
สตาร์ทอัพไทยเปิดตัว "TinyFoundry" นวัตกรรมโมเดลพื้นฐานจิ๋วที่สามารถรันบนไมโครคอนโทรลเลอร์ (MCU) เพื่อวิเคราะห์เสียงและแรงสั่นสะเทือนของเครื่องจักรได้แบบออฟไลน์—เป็นการผสานเทคโนโลยีปัญญาประดิษฐ์ระดับสูงเข้ากับฮาร์ดแวร์ทรัพยากรจำกัด ทำให้การตรวจจับความผิดปกติเกิดขึ้นที่ขอบเครือข่าย (edge) แบบเรียลไทม์ ลดความล่าช้าและความเสี่ยงด้านความเป็นส่วนตัวเมื่อเทียบกับการส่งสัญญาณดิบขึ้นคลาวด์
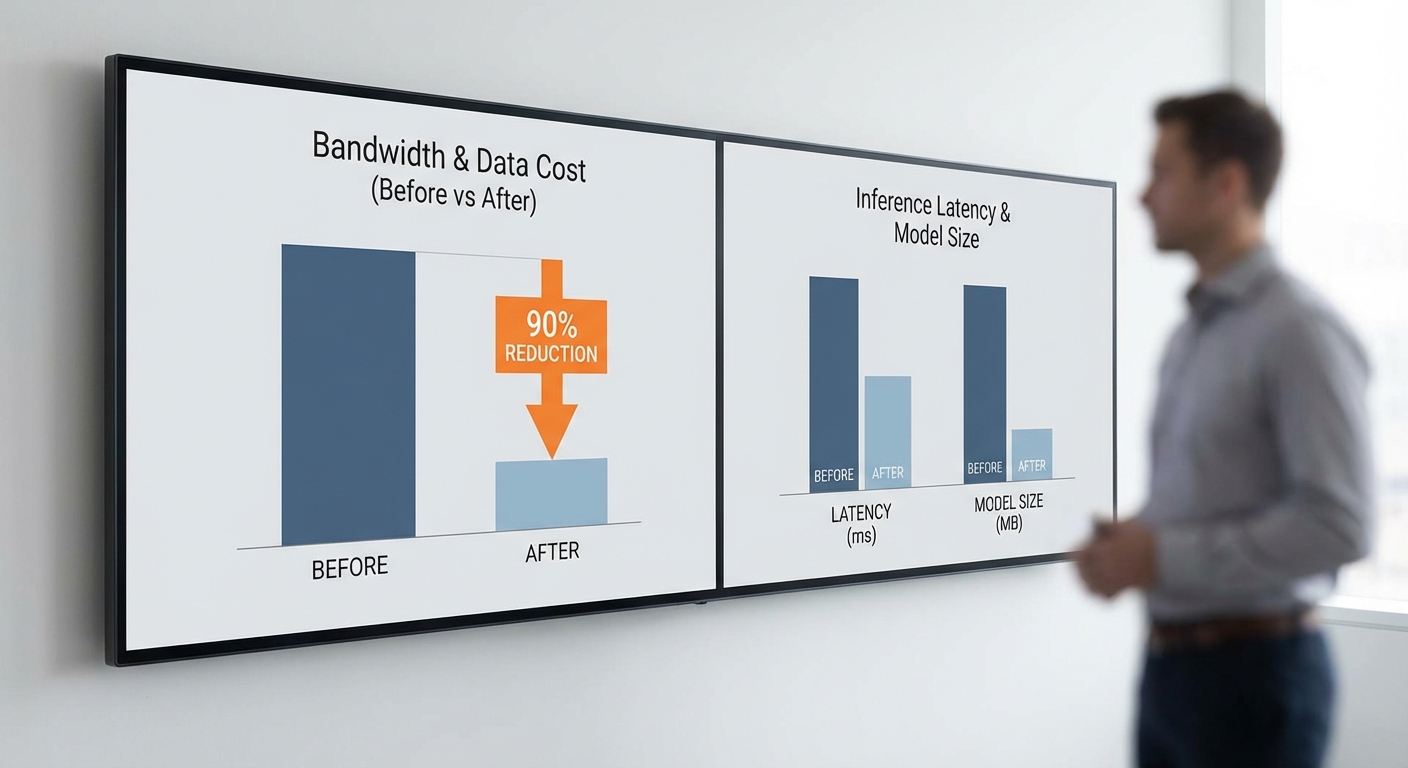
จุดเด่นสำคัญคือความสามารถในการคัดกรองเหตุผิดปกติก่อนส่งข้อมูล: TinyFoundry ช่วยลดการส่งข้อมูลและค่าใช้จ่ายด้านดาต้าได้มากกว่า 90% เหมาะอย่างยิ่งกับงาน predictive maintenance ในโรงงานและอุตสาหกรรมที่มีเซ็นเซอร์จำนวนมาก—ช่วยลดแบนด์วิดท์ ลดภาระการจัดเก็บบนคลาวด์ และสนับสนุนการตรวจจับข้อบกพร่องเร็วขึ้น ทำให้การบำรุงรักษาเป็นเชิงคาดการณ์และลดเวลาหยุดทำงานของเครื่องจักรได้อย่างมีประสิทธิภาพ

ภาพรวม: TinyFoundry คืออะไร ทำไมสำคัญ
ภาพรวม: TinyFoundry คืออะไร ทำไมสำคัญ
TinyFoundry เป็นผลิตภัณฑ์จากสตาร์ทอัพไทยที่นิยามตัวเองว่าเป็น tiny foundation model — โมเดลพื้นฐานขนาดจิ๋วที่ออกแบบเฉพาะเพื่อรันบนไมโครคอนโทรลเลอร์ (MCU) โดยมุ่งเน้นการวิเคราะห์สัญญาณเสียงและแรงสั่นสะเทือนของเครื่องจักรเพื่อคัดกรองความผิดปกติตั้งแต่ที่ขอบเครือข่าย (edge) แทนที่จะส่งข้อมูลดิบทั้งหมดขึ้นไปประมวลผลบนคลาวด์ จุดประสงค์หลักคือช่วยโรงงานและผู้ให้บริการด้านบำรุงรักษาลดปริมาณข้อมูลที่ต้องส่ง ลดค่าใช้จ่ายด้านแบนด์วิดท์ และเพิ่มความรวดเร็วในการตอบสนองต่อเหตุการณ์ผิดปกติ
ฟีเจอร์สำคัญของ TinyFoundry ประกอบด้วยการเป็น โมเดลขนาดเล็กที่เหมาะสมกับข้อจำกัดของ MCU สามารถรันบนฮาร์ดแวร์ที่มีหน่วยความจำและพลังงานจำกัด ใช้เทคนิคการบีบอัดโมเดล (model compression) และการประมวลผลเสียง/แรงสั่นสะเทือนที่ปรับแต่งมาเฉพาะสำหรับการตรวจจับ anomaly แบบเรียลไทม์ นอกจากนี้ระบบรองรับการทำงานแบบออฟไลน์เต็มรูปแบบ (on-device inference) ทำให้ไม่ต้องพึ่งการเชื่อมต่อเครือข่ายอย่างต่อเนื่องและยังคงทำงานได้แม้ในสภาพแวดล้อมที่การเชื่อมต่อไม่เสถียร
ข้อดีเชิงปฏิบัติของการรันโมเดลบน MCU มีหลายประการสำคัญ ได้แก่ ความหน่วงต่ำ (low latency) เนื่องจากการตัดสินใจเกิดที่อุปกรณ์ทันที, ความเป็นส่วนตัวและความปลอดภัย เพราะข้อมูลดิบไม่ถูกส่งออกไปยังคลาวด์, และ ความประหยัดพลังงานและต้นทุน เมื่อเทียบกับการส่งสตรีมข้อมูลความละเอียดสูงขึ้นไปยังศูนย์ข้อมูล ตัวทีม TinyFoundry ระบุว่าเมื่อใช้งานเพื่อตรวจจับความผิดปกติและคัดกรองเหตุการณ์เฉพาะที่สำคัญ ระบบสามารถช่วยลดปริมาณการส่งข้อมูลขึ้นคลาวด์ได้ถึง 90% ซึ่งแปลเป็นการประหยัดแบนด์วิดท์และค่าดาต้าที่ชัดเจนสำหรับโรงงานที่มีเซ็นเซอร์จำนวนมาก
กลุ่มเป้าหมายของ TinyFoundry ได้แก่ โรงงานอุตสาหกรรม โดยเฉพาะโรงงานขนาดกลางและขนาดย่อม (SME) ที่ต้องการโซลูชันคุ้มค่า, ผู้ให้บริการบำรุงรักษา (maintenance providers) ที่ต้องการระบบตรวจจับและแจ้งเตือนล่วงหน้าเพื่อป้องกันการหยุดการผลิต, และ system integrator ที่ต้องการผสานเทคโนโลยี edge AI เข้ากับโซลูชันการผลิตอัจฉริยะ ตัวอย่างการใช้งานจริงได้แก่ การตรวจจับการสึกหรอของตลับลูกปืนด้วยการวิเคราะห์เสียง, การประเมินความผิดปกติของมอเตอร์จากแรงสั่นสะเทือน, และการกรองสัญญาณรบกวนเบื้องต้นก่อนส่งข้อมูลสำคัญขึ้นระบบคลาวด์
เทคโนโลยีเบื้องหลัง: สถาปัตยกรรมโมเดลและแนวทาง TinyML
สถาปัตยกรรมโมเดลพื้นฐานจิ๋ว (Foundation Tiny Model) สำหรับสัญญาณเสียงและแรงสั่นสะเทือน
TinyFoundry ถูกออกแบบเป็นสถาปัตยกรรมแบบ shared encoder + multiple lightweight heads เพื่อรองรับทั้งสัญญาณเสียง (audio) และแรงสั่นสะเทือน (vibration) ด้วยโครงสร้างที่คำนึงถึงข้อจำกัดของไมโครคอนโทรลเลอร์ (MCU) เช่น หน่วยความจำ (RAM) ระหว่าง 64–512 KB และแฟลช 256 KB–2 MB โมเดลหลักเป็นตัวเข้ารหัสขนาดเล็กแบบ 1D-convolutional หรือ separable-conv ที่มีชั้น depthwise pointwise เพื่อให้ได้ receptive field ที่เพียงพอสำหรับลักษณะความถี่ของสัญญาณ แต่ยังคงจำนวนพารามิเตอร์ต่ำ (โดยทั่วไปโมเดล encoder ขนาด 50–300k พารามิเตอร์ ก่อนการบีบอัด)

โครงสร้างแบ่งเป็น
- Shared front-end: รับ feature vector ที่มาจากการประมวลผลเบื้องต้น (เช่น MFCC หรือ time-domain features) เพื่อเรียนรู้ representation ร่วมสำหรับทั้งสองโดเมน
- Domain adapters: บล็อกขนาดเล็กสำหรับปรับสเกลหรือถ่วงน้ำหนักระหว่างเสียงและแรงสั่นสะเทือน เพื่อรองรับความต่างของสเปกตรัม
- Task-specific heads: ส่วนหัวขนาดเล็กสำหรับงานต่าง ๆ เช่น การตรวจจับความผิดปกติ (binary anomaly detection), การจำแนกประเภทเสียง หรือการจำแนกโครงรอยแตกของแรงสั่นสะเทือน
เทคนิคการบีบอัดและเร่งประสิทธิภาพ: Quantization, Pruning และ Knowledge Distillation
เพื่อให้โมเดลรันได้บน MCU ขนาดเล็ก TinyFoundry นำชุดเทคนิคการบีบอัดหลายชั้นมารวมกัน:
- Quantization: ใช้ทั้ง quantization-aware training (QAT) และ post-training quantization (PTQ) เพื่อแปลงพารามิเตอร์เป็น integer formats เช่น int8 เป็นค่าเริ่มต้น และสำหรับกรณีจำกัดมาก ๆ จะทดสอบ int4 โดยใช้การปรับสเกลแบบ per-channel และ calibration dataset เล็ก ๆ การใช้ int8 มักลดขนาดโมเดลประมาณ 4× และ int4 ลดได้เพิ่มเติมจนถึง ~8× ขึ้นกับการจัดเก็บ
- Pruning: ใช้วิธีการแบบ iterative magnitude-based pruning และ structured pruning (เช่นช่องทาง/กริด) เพื่อลด FLOPs โดยคงประสิทธิภาพไว้ผ่านการฝึกซ้ำ (retraining) ตัวอย่างเช่นการตัด 50–70% ของพารามิเตอร์ด้วยการลดความแม่นยำเพียง 1–3% ในงานบางประเภท
- Knowledge Distillation: ฝึกโมเดลจิ๋วให้เรียนรู้จาก teacher model ขนาดใหญ่ (เช่น CNN หรือ Transformer สำหรับสเปกตรัม) โดยใช้ soft targets และค่า temperature ที่เหมาะสม เทคนิคนี้ช่วยให้โมเดลขนาดเล็กรักษาความสามารถเชิงเชิงบริบทได้ดี ขณะที่มีพารามิเตอร์น้อยลง ตัวอย่างเช่น การนำ distillation มาประยุกต์ใน TinyFoundry พบว่าสามารถคืนประสิทธิภาพได้ 90–98% ของ teacher ในขนาดเพียง 10–20% ของพารามิเตอร์
การสกัดคุณลักษณะ (Feature Extraction) แบบน้ำหนักเบา
เพื่อประหยัดทรัพยากร TinyFoundry เลือกใช้ชุดคุณลักษณะที่คำนึงถึงประสิทธิภาพบนฮาร์ดแวร์:
- Audio features: MFCC (13 coefficients โดยเพิ่ม delta + delta-delta เมื่อจำเป็น), log-mel spectrogram ที่ลดจำนวนแถบความถี่ (เช่น 16–32 bands) และการใช้ frame size/stride ที่ปรับให้สั้นลงเพื่อลดพิกัดหน่วยความจำ
- Vibration features: Time-domain (RMS, peak-to-peak, crest factor, zero-crossing rate), envelope, 그리고 spectral features เช่น spectral centroid, spectral rolloff และ cepstral coefficients รวมถึง spectral kurtosis สำหรับการค้นหาความผิดปกติเฉพาะทาง
- Hybrid approach: ในกรณีต้องการความยืดหยุ่น จะทำ front-end บนอุปกรณ์เพื่อสกัดคุณลักษณะพื้นฐาน (lightweight DSP) แล้วส่ง embedding แบบย่อไปยังโมเดลภายใน MCU หรือตัวประมวลผลระดับ gateway เพื่อประเมินเบื้องต้น
Pipeline การฝึกอบรมและการปรับจูน (Training & Fine-tune) ด้วยข้อมูลลูกค้า
กระบวนการฝึกของ TinyFoundry ถูกออกแบบเป็นชั้น ๆ เพื่อรองรับการเรียนรู้ล่วงหน้า (pretraining), การกลั่นความรู้ (distillation) และการปรับจูนเฉพาะลูกค้า (fine-tuning):
- Pretraining: ใช้ชุดข้อมูลขนาดใหญ่ผสมระหว่างเสียงอุตสาหกรรมและสัญญาณแรงสั่นสะเทือนจากหลายแหล่ง เพื่อเรียนรู้ representation พื้นฐาน ในขั้นตอนนี้ใช้โมเดลขนาดใหญ่บนคลาวด์ (teacher)
- Distillation + Pruning: นำ teacher มาช่วยสอนโมเดลจิ๋วด้วย loss ผสม (cross-entropy + KD loss) ทำ iterative pruning และ QAT ระหว่างการฝึกเพื่อให้โมเดลจิ๋วพร้อมสำหรับ deployment
- Fine-tune กับข้อมูลลูกค้า: กระบวนการ fine-tune ทำบนเซิร์ฟเวอร์ของลูกค้าหรือในคลาวด์ภายใต้ข้อกำหนดความเป็นส่วนตัว โดยใช้วิธีการต่อไปนี้เพื่อให้ใช้ข้อมูลจำนวนน้อยได้ผล:
- ปรับเฉพาะ task heads หรือ adapters ขนาดเล็กแทนการปรับน้ำหนักทั้งโมเดล
- ใช้ few-shot learning และ augmentation เข้มข้นเพื่อลดความต้องการข้อมูล
- ให้ตัวเลือกการส่งกลับเฉพาะโมเดลที่ถูกปรับ (delta weights) ขนาดเล็กแทนส่งข้อมูลดิบ ช่วยลดแบนด์วิดท์และความเสี่ยงด้านความเป็นส่วนตัว
การเตรียมข้อมูลและเทคนิคการ Augmentation สำหรับสัญญาณมีนอยส์
ในสภาพแวดล้อมอุตสาหกรรม สัญญาณมักปนด้วยนอยส์สูง TinyFoundry ใช้ชุดเทคนิคการเตรียมข้อมูลและ augmentation เพื่อลดความไวต่อสภาวะเสียงรบกวน:
- ระดับสัญญาณต่อเสียงรบกวน (SNR): ฝึกกับข้อมูลที่มี SNR หลากหลาย เช่น -5 dB ถึง +20 dB เพื่อให้โมเดลทนต่อสภาพจริงได้ดีขึ้น
- Augmentation เฉพาะทาง: สำหรับ audio — additive noise (เครื่องจักร, การทำงานของพัดลม), time-stretching (±10–20%), pitch-shifting เล็กน้อย, SpecAugment (time/frequency masking) เพิ่มความคงทนต่อการหายไปของแถบความถี่ ในขณะที่ vibration — random scaling, time-warping, sensor dropout simulation, channel mixing และการเพิ่ม harmonic/interference signals
- Domain randomization: ผสมค่าส่งสัญญาณจากเซ็นเซอร์หลายยี่ห้อเพื่อให้โมเดลทั่วไปและลด overfitting ต่อลักษณะฮาร์ดแวร์
- Data balancing และ rare-event synthesis: สำหรับเหตุการณ์ความผิดปกติที่เกิดน้อย ใช้เทคนิคการสังเคราะห์สัญญาณหรือ oversampling พร้อมกับ label smoothing เพื่อลด bias
โดยรวม TinyFoundry ผสานสถาปัตยกรรมที่เน้น shared representation, เทคนิคการบีบอัดหลายชั้น และกระบวนการฝึกที่ปรับให้เหมาะกับข้อจำกัดของ MCU ทำให้สามารถรันการวิเคราะห์เสียงและแรงสั่นสะเทือนแบบออฟไลน์ได้ภายใต้ขนาดโมเดลและ latency ที่เหมาะสม — ตัวอย่างเช่นการลดขนาดโมเดลได้ 4–10× และลดแบนด์วิดท์/ปริมาณข้อมูลส่งกลับได้ถึง ~90% เมื่อเทียบกับการส่ง raw waveform ขึ้นคลาวด์ ทั้งนี้ยังคงรักษาความแม่นยำในระดับที่ยอมรับได้สำหรับการคัดกรองความผิดปกติที่ขอบเครือข่าย
การรันบน MCU: ข้อจำกัดและกลวิธีการปรับแต่ง
การรันบน MCU: ข้อจำกัดและกลวิธีการปรับแต่ง
การนำโมเดลวิเคราะห์เสียงและแรงสั่นสะเทือนไปรันบนไมโครคอนโทรลเลอร์ (MCU) มีข้อจำกัดเชิงฮาร์ดแวร์ที่ชัดเจนซึ่งส่งผลต่อการออกแบบโมเดลทั้งด้านขนาด ความซับซ้อน และความเร็วตอบสนอง โดยข้อจำกัดสำคัญได้แก่ หน่วยความจำ RAM และ Flash ที่จำกัด (ทั่วไปอยู่ในช่วงประมาณ 32 KB – หลาย MB ขึ้นกับตระกูล เช่น MCU ตัวเล็กมักมี RAM 32–256 KB ขณะที่ Cortex‑M7/RT มักมี RAM หลายร้อย KB ถึงหลาย MB), ความสามารถของ CPU (clock และจำนวน cycles) ซึ่งมีผลโดยตรงต่อ latency ของการ inference และ ข้อจำกัดด้านพลังงาน เนื่องจากอุปกรณ์มักถูกวางให้ทำงานแบบออฟไลน์หรือติดตั้งในสภาวะแวดล้อมที่ต้องการอายุการใช้งานแบตเตอรี่นาน การออกแบบจึงต้องคำนึงถึงการใช้พลังงานเป็นสำคัญ (เช่น กระแสขณะทำงานอยู่ในระดับสิบถึงร้อยมิลลิแอมป์ ขึ้นกับคล๊อกและภาระงาน เป็นผลให้พลังงานต่อการ inference อยู่ในระดับสิบถึงหลายร้อยไมโจล-จูล ขึ้นกับขนาดโมเดลและการปรับแต่ง)
เพื่อให้โมเดล "จิ๋ว" ทำงานได้ภายใต้ข้อจำกัดเหล่านี้ จำเป็นต้องบูรณาการทั้งเทคนิคซอฟต์แวร์และฮาร์ดแวร์ดังนี้:
- การเลือกซีพียูและชุดคำสั่งที่เหมาะสม: เลือก MCU ที่มี DSP extensions หรือ FPU เช่น Cortex‑M4 (ด้วย FPU/DSP), Cortex‑M7, Cortex‑M33/M55 (Helium SIMD) ซึ่งช่วยลดจำนวน cycles ต่อ MAC และเพิ่มประสิทธิภาพการคำนวณสัญญาณ การมีหน่วยความจำแบบ tightly-coupled (Tightly Coupled Memory) หรือ cache ดีช่วยลด latency ของการดึงข้อมูลจาก Flash
- การใช้ชุดไลบรารีเฉพาะทาง: นำ CMSIS‑DSP/CMSIS‑NN หรือ TensorFlow Lite for Microcontrollers มาช่วยใช้คำสั่ง SIMD/DSP เพื่อเร่งการคำนวณ convolution/fully‑connected และลด footprint ของรันไทม์ ตัวอย่างเช่น CMSIS‑NN ช่วยเพิ่ม throughput ได้หลายเท่าเมื่อเทียบกับการรันแบบ pure C
- Quantization และ Pruning: ลด precision เป็น 8‑bit หรือ mixed‑precision (post‑training quantization) เพื่อลดขนาดโมเดลและความต้องการ RAM/Flash รวมถึงใช้ pruning/structured pruning เพื่อลดจำนวนพารามิเตอร์และ FLOPs โดยยังคงความไวในการตรวจจับด้วยการทำ fine‑tuning หรือ knowledge distillation
- Memory pooling และการจัดการบัฟเฟอร์: ใช้ memory arena และการจัดสรรแบบ static เพื่อลด fragmentation และ overhead ของ dynamic allocation; ใช้แบบ double buffering ร่วมกับ DMA สำหรับ ADC เพื่อให้การอ่านข้อมูลต่อเนื่องโดยไม่ขัดจังหวะ CPU และอนุญาตให้ CPU ทำ inference ขณะ DMA ย้ายข้อมูล
- การเร่งฮาร์ดแวร์/ไลบรารีพิเศษ: พิจารณา MCU ที่มี micro‑NPU หรือตัวเร่ง NN (เช่น ARM Ethos‑U หรือโซลูชันจากผู้ผลิตบางราย) หากต้องการ throughput สูงขึ้นโดยยังอยู่ในข้อจำกัดพลังงาน
นอกจากการลด footprint ของโมเดลแล้ว การปรับกลยุทธ์การเก็บตัวอย่าง (sampling strategy) และการออกแบบสถาปัตยกรรมการตรวจจับมีความสำคัญต่อการรักษาความไว (sensitivity) โดยไม่เพิ่มภาระการประมวลผล:
- Event‑driven sampling / wake‑on‑event: ใช้ฮาร์ดแวร์ตรวจจับเบื้องต้น (เช่น comparator, envelope detector หรือ low‑complexity feature detector) ที่ใช้พลังงานต่ำเพื่อตรวจหาเหตุการณ์น่าสงสัยแล้วค่อยปลุก MCU ให้ทำการประมวลผลเชิงลึก ลดการรันโมเดลในช่วงเวลาที่ไม่มีสัญญาณ
- Adaptive duty‑cycling: ปรับอัตราการเก็บตัวอย่างตามสภาวะ เช่น sampling ต่ำในช่วงเวลาที่ไร้เหตุการณ์และเพิ่มขึ้นเมื่อพบสัญญาณเบื้องต้น เทคนิคนี้สามารถลดการประมวลผลและการใช้พลังงานได้มาก โดยยังคงความไวหาก threshold ถูกตั้งอย่างรอบคอบ
- Feature extraction เบื้องต้นบนฮาร์ดแวร์: คำนวณฟีเจอร์เช่น MFCC, spectral band energy หรือ envelope บน MCU ด้วยอัลกอริทึมที่ถูก optimized (ใช้ Bit‑packed หรือ fixed‑point) แล้วส่งเฉพาะฟีเจอร์ไปให้ classifier ขนาดเล็กทำงาน แทนการส่ง waveform ดิบ ซึ่งช่วยลดความต้องการหน่วยความจำและแบนด์วิดท์
- การรันแบบไฮบริด/แบ่งชั้น: รันโมเดลขนาดเล็กบน MCU เพื่อคัดกรอง (edge screening) เมื่อพบความผิดปกติที่ระดับความเชื่อมั่นสูง จึงส่งข้อมูลหรือเฉพาะเหตุการณ์ไปยัง edge/cluster server สำหรับการวิเคราะห์เชิงลึก—วิธีนี้ลดการส่งข้อมูลได้มาก (ตัวอย่างในโปรเจกต์จริงลดแบนด์วิดท์และค่าดาตาได้ ~90%)
ตัวอย่าง MCU และเกณฑ์การเลือกเชิงปฏิบัติการ:
- เกณฑ์การเลือก: RAM ≥ 128 KB สำหรับระบบ NN รุ่นจิ๋วที่มีฟีเจอร์พื้นฐาน, Flash ≥ 512 KB–1 MB หากต้องการรวมไลบรารีและระบบ bootloader, มี FPU/DSP หรือ SIMD จะช่วยให้ latency ลดลง, มี DMA และ low‑power peripherals (ADC with DMA, event/power manager) และกระแสขณะ idle ต่ำ (สําหรับการ wake‑on‑event)
- ตัวอย่าง MCU ที่ใช้บ่อย:
- Cortex‑M4: STM32L4/STM32F4, NXP Kinetis – เหมาะกับแอปที่ต้องการประสิทธิภาพ DSP เบื้องต้น
- Cortex‑M7 / RT: STM32H7, NXP i.MX RT1060 – ให้ประสิทธิภาพสูงและ RAM/Flash มากขึ้น เหมาะกับโมเดลที่ซับซ้อนขึ้น
- Cortex‑M33 / M55: MCU ที่มี Helium SIMD extension ช่วยเร่ง NN และ DSP workloads ในขนาดและพลังงานที่เหมาะสม
- MCU พร้อม micro‑NPU: บางแพลตฟอร์มเริ่มมีตัวเร่ง NN แบบเบา (เช่น Ethos‑U) สำหรับ use case ที่ต้องการ throughput สูงแต่ยังคงข้อจำกัดด้านพลังงาน
สรุปคือ การรันโมเดลบน MCU จำเป็นต้องออกแบบแบบผสานทั้งการย่อขนาดโมเดล (quantization/pruning/distillation), การใช้ชุดคำสั่งและไลบรารีเร่งความเร็ว, การจัดการหน่วยความจำอย่างมีประสิทธิภาพ รวมถึงการออกแบบกลยุทธ์การเก็บตัวอย่างและระบบ wake‑on‑event ที่ชาญฉลาด เพื่อลดการประมวลผลและการใช้พลังงานโดยไม่ลดทอนความไวในการตรวจจับ — ซึ่งเป็นหัวใจสำคัญของ TinyFoundry ในการนำการตรวจจับความผิดปกติไปไว้ที่ขอบเครือข่ายอย่างมีประสิทธิผล
กรณีใช้งานจริง: การติดตั้งในโรงงานและตัวอย่างสถานการณ์
กรณีใช้งานจริง: การติดตั้งในโรงงานและตัวอย่างสถานการณ์
การนำ TinyFoundry ไปติดตั้งในสายการผลิตสามารถทำได้โดยมุ่งเน้นอุปกรณ์ที่มีความเสี่ยงสูงต่อความล้มเหลวเช่น มอเตอร์ปั๊ม (motor pump), คอมเพรสเซอร์, และสายพานลำเลียง (conveyor belt) ซึ่งแต่ละประเภทมีลักษณะสัญญาณเสียงและแรงสั่นสะเทือนเฉพาะที่บ่งชี้ปัญหา เช่น แบริ่งชำรุด (bearing fault), การถ่วงไม่สมดุล (imbalance), หรือการเยื้องศูนย์ (misalignment) โดยทั่วไปการติดตั้งประกอบด้วยการวางเซนเซอร์ในตำแหน่งสำคัญ การรัน inference บนอุปกรณ์ (MCU) เพื่อตรวจคัดกรองแบบออฟไลน์ แล้วจึงส่งข้อมูลเฉพาะกรณีผิดปกติขึ้นเครือข่ายเพื่อลดแบนด์วิดท์และค่าใช้จ่ายด้านดาต้าได้ถึง 90% เมื่อเทียบกับการส่งสตรีมเต็มรูปแบบตลอดเวลา
ตัวอย่างจุดติดตั้งและคำแนะนำเชิงปฏิบัติ:
- มอเตอร์ปั๊ม: ติดตั้ง accelerometer บริเวณ housing ใกล้แบริ่ง และไมโครโฟน (หากต้องการเสียง) ใกล้ตัวเครื่องหรือท่อทางออก เพื่อจับแพทเทิร์นความถี่สูงที่บ่งชี้ปัญหาแบริ่งหรือ cavitation
- คอมเพรสเซอร์: ติดเซนเซอร์แรงสั่นสะเทือนที่ mounting foot และบริเวณ coupling เพื่อแยกสัญญาณจาก imbalance หรือ misalignment รวมทั้งเก็บเสียงที่จุดดูดและจุดพ่นเพื่อวิเคราะห์สภาพวาล์วและวัฏจักร
- สายพานลำเลียง: ติด accelerometer ที่ idler bearings และ proximity sensor ที่จุดรับ-ส่งสินค้า เพื่อตรวจจับการสั่นผิดปกติจากลูกกลิ้งเสียหรือการตั้งแนวไม่ตรง
flow การทำงานเชิงปฏิบัติสำหรับแต่ละโหนดจะประกอบด้วยขั้นตอนสำคัญดังนี้:
- Sensing: ตัวเซนเซอร์ (accelerometer/microphone) รวบรวมสัญญาณในรูปแบบ time-series โดยทั่วไปใช้ sampling rate ประมาณ 2–16 kHz ขึ้นกับชนิดสัญญาณและย่านความถี่ที่สนใจ — ตัวอย่างเช่น vibration สำหรับแบริ่งอาจเก็บที่ 4–8 kHz ขณะที่เสียงของคอมเพรสเซอร์อาจใช้ 8–16 kHz
- On-device inference: สตรีมข้อมูลถูกประมวลผลบน MCU โดย TinyFoundry ทำการแยกคุณลักษณะ (เช่น spectral features, envelope, MFCCs แบบสังเขป) และคำนวณคะแนนความผิดปกติ (anomaly score) แบบเรียลไทม์ ภายใน latency ต่ำ (ตัวอย่างเช่น <100 ms ต่อหน้าต่างสัญญาณ) เพื่อให้สามารถตอบสนองได้ทันที
- Local filtering: การตั้งค่า threshold หรือระบบ hysteresis บนโหนดใช้เพื่อกรอง false positives — เฉพาะเมื่อ anomaly score เกินเกณฑ์ (เช่น >0.7) ต่อเนื่องตามหน้าต่างเวลาที่กำหนด (เช่น 3–5 วินาที) โหนดจะบันทึก buffer สั้นและเตรียม payload
- Selective uplink: เฉพาะแพ็กเกจเมตา (timestamp, device ID, anomaly score, short compressed clip 2–10 วินาที หรือ extracted features) จะถูกส่งขึ้นระบบคลาวด์หรือระบบ CMMS ผ่าน MQTT/HTTP/OPC-UA ซึ่งลดปริมาณข้อมูลลงได้ถึง 90% เมื่อเทียบกับการส่งสตรีมต่อเนื่อง
การเชื่อมต่อกับระบบบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) และ CMMS/แพลตฟอร์มคลาวด์มีขั้นตอนปฏิบัติที่ชัดเจน:
- เมื่อโหนดส่ง alert ระบบคลาวด์จะทำการรับข้อมูล meta และตัวอย่างสั้น ๆ เพื่อทำการยืนยันหรือตรวจสอบเพิ่มเติมโดยโมเดลระดับคลาวด์ (optional) และสร้าง work order อัตโนมัติใน CMMS พร้อม priority และคำอธิบายความผิดปกติ
- การผสานสามารถทำผ่าน API มาตรฐาน: ข้อมูลที่ส่งรวมถึง device ID, machine tag, anomaly score, confidence, และ artifact ที่บีบอัดเพื่อให้ทีมช่างสามารถเข้าดูรายละเอียดก่อนลงพื้นที่
- ระบบสามารถตั้งค่า escalation workflows: หาก score สูงกว่าระดับวิกฤตหรือมีการ report ซ้ำภายในช่วงเวลาสั้น ระบบจะเปิด ticket แบบ urgent และแจ้งผู้รับผิดชอบทางอีเมลหรือ SMS
ประโยชน์เชิงธุรกิจที่วัดผลได้จากการนำ TinyFoundry มาใช้ ได้แก่การตรวจจับล่วงหน้าที่เพิ่มขึ้น ส่งผลให้ ลด downtime ที่ไม่คาดคิดได้ถึง 30–40% และลดค่าใช้จ่ายการบำรุงรักษาแบบฉุกเฉินประมาณ 20–30% จากการเปลี่ยนไปเป็นกิจกรรมเชิงคาดการณ์มากขึ้น ตัวอย่างเช่น ในโรงงานลำเลียงอาหารหนึ่งแห่ง การติดตั้งโหนดบนสายพานหลัก 50 จุดช่วยลดการส่งช่างฉุกเฉินจาก 12 ครั้ง/ไตรมาส เหลือ 4 ครั้ง/ไตรมาส พร้อมกับประหยัดแบนด์วิดท์และต้นทุนคลาวด์รวมกันมากกว่า 90% เมื่อเทียบกับสตรีมมิงข้อมูลเต็มรูปแบบ
สรุปแล้ว การปรับใช้ TinyFoundry ในโรงงานประกอบด้วยการวางเซนเซอร์ในตำแหน่งเชิงกลยุทธ์ การรันโมเดล anomaly detection บน MCU เพื่อคัดกรองข้อมูลภายในตัวเครื่อง และการส่งเฉพาะเหตุการณ์ที่มีนัยสำคัญไปยังระบบคลาวด์หรือ CMMS ซึ่งโมเดลพื้นฐานจิ๋วที่รันบน MCU ช่วยให้ได้มุมมองเชิงลึกแบบเรียลไทม์ ลดค่าใช้จ่ายด้านเครือข่าย และยกระดับการบำรุงรักษาเชิงคาดการณ์อย่างมีประสิทธิภาพ
ผลการทดสอบเชิงปริมาณ: ประสิทธิภาพ ความแม่นยำ และการประหยัดค่าใช้จ่าย
ผลการทดสอบเชิงปริมาณ: ประสิทธิภาพ ความแม่นยำ และการประหยัดค่าใช้จ่าย
การทดสอบเชิงปริมาณของ TinyFoundry ดำเนินการทั้งในห้องปฏิบัติการและภาคสนามกับเครื่องจักรในโรงงานจริง เพื่อวัดทั้งตัวชี้วัดด้านความแม่นยำ (precision, recall, F1), อัตราเตือนผิดพลาด (false positive rate), ประสิทธิภาพเชิงเวลา (latency) และการใช้พลังงานต่อการทำ inference รวมถึงผลกระทบด้านเครือข่ายและค่าใช้จ่ายตามที่สตาร์ทอัพรายงาน ผลลัพธ์ชี้ให้เห็นว่าโมเดลขนาดจิ๋วสามารถให้การคัดกรองความผิดปกติที่ระดับขอบเครือข่ายได้อย่างมีประสิทธิผล พร้อมลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ถึง 90% และลดค่าใช้จ่ายการรับส่ง/จัดเก็บข้อมูลได้ราว 90% เมื่อเทียบกับการส่งสัญญาณดิบ (raw waveform) ทั้งหมดขึ้นไปประมวลผลบนคลาวด์
ตัวอย่างตัวชี้วัดจากการทดสอบจริง (รวมทั้งการทดสอบกับสัญญาณเสียงและแรงสั่นสะเทือน):
- Precision: 92%–96% (ขึ้นกับเวอร์ชันโมเดลและสภาพแวดล้อม) — ตัวอย่าง: TinyFoundry‑L (ขนาดกลาง) ให้ precision ≈ 96%
- Recall: 88%–94% — ตัวอย่าง: TinyFoundry‑L ให้ recall ≈ 94%
- F1-score: 90%–95% — ตัวอย่าง: TinyFoundry‑L ให้ F1 ≈ 95%
- False positive rate (FPR): 2%–6% ขึ้นกับการตั้งค่า threshold; ในการติดตั้งภาคสนามทั่วไปอยู่ราว 3%–4%
เพื่อแสดงความหลากหลายของการปรับแต่งสำหรับ MCU ที่ต่างกัน ทีมงานรายงานช่วงของขนาดโมเดล, latency และการใช้พลังงานต่อหนึ่ง inference ดังนี้:
- ขนาดโมเดล (หลัง quantization 8‑bit): ประมาณ 50 KB – 500 KB โดยโมเดลที่เล็กสุดเหมาะกับ MCU ระดับต่ำ ส่วนเวอร์ชันที่แม่นยำสูงขึ้นจะอยู่ในช่วง 150–320 KB
- Latency ต่อ inference: ประมาณ 8 ms – 60 ms (ขึ้นกับความถี่นาฬิกาและคอร์ของ MCU) — ตัวอย่าง: TinyFoundry‑L ปฏิบัติการได้ ≈ 12 ms/inference บน Cortex‑M7 ที่ความถี่ปานกลาง
- การใช้พลังงานต่อ inference: ประมาณ 0.5 mJ – 5 mJ — ตัวอย่าง: TinyFoundry‑L ประมาณ 0.9–1.5 mJ/inference ขณะที่เวอร์ชันจิ๋วบน MCU ระดับต่ำอาจใช้ถึง 3–5 mJ/inference
การเทสต์เชิงเปรียบเทียบ “ก่อน vs หลัง” การใช้ TinyFoundry แสดงผลลัพธ์เชิงปริมาณที่ชัดเจนสำหรับเครือข่ายและค่าใช้จ่าย ตัวอย่างเปรียบเทียบมาตรฐาน:
- ก่อนติดตั้ง (ส่งข้อมูลดิบ): เซนเซอร์ 200 ตัว ส่งสัญญาณเสียง/แรงสั่นสะเทือนที่ 8 kHz, 16‑bit → ประมาณ 128 kbps/เซนเซอร์ → รวม ≈ 25.6 Mbps (≈ 270 GB/วัน ≈ 8.1 TB/เดือน)
- หลังใช้ TinyFoundry (คัดกรองที่ขอบเครือข่าย): ส่งเฉพาะเหตุการณ์ผิดปกติเป็นแพ็กเก็ตสรุป (ตัวอย่าง 1 KB ต่อเหตุการณ์) โดยอัตราเหตุการณ์จริงหลังคัดกรอง ≈ 0.1% ของข้อมูลดิบ → ปริมาณข้อมูลลดลง ≈ 90% → เหลือ ≈ 0.81 TB/เดือน
- ผลกระทบด้านค่าใช้จ่ายตัวอย่าง: สมมติค่า ingress/จัดเก็บข้อมูลคลาวด์ที่ $0.09/GB → ค่าใช้จ่ายก่อน ≈ $729/เดือน → หลัง ≈ $72.9/เดือน → ประหยัด ≈ $656/เดือน (≈ 90%)
ตัวอย่างคำนวณ ROI สำหรับโรงงาน (สมมติการติดตั้ง 200 เซนเซอร์):
- ค่าใช้จ่ายก่อนติดตั้ง (รายเดือน) — ค่ารับส่ง/จัดเก็บข้อมูล ≈ $729
- ค่าใช้จ่ายหลังติดตั้ง — ค่ารับส่ง/จัดเก็บข้อมูล ≈ $73
- การประหยัดสุทธิ ≈ $656/เดือน (≈ $7,872/ปี)
- สมมติค่าใช้จ่ายการติดตั้ง TinyFoundry (รวมฮาร์ดแวร์ edge, license และ integration) ต่อเซนเซอร์ ≈ $50 → ต้นทุนติดตั้งรวม ≈ $10,000
- ระยะเวลาคืนทุน (payback period) ≈ $10,000 / $7,872 ≈ 1.3 ปี
ข้อสังเกตเพิ่มเติม: แม้ TinyFoundry จะลดปริมาณข้อมูลและค่าใช้จ่ายได้ชัดเจน แต่การตั้งค่า threshold และกลยุทธ์การรายงานมีผลต่อ precision/recall และอัตรา false positive โดยตรง โรงงานที่ต้องการลด false alarm มากขึ้นอาจเลือกเวอร์ชันโมเดลขนาดใหญ่ขึ้น (trade‑off กับหน่วยความจำและ latency) ขณะที่สถานการณ์ที่ต้องการประหยัดพลังงานสูงสุดสามารถเลือกเวอร์ชันเล็กสุดได้ โดยทีมงานมีชุดเครื่องมือสำหรับปรับจูน threshold และ quantization เพื่อให้สอดคล้องกับข้อกำหนดด้านการดำเนินงานและค่าใช้จ่าย
การผสานระบบ ความปลอดภัยข้อมูล และโมเดลธุรกิจ
การผสานระบบและรูปแบบการเชื่อมต่อ (Selective Uplink)
TinyFoundry ถูกออกแบบให้ทำงานเป็นชั้นวางโมเดลพื้นฐานที่ทำการคัดกรองความผิดปกติได้เองบน MCU ก่อนส่งข้อมูลขึ้นสู่คลาวด์หรือแพลตฟอร์มการจัดการ เพื่อลดแบนด์วิดท์และค่าใช้จ่ายด้านดาต้าโดยรวมประมาณ 90% โครงสร้างการเชื่อมต่อที่แนะนำประกอบด้วยตัวเลือกหลัก 2 แบบ ได้แก่ การเชื่อมต่อผ่าน Gateway ท้องถิ่น และการเชื่อมต่อโดยตรงผ่านโปรโตคอลเบา เช่น MQTT หรือ HTTPS สำหรับกรณีใช้งานอุตสาหกรรมทั่วไป:
- Selective uplink แบบเหตุการณ์ (Event-driven): อุปกรณ์ส่งเฉพาะเหตุการณ์ที่ผ่านเกณฑ์ (anomaly alerts, severity score, timestamp) และตัวชี้วัดเชิงสรุป เช่น feature vectors ขนาดเล็กหรือค่าเชิงสถิติ เพื่อให้คลาวด์ทำการเก็บหรือวิเคราะห์เพิ่มเติมเฉพาะช่วงเวลาที่จำเป็น
- Periodic summary และ heartbeat: ส่งสรุปสถานะเป็นช่วงเวลาที่กำหนด (เช่น ทุกชั่วโมงหรือวันละหนึ่งครั้ง) เพื่อใช้ในการมอนิเตอร์สุขภาพของอุปกรณ์โดยไม่ต้องอัปโหลดสตรีมเสียงหรือข้อมูลดิบอย่างต่อเนื่อง
- On-demand retrieval: กรณีต้องการข้อมูลดิบเพื่อการวิเคราะห์สาเหตุ (root-cause) ระบบสามารถร้องขอเฉพาะคลิปสั้นหรือข้อมูลเวฟฟอร์มที่มีการคัดเลือกและยอมรับจากนโยบายความเป็นส่วนตัว
- Gateway-based protocol translation: Gateway สามารถรวมข้อมูลจากหลาย MCU ทำหน้าที่เป็นตัวกลางที่จัดการ QoS, batching, และ caching ก่อนใช้ MQTT/HTTPS ไปยังคลาวด์ ช่วยลดจำนวนการเชื่อมต่อแบบตรงและสนับสนุนการจัดการแบบรวมศูนย์
แนวทางด้านความปลอดภัยและความเป็นส่วนตัวเมื่อประมวลผลที่ขอบเครือข่าย
เมื่อการประมวลผลเกิดขึ้นที่ขอบเครือข่าย แนวทางด้านความปลอดภัยต้องครอบคลุมตั้งแต่ฮาร์ดแวร์จนถึงคลาวด์เพื่อป้องกันการรั่วไหลของข้อมูลและการปลอมแปลงสัญญาณ ตัวอย่างแนวปฏิบัติที่สำคัญได้แก่:
- Data minimization: ส่งเฉพาะผลลัพธ์ (anomaly flag, score, compressed features) แทนการส่งข้อมูลดิบ เช่น TinyFoundry สามารถส่งเพียง 1–5 KB ต่อเหตุการณ์ แทนการส่งสตรีมเสียงหลายเมกะไบต์
- On-device anonymization และ aggregation: ทำการลบหรือแมสก์ข้อมูลที่สามารถระบุตัวบุคคลได้ (เช่นเสียงคน) โดยใช้เทคนิคเช่นเสียงสะกดทับ (voice masking), hashing ของเมตริกซ์ และการคำนวณสถิติรวมก่อนส่งข้อมูล
- Encryption และ mutual authentication: ใช้มาตรฐานเช่น TLS 1.2/1.3 หรือ DTLS สำหรับการส่งข้อมูลแบบ UDP, การเข้ารหัส payload ด้วย AES-256 และการพิสูจน์ตัวตนแบบ mutual TLS หรือการใช้ X.509 certificates เพื่อให้แน่ใจว่าอุปกรณ์สื่อสารกับเซิร์ฟเวอร์ที่เชื่อถือได้
- Hardware-backed key storage และ secure boot: เก็บกุญแจคริปโตใน Secure Element หรือ TEE, ใช้ secure boot และ signed firmware เพื่อป้องกันการฝังซอฟต์แวร์ที่เป็นอันตราย และรองรับการอัปเดตซอฟต์แวร์ผ่าน OTA ที่ลงนามดิจิทัล
- Encryption of alerts and selective logging: แม้แต่แจ้งเตือนที่ส่งขึ้นคลาวด์ควรเข้ารหัสและมีนโยบายล็อกที่จำกัดการเข้าถึง พร้อมระบบ audit trail เพื่อให้สามารถตรวจสอบการกระทำและตอบสนองต่อเหตุการณ์ความปลอดภัยได้
- Key rotation และ lifecycle management: วางแผนการเปลี่ยนกุญแจเป็นระยะ การเพิกถอนคีย์ และการจัดการสถานะของอุปกรณ์เมื่อถูกนำออกจากงาน (decommissioning)
โมเดลธุรกิจที่เป็นไปได้และข้อเสนอเชิงพาณิชย์
TinyFoundry สามารถรองรับโมเดลรายได้หลายรูปแบบที่สอดคล้องกับผู้ให้บริการระบบและผู้ผลิตอุปกรณ์อุตสาหกรรม โดยจัดรูปแบบเป็นแพ็กเกจเพื่อตอบโจทย์ทั้ง OEM, ผู้ให้บริการบำรุงรักษา และลูกค้าโรงงาน:
- License per device (one-time / recurring): ขายไลเซนส์สำหรับโมเดลที่ติดตั้งบน MCU แบบจ่ายครั้งเดียวหรือแบบต่ออายุปีต่อปี เหมาะกับ OEM ที่ต้องการฝังฟีเจอร์ลงในเครื่องจักรตั้งแต่ต้น
- SaaS สำหรับการวิเคราะห์และแดชบอร์ด: ให้บริการคลาวด์วิเคราะห์ข้อมูลเชิงพฤติกรรม อำนวยความสะดวกในการมอนิเตอร์รวมถึงการแจ้งเตือนแบบเรียลไทม์ คิดค่าบริการแบบรายเดือนหรือคิดตามปริมาณเหตุการณ์ (per-event pricing)
- Integration & managed services: บริการติดตั้ง, ปรับแต่ง, เชื่อมต่อกับระบบ SCADA/CMMS และการบริหารจัดการอุปกรณ์แบบครบวงจร (รวม OTA, security management) โดยคิดค่าแรงงานหรือสัญญาบริการระยะยาว
- Outcome-based contracts: ข้อเสนอเช่นแบ่งรายได้จากการลดเวลาเครื่องหยุดทำงาน (pay-per-uptime หรือ pay-per-avoided-failure) ซึ่งลูกค้าอุตสาหกรรมมักยินดีจ่ายเมื่อตัวชี้วัด ROI ชัดเจน — ตัวอย่างเช่น หากลดชั่วโมงหยุดทำงานได้ 30% ต่อปี ลูกค้าสามารถคำนวณต้นทุนที่ประหยัดเพื่อนำไปชดเชยค่าบริการ
- White-labeling และ OEM partnerships: ให้สิทธิ์ผู้ผลิตนำ TinyFoundry ไปติดตั้งภายใต้แบรนด์ของตน พร้อมสัญญาการสนับสนุนทางเทคนิคและอัปเดตโมเดล
ประเด็นทางกฎหมายและการปฏิบัติตามข้อกำหนดในภาคอุตสาหกรรม
การนำ TinyFoundry ไปใช้ในสภาพแวดล้อมอุตสาหกรรมต้องพิจารณากฎระเบียบและมาตรฐานหลายด้านเพื่อรับประกันความปลอดภัยและความสอดคล้องทางกฎหมาย:
- PDPA (ประเทศไทย) และกฎคุ้มครองข้อมูลส่วนบุคคลอื่นๆ: หากข้อมูลที่ประมวลผลอาจระบุบุคคลได้ ต้องมีพื้นฐานทางกฎหมายสำหรับการประมวลผล เช่น การยินยอมหรือการปฏิบัติตามสัญญา TinyFoundry ควรออกแบบให้รองรับการขอความยินยอมและการลบข้อมูลตามคำขอ
- มาตรฐานความปลอดภัยข้อมูลและอุตสาหกรรม: การปฏิบัติตาม ISO 27001, IEC 62443 (สำหรับ OT/ICS) และการพิจารณา FIPS/crypto certifications หากต้องการใช้ในหน่วยงานที่มีข้อกำหนดเข้มงวด
- ข้อกำหนดด้านความปลอดภัยของเครื่องจักร: ในบางอุตสาหกรรม อาจจำเป็นต้องสอดคล้องกับ IEC 61508/ISO 13849 เมื่อระบบวิเคราะห์เสียงหรือแรงสั่นสะเทือนถูกใช้เพื่อการตัดสินใจที่เกี่ยวข้องกับความปลอดภัยของเครื่องจักร
- Data residency และการแบ่งปันข้อมูล: ลูกค้าบางรายมีนโยบายว่าข้อมูลต้องเก็บในศูนย์ข้อมูลภายในประเทศ ต้องมีตัวเลือกให้ไดเร็กต์อัพโหลดไปยังภูมิภาคเฉพาะหรือ gateway ท้องถิ่น
- สัญญา SLA, liability, และ breach notification: ระบุชัดเจนครอบคลุมประเด็นความรับผิดชอบกรณีการวิเคราะห์ผิดพลาด เวลาให้บริการ และขั้นตอนการแจ้งเหตุการณ์เมื่อเกิดการละเมิดข้อมูล
สรุปแล้ว การผสาน TinyFoundry เข้ากับระบบคลาวด์หรือแพลตฟอร์มการจัดการควรยึดหลัก ส่งเฉพาะสิ่งที่จำเป็น (data minimization) และใช้กลไกความปลอดภัยเช่นการเข้ารหัสแบบ end-to-end, hardware-backed keys, และการอำพรางข้อมูลบนอุปกรณ์ ร่วมกับโมเดลธุรกิจที่ยืดหยุ่นทั้งแบบไลเซนส์, SaaS, และบริการแบบมืดถึงมือ เพื่อให้ตอบโจทย์ทั้งเรื่องต้นทุน ประสิทธิภาพ และการปฏิบัติตามกฎระเบียบสำหรับภาคอุตสาหกรรม
ข้อจำกัด ความเสี่ยง และทิศทางการพัฒนาในอนาคต
ข้อจำกัด ความเสี่ยง และทิศทางการพัฒนาในอนาคต
แม้ TinyFoundry จะนำเสนอข้อได้เปรียบด้านการรันโมเดลพื้นฐานขนาดเล็กบน MCU เพื่อลดแบนด์วิดท์และค่าดาต้าได้มากถึง ประมาณ 90% ในการคัดกรองความผิดปกติที่ขอบเครือข่าย แต่ผู้ใช้งานต้องตระหนักถึงข้อจำกัดเชิงเทคนิคที่สำคัญก่อนการนำไปใช้งานจริง ได้แก่ ข้อจำกัดของหน่วยความจำและคอมพิวต์บน MCU (เช่น โมเดลที่ต้องจุอยู่ในแฟลชขนาดเฉลี่ย 60–256 KB และใช้ RAM ต่ำกว่า 64 KB), ขอบเขตความถี่ของสัญญาณที่สามารถวิเคราะห์ได้ (ไมโครโฟนหรือแอคเซเลอโรมิเตอร์ที่ sampling rate ต่ำจะจำกัดการตรวจจับความถี่สูง) และผลกระทบจากการบีบอัดหรือถ่ายโอนโมเดล (quantization/pruning) ที่อาจลดความแม่นยำของการจำแนกตัวอย่าง เมื่อต้องรับสัญญาณจากสภาพแวดล้อมที่หลากหลายหรือมีการเปลี่ยนแปลงแบบไม่คาดคิด ความแม่นยำของโมเดลอาจลดลงได้อย่างมีนัยสำคัญ (งานภาคสนามระบุการลดของ accuracy ในช่วง 10–30% ในกรณี domain shift ที่รุนแรง หากไม่มีการปรับแต่งเพิ่มเติม)
ในเชิงความเสี่ยงทางการปฏิบัติ (operational risks) ประเด็นสำคัญที่ต้องประเมินได้แก่ความเสี่ยงของ false positives และ false negatives — โดย false positives อาจก่อให้เกิดการหยุดเครื่องหรือการแจ้งเตือนที่ไม่จำเป็นซึ่งเพิ่มค่าใช้จ่ายการบำรุงรักษา ขณะที่ false negatives อาจทำให้พลาดการตรวจจับความผิดปกติที่อาจพัฒนาเป็นความเสียหายรุนแรง นอกจากนี้ยังมีความเสี่ยงด้านความเสถียรของระบบ เช่น latency ในการ inference ที่ต้องเป็นไปตามข้อกำหนดเรียลไทม์, พลังงานที่ใช้จากแบตเตอรี่ (สำคัญในกรณีอุปกรณ์ไร้สาย), การรบกวนจากสัญญาณรบกวน (EMI), และการคงสภาพของเซ็นเซอร์เมื่อเวลาผ่านไป (drift/aging) ซึ่งทั้งหมดย่อมส่งผลต่อความน่าเชื่อถือของการแจ้งเตือนและค่า KPI เช่น precision, recall และ F1-score
การปรับใช้ TinyFoundry ในสภาพแวดล้อมจริงโดยเฉพาะสภาพแวดล้อมที่รุนแรง (เช่น โรงงานที่มีฝุ่น ความชื้น แรงสั่นสะเทือนสูง หรือช่วงอุณหภูมิสุดขั้ว) เผชิญความท้าทายหลายด้าน: การติดตั้งและการวางตำแหน่งเซ็นเซอร์ที่เหมาะสมเพื่อให้สัญญาณมีคุณภาพ, การปกป้องฮาร์ดแวร์และการรับรอง IP rating, การบริหารจัดการ fleet ขนาดใหญ่ (การอัพเดตเฟิร์มแวร์ การจัดการเวอร์ชันโมเดล และการติดตามสุขภาพอุปกรณ์) รวมถึงความไม่ต่อเนื่องของการเชื่อมต่อเครือข่ายที่ทำให้ไม่สามารถพึ่งพา cloud สำหรับการตัดสินใจแบบเรียลไทม์ได้เสมอ การสเกลระบบสู่พันถึงหมื่นอุปกรณ์ยังต้องการระบบ orchestration, telemetry และการมอนิเตอร์ที่มั่นคง พร้อมแนวทางการกู้คืน (fallback) เมื่อเกิดความผิดพลาด ตัวอย่างแนวทางลดความเสี่ยงคือการออกแบบระบบแบบชั้น (hierarchical inference) ให้ edge ทำหน้าที่เป็นตัวกรองเบื้องต้น และส่งเฉพาะเคสที่มีความไม่แน่นอนสูงไปให้ cloud วิเคราะห์ต่อ
สำหรับทิศทางการพัฒนาในอนาคต TinyFoundry มีแนวทางเชิงเทคนิคที่ชัดเจนเพื่อขยายความสามารถและลดความเสี่ยงดังนี้
- Federated learning — พัฒนา pipeline เพื่อให้โมเดลสามารถเรียนรู้จากข้อมูลที่กระจายอยู่บนอุปกรณ์ได้โดยไม่ต้องย้ายข้อมูลดิบไปยังศูนย์กลาง ทั้งนี้ต้องรวมการป้องกันเชิงความปลอดภัย เช่น secure aggregation และเทคนิค differential privacy เพื่อลดความเสี่ยงด้านความเป็นส่วนตัวและการโจมตีแบบ poisoning
- AutoML สำหรับโมเดลจิ๋ว — ใช้การค้นหาโครงสร้าง (NAS) และการปรับ hyperparameter ที่คำนึงถึงข้อจำกัดของ MCU (latency, memory footprint, และพลังงาน) เพื่อสร้างสถาปัตยกรรมที่สมดุลระหว่างความแม่นยำและทรัพยากร
- รองรับเซ็นเซอร์หลายชนิดและมัลติโมดัล — ขยายโมดูลให้รองรับสัญญาณจาก accelerometer, microphone, current/voltage sensors, ultrasound และ temperature sensors พร้อมมาตรฐานการทำ pre-processing และ fusion เพื่อเพิ่มความทนทานต่อสภาวะแวดล้อมที่หลากหลาย
- การเรียนรู้ต่อเนื่องและการปรับตัวโดเมน (continual & domain adaptation) — พัฒนาเทคนิคสำหรับปรับโมเดลแบบภาคสนามโดยไม่ลืมความรู้เก่า (catastrophic forgetting) และใช้การขยายข้อมูลเชิงสังเคราะห์เพื่อรับมือ domain shift
- รองรับ MCU หลากหลายแพลตฟอร์มและเครื่องมือพัฒนา — ขยายไลบรารี runtime ให้ครอบคลุม ARM Cortex-M (M0/M3/M4/M7), RISC‑V และ DSP แบบประหยัดพลังงาน พร้อมการรองรับ toolchain เช่น CMSIS‑NN และ TensorFlow Lite Micro เพื่อให้การพอร์ตและการอัพเดตแบบ over‑the‑air ทำได้ง่ายและปลอดภัย
สรุปแล้ว การนำ TinyFoundry มาใช้ควรเริ่มด้วยการทดสอบในสภาพแวดล้อมจำลองและ pilot deployment เล็ก ๆ เพื่อวัดค่า metrics สำคัญ (precision, recall, F1, latency, memory usage, และการใช้พลังงาน) จากนั้นจึงค่อยขยายสู่การติดตั้งเชิงพาณิชย์ พร้อมระบบมอนิเตอร์และกระบวนการอัปเดตที่แข็งแรง การลงทุนใน federated learning, AutoML สำหรับโมเดลจิ๋ว และการรองรับหลายเซ็นเซอร์จะเป็นกุญแจสำคัญในการยกระดับความแม่นยำและการทนทานของระบบเมื่อสเกลขึ้นในสภาพแวดล้อมจริง
บทสรุป
TinyFoundry นำเสนอนวัตกรรมการตรวจจับความผิดปกติที่ขอบเครือข่าย (edge) โดยใช้โมเดลพื้นฐานขนาดจิ๋วรันบนไมโครคอนโทรลเลอร์ (MCU) เพื่อวิเคราะห์สัญญาณเสียงและแรงสั่นสะเทือนของเครื่องจักรแบบออฟไลน์ ผลลัพธ์ที่ทีมพัฒนาเคลมได้คือการคัดกรองเหตุการณ์ผิดปกติก่อนส่งข้อมูลขึ้นคลาวด์ จนนำไปสู่การลดแบนด์วิดท์และต้นทุนข้อมูลได้สูงถึง 90% พร้อมประโยชน์สำคัญด้าน latency ที่ลดลงอย่างมีนัยสำคัญและการรักษาความเป็นส่วนตัวของข้อมูล เพราะข้อมูลดิบไม่จำเป็นต้องถูกส่งออกจากอุปกรณ์ตัวสุดท้ายก่อนจัดการเบื้องต้น
สำหรับผู้ใช้งานจริงและผู้ตัดสินใจทางด้านไอทีในภาคอุตสาหกรรม ควรพิจารณาข้อมูลเชิงเทคนิคและผลการทดสอบภาคสนามเป็นหลักก่อนนำไปใช้งาน เช่น ความแม่นยำ (accuracy), อัตราการแจ้งเตือนเท็จ (false alarm rate), ความไว/ความจำเพาะ (precision/recall), และการคำนวณผลตอบแทนจากการลงทุน (ROI) ในระยะสั้นและระยะยาว นอกจากนี้ควรประเมินประเด็นการผสานรวมกับระบบเดิม การจัดการวงจรชีวิตของโมเดล (OTA update, การบำรุงรักษา), ความสามารถในการสเกลไปยังไซต์จำนวนมาก และประเด็นด้านความปลอดภัยของโมเดลและข้อมูลก่อนขยายใช้งาน
มองไปข้างหน้า TinyFoundry มีศักยภาพช่วยขับเคลื่อนการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) ในสถานที่ห่างไกลและโรงงานที่มีข้อจำกัดด้านแบนด์วิดท์ เมื่อเทคโนโลยีการบีบอัดโมเดล, เครื่องมือพัฒนา on-device, และแนวทางอย่าง federated learning เติบโตขึ้น การใช้งานแบบผสมผสาน edge–cloud จะช่วยรักษาสมดุลระหว่างความแม่นยำและต้นทุน แต่อุปสรรคสำคัญคือการพิสูจน์เชิงวิศวกรรมผ่านพิลอตจริงและการสร้างมาตรฐานการวัดผลร่วมกัน ผู้ประกอบการควรวางแผนทดลองเชิงสนามเป็นขั้นตอนแรก ก่อนขยายสเกลอย่างเป็นทางการเพื่อลดความเสี่ยงและยืนยันผลประโยชน์เชิงเศรษฐศาสตร์



