
กระทรวงเปิดตัวโครงการนำร่อง "Regulation‑LLM" ซึ่งเป็นระบบปัญญาประดิษฐ์เฉพาะด้านที่ช่วยร่างกฎหมายและคำชี้แจงโดยแนบแหล่งอ้างอิงแบบแทร็กได้ (traceable citations) และบันทึกการเปลี่ยนแปลงเชิงเวอร์ชัน ทำให้กระบวนการออกกฎใหม่สั้นลงอย่างมีนัยสำคัญ—กระทรวงระบุว่ารอบการออกกฎลดลงถึง 60% ในช่วงทดลองใช้งาน ขณะเดียวกันได้กำหนดกรอบรับรองความโปร่งใสและการตรวจสอบย้อนกลับเพื่อยืนยันแหล่งข้อมูล การตัดสินใจ และผู้มีส่วนร่วมในแต่ละขั้นตอน
บทนำนี้จะพาอ่านถึงภาพรวมของโครงการนำร่อง Regulation‑LLM ฟีเจอร์สำคัญ เช่น การแทร็กแหล่งที่มา การจัดการเวอร์ชันและล็อกเหตุผลประกอบการแก้ไข ผลสถิติที่รายงานจากการนำร่อง, กรอบการกำกับดูแลด้านความโปร่งใส และผลกระทบต่อภาคกฎหมาย ราชการ และภาคประชาสังคม พร้อมข้อถกเถียงด้านความน่าเชื่อถือ ความรับผิดชอบ และมาตรการรับประกันว่าการใช้ AI ในการร่างกฎหมายจะไม่ลดทอนกระบวนการตรวจสอบของมนุษย์
บทนำ: ทำความรู้จักกับโครงการ Regulation‑LLM
บทนำ: ทำความรู้จักกับโครงการ Regulation‑LLM
กระทรวงได้เปิดตัวโครงการนำร่อง Regulation‑LLM ในบริบทของความซับซ้อนที่เพิ่มขึ้นของการกำกับดูแล วิวัฒนาการของเทคโนโลยี และความจำเป็นในการเพิ่มความคล่องตัวของหน่วยงานภาครัฐ โครงการนี้มีจุดมุ่งหมายเพื่อผสานความสามารถของโมเดลภาษาขนาดใหญ่ (Large Language Models) เข้ากับกระบวนการร่างกฎหมายและเอกสารชี้แจงที่เกี่ยวข้อง โดยเน้นการสร้างผลลัพธ์ที่มีคุณภาพสูง สามารถตรวจสอบแหล่งที่มาได้ และสอดคล้องกับกรอบความรับผิดชอบสาธารณะ เพื่อสนับสนุนการตัดสินใจเชิงนโยบายที่รวดเร็วและโปร่งใสยิ่งขึ้น

พื้นฐานของโครงการเกิดจากความท้าทายหลายประการ ได้แก่ คิวงานร่างกฎระเบียบที่ยาวขึ้น ต้นทุนบุคลากรในการจัดทำเอกสารเชิงกฎเกณฑ์ และแรงกดดันจากภาคเอกชนและสาธารณะที่ต้องการความชัดเจนและความโปร่งใสมากขึ้น Regulation‑LLM ถูกออกแบบมาเพื่อลดภาระงานบริหารที่ซ้ำซ้อน โดยรักษาการควบคุมเชิงนโยบายผ่านกระบวนการ human‑in‑the‑loop และมาตรการตรวจสอบย้อนกลับ (traceability) ของแหล่งข้อมูลที่ใช้ประกอบการร่าง
โดยสรุป โครงการ Regulation‑LLM ทำหน้าที่สำคัญได้แก่
- ช่วยร่างร่างกฎหมาย ข้อบัญญัติ และคำชี้แจงประกอบที่มีโครงสร้างชัดเจนและเป็นไปตามรูปแบบทางกฎหมายที่กำหนด
- สร้างคำชี้แจงเชิงเหตุผล (explanatory notes) ที่ผนวกการอ้างอิงแหล่งข้อมูลที่ตรวจสอบได้ เพื่อให้ผู้อ่านติดตามแหล่งที่มาได้อย่างชัดเจน
- จัดทำสรุปผลกระทบและช่องทางเลือกเชิงนโยบาย พร้อมเครื่องมือเปรียบเทียบร่างก่อน‑หลัง (redline) เพื่อสนับสนุนการพิจารณาจากคณะกรรมการ
- บันทึกประวัติการตัดสินใจและแหล่งข้อมูลที่ใช้ (audit trail) เพื่อเสริมความโปร่งใสและความรับผิดชอบ
ผลจากการทดลองตามรายงานนำร่องที่กระทรวงเผยแพร่ ระบุว่าโครงการช่วยให้ระยะเวลาในการออกกฎใหม่ลดลงอย่างมีนัยสำคัญ โดย ลดรอบการออกกฎใหม่ได้ราว 60% เมื่อเทียบกับกระบวนการเดิม แนวโน้มนี้สะท้อนถึงความสามารถในการร่นระยะเวลาของการร่างและตรวจทานเอกสารเชิงกฎเกณฑ์ ทั้งยังช่วยให้เจ้าหน้าที่สามารถทุ่มเทเวลามากขึ้นไปกับการตัดสินใจเชิงนโยบายแทนงานเอกสารเชิงเทคนิค
เทคโนโลยีเบื้องหลัง: วิธีการทำงานของ Regulation‑LLM
สถาปัตยกรรมระบบแบบโมดูล: LLM + Retriever + Provenance Tracker
Regulation‑LLM ถูกออกแบบเป็นสถาปัตยกรรมแบบโมดูลเพื่อตอบโจทย์งานร่างกฎหมายที่ต้องการความถูกต้อง โปร่งใส และตรวจสอบย้อนหลังได้ โดยแกนกลางประกอบด้วย LLM core ที่ผ่านการปรับจูนเฉพาะด้านกฎหมาย (legal fine‑tuning & instruction tuning) ทำงานร่วมกับระบบ retriever แบบผสม (hybrid dense + sparse retrieval) และ provenance/citation tracker ที่เก็บเมตาดาต้าเชิงแหล่งอ้างอิงอย่างละเอียด ระบบนี้รองรับการเชื่อมต่อกับฐานข้อมูลกฎหมายหลายรูปแบบ เช่น statutes (พระราชบัญญัติ/ประกาศ), case law (คำพิพากษา), regulatory guidance และเอกสารที่เกี่ยวข้อง (เช่น white papers, regulatory impact assessments)
ในเชิงเทคนิค LLM core ใช้กลยุทธ์ Retrieval‑Augmented Generation (RAG) โดยเมื่อได้รับโจทย์จะส่ง query ไปยัง retriever ที่ประกอบด้วย:
- Dense retriever เก็บ embedding ใน vector store (เช่น FAISS/Milvus) สำหรับการจับความคล้ายเชิงบริบท
- Sparse retriever (เช่น BM25) สำหรับการจับคีย์เวิร์ดและโครงสร้างเอกสาร
- Federated connectors ที่ผสานผลลัพธ์จากฐานกฎหมายภายนอก (เช่นแหล่งของรัฐ ราชกิจจานุเบกษา) และฐานความรู้ภายใน
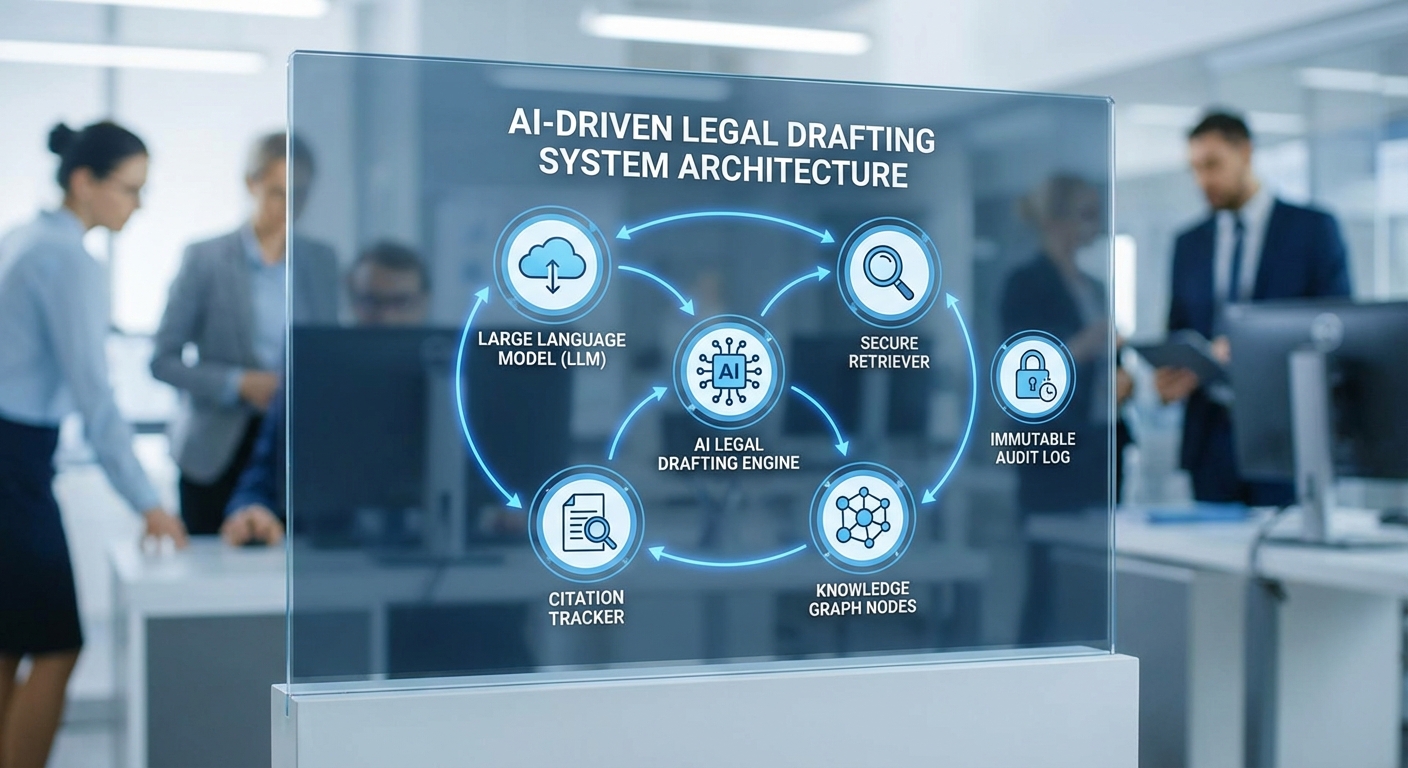
ส่วนของ provenance tracker ทำหน้าที่บันทึกความสัมพันธ์ระหว่างข้อความที่ LLM สร้างกับแหล่งที่มาอย่างละเอียด ประกอบด้วยฟิลด์มาตรฐานเช่น unique source ID, document URI, section/offset, retrieval timestamp, similarity/confidence score และ citation span mapping ที่ชี้กลับไปยังบรรทัดหรือย่อหน้าของเอกสารต้นฉบับ ทำให้ผลลัพธ์ทุกฉบับสามารถย้อนกลับไปตรวจสอบแหล่งข้อมูลดิบได้อย่างแม่นยำ
กระบวนการอ้างอิง: วิธีการสร้างและเชื่อมโยง citations
การสร้างอ้างอิงของ Regulation‑LLM แบ่งเป็น 3 ชั้นหลัก: (1) retrieval & grounding, (2) citation generation, และ (3) provenance anchoring. เมื่อโมดูล retriever ส่งเอกสารที่เกี่ยวข้องกลับมา LLM จะทำการ “ground” ข้อเท็จจริงสำคัญโดยอ้างอิง snippet ที่ตรงกับคำขอ จากนั้นระบบ citation generator จะสร้างรูปแบบการอ้างอิงที่สอดคล้องกับมาตรฐานทางกฎหมายของแต่ละเขตอำนาจ (เช่น หมายเลขมาตรา/วรรค, หมายเลขคดี, วันที่ประกาศ) พร้อมแนบ metadata เช่น URI ของแหล่ง, offset ในเอกสาร, และ confidence score
เมื่อ draft ถูกผลิตขึ้น แต่ละอ้างอิงจะได้รับ provenance token ซึ่งเป็น pointer เชิงโครงสร้างที่ชี้กลับไปยังแหล่งข้อมูลจริง ระหว่างการตรวจสอบผู้เชี่ยวชาญหรือระบบอัตโนมัติสามารถคลิกหรือเรียกดู provenance token เพื่อตรวจสอบข้อความต้นทางได้ทันที ระบบยังสามารถส่งออกบัญชีการอ้างอิงเป็นรูปแบบมาตรฐาน (JSON‑LD / CITATION METADATA) เพื่อการบูรณาการกับเครื่องมือตรวจสอบภายนอก
เวิร์กโฟลว์จากการรับโจทย์จนถึงร่างที่มีแหล่งอ้างอิงและเมตาดาต้า
เวิร์กโฟลว์ของ Regulation‑LLM ถูกออกแบบให้เป็นไปตามกระบวนการร่างกฎหมายจริง โดยมีขั้นตอนสำคัญดังนี้:
- Intake & requirement parsing: รับโจทย์จากหน่วยงาน กำหนดเป้าหมาย ขอบเขต และ jurisdiction ระบบจะสกัดความต้องการเชิงกฎหมายและเมตริกที่ต้องการวัดผล
- Contextual retrieval: ส่ง query แบบหลายมิติไปยัง retriever เพื่อดึง statutes, precedent, guidance, และเอกสารสำคัญอื่นๆ พร้อมบันทึกคะแนนความเกี่ยวข้อง
- Draft generation (RAG): LLM core สร้างร่างเบื้องต้นโดยฝัง citation spans ที่เชื่อมโยงกับแหล่งข้อมูลจริง
- Provenance mapping & metadata attach: ทุก citation ถูกแนบด้วย metadata (source ID, offsets, retrieval timestamp, confidence) และสร้าง audit trail อัตโนมัติ
- Human‑in‑the‑loop review: ผู้เชี่ยวชาญกฎหมายตรวจแก้ เสนอปรับปรุง และอนุมัติ ซึ่งการแก้ไขแต่ละครั้งจะถูกบันทึกใน audit log พร้อมเหตุผลและตัวตนผู้แก้
- Red‑teaming & validation: ทีมทดสอบและระบบอัตโนมัติรันชุดการตรวจสอบ (เช่น conflict checks, legislative style rules, cross‑reference integrity) เพื่อลดความเสี่ยงเชิงนโยบายและข้อผิดพลาดทางกฎหมาย
- Finalization & publication: ผลสุดท้ายพร้อม metadata audit trail ถูกส่งให้หน่วยงานที่เกี่ยวข้องและเก็บเวอร์ชันในระบบแบบ immutable เพื่อการตรวจสอบย้อนหลัง
ตามตัวอย่างเชิงปฏิบัติ ระบบสามารถลดรอบการออกกฎใหม่ได้ประมาณ 60% โดยอาศัยการลดเวลาการค้นหาเอกสารและการร่างเบื้องต้นอัตโนมัติ ขณะที่การมี provenance ครอบคลุมสูง (ระบบตั้งเป้าการจับคู่แหล่งข้อมูล >90% ของ citations ในร่าง) ช่วยให้ผู้ตรวจทานใช้เวลาในการยืนยันเนื้อหาได้สั้นลง
มาตรการเสริมความเชื่อถือ: Human‑in‑the‑loop, Red‑teaming และ Validation
เพื่อให้ผลลัพธ์มีความน่าเชื่อถือและปลอดภัย Regulation‑LLM ใช้ชุดมาตรการเสริมดังนี้:
- Human‑in‑the‑loop (HITL): ผู้เชี่ยวชาญกฎหมายมีบทบาทตัดสินใจขั้นตอนสำคัญ เช่น การเลือกนโยบายหลัก การปรับถ้อยคำเชิงนิติศาสตร์ และการอนุมัติขั้นสุดท้าย โดยทุกการเปลี่ยนแปลงถูกเก็บใน audit log
- Red‑teaming: ทีมภายในและภายนอกจะจำลองกรณีใช้งานที่ก่อให้เกิดความเสี่ยง (เช่น loopholes, ambiguous wording, cross‑jurisdiction conflicts) เพื่อนำมาปรับปรุงโมเดลและกฎการตรวจสอบ
- Automated validation suites: ชุดการทดสอบอัตโนมัติรันเพื่อเช็กความสอดคล้อง (syntactic/legal grammar checks), ความขัดแย้งกับกฎหมายที่มีอยู่, การอ้างอิงข้ามมาตรา และ integrity ของ citation links
- Immutable audit log & cryptographic integrity: ทุกเหตุการณ์สำคัญ (retrievals, drafts, reviews, approvals) ถูกบันทึกในรูปแบบ append‑only พร้อมแฮชเชื่อมโยง (เช่น Merkle tree) เพื่อให้ตรวจสอบความถูกต้องของประวัติการแก้ไขได้ในภายหลัง
- Access control & provenance transparency: สิทธิการเข้าถึงข้อมูลและฟังก์ชันการแก้ไขถูกจัดการด้วยนโยบาย IAM ระดับองค์กร และผู้มีส่วนได้เสียสามารถเรียกดู provenance trail เพื่อยืนยันแหล่งที่มา
โดยสรุป สถาปัตยกรรมแบบโมดูลของ Regulation‑LLM ที่ผสาน LLM ขั้นสูงกับ retriever แบบผสมและระบบ provenance tracker เชื่อมโยงกลับสู่เอกสารต้นฉบับ ทำให้ระบบไม่เพียงลดเวลาการร่าง แต่ยังรักษามาตรฐานการอ้างอิงและความโปร่งใสผ่านการบันทึกเมตาดาต้าและการตรวจสอบจากมนุษย์และเครื่องมืออัตโนมัติ ซึ่งเป็นหัวใจสำคัญของการนำ AI มาใช้งานในกระบวนการออกกฎหมายอย่างรับผิดชอบ
ผลลัพธ์เชิงปริมาณ: ลดรอบการออกกฎใหม่ 60%
ผลลัพธ์เชิงปริมาณ: ลดรอบการออกกฎใหม่ 60%
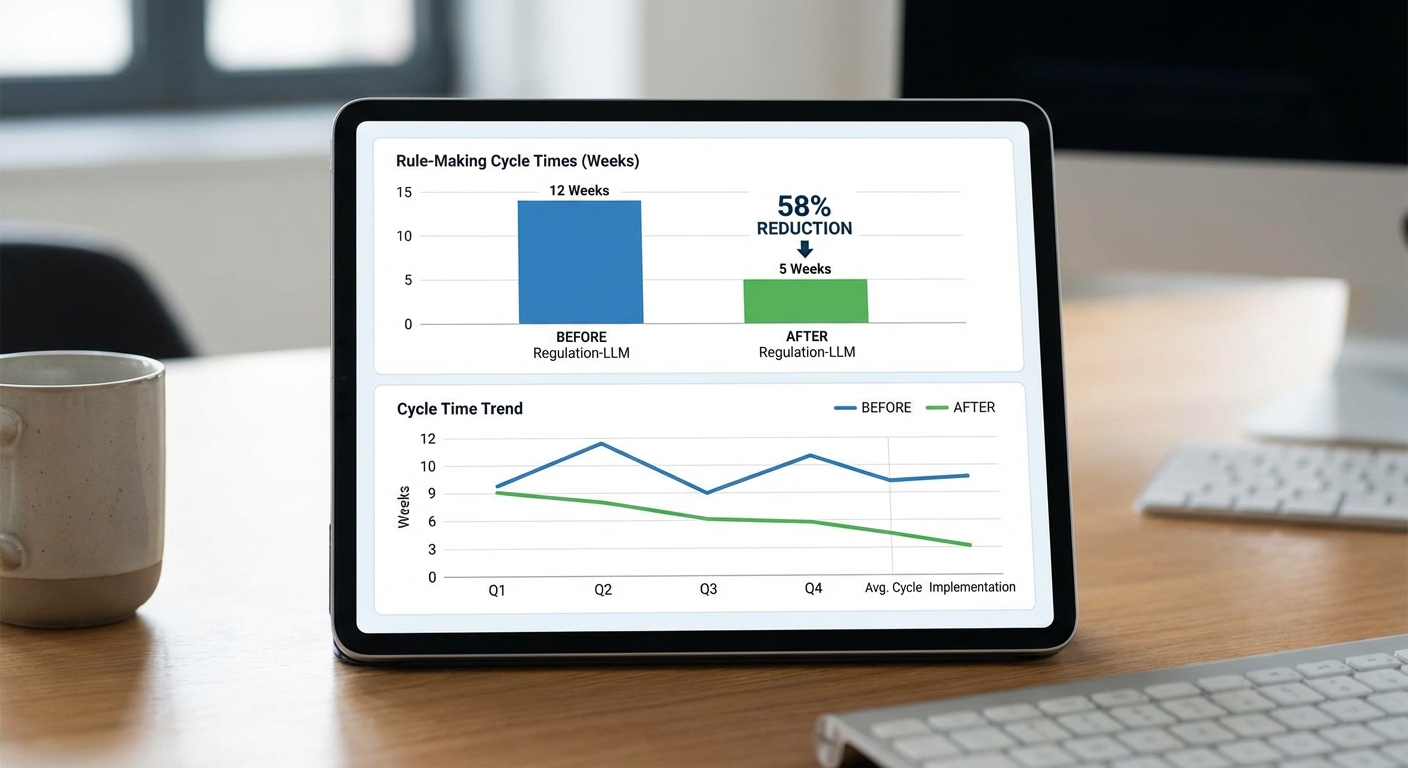
จากการทดลองเชิงนโยบายของกระทรวงกับระบบ Regulation‑LLM ในระยะเวลา 6 เดือน (n = 120 กระบวนการร่างกฎใหม่) พบว่ารอบการออกกฎตั้งแต่การริเริ่มร่างจนถึงร่างสุดท้ายลดลงจากเฉลี่ย 150 วัน เหลือ 60 วัน คิดเป็นการลดลง 60% (การลดลงเฉลี่ย 90 วัน; p < 0.01 เมื่อเทียบกับชุดข้อมูลก่อนทดลอง โดยใช้การทดสอบ t-test ของค่าเฉลี่ยคู่ตัวอย่างและการวิเคราะห์ bootstrap สำหรับค่าความเชื่อมั่น 95%) การตีความเชิงสถิติชี้ว่าเหตุการณ์นี้มีความแตกต่างเชิงสาระสำคัญ ไม่ใช่ความแปรปรวนแบบสุ่ม และผลลัพธ์มีความคงตัวเมื่อแบ่งกลุ่มตามประเภทกฎ (เชิงเศรษฐกิจ/เทคนิค/การคุ้มครองผู้บริโภค)
เมตริกสำคัญที่วัดได้จากการทดลองมีดังนี้:
- เวลาเฉลี่ยจากการริเริ่มร่างถึงร่างสุดท้าย: ลดจาก 150 วัน เป็น 60 วัน (−60%)
- จำนวนร่างที่ผลิต/พิจารณาต่อเดือน: เพิ่มจาก 2.0 เป็น 5.0 ฉบับ/เดือน (+150%) เนื่องจากรอบเวลาสั้นลงทำให้สามารถเปิดร่างใหม่ได้บ่อยขึ้น
- จำนวนรีวิวเฉลี่ยต่อร่าง: ลดจาก 6 รอบ เหลือ 2 รอบ (−66%) — วัดจากจำนวนครั้งที่ร่างถูกส่งกลับเพื่อแก้ไขก่อนการลงนาม
- ความแม่นยำของการอ้างอิงแหล่งอ้างอิง (citation accuracy): เพิ่มจาก 75% เป็น 92% (วัดจากการตรวจสอบโดยทีมกฎหมายภายใน: อ้างอิงตรงกับมาตรา/พ.ร.บ./ข้อบังคับที่ถูกต้อง)
- อัตราการยอมรับของหน่วยงานภายนอก (stakeholder acceptance rate): เพิ่มจาก 68% เป็น 85% โดยประเมินจากการสำรวจความพึงพอใจและสรุปความคิดเห็นหลังการรับฟัง
ตัวอย่างเคสเปรียบเทียบก่อนและหลังใช้ LLM (ย่อเพื่อความกระชับ):
-
ก่อนใช้ LLM — ร่างต้นฉบับ (ตัดตอน):
"หน่วยงานต้นสังกัดจะต้องดำเนินการตรวจสอบและรายงานผลต่อรัฐมนตรีภายในระยะเวลาอันสมควร โดยให้คำนึงถึงบทบัญญัติที่เกี่ยวข้องทั้งหมดและจัดให้มีการประชุมผู้มีส่วนได้ส่วนเสียหากจำเป็น"
-
หลังใช้ Regulation‑LLM — ร่างปรับปรุง (ตัดตอน):
"หน่วยงานต้นสังกัดต้องส่งรายงานการดำเนินการต่อรัฐมนตรีภายใน 30 วัน นับแต่วันที่ได้รับหนังสือมอบหมาย รายงานต้องระบุมาตรการที่ปฏิบัติจริงโดยอ้างอิงมาตรา 12 (พ.ร.บ.ตัวอย่าง พ.ศ. xxxx) และแนบบันทึกการประชุมผู้มีส่วนได้ส่วนเสียเมื่อมีการปรึกษา"
การเปรียบเทียบข้อความข้างต้นแสดงให้เห็น 3 ปัจจัยที่ส่งผลต่อการลดรอบอย่างชัดเจน: (1) ภาษาที่เป็นมาตรฐานและระบุกรอบเวลาเชิงปฏิบัติได้ ซึ่งลดข้อสงสัยและรอบแก้ไข (2) การฝังการอ้างอิงเชิงบริบทไปยังมาตรา/กฎหมายที่เกี่ยวข้องโดยตรง ช่วยลดเวลาตรวจสอบแหล่งอ้างอิง และ (3) การได้รูปแบบคำชี้แจงที่สอดคล้องกับแบบฟอร์มทางราชการ ทำให้ขั้นตอนการลงนามและจัดเก็บเอกสารเร็วขึ้น
วิเคราะห์ต้นตอของการลดลง 60%: เมื่อลงลึกเป็นองค์ประกอบของระยะเวลารวม (ต้นฉบับ = 150 วัน) พบการแจกแจงโดยประมาณดังนี้ (ค่าเป็นค่าเฉลี่ยเชิงพรรณนา):
- ขั้นตอนร่างเนื้อหา (Drafting): เดิม 60 วัน → หลังใช้ LLM 18 วัน (ลด 70%, ประหยัด 42 วัน) — LLM สร้างโครงร่างและภาษามาตรฐานได้ทันที
- วงรอบการตรวจ/แก้ไขภายใน (Internal reviews): เดิม 50 วัน → หลังใช้ 15 วัน (ลด 70%, ประหยัด 35 วัน) — ลดจำนวนรีวิวและเวลารอผู้ตรวจสอบ
- การรับฟังความคิดเห็นภายนอก/การปรึกษา (Stakeholder consultation): เดิม 25 วัน → หลังใช้ 20 วัน (ลด 20%, ประหยัด 5 วัน) — LLM ช่วยสรุปประเด็นเชิงเทคนิคและจัดประเด็นเชิงถามตอบเพื่อให้การรับฟังมีประสิทธิผลขึ้น
- การจัดรูปแบบสุดท้ายและการอ้างอิง (Finalization & citations): เดิม 15 วัน → หลังใช้ 7 วัน (ลด 53%, ประหยัด 8 วัน) — ระบบช่วยเติมฟุตโน้ต/อ้างอิงแบบมีแทร็กและแบบฟอร์มที่รองรับการลงนามอิเล็กทรอนิกส์
รวมการประหยัดเวลาทั้งหมด = 42 + 35 + 5 + 8 = 90 วัน (จาก 150 วัน เหลือ 60 วัน) — นี่คือที่มาของตัวเลขลดรอบ 60% โดยสามารถสรุปเชิงกลไกได้ว่า Regulation‑LLM ไม่ได้ลดเวลาจากขั้นตอนใดขั้นตอนหนึ่งเพียงอย่างเดียว แต่ลดทั้งระยะเวลาการสร้างเนื้อหา การทวนสอบ และการจัดเอกสารซึ่งมีผลรวมทำให้รอบการออกกฎสั้นลงอย่างมีนัยสำคัญ
ข้อสังเกตเพิ่มเติม: แม้จะมีการเพิ่มอัตราการยอมรับและความแม่นยำของการอ้างอิง แต่หน่วยงานยังต้องรักษาการตรวจสอบโดยผู้เชี่ยวชาญด้านกฎหมาย (human-in-the-loop) เพื่อควบคุมความเสี่ยงเชิงนโยบายและเชิงจริยธรรม การทดลองยังชี้ว่าแผนการฝึกอบรมผู้ใช้งาน การกำหนดกฎการตรวจสอบอัตโนมัติ และการบันทึกแทร็กการอ้างอิงเป็นปัจจัยสำคัญที่ทำให้ผลลัพธ์คงอยู่ได้ในระยะยาว
กรณีศึกษา: ตัวอย่างการร่างกฎหมายและการติดตามแหล่งอ้างอิง
กรณีศึกษา: ตัวอย่างการร่างกฎหมายและการติดตามแหล่งอ้างอิง
โครงการนำร่องของกระทรวงที่ทดสอบระบบ Regulation‑LLM แสดงให้เห็นการลดรอบการออกกฎใหม่ได้ถึง 60% จากการใช้โมดูลร่างข้อกฎหมายอัตโนมัติที่ฝังการอ้างอิงแบบแทร็กได้ (traceable citations) โดยในรอบนำร่อง 6 เดือน มีชุดร่างข้อบังคับ 42 ชุดที่ผ่านการร่างเบื้องต้นโดยระบบ ก่อนเข้าสู่กระบวนการพิจารณาภายใน ซึ่งช่วยลดเวลาที่ต้องใช้ในการค้นหาเอกสารและจับคู่ข้อความอ้างอิงได้อย่างมีนัยสำคัญ
ตัวอย่างข้อความ clause ที่ระบบสร้างขึ้นสำหรับร่างกฎหมายด้านคุ้มครองข้อมูลส่วนบุคคล (ตัวอย่างเชิงสาธิต):
ข้อ 12 (การแจ้งเหตุละเมิดข้อมูล)
"ผู้ประกอบกิจการต้องแจ้งเหตุละเมิดข้อมูลส่วนบุคคลต่อเจ้าหน้าที่กำกับภายในเจ็ดวันนับแต่วันที่ทราบเหตุ โดยในประกาศแจ้งต้องระบุลักษณะข้อมูลที่ได้รับผลกระทบ, จำนวนผู้ได้รับผล และแนวทางการบรรเทาความเสี่ยง"
แหล่งอ้างอิง: มาตรา 9 วรรค 2 (คลิก), คำพิพากษา ศาลปกครองที่ 45/2564 วรรค 3 (คลิก), รายงานเชิงนโยบาย สำนักงานคุ้มครองฯ 2023 หน้า 14–17 (คลิก)
ในตัวอย่างข้างต้น แต่ละคำอ้างอิงที่ระบุไว้เป็นรายการที่สามารถคลิกเพื่อเปิดแทร็กแหล่งที่มาได้ (ในอินเทอร์เฟซของระบบผู้ใช้จะเห็นปุ่มคลิกบนคำว่า "คลิก") เมื่อคลิกแล้วจะแสดงรายละเอียดของแหล่ง ได้แก่ชิ้นข้อความต้นฉบับ (วรรค/มาตรา), เลขที่เอกสาร, เวลา/วันที่เข้าถึง, ผู้ให้บริการเอกสาร และคะแนนความมั่นใจของการแมปข้อความ (เช่น Confidence: 92%)
ตัวอย่าง provenance trail ที่ระบบจัดเก็บสำหรับการอ้างอิงหนึ่งรายการประกอบด้วย:
- ID แหล่งที่มา: DOC-2023-CP-0145
- ประเภทเอกสาร: พระราชบัญญัติ / คำพิพากษา / รายงานวิชาการ
- ตำแหน่งข้อความต้นฉบับ: มาตรา 9 วรรค 2
- ข้อความต้นฉบับ (extracted snippet): "ผู้ควบคุมข้อมูลต้องแจ้ง..."
- เวลาที่สกัดข้อมูล: 2025-11-03T09:24:12Z
- อ้างอิงผู้ให้ข้อมูล: หน่วยงานราชการ X / สำนักข่าว Y
- คะแนนความตรงกัน (similarity): 0.92 (92%)
- รหัสตรวจสอบ (provenance hash): a3f4...9c2b
เมตา‑ข้อมูลเหล่านี้ช่วยให้เจ้าหน้าที่สามารถ "ย้อนตรวจสอบ" (trace back) ได้โดยตรงถึงประโยค/มาตรา/คำพิพากษาที่ระบบใช้เป็นฐานข้อมูล ทั้งยังเก็บประวัติการแก้ไขของข้อร่างและบันทึกความคิดเห็นของผู้เชี่ยวชาญเพื่อความโปร่งใสและตรวจสอบได้ตามกรอบรับรองของโครงการ
ความคิดเห็นและคำติชมจากเจ้าหน้าที่ที่ทดลองใช้ระบบมีดังนี้:
- "การที่ระบบแสดงวรรคมาตราและคำพิพากษาที่เชื่อมโยงโดยตรง ช่วยประหยัดเวลาในการตรวจสอบเอกสารพื้นฐานได้มาก — ลดขั้นตอนค้นหาลงกว่า 70% ในงานของผม" — ผู้ร่างกฎหมายอาวุโส, กองนโยบาย
- "ฟีเจอร์ provenance trail ทำให้การอธิบายที่มาของคำวินิจฉัยในที่ประชุมทางกฎหมายชัดเจนขึ้น และช่วยให้คณะทำงานไว้วางใจผลลัพธ์มากขึ้น" — ผู้อำนวยการฝ่ายวินัยทางกฎหมาย
- "ยังต้องปรับจูนการแมปบริบทในบางกรณี เช่น ข้อความของคำพิพากษาที่มีการตีความหลายรูปแบบ แต่โดยรวมเป็นเครื่องมือที่เพิ่มประสิทธิภาพอย่างเห็นได้ชัด" — นักวิเคราะห์นโยบาย
สรุปได้ว่า กรณีศึกษานี้แสดงตัวอย่างเชิงปฏิบัติที่ชัดเจนว่า การผสานความสามารถร่างข้อกฎหมายของ LLM เข้ากับระบบติดตามแหล่งอ้างอิงแบบมีโพรเวแนนซ์ สามารถย่นระยะเวลาในการร่างและตรวจสอบกฎระเบียบได้อย่างมีนัยสำคัญ พร้อมสร้างหลักฐานเชิงตรรกะที่เพียงพอสำหรับการตรวจสอบย้อนหลังและการรับรองความโปร่งใสตามกรอบของกระทรวง
กรอบรับรองความโปร่งใสและการตรวจสอบ
กรอบรับรองความโปร่งใสและการตรวจสอบ
กรอบรับรองความโปร่งใสที่กระทรวงเสนอมีเป้าหมายเพื่อสร้างความเชื่อมั่นต่อสาธารณะและผู้กำหนดนโยบาย โดยอาศัยหลักการบันทึกต้นทางข้อมูล (provenance) ที่เป็นมาตรฐาน ตรวจสอบได้ และสามารถตรึงข้อมูลเชิงบริบทของการตัดสินใจที่เกิดจากระบบ Regulation‑LLM ได้อย่างครบถ้วน กรอบนี้กำหนดให้ระบบต้องเก็บและเผยแพร่เมตาดาต้าหลักอย่างน้อย เช่น หมายเลขเวอร์ชันของโมเดล, แหล่งที่มาของชุดข้อมูล, ขั้นตอนการทำความสะอาดข้อมูลและการแปลง, เทมเพลตคำสั่ง (prompt templates), สถิติเควอลิตี้ (confidence scores, uncertainty estimates), บันทึกการแก้ไขโดยมนุษย์ และ แสตมป์เวลา (timestamps) พร้อมผู้ปฏิบัติงาน เพื่อให้การตรวจสอบย้อนหลังเป็นไปได้อย่างชัดเจนและมีความน่าเชื่อถือ
มาตรฐานการบันทึก provenance อ้างอิงแนวทางสากล (เช่น W3C PROV) และเสริมด้วยข้อกำหนดเชิงปฏิบัติ เช่น การลงลายมือชื่อทางคริปโตกราฟีสำหรับบันทึกสำคัญ การจัดเก็บแบบ immutable audit logs (อาจใช้เทคโนโลยี ledger ที่เหมาะสม) และรูปแบบเมตาดาต้าแบบ machine‑readable ที่สาธารณะสามารถเข้าถึงได้ผ่านพอร์ทัลของรัฐ ตัวอย่างช่องข้อมูลเมตาดาต้าที่ต้องเปิดเผย ได้แก่:
- Source lineage — ต้นทางของข้อมูล (URL, ข้อตกลงการอนุญาตใช้งาน)
- Preprocessing and augmentation — รายการขั้นตอนการเตรียมข้อมูลและสัดส่วนข้อมูลที่ถูกดัดแปลง
- Model provenance — สถาปัตยกรรม, น้ำหนัก (hash), การฝึกซ้ำ, และ checkpoints ที่สำคัญ
- Human‑in‑the‑loop records — ใครแก้ไข อะไร และเหตุผลในการแก้ไข
- Validation and evaluation logs — ผลการทดสอบความแม่นยำ ความเที่ยงธรรม และความทนทาน (robustness)
ในด้านการรับรอง (certification) กระทรวงกำหนดกรอบการตรวจสอบหลายชั้นประกอบด้วยการทดสอบภายใน (self‑audit), การตรวจสอบโดยบุคคลที่สามที่ได้รับการรับรอง (third‑party audit) และการประเมินโดยหน่วยงานอิสระที่มีอำนาจออกใบรับรองตามระดับความเสี่ยง ตัวอย่างมาตรการได้แก่:
- การตรวจสอบเชิงเทคนิค (technical audit) — ตรวจสอบโค้ด ตรวจสอบกระบวนการฝึกและบันทึก provenance รวมถึงการยืนยันความสมบูรณ์ของบันทึกผ่าน hashing/chain of custody
- การประเมินด้านจริยธรรมและความลำเอียง (bias and fairness audit) — ทดสอบผลกระทบต่อกลุ่มประชากรต่าง ๆ และมาตรการแก้ไขการลำเอียง
- การทดสอบความเป็นส่วนตัว (privacy assessment) — ตรวจสอบการบรรลุเป้าหมายเช่น differential privacy, การป้องกันการสกัดข้อมูลส่วนบุคคลจากโมเดล
- การทดสอบความปลอดภัย (red‑teaming / adversarial testing) — ตรวจสอบช่องโหว่และความเสี่ยงต่อการละเมิดหรือใช้งานผิดวัตถุประสงค์
การรับรองแบ่งเป็นระดับ (เช่น Baseline, Enhanced, Critical) ตามความเสี่ยงของการใช้งานและลักษณะข้อมูลที่เกี่ยวข้อง โดยโมเดลหรือชุดข้อมูลที่ผ่านการรับรองจะได้รับ ใบรับรองดิจิทัล พร้อมเมตาดาต้าเชิงสรุปที่เผยแพร่ต่อสาธารณะ ในขณะเดียวกันรายการผลการตรวจสอบฉบับเต็มจะถูกเก็บรักษาไว้ในระบบที่สามารถตรวจสอบย้อนกลับได้ และหน่วยงานอิสระที่ได้รับการแต่งตั้งมีสิทธิเข้าถึงบันทึกฉบับสมบูรณ์เพื่อตรวจสอบเป็นระยะ
นโยบายการเปิดเผยข้อมูลออกแบบให้สมดุลระหว่างความโปร่งใสและความมั่นคง โดยกำหนดหลักการว่า เมตาดาต้าที่ไม่ขัดต่อกฎหมายคุ้มครองข้อมูลส่วนบุคคลหรือความมั่นคงแห่งชาติต้องถูกเปิดเผยต่อสาธารณะในรูปแบบที่สามารถอ่านด้วยเครื่องได้ กระทรวงตั้งเป้าหมายเชิงปฏิบัติว่าอย่างน้อย 85% ของฟิลด์เมตาดาต้าจะต้องเปิดเผยเมื่อไม่ขัดกับข้อจำกัดทางกฎหมาย
สำหรับข้อยกเว้นด้านความมั่นคงและข้อมูลที่เป็นความลับเชิงพาณิชย์ กรอบกำหนดกระบวนการที่ชัดเจน: ต้องมีการร้องขอข้อยกเว้นเป็นลายลักษณ์อักษรพร้อมเหตุผลชัดเจน การทบทวนโดยหน่วยงานอิสระ และการออกคำสั่งจำกัดการเข้าถึง (sealed logs) ที่หน่วยกำกับดูแลสามารถเข้าถึงได้เท่านั้น นอกจากนี้ยังรวมถึงมาตรการควบคุมการเปิดเผยในลักษณะ aggregated หรือ redacted เพื่อให้ยังคงความโปร่งใสเชิงสรุปโดยไม่เปิดเผยข้อมูลที่มีความเสี่ยงสูง
สุดท้าย กรอบนี้กำหนดให้มีการรายงานสาธารณะเป็นระยะ (transparency reports) เกี่ยวกับผลการรับรอง การร้องเรียนที่เกี่ยวข้องกับความโปร่งใส และการบังคับใช้บทลงโทษเมื่อพบการละเมิด ซึ่งรวมถึงการเพิกถอนใบรับรอง การปรับปรุงข้อบังคับ และบทลงโทษทางปกครอง เพื่อให้ภาครัฐ ภาคธุรกิจ และประชาชนสามารถติดตามประสิทธิผลของมาตรการได้อย่างต่อเนื่อง
ความเสี่ยง ข้อกังวล และมาตรการบรรเทา
ความเสี่ยง ข้อกังวล และมาตรการบรรเทา
โครงการ Regulation‑LLM ที่นำโมเดลภาษามาช่วยร่างกฎหมายและคำชี้แจงมีศักยภาพในการย่นรอบการออกกฎและเพิ่มความโปร่งใส แต่ก็ต้องเผชิญกับความเสี่ยงเชิงเทคนิคและเชิงกฎหมายที่มีผลกระทบรุนแรงหากไม่ถูกจัดการอย่างเป็นระบบ
ความเสี่ยงเชิงเทคนิค ที่สำคัญได้แก่ hallucination (โมเดลสร้างข้อเท็จจริงหรืออ้างอิงที่ไม่ถูกต้อง) และการเชื่อมโยง citation ผิดพลาด ซึ่งอาจผลักดันให้ร่างกฎหมายหรือคำชี้แจงอ้างมาตรา ข้อบังคับ หรือแหล่งอ้างอิงที่ไม่มีอยู่จริงหรือไม่ตรงบริบท งานวิจัยและการทดสอบภาคปฏิบัติชี้ให้เห็นว่าอัตราการเกิด hallucination แตกต่างกันตามงานและโมเดล (ตัวอย่างคร่าว ๆ อยู่ในช่วงประมาณ 5–30% ในงานบางประเภท) ซึ่งเมื่อรวมกับการอ้างอิงที่ไม่แม่นยำ อาจก่อให้เกิดผลกระทบต่อความถูกต้องของข้อกฎหมาย ความน่าเชื่อถือของหน่วยงาน และความเสี่ยงทางปฏิบัติการของผู้ใช้ปลายทาง
ความเสี่ยงเชิงกฎหมายและจริยธรรม ครอบคลุมเรื่องความรับผิดชอบ (liability) เมื่อระบบผลิตข้อผิดพลาดที่นำไปสู่ความเสียหาย เช่น ข้อความร่างผิดพลาดที่ทำให้เกิดการบังคับใช้ผิดพลาดหรือการตีความกฎหมายผิด ประเด็นอคติ (bias) ในข้อมูลฝึกและการออกแบบโมเดลก็อาจทำให้ผลลัพธ์ลำเอียงต่อกลุ่มประชาชนบางกลุ่ม ส่งผลต่อความยุติธรรมและเปิดช่องให้ถูกฟ้องร้องหรือถูกตรวจสอบจากหน่วยงานกำกับดูแล นอกจากนี้ ยังมีความเสี่ยงด้านความมั่นคงของข้อมูล (data security) และความเป็นส่วนตัวของข้อมูลที่ใช้ฝึกหรืออ้างอิง ซึ่งอาจละเมิดกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA หรือข้อกำหนดการคุ้มครองข้อมูลระหว่างประเทศ
เพื่อบรรเทาความเสี่ยงเหล่านี้ ควรนำมาตรการเชิงเทคนิคและเชิงบริหารมาปรับใช้ควบคู่กัน โดยมีแนวทางพื้นฐานดังนี้
- Human-in-the-loop และการตรวจสอบโดยผู้เชี่ยวชาญ: กำหนด workflow ที่มีการตรวจทานโดยนักกฎหมายที่ได้รับมอบหมายก่อนเผยแพร่ร่างฉบับใด ๆ ใช้กระบวนการสองชั้น (draft → human review → sign‑off) และบังคับใช้เกณฑ์คุณภาพ (acceptance criteria) เช่น ข้อผิดพลาดเชิงข้อเท็จจริงต้องเป็นศูนย์ก่อนออกใช้งานจริง
- Logging, provenance และ versioning: เก็บบันทึกเหตุการณ์แบบไม่แก้ไข (append‑only audit logs) สำหรับอินพุต เอาต์พุต และการตัดสินใจของมนุษย์ พร้อมการลงลายมือชื่อทางดิจิทัลและ hash ของเอกสาร เพื่อให้สามารถย้อนกลับ ตรวจสอบ และคืนค่าระหว่างเวอร์ชันได้ (semantic versioning ของร่างกฎหมายและ metadata ของแหล่งอ้างอิง)
- Validation protocols และ automated cross‑checks: ผนวกการตรวจสอบอัตโนมัติเพื่อยืนยัน citation กับฐานข้อมูลทางกฎหมายที่ได้รับการรับรอง (official gazettes, national law databases) ใช้หลายแหล่งตรวจสอบข้ามกัน (cross‑referencing) และกำหนดเกณฑ์ความเชื่อมั่น (confidence thresholds) ที่ต้องผ่านก่อนยอมรับ citation ใดๆ
- การจัดการความเสี่ยงทางกฎหมาย: จัดให้มีการทบทวนโดยทีมนิติศาสตร์ภายในหรือที่ปรึกษาภายนอกสำหรับผลลัพธ์ที่มีความเสี่ยงสูง ระบุขอบเขตความรับผิดชอบในสัญญา (SLAs, indemnity clauses) และออกนโยบายการรายงานความผิดพลาดแก่ผู้เสียหายและหน่วยงานกำกับดูแลตามกรอบกฎหมาย
- การควบคุมการเข้าถึงและมาตรการความมั่นคงของข้อมูล: ใช้หลักการ least privilege, RBAC, การพิสูจน์ตัวตนแบบหลายปัจจัย (MFA), การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง และการแยกสภาพแวดล้อม (environment isolation) ระหว่างข้อมูลจริงและข้อมูลทดสอบ รวมทั้งกำหนดนโยบาย data retention และ data minimization
- การประเมินอคติและการทดสอบเชิงจริยธรรม: ดำเนินการตรวจวัด fairness metrics เป็นระยะ ประยุกต์การทดสอบ red‑teaming และ scenario‑based testing เพื่อค้นหาอคติที่อาจปรากฏในผลลัพธ์ และแก้ไขผ่านการปรับชุดข้อมูลหรือโมเดล
- มาตรการตอบสนองต่อเหตุฉุกเฉินและการกู้คืน: วางแผน incident response ที่ชัดเจน ระบุขั้นตอน rollback ของร่างกฎหมายที่ผิดพลาด ประกอบกับ KPI เช่น เวลาในการตรวจจับ (time‑to‑detect) เป้าหมายการแก้ไข และการแจ้งเตือนผู้เกี่ยวข้องภายในกรอบเวลาที่กำหนด
สุดท้าย ควรกำหนดตัวชี้วัดการดำเนินงาน (KPIs) และเกณฑ์ยอมรับความเสี่ยง เช่น อัตราข้อผิดพลาดเป้าหมาย (error rate target), เวลาเฉลี่ยในการตรวจสอบต่อร่าง (review time), และระดับความโปร่งใสของ citation ที่ต้องเก็บไว้เป็นหลักฐาน (provenance completeness). การผนวกมาตรการทางเทคนิคกับนโยบายด้านกฎหมายและจริยธรรมอย่างเป็นระบบจะช่วยให้ Regulation‑LLM สามารถลดความเสี่ยงได้จริงจัง ในขณะที่ยังรักษาประสิทธิภาพการย่นรอบการออกกฎตามวัตถุประสงค์
แนวทางการนำไปใช้จริงและคำแนะนำเชิงนโยบาย
แนวทางการนำไปใช้จริงและคำแนะนำเชิงนโยบาย
การขยายผลจากโครงการทดลอง "Regulation‑LLM" สู่การใช้งานระดับชาติจำเป็นต้องมี โรดแมปเชิงปฏิบัติการ ที่ชัดเจน แบ่งเป็น 3 ระยะหลักคือ pilot → scale → institutionalize โดยแต่ละระยะต้องกำหนดเป้าหมาย เวลา งบประมาณ และกลไกประเมินผลที่เป็นรูปธรรม ตัวอย่างระยะเวลารับได้สำหรับหน่วยราชการทั่วไปคือ ระยะ pilot (6–12 เดือน) ระยะ scale (12–24 เดือน) และระยะ institutionalize (24–36 เดือน) โดยตั้งเป้าว่าในระยะ scale จะต้องบรรลุการลดรอบการร่างกฎอย่างต่อเนื่องให้เทียบเท่ากับการทดลองเริ่มต้นซึ่งแสดงผลว่าลดรอบได้ราว 60% สำหรับการติดตามความก้าวหน้า ควรมีเวิร์กช็อปประเมิน 3 เดือนครั้งและรายงานสถานะเป็นรายไตรมาสเพื่อให้ผู้บริหารระดับสูงรับทราบและตัดสินใจเชิงนโยบาย
ขั้นตอนการนำไปใช้ตามโรดแมปควรรวมองค์ประกอบต่อไปนี้ในเชิงปฏิบัติ:
- Pilot: เลือกหน่วยงานต้นแบบ 2–4 แห่งที่มีรูปแบบงานต่างกัน (เช่น การร่างกฎคุ้มครองข้อมูล, กฎการกำกับดูแลสินทรัพย์ดิจิทัล) ดำเนินการทดสอบในสภาพแวดล้อมควบคุม จัดเก็บร่องรอย (provenance) ของแต่ละเอกสาร และเปิดการประเมินโดยผู้เชี่ยวชาญภายนอก
- Scale: ขยายไปยังหน่วยงานระดับภูมิภาค/กระทรวงเพิ่มเติม ปรับกระบวนการตอบรับความคิดเห็นสาธารณะ (public consultation) ผสานระบบเวอร์ชันคอนโทรลกับระบบราชการเดิม และจัดทำคู่มือปฏิบัติการมาตรฐาน (SOP) สำหรับการใช้งาน LLM ในการร่างกฎหมาย
- Institutionalize: กำหนดกรอบกฎหมายหรือระเบียบรองรับการใช้ Regulation‑LLM เช่น ข้อกำหนดด้านการตรวจสอบย้อนกลับ (traceability), การเก็บบันทึกการตัดสินใจเชิงอัลกอริทึม และการบรรจุในงบประมาณประจำปี พร้อมสร้างหน่วยงานหรือทีมกลางที่รับผิดชอบการบำรุงรักษา ความปลอดภัย และการกำกับดูแลเชิงจริยธรรม
การฝึกอบรมและการมีส่วนร่วมของภาคประชาสังคมเป็นหัวใจสำคัญของกระบวนการนี้ ทั้งในมิติทักษะและการยอมรับสาธารณะ ควรออกแบบโปรแกรมการฝึกอบรมแบบหลายชั้น ได้แก่
- หลักสูตรสำหรับผู้บริหาร: เน้นการตัดสินใจเชิงนโยบาย ความเสี่ยงทางกฎหมาย และการกำกับดูแลเชิงยุทธศาสตร์ (4–8 ชั่วโมงต่อหลักสูตร)
- หลักสูตรเชิงปฏิบัติการสำหรับเจ้าหน้าที่ร่างกฎหมาย: เน้นการใช้งานเครื่องมือ การตรวจสอบแหล่งอ้างอิงที่ระบบสร้าง และการแก้ไขเชิงบริบท (20–40 ชั่วโมง พร้อมการรับรองภายใน)
- โปรแกรมพัฒนาความรู้ด้านจริยธรรมและความเป็นส่วนตัว: บังคับให้มีการอบรมภาคบังคับ สำหรับการประเมินผลกระทบข้อมูล (DPIA) และการจัดการข้อมูลเชิงอ่อนไหว
- การมีส่วนร่วมของภาคประชาสังคม: ตั้งคณะกรรมการที่ปรึกษา (CSO Advisory Panel) เปิดเวทีรับฟังความคิดเห็นสาธารณะ จัด hackathon และ sandbox policy เพื่อให้ชุมชนที่ได้รับผลกระทบมีช่องทางตรวจสอบและเสนอปรับปรุง
กลไกกำกับดูแลและการบรรเทาความเสี่ยงต้องออกแบบให้สมดุลระหว่างนวัตกรรมกับความรับผิดชอบ โดยข้อเสนอเชิงนโยบายหลักได้แก่:
- กำหนดมาตรฐาน traceability ของเนื้อหา ให้ระบบระบุแหล่งอ้างอิงที่ใช้ได้อย่างชัดเจน และต้องมีการเก็บล็อกการตัดสินใจอย่างน้อย 5 ปี
- บังคับการตรวจสอบภายนอก (third‑party audit) รายปี และการทดสอบความปลอดภัย (red teaming) ก่อนขยายผลสู่การใช้งานเต็มรูปแบบ
- กำหนดนโยบายความโปร่งใสต่อสาธารณะ เช่น พอร์ทัลสาธารณะที่เผยแพร่สำเนาร่างกฎ พร้อม metadata แสดงแหล่งอ้างอิงและประวัติการแก้ไข
- สร้างข้อบังคับเรื่องการบันทึกการมีส่วนร่วมของมนุษย์ (human-in-the-loop) ในการรับรองร่างกฎหมาย เพื่อป้องกันการพึ่งพาระบบอัตโนมัติเพียงอย่างเดียว
- กำหนดมาตรการคุ้มครองข้อมูลส่วนบุคคลและการคัดกรองข้อมูลฝึกสอน (data governance) ให้สอดคล้องกับกฎหมายคุ้มครองข้อมูล
เพื่อการติดตามผลอย่างมีประสิทธิภาพ ควรกำหนดชุดตัวชี้วัด (KPI) และระดับเป้าหมายที่ชัดเจน ตัวอย่าง KPI ประกอบด้วย:
- ลดเวลาในการร่าง-ออกกฎ (Time-to-Draft): เป้าหมายลดลงร้อยละ 60 ภายใน 12 เดือนหลังจาก pilot สำเร็จ
- อัตราการอ้างอิงที่สามารถตรวจสอบได้ (Traceability Rate): อย่างน้อย 95% ของข้อมูลอ้างอิงในร่างต้องมีแหล่งที่มาที่ตรวจสอบได้
- คุณภาพเชิงเนื้อหา: คะแนนการประเมินโดยผู้เชี่ยวชาญภายนอก ≥ 4/5 สำหรับความถูกต้องและความสอดคล้องกับกรอบกฎหมาย
- ความพึงพอใจของผู้ใช้ภายใน: คะแนน NPS ≥ +40 จากเจ้าหน้าที่ที่ใช้ระบบ
- จำนวนกรณีร้องเรียนทางกฎหมายหรือการท้าทายทางศาล: ต่ำกว่า X กรณีต่อปี (ตั้งเกณฑ์ตามขนาดประเทศและปริมาณการผลิตกฎหมาย)
- อัตราการรับรองบุคลากร: ≥ 80–90% ของเจ้าหน้าที่ที่เกี่ยวข้องต้องผ่านการฝึกอบรมและได้รับการรับรองภายใน 18 เดือน
สุดท้าย ควรกำหนดกระบวนการประเมินผลระยะยาวรวมถึงการทบทวนนโยบายเป็นประจำ เช่น การประเมินผลทุก 12 เดือนโดยคณะทำงานผสม (multi‑stakeholder review) ที่ประกอบด้วยภาครัฐ ภาควิชาการ ภาคธุรกิจ และภาคประชาสังคม เพื่อปรับเกณฑ์ความเสี่ยง เป้าหมาย KPI และมาตรการคุ้มครองให้สอดคล้องกับวิวัฒนาการของเทคโนโลยี การกำกับที่โปร่งใสและการมีส่วนร่วมของประชาชนจะช่วยสร้างความเชื่อมั่นและทำให้การนำ Regulation‑LLM มาใช้เป็นไปอย่างยั่งยืน
บทสรุป
Regulation‑LLM แสดงศักยภาพชัดเจนในการเร่งกระบวนการร่างกฎหมายและการจัดทําคำชี้แจงแบบมีแหล่งอ้างอิงที่สามารถตรวจสอบย้อนกลับได้ โดยการทดลองของกระทรวงรายงานว่าสามารถลดรอบการออกกฎใหม่ได้ถึง 60% ผ่านการสร้างร่างเบื้องต้นที่มีการฝังแหล่งข้อมูลและคำอธิบายเชิงบริบทอย่างเป็นระบบ ผลลัพธ์เหล่านี้ช่วยลดภาระงานซ้ำซ้อน เร่งการทบทวน และเพิ่มความสอดคล้องของเอกสารข้อกฎหมาย แต่การนำไปใช้เชิงปฏิบัติต้องจับคู่กับกรอบการตรวจสอบที่เข้มแข็ง เช่น การบันทึก provenance ที่เป็นมาตรฐาน, ระบบบันทึกเหตุการณ์ (audit log), การตรวจสอบโดยมนุษย์ และกลไกความรับผิดชอบทางกฎหมาย เพื่อป้องกันความผิดพลาด การบิดเบือนแหล่งข้อมูล และการพึ่งพาผลลัพธ์ที่ไม่โปร่งใส
การขยายผลในวงกว้างจำเป็นต้องมีมาตรการเชิงนโยบายและมาตรฐานกลาง ได้แก่ การกำหนดรูปแบบการบันทึก provenance ที่ชัดเจน (metadata ของแหล่งข้อมูล, เวอร์ชันของโมเดล, คิวรีที่ใช้), เกณฑ์การรับรองความโปร่งใสและความน่าเชื่อถือ (certification framework) และการมีส่วนร่วมของผู้มีส่วนได้เสียทั้งภาครัฐ ภาคเอกชน และภาคประชาสังคมเพื่อค้ำประกันความชอบธรรมและความยอมรับทางสังคม ในอนาคต ควรผสานมาตรการเหล่านี้เข้ากับกฎหมายการกำกับดูแลข้อมูลและกระบวนการตรวจสอบอิสระ เพื่อให้เทคโนโลยีช่วยเพิ่มประสิทธิภาพการกำกับดูแลได้อย่างยั่งยืนโดยไม่ลดทอนความโปร่งใสและความรับผิดชอบต่อสาธารณะ



