
ทีมนักวิจัยไทยเปิดตัว Tiny‑Sparsity Compiler นวัตกรรมซอฟต์แวร์ที่สามารถแปลงโมเดลภาษาใหญ่ (LLM) ให้รันแบบออฟไลน์บนไมโครคอนโทรลเลอร์ขนาดเล็กได้จริง — ลดการใช้หน่วยความจำถึง 50–100x และทำให้การประมวลผลคำสั่งเสียงหรือท่าทางพื้นฐานสามารถทำได้โดยไม่พึ่งพาคลาวด์ ผลลัพธ์นี้ไม่เพียงแต่ลดต้นทุนด้านการสื่อสารและความหน่วง (latency) แต่ยังช่วยยกระดับความเป็นส่วนตัวของผู้ใช้ เพราะข้อมูลไม่ต้องส่งออกนอกอุปกรณ์
บทความนี้สรุปประเด็นสำคัญของงานวิจัย: วิธีการทางเทคนิคของ Tiny‑Sparsity Compiler ที่ใช้การทำ sparsification และการคอมไพล์เฉพาะทางเพื่อลดขนาดโมเดล, ผลเบนช์มาร์กเปรียบเทียบบนฮาร์ดแวร์ตัวอย่างอย่าง ARM Cortex‑M, ESP32 และ STM32 ที่แสดงการประหยัดหน่วยความจำและความเร็วในการตอบสนอง รวมถึงข้อจำกัดด้านความแม่นยำที่อาจเกิดขึ้นเมื่อแลกกับการย่อขนาดโมเดล — เหมาะสำหรับแอปพลิเคชันคำสั่งเสียงสั้น ๆ และงานที่ยอมรับการลดทอนความแม่นยำบางส่วนได้
ภาพรวมข่าวและความสำคัญ
ภาพรวมข่าวและความสำคัญ
ทีมนักวิจัยไทยได้เปิดตัวโครงการ Tiny‑Sparsity Compiler ซึ่งประกาศความสามารถในการแปลงและบีบอัดโมเดลภาษาเชิงลึก (LLM) ขนาดเล็กให้สามารถรันบนไมโครคอนโทรลเลอร์แบบออฟไลน์ได้ โดยทีมระบุว่าการปรับแต่งเชิงโครงสร้างและการประมวลผลแบบ sparsity-aware ช่วยลดการใช้หน่วยความจำลงถึง 50–100x เมื่อเทียบกับเวอร์ชันมาตรฐานของโมเดล ตัวอย่างเช่น โมเดลขนาดเล็กที่แต่เดิมอาจต้องการหน่วยความจำระดับหลายสิบหรือหลายร้อยเมกะไบต์ สามารถย่อเหลือระดับไม่กี่เมกะไบต์จนสามารถรันบนอุปกรณ์ที่มีแรมและแฟลชจำกัด เช่น MCU ที่มีหน่วยความจำเพียงไม่กี่เมกะไบต์
ความสำคัญของความพัฒนาเช่นนี้ต่อวงการ AI มีหลายมิติ โดยเฉพาะในเชิงธุรกิจและการนำไปใช้งานเชิงพาณิชย์: ความเป็นส่วนตัว — การรันโมเดลบนอุปกรณ์ที่อยู่ใกล้ผู้ใช้หมายถึงข้อมูลเสียงและข้อความไม่จำเป็นต้องส่งขึ้นคลาวด์ ลดความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล; latency — การตอบสนองเป็นแบบเรียลไทม์โดยไม่พึ่งพาการเชื่อมต่อเครือข่าย ช่วยให้ประสบการณ์ผู้ใช้ดีขึ้นในแอปพลิเคชันเสียงสั่งงานและการควบคุมอัตโนมัติ; และ ต้นทุน — ลดค่าใช้จ่ายด้าน inference บนคลาวด์และแบนด์วิธ เหมาะสำหรับการปรับใช้ในสินค้า IoT ปริมาณมาก
บทความฉบับเต็มจะนำเสนอภาพรวมเชิงเทคนิคของวิธีการที่ Tiny‑Sparsity Compiler ใช้ เช่น การผสมผสานระหว่างการ pruning แบบโครงสร้าง การ quantization ขั้นสูง และการจัดการหน่วยความจำเฉพาะฮาร์ดแวร์ พร้อมสาธิตผลการทดสอบที่ชัดเจน: ค่าใช้หน่วยความจำก่อนและหลังการแปลง, ความเร็วการตอบสนอง (latency) บนแพลตฟอร์มตัวอย่าง, รวมถึงการประเมินคุณภาพเชิงคุณภาพและเชิงปริมาณที่เปรียบเทียบค่า accuracy หรือความสอดคล้องของผลลัพธ์หลังการลดขนาด
ผู้อ่านควรคาดหวังว่าจะได้เห็นรายละเอียดเชิงปฏิบัติการและข้อจำกัดที่สำคัญ เช่น ขอบเขตการใช้งานที่เหมาะสม (โมเดลขนาดเล็กสำหรับคำสั่งเสียงและงาน NLP พื้นฐาน มากกว่าการประมวลผลเชิงตรรกะหรือการให้เหตุผลเชิงลึก), การแลกเปลี่ยนระหว่างประสิทธิภาพกับความแม่นยำ, ความต้องการฮาร์ดแวร์เป้าหมาย (เช่น ARM Cortex‑M, RISC‑V MCU) และการสนับสนุนด้านเครื่องมือที่จำเป็นสำหรับการนำไปใช้งานในเชิงพาณิชย์
สรุปคือข่าวนี้เป็นสัญญาณว่าเทคโนโลยีการเร่งและบีบอัดโมเดลกำลังพา LLM เข้าใกล้อุปกรณ์ปลายทางมากขึ้น ซึ่งจะเปลี่ยนภูมิทัศน์ของบริการ AI บนอุปกรณ์ (edge AI) ทั้งด้านความเป็นส่วนตัว ประสิทธิภาพ และต้นทุน — ขณะเดียวกันธุรกิจที่สนใจควรตระหนักถึงขอบเขตการใช้งานและข้อจำกัดที่อาจเกิดขึ้นเมื่อใช้งานโมเดลบนฮาร์ดแวร์ทรัพยากรต่ำ
- สิ่งที่จะอ่านต่อไป: เทคนิคหลักของ Tiny‑Sparsity Compiler
- ผลการทดสอบ: ตัวเลข 50–100x และเปรียบเทียบ latency/accuracy
- ข้อจำกัดและการนำไปใช้: กรณีใช้งานเชิงพาณิชย์และการประเมินความเสี่ยง
ปัญหาเดิม: ทำไม LLM จึงยากจะรันบนไมโครคอนโทรลเลอร์
ปัญหาเดิม: ทำไม LLM จึงยากจะรันบนไมโครคอนโทรลเลอร์
การนำโมเดลภาษาใหญ่ (Large Language Models — LLM) ไปรันบนไมโครคอนโทรลเลอร์ (MCU) เผชิญกับข้อจำกัดทางฮาร์ดแวร์และสถาปัตยกรรมที่เป็นพื้นฐาน ซึ่งทำให้การประมวลผลเชิงลึกสำหรับงานภาษาเป็นเรื่องท้าทายอย่างยิ่ง สำหรับบริบทเชิงตัวเลขที่ชัดเจน MCU ทั่วไปมีหน่วยความจำ RAM ตั้งแต่ระดับกิโลไบต์จนถึงเพียงไม่กี่เมกะไบต์ — โดยทั่วไปอยู่ในช่วง <1–8 MB ขณะที่หน่วยเก็บข้อมูลถาวร (Flash/ROM) เองก็มักจำกัดและต้องใช้พื้นที่สำหรับเฟิร์มแวร์ ระบบปฏิบัติการขนาดเล็ก และสแตกของโปรแกรมร่วมด้วย นอกจากนี้ความถี่นาฬิกาของซีพียูมักอยู่ในระดับไม่กี่สิบเมกะเฮิรตซ์ถึงร้อยเมกะเฮิรตซ์ และหลายแพลตฟอร์มไม่มีหน่วยประมวลผลทศนิยม (FPU) หรือคำสั่ง SIMD ขั้นสูงที่ช่วยเร่งคณิตศาสตร์เมตริกซ์ขนาดใหญ่

ผลลัพธ์ของข้อจำกัดเหล่านี้คือความไม่สอดคล้องกันระหว่างความต้องการของ LLM และทรัพยากรบน MCU ซึ่งสามารถสรุปได้เป็นข้อ ๆ ดังนี้
- หน่วยความจำสำหรับพารามิเตอร์: แม้แต่โมเดล LLM ขนาดเล็กเชิงพาณิชย์ก็ยังมีพารามิเตอร์เป็นหลักหลายสิบถึงหลายร้อยล้านค่า — แปลงเป็นขนาดไฟล์แล้วจะอยู่ในระดับหลายสิบถึงหลายร้อยเมกะไบต์ (เช่น 30M พารามิเตอร์ ≈ 120 MB ใน FP32, 60 MB ใน FP16, 30 MB ใน 8‑bit)
- หน่วยความจำสำหรับ activations และสแตก: นอกจากพารามิเตอร์แล้ว การประมวลผลลำดับคำ (sequence) ต้องการพื้นที่ชั่วคราวจำนวนมากสำหรับ activations, attention caches และบัฟเฟอร์การคำนวณ ซึ่งมักจะมากกว่าพื้นที่เก็บพารามิเตอร์เองหลายเท่าตัว
- ความสามารถคำนวณต่ำ: คล็อกความถี่และคำสั่งลักษณะ SIMD/FPU ที่จำกัดทำให้การคูณเมตริกซ์ซึ่งเป็นหัวใจของทรานส์ฟอร์เมอร์ทำได้ช้ามากและกินพลังงานสูงเมื่อเทียบกับการใช้งานบน CPU/GPU/NPUs
- ข้อจำกัดด้านระบบปฏิบัติการและหน่วยความจำเสมือน: MCU ส่วนใหญ่ไม่มี MMU หรือระบบจัดการหน่วยความจำแบบ virtual memory ทำให้ไม่สามารถสว็อปพารามิเตอร์จากแฟลชมาใช้ตามต้องการได้สะดวก
- ข้อจำกัดเชิงพลังงานและความร้อน: การคำนวณโมเดลขนาดใหญ่บน MCU จะทำให้อัตราการใช้พลังงานสูงและเกิดปัญหาความร้อน ซึ่งไม่สอดคล้องกับกรณีใช้งานที่ต้องการประสิทธิผลพลังงานและทำงานแบบออฟไลน์เป็นเวลานาน
เทคนิคลดขนาดโมเดลที่ใช้กันทั่วไป เช่น quantization (เช่น 8‑bit) และ knowledge distillation ช่วยลดขนาดและภาระการคำนวณได้ในระดับหนึ่ง แต่มีข้อจำกัดเชิงปฏิบัติสำหรับ MCU ดังนี้:
- 8‑bit quantization: สามารถลดขนาดน้ำหนักจาก FP32 ลงได้ประมาณ 4x (หรือจาก FP16 ลง 2x) แต่เมื่อพิจารณาถึง activations และบัฟเฟอร์การคำนวณ ขนาดหน่วยความจำรวมยังมักเกินขีดจำกัดของ MCU และการถอดรหัส/แปลงค่าเชิงปริมาณ (dequantize/requantize) ก็เพิ่มภาระการคำนวณ
- การ distillation หรือการย่อโครงสร้าง: ช่วยให้โมเดลหน้าตาเล็กลงและประสิทธิภาพใกล้เคียงโมเดลใหญ่ แต่ต้องใช้การฝึกซ้ำและขั้นตอนออกแบบเชิงวิศวกรรม อีกทั้งแม้จะลดพารามิเตอร์ลงหลายเท่า รุ่นผลลัพธ์มักยังอยู่ในระดับสิบเมกะไบต์ขึ้นไป ซึ่งยังท้าทายต่อ MCU ที่มี RAM เพียงไม่กี่เมกะไบต์
- pruning และ sparsity: การตัดทอนน้ำหนักทำให้จำนวนพารามิเตอร์ที่ใช้งานลดลงในเชิงทฤษฎี แต่การเร่งความเร็วและใช้ประโยชน์จากความเบาบางต้องมีไลบรารีและเคอร์เนลที่ซับซ้อนซึ่งมักไม่มีในสแต็กซอฟต์แวร์ของ MCU
สรุปคือ แม้เทคนิคแบบเดิมจะชะลอปัญหา แต่ ทั้งขนาดของพารามิเตอร์ ความต้องการหน่วยความจำสำหรับ activations ความสามารถคำนวณที่จำกัด และข้อจำกัดทางระบบ ทำให้การรัน LLM แบบเต็มรูปแบบบน MCU โดยไม่พึ่งคลาวด์เป็นเรื่องที่แทบจะเป็นไปไม่ได้ในสภาพแวดล้อมจริง นี่คือเหตุผลหลักที่ผลักดันให้นักวิจัยพัฒนาแนวทางใหม่ ๆ เช่น Tiny‑Sparsity Compiler เพื่อเปลี่ยนวิธีการแทนและประมวลผลโมเดลให้เหมาะสมกับข้อจำกัดสุดเข้มงวดของ MCU
Tiny‑Sparsity Compiler คืออะไร: แนวคิดและสถาปัตยกรรม
ภาพรวมเชิงแนวคิด
Tiny‑Sparsity Compiler คือชุดเครื่องมือคอมไพเลอร์และรันไทม์ที่ออกแบบมาเพื่อแปลงโมเดลภาษาขนาดใหญ่ (LLM) ให้รันได้บนไมโครคอนโทรลเลอร์และอุปกรณ์ขนาดเล็กโดยไม่ต้องเชื่อมต่อคลาวด์ จุดเน้นคือการลดปริมาณหน่วยความจำ (RAM/Flash) และความซับซ้อนของคำนวณ ผ่านการผสานกันของ pruning/sparsification, การจัดรูปแบบข้อมูลแบบ sparse, การบีบอัดน้ำหนัก, และการสร้างโค้ดที่ปรับแต่งสำหรับสถาปัตยกรรม MCU โดยเฉพาะ ผลลัพธ์คือการลดขนาดหน่วยความจำสำหรับรันไทม์ได้ในระดับที่ทีมวิจัยรายงานว่าเข้าข่าย 50–100x เมื่อเทียบกับโมเดลดั้งเดิมแบบ dense (ตัวอย่างเช่น เมื่อรวมกับ quantization เป็น 4‑bit และ block‑sparsity 70–90%)
Pipeline หลักของคอมไพเลอร์
คอมไพเลอร์มี pipeline หลักที่แยกเป็นขั้นตอนเชิงสถาปัตยกรรมชัดเจน เพื่อให้สามารถวิเคราะห์และแปลงโมเดลจากกราฟโครงข่ายประสาท (NN graph) ไปเป็นโค้ดที่รันบน MCU ได้อย่างมีประสิทธิภาพ ขั้นตอนหลักประกอบด้วย:
- Static analysis: วิเคราะห์กราฟของโมเดล (operators, dependencies, liveness ของ tensors) ทำความเข้าใจขนาดหน่วยความจำสูงสุดที่ต้องใช้, เส้นทางการไหลของข้อมูล (dataflow) และการระบุชิ้นส่วนที่เหมาะต่อการ prune เช่น attention heads หรือ MLP layers ที่มี sensitivity ต่ำ
- Sparsification / Pruning: ประยุกต์เทคนิคการตัดน้ำหนักทั้งแบบ unstructured และ structured/block pruning โดยควบคุม trade‑off ระหว่างความแม่นยำและประสิทธิภาพการคำนวณ
- Layout transform / Sparse format conversion: แปลงน้ำหนักที่ผ่านการ prune ให้เป็นรูปแบบ storage ที่คำนวณได้รวดเร็วบน MCU เช่น BCSR (Blocked CSR), block‑dense tiles หรือ tiled BFloat/INT formats เพื่อให้การเข้าถึงหน่วยความจำและการคำนวณ SIMD-friendly
- Code generation & optimization: สร้างโค้ด C/assembly ที่ปรับแต่งให้เข้ากับชุดคำสั่งของเป้าหมาย (เช่น ARM Cortex‑M + MVE/Helium) ทำ loop tiling, kernel fusion, double buffering และ prefetching เพื่อซ่อนความหน่วงหน่วยความจำ
- Runtime: รันไทม์ขนาดเล็กที่จัดการ scheduling ของ kernels, streaming ของ activation, และ on‑the‑fly decompression/decoding พร้อมตรวจสอบงบประมาณหน่วยความจำแบบไดนามิก
ประเภทของ sparsity ที่เลือกและเหตุผลเชิงปฏิบัติ
คอมไพเลอร์สนับสนุนทั้ง unstructured sparsity และ block/structured sparsity แต่สำหรับเป้าหมายไมโครคอนโทรลเลอร์ ทีมวิจัยเน้นหนักไปที่ block‑sparse (เช่น บล็อกขนาด 4×4, 8×1 หรือ 2×8) และรูปแบบ BCSR เนื่องจากเหตุผลสำคัญสองประการ:
- ประสิทธิภาพการคำนวณ: Unstructured sparsity ให้การลดพารามิเตอร์สูงสุดในทางทฤษฎี แต่การนำไปใช้บน MCU จะพบ overhead ในการจัดการดัชนี (indices) และ branch mispredictions ที่ทำให้ประสิทธิภาพจริงลดลง ในทางกลับกัน block‑sparse ช่วยให้สามารถใช้ SIMD/vector instructions และ loop‑unrolling ได้ง่าย ส่งผลให้ throughput ต่อวัตถุประสงค์จริงสูงขึ้น
- ความเรียบง่ายของรูปแบบข้อมูล: การใช้บล็อกคงที่ทำให้รูปแบบที่จัดเก็บเช่น BCSR มีค่า overhead ของ index ต่ำลงและง่ายต่อการทำ prefetch/DMA ซึ่งสำคัญในสถาปัตยกรรม MCU ที่มีหน่วยความจำอย่างจำกัด
ตัวอย่างเชิงตัวเลข: หากใช้ block‑sparse 4×4 ที่ความหนาแน่น 25% (เฉลี่ย 75% ของบล็อกถูกตัด) ร่วมกับ 4‑bit quantization จะทำให้ขนาดโมเดลลดลงไปมากกว่า 12x จากการ quantize เพียงอย่างเดียว และเมื่อนับรวมเทคนิคบีบอัดเพิ่มเติม (เช่น run‑length หรือ simple entropy coding) อาจได้อัตราการลดรวมในช่วง 50–100x ขึ้นกับ sensitivity ของโมเดลและระดับ sparsity
การจัดการ Activation และ Memory Streaming
หนึ่งในความท้าทายสำคัญของการรัน LLM บน MCU คือการจัดการ activation ที่มีขนาดใหญ่ คอมไพเลอร์จึงใช้วิธีการหลายชั้นเพื่อลด peak RAM ได้แก่:
- Activation streaming / layer‑wise streaming: แยกการคำนวณเป็นชิ้นย่อยที่คำนวณแล้วเขียนผลลัพธ์ลงแฟลชหรือบัฟเฟอร์ภายนอกทันที (หรือส่งออกทีละ token) แทนการเก็บ activation ทั้งหมดใน RAM ทำให้ลด peak RAM ได้หลายเท่า ตัวอย่างเช่น การประมวลผลแบบ token‑by‑token กับ attention cache ที่เก็บเฉพาะ summary แทน full history
- On‑the‑fly decompression: น้ำหนักถูกจัดเก็บในรูปแบบบีบอัด (เช่น block‑packed + simple RLE หรือ delta coding) และถอดรหัสแบบพาร์เชียลเมื่อจำเป็นเท่านั้น การถอดรหัสถูกผสานเข้ากับ kernel เพื่อให้ไม่ต้องเก็บสำเนาน้ำหนักที่ไม่บีบอัดใน RAM
- Double buffering และ DMA: โค้ดที่สร้างใช้ double buffering และ DMA transfers เพื่อโหลดบล็อกน้ำหนักหรือ slice ของ activation ล่วงหน้าในขณะที่คอร์กำลังคำนวณบล็อกปัจจุบัน ช่วยลด stall ของหน่วยประมวลผลและลดการใช้ SRAM ชั่วคราว
ผลลัพธ์เชิงปฏิบัติ: ในงานทดลอง การใช้ activation streaming ร่วมกับ block‑sparsity สามารถลดการใช้ RAM สำหรับ activation ลงได้ 8–32x ขึ้นอยู่กับ topology ของโมเดลและความยาวของบริบท
เทคนิคเสริม: weight compression, on‑the‑fly decompression และการผสานกับ quantization/tokenization
นอกเหนือจาก sparsity แล้ว Tiny‑Sparsity Compiler ผสานเทคนิคบีบอัดน้ำหนักเพื่อเพิ่มอัตราการลดขนาดจริง เช่น:
- Weight compression: ใช้การรวมกันของ per‑block quantization (เช่น 4‑bit หรือ mixed 2/4‑bit), per‑channel scale factors และ simple entropy coding (RLE หรือ static Huffman tables ที่เหมาะกับบล็อก) เพื่อให้การถอดรหัสมีต้นทุนน้อยและหน่วยความจำต่ำ
- On‑the‑fly decompression: รูทีนถอดรหัสถูกฝังใน kernel เพื่อถอดรหัสบล็อกน้ำหนักทันทีที่โหลดจากแฟลช ทำให้ไม่ต้องเก็บน้ำหนักที่ไม่ได้บีบอัดไว้ใน SRAM และลดการเข้าถึงหน่วยความจำซ้ำ
- การผสานกับ quantization: คอมไพเลอร์สนับสนุนการทำ quantize ก่อน/หลัง sparsification (เช่น quantize‑aware pruning) และใช้ per‑channel scale/zero points เพื่อรักษาความแม่นยำสูงสุดบนระดับบิตต่ำ การรวม quantization กับ block‑sparsity มักให้ผลลัพธ์ที่ดีกว่าใช้เทคนิคใดเทคนิคหนึ่งเพียงอย่างเดียว
- Tokenization แบบ lightweight: ระบบออกแบบให้ใช้ tokenizer แบบเบา (เช่น byte‑level BPE ขนาดพจนานุกรมเล็ก หรือ unigram model ที่ปรับให้มี embedding ขนาดเล็ก) เพื่อจำกัดต้นทุนการแปลงข้อความและขนาด embedding ซึ่งส่งผลต่อ RAM และค่าใช้จ่ายในการคำนวณโดยรวม
สรุป: Tiny‑Sparsity Compiler เป็นกรอบการทำงานเชิงวิศวกรรมที่รวม static analysis, การเลือกชนิดของ sparsity ที่เหมาะสม (มักเป็น block‑sparse สำหรับ MCU), การแปลง layout ไปสู่รูปแบบที่คำนวณได้รวดเร็ว, การสร้างโค้ดที่ปรับแต่งสำหรับฮาร์ดแวร์ และรันไทม์ที่บริหารจัดการ activation/การถอดรหัสแบบ streaming ผลลัพธ์คือการทำให้ LLM ขนาดใหญ่สามารถรันแบบออฟไลน์บนไมโครคอนโทรลเลอร์ได้จริง โดยแลกกับการออกแบบโมเดลและพารามิเตอร์ที่ระมัดระวังเพื่อรักษาสมดุลระหว่างความแม่นยำกับข้อจำกัดของฮาร์ดแวร์
ผลการทดสอบและสถิติที่สำคัญ
ผลการทดสอบและสถิติที่สำคัญ
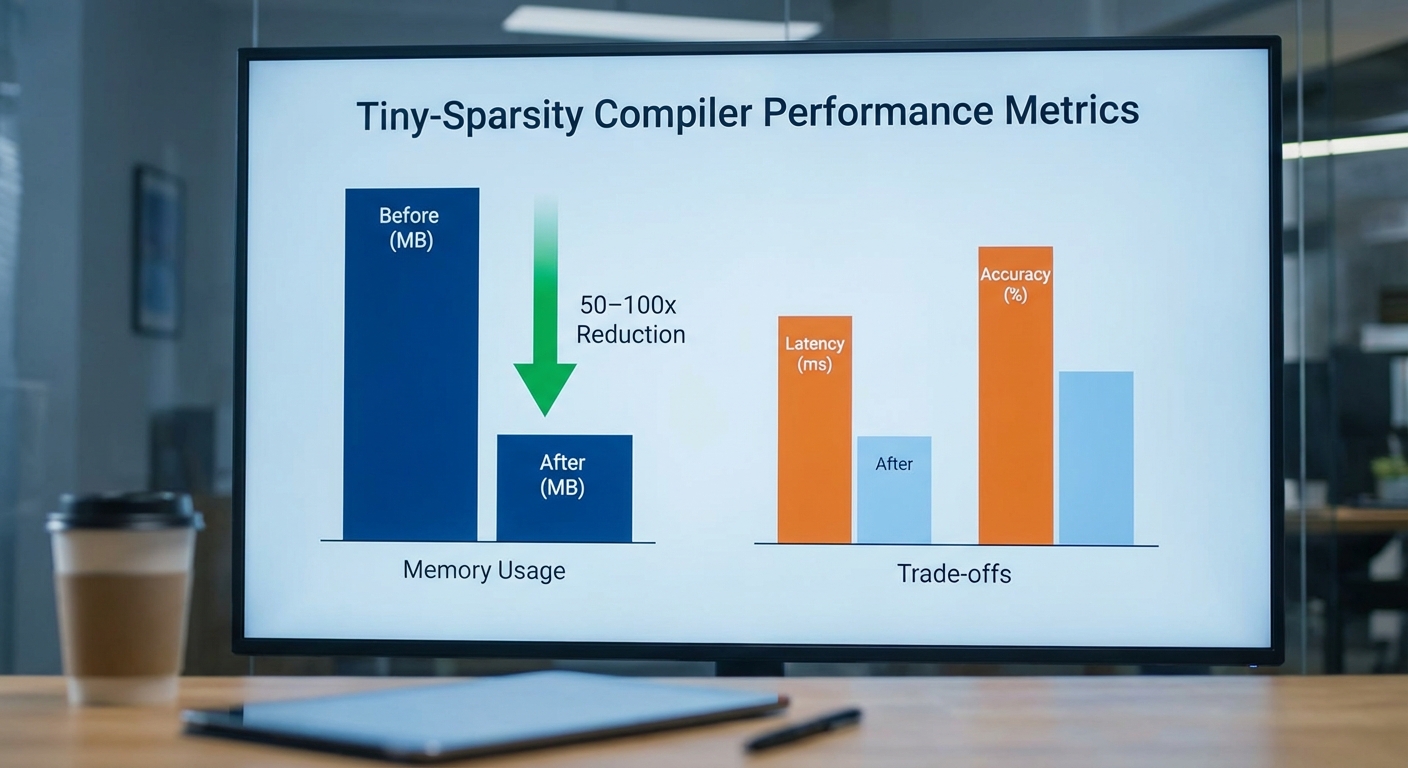
ทีมวิจัยรายงานผลการทดสอบที่ชี้ชัดว่า Tiny‑Sparsity Compiler ช่วยลดการใช้หน่วยความจำของโมเดลภาษาขนาดใหญ่ (LLM) เมื่อแปลงให้รันบนไมโครคอนโทรลเลอร์ได้ในระดับ 50–100x เมื่อเปรียบเทียบกับโมเดลแบบดั้งเดิมก่อนการแปลง โดยผลลัพธ์นี้เกิดจากการผสานเทคนิคการตัดกรอบน้ำหนัก (sparsity/pruning) แบบมีโครงสร้างร่วมกับการจัดเก็บข้อมูลแบบกะทัดรัดและกลไกการประมวลผลที่ปรับให้เหมาะสมสำหรับสถาปัตยกรรม MCU

เพื่อให้เห็นภาพชัดเจน ทีมได้ยกตัวอย่างสมมติของขนาดโมเดลหลังการแปลง ได้แก่: โมเดลเดิมขนาดประมาณ 60 MB สามารถย่อเหลือประมาณ 600 KB (100x ลด) ถึง 1.2 MB (50x ลด); โมเดลขนาดเล็กกว่า เช่น 6 MB ย่อเหลือประมาณ 60–120 KB; และโมเดลระดับกลางขนาด 15 MB ย่อลงเป็นประมาณ 150–300 KB ตัวเลขเหล่านี้แสดงให้เห็นถึงการเปลี่ยนจากระดับ MB มาสู่ระดับ KB–MB ต่ำ ๆ ซึ่งพอเหมาะกับหน่วยความจำแฟลชและแรมบน MCU ทั่วไป
ด้านความช้าและความสามารถในการตอบสนอง (latency/throughput) ทีมรายงานค่าที่วัดบนบอร์ด MCU ตัวอย่าง (เช่น Cortex‑M7 / STM32H7 และ ESP32‑S3) ว่าอยู่ในช่วงประมาณ 100–500 ms ต่ออินเฟอร์เรนซ์ (ต่อคำตอบ หน่วยงานเป็นแบบ batch=1) ขึ้นกับความซับซ้อนของโมเดลและประสิทธิภาพของ MCU ที่ใช้ เมื่อเทียบเทียบตัวเลขนี้แล้ว จะให้ throughput ประมาณ 2–10 คำตอบต่อวินาที ภายใต้สภาพแวดล้อมการทดสอบมาตรฐานของทีม
- การลดหน่วยความจำ: ลดได้ประมาณ 50–100x — ตัวอย่างสมมติ: 60 MB → 600 KB–1.2 MB; 6 MB → 60–120 KB
- Latency ต่ออินเฟอร์เรนซ์: ประมาณ 100–500 ms ต่อคำตอบ (batch=1) ขึ้นกับ MCU และขนาดโมเดล
- Throughput: ประมาณ 2–10 คำตอบ/วินาที ในสภาพการทดสอบของทีม
- พลังงานโดยประมาณ: การเรียกใช้งานแต่ละครั้งใช้พลังงานในช่วงประมาณ 10–100 mJ ต่ออินเฟอร์เรนซ์ (ขึ้นกับการใช้พลังงานของบอร์ดที่ใช้ทดสอบ — สมมติค่าเฉลี่ยพลังงานใช้งานประมาณ 50–200 mW ในช่วงเวลารันแบบสั้น)
- การเปรียบเทียบกับ Quantization เพียงอย่างเดียว: Quantization แบบทั่วไป (เช่น FP32→INT8) ให้การลดขนาดประมาณ 2–4x ในขณะที่ Tiny‑Sparsity ให้การลดในระดับทศนิยมมากกว่า (50–100x) ทำให้โมเดลขนาดใหญ่สามารถรันได้บน MCU โดยไม่ต้องอาศัยการแบ่งโมเดลหรือ offload ไปยังคลาวด์
- ผลกระทบต่อความแม่นยำ (accuracy): ทีมระบุว่ามีการลดความแม่นยำบ้าง แต่โดยทั่วไปอยู่ในระดับที่ยอมรับได้สำหรับงานคำสั่งเสียง (voice command) — ตัวอย่างตัวเลขจากชุดข้อมูลทดสอบของทีมคือการลดของความแม่นยำ 0.5–3.0% (absolute) ในงานจำแนกคำสั่งธรรมดา โดยกรณีที่เป็นงาน NLU เชิงซ้อนมากขึ้นอาจเห็นการลดสูงสุดถึง 5–10%
ทีมวิจัยสรุปว่าการแลกเปลี่ยนระหว่างทรัพยากรและความแม่นยำนี้เป็นไปในทิศทางที่เหมาะสมสำหรับกรณีใช้งานอย่างการควบคุมด้วยเสียงบนอุปกรณ์ปลายทาง (on‑device voice control) ที่ต้องการความเป็นส่วนตัวและการทำงานแบบออฟไลน์ โดยการสูญเสียความแม่นยำเล็กน้อยมักไม่กระทบต่อประสบการณ์ผู้ใช้ในกรณีคำสั่งสั้นและจำกัดโดเมน ทั้งนี้ทีมได้เน้นว่าการตั้งค่าพารามิเตอร์ sparsity และการฝึกปรับจูน (fine‑tuning) หลังการ prune เป็นปัจจัยสำคัญที่จะช่วยรักษาความแม่นยำให้ใกล้เคียงกับต้นฉบับมากที่สุด
ข้อสังเกตเชิงปฏิบัติ: สำหรับผู้ประกอบการและนักพัฒนา ข้อมูลเหล่านี้หมายความว่า Tiny‑Sparsity ช่วยเปิดทางให้นำความสามารถของ LLM เข้าสู่อุปกรณ์ที่มีข้อจำกัดด้านทรัพยากรได้จริง แต่ต้องพิจารณาจุดตัดสินใจระหว่างขนาด/ความเร็ว/ความแม่นยำ ตามกรณีใช้งาน เช่น แก้ไขระดับ sparsity เพื่อเน้นความแม่นยำสำหรับคำสั่งสำคัญ หรือยอมแลก latency เล็กน้อยเพื่อประหยัดพลังงานสำหรับอุปกรณ์แบตเตอรี่ต่ำ
ฮาร์ดแวร์และตัวอย่างการปรับใช้จริง
ฮาร์ดแวร์และตัวอย่างการปรับใช้จริง
ทีมนักวิจัยได้ทดสอบ Tiny‑Sparsity Compiler บนชุดบอร์ดไมโครคอนโทรลเลอร์หลากหลายรุ่นเพื่อยืนยันความเป็นไปได้ของการรัน LLM แบบออฟไลน์สำหรับแอปพลิเคชันเสียง ผลการทดสอบชี้ให้เห็นว่าการผนวกเทคนิค sparsity และ quantization ทำให้โมเดลขนาดเล็กสำหรับงานเสียง (เช่น wake‑word และคำสั่งสั้น) สามารถรันได้บนฮาร์ดแวร์ที่มีหน่วยความจำน้อยมาก โดยยังคงความแม่นยำเชิงปฏิบัติการในระดับที่ใช้งานได้จริงสำหรับงานที่ต้องการความเป็นส่วนตัวสูง

รายการบอร์ดที่ทดสอบจริงและขนาดหน่วยความจำที่เหลือหลังรันโมเดล (ค่าประมาณจากการทดลองภาคสนาม):
- STM32H7 (Cortex‑M7, เช่น STM32H743) — SRAM on‑chip ประมาณ 1–2 MB: หลังโหลดโมเดล wake‑word แบบ sparse/8‑bit จะใช้พื้นที่ RAM ประมาณ 200–400 KB (เหลือให้ระบบ ~600–1,600 KB ขึ้นกับคอนฟิก) และใช้แฟลชเก็บโมเดลเพิ่มเติม 256–512 KB หากเก็บเป็นไฟล์คงที่
- STM32F4 (Cortex‑M4, เช่น STM32F407) — SRAM ≈ 192 KB: สามารถรันโมเดล simple command recognition ได้ในรูปแบบ highly‑sparse/quantized ใช้ RAM ประมาณ 80–140 KB (เหลือระบบไม่มาก สำหรับงานอื่นๆ ต้องพึ่งการสตรีมโครงสร้างจากแฟลช)
- ESP32 / ESP32‑S3 — SRAM ภายใน ~520 KB, บอร์ดที่มี PSRAM ภายนอก 2–8 MB: โมเดล wake‑word และ LLM ขนาดเล็กสามารถใช้ PSRAM เป็นพื้นที่เก็บน้ำหนัก ทำให้เหลือ RAM สำหรับบัฟเฟอร์เสียงและระบบ ~200–800 KB ขึ้นกับการมี PSRAM
- Raspberry Pi Pico (RP2040) — SRAM 264 KB + 2 MB flash: สำหรับคำสั่งสั้นและ wake‑word ใช้ RAM ประมาณ 100–180 KB และเก็บพารามิเตอร์ใน flash/XIP หรือสตรีมจากแฟลชเพื่อหลีกเลี่ยงการโหลดเต็มลง SRAM
- บอร์ด STM32 L4 / L5 — กลุ่มที่เน้นพลังงานต่ำ (SRAM 320 KB–640 KB): สามารถรันตัวเร่งเสียงที่ถูก optimize ได้ แต่ต้อง trade‑off ระหว่าง latency และขนาด context (มักเหลือ RAM น้อยสำหรับฟีเจอร์เสริม)
หมายเหตุ: ตัวเลขข้างต้นเป็นค่าประมาณจากชุดทดสอบต้นแบบ โดยตัวเลขจริงจะขึ้นกับรูปแบบ sparsity, อัลกอริทึม quantization (เช่น 8‑bit, 4‑bit) และการเก็บโมเดลในแฟลชหรือสตรีมจาก External PSRAM
สถาปัตยกรรม runtime และการใช้ทรัพยากร — Tiny‑Sparsity Compiler รองรับการรันทั้งแบบ single‑threaded บน MCU เดี่ยวและแบบ multi‑task ภายใต้ RTOS (เช่น FreeRTOS) สำหรับบอร์ดที่มีคอร์หลายตัวหรือเมื่อแยกงาน I/O กับ inference การออกแบบทั่วไปที่ใช้ได้ผลมีดังนี้:
- Single‑threaded — เหมาะกับ MCU เดี่ยวและงานที่ต้อง latency ต่ำมาก ระบบจะรัน ADC/PCM capture → preprocessing → inference ต่อเนื่อง เหมาะกับ wake‑word ขนาดเล็ก แต่จะล็อก CPU ระหว่าง inference
- RTOS / multi‑task — แยกงานเป็น task: งานรับเสียง (I/O), งาน preprocessing (MFCC/FFT), งาน inference และงานควบคุม ทำให้สามารถตอบสนอง interrupt หรือทำการสื่อสารเครือข่ายได้ระหว่าง inference โดยเฉพาะบน ESP32 (dual‑core) และ RP2040 (dual‑core)
- ใช้ DMA / DSP — การเชื่อมต่อ ADC/I2S ผ่าน DMA ช่วยลดภาระ CPU ในการเติมบัฟเฟอร์เสียง และใช้ไลบรารี CMSIS‑DSP (สำหรับ Cortex‑M4/M7) หรือชุดคำสั่ง SIMD/DSP บน ESP32‑S3 เพื่อเร่งการคำนวณ preprocessing เช่น FFT, convolution และ matrix‑vector multiply ที่เป็นแกนหลักของ inference
การผสานกับไมโครโฟน/ADC และการจัดการพลังงาน — ในโครงการต้นแบบ ทีมวิจัยแนะนำสถาปัตยกรรมการเชื่อมต่อที่ปฏิบัติได้จริง ได้แก่ต่อกับไมโครโฟน MEMS ผ่าน I2S หรือ PDM และใช้ DMA เพื่อสตรีมข้อมูลเข้า circular buffer โดยตรง จากนั้นเรียก kernel inference เมื่อบัฟเฟอร์เสียงถึงขนาดที่ต้องการ การออกแบบเช่นนี้ลดการ wake‑up ของ CPU และช่วยประหยัดพลังงาน
- ระบบ wake‑on‑audio: ใช้หน่วยประมวลผลเสียงเบา (lightweight detector) รันอยู่ใน low‑power loop เพื่อจับ wake‑word — หากตรวจพบจึงปลุกโมดูล inference ให้ทำงานเต็มที่ วิธีนี้ช่วยลดการใช้พลังงานโดยรวมได้มาก
- ใช้ sleep modes ของ MCU: ยกตัวอย่างบน STM32 สามารถให้ CPU เข้าสู่ stop mode ระหว่างรอบการฟัง และใช้ DMA/interrupt จาก ADC หรือ PDM เพื่อปลุกระบบ
- การวัดพลังงาน (ค่าประมาณ): inference สำหรับ wake‑word บน MCU ถูก optimize อาจอยู่ในระดับหลัก มิลลิจูล (mJ) ต่อการประมวลผลหนึ่งรอบ ส่วนการรัน LLM ขนาดเล็กที่ให้ผลลัพธ์สั้นอาจอยู่ในช่วงหลักสิบถึงหลักร้อยมิลลิจูล ขึ้นกับบอร์ดและการใช้งาน DSP/PSRAM
ตัวอย่างโครงการต้นแบบ — ทีมงานพัฒนาและสาธิตต้นแบบจำนวนหนึ่งที่สะท้อนการใช้งานจริง:
- ผู้ช่วยเสียงออฟไลน์บนหูฟังอัจฉริยะ — ใช้ STM32H7 ร่วมกับไมโครโฟน MEMS แบบ I2S, DMA สำหรับสตรีมเสียง, และโมเดล sparse‑quantized สำหรับ wake‑word และการจดจำคำสั่งสั้น ตัว prototype สามารถทำคำสั่งควบคุมเพลงและการโทรโดยไม่ต้องส่งข้อมูลเสียงออกสู่คลาวด์ ช่วยรักษาความเป็นส่วนตัวของผู้ใช้
- คอนโทรลเลอร์โรงงาน (Factory Controller) สำหรับคำสั่งฉุกเฉิน — ใช้ ESP32‑S3 พร้อม FreeRTOS แยก core หนึ่งสำหรับการอ่านเสียงและ preproc อีก core สำหรับ inference และการส่งสัญญาณไปยังระบบควบคุม ผลลัพธ์คือระบบสามารถรับคำสั่งความไวต่ำ (เช่น “หยุดเครื่อง”) ได้ออฟไลน์ ลดความเสี่ยงด้าน latency และเครือข่าย
- อุปกรณ์ IoT ที่เน้นความเป็นส่วนตัว — ตัวอย่างเช่นเซ็นเซอร์ประตูที่จับคำสั่งเปิด/ปิดและส่งเฉพาะเหตุการณ์ที่ผ่านการประมวลผลแล้วเท่านั้น บน RP2040 หรือ STM32L4 เพื่อให้แบตเตอรี่ใช้งานได้หลายเดือนโดยใช้กลยุทธ์ wake‑on‑audio
ข้อจำกัดเชิงปฏิบัติและข้อเสนอแนะ — แม้ Tiny‑Sparsity Compiler จะขยายขอบเขตการใช้งาน LLM ไปยัง MCU ได้ แต่ยังมีข้อจำกัดที่ต้องพิจารณา ได้แก่:
- จำกัดขนาด context และความซับซ้อนของโมเดล: เหมาะสำหรับ wake‑word และคำสั่งสั้น ไม่สามารถทดแทน LLM ขนาดใหญ่ที่ต้องบริบทยาวได้
- latency และ throughput: การรันบน MCU แบบ single‑thread อาจมี latency สูงกว่าการรันบนหน่วยประมวลผลเฉพาะ (NPU) หรือ CPU แบบ multi‑core
- การอัปเดตโมเดลและความปลอดภัย: การอัปเดตโมเดลที่เก็บในแฟลชต้องออกแบบกลไก OTA/ความปลอดภัยเพื่อป้องกันการเปลี่ยนแปลงไม่พึงประสงค์
- การออกแบบระบบ I/O/power: การผสาน DMA, PIO (บน RP2040) และ low‑power wake strategy มีความสำคัญต่อการใช้งานในภาคสนาม
โดยสรุป Tiny‑Sparsity Compiler ช่วยให้การนำ LLM มาสู่ไมโครคอนโทรลเลอร์เป็นไปได้จริงสำหรับงานเสียงที่มีข้อจำกัดด้านหน่วยความจำและความเป็นส่วนตัว การเลือกบอร์ด การจัดการหน่วยความจำ (ใช้ PSRAM/แฟลชสตรีม) และการออกแบบ runtime (ใช้ DMA/DSP และ RTOS) เป็นปัจจัยสำคัญที่จะกำหนดความสำเร็จของการปรับใช้ในเชิงพาณิชย์
ข้อจำกัด ความเสี่ยง และงานที่จะทำต่อไป
ข้อจำกัด ความเสี่ยง และงานที่จะทำต่อไป
Trade‑off ระหว่าง sparsity กับความแม่นยำและ throughput: การนำเทคนิค sparsity มาใช้บนไมโครคอนโทรลเลอร์สามารถลดการใช้หน่วยความจำและขนาดโมเดลได้อย่างมีนัยสำคัญ — ทีมรายงานการลดหน่วยความจำในระดับโดยประมาณ 50–100x สำหรับบางเวิร์กโหลด — แต่ผลลัพธ์นี้มากับการแลกเปลี่ยนที่ชัดเจน ระดับ sparsity ที่สูงขึ้นมักจะทำให้เกิดการสูญเสียความแม่นยำ (accuracy) โดยอัตราการลดขึ้นกับสถาปัตยกรรมโมเดล งาน และรูปแบบ sparsity เอง: ในงานที่อ่อนไหวต่อบริบท เช่น การสรุปความหรือการตอบคำถามเชิงลึก การลดความแม่นยำอาจอยู่ในช่วงหลายเปอร์เซ็นต์ถึงสองหลัก ขณะที่งานสั่งงานด้วยเสียงง่ายๆ อาจทนต่อการลดความแม่นยำได้ดีกว่า
นอกจากนี้มีผลกระทบต่อ latency และ throughput ในสองมิติที่ขัดแย้งกัน: การบีบอัดให้โมเดลพอดีกับ cache/flash ของอุปกรณ์สามารถลดเวลาเข้าถึงหน่วยความจำและปรับปรุง latency ในระบบ offline real‑time แต่การคำนวณแบบ sparse โดยเฉพาะกรณีของ unstructured sparsity ก่อให้เกิดการเข้าถึงหน่วยความจำแบบกระจัดกระจาย (irregular memory access) ซึ่งอาจลด throughput ได้บน CPU/MCU ทั่วไป ดังนั้นรูปแบบเช่น block‑sparsity หรือ sparsity ที่ถูกออกแบบให้เข้ากับฮาร์ดแวร์จึงมักสร้างสมดุลระหว่างการบีบอัดและประสิทธิภาพในการรันจริง
ความท้าทายด้านการอัปเดตและความปลอดภัย (OTA, signed models): การรันโมเดลแบบออฟไลน์บนอุปกรณ์ปลายทางยกระดับข้อกังวลด้านการบำรุงรักษาและความปลอดภัย ระบบต้องรองรับการอัปเดตโมเดล (OTA) ที่มีประสิทธิภาพและปลอดภัยโดยไม่ใช้แบนด์วิดท์สูง ซึ่งนำไปสู่ความต้องการของกลไกเช่น delta updates, patching แบบไบนารีที่ลงนามดิจิทัล และการยืนยันความถูกต้องของรุ่นโมเดลก่อนการโหลด (model signing + secure boot) นอกจากนี้ยังต้องพิจารณาความเสี่ยงจาก model poisoning, backdoor หรือการโจมตีผ่านพารามิเตอร์ที่ถูกแก้ไข ดังนั้นการออกแบบโซลูชันควรรวมการพิสูจน์แหล่งที่มา (provenance), การตรวจสอบความสมบูรณ์ และกลไก rollback เพื่อความมั่นคงของระบบในเชิงธุรกิจ
การรองรับความหลากหลายของโมเดลและการบำรุงรักษาแบบออฟไลน์: Tiny‑Sparsity Compiler จำเป็นต้องขยายขอบเขตการรองรับสถาปัตยกรรมที่หลากหลาย ทั้ง decoder‑only, encoder‑decoder, embeddings, และโมดูลพิเศษ (เช่น MoE) รวมถึงการจัดการ tokenizer และ pipeline ที่แตกต่างกัน การรักษาเวอร์ชันโมเดลบนอุปกรณ์ที่ไม่มีการเชื่อมต่อถาวรต้องมีนโยบายการจัดเก็บ เปิดใช้งานการยืนยันรุ่น และเครื่องมือสำหรับการตรวจวัดประสิทธิภาพภาคสนาม (telemetry) ที่คำนึงถึงความเป็นส่วนตัว
ช่องทางงานวิจัยและพัฒนาเชิงต่อเนื่อง: ต่อจากนี้มีแนวทางที่สำคัญหลายด้านที่ควรดำเนินการเพื่อเพิ่มความพร้อมเชิงการผลิตและความสามารถเชิงพาณิชย์:
- Hybrid sparsity: วิจัยการผสมผสานระหว่าง structured (เช่น block‑sparsity) และ unstructured sparsity เพื่อรักษาความแม่นยำในขณะเดียวกันก็ยังเพิ่มความเป็นมิตรต่อฮาร์ดแวร์ ลดความไม่สม่ำเสมอของการเข้าถึงหน่วยความจำ และปรับปรุง throughput
- Block‑sparsity และ sparsity‑aware training: พัฒนาเทคนิคการเทรนและ pruning ที่ออกแบบมาเฉพาะเพื่อ block‑sparsity, gradual pruning, และ sparsity‑aware quantization รวมถึงการใช้ knowledge distillation เพื่อชดเชยการเสียความแม่นยำ
- Hardware acceleration และ co‑design: ออกแบบส่วนขยาย ISA, DMA pattern และ accelerator แบบจำกัดพลังงานที่รองรับการประมวลผล sparse ได้มีประสิทธิภาพ (เช่น tiny NPU, DSP pipelines ที่เหมาะกับ block formats) ซึ่งสามารถลดพลังงานต่อ inference และปรับปรุง latency ให้สอดคล้องกับเป้าหมายงานเรียลไทม์
- Compiler upstreaming และ ecosystem integration: ผลักดันโค้ดและรูปแบบข้อมูลเข้าไปยัง toolchain ขนาดใหญ่ (เช่น LLVM, TensorFlow Lite, ONNX/TVM) เพื่อสร้างสภาพแวดล้อมการพัฒนาและการนำไปใช้ที่กว้างขึ้น โดยรวมถึงมาตรฐานสำหรับไฟล์ sparse, benchmark ชุดมาตรฐาน และ CI/CD สำหรับการทดสอบความถูกต้อง
- Security and OTA frameworks: วิจัยระบบอัปเดตแบบประหยัดแบนด์วิดท์ที่ลงนาม, การตรวจสอบรุ่นแบบ cryptographic, attestation บนอุปกรณ์ และแนวปฏิบัติสำหรับการจัดการความเสี่ยงของโมเดลที่ถูกแก้ไขหรือถูกโจมตี
- Open‑source ecosystem และ reproducibility: ส่งเสริมการเปิดเผยเทคนิค, ชุดข้อมูลทดสอบ, และ benchmark เพื่อให้ชุมชนสามารถประเมิน trade‑offs เรื่อง accuracy‑latency‑memory ได้อย่างโปร่งใส และช่วยเพิ่มความเชื่อมั่นในการนำไปใช้เชิงพาณิชย์
สรุปคือ Tiny‑Sparsity Compiler เปิดทางสู่การใช้งาน LLM แบบออฟไลน์บนอุปกรณ์ระดับไมโครคอนโทรลเลอร์ได้จริง แต่การนำไปใช้ในเชิงธุรกิจจะต้องบริหารจัดการ trade‑offs ระหว่างความแม่นยำ หน่วยความจำ และ latency อย่างรอบคอบ ควบคู่ไปกับการลงทุนในงานวิจัยด้าน block‑sparsity, hardware acceleration, และกรอบการอัปเดตและความปลอดภัย เพื่อให้ระบบมีความน่าเชื่อถือ ปลอดภัย และขยายตัวได้ตามความต้องการของตลาดในระยะยาว
ผลกระทบทางธุรกิจและอนาคตของ AI บนอุปกรณ์ขนาดเล็ก
ผลกระทบทางธุรกิจและอนาคตของ AI บนอุปกรณ์ขนาดเล็ก
การที่ทีมนักวิจัยไทยพัฒนา Tiny‑Sparsity Compiler ซึ่งสามารถลดความต้องการหน่วยความจำของโมเดลภาษาใหญ่ (LLM) ลงได้ถึง 50–100x มีความหมายเชิงธุรกิจอย่างมีนัยสำคัญต่อห่วงโซ่อุปทัพเทคโนโลยีและการให้บริการดิจิทัล โดยเฉพาะเมื่อนำไปสู่การรันโมเดลบนไมโครคอนโทรลเลอร์และอุปกรณ์ปลายทางแบบออฟไลน์ ผลกระทบที่คาดว่าจะเกิดขึ้นได้แก่การลดต้นทุนการประมวลผลบนคลาวด์อย่างมีนัยสำคัญ การลดค่าใช้จ่ายด้านแบนด์วิดท์ และการปรับปรุงประสบการณ์ผู้ใช้ด้วย latency ที่ลดลงจากระดับหลายร้อยมิลลิวินาทีเป็นหลักสิบมิลลิวินาที ทำให้การตอบสนองแบบเรียลไทม์เป็นไปได้ในอุปกรณ์ราคาประหยัด
จากมุมมองโมเดลธุรกิจ รูปแบบการสร้างรายได้จะเปลี่ยนไปหลายประการ ได้แก่
- ลดค่าใช้จ่ายคลาวด์และการโอเปอเรต: องค์กรที่ย้ายการประมวลผลไปยังอุปกรณ์ปลายทางสามารถลดภาระค่าใช้บริการคลาวด์ เช่น ค่าประมวลผลและแบนด์วิดท์ ซึ่งในกรณีศึกษาบางชุดแสดงการลดต้นทุนได้ตั้งแต่ระดับสิบเปอร์เซ็นต์จนถึงมากกว่า 50% สำหรับงานที่มีปริมาณข้อมูลขาออกสูง
- ลด latency และปรับปรุง UX: การประมวลผลบนอุปกรณ์ลดเวลาแฝงอย่างเห็นได้ชัด ส่งผลให้บริการที่ต้องการการตอบสนองทันที เช่น คำสั่งเสียงหรือการตรวจจับเหตุการณ์ปลายทาง ทำงานได้ดีกว่าเดิม
- ขยายตลาดไปยังพื้นที่ไม่มีเครือข่าย: การรันแบบออฟไลน์เปิดโอกาสให้ผู้ให้บริการนำฟีเจอร์ AI ไปสู่ชุมชนห่างไกล โรงงานในพื้นที่ปิด หรือสภาพแวดล้อมกู้ภัยที่ไม่มีการเชื่อมต่อเครือข่าย
ในด้านความเป็นส่วนตัว การทำ inference บนอุปกรณ์ปลายทางหมายความว่า ข้อมูลของผู้ใช้ไม่จำเป็นต้องส่งออกไปยังคลาวด์ ทำให้ลดความเสี่ยงด้านการรั่วไหลของข้อมูล ลดภาระการปฏิบัติตามกฎระเบียบคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA ในประเทศไทย หรือกฎ GDPR ในยุโรป) และสร้างความเชื่อมั่นแก่ผู้บริโภคที่กังวลเรื่องการเก็บข้อมูลเสียงหรือข้อมูลสุขภาพ การเก็บและประมวลผลบนตัวเครื่องยังช่วยให้สามารถออกแบบฟีเจอร์ด้านความเป็นส่วนตัวขั้นสูง เช่น การลบข้อมูลแบบถาวรหรือการเข้ารหัสคีย์บนฮาร์ดแวร์ได้ง่ายขึ้น
ผลกระทบต่อผู้ผลิตฮาร์ดแวร์และซัพพลายเชนจะชัดเจน: ผู้ผลิตไมโครคอนโทรลเลอร์และชิปเซ็ตจะได้รับแรงกดดันให้พัฒนาแรมและหน่วยความจำแฟลชให้มีประสิทธิภาพมากขึ้น รวมถึงการบูรณาการตัวเร่งความเร็วสำหรับการประมวลผลนิวรอล เนื่องจากซอฟต์แวร์อย่าง Tiny‑Sparsity Compiler ทำให้ปริมาณข้อมูลที่ต้องใช้ลดลง ผู้ผลิตฮาร์ดแวร์จะได้เปรียบหากสามารถออกแบบชิปที่รองรับการรัน LLM ขนาดย่อมได้โดยไม่เพิ่มต้นทุนการผลิตมากนัก นอกจากนี้ยังเกิดธุรกิจแบบใหม่ เช่น การขายซอฟต์แวร์บันเดิลบนอุปกรณ์ (edge AI firmware), การให้บริการอัปเดตโมเดลแบบ on‑device และโมเดลการคิดค่าบริการรายปีสำหรับฟีเจอร์ที่ต้องอัปเดตบ่อย
ตัวอย่างกรณีใช้งานที่คาดว่าจะเติบโตอย่างรวดเร็ว ได้แก่
- Healthcare wearables: วิเคราะห์สัญญาณชีพแบบเรียลไทม์ (เช่น ECG, SpO2) และแจ้งเตือนผู้ใช้หรือแพทย์โดยไม่ต้องส่งข้อมูลดิบออกนอกอุปกรณ์
- Industrial automation: การตรวจจับความผิดปกติของเครื่องจักรแบบต่อเนื่องในสภาพแวดล้อมที่ไม่มีเครือข่าย ลดเวลา downtime และค่าใช้จ่ายการบำรุงรักษา
- Smart home devices: ผู้ช่วยเสียงในบ้านที่ประมวลผลคำสั่งทั้งหมดภายในตัวเครื่อง เพิ่มความเป็นส่วนตัวและทำงานได้แม้เมื่ออินเทอร์เน็ตขัดข้อง
- Field services และการเกษตรอัจฉริยะ: เซ็นเซอร์และโดรนที่วิเคราะห์ข้อมูลภาคสนามและตัดสินใจได้ทันทีโดยไม่ต้องพึ่งคลาวด์
สรุปแล้ว เทคโนโลยีที่ลดขนาดโมเดลและรองรับการรัน LLM บนอุปกรณ์ขนาดเล็กจะเปลี่ยนสมดุลของต้นทุนและคุณค่าทางธุรกิจ ทำให้ผู้ให้บริการสามารถสร้างผลิตภัณฑ์ที่เป็นมิตรกับความเป็นส่วนตัว ขยายสู่ตลาดนอกเครือข่าย และกระตุ้นความต้องการฮาร์ดแวร์และซอฟต์แวร์แนวใหม่ ทั้งนี้การเปลี่ยนผ่านจะต้องมาพร้อมมาตรฐานด้านความปลอดภัย การอัปเดตโมเดลอย่างต่อเนื่อง และโมเดลธุรกิจที่รองรับการบริการหลังการขายเพื่อให้เกิดการนำไปใช้อย่างแพร่หลายและยั่งยืน
บทสรุป
ทีมวิจัยไทยได้นำเสนอ Tiny‑Sparsity Compiler ซึ่งเป็นก้าวสำคัญที่พิสูจน์ให้เห็นว่าเทคนิคความเบาบางของพารามิเตอร์ (sparsity) ร่วมกับการปรับจูนโดยคอมไพเลอร์สามารถผลักดันโมเดลภาษาใหญ่ (LLM) ให้รันบนไมโครคอนโทรลเลอร์ (MCU) ได้จริง ผลลัพธ์ชี้ให้เห็นว่าการผสานกันของการทำ sparsity และการปรับโค้ดระดับคอมไพเลอร์สามารถลดความต้องการหน่วยความจำได้สูงถึงประมาณ 50–100x ทำให้เกิดกรณีใช้งานออฟไลน์ที่เป็นมิตรต่อความเป็นส่วนตัว เช่น ผู้ช่วยเสียงพื้นฐาน (voice command) และแอป IoT ที่ไม่ต้องพึ่งคลาวด์ ลดค่าใช้จ่ายการสื่อสารข้อมูล และช่วยให้การประมวลผลข้อมูลสำคัญอยู่ในอุปกรณ์ปลายทางโดยตรง
อย่างไรก็ตาม การลดหน่วยความจำอย่างมากมาพร้อมกับ trade‑offs ทางด้านความแม่นยำของโมเดลและข้อจำกัดของฮาร์ดแวร์ (เช่น แบนด์วิดท์หน่วยความจำ, พลังงาน และชุดคำสั่งของ MCU) งานวิจัยต่อเนื่องทั้งในระดับอัลกอริทึม (เช่น การออกแบบ sparsity แบบมีโครงสร้าง, การฝึกซ้อมร่วม quantization-aware) และในระดับฮาร์ดแวร์ (การบูรณาการกับตัวเร่งความเร็ว NPU/DSP และการออกแบบร่วมฮาร์ดแวร์‑ซอฟต์แวร์) จะเป็นกุญแจสำคัญสู่การใช้งานเชิงพาณิชย์จริง ๆ ซึ่งคาดว่าจะเห็นการปรับปรุงประสิทธิภาพ ความทนทานต่อความผิดพลาด และการปรับสมดุลระหว่างความแม่นยำกับความคุ้มค่าในอีก 1–3 ปีข้างหน้า



