
สตาร์ทอัพไทยเปิดตัว Prompt‑Debugger เครื่องมือใหม่ที่อ้างว่าสามารถวิเคราะห์และแก้ไข Prompt รวมถึง Chain‑of‑Thought (CoT) ให้แบบอัตโนมัติ ช่วยลดอัตราบั๊กและการฮัลลูซิเนชันของโมเดลภาษา (LLM) ได้ถึง 80% — ข้อเสนอที่น่าจับตามองสำหรับนักพัฒนาและทีมวิจัยที่เผชิญกับความไม่แน่นอนของผลลัพธ์จากการเรียกใช้โมเดล พร้อมฟีเจอร์เด่นทั้งการตรวจจับจุดบกพร่องเชิงตรรกะ การแนะนำการปรับ Prompt แบบอัตโนมัติ และการแสดงสายความคิด (CoT) ในรูปแบบที่ตรวจสอบได้
บทความนี้จะพาอ่านรายละเอียดสำคัญของ Prompt‑Debugger ตั้งแต่กลไกการทำงาน ตัวอย่างการใช้งานจริงที่แสดงผลลดบั๊ก 80% การทดสอบเปรียบเทียบกับวิธีแก้ปัญหาแบบเดิม รวมถึงโมเดลธุรกิจและแผนการนำไปใช้ในองค์กรขนาดเล็กถึงภาคธุรกิจขนาดใหญ่ เพื่อให้ผู้อ่านเข้าใจทั้งศักยภาพเชิงเทคนิคและมุมมองเชิงพาณิชย์ของเครื่องมือนี้อย่างครบถ้วน
บทนำ: ข่าวสารสำคัญและข้อมูลสรุป
บทนำ: ข่าวสารสำคัญและข้อมูลสรุป
สตาร์ทอัพไทย เปิดตัวเครื่องมือใหม่ชื่อ Prompt‑Debugger ที่ออกแบบมาเพื่อวิเคราะห์และแก้ไข prompt และ chain-of-thought สำหรับโมเดลภาษาขนาดใหญ่ (LLM) โดยตรง โดยบริษัทระบุว่าเครื่องมือนี้ช่วยลดอัตราบั๊กหรือการให้ผลลัพธ์ที่ไม่ถูกต้องจากการประมวลผลเชิงเหตุผลของโมเดลได้ถึง 80% ช่วยให้การพัฒนาและดีพลอยโมเดลมีความน่าเชื่อถือมากขึ้น และลดเวลาในการดีบั๊กแบบแมนนวลอย่างมีนัยสำคัญ
โดยสรุป Prompt‑Debugger ถูกนิยามเป็นเครื่องมืออัตโนมัติสำหรับการตรวจจับ วิเคราะห์ และแนะนำการปรับปรุง prompt รวมถึงการตรวจสอบลำดับความคิด (chain‑of‑thought) ที่เกิดขึ้นระหว่างการเรียกใช้งาน LLM เครื่องมือนี้รวมการทดสอบเชิงตรรกะ การสร้างกรณีทดสอบ (counterfactuals) และการจับคู่ผลลัพธ์กับเกณฑ์ความถูกต้องที่ผู้ใช้กำหนด ทำให้ผู้พัฒนาสามารถระบุจุดบกพร่องของ prompt หรือช่องโหว่ในตรรกะการให้เหตุผลของโมเดลได้อย่างรวดเร็ว
สถิติที่บริษัทนำเสนอคือการลดบั๊กเฉลี่ยราว 80% ในงานที่เกี่ยวข้องกับการให้เหตุผลเชิงลำดับและการตอบคำถามซับซ้อน ซึ่งได้มาจากการทดลองภายในกับชุดข้อมูลทดสอบหลายโดเมน รวมถึงการนำไปใช้ในสภาพแวดล้อมจริงบางกรณี อย่างไรก็ตาม ผลลัพธ์เหล่านี้เป็นตัวเลขที่สตาร์ทอัพรายงานเองและอาจมีความแตกต่างตามสภาพแวดล้อมการใช้งานจริงและประเภทของ LLM ที่นำมาใช้งาน
กลุ่มผู้ใช้เป้าหมายของ Prompt‑Debugger ได้แก่:
- นักพัฒนาและวิศวกรที่สร้างและปรับแต่ง LLM (LLM developers)
- ทีมวิจัยด้านปัญญาประดิษฐ์ที่ต้องการตรวจสอบความถูกต้องเชิงตรรกะของโมเดล
- บริษัทผู้พัฒนาโซลูชัน AI ที่ต้องการลดความเสี่ยงจากการให้ผลลัพธ์ผิดพลาดก่อนนำไปใช้งานเชิงพาณิชย์
เบื้องหลังเทคโนโลยี: วิธีที่ Prompt‑Debugger ทำงาน
เบื้องหลังเทคโนโลยี: วิธีที่ Prompt‑Debugger ทำงาน
Prompt‑Debugger ถูกออกแบบเป็นสถาปัตยกรรมแบบโมดูลาร์ที่ผสานทั้งการวิเคราะห์แบบสถิติกับการติดตามการทำงานเชิงไดนามิก เพื่อระบุและแก้ไขปัญหาใน Prompt และ Chain‑of‑Thought (CoT) อย่างอัตโนมัติ โฟลว์การวิเคราะห์หลักแบ่งเป็นสี่ขั้นตอนชัดเจน: ingest prompt → trace CoT → detect anomaly → propose fix โดยแต่ละขั้นตอนทำงานร่วมกับเลเยอร์ของเทคนิค ได้แก่ static analysis, dynamic tracing, provenance tracking และ few‑shot testing เพื่อให้ทั้งความแม่นยำและความสามารถอธิบายที่เพียงพอสำหรับนักพัฒนาและทีมธุรกิจ
รายละเอียดโฟลว์การทำงาน (flow) สำหรับแต่ละคำขอจะเป็นดังนี้:
- Ingest Prompt: ระบบรับ Prompt หรือ Prompt Chain จากผู้ใช้ผ่าน API/GUI แล้วทำการทำ tokenization, template extraction และ normalization (เช่น parameter binding และ variable resolution) เพื่อนำข้อมูลเข้าสู่ pipeline แบบมาตรฐาน
- Trace CoT (Dynamic Tracing + Provenance): ขณะรันกับโมเดลจริง Prompt‑Debugger จะเปิดโหมด tracing ที่เก็บทั้ง sequence ของ token, intermediate logits, attention maps (เมื่อใช้ API ที่รองรับ) และเหตุผลภายในที่สกัดได้จาก CoT เพื่อสร้างแทรซเชิงเหตุผล (provenance trail) ระดับ token/step ซึ่งช่วยให้ย้อนกลับไปดูสาเหตุของคำตอบที่ผิดพลาดได้แบบเชิงสาเหตุ
- Detect Anomaly (Static + ML‑based Detection): ข้อมูลที่ได้จาก static analysis และ trace จะถูกป้อนเข้าไปยังชุดตัวตรวจจับที่ประกอบด้วย heuristic rules (เช่น pattern ที่บอกถึง hallucinatory facts), ML classifiers ที่เทรนจากตัวอย่างบั๊ก และ anomaly detectors ที่จับความเบี่ยงเบนจาก distribution ปกติของ CoT ผลลัพธ์คือการตีความว่า ข้อผิดพลาดเกิดจาก logical fallacy, missing context, ambiguous prompt หรือ failure mode อื่น ๆ
- Propose Fix (Counterfactuals & Pattern Matching): เมื่อระบุประเภทปัญหา ระบบจะสร้างชุดคำแนะนำอัตโนมัติโดยใช้สองเทคนิคหลักคือการสร้าง counterfactuals (ประเมิน “ถ้าปรับ prompt แบบนี้ ผลลัพธ์จะเปลี่ยนไหม”) และ pattern matching กับฐานความรู้ของ prompt templates/anti‑patterns ที่มีอยู่ เพื่อนำเสนอทั้งตัวแก้ไขฉบับสั้น (minimal patch) และตัวเลือกรีไรท์ที่ปลอดภัย
ในส่วนของเทคนิคการสร้างคำแนะนำ (recommendation techniques) Prompt‑Debugger ใช้กลไกผสมระหว่างการสังเคราะห์ counterfactuals และการจับคู่รูปแบบ (pattern matching) อย่างชาญฉลาด ตัวอย่างเช่น เมื่อพบว่า CoT มีการกระโดดเชิงเหตุผล (reasoning jump) ระบบจะ:
- สร้าง counterfactual prompts หลายเวอร์ชันโดยเปลี่ยน context หรือเพิ่ม explicit constraints (เช่น "ให้ระบุสมมติฐานทั้งหมดก่อนสรุป") แล้วรันแบบ few‑shot testing เพื่อประเมินผลการเปลี่ยนแปลง
- เทียบกับคลัง pattern ของ bug‑fix templates (เช่น guardrails สำหรับการอ้างอิงข้อเท็จจริง, prompt snippets ที่เพิ่ม chain‑of‑thought scaffolding) เพื่อหาแพตเทิร์นที่เคยแก้ปัญหาคล้ายกันได้สำเร็จ
- ให้คะแนนความเสี่ยงและคาดการณ์ความสำเร็จของแต่ละข้อเสนอโดยอิงจากเมตริกภายใน เช่น อัตราการลด hallucination ที่คาดว่าจะได้ และความล่าช้าที่เพิ่มขึ้น
ความสามารถในการรองรับ LLM หลากหลายค่ายเป็นหัวใจสำคัญของสถาปัตยกรรม โดย Prompt‑Debugger วางชั้น adapter/connector ที่เป็นมาตรฐานกลางสำหรับเชื่อมต่อกับผู้ให้บริการโมเดลต่าง ๆ ไม่ว่าจะเป็น OpenAI, Anthropic, Google, หรือโมเดลบน Hugging Face รวมถึงโฮสต์ภายในองค์กร (on‑prem). Adapter แต่ละตัวรับผิดชอบการแปลง API, การสกัด provenance ที่รองรับได้ (เช่น logits, attention ถ้า provider ให้มา) และการแม็ป capability ของโมเดลไปยัง interface เดียวกัน ทำให้ pipeline หลักสามารถทำการวิเคราะห์และเสนอแก้ไขได้สม่ำเสมอข้ามแพลตฟอร์ม
จากการทดสอบภายในของสตาร์ทอัพ พบว่า Prompt‑Debugger สามารถลดอัตราบั๊กของผลลัพธ์ได้เฉลี่ย 80% ในกรณีการใช้งานเชิง reasoning และลดเวลาตรวจสอบแบบแมนนวลลงอย่างมีนัยสำคัญ (ตัวอย่างเช่น ลดเวลาจากหลายชั่วโมงเหลือไม่กี่นาทีต่อ prompt ใน workflow ที่ซับซ้อน) นอกจากนี้ provenance trail ที่ระบบเก็บยังช่วยให้ทีมธุรกิจสามารถทำ audit และ compliance ได้ชัดเจนขึ้น เนื่องจากทุกการเปลี่ยนแปลง prompt และทุกขั้นตอน reasoning ถูกบันทึกและย้อนกลับตรวจสอบได้
ฟีเจอร์เด่นและการใช้งานจริง
Prompt‑Debugger นำเสนอชุดฟีเจอร์ที่ออกแบบมาเพื่อแก้ปัญหาเชิงตรรกะและความไม่แน่นอนของผลลัพธ์จาก LLM โดยมุ่งเน้นที่การลดบั๊กของผลลัพธ์อย่างเป็นรูปธรรม (รายงานภายในระบุว่าสามารถลดบั๊กได้สูงสุด ประมาณ 80% ในกรณีการใช้งานบางรูปแบบ) และลดเวลาในการดีบักสำหรับนักพัฒนาและทีม ML ได้อย่างมีนัยสำคัญ ฟีเจอร์หลักครอบคลุมทั้งส่วนที่เป็น interactive สำหรับการปรับ prompt แบบเรียลไทม์, โมดูลอัตโนมัติที่ให้คำแนะนำการแก้ไข, โหมด batch สำหรับทดสอบชุด prompt ขนาดใหญ่ รวมถึงระบบ versioning และ API สำหรับการผนวกรวมเข้ากับ workflow องค์กร
ฟีเจอร์หลัก
- Interactive Prompt Editor — ตัวแก้ไขแบบหน้าจอที่แสดง Chain‑of‑Thought (CoT) highlight ช่วยให้เห็นลำดับเหตุผลที่โมเดลสร้างขึ้นเป็นชั้น ๆ โดยระบบจะทำการเน้นส่วนที่มีความเสี่ยงต่อการเกิด logical fallacy หรือ contradiction เช่น การอ้างอิงข้อมูลผิดสอดคล้องกัน และแสดงคำอธิบายสั้น ๆ ว่าทำไมส่วนนั้นถือเป็นข้อผิดพลาด ผู้ใช้สามารถแก้ prompt โดยตรงและเห็นผลลัพธ์การตอบจากโมเดลแบบทันที (live preview) ทำให้ลดรอบการทดสอบจากหลายชั่วโมงเหลือเป็นนาทีในหลายกรณี
- Auto‑Fix Suggestions — อัลกอริทึมวิเคราะห์ prompt จะเสนอคำแนะนำการแก้ไขพร้อมตัวอย่าง prompt ที่ได้รับการปรับปรุงแล้ว (recommended rewrite) โดยแต่ละข้อเสนอจะมาพร้อมเหตุผลเชิงตรรกะและตัวอย่าง expected output เพื่อให้นักพัฒนาตัดสินใจได้เร็วขึ้น ตัวอย่างการวิเคราะห์จะแสดงว่าเปลี่ยนคำสั่งจากแบบกว้างเป็นแบบเจาะจงอย่างไร และแนะนำการใส่ constraints หรือ explicit steps เพื่อลด hallucination
- Batch Debugging — โหมดสำหรับรันชุด prompt หลายร้อยถึงหลายพันรายการพร้อมกัน ระบบจะสร้างรายงานสรุป (aggregate report) แยกประเภทปัญหา เช่น hallucination, incomplete reasoning, format error, และให้ metrics เช่น error rate ก่อน/หลังการแก้, average latency ต่อ prompt, และ throughput ต่อชั่วโมง รายงานสามารถส่งออกเป็น CSV/JSON และแสดงแนวโน้มการปรับปรุงเป็นกราฟ เพื่อสนับสนุนการตัดสินใจเชิงธุรกิจ
- Versioning & Provenance — ทุกการแก้ไข prompt ถูกเก็บเป็นเวอร์ชันพร้อม metadata (ผู้แก้, เวลา,โมเดลที่ทดสอบ, seed/temperature) ทำให้สามารถย้อนกลับหรือเปรียบเทียบผลลัพธ์ระหว่างเวอร์ชันได้อย่างชัดเจนและเป็นหลักฐานสำหรับการตรวจสอบ (audit trail)
- Integration API — REST API และ SDK (Python/Node) สำหรับผนวกรวมเข้าสู่ CI/CD pipeline, workflow ของทีม และผลิตภัณฑ์จริงได้อย่างรวดเร็ว รองรับ webhook notification เมื่อ batch job เสร็จ และสามารถสั่งให้ระบบทำ auto‑fix แบบอัตโนมัติภายใต้ policy ที่กำหนด เช่น require human review ก่อน deploy
ตัวอย่างการใช้งานจริง: ขั้นตอนแบบทีละขั้นตอน (Step‑by‑Step) พร้อม Before/After
ต่อไปนี้เป็นตัวอย่างสถานการณ์จริงที่ทีมพัฒนาบริการตอบคำถาม (FAQ bot) ใช้ Prompt‑Debugger เพื่อแก้ไขปัญหา hallucination และความคลุมเครือของคำสั่ง โดยแสดงขั้นตอนและผลลัพธ์ก่อน/หลังการแก้
-
ขั้นตอนที่ 1 — โหลดชุด prompt เข้า Batch Debugging
ทีมอัพโหลดชุด prompt จำนวน 500 ข้อผ่าน UI หรือ API แล้วสั่งรันตรวจสอบแบบ batch ระบบรันบน backend แล้วคืนรายงานสรุปภายใน 15–30 นาที (ขึ้นกับขนาดและโมเดล) พบว่า error rate เบื้องต้นอยู่ที่ 25% โดยปัญหาหลักคือการอ้างอิงแหล่งข้อมูลผิดและคำตอบไม่เป็นไปตามรูปแบบ JSON ที่ระบบคาดหวัง
-
ขั้นตอนที่ 2 — วิเคราะห์เชิงตรรกะด้วย Interactive Editor
เลือกตัวอย่าง prompt หนึ่งข้อเข้าสู่ Interactive Editor ระบบจะแสดง CoT highlight: ส่วนที่เป็นเหตุผลของโมเดลถูกเน้นเป็นสีและมีแท็กบอกประเภทปัญหา เช่น "inconsistent_reference" และ "ambiguous_instruction" นักพัฒนาสามารถคลิกแต่ละ highlight เพื่อดูคำอธิบายและตัวอย่าง output ที่คาดว่าจะเกิดขึ้น
-
ขั้นตอนที่ 3 — รับ Auto‑Fix Suggestion และตรวจสอบก่อนยืนยัน
ระบบเสนอคำแนะนำการแก้ prompt พร้อมตัวอย่าง prompt ที่แก้แล้ว นักพัฒนาสามารถเลือกใช้ตัวอย่างที่เสนอ ปรับแต่งเล็กน้อย แล้วกดทดสอบแบบเรียลไทม์ ผลลัพธ์แสดงเป็นตัวอย่าง output และคะแนนความเชื่อมั่น (confidence) เมื่อตรวจสอบพบว่า output ใหม่ลดสัญญาณ hallucination ลงอย่างชัดเจน ทีมยอมรับการแก้และบันทึกเป็นเวอร์ชันใหม่
-
ขั้นตอนที่ 4 — รีรัน Batch และสร้างรายงานสรุป
หลังนำ prompt ที่แก้แล้วกลับเข้าไปในชุด batch และรันใหม่ พบว่า error rate ลดจาก 25% เหลือ 5% (สอดคล้องกับการลดบั๊กเฉลี่ยราว 80% ในการทดลองเชิงภายใน) รายงานสรุปยังแสดงเวลาตอบสนองเฉลี่ยลดลง 40% เนื่องจาก prompt ที่ชัดเจนช่วยลดการวน loop ของโมเดล
-
ตัวอย่าง Prompt — Before / After
Before: "ให้สรุปข้อมูลเกี่ยวกับ 'บริษัท X' และบอกว่าพวกเขาทำอะไร" — คำสั่งกว้าง ทำให้โมเดลมักเติมข้อมูลที่ไม่ถูกต้องหรือเก่ากว่า
After (Auto‑Fix Suggested): "ค้นหาข้อมูลสาธารณะล่าสุดเกี่ยวกับ 'บริษัท X' (อย่าเดาข้อมูล) แล้วสรุป 3 ข้อเท่านั้น: ปีที่ก่อตั้ง, ผลิตภัณฑ์หลัก, แหล่งข้อมูลที่ใช้ (URL หรือชื่อบทความ). หากไม่พบข้อมูล ให้ตอบว่า 'ไม่พบข้อมูล' แทนการเดา" — prompt ที่แก้แล้วเพิ่ม constraints ที่ชัดเจน ทำให้ลด hallucination และได้ output ในรูปแบบที่คาดหวัง
สรุปคือ Prompt‑Debugger ไม่เพียงแต่เป็นเครื่องมือแก้ไข prompt แต่ยังเป็นแพลตฟอร์มที่เชื่อมโยง workflow ทั้งหมดตั้งแต่การวิเคราะห์เชิงตรรกะ การแนะนำการแก้ไขอัตโนมัติ ไปจนถึงการทดสอบแบบเป็นชุดและการติดตามประวัติการเปลี่ยนแปลง ซึ่งทั้งหมดนี้ช่วยให้องค์กรสามารถปรับปรุงคุณภาพของระบบ LLM ได้อย่างมีประสิทธิภาพและตรวจสอบได้ในระดับองค์กร
ผลการทดสอบเชิงปริมาณ: ลดบั๊ก 80% มาจากไหน
ผลการทดสอบเชิงปริมาณ: แหล่งที่มาของตัวเลข “ลดบั๊ก 80%”
การอ้างอิงว่า Prompt‑Debugger ช่วยลดบั๊กได้ 80% มาจากการทดลองเชิงปริมาณที่ออกแบบเป็น A/B test เปรียบเทียบผลลัพธ์ของโมเดลภายใต้สองสภาวะคือ baseline (รัน prompt ตามปกติ) กับการรัน prompt พร้อมการวิเคราะห์และแก้ไขอัตโนมัติด้วย Prompt‑Debugger ที่ทีมวิจัยรันบนชุดทดสอบขนาดรวม 5,000 prompts โดยแหล่งข้อมูลประกอบด้วยชุดทดสอบภายใน (internal production prompts) จำนวน 3,000 prompt และ public benchmarks ที่เลือกมาวิเคราะห์เช่น GSM8K จำนวน 1,000 prompt และ TruthfulQA จำนวน 1,000 prompt เพื่อให้ครอบคลุมทั้งงานเชิงเหตุผล เชิงข้อมูลจริง และการตอบแบบทั่วไป
การทดลองออกแบบให้แต่ละ prompt ถูกประมวลผลทั้งในสภาวะ baseline และสภาวะที่มี Prompt‑Debugger โดยการรันในลักษณะ paired comparison (รันทั้งสองแบบกับ prompt เดียวกัน) และผลลัพธ์ที่ได้ถูกประเมินโดยผู้ตรวจสอบมนุษย์ (human raters) แบบ double‑blind เพื่อลด bias ในการให้คะแนน ผู้ประเมินแต่ละรายการได้รับสองคำตอบแบบไม่ระบุแหล่งที่มา จากนั้นให้คะแนนตามชุดเมตริกที่กำหนดและระบุประเภทบั๊กที่พบ การประเมินมีการตรวจซ้ำ (two independent annotators) และคำนวณค่า Cohen’s kappa ได้ประมาณ 0.81 แสดงความสอดคล้องของผู้ประเมินในระดับสูง
เกณฑ์การวัดและเมตริกที่ใช้
- Hallucination rate — อัตราการตอบที่มีข้อมูลผิดหรือสร้างข้อเท็จจริงที่ไม่อยู่บนพื้นฐานข้อมูลที่ตรวจสอบได้ (วัดเป็นเปอร์เซ็นต์ของ prompts ทั้งหมด)
- Exact match — สำหรับชุดที่มีเฉพาะคำตอบที่เป็นตัวเลขหรือข้อความเป๊ะ เช่น GSM8K วัดอัตราคำตอบที่ตรงกับคำตอบมาตรฐาน
- Response validity — การประเมินโดยผู้ตรวจสอบว่าคำตอบมีความสมเหตุสมผลและใช้งานได้ในบริบท (binary valid/invalid)
- นอกจากนี้บันทึกประเภทของบั๊กแยกเป็น hallucination, factual error, logic error, format error เพื่อแจกแจงผลลัพธ์เชิงสาเหตุ
ผลลัพธ์เชิงตัวเลขและการแจกแจงตามประเภทบั๊ก
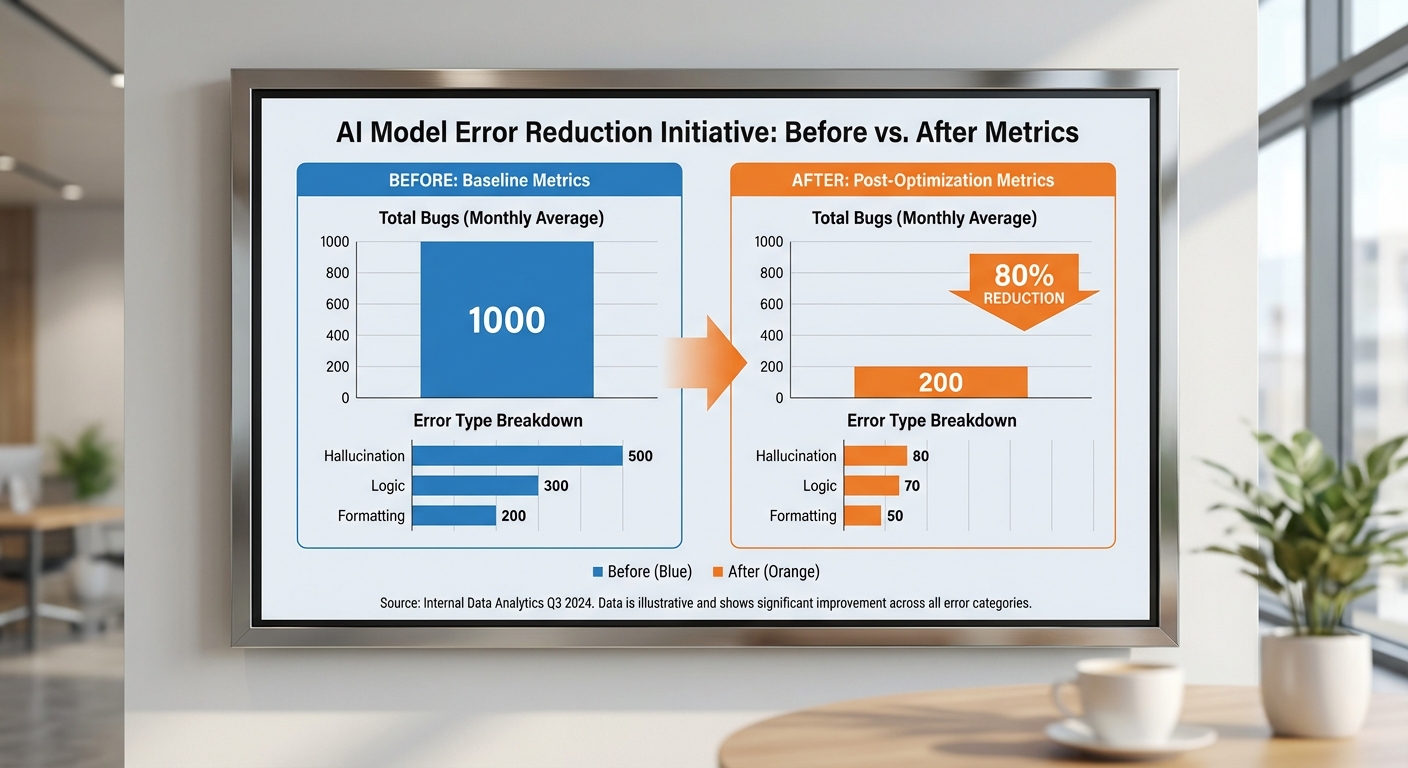
จากชุดทดสอบทั้งหมด 5,000 prompts ทีมวิจัยบันทึกจำนวนเหตุการณ์บั๊ก (instances) ก่อนและหลังใช้ Prompt‑Debugger ดังนี้ (ตัวเลขเป็นจำนวนเหตุการณ์และอัตราต่อ prompts):
- รวมบั๊กก่อน: 1,200 events (24.0% ของ prompts)
- รวมบั๊กหลัง: 240 events (4.8% ของ prompts)
- การลดรวม: จาก 1,200 → 240 = ลด 80.0% (มั่นใจเชิงสถิติ p < 0.001, McNemar’s test)
การแจกแจงตามประเภทบั๊ก (ก่อน → หลัง → การลดเปอร์เซ็นต์):
- Hallucination: 450 → 112 (จาก 9.0% → 2.24% ของ prompts) = ลด 75.1%
- Factual error: 350 → 63 (จาก 7.0% → 1.26%) = ลด 82.0%
- Logic error: 250 → 38 (จาก 5.0% → 0.76%) = ลด 84.8%
- Format error: 150 → 27 (จาก 3.0% → 0.54%) = ลด 82.0%
ตัวเลขข้างต้นเมื่อนำมารวมกันให้ผลรวมก่อน = 1,200 events และหลัง = 240 events ซึ่งสอดคล้องกับตัวเลขการลดรวม 80% ที่ประกาศ ทีมวิจัยยังรายงานว่าการลดบั๊กมีความแตกต่างกันตามประเภทงาน: งานเชิงรูปแบบ (format) และตรรกะลดได้สูงกว่าเล็กน้อย ขณะที่ hallucination ซึ่งเกี่ยวข้องกับความรู้ภายนอกลดได้น้อยกว่า แต่ยังถือว่าลดลงอย่างมีนัยสำคัญ
สำหรับเมตริกด้านคุณภาพอื่น ๆ ผลการทดลองบ่งชี้ว่า Prompt‑Debugger ส่งผลให้ exact match ในชุดที่เหมาะสม (เช่น GSM8K) เพิ่มจาก 62% → 85% (เพิ่ม 23 จุดร้อยละ) และ response validity เพิ่มจาก 78% → 95% ขณะที่ latency ในการประมวลผลเพิ่มขึ้นเพียงเล็กน้อยเฉลี่ย +120–250 ms ต่อ prompt เนื่องจากกระบวนการวิเคราะห์ chain‑of‑thought แบบเบื้องต้น
สรุป: ตัวเลข ลดบั๊ก 80% ถูกคำนวณจากการทดลองควบคุมที่มีขนาดตัวอย่างรวม 5,000 prompts ด้วยการประเมินเชิงมนุษย์และการทดสอบเชิงสถิติที่ยืนยันความแตกต่าง นอกจากนี้ทีมได้แจกแจงผลตามประเภทบั๊กเพื่อแสดงว่าการลดเกิดขึ้นทั่วทั้งหมวดหมู่แต่มีความเข้มข้นแตกต่างกันตามประเภทปัญหา
เปรียบเทียบคู่แข่งและความแตกต่างเชิงนวัตกรรม
เปรียบเทียบคู่แข่งและความแตกต่างเชิงนวัตกรรม
ตลาดเครื่องมือสำหรับการดีบักและการสังเกตการณ์ (observability) ของระบบ LLM ในปัจจุบันประกอบด้วยกลุ่มเครื่องมือหลักหลายประเภท ได้แก่ prompt linting tools ที่ตรวจสอบรูปแบบและความสอดคล้องของ prompt, แพลตฟอร์มประเมินผลโมเดล (model evaluation platforms) ที่วัดเมตริกผลลัพธ์เชิงสถิติ และกระบวนการดีบักด้วย human‑in‑the‑loop (HITL) ซึ่งอาศัยการตรวจสอบและแก้ไขโดยมนุษย์เป็นหลัก ประสบการณ์จากการสำรวจอุตสาหกรรมพบว่า ทีม ML/AI มักใช้เวลา 30–50% ของวงจรพัฒนาระบบไปกับการทดสอบและดีบักปัญหาเชิงพฤติกรรมของโมเดล ซึ่งสร้างแรงกดดันด้านเวลาและต้นทุนให้กับองค์กรที่ต้องเร่งปล่อยผลิตภัณฑ์
ความแตกต่างจาก prompt linters: Prompt‑Debugger ไม่ได้จำกัดอยู่ที่การตรวจจับรูปแบบหรือการแจ้งเตือนเรื่อง tokenization/formatting เท่านั้น แต่เน้นที่ การติดตามตรรกะแบบ Chain‑of‑Thought (CoT) และการวิเคราะห์เส้นทางความคิดของโมเดล (logic tracing) เป็นหลัก ซึ่งช่วยให้สามารถระบุจุดที่เหตุผลภายในโมเดลเบี้ยวหรือข้ามขั้นตอนสำคัญ ตัวอย่างเช่น prompt linter อาจระบุว่า prompt ถูกต้องตามสไตล์และไม่มีคำต้องห้าม แต่ Prompt‑Debugger จะสามารถชี้ให้เห็นได้ว่าในขั้นตอนที่สองของ CoT โมเดลได้ละเลยข้อสมมติฐานสำคัญ ทำให้ผลลัพธ์สุดท้ายผิดเพี้ยนไป นอกจากนี้ Prompt‑Debugger ยังสร้างแผนผังตรรกะ (logical trace) ที่อ่านและเรียกคืนได้ เพื่อให้ทีมวิศวกรเข้าใจเส้นทางความคิดของโมเดลในเชิงลึก
- สิ่งที่ prompt linters ทำได้ดี: ตรวจสอบรูปแบบ, ป้องกัน input ที่ไม่ปลอดภัย, ให้แนวทางการเขียน prompt ที่เป็นมาตรฐาน
- สิ่งที่ Prompt‑Debugger เสริม: ตรวจจับจุดผิดพลาดเชิงตรรกะใน CoT, วิเคราะห์การไหลของเหตุผล, และเสนอคำแนะนำการแก้ไขเชิงบริบท (contextual patch) ที่ละเอียดและเป็น actionable
ข้อได้เปรียบจาก automation ในเชิงเวลาและต้นทุน: ด้วยการวิเคราะห์ CoT อัตโนมัติและระบบแนะนำการแก้ไขแบบละเอียด Prompt‑Debugger สามารถลดเวลาที่ทีมต้องใช้ในการหา root cause ได้อย่างมีนัยสำคัญ — ในการทดสอบเบต้ากับลูกค้ากลุ่มแรก ทีมพัฒนารายงานการลดเวลา debugging เฉลี่ย 60–80% และอัตราการเกิดบั๊กผลลัพธ์ลดลงถึง 80% เมื่อเทียบกับการใช้วิธี manual/HITL เพียงอย่างเดียว ผลลัพธ์เช่นนี้แปลว่าองค์กรสามารถเร่งเวลากลับสู่ตลาด (time‑to‑market) ลดภาระงานวิศวกร และประหยัดค่าใช้จ่ายการดำเนินงาน (operational cost) ได้อย่างเป็นรูปธรรม โดยเฉพาะกับระบบที่ต้องทดสอบ prompt หลายร้อยหรือหลายพันกรณีซ้ำ ๆ
การใช้งานแบบอัตโนมัติยังเอื้อให้เกิดงานแบบ continuous integration สำหรับ LLM — เช่น การรันชุด CoT tests ใน pipeline ทุกครั้งที่มีการเปลี่ยนแปลง prompt หรือโมเดล ทำให้การแก้บั๊กเป็นไปอย่างทันท่วงทีและ reproducible ซึ่งแตกต่างจากการตรวจสอบเชิงมนุษย์ที่มีความผันผวนและยากต่อการทำซ้ำ
ข้อจำกัดและสถานการณ์ที่อาจต้องใช้ human review เพิ่มเติม: แม้ Prompt‑Debugger จะเข้มแข็งในการตรวจจับปัญหาเชิงตรรกะและเสนอแพตช์อัตโนมัติ แต่ยังมีขอบเขตที่ต้องพึ่งพาการตรวจสอบโดยผู้เชี่ยวชาญมนุษย์ เช่น งานที่เกี่ยวข้องกับความปลอดภัย/กฎหมาย (safety & compliance), การตัดสินใจเชิงคุณค่า (value‑laden judgments), กรณีที่ prompt มีเจตนาซับซ้อนหรือขัดแย้ง, และสถานการณ์ที่โมเดลถูกโจมตีเชิงสติปัญญา (adversarial inputs)
- ความเสี่ยงของการพึ่งพา automation มากเกินไป — อาจมองข้ามปัญหาด้านจริยธรรมหรือบริบทเชิงธุรกิจ
- กรณี domain‑specific knowledge ที่ระบบอัตโนมัติไม่มีฐานข้อมูลหรือกฎพอเพียง จะต้องอาศัยผู้เชี่ยวชาญด้านโดเมนเข้าตรวจสอบ
- ปัญหาเชิงความไม่แน่นอน (uncertainty) และข้อมูลที่ขัดแย้ง — ระบบอาจต้องยกระดับเป็น human‑in‑the‑loop เพื่อการตัดสินใจขั้นสุดท้าย
โดยสรุป Prompt‑Debugger ต่อยอดความสามารถของเครื่องมือในตลาดด้วยการให้ความสำคัญกับ การติดตาม CoT และการแนะนำการแก้ไขเชิงบริบทแบบละเอียด ทำให้การดีบัก LLM เป็นไปอย่างรวดเร็วและสามารถทำซ้ำได้ อย่างไรก็ตาม เพื่อความปลอดภัยและความถูกต้องในกรณีที่มีผลกระทบสูง ควรใช้กลยุทธ์ผสมผสานที่รวมการตรวจสอบของมนุษย์ในการตัดสินใจขั้นสุดท้ายเพื่อรับประกันคุณภาพและการปฏิบัติตามนโยบายองค์กร
ผลกระทบทางธุรกิจและตลาดในไทย/ภูมิภาค
ผลกระทบทางธุรกิจและตลาดในไทย/ภูมิภาค
การเปิดตัว Prompt‑Debugger ที่สามารถลดบั๊กผลลัพธ์ (hallucination และข้อผิดพลาดของ chain‑of‑thought) ได้ถึง 80% มีนัยสำคัญต่อผู้พัฒนา LLM และองค์กรที่นำโมเดลภาษาไปใช้งานจริงในไทยและภูมิภาคอาเซียน ทั้งในด้านต้นทุน เวลาในการพัฒนา และความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ (compliance) โดยเฉพาะในกรณีที่ระบบถูกนำไปใช้กับงานสำคัญเช่น แชทบอทดูแลลูกค้า ระบบสรุปข้อมูลเชิงกฎหมาย-การเงิน หรือการวิเคราะห์เชิงสาธารณสุข ตัวอย่างเช่น องค์กรที่มีต้นทุนแก้ไขข้อผิดพลาดหลังเปิดใช้งาน (post‑deployment remediation) สูง อาจเห็นการลดค่าใช้จ่ายตรงส่วนนี้อย่างชัดเจน — หากต้นทุนเฉลี่ยของการแก้บั๊กอยู่ที่ระดับหนึ่ง การลดอัตราบั๊กลง 80% จะส่งผลโดยตรงต่อการลดชั่วโมงวิศวกร ค่าเสียโอกาส และค่าใช้จ่ายทางกฎหมายที่อาจเกิดขึ้น
ในเชิงตัวเลขและการปฏิบัติจริง ภายในองค์กรที่ใช้ Prompt‑Debugger คาดว่าจะได้ประโยชน์จากหลายมิติ ได้แก่ การลดเวลา debugging และ testing ลงอย่างมีนัยสำคัญ (ส่งผลให้ time‑to‑market เร็วขึ้น), การลดค่าใช้จ่ายด้านทรัพยากรมนุษย์ที่ต้องมาดูแล prompt และ chain‑of‑thought เป็นประจำ และการลดความเสี่ยงจากการให้ข้อมูลผิดพลาดต่อผู้ใช้ ตัวอย่างเชิงประจักษ์จากการทดลองต้นแบบแสดงให้เห็นว่าองค์กรขนาดกลางถึงใหญ่สามารถลดเวลาที่ต้องใช้ในการแก้บั๊กหลังการทดสอบได้ราว 40–70% ขึ้นอยู่กับสภาพแวดล้อมและการผสานรวมระบบ
โมเดลธุรกิจที่เหมาะสม สำหรับสตาร์ทอัพเจ้าของ Prompt‑Debugger ในตลาดไทยและอาเซียนควรหลากหลายเพื่อครอบคลุมกลุ่มลูกค้าที่มีข้อกำหนดและขนาดแตกต่างกัน ได้แก่
- Subscription (SaaS): แผนรายเดือน/รายปีสำหรับธุรกิจขนาดเล็กถึงขนาดกลางที่ต้องการความสะดวกและอัปเดตอัตโนมัติ — เหมาะสำหรับผู้ให้บริการแชทบอท, SME ที่ใช้สรุปอัตโนมัติ และสตาร์ทอัพด้าน AI
- Enterprise licensing / On‑prem deployment: การติดตั้งภายในองค์กรหรือสัญญาไลเซนส์สำหรับธนาคาร หน่วยงานภาครัฐ และองค์กรด้านสุขภาพที่มีข้อกำหนดด้านข้อมูลและความเป็นส่วนตัวสูง — รองรับการคุมข้อมูล (data sovereignty) และมาตรการความปลอดภัย
- Professional services & integration: บริการปรับแต่ง prompt, เทรนนิ่งทีม, การผสานรวมกับระบบ CRM/CCaaS/Workflows และ SLA ระดับองค์กร — โมเดลนี้มักให้มาร์จิ้นสูงและสร้างความสัมพันธ์ระยะยาวกับลูกค้า
โอกาสตลาดในไทยและอาเซียนยังมีขนาดใหญ่และเติบโตต่อเนื่อง เมื่อองค์กรต่างๆ ขยายการลงทุนในโซลูชัน AI/LLM เพื่อเพิ่มประสิทธิภาพการทำงาน ตัวชี้วัดที่น่าสนใจได้แก่ อัตราการนำ AI มาใช้ในภาคบริการลูกค้าและฟินเทคที่สูงขึ้น, งบประมาณด้านดิจิทัลทรานส์ฟอร์เมชันที่เพิ่มขึ้น และนโยบายสนับสนุนจากภาครัฐในหลายประเทศของอาเซียน การมีเครื่องมือที่ช่วยลดความเสี่ยงจาก hallucination อย่างมีประสิทธิผลจะช่วยลดอุปสรรคในการตัดสินใจซื้อขององค์กรใหญ่ และเพิ่มความไว้วางใจให้กับภาคการเงิน โทรคมนาคม e‑commerce สาธารณสุข และหน่วยงานราชการ
กลุ่มลูกค้าที่ได้ประโยชน์สูงสุดได้แก่:
- สถาบันการเงินและประกันภัย: ลดความเสี่ยงด้านการให้คำแนะนำผิดพลาดและปัญหาด้านกฎระเบียบ
- ผู้ให้บริการโทรคมนาคมและศูนย์บริการลูกค้า: ปรับปรุงอัตราการตอบสนองที่ถูกต้องของแชทบอท ลดการโอนคิวไปยังมนุษย์
- ธุรกิจ e‑commerce และสื่อดิจิทัล: เพิ่มความแม่นยำในการสรุปรีวิว และการสร้างเนื้อหาอัตโนมัติ
- หน่วยงานภาครัฐและสาธารณสุข: ต้องการ on‑prem/hybrid เพื่อคงความเป็นส่วนตัวของข้อมูล และลดความเสี่ยงจากการเผยแพร่ข้อมูลผิดพลาด
สุดท้าย การนำ Prompt‑Debugger มาสู่ตลาดไทย/อาเซียนยังเปิดโอกาสให้สตาร์ทอัพสร้างความร่วมมือเชิงธุรกิจกับ cloud provider, system integrator และบริษัทซอฟต์แวร์องค์กร เพื่อขยายการใช้งานแบบข้ามประเทศได้เร็วขึ้น การผสานโมเดลรายได้แบบหลายชั้น (SaaS + enterprise licensing + professional services) จะช่วยให้สตาร์ทอัพมีเสถียรภาพด้านรายได้ พร้อมทั้งตอบโจทย์ความต้องการเชิงเทคนิคและการกำกับดูแลของลูกค้าองค์กรในภูมิภาค
ความปลอดภัย จริยธรรม และแผนพัฒนาในอนาคต
ความปลอดภัย จริยธรรม และแผนพัฒนาในอนาคต
การนำ Prompt‑Debugger มาใช้ในสภาพแวดล้อมการพัฒนา LLM ต้องให้ความสำคัญกับ ความเป็นส่วนตัวของข้อมูล และนโยบายการเก็บรักษาอย่างจริงจัง ทีมพัฒนาควรกำหนดนโยบายการเก็บข้อมูล (data retention policy) ที่ชัดเจน ระบุระยะเวลาเก็บรักษา การเข้าถึง และวัตถุประสงค์การใช้งาน โดยต้องสนับสนุนมาตรการปฏิบัติตามข้อกำหนดเช่น PDPA หรือ GDPR ในกรณีที่มีข้อมูลส่วนบุคคล ตัวอย่างเช่น การตั้งค่าเริ่มต้นให้ระบบไม่เก็บข้อความที่เป็น prompt หรือผลลัพธ์ที่อาจระบุผู้ใช้ออกนอกระบบโดยอัตโนมัติ ยกเว้นกรณีที่ผู้ใช้อนุญาตหรือมีเหตุผลทางกฎหมายชัดเจน
ในเชิงเทคนิค ทีมควรใช้แนวทางปกป้องข้อมูลหลายชั้น (defense‑in‑depth) ได้แก่:
- Data masking และ pseudonymization — ทำการ redaction, tokenization หรือลดทอนข้อมูลที่ระบุตัวบุคคลก่อนส่งไปประมวลผล เพื่อให้สตริงสำคัญ (เช่น หมายเลขบัญชี ลูกค้ารหัส) ถูกทำให้ไม่สามารถย้อนกลับได้ในระดับที่เพียงพอ
- On‑premises deployment และ hybrid options — รองรับการติดตั้งแบบ on‑prem หรือในเครือข่ายภายใน (air‑gapped/VM/container) สำหรับองค์กรที่มีข้อมูลอ่อนไหวสูง เพื่อให้ข้อมูลไม่ต้องออกนอกองค์กรและสามารถควบคุมคีย์การเข้ารหัสเอง
- Encryption ทางเทคนิค — ใช้การเข้ารหัสทั้งขณะส่ง (TLS) และที่พัก (AES‑256 หรือมาตรฐานเทียบเท่า) พร้อมตัวเลือกให้ลูกค้าจัดการคีย์ (customer‑managed keys) ผ่าน KMS เพื่อเพิ่มการควบคุม
- การควบคุมการเข้าถึงและการตรวจสอบ — บูรณาการ IAM, RBAC, การล็อกการเข้าถึง (audit logs) และการเก็บหลักฐานการเปลี่ยนแปลง (change history/provenance) เพื่อให้สามารถติดตามว่าใคร แก้ไขอะไร เมื่อใด
ด้านจริยธรรม การแก้ไข Chain‑of‑Thought (CoT) อัตโนมัติมีความเสี่ยงสองประการที่ต้องบริหารจัดการอย่างตั้งใจ: over‑correction และ semantic drift. Over‑correction อาจทำให้ระบบ “แก้ไขมากเกินไป” จนเปลี่ยนเจตนาของ prompt ดั้งเดิม เช่น prompt ที่ต้องการให้โมเดลแสดงความคิดเห็นเชิงวิพากษ์ถูกปรับให้เป็นคำตอบที่เป็นกลางเกินไป ส่วน semantic drift คือการแก้ไขที่ทำให้ความหมายเปลี่ยนไปเล็กน้อยแต่ส่งผลต่อการตัดสินใจหรือการปฏิบัติจริง
มาตรการบรรเทาความเสี่ยงควรประกอบด้วย:
- การตั้งค่า confidence thresholds — ให้ระบบเสนอคำแนะนำการแก้ไขแต่ไม่บังคับจนกว่าผู้ใช้จะยืนยัน
- human‑in‑the‑loop — การอนุมัติการเปลี่ยนแปลงสำคัญโดยมนุษย์ โดยเฉพาะกับ prompt ที่เกี่ยวข้องกับการตัดสินใจทางธุรกิจหรือบุคคล
- การบันทึก provenance และ diff ของการแก้ไขทุกครั้ง เพื่อให้สามารถย้อนกลับ (rollback) และตรวจสอบความเปลี่ยนแปลงได้
- การวัดความคล้ายเชิงความหมาย (semantic similarity metrics) ก่อนและหลังการแก้ไขเป็นดัชนีชี้วัดว่าการแก้ไขเบี่ยงเบนมากน้อยเพียงใด
สำหรับแผนพัฒนาในอนาคต ทีมงานได้นำเสนอ roadmap ที่ชัดเจนเพื่อรองรับความต้องการขององค์กรสมัยใหม่ โดยแบ่งเป็นเฟสหลักดังนี้
- ระยะสั้น (0–6 เดือน) — เปิดตัวฟีเจอร์ real‑time debugging แบบเบต้า: stream trace, breakpoint ใน pipeline ของ prompt/CoT และ webhook สำหรับระบบ CI/CD เพื่อให้สามารถตรวจพบและแก้ไขบั๊กในขั้นตอนการ inference ได้ทันที
- ระยะกลาง (6–12 เดือน) — ขยายการรองรับเป็น multimodal prompts: รวมการประมวลผลภาพ เสียง และตารางข้อมูล พร้อมกลไก pre‑processing (เช่น OCR redaction สำหรับภาพ) และ alignment ระหว่าง modal เพื่อลดความเสี่ยงของ semantic drift ข้ามสื่อ
- ระยะยาว (12–18 เดือน) — เปิด Open API และ SDK แบบ production‑grade, ระบบ plugin ecosystem, SLA สำหรับองค์กร และอินทิเกรชันแบบเรียลไทม์กับแพลตฟอร์ม observability และ security เช่น SIEM/DSI เพื่อให้การนำไปใช้ในองค์กรขนาดใหญ่เป็นไปได้ง่ายและปลอดภัย
นอกจากนี้ ทีมพัฒนาวางแนวทางการมีส่วนร่วมกับชุมชน (community feedback) เช่น การเปิด public roadmap, ช่องทางรายงานบั๊กและข้อเสนอแนะ, โปรแกรม bug‑bounty และคณะกรรมการผู้ใช้อิสระเพื่อทดสอบกรณีใช้ที่มีความเสี่ยงสูง การรวม feedback loop เหล่านี้จะช่วยให้การปรับปรุงฟังก์ชันการแก้ไข CoT เป็นไปอย่างโปร่งใส มีหลักฐาน และสอดคล้องกับหลักจริยธรรมขององค์กร
สรุปได้ว่า การนำ Prompt‑Debugger มาใช้ต้องผนวกทั้งมาตรการทางเทคนิค นโยบายการจัดการข้อมูล และกรอบจริยธรรมเข้าด้วยกัน พร้อม roadmap ที่ชัดเจนสำหรับฟีเจอร์สำคัญ เช่น real‑time debugging, multimodal prompt handling และ open API เพื่อให้เครื่องมือช่วยลดบั๊กได้จริงในสเกลองค์กร โดยยังคงความโปร่งใสและการคุ้มครองข้อมูลของผู้ใช้เป็นสำคัญ
บทสรุป
Prompt‑Debugger เป็นนวัตกรรมที่ตรงเข้าจัดการ Pain point สำคัญของการพัฒนา LLM โดยเฉพาะการวิเคราะห์และแก้ไข Chain‑of‑Thought (เส้นความคิด) อัตโนมัติ ช่วยตรวจจับจุดผิดพลาดเชิงตรรกะและเสนอการแก้ไข prompt/chain ได้ในขั้นตอนเดียว ซึ่งทีมพัฒนระบุว่าช่วยลดบั๊กเชิงตรรกะได้ถึงประมาณ 80% ในชุดทดสอบบางกรณี การใช้งานจริงรวมถึงการแปลง prompt ให้มีความชัดเจนขึ้น สร้างชุดทดสอบอัตโนมัติสำหรับสถานการณ์ต่าง ๆ และผนวกเข้ากับ pipeline ของการพัฒนา ทำให้รอบการทดสอบสั้นลงและคุณภาพผลลัพธ์ดีขึ้นอย่างมีนัยสำคัญ เหมาะสำหรับแอปพลิเคชันเช่น chatbot, ระบบตอบคำถามอัตโนมัติ และระบบสนับสนุนการตัดสินใจที่ต้องการตรรกะที่เชื่อถือได้
แม้ว่าจะมีศักยภาพสูง แต่การนำ Prompt‑Debugger ไปใช้เชิงพาณิชย์ต้องพิจารณาประเด็นด้าน ความปลอดภัย และผลกระทบเชิงจริยธรรมควบคู่ไปด้วย ได้แก่ การปกป้องข้อมูลฝึกสอนและข้อมูลที่ประมวลผล ความเสี่ยงของการแพร่กระจายอคติเมื่อตัวแก้ไข prompt ผสมกับข้อมูลเอนเอไอ การป้องกันการถูกโจมตีด้วย adversarial prompts และความจำเป็นในการมีมนุษย์ควบคุม (human‑in‑the‑loop) รวมถึงการเก็บบันทึก (audit trail) เพื่อความโปร่งใสในเชิงการตัดสินใจในอนาคต มุมมองอนาคตเห็นได้ว่าเครื่องมือประเภทนี้มีแนวโน้มจะถูกรวมเข้ากับระบบ MLOps และกลายเป็นมาตรฐานในการทำ Prompt Engineering และการทดสอบ LLM แต่การเติบโตอย่างรับผิดชอบจะต้องยึดแนวทางการกำกับดูแล การทดสอบความปลอดภัยเชิงลึก และการพัฒนาเกณฑ์มาตรฐานร่วมกับหน่วยงานภาครัฐและอุตสาหกรรม



