA ที่องค์กรควรพิจารณาได้แก่:
- Uptime % — ระดับความพร้อมใช้งานที่รับประกันในช่วงเวลาที่กำหนด (รายเดือน/รายปี) และวิธีคิดเครดิตเมื่อไม่เป็นไปตามข้อกำหนด
- Latency (P95 / P99) — การวัดความหน่วงในเปอร์เซ็นไทล์ที่สำคัญ เช่น P95 บ่งชี้ว่าร้อยละ 95 ของคำขอจะเสร็จภายในค่าที่กำหนด ในขณะที่ P99 ควบคุมกรณีแย่สุดที่มีผลกระทบต่อผู้ใช้
- Response time — เวลาตอบสนองโดยเฉลี่ยและการแยกตามประเภทคำขอ (inference แบบสั้น/แบบยาว, batch vs streaming)
- Support tiers — ระดับการสนับสนุนตั้งแต่ Standard/Business/Enterprise/Platinum พร้อม SLA การตอบกลับ (เช่น 4 ชม. / 1 ชม. / 15 นาที) และช่องทางติดต่อฉุกเฉิน
- RPO / RTO — Recovery Point Objective (ข้อมูลที่อาจสูญหายได้) และ Recovery Time Objective (เวลาที่ระบบต้องกลับมาทำงาน) ในกรณีเกิดเหตุฉุกเฉิน
การจัดการ error budget เป็นส่วนสำคัญของ SLA โมเดลที่ถูกย่อ ซึ่งมีผลโดยตรงต่อการปล่อยฟีเจอร์หรือการขยายระบบ: error budget คำนวณจากเปอร์เซ็นต์ของเวลาที่ระบบอนุญาตให้ล้มเหลวได้ (เช่น SLA 99.9% ให้ error budget ≈ 0.1% ของเวลา) หากสะสมการผิดพลาดจนเผาผลาญ error budget เกินกำหนด ระบบและทีมปฏิบัติการต้องดำเนินมาตรการที่ชัดเจน เช่นการลดการปล่อยฟีเจอร์ใหม่, ย้อนกลับการปรับจูนที่เพิ่งทำ, เปิดโหมดจำกัดอัตรา (rate limiting) หรือลดความซับซ้อนของงานเพื่อคืน error budget ภายในรอบการวัดเดียวกัน พร้อมทั้งตรวจสอบสาเหตุราก (root cause analysis) และแผนป้องกันซ้ำ (post‑mortem)
เมื่อเกิดการละเมิด SLA (breached SLA) บริษัทผู้ให้บริการมักจะมีขั้นตอนรับมือมาตรฐานที่สำคัญ ได้แก่การแจ้งเตือนทันที, การเปิดช่องทางสนับสนุนฉุกเฉิน, การใช้กลไก fallback เช่น fallback to a larger model หรือโหมด degraded ที่ให้ผลลัพธ์สำรอง, การเพิ่มทรัพยากรแบบเร่งด่วน (autoscaling หรือ vertical scaling) และการทดสอบ/rollback ของเวอร์ชันที่เพิ่งนำขึ้นใช้งาน ตัวอย่างเช่น หาก P99 latency พุ่งเกินขีดที่ตกลงกัน ระบบอาจสลับ traffic บางส่วนไปยังโมเดลขนาดใหญ่ที่รันบนคลาวด์หลักเพื่อลดผลกระทบต่อผู้ใช้ ขณะเดียวกันผู้ให้บริการจะต้องมีแผนชดเชย เช่น เครดิตค่าบริการตามสัดส่วนของเวลาที่ไม่เป็นไปตาม SLA
สำหรับองค์กรที่กำลังพิจารณา SLA ของ LLM ที่ถูกย่อ ควรคำนึงถึงประเด็นต่อไปนี้ก่อนรับเงื่อนไข:
- กลยุทธ์ fallback — ต้องตรวจสอบว่า SLA ระบุวิธี fallback ชัดเจนหรือไม่ (เช่นสลับไปยัง model ขนาดใหญ่, หรือใช้ deterministic rule-based fallback) และผลกระทบด้านค่าใช้จ่ายเมื่อใช้ fallback
- autoscaling และ burst capacity — ความสามารถในการขยายทันทีเมื่อเกิดการจราจรหนาแน่น รวมถึง latency ที่เกิดจากการสเกลและ cold start time ของโมเดล
- ความคงที่ของโมเดลหลังย่อ — เมตริกการรับประกัน เช่น ความแตกต่างของความแม่นยำ (accuracy delta < 2–5%), อัตราการสร้างข้อมูลผิด (hallucination rate), ความเสถียรเชิงแนวความคิด (concept drift) และการทดสอบเฉพาะโดเมนที่ตกลงกัน
- การมอนิเตอริ่งแบบเรียลไทม์ — ต้องมี dashboard และ alert ที่รายงาน uptime, latency distribution, error rate, throughput, และตัวชี้วัดคุณภาพโมเดล (เช่น perplexity, F1, หรืออัตราผิดพลาดเชิงความหมาย) พร้อม API สำหรับให้ระบบขององค์กรดึงข้อมูล
- การกำหนดสิทธิ์/ความปลอดภัยและการปฏิบัติตามข้อกำหนด — ระบุชื่อสัญญาเรื่องการรักษาความลับข้อมูล, ระดับการเข้ารหัส, และนโยบายสำรองข้อมูล (backup) ที่สอดคล้องกับ RPO/RTO
โดยสรุป SLA สำหรับบริการ Model‑Tailor ควรให้ทั้งความชัดเจนเชิงตัวเลขและแผนรับมือที่ปฏิบัติได้จริง: การกำหนด uptime และเปอร์เซ็นไทล์ของ latency อย่างชัดเจน, การคำนวณและการจัดการ error budget, เงื่อนไขการชดเชยเมื่อไม่เป็นไปตาม SLA, รวมถึงการรับประกันด้านความคงที่ของโมเดลหลังย่อ (performance delta และ hallucination thresholds) องค์กรที่นำบริการนี้ไปใช้ควรรันการทดสอบแบบผสม (canary/chaos/blue‑green) และมีแผน fallback/escrow เพื่อให้มั่นใจว่าประสบการณ์ผู้ใช้และความต่อเนื่องทางธุรกิจจะไม่ถูกรบกวนเมื่อเกิดเหตุผิดปกติ
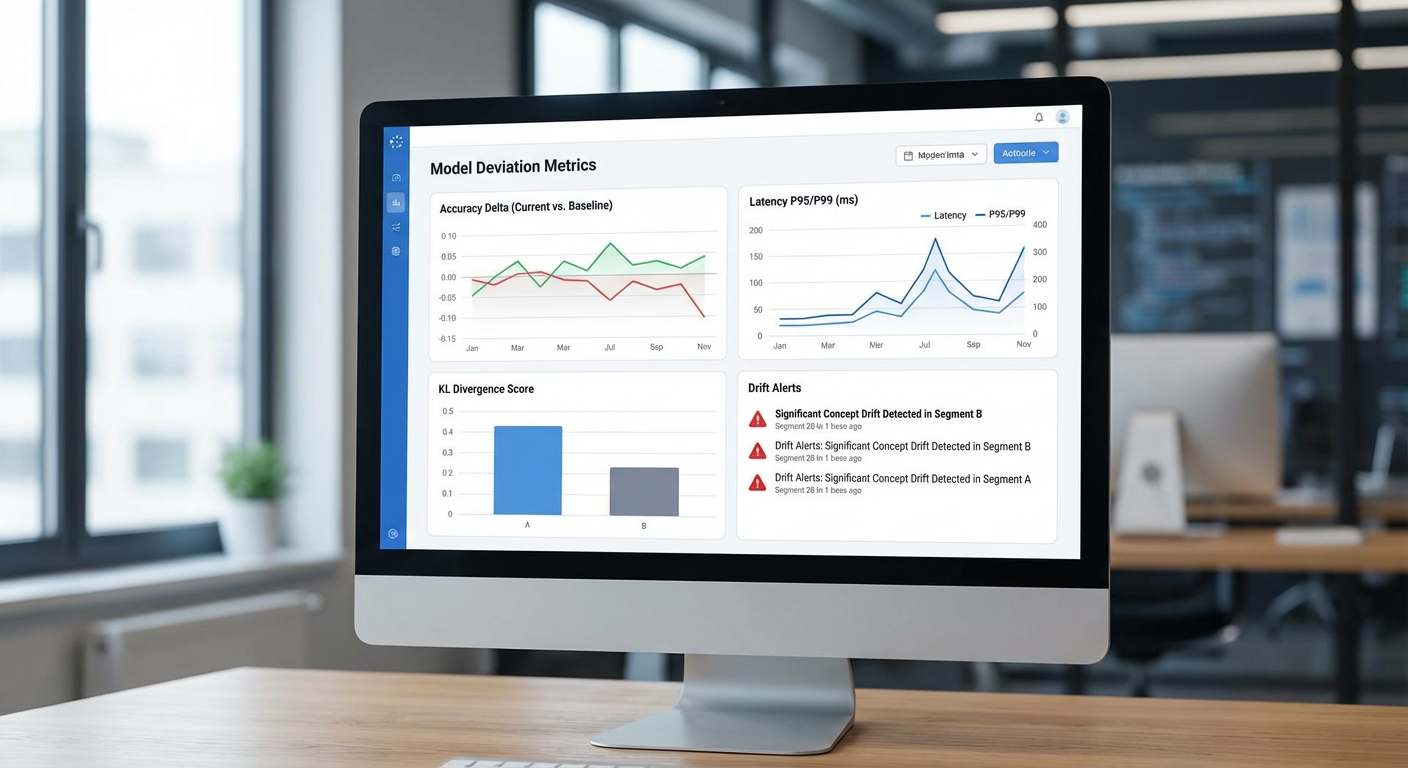
เครื่องมือวัดความเบี่ยงเบนหลังย่อ: metrics, benchmarks และการตรวจจับ drift
เครื่องมือวัดความเบี่ยงเบนหลังย่อ: metrics, benchmarks และการตรวจจับ drift
หลังจากกระบวนการ model‑tailoring — คือการย่อ (distillation / quantization / pruning) หรือปรับแต่งโมเดลให้รันบนคลาวด์ขนาดเล็ก — สิ่งสำคัญสำหรับลูกค้าธุรกิจคือการพิสูจน์ว่าโมเดลที่ถูกย่อยังคงทำงานได้ตามข้อกำหนดด้านคุณภาพและ SLA ที่ตกลงกันไว้ เครื่องมือวัดความเบี่ยงเบน (deviation) ของ Model‑Tailor ประกอบด้วยชุดเมตริกเชิงสถิติและการทดสอบเชิงปฏิบัติการที่ออกแบบมาเพื่อตรวจจับความแตกต่าง ตั้งแต่ความแม่นยำเชิงตัวเลขไปจนถึงพฤติกรรมการตอบกลับของโมเดลที่อาจเปลี่ยนแปลงไปหลังจากการย่อ
รายการเมตริกสำคัญ — ระบบจะคำนวณเมตริกพื้นฐานและเชิงลึกเพื่อเปรียบเทียบโมเดลก่อนและหลังย่อ ได้แก่
- Accuracy delta: ส่วนต่างของความแม่นยำแบบรวมหรือแบบแยกคลาส (เช่น ความแม่นยำลดลงกี่เปอร์เซ็นต์เมื่อเทียบกับต้นแบบ). ตัวอย่างค่าสำคัญ: alert ถ้า delta > 2% (absolute).
- Top‑k match / Top‑k consistency: เปอร์เซ็นต์ของคำตอบที่ตำแหน่ง 1…k ตรงกันระหว่างโมเดลทั้งสอง — เหมาะสำหรับงานตอบคำถามและการจัดอันดับ (เช่น top‑1, top‑3, top‑5).
- KL divergence: ใช้วัดความต่างของการแจกแจงโทเค็นหรือการแจกแจงความน่าจะเป็น (probability distribution) ของการทำนาย — ค่าที่สูงขึ้นบ่งชี้การเปลี่ยนแปลงเชิงพฤติกรรม.
- RMSE / MAE: สำหรับงานเชิงตัวเลขหรือการประมาณค่าต่อเนื่อง (เช่น การทำนายคะแนนหรือระดับความเสี่ยง) จะใช้รากเฉลี่ยของความคลาดเคลื่อน (RMSE) หรือตัววัดค่าผิดพลาดเฉลี่ย (MAE).
- Calibration metrics เช่น Expected Calibration Error (ECE) และ Brier score — วัดว่าความเชื่อมั่น (confidence) ของโมเดลสอดคล้องกับความน่าจะเป็นจริงหรือไม่ ซึ่งสำคัญต่อการตัดสินใจเชิงธุรกิจ.
- Latency / Throughput trade‑offs: P50/P95/P99 latency, throughput (requests per second), และ tail latency — ระบุว่าการย่อช่วยลดค่าใช้จ่ายแต่ส่งผลต่อ SLO อย่างไร.
นอกเหนือจากเมตริกเดี่ยวๆ แล้ว Model‑Tailor ยังรวมการวิเคราะห์เชิงเปรียบเทียบ (delta analysis) และการวัดความเสถียรของผลลัพธ์ (stability) เช่นอัตราการเปลี่ยนแปลงของคำตอบต่อคำถามเดียวกันเมื่อมีการสุ่ม seed หรือ context เพียงเล็กน้อย ซึ่งช่วยให้เข้าใจความเสี่ยงเชิงธุรกิจจากการย่อโมเดลได้ชัดเจนขึ้น
การตั้ง baseline และ automated regression testing — การวัดความเบี่ยงเบนต้องเริ่มด้วยการกำหนด golden baseline โดยใช้ชุดข้อมูลอ้างอิงของลูกค้า (customer canonical dataset) ที่สะท้อนการใช้งานจริง ทั้ง dataset จริงและชุดทดสอบสังเคราะห์ (synthetic augmentation) เพื่อครอบคลุม edge cases ระบบจะสร้าง snapshot ของผลลัพธ์จากโมเดลต้นฉบับเป็น baseline แล้วรันชุดการทดสอบแบบ automated ทุกครั้งที่มีการย่อหรือ deploy ใหม่
- การทดสอบเชิงอัตโนมัติ (CI/CD regression tests): รันทุก commit หรือการ release ใหม่ เปรียบเทียบค่า accuracy delta, top‑k consistency, และ RMSE กับ threshold ที่ตั้งไว้ — หากเกิน threshold ระบบจะ block การ deploy หรือเปิด ticket ให้ทีมรีเวิร์ส
- การทดสอบแบบ cohort และ per‑class: วัดผลต่อแต่ละกลุ่มธุรกิจหรือแต่ละคลาสของข้อมูล เช่น หากความแม่นยำลดลงมากในคลาสที่สำคัญทางธุรกิจ ควรยกเลิกการใช้งานหรือทำ canary rollout
- การตั้ง SLA เชิงปริมาณ: ตัวอย่าง SLA เช่น “delta accuracy ไม่เกิน 1.5% และ P95 latency < 300 ms” — ทีมสามารถเลือกใช้ SLA ของตนและให้ Model‑Tailor เป็นผู้ตรวจสอบอัตโนมัติ
เครื่องมือการมอนิเตอร์แบบ real‑time และการตรวจจับ drift — ใน production Model‑Tailor ให้ชุดเครื่องมือมอนิเตอร์ที่ผสานทั้ง metrics, logs, และ embedding‑level analysis เพื่อจับการเปลี่ยนแปลงของข้อมูลและพฤติกรรมโมเดลแบบเรียลไทม์
- Data drift detection: ตรวจสอบการเปลี่ยนแปลงของ distribution ของฟีเจอร์หรือคำถาม (token distribution, input embeddings) โดยใช้วิธีเชิงสถิติ เช่น Kolmogorov‑Smirnov test, Population Stability Index (PSI), KL divergence และการวัดระยะห่างของ embedding (cosine distance). ระบบจะสรุปเปอร์เซ็นต์ของโดเมนที่เปลี่ยน และยกเหตุการณ์ที่สำคัญขึ้นเป็น alert.
- Concept drift detection: วัดการเปลี่ยนแปลงของความสัมพันธ์ระหว่างอินพุตและผลลัพธ์จริง เช่นการลดลงของ accuracy หรือเปลี่ยนแปลง bias ต่อ class ใด class หนึ่ง — ใช้อัลกอริธึมเช่น ADWIN, Page‑Hinkley และ change‑point detection เพื่อตรวจหา drift แบบออนไลน์.
- Performance regression alerting: ผสานกับระบบมอนิเตอร์เช่น Prometheus/Grafana (หรือแดชบอร์ดเฉพาะของ Model‑Tailor) เพื่อส่ง alert อัตโนมัติทาง Slack / PagerDuty / Email หากค่า metrics เกิน threshold (เช่น accuracy delta > 2%, KL divergence > 0.1, หรือ P95 latency เพิ่มขึ้น 30%).
- Root‑cause analysis และทดลองย้อนกลับ (rollback): เมื่อเกิด alert ระบบจะรวบรวมข้อมูลตัวอย่าง (failing examples), per‑class breakdown, และ drift signatures เพื่อช่วยทีม DevOps/ML วิศวกรระบุสาเหตุ และสามารถทำ canary rollback หรือ retune quantization ได้อย่างรวดเร็ว.
โดยรวมแล้ว Model‑Tailor มุ่งเน้นการให้ลูกค้ามีความโปร่งใสและเครื่องมือเชิงปฏิบัติการที่เพียงพอสำหรับบริหารความเสี่ยงหลังการย่อโมเดล: ตั้งแต่การกำหนด baseline แบบลูกค้าเป็นศูนย์กลาง, การรัน regression tests อัตโนมัติ, ไปจนถึงการมอนิเตอร์และ alerting แบบ real‑time สำหรับทั้ง data drift, concept drift และ performance regression — ทำให้การลดต้นทุนโครงสร้างพื้นฐาน 60–80% สามารถทำได้โดยไม่แลกกับความเสี่ยงที่ธุรกิจยอมรับไม่ได้
กรณีใช้งานจริงและตัวอย่างลูกค้า: ธุรกิจใดได้ประโยชน์บ้าง
กรณีใช้งานจริงและตัวอย่างลูกค้า: ธุรกิจใดได้ประโยชน์บ้าง
สตาร์ทอัพไทยที่ให้บริการ Model‑Tailor ได้ทดลองนำเทคโนโลยีการย่อ LLM (model distillation / quantization และ pruning เฉพาะจุด) ไปใช้งานจริงกับลูกค้าหลากหลายอุตสาหกรรม ผลลัพธ์สะท้อนถึงการลดต้นทุนโครงสร้างพื้นฐานอย่างมีนัยสำคัญโดยยังคงประสิทธิภาพที่ยอมรับได้ภายใต้ SLA และการวัดความเบี่ยงเบนหลังย่อที่มาพร้อมเครื่องมือเฉพาะ สำหรับภาพรวมเชิงตัวเลข ลูกค้ารายใหญ่หลายรายรายงานการลดค่าใช้จ่ายด้าน inference ระหว่าง 60–80% ตามแผนที่นำเสนอ พร้อมกับ SLA ที่ยืนยันความพร้อมใช้งานและ latency ที่ลดลงอย่างชัดเจน
ตัวอย่าง 1 — ธนาคาร (โมเดลจดจำเอกสาร)
ธนาคารขนาดใหญ่ในประเทศไทยนำ Model‑Tailor ไปย่อโมเดล OCR และการจำแนกเอกสารทางการเงิน ผลการทดสอบในสภาพแวดล้อมจริงแสดงให้เห็นว่า ลดค่า inference cost ได้ 65% เมื่อเทียบกับการรันโมเดลเต็มรูปแบบบนคลาวด์ขนาดใหญ่ โดยยังรักษาค่า accuracy ของการจำแนกรายการสำคัญไว้ที่ ลดลงเพียง 0.8–1.5% (จาก baseline 98.5% เหลือประมาณ 97.0–97.7%) นอกจากนี้ธนาคารรายนี้สามารถลดจำนวน instance ของ GPU/CPU ที่ต้องใช้ในพีคโหลดได้ 55% ส่งผลให้ค่า OPEX รายไตรมาสตกลงอย่างมีนัยสำคัญ และระบบยังปฏิบัติตาม SLA ด้านความถูกต้องและเวลาในการตอบกลับภายในเกณฑ์ที่ตกลงไว้
ตัวอย่าง 2 — แพลตฟอร์มแชทบอท / Call Center
แพลตฟอร์มบริการแชทบอทสำหรับลูกค้ารายย่อยนำ Model‑Tailor ไปย่อโมเดลโต้ตอบเชิงภาษา ผลการใช้งานจริงแสดงว่า latency ลดลงประมาณ 30% ทำให้สามารถเพิ่มความสามารถในการจัดการ session ได้เป็น 2x (จากเดิมรองรับ 1,000 concurrent sessions เป็น 2,000 sessions) โดยที่ accuracy ในการตอบคำถามสำคัญยังคงอยู่ในระดับที่ธุรกิจยอมรับได้ (ลดลงไม่เกิน 1.2%) การเพิ่ม throughput นี้ช่วยให้บริษัทลดต้นทุนต่อ session ลงถึง 50% และลดความจำเป็นในการเพิ่มเครื่องเซิร์ฟเวอร์ในช่วงพีคตามเทศกาลหรือแคมเปญ
ตัวอย่าง 3 — E‑commerce (ระบบแนะนำสินค้าและค้นหา)
แพลตฟอร์มอี‑คอมเมิร์ซขนาดกลางใช้ Model‑Tailor ย่อโมเดลแนะนำสินค้าและการจัดอันดับผลการค้นหา ผลการทดลอง A/B testing พบว่าเวลาตอบสนองของ API ค้นหาลดลง 25–40% ส่งผลให้ Click‑through rate (CTR) ของหน้าแสดงผลเพิ่มขึ้น 6% และ conversion เพิ่ม 2.1% ลูกค้ารายนี้ระบุว่า ค่าใช้จ่ายการให้บริการลดลงประมาณ 60% ขณะที่คะแนนความพึงพอใจของผู้ใช้ต่อความรวดเร็วของระบบเพิ่มขึ้นอย่างมีนัยสำคัญ
ตัวอย่าง 4 — Healthtech (การสกัดข้อมูลทางการแพทย์)
สตาร์ทอัพด้านสุขภาพนำ Model‑Tailor ไปใช้กับโมเดลสกัดข้อมูลจากรายงานทางการแพทย์และ HIS integration ผลลัพธ์แสดงว่าโซลูชันที่ถูกย่อสามารถรันบนคลาวด์ขนาดเล็กหรือ edge node ภายในโรงพยาบาลได้อย่างมีเสถียรภาพ โดยลดค่าใช้จ่ายโครงสร้างพื้นฐานลงราว 70% และยังสามารถรักษา sensitivity/recall ของการสกัดข้อมูลสำคัญไว้ที่ระดับ >95% ซึ่งสอดคล้องกับมาตรฐานการใช้งานในทางคลินิกที่ลูกค้าให้ความสำคัญมากที่สุด
ผลลัพธ์เชิงตัวเลขสรุปได้ดังนี้:
- ลดค่าใช้จ่ายด้าน inference: 60–80% (ตัวอย่างจริง: ธนาคาร 65%, Healthtech ~70%)
- ลด latency: 25–30% (ตัวอย่างจริง: แพลตฟอร์มแชทบอท 30%)
- เพิ่ม throughput / concurrent sessions: สูงสุด 2x ในกรณีแชทบอท
- การตกของ accuracy/metric สำคัญ: โดยทั่วไปอยู่ในช่วง 0.5–2.5% ซึ่งธุรกิจส่วนใหญ่ยอมรับได้เมื่อแลกกับการลดต้นทุนอย่างมีนัยสำคัญ
- SLA และการวัดความเบี่ยงเบน: ลูกค้าใช้เครื่องมือของ Model‑Tailor เพื่อตั้งเกณฑ์ alert สำหรับ deviation ที่เกินกว่าระดับที่ยอมรับได้ ทำให้สามารถ rollback หรือปรับ calibrate ได้ทันที
บทเรียนที่ได้ — trade‑offs ระหว่าง cost vs accuracy และการยอมรับทางธุรกิจ
การนำ Model‑Tailor ไปใช้งานจริงเผยให้เห็น trade‑offs ชัดเจน: การลดต้นทุนและ latency มาพร้อมกับความเป็นไปได้ของการลด accuracy เล็กน้อย แต่กรณีส่วนใหญ่ที่นำเสนอแสดงว่าองค์กรสามารถกำหนดเกณฑ์เชิงธุรกิจ (business KPIs) ที่ยอมรับได้ เช่น ตั้งค่าขั้นต่ำของ accuracy หรือ recall ก่อนการย่อ และใช้เครื่องมือวัดความเบี่ยงเบนเพื่อตรวจสอบผลหลัง deployment ผลลัพธ์จากลูกค้าชี้ว่าเมื่อมีการกำกับดูแลเชิงเทคนิคและเชิงธุรกิจอย่างเหมาะสม (เช่น A/B testing, gradual rollout, SLA ที่ชัดเจน) การย่อโมเดลเป็นทางเลือกที่คุ้มค่าทั้งด้านเศรษฐศาสตร์และการปฏิบัติการ
สรุป: สำหรับองค์กรที่ต้องการลดค่าใช้จ่ายโครงสร้างพื้นฐานและเพิ่มความคล่องตัวในการให้บริการโดยยังคงรักษามาตรฐานทางธุรกิจไว้ Model‑Tailor เสนอกรณีใช้งานที่จับต้องได้และผลลัพธ์เชิงตัวเลขที่ชัดเจน แต่การตัดสินใจควรอาศัยการทดสอบเชิงปฏิบัติการและกรอบการวัดผลที่ชัดเจนเพื่อบาลานซ์ระหว่าง cost, performance และ accuracy ให้สอดคล้องกับเป้าหมายเชิงธุรกิจ
ความปลอดภัย กฎระเบียบ และแนวโน้มตลาด
ความปลอดภัยและความเป็นส่วนตัวที่เกี่ยวข้องกับการย่อโมเดล
การย่อโมเดล (model compression) เพื่อให้รันบนคลาวด์ขนาดเล็กมีประโยชน์ในด้านค่าใช้จ่ายและความหน่วง แต่ก็เพิ่มความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัวเฉพาะตัวที่องค์กรต้องพิจารณา ได้แก่
- ข้อมูลรั่วไหลจากการจำลองพฤติกรรม (model leakage) — โมเดลที่ย่อแล้วอาจยังคงฝังข้อมูลเชิงตัวอย่างของชุดข้อมูลต้นทาง ทำให้เสี่ยงต่อการเกิด membership inference หรือ model inversion ที่ผู้โจมตีสามารถสกัดข้อมูลส่วนบุคคลหรือฟีเจอร์สำคัญออกมาได้
- การโจรกรรมโมเดลและ IP extraction — โมเดลขนาดเล็กมักมีการเผยแพร่หรือแจกจ่ายเพื่อรันใกล้ข้อมูล ทำให้ความเสี่ยงต่อการคัดลอกหรือทำซ้ำเพิ่มขึ้น ซึ่งกระทบต่อทรัพย์สินทางปัญญาและความได้เปรียบเชิงธุรกิจ
- การลดทอนความสามารถของการป้องกันเชิงสถิติ — เทคนิคย่อเช่น pruning หรือ quantization อาจทำให้วิธีการตรวจจับพฤติกรรมผิดปกติหรือการตรวจสอบความเที่ยงตรงของโมเดลทำได้ยากขึ้น
- การโจมตีผ่านช่องว่างการควบคุมการเข้าถึง — เมื่อโมเดลกระจายไปยังคลาวด์ขนาดเล็กหรือ edge node การควบคุมการเข้าถึงและการจัดการคีย์ที่ไม่เข้มงวดอาจเปิดช่องให้ผู้ไม่หวังดีเข้าถึงโมเดลหรือข้อมูลที่เกี่ยวข้อง
แนวทางบรรเทาความเสี่ยง (mitigation) ที่แนะนำมีหลากหลายชั้นเพื่อสร้างความมั่นคงทั้งทางเทคนิคและการบริหาร เช่น
- Differential Privacy (DP) — ใช้ DP ในขั้นตอนการฝึก (training) หรือการกลั่นข้อมูล (distillation) เพื่อลดความเสี่ยงการเปิดเผยตัวอย่างเฉพาะบุคคล แม้จะแลกมาด้วยความแม่นยำบางส่วน แต่สามารถลดความเสี่ยงของ membership inference ได้อย่างมีนัยสำคัญ
- การควบคุมการเข้าถึงและการจัดการสิทธิ์ — บังคับใช้ IAM, RBAC, และการจัดการคีย์ (KMS) รวมทั้งใช้ Trusted Execution Environments (TEE) เช่น Intel SGX หรือเทคโนโลยี enclave อื่น ๆ ในกรณีที่ต้องรันโมเดลในสภาพแวดล้อมไม่เชื่อถือ
- Encryption และ Secure Inference — ใช้การเข้ารหัสข้อมูลทั้งขณะเก็บและขณะส่ง โดยพิจารณาเทคนิคขั้นสูงเมื่อจำเป็น เช่น Secure Multi‑Party Computation หรือ Homomorphic Encryption สำหรับกรณีที่ต้องประมวลผลข้อมูลความลับสูง แม้ว่าจะมีค่าใช้จ่ายด้านประสิทธิภาพเพิ่มขึ้น
- Watermarking และ Model Fingerprinting — ป้องกันการคัดลอกและพิสูจน์แหล่งที่มาโดยใส่ลายน้ำเชิงสถิติลงในโมเดล เพื่อใช้ในกรณีพิพาททางสิทธิ์การใช้งาน
- การตรวจสอบหลังการย่อ (post‑compression auditing) — ใช้เครื่องมือวัดความเบี่ยงเบนเชิงพฤติกรรม (drift, bias, accuracy delta) รวมทั้งรัน red‑team tests และ membership inference tests อย่างสม่ำเสมอ
การปฏิบัติตามกฎระเบียบ: PDPA และมาตรฐานสากล
การนำ Model‑Tailor มาใช้ต้องสอดคล้องกับกรอบกฎหมายและมาตรฐานด้านข้อมูลทั้งในประเทศและต่างประเทศ โดยประเด็นสำคัญได้แก่
- PDPA (พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย) — องค์กรต้องมีฐานทางกฎหมายในการเก็บ ใช้ หรือถ่ายโอนข้อมูลส่วนบุคคล เช่น ความยินยอม ความจำเป็นตามสัญญา หรือภารกิจทางกฎหมาย นอกจากนี้ต้องมีมาตรการทางเทคนิคและองค์กร (เช่น การเข้ารหัส การควบคุมการเข้าถึง การทำ DPIA เมื่อจำเป็น)
- GDPR และการโอนข้อมูลข้ามพรมแดน — หากข้อมูลของพลเมืองสหภาพยุโรปถูกประมวลผลหรือโอน การปฏิบัติตาม GDPR เป็นสิ่งจำเป็น โดยเฉพาะการทำ Data Protection Impact Assessment (DPIA) สำหรับระบบความเสี่ยงสูง และข้อจำกัดการโอนข้อมูลไปยังประเทศที่ไม่มีการคุ้มครองเทียบเท่า
- มาตรฐานความมั่นคงของข้อมูล — การรับรองอย่าง ISO/IEC 27001, ISO/IEC 27701 (Privacy Information Management), SOC 2 จะช่วยสร้างความเชื่อมั่นให้ลูกค้าองค์กร โดยเฉพาะเมื่อต้องให้ SLA และรับประกันด้าน security
- กฎระเบียบด้าน AI ที่กำลังเกิดขึ้น — เช่น EU AI Act ที่จัดประเภทระบบ AI ตามความเสี่ยง องค์กรต้องเตรียมหลักฐานการทดสอบความปลอดภัย ความโปร่งใส และการบรรเทาความเสี่ยงสำหรับระบบที่จัดว่า “high‑risk”
ข้อเสนอเชิงปฏิบัติสำหรับการปฏิบัติตามกฎระเบียบได้แก่การจัดชุดเอกสารประกอบ (data processing agreements), การทำ DPIA ก่อนติดตั้ง Model‑Tailor, การจัดการ lifecycle ของโมเดล (logging, versioning, explainability reports) และการรวมมาตรการ technical controls (DP, encryption, TEE) เข้าเป็นมาตรฐานบริการเพื่อให้สอดคล้องกับ PDPA/GDPR และมาตรฐานสากล
แนวโน้มตลาด ตำแหน่งของ Model‑Tailor และข้อเสนอเชิงกลยุทธ์
ความต้องการโซลูชันที่ลดต้นทุนการรัน LLM มีแนวโน้มสูง โดยเฉพาะในภูมิภาคเอเชียตะวันออกเฉียงใต้ (SEA) ที่ค่าใช้จ่ายโครงสร้างพื้นฐานยังเป็นอุปสรรคต่อการนำ LLM มาใช้งานจริง สำรวจหลายแห่งชี้ว่าองค์กรกว่า 60% ต้องการปรับลดต้นทุนต่อคำตอบ (cost per inference) ก่อนจะขยายการใช้งานในเชิงพาณิชย์
ตำแหน่งทางการตลาดของ Model‑Tailor ควรเน้นจุดเด่นที่ชัดเจน:
- ความคุ้มค่า (Cost leadership) — การโฆษณาว่าลดค่าใช้จ่ายโครงสร้างพื้นฐานจริง 60–80% เป็นข้อได้เปรียบเชิงพาณิชย์ที่แข็งแรงสำหรับกลุ่มลูกค้า SME, สตาร์ทอัพ, และธุรกิจท้องถิ่นที่ต้องการ AI แบบใช้งานจริง
- การปฏิบัติตามและ SLA เป็นข้อเสนอขาย (Compliance‑first) — การให้แพ็กเกจสำหรับ PDPA/GDPR, รายงาน DPIA, และมาตรการทางเทคนิคพร้อม SLA จะช่วยสร้างความเชื่อมั่นและลด friction ในการตัดสินใจซื้อ
- การขยายตลาดแบบโซลูชันแนวตั้ง (verticalized solutions) — มุ่งเป้าอุตสาหกรรมที่ต้องการความลับและประสิทธิภาพเช่นการเงิน การแพทย์ และโทรคมนาคม โดยออกแบบการย่อให้สอดคล้องกับข้อกำหนดทางกฎหมายของแต่ละอุตสาหกรรม
- คอนเพติเตอร์และพันธมิตร — คู่แข่งประกอบด้วยโซลูชันโอเพนซอร์ส (เช่น Distil/quantization libraries), ผู้ให้บริการคลาวด์ที่มีเทคโนโลยีเร่งความเร็ว (NVIDIA/TensorRT, AWS Neo, Google Vertex AI) และสตาร์ทอัพด้านการปรับแต่งโมเดลเช่น MosaicML หรือ Hugging Face ในเชิงบริการ Model‑Tailor ควรหาพันธมิตรกับผู้ให้บริการคลาวด์และฮาร์ดแวร์เพื่อเพิ่มมูลค่า
กลยุทธ์การเติบโตที่แนะนำ:
- โมเดลการกำหนดราคาแบบยืดหยุ่น — เสนอ subscription + pay‑per‑inference หรือการคิดค่าบริการตามระดับการบีบอัดและ SLA เพื่อให้ลูกค้าเลือกได้ตามความต้องการ
- ผลิตภัณฑ์แบบแพ็กเกจสำหรับการปฏิบัติตามกฎระเบียบ — ให้บริการพร้อมเอกสาร DPIA, audit trail, และการรับรองความปลอดภัย เพื่อบุกตลาดองค์กรที่มีข้อกำหนดสูง
- บริการต่อเนื่อง (managed service) — เสนอการตรวจสอบหลังย่อ (post‑compression monitoring), การอัปเดตความปลอดภัย และการฟื้นฟูโมเดลเมื่อพบ drift เป็นบริการเสริมสร้างรายได้อย่างยั่งยืน
- เริ่มจากกรณีใช้งานที่มีความต้องการเร็วและมูลค่าสูง — เช่น การให้คำปรึกษาทางการแพทย์ภายในองค์กร (on‑premise), ระบบตอบคำถามทางการเงินภายใน, หรือ customer support ที่ต้องการ latency ต่ำและต้นทุนต่ำ
สรุป: สำหรับองค์กรที่สนใจใช้ Model‑Tailor ควรเริ่มด้วยการทำ DPIA และการทดสอบความเสี่ยงเชิงเทคนิค (เช่น membership inference tests), กำหนดข้อกำหนดด้าน SLA และ security ในสัญญา จัดเตรียมมาตรการทางเทคนิค (DP, encryption, TEE) และเลือกพันธมิตรที่สามารถรับประกันการปฏิบัติตาม PDPA/GDPR เพื่อให้ได้ทั้งประหยัดต้นทุนและความมั่นคงของข้อมูลในระยะยาว
คำแนะนำสำหรับองค์กร: การประเมินและขั้นตอนนำไปใช้งาน
บทสรุปนี้นำเสนอแนวทางเชิงปฏิบัติสำหรับองค์กรที่ต้องการประเมิน ทดลอง และนำบริการ Model‑Tailor ของสตาร์ทอัพไทยไปใช้งานจริง โดยครอบคลุมกระบวนการตั้งแต่การเตรียมความพร้อมเชิงเทคนิค การทดสอบรูปแบบการเปิดใช้งาน ไปจนถึงการตั้ง SLA และการเฝ้าติดตามหลังนำขึ้น production เพื่อให้การลดค่าใช้จ่ายโครงสร้างพื้นฐาน (ตามที่ผู้ให้บริการรายงานว่าอาจลดได้ 60–80%) เกิดขึ้นอย่างปลอดภัย และไม่กระทบต่อประสบการณ์หรือความแม่นยำของบริการ
Checklist ก่อนเริ่ม
ก่อนเริ่ม PoC หรือทดลองใช้งาน ควรทำการตรวจสอบและเตรียมความพร้อมดังนี้เพื่อหลีกเลี่ยงความเสี่ยงทั้งด้านเทคนิคและกฎข้อบังคับ
- Workload profiling: รวบรวมข้อมูลประเภทคำถาม/คำสั่ง ปริมาณคำขอ (QPS), ขนาดอินพุตและเอาต์พุต, รูปแบบ latency ที่ยอมรับได้ และ peak vs. baseline traffic เพื่อประเมินความเหมาะสมของโมเดลหลังย่อ
- SLO targets (service-level objectives): กำหนดเป้าหมายเบื้องต้น เช่น latency P95, latency P99, throughput, availability และ accuracy ที่ยอมรับได้ ทั้งนี้แยกตามกรณีการใช้งาน (mission-critical vs. auxiliary)
- Data privacy & compliance review: ทบทวนว่ายังมีข้อมูลส่วนบุคคลหรือข้อมูลความลับที่ต้องจัดการหรือไม่ ตรวจสอบการเข้ารหัสข้อมูลขณะส่งและขณะพัก การทำ data residency และสัญญา DPA/หากต้องปฏิบัติตาม PDPA/GDPR
- Fallback plan: กำหนดกลไกสำรองเมื่อโมเดลย่อไม่สามารถให้บริการได้ เช่น การคืนค่าไปใช้ LLM บนคลาวด์ขนาดใหญ่, การใช้งาน cached responses, หรือ degrade to rule-based responses
- Security & access control: ตรวจสอบการจัดการคีย์, IAM, network isolation, และการทำ penetration test พื้นฐานก่อนขึ้น production
- Cost baseline: บันทึกค่าใช้จ่ายปัจจุบัน (cost per inference, infrastructure TCO) เพื่อเปรียบเทียบหลังนำ Model‑Tailor มาใช้
คำแนะนำการทดสอบ: การออกแบบ PoC และ rollout แบบค่อยเป็นค่อยไป
การทดสอบต้องเป็นระบบและสามารถวัดผลได้ชัดเจน แนะนำขั้นตอนดังนี้
- เริ่มจาก PoC ในสเกลเล็ก: เลือก use-case ที่มีขอบเขตชัดเจนและความเสี่ยงต่ำ เช่น chat assistants แบบ read-only หรือ task-specific API เพื่อตรวจสอบความแม่นยำและ latency เบื้องต้น
- A/B testing: รัน Model‑Tailor ขนานกับโมเดลเดิม ให้ทราฟฟิคบางสัดส่วน (เช่น 10–20%) เพื่อเปรียบเทียบผลลัพธ์ในเชิงคุณภาพและเชิงปริมาณ วัด metric ที่กำหนดแบบ real-time
- Canary rollout: ค่อยๆ ขยายสัดส่วนการใช้งานจากกลุ่มผู้ใช้ภายในไปสู่ผู้ใช้จริง โดยตั้ง thresholds สำหรับ rollback เช่น accuracy delta > 1% ในกรณี mission-critical หรือ latency P95 เพิ่มเกิน 2x
- Continuous monitoring และ observability: ติดตั้ง logging ระดับคำขอ การเก็บตัวอย่างคำตอบสำหรับการประเมินเชิงคุณภาพ รวมถึงการตั้ง alert สำหรับ drift, error-rate spike, latency degradation และ cost anomalies
- Regression & adversarial testing: รันเทสต์ชุดตัวอย่างที่เคยใช้กับโมเดลเดิมเพื่อวัด accuracy delta และใช้ชุด input ที่อาจก่อปัญหาเพื่อประเมินความทนทาน
ตัวชี้วัดสำคัญ (KPI) ที่ต้องติดตามหลังนำไปใช้งาน
กำหนด KPI เชิงปริมาณและระยะเวลาในการประเมินอย่างชัดเจนเพื่อให้การตัดสินใจต่อเนื่องเป็นไปอย่างมีข้อมูลรองรับ
- Cost per inference: ค่าใช้จ่ายต่อคำขอ (รวม compute, memory, network) เปรียบเทียบกับ baseline ก่อนย่อ — ตั้งเป้าหมายลดค่าใช้จ่ายตามที่ตกลง (เช่น ลด 60–80%) และติดตามแบบรายวัน/รายสัปดาห์
- Accuracy delta / Quality metrics: วัดความแตกต่างด้านความแม่นยำหรือความสอดคล้องของผลลัพธ์ (เช่น F1, BLEU, ROUGE หรือ business metric เฉพาะ) — กำหนดเกณฑ์ยอมรับได้ เช่น <1% สำหรับงานที่ต้องการความแม่นยำสูง หรือ <3–5% สำหรับงานทั่วไป
- Latency (P95 / P99): กำหนดเป้าหมายความหน่วง เช่น P95 <200–500 ms สำหรับ interactive UI, P99 <1s หรือขึ้นกับ SLA ที่ตกลง และตรวจสอบว่ามีการเพิ่มขึ้นในช่วง peak หรือไม่
- Availability / Error rate: เปอร์เซ็นต์เวลาที่บริการพร้อมใช้งาน (เช่น 99.9%, 99.95%) และค่า error-rate ที่ยอมรับได้ (เช่น <0.1%)
- Throughput / Scalability: ทดสอบว่าเมื่อเพิ่ม QPS ระบบสามารถ autoscale หรือรักษา SLO ได้หรือไม่ และมีค่า cost-per-QPS อย่างไร
- Model drift & data drift indicators: ติดตาม distribution ของอินพุตและเอาต์พุต, อัตราความผิดพลาดที่เพิ่มขึ้นเป็นสัญญาณต้องเทรนหรือตรวจสอบโมเดลใหม่
การตั้ง SLA ที่เหมาะสมและการวางแผนรันใน production อย่างปลอดภัย
เมื่อผ่าน PoC และทดสอบจนมั่นใจ ควรจัดทำ SLA ที่ชัดเจนและมีมาตรการรองรับเหตุการณ์ผิดปกติ ดังนี้
- กำหนด SLA ตามระดับความสำคัญ: แบ่งระดับบริการ (critical, standard, best-effort) และกำหนดค่า availability, latency targets (P95/P99) และ support response time ให้สอดคล้องกับผล PoC
- กำหนด SLO และ SLI ที่วัดได้จริง: ระบุ SLI ที่จะถูกรายงาน (เช่น latency P95, error-rate, cost-per-inference) และความถี่ในการรายงาน (hourly/daily/weekly)
- ข้อตกลงเรื่อง incident & rollback: ระบุเงื่อนไขการแจ้งเตือน (e.g., latency P95 เกิน threshold นานกว่า 15 นาที), เวลาตอบกลับของผู้ให้บริการ, และแผน rollback ที่มีเทมเพลตพร้อมใช้งาน
- Rollout automation & feature flags: ใช้ระบบ CI/CD ที่รองรับการ deploy แบบค่อยเป็นค่อยไป เพิ่ม feature flags เพื่อปิดฟีเจอร์หรือสลับกลับเมื่อเกิดปัญหา
- Audit & logging retention: กำหนดนโยบายการเก็บ log เพื่อให้สามารถตรวจสอบเหตุการณ์ย้อนหลังได้โดยคำนึงถึง privacy และ storage cost
- Training & runbook: จัดทำ runbook สำหรับทีมปฏิบัติการ ระบุขั้นตอนตรวจสอบ, การตัดสินใจ rollback, และช่องทางสื่อสารกับผู้ให้บริการ
สรุปแล้ว การนำ Model‑Tailor มาใช้งานให้ปลอดภัยและคุ้มค่านั้นต้องอาศัยการเตรียมความพร้อมทางเทคนิค การทดสอบแบบมีกรอบ และการตั้ง KPI/SLA ที่สมเหตุสมผล โดยควรเริ่มจาก PoC ที่ชัดเจน ขยายแบบค่อยเป็นค่อยไป พร้อมแผนสำรองที่ตรวจสอบได้ เพื่อให้ผลลัพธ์การประหยัดต้นทุนไม่ส่งผลกระทบต่อคุณภาพการให้บริการ
บทสรุป
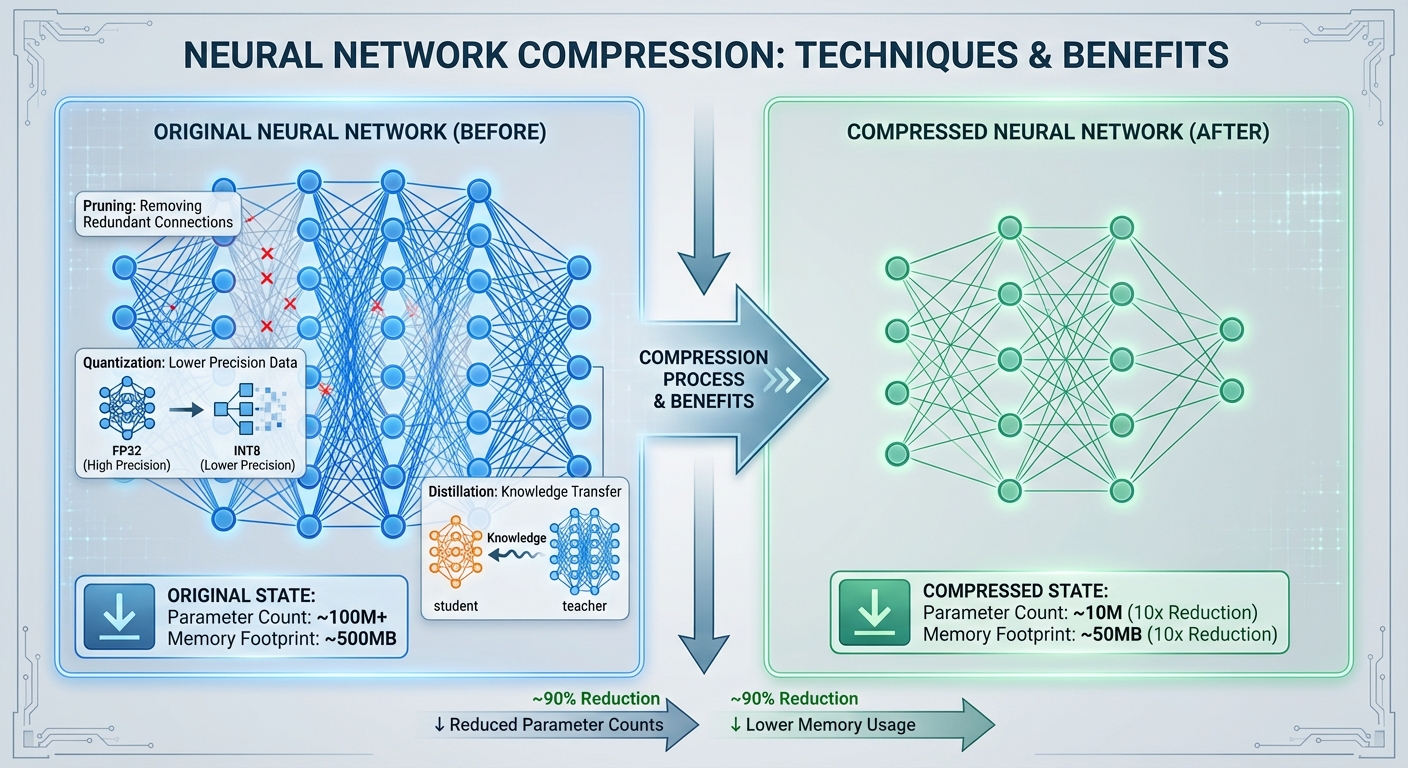
Model‑Tailor เป็นตัวอย่างที่ชัดเจนของการประยุกต์เทคโนโลยีย่อโมเดล (model compression / distillation) เพื่อทำให้การนำ LLM เข้าสู่ production ในองค์กรเป็นไปได้อย่างคุ้มค่าและมีการรับประกันระดับการให้บริการ (SLA) รองรับ โดยสตาร์ทอัพผู้พัฒนาอ้างว่าสามารถลดต้นทุนโครงสร้างพื้นฐานจริงได้ถึง 60–80% ขณะที่ยังมีเครื่องมือสำหรับวัดค่าความเบี่ยงเบนหลังการย่อ (divergence metrics) และกลไกตรวจจับความผิดปกติ ระบบเหล่านี้ช่วยลดข้อจำกัดด้านฮาร์ดแวร์และค่าใช้จ่าย ทำให้ LLM ขนาดใหญ่สามารถรันบนคลาวด์ขนาดเล็กหรือทรัพยากรที่ประหยัดขึ้นได้ โดยที่ยังคงตอบสนองเงื่อนไข SLA ในงานบางประเภท เช่น การตอบคำถามภายในขอบเขตคงที่หรือการจัดหมวดหมู่ข้อความ
อย่างไรก็ตาม องค์กรควรประเมิน trade‑offs ระหว่างต้นทุนและความแม่นยำอย่างรอบคอบก่อนนำไปใช้งานจริง: ตั้งเกณฑ์ยอมรับความคลาดเคลื่อน (เช่น ขีดความแม่นยำที่ยอมให้ลดลงได้สำหรับงานเฉพาะ) กำหนดตัวชี้วัดด้านความเบี่ยงเบนหลังย่อ (เช่น divergence score, A/B comparison, latency, และ error‑rate ตาม use‑case) และเตรียมแผน fallback/roll‑back (เช่น สลับกลับไปใช้โมเดลเต็มขนาดในกรณีความผิดพลาดหรือใช้ human‑in‑the‑loop) เพื่อให้การใช้งานสอดคล้องกับความเสี่ยงทางธุรกิจ ในด้านอนาคต คาดว่าจะเห็นการแพร่หลายของโซลูชันแบบนี้มากขึ้น การพัฒนาเครื่องมือวัดความเบี่ยงเบนมาตรฐาน การผสานรวมกับ MLOps และการกำหนดนโยบาย SLA ที่ชัดเจนจะเป็นปัจจัยสำคัญที่ทำให้การย่อโมเดลกลายเป็นแนวทางปฏิบัติที่ยอมรับได้ในระดับองค์กร



