
บทนำของบทความนี้ชี้ประเด็นหลักที่จะวิเคราะห์เชิงลึก: ไทม์ไลน์ของเหตุการณ์ตั้งแต่การเปลี่ยนแปลงโค้ด การปรับใช้ (deployment) จนถึงเวลาที่ระบบขัดข้อง สาเหตุทางเทคนิคที่เป็นไปได้ — จากโค้ดที่สร้างโดยโมเดล การจัดการการเปลี่ยนแปลงการกำหนดค่า (configuration drift) ไปจนถึงการทดสอบที่ไม่ครอบคลุม ผลกระทบทั้งเชิงธุรกิจและเชิงภาพลักษณ์ และแนวทางป้องกันที่องค์กรยุคดิจิทัลควรนำไปใช้ เช่น นโยบาย human-in-the-loop, การทดสอบอัตโนมัติที่เข้มงวด, การมอนิเตอร์และการกู้คืนแบบค่อยเป็นค่อยไป (canary/blue-green) บทความนี้มุ่งส่งมอบบทเรียนที่ปฏิบัติได้ เพื่อช่วยให้องค์กรสามารถผสานการใช้ AI ในการพัฒนาโดยไม่ลดทอนความน่าเชื่อถือของระบบสำคัญ
บริบทเหตุการณ์และไทม์ไลน์
บริบทเหตุการณ์และไทม์ไลน์
เหตุการณ์หยุดชะงักของบริการ Amazon ที่เกี่ยวเนื่องกับการใช้งานระบบปัญญาประดิษฐ์ในวงการพัฒนาซอฟต์แวร์เริ่มปรากฏเป็นครั้งแรกในช่วงเช้าของวันเหตุการณ์ เมื่อมีการรายงานจากผู้ใช้ภายนอกจำนวนมากถึงปัญหาความล่าช้าและข้อผิดพลาด (error 5xx) ในบริการด้านการพัฒนาและโครงสร้างพื้นฐานบนคลาวด์ ข้อมูลเบื้องต้นจากช่องทางต่าง ๆ ชี้ให้เห็นว่าเหตุการณ์นี้ไม่ได้จำกัดเฉพาะเครื่องมือ AI เพียงอย่างเดียว แต่ส่งผลกระทบต่อบริการพื้นฐานที่รองรับการพัฒนา เช่น การเก็บข้อมูลและการประมวลผล ทำให้ผลกระทบเป็นวงกว้างต่อทั้งองค์กรขนาดกลางและขนาดใหญ่

สรุปไทม์ไลน์เชิงสังเขป (ตามรายงานผู้ใช้ การแจ้งสถานะ และบันทึกระบบ):
- เวลาเริ่มต้น (รายงานแรก): ผู้ใช้ภายนอกและทีมปฏิบัติการเริ่มเห็นข้อผิดพลาดและเวลาตอบสนองช้า โดยทั่วไปรายงานแรกปรากฏภายใน 08:10–08:30 UTC ขึ้นกับโซนเวลาและภูมิภาค
- การแพร่กระจายของปัญหา: ภายใน 30–90 นาทีมีรายงานเพิ่มขึ้นอย่างรวดเร็วจากหลายภูมิภาค โดยเฉพาะในโซนบริการหลักที่มีผู้ใช้งานหนาแน่น ทำให้ฝ่ายปฏิบัติการต้องยกระดับเป็น incident ระดับสูง
- การตอบสนองเบื้องต้น: AWS/Amazon หรือทีมที่เกี่ยวข้องเริ่มเผยแพร่ประกาศผ่านหน้า status page และ AWS Health Dashboard พร้อมการอัปเดตเบื้องต้นบนช่องทางโซเชียล (เช่น X/Twitter) ภายใน 1–2 ชั่วโมงหลังการรายงานครั้งแรก
- การฟื้นฟูบริการ: บริการบางส่วนเริ่มกลับมาทำงานเป็นปกติแบบเป็นลำดับ (gradual recovery) ภายใน 3–6 ชั่วโมง แต่บางจุดจำเป็นต้องดำเนินการแก้ไขเชิงลึก ทำให้การฟื้นฟูทั้งหมดใช้เวลาหลายชั่วโมงถึงมากกว่า 24 ชั่วโมงในกรณีที่มีผลกระทบรุนแรง
- สถานะเมื่อเข้าระบบ post-incident: หลังการฟื้นฟูจะมีการปล่อยรายงานสถานะสรุปเพิ่มเติมและแจ้งให้ลูกค้าที่ได้รับผลกระทบทราบถึงแนวทางชดเชยหรือคำแนะนำการกู้คืน
ขอบเขตของบริการและพื้นที่ที่ได้รับผลกระทบถูกบันทึกจากหลายแหล่งข้อมูล โดยภาพรวมพบว่าได้รับผลกระทบทั้งในส่วนของ:
- บริการพัฒนาและ AI สำหรับโค้ด: เช่น เครื่องมือช่วยเขียนโค้ดอัตโนมัติและบริการ CI/CD ที่พึ่งพาการประมวลผลภายใน (ตัวอย่าง: CodeWhisperer/CodeGuru-like services, CodeCommit/CodeBuild/CodePipeline)
- บริการโครงสร้างพื้นฐานหลัก: บริการจัดเก็บและเรียกใช้งานข้อมูล เช่น S3, EC2, และบริการเชื่อมโยง (เช่น IAM, API Gateway) เมื่อส่วนหนึ่งของระบบพื้นฐานมีปัญหาก็ส่งผลเป็นลูกโซ่ต่อบริการระดับสูง
- ภูมิศาสตร์: รายงานจากผู้ใช้ระบุว่าปัญหาเกิดขึ้นข้ามหลายภูมิภาค โดยเฉพาะโซนที่มีศูนย์ข้อมูลขนาดใหญ่ (หลายรายงานชี้ถึง us‑east‑1 และโซนยุโรป/เอเชียตามลำดับ แต่ระดับผลกระทบจะแตกต่างกันตาม region และ availability zone)
- ขอบเขตผู้ได้รับผลกระทบ: จากการรวบรวมรายงานเบื้องต้น คาดว่ามีผู้ใช้และองค์กรตั้งแต่หลายพันถึงหลักแสนรายได้รับผลกระทบในรูปแบบต่าง ๆ ทั้งการเข้าถึง API ล้มเหลว พาร์ตของ pipeline ขัดข้อง และระบบอัตโนมัติในงานพัฒนาไม่สามารถทำงานได้ตามปกติ
การรายงานเหตุการณ์เกิดขึ้นผ่านหลายช่องทางสำคัญที่ควรติดตามเมื่อต้องการตรวจสอบความถูกต้องและลำดับเวลา:
- หน้า Status Page ของผู้ให้บริการ: ถือเป็นแหล่งข้อมูลอย่างเป็นทางการสำหรับสถานะบริการที่อัปเดตแบบเรียลไทม์
- AWS Health Dashboard / Internal Incident Dashboard: ให้ข้อมูลเฉพาะลูกค้าเกี่ยวกับผลกระทบและคำแนะนำเบื้องต้น
- โซเชียลมีเดียและฟอรัมชุมชน: เช่น X/Twitter, Reddit, Hacker News — แหล่งรายงานผู้ใช้ที่ช่วยยืนยันขอบเขตและตัวอย่างความเสียหาย (แต่ต้องตรวจสอบซ้ำ)
- บันทึกภายในองค์กรและระบบมอนิเตอริ่ง: CloudWatch, Datadog, Splunk หรือระบบที่องค์กรใช้ จะให้ข้อมูลเมตริกเชิงลึก เช่น อัตรา error, latency, และการเพิ่มขึ้นของคำขอที่ล้มเหลว
ข้อสังเกตเชิงนโยบายและความจำเป็นของ postmortem: เหตุการณ์ลักษณะนี้เน้นย้ำถึงความจำเป็นของรายงาน postmortem อย่างเป็นทางการ ซึ่งควรรวบรวมแหล่งข้อมูลทั้งหมด ได้แก่ รายงานสถานะของผู้ให้บริการ โลจไฟล์ที่เกี่ยวข้อง เมตริกการทำงาน เงื่อนไขการเริ่มต้นปัญหา (root cause analysis) ผลกระทบต่อลูกค้าเชิงปริมาณ และมาตรการเยียวยา/ป้องกันในอนาคต องค์กรควรร้องขอ postmortem จากผู้ให้บริการและจัดทำ postmortem ภายในร่วมกันเพื่อลดความเสี่ยงซ้ำ นอกจากนี้การอ้างอิงแหล่งข้อมูลที่น่าเชื่อถือ (status page, official incident report, CloudWatch logs, support cases, และทวีต/ประกาศจากบัญชีทางการ) จะช่วยให้การรายงานข่าวเป็นไปอย่างถูกต้องและตรวจสอบได้
AI ที่ถูกนำมาใช้ในการพัฒนา: เทคโนโลยีและการปรับใช้งาน
ภาพรวมของ AI ที่ถูกนำมาใช้ในการพัฒนา
ในองค์กรเทคโนโลยีชั้นนำ ปัจจุบันมีการผสมผสานเครื่องมือปัญญาประดิษฐ์หลายประเภทเข้าสู่กระบวนการพัฒนาเพื่อเพิ่มความเร็วและลดภาระงานซ้ำซ้อน โดยเครื่องมือเหล่านี้ครอบคลุมตั้งแต่ code completion เช่น Copilot-style assistants, patch generators ที่แนะนำการแก้บั๊กอัตโนมัติ ไปจนถึง test synthesizers ที่สร้างชุดทดสอบพื้นฐานให้กับโค้ดใหม่ ๆ การสำรวจจากแหล่งอุตสาหกรรมหลายแห่งชี้ว่าองค์กรพัฒนาไอทีจำนวนมากในช่วงหลายปีที่ผ่านมาเริ่มนำเครื่องมือช่วยเขียนโค้ดในรูปแบบต่าง ๆ มาใช้ — ประมาณช่วงกว้างของการนำไปใช้ที่รายงานไว้คือระหว่าง 30–60% ขึ้นอยู่กับขนาดและประเภทขององค์กร
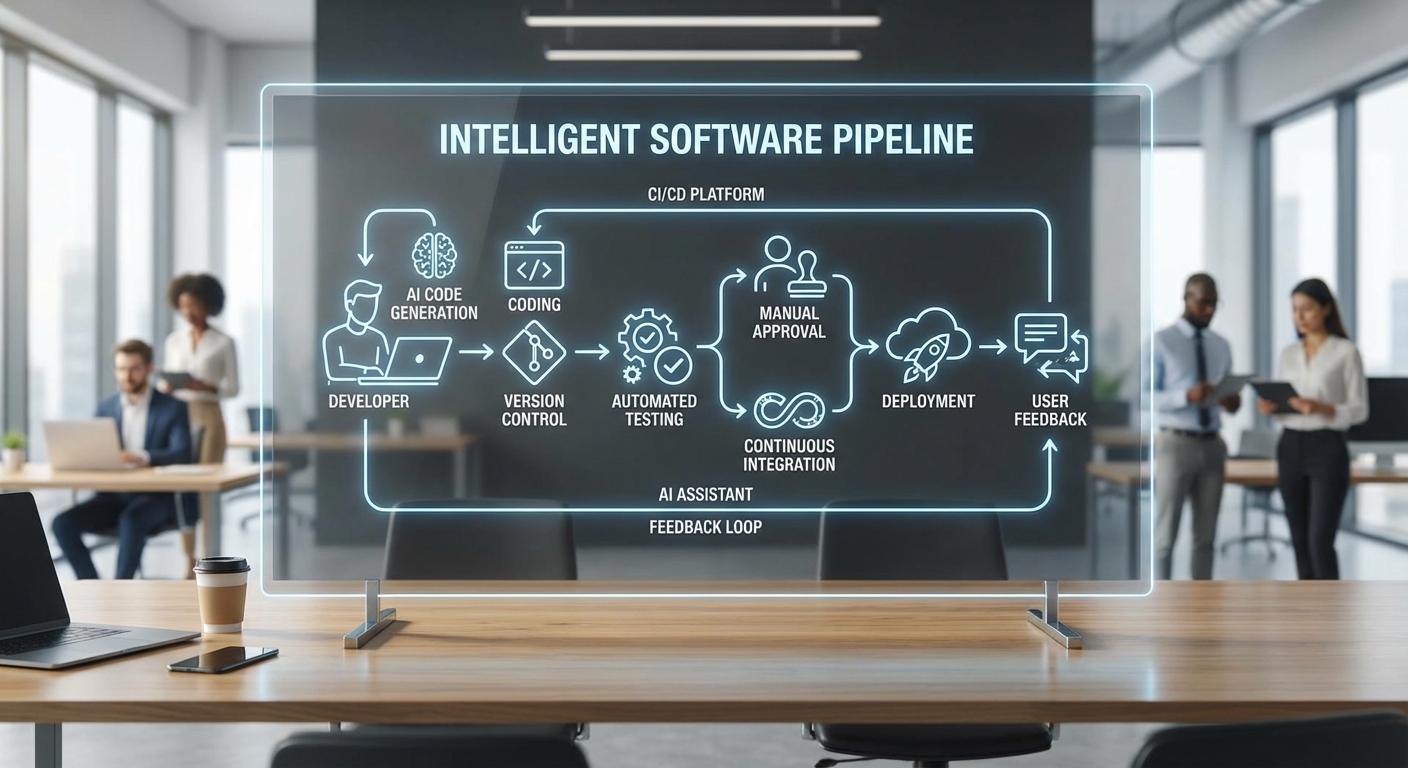
ประเภทของโมดูล AI ที่ใช้งานจริงและตัวอย่างการใช้งาน
การนำ AI มาใช้ในทีมพัฒนามักแบ่งตามหน้าที่การทำงานที่ชัดเจน ดังนี้
- Code completion / Assistants: โมเดลขนาดกลางถึงใหญ่ที่แนะนำโค้ดแบบบรรทัดต่อบรรทัดหรือฟังก์ชัน ยกตัวอย่างเช่น GitHub Copilot, internal LLM ที่เทรนบนโค้ดภายในบริษัท เพื่อช่วยเขียนฟังก์ชันพื้นฐานหรือเสนอโครงร่างการออกแบบ
- Patch generators / Automated fix suggestion: ระบบวิเคราะห์บั๊กและเสนอแพตช์ เช่น เครื่องมือที่เชื่อมกับระบบรายงานบั๊กหรือ SAST เพื่อสร้าง pull request อัตโนมัติที่แก้ไขปัญหาความปลอดภัยหรือปัญหาเชิงโค้ด
- Test synthesizers / Test generation: โมดูลที่สร้าง unit tests, property-based tests หรือ integration tests ให้โดยอัตโนมัติ ช่วยเพิ่มความครอบคลุมของการทดสอบและลดเวลาในการเขียนเทสด้วยมือ
- Code review assistants: ตัวช่วยประเมินคุณภาพโค้ดเบื้องต้น เช่น ตรวจมาตรฐานโค้ด, หาจุดเสี่ยง performance หรือ security heuristics ก่อนส่งให้มนุษย์ตรวจทาน
ตัวอย่างการใช้งานเชิงปฏิบัติ ได้แก่ การให้ AI สร้างโค้ดพื้นฐานแล้วส่งเป็น pull request อัตโนมัติผ่านบอทของระบบจัดเก็บซอร์สโค้ด หรือการใช้ AI วิเคราะห์ log และสร้างแพตช์แก้ปัญหาเบื้องต้น ซึ่งหลังจากนั้นทีมพัฒนาจะเป็นผู้อนุมัติหรือปรับแก้ก่อน merge จริง
จุดเชื่อมต่อกับระบบจริง: CI/CD, IaC และการปรับใช้อัตโนมัติ
AI ที่ใช้ในกระบวนการพัฒนามักถูกเชื่อมต่ออย่างลึกกับ pipeline ขององค์กร ดังนี้
- Integration กับ CI/CD: Pull request ที่สร้างโดย AI จะทริกเกอร์ workflow บนระบบ CI เช่น GitHub Actions, GitLab CI, Jenkins — เพื่อรัน unit test, static analysis และ security scan โดยอัตโนมัติ หากทุกชุดเทสผ่าน ระบบอาจตั้งค่าให้มีการ deploy ต่อแบบอัตโนมัติตาม policy
- เชื่อมกับ Infrastructure as Code (IaC): การเปลี่ยนแปลงที่เกี่ยวกับโครงสร้างพื้นฐาน (เช่น Terraform หรือ CloudFormation) หากสร้างโดย AI จะถูกส่งเข้าเครื่องมือกลางอย่าง Atlantis หรือ Terraform Cloud ที่ทำงานร่วมกับ VCS เพื่อทำ plan และ apply ภายใต้การยอมรับของผู้มีสิทธิ์เท่านั้น
- Automated deployments และ orchestration: เครื่องมืออย่าง Argo CD หรือ Spinnaker มักถูกใช้ควบคุมการ deploy บน Kubernetes/คลาวด์ ระบบสามารถตั้งค่าให้ทำ canary หรือ blue-green deployment เพื่อลดความเสี่ยงก่อนเปิดสู่ผู้ใช้ทั้งหมด
- Webhook และ bot orchestration: บอทจะเป็นตัวกลางรับ/ส่งคำสั่งจาก LLM ไปยัง repository/CI และบันทึกเหตุการณ์ใน audit log เพื่อให้มีหลักฐานการเปลี่ยนแปลง
ในสภาพแวดล้อมที่เติบโตเร็ว มักมีการตั้งค่าให้การเปลี่ยนแปลงบางประเภท เช่นการแก้บั๊กทั่วไป สามารถ merge และ deploy อัตโนมัติได้ แต่การเปลี่ยนแปลงเชิงสถาปัตยกรรม, การเปลี่ยนแปลงโครงสร้างพื้นฐาน หรือการอนุญาตสิทธิ์ จะถูกกั้นด้วยกระบวนการ manual gate ก่อน
นโยบายการตรวจสอบและความรับผิดชอบของมนุษย์
แม้ AI จะเพิ่มประสิทธิภาพ แต่หลายองค์กรวางมาตรการควบคุมเพื่อป้องกันความเสี่ยงเชิงปฏิบัติการและความปลอดภัย นโยบายทั่วไปที่ใช้มีตัวอย่างดังนี้
- Human-in-the-loop (HITL): ทุก pull request หรือแพตช์ที่สร้างโดย AI จะต้องผ่านการรีวิวจากวิศวกรที่มีความชำนาญ บางองค์กรกำหนดระดับการอนุมัติ (peer review, senior review) ตามความรุนแรงของการเปลี่ยนแปลง
- Automated gating และ policy enforcement: ตั้งเกณฑ์บังคับ เช่น ต้องผ่าน security scan, linting, coverage thresholds ก่อน merge; สำหรับ IaC อาจกำหนดไม่ให้มีการ apply อัตโนมัติหากมี resource change ที่อาจเกิดค่าใช้จ่ายสูงหรือสิทธิ์เข้าถึง
- Segmented 권한และการควบคุมสิทธิ์: จำกัดให้ AI bots ไม่มีสิทธิ์ในการทำ deploy ระดับ production โดยตรง — ต้องมี human approver หรือใช้ service accounts เฉพาะที่มีการล็อกกิจกรรม
- Audit, observability และ rollback: บันทึกทุกคำสั่งและผลลัพธ์จาก AI, เปิดใช้ monitoring/alerting และกำหนดแผน rollback/incident response เฉพาะกรณี deployment ที่มาจาก AI
นโยบายเหล่านี้ช่วยลดความเสี่ยงจาก hallucination ของโมเดล, การสร้างโค้ดที่ขาดความปลอดภัย หรือการเปลี่ยนแปลงโครงสร้างพื้นฐานผิดพลาด แต่ก็แลกมาด้วยความจำเป็นในการออกแบบกระบวนการที่สมดุลระหว่างความคล่องตัวและการควบคุม
กลไกของความผิดพลาด: ทำไม AI จึงเป็นปัจจัยหนึ่ง
กลไกของความผิดพลาด: ทำไม AI จึงเป็นปัจจัยหนึ่ง
เมื่อ AI ถูกนำมาใช้ในกระบวนการพัฒนาซอฟต์แวร์ ทั้งในรูปแบบของตัวช่วยเขียนโค้ด (code completion), ตัวแนะนำการตั้งค่า (configuration suggestions) หรือการเปลี่ยนแปลงอัตโนมัติในระบบ (auto-remediation / auto-deploy) มันไม่เพียงเสริมประสิทธิภาพ แต่ยังเพิ่มช่องทางใหม่ที่สามารถก่อให้เกิดข้อบกพร่องได้เช่นกัน การวิเคราะห์เชิงเทคนิคแสดงให้เห็นว่าแหล่งที่มาของบั๊กจาก AI มักมาจากความไม่สอดคล้องกันระหว่างระดับการทดสอบ ข้อจำกัดของข้อมูลที่ฝึกโมเดล และการตัดสินใจเชิงบริบทที่ AI อาจไม่เข้าใจอย่างถ่องแท้
ตัวอย่างลักษณะข้อผิดพลาดที่ AI อาจสร้างได้ชัดเจน เช่น:
- Regression — AI แนะนำโค้ดหรือแก้ไขโค้ดที่ดูเหมาะสมในบริบทของ unit test แต่ไปทำลายฟังก์ชันการทำงานเดิมในระดับ integration หรือ end-to-end; ตัวอย่างเช่น เปลี่ยนพฤติกรรม default ของ API response ที่ unit test ไม่ครอบคลุม ทำให้บริการ downstream เกิดข้อผิดพลาดหลัง deployment
- Race condition / concurrency bug — AI สร้างการปรับปรุงประสิทธิภาพโดยลบหรือลดการล็อก (lock) หรือแนะนำ non-atomic operations ที่ผ่าน static analysis และ unit test แต่ภายใต้ภาระงานจริงจะเกิดการชนกันของทรัพยากร (data race) ทำให้ข้อมูลเสียหายหรือบริการล่ม
- Misconfiguration — การแก้ไข configuration อัตโนมัติ เช่นปรับ timeout/retry policy, เปลี่ยนค่า routing หรือ service discovery อาจสร้าง loop ทางเครือข่าย (redirect loop) หรือ retry storm ที่สร้างภาระให้ระบบเพิ่มขึ้นอย่างรวดเร็ว
- Dependency management failures — AI แนะนำการอัปเดตเวอร์ชันหรือจัดการ dependency โดยไม่ตรวจสอบ compatibility matrix ทำให้เกิดการ downgrade หรือโหลดไลบรารีที่ขัดแย้งกัน ส่งผลให้ build ผ่านแต่ runtime ล้มเหลว
ทำไมโค้ดที่ AI สร้างแล้วผ่านการทดสอบยังมีบั๊ก? ปัญหาอยู่ที่ช่องว่างในกระบวนการตรวจสอบ (verification gaps):
- การทดสอบที่เน้น unit tests มากเกินไป — Unit tests มักรันในสภาพแวดล้อมที่ถูก mock/isolated ทำให้การเปลี่ยนแปลงที่เสี่ยงต่อการผนวกระบบ (integration risk) ไม่ถูกจับ เช่น การเปลี่ยน API contract หรือ schema ที่ส่งผลเมื่อเชื่อมต่อ service จริง
- สภาพแวดล้อมทดสอบไม่จำลองภาระงานจริง — ไม่มีการทดสอบแบบ performance, concurrency, หรือ chaos testing ที่จะเปิดเผย race condition หรือ backpressure scenarios ที่เกิดเฉพาะภายใต้ภาระการใช้งานสูง
- การพึ่งพา mocks และ fixtures เกินไป — AI มักเรียนรู้จากตัวอย่างหรือโค้ดตัวอย่างซึ่งอาจใช้ mocks ที่ไม่สะท้อนพฤติกรรมของระบบจริง ส่งผลให้การตรวจสอบไม่ครอบคลุม
- ขาดชุดทดสอบเชิงพฤติกรรมหรือ property-based testing — เมื่อไม่มีการตรวจสอบ invariants (เช่น idempotency, ordering guarantees) การเปลี่ยนแปลงที่ดูปลอดภัยในเชิงโค้ดอาจละเมิดสมมติฐานเชิงพฤติกรรม
ปัจจัยเสริมที่ทำให้ปัญหารุนแรงขึ้นเมื่อ AI เข้ามามีบทบาท ได้แก่:
- Auto-merge / Auto-deploy without human gate — หากการเปลี่ยนแปลงที่ AI แนะนำถูกผนวกและ deploy อัตโนมัติโดยไม่มี human review หรือ manual approval จะทำให้ข้อผิดพลาดเข้าสู่ production ได้รวดเร็วและกระจายวงกว้าง
- การตั้งค่าการทดสอบที่บกพร่อง — CI/CD pipeline ที่รันชุดทดสอบไม่ครบถ้วน หรือ run tests ใน environment ที่ต่างจาก production จะทำให้ข้อบกพร่องหลุดรอด
- เอกสารและ contract ที่ไม่ครบถ้วน — เมื่อ API contract หรือ configuration spec ไม่ชัดเจน AI อาจอนุมานพฤติกรรมผิดพลาด และสร้างการแก้ไขที่ขัดกับสมมติฐานของระบบอื่น
- การขาดการกำกับด้วยมนุษย์ (insufficient human-in-the-loop) — ผู้ทบทวนอาจพึ่งพา output ของ AI มากเกินไป หรือไม่มีทักษะเชิงบริบทเพียงพอที่จะตรวจจับ corner cases
- Model drift / prompt ambiguity — AI ที่เปลี่ยนแปลงพฤติกรรมตามชุดข้อมูลใหม่หรือ prompt ที่ไม่ชัดเจนอาจให้คำแนะนำที่ไม่สอดคล้องกันเมื่อเวลาผ่านไป
สรุปได้ว่าการที่ AI กลายเป็นหนึ่งในปัจจัยที่นำไปสู่เหตุการณ์ระบบล่มหรือข้อบกพร่องร้ายแรงไม่ได้มาจากคำแนะนำเพียงอย่างเดียว แต่เป็นผลจากการผสมผสานของคำแนะนำที่มีข้อจำกัด ช่องว่างในการทดสอบ การตั้งค่า deployment ที่เอื้อให้เปลี่ยนแปลงสู่ production ได้รวดเร็ว และการขาดการตรวจสอบเชิงบริบทโดยมนุษย์ องค์กรจึงต้องออกแบบกระบวนการควบคุม (governance), เพิ่มการทดสอบในระดับ integration/chaos และรักษา human-in-the-loop เพื่อทำให้การใช้งาน AI ปลอดภัยยิ่งขึ้น
ผลกระทบเชิงปฏิบัติและเชิงธุรกิจ
ผลกระทบเชิงปฏิบัติและเชิงธุรกิจ
เหตุการณ์ที่ Amazon ไม่สามารถให้บริการได้ส่งผลกระทบทันทีและกว้างขวางทั้งในเชิงปฏิบัติ (operational) และเชิงธุรกิจ (business). ในแง่การปฏิบัติงาน ผู้ใช้งานปลายทางจำนวนมากพบการหยุดชะงักของฟังก์ชันสำคัญ เช่น ระบบชำระเงิน การยืนยันตัวตน (authentication) การเข้าถึง API และการดึงข้อมูลสินค้าหรือสถานะการจัดส่ง ซึ่งทำให้กระบวนการธุรกรรมหยุดชะงักเป็นชั่วโมง ขณะที่ลูกค้ารายย่อยและผู้ค้าพันธมิตรต้องเผชิญกับคำสั่งซื้อที่ถูกยกเลิก การคืนสินค้าเพิ่มขึ้น และงานซ่อมแซมระบบเร่งด่วน
การวัดผลกระทบเชิงปฏิบัติสามารถประเมินได้จากตัวชี้วัดที่เป็นมาตรฐานของอุตสาหกรรม เช่น Availability / Uptime, Mean Time To Recovery (MTTR), จำนวนคำร้องเรียน (support tickets) และอัตราการเรียกร้องเครดิตตาม SLA. ตัวอย่างเชิงตัวเลขที่ใช้เปรียบเทียบคือเวลาที่อนุญาตตาม SLA: 99.99% availability เท่ากับเวลาหยุดทำงานประมาณ 52.56 นาทีต่อปี, ขณะที่ 99.9% เท่ากับ 8.76 ชั่วโมงต่อปี. ดังนั้นเหตุการณ์หยุดทำงานเป็นชั่วโมงเดียวอาจทำให้บริการที่สัญญาไว้ภายใต้ SLA เกิดการละเมิดทันที และนำไปสู่การเรียกร้องเครดิตหรือค่าเสียหาย
ในเชิงธุรกิจ ความสูญเสียรายได้มักถูกประเมินโดยใช้สูตรพื้นฐาน: (รายได้เฉลี่ยต่อชั่วโมง) × (ชั่วโมงที่ระบบไม่ทำงาน) × (เปอร์เซ็นต์ของธุรกรรมที่ถูกกระทบ). ยกตัวอย่างการประมาณการสมมติ: หากแพลตฟอร์มอีคอมเมิร์ซสร้างรายได้โดยเฉลี่ย 120,000 ดอลลาร์ต่อชั่วโมง และระบบหยุดทำงาน 2 ชั่วโมงโดยส่งผลกระทบต่อ 60% ของธุรกรรมที่เกิดขึ้น ธุรกิจอาจสูญเสียรายได้ตรงประมาณ 120,000 × 2 × 0.6 = 144,000 ดอลลาร์ (ไม่รวมผลกระทบทางอ้อม เช่น ค่าขนส่งที่ต้องคืน การจัดการคำร้องเรียน และการตลาดเพื่อเรียกคืนลูกค้า). นอกจากนี้ยังมีต้นทุนจากการสนับสนุนลูกค้าที่พุ่งสูงขึ้น: หากมีผู้ใช้ 100,000 คนที่ได้รับผลกระทบและอัตราการยื่นคำร้องอยู่ที่ 2% จะมี ticket เกิดขึ้นถึง 2,000 ราย ซึ่งต้องใช้ทรัพยากรมนุษย์และเวลาในการแก้ไข
ผลกระทบด้านความเชื่อถือ (reputational damage) มักยืนยาวกว่าผลเสียหายทางการเงินระยะสั้น — การสำรวจในอุตสาหกรรมชี้ว่า สัดส่วนลูกค้าที่พิจารณาย้ายผู้ให้บริการหรือเปลี่ยนแบรนด์หลังจากประสบการณ์การใช้งานที่แย่สามารถอยู่ในช่วง 20–60% ขึ้นกับความรุนแรงและความถี่ของเหตุการณ์ (ตัวเลขนี้ใช้เป็นการประมาณการตามการสำรวจพฤติกรรมผู้บริโภคในอุตสาหกรรมเทคโนโลยี). ความเสียหายต่อความเชื่อมั่นยังแปลงเป็นต้นทุนทางการตลาดที่สูงขึ้นเมื่อต้องลงทุนเพื่อกู้คืนชื่อเสียง เช่น แคมเปญ PR, ส่วนลดส่งเสริมการขาย และการประกันคุณภาพที่เพิ่มขึ้น
- การวัดผลกระทบ (ตัวอย่างเชิงปฏิบัติ):
- Users affected: จำนวนผู้ใช้ที่ไม่สามารถเข้าถึงบริการภายในช่วงเวลา (เช่น 50,000 — 1,000,000+ ขึ้นกับขอบเขตเหตุการณ์)
- SLA breach: หาก SLA กำหนด 99.9% การหยุดชะงัก 2 ชั่วโมงจะเท่ากับการละเมิดหลายชั่วโมงเมื่อคำนวณเป็นเปอร์เซ็นต์รายปี
- MTTR: เวลาที่ใช้คืนสู่สถานะปกติ (เช่น 1–6 ชั่วโมง) ซึ่งส่งผลโดยตรงต่อจำนวนธุรกรรมที่สูญเสีย
- ผลกระทบต่อรายได้และต้นทุน:
- รายได้สูญเสียตรง: คำนวณโดย (เนื้อหา/ธุรกรรมต่อชั่วโมง) × (มูลค่าต่อธุรกรรม) × (ชั่วโมงที่ระบบไม่ทำงาน)
- ต้นทุนทางอ้อม: ต้นทุนทีมสนับสนุน, การคืนสินค้า, ค่าชดเชยลูกค้า, และค่าใช้จ่ายกู้ชื่อเสียง
- ตัวอย่างการประมาณการ: ห้างค้าปลีกขนาดกลางที่มี GMV 60,000 USD/ชั่วโมง หากหยุดงาน 3 ชั่วโมงและ 50% ของธุรกรรมถูกกระทบ จะสูญเสีย GMV ประมาณ 90,000 USD
- ความเสี่ยงทางกฎหมายและการปฏิบัติตามข้อบังคับ:
- สัญญาเชิงพาณิชย์กับลูกค้าและพันธมิตรอาจระบุค่าเสียหายหรือสิทธิยกเลิกสัญญา
- หากเหตุการณ์เกี่ยวข้องกับข้อมูลส่วนบุคคล อาจมีความเสี่ยงของการถูกปรับตามกฎหมายเช่น GDPR (ปรับสูงสุดถึง 4% ของรายได้รวมระดับโลกหรือ 20 ล้านยูโร ขึ้นอยู่กับกรณี)
- การฟ้องร้องแบบกลุ่ม (class action) หรือการร้องเรียนจากผู้ค้าพันธมิตรที่ได้รับผลกระทบอาจเพิ่มภาระค่าใช้จ่ายอย่างมีนัยสำคัญ
- ตัวอย่างกรณีและคำพูดจากแหล่งข่าว (ภาพรวม):
- ลูกค้าพันธมิตรรายย่อยในข่าวมักรายงานว่า “การชำระเงินไม่ผ่าน ขณะมีลูกค้ารอคิวจำนวนมาก” ซึ่งสะท้อนผลกระทบทันทีต่อยอดขายและประสบการณ์ลูกค้า
- ผู้ประกอบการแอปพลิเคชันที่พึ่งพา API ของ Amazon ระบุว่าต้องเปิดรีเพลย์คำสั่งซื้อและคืนสถานะข้อมูลเป็นเวลาหลายชั่วโมง ส่งผลให้ต้นทุนการดำเนินงานเพิ่มขึ้นอย่างฉับพลัน
- ข่าวสารอุตสาหกรรมมักรายงานจำนวนคำร้องเรียนและการเรียกร้องเครดิตจากลูกค้าองค์กร ซึ่งเป็นตัวชี้วัดมาตรฐานของความเสียหายเชิงธุรกิจ
สรุปได้ว่า ผลกระทบจากเหตุการณ์ Amazon ไม่สามารถให้บริการได้ไม่ได้จำกัดแค่การหยุดของระบบชั่วคราวเท่านั้น แต่ลุกลามสู่การสูญเสียรายได้โดยตรง ต้นทุนการดำเนินงานที่เพิ่มขึ้น ความเสี่ยงด้านกฎหมาย และความเสียหายต่อความเชื่อมั่นของลูกค้า — ทั้งหมดนี้ควรนำมาพิจารณาเชิงกลยุทธ์ในการจัดการความเสี่ยง (risk management), การออกแบบสถาปัตยกรรมความทนทาน (resilience) และการวางแผน SLA/DR (disaster recovery) ที่ชัดเจนสำหรับผู้ให้บริการและลูกค้า
การตอบสนองของ Amazon: การสื่อสารและมาตรการเยียวยา
การตอบสนองของ Amazon: การสื่อสารและมาตรการเยียวยา
การตรวจจับและการลดผลกระทบเบื้องต้น — ในช่วงเหตุการณ์ที่ระบบของ Amazon มีปัญหาเกี่ยวกับการผสาน AI เข้ากับเวิร์กโฟลว์การเขียนโปรแกรม ทีมปฏิบัติการของบริษัทระบุว่าได้ใช้ระบบมอนิเตอร์เชิงรุก (real-time monitoring) และการแจ้งเตือนอัตโนมัติเพื่อระบุความผิดปกติภายในไม่กี่นาทีหลังเกิดอาการผิดปกติ โดยกระบวนการตอบสนองฉุกเฉินหลักประกอบด้วยการแยกระบบที่ได้รับผลกระทบ (isolation), ยกเลิกการเปลี่ยนแปลงล่าสุดที่เกี่ยวข้อง (rollback), และปรับเส้นทางทราฟฟิกไปยังโหนดสำรอง (failover) เพื่อให้บริการหลักกลับมาใช้งานได้อย่างรวดเร็ว ทั้งนี้ตามแนวปฏิบัติของ SRE ที่ดี การตรวจจับและปิดวงจรปัญหาจากการมอนิเตอร์มักใช้เวลาเป็นนาทีถึงชั่วโมง ขึ้นอยู่กับความซับซ้อนของเหตุการณ์
การสื่อสารต่อสาธารณะและช่องทางที่ใช้ — Amazon ใช้ช่องทางหลายรูปแบบในการสื่อสารเพื่อให้ข้อมูลสถานะและแนวทางการแก้ไขแก่ลูกค้าอย่างต่อเนื่อง ช่องทางสำคัญได้แก่:
- Status dashboard (เช่น AWS Service Health Dashboard) สำหรับอัปเดตสถานะแบบเรียลไทม์และแสดงเวลาที่คาดว่าจะกลับสู่ภาวะปกติ
- ประกาศสื่อมวลชน (press releases) เมื่อเหตุการณ์มีผลกระทบกว้างขวางหรือมีความสำคัญเชิงธุรกิจสูง
- ช่องทางโซเชียลมีเดียและบล็อกทางเทคนิคสำหรับอธิบายสรุปเหตุการณ์และบอกขั้นตอนชั่วคราว (workarounds)
- การแจ้งเตือนตรงไปยังลูกค้าผ่านอีเมลหรือระบบ Ticketing สำหรับลูกค้าที่ได้รับผลกระทบโดยตรง รวมถึงการให้ข้อมูลวิธีลดผลกระทบเฉพาะราย
มาตรการเยียวยาและการชดเชย — หลังการประเมินผลกระทบ Amazon แจ้งมาตรการเยียวยาต่อผู้ได้รับผลกระทบ ซึ่งมักประกอบด้วยการให้เครดิตค่าบริการ การปรับเงื่อนไข SLA และการสนับสนุนทางเทคนิคเพิ่มเติม ตัวอย่างการชดเชยที่มักใช้ในอุตสาหกรรมและปรากฏในเหตุการณ์ครั้งนี้ เช่น เครดิตค่าบริการสำหรับช่วงเวลาที่ระบบหยุดชะงัก (ตัวอย่างเช่น 10–100% ของค่าบริการในช่วงเวลาที่ได้รับผลกระทบ ขึ้นกับระดับความรุนแรง) รวมถึงการมอบบริการสนับสนุนเชิงรุกและการเปิดช่องทางติดต่อสำหรับลูกค้ารายใหญ่เพื่อฟื้นฟูระบบอย่างรวดเร็ว
postmortem และการปรับปรุงระยะสั้น-ระยะยาว — หลังเหตุการณ์ Amazon ปล่อยรายงาน postmortem ที่สรุปไทม์ไลน์ เหตุปัจจัยที่ทำให้เกิดปัญหา มาตรการที่นำมาแก้ไขทันที และรายการการดำเนินการเชิงป้องกันในอนาคต รายงานเหล่านี้มักจะระบุ root cause, การทดสอบยืนยันผลของการแก้ไข และแผนการติดตามผลในระยะยาว เพื่อเพิ่มความน่าเชื่อถือและลดโอกาสเกิดซ้ำ ตัวอย่างของการแยกแยะมาตรการเป็นสองกลุ่มได้แก่:
- Short-term fixes: rollback โค้ดที่เกี่ยวข้อง, เพิ่ม capacity ชั่วคราว, เปิด circuit breakers, หรือแพตช์ความปลอดภัยที่จำเป็นเพื่อคืนบริการเร็วที่สุด
- Long-term changes: ปรับปรุงกระบวนการรีวิวโค้ดและการทดสอบสำหรับโมเดล AI, ขยายการฝึกซ้อมกรณีวิกฤต (chaos engineering), ปรับปรุงการมอนิเตอร์เชิงพฤติกรรมของ AI, และทบทวนข้อตกลง SLA/CR (change requests) เพื่อรองรับสถาปัตยกรรมที่มี AI ประกอบ
การวิเคราะห์ความโปร่งใสและความรวดเร็วในการตอบรับ — โดยรวมแล้วการตอบสนองของ Amazon ถูกประเมินว่าใช้แนวทางที่เป็นระบบและครบวงจร: มีการตรวจจับอัตโนมัติ การดำเนินการฟื้นฟูอย่างเป็นลำดับชั้น และการสื่อสารหลายช่องทางเพื่อแจ้งลูกค้า อย่างไรก็ตาม การประเมินความโปร่งใสยังมีมุมมองผสม—ด้านหนึ่งคือการอัปเดตสถานะและ postmortem ช่วยเพิ่มความชัดเจน แต่ในอีกด้านหนึ่ง ลูกค้าบางกลุ่มอาจต้องการรายละเอียดเชิงเทคนิคเชิงลึกและการกำหนดเวลาในการแก้ไขปัญหาที่ชัดเจนกว่า ตัวชี้วัดสำคัญที่ควรติดตามสำหรับอนาคตได้แก่ Mean Time to Detect (MTTD), Mean Time to Recover (MTTR), อัตราการเกิดซ้ำของปัญหา และระดับความพึงพอใจของลูกค้าหลังการชดเชย
บทเรียนสำหรับองค์กร: แนวปฏิบัติเมื่อผสาน AI เข้ากับ pipeline
การนำระบบ AI เข้าสู่กระบวนการพัฒนาและ deployment ของซอฟต์แวร์เป็นโอกาสและความเสี่ยงในเวลาเดียวกัน องค์กรที่ผสาน AI เข้ากับ pipeline ต้องกำหนดหลักปฏิบัติที่ชัดเจนทั้งด้านการควบคุมการเปลี่ยนแปลง ความปลอดภัย และการฟื้นตัวเมื่อเกิดข้อผิดพลาด บทเรียนจากเหตุการณ์การหยุดให้บริการขนาดใหญ่ เช่น กรณีที่มีการยอมรับคำแนะนำจากโมเดลอัตโนมัติโดยไม่มีการตรวจสอบของมนุษย์ (human-in-the-loop) ชี้ให้เห็นว่าการออกแบบเกตต์ยืนยัน (approval gates) ก่อนการ deploy เป็นหัวใจสำคัญที่ช่วยลดความเสี่ยงได้อย่างมีนัยสำคัญ
หลักการ Human-in-the-loop และเกตต์ยืนยันก่อน deploy
Human-in-the-loop (HITL) ควรถูกออกแบบเป็นมาตรการบังคับเมื่อ AI มีอำนาจเสนอการเปลี่ยนแปลงที่กระทบลูกค้าหรือโครงสร้างพื้นฐาน เช่น การแก้โค้ด การปรับค่า configuration หรือการสั่งการระบบการผลิต ช่องทาง HITL ควรรวมถึงการสรุปความเสี่ยงของการเปลี่ยนแปลง สถานะของเทสที่รันแล้ว และตัวชี้วัดที่ชี้ว่าการแก้ไขปลอดภัยก่อนอนุมัติ การสำรวจจากหลายองค์กรพบว่าองค์กรที่มี gate แบบบังคับสามารถลดความผิดพลาดจากการ deploy อัตโนมัติได้อย่างมีนัยสำคัญ (องค์กรบางแห่งรายงานการลดลงของเหตุการณ์ที่เกี่ยวข้องกับ deployment ราว 40–60%)
เกตต์ยืนยันควรประกอบด้วย: การตรวจทานโค้ดหรือ diff โดยวิศวกรที่มีความเชี่ยวชาญ, การยืนยันว่าผลลัพธ์ของโมเดลไม่ขัดแย้งกับนโยบายความปลอดภัยหรือการคอมไพล์, และ การอนุมัติขั้นสุดท้ายจากเจ้าของบริการ (service owner) ก่อนการปล่อยขึ้น production การออกแบบ UI/UX ของระบบอนุมัติควรแสดงบริบทครบถ้วน เช่น snapshot ของระบบก่อนหน้า, log ที่เกี่ยวข้อง, และประวัติการตัดสินใจของโมเดล
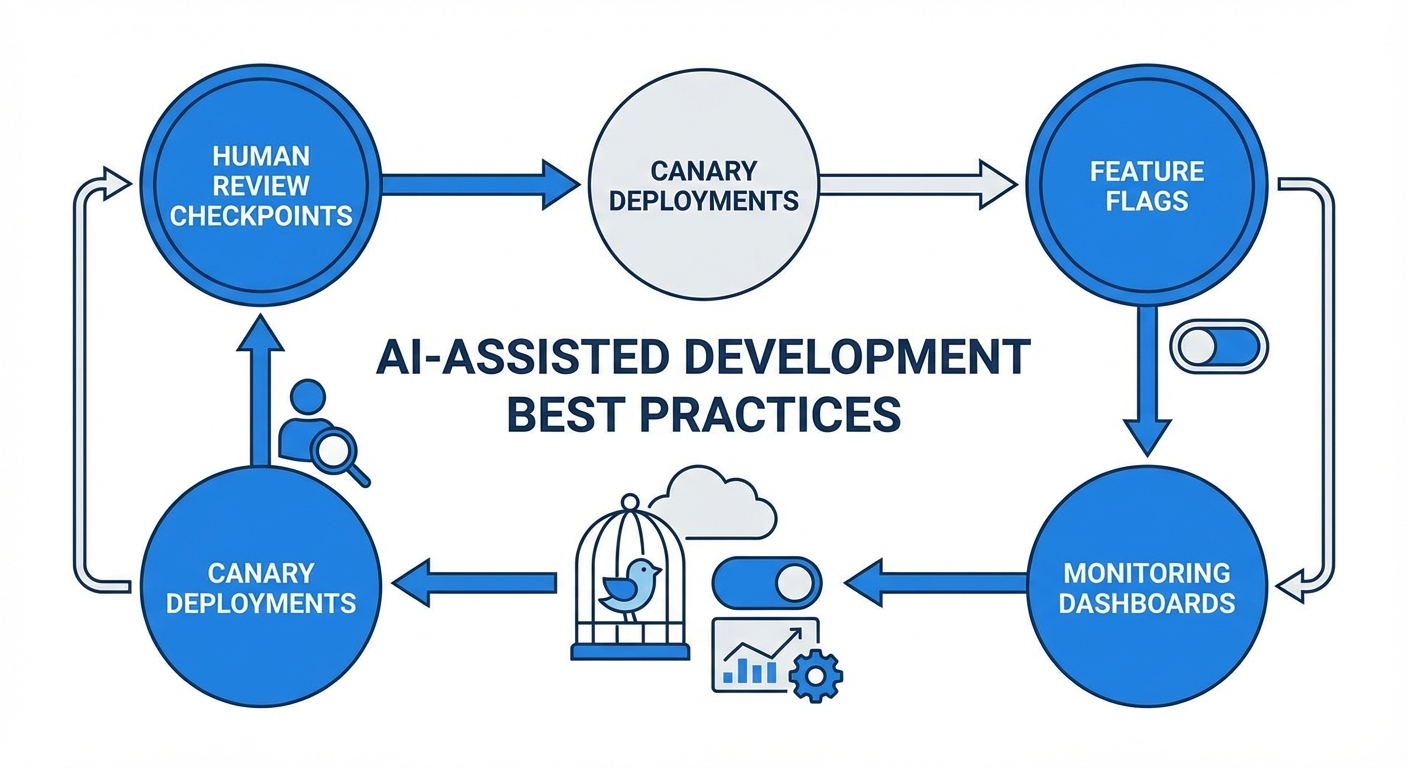
การทดสอบครบถ้วน: Integration, Chaos, Canary
การทดสอบที่ครอบคลุมทั้งบนสภาพแวดล้อม staging และ production เป็นสิ่งจำเป็น เมื่อนำ AI เข้ามาเสนอโค้ดหรือ configuration ควรเพิ่มระดับการทดสอบดังนี้:
- Integration/E2E tests: รันบน pipeline อัตโนมัติทุกครั้งที่มีการเปลี่ยนแปลงที่ AI แนะนำ เพื่อยืนยันการทำงานร่วมกันของส่วนต่างๆ ตั้งแต่ API, database, ไปจนถึง dependency ภายนอก
- Canary releases: ปล่อยการเปลี่ยนแปลงเป็นวงแคบ (เช่น 1% ผู้ใช้) เพื่อตรวจจับปัญหาที่จำเพาะเจาะจงกับ production traffic ก่อนขยายวงกว้าง
- Chaos testing / fault injection: ทดสอบระบบต่อความผิดพลาดเชิงโครงสร้าง เช่น การตัด connection, การหน่วงเวลา, การจำกัดทรัพยากร เพื่อยืนยันว่าแผนสำรองและ circuit breakers ทำงานตามที่ออกแบบ
ตัวอย่าง: หาก AI แนะนำการเปลี่ยนแปลง Query ให้ใช้ index ใหม่ ทีมควรรัน benchmark และ profiling บน traffic เสมือน สังเกต latencies และ error rates ผ่าน canary สำหรับ 24–72 ชั่วโมงก่อนขยาย deployment
การบริหารความเสี่ยง: Access Controls, Feature Flags, Rollback Plans
การจำกัดสิทธิ์ของระบบอัตโนมัติ (least privilege) เป็นข้อบังคับทางปฏิบัติ: สคริปต์หรือบ็อตที่รันคำแนะนำจาก AI ไม่ควรมีสิทธิ์ push โค้ดหรือ deploy โดยตรง ควรกำหนดให้สิทธิ์ดังกล่าวเป็นแบบชั่วคราวและมีการบันทึก (audit logging) ทุกการกระทำ นอกจากนี้ควรใช้ feature flags เพื่อเปิด/ปิดฟีเจอร์ใน runtime ได้อย่างรวดเร็วโดยไม่ต้อง rollback โค้ดทันที
แผนการ rollback ต้องถูกเตรียมไว้เป็นสคริปต์อัตโนมัติที่ทดสอบแล้วและสามารถสั่งใช้ได้จากหน้าควบคุมเดียว พร้อมทั้ง kill switch ที่สามารถตัดการทำงานของ automation หากตรวจพบพฤติกรรมผิดปกติ ควรกำหนด SLA สำหรับการตอบสนองต่อการสั่ง rollback (เช่น ภายใน 5–15 นาทีสำหรับระบบ mission-critical)
Checklist ตัวอย่างสำหรับทีม DevOps และ SRE
- Pre-deploy gates: ยืนยันการทบทวนโดยมนุษย์ (HITL), รายงานผลทดสอบ E2E และประวัติการอนุมัติ
- Testing: Integration tests > Canary (1% → 5% → 20%) > Full rollout; Chaos tests อย่างน้อยทุกสัปดาห์สำหรับบริการสำคัญ
- Static/Dynamic analysis: รัน SAST (เช่น รหัสอันตราย, injection patterns) และ DAST/fuzzing สำหรับ endpoint ที่เสี่ยงก่อน merge
- Least privilege & RBAC: Automation tokens มีเวลาหมดอายุ, แยกบัญชีสำหรับ bot และมนุษย์, บันทึก audit trails
- Feature flags & kill switches: สามารถปิดฟีเจอร์จาก control plane โดยไม่ต้อง deploy ใหม่
- Rollback scripts: สคริปต์ rollback ที่ทดสอบแล้ว, วัน/เวลาทดสอบการกู้คืน (RTO/RPO) ได้ตามเป้า
- Monitoring & Alerting: SLIs/SLOs ชัดเจน, error budget ติดตาม, alert ที่เชื่อมกับ runbook อัตโนมัติ
- Runbooks & On-call: คู่มือตอบเหตุการณ์ที่ชัดเจน, ฝึกซ้อมการกู้คืนเป็นประจำ (game days)
- Post-deploy validation: Smoke tests อัตโนมัติ, sampling ของการตอบกลับจาก production และการตรวจสอบ anomaly ของโมเดล
- Change transparency: บันทึก decision log ของโมเดลและมนุษย์ เพื่อการสอบสวนย้อนหลังและการเรียนรู้
สรุป: เมื่อนำ AI มาใช้ใน pipeline สิ่งสำคัญคือต้องรักษาสมดุลระหว่างความคล่องตัวและการควบคุมความเสี่ยง การออกแบบ HITL และเกตต์ยืนยัน, การทดสอบครบถ้วนทั้งในระดับ integration/canary/chaos, และการบริหารสิทธิ์ร่วมกับ feature flags และแผน rollback ที่ทดสอบแล้ว จะช่วยลดโอกาสของเหตุการณ์หยุดให้บริการและเพิ่มความน่าเชื่อถือของระบบโดยรวม
ผลกระทบต่อกฎระเบียบและอนาคตของงานเขียนโปรแกรม
ผลกระทบต่อกฎระเบียบและอนาคตของงานเขียนโปรแกรม
เหตุการณ์ระบบสำคัญล่มเนื่องจากการนำระบบปัญญาประดิษฐ์ (AI) มาใช้ในการเขียนโปรแกรม เช่น กรณีของ Amazon จะเร่งให้หน่วยงานกำกับดูแลและองค์กรภาครัฐพิจารณาออกข้อกำหนดที่เข้มงวดขึ้นสำหรับการใช้ AI ในระบบที่เป็น mission-critical โดยคาดว่าในระยะกลาง (2–5 ปี) จะเกิดการเสนอร่างมาตรฐานหลายระดับ ตั้งแต่ข้อกำหนดด้านความโปร่งใสของโมเดล (model documentation / model cards) ไปจนถึงข้อกำหนดด้านการทดสอบก่อนนำระบบขึ้นใช้งานจริง เช่น การทดสอบเชิงฉุกเฉิน (chaos engineering) กับโมเดล, การทดสอบเชิงป้องกันการโจมตีเชิง adversarial, และการวัดความถูกต้องภายใต้ภาระงานจริง การเคลื่อนไหวเชิงนโยบายดังกล่าวอาจรวมถึงการขยายกรอบกฎหมายด้านความรับผิดชอบ (liability) และข้อกำหนดด้าน SLA ที่ชัดเจนสำหรับบริการ AI ในระบบสาธารณะและการเงิน
จากมุมมองตลาดแรงงาน เหตุการณ์นี้เร่งให้บทบาทของนักพัฒนาเปลี่ยนแปลงจากการเป็นผู้ลงมือเขียนโค้ดเพียงอย่างเดียว ไปสู่บทบาทที่เน้นการออกแบบสถาปัตยกรรม การควบคุมการตัดสินใจของระบบ และการรับผิดชอบด้านความปลอดภัยและความเที่ยงตรงของโมเดล มากขึ้น นักพัฒนาจะต้องมีทักษะในการประเมินความเสี่ยงของโมเดล การตรวจสอบเอกสาร (model provenance) และการออกแบบแผนการกู้คืนระบบ (incident response) แทนที่จะมุ่งเน้นเพียงการพัฒนา feature ใหม่ ๆ ในเชิงโค้ด ตัวอย่างการเปลี่ยนบทบาทได้แก่การเพิ่มจำนวนตำแหน่งเช่น AI Safety Engineer, Model Validator, และ AI Governance Officer ซึ่งจะทำหน้าที่ร่วมกับทีมกฎหมายและฝ่ายความเสี่ยงเพื่อให้การนำ AI เข้าระบบเป็นไปตามมาตรฐานที่กำหนด
แนวโน้มของตลาดแรงงานยังชี้ชัดว่าความต้องการทักษะด้านการทดสอบและความปลอดภัยจะเพิ่มสูงขึ้น สถิติจากการสำรวจเชิงอุตสาหกรรมหลายฉบับระบุว่าองค์กรมากกว่า 60% กำลังวางแผนเพิ่มการลงทุนในด้าน testing, observability และ security สำหรับโมเดล AI ภายในสองปีข้างหน้า ทักษะที่เป็นที่ต้องการสูงขึ้นได้แก่การทดสอบเชิงระบบ (end-to-end testing) สำหรับ pipeline ของข้อมูล, การทดสอบเชิง adversarial, formal verification สำหรับส่วนสำคัญของระบบ, และความเชี่ยวชาญด้านการสืบสวนเหตุล้มเหลว (root-cause analysis) ในบริบทของระบบที่มี ML เป็นส่วนหนึ่งของการตัดสินใจ มีแนวโน้มว่าบริษัทจะให้ความสำคัญกับใบรับรอง (certification) หรือใบอนุญาตเฉพาะทางสำหรับผู้ที่รับผิดชอบระบบ mission-critical มากขึ้น เพื่อเป็นหลักประกันต่อผู้ใช้งานและหน่วยงานกำกับดูแล
สำหรับผู้ให้บริการคลาวด์และผู้พัฒนาเครื่องมือ AI คาดว่าจะมีการปรับตัวเชิงธุรกิจอย่างเห็นได้ชัด ผู้ให้บริการรายใหญ่จะเริ่มนำเสนอ ชั้นบริการด้านการประกันความปลอดภัยของโมเดล (AI assurance tiers) ที่รวมการตรวจสอบก่อนใช้งาน, การติดตามสภาพการทำงานแบบเรียลไทม์, การสำรองข้อมูลโมเดล และเอกสารการปฏิบัติตามกฎระเบียบ ในขณะเดียวกันจะมีการพัฒนาเครื่องมือที่เน้น explainability, lineage tracking, และ automated compliance reporting มากขึ้น เจ้าของระบบอาจเลือกสถาปัตยกรรมที่ผสมผสานระหว่างการประมวลผลบนคลาวด์ที่ได้รับการรับรองและสภาพแวดล้อม on‑premises เพื่อควบคุมความเสี่ยงและข้อกฎหมาย นอกจากนี้ ตลาดประกันภัย (cyber/AI insurance) อาจขยายตัวอย่างรวดเร็ว เนื่องจากองค์กรต้องการโอนความเสี่ยงบางส่วนออกจากบัญชีของตน ทำให้ต้นทุนการใช้งาน AI ในระบบสำคัญอาจสูงขึ้น แต่แลกด้วยความมั่นคงและความไว้วางใจที่มากขึ้น
- มาตรฐาน/กฎระเบียบใหม่: อาจรวมถึงข้อกำหนดการทดสอบก่อนใช้งาน, การรายงานเหตุการณ์, และการรับรองความปลอดภัยของโมเดลสำหรับระบบ mission-critical
- เปลี่ยนบทบาทนักพัฒนา: จาก coder เป็นผู้วางสถาปัตยกรรมและผู้ควบคุมการตัดสินใจของระบบ พร้อมความรับผิดชอบด้าน governance และ incident management
- แนวโน้มตลาด: ความต้องการทักษะด้าน testing, security, observability, ML Ops และ compliance เพิ่มขึ้นอย่างมีนัยสำคัญ พร้อมการเกิดขึ้นของตำแหน่งและใบอนุญาตเฉพาะทาง
สรุปแล้ว เหตุการณ์ที่ระบบ AI ทำให้บริการล่มไม่เพียงเป็นสัญญาณเตือนด้านเทคนิคเท่านั้น แต่ยังเป็นตัวเร่งให้เกิดการเปลี่ยนแปลงเชิงนโยบาย ตลาดแรงงาน และโมเดลธุรกิจของผู้ให้บริการคลาวด์ ในอีก 2–5 ปีข้างหน้า เราน่าจะเห็นกรอบกฎระเบียบที่ชัดเจนขึ้น เครื่องมือที่มุ่งเน้นความเชื่อถือได้ของ AI เพิ่มขึ้น และการยกระดับบทบาทของนักพัฒนาไปสู่ผู้กำกับดูแลการตัดสินใจของระบบเป็นมาตรฐานใหม่สำหรับองค์กรที่ใช้ AI ในงานที่มีความเสี่ยงสูง
บทสรุป
การผสาน AI เข้ากับการพัฒนาโค้ดให้ประโยชน์ด้านความเร็วและประสิทธิภาพอย่างชัดเจน — งานศึกษาหลายฉบับชี้ว่าการใช้เครื่องมือช่วยเขียนโค้ดด้วย AI สามารถเพิ่มผลผลิตของนักพัฒนาได้ในระดับหลักสิบเปอร์เซ็นต์ แต่มาพร้อมความเสี่ยงหากขาดการกำกับดูแลและกระบวนการตรวจสอบที่เหมาะสม เหตุการณ์ที่ Amazon ประสบปัญหาการให้บริการเป็นกรณีเตือนใจว่าโค้ดหรือการตั้งค่าที่ถูกสร้าง/ปรับโดยระบบอัตโนมัติสามารถลุกลามเป็นความล้มเหลวของระบบได้เร็วหากไม่มีการทดสอบแบบเป็นขั้นตอนและการทบทวนโดยมนุษย์ องค์ประกอบสำคัญที่ควรนำมาใช้ได้แก่ human-in-the-loop สำหรับการอนุมัติโค้ดที่สำคัญ, การทดสอบและตรวจสอบเชิงอัตโนมัติ (unit/integration/chaos testing), กลยุทธ์การปล่อยงานแบบ canary เช่น ปล่อยที่ 1% → 10% → 100% เพื่อจำกัดผลกระทบ, การควบคุมสิทธิ์เข้าถึงแบบ least privilege, และกลไกการมอนิเตอร์-แจ้งเตือนพร้อมแผน rollback ที่ชัดเจน
มุมมองเชิงอนาคตชี้ชัดว่า AI จะยังคงเข้ามาเป็นส่วนหนึ่งของวงจรพัฒนาซอฟต์แวร์ แต่ความสำเร็จขึ้นอยู่กับการผสมผสานมาตรการทางเทคนิคและนโยบายองค์กร เช่น การกำหนดบทบาท human-in-the-loop ในจุดเสี่ยง, การติดตั้งระบบ observability และ SRE, การจัดทำ playbook สำหรับการสื่อสารฉุกเฉินต่อลูกค้า และการบังคับใช้มาตรฐานความปลอดภัยของโมเดล (model governance) เพื่อสร้างความเชื่อมั่น การลงทุนในชุดการทดสอบอัตโนมัติ การฝึกอบรมบุคลากร และการจัดทำนโยบายการเข้าถึงที่เข้มงวด จะช่วยเปลี่ยน AI ให้เป็นตัวเร่งที่ปลอดภัยและเชื่อถือได้ มิฉะนั้นองค์กรเสี่ยงต่อการสูญเสียเสถียรภาพ ระบบ และความเชื่อมั่นจากลูกค้า รวมถึงการเผชิญกับการตรวจสอบทางกฎระเบียบที่เข้มงวดขึ้น
📰 แหล่งอ้างอิง: Financial Times



