
สตาร์ทอัพไทยประกาศเปิดตัว "Green‑LLM Farm" โครงการฟาร์มฝึกโมเดลภาษาขนาดใหญ่ที่ชูจุดขายด้านความยั่งยืนโดยใช้พลังงานหมุนเวียนเป็นหลักร่วมกับเทคนิค quantization ในการลดปริมาณการคำนวณ ทำให้สามารถลดคาร์บอนฟุตพริ้นท์จากการฝึกโมเดลได้ถึง 70% เมื่อเทียบกับการฝึกบนศูนย์ข้อมูลแบบดั้งเดิม พร้อมกับการเปิด API ให้สาธารณะเข้าถึงทั้งการฝึกและการใช้งานโมเดล ซึ่งสตาร์ทอัพระบุว่าเน้นความโปร่งใสทั้งในแง่การวัดการปล่อยก๊าซเรือนกระจกและโครงสร้างต้นทุนที่ชัดเจนสำหรับผู้ใช้รายย่อยจนถึงองค์กรขนาดใหญ่

แนวทางของ Green‑LLM Farm ประกอบด้วยการจ่ายไฟจากแหล่งพลังงานหมุนเวียน เช่น โซลาร์และลม ผสานกับการปรับสถาปัตยกรรมการฝึกผ่าน quantization (เช่น 8‑bit/4‑bit) เพื่อลดจำนวนการคำนวณที่ต้องใช้โดยไม่สูญเสียประสิทธิภาพของโมเดลมากนัก นอกจากนี้ผู้ก่อตั้งระบุว่าจะเปิดเผยเมทริกซ์การวัดคาร์บอนฟุตพริ้นท์แบบเรียลไทม์ พร้อมรายละเอียดค่าใช้จ่ายต่อชั่วโมงการใช้งานใน API เพื่อให้ชุมชนวิจัยและธุรกิจสามารถประเมินต้นทุนด้านสิ่งแวดล้อมและการเงินก่อนตัดสินใจใช้งาน — ประเด็นที่จะเปลี่ยนภาพการพัฒนา AI ในไทยไปสู่การเติบโตที่ยั่งยืนมากขึ้น
สรุปข่าว (Lead) และความสำคัญ
สรุปข่าว (Lead) และความสำคัญ
สตาร์ทอัพไทยประกาศเปิดตัว Green‑LLM Farm แพลตฟอร์มฝึกโมเดลภาษาใหญ่ (Large Language Models) ที่ผสานการใช้พลังงานหมุนเวียนกับเทคนิคการลดความแม่นยำเชิงคอมพิวต์ (quantization) เพื่อลดผลกระทบสิ่งแวดล้อมจากการฝึกโมเดลปัญญาประดิษฐ์ ขณะเดียวกันยังเปิดให้ใช้งานผ่าน API สาธารณะ เพื่อช่วยขยายการเข้าถึงทรัพยากรการเทรนและเร่งนวัตกรรมจากภาคธุรกิจและงานวิจัย
จุดเด่นเชิงเทคนิคของ Green‑LLM Farm ได้แก่ การจัดการพลังงานโดยตรงจากแหล่งพลังงานหมุนเวียน เช่น โซลาร์และลม ผสานกับระบบจัดคิวงานที่ปรับให้เหมาะสมกับช่วงเวลาที่มีพลังงานสะอาดเพียงพอ รวมทั้งการใช้เทคนิค quantization และ mixed‑precision เพื่อจำกัดการใช้ทรัพยากรคอมพิวต์โดยไม่กระทบต่อประสิทธิภาพของโมเดล ผลลัพธ์สำคัญที่เป็นไฮไลท์คือความสามารถในการลด คาร์บอนฟุตพริ้นท์การฝึกโมเดลใหญ่ได้ถึง 70% เมื่อเทียบกับการฝึกบนโครงสร้างพื้นฐานแบบเดิมที่พึ่งพาพลังงานจากกริดทั่วไป
Green‑LLM Farm ยังเปิด API ให้สาธารณะใช้งาน ซึ่งหมายความว่าองค์กรขนาดเล็ก กลุ่มวิจัย และสตาร์ทอัพสามารถเข้าถึงทรัพยากรฝึกโมเดลที่เป็นมิตรต่อสิ่งแวดล้อมโดยไม่ต้องลงทุนสร้างอินฟราสตรักเจอร์เอง การเปิด API นี้จะช่วยลดอุปสรรคด้านต้นทุนและเวลา เพิ่มความสามารถในการทำซ้ำงานวิจัย และเร่งการประยุกต์ใช้โมเดลภาษาในภาคอุตสาหกรรม เช่น การวิเคราะห์ข้อความ การสร้างเนื้อหา และระบบบริการลูกค้าอัตโนมัติ
เหตุผลที่ข่าวนี้สำคัญเชิงกลยุทธ์มีหลายด้าน ได้แก่:
- มุมมองด้าน AI: ช่วยลดต้นทุนและเวลาการฝึกโมเดลขนาดใหญ่ ทำให้การทดลองและการผลิตโมเดลมีความยั่งยืนและเข้าถึงได้กว่าเดิม
- มุมมองด้านสิ่งแวดล้อม: ลดการปล่อยคาร์บอนจากการคำนวณเชิงลึก ซึ่งเป็นแหล่งปล่อยก๊าซเรือนกระจกที่เพิ่มขึ้นจากการเติบโตของ AI
- มุมมองด้านเศรษฐกิจและนโยบาย: ช่วยส่งเสริมเศรษฐกิจดิจิทัลของไทย ลดต้นทุนการดำเนินงานและสนับสนุนเป้าหมายด้าน ESG ขององค์กร ตลอดจนเปิดโอกาสให้ผู้ประกอบการท้องถิ่นแข่งขันในตลาดโลก
โดยสรุป การเปิดตัว Green‑LLM Farm ไม่เพียงเป็นก้าวสำคัญของสตาร์ทอัพไทยด้านเทคโนโลยี AI แต่ยังเป็นนวัตกรรมที่ผสานความรับผิดชอบต่อสิ่งแวดล้อมและความเป็นไปได้ทางธุรกิจ การที่สามารถประกาศการลดคาร์บอนฟุตพริ้นท์ได้ถึง 70% พร้อมกับการเปิด API สาธารณะ ทำให้โครงการนี้มีศักยภาพในการเปลี่ยนแปลงวิธีการพัฒนาและปรับใช้โมเดลภาษาในระดับภูมิภาคและระดับโลก
ภาพรวมเทคโนโลยีและสถาปัตยกรรมของ Green‑LLM Farm
สถาปัตยกรรมฮาร์ดแวร์หลักและการจัดวาง
Green‑LLM Farm ออกแบบฮาร์ดแวร์โดยยึดหลักความสมดุลระหว่างประสิทธิภาพการฝึก (training throughput) และความคุ้มค่าพลังงาน โดยใช้คลัสเตอร์ที่ประกอบด้วย NVIDIA H100/Hopper และ A100/ Ampere เป็นหน่วยเร่งหลักสำหรับงานการฝึกขนาดใหญ่ (dense training) ในขณะเดียวกันมีการผสมผสานกับ accelerator ทางเลือกสำหรับการประมวลผลความละเอียดต่ำ (low‑precision) และ inference เช่น Graphcore IPU, Habana Gaudi หรือ ASIC ที่ปรับแต่งสำหรับ INT8/FP8 เพื่อให้สอดคล้องกับเทคนิค quantization ที่ลดการใช้พลังงาน
การจัดวางฮาร์ดแวร์เป็นแบบโซน (zone) และโหนด (node) โดยแต่ละโหนดจะประกอบด้วย 8–16 GPUs ต่อเซิร์ฟเวอร์เชื่อมต่อด้วย NVLink/NVSwitch ระดับสูงเพื่อให้ latency ต่ำและ bandwidth สูงสำหรับ NCCL All‑reduce และการสื่อสารระหว่างพารามิเตอร์ ตัวอย่างโครงสร้างตัวเลขเชิงปริมาณ ได้แก่คลัสเตอร์ขนาดกลางที่มี 1,024 H100 กระจายใน 128 โหนด พร้อมการเชื่อมต่อเครือข่ายแบบ 100/200 Gbps InfiniBand เพื่อรองรับการเทรนนิ่งแบบ distributed ในระดับ Petaflops–Exaflops

ระบบ orchestration และการจัดคิวงานฝึก
Green‑LLM Farm ใช้สแต็ก orchestration แบบผสมผสานเพื่อตอบโจทย์งานวิจัยและเชิงพาณิชย์: Kubernetes ทำหน้าที่เป็นชั้นคอนเทนเนอร์หลักสำหรับการจัดการบริการพื้นฐาน (API, model serving, data preprocessing) ขณะที่ระบบจัดการงานฝึกแบบกระจายใช้ Ray หรือ Slurm สำหรับ scheduling งานฝึกที่ต้องการการสื่อสารแบบ HPC และใช้ไลบรารีเช่น Horovod/NCCL ในการประสานงาน gradient synchronization
- Energy‑aware scheduler: ตัวจัดคิวของฟาร์มมีนโยบายพลังงาน (energy profile) — เลือกเวลารันงานให้สอดคล้องกับอุปสงค์พลังงานหมุนเวียน เช่น รันงานหนักช่วงกลางวันเมื่อแสงอาทิตย์มาก หรือเลื่อนงานไม่เร่งด่วนไปยังชั่วโมงที่ grid มีคาร์บอนอินเทนซิตี้ต่ำ
- Preemptible/spot mode: มีโหมดรันงานแบบ preemptible ที่ลดค่าใช้จ่ายและใช้ทรัพยากรเหลือใช้ โดยระบบจะ checkpoint งานเป็นระยะ เพื่อให้สามารถ resume ได้หลังการ preemption
- Multi‑tenant isolation: ใช้ Kubernetes namespaces, cgroups และ GPU partitioning (MIG/instance slicing) เพื่อกันทรัพยากรและคิวงานของลูกค้าหลายราย
การผสานกับแหล่งพลังงานหมุนเวียนและมาตรการสำรองพลังงาน
หนึ่งในหัวใจของ Green‑LLM Farm คือการเชื่อมต่ออย่างใกล้ชิดกับแหล่งพลังงานหมุนเวียนเพื่อให้บรรลุเป้าลดคาร์บอนฟุตพริ้นท์ได้ถึง 70% เมื่อเทียบกับการฝึกบนโครงสร้างพื้นฐานแบบดั้งเดิม แนวทางประกอบด้วย:
- พลังงานในไซต์ (on‑site renewables): ติดตั้งโซลาร์เซลล์ (PV) และกังหันลมขนาดเล็กแยกโซน รวมกำลังประมาณ 0.5–2 MW ต่อไซต์ ขึ้นกับขนาดฟาร์ม เพื่อให้สัดส่วนการใช้พลังงานหมุนเวียนสูงสุด
- ระบบกักเก็บพลังงาน (BESS): ใช้แบตเตอรี่ลิเธียม‑ไอออนขนาดหลาย MWh สำหรับรองรับช่วงที่กำลังผลิตไม่เพียงพอ และรองรับการตอบสนองทันทีเมื่อมีการเพิ่มโหลดฝึก
- การซื้อไฟฟ้าจากสัญญา (PPA) และ grid interaction: เซ็ตอัพ PPA ระยะยาวกับผู้ผลิตพลังงานหมุนเวียน และใช้กลไก virtual power plant (VPP) เพื่อขายไฟส่วนเกินกลับเข้า grid ในเวลาที่มีการผลิตสูง
- carbon‑aware scheduling: เชื่อมต่อกับข้อมูลความเข้มข้นคาร์บอนของกริดแบบเรียลไทม์ (เช่น electricityMap) เพื่อปรับลำดับงาน—ตัวอย่างเช่น ย้ายงาน non‑critical ไปช่วงที่คาร์บอนอินเทนซิตี้ต่ำ เพิ่มอัตราการใช้พลังงานหมุนเวียนเฉลี่ยจาก 60% เป็น >85% ในบางช่วง
ความน่าเชื่อถือและความปลอดภัยของข้อมูล
Green‑LLM Farm ให้ความสำคัญกับความต่อเนื่องในการให้บริการและการปกป้องข้อมูลลูกค้า โดยใช้มาตรการหลายชั้นทั้งในระดับฮาร์ดแวร์และซอฟต์แวร์:
- ความต่อเนื่องของพลังงาน: สถาปัตยกรรมไฟฟ้าออกแบบเป็น N+1 พร้อม UPS ระยะสั้น และ BESS เป็นแหล่งสำรองระยะกลาง หากจำเป็นจะมีการใช้ grid หรือเครือข่ายสำรองตามนโยบายฉุกเฉิน
- เครือข่ายและการจัดเก็บข้อมูลแบบทนทาน: ใช้สถาปัตยกรรม leaf‑spine network, ชุดสวิตช์ redundant, และระบบเก็บข้อมูลแบบ distributed (object storage + erasure coding) พร้อม snapshot และ cross‑zone replication เพื่อให้สามารถกู้คืนข้อมูลได้ภายใน SLA ที่กำหนด
- การรักษาความปลอดภัยและการปกป้องข้อมูล: ข้อมูลถูกเข้ารหัสทั้งขณะพัก (AES‑256) และขณะส่ง (TLS 1.3) มีการจัดการกุญแจผ่าน HSM และการควบคุมการเข้าถึงแบบ Role‑Based Access Control (RBAC) พร้อมการบันทึกเหตุการณ์ (audit logs) และระบบ SIEM สำหรับตรวจจับพฤติกรรมผิดปกติ นอกจากนี้มีตัวเลือกใช้ secure enclaves (เช่น AMD SEV หรือ Intel SGX) สำหรับการฝึกโมเดลที่มีข้อมูลอ่อนไหว
- นโยบายความเป็นส่วนตัวและการปฏิบัติการตามกฎระเบียบ: รองรับมาตรฐานระดับสากล เช่น ISO 27001, SOC2 และออกแบบกระบวนการให้สอดคล้องกับ PDPA ของไทย รวมถึงตัวเลือกด้าน privacy‑preserving เช่น differential privacy และ federated learning สำหรับลูกค้าที่ต้องการ
โดยสรุป Green‑LLM Farm ใช้การผสมผสานฮาร์ดแวร์ชั้นนำและ accelerator เชิงพาณิชย์กับระบบ orchestration ที่ปรับแต่งให้เป็น energy‑aware พร้อมกับการผสานพลังงานหมุนเวียนในระดับไซต์และการสำรองพลังงานระดับคลัสเตอร์ ส่งผลให้สามารถเร่งการฝึกโมเดลขนาดใหญ่ได้อย่างมีประสิทธิภาพ ในขณะเดียวกันรักษามาตรฐานด้านความเชื่อถือได้และความปลอดภัยของข้อมูลในระดับองค์กร
แหล่งพลังงานหมุนเวียนและการวัดสภาพแวดล้อม
แหล่งพลังงานหมุนเวียนที่ Green‑LLM Farm ใช้
Green‑LLM Farm ประกาศระบบพลังงานแบบผสมผสานเพื่อสนับสนุนการเทรนโมเดลขนาดใหญ่โดยมีสัดส่วนพลังงานหมุนเวียนที่ ประมาณ 50–80% (ขึ้นกับช่วงเวลาและสัญญาจัดซื้อ) โดยแบ่งเป็นแหล่งหลักดังนี้
- โซลาร์ (On‑site PV): ฟาร์มติดตั้งแผงโซลาร์บนพื้นที่หลังคาและพื้นที่ดินรอบศูนย์ข้อมูล คิดเป็น ~40–60% ของการผลิตพลังงานภายในไซต์ในวันปกติ
- วินด์ (PPA/Contracted wind): มีสัญญาซื้อไฟฟ้าแบบระยะกลาง (PPA) กับฟาร์มกังหันลมในภูมิภาค คิดเป็น ~10–20% ขึ้นอยู่กับฤดูกาลลม
- RECs / PPAs: สำหรับปริมาณไฟฟ้าที่ไม่สามารถจัดหาได้จากโซลาร์หรือวินด์ภายในไซต์ ทางทีมใช้การซื้อ Renewable Energy Certificates (RECs) และ PPA เพื่อชดเชยและยืนยันการจัดหาพลังงานหมุนเวียนในเชิงบัญชี ทำให้ Scope 2 สามารถระบุเป็นไฟฟ้าหมุนเวียนได้ตามมาตรฐานการรายงาน
- แบตเตอรี่สำรอง (BESS): ติดตั้งระบบแบตเตอรี่เพื่อเก็บพลังงานในช่วงผลผลิตสูงของโซลาร์ ช่วยให้ลดการพึ่งพาโครงข่ายในชั่วโมงคืนและลดการใช้เครื่องกำเนิดดีเซลฉุกเฉิน
เมตริกที่ใช้วัดและการรายงานคาร์บอน (CO2e) รวมถึง PUE และการใช้งานพลังงาน
การประเมินผลด้านสิ่งแวดล้อมของ Green‑LLM Farm ยึดตามกรอบงานมาตรฐานสากล เช่น GHG Protocol และแนวปฏิบัติการวัดสำหรับศูนย์ข้อมูล (data center metrics) โดยเมตริกหลักที่รายงานมีดังนี้
- CO2e (kg CO2e): คำนวณจากปริมาณพลังงานที่ใช้ (kWh) คูณด้วยปัจจัยการปล่อยก๊าซสำหรับแหล่งพลังงาน (grid intensity สำหรับไฟฟ้าจากโครงข่าย, lifecycle factor สำหรับพลังงานหมุนเวียน และค่า residual emissions สำหรับ RECs)
- PUE (Power Usage Effectiveness): วัดเป็นอัตราส่วนระหว่างพลังงานทั้งหมดที่ศูนย์ข้อมูลใช้ต่อพลังงานที่ใช้งานโดยอุปกรณ์ IT — Green‑LLM Farm รายงานค่า PUE เฉลี่ยประจำไตรมาส และมีค่าเป้าหมายที่ ~1.15–1.25
- kWh ต่อชั่วโมงการฝึก (kWh / training‑hour): เก็บข้อมูลการใช้พลังงานของคลัสเตอร์เทรนโดยแยกเป็นพลังงานสำหรับ compute (GPU/TPU) และพลังงานรอง (cooling, power distribution) เพื่อคำนวณเป็นหน่วยต่อชั่วโมงการเทรนหรือเป็นหน่วยต่อ job
- Scope 1‑3: รายงานแยกดังนี้
- Scope 1 — การปล่อยโดยตรงจากเครื่องกำเนิดฉุกเฉิน (เช่น ดีเซล) และระบบทำความร้อนภายในไซต์
- Scope 2 — การปล่อยจากการซื้อไฟฟ้า (ระบุทั้งแบบ location‑based และ market‑based โดยรวม RECs/PPA)
- Scope 3 — การปล่อยที่เกี่ยวข้องแต่ไม่ใช่ในความรับผิดชอบโดยตรง เช่น การผลิตฮาร์ดแวร์, ซัพพลายเชน, การเดินทาง และการกำจัดอุปกรณ์ (Green‑LLM Farm ระบุว่าจะนำมาตรฐานการบัญชีของซัพพลายเออร์มารวมในการคำนวณ)
วิธีการคำนวณการลดคาร์บอน 70% — สมมติฐานและตัวอย่างการคำนวณ
คำกล่าวอ้างเรื่องการลดคาร์บอนฟุตพริ้นท์ร้อยละ 70 ของ Green‑LLM Farm เป็นตัวเลขที่ได้จากการรวมผลของหลายปัจจัยหลัก ได้แก่ การใช้พลังงานหมุนเวียน, การลดการคำนวณด้วย quantization และ optimization ของโมเดล และ การปรับปรุงประสิทธิภาพศูนย์ข้อมูล (PUE) โดยทางทีมให้ข้อมูลตัวอย่างสมมติฐานเชิงอนุรักษ์เพื่ออธิบายการคำนวณดังนี้
- สมมติฐานฐานเปรียบเทียบ (baseline):
- พลังงานคอมพิวต์เฉลี่ย = 200 kWh ต่อชั่วโมงการฝึก
- PUE ของศูนย์ข้อมูล baseline = 1.6
- ความเข้มข้นการปล่อยก๊าซของกริด (grid intensity) = 0.50 kg CO2e / kWh
- ดังนั้น CO2e (baseline) ต่อชั่วโมง = 200 × 1.6 × 0.50 = 160 kg CO2e / ชั่วโมง
- สมมติฐานของ Green‑LLM Farm (after):
- การลดพลังงานจาก quantization & model optimization = 40% (คงเหลือ 60% ของพลังงานเดิม → 120 kWh compute)
- PUE ปรับปรุงเป็น = 1.25
- สัดส่วนพลังงานหมุนเวียนที่ใช้จริง (on‑site + PPA/RECs) = 40% และส่วนที่เหลือมาจากกริด
- ค่าการปล่อยสำหรับพลังงานหมุนเวียน (operational/residual) ถือเป็น 0.02 kg CO2e / kWh (conservative lifecycle residual)
- การคำนวณ:
- พลังงานรวมหลังการปรับปรุง = 120 kWh × 1.25 = 150 kWh / ชั่วโมง
- ปริมาณพลังงานจากหมุนเวียน = 150 × 0.40 = 60 kWh; ปล่อย = 60 × 0.02 = 1.2 kg CO2e
- ปริมาณพลังงานจากกริด = 150 × 0.60 = 90 kWh; ปล่อย = 90 × 0.50 = 45 kg CO2e
- ปล่อยรวม (หลัง) = 1.2 + 45 = 46.2 kg CO2e / ชั่วโมง
- การลดเทียบกับ baseline = (160 − 46.2) / 160 = ประมาณ 71%
จากตัวอย่างเชิงอนุรักษ์ข้างต้น จะเห็นว่าการรวมกันของ quantization (ลดเชิงคำนวณ), การเพิ่มสัดส่วนพลังงานหมุนเวียน และการปรับปรุง PUE สามารถให้ผลลัพธ์ที่ใกล้เคียงหรือมากกว่า 70% ขึ้นอยู่กับสมมติฐานเฉพาะ (เช่น ขนาดของการลดพลังงานจาก quantization, สัดส่วนรีนิวเอเบิลจริง, ค่าการปล่อยของกริดในพื้นที่ และ PUE ที่ทำได้จริง)
ท้ายสุด Green‑LLM Farm ระบุว่าจะใช้การตรวจสอบภายนอก (third‑party verification) ตามมาตรฐานเช่น ISO 14064 และแนวทาง GHG Protocol สำหรับการยืนยันข้อมูลการปล่อย เพื่อให้การอ้างสิทธิ์การลดร้อยละ 70 มีความโปร่งใสและตรวจสอบได้ โดยรายงานจะแยกแสดงทั้งค่า Scope 1–3, ค่าพลังงาน (kWh / training‑hour) และค่า PUE เป็นระยะ ๆ เพื่อให้ผู้ใช้ API และลูกค้าสามารถประเมินผลกระทบด้านคาร์บอนของการใช้บริการได้อย่างชัดเจน
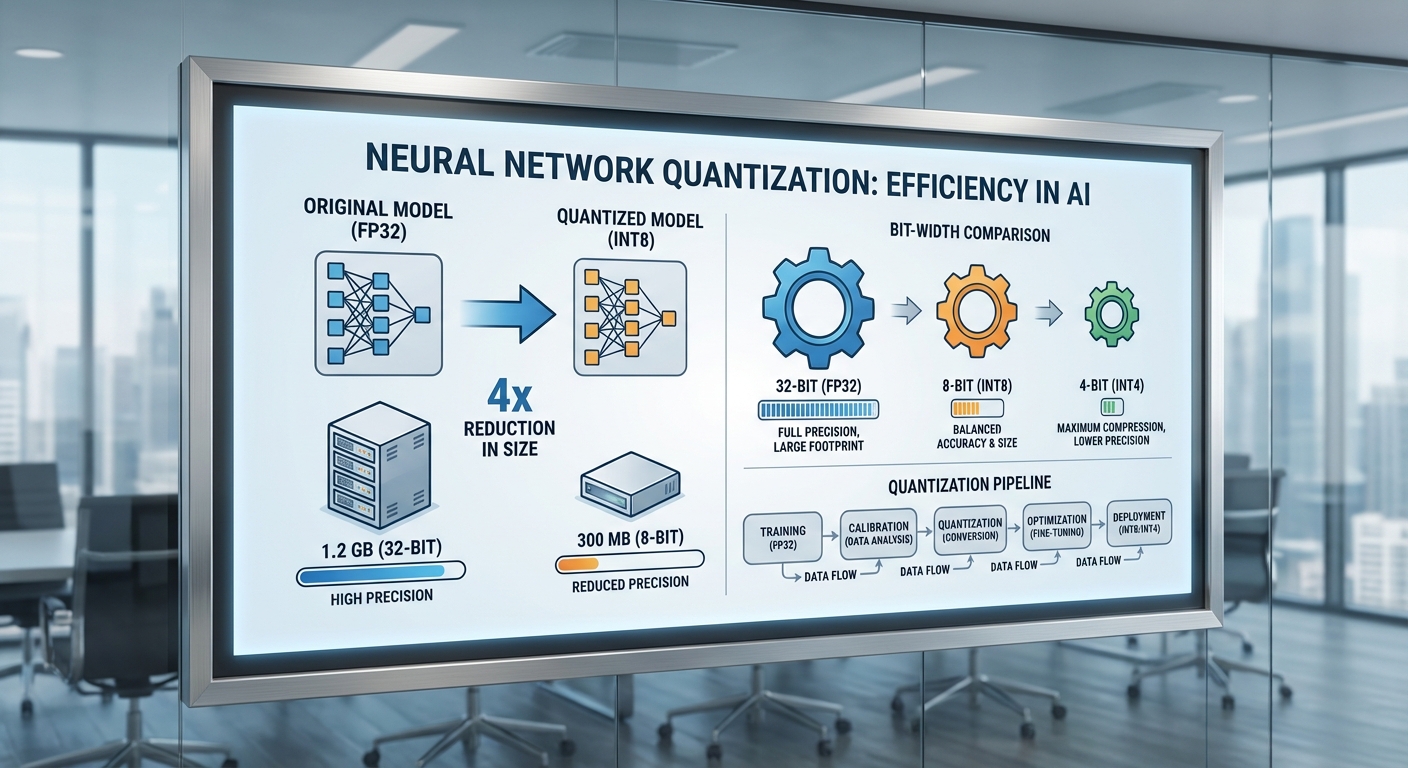
เทคนิค quantization และการปรับประสิทธิภาพโมเดล
เทคนิค quantization ที่นำมาใช้และเหตุผลเชิงธุรกิจ
สตาร์ทอัพ Green‑LLM Farm ใช้กลยุทธ์ quantization แบบหลากหลาย (mixed-precision) เพื่อให้เหมาะสมกับงานเชิงธุรกิจที่ต้องการทั้งความแม่นยำและต้นทุนพลังงานต่ำ โดยหลัก ๆ ประกอบด้วย 8-bit, 4-bit และการใช้เทคนิคขั้นสูงอย่าง GPTQ (post-training quantization) และ QLoRA (quantized low‑rank adaptation) ร่วมกับการทำ pruning และ knowledge distillation เพื่อบีบขนาดโมเดลและลดการคำนวณที่ไม่จำเป็น เหตุผลที่เลือกชุดเทคนิคเหล่านี้คือ:
- 8-bit ให้ trade-off ระหว่างขนาดและความแม่นยำ เหมาะสำหรับส่วนใหญ่ของพารามิเตอร์ที่ไม่ไวต่อความละเอียดพิกัดเล็ก ๆ
- 4-bit ลดขนาดโมเดลอย่างมาก เหมาะกับการ deploy บนฮาร์ดแวร์ที่รองรับและสำหรับบริการ API ที่ต้องการ latency ต่ำ
- GPTQ เป็นวิธี post‑training quantization ที่แก้ปัญหา outlier และรักษาคุณภาพได้ดีเมื่อเทียบกับการ quantize แบบตรง ๆ
- QLoRA ช่วยให้สามารถ fine‑tune โมเดลขนาดใหญ่ในสภาพแวดล้อมหน่วยความจำน้อย (memory‑constrained) โดยไม่ต้องคงสถานะ full‑precision ทั้งหมด
- Pruning และ Distillation ช่วยลดพารามิเตอร์และทำให้โมเดลที่เล็กกว่าทำงานได้ใกล้เคียงกับ teacher model ทำให้ต้นทุนพลังงานและ latency ลดลงในเชิงปฏิบัติ
ผลกระทบต่อประสิทธิภาพและการประเมินความเสี่ยง
การลดความละเอียดตัวเลขมีผลต่อทั้ง accuracy และ latency ซึ่งต้องประเมินเชิงความเสี่ยงก่อนใช้งานเชิงพาณิชย์ ดังนี้:
- ในเชิงความแม่นยำ งานวิจัยและกรณีใช้งานจริงรายงานว่า 8‑bit มักทำให้ performance ลดลงน้อยมาก (มักอยู่ที่ difference ≤ 1% ในเมตริกอย่าง perplexity/accuracy) ในขณะที่ 4‑bit อาจทำให้ loss/perplexity เพิ่มขึ้นเล็กน้อยแต่ยังยอมรับได้หากใช้เทคนิคเช่น GPTQ หรือ per‑channel quantization
- QLoRA ช่วยรักษาคุณภาพการปรับจูน: สามารถ fine‑tune โมเดลขนาดใหญ่โดยให้ผลลัพธ์ใกล้เคียงกับ full‑precision finetune ภายในความแตกต่างประมาณ 1–3% ขึ้นกับงาน (NLP generation, classification)
- ในด้าน latency การใช้ 8‑bit/4‑bit ร่วมกับไลบรารีและ kernel ที่ปรับแต่งแล้วสามารถลดเวลา inference ได้ 20–60% ขึ้นกับฮาร์ดแวร์และการสนับสนุนของไลบรารี
- ความเสี่ยงเชิงปฏิบัติ ได้แก่ การเกิด outlier activation ที่ต้องการ calibration, บริบทที่ต้องการความแม่นยำสูง (เช่น งานทางการแพทย์/กฎหมาย) ที่อาจต้องเก็บบางเลเยอร์เป็น FP16/FP32 และความซับซ้อนในการทดสอบ regression หลัง quantization
การวัดผลเชิงปริมาณ: ขนาดโมเดล, FLOPs และการประหยัดพลังงาน
การประเมินเชิงปริมาณเป็นหัวใจสำคัญของการตัดสินใจเชิงธุรกิจ Green‑LLM Farm ใช้ชุดเมตริกหลักดังนี้:
- ขนาดโมเดล (storage) — การใช้ 8‑bit มักลดขนาดโมเดลลงประมาณ 2× เมื่อเทียบกับ FP16 และ 4‑bit ลดได้ประมาณ ~4× (โดยประมาณขึ้นกับการเก็บสเกลและบิตสำรอง)
- FLOPs — quantization ช่วยลดงานคำนวณเชิงหน่วยความจำและแบนด์วิดท์ ซึ่งนำไปสู่การลด FLOPs ที่มีผลใช้งานจริงประมาณ 30–60% เมื่อรวมกับ pruning ที่ลดพารามิเตอร์อีก 20–50%
- Energy / Carbon — ตัวอย่างกรณีศึกษาและการประมาณการภายในโครงการพบว่าเมื่อรวมการเทรนด้วยพลังงานหมุนเวียนกับการใช้ 4‑bit quantization + pruning + distillation สามารถลดคาร์บอนฟุตพริ้นท์จากการฝึกโมเดลใหญ่ได้ถึง ~70% (ตามการประเมิน lifecycle และลดชั่วโมงการใช้งาน GPU)
- Latency — ในการให้บริการ API จริง การปรับขึ้นเป็น mixed‑precision บางเลเยอร์และการใช้ quantized kernels สามารถลดเวลา response ต่อคำขอเฉลี่ยได้ 20–50% ขึ้นกับปริมาณงานและ batch size
ตัวอย่าง workflow ในการฝึกและปรับโมเดลเพื่อรักษาประสิทธิภาพ
ตัวอย่าง workflow ที่ Green‑LLM Farm ใช้เพื่อ balance ระหว่าง performance กับการประหยัดพลังงาน:
- 1. Pre‑selection ของสถาปัตยกรรม — เลือกโมเดลฐานที่ตอบโจทย์ธุรกิจ (เช่น LLaMA/OPT) และแยกเลเยอร์ที่สำคัญทางสถิติออกจากเลเยอร์ที่ทนต่อ quantization ได้ดี
- 2. Pruning แบบมีเงื่อนไข — ทำ structured pruning ในระหว่าง pre‑training/fine‑tuning เพื่อลดพารามิเตอร์ที่ไม่สำคัญ โดยรักษาเลเยอร์คริติคัลไว้
- 3. QLoRA สำหรับ fine‑tuning — ใช้ QLoRA เพื่อฝึก adapter ขนาดเล็กบน base model ที่ถูก quantize เป็น 4‑bit ทำให้ใช้ VRAM ต่ำและลดเวลา training
- 4. GPTQ / PTQ กับ calibration — ดำเนิน post‑training quantization (GPTQ) พร้อมชุดข้อมูล calibration เพื่อเก็บสเกล per‑channel และทำ bias correction เพื่อลดผลกระทบต่อ accuracy
- 5. Distillation เป็นขั้นสุดท้าย (optional) — หากต้องการ deploy บน edge หรือ API ที่ latency ต่ำ ใช้ knowledge distillation ให้ student model ขนาดเล็กซึ่งยังรักษาผลลัพธ์เชิงธุรกิจไว้ 90–98% ของ teacher
- 6. Benchmarking และ safety checks — ทดสอบ regression บนซีรีส์ dataset, ตรวจวัด latency/throughput, วัดค่า FLOPs และทำ A/B testing ก่อน roll‑out
สรุปคือ การผสมผสานเทคนิค 8‑bit/4‑bit quantization, GPTQ, QLoRA, pruning และ distillation ให้ผลเป็นการลดขนาดโมเดลและการคำนวณอย่างมีนัยสำคัญ โดยการวางแผนที่รอบคอบและการประเมินความเสี่ยงเชิงคุณภาพสามารถรักษาประสิทธิภาพการให้บริการเชิงธุรกิจไว้ได้ ขณะเดียวกันก็ลดค่าใช้จ่ายพลังงานและคาร์บอนฟุตพริ้นท์ตามเป้าหมายของ Green‑LLM Farm
ผลกระทบเชิงสิ่งแวดล้อมและสถิติการลดคาร์บอน
ผลกระทบเชิงสิ่งแวดล้อมและสถิติการลดคาร์บอน
ผลการทดลองภายในของ Green‑LLM Farm รายงานการลดคาร์บอนฟุตพริ้นท์จากการฝึกโมเดลขนาดใหญ่ได้เฉลี่ย ราว 70% เมื่อเปรียบเทียบกับการฝึกแบบดั้งเดิมที่ใช้ศูนย์ข้อมูลทั่วไป โดยค่าสำคัญที่ใช้ในการรายงานคือหน่วย kgCO2e ต่อ 1e18 FLOPs และ kgCO2e ต่อชั่วโมงการฝึก ผลลัพธ์นี้มาจากการรวมมาตรการสองแกนหลักคือ (1) การเปลี่ยนไปใช้พลังงานหมุนเวียนและการจัดซื้อสัญญาพลังงาน (renewable procurement) ที่ลดความเข้มคาร์บอนของไฟฟ้า และ (2) การลดปริมาณการคำนวณ (compute) ผ่านเทคนิค quantization, sparsity และ compiler optimizations ซึ่งช่วยลดการใช้พลังงานของการคำนวณโดยรวม รายละเอียดตัวเลขและสมมติฐานที่ใช้มีดังนี้
สมมติฐานการคำนวณ (ที่ใช้ในการทดลองและการจำลอง)
- ความเข้มคาร์บอนของกริดฐาน (baseline carbon intensity): 0.40 kgCO2e/kWh (เทียบเท่าค่าเฉลี่ยของหลายภูมิภาคที่พึ่งพาก๊าซและถ่านหิน)
- ความเข้มคาร์บอนของ Green‑LLM Farm หลังจัดสรรพลังงานหมุนเวียน: 0.20 kgCO2e/kWh (สมมติการจัดซื้อพลังงานหมุนเวียนและ time‑shifting ลดลงประมาณ 50%)
- การใช้พลังงานต่อหน่วยคำนวณ (baseline): 500 kWh ต่อ 1e18 FLOPs
- การลดการใช้พลังงานจาก quantization/optimizations: 40% (ดังนั้นพลังงานต่อ 1e18 FLOPs ของ Green‑LLM = 300 kWh)
- PUE (Power Usage Effectiveness): สมมติเท่ากันที่ 1.2 ทั้งสองกรณี เพื่อแยกผลจากการจัดการพลังงานและการลด compute
คำนวณผลกระทบต่อ CO2e ต่อ 1e18 FLOPs — จากสมมติฐานข้างต้น:
- Baseline CO2e = 500 kWh × 0.40 kgCO2e/kWh × 1.2 PUE = 240 kgCO2e ต่อ 1e18 FLOPs
- Green‑LLM Farm CO2e = 300 kWh × 0.20 kgCO2e/kWh × 1.2 PUE = 72 kgCO2e ต่อ 1e18 FLOPs
- การลด = (240 − 72) / 240 = 70%
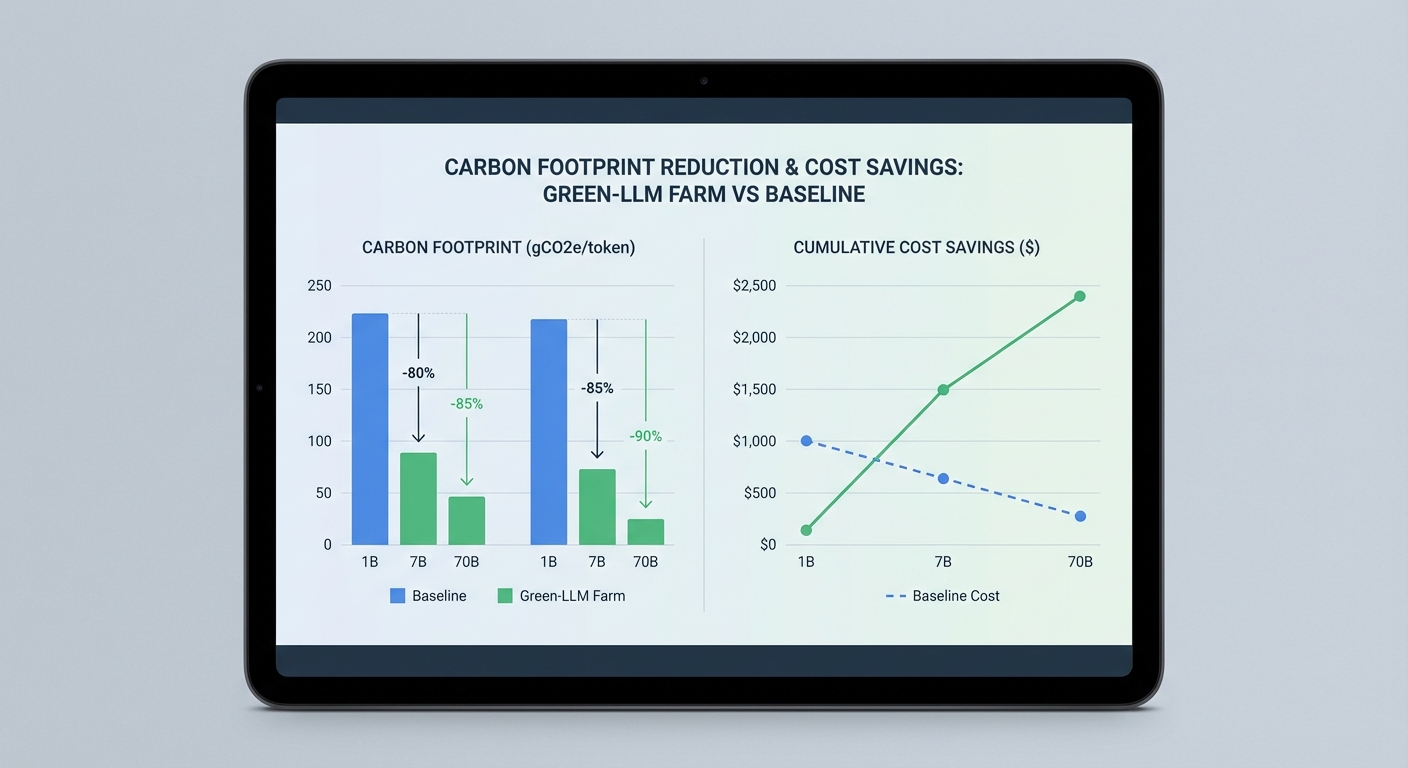
ตัวอย่างการจำลองการเทรนโมเดลขนาดต่าง ๆ (1B, 7B, 70B พารามิเตอร์)
สมมติจำนวนงานคำนวณรวม (total FLOPs) ที่ใช้ในการเทรนแต่ละขนาดเป็นตัวอย่างเพื่อให้เห็นผลกระทบเชิงตัวเลข:
- 1B model ≈ 1.0 × 1020 FLOPs (100 × 1e18)
- 7B model ≈ 7.0 × 1020 FLOPs (700 × 1e18)
- 70B model ≈ 7.0 × 1021 FLOPs (7,000 × 1e18)
ผลลัพธ์เชิงตัวเลข (Baseline vs Green‑LLM Farm)
- โมเดล 1B
- พลังงานรวม (baseline): 100 × 500 kWh = 50,000 kWh
- พลังงานรวม (Green): 100 × 300 kWh = 30,000 kWh
- CO2e (baseline): 100 × 240 kg = 24,000 kgCO2e (24 tCO2e)
- CO2e (Green): 100 × 72 kg = 7,200 kgCO2e (7.2 tCO2e)
- ต้นทุนพลังงาน (สมมติ $0.10/kWh): baseline = $5,000, Green = $3,000 (ประหยัด $2,000)
- ระยะเวลาโดยประมาณ (กรณีใช้คลัสเตอร์ 500 kW): ≈ 100 ชั่วโมง
- โมเดล 7B
- พลังงานรวม (baseline): 700 × 500 kWh = 350,000 kWh
- พลังงานรวม (Green): 700 × 300 kWh = 210,000 kWh
- CO2e (baseline): 700 × 240 kg = 168,000 kgCO2e (168 tCO2e)
- CO2e (Green): 700 × 72 kg = 50,400 kgCO2e (50.4 tCO2e)
- ต้นทุนพลังงาน: baseline = $35,000, Green = $21,000 (ประหยัด $14,000)
- ระยะเวลาโดยประมาณ: ≈ 700 ชั่วโมง (≈ 29 วัน)
- โมเดล 70B
- พลังงานรวม (baseline): 7,000 × 500 kWh = 3,500,000 kWh
- พลังงานรวม (Green): 7,000 × 300 kWh = 2,100,000 kWh
- CO2e (baseline): 7,000 × 240 kg = 1,680,000 kgCO2e (1,680 tCO2e)
- CO2e (Green): 7,000 × 72 kg = 504,000 kgCO2e (504 tCO2e)
- ต้นทุนพลังงาน: baseline = $350,000, Green = $210,000 (ประหยัด $140,000)
- ระยะเวลาโดยประมาณ: ≈ 7,000 ชั่วโมง (≈ 292 วัน)
จากการจำลองข้างต้นจะเห็นว่าการประยุกต์ใช้พลังงานหมุนเวียนร่วมกับการลด compute ผ่าน quantization และ optimization สามารถลดทั้ง ปริมาณ CO2e และค่าใช้จ่ายพลังงาน ได้อย่างมีนัยสำคัญ ตัวอย่างเช่น การเทรนโมเดลขนาด 70B ในกรณีทดลองนี้ลดคาร์บอนจากประมาณ 1,680 ตันลงเหลือ 504 ตัน ซึ่งเป็นการลดประมาณ 1,176 ตัน CO2e ต่อการเทรนหนึ่งรอบ — ตัวเลขที่มีความหมายต่อการกำกับดูแลด้านสิ่งแวดล้อมขององค์กรและการรายงาน ESG
ข้อควรระวังและความไม่แน่นอน: ผลลัพธ์ข้างต้นเป็นการจำลองตามสมมติฐานที่ชัดเจน เช่น ค่า energy per FLOPs, carbon intensity ของกริด และ PUE ค่าเหล่านี้จะแตกต่างตามภูมิภาค ฮาร์ดแวร์ที่ใช้ และรูปแบบการฝึกจริง (เช่น batch size, sequence length, number of epochs) ดังนั้น การวัดเชิงสังเกตจริง (on‑site measurement) ควบคู่กับการเปิดเผยตัวแปรเหล่านี้เป็นสิ่งสำคัญเพื่อยืนยันการประหยัดอย่างแท้จริง
โดยสรุป Green‑LLM Farm แสดงให้เห็นว่าแนวทางผสมผสานระหว่างการจัดหาไฟฟ้าจากแหล่งหมุนเวียนและการลดการคำนวณเชิงตัวเลขสามารถลดคาร์บอนฟุตพริ้นท์ของการฝึกโมเดลขนาดใหญ่ได้ในระดับที่มีนัยสำคัญ (ตัวอย่างการทดลองนี้คือ ประมาณ 70%) พร้อมกับลดต้นทุนพลังงานที่เกี่ยวข้อง ซึ่งเป็นข้อมูลเชิงปริมาณที่สำคัญสำหรับผู้บริหารและนักวางกลยุทธ์ด้าน AI ที่ต้องการผสานเป้าหมายด้านความยั่งยืนเข้ากับการพัฒนาโมเดล
การเปิด API สาธารณะ: การเข้าถึง การใช้งาน และกรณีตัวอย่าง
ภาพรวมบริการ API และสเปกหลัก
Green‑LLM Farm ให้บริการ API สาธารณะในรูปแบบทั้ง REST และ gRPC เพื่อรองรับการผสานรวมกับระบบที่หลากหลาย โดยสเปกพื้นฐานประกอบด้วย endpoint หลัก เช่น /v1/models (เรียกดูรายการโมเดล), /v1/infer (เรียกใช้งาน inference แบบเรียลไทม์), /v1/batch (งาน inference แบบกลุ่ม), และ /v1/fine_tune (ส่งงาน fine‑tuning) ส่วนรูปแบบข้อมูลรองรับ application/json สำหรับ payload ทั่วไป และ multipart/form-data สำหรับการอัพโหลดชุดข้อมูลขนาดใหญ่
โมเดลที่เปิดให้บริการถูกจัดเป็นกลุ่มตามความต้องการใช้งาน ได้แก่ green-llm-small (เบา ค่าทรัพยากรต่ำ), green-llm-base (ทั่วไป), และ green-llm-large-quant (โมเดลขนาดใหญ่ที่ถูก quantization เพื่อลดการใช้พลังงานและหน่วยความจำ) รวมถึงโมเดลสำหรับ fine‑tuning (green-llm-ft) โดยโมเดลขนาดใหญ่ที่ใช้พลังงานหมุนเวียนและเทคนิค quantization สามารถลดคาร์บอนฟุตพริ้นท์การฝึกโมเดลได้ถึง 70% เมื่อเปรียบเทียบกับการฝึกบนโครงสร้างพื้นฐานแบบดั้งเดิม
การยืนยันตัวตน (Auth) และฟอร์แมตการเรียกใช้งาน
การเข้าถึง API ต้องใช้ Bearer Token ที่ออกผ่านระบบบัญชีผู้ใช้ โดยผู้ใช้สามารถสร้างและจัดการ API keys ในหน้าแดชบอร์ด ส่วนการเรียกใช้งาน REST ตัวอย่าง Header สำคัญได้แก่ Authorization: Bearer <API_KEY> และ Content-Type: application/json สำหรับคำขอทั่วไป สำหรับ gRPC มีการแจกไฟล์ .proto พร้อมตัวอย่าง stub ใน SDK
นอกจากการเรียกแบบ synchronous แล้ว API ยังรองรับการส่งงานแบบ asynchronous สำหรับงานฝึกหรือ inference ขนาดใหญ่ ผู้ใช้จะได้รับ job_id เพื่อตรวจสถานะและเรียกผลลัพธ์ในภายหลัง ซึ่งช่วยให้ระบบภายนอกสามารถจัดคิวการประมวลผลและจัดการทรัพยากรได้อย่างมีประสิทธิภาพ
อัตราเรียกใช้ (Rate limits) และรูปแบบราคา (Pricing tiers)
เพื่อลดผลกระทบต่อสิ่งแวดล้อมและบริหารจัดการทรัพยากรอย่างมีประสิทธิภาพ Green‑LLM Farm กำหนดนโยบายอัตราเรียกใช้ดังนี้ (ตัวอย่างมาตรฐาน):
- Free Tier: สูงสุด 60 requests/นาที, ข้อจำกัด 100,000 tokens/เดือน
- Startup Tier: สูงสุด 600 requests/นาที, 1–5 ล้าน tokens/เดือน, ราคาเชิงจ่ายตามการใช้งาน (pay‑as‑you‑go)
- Enterprise Tier: อัตราเรียกใช้ที่กำหนดเอง (SLA), การสำรองทรัพยากร, IP allowlist และการสนับสนุนแบบ dedicated
- Research Grants / Academic Credits: แพ็กเกจสำหรับนักวิจัยที่รวมเครดิตการประมวลผล 200k–2M tokens และคิวพื้นที่สำหรับการทดลองซ้ำ โดยมีข้อเสนอพิเศษและการสนับสนุนด้านเทคนิค
ตัวอย่างโครงราคาอ้างอิง: generation เริ่มต้นที่ 0.0008 USD/1k tokens สำหรับโมเดลขนาดเล็ก และโมเดล quantized ขนาดใหญ่อาจมีราคาต่ำกว่าโมเดลเต็มรูปแบบประมาณ 30–50% เนื่องจากลดต้นทุนฮาร์ดแวร์และพลังงานจากเทคนิค quantization และการใช้พลังงานหมุนเวียน
เอกสาร API และ SDK
เอกสาร API แบบออนไลน์ (OpenAPI / gRPC proto) ให้รายละเอียด endpoint, โครงสร้าง request/response, error codes, ตัวอย่าง payload และแนวทางปฏิบัติที่ดีที่สุด รวมถึงรายละเอียดเกี่ยวกับการ monitor ค่าพลังงานและการคำนวณ carbon footprint ของแต่ละ job เพื่อโปร่งใสด้านสิ่งแวดล้อม
มีแพ็กเกจ SDK อย่างเป็นทางการสำหรับ Python, Node.js, และ Go ซึ่งรวมตัวอย่างการเรียกใช้งาน เช่น การส่งงาน fine‑tune, การเรียก inference แบบ batch และการดึงเมตริกการใช้พลังงาน ตัวอย่างการเรียก REST แบบเร็ว: curl -X POST "https://api.greenllm.farm/v1/infer" -H "Authorization: Bearer <API_KEY>" -d '{"model":"green-llm-base","prompt":"..."}' (รูปแบบโค้ดตัวอย่างเต็มอยู่ในเอกสาร)
ตัวอย่างการใช้งานเชิงปฏิบัติและกรณีตัวอย่าง
1) Fine‑tuning แบบ low‑cost
บริษัท e‑commerce ขนาดกลางในไทยเลือกใช้ green-llm-ft ร่วมกับ quantized checkpoints เพื่อฝึกโมเดลสำหรับงานตอบคำถามลูกค้าโดยเฉพาะ ผลลัพธ์คือค่าใช้จ่ายการฝึกต่อรุ่นลดลงประมาณ 40–60% เมื่อเทียบกับการฝึกบนโครงข่ายคลาวด์ทั่วไป และเวลาในการฝึกลดลงเนื่องจากการประหยัดหน่วยความจำที่มาจาก quantization
2) Inference แบบ batch สำหรับการวิเคราะห์ข้อความจำนวนมาก
องค์กรวิจัยการตลาดสร้าง pipeline แบบ batch เพื่อประมวลผลคอมเมนต์โซเชียลมีเดียหลายล้านข้อความต่อเดือน โดยใช้ endpoint /v1/batch และเลือกรันในช่วงเวลาที่มีพลังงานหมุนเวียนสูงสุด (ตามข้อมูล grid supply) ส่งผลให้ต้นทุนพลังงานต่อข้อความลดลงและได้ตัวชี้วัด carbon footprint ต่ำลงถึง 70% สำหรับส่วนที่ใช้ Green‑LLM Farm
3) การวิจัยที่ต้องฝึกซ้ำบ่อย ๆ
สถาบันการศึกษาได้รับเครดิตการใช้งานเพื่อทำ hyperparameter sweep และการทดลองซ้ำหลายรอบ การได้เครดิตและคิวงานเฉพาะช่วยให้สามารถทำการทดลอง 100+ ครั้งโดยไม่ต้องแบกรับต้นทุนเต็มรูปแบบ ผลการทดลองเผยว่าการใช้โมเดล quantized ช่วยรักษาความแม่นยำในระดับที่ยอมรับได้ ในขณะที่ลดการใช้พลังงานและต้นทุนอย่างมีนัยสำคัญ
ประโยชน์เชิงธุรกิจและสิ่งแวดล้อม
การเปิด API สาธารณะของ Green‑LLM Farm ช่วยให้องค์กรและนักพัฒนาสามารถเข้าถึงโมเดลขนาดใหญ่ที่เป็นมิตรกับสิ่งแวดล้อมได้อย่างมีค่าใช้จ่ายคุ้มค่า โดยรวมประโยชน์หลักได้แก่:
- ลดต้นทุนการฝึกและ inference ผ่าน quantization และการจัดสรรทรัพยากรตามการใช้งานจริง (ตัวอย่าง: ลดต้นทุนการฝึก 40–60%)
- ลดคาร์บอนฟุตพริ้นท์ ของงานฝึกโมเดลใหญ่ได้สูงสุดถึง 70% ด้วยการใช้พลังงานหมุนเวียนและนโยบาย scheduling
- เข้าถึงได้ทั้งฟรีและแบบชำระเงิน รองรับตั้งแต่โปรเจกต์ทดลองจนถึงการใช้งานเชิงพาณิชย์ขนาดใหญ่ พร้อมเครดิตสำหรับนักวิจัยและสตาร์ทอัพ
- ความยืดหยุ่นในการบูรณาการ ผ่าน REST/gRPC และ SDK หลายภาษา ทำให้การนำไปใช้ในระบบสารสนเทศองค์กรเป็นไปได้รวดเร็ว
สรุปแล้ว การเปิด API สาธารณะของ Green‑LLM Farm มุ่งเน้นให้ทั้งนักพัฒนา สตาร์ทอัพ และสถาบันวิจัย สามารถใช้งานโมเดลขนาดใหญ่ได้อย่างประหยัดและเป็นมิตรต่อสิ่งแวดล้อม พร้อมเครื่องมือการจัดการ ควบคุมการใช้งาน และแพ็กเกจราคาเพื่อตอบโจทย์ทุกขนาดองค์กร
โมเดลธุรกิจ ความร่วมมือ ความท้าทาย และทิศทางในอนาคต
โมเดลธุรกิจและช่องทางรายได้
สตาร์ทอัพที่เปิดบริการ Green‑LLM Farm สามารถดำเนินธุรกิจในรูปแบบผสมผสานเพื่อเพิ่มความยืดหยุ่นและการเติบโต ทั้งรูปแบบ B2B สำหรับลูกค้าองค์กรที่ต้องการเทรนหรือปรับจูนโมเดลขนาดใหญ่ด้วย SLA และการรับประกันเชิงพลังงาน, รูปแบบ B2B2C ที่ร่วมกับผู้ให้บริการซอฟต์แวร์เพื่อฝังฟีเจอร์ AI ลดคาร์บอนให้ลูกค้าปลายทาง, และ marketplace สำหรับขายหรือให้เช่าโมเดลที่ผ่านการฝึกด้วยพลังงานหมุนเวียนและการปรับ quantization แล้ว
ช่องทางรายได้สำคัญได้แก่
- API รายเดือน/Pay‑as‑you‑go สำหรับเรียกใช้งานโมเดลที่เทรนไว้และโมเดลที่ให้บริการแบบ inference
- Training‑as‑a‑Service (TaaS) รายงานและบริการจัดการการเทรนแบบครบวงจร รวมถึงการตั้งค่า quantization และ calibration
- Marketplace และ revenue‑share ให้ผู้พัฒนาอัปโหลดโมเดลที่เทรนบน Green‑LLM Farm และแบ่งรายได้จากการขายหรือให้เช่า
- บริการระดับองค์กร (Managed Services & Consulting) ได้แก่ การวางสถาปัตยกรรม การรับรองการลดคาร์บอน และการปรับแต่งมาตรการคุ้มครองข้อมูล
- พรีเมียมด้านความยั่งยืน การคิดค่าใช้จ่ายพิเศษสำหรับ SLA ด้านคาร์บอนต่ำหรือการออกใบรับรองการลดการปล่อยคาร์บอน
ความร่วมมือด้านพลังงานและการวิจัย
การสร้าง Green‑LLM Farm ที่มีประสิทธิภาพด้านคาร์บอนจำเป็นต้องอาศัยพันธมิตรหลายฝ่าย ทั้งผู้ผลิตพลังงานหมุนเวียน ผู้จัดหาแบตเตอรี่และระบบกักเก็บพลังงาน (storage) เพื่อรองรับการทำงานในช่วงที่พลังงานหมุนเวียนไม่เพียงพอ และสถาบันวิจัยที่ช่วยพัฒนาเทคนิคการ quantization และการวัดผลเชิงพลังงานอย่างเข้มข้น
- พันธมิตรด้านพลังงาน เช่น ผู้ให้บริการ PPA (Power Purchase Agreement), โรงไฟฟ้าพลังงานหมุนเวียน และผู้จัดการเครือข่ายไฟฟ้า เพื่อรับรองแหล่งพลังงานที่ใช้จริงและจัดการความผันแปรของ supply
- พันธมิตรด้านฮาร์ดแวร์และซอฟต์แวร์ ได้แก่ ผู้จำหน่ายชิป (GPU/TPU), ผู้ให้บริการระบบจัดเก็บและเครือข่าย เพื่อปรับจูนการใช้งาน quantized models ให้เกิดประสิทธิภาพสูงสุด
- สถาบันวิจัยและมหาวิทยาลัย ในการทำ benchmarking, การวิจัย quantization ขั้นสูง และการตีพิมพ์ผลลัพธ์เพื่อความโปร่งใสและความน่าเชื่อถือ
ความท้าทายด้านการตรวจสอบคำกล่าวอ้าง (verification), ความเป็นส่วนตัว และกฎระเบียบ
แม้จะมีการประกาศว่าลดคาร์บอนฟุตพริ้นท์การฝึกโมเดลได้ถึง 70% แต่การยืนยันตัวเลขดังกล่าวในเชิงวิทยาศาสตร์และกฎระเบียบเป็นเรื่องท้าทาย สตาร์ทอัพต้องรับมือกับประเด็นต่อไปนี้อย่างเป็นระบบ
- การตรวจสอบการลดคาร์บอน — จำเป็นต้องมีมาตรฐานการวัด (เช่น การคำนวณตามหลัก GHG Protocol และการรายงาน Scope 1–3) รวมถึงการตรวจสอบโดยผู้รับรองภายนอก เพื่อป้องกันข้อกล่าวหาเรื่อง greenwashing และเพื่อให้ข้อมูลสามารถเปรียบเทียบได้ในตลาด
- การคำนวณพลังงานสุทธิ — การนับเครดิตพลังงานหมุนเวียนต้องพิจารณาทั้งค่าเฉลี่ยกริดและการใช้พลังงานแบบ marginal/time‑matched เพื่อระบุว่าการฝึกเกิดขึ้นเมื่อใดและด้วยพลังงานประเภทใด
- ความเป็นส่วนตัวและการคุ้มครองข้อมูล — การรับข้อมูลลูกค้าเพื่อนำมาฝึกหรือปรับจูนต้องสอดคล้อง PDPA, GDPR และข้อกำหนดด้าน data residency; ต้องมีมาตรการเชิงเทคนิคเช่น encryption, differential privacy, และ secure enclaves
- ความเสี่ยงด้านคุณภาพโมเดลจาก quantization — การลดความละเอียดโมเดลเพื่อประหยัดพลังงานอาจกระทบประสิทธิภาพ จำเป็นต้องมีการทดสอบ benchmark และ calibration หลัง quantize เพื่อรับประกันคุณภาพ
- ความรับผิดชอบทางกฎหมาย — ข้อกำหนดด้านการเปิดเผยข้อมูลการฝึก การใช้งานข้อมูลที่อาจมีลิขสิทธิ์หรือข้อมูลส่วนบุคคล และการปฏิบัติตามนโยบายภายในประเทศหลายแห่งในการขยายธุรกิจระหว่างประเทศ
โรดแมปอนาคต: ขยายกำลังการผลิต เพิ่มบริการ และการรับรองภายนอก
แผนระยะกลางถึงยาวควรมีองค์ประกอบเชิงกลยุทธ์เพื่อรองรับการเติบโต ทั้งการเพิ่ม capacity, การขยายเชิงภูมิภาค และการยกระดับความน่าเชื่อถือผ่านการรับรองภายนอก
- Scale‑up สถาปัตยกรรม — ขยายศูนย์เทรนเพิ่มเติมในเขตที่มีสัดส่วนพลังงานหมุนเวียนสูงเพื่อกระจายความเสี่ยงและลด carbon intensity ของการเทรน
- Edge deployment และ model distillation — พัฒนาเวิร์คโฟลว์สำหรับ distill/quantize โมเดลให้เหมาะกับการนำไปรันที่ edge เพื่อลดค่าใช้จ่ายและ latency สำหรับแอปพลิเคชันที่ต้องการประสิทธิภาพขณะเดียวกันยังคงคอนเซปต์ความยั่งยืน
- การรับรองและการตรวจสอบภายนอก — ควรทำงานร่วมกับผู้รับรองมาตรฐานการปล่อยก๊าซเรือนกระจก และองค์กรตรวจสอบอิสระ เพื่อออกใบรับรองและทำ audit เป็นระยะ (ตัวอย่างเช่น การรับรองตามมาตรฐาน ISO ที่เกี่ยวข้อง หรือการตรวจสอบตามข้อกำหนดของหน่วยงานสิ่งแวดล้อม)
- แพลตฟอร์มโปร่งใส — พัฒนา dashboard แสดงการใช้พลังงานจริง, การลดคาร์บอนแบบ time‑matched, และรายงานการตรวจสอบ เพื่อสร้างความเชื่อมั่นให้ลูกค้าและหน่วยงานกำกับดูแล
- ความร่วมมือระหว่างประเทศ — ลงนามข้อตกลงกับศูนย์ข้อมูลและผู้ให้พลังงานต่างประเทศ โดยเฉพาะในตลาดที่มีสัดส่วนพลังงานหมุนเวียนสูง เพื่อขยายการให้บริการและลดความเสี่ยงทางกฎระเบียบเมื่อข้ามพรมแดน
- เพิ่มชุดบริการ — ขยายเป็นโซลูชันครบวงจร เช่น การขายเครดิตคาร์บอนเมื่อมีการลดจริง, บริการฝึกโมเดลด้วยข้อกำหนดด้านความเป็นกลางของคาร์บอน, และเครื่องมือ compliance สำหรับลูกค้าองค์กร
สรุปแล้ว การผลักดัน Green‑LLM Farm ให้เติบโตอย่างยั่งยืนนั้นต้องเดินควบคู่กันระหว่างโมเดลธุรกิจที่ยืดหยุ่น การสร้างพันธมิตรเชิงพลังงานและวิจัย การลงทุนในกระบวนการตรวจสอบที่โปร่งใส รวมถึงการออกแบบ roadmap ทางเทคนิคและกฎระเบียบที่ชัดเจน เพื่อให้ข้ออ้างเรื่องการลดคาร์บอนเป็นที่ยอมรับและสามารถขยายบริการได้ในระดับสากล
บทสรุป
Green‑LLM Farm เป็นกรณีศึกษาสำคัญที่แสดงให้เห็นว่าการผสานพลังงานหมุนเวียนกับเทคนิค quantization สามารถทำให้การเทรนโมเดลขนาดใหญ่ทั้งยั่งยืนและมีต้นทุนต่ำลงได้จริง — โครงการรายงานการลดคาร์บอนฟุตพริ้นท์ได้ถึง 70% เมื่อเทียบกับการเทรนแบบดั้งเดิม ด้วยการใช้แหล่งพลังงานจากแสงอาทิตย์และลม ผนวกกับการจัดการพลังงานผ่านแบตเตอรี่และการจัดตารางงาน (scheduling) ตามช่วงเวลาที่พลังงานสะอาดมีมาก รวมทั้งการนำเทคนิค quantization เช่น 8‑bit/4‑bit และ mixed‑precision มาใช้เพื่อลดการใช้หน่วยความจำและการคำนวณ โครงการยังชี้ให้เห็นว่าการแลกเปลี่ยนระหว่างประสิทธิภาพโมเดลกับการลดทรัพยากรสามารถจัดการได้อย่างสมดุล ทำให้ต้นทุนพลังงานและเวลาในการฝึกลดลงอย่างมีนัยสำคัญ (ระดับหลักสิบเปอร์เซ็นต์ในหลายกรณี) โดยยังรักษาคุณภาพผลลัพธ์ของโมเดลไว้ได้ในหลายงานตัวอย่าง
ความสำเร็จเชิงพาณิชย์และการขยายผลของ Green‑LLM Farm ขึ้นอยู่กับความโปร่งใสในการวัดผลและการตรวจสอบภายนอกเป็นสำคัญ — การนำมาตรฐานการบัญชีคาร์บอนเช่น GHG Protocol หรือ ISO 14064 มาใช้ร่วมกับการตรวจรับรองจากหน่วยงานอิสระจะช่วยสร้างความเชื่อมั่นแก่ผู้ใช้และนักลงทุน นอกจากนี้ การออกแบบ API สาธารณะ ที่เข้าถึงได้ (รองรับนักพัฒนา รูปแบบการเรียกใช้งานที่เป็นมาตรฐาน และโครงสร้างราคาแบบเทียร์) จะเป็นกุญแจสำคัญในการเร่งการยอมรับและการนำไปใช้ในวงกว้าง หากมีการรวมมาตรฐานการรายงาน การตรวจสอบโดยบุคคลที่สาม และนโยบายสนับสนุนจากภาครัฐ ผลงานนี้มีศักยภาพจะกลายเป็นต้นแบบที่นำไปคัดลอกได้ทั้งในระดับภูมิภาคและระดับโลก — โดยต้องคำนึงถึงอุปสรรคเช่นต้นทุนลงทุนเริ่มต้นและความผันผวนของพลังงานหมุนเวียน ซึ่งจำเป็นต้องมีกรอบนโยบายและเครื่องมือทางการเงินมาช่วยผลักดันต่อไป



