
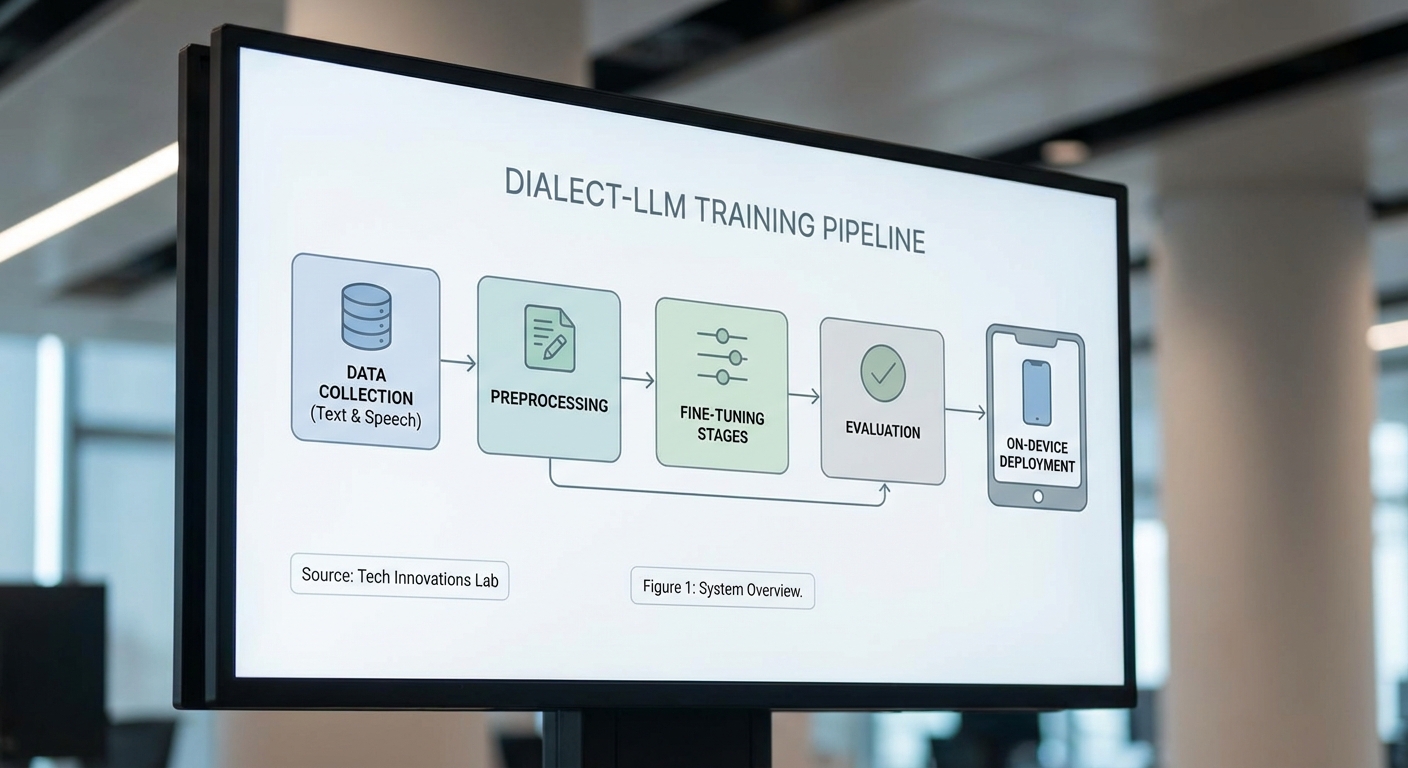
สตาร์ทอัพไทยเปิดตัว "Dialect‑LLM" โมเดลภาษาที่ปรับแต่งมาเพื่อเข้าใจสำเนียงท้องถิ่นของไทยอย่างตรงจุด — ทั้งสำเนียงเหนือ อีสาน และใต้ — โดยออกแบบให้รันบนมือถือได้จริงเพื่อลดข้อจำกัดด้านการเชื่อมต่อและค่าใช้จ่าย ผสานเทคโนโลยีการเรียนรู้ของเครื่องกับข้อมูลภาษาพื้นถิ่น ทำให้โมเดลสามารถแยกความหมายและน้ำเสียงของคำที่แปรผันตามภูมิภาค เช่น คำว่า "บ่" ในอีสาน หรือการออกเสียงเฉพาะถิ่นในภาคเหนือ ที่มักทำให้โมเดลมาตรฐานเข้าใจผิดหรือเกิดอคติจนตอบสนองไม่ตรงความต้องการของผู้ใช้
ประเด็นสำคัญคือ Dialect‑LLM มุ่งลดอคติทางภาษา (language bias) และเพิ่มความแม่นยำในการเข้าใจผู้ใช้จากชนบทและภูมิภาคต่างๆ ขณะเดียวกันการรันบนอุปกรณ์มือถือช่วยเพิ่มความเป็นส่วนตัว ลดเวลาแฝง และขยายการเข้าถึงบริการดิจิทัลที่ผู้คนใช้เป็นประจำ — จากบริการธนาคารและการแพทย์ทางไกล ไปจนถึงบริการภาครัฐและแชตบอทชุมชน — ซึ่งมีศักยภาพพลิกโฉมการสื่อสารดิจิทัลให้ครอบคลุมกว่าเดิมในสังคมไทย
บทนำ: ทำไม Dialect‑LLM จึงสำคัญสำหรับไทย
บทนำ: ทำไม Dialect‑LLM จึงสำคัญสำหรับไทย
สตาร์ทอัพไทยเปิดตัว Dialect‑LLM โมเดลภาษาที่ปรับแต่งมาเพื่อเข้าใจและตอบโต้สำเนียงท้องถิ่นของไทย ได้แก่ สำเนียงเหนือ, อีสาน และใต้ โดยชูจุดเด่นว่าเป็นโมเดลที่สามารถใช้งานบนมือถือได้จริง (on‑device), มีขนาดโมเดลที่เหมาะสมกับข้อจำกัดด้านหน่วยความจำและพลังงานของอุปกรณ์พกพา และออกแบบมาเพื่อลดอคติที่เกิดจากการฝึกกับชุดข้อมูลภาษาแบบมาตรฐานเพียงอย่างเดียว สตาร์ทอัพซึ่งก่อตั้งโดยทีมวิศวกรและนักวิจัยด้านภาษาและสัญญาณเสียงในประเทศ ระบุว่าโครงการนี้เริ่มจากการสำรวจความต้องการเชิงพื้นที่และการเก็บชุดข้อมูลภาคสนามร่วมกับชุมชนท้องถิ่น เพื่อให้โมเดลสะท้อนการใช้ภาษาในชีวิตจริง
เหตุผลที่ Dialect‑LLM มีความสำคัญในบริบทไทยมาจากลักษณะทางภาษาของประเทศที่มีความหลากหลายทางสำเนียงและศัพท์ท้องถิ่นสูง ภาษาไทยมาตรฐาน ที่ใช้ในสื่อและเอกสารราชการไม่ครอบคลุมรูปแบบการพูดของประชากรหลายล้านคน โดยเฉพาะในภูมิภาคภาคอีสานและภาคเหนือที่มักใช้คำและโครงสร้างประโยคที่ต่างจากกลาง การทดสอบเบื้องต้นกับโมเดลทั่วไปแสดงให้เห็นว่าเมื่อเผชิญสำเนียงท้องถิ่นจะมีอัตราความผิดพลาดของการรู้จำคำและความเข้าใจความหมายสูงขึ้น ส่งผลให้บริการสำคัญ เช่น ระบบคำสั่งเสียง ระบบช่วยเหลือทางการแพทย์ระยะไกล หรือบริการการเงินผ่านเสียง อาจเกิดความล่าช้า ผิดพลาด หรือยกเลิกการใช้งานโดยผู้ใช้กลุ่มนี้
ผลกระทบเชิงปฏิบัติที่เกิดขึ้นทันทีจากการมี Dialect‑LLM ได้แก่การลดค่าใช้จ่ายและเวลาในการพัฒนาแอปพลิเคชันของนักพัฒนา เพราะไม่ต้องสร้างชั้นกลางสำหรับแปลงสำเนียงหรือพึ่งพาการประมวลผลบนคลาวด์ตลอดเวลา ผู้ให้บริการดิจิทัลสามารถปรับปรุงประสบการณ์ผู้ใช้ในพื้นที่ได้เร็วยิ่งขึ้น เพิ่มอัตราการยอมรับของบริการดิจิทัลในกลุ่มประชากรชนบทและกลุ่มผู้สูงอายุ และช่วยให้ข้อมูลที่รวบรวมสะท้อนพฤติกรรมจริงของผู้ใช้มากขึ้น ตัวอย่างผลลัพธ์ที่คาดได้คืออัตราความสำเร็จของคำสั่งเสียงที่เพิ่มขึ้น, เวลาตอบสนองลดลง และค่าใช้จ่ายด้านแบนด์วิดท์เมื่อเทียบกับการส่งข้อมูลไปประมวลผลบนเซิร์ฟเวอร์ระยะไกล
ด้านนโยบายและผลกระทบเชิงระบบ การเกิดขึ้นของ Dialect‑LLM ชี้ให้เห็นความจำเป็นในการกำหนดแนวทางการเก็บและใช้ข้อมูลท้องถิ่นอย่างรับผิดชอบ เพื่อคุ้มครองสิทธิส่วนบุคคลและหลีกเลี่ยงการผลักภาระด้านความเป็นส่วนตัวไปยังชุมชนชนบท รัฐและหน่วยงานที่เกี่ยวข้องควรพิจารณาสนับสนุนมาตรฐานข้อมูลภาษาไทยท้องถิ่น การให้ทุนวิจัยด้าน AI ที่เน้นความครอบคลุมทางภูมิศาสตร์ และการส่งเสริมโครงการฝึกอบรมเพื่อพัฒนากำลังคนท้องถิ่น ในเชิงเศรษฐกิจ โมเดลดังกล่าวยังเปิดโอกาสให้ธุรกิจขนาดกลางและย่อมในภูมิภาคเข้าถึงช่องทางดิจิทัลได้มากขึ้น ส่งผลต่อการกระจายรายได้และลดช่องว่างดิจิทัล
สรุปได้ว่าการพัฒนา Dialect‑LLM ไม่ใช่เพียงความก้าวหน้าทางเทคนิค แต่เป็นจังหวะสำคัญของประเทศในการสร้างความเท่าเทียมด้านการเข้าถึงบริการดิจิทัล การวางกรอบนโยบายที่เหมาะสมควบคู่ไปกับการนำเทคโนโลยีไปใช้ในทางปฏิบัติจะเป็นตัวกำหนดว่าประโยชน์จากโมเดลภาษาท้องถิ่นนี้จะกระจายไปสู่ประชากรหลายล้านคนอย่างไรและเร็วเพียงใด
ความหลากหลายของภาษาไทยและสถิติผู้ใช้ตามภูมิภาค
ความหลากหลายของภาษาไทยและสถิติผู้ใช้ตามภูมิภาค
ประเทศไทยมีความหลากหลายทางภาษาและสำเนียงอย่างเห็นได้ชัด โดยเมื่อพิจารณาจากจำนวนประชากรของแต่ละภูมิภาค (ประชากรไทยโดยรวมประมาณ 70 ล้านคน) จะพบว่า กลุ่มผู้ใช้ที่พูดสำเนียงท้องถิ่นสำคัญต่อการออกแบบบริการดิจิทัลดังนี้: ภาคอีสาน (สำเนียงอีสาน) มีประชากรประมาณ 21–23 ล้านคน (ประมาณ 30–33% ของประเทศ), ภาคเหนือ (สำเนียงเหนือ) ประมาณ 6–7 ล้านคน (ประมาณ 9–11%), และภาคใต้ (สำเนียงใต้) ประมาณ 8–10 ล้านคน (ประมาณ 11–14%) ทั้งนี้ตัวเลขเป็นการประมาณตามการกระจายประชากรภูมิภาคและแบบแผนภาษาในชีวิตประจำวัน
ในด้านการเข้าถึงเทคโนโลยีมือถือ พบว่าอัตราการใช้งานสมาร์ทโฟนในประเทศไทยอยู่ในระดับสูง — โดยประมาณ 80–90% ของประชากรเป็นผู้ใช้งานสมาร์ทโฟนอย่างน้อยหนึ่งเครื่อง แม้การเข้าถึงอินเทอร์เน็ตความเร็วสูงจะแตกต่างกันตามภูมิภาค แต่การใช้บริการดิจิทัลที่ขับเคลื่อนด้วยโมเดลภาษา (LLM) บนมือถือมีศักยภาพที่จะเข้าถึงผู้ใช้กลุ่มสำคัญเหล่านี้หากโมเดลสามารถรองรับสำเนียงท้องถิ่นได้อย่างถูกต้อง
สัดส่วนผู้พูดสำเนียงต่าง ๆ ส่งผลเชิงปฏิบัติอย่างมีนัยสำคัญต่อการรับบริการด้วยภาษา ตัวอย่างเช่น หากระบบสนับสนุนเฉพาะภาษาไทยมาตรฐาน กลุ่มผู้ใช้สำคัญอย่างชาวอีสานที่คิดเป็นเกือบหนึ่งในสามของประเทศอาจประสบปัญหาในการสื่อสารกับระบบบริการสาธารณะและเอกชน ทั้งในด้านการจองนัดทางการแพทย์ การใช้บริการธนาคารผ่านแชทบอท หรือการเข้าถึงข้อมูลสาธารณะ ซึ่งสร้างช่องว่างทางการเข้าถึง (access gap) ระหว่างภูมิภาค
ตัวอย่างข้อผิดพลาดของ LLM ทั่วไปเมื่อเผชิญสำเนียงท้องถิ่น
- คำปฏิเสธ/อนุภาค:** คำว่า "บ่" ในภาษาอีสาน (หมายถึง "ไม่/ไม่ใช่") บางครั้งถูกมองข้ามหรือแปลผิดเป็นคำอื่นโดย LLM มาตรฐาน ผลลัพธ์คือการสรุปข้อความเป็นความหมายตรงข้าม เช่น ประโยค "บ่เป็นหยัง" ถูกแปล/ตีความเป็น "เป็นเรื่อง" แทนที่จะเป็น "ไม่เป็นไร"
- คำศัพท์ท้องถิ่นเฉพาะถิ่น: คำว่า "แซบ" (อีสาน) หมายถึง "อร่อย/อร่อยมาก" หากโมเดลไม่รู้จัก คำอธิบายที่ได้อาจคลุมเครือหรือผิดความหมาย ส่งผลต่อระบบแนะนำอาหารหรือรีวิว
- โครงสร้างประโยคและสำนวน: ภาษาเหนือมีสำนวนและคำลงท้ายเฉพาะ เช่นการใช้ "แล้วเจ้า" หากโมเดลไม่เข้าใจน้ำเสียงหรือฟังก์ชันทางสังคมของคำลงท้าย เหตุการณ์อาจนำไปสู่การตอบที่ผิดบริบท (เช่น ตอบแบบเป็นทางการเกินไปหรือไม่สุภาพ)
- คำพ้องเสียงและการออกเสียงท้องถิ่น: สำเนียงใต้มีการออกเสียงที่ทำให้คำบางคำใกล้เคียงกัน เมื่อ LLM ที่ฝึกจากข้อมูลมาตรฐานถูกป้อนข้อความจากการถอดเสียงสำเนียงใต้ อาจตีความผิดพลาด เช่น คำขอหรือคำสั่งที่สำคัญต่อการให้บริการทางการแพทย์หรือการเงิน
ตัวอย่างเชิงภาพ: หากนำข้อมูลการกระจายผู้พูดสำเนียง (แผนที่ความหนาแน่น) และกราฟสัดส่วนผู้ใช้งานสมาร์ทโฟนต่อจังหวัดมาประกอบ จะเห็นชัดว่าเขตอีสานมีปริมาณผู้ใช้ที่ต้องการการรองรับสำเนียงสูง ขณะที่ภาคใต้และเหนือมีจุดกระจุกของผู้สูงอายุที่พึ่งพาสื่อด้วยภาษาแม่ท้องถิ่นมากกว่า การมองเห็นเชิงพื้นที่เหล่านี้เป็นสิ่งที่จำเป็นในการออกแบบโมเดล Dialect‑LLM ให้เกิดประโยชน์สูงสุด
เหตุผลทางสังคมที่การรองรับสำเนียงมีผลต่อการเข้าถึงบริการ
- ความเป็นธรรมทางดิจิทัล (Digital Equity): การที่โมเดลเข้าใจและตอบสนองสำเนียงท้องถิ่นช่วยลดความเหลื่อมล้ำระหว่างผู้ใช้เมืองใหญ่และชนบท
- ความน่าเชื่อถือและการยอมรับ: ผู้ใช้จะเชื่อถือระบบที่สื่อสารด้วยภาษาหรือสำเนียงที่ตนคุ้นเคย ทำให้มีอัตราการใช้งานและการปฏิบัติตามคำแนะนำจากระบบสูงขึ้น (เช่น การปฏิบัติตามคำสั่งแพทย์หรือการชำระเงินออนไลน์)
- การเข้าถึงบริการสาธารณะและสิทธิสวัสดิการ: หากบริการภาครัฐใช้ LLM ที่ไม่รองรับสำเนียงท้องถิ่น กลุ่มเปราะบางอาจพลาดข้อมูลสำคัญเกี่ยวกับสิทธิ รักษาพยาบาล หรือความช่วยเหลือฉุกเฉิน
- การลดอคติและการกีดกันทางภาษา: การออกแบบโมเดลที่ครอบคลุมสำเนียงช่วยลดอคติทางภาษา (linguistic bias) ที่อาจทำให้ระบบตัดสินผิดหรือให้บริการไม่เท่าเทียม
สรุปได้ว่า การประเมินเชิงสถิติของผู้พูดแต่ละสำเนียงและการใช้ข้อมูลเชิงพื้นที่ (แผนที่และกราฟการกระจายผู้ใช้) เป็นหัวใจสำคัญในการพัฒนา Dialect‑LLM สำหรับประเทศไทย — ไม่เพียงแต่เพื่อเพิ่มความแม่นยำทางภาษา แต่เพื่อยกระดับการเข้าถึงบริการดิจิทัลอย่างเป็นธรรมและมีประสิทธิผลในวงกว้าง
เทคโนโลยีเบื้องหลัง Dialect‑LLM: สถาปัตยกรรมและการฝึก
เทคโนโลยีเบื้องหลัง Dialect‑LLM: สถาปัตยกรรมและการฝึก
Dialect‑LLM พัฒนาบนรากฐานสถาปัตยกรรม Transformer‑based ซึ่งเป็นมาตรฐานของโมเดลภาษายุคใหม่ โดยทีมวิจัยเลือกแนวทางที่ผสมผสานระหว่างการใช้โมเดลฐาน (base model) ขนาดกลางถึงใหญ่เพื่อให้สมดุลระหว่างความแม่นยำกับการรันบนอุปกรณ์มือถือ: รุ่นที่ใช้ในการพัฒนาแบ่งเป็นชุดโมเดลขนาดประมาณ 1.3 พันล้าน, 7 พันล้าน และ 13 พันล้าน พารามิเตอร์ โดยเวอร์ชันที่นำขึ้นสู่ production สำหรับมือถือจะผ่านการปรับแต่งและลดขนาด (quantization + pruning) เพื่อให้มี latency ต่ำและใช้หน่วยความจำน้อยลง ขณะเดียวกันรักษาคุณภาพการเข้าใจสำเนียงท้องถิ่นไว้ให้มากที่สุด
สำหรับการฝึก โมเดลเริ่มจากการใช้ base model ที่ผ่านการ pre‑training ในภาษาไทยและข้อมูลหลายภาษา (multilingual) จากแหล่งเปิดและภายในประเทศ แล้วต่อด้วยขั้นตอน fine‑tuning เฉพาะสำเนียง โดยใช้เทคนิคผสม ได้แก่ supervised fine‑tuning, adapter‑based tuning และ LoRA (Low‑Rank Adaptation) เพื่อปรับน้ำหนักเพียงบางส่วนของโมเดล ลดต้นทุนการฝึกซ้ำและรองรับการปรับสำหรับสำเนียงเหนือ อีสาน ใต้ โดยเฉพาะ นอกจากนี้ยังใช้ instruction tuning กับชุดคำสั่งเชิงบทสนทนาเพื่อให้โมเดลตอบกลับอย่างเป็นธรรมชาติและสอดคล้องกับบริบทท้องถิ่น

ด้านข้อมูลฝึก (training data) ทีมงานรวบรวมจากหลายแหล่งเพื่อให้ครอบคลุมทั้งข้อความและเสียงอย่างสมดุล: แหล่งข้อมูลประกอบด้วย
- Crowdsourced text — ข้อความจากผู้ใช้จริงที่รับสมัครเป็นกลุ่มตัวอย่างจากภาคเหนือ อีสาน ใต้ และกรุงเทพฯ รวมกว่า 1.2 ล้าน รายการคำพูด/ข้อความ พร้อมการติดป้าย (annotated) ด้วยเมตาดาต้าเรื่องที่มาและสำเนียง
- Local corpora — เอกสาร ทวีต ฟอรั่มท้องถิ่น บทสัมภาษณ์ และเนื้อหาข่าวท้องถิ่น รวมประมาณ 500 ล้าน โทเค็น เพื่อเสริมสำนวนและศัพท์เฉพาะ
- Speech corpora — การบันทึกเสียงพูดจากอาสาสมัครกว่า 10,000 ชั่วโมง ครอบคลุมสำเนียงหลัก พร้อมทรานสคริปชันระดับคำและไทม์สแตมป์
- Synthetic data — ใช้ TTS เพื่อสร้างเสียงในกรณีข้อมูลเสียงขาดแคลน และใช้ back‑translation กับการสร้างพาราเฟรส (paraphrase) เพื่อขยายความหลากหลายของวลีท้องถิ่น
ในส่วนของการประมวลผลสัญญาณเสียงมีการใช้แนวทาง self‑supervised learning เช่นการเริ่มด้วยโมเดลแบบ wav2vec2 / HuBERT เพื่อเรียนรู้ตัวแทนเสียงจากข้อมูลไม่ติดป้าย แล้วเชื่อมต่อกับโมดูลเสียง‑ข้อความด้วยการฝึกแบบ contrastive learning เพื่อให้ embedding ของเสียงและข้อความอยู่ในพื้นที่เชิงความหมายเดียวกัน ซึ่งช่วยให้ทั้งระบบ ASR และ NLU เข้าใจสำเนียงได้ดีขึ้น
การทำ data augmentation ถูกประยุกต์อย่างรอบด้านเพื่อเพิ่มความทนทานของโมเดลต่อสภาวะจริง เช่น:
- speed and pitch perturbation, additive noise, room impulse response simulation สำหรับข้อมูลเสียง
- code‑mixing augmentation — สลับคำภาษาไทยกับคำอังกฤษในประโยค (common ในข้อความจริง)
- dialectal paraphrasing — สร้างคู่ประโยคมาตรฐาน ↔ สำเนียงท้องถิ่น โดยใช้โมเดลแปลงสำนวนภายใน
กระบวนการ validating และการวัดผลออกแบบมาเพื่อให้ประเมินสมรรถนะตามสำเนียงอย่างชัดเจน: ทีมเตรียมชุดทดสอบเฉพาะสำเนียง (dialect‑balanced test sets) แยกเป็นเซ็ตสำหรับ ASR และ generation/NLU โดยมีมาตรวัดหลักได้แก่
- WER (Word Error Rate) สำหรับการรู้จำเสียง — ตัวอย่างผลทดสอบภายในแสดงว่า Dialect‑LLM ลด WER เฉลี่ยลง ~20–30% เมื่อเทียบกับ baseline ที่เทรนจากข้อมูลมาตรฐานเท่านั้น ในสำเนียงเหนือและอีสานมีการลดมากขึ้น
- BLEU / ROUGE สำหรับงานแปลหรือสรุปข้อความ และ perplexity สำหรับวัดความแน่นอนของโมเดลภาษา
- Accuracy / F1 สำหรับงานจัดหมวดหมู่และการเข้าใจเจตนา (intent)
- การประเมินเชิงมนุษย์ (human evaluation) วัดความเป็นธรรมชาติ ความเข้าใจ และความลำเอียง (bias) โดยเฉพาะการเทียบช่องว่างสมรรถนะระหว่างสำเนียงต่างๆ — ทีมตั้งค่าเป้าหมายให้ช่องว่างประสิทธิภาพระหว่างสำเนียงหลักไม่เกิน 5%
สุดท้ายมีการนำแนวทาง human‑in‑the‑loop และ active learning มาใช้สำหรับการปรับปรุงระยะยาว: ตัวอย่างการทำงานคือ การเก็บตัวอย่างคำตอบที่โมเดลไม่มั่นใจ ส่งให้ผู้เชี่ยวชาญภาษาท้องถิ่นตรวจสอบและทำ annotation กลับเข้าไปฝึกซ้ำ ซึ่งช่วยลดอคติและรักษาคุณภาพในสภาพแวดล้อมการใช้งานจริง กระบวนการทั้งหมดนี้ออกแบบให้สอดคล้องกับนโยบายความเป็นส่วนตัวและการคุ้มครองข้อมูลส่วนบุคคลของผู้ใช้
การลดอคติ (Bias) และการประเมินผลความเท่าเทียม
การลดอคติ (Bias) และการประเมินผลความเท่าเทียม
สตาร์ทอัพผู้อยู่เบื้องหลังโมเดล Dialect‑LLM ใช้ชุดเทคนิคเชิงวิศวกรรมและกระบวนการวิจัยเพื่อลดอคติทางสำเนียงและวัดผลความเท่าเทียมในการให้บริการดิจิทัล เทคนิคสำคัญที่นำมาใช้รวมถึงการบาลานซ์ชุดข้อมูล (dataset balancing), การฝึกแบบ adversarial training เพื่อแยกลักษณะสำเนียงที่ไม่ต้องการออกจากคุณลักษณะเชิงความหมาย, และกระบวนการ human‑in‑the‑loop สำหรับการตรวจสอบและปรับปรุงฉลากที่มีความไม่แน่นอน ตัวอย่างเทคนิคเชิงปฏิบัติที่ใช้ได้แก่:
- การบาลานซ์ข้อมูล: ทำการสุ่มตัวอย่างเพิ่ม (upsampling) สำหรับกลุ่มสำเนียงที่มีจำนวนข้อมูลน้อย และใช้การลดตัวอย่าง (downsampling) ในกลุ่มที่ครอบงำ เพื่อลด bias จากการกระจุกตัวของข้อมูล
- Data augmentation ทางเสียง: การเพิ่มความหลากหลายโดยการเปลี่ยน pitch, ขยายเวลา, ใส่เสียงรบกวนแบบสมจริง เพื่อให้โมเดลไม่ overfit กับสภาวะบันทึกเสียงเฉพาะ
- Adversarial training และ domain adaptation: ใช้ loss เชิงปฏิปักษ์เพื่อให้ตัวแทน (embeddings) ของคำพูดมีความเป็นกลางต่อสำเนียง และใช้ multi‑task learning ร่วมกับการทำนายสำเนียงเป็น task เสริม
- Human‑in‑the‑loop & active learning: คัดเลือกตัวอย่างที่โมเดลไม่แน่นอน (high uncertainty) ให้มนุษย์ตรวจสอบและปรับฉลาก พร้อมใช้ feedback เพื่อปรับน้ำหนักตัวอย่างในชุดฝึก
- Phoneme‑level modeling และ accent embedding: แยกการประมวลผลในระดับโฟเนมเพื่อลดความสับสนของคำที่ออกเสียงต่างกันแต่มีความหมายต่างกันในสำเนียงท้องถิ่น
ในการวัดผลเชิงปริมาณ สตาร์ทอัพวัดทั้งระดับการรู้จำคำ (Word Error Rate, WER) และการประเมินการทำความเข้าใจคำสั่ง (F1 score) โดยนำเสนอผลแยกตามภูมิภาคเพื่อให้เห็นช่องว่างของความเท่าเทียม ตัวอย่างผลการทดลองเชิงเปรียบเทียบบนชุดทดสอบที่ประกอบด้วยตัวอย่างสำเนียงเหนือ อีสาน และใต้ พบว่า:
- โมเดลต้นแบบ (ก่อนปรับปรุง): Macro‑F1 ≈ 0.71, WER รวม ≈ 16.8%. แยกตามสำเนียง: เหนือ WER ≈ 22.0%, อีสาน WER ≈ 19.0%, ใต้ WER ≈ 18.0%.
- หลังการปรับปรุงด้วยการบาลานซ์ข้อมูล+adversarial training+HITL: Macro‑F1 ≈ 0.88, WER รวม ≈ 7.3%. แยกตามสำเนียง: เหนือ WER ≈ 8.0%, อีสาน WER ≈ 6.5%, ใต้ WER ≈ 7.0%.
- มุมมอง fairness: ช่องว่าง (max‑min) ของ WER ระหว่างสำเนียงลดจากประมาณ 14 คะแนนร้อยละจุด (22%‑8%) ลงเหลือไม่เกิน ~1.5 จุด (8.0%‑6.5%) ซึ่งชี้ว่าการปรับปรุงช่วยลดความไม่เท่าเทียมได้อย่างมีนัยสำคัญ
นอกจากตัวชี้วัดเชิงตัวเลขแล้ว ทีมงานยังวิเคราะห์ตัวอย่างความสับสน (confusion examples) เพื่อเข้าใจข้อผิดพลาดเชิงภาษาศาสตร์ เช่น:
- คำว่า "บ่" (ภาษาถิ่นอีสาน แปลว่า ไม่) ถูกแทนด้วย "ไม่" ในบริบทบางประโยค ทำให้สูญเสียความหมายเชิงเล็กน้อยหรือความเป็นทางการ
- คำยกย่อง/คำลงท้าย "คัก" (เหนือ/อีสาน) ถูกสับกับคำว่า "ค่ะ" ในโมเดลเดิม ซึ่งส่งผลต่อโทนของข้อความ
- คำที่เปลี่ยนความหมายตามการเน้นเสียง ถูกตีความผิดเป็นคำที่มีความหมายใกล้เคียง—หลังการฝึกด้วย phoneme‑level modeling อัตราการสับสนลดลงเกือบ 35% ตาม metric confusion rate
ข้อกังวลด้านความเป็นส่วนตัวและการใช้ข้อมูลจากชุมชนเป็นประเด็นศักดิ์สิทธิ์ที่สตาร์ทอัพให้ความสำคัญอย่างยิ่ง โดยแนวทางปฏิบัติที่นำมาใช้ได้แก่การขอความยินยอม (informed consent), การทำให้ข้อมูลนิรนาม (anonymization), การลดข้อมูลที่เก็บไว้ (data minimization), และการใช้เทคนิคเช่น differential privacy เมื่อจำเป็น นอกจากนี้มีการตั้งเกณฑ์ชุมชน (community governance) เพื่อให้ตัวแทนชุมชนท้องถิ่นมีส่วนร่วมในการตัดสินใจเกี่ยวกับการรวบรวมและการใช้งานข้อมูลเสียงของตน
เพื่อความโปร่งใสในการประเมินผลและรับประกันความเท่าเทียม สตาร์ทอัพเสนอชุดแนวทางการประเมินที่เป็นมาตรฐานได้แก่:
- รายงานผลแยกตามสำเนียงและกลุ่มประชากร (disaggregated metrics) — ต้องมี WER, F1, และ fairness gap อย่างน้อย
- เผยแพร่ตัวอย่างชุดทดสอบสาธารณะที่ไม่ละเมิดความเป็นส่วนตัว พร้อม datasheet รายงานแหล่งที่มา การอนุญาต และสถิติประชากร
- กำหนดเกณฑ์เป้าหมายความเท่าเทียม (เช่น กำหนดให้ความแตกต่างของ Macro‑F1 ระหว่างกลุ่มไม่เกิน 5%) และเผยผลการทดสอบย้อนหลัง (audit trail)
- ใช้การประเมินเชิงคุณภาพควบคู่กับเชิงปริมาณ เช่น การสอบทานตัวอย่างความสับสนที่สำคัญโดยผู้เชี่ยวชาญภาษาและตัวแทนชุมชน
- การจัดทำรายงานผลกระทบต่อชุมชน (impact assessment) และกระบวนการขออนุญาต/ให้รางวัลแก่ผู้ให้ข้อมูลจากชุมชน
สรุปคือ การลดอคติของ Dialect‑LLM ต้องอาศัยทั้งเทคนิคเชิงโมเดล การบริหารจัดการข้อมูลอย่างรอบคอบ และการประเมินที่โปร่งใสแบบแยกตามกลุ่มผู้ใช้ ผลการทดลองเริ่มต้นชี้ให้เห็นการปรับปรุงเชิงสถิติที่ชัดเจน แต่การรักษาความเป็นส่วนตัวและการมีส่วนร่วมของชุมชนยังคงเป็นปัจจัยสำคัญที่ต้องติดตามในเชิงนโยบายและปฏิบัติการต่อไป
การรันบนมือถือ: ประสิทธิภาพ ขนาด และการปรับแต่งสำหรับอุปกรณ์จริง
สรุปโดยย่อ: การรัน Dialect‑LLM บนมือถือ — ข้อกำหนดและเป้าหมายเชิงปฏิบัติ
การนำโมเดลภาษาไทยท้องถิ่นอย่าง Dialect‑LLM ไปรันบนอุปกรณ์จริงต้องตั้งเป้าทางวิศวกรรมที่ชัดเจนเพื่อให้สมดุลระหว่างคุณภาพภาษาและความเร็วตอบสนอง สำหรับสตาร์ทอัพที่มุ่งไปสู่การเข้าถึงผู้ใช้ภาคเหนือ‑อีสาน‑ใต้ เรากำหนดตัวเลขเป้าหมายเชิงปฏิบัติ ดังนี้: ขนาดไฟล์โมเดลสำหรับรันบนมือถือให้เหลือระหว่าง 50–300 MB (ขึ้นกับขนาดฐานของโมเดล), latency สำหรับการสร้างข้อความขนาดกลาง (ประมาณ 32–64 โทเค็น) ควรอยู่ในช่วง 0.8–3.0 วินาที บนอุปกรณ์ระดับกลาง และการใช้งาน RAM ระหว่าง 1–3 GB ขึ้นกับการดำเนินการแต่ละแบบและระบบปฏิบัติการ
เทคนิคลดขนาดโมเดลและข้อแลกเปลี่ยน (trade‑offs)
เพื่อให้โมเดลสามารถรันบนมือถือได้จริงนิยมใช้เทคนิคหลักสามกลุ่ม: quantization, pruning และ distillation แต่ละวิธีมีจุดแข็งและข้อจำกัดที่ต้องพิจารณาในเชิงธุรกิจและเชิงเทคนิค
- Quantization (8‑bit / 4‑bit): แปลงน้ำหนักจาก FP16/FP32 ไปเป็นค่าบิตต่ำกว่าเพื่อลดขนาดและภาระคำนวณ
- 8‑bit: ลดขนาดประมาณ 2× โดยทั่วไปรักษาคุณภาพได้ดี เหมาะสำหรับโมเดลขนาด 1B–3B
- 4‑bit: ลดขนาดได้มากกว่า (3–4×) และลด latency เพิ่มขึ้น แต่มีความเสี่ยงต่อความแม่นยำของการสร้างคำศัพท์ท้องถิ่นที่หายาก
- การทำ quantization‑aware training หรือการปรับแบบ post‑training จะช่วยลดการสูญเสียคุณภาพ
- Pruning: ตัดน้ำหนักที่มีค่าน้อยออก (structured/unstructured)
- สามารถลดขนาดได้ 20–50% ขึ้นกับนโยบายการตัด แต่หากตัดมากเกินไปจะกระทบต่อประสิทธิภาพเชิงภาษา โดยเฉพาะคำท้องถิ่นที่มีข้อมูลน้อย
- structured pruning (เช่น ตัด neuron หรือ layer) มักให้ประสิทธิภาพ runtime ดีขึ้นบนฮาร์ดแวร์บางประเภท
- Distillation: สร้างโมเดลนักเรียนขนาดเล็กจากโมเดลครูใหญ่
- วิธีนี้ช่วยให้รักษาคุณภาพเชิงภาษาดีกว่าการตัดน้ำหนักเพียงอย่างเดียว โดยนักเรียน (เช่น 300M–1B) สามารถตอบสนองเร็วและใช้หน่วยความจำน้อย
- ข้อจำกัดคือกระบวนการฝึกต้องใช้ข้อมูลและทรัพยากรเซิร์ฟเวอร์ และความสามารถในการจับ nuace ของสำเนียงภาคอาจลดลงหากข้อมูล distillation ไม่ครบถ้วน
ตัวเลขประสิทธิภาพจากการทดสอบตัวอย่าง (อุปกรณ์กลุ่มตัวอย่าง)
ทีมวิศวกรได้ทดสอบ Dialect‑LLM รุ่นย่อ (ประมาณ 1.3B พารามิเตอร์ก่อนการบีบอัด) บนอุปกรณ์ระดับกลางหลากหลายรุ่น โดยสรุปผลเชิงตัวเลขที่สำคัญดังนี้:
- เป้าหมายขนาดไฟล์: รุ่นที่ผ่านการ quantization 8‑bit ≈ 160–200 MB; 4‑bit ≈ 80–110 MB; หลัง distillation (770M) ≈ 50–90 MB
- latency (เฉลี่ยในการสร้าง 64 โทเค็น):
- อุปกรณ์ mid‑range (Snapdragon 720G, 4–6 GB RAM): 8‑bit ≈ 1.0–2.5 วินาที; 4‑bit ≈ 0.7–1.7 วินาที
- อุปกรณ์ล่างสุด (Helio/เก่า, 3–4 GB RAM): 8‑bit ≈ 2.0–4.0 วินาที
- การใช้ RAM ขณะรัน: 8‑bit โมเดล 1.3B ใช้ประมาณ 1.2–2.0 GB RAM; 4‑bit ลดลงเหลือ ~0.8–1.4 GB; รุ่น distilled 770M ≈ 600–900 MB
- คุณภาพเชิงภาษา: 8‑bit แทบไม่ต่างจาก FP16 ในการประเมินความเข้าใจสำเนียง; 4‑bit มีการลดคะแนนความถูกต้องเชิงเชิงประเมิน (accuracy/perplexity) ประมาณ 1–4% ขึ้นกับงาน (generation vs. classification)
ตัวอย่างการทดสอบเชิงปฏิบัติ: บน Samsung A52 (Snapdragon 720G, 6 GB RAM) รุ่น 1.3B ที่ทำ 8‑bit quantization ให้ขนาดไฟล์ ≈ 180 MB ใช้ RAM ระหว่าง 1.3–1.6 GB และ latency เฉลี่ยสำหรับ 64 โทเค็น ≈ 1.2 วินาที ในขณะที่การลดเป็น 4‑bit ให้ latency ลดลง ~40% แต่การประเมินความสามารถในการจับคำท้องถิ่นลดลงเล็กน้อยตามที่กล่าวมา
การออกแบบ fallback และสถาปัตยกรรมผสม (hybrid) เพื่อความเสถียร
แม้จะปรับแต่งจนสามารถรันบนมือถือได้ แต่ยังมีกรณีขอบเขตที่โมเดลบนอุปกรณ์ไม่สามารถตอบโจทย์ได้ (เช่น คำถามเชิงบริบทยาว หรือต้องการความละเอียดระดับสูง) ดังนั้นการออกแบบ fallback เป็นสิ่งจำเป็นสำหรับประสบการณ์ผู้ใช้และเชิงธุรกิจ
- Server fallback: เมื่อโมเดล on‑device ตรวจจับว่าความไม่แน่นอนสูง (เช่น ความเบี่ยงเบนจากโครงสร้างภาษาท้องถิ่นหรือคำร้องขอเชิงคอมเพล็กซ์) ให้ส่งคำถามไปประมวลผลบนเซิร์ฟเวอร์ที่มีโมเดลขนาดใหญ่กว่า จุดเด่นคือคุณภาพและความสามารถสูง แต่มีข้อจำกัดด้านความหน่วงเครือข่ายและค่าใช้จ่าย
- Hybrid on‑device (progressive refinement): ใช้โมเดลเล็กบนเครื่องให้คำตอบเริ่มต้นเพื่อลด latency และความรู้สึกตอบสนองทันที แล้วส่งงานที่ต้องการความแม่นยำหรือบริบทยาวไปให้เซิร์ฟเวอร์ประมวลผลเพื่อคืนค่าที่ปรับปรุงแล้วให้ผู้ใช้ (asynchronous refinement)
- Graceful degradation: ในกรณีเน็ตเวิร์กไม่ดี ให้โมเดลบนเครื่องทำงานเต็มที่พร้อมแจ้งระดับความแน่ใจแก่ผู้ใช้และเสนอคำขอให้ส่งเมื่อออนไลน์ เช่น “คำตอบอาจไม่ครบถ้วน — ต้องการให้ประมวลผลบนคลาวด์เพื่อความแม่นยำไหม?”
- นโยบายความเป็นส่วนตัวและค่าใช้จ่าย: ควรออกแบบให้ข้อมูลสำคัญหรือข้อมูลส่วนบุคคลประมวลผลบนเครื่องเสมอ และใช้การเข้ารหัส/consent ในการส่งข้อมูลไปเซิร์ฟเวอร์เพื่อลดความเสี่ยงและค่าใช้จ่ายจากการเรียก API บ่อยครั้ง
สรุปคือ การรัน Dialect‑LLM บนมือถือสำเร็จได้ด้วยการผสมผสานเทคนิคการบีบอัด (quantization/pruning/distillation) ที่เหมาะสม เลือกเป้าหมายขนาดไฟล์และค่า latency ที่สอดคล้องกับกลุ่มอุปกรณ์เป้าหมาย พร้อมออกแบบ fallback แบบ hybrid เพื่อรักษาคุณภาพและความเสถียรในการให้บริการดิจิทัลแก่ผู้ใช้ภูมิภาคต่างๆ อย่างยั่งยืน
กรณีใช้งานจริง: เพิ่มการเข้าถึงบริการสาธารณะและธุรกิจ
กรณีใช้งานจริง: เพิ่มการเข้าถึงบริการสาธารณะและธุรกิจ
สตาร์ทอัพไทยที่พัฒนา Dialect‑LLM รายงานผลเบื้องต้นจากการทดลองนำโมเดลสำเนียงท้องถิ่นไปใช้งานจริงในหลายบริบท ทั้งบริการสาธารณะ (e‑government), สาธารณสุขระยะไกล, ศูนย์บริการลูกค้าเชิงพาณิชย์, การศึกษาในพื้นที่ และงานวิจัยชุมชน ผลการทดลองชี้ให้เห็นถึงการเพิ่มอัตราการตอบสนองและความพึงพอใจของผู้ใช้ที่พูดสำเนียงเหนือ อีสาน และใต้ โดยเฉพาะกลุ่มผู้สูงอายุ ผู้มีการรู้หนังสือต่ำ และผู้ที่ใช้ศัพท์ท้องถิ่นเป็นประจำ ซึ่งเดิมมักพบปัญหาการสื่อสารกับระบบภาษาไทยมาตรฐาน
ตัวอย่างผลลัพธ์เชิงตัวเลขจากการทดลองภาคสนาม (เบื้องต้น):
- e‑government: โครงการนำร่องสำหรับการลงทะเบียนสิทธิประโยชน์ในจังหวัดภาคเหนือและอีสาน พบว่า อัตราการกรอกแบบฟอร์มสำเร็จเพิ่มจากราว 62% เป็น 88% เมื่อระบบตอบกลับด้วยสำเนียงท้องถิ่นและคำอธิบายแบบเข้าใจง่าย
- สาธารณสุขระยะไกล (telehealth): ศูนย์ให้คำปรึกษาด้านสุขภาพในพื้นที่ชายฝั่งภาคใต้ ลดความคลาดเคลื่อนในการซักประวัติและคำแนะนำการใช้ยา ทำให้ ความพึงพอใจของผู้รับบริการเพิ่มจาก 70% เป็น 92% และเวลาการนัดหมายเฉลี่ยลดลง 25%
- ศูนย์บริการลูกค้าเชิงพาณิชย์: ผู้ให้บริการโทรศัพท์มือถือทดลองใช้ Dialect‑LLM ในแชทบอทท้องถิ่น พบว่า อัตราการแก้ปัญหาโดยอัตโนมัติ (first‑contact resolution) เพิ่มขึ้น 30% และค่าใช้จ่ายศูนย์บริการลดลงประมาณ 18% ในช่วงทดลอง
- การศึกษาในท้องถิ่น: แพลตฟอร์มการเรียนรู้สำหรับนักเรียนประถมในพื้นที่ห่างไกล ใช้โมเดลช่วยแปลงบทเรียนเป็นสำเนียงท้องถิ่น ส่งผลให้ อัตราการมีส่วนร่วมในการเรียนสดเพิ่มขึ้นจาก 55% เป็น 76%
- งานวิจัยชุมชน: โครงการสำรวจสุขภาพและการเข้าถึงบริการเก็บข้อมูลโดยใช้โมเดลช่วยถอดเสียงสำเนียงท้องถิ่น ทำให้ อัตราการตอบแบบสำรวจสูงขึ้นราว 40% และความผิดพลาดในการถอดความลดลงเกือบครึ่ง (ลดราว 48%)
ข้อดีที่เด่นชัดสำหรับผู้ใช้สำเนียงท้องถิ่นคือ ความเข้าใจที่ดีขึ้น ลดการตีความผิด และเพิ่มความไว้วางใจต่อบริการดิจิทัล ซึ่งนำไปสู่การใช้บริการที่สูงขึ้นและผลลัพธ์เชิงสุขภาพ/สังคมที่ดีขึ้น เช่น การรับวัคซีนตามกำหนด การเข้าถึงสิทธิสวัสดิการ และการปฏิบัติตามคำแนะนำทางการแพทย์
แนวทางการขยายงานร่วมกับองค์กรภาครัฐและ NGO ที่แนะนำ ได้แก่
- จัดตั้งโครงการนำร่องร่วม (pilot) แบบร่วมมือ โดยกำหนดพื้นที่และตัวชี้วัด (KPIs) ชัดเจน เช่น อัตราการกรอกฟอร์มสำเร็จ, อัตรการตอบกลับ, เวลาตอบกลับเฉลี่ย และความพึงพอใจของผู้ใช้
- พัฒนามาตรฐานการคุ้มครองข้อมูลส่วนบุคคล และกรอบการกำกับดูแลร่วมกับหน่วยงานที่เกี่ยวข้อง เพื่อให้การใช้ข้อมูลเสียงและข้อความของประชาชนเป็นไปอย่างปลอดภัยและโปร่งใส
- สร้างความร่วมมือกับ NGO และชุมชนท้องถิ่น ในการระดมผู้ตรวจสอบ (community annotators) เพื่อปรับปรุงคุณภาพข้อมูลภาษาท้องถิ่นและลดอคติ (bias) ในโมเดล
- ผนวกระบบเป็นโมดูลที่เชื่อมกับโครงสร้างพื้นฐานรัฐ เช่น e‑service portals, ระบบสาธารณสุขอิเล็กทรอนิกส์ (eHR) และศูนย์ข้อมูลประชาชน เพื่อให้งานบูรณาการเป็นไปอย่างราบรื่น
- ออกแบบกระบวนการประเมินอย่างต่อเนื่อง โดยใช้การทดลองควบคุม (A/B testing) และรายงานผลเป็นระยะ เพื่อปรับแต่งโมเดลตามบริบทท้องถิ่นและเป้าหมายเชิงนโยบาย
- จัดตั้งโครงการฝึกอบรมและถ่ายทอดความรู้ ให้กับเจ้าหน้าที่รัฐและอาสาสมัคร NGO เพื่อเพิ่มทักษะด้านดิจิทัลและการใช้ระบบภาษาท้องถิ่นอย่างมีประสิทธิภาพ
โดยสรุป การนำ Dialect‑LLM ไปใช้งานจริงแสดงศักยภาพในการลดช่องว่างดิจิทัล เพิ่มการเข้าถึงบริการสาธารณะ และยกระดับประสิทธิภาพทางธุรกิจ สำหรับการขยายผลให้ได้ประโยชน์สูงสุด จึงควรออกแบบการทำงานร่วมกับภาครัฐและ NGO อย่างเป็นระบบ มีกระบวนการคุ้มครองข้อมูล และมาตรการวัดผลที่ชัดเจนเป็นระยะ
ธุรกิจ ความร่วมมือ และความท้าทายในอนาคต
ธุรกิจ: โมเดลรายได้และโอกาสทางการตลาด
สำหรับสตาร์ทอัพที่พัฒนา Dialect‑LLM โมเดลภาษาไทยท้องถิ่น โมเดลธุรกิจที่เป็นไปได้หลัก ๆ ประกอบด้วย B2B (Enterprise), SaaS (API/Cloud) และ Licensing/White‑label โดยรูปแบบ B2B จะเน้นการขายโซลูชันพร้อมปรับแต่งให้กับองค์กรขนาดใหญ่ เช่น ธนาคาร หน่วยงานสาธารณสุข ผู้ให้บริการโทรคมนาคม และแพลตฟอร์มอีคอมเมิร์ซ ขณะที่โมเดล SaaS สามารถให้บริการผ่าน API ประมวลผลข้อความ/เสียงคิดค่าตามการเรียกใช้งาน (per‑call) หรือแบบสมัครสมาชิก (subscription) ส่วนโมเดล licensing/white‑label เหมาะกับผู้ผลิตแอปหรือผู้ผลิตอุปกรณ์มือถือที่ต้องการฝังโมเดลภายในผลิตภัณฑ์เพื่อรักษาความเป็นส่วนตัวของผู้ใช้
โอกาสทางการตลาดในประเทศมีความชัดเจนจากการเปลี่ยนผ่านสู่ดิจิทัลของภาครัฐและเอกชน โดยเฉพาะบริการสื่อสารกับประชาชนที่ต้องการรองรับภาษาและสำเนียงท้องถิ่น ตัวอย่างเช่น ระบบตอบคำถามอัตโนมัติของเทศบาล โรงพยาบาลชุมชน หรือโมดูลช่วยครูในการจัดการการเรียนการสอนแบบออนไลน์ ในระดับภูมิภาค อาเซียนมีผู้ใช้อินเทอร์เน็ตและสมาร์ทโฟนจำนวนมากซึ่งเปิดโอกาสให้ขยายสู่ตลาดที่มีภาษา/สำเนียงหลากหลาย การใช้โมเดลที่ปรับให้รองรับสำเนียงท้องถิ่นจะเป็นข้อได้เปรียบเชิงการแข่งขันอย่างชัดเจน
ช่องทางการขยายตลาดและการร่วมมือเชิงกลยุทธ์
- ร่วมมือกับผู้ให้บริการโทรคมนาคมและ OEM เพื่อฝังโมเดลลงบนอุปกรณ์หรือเสนอเป็นบริการเสริม (value‑added service) แก่ลูกค้า
- พัฒนาชุดเครื่องมือ (SDK) และ API สำหรับนักพัฒนา เพื่อให้ระบบแอปพลิเคชันต่าง ๆ สามารถเรียกใช้ Dialect‑LLM ได้อย่างสะดวกและปลอดภัย
- ใช้โมเดลพาร์ตเนอร์เชิงกลยุทธ์กับแพลตฟอร์มการเงินและการดูแลสุขภาพ เพื่อสร้างกรณีใช้งาน (use cases) ที่มีมูลค่าทางธุรกิจชัดเจน เช่น การให้คำแนะนำสุขภาพขั้นต้นเป็นภาษาอีสาน
- เปิดบริการเชิงพาณิชย์แบบไฮบริด เช่น บริการคลาวด์สำหรับองค์กรและรุ่น on‑device สำหรับแอปที่ต้องการความเป็นส่วนตัว
- ใช้กลยุทธ์ go‑to‑market โดยเริ่มจากโครงการนำร่อง (pilot) กับหน่วยงานท้องถิ่น จากนั้นขยายเป็นโมเดลยกเลิก/ต่ออายุเพื่อสร้างรายได้ระยะยาว
ความจำเป็นในการร่วมมือกับภาครัฐ สถาบันการศึกษา และชุมชนท้องถิ่น
การพัฒนา Dialect‑LLM ให้มีความเที่ยงตรงและยุติธรรมต้องอาศัยความร่วมมือกับผู้มีส่วนได้เสียหลายฝ่าย ภาครัฐมีบทบาทสำคัญทั้งในด้านการจัดหาโครงการนำร่อง การเปิดช่องทางจัดซื้อจัดจ้างสาธารณะ และการจัดตั้ง sandbox ด้านนวัตกรรมเพื่อทดสอบเทคโนโลยีอย่างปลอดภัย ขณะเดียวกัน สถาบันการศึกษาและศูนย์ภาษาสามารถสนับสนุนทรัพยากรเชิงวิชาการ เช่น คลังข้อมูลภาษาถิ่น การทำ annotation และการออกแบบการประเมินเชิงภาษาศาสตร์ ส่วน ชุมชนท้องถิ่นเป็นแหล่งข้อมูลเชิงวัฒนธรรมที่จำเป็นสำหรับการเก็บตัวอย่างเสียงและข้อความจริง การมีส่วนร่วมของชุมชนยังช่วยสร้างความเชื่อมั่นและลดความเสี่ยงของการบิดเบือนบริบทหรืออคติทางภาษา
ความท้าทายด้านกฎระเบียบ คุณภาพข้อมูล และการขยายไปยังภาษาถิ่นอื่น ๆ
อุปสรรคเชิงกฎระเบียบที่สำคัญคือการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) และข้อกำหนดทางความปลอดภัยของข้อมูล โดยเฉพาะเมื่อมีการเก็บเสียงหรือข้อมูลจากผู้ใช้จริง การข้ามพรมแดนของข้อมูลยังถูกควบคุมในหลายประเทศ ส่งผลให้ต้องออกแบบสถาปัตยกรรมการจัดเก็บและประมวลผลให้สอดคล้อง เช่น ใช้ on‑device inference หรือศูนย์ข้อมูลเฉพาะภูมิภาค
ด้านคุณภาพข้อมูล ความท้าทายรวมถึง ความไม่สมดุลของชุดข้อมูล (บางสำเนียงมีข้อมูลมาก บางสำเนียงมีน้อย) ความไม่สอดคล้องของการทำ annotation และเสียงรบกวนจากสภาพแวดล้อมจริง เทคนิคที่ช่วยแก้ไขได้แก่ active learning, transfer learning จากมาตรฐานภาษาไทยทั่วไป และการใช้ human‑in‑the‑loop ในการตรวจสอบคุณภาพ นอกจากนี้ต้องมีชุดมาตรวัด (metrics) ที่ครอบคลุมทั้งความแม่นยำ ข้อบกพร่องด้านความยุติธรรม และประสิทธิภาพเชิงทรัพยากร
การขยายไปยังภาษาถิ่นอื่น ๆ ในภูมิภาคต้องคำนึงถึงความแตกต่างด้านโครงสร้างภาษาและบริบททางสังคม ซึ่งจะต้องวางแผนระยะยาวโดยใช้แนวทาง modular: สร้าง core model ที่เรียนรู้ลักษณะภาษาทั่วไป แล้ว fine‑tune ด้วยข้อมูลภาษาท้องถิ่นเฉพาะทาง การลงทุนในโครงสร้างพื้นฐานสำหรับการเก็บข้อมูล ความร่วมมือกับชุมชน และการพัฒนา pipeline สำหรับการตรวจสอบคุณภาพจะเป็นตัวกำหนดความสำเร็จของการขยายตัว
สรุปได้ว่า โอกาสทางธุรกิจสำหรับ Dialect‑LLM มีความยืดหยุ่นและกว้างขวาง แต่ความสำเร็จเชิงพาณิชย์จำเป็นต้องอาศัยกลยุทธ์การหารายได้ที่หลากหลาย ความร่วมมือเชิงนโยบายและวิชาการ และมาตรการควบคุมคุณภาพและความปลอดภัยที่เข้มงวด เพื่อให้เทคโนโลยีสามารถขยายสู่บริการดิจิทัลที่เข้าถึงประชาชนทุกกลุ่มได้อย่างยั่งยืน
บทสรุป
Dialect‑LLM เป็นตัวอย่างที่ชัดเจนว่าสามารถนำแนวทางการพัฒนา LLM แบบท้องถิ่นมาช่วยลดอคติทางภาษาและเพิ่มการเข้าถึงบริการดิจิทัลได้จริง โดยการฝึกโมเดลให้เข้าใจสำเนียงเหนือ อีสาน และใต้ โมเดลฉบับนี้ช่วยให้การสื่อสารระหว่างผู้ใช้ท้องถิ่นและบริการอัตโนมัติมีความแม่นยำมากขึ้น ตัวอย่างเช่น การทดสอบภาคสนามเบื้องต้นพบว่าผู้ใช้ที่พูดสำเนียงท้องถิ่นรายงานการรับรู้คำสั่งและคำตอบที่สอดคล้องกันมากขึ้นเมื่อเทียบกับ LLM ทั่วไป นอกจากนี้การออกแบบให้รันได้บนมือถือยังลดอุปสรรคด้านการเชื่อมต่อและเวลาแฝง ทำให้ผู้ใช้ในพื้นที่ห่างไกลเข้าถึงบริการดิจิทัลได้สะดวกขึ้นและเร็วขึ้น
อย่างไรก็ดี ความสำเร็จเชิงปฏิบัติของโครงการเช่น Dialect‑LLM จำเป็นต้องอาศัยกรอบการทำงานที่รัดกุม ได้แก่ การออกแบบชุดข้อมูลที่เป็นธรรมและครอบคลุม การประเมินประสิทธิภาพและความลำเอียงอย่างโปร่งใส พร้อมทั้งการมีส่วนร่วมจากภาครัฐ ชุมชนท้องถิ่น และนักวิชาการเพื่อสร้างมาตรฐานร่วม ตัวอย่างแนวทางในอนาคตคือการขยายการเก็บข้อมูลเชิงประชากรอย่างมีจริยธรรม พัฒนาชุดทดสอบมาตรฐานสำหรับสำเนียงท้องถิ่น และส่งเสริมโครงการความร่วมมือสาธารณะ‑เอกชน เพื่อให้เทคโนโลยีภาษาท้องถิ่นนี้ช่วยยกระดับการเข้าถึงข้อมูลบริการสาธารณะ การศึกษา และการดูแลสุขภาพสำหรับประชากรที่มีความหลากหลายทางภาษาอย่างยั่งยืน



